




1 引言
随着互联网技术快速发展和网民数量激增, 社交网络的用户普及率也日益增加。作为典型的社会化媒体网站, 2019年3月, 新浪微博的活跃用户数已达4.65亿[1]。微博、论坛等社交网站不断渗入人们的日常生活, 成为民众针对所关注的社会现象发表自己观点、表达个人意见、传递自身情绪的重要平台和途径。其中, 突发事件往往能够引发热烈的网上讨论, 该类事件常常与大众的日常生活关系密切, 网民参与度高、评论积极且富含个人情感, 涉及全社会的各个阶层。突发事件中, 网络意见领袖代表了一种重要的群体力量, 他们能够对其他网民的态度施加影响, 不仅能促使舆论议题存续, 而且能够转变舆论导向。因此通过识别不同事件内的网络意见领袖, 可以快速发现网民的普遍态度和舆论走向, 以此对民声民意进行捕捉和预测[2]。
意见领袖的识别可以使用人工浏览网页并搜集评论的方式, 但这种方法采用人工评价, 较为主观且效率不高, 难以适应网络海量信息分析与处理的要求。现有的自动化技术主要使用社会网络分析、基于PageRank和构建指标体系的方法, 强调对博主个人信息以及用户间转发、评论关系的梳理, 但是缺乏对用户评论态度的识别与利用, 这可能导致网民虽然对筛选出来的意见领袖进行了广泛评论、但评论的内容大多为不赞成甚至是谩骂博主的情况。这种态势下, 这些所谓的“意见领袖”并不具备意见领袖的基本特征, 无法引领网络事件发展, 不能发挥意见领袖应有的作用, 称之为“伪 意见领袖”。本文通过文本倾向性分析, 识别突发事件中网民的主流情感态度, 挑选出真正的意见领袖。
文本倾向性分析是当前主流的情感态度提取技术, 能够将网民的评论文本划分为“正面”、“中立”和“负面”, 分别计算微博博主回帖中正、负面评论所占的比重, 考查并剔除负面评论占比过重的“伪意见领袖”。该方法能够筛选出引导网络舆论发展方向、对其他受众施加显著影响的真正意见领袖。
2 相关研究
表1 意见领袖识别的主要方法
意见领袖识别的传统方法包括主观判断法、自我报告法和关键人物访谈法等。主观判断法将某类网民(例如讨论区的版主)直接看作意见领袖, 该方法存在的一大问题是采用主观认定, 挑选出来的也许并不是其他网民心目中真正的意见领袖。自我报告法常提供意见领袖量表, 让受访者根据量表的问题进行自我判断, 然后将受访者按一定比例划分为意见领袖和一般受众。该方法实现简单、操作容易, 不过由受访者自己判断, 缺乏客观标准, 同时面对海量网络用户无法进行完备的抽样。可以看出, 传统方法以手工操作为主, 已经很难适应大数据时代海量信息收集、处理和分析的需求, 逐渐被后来的计算机自动识别技术所代替, 包括社会网络分析、PageRank以及指标体系法等。
社会网络分析在网络意见领袖识别中得到了广泛应用, 如Jain等[7]提出一种新的基于社交网络的鲸鱼优化算法(SNWOA),通过使用网络中的各种标准优化功能来衡量用户的声誉,从而找到前N名的意见领袖;Chen等[8]在计算边的相似度(权重)时, 考虑发布文章的平均时间来调整个人之间的相似度。通过一些重要指标的计算, 社会网络分析可以测量中心性、网络密度以及流量等, 从而建立一个以网民为节点,以其间点赞、评论、转发等交互为边的有向网络。意见领袖识别即是在社会网络中寻找那些最关键的节点。意见领袖的看法常常能引起广大网民的关注, 因此该节点的网络密度较大; 中心性反映了节点的重要程度, 因此该节点也常常具有较大的中心性。
PageRank算法认为, 社交网络中用户间的点赞、转发与评论等互动关系与网页之间的链接指向非常类似, 因此网页间链接结构的分析方法也可以用于社交网络用户之间转发、评论等互动关系的分析。网页链接指向与社交网络用户之间的互动都具有方向性, 某个网页被其他网页链接越多说明其影响力越大; 同理, 一个网络用户被其他网民转发、点赞和评论的次数越多, 表明网络大众越认可该用户。另一方面, 网页如果被新浪、腾讯、网易等权威网站链接, 影响力会扩大; 同样, 发帖如果能被知名大V点赞、转发或评论, 帖子的权威度也会明显上升。Qiu等[13]根据PageRank算法的关键思想,考虑到主题敏感分析和时间特征,提出一种新的名为HybridRank的算法,使用主题敏感分析以获得社交网络中的集群,并提出时间分析调查用户随时间变化的影响力。Tsao等[14]根据社交网络中基于问题进行协作学习的学习者之间的互动数据,使用PageRank量度来准确找出社区意见领导者。
分析意见领袖具有的典型特征、构建识别意见领袖的系统指标体系的方法已经越来越广泛地用于突发事件的意见领袖识别中, 该方法即为指标分析法。指标分析法能够设置意见领袖识别中的重点指标, 并且通过给指标赋予不同的权重体现指标的重要程度。王佳敏等[18]从影响力和活跃度两方面识别意见领袖, 其中影响力包括粉丝数、被转发数、被评论数、是否认证4个指标项, 活跃度包括微博数和关注人数两个指标项。Aleahmad等[19]提出OLFinder算法用于寻找意见领袖, 该方法检测给定域中的主要讨论主题, 计算给定域中每个用户的胜任特征和流行分数, 并基于它们计算意见领袖分值, 实现对社交网络用户的排名。吴江等[20]从个人属性、网络特征、行为特征、文本特征等方面考察意见领袖的影响力。通过广泛的文献调研, 笔者发现, 一些指标在研究中被大量使用, 包括“粉丝数”、“被转发数”、“是否认证”等。
本文基于指标分析法, 结合文本倾向性分析, 建立一种新的网络突发事件意见领袖识别框架。
3 潜在意见领袖识别模型
3.1 指标体系构建
意见领袖的评价指标并没有统一的标准, 应用环境不同, 往往衍生出的评价体系也不尽相同。本文结合新浪微博的实际数据, 综合现有研究中的不同指标并引入新的识别指标, 力求得到较为完整的微博意见领袖指标模型。
(1) 系统调研近年意见领袖指标体系构建相关研究, 对涉及指标进行整理归类: 一类为意见领袖识别需要体现的重点指标, 如影响力和活跃度被多个研究所强调; 第二类能够在一定程度上反映意见领袖的特征, 但过于主观、抽象, 无法量化, 难以与实际应用相结合, 暂不考虑这些指标; 第三类为部分文献使用而被其他文献忽视的指标项, 将有选择地引入。
(2) 在借鉴现有文献的基础上, 考虑微博特点, 引入两个新的指标项: “媒介接触度”和“行业性”。一些博主虽自身影响力有限, 却能够与高人气博主接触互动, 从而显著提高自身地位, 这就是“媒介接触度”; 而“行业性”指博主对自身所在行业的说明, 体现了其与网络特定话题的相关性和专业度, 事件不同, 行业范围的选取也不同。结合筛选的指标和新指标, 构建潜在意见领袖识别模型, 如图1所示。
图1
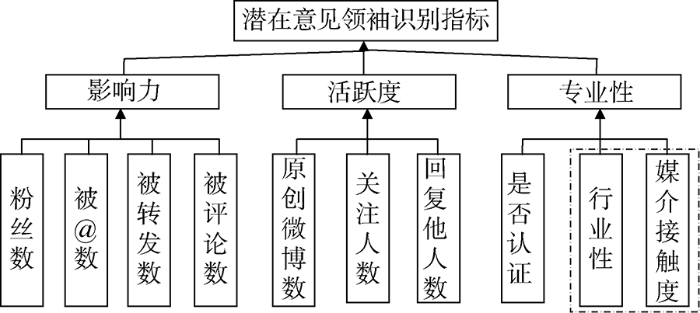
本模型将意见领袖识别指标项分为两级, 一级指标项包括影响力、活跃度和专业性。原因基于意见领袖的如下特点。
(1) 与跟随者常常有相同的兴趣爱好。意见领袖影响的是与他们兴趣或行为相似的人, 而不是在社会秩序中高于或低于他们的人, 他们的影响力更趋向于水平而不是垂直[25]。
(2) 在特定领域中, 被其他网友公认为具有权威性, 见多识广。如果对所涉及的领域、事件或问题一无所知, 则其意见难以被他人接受, 更无法引导别人。
(3) 具有广泛的社会关系, 在社交方面极为活跃, 乐于与其他群体交往[26]。
(4) 更多地利用媒介, 更多地接触与其影响范围相关的媒介[24]。
上述第一点表明网络意见领袖应该有卓越的影响力, 才能吸引志趣相投的人, 通过影响力这一指标来体现。第二和第四点强调了意见领袖的专业性, 表现为自身从事的事业领域和媒体接触是否广泛。第三点突出了网络意见领袖的活跃性, 沉默寡言者难以让他人理解、接受自己的观点, 也就难以引起共鸣。
3.2 指标权重确定
层次分析法(Analytic Hierarchy Process, AHP)适用于分析定量困难的问题, 能够辅助多准则决策。该方法主要分为以下几个步骤: 分解问题, 建立层次结构; 构造判断矩阵; 计算各个元素的相对权重; 得到每层元素的组合权重。本模型中, 层次结构对应的是意见领袖的指标体系。
在一级指标权重设置上, 笔者认为“影响力”是判断意见领袖的最重要指标, 如果影响力较低, 观点就不能被其他网民了解; 专业性是作为意见领袖的基本条件, 没有能力让广大网友信服的只是“跳梁小丑”; 意见领袖作为一群“活跃分子”, “活跃度”也是评判的标准之一。因此, 权重设置上, “影响力”最高, 其次是“专业性”和“活跃度”。二级指标权重的设置过程与一级类似。经过上述计算流程, 最终得到指标权重如表2所示, 一致性检验通过。
表2 意见领袖识别指标权重设置
| 影响力(0.6651) | 活跃度(0.1038) | 专业性(0.2311) | |||
|---|---|---|---|---|---|
| 粉丝数 | 0.1208 | 原创微博数 | 0.0707 | 是否认证 | 0.1245 |
| 被@数 | 0.0915 | 关注人数 | 0.0122 | 行业性 | 0.0687 |
| 被转发数 | 0.2519 | 回复他人数 | 0.0209 | 媒介接触度 | 0.0379 |
| 被评论数 | 0.2009 | ||||
4 文本倾向性分析
本文提出基于语义的文本情感倾向性识别算法, 基本思想为: 进行文本预处理, 在分词的基础上解析句法关系, 找出句子的主导词及修饰词, 比对主导词与正、负面词典, 得到初始词语极性, 再比对修饰词与程度级别词典和否定词词典, 得到修饰词权重, 将两者相乘计算依存关系的情感得分; 提取语句表情符号, 乘以句中所有依存关系的情感分之和, 得到该语句的情感倾向分数。为提高社会化媒体网络语料分析的准确性, 引入基于Word2Vec方法的网络情感新词发现, 自动识别社交媒体口语化的情感新词, 扩充具有关键作用的正、负面情感词典, 从而提升情感倾向性识别的准确率。
4.1 预处理
预处理是对语料进行断句、格式分析、分词和词性标注。从不同来源获取的语料在存储格式和方式上都有所不同, 需要根据语料布局的特点进行格式处理, 设置对应的文本读取方式。语料中, 每段文字长短不一, 需要先对文字进行断句。使用中国科学院计算技术研究所研制的汉语词法分析系统NLPIR[27]对语料进行中文分词和词性标注。该系统使用层叠马尔可夫模型实现分词, 既提高了准确性, 又保证了分词的效率。
4.2 依存关系分析
表3 主要依存关系
| 关系 | 含义 | 实例 |
|---|---|---|
| advmod副词性修饰语 | 用于改变副词的强度 | “战争原本相当残酷, 将战争美化到如同娱乐活动一般, 让人反感”: advmod(残酷-4, 相当-3), 表示“相当”作为副词修饰了“残酷”这个形容词 |
| amod形容词修饰语 | 修饰名词词组 | “近来风靡荧屏的抗日题材电视剧, 越来越类型化”: amod(电视剧-7, 抗日-5), 表示名词性形容词“抗日”修饰了“电视剧” |
| nsubj名词性主语 | 修饰名词性主语 | “不一样的抗日神剧, 好看!”: nsubj(好看-8, 剧-6), 表示“好看”修饰了名词性主语“剧” |
| neg否定修饰词 | 含义反转 | “有人说剧情俗套抗日神剧神马的, 我倒觉得不错, 因为不该死的一个没死, 看着不郁闷”: neg(郁闷-28, 不-27), 表示“不”对“郁闷”进行了否定 |
4.3 词典发现模块
(1) 正、负面情感词典
正、负面情感词典决定了文本正面、负面或中立的基本倾向, 这两个词典需要精心筛选以保证尽量全面。本文正、负面情感词典的基本词汇来自于《知网》情感分析用词语集[29]。
本文处理的是新浪微博的实际事件语料, 其中涉及大量口语化的网络新词, 这些情感新词也需要增加到基本的正、负面情感词典中。通过Word2Vec模型[30]进行网络情感新词发现。Word2Vec利用神经网络传递误差损失, 通过若干轮迭代更新模型参数与词向量, 大大降低了计算复杂度, 可以在线性时间内完成模型的训练, 极利于大规模语料的学习。具体包括如下步骤:
①对1.5GB微博训练文本进行分词处理。
②将分词后的词语输入Word2Vec模型, 通过神经网络对词语进行转化, 形成词向量。
③从《知网》中分别选取100个典型的正面词汇和100个典型的负面词汇。
④这200个典型的正负面词语是引子词, 将它们导入Word2Vec模型提取对应的词向量, 再从词向量集合中找出与这些引子词距离最近的10个近义词。这样获得了2 000个潜在的网络情感新词, 剔除其中已有的情感词以及关系不大的词, 最终识别网络情感新词共计146个, 包括正面情感词50个、负面情感词96个。
⑤将《知网》和识别出的网络情感新词进行合并, 得到本文最终使用的正、负面情感词典。
(2) 程度级别词典
修饰词是表达语句含义最重要的要素之一, 通过《知网》的《程度级别词语》计算语句修饰词的级别, 如表4所示。
表4 程度级别示例
| 程度级别 | 词语(示例) | 权重 | 数量 |
|---|---|---|---|
| “极其|extreme/最|most” | 百分之百、绝对、极其 | 3 | 69 |
| “很|very” | 颇为、格外、实在 | 2 | 42 |
| “较|more” | 多、越是、较为 | 1 | 37 |
| “稍|-ish” | 稍、略为、一点 | 1/2 | 29 |
| “欠|insufficiently” | 不甚、微、没怎么 | -1/2 | 12 |
| “超|over” | 过头、过分、偏 | -1 | 30 |
(3) 否定词词典
否定句是常见的句式。例如“我不赞同这个意见”, 这里“赞同”本来表征正面的情感, 但是否定词“不”的出现, 使得语句的情感倾向性发生了反转。因此, 否定句式在文本倾向性分析中是不可或缺的。本文借鉴霍宗凡[31]的处理模式, 由于无法在neg()句法下提取否定的程度级别, 因此给neg句式加两倍的权重。
(4) 标点符号词典
标点符号在句式表达中起着重要作用, 例如问号表达疑问、感叹号强化语气、省略号使得语气趋向平缓。在句子“这真的值得吗??”中, 如果忽略符号, 就会得出正面情感的结论, 但是它实际上表达的是质疑。因此, 在计算文本倾向性时, 标点符号也应该考虑在内。将一些与情感表达相关的常用标点符号进行整合, 如表5所示。
4.4 情感倾向分值计算
所有相关的词典设置好之后, 进行情感倾向分数的计算, 具体包括如下步骤:
(1) 在正、负面情感词典中比对依存关系主导词(第一个词), 若该词在正面词典中出现, 则赋值为“+1”, 若在负面词典中出现, 则赋值为“-1”, 没有出现则赋值为“0”, 表示中立。该变量命名为rawscore。
(2) 在程度级别词典、否定词词典中比对修饰词, 出现则赋予对应的权重, 变量命名为Intense。
(3) 比对分词结果与标点符号词典, 记为PunIntense。
(4) 将依存关系主导词和修饰词的分数相乘, 再对句子中依存关系的分数进行累加, 得到最终的情感倾向分值, 记为Score, 如公式(1)所示。
其中, n是某个评论包含的句子数, m是句子包含的依存关系数, rawscore是主导词的基本正负面分值(+1、-1或0), Intense是句i的修饰词程度权重或否定词权重, PunIntense是标点权重。
经过文本情感倾向性的识别, 能够得到网络文本的倾向分值, 加上网络情感新词的补充, 该方法将能够识别出帖文中蕴含的个人态度和观点, 为最终的网络意见领袖识别奠定基础。
5 实证研究
5.1 潜在意见领袖识别
选择2014年2月25日凌晨发生在南京口腔医院的“官员殴打护士”事件作为分析对象。利用网络爬虫在新浪微博上抓取该事件的相关数据, 关键词为“官员 打 护士”、“董安庆”、“陈星羽”和“袁亚平”, 起止时间为2014年2月25日0点-2014年4月15日23点。最终共计抓取33 079条原创微博、360 549个微博用户的基本信息、424 898条转发和304 750条评论。根据识别指标框架, 计算每位博主的领袖指标 分值。
在计算领袖分值的基础上, 为便于比较各指标大小, 统一数据之间的量纲, 归一化公式如公式(2)所示。
其中, xi为需要计算的归一化数值, xmin为某一个特征项中的最小值, xmax为对应特征项中的最大值。部分博主的归一化领袖分值如表6所示。
表6 归一化后意见领袖指标数据
| 微博昵称 | 粉丝数 | 被@数 | 被转发数 | 被评论数 | 原创微博数 | 回复他人数 | …… | 媒体接触度 | 领袖值 |
|---|---|---|---|---|---|---|---|---|---|
| 头条新闻 | 1.000000000 | 0.231958763 | 1.000000000 | 1.000000000 | 1.000000000 | 0.000000000 | …… | 1.000000000 | 0.829111545 |
| 央视新闻 | 0.530858376 | 1.000000000 | 0.764969581 | 0.624107143 | 0.343150772 | 0.003816794 | …… | 0.739583333 | 0.651347868 |
| 八卦_我实在是太CJ了 | 0.100473289 | 0.046391753 | 0.691642651 | 0.638149351 | 0.04363392 | 0.026717557 | …… | 0.308035714 | 0.461397104 |
| 江苏身边事 | 0.006707475 | 0.054982818 | 0.74871918 | 0.260227273 | 0.221865622 | 0.003816794 | …… | 0.410714286 | 0.412328209 |
| 人民日报 | 0.590243392 | 0.577319588 | 0.240954211 | 0.111850649 | 0.307349176 | 0.003816794 | …… | 0.342261905 | 0.367892438 |
经过计算, 系统会根据每位博主的领袖值按照从高到低的顺序进行排列。选取排名前15的博主作为候选意见领袖, 再进一步对他们进行文本倾向性分析。
5.2 文本倾向性分析与最终意见领袖识别
文本倾向性分析是筛选意见领袖的一个必要过程, 可以去除那些引发大量网民反对以及批评的“伪意见领袖”。
经过文本倾向性分析处理, 微博评论被分为“正面”、“负面”和“中立”三类。其中, “正面”表示对博主赞同, “负面”表示反对, “中立”则没有明显的情感倾向。计算每个潜在意见领袖评论的“正面”、“负面”和“中立”帖文数量, 统计其中反对的百分比, 可以帮助剔除“伪意见领袖”, 如表7所示。
表7 博主“伪意见领袖”的可能性
| 博主昵称 | “伪领袖” 可能性 | 博主昵称 | “伪领袖” 可能性 | ||
|---|---|---|---|---|---|
| 1 | 头条新闻 | 7.9% | 9 | 财经网 | 8.4% |
| 2 | 央视新闻 | 10% | 10 | 评论员李铁 | 17.4% |
| 3 | 八卦_我实在是太CJ了 | 9.6% | 11 | 南方都市报 | 12.2% |
| 4 | 江苏身边事 | 17.6% | 12 | 泉在流淌 | 11% |
| 5 | 人民日报 | 10.8% | 13 | 孟祥远 | 12% |
| 6 | 赖清辉 | 12.4% | 14 | 暗访小王子 | 13.6% |
| 7 | 南京发布 | 9.6% | 15 | 创业家杂志 | 17.5% |
| 8 | 宋坚 | - |
将“伪意见领袖”可能性超过15%的几位博主从意见领袖中剔除, 因为针对“江苏身边事”、“创业家杂志”和“评论员李铁”的评论多数是对博主持否定意见、不信任博主或与博文本身没有关系的。通过人工对评论进行查阅和验证发现, “评论员李铁”微博下的评论内容为质疑、反对和不相关的概率超过86%, “创业家杂志”为65%以上, “江苏身边事”超过59%, 证明本研究鉴别出的“伪领袖”确实没能获得网友的广泛支持, 不应被看作真正的意见领袖。另外, 作为一个热门博主, “宋坚”关闭了评论功能, 没有起到网络意见领袖应具备的扩大影响范围、引导舆论走向的作用, 因此也将其剔除。最终剩余的11名博主被认为是“官员殴打护士”事件中真正的意见领袖。
5.3 对比与评价
为验证本研究所提识别方法的有效性, 将本方法与基于改进的PageRank算法在相同事件数据集上进行识别结果的对比, 如表8所示。
表8 本文方法与改进的PageRank算法的意见领袖识别 结果对比
| 排名 | 本方法意见领袖 | 基于改进的PageRank意见领袖 |
|---|---|---|
| 1 | 头条新闻 | 新浪江苏 |
| 2 | 央视新闻 | 央视新闻 |
| 3 | 八卦_我实在是太CJ了 | 南京鼓楼医院 |
| 4 | 江苏身边事 | 江苏身边事 |
| 5 | 人民日报 | 人民日报 |
| 6 | 赖清辉 | 南京日报 |
| 7 | 南京发布 | 南方都市报 |
| 8 | 宋坚 | 财经网 |
| 9 | 财经网 | 环球时报 |
| 10 | 评论员李铁 | 南京发布 |
| 11 | 南方都市报 | 头条新闻 |
| 12 | 泉在流淌 | 新浪新闻视频 |
| 13 | 孟祥远 | 马伯庸 |
| 14 | 暗访小王子 | 法制日报 |
| 15 | 创业家杂志 | 评论员李铁 |
(1) 两种方法识别的意见领袖具有较高重合度
基于相同的“官员殴打护士”数据集, PageRank算法通过微博用户之间的转发关系计算意见领袖值。本文计算改进的PageRank数值, 更多地关注转发质量。假设一个网页被其他某个权威站点如新浪、网易或搜狐等网站的首页链接, 则说明该网页具有相当的重要性; 类似地, 如果某个用户的发贴被其他微博大V如李开复、姚晨等转发也能够说明该用户的影响力相对较大。作为一种依赖用户间转发关系的方法, 基于PageRank的微博意见领袖识别具有较高可靠性。
针对同样的数据集, 本文使用改进的PageRank方法, 提取前15名潜在的微博意见领袖。结果显示, 两种方法中总计8名意见领袖相互重合, 重复率超过50%。表明识别出的意见领袖具有相当可靠的转发质量, 能够扩大事件的影响力甚至改变舆论的走向。
(2) 两种算法的识别效果比较
为比较本文方法与改进的PageRank方法的效果, 这里选择各自排在首位的两名意见领袖相互比较, 其一为本文方法的“头条新闻”, 另一名则是基于改进的PageRank方法得到的“新浪江苏”。在“官员殴打护士”事件中, 浏览两名意见领袖针对该事件的第一条微博, 可以发现“新浪江苏”仅是转发他人的发帖, 转发评论之和没有超过百人; “头条新闻”则为针对该事件的原创微博, 且转发、评论的数量均过万。可以看出, 无论是影响力、活跃性, 还是专业度, 本文识别的结果都更为精确, 更加能够起到意见领袖的作用, 扩大舆论范围、引发网民关注。
另一方面, 本文的识别结果中包括了“泉在流淌”这一特殊博主, 其作为该事件的网络第一发布人意义特殊。“泉在流淌”目睹了事件的前后经过, 其所发布信息的真实性和可信性都不是他人能比拟的, 这从其他网友对他微博的热烈响应中可以看出。本文识别出该博主, 而基于改进的PageRank方法没有发现, 体现了本文方法的优越性。
本文还有效识别了“伪意见领袖”。PageRank算法不考虑评论内容本身的情感语义, 将“江苏身边事”、“评论员李铁”等列为意见领袖, 但查阅原微博可以发现, 这些博主帖文下的评论大部分都是对博主言论的质疑。通过人工浏览进行验证, 翻阅“江苏身边事”、“评论员李铁”等博主的评论内容, 发现这些评论几乎被反驳、质疑和谩骂充满。这类博主虽然表面上也拥有很多粉丝和数以千计的转发评论, 但他们并不被粉丝追捧和信任, 不能对粉丝产生影响, 也无法引导舆论。因此, 经过文本倾向性分析, 能够识别“伪意见领袖”, 通过剔除这些虽能在一定程度上引发网民讨论、却没有积极引导网络舆论的博主, 完善了本文真正意见领袖识别的过程。
5.4 实验结论
相比PageRank方法, 本文提出的模型能够更加充分地考查意见领袖的各项识别指标, 更精确地计算领袖值, 衡量博主是否具备成为意见领袖的资质, 在此基础上剔除“伪意见领袖”, 大大提升最终识别结果的准确性、真实性和有效性。通过人工翻阅和验证, 本文识别出的11名意见领袖确实能够在“官员殴打护士”事件中发挥至关重要的作用。例如作为该事件的目击者, “泉在流淌”首先在新浪微博上发布了该事件, 并@了官方微博; 作为事件的第一发布人, 其拥有极高的网民关注度和权威性, 可被概括为事件型意见领袖。第二类本文总结为群体型意见领袖, 包括“央视新闻”和“头条新闻”等, 作为拥有大量粉丝的官方微博, 这些博主对事件的发展演变进行跟踪报道, 扩大该事件的传播范围、增强其影响力, 使“官员殴打护士”事件受到广大网民的关注并引起热议。最后一类可以称为观点型意见领袖, 例如“孟祥远”和“赖清辉”等, 他们针对该事件发表个人观点, 强烈反对官员的粗暴行为并质疑官方遮掩的处理方式, 他们的意见得到了大多数网民的接纳和强烈的赞同。
本文通过文本倾向性分析, 提取微博的评论语义, 剔除了三名“伪意见领袖”, 也就是“意见哄客”。这些人意图通过故意在网络上发表反对主流声音的言论, 以引发公众声讨的手段来提高自身影响力。通过评论中包含的情感词/符号和句法分析, 计算每条回帖的情感分值, 将评论语义划分为正面、负面和中立三类。当某个博主负面评论过多时, 即需要剔除的“伪意见领袖”。针对“官员殴打护士”事件, 通过计算发现“江苏身边事”、“评论员李铁”和“创业家杂志”等博主正是典型的“伪意见领袖”。
本实验识别了三类真正的网络意见领袖, 包括事件型、群体型以及观点型意见领袖, 并剔除了干扰最终结果的三名“伪意见领袖”。通过对比验证和人工评阅, 证明本文方法能够有效地抽取意见领袖, 且能得到更精确、更全面的结果。
6 结 语
本文提出一种基于文本情感倾向性分析的网络意见领袖识别方法: 引入新的评价元素、构建统一的意见领袖识别指标体系, 基于新浪微博的真实数据计算每个博主的意见领袖分值; 为识别真正能够扩大事件影响范围、积极引导舆论走向的意见领袖, 采用文本倾向性方法, 分析微博下的评论内容情感语义, 剔除评论内容中反对声音过高的“伪意见领袖”。
本文采用基于语义词典的文本倾向性分析方法, 为适应微博网络环境, 引入基于Word2Vec的情感新词发现, 在原有情感词典的基础上加入大量具有情感倾向的网络新词, 从而取得更准确的识别结果。
本文的研究方法还可以进一步改进和优化, 例如可以结合建模仿真方法进行动态实验与模拟预测, 在未来某时间内, 观察意见领袖的人选是否会有所不同, 从而监测网友态度是否发生变化、网络舆情会进入什么样的发展态势、突发事件的发展是否会引发强烈的情感反应以及官方媒介是否需要介入引导等。
作者贡献声明
陈芬: 提出研究思路, 设计研究方案;
高小欢: 进行实验;
彭玥: 进行实验与起草论文;
何源: 采集和分析数据;
薛春香: 论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: Lanyan_js@126.com。
[1] 陈芬, 高小欢, 何源, 彭玥, 薛春香. 官员殴打护士微博数据.rar. 新浪微博官员殴打护士数据.
[2] 陈芬, 高小欢, 何源, 彭玥, 薛春香. 意见领袖识别指标数据.xls. 意见领袖值计算结果.
参考文献
Sina Weibo Released the 1st Quarterly Financial Reporting(2019)
[R/OL]. [2019-11-05]. https://tech.sina.com.cn/i/2019-05-23/doc-ihvhiews4060412.shtml .)
微博网络舆情中的意见领袖识别及分析
[J].
Recognition and Analysis of Opinion Leaders in Microblog Public Opinions
[J].
Living Research Methods of Measuring Opinion Leadership
[J].
DOI:10.1111/j.1365-2834.2010.01132.x
URL
PMID:20840368
[本文引用: 1]

To study the leadership and management skills of first-line managers (FLMs) of elderly care and their work environment in Egypt and Sweden.
Opinion Leaders and Changes over Time: A Survey
[J].
DOI:10.1186/1748-5908-6-133
URL
PMID:22204440
[本文引用: 1]
Canada is among the most prosperous nations in the world, yet the health and wellness outcomes of Canadian children are surprisingly poor. There is some evidence to suggest that these poor health outcomes are partly due to clinical practice variation, which can stem from failure to apply the best available research evidence in clinical practice, otherwise known as knowledge translation (KT). Surprisingly, clinical practice variation, even for common acute paediatric conditions, is pervasive. Clinical practice variation results in unnecessary medical treatments, increased suffering, and increased healthcare costs. This study focuses on improving health outcomes for common paediatric acute health concerns by evaluating strategies that improve KT and reduce clinical practice variation.
Opinion Leadership in a Computer-Mediated Environment
[J].DOI:10.1002/(ISSN)1479-1838 URL [本文引用: 1]
Opinion Leader Detection Using Whale Optimization Algorithm in Online Social Network
[J].
A Cluster-Based Opinion Leader Discovery in Social Network
[C]//
A New Opinion Leaders Detecting Algorithm in Multi-Relationship Online Social Networks
[J].DOI:10.1007/s11042-017-4766-y URL [本文引用: 1]
Research on Opinion Leaders Recognition Based on TOPSIS in Open Source Design Community
基于复杂网络的虚拟品牌社区意见领袖识别研究——以魅族Flyme社区为例
[J].
Virtual Brand Community Opinion Leader Recognition Based on Complex Network—— Example of the Meizu Flyme Community
[J].
Identification of Opinion Leader on Rumor Spreading in Online Social Network Twitter Using Edge Weighting and Centrality Measure Weighting
[C]//
Detecting Opinion Leaders in Online Social Networks Using HybridRank Algorithm
[J].
DOI:10.1097/IAE.0000000000002717
URL
PMID:31842189
[本文引用: 2]
To quantify morphologic photoreceptor integrity during anti-vascular endothelial growth factor (anti-VEGF) therapy of neovascular age-related macular degeneration and correlate these findings with disease morphology and function.
Community Detection with Opinion Leaders’ Identification for Promoting Collaborative Problem Based Learning Performance
[J].
基于ActivityRank算法的社会化电商意见领袖识别
[J].
Recognition of Social E-commerce Opinion Leaders Based on ActivityRank Algorithm
[J].
SuperedgeRank Algorithm and Its Application in Identifying Opinion Leader of Online Public Opinion Supernetwork
[J].
DOI:10.1016/j.eswa.2013.08.033
URL
[本文引用: 1]
Opinion leaders on the internet are very important figures in online communities, which play an important role in promoting the formation of public opinions. Many theories have been introduced to identify opinion leaders by social network analysis, text mining and PageRank-based algorithm in different fields, but few has addressed the issue of opinion leader identification by combining the methods above, and there is no research using supernetwork analysis to identify opinion leaders. This paper proposed an SuperedgeRank algorithm for opinion leader identification based on supernetwork theory, which combined the network topology analysis and text mining. First, the study established a supernetwork model with multidimensional subnetworks, which are social, psychological, environmental and viewpoint subnetworks. Then, the study proposed four supernetwork indexes: node superdegree, superedge degree, superedge-superedge distance and superedge overlap. The later two indexes are developed by us to help evaluate the identified opinion leaders. Based on them, our study applied SuperedgeRank algorithm to rank superedges, and used the ranking result to identify opinion leaders in opinion supernetwork model. Finally, the feasibility and innovativeness of this method were verified by a case study. (C) 2013 Published by Elsevier Ltd.
微博转发网络中意见领袖的识别与分析
[J].以微博中的转发关系构建邻接矩阵,通过改进后的HITS算法识别微博意见领袖,并构建基于转发关系的意见领袖网,验证算法有效性并分析意见领袖在网络中的作用。研究表明:改进后的HITS算法能够有效地识别意见领袖;意见领袖的中心值与其粉丝数高度正相关。通过对意见领袖网的分析发现:意见领袖在网络的关键节点中占有重要地位,意见领袖的作用并没有因为微博中信息源的增多而削弱。
The Identification and Analysis of Micro-Blogging Opinion Leaders in the Network of Retweet Relationship
[J].以微博中的转发关系构建邻接矩阵,通过改进后的HITS算法识别微博意见领袖,并构建基于转发关系的意见领袖网,验证算法有效性并分析意见领袖在网络中的作用。研究表明:改进后的HITS算法能够有效地识别意见领袖;意见领袖的中心值与其粉丝数高度正相关。通过对意见领袖网的分析发现:意见领袖在网络的关键节点中占有重要地位,意见领袖的作用并没有因为微博中信息源的增多而削弱。
突发事件中意见领袖的识别和影响力实证研究
[J].
Empirical Study on Recognition and Influence of Opinion Leaders in Emergency
[J].
OLFinder: Finding Opinion Leaders in Online Social Networks
[J].DOI:10.1177/0165551515605217 URL [本文引用: 2]
医疗舆情事件的微博意见领袖识别与分析研究
[J].
Research on Weibo Opinion Leaders Identification and Analysis in Medical Public Opinion Incidents
[J].
网络意见领袖的识别分析、产生逻辑及其应用
[J].
Generating Logic and Application of Network Opinion Leader
[J].
基于主题一致性和情感支持的评论意见领袖识别方法研究
[J].
A Method of Identifying Comment Opinion Leaders Based on Topic Consistency and Emotional Support
[J].
在线知识社群中的意见领袖识别模型研究
[J].
Research on Opinion Leader Identification Model in Online Knowledge Community
[J].
自媒体时代意见领袖的识别与引导对策研究——基于议程设置理论视角
[J].
Research on Identification and Guidance of Opinion Leaders in the Media Age
[J].
Influentials, Networks, Public Opinion Formation
[J].DOI:10.1086/518527 URL [本文引用: 1]
Standford Parser
[EB/OL]. [

{kind=link}
{kind=link}