
 , 钱力, Qian Li
, 钱力, Qian Li【目的】突破基于关键词的传统文献检索方式, 为用户打造科技大数据知识发现平台, 实现文献检索到知识检索的转型升级。【方法】利用数据挖掘技术进行科研实体抽取与关系计算, 基于实体知识图谱构建分布式索引, 实现知识多维度检索呈现和关联导航。【结果】本文研发的知识发现平台, 在论文、项目、学者、机构等10类科研实体构建的知识图谱上实现了智能语义搜索和多维知识集成检索发现。【局限】当前知识发现平台主要建立在实体级别上, 语义检索有待进一步研究深化。【结论】基于知识图谱构建的知识发现平台实现了数据在知识层面的组织索引, 满足了用户精准知识检索需求, 提升了用户体验。
[Objective] This paper tries to create a big data platform for sci-tech knowledge discovery, aiming to transform the keyword-based literature retrieval to knowledge retrieval. [Methods] First, we extracted and annotated scientific research entities and calculated their relationship with data mining techniques. Then, we created distributed indexes based on entity knowledge graph, which achieved multi-dimensional knowledge retrieval and correlated navigation. [Results] This study generated knowledge graphs for 10 research entities, such as papers, projects, scholars and institutions, etc. The proposed platform could conduct intelligent semantic search and multi-dimensional knowledge discovery with these knowledge graphs. [Limitations] Our study is at the entity level, and more research is needed for the semantic retrieval. [Conclusions] The proposed platform organizes data at the knowledge level, which meets user’s precise knowledge retrieval demands and improves user experience.
大数据时代, 信息呈现出数据量巨大、数据类型繁多、价值密度低及速度快、时效高等特点, 对科技情报信息的研究获取和有效利用构成了严峻挑战。随着机器学习、知识图谱技术的迅速发展和其在资源发现平台中的应用, 如何深度发掘知识间关联关系, 充分利用知识和体现知识价值, 是当前资源发现平台关注的重点。
中国科学院文献情报中心一直致力于对科技资源的精准获取和深入挖掘利用, 目前中心积累的知识资源总体量已达到数十亿级别。“关键词+文献列表”的检索模式已经不能满足用户对于知识的需求。在中国科学院“十三五”规划中, 基于知识图谱技术从科研主体、科研动态、科研活动、科研成果等方面, 提出了面向科研全过程链条建设新型知识检索发现服务。
知识图谱在搜索引擎中的应用可以更好地理解用户需求, 并且能够提供给用户更加智能、精准和人性化的服务。谷歌搜索依托于Google Knowledge Graph[1]智能分析用户输入, 除了显示其他网站的链接列表, 还提供结构化的主题信息, 并生成关联的百科知识, 很大程度提升了用户检索体验。但由于在国内谷歌访问受限, 给用户带来很大不便。WolframAlpha[2]利用其庞大的专家级知识库和知识图谱实现了智能计算知识引擎, 对用户输入的问题能够智能解析、搜索并给出相关答案。随着信息数据量的快速增长, 基于知识图谱的信息查询与检索在科技情报领域的重要性越来越明显, 开发高质量的知识发现平台越来越重要。
在数字图书馆领域, 一些以知识图谱为基础构建的学术知识发现平台不断涌现, 如Springer Nature的开放关联数据平台SciGraph旨在借助知识图谱提升内容的可发现性与可获得性, 在知识组织的基础上, 通过数据融合、知识发现、内容计算, 实现内容价值增值与知识服务。该平台的搜索和导航功能使得用户能够探索书目的元数据, 并基于元数据的分类帮助用户找到想要的内容, 分类包括作者、机构、研究领域、项目基金、会议和地点[3]。Taylor & Francis基于构建的知识图谱开发Wizdom.ai平台, 提供对出版物、专利、作者、机构等科研实体的分类检索[4]。清华大学研发的AMiner学术知识服务平台, 集成了学术大数据融合、专家档案智能抽取、专家智能搜索等研究成果, 在论文文献搜索以外, 提供了针对研究者信息的强大搜索能力[5]。
上述研究为本文的科技大数据知识发现平台提供了有益的借鉴。本文基于中国科学院文献情报中心构建的全领域学术知识图谱, 以结构化与语义化的知识图谱为核心搜索引擎, 实现论文、专利、标准、项目、期刊、会议、学者、资讯、报告、机构10类科研实体的智能语义发现, 突破了基于关键词的传统文献检索方式, 实现文献检索到知识检索的转型升级, 支持对海量数据的挖掘计算、智能语义搜索、科研实体搜索和实体关联导航, 最大化探索与挖掘数据资源的价值, 为用户提供智能化服务。
利用知识图谱技术, 利用机构、学者、期刊、项目、基金等数据规范库和知识抽取技术对汇聚的数据进行规范化与实体化, 实现对论文、专利、学者、项目等10类科研实体的抽取、语义组织和实体关联, 并利用数据采集、数据解析和数据融合技术借助其他来源的数据对科研实体进行数据丰富化与数据增值, 构建全领域学术知识图谱。
以知识图谱为核心搜索引擎, 以ElasticSearch[6]分布式集群作为大数据索引技术支撑, 形成知识图谱索引的解决方案, 实现对知识图谱的多维索引。构建科技大数据知识发现服务平台, 提供对上述10类科研实体的快速关联发现, 并利用自然语言处理与机器学习技术实现海量文献数据资源的智能语义检索、科研综述和主题聚合探索分析等知识发现与情报决策分析服务, 打破过去单一的文献知识资源类型检索发现模式, 以满足新知识服务时代用户的新需求。
通过对知识图谱进行索引实现对海量数据的快速存储、搜索和分析。目前最为流行的知识图谱存储和索引工具是基于RDF三元组的Virtuoso数据库, 尽管Virtuoso数据库本身提供全文检索功能, 但在数据规模较大的情况下, 其检索性能并不理想, 不能很好地支持对海量数据的存储和实时检索。
本文选用ElasticSearch进行大规模知识图谱的存储和索引工作, 完成了ElasticSearch分布式集群的搭建, 构建了一个稳定可靠的分布式多用户能力的全文搜索引擎, 并主要从以下三个方面对ElasticSearch进行性能优化:
(1) 索引字段的设计
由于ElasticSearch的join查询功能的较弱, 通常情况下, 每个文档都包含大量字段, 有些字段用来检索过滤, 有些字段仅仅用来存储数据。因而在设计索引的时候, 对于无需检索的字段设置enable= false, 这样只存储不索引, 可以提高索引速度。
(2) 多线程数据写入
单线程发送bulk请求无法最大化ElasticSearch集群写入的吞吐量。如果利用集群的所有资源, 就需要使用多线程并发将数据bulk写入集群中。为了更好地利用集群的资源, 使用多线程并发写入, 从而可以减少每次底层磁盘fsync的次数和开销。
(3) 预索引数据
为了提高检索和聚合的速度, 可以对某些字段进行预分组。如项目经费字段经常需要按照经费金额区间进行检索或聚合, 这种情况下, 可以在每个文档 增加经费金额区间这个字段, 大大提高检索和聚合的速度。
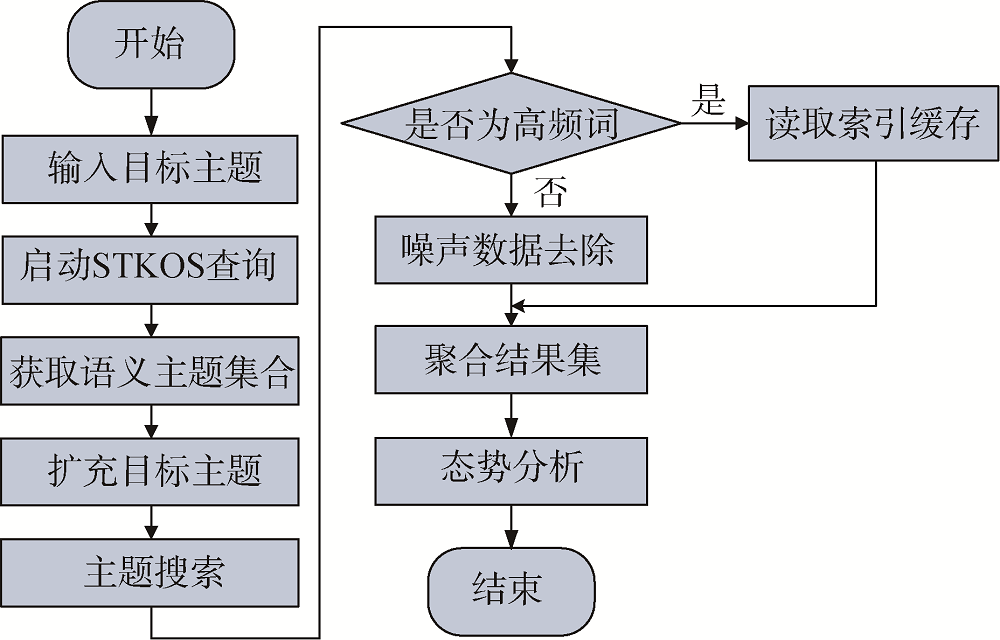
本文基于构建的知识图谱索引建立语义搜索模型, 通过提供精准、高效的关键词和实体标注主题的匹配、对实体进行主题标注三个方面实现对科研实体的语义检索、智能排序和相关推荐功能。实现流程如图2所示。
首先利用STKOS[7,8]语义知识库和数据挖掘算法获取关键词的语义主题集合作为候选词, 并使用余弦相似度算法计算候选词可以组成的研究概念, 最后根据相关度排序推荐相关概念, 帮助用户找出其最想表达的含义, 并为用户提供更多相关方向的关键词。在知识图谱索引构建过程中, 已利用STKOS语义知识库和数据挖掘算法完成了科研实体的主题标注, 利用Word2Vec[9]将实体主题标注和搜索关键词的语义主题集合都映射为语义标签向量, 通过余弦相似度算法计算搜索关键词语义标签向量和实体语义标签向量的相似度, 根据检索排序规则返回实体检索结果。
本文涉及的10类科研实体均可依据时间、相关度等单一维度进行排序, 由于论文质量参差不齐, 数据超载现象日益严重, 用户输入关键词后得到的检索结果不仅数量大, 而且其中充斥着不重要的信息, 这严重干扰了文献的选择与获取。因此将以下三个因素融入到排序算法中: 时间因素、期刊影响因子和文献被引频次, 计算公式为:
其中,
利用研发的语义智能检索技术, 智能识别用户检索的真正意图, 准确地向用户返回最符合其需求的搜索结果, 进而利用智能排序算法将近期发表的高质量论文优先推荐给用户。从用户反馈的角度来看, 在考虑时间因素、论文被引频次和期刊影响因子后, 能很好地对文献检索结果进行排序, 有利于减轻信息冗余现象, 提高文献检索效率。
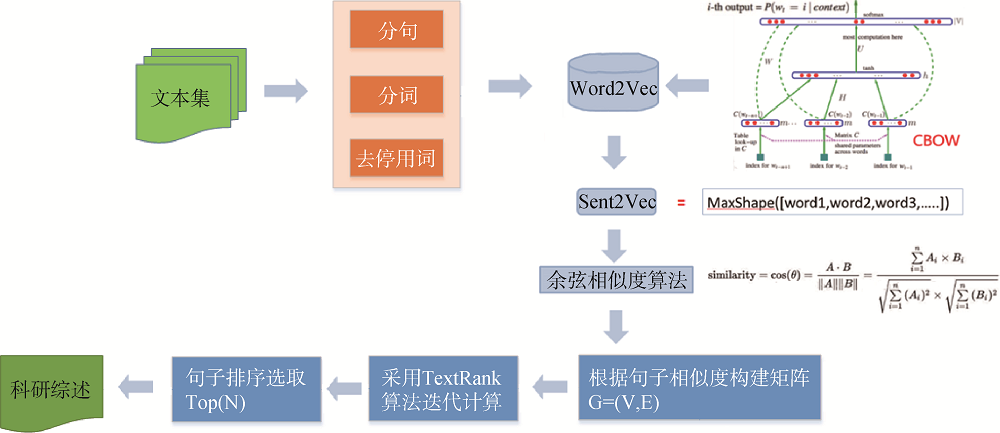
科研综述智能生成技术可以快速提取多篇文档的文摘内容并以少数句子展示关键信息, 让用户可以在几分钟内了解整个话题, 为用户节省大量时间和精力。图3展示了本文科研综述生成的实现流程。
首先对搜索结果进行重要度排序, 选取前50篇文献的摘要形成文本集, 然后对文本集进行分句、分词、去停用词等预处理操作, 通过Word2Vec利用训练好的词向量库将文本集中所有词汇进行向量表征, 这样就可以定量地度量词与词之间的关系, 挖掘词之间的联系。
CBOW和Skip-gram都是在Word2Vec中用于文本向量表示的实现方法。在CBOW方法中是利用周围词预测中心词, 进而以中心词的预测结果、使用GradientDesent方法, 不断调整周围词的向量。当训练完成之后, 每个词都会作为中心词, 对周围词的词向量进行调整, 这样即获得整个文本中所有词的词向量。可以看到, CBOW预测行为的次数与整个文本的词数几乎是相等的。而Skip-gram是用中心词预测周围的词。在Skip-gram中, 利用周围词的预测结果、使用GradientDecent不断调整中心词的词向量, 最终遍历完毕所有文本, 即得到文本所有词的词向量。可以看出, Skip-gram进行预测的次数要多于CBOW: 因为每个词在作为中心词时, 都要使用周围词预测一次。这样相当于比CBOW的方法多进行K次(假设K为窗口大小), 因此时间复杂度为O(KV), 训练时间要比CBOW长。因此, 本文选取CBOW模型对文本进行 训练。
对文档集中的句子选取最大维数, 利用建好的词向量生成句向量Sent2Vec, 然后利用余弦相似度算法, 得到句子间两两相似度, 构建句子相似度矩阵, 进而利用TextRank[10-11] 算法迭代计算, 当迭代计算相邻两次的计算结果差异较小时, 则停止迭代计算, 即迭代计算结果已经收敛。在收敛之后, 对所有句子节点的当前权重降序排列, 选取Top(N)个句子作为文档集的科研综述进行输出。
上述科研综述智能生成技术, 可以从大量文章中快速且有效地获取话题内容, 满足现代人快餐式地获取各种信息的需求。
利用本文构建的语义搜索引擎, 支撑科研用户、企业用户从主题的研究视角, 深度探索主题的发展趋势、研究热点、热门期刊、研究学者、研究机构和研究论文等。
为了更全面地检索到与某一主题相关的资源, 利用STKOS获取与该主题相关主题或子主题, 利用本文构建的主题搜索引擎找到与主题密切相关的科技论文、学者、机构、期刊等资源, 由于一词多义等因素可能导致检索结果与目标主题内容偏离, 因此需要噪声数据去除这一校验环节, 以免对主题聚 合结果造成影响。主题聚合分析的实现方法如图4 所示。
噪声数据去除是主题聚合部分的重要环节, 也是本文重点攻克的技术难点, 基于4.1节实体主题标注结果判断实体之间的相似性, 可通过Word2Vec对实体之间的主题进行向量化, 再利用欧氏距离或者余弦相似性进行求解, 不过这种方法有着致命的缺陷, 即无法从实体整体上考虑相似性, 仅仅是基于词会造成很大的信息缺失问题, 因此本文采用词移距离(WMD)计算方法, 从整体上考虑两个实体之间的相似性。在科技论文、学者、机构等众多资源实体中, 科技论文包含的内容较多, 因此相似性过滤过程最为复杂, 以科技论文为例, 阐述词移距离计算方法的具体应用 过程。
Word2Vec将词映射为一个词向量, 在这个向量空间中, 语义相似的词之间距离会比较小, Word2Vec得到的词向量可以反映词与词之间的语义差别。本文将实体距离建模成两个实体中主题语义距离的一个组合, 比如对两个文档的词向量求欧氏距离再加权求和, 计算公式为: $\sum\nolimits_{i,j=1}^{n}{{{T}_{ij}}c(i,j)}$, 其中
通过对噪声数据过滤后的结果集的研究论文、研究机构、研究学者、研究热点、研究主题等指标体系进行可视化态势分析, 获得研究主题的科研发展历程和发展趋势, 从而实现海量科技大数据与主题相关知识的智能聚合。
基于中国科学院文献情报中心数十亿级的科研学术数据, 构建科技大数据学术图谱, 以知识图谱为核心搜索引擎, 实现论文、专利、标准、项目、期刊、会议、学者、资讯、报告、机构10类科研实体的智能语义搜索和多维知识集成检索发现, 并基于机器学习和数据挖掘技术实现对检索结果的智能科研综述和主题聚合分析服务, 为科研院所、科技企业、高等院校与政府机构等聚焦前沿科技的行业客户提供精准知识服务。
基于知识图谱建立的知识网络, 打破了原有基于关键词的文献获取单一模式, 转型升级到“文献+互联网+专业数据集+科研实体”的多维度立体知识检索发现服务模式。建设效果如图5所示。
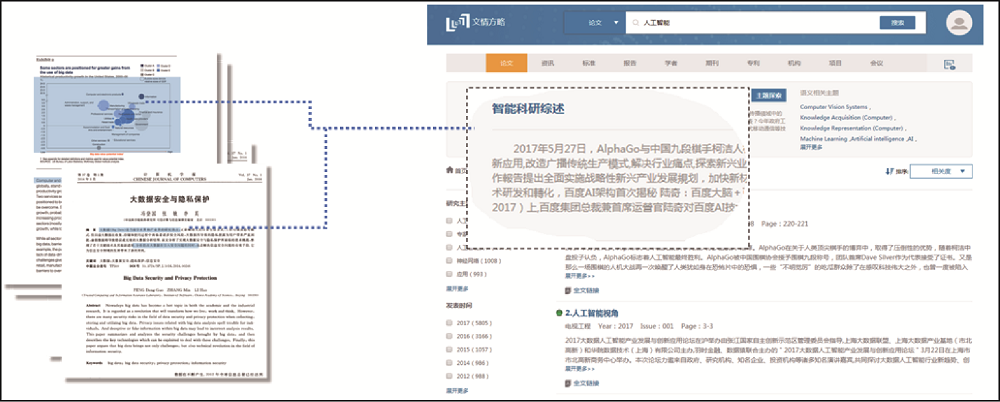
集成STKOS全领域超级语义知识网络, 利用科研综述智能生成技术可以快速地对多篇文档进行提炼总结, 用户只需阅读短短十几句或几十句的总结便可以了解相关信息, 实现了从浅层文献篇章获取模式转型升级到深度的知识挖掘、组织、发现模式。建设效果如图6所示。
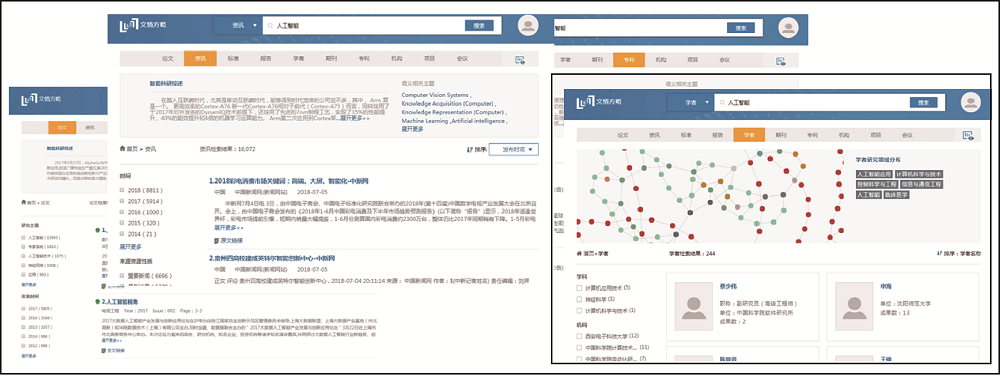
利用自然语言处理与深度学习技术, 实现海量学术科技大数据的主题标注与主题相关知识的智能聚合, 支撑科研用户、企业用户从主题的研究视 角, 深度探索主题构成与发展演化。建设效果如图7所示。
基于全球海量科技数据建设的学术知识图谱构建了研究人员、机构、期刊、论文、项目、基金、专利等实体相互关联的复杂网络, 实现了知识层面的数据融合与集成, 并以知识图谱为核心搜索引擎, 完成了科技大数据知识发现平台的建设。面向科研院所、科技企业、高等院校与政府机构, 该平台提供对论文、专利、学者、机构、项目等10类科研实体的检索关联发现, 提供对海量文献数据资源的智能语义检索和主题聚合探索分析等知识发现与情报决策服务, 并为用户呈现科研实体的关联关系、发展历程和发展态势、科研学者的合作网络和学术成果, 有助于全方位跟踪关注领域的发展动向, 洞察有研究价值的科研论点和寻求可以合作的潜在学者、研究机构等。
面向未来, 科技大数据知识发现平台需要通过数据规范库建设持续进行数据规范, 保障数据质量, 提升对精准知识发现服务的支撑能力; 随着数据量的不断增大, 平台需要继续优化搜索策略, 保障服务效率; 平台实现的知识发现主要建立在实体级别上, 后续需要进行语义级别的深入挖掘, 使其成为支持各类信息机构和科研机构有效利用的知识发现服务平台。
胡吉颖: 平台系统设计, 提出研究方案, 系统研发, 论文撰写;
谢靖: 平台架构设计, 提出研究方案, 论文修改、修订;
钱力: 平台架构设计, 论文修订;
付常雷: 科研综述算法研发和内容撰写。
所有作者声明不存在利益冲突关系。
| [1] |
URL
[本文引用:1]
|
| [2] |
URL
[本文引用:1]
|
| [3] |
URL
[本文引用:1]
|
| [4] |
URL
[本文引用:1]
|
| [5] |
[本文引用:1]
|
| [6] |
[本文引用:1]
|
| [7] |
【目的】为实现科技知识组织体系(STKOS)的共享和利用。【应用背景】构建知识组织体系有机存储与访问的引擎系统是实现知识组织体系有效利用的前提条件。【方法】构建支持STKOS各类元素检索、浏览、关联、导航的语义存储与索引体系、语义查询与推理内核以及STKOS API,并对外提供开放查询与推理接口。【结果】该引擎系统支持STKOS发布服务平台建设以及STKOS在第三方检索服务系统的应用。【结论】通过STKOS开放引擎系统,科技文献信息机构和研究人员能够方便有效地利用STKOS。
URL
[本文引用:1]
|
| [8] |
为了实现海量外文科技文献信息的知识组织,促进文献信息内容的知识关联和知识发现,国家科技文献信息中心组织实施了“面向外文科技文献信息的知识组织体系建设和示范应用”国家科技支撑计划项目,提出构建以内容建设为核心,加工协作和开放服务平台为依托,以自动处理智能检索和知识服务应用为基础的知识组织体系建设和示范应用.论文在系统分析现行知识组织建设的4种模式可供借鉴特点,说明了该项目的目标、主要建设内容,最后总结信息组织基础设施建设中的难点.
|
| [9] |
随着近些年深度学习的兴起,词语在计算机中的表示有了重大突破;而长期以来关键词提取算法均以词语作为特征进行计算,效果并不理想。因此,本文提出了一种基于深度学习工具word2vec的关键词提取算法。该算法首先使用word2vec将所有词语映射到一个更抽象的词向量空间中;然后基于词向量计算词语之间的相似度,最终通过词语聚类得到文章关键词。实验表明该算法对于篇幅长文章的关键词提取的准确率要明显高于其他算法。
|
| [10] |
经典的TextRank算法在文档的自动摘要提取时往往只考虑了句子节点间的相似性,而忽略了文档的篇章结构及句子的上下文信息。针对这些问题,结合中文文本的结构特点,提出一种改进后的iTextRank算法,通过将标题、段落、特殊句子、句子位置和长度等信息引入到TextRank网络图的构造中,给出改进后的句子相似度计算方法及权重调整因子,并将其应用于中文文本的自动摘要提取,同时分析了算法的时间复杂度。最后,实验证明iTextRank比经典的TextRank方法具有更高的准确率和更低的召回率。
|
| [11] |
【目的】通过将单一文档内部的结构信息和文档整体的主题信息融合到一起进行关键词抽取。【方法】利用LDA对文档集进行主题建模和候选关键词的主题影响力计算,进而对TextRank算法进行改进,将候选关键词的重要性按照主题影响力和邻接关系进行非均匀传递,并构建新的概率转移矩阵用于词图迭代计算和关键词抽取。【结果】实现LDA与TextRank的有效融合,当数据集呈现较强的主题分布时,可以显著改善关键词抽取效果。【局限】融合方法需要进行代价较高的多文档主题分析。【结论】关键词既与文档本身相关,也与文档所在的文档集合相关,二者结合是改进关键词抽取结果的有效途径。
URL
[本文引用:1]
|







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}