
 , 郭轶博, Guo Yibo
, 郭轶博, Guo Yibo【目的】从社交媒体用户生成内容中发现未知情感词, 构造领域情感词典, 应用于汽车评论的情感分析。【方法】选取HowNet情感词典作为种子, 以实际汽车评论作为语料, 分别利用PMI和Word2Vec算法识别新词情感极性, 根据集成规则对二者识别结果综合判定, 通过情感分类实验对比显示本文算法的有效性。【结果】按照该方法构造的情感词典准确率比HowNet情感词典提高21.6%, 较分别使用PMI和Word2Vec算法构建的词典分别提升3.7%和2.1%, 同时正面、负面情感词数量均有大幅增加。【局限】语料来源单一, 应用于其他领域具有一定局限性。【结论】该方法构造的情感词典可有效应用于社交媒体文本情感分析。
[Objective] This study aims to construct a domain sentiment lexicon by discovering unrecognized sentiment words from user-generated contents on Chinese social media to apply it to automotive comments sentiment analysis. [Methods] First, words in HowNet are selected as the seeds, and PMI and Word2Vec algorithm are used to calculate the sentiment polarity of the candidates respectively on real automative corpus. Then the results of the two discriminations are judged synthetically according to the ensemble rules. Finally the proposed method was shown effective by the comparison of the sentiment classification experiments. [Results] The accuracy rate of the lexicon constructed according to proposed method is 21.6% higher than that of HowNet. The lexicon constructed by PMI and Word2Vec respectively increase 3.7% and 2.1%. Meanwhile the number of positive and negative emotional words are greatly increased. [Limitations] The source of corpus is single, and it has certain limitations in guiding other fields. [Conclusions] The sentiment lexicon constructed by this method can be applied to sentiment analysis of social media texts effectively.
情感词典是社交媒体文本情感分析的重要技术手段[1,2], 情感词典的表现效果很大程度取决于情感词的选择。一个拥有准确情感倾向同时能够覆盖大部分情感词的情感词典, 在文本的情感分类、主题分类等任务中能够获得较高的准确率[3]。随着社交媒体内容的多元化发展, 情感词典的领域特性日益明显, 新词、专有名词不断涌现, 传统的通用情感词典由于覆盖度低无法涵盖领域依赖的情感词。因此, 基于种子词进行领域内自动扩展构建情感词典的方法成为当前一项热门研究内容, 其核心问题在于如何准确判别未知新词的情感极性。本文提出一种面向中文社交媒体汽车领域环境下情感词典自动扩建方法, 利用点互信息PMI和词向量Word2Vec算法分别判断候选词的情感极性, 再根据本文提出的集成规则对情感词进行最终倾向判别, 从而快速构建出具有较好分类效果的领域情感 词典。
情感词典构建方法主要分为人工标注和自动扩展两种方式。早期情感词典多是由专家标注情感词人工构建而成, 例如英文领域著名的WordNet词典[4]、General Inquirer(GI)词典[5]、SentiWordNet[4]词典、Opinion Lexicon等, 中文领域常见的如知网情感库HowNet词典[6]、中国台湾大学通用中文情感词典NTUSD[7]等。人工标注构建的方法耗时费力, 只能识别有限的情感词, 而且不能很好地适应社交媒体环境下文本的情感分析任务。一方面, 社交媒体环境下文本新词多, 词语多义现象普遍, 传统的情感词典很难覆盖到新的情感词, 同时也无法甄别早期情感词的新情感倾向变化情况。另一方面, 社交媒体的文本内容具有领域特征, 而早期的情感词典只包含通用情感词, 无法适应社交媒体多领域的特点。文献[8]发现利用通用的情感词典进行特定领域的情感分析, 可能会造成严重的信息误判, 因此无法胜任社交媒体环境下用户生成内容的情感分析任务。
对专家标注的情感词作为种子进行自动扩展得到领域情感词典是目前主流的做法。扩展的核心问题是衡量候选词与种子词之间的距离, 从而计算新词的情感极性。目前, 自动扩展的构建方法可以分为基于词间共现概率法和语义相似度衡量法两种。词间共现(Co-occurrence)概率是一种统计量, 可用于发现情感词。基于这种思想的方法有点互信息PMI(Pointwise Mutual Information)[9]、SO-PMI(Semantic Orientation- Pointwise Mutual Information)[10]等。这种方法的原理是通过使用一个足够大的语料库计算两个词或词组之间的文本共现率, 从而衡量未知情感极性的新词与已知情感极性的种子词之间的紧密程度。文献[11]面向英文社交平台股票领域, 将候选词分为4类8个集合, 使用PMI算法计算不同候选词和不同情感词典情况下扩展得到的情感词典。文献[12]以图书评论作为语料, 人工选取7类情感种子词, 利用改进的SO-PMI算法构建一个面向中文图书评论领域的情感词典并取得一定效果。文献[13]提出一个两阶段的领域情感词典构建方法, 其中第一阶段使用PMI计算每个新词的情感倾向。但是利用共现情况或者互信息衡量两个词的联系紧密程度, 需要依赖情感词在语料库中的分布规律。无法保证大规模较为完整的语料库时, 若某一情感词在一条语料下出现次数较多而在其他语料下出现次数很少甚至不出现, 这样将无法计算候选词与种子词之间的情感值。
利用语义衡量候选词与种子词之间的距离是另一种主要的识别新词情感极性的方法。早期主要通过HowNet计算语义相似度。这种方法也是通过选择一些已知情感词作为种子, 然后衡量新词与种子词之间的紧密程度。与PMI方法使用共现率衡量不同, 这种方法是基于知网的相似度计算。文献[14]使用HowNet的语义相似度计算一个词与正面词集和负面词集的相似度差值作为新词的情感极性。但是这种计算语义相似度的方法严重依靠知网词典的完善性。Word2Vec[15]是一种通过神经网络语言模型将语料库中的词映射到N维向量空间的高效工具, 利用大量的文本阅读充分学习语料库中全局的语法信息和语义信息, 然后通过神经网络训练的模型将词映射成固定维度的向量, 使得将对文本的处理简化为N维空间向量的运算。近年, Word2Vec越来越多地应用于文本分析相关领域。基于Word2Vec的情感词典扩建方法能够同时考虑语义信息以及词语的领域特征, 在处理不同文字、但是在相似语境下的词具有明显的优势。文献[16]发现, 通过这种方法映射的向量计算出余弦相似度能够很好地反映词之间的语义关系程度。文献[17]对情感进行10种维度细粒度的划分, 使用大规模的语料利用Word2Vec构建多维度的跨领域通用情感词典。文献[18]通过人工筛选和Word2Vec词聚类构建情感词典, 并通过实验证明该词库比一般情绪词表在准确率上有提升。但具有相同语义的词并非带有相同的情感, 另外也需要保证语义相似度计算的准确率, 因为有些语义非常相似的词但余弦相似性可能并不高, 这依赖于Word2Vec内部的参数设置。
综上, 使用点互信息和语义相似度均可以判别候选词的情感极性。但是PMI和Word2Vec算法本身需要满足严格的条件, 前者依赖情感词在语料库中的分布规律, 需要完备的语料库作为支撑; 后者依赖神经网络内部的参数调整以保证准确表达并计算语义。为克服这两种方法的局限性, 本文提出一种融合PMI和Word2Vec识别的领域情感词典扩建方法。
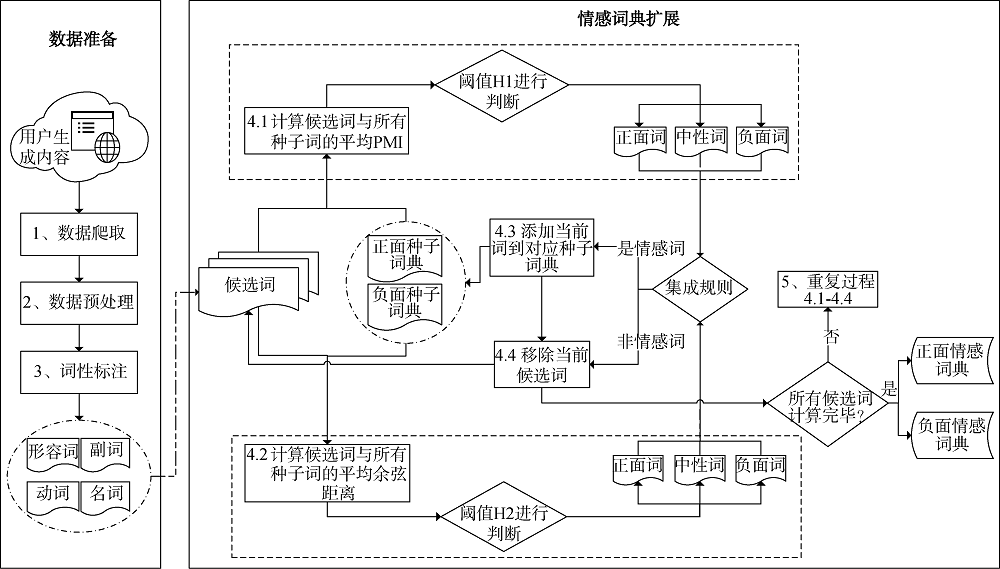
本文构建中文社交媒体环境下基于PMI和Word2Vec混合识别的领域情感词典自动扩展框架, 如图1所示。该框架包含两个子过程:
(1) 数据准备阶段, 这一过程主要是将社交媒体环境下半结构化、非结构化的用户生成内容转化为结构化的、有利于下一步分析使用的文本数据, 具体包括数据爬取、数据预处理、词性标注三个环节。此阶段产出从语料库中提取的候选词。
(2) 情感词典扩建阶段, 这一过程是进行情感词的识别并构建最终的词典, 具体包括利用PMI计算共现率和利用Word2Vec计算语义相似度分别判断候选词的极性, 然后通过集成规则将候选词分类到相应的集合中, 最终构造出领域情感词典。
形容词和副词具有天然的情感极性, 因此多数现有文献[12,19]在构建情感词典时将形容词和副词作为潜在的情感词。但是部分的动词和名词也是拥有情感的, 这种特点在领域环境下尤为突出。如“这款车经常漏油!”, 此句中的动词“漏油”是一个明显的负面情感词。再比如: “真奇葩!每次启动都是龟速!”, 此句中的名词“奇葩”和“龟速”的情感极性都是负面的。文献[11]证明了英文环境下股票领域和政治领域词性的不同会带来情感词典表现差异, 但是中文和英文具有明显的语言差异, 尚没有研究文献表明中文环境下汽车领域情感词的词性对情感词典的效果具有明显差异。笔者认为在中文环境下情感词的词性会影响情感词典的表现。因此, 在本文提出的情感词典自动扩展框架中, 当进行词性标注后只保留名词、动词、形容词和副词这4类词作为潜在的情感词, 候选词集使用这4类词的组合: 形容词+副词、形容词+副词+动词、形容词+副词+名词、形容词+副词+动词+名词。
PMI可以通过计算两个词或词组之间的文本共现率从而衡量它们之间的相似性[9], 因此使用PMI计算候选词与种子词之间的共现率。假设用${{w}_{1}},{{w}_{2}}$分别代表两个词或词组, 则PMI的计算如公式(1)所示。
$PMI({{w}_{1}},{{w}_{2}})=\mathrm{lo}{{\mathrm{g}}_{2}}\frac{p({{w}_{1}},{{w}_{2}})}{p({{w}_{1}})p({{w}_{2}})}$ (1)
其中, $p({{w}_{i}})$表示${{w}_{i}}$在语料库中出现的概率, $p({{w}_{1}},{{w}_{2}})$表示${{w}_{1}},{{w}_{2}}$在语料库中同时出现的概率, $PMI({{w}_{1}},{{w}_{2}})$表示${{w}_{1}},{{w}_{2}}$的关联程度。通过PMI公式计算候选词与种子词典里所有正面种子和负面种子的平均关联程度, 由此计算出候选词
$\begin{align} & SentiScore(word)=\frac{1}{{{N}_{pos}}}\sum\limits_{i=1}^{{{N}_{pos}}}{PMI(word,posSee{{d}_{i}})-} \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \frac{1}{{{N}_{neg}}}\sum\limits_{j=1}^{{{N}_{neg}}}{PMI(word,negSee{{d}_{j}})} \\ \end{align}$(2)
其中, $posSee{{d}_{i}}$和$negSee{{d}_{j}}$分别表示种子词典中的正面情感词和负面情感词, 对应的${{N}_{pos}}$和${{N}_{neg}}$分别表示正面情感词个数和负面情感词个数。因此, 使用PMI判断候选词
$polarity(word)=\left\{ \begin{align} & positive\ \ SentiScore(word)>{{H}_{1}} \\ & neutral\ \ \ -{{H}_{1}}<SentiScore(word)<{{H}_{1}} \\ & negative\ SentiScore(word)<-{{H}_{1}} \\ \end{align} \right.$(3)
其中, 阈值${{H}_{1}}$是一个非负数。当计算的候选词情感得分大于${{H}_{1}}$时, 该候选词被识别为正面词, 添加到正面种子词典; 当情感得分小于-${{H}_{1}}$时, 被识别为负面词, 对应添加到负面种子词典; 当情感得分介于-${{H}_{1}}$和${{H}_{1}}$时, 该候选词被识别为中性词。显然, 阈值${{H}_{1}}$越小, 最终的情感词典规模越大, 但是也有可能带来更多噪音, 影响情感分类的准确率。因此, 本文通过敏感性分析调整最佳阈值${{H}_{1}}$。
Word2Vec技术能够将语料库中的每个词映射成固定维度的向量, 当使用这种方法构造的词向量在计算两个词之间的夹角余弦距离时, 向量的夹角余弦值反映两个词之间的语义相似度[20,21]。假设用${{w}_{1}},{{w}_{2}}$分别代表两个词或词组, 利用Word2Vec将词映射成
$\cos ({{w}_{1}},{{w}_{2}})=\frac{\sum\limits_{i=1}^{n}{{{x}_{i}}{{y}_{i}}}}{\sqrt{\sum\limits_{i=1}^{n}{x_{i}^{2}}}\sqrt{\sum\limits_{i=1}^{n}{y_{i}^{2}}}}$ (4)
$\begin{align} & SentiScore(word)=\frac{1}{{{N}_{pos}}}\sum\limits_{i=1}^{{{N}_{pos}}}{\cos (word,posSee{{d}_{i}})-} \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \frac{1}{{{N}_{neg}}}\sum\limits_{j=1}^{{{N}_{neg}}}{\cos (word,negSee{{d}_{j}})} \\ \end{align}$(5)
其中, 计算向量${{w}_{1}},{{w}_{2}}$的夹角余弦, 亦即${{w}_{1}},{{w}_{2}}$两个词之间的语义相似度。公式(5)计算在使用语义相似度的情况下候选词
$polarity(word)=\left\{ \begin{align} & positive\ \ SentiScore(word)>{{H}_{2}} \\ & neutral\ \ \ -{{H}_{2}}<SentiScore(word)<{{H}_{2}} \\ & negative\ \ SentiScore(word)<-{{H}_{2}} \\ \end{align} \right.$ (6)
其中, 参数${{H}_{2}}$是一个非负数。与利用PMI判断候选词的情感极性类似, 当阈值${{H}_{2}}$越大, 则识别的情感词数量越少; 当阈值${{H}_{2}}$越小, 则识别的情感词数量越多, 但是也会识别出较多不相关的情感词, 从而造成情感词典表现效果的下降。因此, 需要通过敏感性分析设置合理的阈值${{H}_{2}}$。
集成学习是一种常用且有效的机器学习方法, 基本思想是先训练构造出一组基学习器, 然后设计特定的规则将基学习器的结果进行融合作为最终的模型输出[20]。假设有
传统的投票规则Majority Vote Rule将每个基分类器的权重都视为单位1, 直接比较每个类标
假设1: $P({{Y}_{-1}})<P({{Y}_{0}})P({{Y}_{1}})<P({{Y}_{0}})$
假设2: 若
提出假设1是因为在一个足够大的语料库中正面词、负面词出现的频率要小于中词性, 从而分类器对某个候选词分成正面词、负面词的概率小于分成中性词的概率。提出假设2是因为在
$max\left\{ \sum\limits_{{{C}_{1}},{{C}_{2}}}{{{Y}_{-1}}/P({{Y}_{-1}})},\sum\limits_{{{C}_{1}},{{C}_{2}}}{{{Y}_{0}}/P({{Y}_{0}}),}\sum\limits_{{{C}_{1}},{{C}_{2}}}{{{Y}_{1}}/P({{Y}_{1}})} \right\}$ (7)
在Adjusted Majority Vote Rule规则下, 两个分类器的融合规则是计算每个类标所获投票数与每个类标的分类概率乘积, 取结果最大的所在类标作为最终分类结果。例如当
从汽车之家的论坛频道[25]获取评论作为汽车领域用户生成内容的语料库, 删除只有标点符号而无文字的评论后共计309 937条。为构造测试集, 从语料库中随机抽取5 000条评论进行人工标注, 标注过程请三位研究生共同参与。本文关注情感词典进行二分类任务的准确率, 因此删除标注结果里的中性和无关评论。为剔除数据不平衡对分类带来的影响, 只保留等量的正面和负面评论, 最终测试集包含正面评论和负面评论各600条。使用HowNet情感词典作为种子词典, 其中褒义词数836个, 贬义词1 254个。
数据预处理方面, 使用Python调用jieba[26]分词包进行中文分词和词性标注, 加入搜狗输入法词库频道的汽车词库[27]作为用户词典。词性标注环节保留名词、动词、形容词和副词作为候选词, 其中名词的数量大约是其他三类候选词总数的两倍多。因为有些名词很少含有情感, 为了提高实验的效率, 将专有名词、地点名词、人物名词从名词候选词集中进行剔除。将候选词集按照词性分成4组, 每组候选词的词性和数量如表2所示。
将不同方法构造的情感词典在测试集上进行情感分类实验, 通过对比情感词典的表现差异以验证方法的有效性。利用SentiStrength[28]情感分析工具进行文本情感二分类任务, 评价指标选择准确率(Accuracy)。首先需要确定基于PMI和基于Word2Vec扩展方法的最优候选词集和阈值。这一过程设计9组实验, 每组的情感词典如表3所示, 对每组在测试集上的分类准确率为标准进行敏感性分析, 从中获得准确率最高情况下的参数组合。
表4和表5分别表示在基于PMI扩展方法下和在基于Word2Vec扩展方法下不同的候选词集与阈值
表4和表5分别显示
表6通过5组对比实验展示不同扩展方法生成的情感词典准确率。
第4组MajorityVoteRule_Lexicon表示使用传统投票法规则的基于PMI和Word2Vec方法生成的词典, 平均准确率为0.849。第5组AMVR_Lexicon代表使用本文提出的Adjusted Majority Vote Rule的基于PMI和Word2Vec方法生成的情感词典。其准确率达到最高的0.862, 高于第4组1.3%。第4组和第5组词典的平均准确率分别高于第1组原始情感词典HowNet 20.3%和21.6%, 高于第2组使用PMI得到的PMI_How Net_best词典2.4%和3.7%, 高于第3组使用Word2Vec得到的Word2Vec_HowNet_best词典0.8%和2.1%。上述结果说明综合利用PMI和Word2Vec构造情感词典能显著提高准确率, 同时验证了本文提出的AMVR投票集成规则在识别情感词分类场景下准确率要优于传统的投票集成规则。另外, 第5组词典的正面情感词数、负面情感词数均多于对比组HowNet、PMI_HowNet_best、Word2Vec_HowNet_best, 说明AMVR投票集成规则能同时准确覆盖较多的领域情感词汇。表7展示了使用ARVR集成规则构造的领域情感词典的部分情感词。
针对现有情感词典自动构建过程中使用单一识别算法存在的缺点进行改进, 综合点互信息和语义相似度识别新词的情感极性。情感分类对比实验表明该方法在保证准确率提升的同时, 能够大幅增加识别的情感词数量。另外通过实验验证了情感词典的词性分布能够影响情感词典表现效果。
由于语料来源单一, 所提出的领域情感词典扩展框架具有一定的局限性。后期计划应用于不同的业务场景, 以验证这种框架在不同领域的适应性。
蒋翠清: 提出研究思路, 设计研究方案;
郭轶博, 刘尧: 分析数据;
郭轶博: 完成实验, 撰写论文;
蒋翠清, 郭轶博, 刘尧: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail:guoyibo2016@163.com。
[1] 蒋翠清, 郭轶博, 刘尧. UGC_corpus.txt. 汽车评论语料数据.
[2] 郭轶博. PMI.py. PMI实验脚本程序.
[3] 郭轶博. Word2Vec.model. 词向量输出文件.
[4] 郭轶博. SentiStrength_output.xlsx. 情感分析标记结果和输出结果文件.
| [1] |
[本文引用:1]
|
| [2] |
61We explore the expansion of lexicon-based sentiment analysis from English to Dutch.61We map sentiment from an English lexicon to a new one for Dutch through semantics.61Our method significantly outperforms machine translation approaches.61Language-specific lexicon creation has potential as well, if large seed sets exist.61Sentiment not only relates to word meanings, but also has language-specific aspects.
|
| [3] |
61An effective and efficient method to detect the popular use-invented new words in Chinese microblogs.61Three kinds of heterogenous sentiment knowledge are extracted for building sentiment lexicon.61A unified framework incorporating various kinds of sentiment knowledge for microblog-specific sentiment lexicon construction.61Our microblog-specific sentiment lexicon outperforms existing sentiment lexicons.
|
| [4] |
[本文引用:2]
|
| [5] |
[本文引用:1]
|
| [6] |
[本文引用:1]
|
| [7] |
<p>情感词典作为判断词语和文本情感倾向的重要工具, 其自动构建方法已成为情感分析和观点挖掘领域的一项重要研究内容. 本文整理了现有的中、英文情感词典资源, 同时分别从知识库、语料库、以及两者结合的角度, 归纳现有英文和中文情感词典的构建方法, 分析了各种方法的优缺点, 并总结了情感词典构建中的若干难点问题. 之后, 我们回顾了情感词典性能评估方法及相关评测竞赛. 最后总结了情感词典构建任务的发展前景以及一些亟需解决的问题.</p>
|
| [8] |
ABSTRACTPrevious research uses negative word counts to measure the tone of a text. We show that word lists developed for other disciplines misclassify common words in financial text. In a large sample of 10-Ks during 1994 to 2008, almost three-fourths of the words identified as negative by the widely used Harvard Dictionary are words typically not considered negative in financial contexts. We develop an alternative negative word list, along with five other word lists, that better reflect tone in financial text. We link the word lists to 10-K filing returns, trading volume, return volatility, fraud, material weakness, and unexpected earnings.
|
| [9] |
[本文引用:2]
|
| [10] |
|
| [11] |
61We propose a method to adapt existing sentiment lexicons for domain-specific sentiment classification.61The proposed method addresses challenges from both content domain and language domain.61We evaluate our method using two large developing corpora and five existing sentiment lexicons as seeds and baselines.61The evaluation results demonstrate the usefulness of our method.
|
| [12] |
【目的】探讨中文图书评论情感词典构建方法,以便进行用户图书评论的情感分析。【方法】参照相关研究将用户情感分为7类,对采集到的语料库进行分词,结合基础情感词典得到中文图书评论的情感词集,选取各类情感种子词;利用改进的SO-PMI算法和同义词词林扩展方法判别词语的情感类别;以实际的图书评论作为语料进行实验验证。【结果】提出一种中文图书评论的情感词典构建方法,其平均准确率、平均召回率及F1的均值分别为0.90、0.83和0.85。【局限】语料库小,样本范围具有一定的局限性。【结论】实验结果表明本文方法具有较高的有效性和可靠性,能够有效地进行用户图书评论的情感分析。
URL
[本文引用:2]
|
| [13] |
领域情感词典是情感分析最重要的基础。由于产品评论的数量巨大、领域众多,如何自动构建领域情感词典已经成为近年来的一个研究热点。该文提出了一个两阶段的领域情感词典构建算法。第一阶段,利用情感词间的点互信息和上下文约束,使用基于约束的标签传播算法构造基本情感词典;第二阶段,根据情感冲突的频率来识别领域相关情感词,并根据其上下文约束以及修饰的特征完善领域情感词典。实验结果表明,该方法在实际产品评论数据集上取得了较好的效果。<br/>
|
| [14] |
在互联网技术快速发展、网络信息爆炸的今天,通过计算机自动分析大规模文本中的态度倾向信息的技术,在企业商业智能系统、政府舆情分析等诸多领域有着广阔的应用空间和发展前景。同时,语义褒贬倾向研究也为文本分类、自动文摘、文本过滤等自然语言处理的研究提供了新的思路和手段。篇章语义倾向研究的基础工作是对词汇的褒贬倾向判别。本文基于HowNet,提出了两种词汇语义倾向性计算的方法:基于语义相似度的方法和基于语义相关场的方法。实验表明,本文的方法在汉语常用词中的效果较好,词频加权后的判别准确率可达80%以上,具有一定的实用价值。
|
| [15] |
[本文引用:1]
|
| [16] |
[本文引用:1]
|
| [17] |
情感词典的构建是文本挖掘领域中重要的基础性工作。近几年,情感词典的极性标注从二元褒贬标注向多元情绪标注发展,词典的领域特性也日趋明显。但是情感类别的手工标注不但费时费力,而且情感强度难以得到准确量化,同时对领域性的过分关注也大大限制了情感词典的适用性[1]。通过神经网络语言模型对大规模中文语料进行统计训练,并在此基础上提出了基于转换约束集的多维情感词典自动构建方法;然后研究了基于词分布密度的感情色彩消歧方法,对兼具褒贬意味词语的感情极性进行区分和识别,并分别计算两种感情色彩下的情感类别与强度;最后提出基于多个语义资源的全局优化方案,得到包含10种情绪标注的多维汉语情感词典SentiRuc。实验证实该词典1)在类别标注检验、强度标注检验、情感消歧效果及情感分类任务中均具有良好的效果,其中的情感强度检验证实该词典具有极强的情感语义描述力。
|
| [18] |
[目的/意义]通过基于Word2vec的文本情感分析技术对某显示器品牌的产品与服务的在线评论进行分析,研究消费者的品牌认知和品牌口碑,为管理者建立更科学的品牌管理体系提供有针对性的建议。[方法/过程]首先利用自然语言处理技术,对评论语料库进行预处理,结合深度学习的Word2vec词向量技术构建产品特征词和情感词词库,进一步构造情感概念对进行情感评分,并将其用于分析品牌产品特定特征的用户情感。[结果/结论]通过Word2vec构建的情感词典相较于传统方法(例如一般的情绪词表)进行情感分析,在情感分析的准确率上有所提高,再结合有效的情感概念对构造与情感评分,可以有效地理解用户的品牌认知。
|
| [19] |
[本文引用:1]
|
| [20] |
Ensemble of Classifiers are composed of parallel-organized components (individual classifiers) whose outputs are combined using a combination method that provides the final output for an ensemble. In this context, Dynamic Ensemble Systems (DES) is an ensemble-based system that, for each test pattern, a different ensemble structure is defined, in which a subset of classifiers is selected from an initial pool of classifiers. During the selection process of a DES, any criterion can be used, being the most important ones accuracy and distance. Distance measures are used to assess the distance of the classifier outputs within a validation set and the main examples of this measure are diversity and similarity. In this paper, we investigate the impact of selection criteria in DES methods. More specifically, we focus on the use of different distance measures (diversity and similarity) as selection criteria. In other to do this, an empirical analysis has been conducted using six different DES methods (three of them are existing methods and the remaining three are proposed in this paper) and with 20 different classification datasets. Our findings indicated that a distance measure improves the overall performance of the state-of-the-art ensemble generation methods.
|
| [21] |
[本文引用:3]
|
| [22] |
情感分类是目前自然语言处理领域的一个具有挑战性的研究热点,该文主要研究基于半监督的文本情感分类问题。传统基于Co-training的半监督情感分类方法要求文本具备大量有用的属性集,其训练过程是线性时间的计算复杂度并且不适用于非平衡语料。该文提出了一种基于多分类器投票集成的半监督情感分类方法,通过选取不同的训练集、特征参数和分类方法构建了一组有差异的子分类器,每轮通过简单投票挑选出置信度最高的样本使训练集扩大一倍并更新训练模型。该方法使得子分类器可共享有用的属性集,具有对数时间复杂度并且可用于非平衡语料。实验结果表明我们的方法在不同语种、不同领域、不同规模大小,平衡和非平衡语料的情感分类中均具有良好效果。
|
| [23] |
The class imbalance problems have been reported to severely hinder classification performance of many standard learning algorithms, and have attracted a great deal of attention from researchers of different fields. Therefore, a number of methods, such as sampling methods, cost-sensitive learning methods, and bagging and boosting based ensemble methods, have been proposed to solve these problems. However, these conventional class imbalance handling methods might suffer from the loss of potentially useful information, unexpected mistakes or increasing the likelihood of overfitting because they may alter the original data distribution. Thus we propose a novel ensemble method, which firstly converts an imbalanced data set into multiple balanced ones and then builds a number of classifiers on these multiple data with a specific classification algorithm. Finally, the classification results of these classifiers for new data are combined by a specific ensemble rule. In the empirical study, different class imbalance data handling methods including three conventional sampling methods, one cost-sensitive learning method, six Bagging and Boosting based ensemble methods, our previous method EM1vs1 and two fuzzy-rule based classification methods were compared with our method. The experimental results on 46 imbalanced data sets show that our proposed method is usually superior to the conventional imbalance data handling methods when solving the highly imbalanced problems. (C) 2014 Elsevier Ltd. All rights reserved.
|
| [24] |
Learning from imbalanced data, where the number of observations in one class is significantly rarer than in other classes, has gained considerable attention in the data mining community. Most existing literature focuses on binary imbalanced case while multi-class imbalanced learning is barely mentioned. What's more, most proposed algorithms treated all imbalanced data consistently and aimed to handle all imbalanced data with a versatile algorithm. In fact, the imbalanced data varies in their imbalanced ratio, dimension and the number of classes, the performances of classifiers for learning from different types of datasets are different. In this paper we propose an adaptive multiple classifier system named of AMCS to cope with multi-class imbalanced learning, which makes a distinction among different kinds of imbalanced data. The AMCS includes three components, which are, feature selection, resampling and ensemble learning. Each component of AMCS is selected discriminatively for different types of imbalanced data. We consider two feature selection methods, three resampling mechanisms, five base classifiers and five ensemble rules to construct a selection pool, the adapting criterion of choosing each component from the selection pool to frame AMCS is analyzed through empirical study. In order to verify the effectiveness of AMCS, we compare AMCS with several state-of-the-art algorithms, the results show that AMCS can outperform or be comparable with the others. At last, AMCS is applied in oil-bearing reservoir recognition. The results indicate that AMCS makes no mistake in recognizing characters of layers for oilsk81-oilsk85 well logging data which is collected in Jianghan oilfield of China.
|
| [25] |
URL
[本文引用:1]
|
| [26] |
URL
[本文引用:1]
|
| [27] |
URL
[本文引用:1]
|
| [28] |
[本文引用:1]
|



{kind=link}
{kind=link}