1 引 言
大数据的背景下, 数据资源爆炸式增长和量式聚集使知识网络结构越来越复杂, 同质节点、异质节点间形成错综复杂的多重知识关联关系, 而一般的复杂网络不能全面揭示各知识实体间的关联关系, 因此需要有超越一般网络的思想, 运用更加符合真实世界网络特征的方法与技术描述知识网络, 解释知识网络要素间的关联。超网络的出现为更加客观真实地刻画知识网络提供了很好的解决办法。超网络作为一种“网络中的网络”, 以不同性质的网络节点为基础, 通过节点间的关系相互连接而构成, 是一种由异质节点和异质关系构成的异构网络, 具有多层级、多维度、多重关系、嵌套性的属性[1 ] 。因此运用超网络理论与方法构建知识超网络, 可以较为全面完整地描述知识网络, 揭示知识网络的多重复杂关系, 挖掘知识网络中的隐含关联。
面对当前专家资源稀缺, 国家政府、大中型企业以及高校、科研机构评价发现专家难、无法选拔专家、专家评价不够科学客观的现状, 如何客观科学地识别出拥有专业知识与技能、满足需求的领域专家是一个值得深入研究和解决的问题。在当今知识社会, 精确地识别出领域内的专家, 是用户知识需求趋于精准化的体现, 同时也是知识服务领域的研究热点。
2 研究现状
2.1 知识超网络
哲学上将联系视为世界上一切事物的客观本性, 联系即可用网络模型进行表示和描述, 任何系统也都可以抽象为网络模型。根据网络中节点的性质以及网络结构, 可以将网络模型大致分为三类。
(3) 超网络模型: 以网络为节点构成的网络, 或由网络嵌套构成的网络。
超网络概念最早在1985年由Denning[2 ] 从计算机科学角度提出, Nagurney等[3 ] 对超网络进行了深入研究, 将其定义为高于而又超于现存网络的网络[4 ] , 这一定义被广泛接受并引起了各领域的关注。现实世界中, 大多数系统具有复杂的网络结构和特性, 一般的复杂网络已经无法全面完整地描述复杂系统以及揭示各要素之间复杂的关联关系。而超网络以其多层级、多重性和嵌套性的特性, 能够更加全面真实地描述现实世界的网络以及其间的相互作用关系和影响, 揭示同构网络的多重关联关系和异构网络的映射关系, 在对复杂系统的网络建模上具有得天独厚的优势。
知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出。国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型。于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络。目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面。在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] 。在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] 。在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] 。在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] 。
(1) 目前构建的知识超网络模型大多包含三层子网络, 网络节点不够多, 不能足够全面地描述现实知识网络的复杂结构;
(2) 知识超网络主要应用在知识组织、知识传播和知识共享方面, 应用领域较窄, 有待进一步扩展;
(3) 知识超网络能够更好地揭示知识网络同质节点的关联关系和异构节点间的映射关系, 使得知识间的隐性关联得以显现。
2.2 领域专家识别
专家识别是专家评价、遴选、推荐的基础, 主要通过一系列的技术和方法发现各领域拥有丰富专业知识、技能与经验的专家。目前专家识别方法主要包括:
(1) 基于本体的专家识别方法, 主要通过领域本体构建专家知识库进行专家识别, 发现专家专长[17 ,18 ] , 但需要构建领域本体, 工作量较大。
(2) 基于文献计量的方法, 主要以作者的论文为计量对象, 从作者的合作角度、被引角度, 依据作者的发文数、合作率、总被引量、篇均被引、h指数、g指数、p指数等指标对学者的学术影响力进行评价, 从而发现领域专家, 实现专家推荐或遴选[19 ,20 ,21 ] , 但缺乏对专家学术内容的分析, 不能发现专家的领域专长。
(3) 基于社会网络分析法, 以作者及其论文作为网络节点, 将专家或论文之间的联系当作网络的边, 从而建立网络模型, 计算网络的拓扑结构, 进行专家识别[22 ,23 ,24 ] , 但往往只从单种关系进行专家识别, 不能全面揭示专家网络的关联关系。
(4) 基于主题的专家聚类的领域专家识别方法, 通过文本语义挖掘, 发现专家的研究领域及专长, 常用的算法包括PLSA、LDA等主题模型[25 ,26 ] , 虽考虑了内容的语义, 而且能实现大量数据的处理, 但忽略了文献计量指标对专家影响力评价的重要作用。
领域专家识别的方法较多, 但都各有优缺点, 笔者发现少有运用超网络进行领域专家识别的研究。本文运用超网络的理论与方法, 构建知识超网络模型, 同时融合文献计量学、社会网络分析法、主题聚类的方法, 既考虑知识实体间的关联, 又从语义角度细粒度挖掘文献的知识元, 从而进行领域专家识别, 提供了一种新的方法与思路。
3 知识超网络模型构建
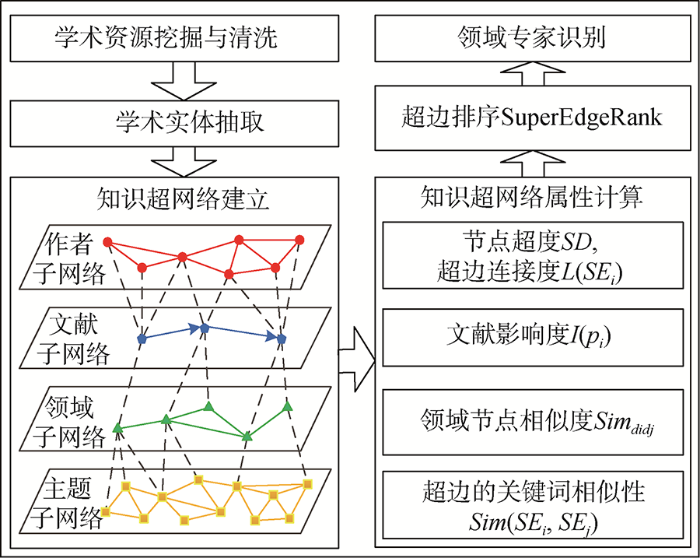
经典的知识超网络模型由知识元、知识载体及知识主体三要素构成, 目前领域专家主要通过合著网络、共引网络、耦合网络、共词网络、主题聚类等进行识别, 本文将其结合, 建立由作者子网络、文献子网络、领域子网络、主题子网络构成的知识超网络模型。
3.1 作者子网络
作者是知识网络中的知识主体, 在知识网络中占有重要地位。以作者为节点, 以作者间的合著关系为边连接作者节点, 从而建立作者子网(Author Subnetwork)。
定义: 节点为文献中的作者, 以作者的共现关系构造无向边, 因此构造的作者合作关系网络如公式(1)所示。
(1) SA =(A , EA – A
其中, A ={A 1 , A 2 , …, An }是合作作者的有限集合, EA – A
(2) EA – A Ai , Aj )} (i , j =1, 2, ··· n )
(3) $\text{ (}{{A}_{i}},{{A}_{j}}\text{)}=\left\{ \begin{align} & 0\mathrm{,}{{A}_{i}}{{A}_{j}} \\ & 1\mathrm{,}{{A}_{i}}{{A}_{j}} \\ \end{align} \right.$
其中, A 1 , A 2 , …, An 是科研作者, 是SA 网络中点的集合; (Ai , Aj )为SA 网络中边的集合。
3.2 文献子网络
文献作为知识网络中的知识载体, 同时也是知识主体的智慧结晶, 常作为评价学者影响力的重要因素或指标。以文献为节点, 文献间的被引关系作为边, 构建知识超网络模型的文献子网络(Paper Subnetwork)。
定义: 节点为文献, 以不同文章间的被引关系构造有向边, 构造文献子网络如公式(4)所示。
(4) SP =(P , EP → P
其中, P ={P 1 , P 2 , …, Pn }是文献的有限集合, EP → P
(5) EP → P Pi , Pj )} (i , j =1, 2, ··· n )
(6) $(P_{i},P_j)=\left\{ \begin{align}& 0,P_{i}与P_j不存在被引关系 \\ & 1,P_{i}与P_j存在被引关系 \end{align} \right.$
其中, P 1 , P 2 , …, Pn 是文献, 是SP 网络中点的集合; (Pi , Pj )为SP 网络中边的集合。
3.3 领域子网络
研究领域是专家分类的依据, 是专家身上的知识符号, 同时也是专家的识别标签。建立以领域为知识元的知识超网络领域子网络(Domain Subnetwork), 以学者的研究领域为节点, 领域之间的相关关系连接领域节点。
定义: 节点为网络中的研究领域, 按领域间的相关关系构造无向边, 构造的研究领域网络如公式(7)所示。
(7) SD =(D , ED – D
其中D ={D 1 , D 2 , …, Dn }是作者研究方向的有限集合, ED – D
(8) ED – D Di , Dj )}(i , j =1, 2, ··· n )
(9) $(D_{i},D_j)=\left\{ \begin{align}& 0,D_{i}与D_j不存在被引关系 \\ & 1,D_{i}与D_j存在被引关系 \end{align} \right.$
其中, D 1 , D 2 , …, Dn 是研究方向, 是SD 网络中点的集合, (Di , Dj )为SD 网络中边的集合。
3.4 主题子网络
主题关键词是反映文献主题内容最重要的词, 是作者研究主题或方向的体现, 因此, 以作者发表的主题关键词为节点, 关键词之间的关联关系为边, 建立主题子网(Keyword Subnetwork)。
定义: 节点为网络中的主题关键词, 以关键词的共现关系构造无向边, 构造的主题关系网络如公式(10)所示。
(10) SK =(K , EK – K
其中, K ={K 1 , K 2 , …, Kn }是主题关键词的有限集合, EK – K
(11) EK – K Ki , Kj )}(i , j =1, 2, ··· n )
(12) $(K_{i},K_j)=\left\{ \begin{align}& 0,K_{i}与K_j不存在被引关系 \\ & 1,K_{i}与K_j存在被引关系 \end{align} \right.$
其中, K 1 , K 2 , …, Kn 是主题关键词, 是SK 网络中节点的集合; (Ki , Kj )为SK 网络中边的集合。
3.5 知识超网络模型
根据作者层、文献层、领域层、主题层4层子网络的层内关系和层间映射关系, 构建知识超网络模型。
(13) $\begin{align} & S{{E}_{A-P-D-K}}= \\ & \left\{ {{A}_{i}},{{P}_{j}},{{D}_{m}},{{K}_{n}}\left| \begin{matrix} \alpha ({{A}_{i}},{{P}_{j}})=1,\alpha ({{A}_{i}},{{D}_{m}})=1,\alpha ({{A}_{i}},{{K}_{n}})=1 \\ \alpha ({{P}_{j}},{{D}_{m}})=1,\alpha ({{P}_{j}},{{K}_{n}})=1,\alpha ({{D}_{m}},{{K}_{n}})=1 \\ \end{matrix} \right. \right\} \\ \end{align}$
其中, 超边SE 表示作者Ai , 从事领域Dm 的研究工作, 并发表了主题关键词为Kn 文献Pj 。
因此建立的知识超网络模型(KSN)如公式(14)所示。
(14) KSN ={SA , SP , SD , SK , SEA - P - D - K
4 基于知识超网络的领域专家识别方法
4.1 知识超网络度量指标
在进行领域专家识别前需要引入两个超网络属性指标, 节点超度SD 和超边连接度L (SEi )[27 ,28 ] 。
(1) 节点超度SD : 超网络中的节点超度与社会网络分析法中的节点连接度类似, 某个节点的节点超度SD 定义为该节点参与组成的超边数。
(2) 超边连接度L (SEi ): 在超网络中, 每条超边都包含多个节点, 若两条超边包含有相同的节点, 那么这两条超边通过共同的节点相连。超边连接度L (SEi )即为与该条超边具有共同节点的其他超边的数目。
4.2 文献子网中文献影响度
领域专家是在某个研究领域具有一定学术影响力的学者, 而这种影响力体现在其研究成果在该领域具有较大的影响度。不同文献的影响程度不同, 将其定义为文献影响度I (pi )。文献影响度取决于两个指标。
(1) 文献的影响广度R (pi )指文献pi 的被引情况, 可通过文献pi 的引证文献pj 参与组成的总超边数衡量, 即文献pj 共参与组成的超边数目与超网络模型中总的超边数目的比值。
(2) 文献的影响深度D (pi )指文献pi 被知识主体作者传播的深入程度, 可通过文献pi 的引证文献的知识主体个数衡量。
文献影响度I (pi )的计算方法如公式(15)所示。
(15) $\begin{align} & I\text{(}{{p}_{i}}\text{)}=R\text{(}{{p}_{i}}\text{)}\times D\text{(}{{p}_{i}}\text{)}= \\ & \frac{F({{p}_{i}})}{N}\times \frac{F({{p}_{i}})/A({{p}_{i}})}{N/{{N}_{a}}}=\frac{F{{({{p}_{i}})}^{2}}\cdot {{N}_{a}}}{N\cdot A({{p}_{i}})} \\ \end{align}$
其中, F (pi )表示文献pi 在知识超网络模型中引证文献参与组成的总超边数, A (pi )表示作者子网络中与文献pi 的引证文献共同组成超边的作者总数, N 表示超网络模型中总超边数, Na 表示作者子网络中总的作者数量。
4.3 领域子网络领域标签相似度计算
LDA主题模型是一种非监督机器学习技术, 主要用于主题挖掘, 常用来挖掘文档集中的潜在主题。本文在进行领域标签提取时采用LDA主题模型, 根据LDA主题模型获取主题-特征词概率分布, 从中提取领域标签, 再根据每个领域下特征词分布概率计算领域标签节点之间相似度, 这里可以使用统计自然语言常用的KL距离计算领域标签的相似度。KL距离越大则表示领域标签之间的相似度越低, 因此定义领域标签语义相似度Simdidj 表示领域节点di 和dj 的相似度, 与KL距离成反比, 考虑到KL距离公式的不对称性, 运用JS距离解决KL距离非对称的问 题[29 ] , 因此领域节点di 和dj 的相似性计算公式如公式(16)所示。
(16) $\begin{align} & Si{{m}_{didj}}= \\ & \frac{1}{{{D}_{JS}}(P,Q)}=\frac{1}{\frac{1}{2}\left[ {{D}_{KL}}(P,\frac{P+Q}{2})+{{D}_{KL}}(Q,\frac{P+Q}{2}) \right]} \\ \end{align}$
其中, ${{D}_{KL}}(P,Q)=\sum\limits_{j=1}^{T}{P(i)\cdot }\ln \frac{P(i)}{Q(j)}$, P 和Q 分别表示所有词项以di 和dj 话题分布出现的事件。P (i )表示领域di 的特征词概率分布, Q (j )表示领域dj 的特征词概率分布, 通过LDA主题模型计算的主题-特征词概率分布获得[30 ] 。
4.4 主题子网中超边主题相似度计算
在主题子网络中, 文献的主题关键词通过TF-IDF提取, 通过计算文档中词项的TF-IDF值, 取TF-IDF值最大的5个词项作为文献的主题关键词, 从而可以得到每个超边中主题关键词的权重分布。以向量空间模型为基础, 构造关键词在超边中的权重分布矩阵, 矩阵中的元素wij 表示关键词kj 在超边SEi 中对应的权重。在知识超网络模型中, 两条不同超边的关键词相似 性可以借助余弦相似度计算获得。如超边SE 1 和超 边SE 2 的相似度Sim (SE 1 ,SE 2 )计算方法如公式(17)所示。
(17) $Sim(S{{E}_{\text{1}}},S{{E}_{\text{2}}})=Si{{m}_{\text{12}}}=\text{Cos}\theta =\frac{\sum\limits_{j=1}^{m}{{{w}_{1j}}\times }{{w}_{2j}}}{\sqrt{(\sum\limits_{j=1}^{m}{w_{1j}^{2})\times }(\sum\limits_{j=1}^{m}{w_{2j}^{2})}}}\text{ }$
其中, w 1 j w 2 j SE 1 , SE 2 第j 个关键词的权重值。
4.5 超边排序SuperEdgeRank算法
识别领域专家本质上是对专家学术影响力的排名, 为更加全面客观地对学者影响力进行评价, 不仅要考虑专家的发文量, 还要考虑专家的论文质量, 并从语义层面发现专家的研究专长。借鉴PageRank算法的思想及原理, 本研究提出知识超网络模型中的超边排序SuperEdgeRank算法, 综合考虑不同超边之间所包含的文献影响度、领域相似度和主题关键词相似性等因素。在文献子网中, 某超边所包含的文献节点的影响度越高, 则该条超边越容易被“发现”, 即被其他超边链接的概率越大; 在领域子网中, 某超边所在的领域与其他领域相似度越大, 则该超边与其他超边链接获得“分值”越大; 在主题子网络中, 某超边所包含的主题关键词与其他超边主体关键词相似性越大, 则该超边与其他超边链接获得“分值”也越大。由此, 得到SuperEdgeRank算法如公式(18)所示。
(18) $SER(S{{E}_{i}})=\frac{1-{{I}_{\text{p}i}}}{N}+{{I}_{pi}}\sum\limits_{S{{E}_{j}}}{\frac{SER(S{{E}_{j}})\times Si{{m}_{didj}}\times Si{{m}_{ij}}}{L(S{{E}_{j}})}}$
其中, N 表示所有超边数, Ipi 表示文献影响度, Simdidj 表示领域di 与领域dj 之间的关联关系, Simij 表示超边SEi 与超边SEj 所包含关键词的相似性; L (SEi )表示超边SEi 的超边连接度。
4.6 基于知识超网络的领域专家识别机制
基于知识超网络进行领域专家识别时, 首先建立知识超网络模型, 然后分别对应作者子网络、文献子网络、领域子网络和主题子网络计算作者子网络各个知识主体参与形成超边的属性, 利用SuperEdgeRank算法对超边进行排序, 统计作者ai 参与形成的所有超边的分值, 计算各个作者的平均超边分值S (ai ), 对学者进行排名, 排名靠前面的学者即为该领域的专家, S (ai )计算方法如公式(19)所示。基于知识超网络的领域专家识别框架如图1 所示。
(19) $S({{a}_{i}})=\frac{\sum{SER(S{{E}_{ai}})}}{S{{D}_{ai}}}$
其中, SER (SEai )为作者节点ai 参与形成的超边的分值; SDai 为节点ai 的节点超度值。
图1
5 基于知识超网络的图情领域专家识别实证分析
5.1 实验数据收集
选取图书情报领域较为权威的4种CSSCI来源期刊《中国图书馆学报》、《情报学报》、《图书情报工作》和《情报理论与实践》2000年-2018年的论文数据作为实验数据(《情报学报》的论文数据有缺失), 剔除专题序、会议通知、征文启事、选题指南等非期刊论文数据, 以及信息缺失的论文。将采集的数据进行清洗, 主要保留字段包括: Title(标题)、Author(作者)、Keywords(关键词)、Abstract(摘要)等, 共收集18 517条数据。
5.2 实验方法与步骤
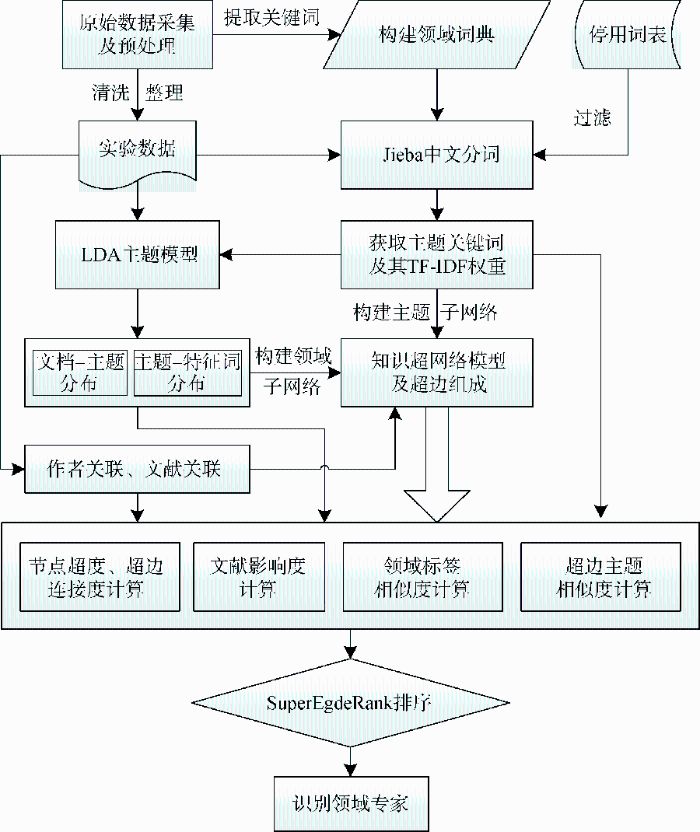
对采集的数据进行预处理, 提取作者、文献题名、关键词等, 根据作者的合作关系, 构建作者子网络; 根据文献间的引证关系, 构建文献子网络; 依据作者与文献间的发表关系, 将作者子网络与文献子网络进行链接。部分关键实验步骤的实施过程如图2 所示。
图2
Jieba分词是目前比较流行的一种开源中文分词方法, 由于其开箱即用的特点, 备受欢迎。采用Jieba分词的精准模型进行中文分词, 并计算每篇论文摘要分词后的TF-IDF值。提取出原始文本中的关键词, 建立领域词典userdic.txt; 删除原始文本中的标点符号和英文符号, 利用Python的Jieba分词模块对原始文本的题目、关键词、摘要进行分词, 并将领域词典作为自定义词典导入, 同时导入停用词表, 以提高分词效果; 最后基于TF-IDF算法进行关键词抽取, 将每篇文章TF-IDF值Top5的词作为文献的主题关键词, 以构建知识超网络模型的主题子网络。
对文本分词后, 将文本预处理与特征选择后的数据进行主题分类, 主题分类算法采用LDA模型。在LDA建模过程中, 领域标签抽取由基于Python语言的机器学习包Gensim实现。Gensim是Python中一个开源的第三方工具包, 用于无监督地挖掘文本隐层的主题, 支持LSA、LDA等多种主题模型。LDA_gensim的主函数初始化参数设置为: Topic的初始个数K =50、α =50/K 、β =0.01, 迭代次数为1 000次。其中主题数K 的取值依次为25, 50, 75, 100, 150, 200。利用不同主题数进行多次聚类实验, 获得最优主题数K =50, 并获得文档-主题、主题-特征词的概率分布。
5.3 图情领域知识超网络模型
根据原始文献的作者合作关系以及文献的引用关系, 建立作者子网络和文献子网络, 并根据作者与文献的发表关系, 建立作者子网络与文献子网络间的关联关系, 根据LDA主题模获得主题-特征词分布, 对每个研究主题进行人工识别, 确定领域标签, 并根据文献-主题分布, 建立文献子网络与领域子网络间的链接关系, 同时将文献的TF-IDF值Top5的关键词提取作为主题子网络的节点, 依据关键词间的共现关系构建主题子网络。最终构建的图书情报领域的知识超网络, 作者子网络共有14 946个作者节点, 文献子网络包含18 517个文献节点, 领域子网络中包含50个领域节点, 主题子网络中包含24 484个关键词节点, 共形成36 817条超边, 部分超边的组成情况如表1 所示。
5.4 实验结果分析
借助Python语言实现本文所提超边排序算法, 对所有超边进行计算, 获得每条超边的SuperEdgeRank排序结果, 根据超边排序结果, 计算(发文量10篇以上)作者的平均超边分值(简称S值), 根据作者的平均超边分值排序, 识别出领域专家(Top20)。为验证本文所提专家识别算法的有效性与合理性, 通过与h指数、p指数、社会网络分析法的中心度Degree等指标进行对比评价, 不同指标的计算结果如表2 所示。
将本文所提算法的排序结果(S值)分别与h指数、p指数、社会网络分析法中心度Degree指标的排序结果进行相关性分析, 计算结果如表3 所示。
S值排名与h指数、p指数排名的相关性比较显著, S值排名与h指数排名的Pearson相关指数高达到0.725, 相关性在0.01上显著, 说明本文的超边排序结果与h指数排序结果具有一定的一致性。h指数作为学术评级及学者影响力评价中应用较广泛的客观评价指标, 说明本文所提超边排序算法在一定程度上具有客观性及合理性。但h指数也存在一些不足, h指数反映的是学者的累计科研产出, 在评价资质较老的学者时具有较好的效果, 由于年轻学者累计科研产出还不够多, 文献发表时间较新, 引用量还在增长, 对优秀的年轻学者不太实用。而p指数改善了h指数对学者影响力评价区分度不明显的情况, 在进行学术评价时更具客观性及合理性, S值排名与p指数排名的Pearson相关指数高达到0.956, 相关性在0.01上显著, 说明超边排序算法与p指数排序结果基本一致, p指数既考虑学者发表论文的数量又兼顾论文质量, 同时继承了h指数的优点又弥补了h指数的缺点, 在学术评价中具有较好的效果, 而超边排序算法与p指数具有较好的相关性, 说明该算法具有可靠性及合理性。但S值排名与中心度Degree排名的相关性指数比较小, 相关性不显著。笔者计算发现发文量与中心度Degree具有较好的相关性, 线性相关系数达到0.525, 说明中心度Degree与发文量具有较大的关系, 考虑到本文的中心性是基于作者合作网络得到的, 而在合作网络中, 作者发文量越大, 其合作者也相对较多, 因此在合作网络中中心度较大, 而S值与中心度Degree相关性较差, 说明S值不是仅仅依靠作者的发文量进行学者的影响力评价。
相较于h指数、p指数、社会网络分析, 本文所提超边排序算法具有以下几个优势:
(1) 多源融合, 较为全面地进行学术评价。超边排序算法从文献计量角度考虑了学者的发文量与被引量等外部数据, 同时从社会网络角度考虑了学者的科研合作影响力, 最重要的是还从细粒度语义层面考虑了文献的学术价值, 多角度全方位地对学者进行学术影响力评价, 从而较为客观地进行专家识别。
(2) 细粒度挖掘知识元特征, 识别专家研究领域。本文深入挖掘文献的细粒度知识元, 从语义层面考虑文献的关键词与领域标签的相似度特征, 体现文献的学术价值以反映学者影响力, 同时从语义角度识别出学者的主要研究领域和方向, 发现专家的专长, 弥补了h指数、p指数无法反映学者研究领域的缺点。
6 结 语
本文运用超网络的理论与方法, 在经典的知识网络模型基础上, 构建由作者子网络、文献子网络、领域子网络、主题子网络构成的知识超网络模型。相比以往由单一节点、单一关系构成的同质网络或者简单的异质网络, 能更好地描述知识网络以及揭示各知识实体间的关联关系, 更符合现实知识网络多层级、多维度、多重关系、多属性、嵌套性的网络特征, 为更全面、更真实地刻画知识网络、开展知识网络研究拓展了路径。在构建的知识超网络模型的基础上, 运用超网络的度量方法考虑网络拓扑结构, 从计量角度考虑作者学术成果的影响力, 并运用领域相似度及主题相似度从语义层面细粒度提取知识元, 提出基于知识超网络的领域专家识别机制与算法。并以图书情报领域为例, 构造知识网络模型, 识别图情领域专家, 通过与其他专家识别方法进行相关性分析, 验证了算法的有效性及合理性, 达到预期研究目的。但本研究还存在以下局限:
(1) 本文构建的知识超网络模型相比以往的知识超网络模型有所扩展, 但还有许多其他重要的知识实体没有加入, 如机构、期刊、基金等, 因此, 构建的知识超网络未能全面刻画知识网络的所有节点。
(2) 在实验中, 虽然用到了很多工具, 但也有不少地方需要人工干预和识别, 未能实现全自动化完成, 耗费较多的时间与人力; 另外只选取图情领域4种中文期刊的论文作为实验数据, 样本数据还不够充分, 学者最终排名与实际可能有所差距, 故在今后的研究中会进一步突破。
作者贡献声明
许鹏程: 论文撰写, 负责实验, 数据处理和分析;
支撑数据
支撑数据由作者自存储, E-mail: xupchup@protonmail.com。
[1] 许鹏程. data.zip. 原始论文数据.
[3] 许鹏程. result.xlsx. 排序结果.
参考文献
View Option
[1]
郭秋萍 , 华康民 . 超网络研究分析综述
[J]. 管理工程师 , 2016 ,21 (4 ):51 -55 .
[本文引用: 1]
( Guo Qiuping Hua Kangmin . A Review of Research on Supernetwork
[J]. Management Engineer , 2016 ,21 (4 ):51 -55 .)
[本文引用: 1]
[2]
Denning P J . The Science of Computing-Supernetworks
[J]. American Scientist , 1985 ,73 (3 ):225 -227 .
DOI:10.1055/a-1044-2397
URL
PMID:31842246
[本文引用: 1]
This study investigated the effect of endurance training and regular post-exercise cold water immersion on changes in microvascular function. Nine males performed 3 sessions∙wk-1 of endurance training for 4 weeks. Following each session, participants immersed one leg in a cold water bath (10°C; COLD) for 15 min while the contra-lateral leg served as control (CON). Before and after training, microvascular function of the gastrocnemius was assessed using near-infrared spectroscopy, where 5 min of popliteal artery occlusion was applied and monitored for 3 min upon cuff release. Changes in Hbdiff (oxyhemoglobin - deoxyhemoglobin) amplitude (O-AMP), area under curve (O-AUC) and estimated muscle oxygen consumption (mVO2 ) were determined during occlusion, while the reperfusion rate (R-RATE), reperfusion amplitude (R-AMP) and hyperemic response (HYP) were determined following cuff release. Training increased O-AMP (p=0.010), O-AUC (p=0.011), mVO2 (p=0.013), R-AMP (p=0.004) and HYP (p=0.057). Significant time (p=0.024) and condition (p=0.026) effects were observed for R-RATE, where the increase in COLD was greater compared with CON (p=0.026). In conclusion, R-RATE following training was significantly higher in COLD compared with CON, providing some evidence for enhanced microvascular adaptations following regular cold water immersion.
[3]
Nagurney A Dong J Supernetworks: Decision-Making for the Information Age [M]. Cheltenham : Edward Elgar Publishing , 2002 .
[本文引用: 1]
[4]
Dong J Nagurney A . A Supernetwork Model for Commuting Versus Telecommuting Decision Making
[A]// Transportation Planning and Management in the 21st Century [M]. 2001 : 386 .
[本文引用: 1]
[5]
王志平 , 王众托 . 超网络理论及其应用 [M]. 北京 : 科学出版社 , 2008 .
[本文引用: 2]
( Wang Zhiping Wang Zhongtuo Hypernetwork Theory and Application [M]. Beijing : Science Press , 2008 .)
[本文引用: 2]
[7]
于洋 . 组织知识管理中的知识超网络研究
[D]. 大连: 大连理工大学 , 2009 .
[本文引用: 1]
( Yu Yang . Researches on Knowledge Supernetwork in Organizational Knowledge Management
[D]. Dalian: Dalian University of Technology , 2009 .)
[本文引用: 1]
[8]
Yu Y Dang Y Xu P , et al . Knowledge Resources Integrated Model of Basic Scientific Research Achievements Based on Supernetwork
[C]// Proceedings of the 2008 International Seminar on Business and Information Management. 2008 : 505 -508 .
[本文引用: 1]
[9]
Chen T Shao Y Han Y . Collaborative Innovation Model Research Based on Knowledge-Supernetwork and TRIZ
[C]// Proceedings of the 4th International Conference on Logistics, Informatics and Service Science. 2015 : 1169 -1174 .
[本文引用: 1]
[10]
康阳春 , 王海南 . 基于知识超网络的知识服务体系研究
[J]. 图书情报工作 , 2018 ,62 (S1 ):64 -67 .
[本文引用: 1]
( Kang Yangchun Wang Hainan . Research on Knowledge Service System Based on Knowledge Hypernetwork
[J]. Library and Information Service , 2018 ,62 (S1 ):64 -67 .)
[本文引用: 1]
[11]
田儒雅 , 孙巍 , 吴蕾 , 等 . 基于超网络的图书情报领域知识合作特征分析
[J]. 情报理论与实践 , 2016 ,39 (10 ):25 -30 .
[本文引用: 1]
( Tian Ruya Sun Wei Wu Lei , et al . Feature Analysis of Knowledge Cooperation in the Field of Library and Information Science Based on Supernetwork
[J]. Information Studies: Theory & Application , 2016 ,39 (10 ):25 -30 .)
[本文引用: 1]
[12]
肖璐 . 基于知识超网络的网络社区学术资源多粒度聚合研究
[J]. 情报杂志 , 2018 ,37 (12 ):182 -187, 194 .
[本文引用: 1]
( Xiao Lu . Research on the Multi-Granularity Integration for Academic Resource in Network Community Based on the Knowledge Supernetwork
[J]. Journal of Intelligence , 2018 ,37 (12 ):182 -187, 194 .)
[本文引用: 1]
[13]
Zhao L Zhang H Wu W . Cooperative Knowledge Creation in an Uncertain Network Environment Based on a Dynamic Knowledge Supernetwork
[J]. Scientometrics , 2019 ,119 (2 ):657 -685 .
DOI:10.1007/s11192-019-03049-4
URL
[本文引用: 1]
[14]
李纲 , 巴志超 . 科研合作超网络下的知识扩散演化模型研究
[J]. 情报学报 , 2017 ,36 (3 ):274 -284 .
[本文引用: 1]
( Li Gang Ba Zhichao . Research on Evolutionary Dynamics of Knowledge Diffusion Based on Collaboration Hypernetwork
[J]. Journal of the China Society for Scientific and Technical Information , 2017 ,36 (3 ):274 -284 .)
[本文引用: 1]
[15]
廖开际 , 杨彬彬 . 基于加权超网络模型的组织知识共享研究
[J]. 情报学报 , 2013 ,32 (5 ):503 -510 .
[本文引用: 1]
( Liao Kaiji Yang Binbin . Research on Organizational Knowledge Sharing Based on the Weighted Supernetwork Model
[J]. Journal of the China Society for Scientific and Technical Information , 2013 ,32 (5 ):503 -510 .)
[本文引用: 1]
[16]
Xia H Wang Z Luo S , et al . Toward a Concept of Community Intelligence: A View on Knowledge Sharing and Fusion in Web-Mediated Communities
[C]// Proceedings of the 2008 IEEE International Conference on Systems, Man and Cybernetics. 2008 : 88 -93 .
[本文引用: 1]
[17]
陆伟 , 刘杰 , 秦喜艳 . 基于专长词表的图情领域专家检索与评价
[J]. 中国图书馆学报 , 2010 ,36 (2 ):70 -76 .
[本文引用: 1]
( Lu Wei Liu Jie Qin Xiyan . Expert Search and Evaluation Based on Expertise Vocabulary in the Field of Library and Information Science
[J]. Journal of Library Science in China , 2010 ,36 (2 ):70 -76 .)
[本文引用: 1]
[18]
胡月红 , 刘萍 . 基于本体概念的专长表示研究
[J]. 图书情报工作 , 2012 ,56 (4 ):17 -21 .
URL
[本文引用: 1]
传统的专家识别系统大多采用一组带权重的关键词来表征专家的专长,然而这种基于关键词的专长描述不足以概括专家的研究主题。提出基于领域本体概念的专长表示方法,通过构建相应的领域本体来描述领域核心概念和概念间关系,利用谷歌距离来计算关键词到本体概念的语义相似度,完成关键词到概念的映射,从而得到基于本体概念的专长表示。
( Hu Yuehong Liu Ping . An Ontology Based Approach for Expertise Representation
[J]. Library and Information Service , 2012 ,56 (4 ):17 -21 .)
URL
[本文引用: 1]
传统的专家识别系统大多采用一组带权重的关键词来表征专家的专长,然而这种基于关键词的专长描述不足以概括专家的研究主题。提出基于领域本体概念的专长表示方法,通过构建相应的领域本体来描述领域核心概念和概念间关系,利用谷歌距离来计算关键词到本体概念的语义相似度,完成关键词到概念的映射,从而得到基于本体概念的专长表示。
[19]
Bornmann L Daniel H D . Does the h-index for Ranking of Scientists Really Work?
[J]. Scientometrics , 2005 ,65 (3 ):391 -392 .
DOI:10.1007/s11192-005-0281-4
URL
[本文引用: 1]
h -index as a single-number criterion to evaluate the scientific output of a researcher (Ball, 2005): A scientist has index h if h of his/her N p papers have at least h citations each, and the other (N p − h ) papers have fewer than h citations each. In a study on committee peer review (Bornmann & Daniel, 2005) we found that on average the h -index for successful applicants for post-doctoral research fellowships was consistently higher than for non-successful applicants.
[20]
邱均平 , 缪雯婷 . h指数在人才评价中的应用——以图书情报学领域中国学者为例
[J]. 科学观察 , 2007 (3 ):17 -22 .
[本文引用: 1]
( Qiu Junping Miao Wenting . Application of h-index in Evaluating Individual’s Performances
[J]. Science Focus , 2007 (3 ):17 -22 .)
[本文引用: 1]
[21]
李江 , 李东 , 冯培桦 , 等 . 基于专长吻合度、学术影响力与社会关联值的专家推荐模型研究
[J]. 情报学报 , 2017 ,36 (4 ):338 -345 .
[本文引用: 1]
( Li Jiang Li Dong Feng Peihua , et al . An Expert Recommendation Model Based on the Speciality, Scientific Impact of Experts, and Social Relationship Between Experts and Applicants
[J]. Journal of the China Society for Scientific and Technical Information , 2017 ,36 (4 ):338 -345 .)
[本文引用: 1]
[22]
Gu G Deng W . Identification and Evaluation Methods of Expert Knowledge Based on Social Network Analysis
[C]// Proceedings of the 2011 MSEC International Conference on Multimedia, Software Engineering and Computing. 2011 : 219 -225 .
[本文引用: 1]
[23]
Garces E Anthony J . Identification of Experts Using Social Network Analysis(SNA)
[C]// Proceedings of the 2016 Portland International Conference on Management of Engineering & Technology. IEEE , 2016 : 1882 -1896 .
[本文引用: 1]
[24]
王菲菲 , 王筱涵 , 刘扬 . 三维引文关联融合视角下的学者学术影响力评价研究——以基因编辑领域为例
[J]. 情报学报 , 2018 ,37 (6 ):610 -620 .
[本文引用: 1]
( Wang Feifei Wang Xiaohan Liu Yang . Evaluation of Scholarly Impact from an Integrated Perspective of Three-Dimensional Citations: A Case Study of Gene Editing
[J]. Journal of the China Society for Scientific and Technical Information , 2018 ,37 (6 ):610 -620 .)
[本文引用: 1]
[25]
Kongthon A Haruechaiyasak C Thaiprayoon S . Expert Identification for Multidisciplinary R&D Project Collaboration
[C]// Proceedings of the 2009 Portland International Conference on Management of Engineering & Technology. IEEE , 2009 : 1474 -1480 .
[本文引用: 1]
[26]
张晓娟 , 陆伟 , 程齐凯 . PLSA在图情领域专家专长识别中的应用
[J]. 现代图书情报技术 , 2012 (2 ):76 -81 .
URL
[本文引用: 1]
基于图情领域权威期刊论文数据集,利用概率潜在语义分析(PLSA)算法对表征专家专长的文档进行处理,以此来定位图情领域专家的研究领域。实验结果表明,该方法具有可行性并取得较好的实验结果。
( Zhang Xiaojuan Lu Wei Cheng Qikai . Application of PLSA on Expertise Identifying in the Field of Library and Information Science
[J]. New Technology of Library and Information Service , 2012 (2 ):76 -81 .)
URL
[本文引用: 1]
基于图情领域权威期刊论文数据集,利用概率潜在语义分析(PLSA)算法对表征专家专长的文档进行处理,以此来定位图情领域专家的研究领域。实验结果表明,该方法具有可行性并取得较好的实验结果。
[27]
梁晓贺 , 田儒雅 , 吴蕾 , 等 . 基于超网络的微博舆情主题挖掘方法
[J]. 情报理论与实践 , 2017 ,40 (10 ):100 -105 .
[本文引用: 1]
( Liang Xiaohe Tian Ruya Wu Lei , et al . A Method of Public Opinion Topic Mining in Micro-blog Based on Super-network
[J]. Information Studies: Theory & Application , 2017 ,40 (10 ):100 -105 .)
[本文引用: 1]
[28]
马宁 , 刘怡君 . 基于超网络中超边排序算法的网络舆论领袖识别
[J]. 系统工程 , 2013 ,31 (9 ):1 -10 .
[本文引用: 1]
( Ma Ning Liu Yijun . Recognition of Online Opinion Leaders Based on SuperEdgeRank Algorithm of Supernetwork
[J]. Systems Engineering , 2013 ,31 (9 ):1 -10 .)
[本文引用: 1]
[29]
王鹏 , 高铖 , 陈晓美 . 基于LDA模型的文本聚类研究
[J]. 情报科学 , 2015 ,33 (1 ):63 -68 .
[本文引用: 1]
( Wang Peng Gao Cheng Chen Xiaomei . Research on LDA Model Based on Text Clustering
[J]. Information Science , 2015 ,33 (1 ):63 -68 .)
[本文引用: 1]
[30]
张磊 , 马静 , 李丹丹 , 等 . 语义社会网络的超网络模型构建及关键节点自动化识别方法研究
[J]. 现代图书情报技术 , 2016 (3 ):8 -17 .
[本文引用: 1]
( Zhang Lei Ma Jing Li Dandan , et al . Hypernetwork Model for Semantic Social Network and Automatic Identification of Key Nodes
[J]. New Technology of Library and Information Service , 2016 (3 ):8 -17 .)
[本文引用: 1]
超网络研究分析综述
1
2016
... 大数据的背景下, 数据资源爆炸式增长和量式聚集使知识网络结构越来越复杂, 同质节点、异质节点间形成错综复杂的多重知识关联关系, 而一般的复杂网络不能全面揭示各知识实体间的关联关系, 因此需要有超越一般网络的思想, 运用更加符合真实世界网络特征的方法与技术描述知识网络, 解释知识网络要素间的关联.超网络的出现为更加客观真实地刻画知识网络提供了很好的解决办法.超网络作为一种“网络中的网络”, 以不同性质的网络节点为基础, 通过节点间的关系相互连接而构成, 是一种由异质节点和异质关系构成的异构网络, 具有多层级、多维度、多重关系、嵌套性的属性[1 ] .因此运用超网络理论与方法构建知识超网络, 可以较为全面完整地描述知识网络, 揭示知识网络的多重复杂关系, 挖掘知识网络中的隐含关联. ...
超网络研究分析综述
1
2016
... 大数据的背景下, 数据资源爆炸式增长和量式聚集使知识网络结构越来越复杂, 同质节点、异质节点间形成错综复杂的多重知识关联关系, 而一般的复杂网络不能全面揭示各知识实体间的关联关系, 因此需要有超越一般网络的思想, 运用更加符合真实世界网络特征的方法与技术描述知识网络, 解释知识网络要素间的关联.超网络的出现为更加客观真实地刻画知识网络提供了很好的解决办法.超网络作为一种“网络中的网络”, 以不同性质的网络节点为基础, 通过节点间的关系相互连接而构成, 是一种由异质节点和异质关系构成的异构网络, 具有多层级、多维度、多重关系、嵌套性的属性[1 ] .因此运用超网络理论与方法构建知识超网络, 可以较为全面完整地描述知识网络, 揭示知识网络的多重复杂关系, 挖掘知识网络中的隐含关联. ...
The Science of Computing-Supernetworks
1
1985
... 超网络概念最早在1985年由Denning[2 ] 从计算机科学角度提出, Nagurney等[3 ] 对超网络进行了深入研究, 将其定义为高于而又超于现存网络的网络[4 ] , 这一定义被广泛接受并引起了各领域的关注.现实世界中, 大多数系统具有复杂的网络结构和特性, 一般的复杂网络已经无法全面完整地描述复杂系统以及揭示各要素之间复杂的关联关系.而超网络以其多层级、多重性和嵌套性的特性, 能够更加全面真实地描述现实世界的网络以及其间的相互作用关系和影响, 揭示同构网络的多重关联关系和异构网络的映射关系, 在对复杂系统的网络建模上具有得天独厚的优势. ...
1
2002
... 超网络概念最早在1985年由Denning[2 ] 从计算机科学角度提出, Nagurney等[3 ] 对超网络进行了深入研究, 将其定义为高于而又超于现存网络的网络[4 ] , 这一定义被广泛接受并引起了各领域的关注.现实世界中, 大多数系统具有复杂的网络结构和特性, 一般的复杂网络已经无法全面完整地描述复杂系统以及揭示各要素之间复杂的关联关系.而超网络以其多层级、多重性和嵌套性的特性, 能够更加全面真实地描述现实世界的网络以及其间的相互作用关系和影响, 揭示同构网络的多重关联关系和异构网络的映射关系, 在对复杂系统的网络建模上具有得天独厚的优势. ...
A Supernetwork Model for Commuting Versus Telecommuting Decision Making
1
2001
... 超网络概念最早在1985年由Denning[2 ] 从计算机科学角度提出, Nagurney等[3 ] 对超网络进行了深入研究, 将其定义为高于而又超于现存网络的网络[4 ] , 这一定义被广泛接受并引起了各领域的关注.现实世界中, 大多数系统具有复杂的网络结构和特性, 一般的复杂网络已经无法全面完整地描述复杂系统以及揭示各要素之间复杂的关联关系.而超网络以其多层级、多重性和嵌套性的特性, 能够更加全面真实地描述现实世界的网络以及其间的相互作用关系和影响, 揭示同构网络的多重关联关系和异构网络的映射关系, 在对复杂系统的网络建模上具有得天独厚的优势. ...
2
2008
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
... [5 ]在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
2
2008
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
... [5 ]在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
Students Staying Home: Questioning the Wisdom of a Digital Future for Australian Universities
1
1998
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
组织知识管理中的知识超网络研究
1
2009
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
组织知识管理中的知识超网络研究
1
2009
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
Knowledge Resources Integrated Model of Basic Scientific Research Achievements Based on Supernetwork
1
2008
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
Collaborative Innovation Model Research Based on Knowledge-Supernetwork and TRIZ
1
2015
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
基于知识超网络的知识服务体系研究
1
2018
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
基于知识超网络的知识服务体系研究
1
2018
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
基于超网络的图书情报领域知识合作特征分析
1
2016
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
基于超网络的图书情报领域知识合作特征分析
1
2016
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
基于知识超网络的网络社区学术资源多粒度聚合研究
1
2018
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
基于知识超网络的网络社区学术资源多粒度聚合研究
1
2018
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
Cooperative Knowledge Creation in an Uncertain Network Environment Based on a Dynamic Knowledge Supernetwork
1
2019
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
科研合作超网络下的知识扩散演化模型研究
1
2017
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
科研合作超网络下的知识扩散演化模型研究
1
2017
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
基于加权超网络模型的组织知识共享研究
1
2013
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
基于加权超网络模型的组织知识共享研究
1
2013
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
Toward a Concept of Community Intelligence: A View on Knowledge Sharing and Fusion in Web-Mediated Communities
1
2008
... 知识超网络作为超网络的一个重要研究方向[5 ] , 最早是由Hearn等[6 ] 在研究教育学习时提出.国内王志平等[5 ] 在《超网络理论与应用》中阐述了知识超网络概念, 并构建了经典的知识超网络模型.于洋[7 ] 在Nagurney等对超网络的定义的基础上, 将知识超网络定义为由知识元网络、知识载体网络(人员网络、物质载体网络等)中的一种或多种, 根据它们之间的关联关系而构成的超网络.目前知识超网络研究主要集中于知识组织、知识传播和知识共享方面.在知识组织方面, 主要应用超网络的理论与方法对知识资源进行组织, 构建了人员-载体-知识三维的知识超网络模 型[8 ,9 ] , 并将其应用在知识管理与服务中[10 ] .在知识元的细粒度组织上, 主要利用超网络从词语和文本层面进行知识关联体系描述, 建立作者、机构、领域、主题等知识实体间的关联关系, 构建学术资源的知识超网络, 实现资源的多粒度聚合[11 ,12 ] .在知识传播方面, 运用超网络的理论构建动态知识超网络模型, 探究知识创建和知识扩散机制[13 ] , 分析知识的传播扩散特 征[14 ] .在知识共享方面, 基于知识超网络模型, 运用超网络的计算方法对知识共享进行定量分析[15 ] , 并应用于组织的知识共享与融合[16 ] . ...
基于专长词表的图情领域专家检索与评价
1
2010
... (1) 基于本体的专家识别方法, 主要通过领域本体构建专家知识库进行专家识别, 发现专家专长[17 ,18 ] , 但需要构建领域本体, 工作量较大. ...
基于专长词表的图情领域专家检索与评价
1
2010
... (1) 基于本体的专家识别方法, 主要通过领域本体构建专家知识库进行专家识别, 发现专家专长[17 ,18 ] , 但需要构建领域本体, 工作量较大. ...
基于本体概念的专长表示研究
1
2012
... (1) 基于本体的专家识别方法, 主要通过领域本体构建专家知识库进行专家识别, 发现专家专长[17 ,18 ] , 但需要构建领域本体, 工作量较大. ...
基于本体概念的专长表示研究
1
2012
... (1) 基于本体的专家识别方法, 主要通过领域本体构建专家知识库进行专家识别, 发现专家专长[17 ,18 ] , 但需要构建领域本体, 工作量较大. ...
Does the h-index for Ranking of Scientists Really Work?
1
2005
... (2) 基于文献计量的方法, 主要以作者的论文为计量对象, 从作者的合作角度、被引角度, 依据作者的发文数、合作率、总被引量、篇均被引、h指数、g指数、p指数等指标对学者的学术影响力进行评价, 从而发现领域专家, 实现专家推荐或遴选[19 ,20 ,21 ] , 但缺乏对专家学术内容的分析, 不能发现专家的领域专长. ...
h指数在人才评价中的应用——以图书情报学领域中国学者为例
1
2007
... (2) 基于文献计量的方法, 主要以作者的论文为计量对象, 从作者的合作角度、被引角度, 依据作者的发文数、合作率、总被引量、篇均被引、h指数、g指数、p指数等指标对学者的学术影响力进行评价, 从而发现领域专家, 实现专家推荐或遴选[19 ,20 ,21 ] , 但缺乏对专家学术内容的分析, 不能发现专家的领域专长. ...
h指数在人才评价中的应用——以图书情报学领域中国学者为例
1
2007
... (2) 基于文献计量的方法, 主要以作者的论文为计量对象, 从作者的合作角度、被引角度, 依据作者的发文数、合作率、总被引量、篇均被引、h指数、g指数、p指数等指标对学者的学术影响力进行评价, 从而发现领域专家, 实现专家推荐或遴选[19 ,20 ,21 ] , 但缺乏对专家学术内容的分析, 不能发现专家的领域专长. ...
基于专长吻合度、学术影响力与社会关联值的专家推荐模型研究
1
2017
... (2) 基于文献计量的方法, 主要以作者的论文为计量对象, 从作者的合作角度、被引角度, 依据作者的发文数、合作率、总被引量、篇均被引、h指数、g指数、p指数等指标对学者的学术影响力进行评价, 从而发现领域专家, 实现专家推荐或遴选[19 ,20 ,21 ] , 但缺乏对专家学术内容的分析, 不能发现专家的领域专长. ...
基于专长吻合度、学术影响力与社会关联值的专家推荐模型研究
1
2017
... (2) 基于文献计量的方法, 主要以作者的论文为计量对象, 从作者的合作角度、被引角度, 依据作者的发文数、合作率、总被引量、篇均被引、h指数、g指数、p指数等指标对学者的学术影响力进行评价, 从而发现领域专家, 实现专家推荐或遴选[19 ,20 ,21 ] , 但缺乏对专家学术内容的分析, 不能发现专家的领域专长. ...
Identification and Evaluation Methods of Expert Knowledge Based on Social Network Analysis
1
2011
... (3) 基于社会网络分析法, 以作者及其论文作为网络节点, 将专家或论文之间的联系当作网络的边, 从而建立网络模型, 计算网络的拓扑结构, 进行专家识别[22 ,23 ,24 ] , 但往往只从单种关系进行专家识别, 不能全面揭示专家网络的关联关系. ...
Identification of Experts Using Social Network Analysis(SNA)
1
2016
... (3) 基于社会网络分析法, 以作者及其论文作为网络节点, 将专家或论文之间的联系当作网络的边, 从而建立网络模型, 计算网络的拓扑结构, 进行专家识别[22 ,23 ,24 ] , 但往往只从单种关系进行专家识别, 不能全面揭示专家网络的关联关系. ...
三维引文关联融合视角下的学者学术影响力评价研究——以基因编辑领域为例
1
2018
... (3) 基于社会网络分析法, 以作者及其论文作为网络节点, 将专家或论文之间的联系当作网络的边, 从而建立网络模型, 计算网络的拓扑结构, 进行专家识别[22 ,23 ,24 ] , 但往往只从单种关系进行专家识别, 不能全面揭示专家网络的关联关系. ...
三维引文关联融合视角下的学者学术影响力评价研究——以基因编辑领域为例
1
2018
... (3) 基于社会网络分析法, 以作者及其论文作为网络节点, 将专家或论文之间的联系当作网络的边, 从而建立网络模型, 计算网络的拓扑结构, 进行专家识别[22 ,23 ,24 ] , 但往往只从单种关系进行专家识别, 不能全面揭示专家网络的关联关系. ...
Expert Identification for Multidisciplinary R&D Project Collaboration
1
2009
... (4) 基于主题的专家聚类的领域专家识别方法, 通过文本语义挖掘, 发现专家的研究领域及专长, 常用的算法包括PLSA、LDA等主题模型[25 ,26 ] , 虽考虑了内容的语义, 而且能实现大量数据的处理, 但忽略了文献计量指标对专家影响力评价的重要作用. ...
PLSA在图情领域专家专长识别中的应用
1
2012
... (4) 基于主题的专家聚类的领域专家识别方法, 通过文本语义挖掘, 发现专家的研究领域及专长, 常用的算法包括PLSA、LDA等主题模型[25 ,26 ] , 虽考虑了内容的语义, 而且能实现大量数据的处理, 但忽略了文献计量指标对专家影响力评价的重要作用. ...
PLSA在图情领域专家专长识别中的应用
1
2012
... (4) 基于主题的专家聚类的领域专家识别方法, 通过文本语义挖掘, 发现专家的研究领域及专长, 常用的算法包括PLSA、LDA等主题模型[25 ,26 ] , 虽考虑了内容的语义, 而且能实现大量数据的处理, 但忽略了文献计量指标对专家影响力评价的重要作用. ...
基于超网络的微博舆情主题挖掘方法
1
2017
... 在进行领域专家识别前需要引入两个超网络属性指标, 节点超度SD 和超边连接度L (SEi )[27 ,28 ] . ...
基于超网络的微博舆情主题挖掘方法
1
2017
... 在进行领域专家识别前需要引入两个超网络属性指标, 节点超度SD 和超边连接度L (SEi )[27 ,28 ] . ...
基于超网络中超边排序算法的网络舆论领袖识别
1
2013
... 在进行领域专家识别前需要引入两个超网络属性指标, 节点超度SD 和超边连接度L (SEi )[27 ,28 ] . ...
基于超网络中超边排序算法的网络舆论领袖识别
1
2013
... 在进行领域专家识别前需要引入两个超网络属性指标, 节点超度SD 和超边连接度L (SEi )[27 ,28 ] . ...
基于LDA模型的文本聚类研究
1
2015
... LDA主题模型是一种非监督机器学习技术, 主要用于主题挖掘, 常用来挖掘文档集中的潜在主题.本文在进行领域标签提取时采用LDA主题模型, 根据LDA主题模型获取主题-特征词概率分布, 从中提取领域标签, 再根据每个领域下特征词分布概率计算领域标签节点之间相似度, 这里可以使用统计自然语言常用的KL距离计算领域标签的相似度.KL距离越大则表示领域标签之间的相似度越低, 因此定义领域标签语义相似度Simdidj 表示领域节点di 和dj 的相似度, 与KL距离成反比, 考虑到KL距离公式的不对称性, 运用JS距离解决KL距离非对称的问 题[29 ] , 因此领域节点di 和dj 的相似性计算公式如公式(16)所示. ...
基于LDA模型的文本聚类研究
1
2015
... LDA主题模型是一种非监督机器学习技术, 主要用于主题挖掘, 常用来挖掘文档集中的潜在主题.本文在进行领域标签提取时采用LDA主题模型, 根据LDA主题模型获取主题-特征词概率分布, 从中提取领域标签, 再根据每个领域下特征词分布概率计算领域标签节点之间相似度, 这里可以使用统计自然语言常用的KL距离计算领域标签的相似度.KL距离越大则表示领域标签之间的相似度越低, 因此定义领域标签语义相似度Simdidj 表示领域节点di 和dj 的相似度, 与KL距离成反比, 考虑到KL距离公式的不对称性, 运用JS距离解决KL距离非对称的问 题[29 ] , 因此领域节点di 和dj 的相似性计算公式如公式(16)所示. ...
语义社会网络的超网络模型构建及关键节点自动化识别方法研究
1
2016
... 其中, ${{D}_{KL}}(P,Q)=\sum\limits_{j=1}^{T}{P(i)\cdot }\ln \frac{P(i)}{Q(j)}$, P 和Q 分别表示所有词项以di 和dj 话题分布出现的事件.P (i )表示领域di 的特征词概率分布, Q (j )表示领域dj 的特征词概率分布, 通过LDA主题模型计算的主题-特征词概率分布获得[30 ] . ...
语义社会网络的超网络模型构建及关键节点自动化识别方法研究
1
2016
... 其中, ${{D}_{KL}}(P,Q)=\sum\limits_{j=1}^{T}{P(i)\cdot }\ln \frac{P(i)}{Q(j)}$, P 和Q 分别表示所有词项以di 和dj 话题分布出现的事件.P (i )表示领域di 的特征词概率分布, Q (j )表示领域dj 的特征词概率分布, 通过LDA主题模型计算的主题-特征词概率分布获得[30 ] . ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}