
 , 付常雷, Fu Changlei
, 付常雷, Fu Changlei【目的】改进Bootstrapping方法, 建立深度学习模型从文本中抽取多类型细粒度的知识元。【方法】利用搜索引擎和Elsevier关键词构建知识元词库; 基于Bootstrapping技术自动构建大规模的标注语料库, 利用知识元评分模型和模式评分模型控制标注的质量; 基于已标注多类型知识元的语料库训练LSTM-CRF模型, 从文本中抽取新的知识元。【结果】基于17 756篇ACL论文摘要抽取“研究范畴”、“研究方法”、“实验数据”、“评价指标及取值”这4种知识元, 其人工评价平均正确率为91%。【局限】模型参数的预设与调整需要人工参与, 未对不同领域文本进行适用性验证。【结论】引入知识元与模式的评分模型, 能够有效缓解“语义漂移”问题; 基于深度学习模型抽取知识元实现快速且正确率高, 为情报大数据智能分析提供了一种高效可靠的数据获取手段。
[Objective] This paper tries to extract fine-grained knowledge units from texts with a deep learning model based on the modified bootstrapping method. [Methods] First, we built the lexicon for each type of knowledge unit with the help of search engine and keywords from Elsevier. Second, we created a large annotated corpus based on the bootstrapping method. Third, we controlled the quality of annotation with the estimation models of patterns and knowledge units. Finally, we trained the proposed LSTM-CRF model with the annotated corpus, and extracted new knowledge units from texts. [Results] We retrieved four types of knowledge units (study scope, research method, experimental data, as well as evaluation criteria and their values) from 17,756 ACL papers. The average precision was 91%, which was calculated manually. [Limitations] The parameters of models were pre-defined and modified by human. More research is needed to evaluate the performance of this method with texts from other domains. [Conclusions] The proposed model effectively addresses the issue of semantic drifting. It could extract knowledge units precisely, which is an effective solution for the big data acquisition process of intelligence analysis.
文献是科研工作者接触最为频繁的数据, 包括论文、专利、项目、报告等。在大数据时代, 信息来源众多、知识负载加重, 科研工作者很容易陷入海量文献数据的泥潭中。面对信息过载, 科研工作者如何快速定位前沿的研究方向?如何准确凝练重大的科学问题?如何敏锐感知关键技术的变化趋势?这些需求对情报大数据智能分析提出新的挑战。
知识元是组成知识的基本单位和结构要素, 一般以词语、概念、术语表征文献内容[1]。知识元抽取已经成为情报大数据智能分析的关键技术之一。细粒度知识元抽取旨在根据领域需求为非结构化文本添加多层次细粒度的语义标签, 例如一篇论文中的研究范畴、方法、数据、指标、指标值等[2]。不同于文献元数据(标题、作者、摘要、关键词等), 从文本内容中抽取知识元有利于了解知识的产生、传播和应用, 追踪知识的基础、中介和前沿, 研究知识的结构、演化和重组[3]。
本文提出一种文本蕴含细粒度知识元抽取的深度学习方法: 利用搜索引擎和Elsevier关键词构建知识元词库; 基于Bootstrapping技术自动构建大规模的标注语料库, 利用知识元评分模型和模式评分模型控制标注的质量; 并基于已标注多类型知识元的语料库训练LSTM-CRF模型, 从文本中抽取新的知识元。本文的创新点如下。
(1) 细粒度挖掘数据的语义: 将知识元类型从“人物”、“机构”、“主题词”、“术语”扩充到更细粒度的“研究范畴”、“方法”、“数据”、“指标”和“指标值”, 有助于丰富现有的知识组织模型和改善知识服务模式, 以满足不同信息粒度上对象及对象间关系的认知需求;
(2) 深度学习方法抽取知识元: 基于Bootstrapping策略自动构建标注语料库, 增强方法的移植性; 基于句子词法特征构建知识元表示模板, 降低对自然语言深度语义解析工具(句法解析、依存解析等)的依赖性, 改善方法的灵活性; 分别对知识元和模板建立评分模型, 保证Bootstrapping迭代收敛性, 提高方法的精度。
文本蕴含知识元抽取的研究集中于主题标引[4,5]和术语识别[6,7]: 通过词频统计[8]、主题聚类(例如LDA模型[9]、Clique聚类[10])等方法, 识别文本中的重要词汇作为主题或者关键术语。由于主题和术语的语义粒度较粗, 仅能反映领域内的重要概念和概念间的共现和上下位关系, 其研究成果主要用于构建领域本体或揭示领域发展概貌[11], 无法提供面向知识层次的精细化服务。
随着情报大数据智能分析服务不断精细化, 知识元抽取研究范畴逐步从论文元数据(题录信息)提取、主题和术语抽取扩展到面向自然语言描述文本的语义标注。现有的知识元抽取方法可概括为4类:
(1) 人工标注[12,13]: 先由领域专家建立文本语义标注规范, 在领域专家的指导下多人为同一文本添加语义标签, 经过多轮交叉验证与修正获得标注语料。Zadeh等[13]通过人工标注方式为300篇ACL论文摘要添加7种语义标签: method、tool、language resource、language resource product、model、measures、other。Augenstein等[7]人工标注500篇论文的关键短语, 涵盖计算机科学、材料科学、物理三个领域。Tateisi[12]人工标注了130篇IPSJ日文论文摘要, 包括三种知识元(对象、术语和度量方法)和16种语义关系。人工标注方法建立的知识元标注语料库因其质量可靠, 常作为金标准用于评价知识元抽取系统的性能。然而, 该类方法依赖于专家知识且耗时费力, 语义标注内容和规模均难以扩展。
(2) 基于规则的方法[14]: 情报分析人员最早基于规则的方法识别论文、专利等文献中的作者和机构两类命名实体。该类方法准确率高, 但不同领域需要语言学专家重新编写规则, 耗时费力。为了降低构建规则的成本, 一些研究者通过Bootstrapping技术自动挖掘规则[15,16,17]: 先由领域专家指定少量的知识元实例作为种子; 再利用前后词语、词性、句法解析树、依存解析树等特征, 将自然语言描述种子的句子抽象为模板, 加入到规则库; 通过规则匹配从文本中挖掘新的知识元实例, 加入到种子库。如此迭代, 直到规则库或种子库不再发生变化。然而, Bootstrapping技术在多轮迭代过程中容易发生“语义漂移”, 严重影响模板挖掘的质量。总之, 有限的规则难以应对自然语言表达的灵活性, 知识的覆盖性和完备性决定了基于规则的方法性能。
(3) 基于统计的机器学习方法[18,19]: 考虑到基于规则方法的诸多弊端, 研究者逐步将基于统计的机器学习方法引入到情报学领域, 并基于决策树(DT)、支持向量机(SVM)、条件随机场(CRF)、马尔科夫逻辑网络(MLN)等模型在诸多领域开展了广泛的研究。例如基于DT模型, 抽取业务报告中的结构化数据, 为政府决策提供及时有效的信息[20]; 基于SVM模型, 识别电子病历中的疾病信息[21]; 基于CRF模型, 识别学术论文中的基因、蛋白质、药物等名称[22]; 基于MLN模型, 从专利文献中识别技术、材料、过程、组织结构等信息[23]。基于统计的机器学习方法对未知信息具有良好的发现能力, 在命名实体识别任务中表现突出。然而, 大部分利用统计机器学习模型进行特征选择的任务都是劳动密集型的, 需要领域专家结合实际需求对不同类型的知识元分别建立特征模板; 且模型训练依赖大规模的标注语料, 有限的标注语料中难以体现不常见自然语言描述的规律性。统计机器学习方法的鲁棒性受到考验。
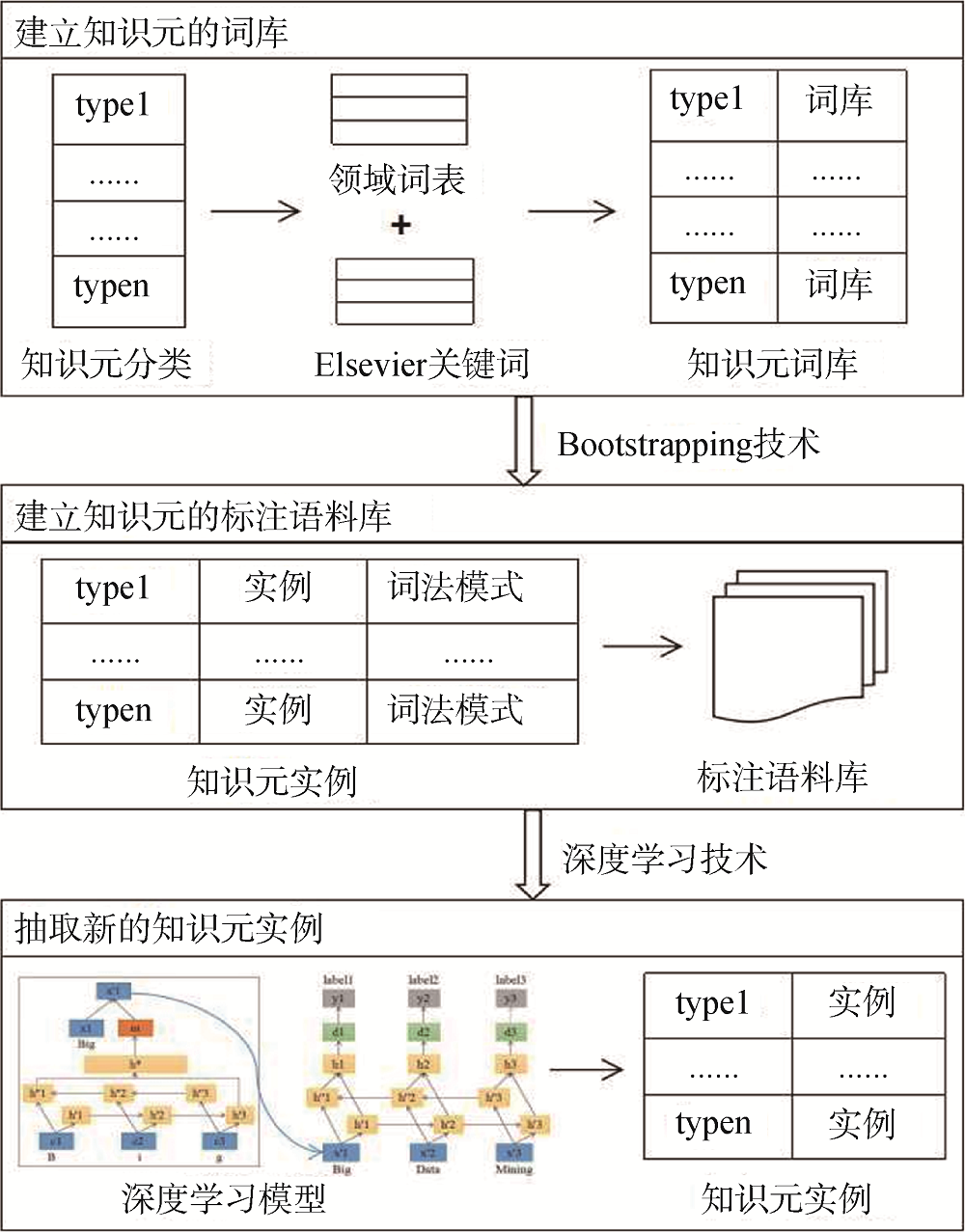
本文提出一种面向细粒度知识元抽取的深度学习方法, 总体路线如图1所示。结合领域需求定义细粒度知识元的类型, 并从网络上搜集领域词表, 同时补充Elsevier的关键词, 通过人工分类为每一种知识元建立词库; 针对每种类型的知识元, 基于Bootstrapping技术挖掘新的知识元实例, 为文本添加多种类型的知识元语义标签, 构建标注语料库; 基于已标注多种类型知识元的语料库训练深度学习模型, 利用训练好的模型从文本中抽取新的知识元实例。
深度学习模型虽然在命名实体识别任务中表现突出, 但是它仍需要大规模的标注语料库以训练模型的参数。人工构建标注语料库耗时费力, Bootstrapping技术构建标注语料库又存在“语义漂移”的问题。为了降低标注语料库的构建成本, 本文改进了基于Bootstrapping技术自动构建语料库的方法: 在Bootstrapping每轮迭代过程中增加模式评价和知识元评价, 以提升Bootstrapping挖掘模式和知识元的质量, 保证多轮迭代的“语义一致性”。针对指定的知识元类型
(1) 基于词典匹配的方法, 在文本中查找类型为
(2) 从文本中提取每个知识元的词法表达式, 筛选出新增的词法表达式, 加入到类型为
(3) 计算每个候选模式的得分, 选择得分大于阈值
(4) 基于模式匹配的方法, 识别文本中类型为
(5) 筛选出新增的知识元, 计算每个新增知识元的得分, 选择得分大于阈值
(6) 循环上述步骤, 直到类型
知识元的词法表达式由知识元的前后词语组成。例如, 句子“In this paper, we propose a new approach, Dict2vec, for describing words - natural language dictionaries”中包含类型为“研究范畴”的知识元实例“describing words - natural language dictionaries”, 可抽取“研究范畴”的模式“we propose ([^,;\?:]{1,}) for ()”; 还包含类型为“研究方法”的知识元实例“Dict2vec”, 可抽取“研究方法”的模式“we propose a new approach () for”。
类型为
$score(T|K)=\frac{N(T|K)}{N(T)}$ (1)
类型为
$score(i|K)=-\sum\limits_{w\in W}{p(w){{\log }_{2}}}p(w)$ (2)
$p(w)=\frac{f(w)}{\sum\limits_{w'\in W}{f(w')}}$ (3)
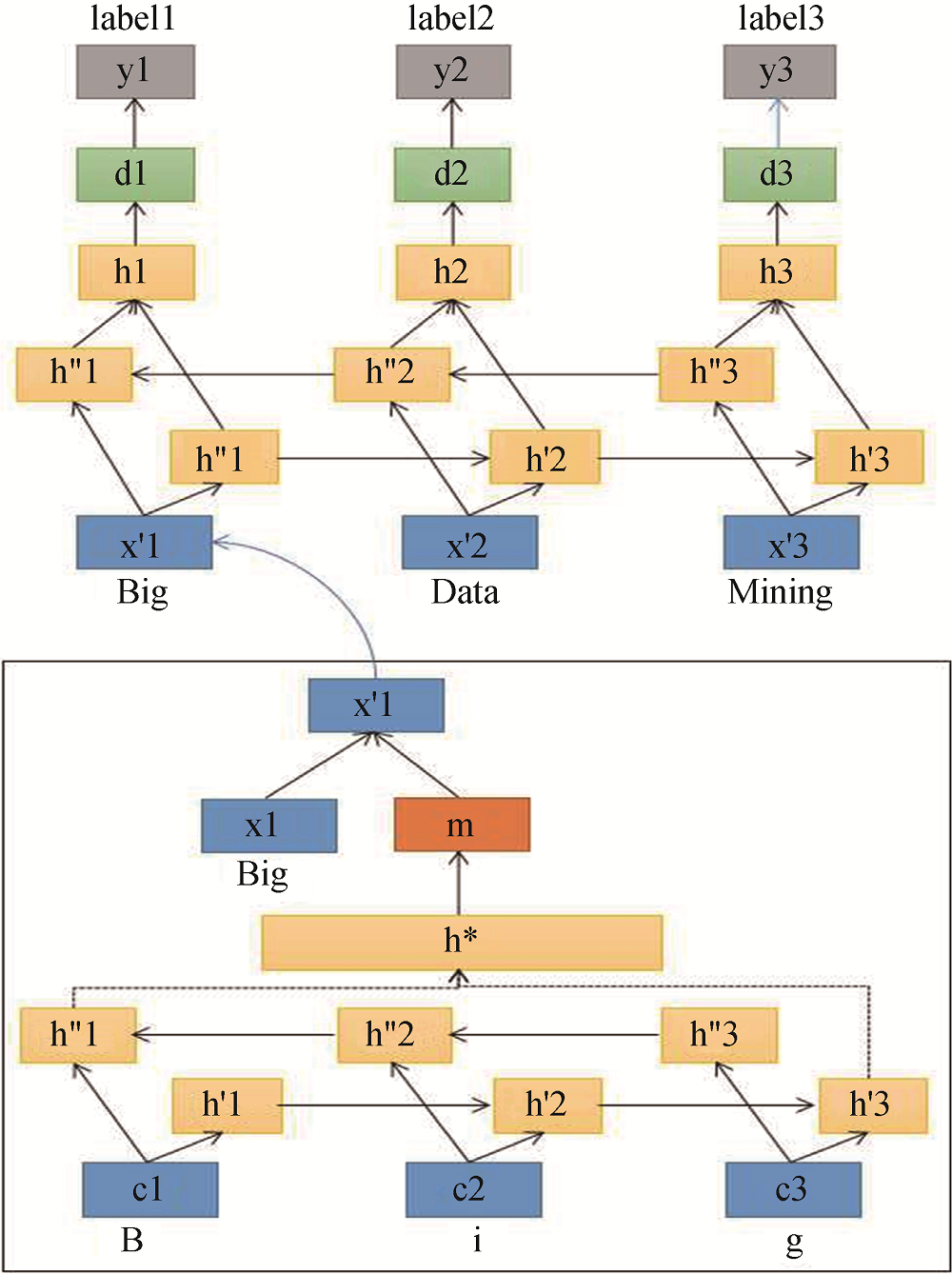
长短期记忆模型(Long-Short Term Memory, LSTM)因其有效避免了“梯度消失”问题, 具有长时间范围内的记忆功能, 被广泛用于自然语言处理任务。本文基于Rei等[27]提出的“词语级向量与字符级向量组合的LSTM-CRF模型”, 抽取多类型细粒度的知识元。模型的网络结构如图2所示。
图2中, 网络结构的最后一层y基于CRF模型来预测每个词语标注为各类语义标签的概率。词语级向量x1直接由词语映射到分布式的向量空间得到(例如基于Word2Vec模型实现)。字符级向量m的计算方式为: 首先将每个词语拆分成单个字符, 将每个字符映射成一个字符向量; 然后输入到LSTM模型中, 级联前后两个方向的向量表达式得到h*; 最后通过线性变换得到一个词语的多个字符的向量表达式m。词语级向量x1和字符级向量m级联得到x'1, 输入到知识元抽取模型。融入字符级向量后, LSTM模型能有效利用词语的前后缀信息, 以计算未知词语的向量。同时, 在LSTM模型的顶端还增加了一个隐含 层d, 允许模型检测更高级的特征组合, 以关注更加泛化的模式。
从NSTL成员单位加工的印本数据中检索出Annual Meeting of the Association for Computational Linguistics自1980年至2017年发表的论文摘要, 共计17 756篇作为实验数据。基于开源的深度学习模型LSTM-CRF①(①https://github.com/marekrei/sequence-labeler.), 从上述会议论文摘要中自动抽取4种知识元: “研究范畴”、“研究方法”、“实验数据”、“评价指标及取值”。
针对上述的4种知识元类型, 分别从网络上搜集计算机科学领域的词表, 同时补充Elsevier的关键词, 再通过人工分类为每种类型的知识元建立词库。然后, 基于Bootstrapping技术, 分别扩充4种知识元 的词库。最终挖掘出的知识元数量和模板数量如表1所示。
表1结果显示, 基于网络资源和文献关键词构建的原始知识元词库的规模非常有限, 且需要人工分类整理。基于Bootstrapping技术自动扩充词库, 可快速地挖掘出大量新增的知识元, 降低了人工成本。同时, Bootstrapping迭代次数反映出“实验数据”和“评价指标及取值”两类知识元的收敛速度更快。原因是“实验数据”和“评价指标及取值”的词库规 模更小, 语言表达形式更简单, Bootstrapping技术 在每轮迭代中能快速捕捉到大多数知识元的表达 模式。
分别从每种知识元扩充后的词库中随机采样100个结果进行人工评价, 其正确率如表2所示。分析采样数据, 自动扩充的知识元词库的错误情况分为三种:
(1) 知识元边界不准确, 例如“submission to the Text Classify Task”应该为“Text Classify Task”。本文通过检测结果中知识元两端的介词和动词来修正知识元的边界。
(2) 无意义的词汇, 例如将“main task”标注为“研究范畴”, 将“advance model”标注为“研究方法”。本文分别为4类知识元建立通用词表(如表3所示), 通过检测结果的通用词、形容词或副词等修饰词, 过滤掉无意义的标注。
(3) 错误的分类, 例如将句子“a beneficial resource for sentiment analysis is built”中“研究范畴”“sentiment analysis”标注为“实验数据”, 原因是“研究范畴”与“实验数据”的模式发生了冲突。规定模式匹配的优先级为: “研究范畴>研究方法>实验数据>评价指标及取值”, 以解决模式冲突的问题。
基于自动扩充的知识元词库, 为上述会议论文摘要添加4种知识元的语义标签, 构建了一个大规模的标注语料库, 包括3 634个“研究范畴”、2 583个“研究方法”、1 012个“实验数据”, 722个“评价指标及取值”, 用于训练知识元抽取的深度学习模型。
基于Bootstrappinng技术自动构建的大规模标注语料库, 利用LSTM-CRF模型从17 756篇ACL会议论文摘要中抽取4种类型的知识元。分别从每种知识元抽取结果中随机采样100个进行人工评价, 其正确率如表4所示。
表4结果显示, 深度学习模型对于抽取“实验数据”和“评价指标及取值”两类知识元非常有效, 原因是它们的标注语料质量更加可靠, 模型训练的效果更好。同时, 由于“研究范畴”和“研究方法”的自然 描述形式更加灵活多样, 模型抽取出的实例数量 更多。
为了直观展示多类型细粒度知识元的抽取效果和关联关系, 为科研工作者提供深入文本内容的智能查询服务, 开发了如下两个系统:
(1)“知识元在线识别工具”: 用户输入任意一段文本, 系统可自动识别出文本中4类知识元: “Problem”、“Methods”、“DataResources”、“Metrics”, 并使用不同颜色高亮显示各类型的知识元。如图3所示, 系统自动识别出的“Problem”知识元: speech and language processing, speech recognition, natural language processing tasks, question answering, semantic parsing; 识别出的“Methods”知识元: deep learning。
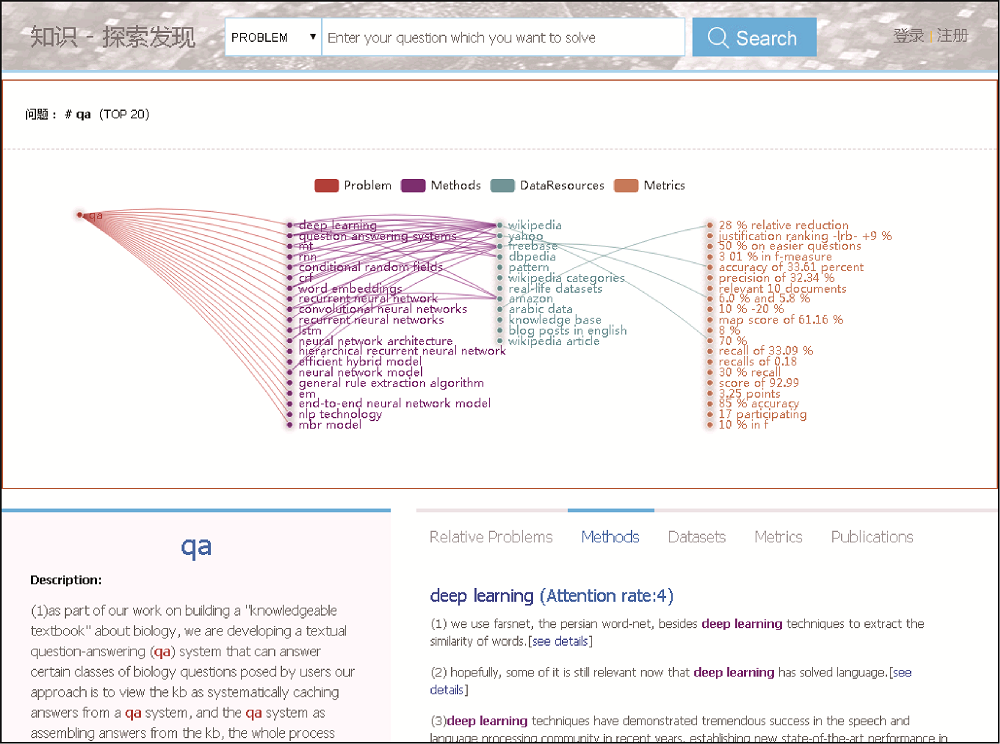
(2)“知识-探索发现平台”: 用户选择任意一种知识元类型, 输入知识元实例的名称, 系统可搜索出该类型知识元关联的其他类型的知识元。如图4所示, 输入类型为“Problem”的知识元实例“qa”, 系统搜索到与“qa”相关的“Methods”: deep learning、rnn、crf 等; 相关的“DataResources”: wikipedia、yahoo、freebase等; 相关的“Metrics”: 3.01% in f-measure、accuracy of 33.61 percent、precision of 32.34%等。该系统还可展示与查询知识元关联的“relative problems”和“publications”。
本文提出一种面向文本内容抽取细粒度知识元的深度学习方法。通过引入知识元与模式的评分模型, 有效控制了Bootstrapping的迭代次数, 缓解了“语义漂移”问题, 自动构建了一个大规模的标注语料库, 降
低了人工成本, 并成功用于深度学习模型从文本中识别出“研究范畴”、“研究方法”、“实验数据”和“评价指标及取值”4类细粒度的知识元, 为情报大数据的智能分析提供了重要的数据支撑。未来工作将对抽取出的知识元进行语义聚类, 以降低数据冗余; 并研究关系抽取方法, 建立各类型知识元间的语义关系网络, 服务于情报大数据的知识挖掘与推理。
钱力: 提出研究问题与研究思路, 论文最终版本修订;
余丽: 设计研究方案, 核心算法设计与实现, 论文起草及最终版本修订;
付常雷, 赵华茗: 采集、清洗和分析数据, 进行实验。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: yul@mail.las.ac.cn。
[1] 余丽. acl.csv. 1980年-2017年的ACL论文元数据和摘要.
[2] 余丽. elsevier-cs-keywords.csv. Elsevier计算机科学领域的期刊论文的关键词.
| [1] |
[本文引用:1]
|
| [2] |
提出用于描述科技文献核心知识的"研究设计指纹"概念,综合研究分析了相关的科技文献规范描述框架,创建"基于科技文献的研究设计指纹描述框架",以增强科技文献的机器计算可执行性、知识粒度性、知识关联性、结构的扩展性以及研究设计思路的可视性,为科研人员快速发现研究设计方法、研究设计工具等指纹提供了新的思路与方法。
|
| [3] |
[本文引用:1]
|
| [4] |
基于被引次数的引文分析无法直接揭示论文的研究内容,利用关键词或从标题、摘要和全文中抽取的主题词很难客观反映论文的被引原因。本文以碳纳米管纤维研究领域的高被引论文为研究对象进行引文内容抽取和主题识别,经人工判读验证:基于引文内容分析的高被引论文识别的核心主题能够较好地揭示高被引论文的被引原因(引用动机),而且与论文的研究内容相符合;与基于全文、基于标题和摘要的主题识别相比,在引文内容分析基础上识别的主题具有更好的主题代表性,能够有效揭示被引文献的研究内容,是对原文相关信息的重要补充。本文的实验表明基于引文内容分析的高被引论文主题识别是可行而且有效的。图4。表4。参考文献31。
|
| [5] |
【目的】自动甄别科技论文中描述研究主题的关键语句。【方法】以论文小节为单位组织句子集,通过训练领域词向量计算句子间WMD距离得到相应语义相似度,优化TextRank算法迭代过程,利用外部特征对所得权值进行调整,按句子权值降序选取关键主题句。【结果】以气候变化领域科技论文作为实验数据,以人工标注的结果为基准对本文的算法和传统的TextRank算法进行对比实验,初步结果表明该方法的识别效果(F值)比传统TextRank算法提升约5%。【局限】句子特征提取有待提高,词向量训练及方法中的相关参数需要做进一步优化。【结论】基于领域词向量,融合WMD语义相似度的TextRank改进算法,能够较好地甄别科技论文小节内部中心句,辅以外部特征的权值调整后可以较好地识别出一篇论文的核心主题句。
URL
[本文引用:1]
|
| [6] |
【目的】建设面向知识层次的标准文献服务系统,推进标准文献信息服务的知识化进程。【应用背景】标准文献知识服务系统能够对标准文献中的知识单元进行语义抽取,依据标准文献知识之间的关联关系进行有效组织,并为用户提供面向知识层次的标准文献信息服务。【方法】采用光符识别、自然语占处理、信息可视化等技术实现标准文献的语义组织、知识抽取、本体构建、知识图谱、本体检索等功能。【结果】用户利用标准文献知识服务系统,能够获得面向知识层次的标准文献信息服务,包括标准知识图谱和基于本体的标准知识检索服务。【结论】标准史献知识服务系统能够改善用户体验,满足用户的标准文献知识需求。
URL
[本文引用:1]
|
| [7] |
[本文引用:2]
|
| [8] |
【目的】为提高科技文献信息的组织和检索效率,从解决科技文献术语抽取这一基础研究问题人手,提出一种基于科技文献术语特点和统计计算相结合的科技文献术语自动抽取方法。【方法】核心技术是结合科技文献术语的语言特点,以及术语在文献中的词语组合强度和出现位置等统计计算信息,构建科技文献术语自动抽取算法。【结果】实验测试结果表明,获取的科技文献术语词语的平均准确率可以达到51.2%。【局限】在统计计算算法和数据处理方面,还需进一步改进算法和提高数据质量。【结论】提出的基于科技文献术语特点和统计计算相结合的科技文献术语自动抽取方法是有效的。
URL
[本文引用:1]
|
| [9] |
[本文引用:1]
|
| [10] |
在网络成为最主要科学交流和信息传播渠道的今天,越来越多的机构将其研究成果以电子化形式呈现,这些电子化的文本资源中蕴涵着丰富的语义信息。面对这些海量的资源,科研人员很难在短时间内快速捕获文本中的主旨内容。如何高效准确地呈现文本资源中的核心主题,辅助科研人员对文本集中的重要关联信息进行聚焦,提高科研效率,一直是文本挖掘研究中的一个重要问题。在对现有有益研究成果借鉴的基础上,结合文本中术语和术语关系的特点,论文提出将文本中的术语和术语间的共现、句法和语义关系利用图结构进行表示,识别文本关系图中的紧密关联子团,基于所得到的紧密关联子团聚类来揭示文本子主题的整体研究思路。开展了两个方面的研究:①将文本集中的术语和术语间各种关系属性进行叠加归并,构建多重文本关系叠加模型;②基于clique子团间相似性距离和语义标识,进行聚类识别文本集中所包含的重要子主题。论文采用"migraine disorders"主题中近五年的文献构建文本集,对提出的方法开展了2个有效性实验。实验1与文本中领域专家所给出的标引词按语义类型分组结果对比,结果表明论文提出的方法与领域专家给出的标引词语义类型分组结果具有一致性;实验2与目前广泛使用的LDA方法结果进行对比,在准确率和召回率上都较LDA方法有所提高。2个实验均证明了文中方法的有效性。
|
| [11] |
从一篇文献入手开展文献调研分析是研究者常用的做法,对任一文献的主题开展追踪研究以揭示作者研究该主题的思路来源及后人在此基础上所做的发展,可为读者提供思路上的启发。揭示学科(领域)主题在时间上的发展、变化趋势已成为情报研究的一项重要内容,但鲜有研究从单篇文献的角度出发,动态分析其主题的来源路径与走向趋势。尽管现有的常用文献数据库提供了引文追踪功能,然而这些功能大都只是罗列出相关的引文,缺乏对引文主题的梳理及主题研究侧重点变化的分析。在此背景下,本文开展了从单篇文献的引文网络中挖掘主题的来源与走向的研究。 本研... 展开 从一篇文献入手开展文献调研分析是研究者常用的做法,对任一文献的主题开展追踪研究以揭示作者研究该主题的思路来源及后人在此基础上所做的发展,可为读者提供思路上的启发。揭示学科(领域)主题在时间上的发展、变化趋势已成为情报研究的一项重要内容,但鲜有研究从单篇文献的角度出发,动态分析其主题的来源路径与走向趋势。尽管现有的常用文献数据库提供了引文追踪功能,然而这些功能大都只是罗列出相关的引文,缺乏对引文主题的梳理及主题研究侧重点变化的分析。在此背景下,本文开展了从单篇文献的引文网络中挖掘主题的来源与走向的研究。 本研究主要从以下三个方面展开:第一,单篇文献中的主题识别,采用了领域词典和统计相结合方法从文献的标题、关键词、摘要中获取文献主题,其中领域词典由领域本体和关键词组合而成;第二,面向单篇文献主题的引文网络构建,从单篇文献的引文网络中筛选与目标主题相关的文献作为网络节点,结合文献的引用关系和文献主题计算文献间的相关度,最终构建出带权重的主题引文网络;第三,单篇文献主题的来源与走向追踪,采用增量聚类的方式从引文网络中获取主题的来源与走向,并对噪音方向进行过滤,形成主题来源与走向演化图,同时,针对无法构建参考网络的主题,通过制定规则探测领域的潜在新主题。 实验与应用。本文通过在肿瘤领域英文核心期刊文献数据上的实验,验证了上述三方面研究方法的可行性和有效性,实现了追踪单篇文献主题来源与走向的目的,并将研究成果应用到项目系统。然后,对比分析了领域主题追踪与单篇文献主题追踪结果,从比较中讨论了两种方法的优劣势和适用性。 最后,总结了本研究的不足点并提出未来研究展望。 本文的创新点表现在:从单篇文献引文网络的视角对主题来源与走向进行追踪研究,帮助读者快速了解文献主题及其来龙去脉;提出文献引用关系和文献内容相结合的文献相关度计算方法,解决了引文分析中注重引用关系而忽略文献内容的问题;采用领域本体和关键词相结合的方法构建领域词表,提高了文献主题识别的准确性。 收起
URL
[本文引用:1]
|
| [12] |
[本文引用:2]
|
| [13] |
[本文引用:2]
|
| [14] |
[目的/意义]从科技论文中自动识别与抽取研究设计指纹,能够为科研人员项目设计、研究方法的有效性评估、研究过程问题诊断、研究结果鉴别与评价提供重要的方法论和研究操作支撑.[方法/过程]基于科技论文研究设计指纹的概念模型,提出基于多规则模式混合机器学习方法,设计并实现指纹识别算法,并以数据挖掘领域的期刊文献数据为例,对识别算法的可行性与有效性进行分析验证.[结果/结论]除研究数据与研究趋势外,其他研究设计指纹识别准确率的认可度都基本达到80%以上,覆盖率的认可度,除研究工具与研究数据外,基本达到80%以上.
|
| [15] |
【目的】科技论文中数值指标的大小有多种描述形式,本文旨在从不同形式的描述句中准确识别数值指标的实际取值。【方法】分析数值指标句中指标实体与数字实体间最小句法树路径,采用远程监督学习数值指标句的句法特征及描述特征,从领域候选句中识别数值指标句;利用少量语义标注数据学习"大于"、"小于"、"等于"、"倍数"4类取值关系模板,通过模板识别数值指标句的取值关系类别,依据不同取值关系模板对应的数值指标实际取值换算关系计算指标实际数值的大小。【结果】在气候变化领域和天文学领域开展实验,F值分别达到82.35%和77.55%,识别效果达到同类研究平均水平之上。【局限】以单句为数据单元开展识别研究,对于跨句间的指标取值问题未做考虑。【结论】本方法能够有效识别单句中数值指标的实际取值,识别过程不需要大量人工标注语料,迁移到其他领域时不做额外处理,系统性能不会明显下降,具有一定的实用性。
URL
[本文引用:1]
|
| [16] |
Every field of research consists of multiple application areas with various techniques routinely used to solve problems in these wide range of application areas. With the exponential growth in research volumes, it has become difficult to keep track of the ever-growing number of application areas as well as the corresponding problem solving techniques. In this paper, we consider the computational linguistics domain and present a novel information extraction system that automatically constructs a pool of all application areas in this domain and appropriately links them with corresponding problem solving techniques. Further, we categorize individual research articles based on their application area and the techniques proposed/used in the article. k-gram based discounting method along with handwritten rules and bootstrapped pattern learning is employed to extract application areas. Subsequently, a language modeling approach is proposed to characterize each article based on its application area. Similarly, regular expressions and high-scoring noun phrases are used for the extraction of the problem solving techniques. We propose a greedy approach to characterize each article based on the techniques. Towards the end, we present a table representing the most frequent techniques adopted for a particular application area. Finally, we propose three use cases presenting an extensive temporal analysis of the usage of techniques and application areas.
URL
[本文引用:1]
|
| [17] |
[本文引用:1]
|
| [18] |
[本文引用:1]
|
| [19] |
Technology Opportunity Discovery is a service to detect and provide opportunities for the new technologies. Patent-based information is extracted by natural language processing techniques. All patents published during the past 20 years are target resources and product names and their Part-of relations are target information. A dictionary and similarity-based named entity recognition, a pattern-based relation extraction, and a machine learning-based filtering have been used and showed an encouraging performance.
|
| [20] |
URL
[本文引用:1]
|
| [21] |
Information extraction in clinical texts enables medical workers to find out problems of patients faster as well as makes intelligent diagnosis possible in the future. There has been a lot of work about disorder mention recognition in clinical narratives. But recognition of some more complicated disorder mentions like overlapping ones is still an open issue. This paper proposes a multi-label structured Support Vector Machine (SVM) based method for disorder mention recognition. We present a multi-label scheme which could be used in complicated entity recognition tasks. We performed three sets of experiments to evaluate our model. Our best F1-Score on the 2013 Conference and Labs of the Evaluation Forum data set is 0.7343. There are six types of labels in our multi-label scheme, all of which are represented by 24-bit binary numbers. The binary digits of each label contain information about different disorder mentions. Our multi-label method can recognize not only disorder mentions in the form of contiguous or discontiguous words but also mentions whose spans overlap with each other. The experiments indicate that our multi-label structured SVM model outperforms the condition random field (CRF) model for this disorder mention recognition task. The experiments show that our multi-label scheme surpasses the baseline. Especially for overlapping disorder mentions, the F1-Score of our multi-label scheme is 0.1428 higher than the baseline BIOHD1234 scheme. This multi-label structured SVM based approach is demonstrated to work well with this disorder recognition task. The novel multi-label scheme we presented is superior to the baseline and it can be used in other models to solve various types of complicated entity recognition tasks as well.
|
| [22] |
生物命名实体识别,就是从生物医学文本中识别出指定类型的名称。目前,面向生物医学领域的实体识别研究不断出现,从海量生物医学文本自动提取生物实体信息的技术变得尤为重要。该文介绍了一个面向生物医学领域的多实体识别系统MBNER(Multiple Biomedical Named Entity Recognizer)。该系统可以在生物医学文本中同时识别出基因(蛋白质)、药物、疾病实体,其对基因(蛋白质)、药物、疾病实体识别在各自数据集上分别得到了89.05%,76.73%,90.12%的综合分类率(F-score)。该系统以可视化的形式给出对三种命名实体的识别结果。<br>
|
| [23] |
[本文引用:1]
|
| [24] |
[本文引用:1]
|
| [25] |
[本文引用:1]
|
| [26] |
【目的】中文机构名结构复杂、罕见词多,识别难度大,对其进行正确识别对于信息抽取、信息检索、知识挖掘和机构科研评价等情报学中的后续任务意义重大。【方法】基于深度学习的循环神经网络(Recurrent Neural Network,RNN)方法,面向中文汉字和词的特点,重新定义了机构名标注的输入和输出,提出汉字级别的循环网络标注模型。【结果】以词级别的循环神经网络方法为基准,本文提出的字级别模型在中文机构名识别的准确率、召回率和F值均有明显提高,其中F值提高了1.54%。在包含罕见词时提高更为明显,F值提高了11.05%。【局限】在解码时直接使用了贪心策略,易于陷入局部最优,如果使用条件随机场算法进行建模可能获取全局最优结果。【结论】本文方法构架简单,能利用到汉字级别的特征来进行建模,比只使用词特征取得了更好的结果。
URL
[本文引用:1]
|
| [27] |
[本文引用:1]
|




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}