
 , 朱立平, Zhu Liping
, 朱立平, Zhu Liping【目的】利用HS编码数据中所蕴含的规律, 为海关税收风险判断分析提供有效的知识服务。【方法】提出直接以HS编码作为风险判别目标和以HS编码正误作为风险判别目标两种基于机器学习的自动分类方案解决HS编码风险判断问题, 针对编码目标的结构、特征的性质、文本的长短等特征构建与方案对应的SVM预测模型并进行相应实验。【结果】对以HS编码作为判别目标和以HS编码正误作为判别目标两种预测海关报关风险方案进行探讨与分析, 发现后者对训练数据的要求更低, 预测速度更快, 风险的识别效果也更好。【局限】仅获得4个月的数据, 可能存在样本代表性不足的问题。【结论】最终经过测试获得风险预测率较高的分类器, 为形成可实用的分类模型和判别系统提供了良好的知识基础。
[Objective] This study tries to utilize patterns from the HS codes to provide effective knowledge service for the China customs taxation. [Methods] We proposed two machine learning-based automatic classification schemes. The first one directly used original HS codes as risk identifiers while the other one relied on the correctness of the HS codes. We also built a SVM prediction model and examined the two schemes from the perspectives of target structures and features, as well as the text length. [Results] We found that the second model required less training efforts and processing time and then reached better accuracy. [Limitations] Only used four-month-data to train the new models. [Conclusions] This study finds an effective way to forecast customs risks, and indicate directions of applicable products.
随着世界经济全球化的发展与科学技术浪潮的来临, 海关平台在国家日常管理中扮演了比以往更加重要的角色[1]。国际贸易的发展显著增加了海关部门的工作量, 使其积累了大量进出口报关数据, 这些数据在当今社会大数据的背景下显示出了对今后海关决策工作的重要参考价值与实际使用意义[2]。
海关审单是海关管理工作中重要的一环, 指依据有关规定, 以风险分析和信息技术为手段, 对报关单的合法性、规范性、有效性、准确性进行审核的执法行为[3]。从总体看, 海关数据仍处于“数据多、知识少”的阶段, 因此尽管大部分进出口交易是合法的, 但审单依旧是一项查获率低、需要大量人力与时间的工作。报关问题中, 报关商品的归类错误是海关面临的主要风险之一, 这一风险主要涉及商品与HS编码的匹配问题[4], 传统的审核过程涉及报关员的知识背景、对商品类目的熟悉程度以及人为操作等主客观因素[5]。目前利用大数据技术实现报关单的自动风险评估成为一种趋势[6], 依据历史报关数据构建模型, 实现此类风险的机器判定[7], 也成为一个亟待解决的问题。
本文利用海关历史报关数据, 通过机器学习与文本分类方法, 针对HS编码对商品归类风险的机器自动判定问题进行探究。主要关注商品归类过程中汉字文本的判断问题, 寻求有利于风险规避的有效方案; 利用特定方案训练出的模型测试报关数据, 从而对海关报关风险问题的大规模自动解决提供具体参考, 为构建海关报关商品归类风险平台提供方案基础。
本文通过对海关数据的分析, 寻找HS编码风险预测方案, 因此研究重点在于海关风险判别和其他领域的编码判别以及风险识别这两个问题上。
各国海关自20世纪90年代中期起开展信息化建设, 虽然真正自动化处理海关数据的应用还相对较少, 但也出现了适应海关业务的应用系统[8], 如南京海关利用知识库中的匹配规则自动识别一些数值型错误[9]; 美国海关开发了预进口复审系统(PIRP)[10]和自动化瞄准系统(ATS)[11]; 韩国海关根据商品历史表现决定审单的严格程度[12,13]; 印度海关的RMS系统通过数据挖掘工具选择检验的预测模型[14]; 西非5个国家联合开发了将风险类别与简单的规则相结合的海关报关系统[15]。在海关风险评估信息化需求的背景下, 这一领域的研究还较少, 有Shao等[16]、任尔伟等[17]和张云波等[18]采取决策树算法构建系统对青岛海关数据进行测试; 卢金秋利用BP神经网络评估进口企业, 辅助海关对不同商品采取不同的通关策略[19]; 喻宇使用K邻近值的离群数据挖掘方法判断重庆海关的异常数据[20]; 杨波利用关联规则方法对大连海关审单商品进行实例验证, 提高通关效率[21]; 刘昌伟等基于因子分析法将数据挖掘方法运用到海关数据中, 完成对数据的降维与简化[22]; 周欣等采用决策树方法, 以上海海关数据中的查获与否作为分类标号得到高查获率的预测模型[6]。
目前中国对商品使用的海关HS编码为每2位为一级, 不断细分的5级10位编码[23], 这种海关HS编码规则与其他某些领域的编码判别问题较为类似, 如王克海将产品作业逻辑关系分解为零部件代号和工艺过程两部分, 用在作业事项号的自动生成研究中[24]; 陈东明等根据企业的编码结构特征, 提出基于分段代码自动生成产品结构树的算法[25]; 王昊等提出该类结构编码的判别问题可以采用单层分类法(Flat Classification)[26]和层次分类法(Hierarchical Classification)[27]实现文本分类。单层分类法认为编码是独立的, 将数据归到置信度最高的类别中; 层次分类法则根据类目之间的关系将复杂分类任务简化为较小分类[28,29], 降低了计算复杂度, 适用于大规模的自动分类[30]。可以发现编码的自动生成与判别研究主要集中在编码的结构问题上, 如何利用编码特征辅助编码生成是研究者关注的重点。除此以外, 一般研究者通常将风险的识别转化为分类问题解决。如谢小楚将案件分为一般案件、简单案件和简易程序案件三种, 完成海关缉私案件的预测[31]; 严俊龙等将网络安全性转化为安全与不安全两类, 构建网络安全风险评估模型[32]; 罗方科等在个人小额贷款信用风险评估研究中, 将用户分为违约与履约两类进行模型构建[33]。当前海关审单广泛采取根据风险高低将商品分为不同类别, 从而选择不同通关渠道的通关措施, 那么在海关HS编码的风险建模中是否可以采取这种分类方式也是本研究需要探讨的问题。
海关风险预测领域已存在部分研究与应用, 但多数针对某一类别的商品, 且通常仅从数值型数据展开, 其实用性还有待观察与改进; 海关HS编码由于其结构和性质的特殊性, 可参考编码分类以及风险分类领域的研究。
本文数据来自中国某海关2016年3月-2016年6月的报关数据。对原始数据整理后, 每条记录均对应164个字段。经过清洗残缺或无效的数据等处理后, 最终得到有效实验数据共计241 585条, 其中海关人工审单中未发现风险的记录234 327条, 发现风险的记录7 258条, 为表述方便分别将以上两者称为正样本与负样本。
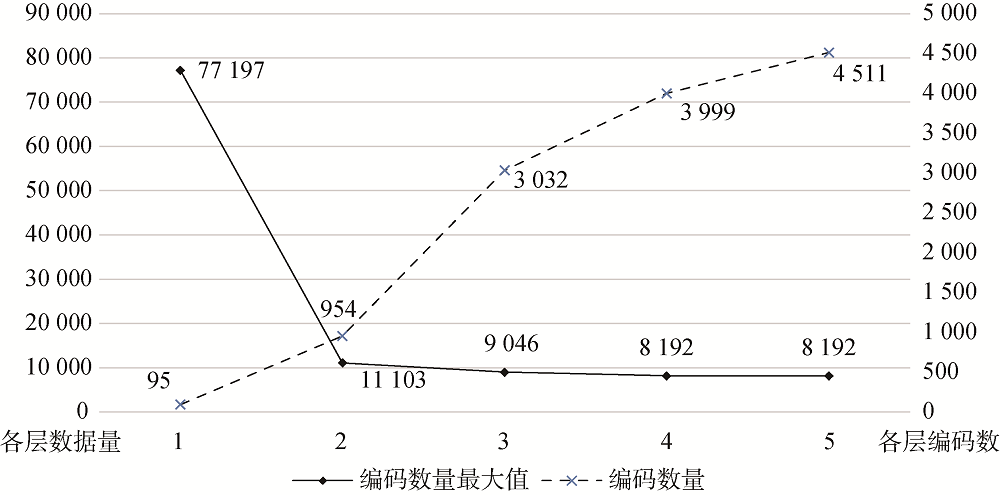
目前全球贸易总量98%以上的商品都以《商品名称及编码协调制度的国际公约》规定的统一海关编码进行交易识别, 简称为协调制度(Harmonized System, HS)[34], 该编码综合涵盖了《海关合作理事会税则商品分类目录》(Customs Co-operation Council Nomenclature, CCCN)和《国际贸易标准分类》(Standard International Trade Classification, SITC)两大分类编码体系[35]。根据商品种类的不同, 通常按层级从高到低由每2位码逐层深入组合得到完整的HS编码。根据《中华人民共和国海关进出口税则》, 中国的HS编码有10位[36], 在讨论具体模型与特征前, 笔者对实验数据的HS编码情况进行统计, 如图1所示。
(1) 由于HS编码的层次结构, 显然其种类会随着HS编码层次的上升而增长。依据规定中国商品分为22类98章(即HS编码有98个2位数(1层)的税目), 1 241个4位数(2层)税目, 5 113个6位数(3层)子目。本实验数据涵盖半数以上的前6位编码。
(2) 中国规定编码前8位称为主码, 后2位称为附加码, 目前共计有7 900余个8位数商品编号[37], 实际上编码的留空、废除、更新等原因会导致真实出现数量进一步减少, 且一些商品在报关中较为罕见, 故后4位编码数量与实际可能出现的数量有差距。
(3) 从各层级的数据量看, 每层中拥有最少数据量的编码均只有1条数据, 这在训练中容易导致模型对数据量偏少的类目不敏感; 相反, 每层中数据量最多的类目在总数据中占据相当的比重, 尤其在第1层, “85”类有77 197条数据, 占总数据的近三分之一, 在模型训练时应控制各类数据量, 避免出现部分类目的过分学习。
(4) 随着层级深入, 各层类目中数据量最大值的下降趋势与类目数量的增长趋势保持相对一致, 前3层类目快速增加时, 数据量最大值快速下降; 虽然数据量最大值在前3层上数量非常多, 但由于下位类出现更详细的划分, 因此实际上大多数10位HS编码类别拥有的数据量是有限的。
(5) 总体上来说, 本研究可使用的数据分布较为广泛, 并在前6位按其编码规则呈现指数上涨趋势, 后4位也符合数量增长趋势变缓的实际情况, 整体 上涵盖了大部分可能出现的HS编码, 具有相当的代表性。
由于本研究尤其关注对报关单中的风险数据, 故笔者对负样本的分布也进行相应统计, 如表1所示。
(1) 从编码层级来看, 各层编码均会出现分类错误, 自2位HS编码开始就有条目出现归类错误。
(2) 从数据上看, 1层出现错误的归类错误条目数占5层出现错误条目总数的约三分之一, 即有近三分之二在这一阶段还未出现错误, 那么通过对各层级HS编码的训练理论上可以加强模型对数据的理解。
(3) 从各层2位编码出现负样本数占总负样本的比重看, 该值在3层和4层之间出现明显分界, 即商品出错问题主要发生在类目种类多、增长快的前6位国际规定编码上, 比重几乎占全部出错的80%, 因此在模型构建中需要对前3层重点关注。
(4) 对于错误出现层级来说, 各层均有一定错误率, 风险随分类的深入逐渐递增, 增长趋势与该层出现编码种类数的增长趋势一致。从负样本的集中状态与分布情况显然无法准确探知风险所在的具体编码或层次, 报关数据内容本身才是识别风险的重点。
(5) 相对总数据量来说, 出现错误的负样本数据在总数据中所占比例并不高, 因此需要在实验中控制正负样本的比例, 防止出现由于模型中部分类目数据过少、学习不充分而引起判别效果差的问题。
通过对海关数据的初步统计分析以及对海关风险判别的了解, 本研究采取两种方式构建模型: 一是考虑其他领域类似HS编码结构的编码识别研究常用方法, 以编码结构作为重点关注对象, 将HS编码作为风险判别目标进行模型构建; 二是考虑海关监管工作中认为出现过错误的编码为高风险项的理论基础, 以HS编码正误作为风险判别目标构建模型。
(1) 以HS编码作为风险判别目标
以HS编码作为风险判别目标直接生成HS编码, 即直接预测报关商品本身应属的HS码, 再将生成的HS编码与企业报关时的编码进行比对, 从而判断该报关记录的正误。直接判断HS编码的方案主要利用国际通行的HS编码构成原理进行, 根据上文统计数据, 模型中可能出现的HS编码总计约有4 500余种, 参考图书分类中多类目分类法的特点, 可以采取单层分类法与层次分类法两种方式构建分类模型。
①单层分类法
近期相关研究中提到单层分类法忽略编码间的关系, 分类时认为所有编码之间都是独立的, 如图2所示。无论数据是否有层次结构, 数据的层次结构是显性或隐形, 或数据的层次结构有几层, 单层模型的构建中均不考虑中间层问题, 直接进行“一步到位”式的分类。
在构造HS编码的单层分类模型实验中, 笔者以含10位数字的完整类目号作为分类目标, 预测海关HS编码, 即使用每条记录对应的HS编码组成一个列向量作为其分类标记进行实验。
②层次分类法
层次分类法要求数据之间存在层次关系, 根据HS编码的制定规则可知其上下类之间有明确区别, 即存在显性的层次关系, 除根节点以外的每个节点都对应着原始类别中的一个类[38]。从方向上看, 层次分类法可以分为自顶向下与自底向上两种[39], 通过层次分类法构造的分类器称为层次分类器, 其定义包括类别的层次和分类器两个部分。在HS编码判别问题中, 类别层次问题由于编码本身5层10位的组织结构而非常清晰, 只需依据该规则构建自顶而下的分类器, 将编码分类过程分成多个阶段以减少判别压力, 最终通过逐层深入的训练与组合得到完整HS编码。
在大型文本分类研究中认为当编码类别数量过多时, 由于计算复杂度的急剧上升, 会出现类目区别能力的显著下降, 分析准确度也迅速下滑[40]。在HS编码数量过多、训练条件有限的情况下, 训练样本通常无法实现对所有类别的充分覆盖, 但为了验证单层分类法与层次分类法在HS 编码判别领域的分类效果, 本研究对两种方法均进行实验验证。
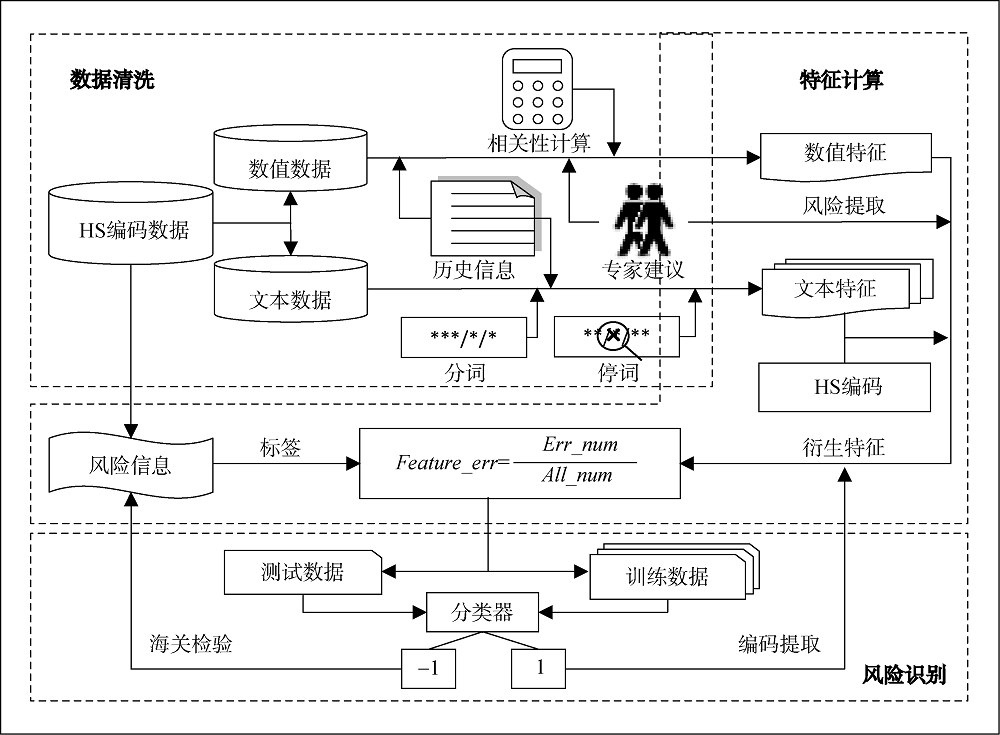
实际海关报关单中对商品进行描述的字段主要有两个: P_name(商品名称)和P_model(商品类型)。P_name的文本较短, 通常是商品名称或对商品的直接描述; P_model的文本较长, 通常是对商品的具体说明, 如尺寸、原材料、成份、用途等。为充分利用文本信息, 对P_name与P_model进行拼接、清洗、分词与停词等处理, 清理后的文本特征称为术语。采用Presence作为术语权重, 即术语在记录中出现则记为1, 否则记为0, 形成记录×术语矩阵(Records×Terms Matrix, RTM), 每行表示一条商品记录, 每列表示一个术语, 矩阵值为0或1; 每条记录对应的HS编码另外组成一个列向量作为其分类标记进行实验。
在构造层次分类模型的实验中, 受到来源数据量在后两层迅速减少, 且风险数据增长较慢的影响, 分别选取HS编码的前2、4、10位作为分类目标, 分次对海关HS编码进行预测实验, 具体内容将在实验结果部分说明。
(2) 以HS编码正误作为风险判别目标
对HS编码正误进行风险判断, 即对企业报关时自行确定使用的HS编码是否符合海关分类要求进行正误判断, 是基于历史数据的一种预测方法, 由于海关风险的判断本身是对报关数据的一种检查, 因此这种方案的理论基础是在曾经出现问题的某类商品、某个公司或某个国家等具体特征下的新报关商品可能较其他商品有更大风险出现错误[41]。目前大多数国家的自动审单系统采取这种方式, 对一些拥有高风险的特征赋予更高权重, 使拥有这些特征的商品进入更加严格的审核通道进行审核。一般对数据进行多方面的分析, 找出可能导致风险的特征并于这些违规行为中推断出统计性规律, 在模型中对这些特征赋予相应风险的权重, 使训练模型在预测中对这些特征更加敏感。这种方法对风险预测模型的训练针对性较强, 训练复杂度显著降低。
具体操作为将出现过风险的记录记为“-1”, 未出现风险的记录记为“1”, 使复杂的HS编码风险判断问题转化为相对简单的二分类问题。之后根据此方案的特点进行特征衍生, 认为之前发生过归类错误的商品条目是重点核查对象, 具有这些特征的商品在报关时有可能继续出现错误, 因此通过计算特征归类错误率
$Feature\_err=\frac{Err\_num}{All\_num}$ (1)
其中,
①数值特征
目前海关在风险预测问题上使用的多为数值型字段, 故本方案使用数值型字段针对
②文本特征
实际上人工确定HS编码时取决于商品的文字描述, 即海关商品的HS编码与商品自身文本信息直接相关, 因此文本特征也是本方案的主要关注特征, 处理时使用的文本与上一方案相同, 均为P_name和P_model经过清洗、分词、停词后的术语数据。字符串通常有具体的特殊含义, 因而保留所有字符串, 仅对汉字进行分词与停用词处理。由于文本特征较多以及汉字多含义的特殊性, 若将其直接作为特征在训练中使用可能会使术语在某类商品中的风险概率影响其在另一类商品中的判断, 故将文本特征与HS编码联合作为文本-编码(Text-Code)联合衍生特征, 根据每条记录中文字出现次数赋予对应权重, 并利用公式(1)计算其
使用正确率P、各类别正确率Micro_Pi、各类别召回率Micro_Ri和调和平均值Micro_F1i对实验结果进行衡量与评价, 各指标计算方法如公式(2)-公式(5)所示。其中,
$P=\frac{P\_num}{Sum\_num}\times 100%$ (2)
$Micro\_{{P}_{\text{i}}}=\frac{TP\_num}{TP\_num+FP\_num}\times 100%$ (3)
$Micro\_{{R}_{\text{i}}}=\frac{TP\_num}{TP\_num+FN\_num}\times 100%$ (4)
$Micro\_F{{1}_{\text{i}}}=\frac{2\times Micro\_{{P}_{i}}\times Micro\_{{R}_{i}}}{Micro\_{{P}_{i}}+Micro\_{{R}_{i}}}\times 100%$(5)
经过整理后发现数据量较大, 故主要使用2016年3月-2016年4月的数据进行模型构建与实验。在单层分类实验中将数据随机分为10份, 每次抽取其中1份作为实验样本, 在此基础上再分出训练集与测试集进行实验。在层次分类实验中, 受数据量影响, 采取相应的数据抽取与特征限制措施。
(1) 单层分类法实验分析
在单层分类法实验中, 以含10位数字的完整HS编码作为分类目标, 进行模型构建与测试, 发现实验中没有编码被正确分类, 即最终的准确率为0%。从测试结果可以发现:
①以5层10位HS编码作为分类目标时, 模型无法召回正确类目, 准确率为0%;
②从数据上看, 由于训练样本与测试样本数据量的限制, 本研究所覆盖的4 511个HS类目没有全部参与训练, 操作时随机抽取数据进行模型训练与测试, 类目间数据量不均衡;
③数据量均衡问题虽然可能在模型中引起对出现类目较少的数据训练不充分的问题, 但是在实际应用场景中, 数据本身就呈现不均匀分布状态, 这也是导致模型难以训练的原因之一;
④从实验结果看, HS编码的数量严重影响到模型构建与预测的准确率, 其中最显著的原因是HS编码类别过多, 导致有限的训练样本无法实现对所有编码的充分覆盖, 引起机器学习不充分, 分类效果很不理想。
(2) 层次分类法实验分析
根据层次类目与数据量变化, 在层次分类实验中分别选取HS编码的前2、3-4、5-10位作为其分类标记。需要说明的是:
①来源数据类目间数据量差异较大, 部分类目数据量过少, 因此在取编码前2位作为分类标记时, 只抽取来源数据中数据量最大的5个类, 并保证了各类之间数据量的相对平衡。
②在4位标记编码的实验中, 为保证下位类的充分学习, 抽取数据量最大的“85”类进行实验。前2位为“85”的3-4位编码, 共包括45种, 即在该层次的模型构建中分类标记共45种。
③下一层的实验按计划应抽取“85”类包括的45种下位类中数据量合适的6位标记编码, 但经过数据统计检查发现报关数据中细分的后6位类数据量过少, 因此本实验采取其中数据量较大、类别较多的“8536”进行测试, 并加入2016年5月-2016年6月数据中的该类数据, 此处的分类标记为HS编码的5-10位共计13种。
④受数据量影响, 对应的文字特征也会随之变化。在现有实验室条件下, 当数据量过大时过多的文本特征会使RTM矩阵的构造与训练产生困难, 故使用出现频次筛选文本, 尽量保留更多的数据: 在1-2位的实验中保留出现频次大于1的文本, 3-4位的实验中保留频次大于3的数据, 5-10位的实验中保留频次大于1的文本。各层次实验具体情况如表2-表4所示。
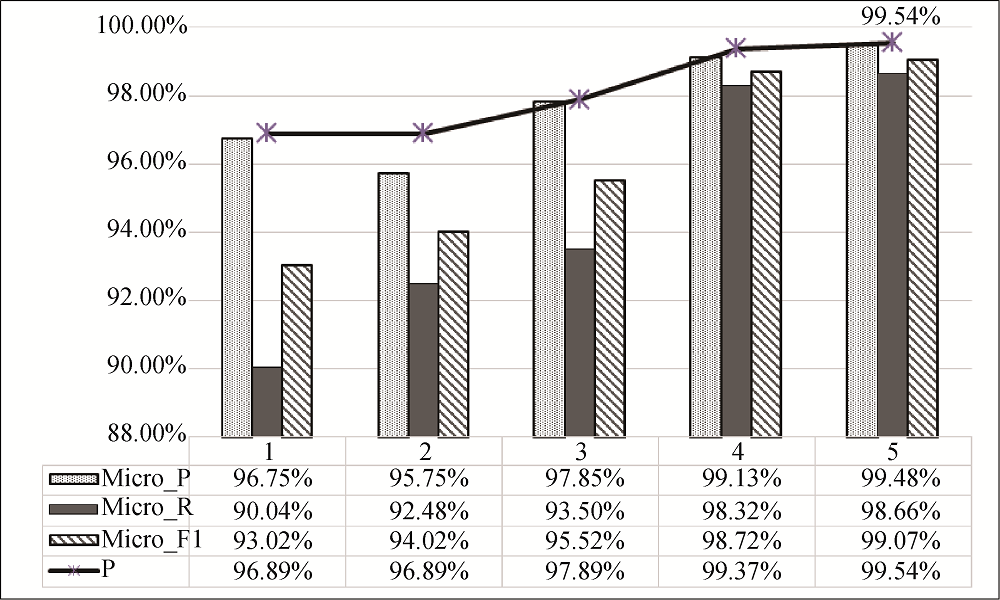
从表2可知: 以前2位编码作为分类目标时, 总准确率接近96%, 仅从该值看较为理想; 实验选取的5个大类中, 虽然测试集中数据量并不均匀, 但实际上各类预测效果较接近, 没有出现较大差距; 对比各类别的评价指标, 准确率最高的类别为“73”, 可能由于其训练数据与测试数据的比值最大, 相对其他编码训练更为充分, 从而提升了其准确率; 召回率最高的类别为“90”, 从数据量看该类没有突出特征, 但经过查证, 其他类目的内容偏向于工业制品, 而“90”类偏向于电子产品, 性质的特殊性使它具有较高的召回率; “84”与“85”两类分别代表“核反应堆、锅炉、机器、机械器具及其零件”和“电机、电气设备及其零件; 录音机及放声机、电视图像、声音的录制和重放设备及其零件、附件”, 二者作为数据中出现最多的两个类目, 文本相似度高, 训练时模型对二者的区分有限, 因此最终指标较其他类相对较差。
从表3可知: 3-4位HS编码作为分类目标时的分类准确率达到96%以上; 从训练与测试数据量上看, 随机抽取的样本可以反映出实际来源数据中各类目之间数据量的不平衡分布状态, 且受实验数据量影响, 样本抽取时测试集中缺少部分数据量较少的类目, 引起训练不充分的问题, 即在测试中部分类目编码的数据没有被识别。因此各编码的训练效果存在较大差异, 其总平均准确率、平均召回率和调和平均值较低, 均不足80%; 虽然各编码类目表现不均衡, 平均评价指标均不高, 但由于多数类目表现较好, 尤其是训练数据量与测试数据量比值较大的类目, 所以该模型在总准确率上的表现仍相对理想; 参考前1-2位HS编码的实验结果可以得到1-4位HS编码的识别准确率为92.24%。
从表4可知: 5-10位的HS编码识别准确率依旧较为稳定, 为95.92%; 受实验训练样本数据分布不平衡的限制, 模型在各类目上表现不稳定; 综合前两层实验结果可以发现, 在按3层共计10位的HS编码作为分类目标的实验中, 准确率在每一层均较为稳定, 维持在96%左右, 但是由于每层均存在一定的出错概率, 经过3层的叠加后, 总准确率最终为88.473%。
结合以上3个层次的实验可知, 本研究的实验环境中, 层次分类法的效果在各层次上表现较为稳定, 且维持在较高水平; 各类目实际训练效果受训练数据量与测试数据量比值影响, 该值越小, 模型所受的训练相对测试数据来说越充分, 效果越好。
本方案使用全部4个月的数据进行实验, 因为实际海关数据中负样本数量相对正样本数量较少, 为使模型通过训练可以对负样本敏感, 将正负样本分开, 从两类中随机抽取一定量的数据组合作为实验数据, 以保证训练集中正负样本的比例。
(1) 数值特征
HS编码进行风险判别的数值特征归错率的实验数据情况如表5所示。
由于数值衍生特征较多, 在对每个特征单独进行实验后还对这些特征进行依次叠加的实验。受篇幅影响, 只列出实验效果最优的所有11个数值衍生特征叠加的实验结果, 如图4所示。
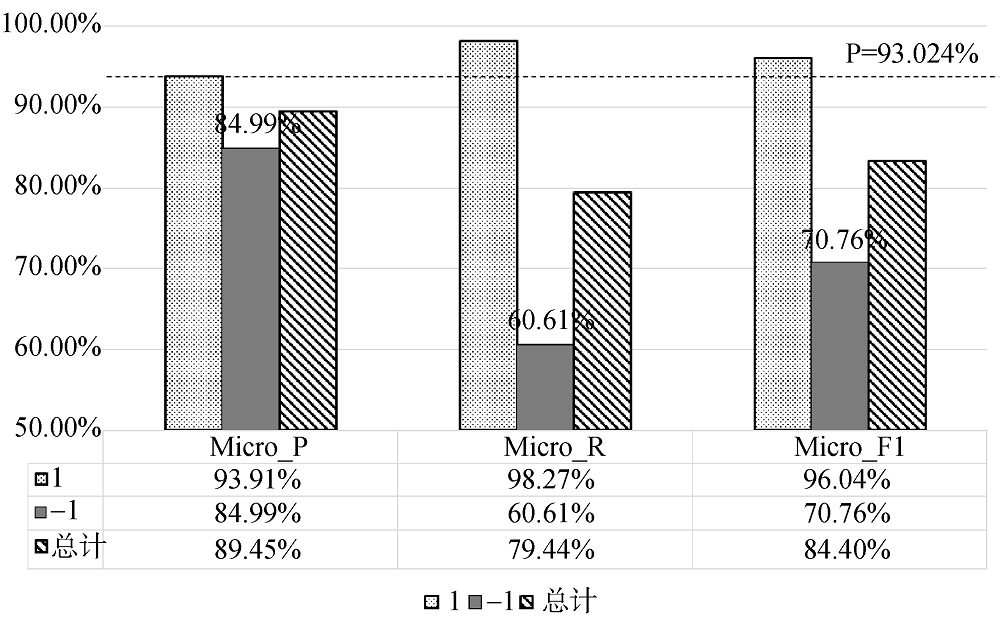
从实验结果来看, 在未具体列出的数值特征单独实验中, 只有经营单位、货主单位、申报单位和商品编号计算的衍生归类错误率效果较好, 即使这些特征的总正确率已经达到90%左右, 但负样本的召回率均很低; 在总体叠加的衍生特征实验中, 实验效果主要依靠单个表现较好的特征体现, 趋势与之前确定方案特征时计算的相关性结果一致; 实际上各特征在正样本上的表现差距并不明显, 而负样本上的表现则决定了最终训练效果, 提高负样本召回率是增强分类效果的关键所在。在所有衍生特征的共同作用下, 分类效果已经提升到93%以上。
(2) 文本特征
文本特征的实验结果如图5所示。
①P_name对应的特征中, cgns_err、cgna_err这样的单个特征训练结果已经明显优于非文字特征叠加的训练结果, 尤其是cgna_err, 其对负样本的召回率已超过85%, 对两类样本的召回率也达到92%以上, 说明文本特征对HS编码的判别有重要的积极作用;
②P_model的引入使测试结果进一步显著提升, cgms_err对负样本的召回率达到87%以上, 而cgma_err更是使该值第一次上升到90%以上, 这使总召回率达到98%, 故总正确率也进一步提升;
③P_name的文本较短, 经过停词后文字数量显著下降, 与拥有较长说明性文本的P_model相比可能失去了过多的特征, 从而导致准确率较P_model低;
④每条记录对应文本特征的总值与平均值在P_name与P_model中的结果均呈现出平均值效果优于总值的现象, 这是因为每条记录对应的文本数量不是定值, 若某条记录文本较长, 计算总值会使其特征过大, 这显然在放大特征的同时带来了误判的可能性, 在这种情况下, 使用平均值作为对应记录的特征更为合理;
⑤由于数值衍生特征训练效果较好, 将其与文本特征叠加后同样得到较好的实验结果, 其中负样本召回率达到97%以上, 整个实验的准确率也达到99%以上, 较为理想。
以HS编码作为风险判别目标时, 单层分类法与层次分类法的编码识别差距显著:
(1) 单层分类法显然不适合海关报关商品可能高达几千种HS编码的情况, 在现有实验室环境和有限的报关数据条件下, 要达到对近8 000种编码的 充分学习非常困难, 其实验结果也符合对该方法的预期;
(2) 层次分类法在每层上的准确率均在96%左右, 结果比较理想, 说明直接生成HS编码的方案在采取分层举措减少大量编码种类、增强目标特征后, 是切实可行的;
以HS编码正误作为风险判别目标时, 对风险预测模型的训练针对性较强, 预测效果也较为理想, 最后叠加的模型召回率达到98%以上, 准确率也达到99%以上, 除此以外:
(1) 由于问题被简化为只有1与-1两个分类目标的二分类问题, 即使模型随机将数据归类, 理论上也有50%的准确率, 故该方案在风险识别中对负样本的历史数据量有一定要求;
(2) 数值衍生特征的实验效果已经较好, 但实际上负样本的召回率很低, 显然提高负样本的召回率是增强HS编码正误风险预测效果的关键所在;
(3) 引入文字特征后预测准确率得到显著提升, 这与实际审单工作中人工依靠文字判断商品类别确定HS编码的行为一致;
(4) P_name与P_model分别作为短文本与长文本的代表, 从实验结果来看显然文本越长, 为训练与测试提供的信息与特征越多, 测试结果越好;
(5) 文本衍生特征的具体实验中, 记录-文本特征的总值准确率逊于记录文本特征的平均值, 说明每条记录受文本长度的影响不一致, 平均值在训练中更有效; 叠加数值衍生特征后, 总准确率会出现小幅上升;
(6) 所有实验中虽然预测准确率已经较高, 但经过观察这主要是以牺牲正样本的准确率为代价得到的, 因此这种方案在负样本数据量有限的情况下, 应当将测试重点放在提高模型对负样本的敏感程度上。
综上所述可以发现:
(1) 从数据量要求上看, 以HS编码作为风险判别目标时对总数据量依赖程度较小, 但对数据中各类目的数据量要求较高。通常需要样本中包含的HS编码数据较为平衡且均匀, 以获得较好的训练效果; 以HS编码正误作为风险判别目标时, 训练模型对总数据量依赖程度更高, 尤其表现在对数据中负样本的需求, 当负样本数据缺乏时, 负样本特征训练不充分, 容易导致部分未出现过的负样本难以识别。
(2) 从训练代价上看, 以HS编码作为风险判别目标需要构建巨大的记录-文本矩阵, 且由于涉及的HS编码较多, 在SVM中寻找训练的最优参数需要耗费更多资源; 以HS编码正误作为风险判别目标时, 虽然计算特征较为复杂, 但由于该方案将问题简化为二分类问题, 且其文本特征可以通过总值与平均值代替, 故训练代价较小, 风险识别速度较快。
(3) 从最终的训练效果来看, 以HS编码作为风险判别目标在各层级上均获得了稳定的识别效果, 最终准确率也较高。然而本研究中的类目与数据量是为了符合实验要求, 在一定条件下筛选得到的, 假设在随机挑选的数据中, 每个层次的准确率仍能维持在较为理想的96%, 那么经过5层的正确率叠加后, 总准确率会呈显著下滑趋势, 如图6(a)所示, 最终可能只维持在81%; 而以HS编码正误作为风险判别目标时, 引入文本特征后分类器的训练准确率高达99%, 但是由于实验数据量有限, 本实验中测试集的特征由同一批数据计算而来, 如图6(b)所示, 实际应用中若有部分风险项或全部风险项均未出现过时, 利用有限的训练样本还能否得到如此效果, 值得进一步研究。
本研究旨在利用已有海关数据所蕴含的背景知识和理论, 为现有的海关报关风险问题提供有效的知识服务。研究中提出了基于机器学习的自动分类方法解决报关商品归类判断问题, 进而依据以HS编码作为风险判别目标和以HS编码正误作为风险判别目标两种方案进行模型构建与实验论证, 得到对应的实验结果, 为下一步深入分析和探讨有效分类特征并最终形成可实用的分类模型和判别系统提供知识基础。
在对海关风险预测中的关键问题进行探究时, 本文将问题集中在报关商品HS编码的判定上, 对常见的两个编码判定方案分别进行模型构造与分析探讨。具体模型构建中, 根据已有研究和实际掌握的数据情况, 对风险判断中的分类特征选择进行循序渐进的研究, 对目标的结构(单层与多层)、特征的性质(数值与文本特征)、文本的长短(短文本与长文本)等进行了详尽实验, 对比两种方案在具体情境中的实际使用效果, 最终得到的两种归类风险预测模型效果较海关的实际人工常规查获率有显著提高[44]。由于目前该领域的研究较少, 因此本文暂时仅对两种方法进行初步的实现与对比, 针对本文得到的初步结论, 未来将针对两种模型的优缺点展开详细的特征探索与模型构建研究, 探索更成熟的风险自动化解决方案。
然而研究中还存在以下问题: 以HS编码正误作为风险判别目标的模型中, 测试集的特征是与训练集一起计算得到的, 在面对未出现过的新数据时准确率可能没有实验环境这么理想; 本实验只获得了4个月的海关报关数据, 可能存在代表性不足、模型不能得到充分训练的问题, 这也是后续研究需要解决的问题。
张紫玄: 设计与讨论研究思路, 进行数据处理与实验, 撰写论文;
王昊: 设计与讨论研究思路, 制定方案, 论文修订;
朱立平: 设计与讨论研究思路, 论文修订;
邓三鸿: 设计与讨论研究思路。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: MF1614058@smail.nju.edu.cn。
[1] 朱立平. haiguan.json. 由海关处获得的原始数据.
[2] 张紫玄. abc.dat. 经整理后的实验所用数据.
| [1] |
[本文引用:1]
|
| [2] |
[本文引用:1]
|
| [3] |
[本文引用:1]
|
| [4] |
This paper provides and describes concordances between the ten-digit Harmonized System (HS) categories used to classify products in U.S. international trade and the four-digit SIC and six-digit NAICS industries that cover the years 1989 to 2006. We also provide concordances between ten-digit HS codes and the five-digit SIC and seven-digit NAICS product classes used to classify U.S. manufacturing production. Finally, we briefly describe how these concordances might be applied in current empirical international trade research.
|
| [5] |
正(2006年3月20日海关总署令第146号公布自2006年6月1日起施行)第一章总则第一条为了加强报关员执业管理,保障报关员合法权益,根据《中华人民共和国海关法》和其他有关法律、行政法规的规定,制定本办法。
URL
[本文引用:1]
|
| [6] |
海关业务每日产生的海量记录中蕴藏着数据“金矿”有待进一步挖掘,为加强海关风险识别的准确性,让大数据的价值进一步得到显现,本文采用数据挖掘分类分析的方法,对历史报关单数据进行分析,根据其查获情况,将有查获与否作为,
|
| [7] |
[本文引用:1]
|
| [8] |
[本文引用:2]
|
| [9] |
[本文引用:2]
|
| [10] |
正 “预进口复审系统”(PRE—IMPORTATION REVIEW PROGRAM,简称PIRP)是美国海关为统一执法尺度,进行自动化处理业务等而开发的系统,通过该系统,海关可在进口和报关之前就能与进口单位进行有 关信息的沟通和交换,它是旨在进口之前,为加快进口通关速度,解决商品分类、估价和是否接受报关等方面的问题。其主要目标是:加强海关与进口单位在货物实 际进口之前的联系;减少有关进口要求和费用的不确定性;允许进口商对他们所进口的商品予以描述;提高商品分类和估价的准确性;
URL
[本文引用:1]
|
| [11] |
ABSTRACT Estimates of money laundering and terrorist financing are based on the analysis of historical price data. This analysis could be conducted in real time to determine which transactions should be audited and which cargo shipments should be inspected. The US now requires that manifest information be sent to the US Customs Agency 24 hours in advance of shipment from a foreign port. This requirement will help facilitate real-time audits and inspections of abnormally priced imports and exports. The efficient evaluation of data will be crucial to winning the war on terrorism. Intelligence is an inexact science, but the utilization of information technology and data mining techniques applied to financial transactions can contribute to increasing the quality of intelligence information.
|
| [12] |
[本文引用:1]
|
| [13] |
应韩国海关及KOICA(韩国国际协力团)的邀请,2001年4月,我有幸在韩国海关进行了学习考察.这期间,我们参观了仁川机场海关、机场关保税仓库、 浦项钢铁厂等韩国有关海关和工商部门.通过考察和研究分析,我们认为韩国海关的风险管理机制和海关自动化建设方面有不少值得我国海关借鉴的经验和做法.
|
| [14] |
过去一年内,印度进口商发觉印度全国各大口岸海关的办事效率和清关手续操作大有改观,货物清关速度大幅度提高。 事实证明,在印度,由私人公司承包经办一部分非主要通关业务的质量并不低于海关自身水平。
|
| [15] |
[本文引用:1]
|
| [16] |
[本文引用:1]
|
| [17] |
本文分析了海关加入 WTO 后面临的打击走私和加强税收的严峻形势,提出运用数据挖掘技术寻找查验和价格分析规律的系统解决方案,帮助海关业务人员加强查验和审价工作的针对性和有效性,以提高查获率和打击价格瞒骗行为。
URL
[本文引用:1]
|
| [18] |
将数据挖掘引用到海关风险管理中尚属首次,本文介绍了数据挖掘在海关商品查验中的方案设计,并探讨了其实现方法与关键技术。
URL
[本文引用:1]
|
| [19] |
针对目前我国海关企业风险评估过程中存在的问题,主要介绍了基于BP神经网络的数据挖掘方法,并开创性地将一种基于Levenberg-Marquardt学习算法的BP神经网络引入到海关企业风险评估工作中来。通过企业风险评估模型的实际运行,证明了该改进算法的有效性,同时也有力地提高了海关的企业风险监控水平。
|
| [20] |
[本文引用:1]
|
| [21] |
归类风险在审单风险中的影响举足轻重,为进一步提高归类水平、降低归类风险,有必要深入分析商品归类错误的原因.根据2015年以来长江经济带12个关区定期反映的代表性审单风险情况,本文从归类错误的表象原因入手,进一步挖掘归类风险背后的深层次原因,并提出相应的防范建议.
URL
[本文引用:1]
|
| [22] |
近年来,海关风险管理平台、执法评估系统等风险分析系统逐步由理论研究走向实际应用,但依然无法满足海关大量数据的快速挖掘与使用需要,为弥补目前海关已有的研究方法对海关风险管理进行定量综合评价的不足,缓解海关风险管理的过程中缺乏将产生的数据进行科学化分析的局面.文章在现有海关风险管理研究框架的基础上,融入因子分析法,通过实例分析将数据挖掘方法运用到海关工作积累的数据当中,为海关管理决策与风险管理提供帮助.
|
| [23] |
正 根据海关合作理事会的决定,《商品名称及编码协调制度国际公约》(简称HS公约)的缔约国将于1996年1月1日起正式采用1996年版《商品名称及编码协调制度》(简称1996年版《HS》)。我国作为HS公约的缔约国,1996年的《海关进出口税则》、《海关统计目录》也将采用1996年版《HS》。目前,1996年版《HS》的翻译工作已基本结束,即将进行税目及税率的转换。为给转换工作做好准备,也为使海关人员和其他有关部门对1996年版《HS》的修改及其对我国税则的影响有一初步了解,现将有关情况介绍如下:
URL
[本文引用:1]
|
| [24] |
None Practical technique that aids in scheduling largescaled producting task has been reported. The main reason is that there is lacking of concise,ping pointing arithmetic model that meets the needs of the real world practice, In addition, up to thousands tasks cannot be ordered automatically to the event number in the network diagram via the interior logic relationship and remained unchanged in the rnaking and revising the whole plan. It is the very topic that will solve the problem, TLZ model and the implementation, in this paper, Practice in more than two years has proven the correctness of the model and the arithmetic as well as the efficiency of the program. In January this year,TLZ was evaluated by the provincial experts who consider that it is valuable and widely used in the scholarly work.
URL
[本文引用:1]
|
| [25] |
提出了一种基于分段代码自动生成产品结构树的算法.企业的编码分 为识别码与分类码,识别码是零部件的惟一标志,往往采用分段的方式进行组织,可按固定段长或分隔符分界分段.识别码的分段信息与零部件在产品结构中的结构 信息一致.充分利用编码本身的结构信息解析字符串,具有较强的通用性.此算法已应用于设计研究院的产品数据管理系统中,形成了以设备清单生成产品结构树枝 干、以图纸代号生成叶节点的产品结构树自动生成算法.
|
| [26] |
面对与日俱增的图书出版量,图书馆编目人员的手工书目分类显得力不从心,如何实现由计算机自动完成图书分类成为数字图书馆建设中亟待解决的关键问题之一。本文尝试将BP神经网络和支持向量机等机器学习算法引入到书目分类中,建立了面向中图法的基于机器学习的书目层次分类系统模型,提出了采用特征加权方式描述书目和浅层次分类体系构建的设计思路,并通过大规模实验验证了该模型的可行性和合理性,基本上解决了没有主题标注情况下书目的自动分类问题。图9。表5。参考文献14。
URL
[本文引用:1]
|
| [27] |
[本文引用:1]
|
| [28] |
[本文引用:1]
|
| [29] |
Automatic classification of proteins using machine learning is an important problem that has received significant attention in the literature. One feature of this problem is that expert-defined hierarchies of protein classes exist and can potentially be exploited to improve classification performance. In this article, we investigate empirically whether this is the case for two such hierarchies. We compare multiclass classification techniques that exploit the information in those class hierarchies and those that do not, using logistic regression, decision trees, bagged decision trees, and support vector machines as the underlying base learners. In particular, we compare hierarchical and flat variants of ensembles of nested dichotomies. The latter have been shown to deliver strong classification performance in multiclass settings. We present experimental results for synthetic, fold recognition, enzyme classification, and remote homology detection data. Our results show that exploiting the class hierarchy improves performance on the synthetic data but not in the case of the protein classification problems. Based on this, we recommend that strong flat multiclass methods be used as a baseline to establish the benefit of exploiting class hierarchies in this area.
|
| [30] |
[Objective] Under the computing mode of machine learning, using the methods of feature weighting and shallow-hierarchical classification can effectively achieve Chinese Library Classification (CLC) classification for periodical articles. [Context] The traditional way of artificial classification shows its own limits in the background of "Big Data", and the trend of periodicals electronic makes that automatic classification techniques can effectively relief the pressure of artificial classification jobs. [Methods] This paper introduces the thinking of machine-learning into the field of automatic classification of periodical articles. It analyzes and compares the effects of Support Vector Machine(SVM) and BP Neural Networks Algorithm(BPNN) in the procedure of automatic classification, transforms CLC into another classification system with three levels in the thoughts of hierarchical classification, and sets the weights based the sources of classification features. [Results] The experiments of classification tests show that SVM is more reasonable than BPNN under the condition of large-scale sparse data, the accuracy rates of these three levels reach 95.05%, 92.89% and 89.02%, and the integrated accuracy rate is close to 80%, and the feature weights from mulit-sources can lead to better classification results than single-source. [Conclusions] The study proves that the model of machine-learning with feature weighting and shallow-hierarchical classification in automatic classification of periodical articles has higher feasibility, rationality and effectiveness, and a new idea on automatic classification of periodical articles has been presented.
URL
[本文引用:1]
|
| [31] |
[本文引用:1]
|
| [32] |
网络安全风险评估是解决网络安 全行之有效的措施之一,本文以支持向量机为基础,将网络安全风险评估归纳为一个支持向量回归问题,结合组合核函数的优点,建立了基于SVM的二分类网络安 全风险评估模型,并给出了模型实现方法;以资产、威胁和脆弱性为风险评估指标,以及低、较低、中、较高、高五个风险程度等级建立了综合评估体系。结合某企 业6月份网络安全记录样本,以组合核函数为评估模型的核函数,通过交叉验证和最速下降法,得到了最优预测模型。实践证明,该模型对网络安全风险评估是可行 的。
|
| [33] |
构建二分类Logistic信用风险评估模型,运用光大银行某分行样本数据,评估商业银行互联网金融个人小额贷款信用风险。结果显示:客户性别、学历、年龄、收入、职业、属地等因素对个人小额贷款信用风险影响显著。其中,年龄、收入、学历等与客户信用等级呈正向关系,女性信用风险显著低于男性,持有信用卡、存贷比越低的客户其信用等级越高;一、二线城市客户的履约率普遍高于县地级市客户的履约率。鉴此,商业银行应对互联网金融个人小额贷款信用风险进行有效规避和分散。
URL
[本文引用:1]
|
| [34] |
[本文引用:1]
|
| [35] |
正 我国海关已于今年1月1日起正式实施以《商品名称及编码协调制度》(HS) (以下简称"协调制度")为基础的新税则,并加入《商品名称及编码协调制度公约》(以下简称"公约"),同时,以《海关合作理事会商品分类目录》(CCCN)为基础的税则停止实施.协调制度的实施不仅给海关作业制度带来重大变化,而且对贸易管理也带来一定的影响.为了帮助有关方面了解协调制度及公约,适应新的海关作业制度以及贸易管理措施的变化,兹对协调翻度的产生、特点及公约的有关内容作一系统的介绍.
URL
[本文引用:1]
|
| [36] |
[本文引用:1]
|
| [37] |
[本文引用:1]
|
| [38] |
层次分类方法利用类别层次结构来分解问题和组织分类器,可有效解决多类分类问题。依据是否要求类别之间存在显式层次关系,层次分类方法可分为两大类。文中对不要求类别之间存在显式层次关系的层次分类方法进行综述。首先归纳和阐述此类方法所采用的基本框架,然后介绍和分析其中若干关键技术的研究进展,最后从算法和应用两个角度对国内外相关研究进行详细叙述,进而对现有方法进行总结,并给出进一步研究的方向。
Magsci
[本文引用:1]
|
| [39] |
[本文引用:1]
|
| [40] |
[本文引用:1]
|
| [41] |
海关商品归类是一项专业性、技术性很强的工作,是海关征税、监管、统计、缉私等各项业务活动的基础,体现国家的关税和监管要求。然而,在当前的这类工作中,经常出现商品归类错误的现象,这对我国的对外贸易造成了极大的损失,并在一定程度上延缓了外贸企业的通关时间,制约了海关的通关效率。本文主要分析我国海关商品归类中最易出现的几种错误及风险,并对如何防范该类错误风险提出具体对策。
|
| [42] |
[本文引用:1]
|
| [43] |
We introduce a new sequence-similarity kernel, the spectrum kernel, for use with support vector machines (SVMs) in a discriminative approach to the protein classification problem. Our kernel is conceptually simple and efficient to compute and, in experiments on the SCOP database, performs well in comparison with state-of-the-art methods for homology detection. Moreover, our method produces an SVM classifier that allows linear time classification of test sequences. Our experiments provide evidence that string-based kernels, in conjunction with SVMs, could offer a viable and computationally efficient alternative to other methods of protein classification and homology detection.
|
| [44] |
[本文引用:1]
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}