
 , 钱力, Qian Li
, 钱力, Qian Li【目的】研究从科技大数据中提取结构化知识、构建学术知识网络的模型与方法, 支持智能知识服务产品的研发提升精准知识发现能力。【方法】提出科技大数据知识图谱的构建模型和技术架构, 在汇聚和融合科技大数据知识资源的基础上, 以大数据平台分布式存储和高性能计算为支撑环境, 详细设计和实现科研实体知识抽取、实体对齐和关系发现、知识融合与语义丰富化、语义化存储、质量管理等知识图谱构建技术。【结果】构建3亿实体和11亿关系的科技大数据知识图谱, 有效支撑科技大数据知识发现平台和“慧科研”智能随身助手的服务。【局限】由于数据的规模和复杂性, 知识图谱的质量管理仍需花费大量的人力, 实体对齐的准确度也有待于提高。【结论】本文提出的知识图谱建设方案适用于科技大数据的知识管理和深加工, 有助于科技知识的有效 利用。
[Objective] This paper tries to extract information from Sci-Tech big data and build an academic knowledge network, aiming to develop smart knowledge services. [Methods] We proposed an Ontology schema and a framework to contruct knowledge graph based on the distributed storage and high-performance computing of big data platform. The proposed model helped us extract and align research entities for relationship discovery. We also adopted the knowledge merging and enrichment, semantic storage and quality management techniques. [Results] We created a huge knowledge graph including more than 300 million entities and 1.1 billion relations. It also supported knowledge discovery platform and smart personal research assistant apps for scientific big data. [Limitations] More research is needed to improve the quality management of knowledge graph, as well as the precision of entity alignment. [Conclusions] The proposed method improve the knowledge management of scientific and technology big data.
目前, 科技信息呈现爆炸式增长的态势, 具有大规模、异质多元、组织结构松散的特点, 为科研人员有效获取信息和知识提出挑战。2012年5月, Google提出知识图谱(Knowledge Graph)[1], 旨在改善搜索结果, 描述真实世界中存在的各种实体和概念以及这些实体、概念之间的关联关系, 将知识系统化地呈现给用户。国内外互联网搜索引擎公司和研究机构也纷纷构建知识图谱, 如微软的Probase[2]、百度知识图谱[3]、搜狗的知立方[4]、中国科学院计算技术研究所基于OpenKN(开放知识网络)的“人立方、事立方、知立方”系统[5]、上海交通大学的中文知识图谱研究平台zhishi.me[6]、复旦大学中文概念图谱CN- Probase[7]等。知识图谱的重要性也受到政府关注, 《新一代人工智能发展规划》中提出, 重点突破知识加工、深度搜索和可视交互核心技术, 实现对知识持续增量的自动获取, 具备概念识别、实体发现、属性预测、知识演化建模和关系挖掘能力, 形成涵盖数十亿实体规模的多源、多学科和多数据类型的跨媒体知识图谱[8]。
钱力等[9]认为科技大数据不同于传统的期刊论文数据, 也不同于一般意义上的网络及行业大数据, 数据内容包括各学科内的记录数据、资料、文献、报告、网络科技报道等科技成果数据, 科技项目、学术会议、科技人才、科技机构、科技奖项、科技主题、科技概念、研究设备、研究模型、研究方法等科技实体及其语义关系的科技活动数据以及科技领域特色数据。笔者针对以上科技大数据, 开展了学术知识图谱的建设工作, 以有效支持海量数据的精准检索、个性化推荐、学科知识网络描绘等知识发现与科技情报服务。本文以应用实践为基础, 介绍了科技大数据知识图谱模型、技术架构、关键技术设计与实现方案以及基于知识图谱的示范应用。
知识图谱在语义搜索、智能问答、数据挖掘、推荐系统等领域有着广泛应用。在数字图书馆领域, 一些大型出版商也已开始以科技文献数据为基础构建知识图谱, 如Springer Nature的SciGraph不断地从期刊/文章、书籍/章节、组织、机构、资助者、研究资助、专利、临床试验、会议系列、事件、引用网络、Altmetrics、研究数据集等方面扩展数据, 其目标是创建学术领域最先进的关联数据聚合平台, 从内部和外部数据仓储中摄取数据, 将其转换为整个企业和研究领域可重用的知识[10]。Elsevier基于其丰富的数据和内容资源如论文、图书、引文、作者、机构、基金、化学物质、药物、EHRs等构建面向研究、生命科学和医疗健康的知识图谱[11]。Taylor & Francis开发了知识图谱工具Wizdom.ai, 其知识图谱涵盖9 000万出版物、1亿专利、5 800万作者、8万机构、6亿概念映射、42亿事实, 数据总量达150TB[12]。清华大学AMiner利用信息抽取方法从海量文献及互联网信息中自动获取研究者相关信息(包括: 教育背景、基本介绍)并建立研究者描述页面, 提供搜索、学术评估、合作者推荐、审稿人推荐、话题趋势分析等多样化服务, 目前AMiner中包括2.3亿论文、1.3亿研究人员、800万概念、 7.5亿引文关系[13]。上海交通大学Acemap知识图谱涵盖了1.1亿学术实体如6 100万论文、5 200万作者、 5万研究领域、1.9万机构、2.2万期刊等, AceKG为每个实体提供了丰富的属性信息, 在网络拓扑结构的基础上加上语义信息, 可以为众多学术大数据挖掘项目提供全面支持[14]。这些研究为本文提供了非常有益的借鉴, 特别是AMiner系统在作者消歧方面的研究思路。区别于上述研究, 本文数据来源为中国科学院文献情报中心长期积累的科技文献数据、科技活动数据以及领域特色数据, 数据类型更加多样和复杂, 并且为处理大规模数据笔者在知识图谱构建技术方面依托了大数据支撑平台。
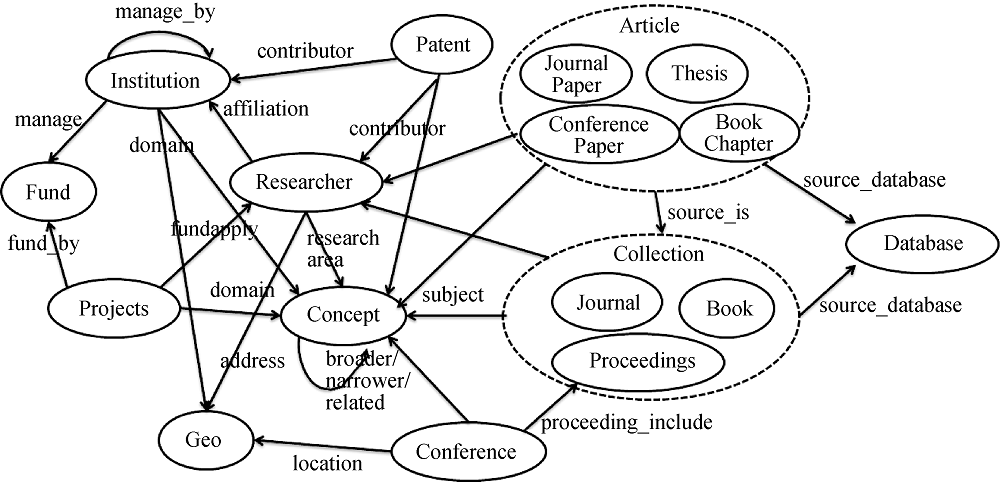
科技大数据知识图谱旨在描述科学研究活动中存在的实体、概念及其关系, 其本质是一种揭示实体关系的复杂网络。为提炼和抽象化科技大数据的相关知识, 本文首先构建如图1所示的知识图谱本体模型, 确定实体的基本类型或分类、各类实体具有的属性和属性值类型、不同类型实体之间的关系类型、关系的定义域以及关系值域等。遵循此模型构建知识图谱, 支撑知识的扩展与关系的丰富化, 既有助于知识的标准化, 又便于知识图谱的后续使用。本体模型中的实体类型主要包括: 期刊论文、学位论文、会议论文、图书章节、期刊、图书、会议论文集、研究人员、机构、基金、项目、会议、数据库、概念等。实体间关系包括贡献关系、隶属关系、资助关系、举办关系、发表关系、收录关系等。每一个实体都有详细的属性描述, 如研究人员(Researcher)的属性包括中文规范名称、英文规范名称、其他名称、性别、出生日期、ORCID、学位、社会任职、职务、职称、专业、研究方向、个人简介、邮箱、电话号码等。
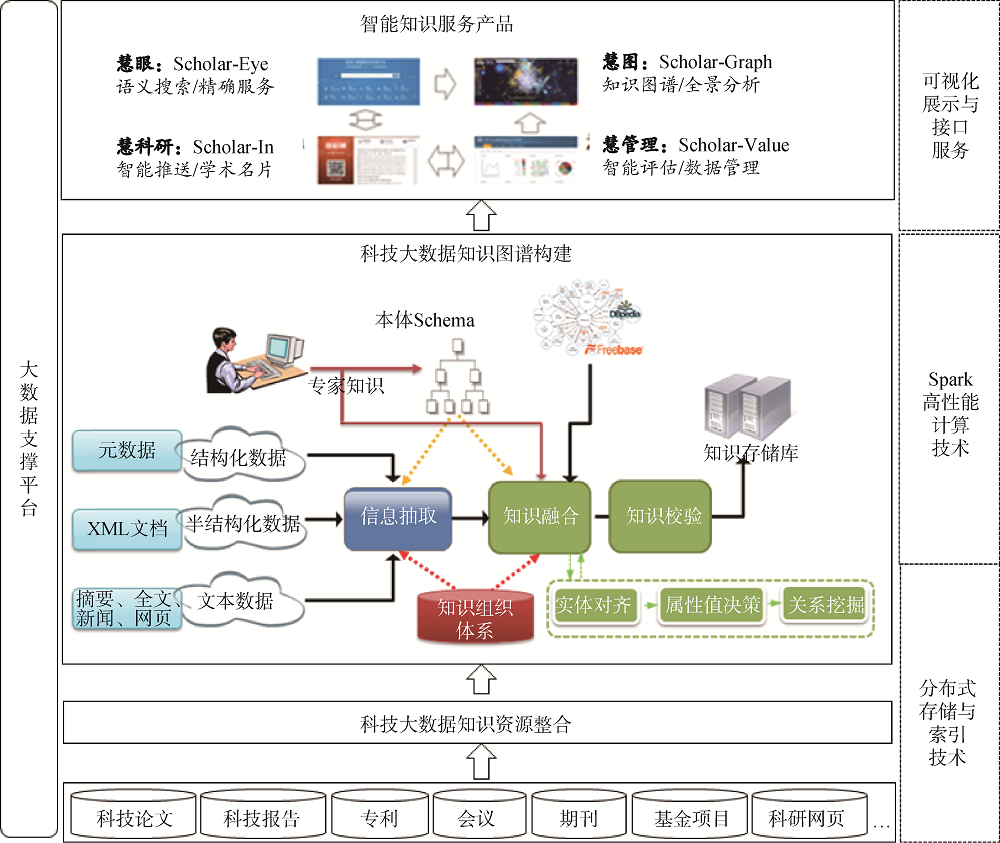
为构建以上述实体和关系为核心的科技大数据知识图谱, 本文设计了学术知识图谱的技术架构, 如图2所示。
(1) 制定一套数据描述标准和存储规范, 对期刊论文、学位论文、会议论文、科技报告、专利、基金项目、机构网站、科研网页等科技大数据进行资源汇聚和整合。采用大数据分布式存储与索引技术对科技大数据和知识图谱进行有效存储。
(2) 利用Spark等高性能计算技术完成知识图谱加工过程的数据计算, 在本体和知识组织体系(叙词表、分类体系、词典等)的指导下对结构化元数据、半结构化数据、文本数据进行信息抽取, 获得实体、属性和实体之间的关系, 形成知识图谱的实体网络, 并对其进行数据规范、实体对齐、属性值决策、关系挖掘以及融合外部知识(如DBpedia①(①http://dbpedia.org.)、机构网页、百科数据)等。此外, 采用自动检测和人工辅助的方式对知识图谱中的数据进行校验, 不断提高数据的质量。
(3) 开发可视化展示和接口服务, 促进科研大数据知识图谱有效支撑, 如慧眼、慧图、慧科研、慧管理等智能知识服务产品的研发。
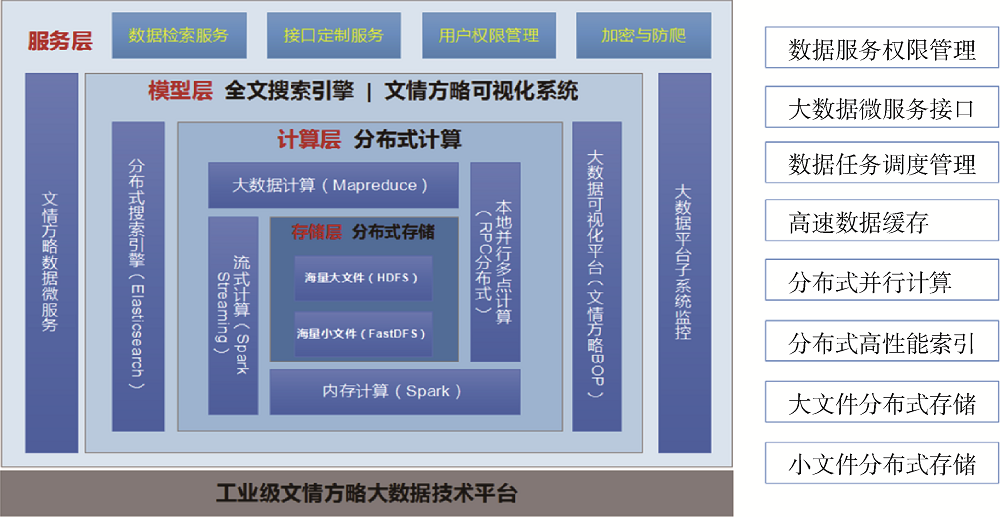
为实现海量科技大数据的统一管理与计算, 笔者所在机构搭建了大数据支撑管理平台, 通过海量数据分布式存储和高性能计算在技术上保障知识图谱的建设。大数据平台目前拥有24台高容量、高内存、双CPU、千兆四端口配置的服务器, 总容量约1PB, 内存3.5TB, 576内核CPU, 千兆以太网适配器支撑。其软件架构如图3所示。
(1) 存储层组件包括HDFS(面向大文件数据的存储)、FastDFS(面向小文件数据的存储);
(2) 计算层包括MapReduce(ETL处理)、Spark(模型计算、迭代计算)、SparkStreaming(流处理计算)、RPC工程(小分布式系统);
(3) 模型层包括Spark-模型库、自研算法(如知识图谱实体识别和关系发现的模型库, 作者识别、智能摘要、实体识别等)、ElasticSearch(全文搜索引擎, 支持检索、知识图谱构建等)、科技大数据管理平台;
(4) 服务层包括SpringCloud微服务、用户权限管理系统。通过软硬件基础设施建设保障稳定高效的计算能力。
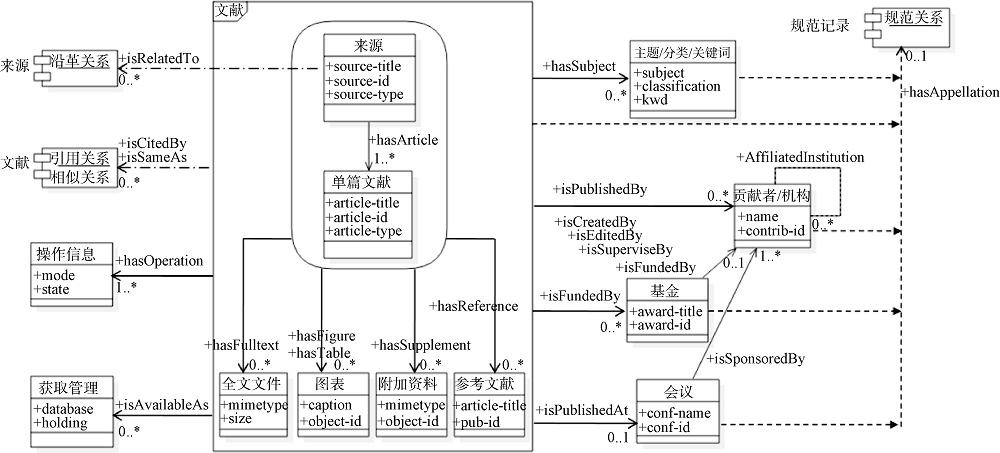
科技大数据既包括科技文献数据如图书、期刊论文、会议论文、学位论文、科技报告、专利、标准等, 也包括科研人员、基金项目、会议、机构、科技概念等科技活动数据, 不同来源的数据格式往往不同, 遵循的元数据标准也有所差异。为实现数据资源的统一治理并便于在此基础上构建知识图谱, 对不同来源的数据如WOS数据库、CSCD数据库、维普数据库、中国科学院学位论文库等的元数据格式进行分析, 设计统一元数据格式进行存储和管理。由于NSTL统一文献元数据标准适用于科技类信息资源, 可对期刊、会议录、科技丛书、科技专著、文集汇编、工具书、科技报告、期刊论文、会议论文、学位论文、开放课程、开放课件等文献进行统一描述和组织(其Schema如图4所示), 并具有扩展性[15], 本文以此为基础, 将文献集(如期刊、图书、论文集等)、单篇文献(如期刊论文、会议论文、学位论文、图书章节等)、主题/分类/关键词、贡献者、机构、会议、基金项目等元素分别进行描述和扩展, 并增加专利元数据描述。
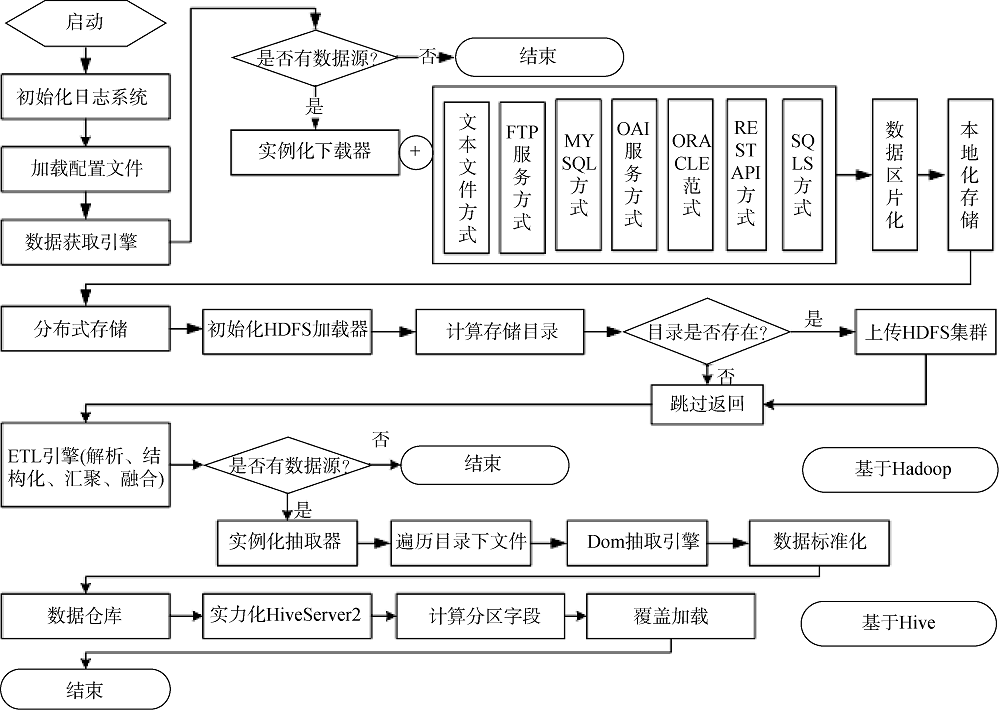
根据各数据源提供的接口和下载地址, 利用OAI协议、FTP、数据库等方式对数据进行采集和收割。针对不同格式的数据源分别开发了对应的解析工具, 利用如图5所示的配置化数据处理引擎框架, 通过配置文件设置解析和处理方式, 调用数据获取引擎, 判断分布式存储方式上传至HDFS集群, 使用ETL引擎对来源数据进行解析、抽取和结构化处理, 保证从各数据源采集的数据可以进行统一的清洗、规范、管理和使用, 并严格按照统一数据标准进行存储。
在解析过程中, 利用已建立的规范库或词典对期刊、研究人员、机构、文献关键词等进行规范化处理。例如分词器抽取文本中关键词时直接对照规范库进行规范化, 并利用规范库和自定义规则对机构名称、机构缩写、机构地址、研究人员中英文姓名等关键数据进行规范化, 此外针对个别数据源的特殊情况如大小写转换、名称分隔符切分等分别进行处理。
科技文献情报资源作为科学产出, 蕴含着丰富的科技知识, 是科技大数据知识图谱构建的基本数据 资源。
(1) 从科技文献元数据中提取结构化数据, 生成不同类型的实体, 获得实体的属性值。如图6所示, 将一篇期刊论文作为一个实体, 并提取题名、作者、机构、摘要、关键词、出版卷期等属性信息, 每个论文作者新建为研究人员, 具有属性信息如邮箱、机构地址等, 同样地提取机构实体、期刊实体等, 并建立期刊论文与期刊之间的来源关系、与研究人员之间的贡献关系, 研究人员与机构之间的所属关系等。
(2) 从外部资源如维基百科的infobox和百度百科的属性表格、机构网站、个人主页等半结构化网页中解析更为丰富的属性信息, 对实体属性和关系进行补充。针对各垂直站点分别制定规则生成包装器(或称为模板), 并根据包装器提取属性信息。例如从某研究人员个人主页中获取出生年月、国籍、教育背景、研究领域、联系方式等。
(3) 利用自然语言处理技术从非结构化文本中提取实体或概念如任务、方法、指标、工具等, 发现实体之间的语义关系并建立实体与论文实体之间的关联。
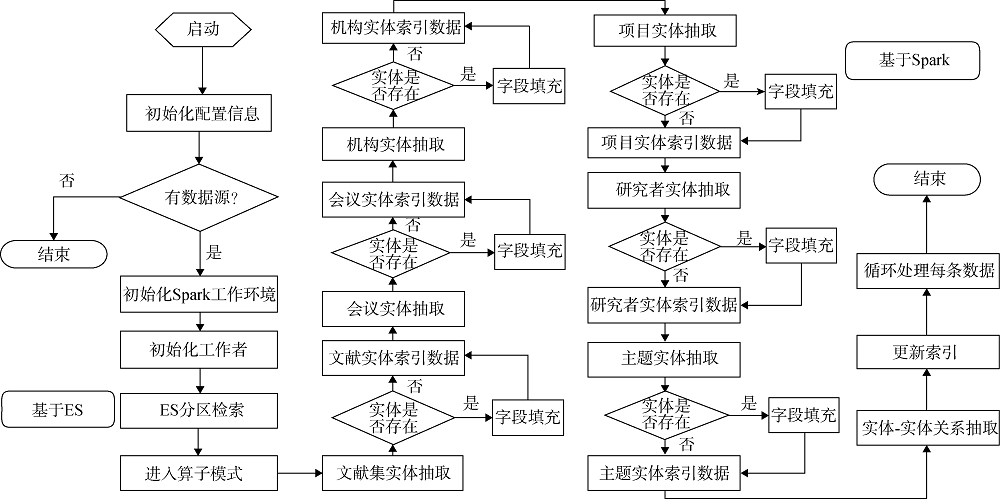
科技大数据知识图谱进行知识抽取和实体关系抽取的流程如图7所示, 依托大数据平台中Spark并行计算能力对海量科研数据进行分析和处理。分别进行文献集、单篇文献、会议、机构、项目、研究人员、主题等实体的提取工作, 并进行相关属性字段的填充, 建立实体之间的语义关系。
由于不同来源数据的描述方式存在差异, 并且存在不同作者具有相同的名称、机构缩写或别名、期刊名称全拼缩写等中英文名称的歧义问题, 需要对知识抽取获得的实体进行对齐和共指消歧。为此, 首先针对不同的实体类型提出如表1所示的基础排重规则, 对不同来源的实体进行甄别、筛选和区分, 将不同数据来源中表示同一对象的实体归并为一个具有统一标识的实体添加到知识图谱中。例如使用DOI、ISSN、ISBN、ORCID等唯一标识符分别进行期刊论文、期刊、图书、研究人员实体去重, 使用标题、作者、出版年份确定同一篇期刊论文, 论文名称、会议名称、地点、日期等区分会议论文, 使用标题、作者、毕业院校、年份、指导教师区别学位论文, 使用标题和日期区分科技报告, 研究人员也可通过邮箱、姓名、所属机构区分判断, 机构通过名称和地点区分判断, 会议通过会议名称、会议时间、地点区分判断, 项目通过资助编号、项目名称和资助年份区分判断。
相比论文、报告、会议、项目实体, 机构、研究人员、概念/术语由于存在同名异义、多种名称变形、同义词等问题, 并且从科技数据资源中获得的信息量有限, 进行实体对齐难度较大。因此, 在基础排重规则的基础上进一步设计各自的处理规则。
针对机构借助已有规范库和词表进行数据清洗和规范。
(1) 城市、国家、邮编提取;
(2) 大学、院系、实验室拆分;
(3) 研究所、实验室、部门拆分;
(4) 缩略形式规范化;
(5) 映射规范机构库。
针对研究人员进行邮箱拆分、多个所属机构拆分; 采用基于规则的算法, 设定强规则相同ORCID、相同E-mail为同一人, 弱规则中英名称变体、一级机构、二级机构、合作关系、研究领域(关键词、主题词)等进行相似度计算, 此外考虑研究人员其他背景信息如研究人员简历等, 借助其个人主页的出版物进行反向对比。
对概念/术语分别采取原型化处理、中英文翻译、利用现有叙词表如STKOS、WordNet等进行映射处理, 并进行共现计算、聚类分析等, 计算获得同义词、主题词关联等。
当融合来自不同数据源的信息构成知识图谱时, 有一些实体会同时属于两个互斥的类别或某个实体的一个属性对应多个值时, 需要决定选用哪个类别或哪个值, 进行属性值决策。为此本文根据各实体类型分别考虑数据源的可靠性和丰富度以及不同信息在各个数据源中出现的频度等因素。
此外, 开展关系挖掘工作, 利用原始关系推理生成新的数据, 建立更多的实体间的链接关系, 增加知识图谱中边的密度, 例如同一篇论文的贡献者的合作关系, 论文作者的机构与该论文之间的贡献关系, 具有相同合作者的研究人员之间潜在合作关系等。
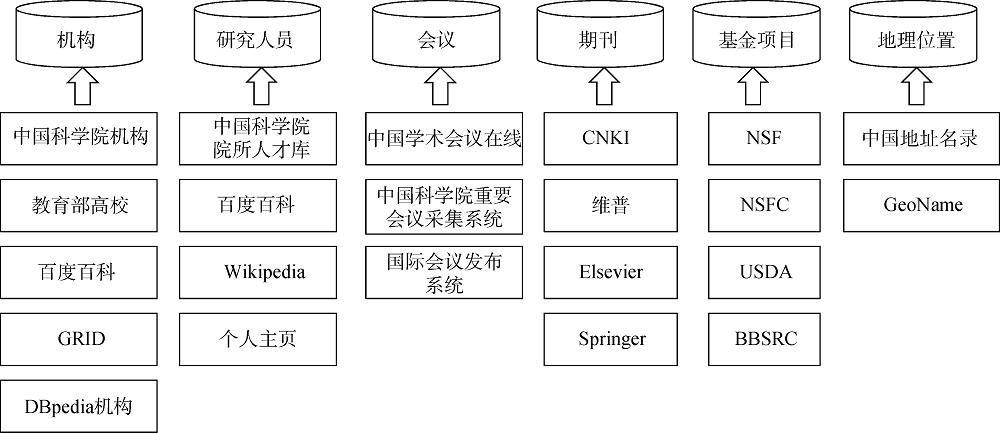
为完善从科技文献和其他资源中抽取的实体信息, 从图8所示的多个来源获取数据, 进行知识融合和语义丰富化。例如采集和下载中国科学院机构名录、教育部高校名录作为规范库, 并利用百度百科、GRID①(①https://www.grid.ac/.)、DBpedia等机构数据对知识图谱中机构的属性信息进行补充, 利用中国科学院院所人才库、个人主页等补充研究人员的属性信息, 采集中国学术会议在线②(②http://www.meeting.edu.cn.)、国际会议发布系统③(③http://csp.escience.cn.)、中国科学院重要会议采集系统④(④http://or.clas.ac.cn.)等完善会议属性, 从CNKI、维普、Elsevier、Springer中的期刊主页获取期刊详细信息, 从美国、日本、英国、加拿大、中国等多个国家的基金资助机构NSF①(①https://www.nsf.gov.)、USDA②(②http://www.usda.gov.)、BBSRC③(③http://www.bbsrc.ac.uk.)、NSFC④(④http://www.nsfc.gov.cn.)中获得项目数据, 利用 中国地址名录和GeoName数据库⑤(⑤http://www.geonames.org.)丰富地理位置信 息等。
同时, 融合分类词表、叙词表、主题词表、科研本体等领域知识, 如充分利用科技知识组织体系STKOS超级科技词表, 建立论文关键词之间的映射和关联, 获取概念之间上下位关系、相关关系等, 同时在知识图谱建设过程中不断逐步丰富概念关系。并通过关联DBpedia、CNDBpedia⑥(⑥http://kw.fudan.edu.cn/cndbpedia/.)、YAGO⑦(⑦http://www.mpi-inf.mpg.de/yago-naga/yago/.)、BabelNet⑧(⑧http://babelnet.org.)等知识图谱和数据集, 丰富和完善知识 图谱。
如何对知识图谱进行表示与存储是构建和应用知识图谱过程中需要解决的重点问题。知识图谱本质上是一种复杂网络, 网络的每个节点带有实体标签和属性信息, 节点之间的每条边带有有向关系标签, 并且知识图谱的相关应用往往需要借助于图算法完成, 因此知识图谱一般采用图数据库或网络方式存储。然而基于网络的表示方法面临很多困难, 如数据稀疏问题、图算法计算复杂度问题等, 大规模知识图谱需面向具体数据情况和应用需求进行 设计。
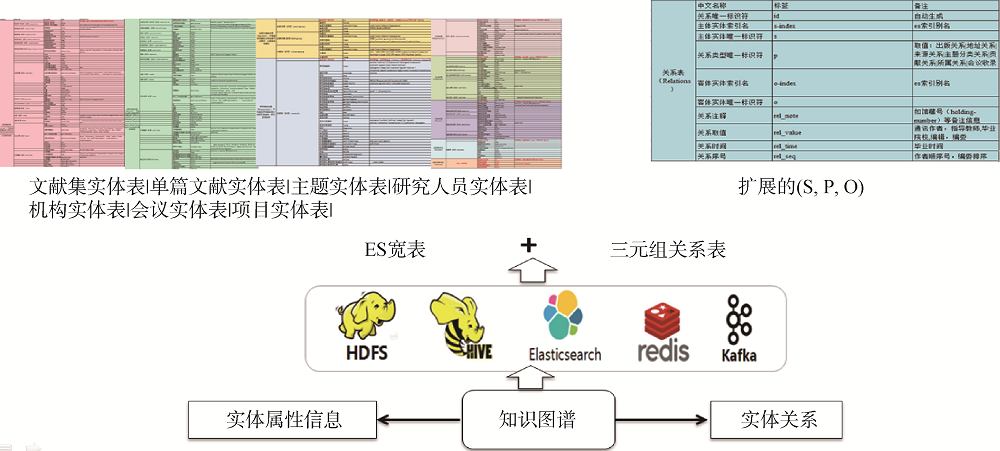
由于科技大数据知识图谱中各实体的属性信息比较丰富, 属性信息的数据量远大于关系的数据量, 在实际应用中对于实体属性信息的检索需求也较大。基于此, 本文设计如图9所示的存储模式, 利用大数据平台快速存取和处理技术对知识图谱数据进行存储和管理。将知识图谱数据分成实体属性信息、实体关系两部分分别存储, 以宽表的形式将实体各个属性作为存储字段分别为文献集、单篇文献、主题、研究人员、机构、会议、项目等, 创建ElasticSearch(ES)索引进行存储。通过创建关系ES索引扩展三元组(uuid, s, s_index, p, o, o_index, rel_note, rel_value, rel_time, rel_seq)存储实体关系数据。在关系计算方面, 采用图算法进行数据处理并离线计算预存储的方式提高图计算的效率。此外, 为减少检索多次查询或遍历引起的时效问题, 对数据字段进行冗余处理, 如文献索引中仍存储研究人员及机构信息并保证与研究人员、机构索引的数据一致性, 在检索时避免了对实体关系表的多次查询操作。
科技大数据知识图谱采用迭代式构建、版本式发布的方式推出。为了保证知识图谱的质量, 提高知识图谱的覆盖率和准确度, 需要对知识图谱进行不断维护与更新, 构建过程中由质量审核人员全程进行质量监管, 在数据加工处理流程抽样发现问题并及时修正。此外, 设置相关规则对存在矛盾和问题的数据进行自动检测, 也通过人工辅助的方式发现数据问题并予以修正。
加入到知识图谱的数据不是一成不变的, 特别是网络环境下科技数据的更新频率较快, 某一类型对应的实体是动态变化的, 例如研究人员的任职情况。为此, 通过定期检测不同数据源的数据增量更新情况以及实体和关系的增删改情况, 基于本体模型发现存在影响的关系和实体, 制订针对这些更新能够采取的应对策略, 设置相关规则, 将检测到的数据更新情况及时反馈到知识图谱中。
截至目前, 已建成的科技大数据知识图谱实体规模达3亿, 其中科技论文1.08亿, 专利0.9亿, 科研人员8 433万、机构1 856万、期刊9.3万、基金项目1 019万, 实体间关系已达到11.33亿, 存储总量达到了7.84T。知识图谱采用多维ES分布式索引方式存储, 分别对各实体类型和关系进行扁平化存储, 保障了大规模数据的快速检索。建成的知识图谱作为大规模知识库有效支撑了基于科技大数据 的知识发现平台和“慧科研”智能随身助手应用的 服务。
以知识图谱为引擎, 构建科技大数据知识发现平台, 为用户提供科技论文、资讯、报告、专利、标准、学者、机构、项目、会议、期刊10类科研实体的普适性科研信息检索发现服务。
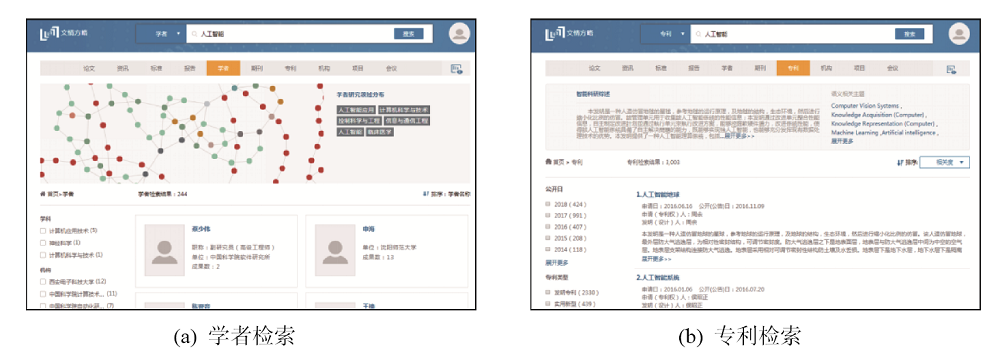
如图10所示, 分别检索“人工智能”相关的 学者、专利实体, 平台实现了科研实体搜索、研 究主题探索、语义主题关联、专利关联发现等功 能, 揭示了该主题相关学者研究领域分布、研究学者、研究机构和研究论文、发展趋势、相关主题、热门期刊等, 辅助科研人员了解当前关注方向的 专利产出, 并有助于企业、研究机构寻求科研合作关系。此外, 通过构建学者个人主页、机构主页、期刊主页等, 实现各实体的信息展示和关联发现, 图11展示对学者的关联发现, 如学术贡献分析、学术成果自动汇聚、合作学者网络、学者研究兴趣的变化和发展等功能。
本文结合实际建设经验, 提出科技大数据知识图谱构建方法, 建立研究人员、机构、期刊、论文、项目、基金、专利等实体相互关联的复杂网络, 实现知识层面的数据融合与集成, 进一步加强科研数据资源的深层整合, 将有效支持海量文献数据资源的精准检索、个性化推荐、学科知识网络描绘等知识发现与情报决策服务。本研究也存在一些问题和不足, 未来工作将进一步提高知识计算的效率和准确度, 搭建知识加工平台, 采用众包方式通过人工加工和审核进一步保障知识图谱质量, 并提升机器自动检测和处理功能, 降低人力成本。此外, 笔者也发现目前学术知识图谱研究大多从文献的元数据层面提取实体或仅对文献进行领域概念的标注, 并没有对科技资源内部隐藏的知识进行深入挖掘和利用, 为此, 下一步将对此开展研究和实验, 通过细粒度化的挖掘和关联, 促进科技知识的计算和利用, 让科技大数据发挥更大的效用。
王颖, 钱力, 谢靖:提出研究思路, 设计研究方案;
王颖, 常志军, 孔贝贝: 数据加工、清洗, 系统开发与分析;
王颖: 论文起草;
钱力: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: wangying@mail.las.ac.cn。
[1] 王颖, 钱力, 谢靖, 常志军, 孔贝贝. Resource. ES索引科技数据存储库.
[2] 王颖, 钱力, 谢靖, 常志军, 孔贝贝. ResourceSchema.xml.知识资源统一描述规范.
[3] 王颖, 钱力, 谢靖, 常志军, 孔贝贝. KGOntology.owl. 知识图谱本体文件.
[4] 王颖, 钱力, 谢靖, 常志军, 孔贝贝. kg. ES索引. 知识图谱存储数据集.
[5] 王颖, 钱力, 谢靖, 常志军, 孔贝贝. ExternalResource.sql. 外部资源规范库.
| [1] |
URL
[本文引用:1]
|
| [2] |
[本文引用:1]
|
| [3] |
URL
[本文引用:1]
|
| [4] |
URL
[本文引用:1]
|
| [5] |
[本文引用:1]
|
| [6] |
[本文引用:1]
|
| [7] |
URL
[本文引用:1]
|
| [8] |
URL
[本文引用:1]
|
| [9] |
[本文引用:1]
|
| [10] |
URL
[本文引用:1]
|
| [11] |
URL
[本文引用:1]
|
| [12] |
URL
[本文引用:1]
|
| [13] |
[本文引用:1]
|
| [14] |
URL
[本文引用:1]
|
| [15] |
URL
[本文引用:2]
|






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}