
 , 张华平, Zhang Huaping
, 张华平, Zhang Huaping【目的】从海量的文本数据中挖掘创新主题。【方法】以学术知识图谱数据为基础, 根据知识点的“热度”、“新颖度”、“权威度”三维指标, 筛选出权重较高的作为创新种子, 然后根据知识图谱的路径对创新 种子进行知识关联计算, 计算结果输入一个用大量科技论文数据训练而成的深度学习模型, 从而生成创 新主题; 采用的模型为由双向LSTM层组成的Sequence to Sequence模型。【结果】以人工智能领域内中 文科技论文作为实验数据, 实验结果表明, 模型的挖掘结果经过专家人为判断验证, 创新效果平均值为6.52。【局限】目前知识图谱的知识丰富度和关联性有限、用于训练模型的训练集质量和体量还有待于进一步提升。【结论】本文模型实现了从文本数据中挖掘出创新主题, 但创新主题识别模型的整体水平仍然需要进一步完善优化。
[Objective] This paper aims to identify innovative topics from massive volumes of texts. [Methods] First, we extracted knowledge points with heavier weights from the data of scholarly knowledge graph. Then, these knowledge points were labeled as innovative seeds from the perspectives of “popularity”, “novelty” and “authority”. Third, we computed the knowledge correlation of the innovative seeds. Finally, the results were input to a deep learning model trained by large amounts of sci-tech papers to generate innovative topics. Note: the model is sequence to sequence with Bi-LSTM. [Results] We used Chinese research papers on artificial intelligence as the experimental data and found the average innovation score of the retrieved topics was 6.52, which were evaluated by experts manually. [Limitations] At present, contents of the knowledge graph and the training datasets need to be improved. [Conclusions] The proposed model, which identifies innovative topics from scholarly papers, could be optimized in the future.
随着科学研究的不断发展与进步, 科技信息正以惊人的速度增长, 科技数据进入了大数据时代[1]。与此同时, 面对大数据的多、冗、杂、乱、新等 特征, 传统的知识组织方法和策略[2,3]已无法满足知识组织与服务的进一步需求。近年, 随着人工智 能技术的快速发展, 尤其是深度学习技术的实现 与成功, 给大数据时代的知识计算带来新的可行性方案。
创新主题的挖掘能有效地揭示科技研究领域内新颖的研究方向, 甚至能揭示领域内潜在的研究主题与方向。因此, 在知识组织和服务方面具有很好的实用价值, 在帮助科研人员选取科研方向和方法上具有较高的参考价值。本文基于科技学术论文的创新分布特征, 建立一个神经网络深度学习模型, 通过大量的科技文献数据对其训练, 构建一个智能挖掘与生成创新主题的智能机器模型。
从海量的文本中挖掘创新内容是自然语言处理领域比较流行的研究主题, 也是目前较难解决的一个问题。其目的是研究一种方法能有效地挖掘文本数据中较新颖和关注度高的信息。早期的方法大都基于语句的特征规则匹配, 如文献[4]提出一种根据传统的语言特点挖掘包含创新知识元的句子方法; 文献[5,6,7]介绍了利用语义特征规则挖掘科技文 献 中的提出的新的方法、概念、定义等重要信息, 所采用的特征包含词语分布、词性、词频等语义特征; 文献[8]则采用语义角色标注以及依存句法分析, 并借助领域本体层次关系词表, 构建创新知识点的基础识别规则, 进而挖掘科技文献中存在的创新句子。
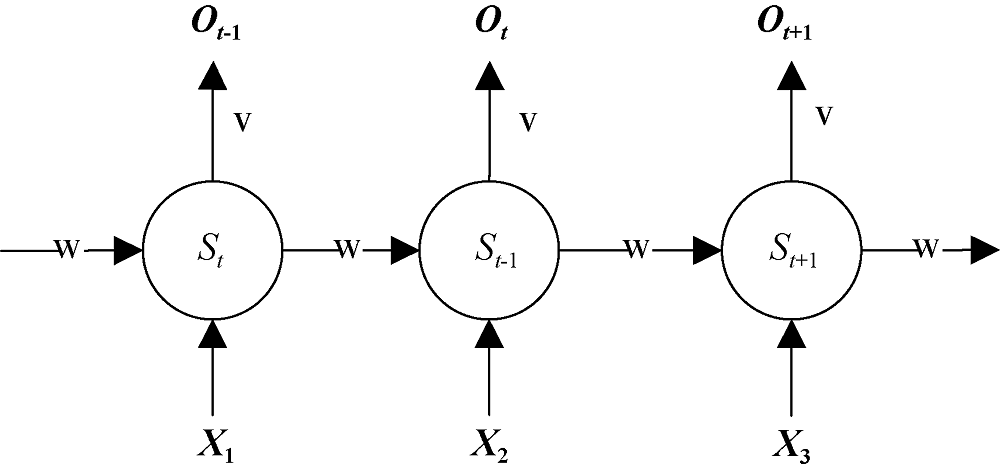
随着深度学习技术的快速发展, 自然语言处理效率和质量得到很大的提高。在2013年, Mikolov等提出一种Word2Vec[9,10]的工具包, 能将文本语言转换为可计算的向量形式, 并取得了很好的效果, 基本解决了文本数据向量化问题; 同时, 为深度学习技术进入自然语言处理领域提供了可能。传统的多层感知机(Multi-Layer Perceptron, MLP)结构的神经网络虽在识别个体案例上表现突出, 但自然语言信息之间存在语义的整体逻辑序列, 以及彼此之间存在复杂的时间关联性, 且长度不一, MLP识别和记忆这种特征数据上就表现得无能为力。循环神经网络(Recurrent Neural Network, RNN)正是为了解决这种序列问题应运而生, 其关键之处在于用一个状态层链接隐藏层上下神经元, 前一个神经元的输出信息, 经加权后输入到后一个神经元[11,12], 如图1所示。这种网络结构解决了自然语言中句子内部词语序列识别和记忆的问题, 并有效地将文本上下文之间的关系建立起来。但是由于梯度消失/梯度爆炸的问题,传统RNN在实际中很难处理长期依赖[13], 因此RNN在处理长时间序列数据时表现效果较差。
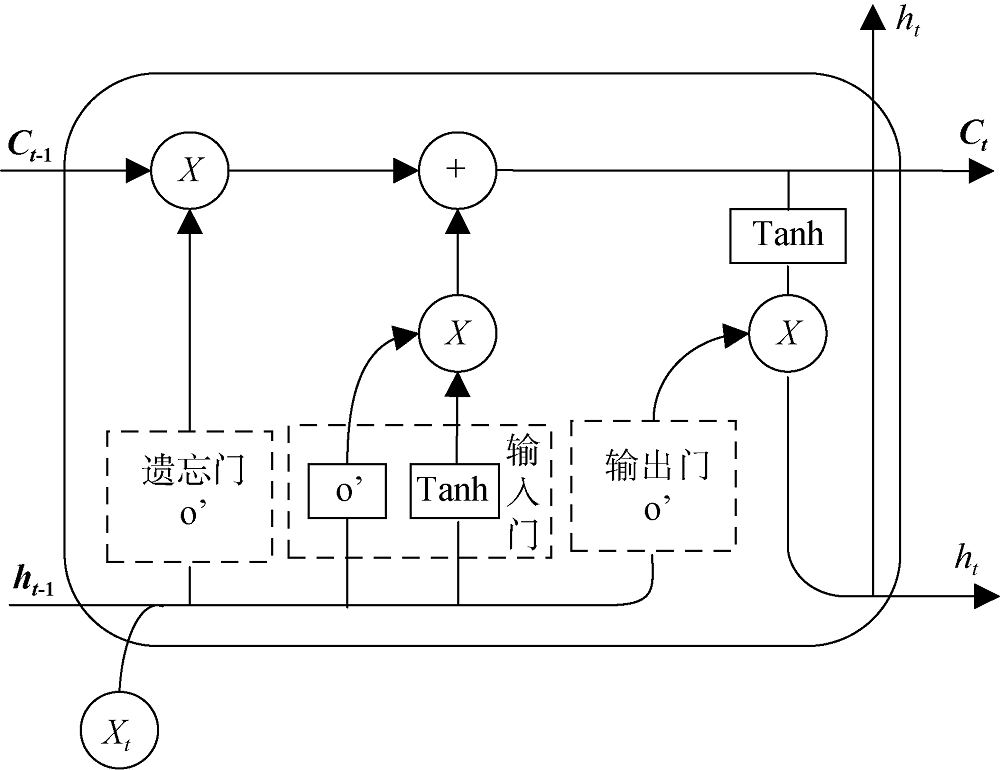
为了解决RNN结构的神经网络在处理长序列输入数据的长期依赖难题, 文献[14,15]提出一种以RNN结构为基础的长短期记忆网络(Long Short-Term Memory, LSTM)。LSTM中每个神经元分别增加三个“门”结构来影响输出状态, 这三个“门”为输入门、遗忘门和输出门, 如图2所示。所谓“门”的结构就是结合Sigmod神经网络和一个按位做乘法的操作, 以判断一个进入LSTM的网络中的信息是否有用的规则, 符合规则的信息可以通过输出门继续留在网络内部, 不符合的则通过遗忘门被遗弃。因此, LSTM能有效地记忆长序列输入数据中的信息。
为了加强神经网络对语义上下文之间关系的学习, 往往采用双向LSTM结构(Bi-directional LSTM, Bi-LSTM)的神经网络。针对多领域数据语义解析, 采用Bi-LSTM结构的神经网络的处理效果优于单向LSTM结构的网络[16]; Bi-LSTM与抽样算法结合的模型经常用于对语义序列中的实体识别和标注, Lample等和Ma等采用Bi-LSTM与CRF结合的模型对文本中的实体进行标注[17,18]。
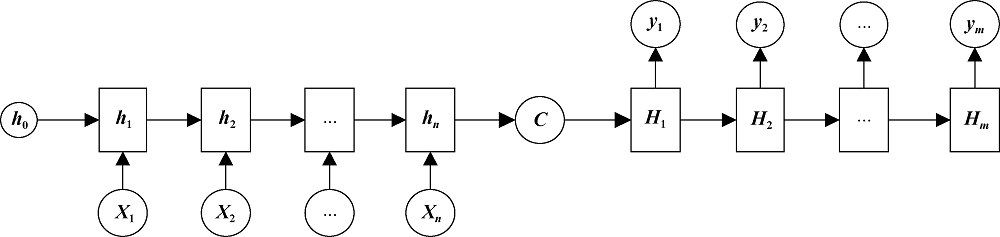
基于LSTM和Bi-LSTM的应用, 产生了一种Sequence to Sequence (Seq2Seq)的模型[19], 其在机器翻译、对话生成、文本摘要生成等各种预测任务中取得了良好的效果, Seq2Seq模型结构主要分为两层, 即用于语义编码的Encoder层和用于语义解码的Decoder层, Encoder层和Decoder层内部结构都是神经网络模型, 因此Seq2Seq模型也称为Encoder- Decoder模型。Seq2Seq模型基本结构如图3所示。其基本流程为: 词序列数据$[X1,X2,\cdot \cdot \cdot ,Xn]$输入到Encoder层进行解码, 形成解码语义向量
当Encoder阶段输入序列过长时, 越往后被输入的序列, 对原始时间步输出的结果影响越来越大, 这是由于原始的这种时间步模型设计结构有缺陷, 即Encoder将所有输入序列编码成一个
在科技学术论文中, 作者往往对多个知识点进行融合与研究, 形成创新观点与主题[21]。从论文组织和结构分析, 论文中作者所提出的方法、概念、定义都是论文的创新知识点所在, 论文标题则是对整篇文章知识点的总结, 是创新主题的文本表示[22,23]。
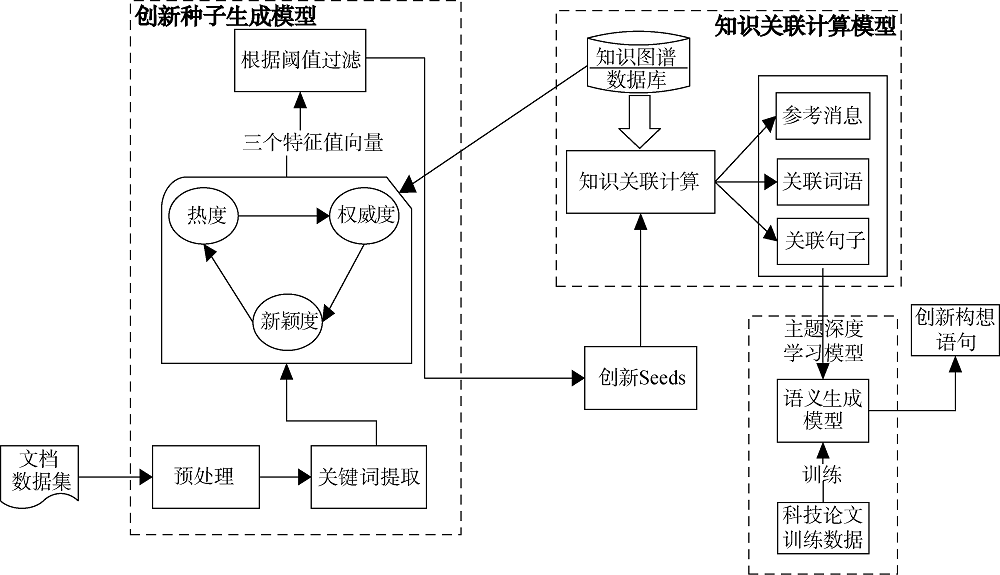
本文提出的创新主题智能算法主要目的是建立一个语义识别和处理的神经网络模型, 针对论文数据的特点, 构造可供模型训练的数据集, 从中提取创新知识点进行学习训练, 形成具有创新主题的智能挖掘的机器模型。整体流程可以分为三个模块: 创新种子生成模型、知识关联计算模型、主题深度学习模型。模型构成如图4所示。
创新种子计算模型提取待求解文档数据中的关键词, 从三个维度(热度、新颖度、权威度)过滤关键词, 形成创新种子。将创新种子映射到结构化的知识图谱中进行知识关联计算, 目的是获取与创新种子相关的拓展知识点(包含三方面: 参考信息、关联词语、关联句子)。最后, 构建一个语义生成深度学习模型, 并用大量科技论文数据进行训练, 将创新种子拓展知识点根据训练数据的规则智能映射为创新主题语句。
创新种子计算模型的处理主要包括三个流程: 预处理、关键词提取、三维指标以及创新阈值计算。文档的预处理过程主要包括分词、去标点符号与去停用词。关键词提取主要采用频繁短语挖掘算法[24], 输出结果为短语集$\{W1,W2,W3,\cdot \cdot \cdot ,Wn\}$和对应的短语词频集$\text{ }\!\!\{\!\!\text{ }F\text{1,}F\text{2,}F\text{3,}\cdot \cdot \cdot \text{,}F\text{n }\!\!\}\!\!\text{ }$。
创新种子计算模型主要从热度、新颖度、权威度这三个维度指标定义创新, 为了计算这三个维度的指标, 首先需要将每个短语从知识图谱中检索词频数据、时间分布、来源出处数据, 形成词频分布特征集、时间分布特征集、来源分布特征集。为了更好地描述本文的方法, 在此引用一些标记符号, 如表1所示。
根据表1中所定义的符号, 假设已经求得
$IN-Score(i)=C\times Fi\times \text{log}HS\text{(}i\text{)}\times NS\text{(}i\text{)}\times AS\text{(}i\text{)}$ (1)
其中,
(1) 热度计算
热度值主要计算
$HS(i)=\frac{\sum\limits_{j=0}^{Ni}{FWi,j}}{Ni}$ (2)
其中,
(2) 权威度计算
权威度值用来衡量关键词
$AS\text{(}i\text{) = max(}SWi\text{)}$ (3)
(3) 新颖度计算
知识点新颖度从传统思维解释就是出现的时间近, 且出现次数较少, 与热度存在一定的矛盾性。在科技论文中, 学术观点的重复率越高, 时间跨度越长, 则其新颖度越低。基于此观点, 本文借鉴逆文档频率的新颖度度量方法[25], 以年份为时间跨度单位, 定义新的关键词新颖度计算方法。
定义1 若
定义2
$NS\text{(}q\text{) = }\frac{\sum\limits_{i=1}^{nq}{DWIDF(q,i)}}{Nq}$ (4)
知识关联计算目的是为了从知识图谱中挖掘与创新种子关联最近的信息。而基于学术知识图谱, 面对不同层面的需求, 挖掘节点之间关系的方法很多。本文主要以知识图谱的路径作为关联计算的依据, 节点之间的权重值为距离衡量标准。采用最短距离算法, 计算流程分为4个步骤:
(1) 输入创新种子Seed和需要提取的输出的节点数量TopN。
(2) 在知识图谱中, 将Seed与节点的各个属性进行匹配, 得到相似度最高的节点NodeS。
(3) 以节点NodeS为出发点, 计算与其相邻的节点的距离, 然后进行倒序排序, 取前TopN个节点, 存入NodeN。
(4) 从NodeS和NodeN的属性中提取出摘要信息、短语概念、包含NodeS或者NodeN的语句, 形成输出信息内容格式Seed_info{参考信息, 关联词语, 关联句子}, 数据格式为JSON格式。
以创新种子“文化算法”为输入Seed, TopN输入值为5, 按照以上计算步骤, 在科技文献知识图谱中输出的结果如表2所示。
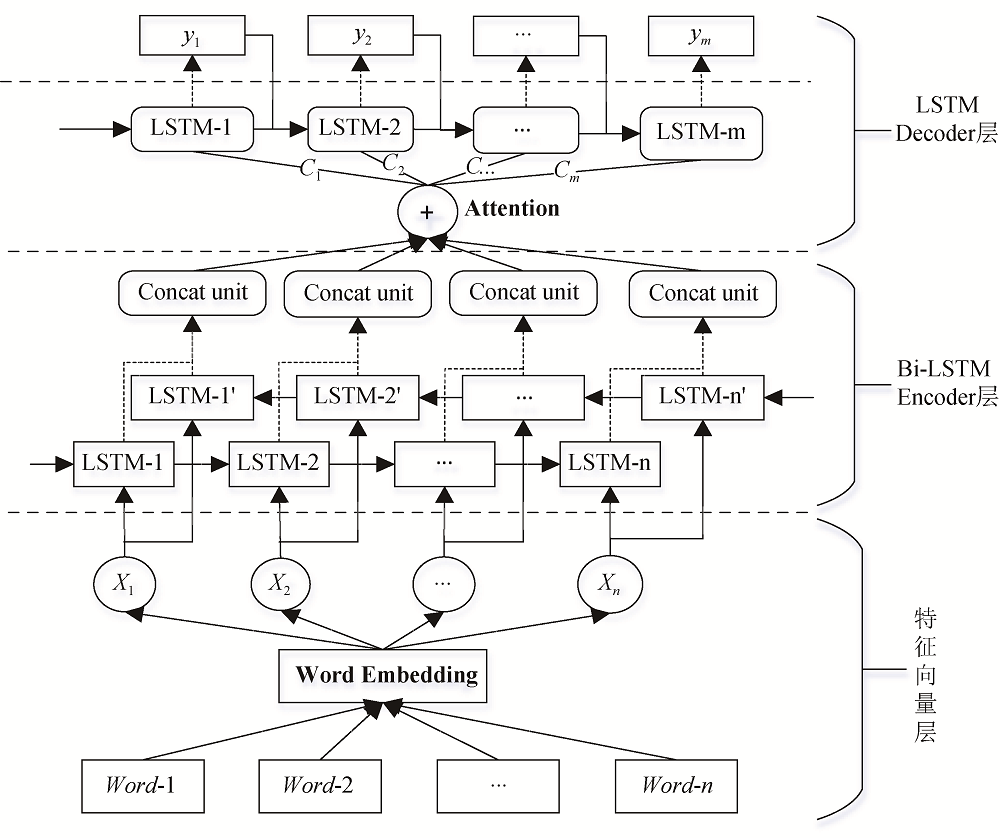
主题深度学习模型结构采用Seq2Seq[19], 以科技文献的摘要、关键词、标题三元结构的数据作为训练数据。针对训练数据, 在模型中加入特征向量层, 目的是为了将训练数据中的词语转化为可计算的向量, 模型的框架如图5所示。
(1) 特征向量层
采用文献[26]提出的Skip-Gram模型的训练方式, 将文本中的词语转成维度为
(2) Seq2Seq模型的设计
模型的训练是一个反向传播优化过程, 其目的是通过最小化预测值和实际值之间的损失值优 化神经网络中的参数值。模型的训练流程如图6 所示。
模型训练流程的设计主要考虑以下两个方面。
(1) 训练数据的设计
本文训练数据内容为采用科技文献的摘要、关键词、标题。其中摘要和关键词数据为输入数据
(2) 损失值的计算与神经网络的优化
由于本文模型结构比较复杂, 待优化的参数较多, 为了解决过度拟合的问题, 采用交叉熵的方式计算损失值, 根据模型的输出值为序列化的多个词语向量值组合而成的句子, 因此本文损失函数的计算方式采用的是序列预测结果交叉熵损失值的计算函数Sequence-Loss Cost Function[28]。
神经网络优化的主要目的是调整网络中的参数, 使损失值函数的结果值最小化。针对海量的数据, 为了加强训练过程, 采用Adam优化算法[29]对待优化的参数进行优化。
从中图分类号数据库[30]中查询得到人工智能理论的分类号为TP181-TP183, 根据中图分类号对维普数据库的中文期刊论文数据进行筛选, 限定发布时间在2008年至2017年范围之内, 最终得到84 357篇中文期刊论文的元数据, 以元数据中的摘要、关键词、标题作为实验数据。根据实验需求, 将实验数据随机分为两部分: 随机抽取12 306篇科技论文的摘要数据作为用于求解的数据集合A; 其余作为深度学习模型的训练数据集合B。知识图谱数据采用中国科学院文献情报中心构建的人工智能领域知识图谱。
利用jieba中文分词程序[31]和自然语言处理工具gensim[32]对数据集合A进行预处理。处理流程如下: 首先对数据集合A中的摘要数据进行分词得到文档集D', 再利用gensim工具对D'中的每个词语进行词频统计, 得到词频数据集FD'。
根据文献[20]的频繁短语挖掘方法, 取阈值为
将数据集B中的摘要数据去标点符号和中文停用词后进行分词, 得到数据集AD, AD与数据集B中的关键词作为训练数据的输入数据
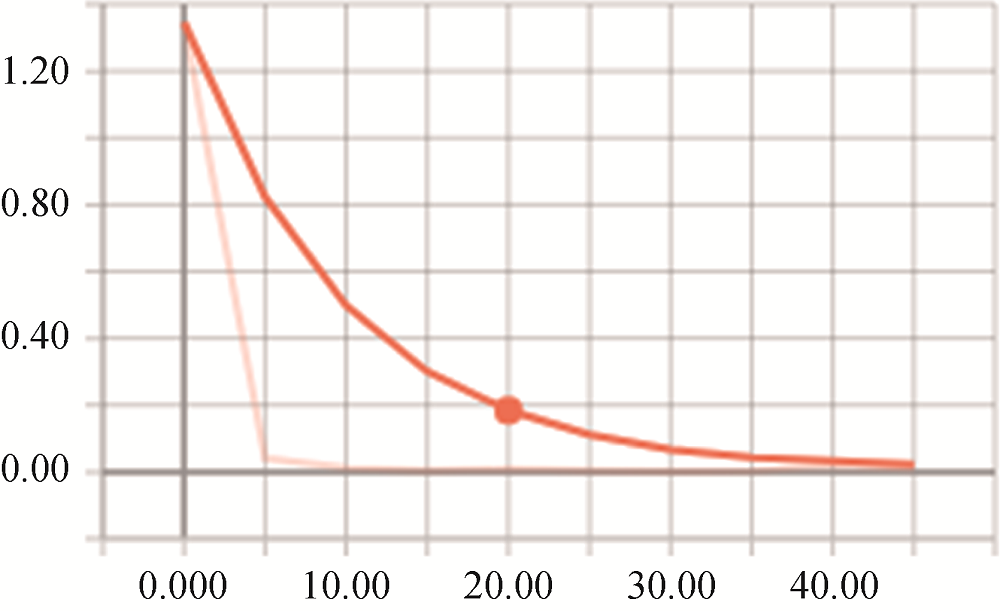
本实验利用TensorFlow框架进行深度学习模型的建模, 运算GPU为单个NVIDIA GTX TITAN 1080ti。设定每次输入训练数据的Batch大小为60, 词向量维度为100。经过45次训练迭代, 时长为33小时50分钟, 模型根据输入的训练数据对[
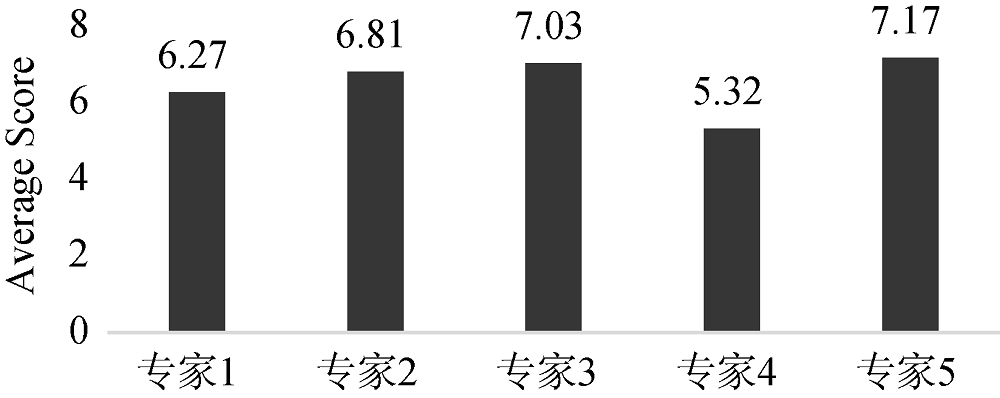
本文提出一种基于深度学习模型的创新主题挖掘模型。模型主要由三部分组成: 首先创新种子计算模型挖掘出文本数据中的创新知识点; 然后利用知识关联计算模型在知识图谱中挖掘与创新种子具有重要关联关系的知识内容; 最后利用训练好的深度学习模型生成创新主题语句。该模型的结构设计和实现具有一定的探索性, 从领域专家对实验结果的人为评价结果来看, 创新效果平均值为6.52, 达到十分制的及格线, 说明该模型在创新主题挖掘研究方面具有一定的实用和参考价值。下一步将根据语义特征优化模型的结构, 增强训练数据集, 训练一个能够从创新语义层面自动挖掘创新构想的智能模型。
钱力: 提出研究思路, 设计研究方案, 论文主体内容撰写;
付常雷: 论文内容撰写, 算法功能实现;
张华平: 参与算法模型设计;
赵华茗: 参与算法功能实现;
谢靖: 参与算法设计。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: qianl@mail.las.ac.cn。
[1] 付常雷. keyWordchinese.xls. 1570个关键词.
[2] 付常雷. train_cn_x. 训练数据的输入数据x.
[3] 付常雷. train_cn_y. 前向传播比对数据y.
[4] 付常雷. x_cn_dic. 177522个词的词典.
[5] 付常雷. y_cn_dic. 38667个词的词典.
[6] 付常雷. model_save.zip. 模型训练过程与结果.
[7] 付常雷. outputResult.zip. 创新主题生成结果.
| [1] |
大数据分析相比于传统的数据仓库应用,具有数据量大、查询分析复杂等特点.为了设计适合大数据分析的数据仓库架构,文中列举了大数据分析平台需要具备的几个重要特性,对当前的主流实现平台——并行数据库、MapReduce及基于两者的混合架构进行了分析归纳,指出了各自的优势及不足,同时也对各个方向的研究现状及作者在大数据分析方面的努力进行了介绍,对未来研究做了展望.
|
| [2] |
简述信息与知识、信息组织与知识组织的概念及內涵;探讨基于内部结构特征的知识组织的两种方式:以知识单元为基础的知识组织方式和以知识关联为基础的知识组织方式;详细分析知识组织的7种方法:知识表示、知识重组、知识聚类、知识存检、知识编辑、知识布局和知识监控;提出采用分类主题一体化、运用元数据以及采用专家系统等知识组织策略。
|
| [3] |
正主持人导语我们处于大数据环境中,大数据的多、冗、杂、乱、新等特征,既给数据处理带来了许多麻烦,也为知识服务带来了新的挑战。面对庞大繁杂、急剧膨胀的大数据,要保证它们在知识服务中发挥的作用,并使其有序化地收敛于高效的知识服务就必须加强知识组织的研究。可以认为,知识组织研究已成为大数据环境中知识服务的基础,也为数据处理与组织研究开辟了新的空间。目前,我们正承担着国家自然科学基金项目"面向知识服务的知识组织模型与应用研究"(71273126),其主要
|
| [4] |
本文提出基于创新点构建知识元以解决论文创新知识的有效发现和利用问题.对科技论文知识创新生产、知识增值管理、知识集成利用做了分析,对文本创新点的表现形式做了探讨,对创新点的挖掘做了试验,结果表明基于创新点的知识元挖掘是文本知识挖掘的一种有效方法.
|
| [5] |
The problem addressed in this paper concerns the automatic identification and extraction of medical terms along with their definitions and modifiers from full text consumer-oriented medical articles. The system, DEFINDER (Definition Finder), uses rule-based techniques. The output of our system can be used in several applications: creation and/or enhancement of on-line terminological resources, summarization and text categorization according to level of expertise, e. g. lay vs. technical.
|
| [6] |
[本文引用:1]
|
| [7] |
针对目前知识抽取技术无法精确抽取学术文献中提及的具体理论方法和性能指标参数等问题,综合运用语义标注技术、规则抽取技术以及正则表达式技术,提出一种面向科技文献的混合语义信息抽取方法。该方法首先对科技文献进行语义标注,得到相关学术术语。然后,构造抽取规则,抽取文献提及的与具体性能指标相关的句子。最后,采用正则表达式技术从相关句子中精确抽取出关键性能指标。对碳纳米管研究领域科技文献语义的信息抽取证明,该方法能迅速、有效和准确地抽取科技文献主要创新研究内容和性能指标。
|
| [8] |
【目的】抽取领域科技文献中句子级创新点。【方法】面向文献中的句子,以领域词表和本体中的关系为基础构建识别规则,采用基于主题词重叠度的冗余度计算方法过滤创新点候选集。【结果】选取肿瘤领域的数据集进行实验,抽取结果的准确率为89.42%,召回率为60.14%。【局限】规则有待进一步完善,提高召回率。【结论】利用领域词表和本体中的关系能有效地抽取科技文献中的句子级创新点。
URL
[本文引用:1]
|
| [9] |
[本文引用:1]
|
| [10] |
[本文引用:1]
|
| [11] |
对动态回归神经网络模型结构与算法进行了分析,采用多层反馈RNN网络,以典型的非线性化工过程CSTR为应用对象,比较了采用前馈BP网络和Elman的RNN网络进行模型化与模拟,最后用一个时变过程和苯酐工业生产过程模拟验证。结果表明,动态回归神经网络具有较好的收敛性和稳定性,可用于复杂动态过程的工业应用。
URL
[本文引用:1]
|
| [12] |
[本文引用:2]
|
| [13] |
[本文引用:1]
|
| [14] |
[本文引用:2]
|
| [15] |
[本文引用:1]
|
| [16] |
[本文引用:2]
|
| [17] |
Abstract: State-of-the-art named entity recognition systems rely heavily on hand-crafted features and domain-specific knowledge in order to learn effectively from the small, supervised training corpora that are available. In this paper, we introduce two new neural architectures---one based on bidirectional LSTMs and conditional random fields, and the other that constructs and labels segments using a transition-based approach inspired by shift-reduce parsers. Our models rely on two sources of information about words: character-based word representations learned from the supervised corpus and unsupervised word representations learned from unannotated corpora. Our models obtain state-of-the-art performance in NER in four languages without resorting to any language-specific knowledge or resources such as gazetteers.
|
| [18] |
Abstract: State-of-the-art sequence labeling systems traditionally require large amounts of task-specific knowledge in the form of hand-crafted features and data pre-processing. In this paper, we introduce a novel neutral network architecture that benefits from both word- and character-level representations automatically, by using combination of bidirectional LSTM, CNN and CRF. Our system is truly end-to-end, requiring no feature engineering or data pre-processing, thus making it applicable to a wide range of sequence labeling tasks. We evaluate our system on two data sets for two sequence labeling tasks --- Penn Treebank WSJ corpus for part-of-speech (POS) tagging and CoNLL 2003 corpus for named entity recognition (NER). We obtain state-of-the-art performance on both the two data --- 97.55\% accuracy for POS tagging and 91.21\% F1 for NER.
|
| [19] |
Abstract: Deep Neural Networks (DNNs) are powerful models that have achieved excellent performance on difficult learning tasks. Although DNNs work well whenever large labeled training sets are available, they cannot be used to map sequences to sequences. In this paper, we present a general end-to-end approach to sequence learning that makes minimal assumptions on the sequence structure. Our method uses a multilayered Long Short-Term Memory (LSTM) to map the input sequence to a vector of a fixed dimensionality, and then another deep LSTM to decode the target sequence from the vector. Our main result is that on an English to French translation task from the WMT'14 dataset, the translations produced by the LSTM achieve a BLEU score of 34.8 on the entire test set, where the LSTM's BLEU score was penalized on out-of-vocabulary words. Additionally, the LSTM did not have difficulty on long sentences. For comparison, a phrase-based SMT system achieves a BLEU score of 33.3 on the same dataset. When we used the LSTM to rerank the 1000 hypotheses produced by the aforementioned SMT system, its BLEU score increases to 36.5, which is close to the previous best result on this task. The LSTM also learned sensible phrase and sentence representations that are sensitive to word order and are relatively invariant to the active and the passive voice. Finally, we found that reversing the order of the words in all source sentences (but not target sentences) improved the LSTM's performance markedly, because doing so introduced many short term dependencies between the source and the target sentence which made the optimization problem easier.
URL
[本文引用:3]
|
| [20] |
[本文引用:2]
|
| [21] |
从创新性成果的基本特点出发,通过对科技论文若干实例创新点的剖析,提出了科技论文创新性判断的方法.方法的简单概括是:分项寻找创新点,按创新性大小赋分,综合比较.应用这一方法,对指导科技期刊编辑的选题、组稿工作和科技期刊的创新导向有十分重要的意义.
|
| [22] |
This paper attempts to identify knowledge claims in the introduction section of 50 English research articles in economics and linguistics. The articles are part of the KIAP Corpus. My analysis reveals that the introductions in both disciplines typically state claims. The construction of the claims is quite complex, with text sequences containing so-called preview sentences as well as claim sentences proper; in linguistics, preview and actual claim may even be combined within the same sentence. Claims in both disciplines tend to be unhedged, but with slightly more hedging in linguistics than in economics. Claims in both disciplines may be signalled by expression such as The key message is鈥, but this feature is most prominent in economics. It is argued that the reason for this is that economics is a more competitive field than linguistics, encouraging explicit signalling of new claims in order to attract the attention of the research community.
|
| [23] |
Writing the Discussion section of a laboratory report or dissertation is difficult for students to master. It involves complex causal, conditional and purposive argument; this argument guides the reader from acceptance of the relatively uncontroversial data to acceptance of the writer’s knowledge claim. Students benefit therefore if they are assisted in acquiring the lexico-grammar commonly used in discussion of results. To explore the lexico-grammar of Discussions, this article relies on two small corpora, one of physics research articles and the other of student physics laboratory reports. The article employs both a clause by clause analysis and concordancing software to identify the key ways of expressing these meanings. It finds the means employed in the student writing to be more congruent, more emphatic and less closely argued than in the research article corpus, and suggests specific grammatical resources which might form the subject of tasks from which students could benefit.
|
| [24] |
While most topic modeling algorithms model text corpora with unigrams, human interpretation often relies on inherent grouping of terms into phrases. As such, we consider the problem of discovering topical phrases of mixed lengths. Existing work either performs post processing to the inference results of unigram-based topic models, or utilizes complex n-gram-discovery topic models. These methods generally produce low-quality topical phrases or suffer from poor scalability on even moderately-sized datasets. We propose a different approach that is both computationally efficient and effective. Our solution combines a novel phrase mining framework to segment a document into single and multi-word phrases, and a new topic model that operates on the induced document partition. Our approach discovers high quality topical phrases with negligible extra cost to the bag-of-words topic model in a variety of datasets including research publication titles, abstracts, reviews, and news articles.
|
| [25] |
文章吸收词频原则、逆文档频率原则以及共词分析的思想,提出解决文档主题新颖度量化问题的4个原则,在此基础上定义带时间戳关键词逆文档频率、带时间戳关键词对逆文档频率、文档新颖度等3个概念,给出文档新颖度的计算公式,并对该公式的实用性与合理性进行实证研究.实验结果表明:文中提出的文档主题新颖度量化方法是科学的、合理的、可操作的,但是,不规范的标引词标引、关键词个数过少等现象对主题新颖度计量结果的准确性影响较大.
URL
[本文引用:2]
|
| [26] |
Dictionaries and phrase tables are the basis of modern statistical machine translation systems. This paper develops a method that can automate the process of generating and extending dictionaries and phrase tables. Our method can translate missing word and phrase entries by learning language structures based on large monolingual data and mapping between languages from small bilingual data. It uses distributed representation of words and learns a linear mapping between vector spaces of languages. Despite its simplicity, our method is surprisingly effective: we can achieve almost 90% precision@5 for translation of words between English and Spanish. This method makes little assumption about the languages, so it can be used to extend and refine dictionaries and translation tables for any language pairs.
URL
[本文引用:1]
|
| [27] |
Abstract: When a large feedforward neural network is trained on a small training set, it typically performs poorly on held-out test data. This "overfitting" is greatly reduced by randomly omitting half of the feature detectors on each training case. This prevents complex co-adaptations in which a feature detector is only helpful in the context of several other specific feature detectors. Instead, each neuron learns to detect a feature that is generally helpful for producing the correct answer given the combinatorially large variety of internal contexts in which it must operate. Random "dropout" gives big improvements on many benchmark tasks and sets new records for speech and object recognition.
|
| [28] |
[本文引用:1]
|
| [29] |
Abstract: We introduce Adam, an algorithm for first-order gradient-based optimization of stochastic objective functions, based on adaptive estimates of lower-order moments. The method is straightforward to implement, is computationally efficient, has little memory requirements, is invariant to diagonal rescaling of the gradients, and is well suited for problems that are large in terms of data and/or parameters. The method is also appropriate for non-stationary objectives and problems with very noisy and/or sparse gradients. The hyper-parameters have intuitive interpretations and typically require little tuning. Some connections to related algorithms, on which Adam was inspired, are discussed. We also analyze the theoretical convergence properties of the algorithm and provide a regret bound on the convergence rate that is comparable to the best known results under the online convex optimization framework. Empirical results demonstrate that Adam works well in practice and compares favorably to other stochastic optimization methods. Finally, we discuss AdaMax, a variant of Adam based on the infinity norm.
URL
[本文引用:1]
|
| [30] |
URL
[本文引用:1]
|
| [31] |
URL
[本文引用:1]
|
| [32] |
URL
[本文引用:1]
|




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}