

【目的】探讨实体解析理论中经典的实体解析方法及逻辑思路。【文献范围】在Google Scholar和CNKI中分别以检索词“Entity Resolution”、“Collective Analysis”、“Crowdsourced”、“Active Learning”、“Privacy-Preserving”和“实体解析”进行文献检索, 再结合主题筛选, 精读并使用追溯法获得实体解析研究的代表性文献共86篇。【方法】针对每种实体解析方法, 归纳分析该方法的基本思想, 并通过图示直观地呈现其中的解析过程; 重点分析梳理方法实现过程中, 现有研究所采用的关键策略、算法或技术等。【结果】实体解析是数据质量管理的基本操作, 也是发现数据价值的关键步骤。【局限】未深入分析各实体解析方法的评价指标和应用情况。【结论】尽管现有实体解析方法能在一定程度上满足大部分应用的需求, 但在大数据环境下其仍然面临着数据混杂性、隐私保护和分布式环境等方面的挑战。
[Objective] This paper discusses the classical entity resolution methods and logical thinking in entity resolution theory. [Coverage] Google Scholar and CNKI were respectively used to search literatures with the keywords “Entity Resolution”, “Collective Analysis”, “Crowdsourced”, “Active Learning”, “Privacy-Preserving” and “Entity Resolution” in Chinese. I then obtained a total of 86 representative literatures in conjunction with topic screening, intensive reading and retrospective method. [Methods] For each entity resolution method, the paper first summarizes and analyzes the basic idea of the method, and presents the resolution process through illustration, and then focuses on analyzing the key strategies, algorithms or techniques adopted by the existing research in the process of implementation of the method. [Results] Entity resolution is the basic operation of data quality management, and the key step to find the value of data. [Limitations] There is no in-depth analysis of the evaluation indicators and application of each entity resolution method. [Conclusions] Although existing entity resolution methods can meet the requirements of most applications to some extent, they still face challenges in data heterogeneity, privacy protection and distributed environment in the big data environment.
大数据环境下, 促进各种不同环境中所收集数据的集成共享, 并减少数据分析成本, 成为众多大数据应用的一项核心要求。然而, 有关数据质量、计算复杂度和数据演化等问题让大数据应用面临诸多挑战。在这一背景下, 作为大数据应用中关键技术之一的实体解析(Entity Resolution, ER), 也相应地引起国内外人工智能、深度学习和信息融合等领域学者高度关 注[1,2,3,4]。实体解析指识别出数据集(或数据库)中那些描述同一现实世界实体的数据对象, 以此达到数据清洗和集成的目的[5]。这里的数据对象是结构化的, 又称为数据记录或近似重复记录(Approximate Duplicate Records), 通常包括多个属性, 例如姓名、年龄和地址等。
自Newcombe等[6]于1959年首次提出应用计算机自动进行数据识别, 并提出实体解析概念以来, 实体解析研究已取得一系列重要发展和创新, 主要包括以下方面: 相似度计算、通用扩展、协同分析、众包模式、主动学习、实时应用和隐私保护等。然而, 随着信息技术和互联网技术的迅猛发展, 各种数据呈现出爆炸式增长态势, 其所具有的大规模性、类型多样性和关联复杂性等给现有的实体解析研究带来巨大挑战, 例如需根据实际情况重新设计算法等, 进而影响大数据应用前景。鉴于此, 本文对现有实体解析的基本方法及逻辑思路进行梳理, 以期为大数据环境下的实体解析研究提供进一步的理论指导和实践参考。
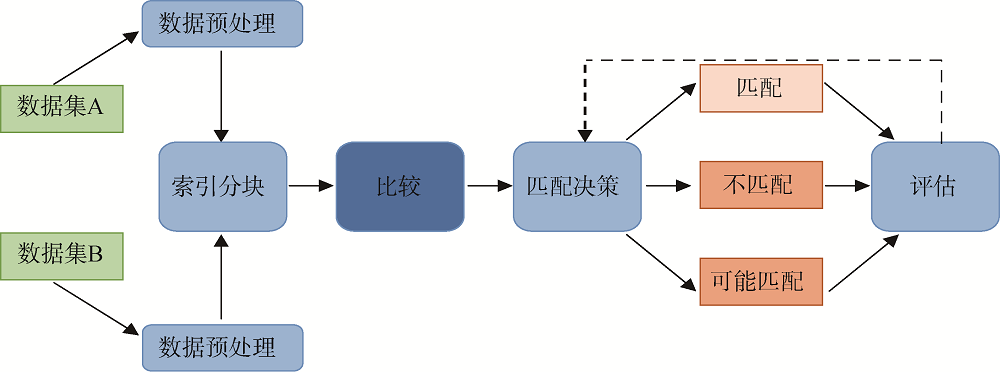
基于概率决策的实体解析方法(Probabilistic Entity Resolution)的基本思想是: 通过计算对应属性值之间的相似度, 并结合属性级阈值和记录级阈值, 决定两条记录是否匹配[7]。解析过程如图1所示, 其中的“比较”模块涉及记录之间两两成对比较, 这里暂不讨论“索引分块”和“匹配决策”两个模块。
该方法的典型代表是Fellegi等[8]提出的Fellegi- Sunter解析模型, 该模型将实体解析问题视为传统分类问题, 即在属性间条件独立的假设下, 汇总所有对应属性值之间的相似性得分(相似度), 并计算当前记录对的条件概率比值(R), 然后将R与上下两个阈值(记录级)进行比较以判定当前记录对的匹配状态(匹配、不匹配或可能匹配)。很显然, 字符串相似度计算是实体解析中的核心基础模块。为从字符串相似度计算角度实现基于概率决策的实体解析, 现有研究主要从三个方面开展工作: 基于词项的相似度、基于编辑距离的相似度和基于混合的相似度。
这类相似度算法将属性值看作词项(token)的集合, 主要包括Jaccard相似度、TF-IDF相似度和q-grams相似度。Jaccard相似度是一种常见的判定相似程度的指标, 作用在两个集合上, 其值为集合交与集合并的比值[9]。Jaccard相似度多用于检测无拼写错误字符串的相似度, 且对字符串内各词项顺序的变化不敏感。TF-IDF相似度将属性值作为文档(包含词项)处理, 并用向量表示, 最后通过余弦算法计算出两个向量之间的相似度, 以表示属性值之间的相似度[10]。TF-IDF相似度背后隐含的直觉是如果两个字符串有相同的可区分项, 则它们是相似的。q-grams相似度首先将各字符串切割成长度为q的grams, 然后再基于Jaccard相似度算法或余弦算法对它们进行相似度计算[11]。q-grams相似度计算更适用于比较存在拼写错误的字符串。
基于混合的相似度结合前述两类相似度算法的优点, 主要包括泛Jaccard相似度(Generalized Jaccard)、泛TF-IDF相似度(Soft TF/IDF Similarity)和Monge-Elkan相似度。泛Jaccard相似度是Jaccard相似度的一种自然泛化, 即弱化词项间的匹配要求, 只要求彼此相似即可, 而不必完全一致[15]。泛Jaccard相似度考虑词项可能相似这一情形, 是因为现实中单词有可能会拼错。类似于泛Jaccard相似度方法, 泛TF-IDF相似度是在TF-IDF相似度的基础上, 结合应用辅助相似度函数(例如Jaro-Winkler)计算词项的相似度得分, 并用它作为最后字符串相似度计算的权重[16,17]。Monge-Elkan相似度通过对子字符串设置辅助相似度方法sʹ对字符串相似度有更多控制[18]。例如, sʹ可以判定如果
面向通用扩展的实体解析方法(Generic Entity Resolution)的思想是: 仅从可扩展层面设计算法, 以大大减少调用通用“黑盒”函数的次数, 并且不考虑用作匹配、合并记录的“黑盒”函数的具体实现[19,20]。这一解析过程如图2所示, 其中, “匹配”函数用于判定两条记录是否匹配(只有若干对应属性值之间的相似度满足条件时才返回记录对匹配, 否则返回不匹配), “合并”函数用于组合并统计匹配记录对的对应属性值(可能不同)以产生新的合并后的记录(如
这种方法的典型代表是斯坦福信息实验室开发的SERF解析模型[21], 该模型定义了用于“匹配”、“合并”函数的以能产生有效解析策略的4种性质: 幂等性(Idempotence)、交换性(Commutativity)、结合性(Associativity)和代表性(Representativity)。为进一步说明如何在不同情况下利用上述性质实现较优的解析, 针对三种不同情况分别设计三个算法: G-Swoosh算法(记录层面, 避免不必要的比较)、R-Swoosh算法(记录层面, 进一步避免G-Swoosh算法中不必要的比较)和F-Swoosh算法(属性层面, 避免重复的属性比较)。对于每个算法, 实验表明不仅能计算出正确的解析结果, 而且就执行的比较次数而言也是“最优的”。为从算法设计角度开展面向通用扩展的实体解析研究, 现有研究主要从三个方面开展工作: 基于并行算法、基于缓冲算法和基于分布式算法。
Kawai等[22]认为实体解析过程通常是计算密集型的, 因此在多个处理器之间分配解析负载将是非常重要的。为此, 提出并行算法P-Swoosh, 它使用通用的匹配和合并函数, 同时考虑在处理器之间实现负载平衡。实验结果显示, P-Swoosh算法具有三方面优点: 即使在并行环境中, 算法也可以避免许多冗余比较; 算法可以降低R-Swoosh算法中合并记录时的计算成本; 无论是否具有领域知识, 算法在2-15个处理器上具有较好的线性可扩展性。类似地, Kim等[23]认为合并的记录可能会与数据集中其他记录匹配, 因此要求解析方案必须是可迭代的, 这会让解析过程复杂化。鉴于此, 提出基于数据“特征(Characteristics)”的并行算法, 例如a包含b、a等同于b, 以及a和b重叠等特征, 从而使得多处理器之间的冗余计算和开销最小化。
Kawai等[24]认为尽管解析过程的成本很高, 但对于有限的内存或非常大的数据集来说, 解析过程中磁盘I/O读写的成本同样可能是关键的, 因此在给定“匹配”、“合并”函数的情况下, 在内存有限的单处理器中缓冲(buffer)一个大的数据集是必要的。鉴于此, 提出基于延迟磁盘更新(Lazy Disk Update)和位置感知匹配调度(Locality-Aware Match Scheduling)的缓冲算法Bufoosh, 利用初始记录排序定位内存中的匹配候选对象。实验结果显示, 算法可以实现非常高的命中率并能显著降低磁盘I/O读写次数。
为能在多个处理器上并行运行解析过程, Benjelloun等[25]对R-Swoosh算法进行扩展, 并提出分布式算法D-Swoosh, 以在多个处理器之间分配解析工作负载。D-Swoosh算法使用多种范围函数(Scope Functions)和负责函数(Responsible Functions), 前者用于将输入记录分发给处理器, 后者用于避免冗余的比较。这些函数中的一些用于针对没有语义知识的场景, 另一些则利用ER应用程序中经常出现的知识。
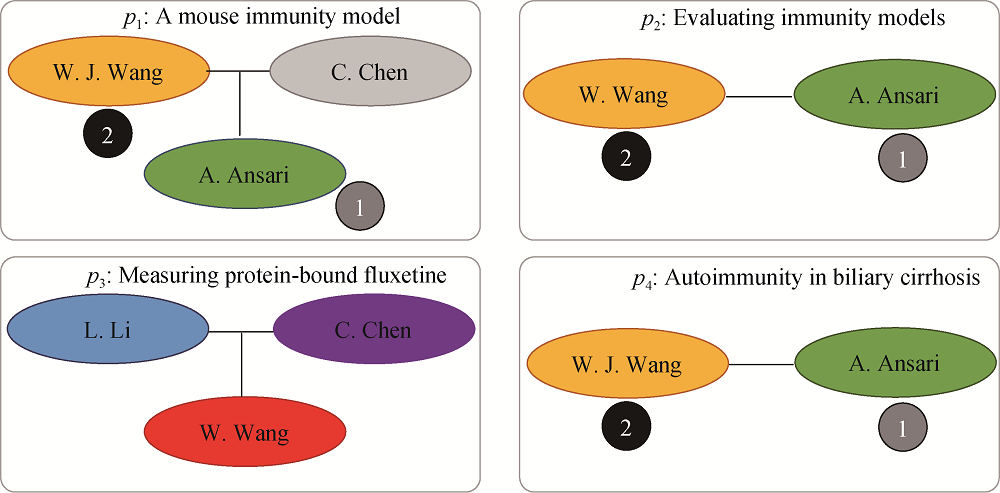
基于协同分析的解析方法(Collective Entity Resolution)的思想是: 以迭代的方式对共同出现的多种类型或同种类型的数据对象协同而非独立地进行解析[26]。与传统上使用记录属性的成对相似度进行解析的方法不同, 这种方法通过考虑在早期迭代中已经发现的实体关系作为证据递增地解析实体。以通过共同作者这一关系来解析出其他作者为例, 这一解析过程如图3所示。其中, 矩形表示一篇学术论文(
这种方法的典型代表是Bhattacharya等[26]提出的协同解析学术论文中共同作者是否为同一实体的方法。为进一步理解这种协同解析过程, 本文对这一过程的理论分析如下:
(1) 解析过程从最有信心的数据对象开始, 例如两个名为“A. Ansari”的数据对象更可能表示同一实体(如标记1指示的绿色椭圆), 因为“A. Ansari”是一个不常见的姓名, 这为解析其他数据对象提供额外的证据。
(2) 在名为“A. Ansari”的数据对象被解析后, 那么分别来自论文
基于关联算法的思想是针对复杂信息空间中多类型的数据对象相互关联, 并且每个数据对象仅具有少量属性的特点, 利用数据对象间丰富的关联关系帮助进行实体解析, 并将一些数据对象的实体解析结果传递到其关联的数据对象, 同时通过解析过程中的信息增益解决部分数据对象属性信息不足的问题[29]。Dong等[29]提出一个面向复杂信息空间的协同实体解析方法(Joint Entity Resolution in Complex Information Space, JER-CIS), 其基本思想是利用数据对象间丰富的关联关系来帮助进行实体解析, 并迭代地处理整个过程。具体来说, 首先利用数据对象的多种上下文信息进行数据对象匹配; 之后, 将一些数据对象的实体解析结果传递到与其关联的数据对象, 实现匹配传播。当两个数据对象匹配后, 它们的属性值将分别组成属性值集合, 以产生数据对象信息增益, 从而解决部分数据对象属性信息不足的问题, 进而提升后续数据对象的匹配准确性。总之, JER-CIS方法通过挖掘上下文信息、匹配传播和数据对象信息增益得到更精确的实体解析结果。类似地, 孙琛琛等[30]提出一种基于图形的迭代协同解析方法(Graph-Based Iterative Joint Entity Resolution Approach, GBi-JER), 该方法与领域无关, 且适合于任何关联的数据。GBi-JER方法充分发掘逐渐收敛的对象图, 迭代地对多类型关联数据对象进行协同解析, 并利用不同数据对象间的关系促进彼此的匹配。
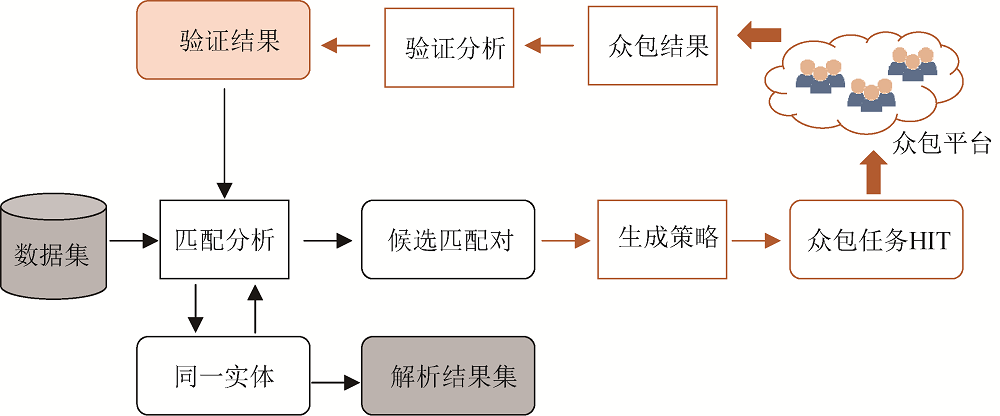
基于众包模式的实体解析方法(Crowdsourced Entity Resolution)的思想是: 通过整合计算机和互联网上未知的大众(工作者), 完成计算机难以单独完成的人类智能任务(Human Intelligence Tasks, HIT), 从而有效提高实体解析准确率[32,33]。该方法包括三个典型步骤:
(1) 由机器对所有数据进行预处理, 并将待验证的最有影响力的候选匹配对提交到众包平台上;
(2) 由大众通过众包平台验证最可能的匹配对;
(3) 验证过程分析平台返回的结果, 确定最终匹配结果。
众包解析过程如图4所示, 生成策略是关键步骤, 关系到如何以最小代价获得最佳收益, 即通过算法选出最有影响力的候选匹配对放在众包平台上, 当其数量达到预算的时候则停止执行算法。
为从众包角度开展实体解析研究, 现有研究主要从三个方面开展工作: 结合聚类或迭代步骤、结合HIT生成步骤和结合返回结果验证步骤。
为在众包过程中生成批处理的HIT, 并平衡花费、质量和时间等问题, Wang等[34]提出两种典型的众包任务生成策略: 基于成对的批处理方法和基于聚簇的批处理方法。前者将候选匹配对简单地按照HIT的最大量划分, 即每个HIT都由候选匹配对组成。例如, 在一个HIT上需要大众判定记录1和2、5和7是否描述同一实体。后者在给出一聚簇记录时, 要求大众判断哪些描述同一实体。例如, 在HIT上需要大众判定记录1、2、5和7中的哪些描述同一实体。事实上, 划分记录聚簇的工作已被证明是图上的简化问题, 并且是NP难的, 因此可以采用优化方法解决[10]。最后, 实验证明划分聚簇的方法比成对的方法更适合众包。
在确定返回结果中的匹配对方面, 现有研究主要采用4种方法: 基于投票的方法、黄金标准数据法、期望最大化的评估方法和结合传递性的方法。
(1) 基于投票的方法将一个任务分配给多个工作者独立回答, 然后将答案通过投票方式进行整合, 最后将大多数的意见作为最终的正确结果[35]。这种方法假定每个工作者的准确率一致。
(2) 黄金标准数据法通过设计一些具有标准答案的问题作为测试题目, 在任务开始前或者在任务进行过程中由工作者回答, 最后根据答题结果识别欺诈者, 同时对工作者的准确率进行评估, 进而依据贝叶斯模型或概率模型获得任务的最终结果[36,37]。这种方法假定每个工作者的答题准确率是固定的。
(3) 期望最大化的评估方法通过对任务结果和工作者的准确率不断进行迭代估计, 直至收敛得到任务结果[36]。这种方法能够实现对任务结果的精确评估, 但当任务或工作者较多的时候, 算法运行效率较低。
(4) 结合传递性的方法通过数据对象匹配的传递关系减少所需HIT的数量。例如, 如果a和b描述同一实体, b和c不是同一实体, 显然a和c不是同一实体。这种方法通过考虑传递关系提高实体解析效率。
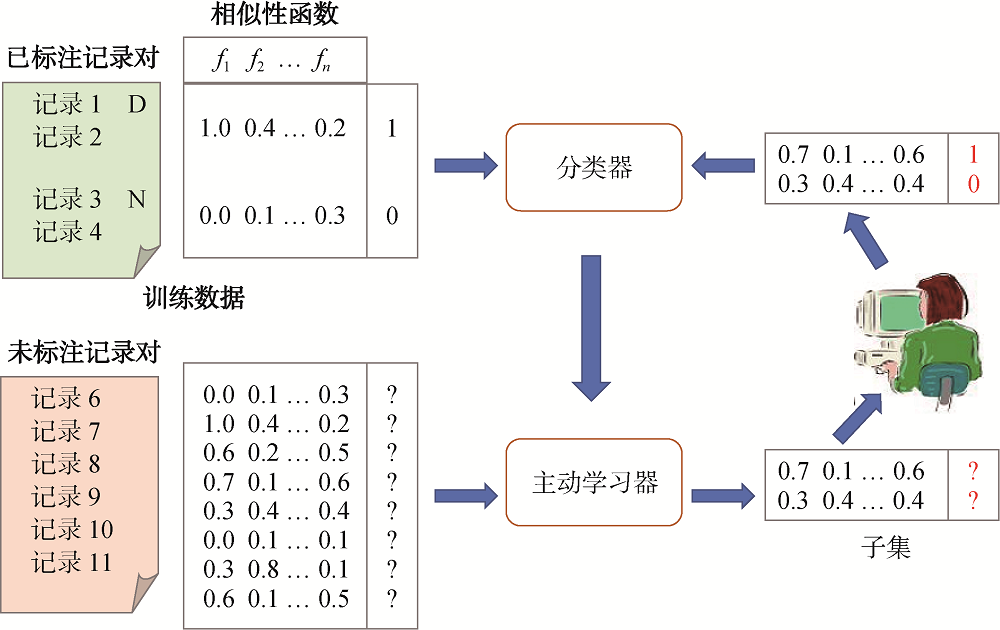
基于主动学习的实体解析方法(Entity Resolution Using Active Learning)的思想是: 通过主动学习器(Active Learner)从未标注数据对象集中有策略性地选出某些数据对象以让专家进行标注, 标注后的数据对象有助于以最快的速度加强分类器[38,39]。主动学习本质上是一种机器学习方法。这一解析过程如图5所示, 主动学习器试图迭代地从未标注数据对象集中选择信息最丰富的数据对象, 而不是错误或无关的数据对象, 以让专家对该数据对象进行标注, 这对学习有效的分类器最有用。
这种方法的典型代表是Sarawagi等[40]提出的基于主动学习的交互式实体解析系统ALIAS, 在专家标注的基础上分别实现基于决策树(Decision Trees)、基于朴素贝叶斯(Naive Bayes)以及基于支持向量机(Support Vector Machines, SVM)的分类方法来训练分类器, 并对这些方法的性能进行比较。由于ALIAS系统通过主动学习自动构建匹配函数, 因而能较好地解决匹配函数难以确定、词汇共现度难以利用等问题。类似地, Tejada等[41]提出Active Atlas解析系统, 它使用由三个决策树分类器组成的委员会来学习区分匹配和非匹配的最佳规则。从主动学习角度开展实体解析研究, 主要包括从基于采样策略和基于其他策略两方面的工作。
Qian等[44]提出一种主动学习系统, 该系统可以大规模地学习多个规则, 每个规则都具有对重复空间的显著覆盖, 从而在高精确度的基础上实现高召回率。具体来说, 其中的算法可以通过最大化召回率来学习规则, 同时满足给定的一组标注示例的高精度约束。Fisher等[45]应用主动学习技术产生训练数据, 以用于基于马尔可夫逻辑网络(Markov Logic Networks, MLNs)的实体解析模型, 同时学习马尔可夫逻辑网络公式中必要的权重系数。此外, 作者提出一种允许领域专家向马尔可夫逻辑网络添加新规则的方法, 以捕获现有模型未正确分类的记录对。此外, Fu等[46]从实例选择角度研究已有的主动学习研究成果并将其分为两类: 一类是仅基于独立同分布(Independent and Identically Distributed, IID)实例的不确定性; 另一类是基于实例相关性。在上述分类基础上, 作者总结该领域的主要方法以及其技术优势和劣势, 进行简单的运行时性能比较, 并讨论新兴的主动学习应用程序和其中的实例选择挑战。
面向实时应用的实体解析方法(Real-Time Entity Resolution)的思想是: 通过索引技术从数据集中选取一个记录块(记录子集), 用该记录块解析到来的查询记录流(Stream of Query Records), 这一过程持续时间(响应时间)为亚秒级[47,48]。这一解析过程如图6所示, 其中, 比较次数由|D|次减少为|B1|、|B2|或|B3|次。这种解析方法主要考虑两个因素: 如何根据到来的查询记录(Query Record)快速确定记录块; 如何快速确定块中的记录是否与查询记录匹配。显然, 在大数据环境下的解析过程中, 前者比后者更难处理。值得一提的是, 这种解析方法在功能上与文本和网络搜索引擎有相同之处: 实时、近似匹配和结果排名[49,50,51]。
面向实时应用的实体解析研究工作主要包括三个方面: 基于索引过滤、基于Meta-Blocking过滤和基于其他策略。
索引(Indexing)技术的思想是通过定义某种形式的块键(Blocking Key), 以让尽可能多的真实匹配对包括在候选记录对集合中[52]。Christen等[53]提出一种适用于实时解析的相似感知倒排索引技术(Similarity-Aware Inverted Index), 主要思想是预先计算同一块中属性值之间的相似度, 并存储在主存储器中, 以便在后续匹配查询记录的过程中使用。由于在匹配过程中避免了相似度计算, 因而该技术能显著减少匹配时所需的时间。但该技术的缺点是只能处理静态数据集, 因为索引一旦被创建, 新的记录和属性值就不能被加入其中。鉴于此, Ramadan等[54]提出一种更具灵活性的动态相似感知倒排索引技术(Dynamic Similarity-Aware Inverted Indexing, DySimII), 每当处理新的查询记录时相应的属性值就能加入到索引中。具体来说, 采用三种索引结构克服最初相似感知倒排索引技术的局限性: 块索引(Block Index, BI), 用来存储唯一的属性值及其关联的块键; 相似性索引(Similarity Index, SI), 用来存储相同块中属性值之间预计算的相似度; 记录索引(Record Index, RI), 用来存储所有唯一属性值及它们关联的记录标识符。类似地, Ramadan[47]在以前研究的基础上提出三种动态索引技术: 基于分块的DySimII索引技术, 每当新查询记录到达时索引便会更新; 基于树(Tree-Based)的DySNI动态索引技术; 基于多树(Multi-Tree Based)的F-DySNI索引技术, 它在索引数据结构中使用多个不同的树, 其中每棵树都有唯一的排序键, 该索引技术的目标是减少属性值开始处错误和变种的影响。此外, Ramadan等[55]提出一种可自动选择最优块键的无监督学习方法, 构建可用于实时解析的索引。
索引过滤技术在进行分块时会产生重叠的块, 从而导致比较冗余, 而Meta-Blocking技术则可清除重叠的块以避免不必要的比较, 从而进一步提高解析效率。Papadakis等[56]提出利用Meta-Blocking技术直接优化重叠的分块, 将信息封装在块到实体关系(Block-to-Entity Relationships)中并构建块图(Blocking Graph); 将问题转化为度量图中边的权重和图修剪问题。这种做法独立于底层的索引技术, 与模式无关, 并具有通用性。Meta-Blocking技术并不取代现有索引技术, 而是对其进行补充。为进一步提高Meta-Blocking技术的效率, Efthymiou等[57]从并行计算角度提出基于MapReduce的Meta-Blocking变种技术, 其中包含两种替代策略: 具有更高可扩展性的基本策略(显式地构建块图)和高级策略(隐式地构建块图, 减少数据交换的开销)。
Dragut等[58]针对在线环境中的实体解析提出一种基于迭代缓存(Iterative Caching)的方法, 该方法的思想是解析并缓存一组频繁请求的记录以用作将来参考, 其中记录是通过从不同Web数据库中采样(Sampling)获得。在这种方法中, 响应查询的新到达记录将与缓存中的记录一起被解析, 解析后的结果呈现给用户并适当地追加到缓存中。这种方法允许对当前查询进行“快速”响应, 并为后续查询提供“改进”的数据质量。类似地, Gruenheid等[59]提出一种可增量、有效更新解析结果的端到端框架, 可以在数据更新到达时逐步有效地更新解析结果, 其中的算法不仅允许将数据更新中的记录与现有聚簇合并, 还允许利用其中的新证据修正以前的错误解析。Whang等[60]提出一种即付即用解析方法(Pay-as-you-go Entity Resolution), 这种方法建议使用提示(Hints)提供关于记录的信息, 这些记录可能描述同一现实世界实体。提示可以用各种格式表示(例如, 根据匹配的可能性对记录进行分组), 实体解析可以使用这些信息作为首先比较哪些记录的指南。该方法的目的是通过匹配的可能性排序候选记录对, 从而在仅占用总运行时间的一小部分时间内找到大多数匹配记录, 进而改进解析过程。
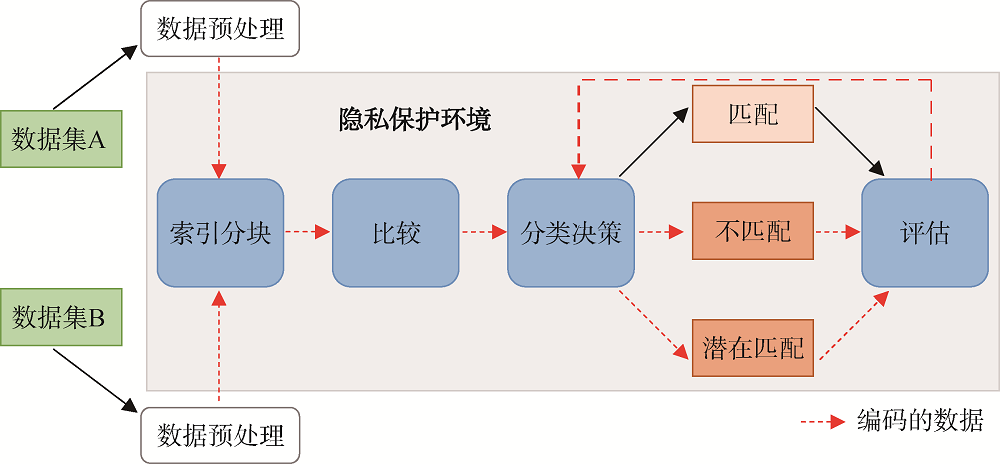
隐私保护下的实体解析方法(Privacy-Preserving Entity Resolution)的思想是: 确定两个或多个组织之间的数据集中是否包含描述同一现实世界实体的记录, 同时又不会向对方或其他任何组织泄露除匹配记录以外的任何信息[61,62]。解析过程如图7所示, 其中灰色框部分表示步骤中的任何敏感数据都要以某种方式进行编码, 以免任何一方了解任何其他方的数据, 这是与图1中明显不同的地方。数据预处理步骤可以由数据集所有者单独进行, 因此这一步骤在隐私保护范围之外。
实体解析中的隐私保护主要涉及两个方面: 如何保证数据在应用过程中不泄露隐私; 如何更有利于数据的应用。鉴于此, 现有研究主要从三个方面开展: 基于数据扰乱、基于数据重构和基于数据加密[63]。
数据扰乱技术主要采用
(1)
(2) 差分隐私
差分隐私是另一种强大的数据隐私保护模型, 不依赖于任何假设, 例如攻击者的背景知识等, 其基本思想是通过对原始数据进行变换或对统计结果添加噪声来实施数据隐私保护[67]。差分隐私可以保证在数据集中添加或删除一条记录时, 不影响实体解析结果, 因此即便在最坏情况下, 攻击者已知除一条记录之外的所有敏感数据, 仍可以保证这条记录的敏感信息不会被泄露[68,69]。事实上, 差分隐私与大数据之间有天然的匹配性, 因为大数据的大规模性和多样性导致在数据集中添加或删除记录时对整体数据的影响非常小, 这一特性与差分隐私的内涵相吻合[70]。差分隐私的优点是加入的噪声与数据集大小无关, 因此对于大型数据集来说, 仅通过添加极少量的噪声就能达到高级别的隐私保护。其缺点是无法主动控制隐私参数, 从而导致隐私性偏低或偏高。此外, 大数据之间的关联性也有可能弱化差分隐私保护效果。
数据重构技术指将记录信息转换为其他数值形式, 同时保留某些统计学特征而不保留真实数值。现有研究通常采用布隆过滤器(Bloom Filter)将属性值集合转换为位数组以实现数据重构[71]。布隆过滤器是Bloom[72]提出的用于有效检查集合成员的数据结构, 也可以用来确定两个集合是否近似匹配[73]。尽管通过布隆过滤器得到的位数组, 在一定程度上代表转换前的记录并保护了记录隐私, 但转换后的位数组并不是绝对安全的, 无法抵御基于频率的密码学分析。鉴于此, Durham等[74]提出一种利用布隆过滤器的可以抵御基于频率的密码学分析的实体解析方法。
类似地, Vatsalan等[75]提出一种可扩展的基于“与”运算, 并结合安全合计(Secure Sum)与Dice相似度函数(Dice Coefficient Similarity)的多方隐私保护下的实体解析方法, 但该方法在处理存在质量问题的数据(Data with Quality Issues, DQI)时, 会丢失较多真实匹配的记录, 从而导致查全率过低, 进而使其实际应用价值偏低。韩姝敏等[62]认为大部分多方隐私保护下的实体解析方法采用精确匹配方式, 因而不具有容错性, 而那些少部分具有容错性的方法, 却在处理存在质量问题的数据时由于容错性差和时间代价大而不能有效找出数据源间的共同实体。鉴于此, 作者提出一种结合布隆过滤器、安全合计、动态阈值、检查机制和改进Dice相似度函数的改进方法, 以解决存在的可扩展性差、容错性差等问题。此外, Randall等[76]提出一种使用布隆过滤器来加密个人信息的解析方法。
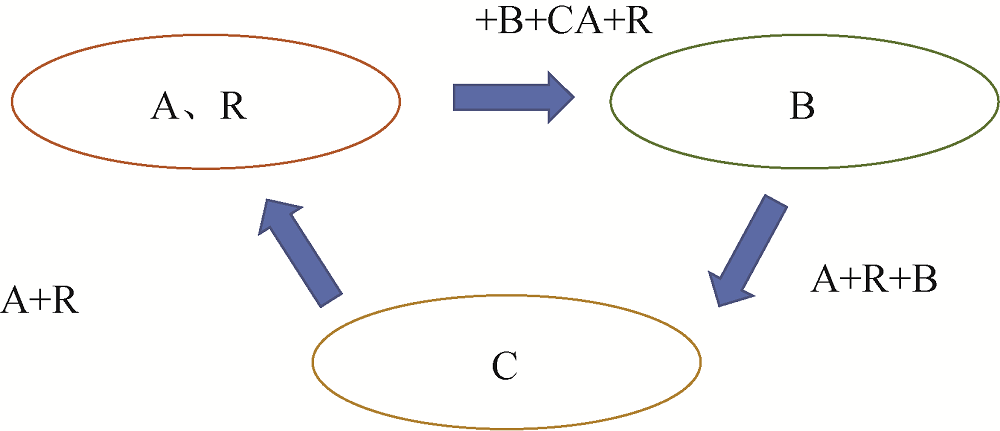
数据加密技术常用的一种方法是安全多方计算(Secure Multiparty Computation, SMC)[77,78], 与零知识(Zero Knowledge)概念密切相关[79,80], 例如, 可以在不透露两位百万富翁净资产的情况下计算哪一个更富有。安全多方计算的基本思想是, 在分布式环境下基于多方参与者提供的数据计算出相应函数值, 并确保除参与者的输入以及输出信息外, 不会额外地暴露参与者的任何其他信息。简单来说, 它是指一组互不信任的参与者在不泄露各自隐私信息的前提下进行多方合作计算。这一计算过程如图8所示: 假如有三个参与方A、B、C, 要对其中的数据进行安全合计, 首先将扰乱数据R传入A, 并与A中的数据进行加和运算, 然后将结果传入B, 继续进行加和运算后传入C, 参与方C无法得知A、B中的数据, 继续进行加和运算后传回参与方A, 减去扰乱数据R, 即得到三者之和, 该过程中任意一方均不知道其他参与方的数据。该方法的缺点是大数据环境下计算过程易陷入循环怪圈。
此外, Lindell等[81]研究了安全多方计算的基本范式和概念, 并讨论了它们与保密数据挖掘领域的关系。
对大数据进行充分开发和利用以发挥大数据的大价值, 是人工智能发展过程中不可避免的趋势, 也是社会进步的重要推力。随着数据量和数据种类的增加, 实体解析与人工智能等技术之间的联系也会越来越紧密。鉴于此, 本文从某种程度上探讨和研究了实体解析理论中经典的实体解析方法及逻辑思路, 并总结了各方法的性能特点和局限性, 如表1所示, 以期为大数据环境下的实体解析研究提供进一步的理论指导和实践参考。
展望未来, 随着大数据应用需求持续加大, 以及研究不断深入和拓展, 实体解析技术在数据混杂性、隐私保护和分布式环境等方面仍存在一些开放性的研究方向。
(1) 数据混杂性下的实体解析
在真实数据集中, 数据对象的属性值可能存在诸多问题, 例如错误、缺失、重复、表示多样化和随时间演化等[82]。然而, 传统上用于实体解析的一些字符串相似度函数却并不能很好地克服这些问题, 即不能合理计算出存在诸多问题的属性值之间的相似度。显然, 为计算出数据混杂性环境下属性值之间的相似度, 需要一种解析能力更强的数据模型, 以充分发掘出海量数据中蕴藏的丰富内在信息和发现更好的特征, 继而据此计算出相似度。事实上, 深度学习模型本质上是通过构建具有很多隐层的机器学习模型和海量的训练数据来学习文本中更有用的特征, 从而最终提升分类或预测的准确性[83,84]。因此如何基于深度学习模型中的词嵌入(Word Embedding, 将记录对表示为N-gram嵌入)和深度神经网络(Deep Neural Networks, 将记录对分类为匹配和不匹配)技术进行数据混杂性下的实体解析是一个有意义的研究问题。
(2) 隐私保护下的实体解析
大数据时代下, 人们在享有大数据共享带来便捷化、精准化的同时, 也逐渐关注随之而来的数据安全、个人信息保护等问题。考虑到实体解析是实现大数据共享的一种关键技术, 因此研究如何在数据隐私保护的前提下有效进行实体解析将具有广泛而深远的现实意义[85]。事实上, 现有隐私保护下的实体解析方法存在一些局限, 严重阻碍了其在现实世界中的应用, 例如可扩展性差导致其无法应用于大数据集、容错性差导致其会丢失较多真实匹配的记录或比较能力差导致其无法应用于多方数据源之间多记录的比较。因此解决现有解析方法中存在的上述问题, 使其更好地应用到现实世界中, 将成为未来研究的热点和发展方向。
(3) 分布式环境下的实体解析
大数据时代的数据量达到PB或以上级别, 而且数据演化速度也较快, 因此如何通过分布式计算来高效利用这些数据, 是实体解析研究的另一主要任务, 例如基于Spark或MapReduce的分布式实体解析[86]。分布式实体解析通常基于分块技术, 然而现实世界中非均匀的数据分布, 往往会导致其产生大小不一的、冗余的分块, 这给分布式实体解析带来了负载均衡的挑战(涉及在多台机器上并行计算)。因此如何更合理地分配子解析任务, 以及提出有效的冗余去除技术, 以进一步提高分布式环境下的实体解析效率将是未来研究中的重点。
所有作者声明不存在利益冲突关系。
| [1] |
随着大规模数据的关联和交叉,数据特征和现实需求都发生了变化.以大规模、多源异构、跨领域、跨媒体、跨语言、动态演化、普适化为主要特征的数据发挥着更重要的作用,相应的数据存储、分析和理解也面临着重大挑战.当下亟待解决的问题是如何利用数据的关联、交叉和融合实现大数据的价值最大化.认为解决这一问题的关键在于数据的融合,所以提出了大数据融合的概念.首先以Web数据、科学数据和商业数据的融合作为案例分析了大数据融合的需求和必要性,并提出了大数据融合的新任务;然后,总结分析了现有融合技术;最后针对大数据融合问题可能面临的挑战和大数据融合带来的问题进行了分析.
|
| [2] |
[本文引用:1]
|
| [3] |
[本文引用:1]
|
| [4] |
|
| [5] |
[本文引用:2]
|
| [6] |
|
| [7] |
[本文引用:1]
|
| [8] |
|
| [9] |
[本文引用:1]
|
| [10] |
[本文引用:3]
|
| [11] |
[本文引用:1]
|
| [12] |
[本文引用:1]
|
| [13] |
|
| [14] |
[本文引用:1]
|
| [15] |
[本文引用:1]
|
| [16] |
[本文引用:1]
|
| [17] |
[本文引用:1]
|
| [18] |
[本文引用:1]
|
| [19] |
[本文引用:1]
|
| [20] |
[本文引用:1]
|
| [21] |
|
| [22] |
[本文引用:1]
|
| [23] |
[本文引用:1]
|
| [24] |
[本文引用:1]
|
| [25] |
[本文引用:1]
|
| [26] |
|
| [27] |
[本文引用:1]
|
| [28] |
实体解析问题是数据挖掘数据清理过程中的基本问题. 异质网络数据的大量涌现, 要求能够针对包含多种类型对 象的数据同时进行实体解析. 针对包含两种对象的实体解析问题, 提出了一种基于联合聚类思想的协同实体解析算法. 将两种对象分为决定 对象和辅助对象, 提出了一个基于联合聚类思想的两阶段协同实体解析框架, 能够同时获得决定对象和辅助对象的各 自聚类结果, 其中每一个类包含的若干实体参考表示是对现实世界中同一实体的共同引用. 最后对提出的算法进行了数值实验.
Magsci
[本文引用:1]
|
| [29] |
[本文引用:2]
|
| [30] |
[本文引用:1]
|
| [31] |
|
| [32] |
[本文引用:1]
|
| [33] |
|
| [34] |
|
| [35] |
[本文引用:1]
|
| [36] |
[本文引用:2]
|
| [37] |
|
| [38] |
[本文引用:1]
|
| [39] |
[本文引用:1]
|
| [40] |
[本文引用:1]
|
| [41] |
[本文引用:1]
|
| [42] |
[本文引用:1]
|
| [43] |
[本文引用:1]
|
| [44] |
[本文引用:1]
|
| [45] |
[本文引用:1]
|
| [46] |
|
| [47] |
[本文引用:3]
|
| [48] |
[本文引用:1]
|
| [49] |
[本文引用:1]
|
| [50] |
[本文引用:1]
|
| [51] |
|
| [52] |
|
| [53] |
[本文引用:1]
|
| [54] |
[本文引用:1]
|
| [55] |
[本文引用:1]
|
| [56] |
|
| [57] |
[本文引用:1]
|
| [58] |
[本文引用:1]
|
| [59] |
|
| [60] |
|
| [61] |
[本文引用:2]
|
| [62] |
[本文引用:2]
|
| [63] |
[本文引用:1]
|
| [64] |
|
| [65] |
|
| [66] |
[本文引用:1]
|
| [67] |
[本文引用:1]
|
| [68] |
[本文引用:1]
|
| [69] |
[本文引用:1]
|
| [70] |
信息化和网络化的高速发展使得大数据成为当前学术界和工业界的研究热点,是IT业正在发生的深刻技术变革.但它在提高经济和社会效益的同时,也为个人和团体的隐私保护以及数据安全带来极大风险与挑战.当前,隐私成为大数据应用领域亟待突破的重要问题,其紧迫性已不容忽视.描述了大数据的分类、隐私特征与隐私类别,分析了大数据管理中存在的隐私风险和隐私管理关键技术;提出大数据隐私主动式管理建议框架以及该框架下关于隐私管理技术的主要研究内容,并指出相应的技术挑战.
|
| [71] |
[本文引用:1]
|
| [72] |
|
| [73] |
[本文引用:1]
|
| [74] |
|
| [75] |
[本文引用:1]
|
| [76] |
|
| [77] |
[本文引用:1]
|
| [78] |
|
| [79] |
|
| [80] |
[本文引用:1]
|
| [81] |
[本文引用:1]
|
| [82] |
[本文引用:1]
|
| [83] |
[本文引用:1]
|
| [84] |
|
| [85] |
[本文引用:1]
|
| [86] |
[本文引用:1]
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}