
 , 巴志超, 李纲
, Ba Zhichao, Li Gang
, 巴志超, 李纲
, Ba Zhichao, Li Gang
【目的】通过探究实际微信群内部的话题结构及演化特征, 对微信用户交互行为特点及信息传播规律进行探讨。【方法】以三个典型性微信群对话样本作为研究对象, 引入语言学中的会话分析理论, 分析微信群会话语言现象及特点, 设计基于成员活跃度、交流强度及话轮密度的话题强度计算模型, 并进一步探究不同类型的微信群中会话的话题结构特征及演化规律。【结果】微信群会话与日常会话的语言现象具有同一性及差异性, 将话轮纳入话题强度计算模型较消息条数有明显优势, 不同类型的微信群享有各自的话题演化规律。【局限】微信群类型丰富性可以进一步增加。【结论】本研究有利于把握话题在微信群中的发展规律, 对网络舆情监控及灾害防治有重要意义。
[Objective] This paper aims to study the characteristics of WeChat user interaction and information dissemination by exploring the topic structure and evolution characteristics within the actual WeChat group. [Methods] Taking three typical WeChat group conversation samples as research objects, we introduce the conversation analysis theory in linguistics, and analyze the phenomenon and characteristics of the WeChat group conversation, and design the topic intensity calculation model based on the activeness of membership, the intensity of communication and turn density, and further explore the topic structure characteristics and evolution rules in different types of WeChat groups. [Results] The linguistic phenomena of WeChat group conversations and daily conversations have the sameness and difference. The inclusion of the turn-taking into the topic intensity calculation model has obvious advantages over the number of messages. Different types of WeChat groups respectively own their topic evolution rules. [Limitations] The richness of WeChat group type can be increased. [Conclusions] This study is conducive to grasp the development law of topics in the WeChat group, and is of great significance to the monitoring of Internet public opinion and disaster prevention.
根据腾讯调研数据显示, 截至2016年12月, 微信月活跃用户已达8.89亿人[1]。微信作为一个集信息共享、即时通讯、手机支付、城市服务于一体[2,3]的集合性服务体, 使用户个体固有的社会关系网络化。其中的微信群功能为参与者提供围绕话题开展信息交互的平台。随着时间推移, 微信群话题将以话轮转换的形式呈现出从开始到高潮再到衰落的过程。微信群话题生命周期的探究, 不同类型微信群各话题演化差异的对比, 对监控舆情的发展及网络交互群体行为的研究有着重要意义。
话题演化的研究是根据文本内部的话题相似性信息及时间属性获取话题随着事件信息的迁移遍历路程。话题演化又分为内容演化和强度演化。前者研究集中在对话题关键词的把握以考量话题的发展; 而后者研究集中在强度计算模型的建立, 时间序列上的强度变化表征话题的稳定度或关注度的变化过程。目前话题模型主要是采用VSM[4,5]、PLSA[6,7]、LDA[8,9,10]及其拓展模型等方法。由于话题内容演化方法基于对文本特征的度量[11,12], 而微信群成员规模限制导致群消息语料库文本特征量不足, 缺乏话题模型使用的必要条件。因此本文仅采用人工识别方法开展话题生命周期的研究。其次在话题强度计算上, 当前研究主要 采用话题支持文档数量[13,14,15]、基于语料库的话题概 率[16,17]、基于文本的话题显著性[18]三种计算模型。孙孟孟[19]以期刊论文为对象, 比较上述三种计算方法后得到: 长文本下三种方法均能得到一致性结果; 方法一与方法三的研究对象必须为包含多话题的长文本语料, 而方法二可以研究微博等短文本(契合本文研究对象); 方法一计算结果较方法三更显著。
为此, 本文结合语言学中的会话分析理论, 以真实微信群中的会话为例, 分析话轮转换与话题转换的关系, 并将话轮作为度量话题强度的基本单位, 采用基于语料库话题概率的话题强度计算方法, 构建基于成员活跃度、交流强度及话轮密度的群聊会话话题强度计算模型, 研究不同类型微信群话题演化的差异并分析其原因。
微信群是以社会交友、集体交流为主要目的, 通过说话者与听话者身份的互换, 围绕一个或多个话题展开交流的互联网社交空间。本文首次尝试引入语言学中会话分析理论来探究微信群中的会话特征。会话分析起源于民族志方法, 由Sacks等[20]创立于20世纪70年代, 早期用于分析自然会话。他们关注于话轮转换的基本内容和理论框架[20]、会话的序列组织[21]、会话修正[22]等, 以揭示人们的社会行为及之间互动交际行为的内在组织结构及其所反映的社会秩序和规律。当前国内外学者对日常会话分析的研究主要有: 会话分析视角的社会学研究[23,24]; 以会话为本体的研究[25]; 会话分析的方法在其他语言研究领域的探索[26]; 会话中的语言现象。微信群会话作为一种独特的电子群体会话交流形式, 将其纳入会话分析理论的框架下为拓展会话分析理论的研究范围、深入挖掘微信群会话的内部规律具有重要意义。
结合会话分析理论, 本文从微信群的会话结构、会话序列组织、会话修正、话题结构、话题与话轮关系5个维度, 进行微信群内部的会话分析。微信群会话结构分为总体结构和局部结构, 前者是微信群中一个完整的话题在展开过程中依照交际要求所形成的功能模式, 通常认为由开头、主体和结尾三个部分构成; 后者是微信群用户交替发话这一合作活动所形成的轮番说话的功能组合方式。会话序列组织是会话在局部发生话轮转换过程中所包含内容上的逻辑序列变换。这种序列相关性体现了话轮的双重语境特征: 微信群中用户产生的任何当前话轮既由之前的语境塑造, 又为后面的话轮创造新的语境[27]。最能体现序列组织模式的概念是相邻对, 其相互搭配, 共同构成呼应或对应关系, 是一对更加紧密联系的话轮转换。微信群作为参与人数较多的即时通信平台, 其所产生的会话序列更为繁复, 当引入身份信息, 并通过时间区间定义并发送消息时, 可认为话题产生了并发的会话序列。会话修正是用户在微信群会话过程中对自身或他人言语不当时加以改正的过程。由于微信群以非正式交流、以键入形式为主开展会话, 因此较日常会话而言, 存在更多更正输入错误的会话修正现象, 进而导致话轮数目的意外增加, 影响了该时间片段内的话题强度。微信群话题结构分为单线式和多线并存式。单线式即群内成员围绕一个话题开展直至结束, 期间未发生话题转换; 多线并存式即多用户围绕两个或两个以上话题推进会话行进, 同时存在群聊成员从一个话题转换至新话题的线性式讨论, 以及部分用户针对一个话题, 部分用户针对其他话题的并行式讨论[28]。话轮、话题作为会话结构的基本构件, 前者是表层的语言形式, 后者是深层的语义内涵。话轮作为话题推进的表现形式, 对话题的引发、转换具有影响力, 甚至约束力; 另外话轮虽为会话行进的表现形式, 但话题的转换并非完全依托话轮转换进行。话题转换与话轮转换存在以下4种情形: 话轮转换, 话题不转换; 话轮不转换, 话题不转换; 话轮不转换, 话题转换; 话轮转换, 话题转换。话轮转换与话题转换作用于会话结构并推动会话的变化及发展。
相较于有学者使用群成员发言的消息条数作为话题强度的影响因子而言, 笔者以为微信群存在成员通过数次发言完成一个话轮的现象, 此计数方法受群成员发言习惯影响较大进而降低结果可信度。因此本文将话轮作为衡量话题强度的基本计数单位, 不发生较长时间沉默及发语者听语者身份转换的群聊消息均从属一个话轮。话题包含的话轮数量越多, 用户对于该话题的讨论活跃性更高, 话题强度越大; 反之, 话题使用的话轮数量越少, 则群体用户对于该话题缺乏讨论兴趣, 话题强度越小。
微信群内部的会话交流本质上属于一种非正式的“社会性交互”, 而话题是群成员之间进行信息交互陈述对象以及表述事实的出发点。区别于话题参与人数、话轮数等直接观测变量, 话题强度是话题本身具有的一种抽象属性概念, 是描述话题受关注程度的统计量。前文已比较过各话题强度计算模型差异, 因此本文使用“基于语料库中话题概率的话题强度计算”作为本文话题强度的基础模型。结合微信群会话特点, 考虑单位时间内目标话题话轮数占总话轮数的比值作为话题交流强度。为全面表征微信群会话话题强度, 除了话题交流强度外, 另考虑将其他因素纳入话题强度的计算模型。成员活跃度, 表示目标话题参与人数, 是微信群话题话轮数量、持续时间的重要影响因子之一; 话轮密度将时间因素加入计算模型中, 体现用户对于目标话题讨论的激烈程度。本文将三种话题强度影响因素分别赋予权重, 构建集成化度量模型, 如公式(1)所示。
$St{{r}_{t}}=\alpha \cdot \frac{me{{m}_{i}}}{TMe{{m}_{i}}}+\beta \cdot {{\theta }_{i}}\frac{sp{{e}_{i}}}{TSp{{e}_{i}}}+\gamma \cdot {{\mu }_{i}}$ (1)
其中, $\alpha、\beta、\gamma $分别表示成员活跃度、有效交流强度、话轮密度对话题强度的影响因子。
因此, 微信群会话话题计算的整个过程如下: 基于内容分析法对微信群内成员的对话样本进行分析, 针对所研究的不同话题构建语料库, 统计各个话题的相关性指标; 通过对微信群话题发展特征的挖掘, 检验不同指标对度量话题强度的有效性; 提出采用成员活跃度、有效交流强度、话轮密度三个指标计算微信群会话话题强度。
微信群话题在发展过程中依靠逻辑展开关联性运动, 通常会遍历从产生到失去效用价值的整个过程[29]。话题演化生命周期即话题在其开启至结束时间区间内的动态发展过程。微信群会话话题生命周期的研究是管理微信群海量信息的基础, 同时对于微信群舆论引导, 疾病、灾害预警等有指导价值[30]。综合会话分析理论与微信群会话话题研究现状, 延用语言学上话题在会话结构中的运行规律分析, 采用纵向分析法将微信群会话话题的形成、演变过程分为6个阶段。
(1) 话题启动: 指用户通过直接或间接的方式在群聊交互过程中提出话题, 确立会话框架及核心[31]。微信群话题启动形式以文本、网页链接、动画表情及其结合体为主。
(2) 话题延续: 指微信群用户对同一话题不断改变谓述, 但至始至终均未改变话题的过程[32]。微信群用户对于话题提出者提出的话题饱有较高的兴趣, 无意或持续未表达出更改话题的意向, 一直对话题补充述谓。
(3) 话题迁移: 即话题间的派生关系, 指微信群用户在话题延续的过程中以原始话题为出发点引出与之有内容相关性新话题的过程[32]。当用户在对原始话题讨论接近尾声或讨论过程中产生相关联想时, 会提出新的相关话题。
(4) 话题转换: 指微信群会话过程中, 突然因为某种原因, 无人继续原话题的讨论, 转换出一个新的、与初始话题毫无联系的新话题[31]。当用户对于原话题的持续讨论失去兴趣, 自然转入下一话题; 或因某种情况突然发生, 另一话题的突然加入使得会话框架 中的原核心要素下降, 附属话题要素上升, 发生话题转换。
(5) 话题回逆: 指在已经发生话题迁移或转换的情况下, 群聊话题又回到初始已讨论过的话题上, 对旧话题增加新的述谓的过程[32]。话题回逆现象的发生往往是在该话题讨论期间被其余话题打断, 该话题讨论尚未结束, 在其余话题讨论完后回归原话题, 或者在原话题讨论自然结束, 转向其余话题的讨论之时, 存在用户有对原话题补充谓述的意愿。
(6) 话题结束: 指交际双方或多方不再提及该话题。在原话题行进中, 有成员提出新话题, 其余成员对新话题的兴趣度大于旧话题, 原话题的讨论热度逐步衰减直至为零。
语言同一性导致微信群聊会话与日常会话具有类似的会话结构, 只是微信群聊会话结构的部分缺省并不导致会话的失败, 而是一种正常现象。当话题具有完整的会话结构时, 便完成一个完整的生命周期。基于话题强度, 微信群会话话题的一个完整的生命周期如图2所示。
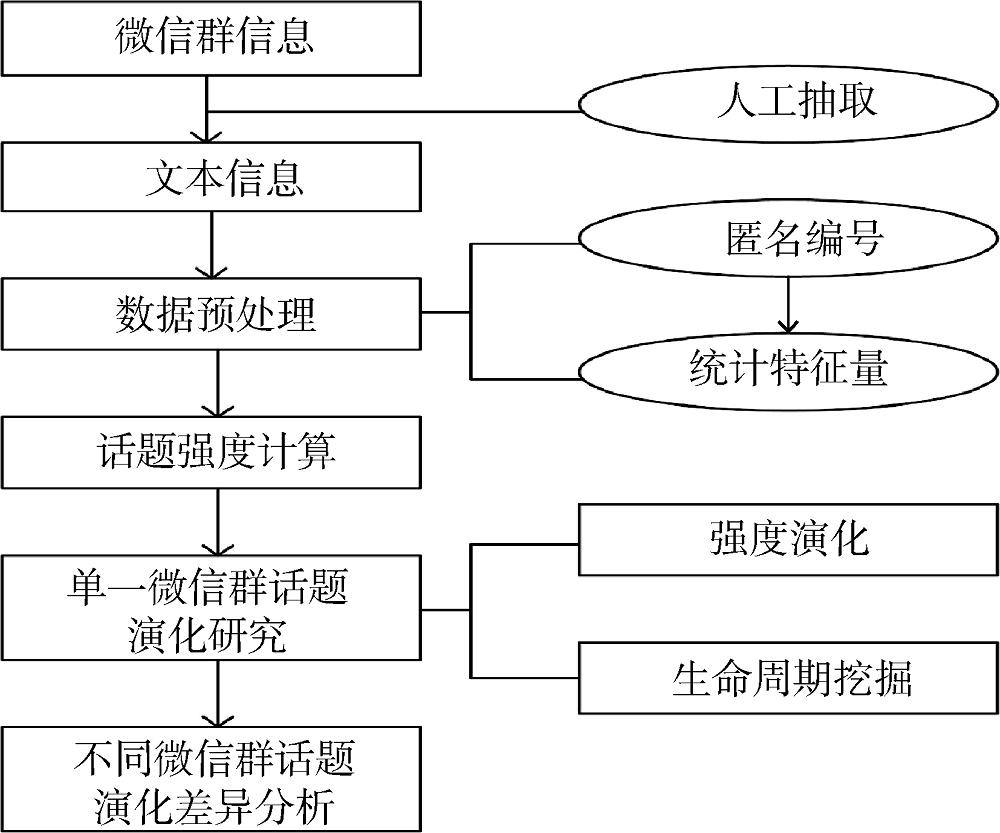
本文的研究框架如图3所示。
本文分别选取学习工作群、朋友群与兴趣群作为研究对象, 并从各类型中分别选取一个微信群进行深度案例分析。其中在微信群的选取上, 成立时间 及消息条数的筛选保证微信群长久稳定且样本量 规模足够大。所选取的三个微信群的基本信息如表1所示。
抓取群内成员信息交流的数据作为分析文本, 包括每条记录发言者ID、消息状态、消息类型及消息内容。为保护微信群成员的隐私, 本研究之初将成员进行匿名标号处理, 消息内容仅记录话题关键词及同一话题下特征统计量的变化情况。另外, 考虑目标话题集在微信群中讨论时长, 提升实验结果显著性, 以产生连续性话题强度演化图。将20分钟视为一个时间片段, 且根据群聊成员交流习惯, 去除群聊“沉默”的时间区间(如夜间睡眠时间), 将“沉默”后首次出现该话题的消息改为上一消息发出10分钟后, 且该条消息不计入前一消息密集讨论区间内。
以选取的兴趣群为研究对象, 抽取10个话轮数大于40, 消息条数大于50的话题。统计其话轮数、该话题持续时间片段内总话轮数、该话题参与人数、微信群总人数、密集讨论话轮数、该话题有效消息条数、该话题持续时间片段内总消息条数、密集讨论消息条数, 并分别应用话轮数计数法与消息条数计数法计算两种方法下的话题强度(保留小数点后4位), 如表2所示。其中, 同一发语人两条消息间隔超过20分钟则视为两个话轮, 相邻话轮(消息)间隔5分钟之内视为密集讨论话轮(消息)。
可知, 消息条数相关统计量均大于话轮数相关统计量, 其是用户在群中短时间连续发言现象导致两种计数方法结果产生差异的主要原因。为量化两种反映用户发言统计量的优劣, 改进上文提出的话题强度计算模型如下。
$Str{{'}_{t}}=\alpha \cdot \frac{me{{m}_{i}}}{TMe{{m}_{i}}}+\beta \cdot {{\theta }_{i}}\frac{Me{{s}_{i}}}{TMe{{s}_{i}}}+\gamma \cdot \mu {{'}_{i}}$
其中, 消息条数计数下的话题强度$St{{r}_{t}}\text{ }\!\!'\!\!\text{ }$的有效交流强度改为该时间片话题有效消息条数占总消息条数的比值; 话轮密度改为消息密度${{\mu }_{i}}\text{ }\!\!'\!\!\text{ }$。分别计算话轮数与话轮计数方法下的话题强度的相关系数、消息条数与消息条数计数方法下的话题强度相关系数。由于两模型反映用户发言数量的模型共享权重
(1) 微信群话题强度演化分析
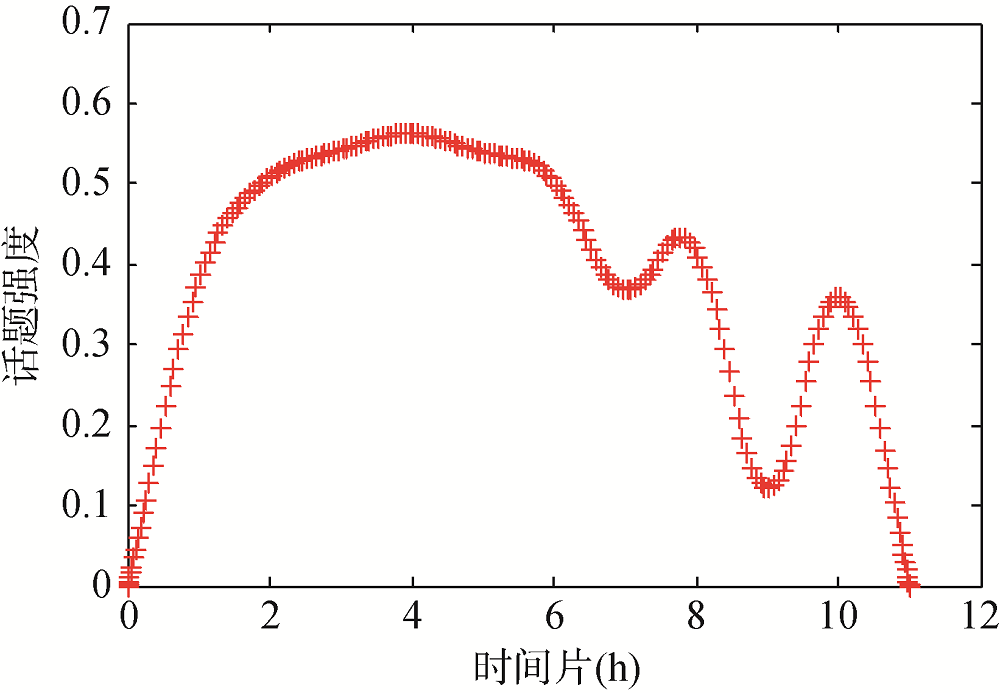
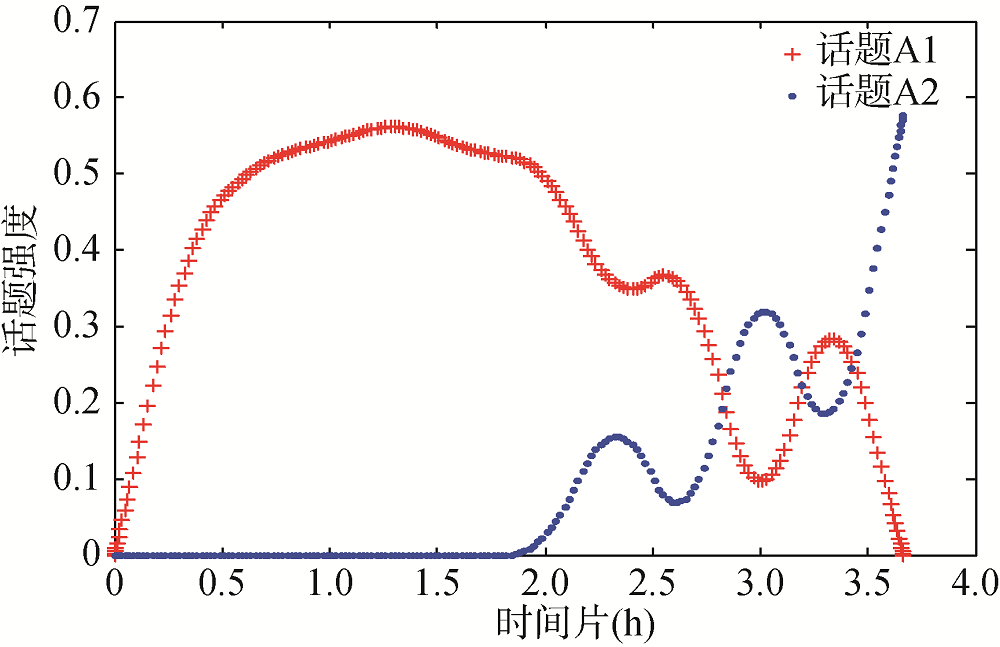
话题强度表示用户针对话题讨论的热烈程度, 话题强度的变化趋势反映话题的演化趋势[33]。抽取某学习工作群话题A1发展周期内的全部消息记录, 进行人工话题识别, 依照2.2节提出的话题强度模型, 计算各个话题强度相关统计量, 并整合得到各话题在连续时间片段的话题强度, 其中表3展现话题A1在连续时间片的各统计量实际数据。为直观表示话题强度随时间的演化规律, 链接各话题相邻时间片段的话题强度, 绘制如图4所示的平滑曲线散点图。
从图4可以看出, 话题A1强度自话题开启后迅速上升, 在经历一段时间到达顶峰。随着话题A2开启, 话题A1强度发生波动, 开始逐渐下降。随着话题A2强度趋于顶峰, 话题A1强度最终趋于0。由此可知, 微信群话题强度会经历迅速上升至顶峰, 而后产生波动下降为0的过程。为量化表示插入话题对原话题的影响, 现采用相关系数计算方法, 其结果越接近1表示正相关越显著, 越接近-1表示负相关越显著, 越接近0表示无明显相关性。经计算连续时间片上A1、A2话题强度相关系数为-0.952, 因此两话题呈负相关性, 插入话题对原话题会产生负向影响。
另外, 在时间片段(0,1)内话题强度只存在单线条推进的形式, 在时间片段(2,3)内存在多线条交叉推进的形式。因此可以推测微信群话题结构存在单话题推进和多话题推进两种形式。由此说明网络环境的特殊性使得多话题交叉并行的话题结构在微信群的会话结构中是更为普遍的存在。
(2) 微信群话题生命周期演化分析
随着会话的进行, 不断有旧话题沉寂、新话题引入使得微信群信息交互进行。从整体内容上看, 微信群的会话过程均由话题的延续、转移以及回逆所构成, 而在同一话题下的过程也包含话题启动、延续、迁移、转换、回逆及结束多个阶段。为探究话题生命周期演化规律[34], 仍使用某学习工作群话题A1生命周期内的历史消息及根据话题强度模型绘制的强度演化图进行研究。
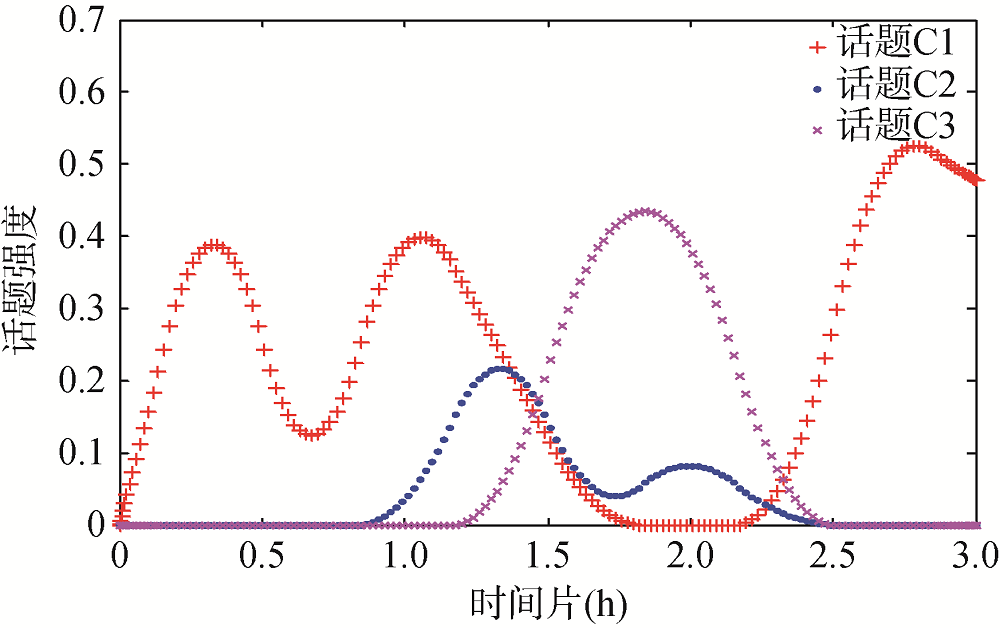
微信群成员在微信群中开展活动具有动态性, 话题作为用户在微信群中的行为产物也会随时间发生变化。为研究不同类型[35]微信群中的话题演化关系, 本节除采用已绘制的学习工作群话题强度演化图外, 另选取如图5所示的兴趣群及如图6所示的朋友群的话题强度演化图。
首先, 从图4-图6均可看出话题强度随时间发生规律性波动, 各个群聊中的话题在发展过程均处于微信群会话话题生命周期的某一阶段。说明话题演化的生命周期相似性由其语言特征决定, 并非群聊类型。其次, 三幅话题演化图均存在某时间片段单线条推进及某时间片段多线条交叉推进的情形。说明微信群聊会话中单话题推进及多话题交叉推进的形式均普遍存在, 微信群中话题结构的多样性不由其群聊类型决定, 而是其自身依托网络, 不受范式约束的自由属性所决定的。
从各条曲线差异性来看, 图4所示的学习工作群话题强度演化曲线具有整体波动性大、持续时间较长的特点。曲线的波动是话题延伸与转移的外化表现形式, 说明该群聊话题具有较为完整的生命周期。分析得出用户在学习工作群中对于话题的讨论较为深入, 思维多样性的表达导致话题通常经过完整的生命周期后才结束。且用户之间社会关系仅基于工作产生, 缺乏深入的情感往来, 用户交流更为正式, 不会在一个话题行进过程中随意插入话题。因此笔者认为学习工作群存在话题数量有限, 话题生命周期完整且无话题随意插入的特点。图5所示的兴趣群的话题强度演化曲线存在变化较快, 持续时间较短, 三个话题在短时间内达到高潮后迅速衰退, 并在一定时间之后发生回逆性上升的现象。其话题生命周期通常经历开启、延续、回逆、结束的阶段, 缺乏话题的迁移、转换的过程。说明兴趣群的话题具备多样性, 但缺乏对于单个话题的深入讨论。推测仅靠某种需求或兴趣聚集形成的微信群, 生活交集较为单一, 情感程度有限, 相对而言缺乏话题迁移等会话过程的驱动力与现实条件。话题回逆的发生是由于用户不会及时关注该群聊对话, 往往在该话题讨论过后通过历史记录关注到该话题, 当该话题与兴趣群主题相关时, 用户会针对兴趣话题继续进行自我补充并产生小范围讨论。因此可以认为兴趣群话题具有种类多、数量大, 话题生命周期缺乏延伸、转移的过程, 但常会发生话题回逆的特点。图6所示的朋友群话题强度演化曲线具备变化快, 话题强度直线上升后无波动性下降, 各话题强度曲线重合较为密集的特点。说明该群话题数量多, 且并行推进的现象更为明显, 生命周期较为简单。说明朋友群成员生活中交集程度较高, 话题丰富性较大。而且成员之间处于同一等级和地位, 会话过程缺乏对日常会话“准则”的严格遵守, 因此话题的插入更为普遍。另外, 用户在该群聊中开展话题以维系感情为主, 话题多样性使得用户缺乏对单一话题的深入讨论, 缺乏话题延伸、转移等现象。同时对现有话题的讨论已能实现感情维系的目的, 无再次提起的必要, 导致回逆现象也较为少见。因此朋友群话题往往仅经历话题的开启、延续、结束过程, 偶尔存在话题回逆阶段, 且话题并行现象更为普遍。
通过总结发现, 表述形式和群体依托的同一性导致不同微信群话题演化相似性的存在, 而各个微信群组建性质不同导致不同群话题演化存在差异性。其中, 学习工作群话题数量有限, 单一话题探究较为深入, 话题讨论持续时间较长, 话题的生命周期也较为完整。同时由于话题较为正式, 其他话题的插入现象较少存在, 前一话题趋于尾声, 新话题才逐渐进入; 兴趣群话题多样, 单一话题的讨论缺乏延展性, 生命周期往往缺乏话题延伸及转移阶段, 但由于用户对于该群聊对话关注不及时, 翻看历史消息再次讨论过往话题更为常见, 因此话题回逆现象较多; 朋友群就话题讨论的灵活性与兴趣群有一定的相似度, 尤其是话题的多样性, 生命周期缺乏话题延伸与转移阶段。不同的是, 其话题回逆现象较少, 且关系的平等与情感的深入导致话题并行发展现象更多。
本文以三个类型微信群中的对话样本数据进行分析, 引入语言学中的会话分析理论, 分析微信群聊消息的整体、局部特点及微信群会话话轮与话题转换关系, 设计基于成员活跃度、交流强度及话轮密度的话题强度计算模型, 把握微信群话题演化的生命周期规律及其话题结构特点, 并进一步探究不同类型的微信群中会话的话题结构特征与演化规律的异同性及其产生的原因。
本文研究存在一定的局限性。首先各类型只选择一个典型性的微信群, 导致结果存在偶然性, 无法全面揭示不同类型群的共性及差异; 其次, 话题强度计算模型的构建缺乏理论依据, 指标测度的计算方法在微信群中应用的普适性和有效性有待探讨; 最后, 仅基于内容分析方法对微信群的文字对话样本进行统计和描述分析, 缺乏对交流内表情包等形式数据所传达的语用功能的挖掘。未来将就多形式微信群消息的语义挖掘、构建科学合理的话题强度计算模型、多类型微信群的话题演化分析等问题进行深入研究。
汪鸿沁泠: 模型构建, 论文撰写;
巴志超: 搭建研究框架, 设计研究方案;
李纲: 主题选择, 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail:18366112267@163.com。
[1] 汪鸿沁泠. WechatData.zip. 微信群文本数据.
[2] 汪鸿沁泠. StatsData.zip. 微信群文本统计数据.
| [1] |
URL
[本文引用:1]
|
| [2] |
[本文引用:1]
|
| [3] |
[本文引用:1]
|
| [4] |
[本文引用:1]
|
| [5] |
网络信息主题特征的提取是网络信息利用的一个非常重要的环节,基于向量空间模型的网络信息主 题特征提取是目前使用最普遍的一种提取模型。在对向量空间分析的基础上,改进了向量空间模型特征权值的计算方法,充分利用检索词在结构化网络信息中的位 置、用户使用的频度和检索词的专业性等特征。使关键词特征权值的计算更加合理,相关性更强。
|
| [6] |
[本文引用:1]
|
| [7] |
针对现有的关于网络舆情内容进行情感分析的研究不能满足舆情情感 深度挖掘的需求,提出一种基于概率潜在语义分析( PLSA)的网络舆情话题情感分析方法,利用PLSA模型对不同时间段上的网络舆情话题进行子话题提取和情感词表构建,综合考虑修饰词对情感词的影响以及 情感词对子话题的贡献程度,最终得到一个时间序列上各个子话题的情感倾向值以及整个话题的情感变化趋势。实验结果证明该方法不仅可以描述同一个子话题随时 间的情感演化过程,还可以描述话题情感随子话题维度和内容的演变情况。
|
| [8] |
[本文引用:1]
|
| [9] |
基于LDA思想,用先离散时间型话题模型思路建立网络突发事件话题的空间模型,并根据特征词之间的关联度使用社会网络分析方法进行话题演化路径的分析。实验表明,此思路能够较全面体现话题演化路径,为网络突发事件分析提供有效途径。
URL
[本文引用:1]
|
| [10] |
本文提出了潜在狄利克雷分布模型与自然语言处理技术相结合的一种挖掘用户评论热点的方法。为验证该方法的有效性,以22157篇餐馆评论为样本,利用Gibbs抽样计算模型参数,获取了评论热点及相应的热点词语。实验获得的9个主题内容较好地反映了餐馆评论中的热点,与现实生活中用户所关心的餐饮热点基本吻合,表明该模型具有较好的热点识别效果。
URL
[本文引用:1]
|
| [11] |
A Hot Topics Analysis System (HTAS) based on time sliced network data was proposed. HTAS realized the network hot topic data source automatically collected, acquisition and storage. HTAS integrated the google revenue segmentation system IKAnalyzer to batch processing of Chinese documents. HTAS used LDA model to extract and time label to find the evolution of the hot topics on the network. Experiments of Diaoyudao as the hot event show that, the system can effectively acquire, store and analyze this hot topic evolution trend.
|
| [12] |
针对社交媒体信息,提出不同时间段话题特征词选择方法,构建动态共词网络,运用社群发现算法对共词网络进行社群划分,以共词网络社群表示社交媒体话题讨论的子话题。在不同时间段子话题相似性识别的基础上,将子话题演化过程划分为子话题产生、子话题扩散和子话题消退三个阶段。实证分析表明:共词网络社群表示子话题具有易理解、降噪等优势;在共词网络社群基础上可以清楚地理清子话题的发展路径和变化趋势。
URL
[本文引用:1]
|
| [13] |
|
| [14] |
自动挖掘科技文献话题,总结发展趋势及最新研究动态,有助于科技工作者的研究。该文提出一种话题发现和趋势分析的方法,该方法首先利用LDA话题模型抽取科技文献的话题,然后计算话题的强度和影响力,最后针对热门和冷门话题以及影响力高和影响力低的话题,进行了趋势分析。该文提出的话题强度和影响力计算方法,可以针对任何文集。对ACL 论文集的实验,显示了计算语言学领域过去的发展状况。和其他方法的对比实验,也验证了该文提出的话题强度和影响力的计算方法是正确和可行的。
|
| [15] |
语义歧义增加了生物事件触发词检测的难度,为了解决语义歧义带来的困难,提高生物事件触发词检测的性能,该文提出了一种基于丰富特征和组合不同类型学习器的混合模型。该方法通过组合支持向量机(SVM)分类器和随机森林(Random Forest)分类器,利用丰富的特征进行触发词检测,从而为每一个待检测词分配一个事件类型,达到检测触发词的目的。实验是在BioNLP2009共享任务提供的数据集上进行的,实验结果表明该方法有效可行。<br>
|
| [16] |
[本文引用:1]
|
| [17] |
[本文引用:1]
|
| [18] |
[本文引用:1]
|
| [19] |
[本文引用:1]
|
| [20] |
The organization of taking turns to talk is fundamental to conversation, as well as to other speech-exchange systems. A model for the turn-taking organization for conversation is proposed, and is examined for its compatibility with a list of grossly observable facts about conversation. The results of the examination suggest that, at least, a model for turn-taking in conversation will be characterized as locally managed, party-administered, interactionally controlled, and sensitive to recipient design. Several general consequences of the model are explicated, and contrasts are sketched with turn-taking organizations for other speech-exchange systems.
|
| [21] |
[本文引用:1]
|
| [22] |
An 'organization of repair' operates in conversation, addressed to recurrent problems in speaking, hearing, and understanding. Several features of that organization are introduced to explicate the mechanism which produces a strong empirical skewing in which self-repair predominates over other-repair, and to show the operation of a preference for self-repair in the organization of repair. Several consequences of the preference for self-repair for conversational interaction are sketched.
|
| [23] |
[本文引用:1]
|
| [24] |
[本文引用:1]
|
| [25] |
[本文引用:1]
|
| [26] |
[本文引用:1]
|
| [27] |
会话分析(CA)将会话视为一种社会行为.这种社会学研究取向决定了CA从发轫之始便没有将非语言交际行为排除在研究视野之外.本文讨论了从民俗方法学到CA再到基于CA的多模态交际研究奠基阶段的学理传承和发展,着重探讨序列分析在多模态交际研究中的优势、问题以及未来的发展方向.序列组织是会话组织的核心原则.在基于会话分析的多模态交际研究中,序列分析的优势在于它为研究者理解和处理交际行为提供了一套实用方法和一种基于语料本身的验证程序.存在的问题是:不同于会话组织中相对严格的序列性,多模态交际中除了序列性外还有共时性,这给序列中交际行为起始点的切分造成了一定难度.此外,本文还探讨了CA多模态交际学者处理语料的方法.CA多模态交际转写沿续了CA转写的严格性、精细性和清晰度,其中Christian Heath的转写体例最为典型.最后,我们提出,Charles Goodwin的具身参与框架和Sigrid Norris的模态密度的概念有利于解决序列分析的共时性问题.
|
| [28] |
[本文引用:1]
|
| [29] |
本文将网络信息的生命周期定义为网络信息从产生到失去效用价值所经历的各个阶段和整个过程,选取中文学术资源网、外文学术资源网、论坛网站、新闻网站和大型网站为研究对象,采取引文分析法和链接分析法,对网络信息的生命周期现象进行了观察和记录,通过对数据的处理和分析,揭示了一般意义上网络信息生命周期的基本规律和特性。
URL
[本文引用:1]
|
| [30] |
作为一种新环境下的信息资源,微博产生的海量数据也具有相应的生命周期。,以3个微博热门话 题数据为分析对象,将评论数作为微博信息生命周期的表征量,分析微博信息生命周期的特征、分布类型、半衰期等。发现微博信息生命周期有负指数型、平缓型、 爆发型和锯齿型4种类型,其类型特征与微博活跃度无关,并且微博信息不具有特定的半衰期。
|
| [31] |
[本文引用:2]
|
| [32] |
[本文引用:3]
|
| [33] |
结合时序分析、聚类分析与复杂网络分析,对社交博客用户分层及话题演化进行了分析.依据用户在社交媒体中的活跃程度,设置关联强度阈值和比例,提取核心用户群体.统计各年度整个用户群体关注的热点话题,对比核心用户群体关注的热点话题,评估核心用户群体对热点话题衍生的影响大小.实证分析可知核心用户群体对热点话题衍生具有显著影响,长尾效应使得非核心用户群的影响也不能忽视.
|
| [34] |
本文以突发自然灾害事件网络新闻数据为研究对象,采用生存分析法和内容分析法描述了地震灾害事件和台风灾害事件的网络媒体报道的生命周期,探索了影响生存过程的因素,并总结了两类灾害的媒体报道周期特征。分析发现灾难发生时的死伤人数、灾难级别和相关预警信息对灾害报道的生命周期有着明显的影响。地震的网络新闻报道具有"爆发"和"长尾"特征,台风的网络新闻报道则具有"前紧后松"的特点。该研究揭示了网络媒体对突发自然灾害事件的报道规律。
|
| [35] |
微信已经成为移动网络用户进行信息交流、知识共享和协同工作的重要工具,但迄今对于微信群的成长规律、内部社会结构和群间衍生关系仍然缺乏深入了解。本文以在线社群理论和社会认同理论为引导,对9个真实的学术活动类微信群进行了案例研究,提出了微信群演化社会动因模型。采用统计描述、社会关系网络和文本挖掘等方法对群特征随时间变化情况和群内交流文本数据进行了分析,提出了群生命周期6阶段模型,定义了群成员核心度算法并据此对群内部社会结构进行了分析,发现了群外部社会属性、群内部社会关系对群生命周期变化及群间衍生关系的影响,以及群间演化的收缩机制与资源更新规律。
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}