
 , 赵富强, Zhao Fuqiang
, 赵富强, Zhao Fuqiang【目的】基于用户网络评论构建有效的评分预测模型, 挖掘用户消费行为特征。【方法】基于LDA模型,量化用户评论为主题特征向量作为解释变量, 将用户评分作为被解释变量, 采用XGBoost算法, 并加入样本扰动和属性扰动生成多个模型进行集成, 构建用户评分预测模型。【结果】针对某汽车门户网站的用户评论评分预测结果表明, 该模型较好地揭示了用户对汽车商品的偏好。较逻辑回归、随机森林算法, 其预测准确度分别高出13.73%、0.64%, 且具有较高的计算效率。【局限】未融合其他方面的数据对用户行为特征进行更全面的刻画。【结论】将用户评论量化为主题特征向量, 基于XGBoost算法能够准确、高效地预测用户评分。
[Objective] This study aims to build a model for effectively predicting ratings of user reviews and analysing consumer behaviours. [Methods] First, we applied the Latent Dirichlet Allocation model to set the topic features from user reviews as independent variable and user ratings as dependent variable. Then, we built a user rating prediction model based on the eXtreme Gradient Boosting algorithm. Finally, we added the disturbances of samples and attributes to the proposed model for rating prediction. [Results] We used the new model to predict user’s comments on a domestic automobile online portal, and identified their preferences of automobile. Compared with the Logical Regression and Random Forest algorithms, the proposed model has better precision and efficiency. [Limitations] We need to include data from other fields to more comprehensively describe user’s behaviours. [Conclusions] The proposed model could quantify user’s reviews and then predict their ratings effectively.
随着互联网和社交网络的快速发展, 越来越多的厂商和消费者开始关注商品的用户评价。用户评价既是消费者消费决策的参考, 也是生产厂商掌握消费者偏好、优化生产行为的重要依据。
商品的用户评价是指消费者对所购买商品属性特征的主观感受, 反映消费者对购买商品的偏好和满意度, 包括用户对商品的评分信息和文本评论信息。其中, 用户评分是消费者对商品属性特征以及使用满意度的综合评价, 消费者和厂商通常会优先关注评分较高的商品; 商品评论中蕴含着描述商品属性特征和用户满意度的关键词等信息。鉴于用户评论和评分之间存在关联性, 如何将用户评论与评分有效结合, 构建预测准确度高、时效快的评分预测模型, 以预测用户消费偏好, 为产品研发决策和商品推荐提供参考是一个重要的研究课题。
基于此, 本文在回顾已有方法的基础上, 结合用户评论与评分信息, 构建一种基于XGBoost算法的用户评分预测模型。利用LDA(Latent Dirichlet Allocation)模 型提取用户评论的主题特征, 并依据主题特征及其概率分布将文本评论信息量化成主题特征向量; 针对主题特征向量与用户评分, 加入数据样本扰动和属性扰动建立多个不同的XGBoost(eXtreme Gradient Boosting)模型, 采用投票法进行集成, 提高模型的泛化能力。通过改善用户评分预测准确性, 提高计算效率, 以分析用户评论主题与评分之间的相关性, 挖掘用户消费偏好。
评分预测问题是推荐系统研究的一个分支, 评分预测的准确性将很大程度上影响推荐系统的性能, 很多学者针对评分预测问题展开研究。早期关于评分预测的研究, 多是基于用户历史评分行为和物品属性特征进行建模[1,2,3]。随着互联网和电子商务的快速发展, 用户参与度不断提高并生成大量的评论信息。相对于评分和物品属性特征而言, 用户评论信息蕴含的内容更为丰富, 能够更加具体、准确地表达用户对物品的喜好, 这为评分预测模型的构建提供了新研究思路。研究人员开始关注将评分与评论相结合的方法, 从评论文本中挖掘用户偏好提高评分预测的质量。Li等[4]通过手动建立部分主题词, 将评论文本主题与评分矩阵分解模型融合, 估计用户在不同方面的偏好。Fan等[5]从Yelp餐馆评论数据中提取高频词和高频形容并词创建词袋, 通过与评分数据相结合, 利用线性回归模型实现评分预测。张红丽等[6]针对电影评论数据, 提取用户语料中的情感特征作为辅助预测指标, 并结合评论人数等与评论相关联的指标作为自变量, 利用回归分析构建评分预测模型。高祎璠等[7]基于餐馆评论数据, 利用用户评论的主题分布建立用户画像和商品画像, 基于逻辑回归建立评分预测模型, 预测准确度为52%, 在个别子数据集上预测准确度可达66%。虽然现有方法在一定程度上利用用户评论信息, 构建的用户评分预测模型仍面临准确率较低的问题, 如何将用户评论与评分有效结合, 构建准确、高效的用户评分预测模型, 这项工作还有待深入研究。
在实际应用中, 用户评分往往会依据分值大小进行分类, 将评分预测问题转化为二分类或多分类问题。分类模型的选择将会影响评分预测模型的性能。常用的分类模型有朴素贝叶斯、逻辑回归、随机森林等。其中, 朴素贝叶斯分类方法假设样本的各个属性相互独立, 在实际问题中被广泛应用, 但如果用户评分之间存在相互依赖关系时, 将会影响算法的准确性。线性回归方法是基于用户历史评分的线性推荐算法, 线性回归模型的参数估计基于用户-项目矩阵, 当矩阵存在稀疏、噪声等问题时, 方法准确率可能会降低[8]。
现有研究结果显示, 相对于逻辑回归、决策树等单一分类器, 根据训练数据构建一组个体学习器, 并采用某种策略将多个学习器进行集成的学习方法具有更高的准确度和更好的稳健性[9,10]。集成学习方法主要分为两类: Bagging方法(如RF算法等); Boosting方法(如XGBoost算法等)。其中, RF[11]算法利用样本扰动和属性扰动实现基学习器的多样性, 提升算法的泛化性能, 但该算法需要存储每棵决策树及其每个节点不同的样本集合, 内存开销较大, 模型训练速度较慢。XGBoost[12]算法依据损失函数在梯度下降方向上组合多个CART树, 以最小化损失函数, 且能够自动利用CPU的多线程进行分布式学习和多核计算, 在保障分类准确度的前提下可以提高计算效率, 适用于处理大规模数据。近年来, XGBoost算法在文本数据中的应用也开始受到关注, 取得较好的效果[13,14]。鉴于此, 本文在模型底层使用XGBoost算法进行Boosting集成, 以提高算法效率; 在顶层, 为了增加集成学习中个体学习器的多样性, 利用Bagging的思想加入数据样本扰动和属性扰动, 以建立多个好而不同的XGBoost模型, 并采用投票法进行集成, 提高模型的泛化能力。
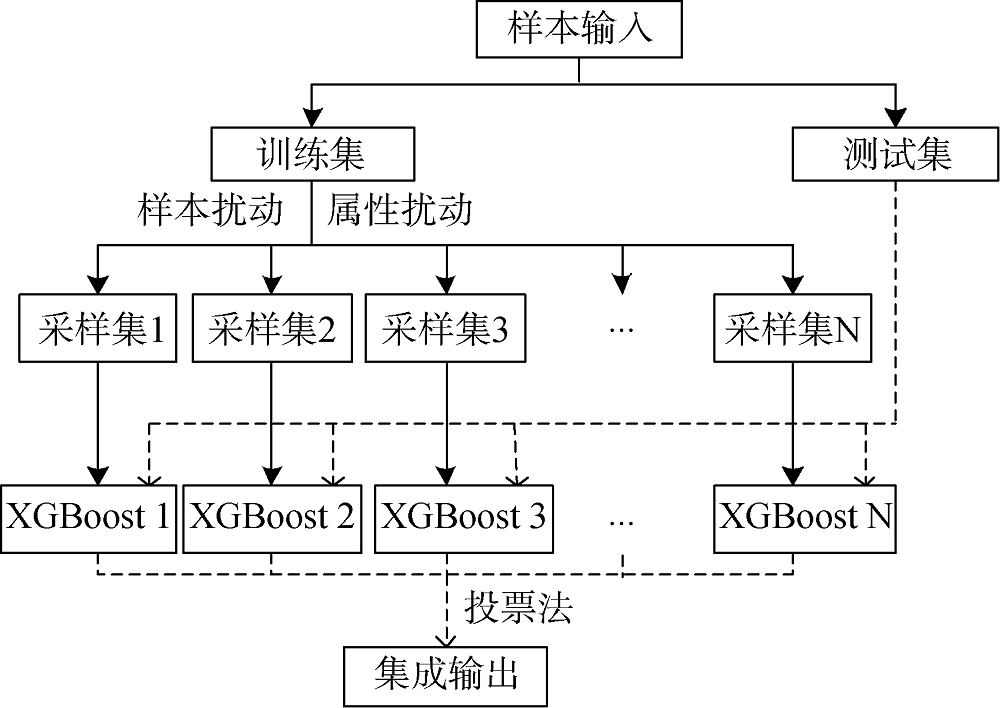
基于XGBoost算法的用户评分预测模型主要包括评分矩阵的生成和评分预测, 模型框架如图1所示。
评分矩阵的生成是将用户的文本评论量化成结构化数据[15]。LDA[16]主题模型是由Blei等提出的包含词、主题和文档三层结构的贝叶斯概率模型, 通过在文档和词之间引入主题维度, 实现对向量空间的降维, 可以处理大规模语料。该模型采用词袋的方法, 将每篇文档视为一个词频向量, $\alpha $和
根据用户评论中出现的各主题词的数量及其概率 分布, 将用户评论量化成主题特征向量。记评论
${{\theta }_{is}}=\sum\nolimits_{v=1}^{V}{({{\varphi }_{sv}}\times {{n}_{iv}})}$ (1)
其中,
将包含
${{\hat{y}}_{i}}=\varphi ({{x}_{i}})=\sum\nolimits_{k=1}^{K}{{{f}_{k}}({{x}_{i}})}$ (2)
其中, ${{f}_{k}}\in F$,
变, 加入新函数
${{L}^{(t)}}=\sum\nolimits_{i=1}^{n}{l({{y}_{i}},\hat{y}_{i}^{(t-1)}+{{f}_{t}}({{x}_{i}}))+\Omega ({{f}_{t}})+\mathrm{constant}}$ (3)
$\Omega ({{f}_{t}})=\gamma T+\frac{1}{2}\lambda \sum\nolimits_{j=1}^{T}{w_{j}^{2}}$ (4)
其中, $l(\cdot ,\cdot )$是训练误差, 描述预测值与真实值之间差异的损失。$\Omega (\cdot )$是模型复杂度的正则项惩罚函数,
XGBoost算法采用贪心算法[17]从根节点开始, 递归地选择树结构的最优特征, 据此特征对训练数据进行分割。假设
${{L}_{split}}=\frac{1}{2}\left[ \frac{{{(\mathop{\sum }_{i\in {{I}_{L}}}{{g}_{i}})}^{2}}}{\mathop{\sum }_{i\in {{I}_{L}}}{{h}_{i}}+\lambda }+\frac{{{(\mathop{\sum }_{i\in {{I}_{R}}}{{g}_{i}})}^{2}}}{\mathop{\sum }_{i\in {{I}_{R}}}{{h}_{i}}+\lambda }-\frac{{{(\mathop{\sum }_{i\in {{I}_{{}}}}{{g}_{i}})}^{2}}}{\mathop{\sum }_{i\in {{I}_{{}}}}{{h}_{i}}+\lambda } \right]-\gamma $ (5)
其中, ${{I}_{j}}=\left\{ i|q({{x}_{i}})=j \right\}$为节点
集成学习的关键是如何生成好而不同的个体学习器, 个体学习器准确性越高、多样性越大, 则集成效果越好。相对于LR、NB等稳定分类模型, 树模型是一种对样本扰动比较敏感的不稳定分类模型。决策树因为其简单直观, 具有很强的可解释性, 常被作为集成学习的个体学习器。相比于ID3和C4.5, CART[18]采用二元递归划分方法构建二叉树, 分裂特征可以重复使用, 既可以用于分类也可以用于回归。基于集成学习的优良性, 本文在模型底层选用以CART树为基学习器的XGBoost算法建立评分预测模型。同时, 为了增加集成学习中个体学习器的多样性, 提高模型的泛化能力, 在顶层利用Bagging思想加入数据样本扰动和属性扰动, 以建立多个好而不同的XGBoost模型, 并采用投票法进行模型集成, 集成方法如图2所示。
对于二分类任务, 类别标记集合记为$\{{{y}_{0}},{{y}_{1}}\}$。将样本
$\hat{y}(x)={{y}_{\underset{j\in \{0,1\}}{\mathop{argmax}}\,\sum\nolimits_{n=1}^{N}{\varphi _{n}^{j}(x)}}}$ (6)
基于XGBoost算法的用户评分预测模型将用户评论的主题特征向量作为解释变量
(1) 数据预处理
①收集用户在线评论, 并进行筛选、分词、去停用词等数据预处理。
②采用LDA模型提取用户评论的主题特征及其概率分布, 将用户评论量化成主题特征向量。
③以主题特征向量为解释变量, 用户评分作为被解释变量构建样本集, 并将样本集划分为训练集和测试集。
(2) 利用训练集建立基于XGBoost算法的用户评分预测模型
④加入样本扰动和属性扰动对训练集样本进行随机采样, 生成多个采样集。
⑤对每一个采样集, 重复步骤1)-步骤3):
1) XGBoost算法根据公式(5)从根节点开始, 递归地选择树结构的最优特征, 据此特征对数据集进行划分, 直到达到提前设定的划分停止条件(如树的最大深度等), 至此所有样本被分配到叶子节点, 生成一棵CART树。
2) 重复步骤1), 在损失函数梯度下降方向上依次建立多棵CART决策树。
3) 组合多棵CART决策树建立基于XGBoost算法的用户评分预测模型。
⑥对步骤⑤生成的多个评分预测模型利用投票法进行集成, 生成最终的用户评分预测模型。
(3) 利用测试集对用户评分预测模型进行评价
⑦对于测试集的每条样本, 利用步骤⑤生成的多个XGBoost模型, 分别计算所有CART树叶子节点上的预测分数之和, 若其属于正类的概率大于0.5, 将其划分为正类; 否则将其划分为负类。
⑧根据公式(6)对多个XGBoost模型的预测结果进行集成, 得到样本的预测类别。
⑨计算用户评分预测模型准确性指标: 准确度(Accuracy)和ROC(Receiver Operating Characteristic)曲线, 评价评分预测模型的预测准确性。准确度是指分类正确的样本数占样本总数的比例。通常来说, 分类准确度越高, 算法越好。
实验数据来自于国内某汽车门户网站的2015年1月至2016年6月的汽车用户在线评论, 包括用户评分和评论数据。用户评分为两类: 1为评分高, 0为评分不高。利用汽车门户网站用户评论, 预测用户评分, 检验预测效果。
选取紧凑型SUV里评论热度较高的汽车品牌, 这些品牌价格适中且购买量较大。首先抓取用户评论、评分及车型、价格等信息。从抓取到的数据中筛选出裸车价格在15万到25万之间的汽车用户评论数据, 删除内容较少的评论。然后进行分词、去停用词、去标点符号等文本数据预处理操作。另外, 在评论量化后的数据中, 出现了少量在某些维度上为0的主题特征向量, 这部分数据较少, 对其进行了剔除处理。最终有效实验数据统计信息如表1所示, 共计13 628条。表1的第2-11列为评论数最多的10种车型, 共有 5 702条评论(约42%)。第12列为其他车型的7 926条评论(约58%)。评分为1的用户占比约为47%, 评分为0的用户占比约为53%。
本文使用LDA模型对汽车用户评论进行主题分析, 估计汽车用户评论的主题特征分布
根据图3实验结果, 用户关注的紧凑型SUV车型特征为: 外观方面关注是否大气、时尚; 动力方面关注起步、油门、加速等; 空间方面关注后排和后备箱等空间是否够用; 内饰方面关注做工、座椅、用料等; 油耗方面关注跑市区和高速时的百公里油耗; 操控方面关注方向盘是否轻盈、转向是否精准、底盘是否稳健。
选取每个主题中出现概率较高的前30个代表性词汇, 即
从量化后的13 628条有效数据中, 随机抽取70%作为训练集, 30%作为测试集。训练集和测试集中
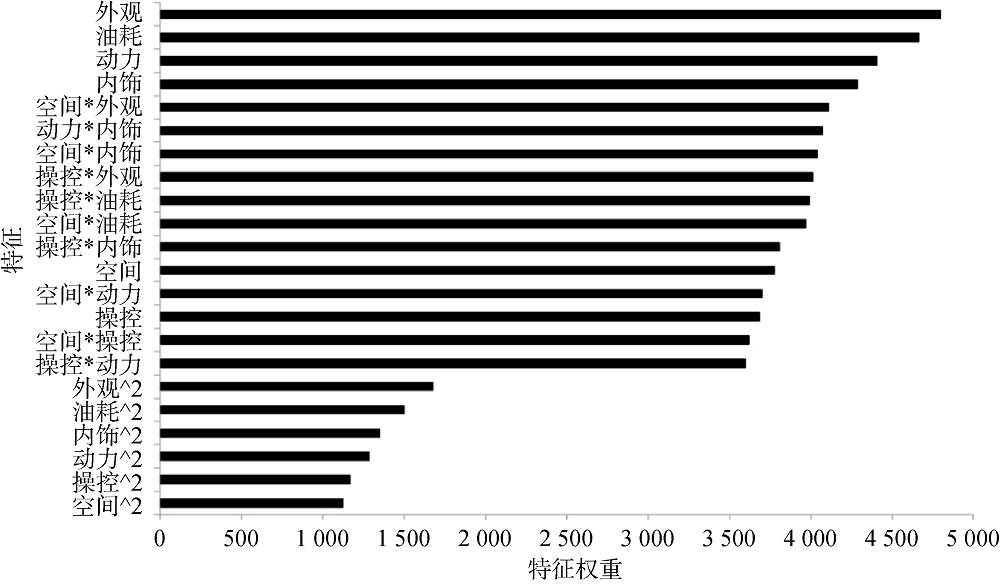
选择用户评论的6个主题特征, 同时考虑到主题特征之间可能会存在交互效应, 即一个主题特征在另一个主题特征不同水平上可能会产生不同效果, 实验设计中增加了6个主题特征的二次乘积项, 用以表达不同主题特征之间的交互效应。用Logistic回归方法筛选出对模型贡献较高的22个特征, 选择在生成所有树的过程中特征被用作分裂特征的次数作为特征权重, 特征重要性排序如图4所示。特征重要性排序可以理解为大多数用户对紧凑型SUV不同角度的偏好, 由图4可以看出, 大多数用户对价格在15-20万之间的紧凑型SUV比较注重外观、油耗、动力、内饰等因素, 用户在选车时考虑外观的同时会考虑空间、操控, 考虑动力的同时也会考虑内饰等其他交互因素。
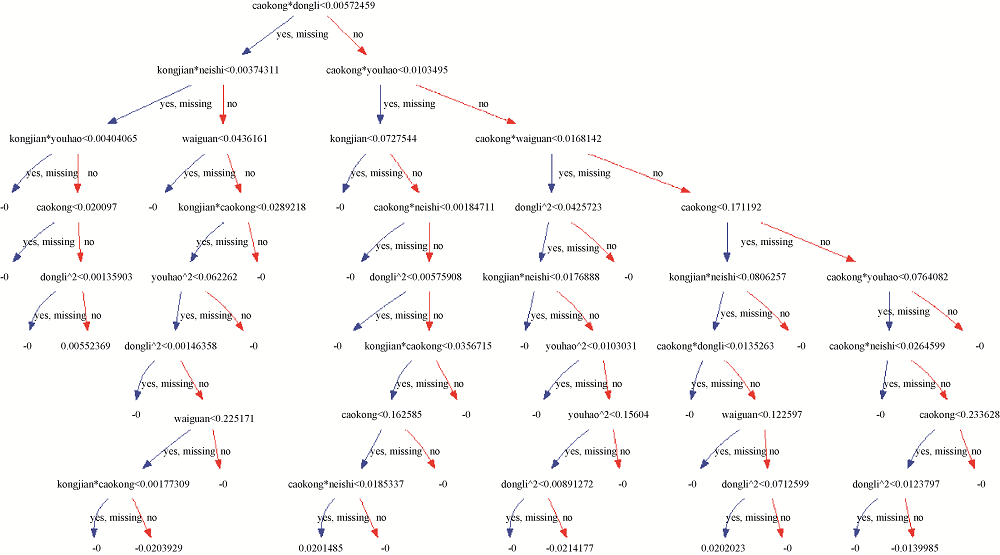
经实验发现, 迭代次数为1 000时效果最优, 1 000棵CART树作为最终的用户评分预测模型。对于测试集的每条样本, 利用生成的1 000棵CART树的决策规则对其进行预测, 计算所有CART树对应叶子节点上的预测分数之和, 若其属于正类的概率大于0.5, 预测评分为1; 否则预测评分为0。XGBoost算法生成的第1000棵CART树如图5所示。
为了演示用户评分预测过程, 选取测试集中一条汽车用户评论。该用户对这款车的评分类别为1。量化后的主题特征向量见表2中第一条样本。
外观大气漂亮, 内饰做工精细, 空间大, 油耗低。后排乘坐非常舒适。车内空间宽敞, 座椅的包裹性不错, 后排座椅空间还是蛮大, 乘坐舒适, 后备箱空间有点小, 美中不足的是全尺寸备胎导致的后箱隆起。动力不错, 2.0开起来一点也不弱, 无论是在市里还是在高速上, ······。
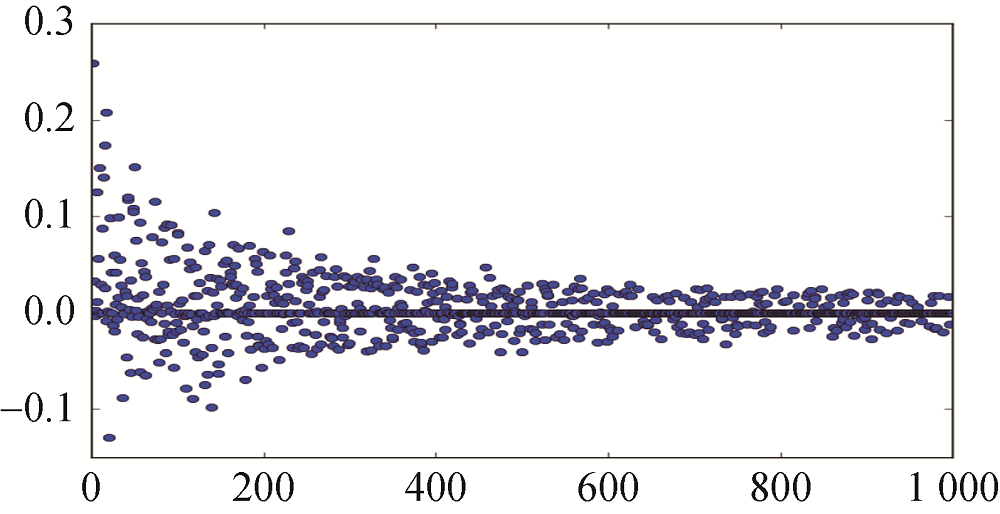
该条样本得分的最小值低于-0.1, 最大值高于0.2, 波动幅度较大。随着CART树数量的增加, 波动幅度逐渐较小, 趋于0值附近。总体来看, 得分为正值的情况相对更多。将1 000棵CART树的叶子节点得分相加为4.650 830 244, 用Logistic函数进行转换, 得到其类别为1的概率为0.990 536 742, 概率值大于0.5, 其预测评分类别为1。对比图3可以看出, 该评论中出现了外观、漂亮、大气、座椅、内饰、空间、后排等高频词汇。用户评分预测类别与真实类别一致。
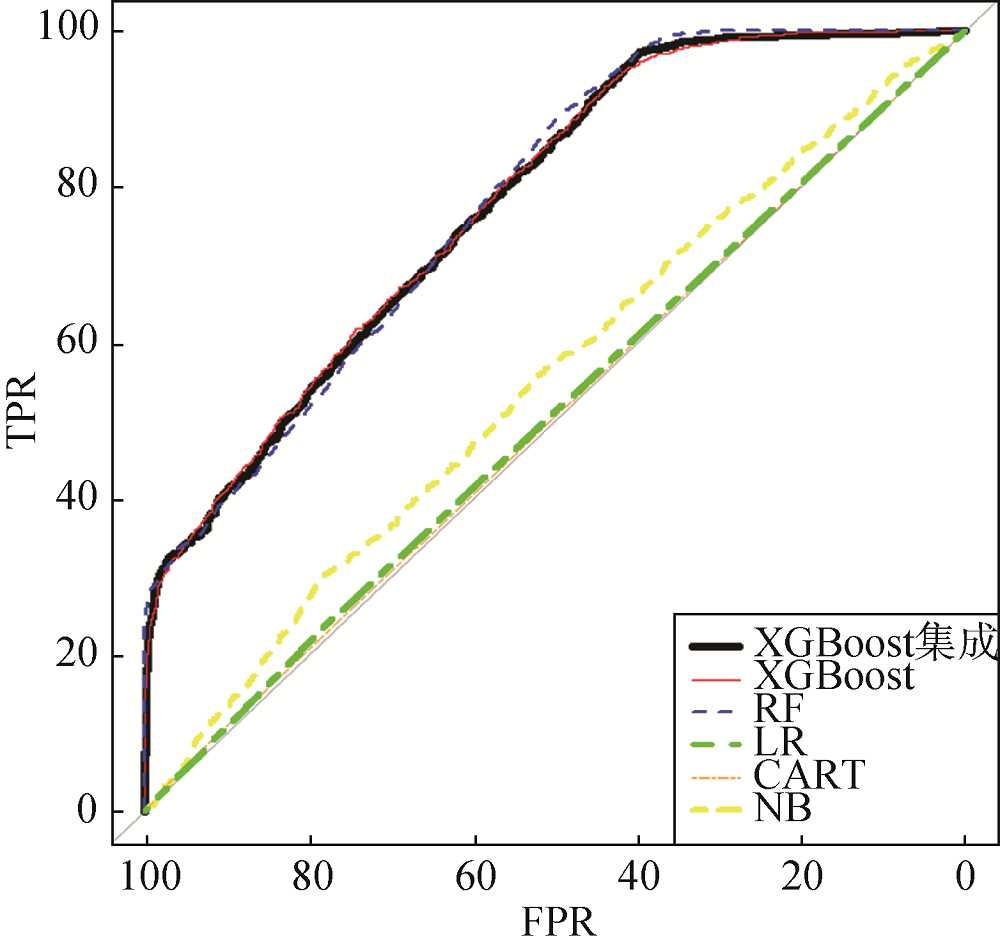
本文选用准确度、ROC曲线对基于XGBoost算法的用户评分预测模型准确性进行评价。为了验证本文方法的优良性, 分别选择对数据扰动不敏感的稳定分类算法NB、LR, 以及对数据扰动敏感的树类模型CART、RF算法进行比较。各分类算法预测结果的ROC曲线如图7所示。纵轴是TPR, 横轴是FPR。
XGBoost集成、XGBoost和RF算法的ROC曲线明显包住NB、LR、CART树, 说明XGBoost集成、XGBoost和RF的预测准确性明显优于NB、LR、CART算法。
为了进一步比较预测准确度, 对量化后的13 628条有效数据, 采用5次五折交叉验证, 分别建立评分预测模型, 结果如表3所示。第2列至第6列分别为五折交叉验证的预测准确度, 第7列为平均值。表3显示, XGBoost集成、XGBoost和RF算法的预测准确度明显优于NB、LR、CART算法。由平均值可知, XGBoost算法的预测准确度达到67.75%, 比RF算法的预测准确度67.54%高出约0.21个百分点。通过加入样本扰动和属性扰动对XGBoost算法集成以后, 模型的泛化能力有所提高, 预测准确度在XGBoost基础上提高约0.43%, 比随机森林高约0.64%。表3中各方法的预测准确度与图7结论一致。
由于样本数据规模略大, 计算速度会受算法影响。通过实验证明, XGBoost算法在迭代次数为1 000时, 预测准确度趋于最大值, 建模过程平均耗时约9秒。对XGBoost算法集成以后, 迭代次数为500时, 预测准确度趋于最大值, 建模过程耗时约50秒。随机森林算法的决策树数量为500时, 预测准确度趋于最大值, 建模过程平均耗时约120秒。XGBoost算法及其集成的计算速度明显优于随机森林。综上可知, 基于XGBoost算法集成的用户评分预测模型具有较高的预测准确度和较高的计算效率。
选取国内某汽车门户网站的汽车用户在线评论数据, 进行数据清洗和用户评论的主题特征提取及量化, 构建基于XGBoost算法的用户评分预测模型。数据分析结果显示, 该模型能够将用户评论信息与评分有效结合, 揭示出用户对紧凑型SUV汽车的消费偏好, 其预测准确度高于LR、NB等模型, 且计算效率的优势更为明显, 能够更好地了解汽车用户需求, 为汽车行业整体结构的优化提供参考。
本文将用户评论与评分相结合, 利用LDA模型挖掘用户评论中的主题特征, 并将评论量化成基于各主题特征的向量作为解释变量, 将用户评分作为被解释变量, 并在传统XGBoost算法的基础上加入数据样本扰动和属性扰动以建立多个不同的XGBoost模型, 通过投票法对模型进行集成, 提出一种基于XGBoost算法的用户评分预测模型。以国内某汽车门户网站用户口碑评论数据为研究对象, 对汽车产品的真实用户评论数据进行主题特征提取和建模, 并与NB、LR、RF等算法进行对比, 实验结果表明基于XGBoost集成的用户评分预测模型具有较好的预测准确度和计算效率, 泛化能力较强, 适用于处理大规模数据。
在未来研究中, 将分别从用户与商品角度挖掘用户偏好和建立商品画像, 用于商品推荐的评分预测。此外, 还将继续寻找XGBoost算法集成的参数优化和模型融合方法, 以进一步提高XGBoost算法集成的分类准确性和计算效率, 完善用户评分预测模型及其应用。
杨贵军, 徐雪: 提出研究思路, 设计研究方案, 论文最终版本修订;
徐雪: 进行实验, 论文起草;
赵富强, 徐雪: 采集、清洗和分析数据。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: xuxue2017@163.com。
[1] 杨贵军, 徐雪, 赵富强. ASUVp(15-25)_comment.csv. 汽车网站用户评论数据.
[2] 杨贵军, 徐雪, 赵富强. LDA_twords.dat. LDA实验结果.
[3] 杨贵军, 徐雪, 赵富强. train.csv, test.csv. 训练集与测试集 数据.
[4] 杨贵军, 徐雪, 赵富强. fold1.csv, fold2.csv, fold3.csv, fold4.csv, fold5.csv. 五折交叉验证数据.
[5] 杨贵军, 徐雪, 赵富强. LDA源代码. docx. Python下LDA源代码.
[6] 杨贵军, 徐雪, 赵富强. XGBoost源代码. docx. Python下XGBoost源代码.
| [1] |
As the Netflix Prize competition has demonstrated, matrix factorization models are superior to classic nearest neighbor techniques for producing product recommendations, allowing the incorporation of additional information such as implicit feedback, temporal effects, and confidence levels.
|
| [2] |
[本文引用:1]
|
| [3] |
协同过滤是电子商务推荐系统中广泛应用的推荐技术, 但面临着严重的用户评分数据高维化和稀疏性问题. 同时, 传统协同过滤中的相似度度量方法没有考虑用户评分行为对其他用户的影响, 因而对评分预测的精度影响较大. 此外, 在移动环境下, 传统协同过滤未结合情境信息, 导致推荐质量下降. 对此, 提出一种基于情境聚类和用户评级的协同过滤模型. 首先, 根据情境信息对用户进行聚类, 降低用户评分数据维度和稀疏性; 然后, 引入社会网络理论分析用户间关系, 建立用户评级模型用于评价用户推荐能力, 并结合评级指标进行评分预测. 通过MovieLens和NetFlix数据集对基于该模型的SlopeOne算法和其它三种方法的比较验证结果表明: 本模型在所有数据集上都获得了最高的预测精度, 同时还具有最佳的推荐覆盖度, 可显著提高预测精度, 更适用于移动电子商务环境下的个性化推荐问题.
|
| [4] |
[本文引用:1]
|
| [5] |
[本文引用:1]
|
| [6] |
【目的】通过网络用户评论,为评论网站构建有效的评分预测机制。【方法】提出基于网络用户评论的评分预测模型,该模型包括4个模块:网络用户评论获取模块、预测变量获取模块、预测分析模块以及预测结果评价模块。抓取30部不同类型的电影评论数据,27部用于构建模型,3部用于检验模型。【结果】使用逐步回归方法筛选出变量:参与评分人数、参与评论人数、想要观看人数和电影正向评论情感均值,构建评分预测模型。使用3部电影验证,预测评分与IMDb评分相差最大值为0.0644,最小值为0.0227。【局限】在数据样本量、情感特征提取精度、模型普适性验证等方面有待进一步提升。【结论】该模型能够依据用户评论对评分进行有效预测,在网络水军探测方面也能发挥一定的作用。
URL
[本文引用:1]
|
| [7] |
推荐系统广泛地应用在网络平台中,推荐模型需要预测用户的喜好,帮助用户找到适合的电影、书籍、音乐等商品.通过对用户评分和评论信息的分析,可以发现用户关注的商品特征,并根据商品的特征,推测用户对该商品的喜好程度.本文提出将评论中隐含的语义内容与评分相结合,设计并实现了一种新颖的商品推荐模型.首先利用主题模型挖掘评论文本中隐含的主题分布,用主题分布刻画用户偏好和商品画像,在逻辑回归模型上训练主题与打分的关系,最终评分可以被视为是对用户偏好和商品画像的相似程度的量化表示.最后,本文在真实数据上进行了大量对比实验,结果证明该模型比对比系统性能优越且稳定.
|
| [8] |
[本文引用:1]
|
| [9] |
In this paper, we set out to compare several techniques that can be used in the analysis of imbalanced credit scoring data sets. In a credit scoring context, imbalanced data sets frequently occur as the number of defaulting loans in a portfolio is usually much lower than the number of observations that do not default. As well as using traditional classification techniques such as logistic regression, neural networks and decision trees, this paper will also explore the suitability of gradient boosting, least square support vector machines and random forests for loan default prediction. Five real-world credit scoring data sets are used to build classifiers and test their performance. In our experiments, we progressively increase class imbalance in each of these data sets by randomly under-sampling the minority class of defaulters, so as to identify to what extent the predictive power of the respective techniques is adversely affected. The performance criterion chosen to measure this effect is the area under the receiver operating characteristic curve (AUC); Friedman statistic and Nemenyi post hoc tests are used to test for significance of AUC differences between techniques. The results from this empirical study indicate that the random forest and gradient boosting classifiers perform very well in a credit scoring context and are able to cope comparatively well with pronounced class imbalances in these data sets. We also found that, when faced with a large class imbalance, the C4.5 decision tree algorithm, quadratic discriminant analysis and k-nearest neighbours perform significantly worse than the best performing classifiers.
|
| [10] |
在全球化的市场竞争中,企业如何利用现有资源,提高客户满意度,保住现有客户,已成为企业面临的主要问题,客户流失预测越来越受到企业关注。本文针对实际客户流失数据中正负样本数量不平衡而且数据量大的特点,提出一种改进的平衡随机森林算法,并将其应用于某商业银行的客户流失预测。实际数据集测试结果表明,与传统的预测算法比较,这种算法集成了抽样技术和代价敏感学习的优点,适合解决大数据集和不平衡数据,具有更高的精确度。
|
| [11] |
|
| [12] |
[本文引用:4]
|
| [13] |
[本文引用:1]
|
| [14] |
|
| [15] |
[本文引用:1]
|
| [16] |
[本文引用:1]
|
| [17] |
[本文引用:1]
|
| [18] |
[本文引用:1]
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}