

【目的】通过自动从海量用户评论中抽取有效关键词, 帮助用户和商家快速有效地发现有价值的信息, 从而更好地为用户购买行为提供决策支持, 为商家改善服务质量提供信息反馈。【方法】界定面向用户评论的关键词抽取的问题定义, 从商家和用户两个角度提出面向用户评论的关键词抽取的评价准则; 提出一种基于语言模型的用户评论关键词抽取方法(LMKE), 采集美团网用户评论构建实验数据集, 并与TF-IDF和TextRank两种关键词抽取方法进行对比。【结果】LMKE方法在P@5、P@10、P@20、nDCG@5、nDCG@10和nDCG@20的最高得分分别为0.7665、0.6701、0.6200、0.8187、0.7326和0.6743。【局限】实验仅以美团网武汉地区自助餐厅的所有用户评论为例, 具有一定的局限性。【结论】相较于TF-IDF和TextRank, LMKE方法的效果更优, 且在LMKE方法中基于区分度的策略能获得最优评价指标。
[Objective] This paper tries to automatically extract keywords from user comments, aiming to help both buyers and sellers find valuable information. It supports the decision making of customers and provides feedbacks to improve online services. [Methods] Firstly, we defined the task of extracting keywords from user comments. Then, we proposed evaluation criteria from the perspectives of merchants and customers. Thirdly, we constructed a language model based keyword extraction method (LMKE). Finally, we collected experimental data from Meituan.com, and compared the performance of our method with two existing ones, i.e., TF-IDF and TextRank. [Results] The scores of our LMKE method were 0.7665, 0.6701, 0.6200, 0.8187, 0.7326 and 0.6743 with P@5, P@10, P@20, nDCG@5, nDCG@10 and nDCG@20. [Limitations] Our dataset was only built with user’s comments on buffet services in Wuhan, China. [Conclusions] The discriminative LMKE model has better performance than those of the TF-IDF and TextRank.
在Web2.0时代, 越来越多的用户参与到互联网信息的生产与发布过程中, 用户不再只是信息的消费者, 同时也成为信息的生产者。互联网中由用户生成的原创内容一般被称为用户生成内容(User Generated Content), 不仅丰富了互联网上的信息来源和内容, 同时也为基于数据挖掘的互联网信息服务提供了新的机遇。用户评论是用户生成内容的重要组成部分, 其包含大量用户对于产品和服务的观点、态度等有用信息, 这些信息已成为用户选择产品、商家改善服务时的重要参考[1]。例如: 出外就餐时, 人们会参考餐厅的用户评论, 从而选择口碑较好的餐厅, 而餐厅可以针对用户评论中讨论最多的内容改善服务; 计划旅游时, 人们通过用户评论比较不同的旅游景点, 从而确定旅游线路, 而旅游公司可以根据用户评论中最关心的内容设计旅游产品。然而, 海量的用户评论数据为用户和商家带来便捷的同时, 也增加了用户和商家的认知负担, 即用户和商家需要花费大量的时间和精力阅读用户评论文本, 才能发现自己所需要的有效信息[2]。
关键词标引已在新闻编辑、科技文献出版等领域经过了长期的实践检验, 关键词能够表达文档(长文本)的重点信息, 是一种有效的信息压缩和表达手段。笔者认为利用关键词对海量用户评论进行概括性表达, 是解决用户和商家认知负担的有效途径。基于上述分析, 利用用户评论信息对关键词进行抽取, 不仅可以为用户提供决策依据, 还可以为商家改善服务提供有效及时的反馈信息。
自Web2.0兴起以来, 如何从用户评论中挖掘有价值的信息为用户、商家、政府提供服务成为一个研究热点[2]。在用户评论有用性方面, 文献[3]以时间距离、社会距离和解释水平理论为基础, 在8种不同场景下分析消费者对在线用户评论的有效性评价, 其实验结果表明时间和社会距离较近时, 包含商品细节性信息或服务信息的评论更有价值, 而时间和社会距离较远时, 包含商品抽象性信息的评论更有价值; 文献[4]基于8项影响移动O2O在线评论有效性的指标, 采用模糊层次分析法和加权灰色关联分析方法构建用户评论有用性计算和排序模型, 并利用美团网用户评论数据进行验证, 结果表明其方法有效。在用户评论主题挖掘方面, 文献[5]提出一种基于改进K-means聚类的在线新闻评论主题抽取方法, 利用同义词替换和领域词典对用户评论进行预处理, 缓解数据稀疏性问题, 然后使用隐藏长评论—最大距离法选取K-means算法的聚类初始点, 进行K-means聚类抽取新闻评论主题; 文献[6]则利用LDA主题模型对穿戴设备在线评论进行主题挖掘, 其主题挖掘的结果可用于了解不同品牌用户关注主题的排序、分析不同用户群体对产品功能关注度的变化。在用户评论信息质量方面, 文献[7]以内容完整性、情感平衡性、评论时效性和发布者身份明确性为4类特征, 采用条件随机场模型进行评论可信度分类, 分类正确率达到75%以上; 文献[8]基于信息采纳模型, 构建影响用户评论信息质量的评价指标体系, 该评价指标体系包括3个一级指标、8个二级指标和25个三级指标, 并应用层次分析法计算得到各项指标的权重。此外, 用户评论情感分析也是用户评论挖掘研究的重要分支, 文献[9]提出一种基于卷积神经网络的在线评论情感分类模型, 该模型能够有效识别用户评论的情感类别。为解决通用情感词典在特定领域中的不适配问题, 文献[10]提出一种基于领域专用特征—情感词本体的网络产品评论情感分析方法, 实验结果表明与采用通用情感词典Senti-HowNet的情感倾向分析方法相比, 该方法的准确率和召回率都有显著提高; 文献[11]以企业产品的用户评论为数据源, 利用情感识别分析企业产品的优劣, 构建优势与劣势特征集, 并将待分析产品转化为向量, 最终基于向量相似度计算发现与本企业产品优势相似及劣势互补的候选竞争产品; 文献[12]通过机器学习方法提取电商网站用户评论标签信息, 并对特征词和情感词进行识别, 最终来判别用户情感类型。综上, 当前用户评论挖掘研究主要集中在评论有效性、评论信息质量、评论主题挖掘和评论情感分析等方面, 而关于用户评论关键词抽取的研究较少。
关键词抽取一直是自然语言处理等领域的重要热点[13]。早在1957年, 美国IBM公司的Luhn就提出一种基于词频统计的关键词抽取方法[14], 主要目的在于从文献中抽取关键词对文献进行自动标引。目前关键词抽取主要有统计法、基于主题模型的方法、基于网络图的方法、基于学术文本的结构功能识别的方法等。统计法利用文档中词语的统计信息来抽取文档中的关键词, 其最重要的研究成果是TF-IDF模型及其变种, 例如文献[15]研究了TF-IDF模型在中文科技文献关键词抽取的效果。文献[16]在考虑文本类别的基础上, 提出基于类别加权的TF-IDF改进方法, 增加了一个类别中频繁出现的特征项的权重。近年, 一些研究试图将主题模型应用于关键词抽取过程, 例如文献[17]在主题模型的基础上提出TDCS模型, 该模型可以对少量文档关键词中隐含的主题进行建模和分析。文献[18]提出一种结合LDA与TextRank的关键词抽取模型, 并在中短型文本数据集Huth2003和长文档数据集DUC2001上进行实验, 结果表明了该方法的有效性。基于网络图的关键词抽取方法需要构建文档的词汇网络, 对词汇网络进行分析寻找起重要作用的词, 并将这些词语抽取出来作为关键词, 最著名的基于网络图的关键词抽取方法是TextRank和其变种[19,20,21]。文献[22]基于学术文本的结构功能识别方法, 提出融合学术文本结构功能特征的多特征组合提取方法, 并利用学术文本的章节标题对其结构功能进行识别, 分别通过SVM二分类和LambdaMART学习排序算法在计算机语言学领域的文献集上进行关键词抽取, 实验结果表明, 相比基准特征, 多特征组合在关键词提取的效果上取得了较大的提升。
国内外已有关于关键词抽取的研究成果, 但这些研究抽取的对象主要是科技文献、网页文档和新闻文本, 提出的关键词抽取方法主要有一定的应用场景和数据集差别, 并且现有方法是否适用于短文本用户评论还需进一步探讨。
面向用户评论的关键词抽取旨在“从海量用户评论文本中, 自动发现对用户和商家有价值的信息, 并使用关键词进行概括”, 其形式化描述如下:
若将商家
$S\left( C,V \right)\to R$
且排在列表
现有研究表明用户评论中包含两类有价值的信息: 能够辅助用户决策的信息[25]; 为商家改善服务提供反馈的信息[26]。因此, 本文将与上述两类信息相关的词项称为有效关键词, 与上述两类信息无关的词项称为无效关键词, 面向在线评论的关键词抽取评价准则, 如表1所示。
以美食网站为例, 商家是提供就餐服务的餐厅, 用户是希望就餐的群众。从商家角度看, 用户评论中包含用户关注商家服务的重点方面。比如给定用户评论“他们家的环境不错”、“老板人很好, 菜分量很足”、“服务员的服务态度非常好, 还会再来”、“店面太小了, 人一多就坐不下”和“分量很少, 性价比低, 不适合多人聚餐”, 其中“环境”、“分量”、“服务态度”、“店面”和“性价比”等词项在一定程度上体现了用户关注的重点方面, 与商家改善服务的努力方向相关, 属于有效关键词。从用户角度看, 用户评论中出现了很多关于商家菜品的观点。比如给定用户评论“寿司很好吃”、“他们家的咖喱饭值得推荐”、“特地来吃他们家的醉虾”、“糯米饭超好吃, 生鱼片有点不新鲜”和“火锅味道一般般”, 其中“寿司”、“咖喱饭”、“醉虾”、“糯米饭”、“生鱼片”和“火锅”等词项与用户点餐决策相关, 因此也属于有效关键词。而“家”、“老板”、“服务员”、“推荐”、“好吃”等词项既不与商家改善服务的努力方向相关, 也不与用户点餐决策相关, 因此属于无效关键词。
值得注意的是, 用户评论对于有效关键词存在三种不同的情感极性: 积极的(如“服务态度\非常好”), 消极的(如“店面\太小”)或者中性的(如“火锅\味道一般般”)。然而无论用户对于有效关键词(如“服务态度”、“店面”和“火锅”)的情感极性如何, 这些词项一定程度上都与“辅助用户决策”和“为商家提供反馈”相关, 都包含有价值的信息。本文的目的是“从用户评论中挖掘有价值的信息”, 因此暂不考虑用户对于有效关键词的情感极性。
在信息检索研究中, 语言模型可被用于估计文档
$P\text{(}{{t}_{i}}|{{\theta }_{{\tilde{c}}}}\text{)}=(1-\lambda )P\text{(}{{t}_{i}}\text{ }\!\!|\!\!\text{ }\tilde{c}\text{)}+\lambda P({{t}_{i}})$ (1)
其中, ${{t}_{i}}\in V$表示评论语料中的任一词项; $\tilde{c}$表示一条评论; $P\text{(}{{t}_{i}}|\tilde{c}\text{)}$表示从评论$\tilde{c}$中生成词项${{t}_{i}}$的概率; $P({{t}_{i}})$表示从评论语料中生成词项${t}_{i}$的概率; $\lambda$为平滑参数。一般而言$P({{t}_{i}})$的计算方法如公式(2)所示[27]。
$P({{t}_{i}})=\frac{n({{t}_{i}})}{\mathop{\sum }_{{{t}_{j}}\in V} n({{t}_{j}})}$ (2)
其中, $n({{t}_{i}})$表示词汇${{t}_{i}}$的文档集频率,
如何估计条件概率$P\text{(}{{t}_{i}}\text{ }\!\!|\!\!\text{ }\tilde{c}\text{)}$是LMKE方法的核心, 本研究提出三种不同的估算策略。
(1) 基于流行度的策略(Popular), 该策略假设越常见的词语越有价值, 此时条件概率$P\text{(}{{t}_{i}}\text{ }\!\!|\!\!\text{ }\tilde{c}\text{)}$的计算方法如公式(3)所示。
$P\text{(}{{t}_{i}}|\tilde{c}\text{)}=\frac{n({{t}_{i}},\tilde{c})}{\mathop{\sum }_{{{t}_{j}}\in \overset{{}}{\mathop{{\tilde{c}}}}\,\ }n({{t}_{i}},\tilde{c})}$ (3)
其中, $n({{t}_{i}},\tilde{c})$表示词项
(2) 基于区分度的策略(Discriminative), 该策略假设具有区分能力的词语有更高的价值, 此时条件概率$P\text{(}{{t}_{i}}\text{ }\!\!|\!\!\text{ }\tilde{c}\text{)}$的计算方法如公式(4)所示。
$P\text{(}{{t}_{i}}\text{ }\!\!|\!\!\text{ }\tilde{c}\text{)}=\frac{b\text{(}{{t}_{i}},\tilde{c}\text{)}}{P\text{(}{{t}_{i}}\text{)}\mathop{\sum }_{{{t}_{j}}\in \tilde{c}}\frac{b\text{(}{{t}_{j}},\tilde{c}\text{)}}{P({{t}_{j}})}}$ (4)
其中, $P\text{(}{{t}_{i}}\text{)}$按公式(2)计算, $b\text{(}{{t}_{i}},\tilde{c}\text{)}$表示词项${{t}_{i}}$在用户评论$\tilde{c}$中是否出现, 出现为1, 不出现则为0。
(3) 基于组合的策略(Combination), 该策略综合考虑了流行度和区分度, 计算方法如公式(5)所示。
$P\mathrm{(}{{t}_{i}}\text{ }\!\!|\!\!\text{ }\tilde{c}\mathrm{)}=\frac{n({{t}_{i}},\tilde{c})\log \frac{N}{df\text{(}{{t}_{i}}\text{)}}}{\mathop{\sum }_{{{t}_{j}}\in \tilde{c}}(n({{t}_{j}},\tilde{c})\log \frac{N}{df\text{(}{{t}_{j}}\text{)}})}$ (5)
其中, $n({{t}_{i}},\tilde{c})$表示词${{t}_{i}}$在用户评论$\tilde{c}$中出现的频次, $df\text{(}{{t}_{i}}\text{)}$表示评论语料中包含词${{t}_{i}}$的用户评论数量, $df\text{(}{{t}_{j}}\text{)}$表示评论语料中包含词${{t}_{j}}$的用户评论数量,
LMKE可以根据单个评论$\tilde{c}$为词项${{t}_{i}}$打分。给定一个商家
$P\text{(}{{t}_{i}}|{{\theta }_{C}}\text{)}=\underset{\tilde{c}\in C}{\mathop \sum }\,P\mathrm{(}{{t}_{i}}|{{\theta }_{{\tilde{c}}}}\mathrm{)}$ (6)
以美团网美食板块的用户评论为例, 使用Python网络爬虫抓取美团网(meituan.com)中武汉地区所有自助餐厅的用户评论数据, 共包含328个商家, 891 006条用户评论, 其中包含商家标识符(bid)、商家名称(bname)、综合评分(bgrade)、商家地址(addr)、商家链接(url)、推荐商/菜品(recommendation)、用户标识符(uname)、用户评论(content)、用户打分(ugrade)和评论时间(comment_time)等多个字段。然而, 其中部分商家仅有非常少量的用户评论, 这些商家的数据会影响后续实验, 因此将其从数据集中剔除掉。另外, 由于很多用户仅仅为商家进行打分, 而没有编写具体的评论内容, 即用户评论(content)字段为空, 这种数据也不利于后续实验, 将其从数据集中清理掉。最终得到159个商家的626 916条有效用户评论数据, 数据样例如表2所示。
数据处理过程主要包括:
(1) 从采集数据中提取商家用户评论文件“name_and_contents.csv”, 该文件每行都记录了某个商家的名称(bname)和一条用户评论内容(content);
(2) 对用户评论文件“name_and_contents.csv”中的用户评论进行分词、词性标注、去停用词、词性选择等处理。
具体而言, 采用jieba分词工具对每条用户评论进行分词和词性标注, 然后从分词结果列表中去除中文停用词表中的词语, 并进一步剔除非名词词语, 最终将用户评论转化为词语列表。如表2评论其处理结果为词语列表[“服务员”, “热情”, “菜”, “刺身”, “味道”, “菜”, “甜虾”]。
将LMKE与两种传统的关键词抽取方法TF-IDF[23]和TextRank[24]进行对比。对于TF-IDF方法, 将预处理后的626 916条用户评论作为语料, 计算每个词项的逆文档频率; 在每个商家的所有评论上计算词项的词频; 得到商家评论中出现的所有词项的TF-IDF得分; 最后根据商家评论中出现的所有词项的TF-IDF得分对词项进行排序, 取得分最高的20个词项作为关键词。对于TextRank方法, 将每个商家预处理后的所有评论作为输入, 使用jieba分词工具自带的TextRank算法抽取商家用户评论得分最高的20个关键词。
针对LMKE方法, 将预处理后的626 916条用户评论作为评论语料, 将评论语料中所有出现的词汇列入词汇表
使用TF-IDF、TextRank和LMKE三种方法分别为数据集中的每个商家抽取评论关键词; 三位标注者分别对抽取到的关键词进行标注, 即按照3.2节的评价准则, 如果抽取的关键词
采用P@K和nDCG@K两种指标对关键词抽取的结果进行评价, 其中
$\text{PK}=\frac{r(K)}{K}$ (7)
其中,$r(K)$表示抽取到的前
$\text{nDCGK}=\frac{DCG}{iDCG}\mathrm{,}\ DCG=\sum\nolimits_{i=1}^{K}{\frac{{{2}^{r(l)}}-1}{{{\log }_{2}}(i+1)}}$ (8)
其中, $r(l)$表示排序列表
(1) 对比TF-IDF和TextRank两种传统的关键词抽取方法, 除了P@20指标, TF-IDF在其他所有指标上均优于TextRank方法;
(2) 基于流行度策略的LMKE方法(LMKE- Popular)结果较差, 在大部分指标上其得分最低;
(3) 在所有方法中, 基于区分度策略的LMKE方法(LMKE-Discriminative)取得了最佳效果, 其P@5、P@10、P@20得分分别为0.7665、0.6701、0.6200, 相比TextRank方法分别提高4.50%、4.16%和0.32%。其nDCG@5、nDCG@10、nDCG@20得分分别为0.8187、0.7326、0.6743, 相比TextRank方法分别提高5.07%、4.84%、1.68%;
(4) 比较TF-IDF和基于组合策略的LMKE方法(LMKE-Combination), 发现除P@5之外的所有指标上, 两个方法均表现出相当的性能。
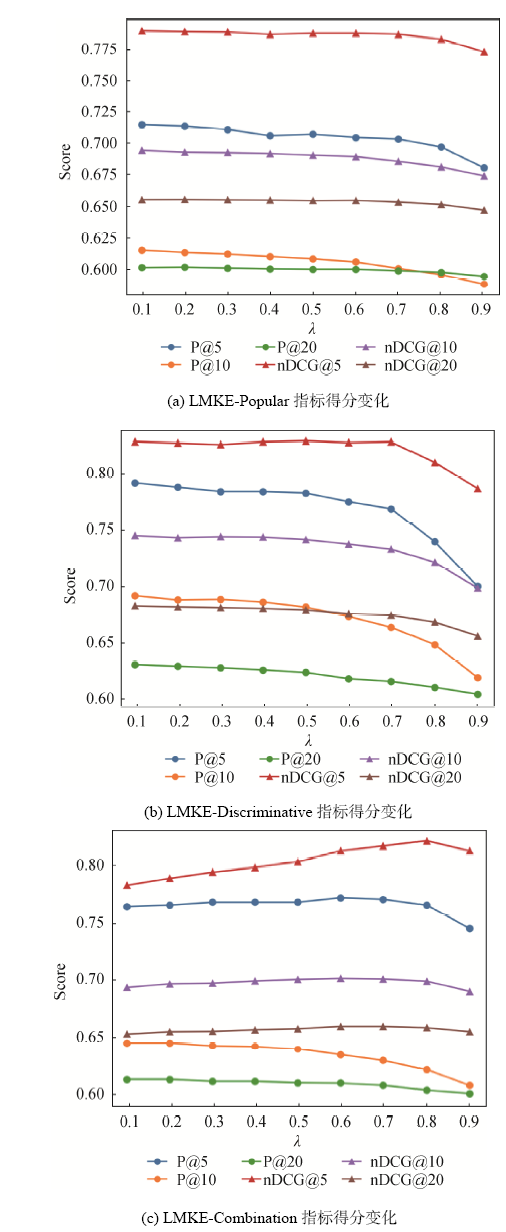
由图1可知, 对于基于流行度策略的LMKE方法(LMKE-Popular), 在[0, 0.7]区间随着平滑参数
此外, 笔者人工地查看了TF-IDF、TextRank和LMKE-Discriminative抽取的关键词, TF-IDF和TextRank方法抽取到的关键词多是有利于改善商家服务、面向整个餐饮行业的有效关键词, 而LMKE- Discriminative方法有能力抽取出用户喜爱的菜品。例如, 对于“深海渔场海鲜自助餐厅(循礼门店)”餐厅, TF-IDF方法从用户评论中抽取的前10个关键词为“味道, 菜品, 环境, 还不错, 吃的, 品种, 感觉, 种类, 服务态度, 服务员”, TextRank方法从用户评论中抽取到的前10个关键词为“菜品, 味道, 环境, 品种, 感觉, 服务员, 种类, 有点, 服务态度, 口味”, LMKE- Discriminative方法抽取的前10个关键词为“菜品, 味道, 虾, 环境, 食材, 种类, 性价比, 品种多, 价格, 螃蟹”。
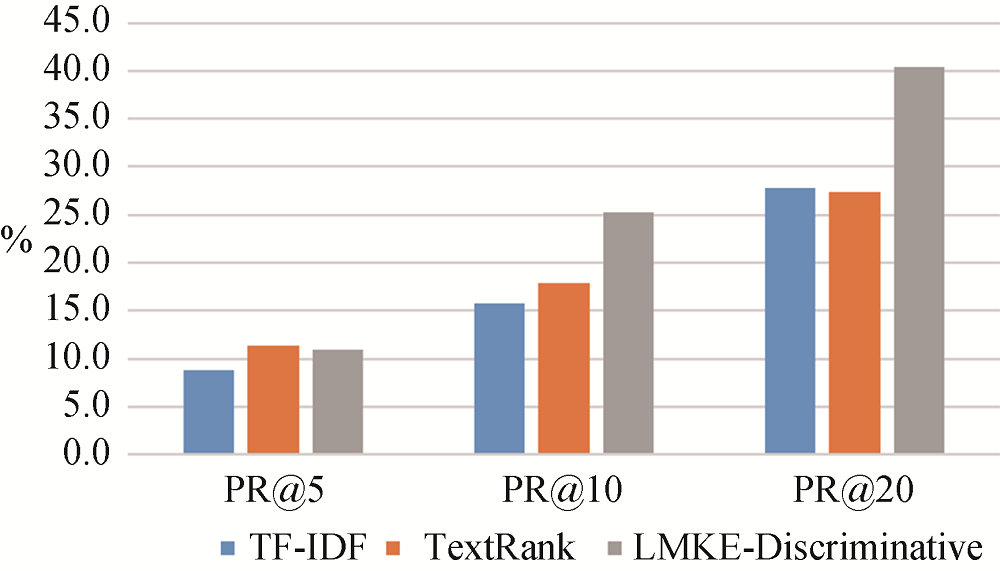
为进一步比较TF-IDF、TextRank和LMKE- Discriminative在菜品关键词抽取上的效果, 随机采样100个商家, 使用有效召回比率PR@K对三种方法进行评价, 笔者提出有效召回比率的计算方法如公式(9)所示。
$\text{PRK}=\frac{\sum\nolimits_{i=1}^{K}{r(i)}}{R(K)},r(i)\in \{0,1\}$ (9)
其中, $R(K)$表示方法抽取的前
本文探索了面向用户评论的关键词抽取这一问题, 即“从海量用户评论文本中, 自动发现对用户和商家有价值的信息, 并使用关键词进行概括”。从商家和用户两个角度, 明确了用户评论关键词抽取的目标是抽取用户评论中的有效关键词, 即与“辅助用户决策”或者“改善商家服务”相关的词项; 提出一种基于语言模型的用户评论关键词抽取方法, 在美团网159位商家的用户评论数据上进行实验, 结果表明基于语言模型的用户评论关键词抽取方法的有效性。本文的不足之处在于, 实验仅以美团网武汉地区自助餐厅的所有用户评论为例, 具有一定的局限性, 在其他类型的网络平台(如购物网站、旅游服务网站)中是否能得到一致性的实验结果有待进一步探讨。另外, 仅考虑了关键词是否与“辅助用户决策”和“为商家提供反馈”相关, 忽略了用户评论对关键词的情感极性, 进一步细化考虑关键词的情感极性是未来的研究方向。
张震: 提出研究思路, 设计实施方案, 收集数据, 起草与修订论文;
曾金: 设计研究方法, 数据集预处理, 起草与修订论文。
所有作者声明不存在利益冲突关系。
支撑数据见期刊网络版, http://www.infotech.ac.cn。
[1] 张震, 曾金. 面向用户评论的关键词抽取研究.xlsx. 关键词抽取实验结果.
| [1] |
[本文引用:1]
|
| [2] |
[本文引用:2]
|
| [3] |
[本文引用:1]
|
| [4] |
[本文引用:1]
|
| [5] |
[本文引用:1]
|
| [6] |
[本文引用:1]
|
| [7] |
[本文引用:1]
|
| [8] |
[本文引用:1]
|
| [9] |
[本文引用:1]
|
| [10] |
[本文引用:1]
|
| [11] |
[本文引用:1]
|
| [12] |
[本文引用:1]
|
| [13] |
[本文引用:1]
|
| [14] |
|
| [15] |
[本文引用:1]
|
| [16] |
[本文引用:1]
|
| [17] |
[本文引用:1]
|
| [18] |
[本文引用:1]
|
| [19] |
[本文引用:1]
|
| [20] |
[本文引用:1]
|
| [21] |
[本文引用:1]
|
| [22] |
[本文引用:1]
|
| [23] |
[本文引用:2]
|
| [24] |
[本文引用:2]
|
| [25] |
[本文引用:1]
|
| [26] |
意见挖掘是针对主观性文本自动获取有用的意见信息和知识,它是一个新颖而且十分重要的研究课题。这种技术可以应用于现实生活中的许多方面,如电子商务、商业智能、信息监控、民意调查、电子学习、报刊编辑、企业管理等。本文首先对意见挖掘进行了定义,然后阐述了意见挖掘研究的目的,接着从主题的识别、意见持有者的识别、陈述的选择和情感的分析四个方面对意见挖掘的研究现状进行了综述,并介绍了几个成型的系统。此外,我们针对汉语的意见挖掘做了特别的分析。最后对整个领域的研究进行了总结。
Magsci
[本文引用:1]
|
| [27] |
[本文引用:4]
|
| [28] |
[本文引用:2]
|
| [29] |
[本文引用:2]
|



{kind=link}
{kind=link}
{kind=link}
{kind=link}