
 , 侯琳琳, Hou Linlin
, 侯琳琳, Hou Linlin【目的】引入产品画像概念, 解决现有电商平台上对产品静态信息和动态评论关联上的不足。【方法】将知识图谱作为挖掘、组织、存储、展示产品信息的方法, 引入到产品画像的构建研究中, 提出基于知识图谱的产品画像构建方法。【结果】通过设计三项实验生成手机知识图谱数据层, 其中命名实体抽取实验的F值达到77.52%, 评价对象-评价词抽取实验的F值达到76.04%, 同义词发现实验的F值为63.16%。其实验结果验证了所提方法的有效性。【局限】产品画像构建中的关系抽取限定了关系类别, 使得画像中的关系数量有限; 对产品市场流通维度的分析有限。【结论】本研究能够有效帮助购物平台改善产品对比和产品搜索等机制, 为用户提供更好的产品服务。
[Objective] To solve the deficiencies of the static information and dynamic comments on the existing e-commerce platform, the concept of product profile was introduced. [Methods] As a method of mining, organizing, storing and displaying product information, knowledge map is introduced into the research of product profile construction, and a product profile construction method based on knowledge map is proposed. [Results] Three experiments were designed to generate the mobile phone knowledge map data layer, in which the F value of the named entity extraction experiment reached 77.52%, the F value of the evaluation object-evaluation word extraction experiment reached 76.04%, and the F value of the synonym discovery experiment was 63.16%. The experimental results verified the effectiveness of the proposed method. [Limitations] The relationship extraction in product profile construction limits the relationship category, so that the number of relationships in profile is limited; the analysis of the product market circulation dimensions is limited. [Conclusions] This study has effectively helped the shopping platform to improve product comparisons and product search mechanisms to provide users with better products and services.
据中国互联网络信息中心(CNNIC) 2017年8月发布的第40次《中国互联网络发展状况统计报告》显示, 网购市场消费升级的特征正进一步显现, 用户偏好逐步向品质、智能、新品类消费转移, 线上线下融合向数据、技术、场景等领域深入扩展, 电商平台积累的庞大用户数据资源进一步得到重视[1]。如何有效组织、存储和挖掘平台积累的产品和用户数据资源、提升消费者的网络购物体验和效率正成为不同购物平台亟待解决的问题。
(1) 服务方视角。作为在线购物服务提供商, 面临的重要问题是如何对购物平台上的产品信息进行标准化和规范化管理, 并通过数据挖掘等手段, 打造全网产品智能服务体系, 服务于搜索、前端导购、平台治理、智能问答、品牌商运营等核心业务生态系统。
(2) 消费者视角。目前购物平台的搜索引擎大多基于用户关键词检索产品, 而同一产品可能有不同的名称或表述, 且不同商家会给产品添加多个歧义关键词, 导致消费者不能有效锁定所需产品。并且产品评论中包含消费者对产品的有效反馈, 因此需要对产品评论进行口碑挖掘并嵌入到产品检索和产品对比中, 从而改善消费者的购物体验和效率。
在此背景下, 本研究立足电商环境下的产品信息组织与挖掘, 将产品的静态信息和动态口碑结合, 引入知识图谱方法构建产品知识图谱, 旨在帮助购物平台改善产品多维信息的组织与关联, 为用户提供更好的产品服务。
目前, 对于产品信息的研究多使用XML/RDF方式[2,3]或者构建产品领域本体的方式[4]进行信息组织, 但是这些方法有一定的局限性, 前者不能很好地展示动态信息, 后者适用性有待提高。周妍等借鉴分面分类等传统信息组织理论与方法, 提出电商平台产品信息组织机制的三层结构[5], 但该方法也只是对商品属性等静态信息的分类和整序, 没有对商品评论等动态信息提出组织机制。将知识图谱的逻辑架构和技术流程应用到产品信息的组织、挖掘和展示过程中, 引入产品知识图谱的概念, 可以将产品静态信息和评论动态信息结合起来, 改善产品信息组织现状。
国内外学术界和工业界均已经提出产品图谱(Product Map或Product Graph)和产品知识图谱(Product Knowledge Map或Product Knowledge Graph)的概念, 并取得了一系列研究成果。
杨美婷等首次在正式出版的文献中提出“产品画像”概念, 认为将“用户画像”的研究对象扩展至产品, 即为“产品画像”, 提出“用户画像技术”和“数据挖掘技术”是构建“产品画像”的关键技术, 并以乳制品为例, 提取乳制品的相关安全属性并确定属性权重, 建立乳制品安全预警系统[6]。邵元新设计实现了基于Web的工业产品知识图谱构建及应用系统[7]。
在产品图谱方面, Yang等提出利用产品实体图谱(Product Entity Graph)的方法描述产品结构化信息, 并以三星电脑为例, 将产品结构信息用“实体和实体属性”关联[8]。Liao等立足于化妆品行业的新产品开发, 利用数据挖掘技术构建产品图谱, 挖掘的数据包括产品属性、消费者属性、交易记录等[9]。Kagie等为解决消费者网购时选择困难的问题, 利用多维尺度变换的方法, 根据产品属性的相似度和不相似度构建产品图谱, 简化产品搜索和产品比较的过程[10]。Kim为帮助消费者掌握电子设备的特征和功能, 利用产品管理系统和开放数据源中的数据构建产品图谱, 并在此基础上开发销售辅助系统“God of Sales”, 向消费者解释、说明、推荐产品[11]。
产品图谱以产品描述性信息或开放式产品信息为依据, 通过映射(Map)或图谱(Graph)的方式组织产品信息, 服务于产品营销、产品推广等商务过程。相比而言, 产品知识图谱则更多地应用于产品开发与设计, 例如Liu等将复杂产品开发过程中的知识图谱分为概念知识图谱、过程知识图谱、专家知识图谱和整体框架知识图谱, 不同部门负责维护不同的图谱, 整体服务于复杂产品设计[12]。苏海等结合产品设计过程中知识的上下文特征, 提出基于元知识和XML的知识图谱映射方法, 通过元知识结构化描述知识内容及其上下文, 利用概念知识图谱和过程知识图谱解决设计过程中的知识孤岛问题[13]。Lv等以用户知识需求和知识关联为基础构建知识图谱模型, 以解决复杂产品设计过程中的知识过载问题[14]。
总的来说, 产品图谱与产品知识图谱的研究和应用已引起学术界和工业界的关注, 但产品图谱的构建技术限于数据挖掘方法, 产品知识图谱的应用限于产品设计开发。本研究将两者结合, 采用知识图谱方法, 基于电商数据构建产品知识图谱, 旨在有效组织与挖掘电商视角下的产品数据, 服务于电商用户。
电商环境中产品相关的电商数据除了来自电商类信息源之外, 还涉及官网类信息源、行业信息源、百科类信息源。产品知识图谱融合了产品静态信息和产品动态评论, 其中产品静态信息来自官网类信息源、行业信息源、百科类信息源, 产品动态评论来自行业信息源和电商类信息源。
产品知识图谱采用自上而下的构建方法, 即先搭建出产品知识图谱的模式层, 在模式层的约束下填充数据层, 最终形成结构化的产品知识图谱。按照知识图谱的逻辑架构和一般过程, 设计产品知识图谱的构建流程, 如图1所示。
模式层是知识图谱的“骨架”, 其构建将对产品知识图谱中涉及的术语、概念及关系展开抽取和定义研究, 以明确图谱的整体范围, 并规范产品知识图谱中的表达。产品知识图谱模式层的构建不需要从零开始, 可以借助现有的结构化知识, 如领域本体、开放链接数据库(Freebase)等。
(1) 术语与概念获取
术语的特点是领域性较强, 且具有领域内流通性高的特征。从专业化、权威化的信息源出发, 产品知识图谱模式层的术语获取应充分依赖产品说明书、官方网站这类信息源。为便于用户理解, 该类信息源中产品固有功能等信息往往通过表格、表单等半结构化的方式呈现, 因而产品知识图谱模式层中的术语可直接通过网页采集、表单解析等方式获取。
概念的含义比实体更加抽象, 抽取方法也更加复杂, 鉴于产品领域内概念数量有限的特点, 产品知识图谱模式层构建将从务实的角度出发, 不采用复杂的方法抽取领域概念, 只利用高可信度信息源(如官网和产品说明书), 从其结构化、半结构化的信息中直接获得产品领域的相关概念信息。值得注意的是, 除了从专业性高的信息资源中获取概念、术语, 还可以复用现有的领域资源(领域词典、领域本体)等, 进一步确保产品知识图谱模式层的全面性和严谨性。如手机知识图谱的术语和概念可以从手机官网和行业网站的结构化数据中直接获取, 也可以复用现有的一些手机类本体结构。
(2) 关系定义和抽取
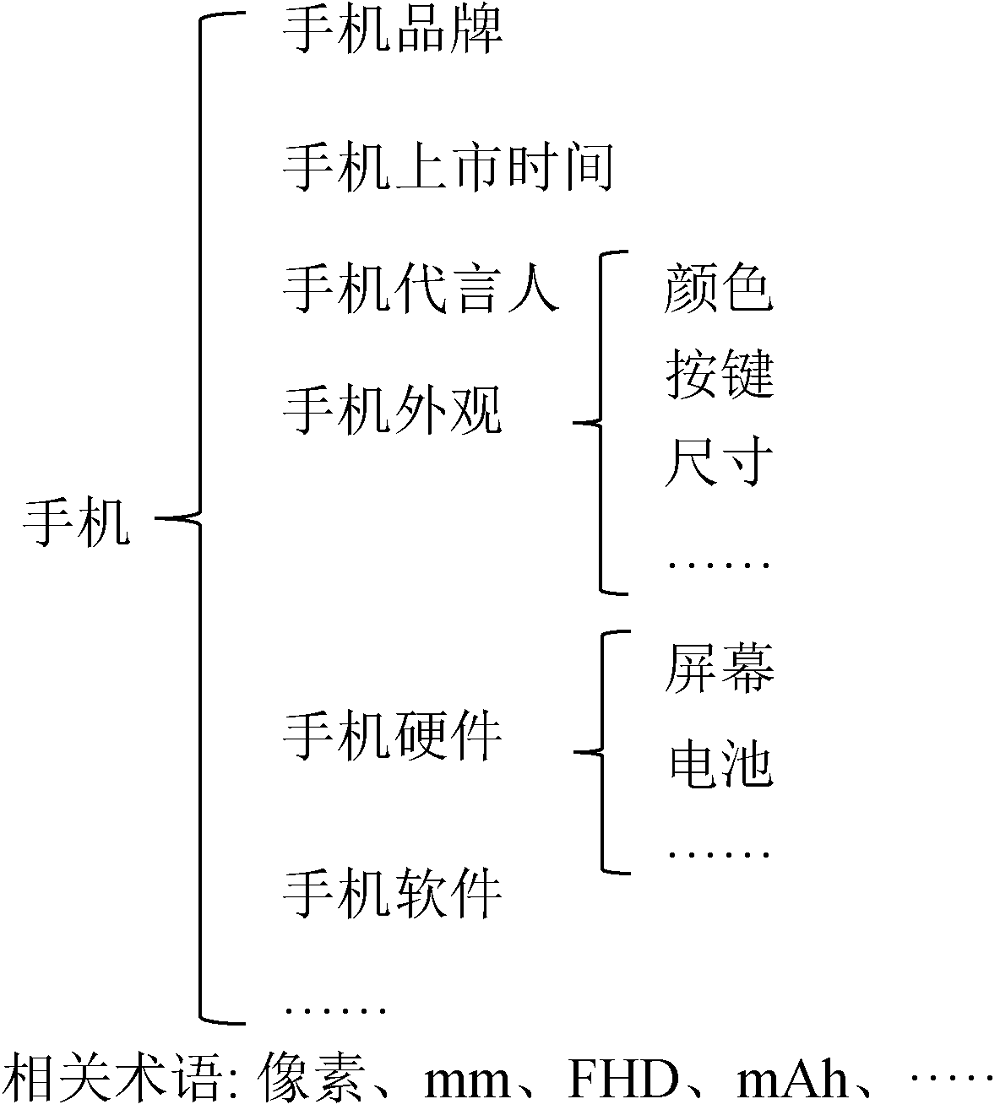
从电商视角下的产品功能及产品市场流通角度, 将产品知识图谱模式层中的关系细分为4类: 同义关系、上下位关系、整体-部分关系和属性关系。不同类型关系的特征不同, 所采取的抽取方法也 不同。
①同义关系: 指在概念层面上相同或相似的语言表达, 存在于概念、实体或属性间, 例如手机领域内“屏幕”和“显示器”, “握感”和“手感”等。同义关系抽取的目标是发现字面表述不同, 但代表同一概念、实体或属性的术语。产品知识图谱模式层的同义关系的抽取将利用同义词典以及百科网站的“别称”词条, 其中, 同义词典依赖哈尔滨工业大学的同义词词林扩展版[15]。具体而言, 将产品领域内的概念输入同义词典, 返回其对应同义词, 从而获得同义关系。将产品领域内的概念输入百科系统, 利用百科页面的“别称”词条, 抽取概念的同义词, 进一步补充同义关系。
②上下位关系: 又叫作层次关系, 即根据范围确定概念和子概念, 如“国家”的下位词包括“中国”、“美国”。鉴于领域内该类关系的数量有限, 从抽取成本和效率出发, 依赖百科网站的分类体系获取领域概念间的上下位关系。具体而言, 利用百科网站的分类体系, 抽取出概念和子概念, 将其匹配, 获得有上下位关系的概念对。
③整体-部分关系: 主要出现在产品的组成中, 产品部件和产品整体之间存在整体-部分关系, 例如数码领域的“电脑”和“CPU”。和上下位关系相同, 产品领域内的整体-部分关系抽取也依赖百科网站。具体而言, 利用概念在百科网站中所属的类, 获得概念及其父级概念, 匹配为有整体-部分关系的概念对。
④属性关系: 一般用<对象, 属性, 值域>三元组来表示, 涉及产品或产品部件的特征及特征值等, 从开放式链接数据库和半结构化网页中获取。
以手机类产品为例, 从百科网站和行业测评网站的分类体系中抽取上下位及整体-部分关系, 从百科页面的信息盒或行业测评网站的产品介绍页表单中获取产品概念及其可能的属性值, 组成概念间的属性关系。
产品知识图谱数据层的构建分为抽取和融合两个阶段。在抽取阶段, 以图谱的模式层为基础展开实体抽取、属性抽取等; 在融合阶段, 以同义词发现为基础, 在抽取数据集上进行实体链接和属性链接。最终获得实体关系对、实体属性对、同义词组等, 完成图谱数据层的构建。
(1) 实体抽取和属性抽取
产品知识图谱的实体抽取基于官网数据和行业测评数据, 抽取出的实体除了名称外, 还包括实体的属性、图片、同义词等。
①实体抽取
与通用实体(人名、地名、机构名、时间和数量)相比, 产品知识图谱的实体具有更强的领域性。产品官网及行业测评类信息源的领域性和权威性较高, 包含大量领域实体, 可直接用于填充图谱的数据层, 故本研究将直接从产品官网和行业测评网站的结构化、半结构化页面中提取实体实例, 完成产品领域的实体抽取。抽取出的产品实体除了用于填充产品知识图谱的数据层, 还将用于中文分词, 以提高产品领域中文分词的准确性, 服务于产品知识图谱构建过程中的其他抽取任务。
依据实体的特征, 以产品的品牌名为中心, 总结面向产品画像领域的产品命名实体抽取规则, 如表1所示。按照规则的优先级(规则一至规则四优先级递减), 实现产品命名实体的抽取。
②属性抽取
产品知识图谱中实体的属性抽取分两种情况: 一种是实体所对应的概念含有属性, 只需抽取其属性值; 另一种是实体所属概念没有属性, 需要抽取其属性和属性值。
针对第一种情况, 模式层中的关系抽取包含对概念间属性关系的抽取, 抽取结果为<对象, 属性, 值域>, 即包含属性及属性值范围等信息。因此, 在数据层构建时, 可以复用模式层的部分数据(概念和值域等)。第二种情况则完全依赖实体的属性抽取。属性抽取较有效的方式是利用结构化和半结构化信息资源。
电商领域存在很多与产品相关的高质量网站, 如产品官方网站、行业测评类网站等, 属性抽取可以借助这些网站上的半结构化信息, 直接获取实体的属性及属性值。
(2) 评价对象及评价词抽取
产品评论代表用户对产品性能、属性、流通等方面的观点, 需要将评论挖掘的结果融入到产品知识图谱中, 由此本研究将在产品评论上展开细粒度的评价对象及评价词抽取。鉴于构建产品知识图谱过程中, 除了识别评价对象还需识别与之对应的评价词, 利用评价对象和评价词关系的抽取方法能直接完成这两项抽取任务, 且不需要标注语料, 故从评价对象和评价词的关系出发, 用无监督的模式匹配完成评价对象及其评价词的抽取。
评价对象和评价词在评论句中的关系分为距离和句法两个层面, 距离层面指在一定窗口的距离内, 两者间隔的字数, 而句法层面指两者在句子成分上的依赖关系。中文语言的复杂性导致距离层面的关系极其不稳定, 与之相比, 以句子成分为基础的句法关系比距离关系泛化能力更强, 因此在无监督的抽取中应用更多。整理产品评论中常见的评价句式, 对评价句中评价对象和评价词的句法路径和词性特征进行归纳, 定义抽取模板如表2所示, 其中模板1-模板8借鉴了陶新竹等[16]的评价搭配模板, 模板9和模板10为根据产品评论的评价对象和评价词的特征定义的特定模板。模板9指由动宾关系修饰的名词性短语的句法路径, 如从句子“花了这么多钱买了有瑕疵的手机”中抽取出的关系为<手机, 有瑕疵>; 模板10指间接的主谓动宾关系结合的句法路径, 如从句子“手机是正品”中抽取出的关系为<手机, 是正品>。
(3) 实体间关系抽取
为建立有效的实体关系三元组填充产品知识图谱, 必须在获取的实体、属性上展开关系抽取。与模式层中的关系抽取不同, 数据层的关系抽取旨在发现实体、属性及评价对象间的潜在关系。鉴于数据层中的实体、属性、评价对象来自不同的电商信息源, 专业性和规范性不高, 关系抽取无法直接依赖百科网站的分类体系。因此, 以模式层中的关系类别为基础, 将数据层上的关系分为4类: 整体-部分关系、上下位关系、同义关系和属性关系。
①上下位关系和整体-部分关系复用
产品知识图谱中上下位关系及整体-部分关系数量有限, 且领域性强。本研究选择基于Ontology的关系抽取方法, 以构建的模式层为基础, 完成数据层中的关系抽取。具体而言, 依据实体词在模式层中对应的概念, 复用概念的上下位关系或整体-部分关系, 实现实体间的关系抽取。以手机类产品为例, 该领域内“ROM”对应模式层的概念为“内存”, 可根据“手机存储”和“内存”的整体-部分关系, 推断出“手机存储”和“ROM”的整体-部分关系。
②同义关系和属性关系抽取
模式层中的同义关系对数量有限, 除了复用部分概念间的同义关系之外, 还将借助百科的词条注释或信息盒的“别称”属性, 实现同义关系抽取。对实体-属性关系, 属性抽取过程中可直接获取, 组成“实体-属性-属性值”的三元组。
(4) 实体链接和属性链接
产品知识图谱数据层上的链接分两种情况: 表述灵活的实体需链接到统一、规范的实体对象; 已抽取的评价对象需链接到对应的实体对象、实体属性。因数据来源、信息体裁、语言习惯等因素, 产品知识图谱中的实体和属性存在多种表述。对于产品领域内的实体词和属性词, 从相似度的角度实现链接。衡量实体词、属性词的相似度可从语义关系(语义知识词典)和统计学(词向量)角度出发, 鉴于产品知识图谱中的实体和属性具有较强的领域性, 借助现有语义知识词典肯定无法满足链接需求, 人工构建实体-实体别称词典和属性-属性别称词典的成本过大且适用性不强。因此本研究选择后者, 即从统计角度出发, 利用词向量衡量实体词、属性词的语义相似度。
词向量衡量实体相似性的原理是基于大规模的训练语料, 将实体词语映射到统一的向量空间模型中, 通过空间距离衡量语义上的相似度。词向量的质量取决于训练模型和训练语料的选择。为适应产品知识图谱中实体链接、属性链接任务的领域性, 将通用语料和领域专有语料结合作为训练语料, 并借助性能优越、受业界广泛认可的Word2Vec模型训练词向量。基于训练得到的词向量模型, 通过比较词向量距离, 获取语义相同或相近的同义词对, 完成实体链接和属性链接。
以手机类产品为例, 其训练语料除了包括中文维基百科、搜狗百科数据、人民日报新闻等信息资源, 还包括手机新闻数据、手机测评数据、手机行业报告等资源。训练获得手机领域的词向量模型后, 将手机领域内待链接的实体、属性、评价对象转化为对应的词向量, 计算其向量距离衡量语义相似性, 实现手机领域的同义词发现, 最终将语义相同或相近的手机实体、手机属性链接到图谱中的同一实体对象、同一属性中。
为使产品知识图谱能适用于各大电商平台及相关行业网站, 选择市场占有率较高且性能稳定的Neo4j存储图谱数据。Neo4j的核心是节点、关系和属性, 利用它存储产品知识图谱的本质是将图谱数据完整地转换为节点、关系和属性。产品知识图谱中的主要数据格式分为5类, 通过节点、关系、属性存储这5类数据格式的方法如表3所示。
产品知识图谱的实体一般是现实中独立存在的对象, 这类独立对象在Neo4j中可存储为节点, 而实体间的关系可作为节点间的关系存储。虽然可以对图数据库中的节点、关系添加属性, 但图谱中的属性不适宜作为节点的属性直接存储。如表3中序号2-序号5的数据格式, 产品知识图谱中的属性将关联属性值、评价词及同义词, 若将其作为节点的属性存储, 则属性对应的关联信息难以存储。因此, 本研究将产品实体的属性也作为一种节点存储, 并在实体节点和这类节点间定义“属性”关系来表达依附关系。以此类推, 序号3的数据格式存储为实体节点、属性节点及“属性”关系, 而属性值作为属性节点的属性存储。序号4中, 与实体(或属性)关联的评价词, 实质是对实体(或属性)的进一步描述, 可看作是一种依附属性。对应在Neo4j中, 将“评价”作为实体节点(或属性节点)的一个属性, 评价词作为属性值存储。产品知识图谱中一个实体(属性)会关联多个评价词, 相应地, “评价”属性的属性值将用词表(数组格式)存储。序号5的实体词(或属性词)和同义词表, 是实体链接、属性链接等任务的基础, 数据容量不大, 在产品知识图谱存储、绘制过程中需要多次调用, 可按照键-值对(Key-Value)的方式本地化存储到文件中。
基于提出的产品知识图谱构建方法, 本文以手机类产品为例, 按照模式层构建、数据层构建等一系列方法流程, 生成手机类产品知识图谱并进行相关应用。
手机知识图谱的生成基于电商类网站及手机行业测评网站上的手机静态信息和动态评论。手机行业测评网站较多, 质量参差不齐。本文结合李洁娜等[17]对手机类网络信息源质量的排序, 同时考虑网站的Alexa流量排名和行业排名, 行业测评类网站选择手机之家、中关村手机在线、IT168手机频道、太平洋电脑网手机频道作为手机类知识图谱的信息源; 电商类网站选择京东商城、苏宁易购和亚马逊中国作为手机类知识图谱的信息源。对行业测评类网站主要采集测评及新闻类的非结构化长文本数据, 对电商类网站主要采集评论数据。手机知识图谱的信息源及采集数据量如表4所示。
静态信息利用DOM树结构采集技术获取, 动态评论信息则通过解析评论页Ajax异步传输数据获得。共采集静态非评论网页63个, 动态评论网页5 579个, 获得非重复评论数据8 307条。对获取的初始数据集进行基本数据清洗和预处理, 包括特殊字符过滤、中文分词和词性标注等。其中, 中文分词、词性标注及句法分析借助哈尔滨工业大学的LTP平台[18]。
依据3.3节提出的方法进行抽取和链接, 首先进行实体抽取实验, 然后展开评价对象-评价词抽取和基于Word2Vec的同义词发现实验。
(1) 手机命名实体抽取实验
本实验采用随机抽样的方式选取1 000篇测评网站上的手机类测评及新闻数据作为语料。对语料进行预处理, 从分词结果中去除停用词, 然后按照提出的4条抽取规则, 根据其不同的优先级, 利用Python进行程序设计, 从语料中抽取出手机命名实体, 抽取算法描述如下。其中常用手机品牌名称集Brandlist借助手机行业网站、电商手机频道的品牌分类目录, 通过人工构建获得。
输入: 手机测评、新闻语料集DataSet{S1,S2,S3···Sn}, 常用手机品牌名称集Brandlist
输出: 手机产品实体集EntitySet{e1,e2···em}
①对DataSet中的每一篇语料Si, 利用LTP工具分词, 并加载停用词表, 过滤句子中的停用词, 将剩余的词语组成列表Wi。将所有语料的词表Wi组合成新的数据集Wordlist。
②选择Wordlist的元素Wi, 按照规则一抽取产品实体, 若存在符合规则一的产品实体, 则存到EntitySet集中, 跳转至步骤⑥, 否则, 继续执行步骤③。
③对词表Wi按照规则二抽取产品实体, 若符合抽取条件, 则抽取出产品实体, 存入到EntitySet中, 跳转至步骤⑥, 否则, 执行步骤④。
④对词表Wi按照规则三抽取产品实体, 若符合抽取条件, 则抽取出产品实体, 存入到EntitySet中, 跳转至步骤⑥, 否则, 执行步骤⑤。
⑤遍历手机品牌列表Brandlist, 判断Wi中是否出现了品牌名(规则四), 若出现, 则品牌名作为产品实体, 存入EntitySet, 否则, 丢弃该Wi, 执行步骤⑥。
⑥Wordlist中其余元素执行步骤②, 直至完全遍历Wordlist。
按照上述实验步骤, 在实验语料中共计抽取出手机命名实体219个。人工对实验语料进行手机命名实体标注, 与实验抽取结果对比, 计算出实验准确率为87.67%, 召回率为69.57%, F值为77.52%。
虽然和现有中文产品命名实体识别方法相比, 本文方法存在准确率、召回率不高的问题, 但这种基于品牌列表和规则模板的方法实现简单, 不需要训练语料且效率高, 仅依靠人工维护的品牌列表即可适用于不同领域的产品命名实体抽取。通过上述规则提取出的手机命名实体中仍含有一定的噪音, 后期集成到手机画像时, 需对这些手机命名实体进行过滤和链接。
(2) 基于句法分析的评价对象-评价词抽取
从清洗过滤后的数据集中, 采用随机抽样的方法, 抽取出2 000条手机评论数据作为语料(其中行业测评类网站641条, 电商网站1 359条), 共计抽取出评价对象-评价词对1 484个, 实验准确率为70.35%, 召回率为82.72%, F值为76.04%。抽取的评价对象-评价词对包括“色彩-细腻”、“屏幕-清晰”、“电池-耐用”、“手感-不错”等。导致抽取性能不高的原因有两个: 一方面实验语料质量影响了规则模板的抽取性能。陶新竹等[16]在实验中先进行了评论核心句识别和冗余成分删除环节, 再利用规则模板进行实验抽取, 故规则处理的语料质量更高, 而本实验中直接用评论数据作为语料。另一方面, 不同领域语料内容本身也会影响抽取性能。其使用的语料为酒店评论, 本实验选择的是手机评论语料, 语料领域性不同, 造成抽取性能有差距。可见, 使用基于句法分析的抽取模板具有实现简单、适用性强等优点, 但将抽取的评价对象及评价词集成到手机知识图谱之前, 需要进行过滤和实体链接等任务, 以保证图谱数据的准确性。抽取算法流程如下。
输入: 评论集合Comment
输出: 抽取出的<评价对象, 评价词>集合, TagSet={(object1,word1), (object2,word2)···(objectm,wordm)}
①对Comment集中的句子分句, 形成句子集Sentence={S1,S2···Sn}。
②加载LTP的分词、词性标注、句法分析模型。
③从Sentence中选择单句Si, 进行分词、词性标注和句法结构分析并保存。
④依次遍历规则模板, 判断Si的分析结果是否符合词性和句法模板, 若符合, 则抽取出<评价对象, 评价词>, 存入到TagSet中。
⑤重复执行步骤③, 直至遍历整个Sentence集。
(3) 基于Word2Vec的同义词发现实验
同义词发现实验分为Word2Vec模型训练和同义词发现两个环节。Word2Vec模型使用Python的第三方包Gensim, 模型参数设置和训练说明如表6所示。
训练生成的词向量模型保存为“chinese_mobilephone. model”, 利用该模型, 基于词向量衡量词语间的相似度值, 实现实体和属性的同义词发现, 算法步骤如下。
输入: 模型文件chinese_mobilephone.model, 词表EntityList={entity1, entity2···entityn}, 阈值
输出: 词语-同义词表EntitySimilarList={entity1:[sim1, sim2···], entity2:[sim1, sim2···], ···entityn:[sim1, sim2···]}
①加载模型文件chinese _mobilephone.model。
②从EntityList中取一个词语entityi, 新建其同义词列表为entityi_sim。
③遍历EntityList, 计算entityi和EntityList中其他词语的相似度, 若相似度大于阈值
④将entityi_sim列表保存到EntitySimilarList中。执行步骤②, 直至完全遍历EntityList。
将数据层生成中获取的手机实体、评价对象经人工筛选过滤掉抽取错误, 选择其中的1 000个词语作为实验语料。设置并比较12组过滤阈值后, 最终确定阈值为0.7时, 性能(F值)较稳定。在此阈值下, 从实验语料中共计识别出同义词对74对, 同义词识别准确率为50%, 召回率为85.71%, F值为63.16%。从实验结果来看, 基于词向量的同义词发现不仅能识别“外形-外观”、“实用性-内用性”这类同义词, 还能够识别领域性强的同义词对, 例如“电池容量-耗电量”、“分辨率-清晰度”、“手感-握感”等, 表明选取的领域语料对手机领域的同义词识别有积极作用。实验整体准确率不高、召回率高的原因归结为两方面: 一方面词向量的本质是基于语料的训练结果, 利用大规模语料表达词语语义信息的方法本身存在一定的瓶颈; 另一方面, 手机数码属于专业性较强的领域, 领域内本身的同义词、近义词数量有限。上述实验证实了本文提出的同义词发现方法能将实体、属性的语义特性和领域特性结合, 实现领域内的同义词发现, 具有较高的可行性和有效性。
基于获取的手机领域同义词对, 完成手机知识图谱上的实体链接和属性链接, 生成手机知识图谱的数据层。最后, 借助Neo4j存储手机知识图谱。
(1) 手机知识图谱可视化
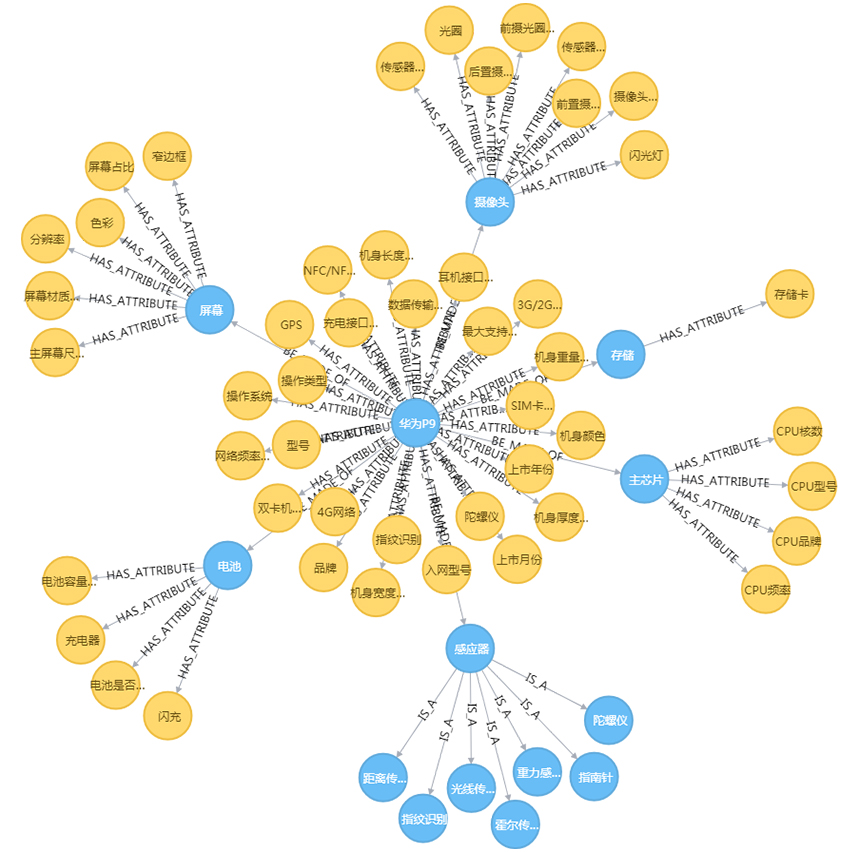
以华为P9手机为例进行可视化展示。华为手机知识图谱共涉及实体15个, 实体的属性47个, 关系61对。利用图数据库存储图谱的关联关系, 如图3所示。
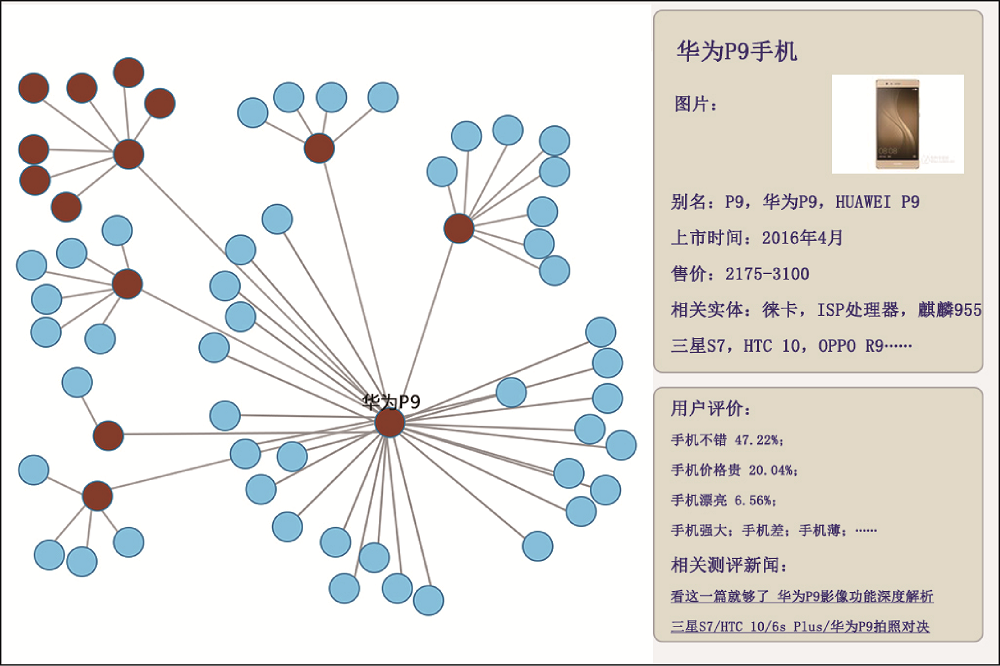
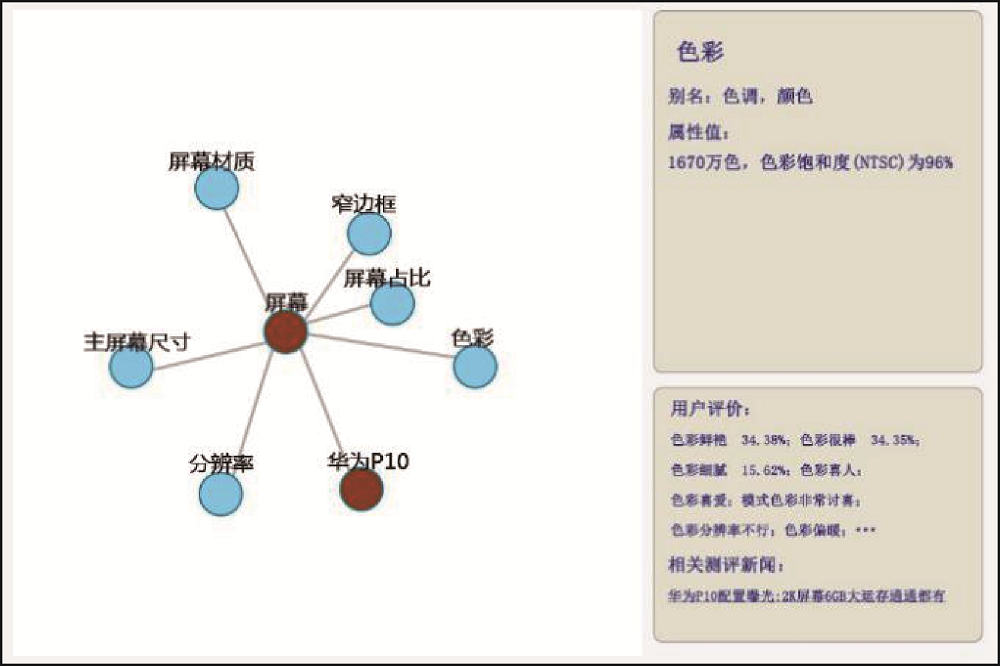
对于图数据库中节点关联的详细信息, 仍需使用Cypher语句检索查看。因而, 在Neo4j存储图谱数据的基础上, 借助可视化组件D3.js, 使用网络节点图绘制出手机知识图谱, 并通过信息栏动态展示节点详情, 如图4所示。
图4左侧展示P9手机知识图谱的整体结构, 由实体节点、属性节点和关系组成(鉴于该图谱整体节点数量较多, 在整体产品知识图谱上隐藏节点名称, 只浮动显示选中节点的名称)。通过左侧的网络节点图可以查看该款手机的组成及关联属性。选中“华为P9手机”节点, 右侧信息栏展示该实体的详细信息及用户评价。信息栏分静态信息和动态评论两块, 其中, 信息项“别名”依据实体链接的结果; “相关实体”和“相关测评新闻”以手机实体抽取实验和实体链接为基础, 统计不同手机实体在相关测评新闻中的出现频次, 按频次由高到低排序; “用户评价”融合了评论对象及评价词抽取和实体链接的结果, 将实体关联的评价标签量化统计; 其他信息来自属性抽取等任务。
整体上, 华为P9手机画像中的节点关系清晰, 可查看该手机的实体节点及其关联的属性节点, 同时每个节点都关联了属性值、别称、相关实体、用户评价、相关新闻等多维信息, 如图4中华为P9手机节点分为客观信息展示(图片、别名、售价、相关实体)、用户评价显示(手机不错、手机价格不贵、手机漂亮)和相关测评新闻显示, 其中用户评价部分根据评价对象和评价词抽取获得, 并按照词频出现的大小进行排序, 词频为前三的以百分比形式显示在图中, 频率不在前三位但大于设定阈值5%的只显示评价对象和评价词。
(2) 系列手机产品深度对比分析
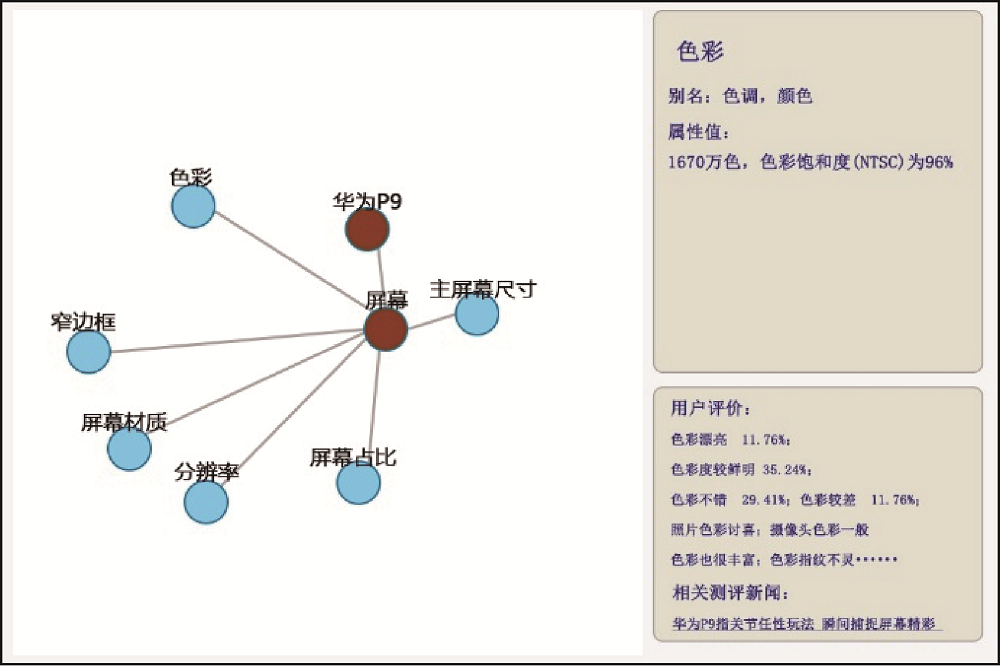
手机产品更新快, 产品每次“升级”后, 用户评价口碑的改变是手机供应商(生产者)继续研发和完善产品的基础, 对产品供应商(生产者)而言, 通过分析不同型号产品的知识图谱, 不仅能发现产品属性间的关联, 还能及时了解产品改进后用户对产品“升级”属性的评价反馈, 从汇总数据深入到细节数据进行观察, 为产品生产或销售及时做出更加正确的决策。以华为P9和华为P10的节点为例, 如图5和图6所示, 在两款手机画像中, “色彩”节点的属性值均为“1 670万色, 色彩饱和度(NTSC)为96%”, 但在用户评价方面, P10手机中正面评价占比高于P9手机, 且“鲜艳、细腻”等评价明显增多。分析其原因, 用户在评价手机的色彩属性时, 不仅仅考虑屏幕本身的显示, 往往还关联手机的拍照功能, 如评价“拍照色彩喜人”、“徕卡色彩较浓”等。进一步分析华为P9和P10两款型号的手机在摄像方面的属性差异, 型号P9升级到P10, 摄像方面由“双1 200像素”提升为“2 000像素黑白+1 200像素”, 由“徕卡双摄”提升为“徕卡三摄”等, 这些优化使得手机拍照功能更加稳定, 导致用户在评价P10手机时对色彩方面的关注增多, 提及较多与“色彩”相关的内容。这也进一步证实产品画像中的实体和属性是存在关联的, 用户在评价手机“屏幕”时往往会提及“摄像头”等相关实体。以手机图谱为基础, 产品对比的维度不再局限于客观属性及属性值的对比, 还能进一步关联到用户评价, 将手机客观属性和用户评价关联, 进一步分析手机产品属性和属性之间的关联、属性差异造成用户评价的变化等。
本研究以电子商务背景下的产品数据为基础, 提出构建产品知识图谱的一系列方法, 并以手机类产品为例, 进行手机知识图谱的生成和展示。通过实例证实产品知识图谱能够有效关联产品描述信息与用户评论, 在产品对比中有一定的应用价值。
产品知识图谱的关系抽取限定了关系类别, 使得图谱中关系数量有限。未来可在产品实体间进行开放性关系抽取, 并对抽取的实体关系进行分类、聚类研究, 不再局限于既定的关系类型。另外, 产品知识图谱的更新和维护也是后期相关研究的重点。
丁晟春: 提出研究思路, 设计研究方案;
侯琳琳: 设计产品知识图谱构建流程, 并选取实例进行产品知识图谱的构建和可视化, 起草论文;
王颖: 设计方案补充, 构建模式层、数据层, 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: todingding@163.com。
[1] 丁晟春, 侯琳琳, 王颖. Comment data.txt. 手机评论数据.
| [1] |
[本文引用:1]
|
| [2] |
目前的电子商务模式中存在着两个问题。一是缺乏多站点间商品信息的统一描述规范,其二是没有一种有效机制根据统一的描述形式建立高效率的站点关系。给出一种基于XML的二元电子商品统一描述和关系模型,解决上述的第一个问题。提出一个以该模型为基础的分布式智能体框架,实现一套基于商品营销关系的多站点检索机制。
|
| [3] |
[本文引用:1]
|
| [4] |
[本文引用:1]
|
| [5] |
[本文引用:1]
|
| [6] |
[本文引用:1]
|
| [7] |
[本文引用:1]
|
| [8] |
[本文引用:1]
|
| [9] |
|
| [10] |
[本文引用:1]
|
| [11] |
|
| [12] |
[本文引用:1]
|
| [13] |
[本文引用:1]
|
| [14] |
[本文引用:1]
|
| [15] |
URL
[本文引用:1]
|
| [16] |
[本文引用:2]
|
| [17] |
[本文引用:1]
|
| [18] |
URL
[本文引用:1]
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}