1 引 言
随着“互联网+”信息技术的飞速发展, 网络上的文本信息数量呈爆发式增长, 如何对海量文本信息进行正确的分类, 逐渐成为人们研究的课题。文本分类是数据挖掘的重要技术手段, 通过文本分类, 可以将无类别标注的文档进行归类。但传统的人工分类方法成本高、效率低, 机器学习的快速发展使人们意识到可以通过制定分类规则让计算机自动学习文本分类的有关知识, 从而实现文本的分类。
目前普遍的做法是对文本进行预处理操作并将文本词汇向量化, 然后对文本类别标签采用独热(One-Hot)编码构造标签向量, 再借助一些机器学习算法构造分类模型, 通过训练模型, 实现分类。但这种分类方法存在以下不足: 文本词汇向量化针对的是文本经过预处理后的所有词汇, 数量多、内容杂, 且数据处理时间长, 不利于模型训练; 文本内容与类别标签向量之间没有直接关联, 导致文本分类的准确率不高。
本文借助关键词抽取技术, 抽取一定数量的关键词来代替所有词汇, 既减少了数据维度又提高了数据质量; 同时, 提出类别标签表示算法将文本内容与标签向量直接关联起来, 提高分类准确率; 再结合基于注意力机制的胶囊网络, 强化文本的核心内容并减少模型计算量, 最后构成新的文本分类模型——KACC模型。
2 相关研究
2.1 文本内容表示
文本分类以文本内容表示为基础[1 ,2 ] 。文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点。最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果。
因此, 本文从词语的多重特征角度出发设计关键词权重计算公式, 在TF-IDF公式基础上进行改进, 考虑词频-逆文档频率特征的同时, 也考虑词语的长度特征、首次出现的位置特征和词跨度特征, 并针对长度特征、位置特征和词跨度特征提出新的计算公式, 在避免上述问题出现的同时, 显著提高了数据的质量。
2.2 文本分类模型
常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等。朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别。基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题。上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现。魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率。谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题。卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率。由此可见, 引入恰当的注意力机制对提高分类效果有显著影响。2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率。
综上, 目前分类效果较好的分类器为胶囊网络, 并且引入注意力机制可以提高模型的分类效果。因此, 本文在语料数据有限的情况下, 采用胶囊网络作为分类器并加入合理的注意力机制, 提出基于注意力机制的胶囊网络, 以到达提高分类准确率的效果。
2.3 文本类别标签表示
常用的文本类别标签表示方法是根据语料中文本的所属类别采用独热编码的方式, 间接形成文本的标签向量, 此过程仅与文本的类别有直接关系, 与文本内容无直接关系。同时, 在文本类别数目较多的情况下, 该方法会生成较大的稀疏矩阵, 造成空间浪费, 会影响文本分类的效果。因而, 本文提出一种类别标签表示方法, 将标签向量与文本内容直接关联起来, 以提高分类效果。
综上, 本文改进关键词抽取方法(Keywords Extraction, KE), 抽取一定数量的关键词并用Word2Vec模型向量化形成关键词向量, 用来代表文本内容; 提出类别标签表示(Category Label Representation, CLR)算法生成文本类别标签向量, 解决标签向量与文本内容没有直接关联的问题; 最后, 结合本文提出的基于词向量注意力机制的胶囊网络(Attention-Capsnet), 将关键词向量作为输入, 标签向量作为输出, 构建一种新的文本分类模型——KACC(KE-Attention-Capsnet- CLR)模型。
3 KACC模型
3.1 模型总体流程
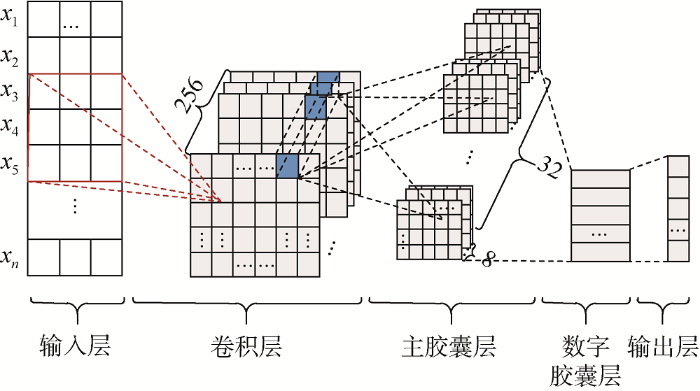
KACC模型由数据的获取与处理、权重计算与词向量化、模型训练以及预测与评价4部分组成。其流程图如图1 所示。
图1
从腾讯新闻、网易新闻等网站爬取5 000条新闻数据, 进行数据清洗和数据结构化处理, 主要包括: 删除空数据、删除无意义的特殊字符、将新闻正确分类并标注类别标签等, 最终得到实验语料, 包括文化、娱乐、历史、文学和军事5类新闻, 各1 000篇。引入领域词典, 对实验语料作分词处理, 并训练Word2Vec模型, 得到词向量。引入停用词表, 对分词后的数据进行去停用词操作。
依据本文所提类别标签表示算法, 对经过预处理后的数据进行相关度、依赖度和代表度的计算, 将代表度按从大到小的顺序排序, 选取排名前20的词作为类别代表词, 再结合上一步获得的词向量, 计算文本的类别标签向量, 从而得到文本的标签向量。同时, 依据本文所提关键词权重计算公式, 抽取权重排名前20的词作为文本的关键词, 再结合上一步获得的词向量, 最终得到文本的关键词向量。
将数据集以8:2的比例划分为训练集和测试集。对训练集数据采取以下处理: 将获得的文本关键词向量作为基于关键词向量注意力机制的胶囊网络的输入, 所对应的文本标签向量作为输出, 进行模型训练。
对测试集数据采取以下处理: 结合上一步训练得到的分类模型, 将关键词向量作为模型的输入, 进而得到文本标签的预测结果。从准确率、召回率、F值三个方面对实验结果进行评价与分析。
3.2 关键词抽取
关键词抽取是指从文档中快速获取有代表性的词语, 用以反映文档的主题和核心内容。使用关键词代表文本进行分类, 能降低模型的计算复杂度。衡量词语是否为关键词, 不能从单一角度考虑, 因而, 本文从词频-逆文档频率(TF-IDF)特征、长度特征、首次出现的位置特征、词跨度特征4个角度设计公式, 通过比较文本词汇的综合权重, 进而求出文本关键词。综合权重V 的计算方法如公式(1)所示。
(1) $V=TF\times IDF\times {{\log }_{2}}(l)\times (1+{{e}^{-s}})\times (1+\frac{t-s}{n})$
其中, $TF$为词出现的频率, $IDF$为词的逆文档频率, $l$为词的长度, $s$为词首次出现的位置, $t$为词最后一次出现的位置, $n$为文本词汇总数。
词频$TF$是指在给定文本中词语出现的频率, 通常认为词频越高, 在文本中的重要程度越高, 成为关键词的可能性越大。逆文档频率$IDF$是指词语所在的文本在整个语料库的频率, 通常认为逆文档频率越大, 该词越重要。词频-逆文档频率特征是衡量词语重要程度最常用的特征之一。
长度特征是指词的长度。通常关键词的长度在2-8个字左右, 具有较好的区分性。选用以2为底的对数函数计算长度特征, 是因为该函数的函数值具有在一定范围内会随词长$l$的变化产生比较明显的变化, 且当$l$较大时, 不会产生明显变化的特点。
通常认为关键词会出现在文本比较靠前的位置。此处选用指数函数的原因同上面的对数函数。同时, 为防止在$l$较大时, 函数值趋于零的情况发生, 公式设置基数1, 即用$(1+{{e}^{-s}})$计算首次出现的位置特征。
通常认为关键词应该贯穿整个文本, 即文本首末位置都应该提到, 因而当词跨度较大时, 更易成为关键词。将公式设计为$(1+\frac{t-s}{n})$是为了防止当词在文本中仅出现一次, 即首末位置相同时, 词跨度值为零, 影响综合权重计算结果的情况发生。
编写网络爬虫程序爬取网易新闻共315条, 经过数据清洗、分词、去停用词之后作为实验语料, 对语料进行人工关键词标注。
将公式(1)中去掉长度特征、去掉首次出现的位置特征、去掉词跨度特征的关键词抽取方法, 以及经典的TF-IDF和TextRank关键词抽取方法分别作对比实验。将上述模型按照提及次序分别记为模型1、模型2、模型3、模型4和模型5, 将公式(1)的关键词抽取方法记为模型6。
采用的第一类评价指标有三个: 准确率(Precision, P)、召回率(Recall, R)和综合评价指标(F1-Measure, F), 计算方法如公式(2)-公式(4)所示。
(2) $P=\frac{A}{A+B}$
(3) $R=\frac{A}{A+C}$
(4) $F=\frac{2\times P\times R}{P+R}$
其中, A 代表正确抽取到的关键词数, B 代表错误抽取到的关键词数, C 代表属于关键词但未被抽取到的词数。
第二类评价指标为针对有序的关键词抽取结果的评价指标, 包括平均倒数等级(Mean Reciprocal Rank, MRR)和二元偏好度量(Binary preference measure, Bpref)。这两个指标考虑了关键词的排名信息, 使用时要求事先给定关键词有序序列。其中, MRR用来度量每个文档第1个被准确提取的关键词的排名情况, 而Bpref则用来度量提取结果中错误提取的词语的排名情况, 具体的计算方法如公式(5)和公式(6)所示。
(5) $MRR=\frac{1}{|D|}\cdot \sum\nolimits_{d\in D}{\frac{1}{{{r}_{d}}}}$
(6) $Bpref=\frac{1}{|D|}\cdot \sum\nolimits_{r\in C}{\left( 1-\frac{|F|}{|E|} \right)}$
其中, $D$是所有文档的集合, ${{r}_{d}}$为文档d 第一个正确提取结果的排序; $C$是正确的关键词的集合, $|F|$表示排列在正确提取词$r\in C$之前的提取错误的词的数目, $|E|$表示所有提取词的数目。
通过实验结果可以看出, 本文采用的关键词抽取模型在MRR、Bpref、准确率和综合评价指标上均取得了最好的效果, 在召回率方面取得了较好的效果, 说明本文改进的关键词抽取公式具有很好的关键词抽取能力。
3.3 基于注意力机制的胶囊网络
注意力机制最早应用于图像处理领域, 近年来也被逐渐应用在文本数据处理领域。为解决普通卷积神经网络输入的词语之间相互独立的问题, Zhao等[16 ] 提出一种词向量注意力机制, 通过计算句子中每个词语的上下文向量, 并与该词语对应的词向量连接作为输入, 能够使得句子中与其他词语关系较大的词语得到更多关注。但是, 这种做法存在明显不足: 一方面文本词汇数量过多, 会造成严重的空间浪费; 另一方面, 词汇与上下文向量一一对应, 由此带来的计算消耗 较大。
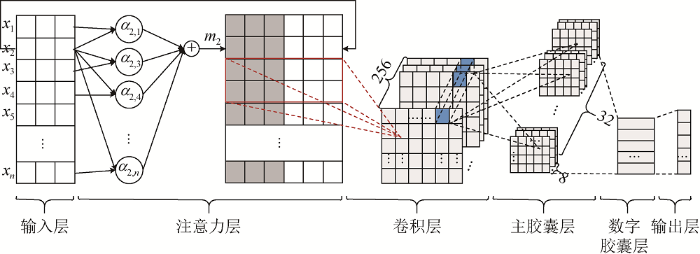
为解决不足, 本文对词向量注意力机制进行向量内容的改进: 减少所需的文本词汇数量, 通过关键词抽取公式获取一定数量的关键词; 由于关键词能够代表文本的核心内容, 因而将计算每个词语的上下文向量改进为计算关键词向量, 这样更能强化文本所要表达的内容。其核心结构如图2 所示[16 ] 。
图2
假定抽取单个文本的关键词数为n , Ki ∈Rw (1≤i ≤n )为第i 个关键词对应的w 维向量表示。在图2 中, n =5, K 1 -K 5 是对应的词向量表示。令mi 为Ki 的关键词向量, mi 由多个词向量的加权和得到, 如公式(7)所示[16 ] 。
(7) ${{m}_{i}}=\sum\nolimits_{j=1,j\ne i}^{n}{({{\alpha }_{i,j}}{{K}_{j}})}$
其中, ${{\alpha }_{i,j}}$为注意力权重, 通过Softmax函数得到, 如公式(8)所示[16 ] 。
(8) ${{\alpha }_{i,j}}=\frac{\exp (Score({{K}_{i}},{{K}_{j}}))}{\sum\nolimits_{{{j}^{*}}=1}^{n}{\exp (Score({{K}_{i}},{{K}_{{{j}^{*}}}}))}}$
从公式(3)可以得到: ${{\alpha }_{i,j}}\ge 0,\sum\nolimits_{j=1}^{n}{{{\alpha }_{i,j}}=1}$。
Score函数用来计算两个关键词间的关联系数, 函数定义如公式(9)所示[16 ] 。
(9) $Score({{K}_{i}},{{K}_{j}})={{v}_{a}}^{\mathrm{T}}\mathrm{thah}({{W}_{a}}[{{K}_{i}}\oplus {{K}_{j}}])$
图3
第一层是输入层, 由用户输入文本关键词向量。第二层是普通的卷积层, 作用是局部特征检测, 卷积层有256个步长为1的9×9×1卷积核, 使用ReLU激活。第三层是主胶囊层, 接受卷积层检测到的基本特征, 生成特征的组合, 这一层包含32个主胶囊, 每个主胶囊采用8个9×9×256的卷积核, 这种分组的方式实现了将卷积对象从标量变为矢量的逻辑。第四层是数字胶囊层, 这一层包含10个数字胶囊, 每个胶囊对应一个数字, 每个胶囊接收来自主胶囊层的输出作为输入。最后一层是全连接输出层, 即输出文本的标签向量。
本文提出的基于关键词向量注意力机制的胶囊网络结构如图4 所示。
图4
基于关键词向量注意力机制的胶囊网络在输入层和卷积层之间加入注意力层, 以注意力层的输出作为卷积层的输入。注意力层的参数也在模型训练过程中不断调整, 使模型整体是端对端模式。
3.4 类别标签表示算法
本文提出的类别标签表示算法是通过求类别的特征词集以实现将文本内容与标签向量直接关联起来, 从而提高文本分类的精确度。算法给出了相关度${{\rho }_{cj}}$、依赖度${{F}_{cj}}$、代表度${{R}_{cj}}$的计算公式。根据代表度${{R}_{cj}}$的大小, 对类别c 下的词进行降序排列, 取前20个词作为该类别的代表词, 进而对它们的词向量进行加权求平均的计算, 得到文档类别c 的类别标签向量${{L}_{c}}$。
${{\rho }_{cj}}$表示词${{w}_{j}}$与文档类别c 的相关度, 计算方法如公式(10)所示。${{Q}_{C}}$表示在类别c 中包含${{w}_{j}}$的文档数, $\frac{\mathop{\sum }_{i=1}^{n}{{Q}_{i}}}{n}$表示平均每个文档类别下包含词${{w}_{j}}$的文档数, tanh是一个双曲正切函数, 值域为(-1,1), 当${{\rho }_{cj}}$为0时, 说明词${{w}_{j}}$平均分布在每个类别中, 即类别c 与词${{w}_{j}}$不相关; 当${{\rho }_{cj}}$小于0时, 说明词${{w}_{j}}$与类别c 负相关; 当${{\rho }_{cj}}$大于0时, 说明词${{w}_{j}}$与类别c 正相关, ${{w}_{j}}$是组成文档类别特征词集的候选之一。
(10) ${{\rho }_{cj}}=\tanh \left( \frac{{{Q}_{c}}}{\frac{\sum _{i=1}^{n}{{Q}_{i}}}{n}+1}-1 \right)$
${{F}_{cj}}$表示词${{w}_{j}}$与文档类别c 的依赖度, 计算方法如公式(11)所示。${{f}_{c}}$表示在类别c 中词${{w}_{j}}$出现的频数, $\frac{\mathop{\sum }_{i=1}^{n}{{f}_{i}}}{n}$表示平均每个类别下词${{w}_{j}}$的平均频数, tanh是一个双曲正切函数, 值域为(-1,1), ReLU是一个激活函数, 当函数自变量的取值不大于0时, 函数值为0, 当函数自变量的取值大于0时, 函数值等于自变量的值。通过计算可知, 当${{F}_{cj}}$为0时, 说明词${{w}_{j}}$不依赖于类别c , 当${{F}_{cj}}$大于0时, 该值可以表示词${{w}_{j}}$与类别c 的依赖度。
(11) ${{F}_{cj}}=\operatorname{Re}\mathrm{LU}\left( \tanh \left( \frac{{{f}_{c}}}{\frac{\sum _{i=1}^{n}{{f}_{i}}}{n}+1}-1 \right) \right)$
${{R}_{cj}}$表示词${{w}_{j}}$对文档类别c 的代表程度, 计算方法如公式(12)所示。用文档词${{w}_{j}}$与文档类别c 的相关度${{\rho }_{cj}}$和词${{w}_{j}}$与文档类别c 的依赖度${{F}_{cj}}$的乘积结果表示代表度${{R}_{cj}}$。
(12) ${{R}_{cj}}={{F}_{cj}}\cdot {{\rho }_{cj}}$
${{L}_{c}}$表示类别c 的类别标签, 计算方法如公式(13)所示。其中, ${{V}_{j}}$为词${{w}_{j}}$的词向量, ${{R}_{cj}}$为词${{w}_{j}}$对类别c 的代表程度。目的在于选取各个类别的代表词组成类别特征词集。
(13) ${{L}_{c}}=\sum\nolimits_{j=1}^{m}{({{R}_{cj}}\cdot {{V}_{j}})}$
4 实验验证
4.1 实验环境
本文所提算法模型均采用Python编程实现, Word2Vec使用Gensim模块编程实现, 神经网络部分使用Google研发并开源的TensorFlow模块搭建。本实验所有的模型训练计算环境主要参数为GPU卡: 1*Nvidia Tesla M40, 内存为32GB。
4.2 实验数据
为使实验结果更具代表性, 从腾讯新闻、网易新闻等网站爬取5 000条新闻数据作为实验语料。在语料库中选用5个类别下的文档作为长文本实验数据, 每个类别下有1 000篇文章, 按照8:2的比 例将文档分为训练集和测试集, 其组成情况如表2 所示。
4.3 实验设计
为对比分析基于关键词的文本表示方法对文本分类效率、效果的影响, 使用基于全文的卷积神经网络文本分类模型(Full Text CNN OneHot, FT+CNN+ OneHot)进行对比实验。为分析Attention与类别标签向量在基于卷积神经网络的文本分类模型中的影响, 使用基于关键词文本表示的KE+CNN+OneHot、KE+ Attention+CNN+OneHot、KE+Attention+CNN+CLR模型。为分析Attention与类别标签向量在基于胶囊网络的文本分类模型中的影响, 以及比较胶囊网络与CNN在文本分类中的效果, 使用KE+Capsnet+OneHot、KE+Attention+Capsnet+OneHot、KE+Attention+Capsnet+ CLR模型。
为排除由于特征构建方式的不同而导致实验结果的不可比性, 在向量化阶段均使用预训练的Word2Vec模型, Skip-gram模式, 词向量长度600维。
模型训练过程均使用Adam优化器, 损失函数为交叉熵函数, 学习速率为0.001, 激活函数为ReLU, 输出层激活函数为Softmax, 训练终止条件为连续三次迭代损失值减小低于0.001。
本文采用的评价指标有三个: 准确率(Precision, P)、召回率(Recall, R)和综合评价指标(F1 -Measure, F), 如公式(14)-公式(16)所示。
(14) $P=\frac{A}{A+B}$
(15) $R=\frac{A}{A+C}$
(16) ${{F}_{1}}-Measure=\frac{2\cdot P\cdot R}{P+R}$
其中, A 代表正确分类到该类的文本数, B 代表错分到该类的文本数, C 代表属于该类但未被分到该类的文本数。
4.4 实验结果与分析
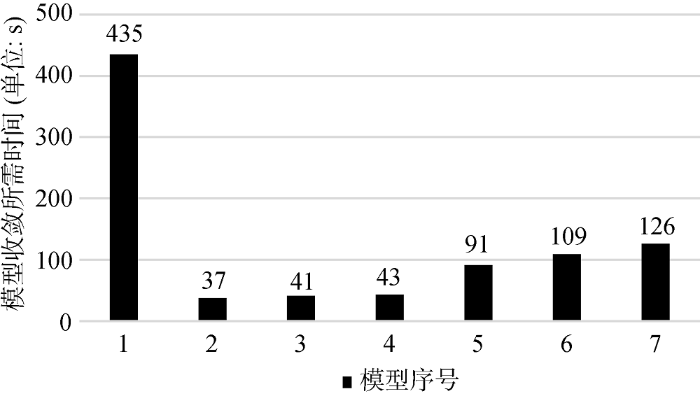
7种模型在实验语料上测试得到的准确率、召回率和F1 值结果如表3 所示。各模型训练达到收敛所需时间如图5 所示。
图5
通过模型1与模型2的对比可以得知本文所提关键词抽取方法在文本分类实验中可以将训练效率提升11倍左右, 能有效缩短模型收敛所需要的时间; 通过模型2与模型3、模型5与模型6的对比可以得知加入关键词向量注意力机制能较大幅度地提高文本分类的准确率且对模型训练效率影响较小; 通过模型2与模型5、模型3与模型6、模型4与模型7的结果对比可以得知基于Capsnet的分类模型比基于CNN的分类模型准确率高7%左右, 但模型训练效率降低约2/3; 通过模型3与模型4、模型6与模型7的结果对比可知采用类别标签表示算法可以提高2%左右的分类准确率, 同时提升4%左右的召回率。
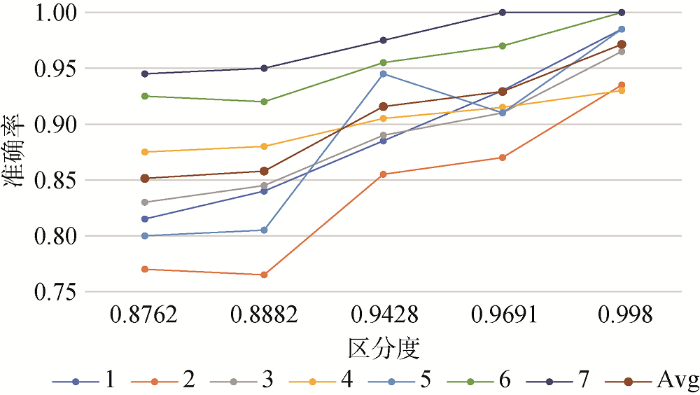
此外, 本文还针对类别区分度与分类准确率的相关关系进行分析, 以类别代表词的代表度的均值作为类别区分度。各实验中的各类别准确率以及类别区分度结果如表4 所示, 对比结果如图6 所示。可以看出, 在各个实验中分类的准确率几乎均随着类别区分度的增大而增大, 说明类别区分度可以作为衡量一个类别分类难易程度的指标。
图6
5 结 语
目前分类方法存在文本输入维度过大、数据质量不高以及文本内容与类别标签向量之间没有直接关联等不足, 本文基于关键词抽取技术, 在降低输入数据维度以提升分类效率的同时充分突出关键信息去除噪音, 将胶囊网络应用于文本分类以提升分类效果, 同时引入关键词向量注意力机制和类别标签表示算法以增强输入与输出数据之间的关联性。
爬取新闻语料进行多模型对比实验, 通过多组结果对比分析得出结论: 本文所提关键词降维方法可以将训练效率提升11倍左右, 类别标签方法可以提高2%左右的分类准确率和4%左右的召回率, 并且引入注意力机制也可以有效提升文本的分类准确率。此外本文还提出了类别区分度的概念, 通过实验, 验证了区分度可以衡量一个类别分类难易程度。
本研究还存在一些局限, 实验结果受数据规模限制影响, 未来考虑增大语料规模, 理论上在更大规模语料上该模型会有更好的分类效果。另外, 未对类别区分度在其他语料上的代表性进行探究, 考虑在以后的工作中进行实验分析, 以实现不同语料分类效果的标准化。
作者贡献声明
李钰曼: 设计整体解决方案, 编程进行文本分类的实验, 撰写、修改论文;
支撑数据
支撑数据由作者自存储, E-mail: 1033042436@qq.com。
[1] 李钰曼. model.rar. 实验所用的模型源码.
[2] 李钰曼. result.rar. 实验结果统计.
参考文献
View Option
[1]
江伟 , 金忠 . 基于短语注意机制的文本分类
[J]. 中文信息学报 , 2018 ,32 (2 ):102 -109, 119 .
[本文引用: 1]
( Jiang Wei Jin Zhong . Text Classification Based on Phrase Attention Mechanism
[J]. Journal of Chinese Information Processing , 2018 ,32 (2 ):102 -109, 119 .)
[本文引用: 1]
[2]
孙飞 , 郭嘉丰 , 兰艳艳 , 等 . 面向文本分类的有监督显式语义表示
[J]. 数据采集与处理 , 2017 ,32 (3 ):550 -558 .
[本文引用: 1]
( Sun Fei Guo Jiafeng Lan Yanyan , et al . Supervised Explicit Semantic Representation for Text Categorization
[J]. Journal of Data Acquisition and Processing , 2017 ,32 (3 ):550 -558 .)
[本文引用: 1]
[3]
Salton G Yu C T . On the Construction of Effective Vocabularies for Information Retrieval
[C]// Proceedings of the 1973 Meeting on Programming Languages and Information Retrieval. ACM , 1973 : 48 -60 .
[本文引用: 1]
[4]
杨凯艳 . 基于改进的TFIDF关键词自动提取算法研究
[D]. 湘潭: 湘潭大学 , 2015 .
[本文引用: 1]
( Yang Kaiyan . Research on Automatic Keyword Extraction Algorithm Based on Improved TFIDF
[D]. Xiangtan:Xiangtan University , 2015 .)
[本文引用: 1]
[5]
程岚岚 . 面向领域的中文搜索引擎若干关键技术研究
[D]. 天津: 天津大学 , 2006 .
[本文引用: 1]
( Cheng Lanlan . The Study of Key Technologies for Chinese Domain-Oriented Search Engine
[D]. Tianjin: Tianjin University , 2006 .)
[本文引用: 1]
[6]
李华灿 . 基于统计与协同过滤的关键词提取研究
[D]. 西安: 西安电子科技大学 , 2015 .
[本文引用: 1]
( Li Huacan . Keyword Extraction Base on Statistical and Collaborative Filtering
[D]. Xi’an: Xidian University , 2015 .)
[本文引用: 1]
[7]
谢晋 . 基于词跨度的中文文本关键词提取及在文本分类中的应用
[D]. 杭州: 浙江工业大学 , 2011 .
[本文引用: 1]
( Xie Jin . Chinese Keyword Extraction Method Based on Word Span and Its Application in Text Classification
[D]. Hangzhou: Zhejiang University of Technology , 2011 .)
[本文引用: 1]
[8]
陈凯 , 黄英来 , 高文韬 , 等 . 一种基于属性加权补集的朴素贝叶斯文本分类算法
[J]. 哈尔滨理工大学学报 , 2018 ,23 (4 ):69 -74 .
[本文引用: 1]
( Chen Kai Huang Yinglai Gao Wentao , et al . An Improved Naive Bayesian Text Classification Algorithm Based on Weighted Features and Its Complementary Set
[J]. Journal of Harbin University of Science and Technology , 2018 ,23 (4 ):69 -74 .)
[本文引用: 1]
[9]
姚全珠 , 宋志理 , 彭程 . 基于LDA模型的文本分类研究
[J]. 计算机工程与应用 , 2011 ,47 (13 ):150 -153 .
DOI:10.3778/j.issn.1002-8331.2011.13.043
URL
Magsci
[本文引用: 1]
针对传统的降维算法在处理高维和大规模的文本分类时存在的局限性,提出了一种基于LDA模型的文本分类算法,在判别模型SVM框架中,应用LDA概率增长模型,对文档集进行主题建模,在文档集的隐含主题-文本矩阵上训练SVM,构造文本分类器。参数推理采用Gibbs抽样,将每个文本表示为固定隐含主题集上的概率分布。应用贝叶斯统计理论中的标准方法,确定最优主题数T。在语料库上进行的分类实验表明,与文本表示采用VSM结合SVM,LSI结合SVM相比,具有较好的分类效果。 <BR>
( Yao Quanzhu Song Zhili Peng Cheng . Research on Text Categorization Based on LDA
[J]. Computer Engineering and Applications , 2011 ,47 (13 ):150 -153 .)
DOI:10.3778/j.issn.1002-8331.2011.13.043
URL
Magsci
[本文引用: 1]
针对传统的降维算法在处理高维和大规模的文本分类时存在的局限性,提出了一种基于LDA模型的文本分类算法,在判别模型SVM框架中,应用LDA概率增长模型,对文档集进行主题建模,在文档集的隐含主题-文本矩阵上训练SVM,构造文本分类器。参数推理采用Gibbs抽样,将每个文本表示为固定隐含主题集上的概率分布。应用贝叶斯统计理论中的标准方法,确定最优主题数T。在语料库上进行的分类实验表明,与文本表示采用VSM结合SVM,LSI结合SVM相比,具有较好的分类效果。 <BR>
[10]
Routray S Ray A K Mishra C , et al . Efficient Hybrid Image Denoising Scheme Based on SVM Classification
[J]. Optik , 2018 ,157 :503 -511 .
[本文引用: 1]
[11]
魏勇 . 关联语义结合卷积神经网络的文本分类方法
[J]. 控制工程 , 2018 ,25 (2 ):367 -370 .
[本文引用: 1]
( Wei Yong . A Text Classification Method Based on Associative Semantics and Convolution Neural Network
[J]. Control Engineering of China , 2018 ,25 (2 ):367 -370 .)
[本文引用: 1]
[12]
谢志峰 , 吴佳萍 , 马利庄 . 基于卷积神经网络的中文财经新闻分类方法
[J]. 山东大学学报: 工学版 , 2018 ,48 (3 ):34 -39, 66 .
[本文引用: 1]
( Xie Zhifeng Wu Jiaping Ma Lizhuang . Chinese Financial News Classification Method Based on Convolutional Neural Network
[J]. Journal of Shandong University: Engineering Science , 2018 ,48 (3 ):34 -39, 66 .)
[本文引用: 1]
[13]
卢玲 , 杨武 , 王远伦 , 等 . 结合注意力机制的长文本分类方法
[J]. 计算机应用 , 2018 ,38 (5 ):1272 -1277 .
[本文引用: 1]
( Lu Ling Yang Wu Wang Yuanlun , et al . Long Text Classification Combined with Attention Mechanism
[J]. Journal of Computer Applications , 2018 ,38 (5 ):1272 -1277 .)
[本文引用: 1]
[14]
Sabour S Frosst N Hinton G E . Dynamic Routing Between Capsules
[C]// Proceedings of the 31st Conference on Neural Information Processing Systems. 2017 : 3856 -3866 .
[本文引用: 1]
[15]
Afshar P Mohammadi A Plataniotis K N . Brain Tumor Type Classification via Capsule Networks
[C]// Proceedings of the 25th IEEE International Conference on Image Processing. 2018 : 3129 -3133 .
[本文引用: 1]
[16]
Zhao Z Wu Y . Attention-based Convolutional Neural Networks for Sentence Classification
[C]// Proceedings of the 2016 Annual Conference of the International Speech Communication Association, San Francisico, CA, USA. ISCA , 2016 : 705 -709 .
[本文引用: 6]
基于短语注意机制的文本分类
1
2018
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
基于短语注意机制的文本分类
1
2018
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
面向文本分类的有监督显式语义表示
1
2017
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
面向文本分类的有监督显式语义表示
1
2017
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
On the Construction of Effective Vocabularies for Information Retrieval
1
1973
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
基于改进的TFIDF关键词自动提取算法研究
1
2015
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
基于改进的TFIDF关键词自动提取算法研究
1
2015
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
面向领域的中文搜索引擎若干关键技术研究
1
2006
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
面向领域的中文搜索引擎若干关键技术研究
1
2006
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
基于统计与协同过滤的关键词提取研究
1
2015
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
基于统计与协同过滤的关键词提取研究
1
2015
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
基于词跨度的中文文本关键词提取及在文本分类中的应用
1
2011
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
基于词跨度的中文文本关键词提取及在文本分类中的应用
1
2011
... 文本分类以文本内容表示为基础[1 ,2 ] .文本的关键词是文本内容的重要特征, 用少量的文本关键词代表文本, 可以降低文本数据的输入维度, 减小模型计算的复杂度, 因而设计合理的关键词抽取公式成为众多研究者研究的热点.最初, Salton等[3 ] 直接利用词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)提取关键词, 但这种方法忽略了其他特征对词语重要程度的影响[4 ] ; 程岚岚[5 ] 通过引入词语首次出现的位置这一指标, 提高关键词的权重, 但计算结果易出现极端值; 李华灿[6 ] 通过引入长度特征和位置特征, 分别对不同位置和不同长度的词语赋予不同权重值, 从而提高关键词的抽取效果, 但所赋的权重值在一些情况下会有零值出现, 对权重计算结果影响较大; 谢晋[7 ] 提出基于词跨度的关键词提取方法, 通过考虑词语在文中首次出现和末次出现的距离, 提出词跨度计算公式, 提高了关键词的抽取效果. ...
一种基于属性加权补集的朴素贝叶斯文本分类算法
1
2018
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
一种基于属性加权补集的朴素贝叶斯文本分类算法
1
2018
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
基于LDA模型的文本分类研究
1
2011
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
基于LDA模型的文本分类研究
1
2011
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
Efficient Hybrid Image Denoising Scheme Based on SVM Classification
1
2018
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
关联语义结合卷积神经网络的文本分类方法
1
2018
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
关联语义结合卷积神经网络的文本分类方法
1
2018
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
基于卷积神经网络的中文财经新闻分类方法
1
2018
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
基于卷积神经网络的中文财经新闻分类方法
1
2018
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
结合注意力机制的长文本分类方法
1
2018
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
结合注意力机制的长文本分类方法
1
2018
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
Dynamic Routing Between Capsules
1
2017
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
Brain Tumor Type Classification via Capsule Networks
1
2018
... 常用的文本分类模型有朴素贝叶斯分类模型、LDA分类模型、支持向量机分类模型和神经网络分类模型等.朴素贝叶斯分类模型基于贝叶斯概率模型, 在数据量小的情况下具有很好的分类效果和计算速度, 陈凯等[8 ] 提出一种属性加权补集的朴素贝叶斯文本分类算法, 解决了分类模型容易倾向大类别而忽略小类别的问题; 姚全珠等[9 ] 使用LDA模型对文本进行自动分类, 通过文本在固定主题上的概率分布确定文本的类别.基于支持向量机的分类方法[10 ] 通过得到恰当的分类决策函数来实现分类, 但其在分类过程中没有考虑语义问题.上述传统分类模型由于存在人为的假设前提且模型简单, 分类效果受局限, 随着机器学习技术的发展, 神经网络在文本分类中的应用研究大量涌现.魏勇[11 ] 提出一种结合关联语义和卷积神经网络的文本分类方法, 考虑单词语义信息的问题, 提高了分类准确率.谢志峰等[12 ] 充分利用词语本身的特征及上下文语义信息, 提出一种基于卷积神经网络的中文财经新闻分类方法, 有效地解决了中文财经新闻的分类问题.卢玲等[13 ] 在构建卷积神经网络分类模型时, 引入注意力机制, 显著提高分类准确率.由此可见, 引入恰当的注意力机制对提高分类效果有显著影响.2017年, Sabour等[14 ] 提出胶囊网络, 与卷积神经网络相比, 同等情况下需要的训练数据少且测试准确率高, 例如, Afshar等[15 ] 为克服卷积神经网络需要大量训练数据的弊端, 将胶囊网络应用于脑肿瘤分类问题, 最大限度地提高了分类准确率. ...
Attention-based Convolutional Neural Networks for Sentence Classification
6
2016
... 注意力机制最早应用于图像处理领域, 近年来也被逐渐应用在文本数据处理领域.为解决普通卷积神经网络输入的词语之间相互独立的问题, Zhao等[16 ] 提出一种词向量注意力机制, 通过计算句子中每个词语的上下文向量, 并与该词语对应的词向量连接作为输入, 能够使得句子中与其他词语关系较大的词语得到更多关注.但是, 这种做法存在明显不足: 一方面文本词汇数量过多, 会造成严重的空间浪费; 另一方面, 词汇与上下文向量一一对应, 由此带来的计算消耗 较大. ...
... 为解决不足, 本文对词向量注意力机制进行向量内容的改进: 减少所需的文本词汇数量, 通过关键词抽取公式获取一定数量的关键词; 由于关键词能够代表文本的核心内容, 因而将计算每个词语的上下文向量改进为计算关键词向量, 这样更能强化文本所要表达的内容.其核心结构如图2 所示[16 ] . ...
... [
16 ]
![]()
假定抽取单个文本的关键词数为n , Ki ∈Rw (1≤i ≤n )为第i 个关键词对应的w 维向量表示.在图2 中, n =5, K 1 -K 5 是对应的词向量表示.令mi 为Ki 的关键词向量, mi 由多个词向量的加权和得到, 如公式(7)所示[16 ] . ...
... 假定抽取单个文本的关键词数为n , Ki ∈Rw (1≤i ≤n )为第i 个关键词对应的w 维向量表示.在图2 中, n =5, K 1 -K 5 是对应的词向量表示.令mi 为Ki 的关键词向量, mi 由多个词向量的加权和得到, 如公式(7)所示[16 ] . ...
... 其中, ${{\alpha }_{i,j}}$为注意力权重, 通过Softmax函数得到, 如公式(8)所示[16 ] . ...
... Score函数用来计算两个关键词间的关联系数, 函数定义如公式(9)所示[16 ] . ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}