
 , 都云程, Du Yuncheng
, 都云程, Du Yuncheng【目的】通过隐马尔科夫模型解决新闻网页中标题、日期、来源、正文等关键信息抽取问题, 并根据应用场景对算法做出改进以提高抽取效果。【方法】将网页文档转为DOM树并进行预处理, 映射待抽取信息项为状态, 映射待抽取观测项为词汇, 研究隐马尔科夫模型在网页新闻关键信息抽取中的应用并对算法提出改进。【结果】使用隐马尔科夫模型的改进算法, 在已构建抽取模型的网站中, 平均准确率可达97%。【局限】抽取模型在分类能力上稍有不足, 无法对细微差别信息进行准确抽取。【结论】该方法具有识别准确率高、建模能力强、训练数据小、训练速度快的优点。
[Objective] This paper aims to solve key information extraction problems in news web pages, such as title, date, source, and text, by Hidden Markov Model (HMM). [Methods] The web document was transformed into a DOM tree and preprocessed. The information items to be extracted were mapped to state, and the observation value of the extracted items was mapped to vocabulary. The application of HMM in key information extraction of web news was studied, and the algorithm was improved. [Results] Using the improved HMM algorithm, the accuracy rate can reach 97% on average in the websites. [Limitations] The extraction model is slightly insufficient in classification ability, and it is impossible to accurately extract the slightly differences. [Conclusions] The experiment proves that this method has the advantages of high recognition accuracy, strong modeling ability, and fast training speed with small set of tracing data.
随着互联网的迅速发展, 网页中信息呈指数级增长[1], 新闻网站作为人们获取信息的重要工具而蓬勃发展, 新闻网页中的关键信息如标题、日期、来源、正文对舆情分析有着重要意义[2]。但是新闻网页中广告、导航栏、评论等噪音信息较多[3], 且网页文档没有统一的布局, 灵活性较强, 计算机难以直接从网页中准确提取所需信息。因此,如何准确地从半结构化的网页文档中提取出新闻关键信息成为重点和难点, 解决这一问题的主要方法是开发相应的信息抽取工具。
作为可用于标注问题的统计学模型[4], 隐马尔科夫模型由于其强大的建模能力已经成功应用于半结构化的文本信息抽取中, 在对网页信息进行抽取时, 由于待抽取项在布局上有时序性的特征, 因此使用待抽取项的格式、位置等特征信息作为词汇的抽取方法。
针对该网页信息抽取问题, 本文提出一种基于隐马尔科夫模型的网页信息抽取方法, 着重探讨隐马尔科夫模型在网页信息抽取中的应用, 并对隐马尔科夫模型在网页信息抽取中的应用提出改进。
国内外开展了很多研究自动化、半自动化地解决网页信息抽取问题。主要的网页信息抽取方法有基于模板的方法、基于统计的方法、基于网页分块的方法。
(1) 基于模板的方法
利用包装器(Wrapper)抽取网页中信息。包装器是一个程序, 它针对特定页面的布局特征, 编写解析器, 解析出待抽取信息在网页中的位置。
基于模板的方法具有配置简单、易于实现的优点, 且由于针对特定页面编写解析器, 抽取的准确率极高; 缺点是通用性较差, 针对不同的网页通常需要编写不同规则, 不适合大规模页面的抽取, 并且一旦页面布局发生细微改动, 就可能导致抽取失败。
基于模板的网页信息抽取维护成本较高, 许多研究者也针对如何较为容易地构造出一个包装器所需规则做了大量工作。文献[5]介绍一种包装器感应方法, 使用一组数据样本对XPath进行排序, 以确定它们是否适合从某个站点的Web页面中提取特定字段, 实现自动动态包装器的创建。文献[6]使用卷积神经网络学习一个包装器, 可以从看不见的模板中提取信息。因此, 这个包装器不需要任何特定于站点的初始化, 并且能够从单个Web页面中提取信息。
这种方法在一定程度上降低了包装器的维护成本, 却没有从根本上解决该方法的种种弊端。但由于基于模板的方法具有准确率极高且易于实现的优点, 在业界得到广泛应用。
(2) 基于统计的方法
从不同角度对网页特征进行提取, 采用统计学的算法进行特征统计, 进而抽取信息, 是当前网页信息抽取研究中比较受关注的方法。文献[7,8,9]分别从不同角度对页面中标签属性、文本密度、DOM树路径等特征进行统计, 使用不同的统计学算法对其进行分析。本文将要讨论的网页新闻关键信息抽取是一种基于统计的抽取方法, 主要从待抽取信息的标签属性和DOM树路径的角度进行分析。
这种方法的优点是与基于模板的方法相比通用性好且维护成本较低, 无需对特定网页单独编写规则。缺点是准确率相对较低, 且训练数据量较大, 在实际应用中通常会借鉴模板方法的经验, 能够在一定程度上提高信息抽取的准确率。
(3) 基于网页分块的方法
针对网页中内容布局结构特征, 从不同角度使用不同方法对网页内容进行分块, 找到待抽取信息所在信息块。文献[10]提出基于视觉特征分块的网页信息抽取方法, 使用VIPS算法将DOM树划分为语义块, VIPS算法是微软亚洲研究院提出的基于视觉的语义块提取方法。根据块的位置找到标准块, 然后将标准块作为中心块, 通过逆向遍历DOM树查找所有相似的视觉块, 即所有待抽取的信息块。文献[2]针对新闻网页正文抽取问题, 利用新闻网页在页面布局上的特征, 基于分块对噪音块进行清洗, 并根据起始块和终止块对新闻内容进行抽取。
这种方法的优点是通用性较好, 缺点是实验过程较为复杂, 如VIPS算法中的赋值过程要遵循的规则较多, 且抽取的信息块中仍有少量噪音。因此, 基于分块的方法有待进一步改进。
隐马尔科夫模型(Hidden Markov Model, HMM)是时间序列的概率模型, 描述了由隐藏的状态序列组成的一条马尔科夫链和由其中的每一个状态生成的观测所构成的观测序列。序列中每一个位置都可视为一个时刻[11]。
马尔科夫模型中状态是不可见或不确定的, 只有状态生成的观测是可以被直接观察到的[12], 状态的值由通过训练生成模型参数再由识别算法解码得到状态序列确定。隐马尔科夫模型生成的状态随机序列$I=({{i}_{1}},{{i}_{2}},\cdot \cdot \cdot ,{{i}_{T}})$, 称为状态序列; 每个状态随机发射出一个或多个观测值, 组成随机观测序列$O=({{o}_{1}},{{o}_{2}},\cdot \cdot \cdot ,{{o}_{T}})$, 称为观测序列。一个隐马尔科夫模型可用一个五元组$lambda =\{Q,V,A,B,\pi \}$表示[11], 定义如下。
$Q=\{{{q}_{1}},{{q}_{2}},\cdot \cdot \cdot ,{{q}_{N}}\}$是所有可能的状态的集合, 共
在一个隐马尔科夫模型中, 状态序列由状态转移概率分布
隐马尔科夫模型主要解决三个问题[4]。
(1) 估值问题: 已知观测序列$O=\{{{o}_{1}},{{o}_{2}},\cdot \cdot \cdot ,{{o}_{T}}\}$, 给定隐马尔科夫模型$\lambda =(A,B,\pi )$, 计算给定模型$\text{ }\!\!\lambda\!\!\text{ }$的前提下, 观测序列$O$出现的概率,解决该问题的算法一般为基于动态规划算法的前向-后向算法;
(2) 识别问题: 已知观测序列$O=\{{{o}_{1}},{{o}_{2}},\cdot \cdot \cdot ,{{o}_{T}}\}$, 给定隐马尔科夫模型$\lambda =(A,B,\pi )$, 求给定观测序列条件概率$P(I|O,\lambda )$最大的状态序列
(3) 学习问题: 已知观测序列$O=\{{{o}_{1}},{{o}_{2}},\cdot \cdot \cdot ,{{o}_{T}}\}$, 估计模型的参数$\lambda =(A,B,\pi )$, 使得在该模型下出现该观测序列概率$P(O|\lambda )$最大, 本文使用的学习算法为监督学习且计算速度较快的极大似然估计法。
本文在网页信息抽取的应用中解决的问题为学习问题和识别问题。
本文研究的基于隐马尔科夫模型的网页信息抽取模型, 具有建模速度快、效率较高、准确率较高等优势。然而, 该模型在网页信息抽取中的准确率与效率还有待进一步提高。隐马尔科夫模型在网页信息抽取中存在三个问题。
(1) 映射问题: 在隐马尔科夫模型中, 词汇集为训练数据中所有观测的集合, 在模型建立后, 将待抽取网页文档中的每一个观测映射为词汇集中的一个词汇, 然后调用维特比算法识别出最佳状态序列。本文在网页新闻关键信息抽取中, 将待抽取项DOM树节点路径映射为词汇, 而在实际应用中, 由于网页上信息的多变性与复杂性, 可能会由于词汇集中不存在该观测而出现无法直接映射的情况, 从而无法对信息进行准确识别。
(2) 数据稀疏问题: 在网页新闻信息抽取中, 由于训练数据量或待抽取项在网页中的分布情况等原因, 训练好的隐马尔科夫模型的参数$A,B,\pi$的概率分布中可能会有概率为0的情况发生, 如观测概率分布
(3) 减少计算量: 本文的隐马尔科夫模型学习算法使用最大似然估计法已极大地减少了计算量, 但在识别阶段可进一步减少计算量, 提高网页信息提取效率。
根据网页信息抽取的特点, 针对隐马尔科夫模型存在的映射观测为词汇问题、数据稀疏问题、减少计算量问题, 在实际应用中对隐马尔科夫模型做如下改进。
在本文中, 每一状态所对应的观测都是唯一确定的DOM树节点路径, 网页中包含不同状态信息的节点在DOM树中的公共路径很少, 而包含同一状态信息的节点在DOM树中的公共路径很多。针对映射观测为词汇的问题, 使用计算DOM树节点路径相似度[14]的方法, 给定一个观测, 令其在词汇集中路径相似度最大的词汇作为它的映射, 通过该方法, 对于在词汇集中存在的观测, 可找到其对应词汇; 对于词汇集中不存在的观测, 找到与其DOM树节点路径最为接近的词汇作为观测的映射。计算DOM树节点路径相似度的方法如下。
记任一DOM树节点路径为$N=\{{{N}_{a}},{{N}_{b}},{{N}_{c}},\cdot \cdot \cdot \}$, 记深度
$sim\text{(}{{T}_{A}},{{T}_{B}}\text{)}=\left\{ \begin{align} & \frac{1}{{{2}^{depth}}}\ \ {{T}_{A}}={{T}_{B}} \\ & 0\ \ \ \ \ \ \ \ \ {{T}_{A}}\ne {{T}_{B}} \\ \end{align} \right.$ (1)
据此, 给出计算任意两个节点的DOM树节点路径相似度方法如公式(2)和公式(3)所示。
$sim\text{(}{{N}_{A}},{{N}_{B}}\text{)}=\sum\nolimits_{depth=1}^{dept{{h}_{A}}}{sim\text{(}{{T}_{A}},{{T}_{B}}\text{)}}\ \ dept{{h}_{A}}\le dept{{h}_{B}}$(2)
$sim\text{(}{{N}_{A}},{{N}_{B}}\text{)}=\sum\nolimits_{depth=1}^{dept{{h}_{B}}}{sim\text{(}{{T}_{A}},{{T}_{B}}\text{)}}\ \ dept{{h}_{A}}>dept{{h}_{B}}$(3)
该方法根据等比数列求和的原理计算DOM树节点路径相似度, 例如, 对两个节点深度为5且每层节点都相等的DOM树节点路径, 相似度为$\frac{1}{{{2}^{1}}}+\frac{1}{{{2}^{2}}}+$ $\frac{1}{{{2}^{3}}}+\frac{1}{{{2}^{4}}}+\frac{1}{{{2}^{5}}}=\frac{31}{32}\approx 0.9688$。据此计算方法, 当两个DOM树节点路径完全相同且深度
本文使用拉普拉斯平滑[15](Laplace Smoothing)解决模型参数中零概率的问题, 拉普拉斯平滑的思想是用加1的方法估计没有出现过的观测的次数, 当训练数据较大时, 由每个分量
${{b}_{j}}(k)=\frac{{{B}_{jk}}+1}{\sum\nolimits_{k=1}^{M}{{{B}_{jk}}+M}}$ (4)
对未观测到值的概率处理如公式(5)所示。
${{b}_{j}}(k)=\frac{1}{\sum\nolimits_{k=1}^{M}{{{B}_{jk}}+M}}$ (5)
拉普拉斯平滑对未观测到值的概率进行相同的处理, 不区分概率分布各部分中未观测值情况出现的多少, 而实际上各部分中未观测值出现的概率数量不等, 因此对拉普拉斯平滑做出改进[14]如公式(6)所示。
${{b}_{j}}(k)={{b}_{j}}(k)-\delta$ (6)
其中, $\delta$表示未观测到值时的概率, 计算方法如公式(7)所示。
$\delta =\frac{1-\sum\nolimits_{k=1}^{M}{{{B}_{jk}}}}{\sum\nolimits_{k=1}^{M}{{{B}_{jk}}}+M}$ (7)
对初始状态概率分布$\pi $, 状态转移概率分布
针对减少计算量问题, 可以通过在隐马尔科夫模型中结合规则来解决。在一个信息抽取系统中, 除了存在不确定状态和其不确定释放的观测以外, 还有确定状态释放观察值的情况。确定状态在隐马尔科夫模型中作为已知状态, 其观测释放概率设为1。该方法通过匹配模板库, 利用规则的方法, 在使用Viterbi算法确定最佳状态序列之前确定部分状态, 既可以减少Viterbi算法循环次数, 从而减少运行时间, 提高效率, 又可以减少由于数据稀疏等问题带来的对模型参数的负面影响。
在网页新闻关键信息抽取中, 每一个HTML标签所包含的信息对应于待抽取信息中的一类或不需抽取的信息, 且待抽取信息在网页文档中的分布具有一定的次序关系, 如网页新闻关键信息之间的前后关系可能为标题、日期、来源、正文或标题、来源、日期、正文等。而隐马尔科夫模型具有考虑模式的时序性、强建模能力等优点[11], 可以利用待抽取信息在布局上的突出特点更好地建立模型, 因此, 相较于其他模型, 隐马尔科夫模型在网页信息抽取中具有较为突出的优势。
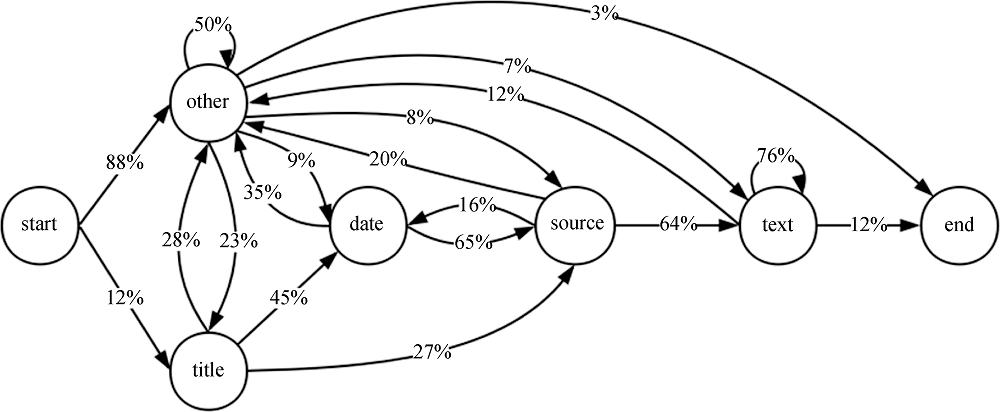
隐马尔科夫模型应用于网页新闻关键信息抽取需要每个状态对应于一个待抽取的信息, 如标题、日期、来源、正文等。一个状态转移概率示例如图1所示。
每一个状态通过观测概率分布
一个搜狐网新闻网页实例如图2所示, 包含标题、日期、来源、正文的信息。
其中, 网页文档的HTML标签序列如图3所示。
定义DOM树中叶节点到根节点的路径及叶节点或其父节点的标签属性为DOM树节点路径。
由于新闻网页中标题、日期、来源、正文等关键信息都存储在DOM树的叶节点中[8], 且不同信息的标签类型、标签属性和节点深度是不同的, 如: 标题信息一般被“<h1>”和“<h1>”标签所包围; 来源信息的标签属性值一般为“source”或“origin”; 日期节点的class属性值很可能为“date”或“time”, 且一般与来源节点的深度相同; 新闻正文一般被多个“<p></p>”标签包围且具有节点深度相等、父节点相同等特点。因此不同新闻网页的模板中相同待抽取项的位置相似, DOM树节点路径具有很高的参考价值。
令状态集
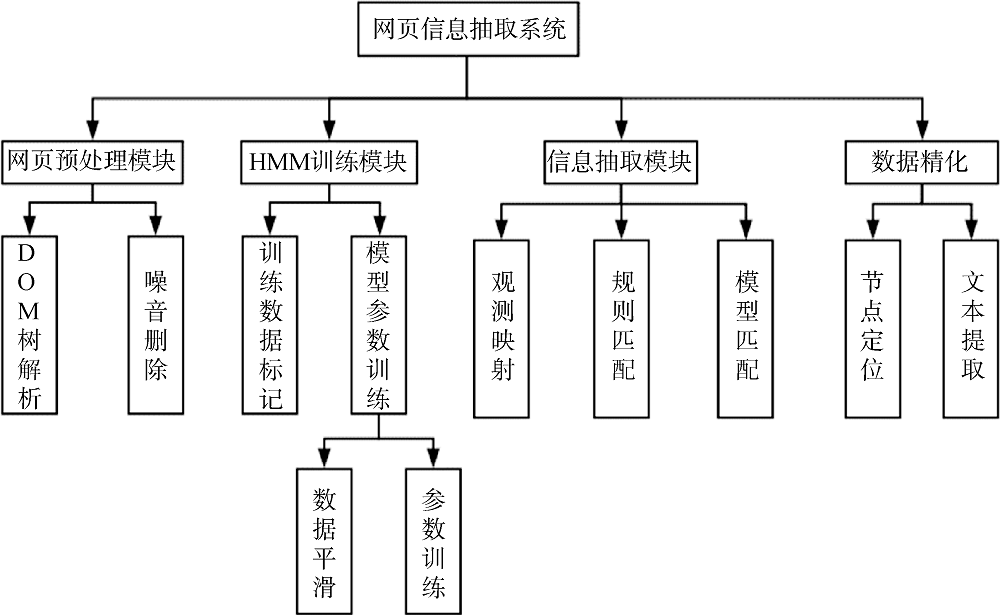
基于隐马尔科夫模型的网页新闻关键信息抽取分为网页预处理、模型训练、信息抽取、数据精化4个步骤。各个功能模块的功能结构如图4所示。
对抓取的网页进行初步处理。为减少算法计算量, 提高处理效率, 将网页文档解析为DOM树并将其中的样式、列表、脚本、注释等噪音信息删除, 提取DOM树叶节点的DOM树节点路径写入训练数据集。
本文使用Python的BeautifulSoup库进行网页文档的解析与操作, BeautifulSoup将一个网页文档解析为一棵DOM树且提供了一些简单而强大的方法来浏览、搜索、解析DOM树。利用BeautifulSoup删除噪音信息的具体步骤如表1所示。
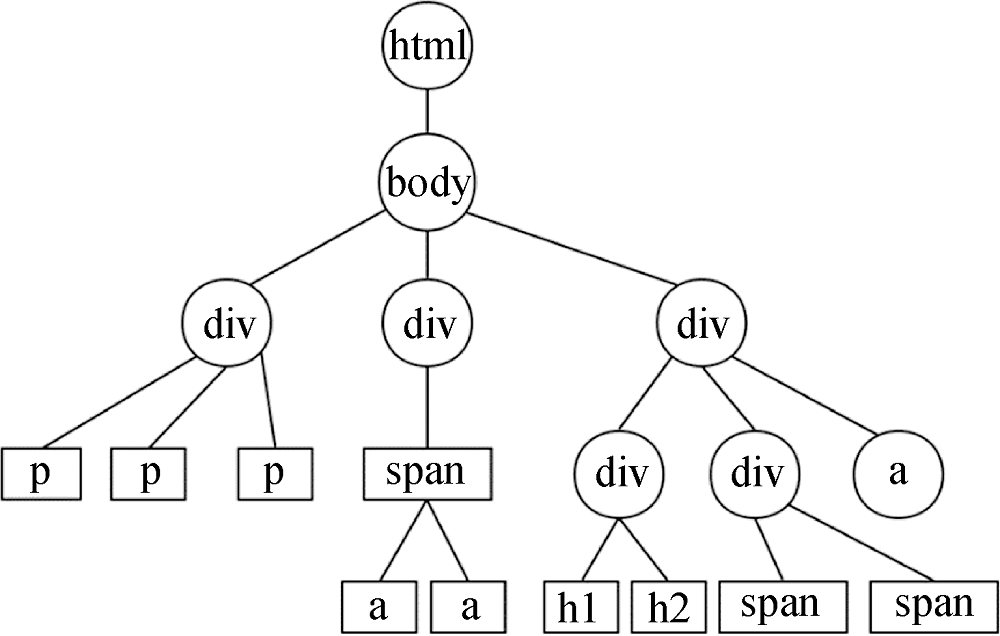
经过预处理的DOM树式样如图5所示。
遍历DOM树, 对所有的叶节点, 找出它们从根节点到叶节点的路径, 不同深度的标签以“/”分隔, 若叶节点有class属性, 则将class属性加到叶节点标签之后, 否则加入其父节点的class属性, 得到DOM树节点路径, 得到的DOM树节点路径之 间的顺序依然与原网页文档中文本间的布局顺序一致。
将网页预处理后得到的DOM树节点路径写入未标记训练数据集。去重后作为隐马尔科夫模型的词汇集合, 写入词汇数据集。每一状态的部分词汇如表2所示。
在利用模型进行信息抽取之前, 对未标记训练数据进行人工标记, 标记标题为title,日期为date, 来源为source, 正文为text, 不抽取信息为other, 在DOM树节点路径后用“+标记”的方式进行标记, 写入已标记训练数据集。标记方法如表3所示。
逐条取出已标记训练数据集中的数据, 根据“+”后的标记判断取出的训练数据所属状态, 使用隐马尔科夫模型的学习算法极大似然估计法进行概率分布的计算, 使用改进的拉普拉斯平滑方法解决数据稀疏问题, 得到训练好的模型参数$A,B,\pi$。
使用模板库中的规则进行匹配得到确定状态, 将网页预处理后得到的DOM树节点路径作为观测输入,使用最大路径相似度方法将其映射为词汇集中词汇, 使用Viterbi算法将映射后的词汇序列输入, 得到最佳状态序列, 即每一DOM树节点路径所对应信息的最可能状态所组成的序列。
根据模型识别出的DOM树节点路径所对应信息的状态, 找出对应于标题、日期、来源、正文状态的DOM树节点, 使用BeautifulSoup库中的.get_text()方法取出节点中文本信息, 调用数据库管理模块将文本信息写入表中, 至此完成新闻网页中半结构化信息抽取为结构化信息的转换。
从新浪、搜狐、腾讯、网易等16个新闻网站采集新闻网页链接, 每个新闻网站爬取500个网页作为原始实验数据。为保证数据的多样性, 同时保证实验数据的有效性, 从采集的网页中筛选出2 000篇作为训练数据, 500篇作为测试数据, 训练数据和测试数据均从每个网站中平均选取。
实验环境为Windows10系统, CPU为Intel 4核, 内存为8GB, 开发语言使用Python3.6, 开发工具使用PyCharm 2018, 网页文档爬取解析工具包采用“BeautiflulSoup”, 机器学习库使用“hmmlearn”开发。
使用精确率
$P=\frac{正确抽取出信息的节点数}{所有抽取的信息节点数}\times 100%$ (8)
$R=\frac{正确抽取出信息的节点数}{所有正确的信息节点数}\times 100%$ (9)
$F=\frac{2\times P\times R}{P+R}\times 100\text{ }\!\!%\!\!\text{ }$ (10)
两种方法实验结果对比如表6所示。
对比表4-表6可以看出, 经典隐马尔科夫模型对新闻关键信息抽取的效果较好, 且经过改进的算法进一步提高了抽取准确度。这是因为新闻网页中关键信息之间本身就有一种时序性的关系, 符合隐马尔科夫算法的思想, 且经过改进的隐马尔科夫模型中解决了平滑问题和词汇映射问题, 很大程度上避免了零概率问题对训练和抽取效果的负面影响。
纵向对比, 发现标题的抽取准确度最高, 这是因为标题普遍在标签“<h1>”和“</h1>”中, 且DOM树节点路径与其他待抽取项差异较大, 特征最为明显, 容易被模型学习到抽取规则。同理发现正文的抽取准确率也相对较高, 这是因为正文节点在DOM树中深度一般相同, 且分布较为集中, 正文节点之间的状态转移概率较高, 因此容易被模型学习到并正确抽取出来。
文献[17]也是一种基于隐马尔科夫模型的网页新闻抽取方法, 对新闻标题和正文进行抽取研究, 对网页文档中“<Title>”与“</Title>”标签所直接包含的字符串进行一定的匹配作为标题, 以标题位置作为正文的开始位置, 使用隐马尔科夫模型, 以文本内容特征作为模型的观察值, 查找正文结束位置确定正文。其抽取标题准确率为94.41%, 抽取正文准确率为92.63%。本文方法对标题和正文抽取的准确率分别为98.68%和98.05%, 由于充分考虑了网页信息抽取相较于传统文本信息抽取在布局结构上的特性, 考虑待抽取项的次序关系, 因而网页信息抽取效果更佳。
文献[18]提出的CEPR算法基于标签路径特征融合对网页新闻正文内容进行抽取, 抽取的准确率与本文基本相当, 但对网页新闻中精准的细粒度内容(如标题、日期、来源等信息)抽取不理想。而本文利用隐马尔科夫模型的时序性特征并结合网页文档的特点, 较好地实现了细粒度内容的抽取。
随着某些领域的特殊需求不断增加, 网页信息抽取的重要性不断提高, 本文使用隐马尔科夫模型进行网页新闻关键信息抽取, 并根据实际应用中的平滑问题和词汇映射问题对算法做出改进, 取得了比较好的抽取效果, 为之后的新闻内容挖掘、分类、舆情分析等工作奠定了基础[19]。
实验结果证明基于隐马尔科夫模型的网页新闻关键信息抽取具有抽取准确率高的优点; 利用最大似然估计法进行特征学习, 具有计算速度快的优点; 隐马尔科夫模型强大的建模能力带来了所需训练数据小的优点。
但该方法对细微差别的信息分类能力有所欠缺, 根据应用场景进一步改进网页信息抽取算法, 加强算法分类能力以提高信息抽取的准确率, 是今后的工作重点。
都云程, 施水才: 确定研究方向, 提出研究思路, 修改论文;
刘志强: 设计研究方案, 实验设计, 算法改进, 实验实施, 起草论文;
刘志强, 都云程, 施水才: 论文修改及最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 670625445@qq.com。
[1] 刘志强. NewsHMM.rar. 基于隐马尔科夫模型的网页新闻抽取项目代码.
[2] 刘志强. A.txt, B.txt, pai.txt. 隐马尔科夫模型训练参数.
[3] 刘志强. result.xlsx. 抽取效果数据统计表.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}