1 引 言
在信息爆炸的大数据时代, 人们每天都在接收并传递着海量的文本信息。面对这些非结构化的信息, 利用信息技术对其进行文本挖掘可以大幅提高获取所需内容的效率。在文本挖掘领域, 文本相似度计算是最基础也是最关键的技术之一[1 ] , 通过衡量不同文本之间的相似性以实现信息检索、摘要提取及文本分类等。此外, 文本语义相似度还被广泛应用于对话系统、机器翻译、词义消歧等多种领域。因此, 文本相似度计算成为各领域的研究热点并被不断优化[2 ] 。
在中文文本中, 文本的最小单元是字, 但通常研究单个汉字并没有实际意义, 因此对中文文本的相似度研究多数以词语、句子或段落为单位, 通过计算文本中词语、句子或段落之间的相似程度, 并进行相应处理后得到不同文本之间的相似性。从计算步骤来看, 文本相似度主要分为文本表示、特征提取和相似度计算三个过程[3 ] 。由于文本相似度计算的多样性和广泛适用性, 不同领域的学者针对这三个过程分别从不同的角度提出文本相似度的计算方法。
文本表示通过相关模型将非结构化文本数据以形式化方式表示, 使计算机可以对其进行处理, 作为文本挖掘的第一步, 决定了对原始文本的保留度。在已有研究中, 文本表示模型主要可分为两种: 基于词袋模型和基于语义模型[4 ] 。在词袋模型中, 由于向量空间模型(Vector Space Model, VSM)[5 ] 简单高效, 因此成为应用最广泛的文本表示模型, 然而该模型往往存在稀疏性、高维性和语义缺失等问题。为此, 众多学者在VSM的基础上加入词汇间的语义关系形成了基于语义模型的文本表示方法。Ezzikouri等[6 ] 引入WordNet概念词典, 将概念作为文本特征项, 解决了传统VSM中多义词和同义词问题, 但概念词典词汇量有限, 更新速度慢。Garg等[7 ] 考虑到同一句子中的共现关系及共现频率建立文本复杂网络模型, 通过分析其拓扑性质, 更为准确地提取微博文本中的关键词。唐晓波等[8 ] 发现词共现网络引入了大量语法无关的词语对, 因此基于依存句法提取具有语法关系关联词, 并分析了其在不同句子结构中语法的差异性。实验结果表明, 该方法相比于词共现网络效果更优。
文本经过预处理得到相应的形式化表示后, 往往会得到大量的特征项, 而部分特征项不仅对文本信息没有太大用处, 还会使文本挖掘工作变得繁杂, 因此一些学者从改进特征提取方法入手, 在保证仅丢失无关信息的同时实现文本降维。传统的TF-IDF方法忽略了上下文的结构信息, 周德志等[9 ] 在构建词共现网络后, 以节点的加权度、聚类系数和介数为指标, 计算特征项的综合特征值并设定阈值进行特征选择, 在不影响计算复杂度的情况下最大限度地保留了语义结构。为了同时考虑相邻节点重要性间的相互影响, Zhao等[10 ] 通过改进PageRank算法提取文本关键词, 准确率比传统方法最高提升了19%。
传统VSM在特征提取后只能利用文本间相同词计算相似度, 忽略了不同词间的相关度。Qu等[11 ] 利用维基百科知识库计算出词语间的语义距离, 并结合内容相似度解决了传统VSM语义缺失的问题, 然而维基百科作为网络知识虽然信息更新迅速, 但其数据噪声大且结构性差[12 ] 。Word2Vec[13 ] 自被提出以来, 可以成功解决文本特征的维数灾难问题, 运用词嵌入方法, 无需引入外部知识库也能计算词语的语义相似度。李琳等[14 ] 运用Word2Vec针对英文长文本进行相似度计算, 准确率高达92%。
上述研究中, 虽然学者都从不同的角度对文本相似度进行不同程度的改进, 但综合来看, 仍存在以下问题: 句法网络虽考虑了句子中词语的语法成分, 但却忽视了词语间的距离在网络中所带来的影响; 基于网络拓扑性质的特征提取, 指标的权重大小难以确定, 需要反复调参; Word2Vec通过词嵌入, 计算出文本语义相似度, 但未能结合句法信息以及词语在文本中的词频信息。
针对这些问题, 本文提出一种融合共现距离的句法网络模型, 采用信息熵方法获取指标权重进行特征选择实现文本降维, 避免了繁琐的调参过程, 并在此基础上结合句法信息和语义信息计算文本相似度。
2 融合共现距离的句法网络模型构建及特征提取
文本复杂网络将文本内容表示成网络图的形式, 实现了文本信息可视化。不同于共现词网络, 本文运用依存句法作为节点间的连边规则, 同时选取信息熵法决定节点网络参数的权重, 计算节点的综合特征值以获得能够表征文本原始信息的特征项。
2.1 依存句法
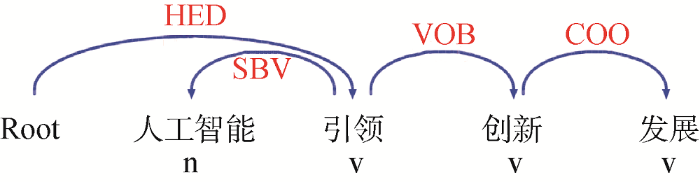
在共现词网络中, 节点特征项之间的关联关系由同一句子中词语间的距离决定, 然而语言学表明, 句子中成分间存在句法结构, 因此由依存句法分析确定关联词对更符合实际。依存句法分析法最先由Tesniere[15 ] 提出, 通过分析语言单位间的依存关系研究其句法结构, 其关系主要包括主谓关系(SBV)、动宾关系(VOB)、状中结构(ADV)等。此外, 依存句法结构中词语间是互相支配的, 即词语的关联具有方向性。本文借助Python[16 ] 调用哈尔滨工业大学开发的语言技术平台(LTP)[17 ] 进行依存句法分析。以“人工智能引领创新发展”一句为例, LTP模型首先对句子进行分词和词性标注, 然后分析依存句法结构, 结果如图1 所示。其中特征项及其之间的关联方向为“引领→人工智能”、“引领→创新”、“创新→发展”。
图1
2.2 句法网络构建
复杂网络以图论为理论支撑, 其模型由节点、连边和边权组成, 记为G =(V , E , W )。研究表明语言网络具有小世界和无标度等复杂网络的独特特性[18 ] , 这意味着复杂网络模型可以更好地表示出文本内在信息。
中文文本中词语间没有明显的分割标志, 因此在构建文本复杂网络前需要进行文本预处理, 即文本分句、分词和去停用词。为了去除噪声影响, 对分词后的结果进行词性标注, 仅保留能够表征文本含义的名词、动词及形容词。在文本集合D 中, 对每篇文本Di 预处理后得到的词语便是本文所构建的句法网络中的节点, 节点间的边和边的方向由依存句法分析决定, 对于边的权重, 本文在句法分析的基础上融合共现距离, 更全面地保留了原始文本信息, 权重的计算公式如公式(1)所示。
(1) $\begin{align} & w\mathrm{(}{{v}_{i}},{{v}_{j}}\mathrm{)}=\frac{fre\mathrm{(}{{v}_{i}},{{v}_{j}}\mathrm{)}}{\max (fre\mathrm{(}{{v}_{i}},{{v}_{j}}\mathrm{)})}+ \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \frac{1}{fre\mathrm{(}{{v}_{i}},{{v}_{j}}\mathrm{)}}\left( \sum\nolimits_{k=1}^{fre\mathrm{(}{{v}_{i}},{{v}_{j}}\mathrm{)}}{\frac{1}{{{d}_{k}}\mathrm{(}{{v}_{i}},{{v}_{j}}\mathrm{)}}} \right) \\ \end{align}$
其中, fre (vi , vj )为Di 中节点词vi 和vj 间存在句法关系的频次, dk (vi , vj )表示不同句子中具有句法结构的节点词vi 和vj 间的距离。以《网络时代的许诺: “人人都可成为艺术家”》一文为例, 句法分析后共得到853个节点和1 156条边, 其融合共现距离的句法网络如图2 所示, 部分节点、边和边权如表1 所示。
图2
2.3 文本特征提取
复杂网络模型将文本表示网络后, 常用节点强度、聚类系数、接近度中心性、中介中心性、PageRank等相关动力学特征指标衡量网络中节点特征项的重要性。鉴于文本中特征项在同一句子中承担了不同的语法角色, 同时不同特征项间的距离及其出现的频率不同, 本文构建有向加权的文本复杂网络, 其相应的特征指标定义如下:
(1) 节点强度: 若一个网络中有ki 个节点与节点vi 相连, 则称ki 为节点vi 的度。在加权网络中, 除了考虑相邻节点的个数外, 还需考虑边的权重, 因此引入节点强度的概念, 计算如公式(2)所示。
(2) ${{S}_{i}}=\sum\nolimits_{j=1}^{N}{({{w}_{ij}}+{{w}_{ji}})}$
其中, wij 为节点vi 指向邻节点vj 的边的权重, 若节点vi 和vj 不相邻, 则wij =0; N 为网络中的节点个数。
(2) 聚类系数: 衡量网络中节点的聚集程度, 选取Onnela定义[19 ] 如公式(3)所示。
(3) ${{C}_{i}}=\frac{\mathop{\sum }_{j,k}{{(w_{ij}^{'}w_{jk}^{'}w_{ki}^{'})}^{1/3}}}{{{k}_{i}}({{k}_{i}}-1)}$
其中, ki 为节点vi 的度, $w_{ij}^{'}={{w}_{ij}}/\max ({{w}_{ij}})$为归一化权重。
(3) 介数中心性: 衡量网络中相应节点的枢纽作用, 数学公式如公式(4)所示。
(4) ${{B}_{i}}=\sum\nolimits_{\begin{matrix} 1\le j\le l\le N \\ j\ne i\ne l \\\end{matrix}}{\frac{{{n}_{jl}}(i)}{{{n}_{jl}}}}$
其中, nij 为节点对之间的最短路径的数目, nij (i )代表节点对最短路径经过节点vi 的条数。将其归一化后引入介数中心性(CB )的概念, 计算如公式(5)所示。
(5) ${{C}_{B}}({{v}_{i}})=\frac{{{B}_{i}}}{[(N-1)(N-2)]}$
(4) 接近度中心性: 反映节点处于网络中心的程度, Freeman[20 ] 将其定义为公式(6)。
(6) ${{C}_{c}}({{v}_{i}})=\frac{N-1}{\mathop{\sum }_{\begin{matrix} j=1 \\ j\ne 1 \\\end{matrix}}^{N}{{d}_{ij}}}$
(5) PageRank值: 由传入链接的结构计算网络中节点的排名, 定义为公式(7)。
(7) $PR({{v}_{i}})=\frac{1-d}{N}+d\times \sum\nolimits_{j\in in({{v}_{i}})}{\frac{PR({{v}_{j}})}{{{k}_{j}}}}$
其中, PR (vj )为指向i 的节点j 的PageRank值, d 为模型参数。
在以往研究中, 在计算节点的综合特征值时, 针对网络指标的权重均通过不断地调整参数来确定。为避免这一繁琐过程, 本文采取信息熵法[21 ] 。
假设文本Di 经过预处理后共得到n 个节点词, 在5个网络指标中, 第i 个节点词的第j 个指标值为aij , 由此得到决策矩阵A =(aij )n×m i= 1,2,…,n ; j =1,2,…,m )。由于各个指标的量纲不同, 需要对矩阵A 进行规范化处理, 得到规范化矩阵R 。这5个网络指标均为正向指标, 则规范化公式为公式(8)。
(8) ${{r}_{ij}}=\frac{{{a}_{ij}}-{{\min }_{i}}{{a}_{ij}}}{{{\max }_{i}}{{a}_{ij}}-{{\min }_{i}}{{a}_{ij}}}$
对矩阵R 进行归一化处理得到归一化矩阵, 如公式(9)所示。
(9) $\dot{R}={{({{\dot{r}}_{ij}})}_{n\times m}}=\frac{{{r}_{ij}}}{\mathop{\sum }_{j=1}^{n}{{r}_{ij}}}$
根据信息熵法计算第j 个指标的信息熵值, 如公式(10)所示。
(10) ${{E}_{j}}=-\frac{1}{\ln n}\sum\nolimits_{i=1}^{n}{{{{\dot{r}}}_{ij}}\ln {{{\dot{r}}}_{ij}}\ \ j=1,2,\cdot \cdot \cdot ,m}$
(11) ${{\omega }_{j}}=\frac{1-{{E}_{j}}}{\mathop{\sum }_{k=1}^{m}(1-{{E}_{k}})}\ \ j=1,2,\cdot \cdot \cdot ,m$
$c{{f}_{i}}=\sum\nolimits_{j=1}^{m}{{{r}_{ij}}{{\omega }_{j}}\ \ i=1,2,\cdot \cdot \cdot ,n}$
为了实现文本降维, 在得到节点词的综合特征值后, 按其值大小排序, 选取前TOP比例的词语作为文本Di 的特征项表征原始文本内容。
3 结合句法关系和词汇语义的文本相似度计算
本文在计算文本相似度时, 综合考虑文本内容中词语的出现频次、句法信息和语义关系, 解决了因只关注某一种信息而造成的维度灾难、语义缺失、噪声干扰、关联无向等多种问题。
3.1 TF-IDF
TF-IDF[22 ] 是词袋模型中应用最广、效果最优的文本特征权重计算方法, 通过计算文本中特征项出现的频率(Term Frequency, TF)及其倒排档文本频率(Inverse Document Frequency, IDF)衡量特征项的重要程度。TF考虑了特征项在文本中的使用次数, 但存在部分高频特征项对单个文本毫无意义, 因此引入IDF消除这类词的干扰, 则文本Di 中特征词i 的TF-IDF值计算如公式(12)所示。
(12) $t{{i}_{i}}=\frac{fr{{e}_{i}}}{\mathop{\sum }^{}fr{{e}_{i}}}\times \ln \frac{N}{{{n}_{i}}}$
其中, frei 为文本Di 中特征词i 的频次, N 为总文本数, ni 表示包含特征词i 的文本数。
3.2 余弦相似度
文本相似度计算采用余弦相似度理论, 以文本中词语的特征值生成文本内容向量, 以整个文本集为向量空间, 通过计算每两个文本向量之间的余弦值衡量文本之间的相似程度, 即文本Di 和文本Dj 之间的相似度如公式(13)所示。
(13) $\cos ({{D}_{i}},{{D}_{j}})=\frac{\mathop{\sum }_{{{t}_{i}}={{t}_{j}}}{{w}_{{{d}_{i}}}}({{t}_{i}}){{w}_{{{d}_{j}}}}({{t}_{j}})}{\sqrt{\mathop{\sum }_{{{t}_{i}}={{t}_{j}}}{{w}_{{{d}_{i}}}}{{({{t}_{i}})}^{2}}{{w}_{{{d}_{j}}}}{{({{t}_{j}})}^{2}}}}$
其中, ${{w}_{{{d}_{i}}}}({{t}_{i}})$表示特征项ti 在文本Di 中的特征值。显然, 传统的余弦相似度[23 ] 只能依靠文本中具有的相同词语计算文本相似度, 而忽略了词语间的语义关系和语法关系。因此, 本文在此基础上对其做出改进, 以期更完整、更高效地利用词语计算文本相似性。
3.3 文本语义相似度计算
在计算文本语义相似度之前, 需要计算文本特征项之间的相似度, 本文采用Word2Vec模型通过词嵌入基于神经网络训练大量语料库, 将训练集中每个词语映射为特定长度的向量, 以此计算词语间的语义相似度。通过训练及计算, 可以得到文本集中所有特征词的相似性矩阵M 。同时, 由于不同句子中相同词语所充当的语法角色不同, 引入句法网络节点词的综合特征值, 则基于句法和语义的文本相似度计算如公式(14)所示。
(14) $PSSim({{D}_{i}},{{D}_{j}})=\frac{\mathop{\sum }^{}\mathop{\sum }^{}C{{F}_{i}}^{T}{{M}_{ij}}C{{F}_{j}}}{\sqrt{(\mathop{\sum }^{}C{{F}_{i}}^{T}{{M}_{ii}}C{{F}_{i}})\times (\mathop{\sum }^{}C{{F}_{j}}^{T}{{M}_{jj}}C{{F}_{j}})}}$
其中, CFi , CFj 分别表示文本Di 和Dj 中特征项的特征值向量, Mij 为文本Di 和Dj 中包含的特征项之间的语义相似度矩阵。仅考虑句法和语义对特征词的影响, 容易被高频低效的词所干扰, 所以本文加入特征词的TF-IDF的余弦相似度解决这一问题, 最终文本语义相似度计算如公式(15)所示。
(15) $\begin{align} & TSim({{D}_{i}},{{D}_{j}})=\alpha \frac{\mathop{\sum }^{}\mathop{\sum }^{}C{{F}_{i}}^{T}{{M}_{ij}}C{{F}_{j}}}{\sqrt{(\mathop{\sum }^{}C{{F}_{i}}^{T}{{M}_{ii}}C{{F}_{i}})\times (\mathop{\sum }^{}C{{F}_{j}}^{T}{{M}_{jj}}C{{F}_{j}})}}+ \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (1-\alpha )\frac{T{{I}_{i}}\times T{{I}_{j}}}{\sqrt{T{{I}_{i}}^{2}\times T{{I}_{j}}^{2}}}\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ \end{align}$
其中, $\alpha $为可调节参数, TIi , TIj 表示整个文本Di 和Dj 中特征词的TF-IDF值。
3.4 算法流程
输出: Di 和Dj 的相似度TSim (Di , Dj )
①文本预处理, 包括文本分句、分词、词性标注和去停用词;
②依存句法分析, 根据步骤①中分词和词性标注的结果进行依存句法分析, 得到具有语法结构的词语对;
③构建文本复杂网络, 由步骤②词语对确定文本网络中的源节点和目标节点, 同时根据公式(1)计算边的权重, 得到邻接表;
④特征提取, 根据复杂网络的拓扑性质, 计算每个节点词的各网络指标值, 同时运用信息熵法得到节点词的综合特征值cfi , 按其大小排序, 选取TOP比例的节点词作为文本特征项;
⑤计算特征项的TF-IDF值, 将Di 和Dj 表示为向量TIi 和TIj ;
⑥词语语义相似度计算, 计算整个文本集中所有词语对的语义相似度矩阵M ;
⑦文本相似度计算, 由步骤④-步骤⑥得到的结果依据公式(15)计算文本相似度TSim (Di , Dj )。
4 实验设计与分析
4.1 实验数据及方法
本文实验数据选自文本挖掘领域的标准评测数据集——复旦大学语料库, 从中选取艺术、历史、计算机、环境、农业、经济、政治、体育8个类别, 每个类别300篇, 共2 400篇实验文本集。借助Python调用哈尔滨工业大学LTP模型对文本集进行分词、词性标注和依存句法分析, 得到邻接表后, 在Python NetworkX包的基础上分析句法网络的拓扑性质, 以信息熵法确定其权重计算综合特征值, 并选取特征值前TOP比例的词语作为特征项, TOP取30%。在计算词语语义相似度时, 选择维基百科中文数据集加本文实验文本集作为语料库进行Word2Vec模型训练, 词向量维数为300维。
实验采用KNN[24 ] 分类算法衡量文本相似度算法的效果, 其中K取16。为了保证分类器的准确性, 进行十折交叉验证, 并取评判其优劣结果的平均值作为最终分类优劣的结果值。在验证本文所提出的相似度算法效果的同时, 进行两组对比实验。具体实验过程为: 第一组实验为本文提出的借助句法网络得到的综合特征值和词嵌入法的词语语义相似度相融合的文本相似度算法; 第二组实验采用根据句法网络得到的特征项及其TF-IDF值的文本相似度算法; 第三组实验为传统共现词网络得到的综合特征值和词嵌入法结合的文本相似度算法。
4.2 实验结果分析
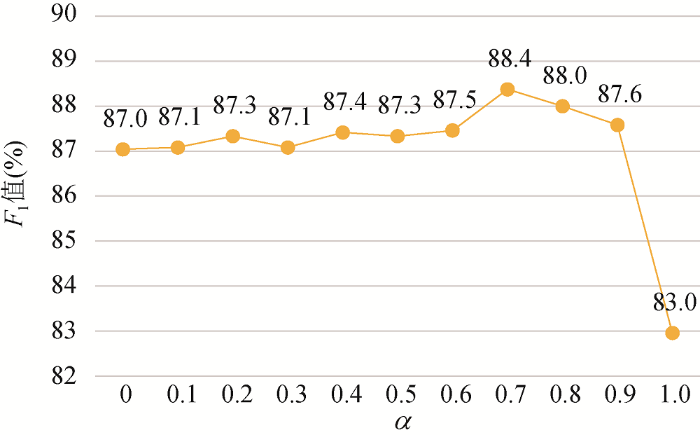
在评估实验结果优劣时, 采用广泛使用的F 1 度量值。对于本文的文本语义相似度计算, 需要确定计算公式中调节参数$\alpha $的值。如图3 所示, 不同$\alpha $的值下文本相似度算法的F 1 值存在明显差异性, 当$\alpha $的值取0.7时, F 1 值最大。
图3
图3
参数$\alpha $对相似度分类效果的影响
对于本文算法, 十折交叉验证中的每次结果的类别平均正确率、平均召回率和平均F 1 值如表2 所示。可以看出, F 1 值最优结果可达93.8%, 而最差效果为80.4%, 这表明分类结果差异性较大。相比于随机生成训练集和测试集, 运用十折交叉验证法可以更全面、更真实地反映相似度的分类效果。同时, 从正确率、召回率和F 1 值三类指标来看, 其效果优劣基本保持一致, 因此可以仅选用F 1 值对各组实验结果进行评判。
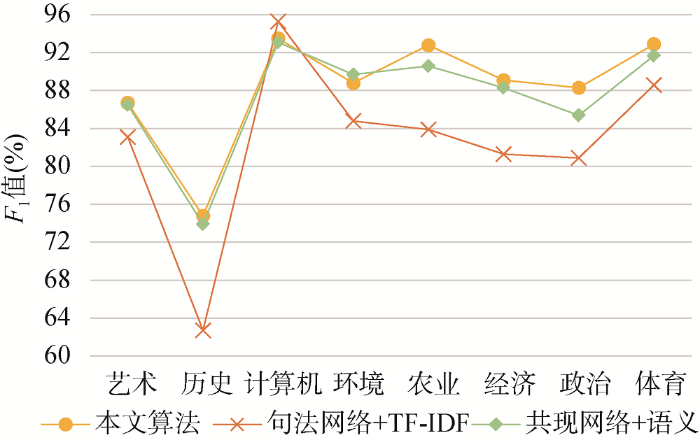
三组实验分类结果中每个类别的F 1 值的十折交叉验证平均值如表3 所示。从类别的分类效果来看, 计算机类、农业类和体育类的分类效果最好, 历史类的均较差, 通过分析原始文本发现导致其现象的原因主要为计算机、农业和体育文本集中都具有很多相应类别的特有词语, 使其文本与其他文本具有较大的区分度, 而在历史类中的文本集往往与文化类中的文本相似性较高, 导致分类出现一定的偏差, 而这也符合实际认知。
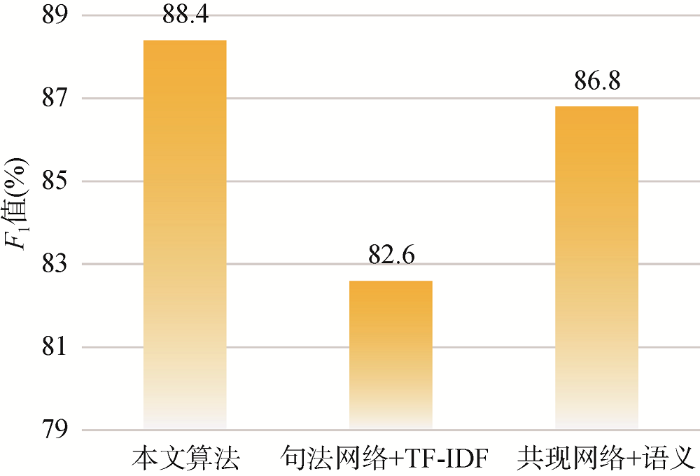
从不同实验组来看, 由本文所提出算法的实验结果的F 1 值在不同类别下基本均高于句法网络+TF-IDF方法和共现网络+语义方法的实验结果, 且本文算法比句法网络+TF-IDF方法实验最高(历史类)提高12.1%, 比共现网络+语义方法实验最高(经济类)提高了5.8%。从各类别分类效果的平均F 1 值来看, 本文算法也均优于句法网络+TF-IDF方法和共现网络+语义方法, 其中本文算法比句法网络+TF-IDF方法提高了5.8%, 比共现网络+语义方法最高提高了1.6%。
从三组实验结果的折线图(图4 )和柱状图(图5 )也可以看出, 本文通过构建句法网络提取特征项, 并引入词频信息、句法结构和语义关系的文本相似度计算方法比传统的共现网络和TF-IDF有效地提高了文本分类精度。这说明融合共现距离的句法网络对特征项的提取和结合多种词项信息的相似度计算对提高文本相似度计算的正确率都有一定的有效性和可行性。
图4
图5
5 结 语
本文基于融合共现距离的句法网络所提出的文本语义相似度计算方法, 利用依存句法分析和词嵌入综合考虑文本中词语间的共现距离、句法结构和语义关系等多种文本特征信息, 与传统的词袋模型和词共现网络相比, 实现了文本降维并极大程度上保留了文本原始信息, 解决了相似度计算中缺失句法结构和语义信息的问题, 此外, 选取信息熵法以衡量句法网络中相关拓扑性质的重要性, 避免了计算综合特征值时调节参数带来的不必要的麻烦。KNN分类实验表明, 不论是从单个文本类别还是从整体分类效果来看, 本文的相似度算法都一定程度上提高了最终的分类效果。
在文本相似研究这一领域, 相关的改进算法层出不穷。本文利用句法网络, 考虑常用的几类拓扑性指标, 在未来的研究中可以加入更多指标, 更加全面区分节点间的重要性。同时, 改进现有的信息熵法计算综合特征值, 以排除指标被同视化, 更合理地进行文本相似度计算, 进而为文本分类、关键词提取、摘要提取等提供有效的帮助。
作者贡献声明
严娇: 提出研究思路, 设计研究方案, 进行实验, 起草与修订论文;
支撑数据
支撑数据由作者自存储, E-mail: majing5525@126.com。
[1] 严娇, 马静, 房康. 文本集.zip. 实验文本语料库.
[2] 严娇, 马静, 房康. program.zip. 程序源码.
[3] 严娇, 马静, 房康. edges.zip. 句法网络边信息.
[4] 严娇, 马静, 房康. property.zip. 网络特征指标值计算结果.
[4] 严娇, 马静, 房康. result.zip. 实验及对比实验结果.
参考文献
View Option
[1]
Gali N Mariescu-Istodor R Hostettler D , et al . Framework for Syntactic String Similarity Measures
[J]. Expert Systems with Applications , 2019 ,129 :169 -185 .
[本文引用: 1]
[2]
An H Gao X Wei F , et al . Research on Patterns in the Fluctuation of the Co-movement Between Crude Oil Futures and Spot Prices: A Complex Network Approach
[J]. Applied Energy , 2014 ,136 :1067 -1075 .
[本文引用: 1]
[3]
杜坤 , 刘怀亮 , 郭路杰 . 结合复杂网络的特征权重改进算法研究
[J]. 现代图书情报技术 , 2015 (11 ):26 -32 .
[本文引用: 1]
( Du Kun Liu Huailiang Guo Lujie . Study on the Modified Method of Feature Weighting with Complex Networks
[J]. New Technology of Library and Information Service , 2015 (11 ):26 -32 .)
[本文引用: 1]
[4]
Zhang W Li Y Wang S . Learning Document Representation via Topic-enhanced LSTM Model
[J]. Knowledge-Based Systems , 2019 ,174 :194 -204 .
[本文引用: 1]
[5]
Salton G Wong A Yang C S . A Vector Space Model for Automatic Indexing
[J]. Communications of the ACM , 1975 ,18 (11 ):613 -620 .
[本文引用: 1]
[6]
Ezzikouri H Madani Y Erritali M , et al . A New Approach for Calculating Semantic Similarity Between Words Using WordNet and Set Theory
[J]. Procedia Computer Science , 2019 ,151 :1261 -1265 .
[本文引用: 1]
[7]
Garg M Kumar M . The Structure of Word Co-occurrence Network for Microblogs
[J]. Physica A: Statistical Mechanics and Its Applications , 2018 ,512 :698 -720 .
[本文引用: 1]
[8]
唐晓波 , 肖璐 . 基于依存句法网络的文本特征提取研究
[J]. 现代图书情报技术 , 2014 (11 ):31 -37 .
[本文引用: 1]
( Tang Xiaobo Xiao Lu . Research of Text Feature Extraction on Dependency Parsing Network
[J]. New Technology of Library and Information Service , 2014 (11 ):31 -37 . )
[本文引用: 1]
[9]
周德志 , 刘怀亮 , 张倩 . 基于复杂网络的文本语义社区的构建
[J]. 情报杂志 , 2013 ,32 (10 ):136 -140 .
[本文引用: 1]
( Zhou Dezhi Liu Huailiang Zhang Qian . Constructing Text Semantic Community Based on Complex Networks
[J]. Journal of Intelligence , 2013 ,32 (10 ):136 -140 .)
[本文引用: 1]
[10]
Zhao W X Jiang J He J , et al . Topical Keyphrase Extraction from Twitter
[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. 2011 .
[本文引用: 1]
[11]
Qu R Fang Y Bai W , et al . Computing Semantic Similarity Based on Novel Models of Semantic Representation Using Wikipedia
[J]. Information Processing & Management , 2018 ,54 (6 ):1002 -1021 .
[本文引用: 1]
[12]
王春柳 , 杨永辉 , 邓霏 , 等 . 文本相似度计算方法研究综述
[J]. 情报科学 , 2019 ,37 (3 ):158 -168 .
[本文引用: 1]
( Wang Chunliu Yang Yonghui Deng Fei , et al . A Review of Text Similarity Approaches
[J]. Information Science , 2019 ,37 (3 ):158 -168 .)
[本文引用: 1]
[13]
Mikolov T C K Chen K Corrado G , et al . Efficient Estimation of Word Representations in Vector Space
[OL]. arXiv Preprint , arXiv : 1301.3781.
[本文引用: 1]
[14]
李琳 , 李辉 . 一种基于概念向量空间的文本相似度计算方法
[J]. 数据分析与知识发现 , 2018 ,2 (5 ):48 -58 .
[本文引用: 1]
( Li Lin Li Hui . Computing Text Similarity Based on Concept Vector Space
[J]. Data Analysis and Knowledge Discovery , 2018 ,2 (5 ):48 -58 .)
[本文引用: 1]
[15]
吕西安·泰尼埃尔 . 结构句法基础
[M]. 方德义译. 北京: 中国人民大学语言文学系 , 1987 .
[本文引用: 1]
( Tesniere L . The Basis of Structure Syntax
[M]. Translated by Fang Deyi. Beijing: Language and Literature Department of Renmin University of China , 1987 .)
[本文引用: 1]
[16]
Python 3.7.0 [EB/OL].(2018 -06 -27 ). https://www.python.org/downloads/release/python-370/.
URL
[本文引用: 1]
[17]
Che W Li Z Liu T . LTP: A Chinese Language Technology Platform
[C]// Proceedings of the 23rd International Conference on Computational Linguistics: Demonstrations, Beijing, China. Stroudsburg: Association for Computational Linguistics , 2010 : 13 -16 .
[本文引用: 1]
[18]
Wachs-Lopes G A Rodrigues P S . Analyzing Natural Human Language from the Point of View of Dynamic of a Complex Network
[J]. Expert Systems with Applications , 2016 ,45 :8 -22 .
[本文引用: 1]
[19]
Onnela J P Saramaki J Kertesz J , et al . Intensity and Coherence of Motifs in Weighted Complex Networks
[J]. Physical Review E, Statistical, Nonlinear, and Soft Matter Physics , 2005 ,71 (6 ):065103 .
[本文引用: 1]
[20]
Freeman L C . Centrality in Social Networks Conceptual Clarification
[J]. Social Networks , 1978 ,1 (3 ):215 -239 .
[本文引用: 1]
[21]
Shannon C E . A Mathematical Theory of Communication
[J]. Bell Labs Technical Journal , 1948 ,27 (4 ):379 -423 .
[本文引用: 1]
[22]
Salton G Yu C T . On the Construction of Effective Vocabularies for Information Retrieval
[J]. ACM Sigplan Notices , 1975 ,10 (1 ):48 -60 .
[本文引用: 1]
[23]
Singhal A Google I . Modern Information Retrieval: A Brief Overview
[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering , 2001 ,24 (24 ):35 -43 .
[本文引用: 1]
[24]
Cover T M Hart P E . Nearest Neighbor Pattern Classification
[J]. IEEE Transactions on Information Theory , 1967 ,13 (1 ):21 -27 .
[本文引用: 1]
Framework for Syntactic String Similarity Measures
1
2019
... 在信息爆炸的大数据时代, 人们每天都在接收并传递着海量的文本信息.面对这些非结构化的信息, 利用信息技术对其进行文本挖掘可以大幅提高获取所需内容的效率.在文本挖掘领域, 文本相似度计算是最基础也是最关键的技术之一[1 ] , 通过衡量不同文本之间的相似性以实现信息检索、摘要提取及文本分类等.此外, 文本语义相似度还被广泛应用于对话系统、机器翻译、词义消歧等多种领域.因此, 文本相似度计算成为各领域的研究热点并被不断优化[2 ] . ...
Research on Patterns in the Fluctuation of the Co-movement Between Crude Oil Futures and Spot Prices: A Complex Network Approach
1
2014
... 在信息爆炸的大数据时代, 人们每天都在接收并传递着海量的文本信息.面对这些非结构化的信息, 利用信息技术对其进行文本挖掘可以大幅提高获取所需内容的效率.在文本挖掘领域, 文本相似度计算是最基础也是最关键的技术之一[1 ] , 通过衡量不同文本之间的相似性以实现信息检索、摘要提取及文本分类等.此外, 文本语义相似度还被广泛应用于对话系统、机器翻译、词义消歧等多种领域.因此, 文本相似度计算成为各领域的研究热点并被不断优化[2 ] . ...
结合复杂网络的特征权重改进算法研究
1
2015
... 在中文文本中, 文本的最小单元是字, 但通常研究单个汉字并没有实际意义, 因此对中文文本的相似度研究多数以词语、句子或段落为单位, 通过计算文本中词语、句子或段落之间的相似程度, 并进行相应处理后得到不同文本之间的相似性.从计算步骤来看, 文本相似度主要分为文本表示、特征提取和相似度计算三个过程[3 ] .由于文本相似度计算的多样性和广泛适用性, 不同领域的学者针对这三个过程分别从不同的角度提出文本相似度的计算方法. ...
结合复杂网络的特征权重改进算法研究
1
2015
... 在中文文本中, 文本的最小单元是字, 但通常研究单个汉字并没有实际意义, 因此对中文文本的相似度研究多数以词语、句子或段落为单位, 通过计算文本中词语、句子或段落之间的相似程度, 并进行相应处理后得到不同文本之间的相似性.从计算步骤来看, 文本相似度主要分为文本表示、特征提取和相似度计算三个过程[3 ] .由于文本相似度计算的多样性和广泛适用性, 不同领域的学者针对这三个过程分别从不同的角度提出文本相似度的计算方法. ...
Learning Document Representation via Topic-enhanced LSTM Model
1
2019
... 文本表示通过相关模型将非结构化文本数据以形式化方式表示, 使计算机可以对其进行处理, 作为文本挖掘的第一步, 决定了对原始文本的保留度.在已有研究中, 文本表示模型主要可分为两种: 基于词袋模型和基于语义模型[4 ] .在词袋模型中, 由于向量空间模型(Vector Space Model, VSM)[5 ] 简单高效, 因此成为应用最广泛的文本表示模型, 然而该模型往往存在稀疏性、高维性和语义缺失等问题.为此, 众多学者在VSM的基础上加入词汇间的语义关系形成了基于语义模型的文本表示方法.Ezzikouri等[6 ] 引入WordNet概念词典, 将概念作为文本特征项, 解决了传统VSM中多义词和同义词问题, 但概念词典词汇量有限, 更新速度慢.Garg等[7 ] 考虑到同一句子中的共现关系及共现频率建立文本复杂网络模型, 通过分析其拓扑性质, 更为准确地提取微博文本中的关键词.唐晓波等[8 ] 发现词共现网络引入了大量语法无关的词语对, 因此基于依存句法提取具有语法关系关联词, 并分析了其在不同句子结构中语法的差异性.实验结果表明, 该方法相比于词共现网络效果更优. ...
A Vector Space Model for Automatic Indexing
1
1975
... 文本表示通过相关模型将非结构化文本数据以形式化方式表示, 使计算机可以对其进行处理, 作为文本挖掘的第一步, 决定了对原始文本的保留度.在已有研究中, 文本表示模型主要可分为两种: 基于词袋模型和基于语义模型[4 ] .在词袋模型中, 由于向量空间模型(Vector Space Model, VSM)[5 ] 简单高效, 因此成为应用最广泛的文本表示模型, 然而该模型往往存在稀疏性、高维性和语义缺失等问题.为此, 众多学者在VSM的基础上加入词汇间的语义关系形成了基于语义模型的文本表示方法.Ezzikouri等[6 ] 引入WordNet概念词典, 将概念作为文本特征项, 解决了传统VSM中多义词和同义词问题, 但概念词典词汇量有限, 更新速度慢.Garg等[7 ] 考虑到同一句子中的共现关系及共现频率建立文本复杂网络模型, 通过分析其拓扑性质, 更为准确地提取微博文本中的关键词.唐晓波等[8 ] 发现词共现网络引入了大量语法无关的词语对, 因此基于依存句法提取具有语法关系关联词, 并分析了其在不同句子结构中语法的差异性.实验结果表明, 该方法相比于词共现网络效果更优. ...
A New Approach for Calculating Semantic Similarity Between Words Using WordNet and Set Theory
1
2019
... 文本表示通过相关模型将非结构化文本数据以形式化方式表示, 使计算机可以对其进行处理, 作为文本挖掘的第一步, 决定了对原始文本的保留度.在已有研究中, 文本表示模型主要可分为两种: 基于词袋模型和基于语义模型[4 ] .在词袋模型中, 由于向量空间模型(Vector Space Model, VSM)[5 ] 简单高效, 因此成为应用最广泛的文本表示模型, 然而该模型往往存在稀疏性、高维性和语义缺失等问题.为此, 众多学者在VSM的基础上加入词汇间的语义关系形成了基于语义模型的文本表示方法.Ezzikouri等[6 ] 引入WordNet概念词典, 将概念作为文本特征项, 解决了传统VSM中多义词和同义词问题, 但概念词典词汇量有限, 更新速度慢.Garg等[7 ] 考虑到同一句子中的共现关系及共现频率建立文本复杂网络模型, 通过分析其拓扑性质, 更为准确地提取微博文本中的关键词.唐晓波等[8 ] 发现词共现网络引入了大量语法无关的词语对, 因此基于依存句法提取具有语法关系关联词, 并分析了其在不同句子结构中语法的差异性.实验结果表明, 该方法相比于词共现网络效果更优. ...
The Structure of Word Co-occurrence Network for Microblogs
1
2018
... 文本表示通过相关模型将非结构化文本数据以形式化方式表示, 使计算机可以对其进行处理, 作为文本挖掘的第一步, 决定了对原始文本的保留度.在已有研究中, 文本表示模型主要可分为两种: 基于词袋模型和基于语义模型[4 ] .在词袋模型中, 由于向量空间模型(Vector Space Model, VSM)[5 ] 简单高效, 因此成为应用最广泛的文本表示模型, 然而该模型往往存在稀疏性、高维性和语义缺失等问题.为此, 众多学者在VSM的基础上加入词汇间的语义关系形成了基于语义模型的文本表示方法.Ezzikouri等[6 ] 引入WordNet概念词典, 将概念作为文本特征项, 解决了传统VSM中多义词和同义词问题, 但概念词典词汇量有限, 更新速度慢.Garg等[7 ] 考虑到同一句子中的共现关系及共现频率建立文本复杂网络模型, 通过分析其拓扑性质, 更为准确地提取微博文本中的关键词.唐晓波等[8 ] 发现词共现网络引入了大量语法无关的词语对, 因此基于依存句法提取具有语法关系关联词, 并分析了其在不同句子结构中语法的差异性.实验结果表明, 该方法相比于词共现网络效果更优. ...
基于依存句法网络的文本特征提取研究
1
2014
... 文本表示通过相关模型将非结构化文本数据以形式化方式表示, 使计算机可以对其进行处理, 作为文本挖掘的第一步, 决定了对原始文本的保留度.在已有研究中, 文本表示模型主要可分为两种: 基于词袋模型和基于语义模型[4 ] .在词袋模型中, 由于向量空间模型(Vector Space Model, VSM)[5 ] 简单高效, 因此成为应用最广泛的文本表示模型, 然而该模型往往存在稀疏性、高维性和语义缺失等问题.为此, 众多学者在VSM的基础上加入词汇间的语义关系形成了基于语义模型的文本表示方法.Ezzikouri等[6 ] 引入WordNet概念词典, 将概念作为文本特征项, 解决了传统VSM中多义词和同义词问题, 但概念词典词汇量有限, 更新速度慢.Garg等[7 ] 考虑到同一句子中的共现关系及共现频率建立文本复杂网络模型, 通过分析其拓扑性质, 更为准确地提取微博文本中的关键词.唐晓波等[8 ] 发现词共现网络引入了大量语法无关的词语对, 因此基于依存句法提取具有语法关系关联词, 并分析了其在不同句子结构中语法的差异性.实验结果表明, 该方法相比于词共现网络效果更优. ...
基于依存句法网络的文本特征提取研究
1
2014
... 文本表示通过相关模型将非结构化文本数据以形式化方式表示, 使计算机可以对其进行处理, 作为文本挖掘的第一步, 决定了对原始文本的保留度.在已有研究中, 文本表示模型主要可分为两种: 基于词袋模型和基于语义模型[4 ] .在词袋模型中, 由于向量空间模型(Vector Space Model, VSM)[5 ] 简单高效, 因此成为应用最广泛的文本表示模型, 然而该模型往往存在稀疏性、高维性和语义缺失等问题.为此, 众多学者在VSM的基础上加入词汇间的语义关系形成了基于语义模型的文本表示方法.Ezzikouri等[6 ] 引入WordNet概念词典, 将概念作为文本特征项, 解决了传统VSM中多义词和同义词问题, 但概念词典词汇量有限, 更新速度慢.Garg等[7 ] 考虑到同一句子中的共现关系及共现频率建立文本复杂网络模型, 通过分析其拓扑性质, 更为准确地提取微博文本中的关键词.唐晓波等[8 ] 发现词共现网络引入了大量语法无关的词语对, 因此基于依存句法提取具有语法关系关联词, 并分析了其在不同句子结构中语法的差异性.实验结果表明, 该方法相比于词共现网络效果更优. ...
基于复杂网络的文本语义社区的构建
1
2013
... 文本经过预处理得到相应的形式化表示后, 往往会得到大量的特征项, 而部分特征项不仅对文本信息没有太大用处, 还会使文本挖掘工作变得繁杂, 因此一些学者从改进特征提取方法入手, 在保证仅丢失无关信息的同时实现文本降维.传统的TF-IDF方法忽略了上下文的结构信息, 周德志等[9 ] 在构建词共现网络后, 以节点的加权度、聚类系数和介数为指标, 计算特征项的综合特征值并设定阈值进行特征选择, 在不影响计算复杂度的情况下最大限度地保留了语义结构.为了同时考虑相邻节点重要性间的相互影响, Zhao等[10 ] 通过改进PageRank算法提取文本关键词, 准确率比传统方法最高提升了19%. ...
基于复杂网络的文本语义社区的构建
1
2013
... 文本经过预处理得到相应的形式化表示后, 往往会得到大量的特征项, 而部分特征项不仅对文本信息没有太大用处, 还会使文本挖掘工作变得繁杂, 因此一些学者从改进特征提取方法入手, 在保证仅丢失无关信息的同时实现文本降维.传统的TF-IDF方法忽略了上下文的结构信息, 周德志等[9 ] 在构建词共现网络后, 以节点的加权度、聚类系数和介数为指标, 计算特征项的综合特征值并设定阈值进行特征选择, 在不影响计算复杂度的情况下最大限度地保留了语义结构.为了同时考虑相邻节点重要性间的相互影响, Zhao等[10 ] 通过改进PageRank算法提取文本关键词, 准确率比传统方法最高提升了19%. ...
Topical Keyphrase Extraction from Twitter
1
2011
... 文本经过预处理得到相应的形式化表示后, 往往会得到大量的特征项, 而部分特征项不仅对文本信息没有太大用处, 还会使文本挖掘工作变得繁杂, 因此一些学者从改进特征提取方法入手, 在保证仅丢失无关信息的同时实现文本降维.传统的TF-IDF方法忽略了上下文的结构信息, 周德志等[9 ] 在构建词共现网络后, 以节点的加权度、聚类系数和介数为指标, 计算特征项的综合特征值并设定阈值进行特征选择, 在不影响计算复杂度的情况下最大限度地保留了语义结构.为了同时考虑相邻节点重要性间的相互影响, Zhao等[10 ] 通过改进PageRank算法提取文本关键词, 准确率比传统方法最高提升了19%. ...
Computing Semantic Similarity Based on Novel Models of Semantic Representation Using Wikipedia
1
2018
... 传统VSM在特征提取后只能利用文本间相同词计算相似度, 忽略了不同词间的相关度.Qu等[11 ] 利用维基百科知识库计算出词语间的语义距离, 并结合内容相似度解决了传统VSM语义缺失的问题, 然而维基百科作为网络知识虽然信息更新迅速, 但其数据噪声大且结构性差[12 ] .Word2Vec[13 ] 自被提出以来, 可以成功解决文本特征的维数灾难问题, 运用词嵌入方法, 无需引入外部知识库也能计算词语的语义相似度.李琳等[14 ] 运用Word2Vec针对英文长文本进行相似度计算, 准确率高达92%. ...
文本相似度计算方法研究综述
1
2019
... 传统VSM在特征提取后只能利用文本间相同词计算相似度, 忽略了不同词间的相关度.Qu等[11 ] 利用维基百科知识库计算出词语间的语义距离, 并结合内容相似度解决了传统VSM语义缺失的问题, 然而维基百科作为网络知识虽然信息更新迅速, 但其数据噪声大且结构性差[12 ] .Word2Vec[13 ] 自被提出以来, 可以成功解决文本特征的维数灾难问题, 运用词嵌入方法, 无需引入外部知识库也能计算词语的语义相似度.李琳等[14 ] 运用Word2Vec针对英文长文本进行相似度计算, 准确率高达92%. ...
文本相似度计算方法研究综述
1
2019
... 传统VSM在特征提取后只能利用文本间相同词计算相似度, 忽略了不同词间的相关度.Qu等[11 ] 利用维基百科知识库计算出词语间的语义距离, 并结合内容相似度解决了传统VSM语义缺失的问题, 然而维基百科作为网络知识虽然信息更新迅速, 但其数据噪声大且结构性差[12 ] .Word2Vec[13 ] 自被提出以来, 可以成功解决文本特征的维数灾难问题, 运用词嵌入方法, 无需引入外部知识库也能计算词语的语义相似度.李琳等[14 ] 运用Word2Vec针对英文长文本进行相似度计算, 准确率高达92%. ...
Efficient Estimation of Word Representations in Vector Space
1
... 传统VSM在特征提取后只能利用文本间相同词计算相似度, 忽略了不同词间的相关度.Qu等[11 ] 利用维基百科知识库计算出词语间的语义距离, 并结合内容相似度解决了传统VSM语义缺失的问题, 然而维基百科作为网络知识虽然信息更新迅速, 但其数据噪声大且结构性差[12 ] .Word2Vec[13 ] 自被提出以来, 可以成功解决文本特征的维数灾难问题, 运用词嵌入方法, 无需引入外部知识库也能计算词语的语义相似度.李琳等[14 ] 运用Word2Vec针对英文长文本进行相似度计算, 准确率高达92%. ...
一种基于概念向量空间的文本相似度计算方法
1
2018
... 传统VSM在特征提取后只能利用文本间相同词计算相似度, 忽略了不同词间的相关度.Qu等[11 ] 利用维基百科知识库计算出词语间的语义距离, 并结合内容相似度解决了传统VSM语义缺失的问题, 然而维基百科作为网络知识虽然信息更新迅速, 但其数据噪声大且结构性差[12 ] .Word2Vec[13 ] 自被提出以来, 可以成功解决文本特征的维数灾难问题, 运用词嵌入方法, 无需引入外部知识库也能计算词语的语义相似度.李琳等[14 ] 运用Word2Vec针对英文长文本进行相似度计算, 准确率高达92%. ...
一种基于概念向量空间的文本相似度计算方法
1
2018
... 传统VSM在特征提取后只能利用文本间相同词计算相似度, 忽略了不同词间的相关度.Qu等[11 ] 利用维基百科知识库计算出词语间的语义距离, 并结合内容相似度解决了传统VSM语义缺失的问题, 然而维基百科作为网络知识虽然信息更新迅速, 但其数据噪声大且结构性差[12 ] .Word2Vec[13 ] 自被提出以来, 可以成功解决文本特征的维数灾难问题, 运用词嵌入方法, 无需引入外部知识库也能计算词语的语义相似度.李琳等[14 ] 运用Word2Vec针对英文长文本进行相似度计算, 准确率高达92%. ...
结构句法基础
1
1987
... 在共现词网络中, 节点特征项之间的关联关系由同一句子中词语间的距离决定, 然而语言学表明, 句子中成分间存在句法结构, 因此由依存句法分析确定关联词对更符合实际.依存句法分析法最先由Tesniere[15 ] 提出, 通过分析语言单位间的依存关系研究其句法结构, 其关系主要包括主谓关系(SBV)、动宾关系(VOB)、状中结构(ADV)等.此外, 依存句法结构中词语间是互相支配的, 即词语的关联具有方向性.本文借助Python[16 ] 调用哈尔滨工业大学开发的语言技术平台(LTP)[17 ] 进行依存句法分析.以“人工智能引领创新发展”一句为例, LTP模型首先对句子进行分词和词性标注, 然后分析依存句法结构, 结果如图1 所示.其中特征项及其之间的关联方向为“引领→人工智能”、“引领→创新”、“创新→发展”. ...
结构句法基础
1
1987
... 在共现词网络中, 节点特征项之间的关联关系由同一句子中词语间的距离决定, 然而语言学表明, 句子中成分间存在句法结构, 因此由依存句法分析确定关联词对更符合实际.依存句法分析法最先由Tesniere[15 ] 提出, 通过分析语言单位间的依存关系研究其句法结构, 其关系主要包括主谓关系(SBV)、动宾关系(VOB)、状中结构(ADV)等.此外, 依存句法结构中词语间是互相支配的, 即词语的关联具有方向性.本文借助Python[16 ] 调用哈尔滨工业大学开发的语言技术平台(LTP)[17 ] 进行依存句法分析.以“人工智能引领创新发展”一句为例, LTP模型首先对句子进行分词和词性标注, 然后分析依存句法结构, 结果如图1 所示.其中特征项及其之间的关联方向为“引领→人工智能”、“引领→创新”、“创新→发展”. ...
1
2018
... 在共现词网络中, 节点特征项之间的关联关系由同一句子中词语间的距离决定, 然而语言学表明, 句子中成分间存在句法结构, 因此由依存句法分析确定关联词对更符合实际.依存句法分析法最先由Tesniere[15 ] 提出, 通过分析语言单位间的依存关系研究其句法结构, 其关系主要包括主谓关系(SBV)、动宾关系(VOB)、状中结构(ADV)等.此外, 依存句法结构中词语间是互相支配的, 即词语的关联具有方向性.本文借助Python[16 ] 调用哈尔滨工业大学开发的语言技术平台(LTP)[17 ] 进行依存句法分析.以“人工智能引领创新发展”一句为例, LTP模型首先对句子进行分词和词性标注, 然后分析依存句法结构, 结果如图1 所示.其中特征项及其之间的关联方向为“引领→人工智能”、“引领→创新”、“创新→发展”. ...
LTP: A Chinese Language Technology Platform
1
2010
... 在共现词网络中, 节点特征项之间的关联关系由同一句子中词语间的距离决定, 然而语言学表明, 句子中成分间存在句法结构, 因此由依存句法分析确定关联词对更符合实际.依存句法分析法最先由Tesniere[15 ] 提出, 通过分析语言单位间的依存关系研究其句法结构, 其关系主要包括主谓关系(SBV)、动宾关系(VOB)、状中结构(ADV)等.此外, 依存句法结构中词语间是互相支配的, 即词语的关联具有方向性.本文借助Python[16 ] 调用哈尔滨工业大学开发的语言技术平台(LTP)[17 ] 进行依存句法分析.以“人工智能引领创新发展”一句为例, LTP模型首先对句子进行分词和词性标注, 然后分析依存句法结构, 结果如图1 所示.其中特征项及其之间的关联方向为“引领→人工智能”、“引领→创新”、“创新→发展”. ...
Analyzing Natural Human Language from the Point of View of Dynamic of a Complex Network
1
2016
... 复杂网络以图论为理论支撑, 其模型由节点、连边和边权组成, 记为G =(V , E , W ).研究表明语言网络具有小世界和无标度等复杂网络的独特特性[18 ] , 这意味着复杂网络模型可以更好地表示出文本内在信息. ...
Intensity and Coherence of Motifs in Weighted Complex Networks
1
2005
... (2) 聚类系数: 衡量网络中节点的聚集程度, 选取Onnela定义[19 ] 如公式(3)所示. ...
Centrality in Social Networks Conceptual Clarification
1
1978
... (4) 接近度中心性: 反映节点处于网络中心的程度, Freeman[20 ] 将其定义为公式(6). ...
A Mathematical Theory of Communication
1
1948
... 在以往研究中, 在计算节点的综合特征值时, 针对网络指标的权重均通过不断地调整参数来确定.为避免这一繁琐过程, 本文采取信息熵法[21 ] . ...
On the Construction of Effective Vocabularies for Information Retrieval
1
1975
... TF-IDF[22 ] 是词袋模型中应用最广、效果最优的文本特征权重计算方法, 通过计算文本中特征项出现的频率(Term Frequency, TF)及其倒排档文本频率(Inverse Document Frequency, IDF)衡量特征项的重要程度.TF考虑了特征项在文本中的使用次数, 但存在部分高频特征项对单个文本毫无意义, 因此引入IDF消除这类词的干扰, 则文本Di 中特征词i 的TF-IDF值计算如公式(12)所示. ...
Modern Information Retrieval: A Brief Overview
1
2001
... 其中, ${{w}_{{{d}_{i}}}}({{t}_{i}})$表示特征项ti 在文本Di 中的特征值.显然, 传统的余弦相似度[23 ] 只能依靠文本中具有的相同词语计算文本相似度, 而忽略了词语间的语义关系和语法关系.因此, 本文在此基础上对其做出改进, 以期更完整、更高效地利用词语计算文本相似性. ...
Nearest Neighbor Pattern Classification
1
1967
... 实验采用KNN[24 ] 分类算法衡量文本相似度算法的效果, 其中K取16.为了保证分类器的准确性, 进行十折交叉验证, 并取评判其优劣结果的平均值作为最终分类优劣的结果值.在验证本文所提出的相似度算法效果的同时, 进行两组对比实验.具体实验过程为: 第一组实验为本文提出的借助句法网络得到的综合特征值和词嵌入法的词语语义相似度相融合的文本相似度算法; 第二组实验采用根据句法网络得到的特征项及其TF-IDF值的文本相似度算法; 第三组实验为传统共现词网络得到的综合特征值和词嵌入法结合的文本相似度算法. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}