
 , 胡一鸣
, Hu Yiming
, 胡一鸣
, Hu Yiming
【目的】针对专利引文类别繁多的问题, 研究自动识别其中专利科学引文这一特定类别的方法, 进而准确抽取专利科学引文的标题特征项, 支撑后续专利科学引文深度分析与挖掘。【方法】引入表示学习方法Doc2Vec实现专利科学引文整体的语义向量表示, 结合机器学习分类方法实现专利科学引文这一特定类别的识别; 在此基础上, 利用表示学习方法实现专利科学引文标题等内容元数据的语义向量表示, 结合机器学习分类方法抽取专利科学引文标题。【结果】在基因领域专利的实验中, 专利科学引文的识别精确率达到99.27%, 专利科学引文标题抽取精确率达到92.59%, 抽取精确率较单纯的机器学习方法提高5.96%。【局限】人工标注训练集较为耗时; 对实验数据格式有一定要求。【结论】本文方法在专利科学引文识别和标题抽取上具有良好效果。
[Objective] This paper aims to automatically identify scientific references in patent(SRP), and then extract titles from SRP to support in-depth data mining. [Methods] Firstly, we used the Doc2Vec method to generate vectors for the patent citations. Then, we identified the SRPs with support vector machine (SVM). Third, we created vectors for the metadata (such as titles) of SRP, and extracted titles with SVM. [Results] We examined the proposed method with patent citations from the genetic field. The accuracy of SRP recognition and titles extraction reached 99.27% and 92.59% respectively. The latter was 5.96% higher than those of the traditional methods. [Limitations] Manually tagging the training set was very time consuming, and there are format requirements for the experimental data. [Conclusions] The proposed method could effectively identify and extract patent citations and titles.
专利科学引文是专利引文的一个子类。专利的引文类型分为两类: 一类是在专利文件中列出的与本专利申请相关的专利文献; 另一类是专利引用的非专利文献, 称为非专利引文(Non-Patent References, NPR)。非专利引文包括期刊论文、会议论文、著作、文件等多种类型, 其中的科学论文又被称为专利科学引文(Scientific References in Patent, SRP)。专利科学引文作为非专利引文的一个子类, 是科学知识(科学论文)与技术创新(专利)之间产生关联关系的媒介, 识别专利科学引文及其内容特征项具有重要意义, 主要体现在两个方面: 通过识别非专利引文中的专利科学引文这一特定类别, 而非笼统地以所有非专利引文表示科学知识, 能够更准确地统计并计算科学技术间的关联强度, 提升科学技术转化转移和关联关系分析的准确性[1]; 通过识别专利科学引文的标题特征项等元数据, 并以此表示专利引用的科学知识内容, 可以更准确全面地从内容角度发掘科学技术在哪些学科、哪些领域、哪些技术间产生知识流动并产生何种影响, 实现专利科学引文的深层次内容挖掘。
专利科学引文标题特征项抽取主要包括三种方法, 分别为基于规则、基于模板和基于机器学习的专利科学引文标题抽取。基于规则和基于模板的方法先根据待抽取引文设计对应的规则、模板, 再结合规则、模板进行相应匹配。这两种方法抽取效率较高, 但由于规则和模板的设计比较依赖于主观经验, 且需针对不同类型的数据设计特定规则和模板, 其可适应性有待提高; 基于机器学习的方法将专利科学引文标题抽取问题转化为分类问题, 再利用机器学习技术实现分类, 该方法抽取准确率较高, 但还需进一步融入更丰富的文本上下文语义信息。基于此, 姜霖等[2]引入表示学习方法实现文本语义表示, 并结合机器学习方法实现期刊引文元数据抽取, 取得了较好效果。与期刊引文相比, 专利中的科学引文类型多样, 格式杂乱[3], 模板很难穷尽所有规则, 典型格式问题包括作者等信息不全或缺失、各元数据间无固定分隔符、多种特殊符号穿插、期刊年份等信息不全或缺失等, 需要改进现有方法, 形成特定领域下的专利科学引文识别及其标题信息抽取方法。
因此, 本文引入表示学习方法实现专利科学引文整体的语义向量表示, 结合机器学习分类方法实现专利科学引文这一特定类别的识别; 在此基础上, 利用规则方法将专利科学引文分割成块, 再利用表示学习方法实现专利科学引文分割块的语义向量表示, 结合机器学习分类方法识别专利科学引文标题。
在相关研究中, 基于规则的方法得到了广泛应用。Wei等[4]通过格式属性层和字典语义层的逐步标注方法, 实现了专利引文标题的自动抽取。钱建立等[5]通过对论文网页进行分析, 发现论文摘要页面的各种元数据在长度、前置引导词、分隔符等方面都具有特定规律, 据此提出基于元数据特征的论文标题抽取算法, 并分别采用正则表达式方法和特征相似度方法进行实验, 实验中特征相似度方法取得了较好效果。杨宇等[6]设计并实现了一种按照指定规则自动抽取课程标题的方法, 能够按照多优先级规则进行匹配并按照两步抽取的方法进行精细化处理, 且针对不同问题可以使用不同规则进行抽取。
基于规则的方法抽取效率较高, 但由于需事先设计抽取规则, 每当处理新数据时, 就要针对性地增加新规则; 此外, 规则一旦被定义, 后续修改调整比较困难, 适应性还需进一步提高。
基于模板的方法是专利科学引文标题抽取研究中另一种被广泛使用的方法, 其一般步骤是: 首先建立模板数据库; 然后查找和匹配模板; 最后基于模板完成待匹配数据的抽取。Day等[7]采用一种层次化的知识表示框架抽取科技引文的标题, 这种层次化的知识表示框架提供了一个集成的层次化模板编辑环境及一个灵活的模板匹配引擎, 其抽取效果优于一般的基于模板的抽取方法。Cortez等[8]提出一种无监督科技引文标题抽取方法, 与传统的人工构建模板方法相比, 这种方法是从训练样本集中自动产生模板。
基于模板的标题抽取方法易于实现, 但其抽取效果取决于引文数据的风格和版式。与基于规则的方法相同, 基于模板的方法也存在适应性一般的问题。
基于机器学习的抽取方法利用机器学习技术来抽取引文标题等元数据, 其中主要应用到的方法有隐马尔可夫模型(Hidden Markov Model, HMM)、支持向量机(Support Vector Machine, SVM)模型和条件随机场(Conditional Random Field, CRF)模型等。Seymore等[9]利用HMM模型从计算机领域文献中抽取引文标题。Nanba等[10]利用CRF模型从日文和英文专利文本的背景技术中提取学术论文引用文献, 并提取论文标题等元数据。Han等[11]采用支持向量机抽取元数据, 将每种元数据看作一个类, 将元数据抽取问题转化成分类问题, 实现标题抽取, 实验准确率达92.9%。张铭等[12]综合HMM和SVM两种机器学习方法进行论文标题抽取, 实验结果表明, 该方法效果优于单独利用HMM和SVM进行抽取的效果。姜霖等[2]结合语义学知识和机器学习方法, 对引文标题的自动抽取方法进行探索, 选择的分类方法是支持向量机。
基于机器学习的标题抽取方法适应性和鲁棒性较好, 但一般需要对训练语料进行人工标注, 较费时费力, 且在对文本语义信息的利用上有待提高; 此外, 当前研究主要以科学论文中的参考文献为研究对象, 有必要在专利引文, 尤其是专利科学引文方向上深入研究。如何针对专利科学引文类型多样、格式杂乱等特点, 应用和改进该方法实现更准确的专利科学引文及其特征项识别是研究中需要解决的问题。因此, 本文引入表示学习方法实现专利引文文本的语义表示, 将其与基于机器学习的方法相结合, 希望通过对专利科学引文中语义特征的利用, 将专利科学引文与其他类型的专利引文区分开来, 继而从各种格式、类型的专利科学引文中实现对其标题的抽取。
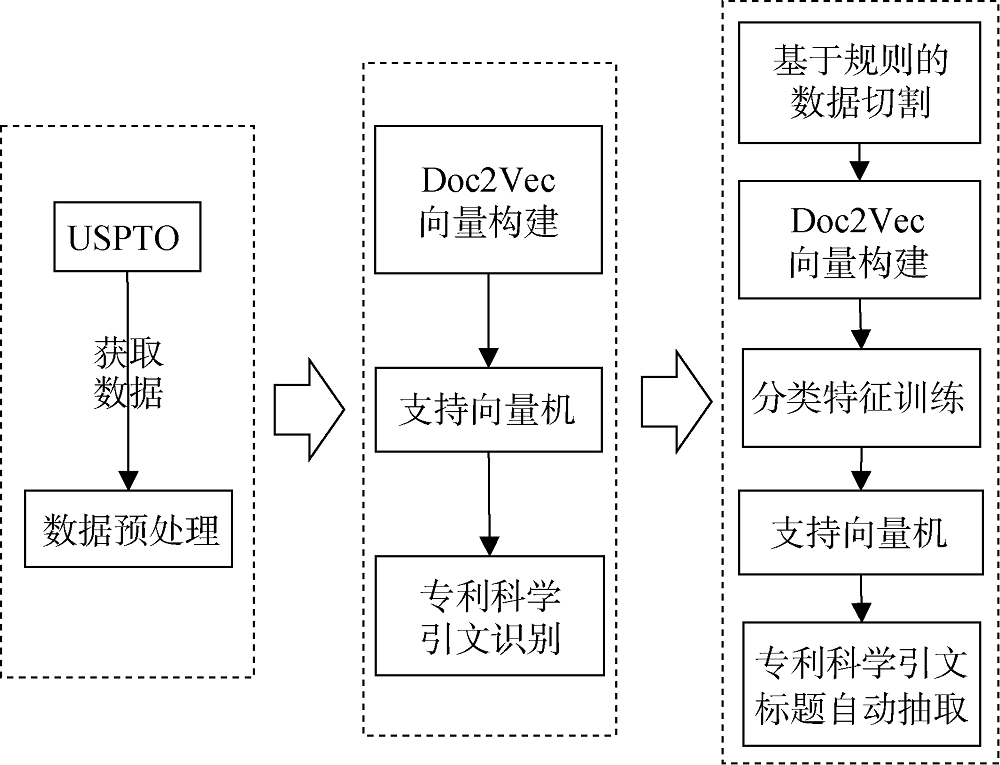
本文所提方法主要包含三部分研究内容。具体技术路线如图1所示。
(1) 下载专利引文数据并对其进行预处理;
(2) 利用表示学习方法Doc2Vec对每条专利引文数据整体进行向量化表示, 结合支持向量机机器学习方法识别出非专利引文中的专利科学引文;
(3) 利用规则方法对识别出的专利科学引文进行切割, 并采用表示学习方法Doc2Vec对各切割单位的不同特征进行向量化表示, 结合支持向量机机器学习方法对切割单位进行分类, 识别出专利科学引文标题这一类别。
由于中文专利引文文献自身存在一定局限性, 如中文专利文献中引文的格式不规范、中文分词结果可能不准确等, 这些局限性可能会对实验结果产生一定影响, 因此选用英文专利引文文献作为实验数据。本文实验数据来源于美国专利和商标局(United States Patent and Trademark Office, USPTO)网站, 数据可直接从该网站下载。选取的检索时间范围为2007年到2016年, 检索关键词为“gene”, 通过检索得到在选定时间范围内所有标题含有“gene”字段的授权专利数据。其中的非专利引文已经单独列出, 但是仍旧包含部分专利申请或授权数据, 部分具有代表性的数据如表1所示。
数据(1)是某专利引用的专利文献, 而不是非专利引文; 数据(2)的引用格式不规范, 标题、年份等信息缺失, 且期刊信息后的标点缺失; 数据(3)的标题信息缺失, 且作者、期刊信息后的标点缺失; 数据(4)格式较规范, 但其中含有“&”字样的字符, 会对后续步骤产生影响, 应在预处理时将其进行替换。根据英文文献的一般特点[13], 结合对实验数据的观察, 对数据进行如下预处理: 对于标点符号使用不规范的情况, 将点号以外的其他标点符号统一替换为点号(书名号、双引号、冒号和括弧等符号保持不变); 对于数据中存在的如“Fcγ”、“×”之类意义不明的字符, 用空格对其进行替换。经过预处理后, 选取共计1 000条数据作为本实验数据。
通过对预处理后的数据进行观察发现, 此处的非专利引文数据中实际上包含各种类型的专利引文文献, 因此还需对其中的专利科学引文进行识别。部分实验数据及其所属类别如表2所示。
实验数据中的引文分属很多类别, 因此需要从中识别出专利科学引文。本文将专利科学引文的识别问题视为分类问题, 将所有的专利引文数据分为“专利科学引文”和“非专利科学引文”两类, 这样便可以获得所需的“专利科学引文”数据。
(1) 基于表示学习方法的专利引文向量化表示
本实验基于表示学习方法Doc2Vec[14]对实验数据进行向量化表示。作为表示学习方法Word2Vec[15]的拓展, Doc2Vec不仅能将单词表示为每一维都具有一定语义信息的词向量, 还能将每一条专利引文数据用一个固定维度的向量表示出来。词向量(Distributed Representation)的概念由Hinton[16]提出, 认为在由词向量组成的空间中, 相似词汇对应的词向量会相对集中在同一片区域。根据这一思路, 在完成专利引文的向量化表示后, 将所有这些向量放在一起形成一个词向量空间, 同一类型的专利引文中经常出现的词会相对集中在同一片区域内, 利用该特性可以对不同类型的专利引文进行区分, 进而识别出其中的专利科学引文。
本实验的专利引文向量构建基于Python2.7.2版本gensim包中的Doc2Vec模块进行。其中重要的参数设置为: “dm=1”, 即采用Doc2Vec中的Distributed Memory(DM)模型; “size=100”表示向量维度为100, 即每条数据都表示为100维空间中的一个点; “window=5”表示取距离当前位置为5的词作为上下文信息。具体的命令为“dm=1, size=100, window=5, min_count=1, dbow_words=1, iter=10, alpha=0.015, dm_concat=1”。
与Word2Vec模型相比, Doc2Vec的主要区别在于训练过程中新增了一个输入项“paragraph ID”, 即训练语料中每个句子都有一个唯一的ID。本文的专利引文向量构建流程如下:
①将专利引文文本中的所有词语转化为Word2Vec词向量;
②为每一条专利引文数据分配一个ID, 同样将其映射成一个Word2Vec向量;
③将专利ID向量和词的Word2Vec向量输入DM模型, 模型中的隐藏层会将这些向量累加, 得到的结果作为输出, 即该专利引文的Doc2Vec向量[14]。
使用Doc2Vec模型进行专利引文文本的向量化表示主要有两个优势:
①在一条专利引文数据的训练过程中, 专利ID保持不变, 最后得到的向量相当于融合了其中每个词的语义信息;
②能够解决数据稀疏问题, 压缩维度, 方便之后将结果放入支持向量机分类器进行分类[17]。
通过Doc2Vec进行的专利引文文本向量化, 可以学习到专利引文文本中的语义信息, 从而将语义相似度作为特征引入专利科学引文的识别中, 通过语义的不同, 将专利科学引文与其他类型引文区分开来。
(2) 基于机器学习方法的专利科学引文识别
本实验采用的专利科学引文识别方法是机器学习算法中较广泛使用的支持向量机算法。由于本文将专利科学引文识别视为一种文本数据向量的二值分类问题, 而支持向量机对于二值分类问题具有良好的分类效果, 因此选择其作为本实验的分类算法。具体识别步骤如下:
①根据得到的Doc2Vec向量, 标注对应专利引文所属类别作为训练集;
②利用支持向量机进行分类模型训练;
③对剩下的测试集数据进行分类, 将所有数据分为“专利科学引文”及“非专利科学引文”两类, 从而实现专利科学引文的识别。
在识别出专利科学引文的基础上, 方可进行后续的专利科学引文标题抽取实验。
实验数据中的部分专利科学引文格式如表3所示。
实验数据中的专利科学引文有多种引用格式。除去表3中列举的之外, 实验数据中还有一些不规范的引用格式, 杂乱的引用格式也使常规的基于模板的引文元数据抽取方法较难实现。因此在专利科学引文标题的抽取问题上, 采用与之前的专利科学引文识别相似的思路: 利用词向量空间中相似词汇对应的词向量会相对集中在同一片区域的特性, 用词向量间的距离表示词之间的相似性, 再通过机器学习分类算法将专利科学引文标题中的词与专利科学引文中其他部分的词区分开, 从而识别出专利科学引文的标题。此外, 本文将专利科学引文标题在引文中的位置作为第二个分类特征。对于大部分格式的专利科学引文数据来说, 标题在其中的位置是相对固定的, 一般位于整条引文数据的前半部分。因此, 将位置特征作为识别专利科学引文标题的另一个特征。
综上, 完整的专利科学引文标题抽取过程包括如下4个部分:
(1) 基于规则的专利科学引文数据分割
实验的训练数据通过对识别出的专利科学引文数据进行分割来获取。参考Wei等[3]的方法, 实验数据中的部分专利科学引文格式见表3, 选择标点符号作为分隔符, 按照分隔符将每条专利科学引文数据划分成块。由于本实验抽取的是专利科学引文的标题, 因此不需要将所有类型的元数据都分割出来, 只要在分割时尽量保持标题部分完整。根据这一需求, 结合专利科学引文数据的一般特点, 设计下列规则进行专利科学引文数据分割。
①当点号前是一个大写字母, 或是“点号+大写字母+点号”的形式时, 这时往往是英文的人名, 此时点号不应作为分割符使用;
②当点号前是“vol”、“pp”等缩写词时(“et”、“al”等除外), 该缩写词后的点号不作为分割符使用, 该缩写词之前的点号需作为分割符;
③当点号前是一串数字时, 点号不作为分割符使用;
④书名号、双引号和括弧等成对出现的标点符号所包含的内容作为一个整体, 不被分隔符隔开;
⑤介词、连词(at、and、is等)前后的点号不作为分隔符使用。
以“Soutschek. J. et al. Therapeutic silencing of an endogenous gene by systemic administration of modified siRNAs. Nov. 2004. Nature. vol. 432. pp. 173-178.”此条专利科学引文为例, 依据上述规则, 可将其分割成“Soutschek. J. et al”、“Therapeutic silencing of an endogenous gene by systemic administration of modified siRNAs”、“Nov. 2004”、“Nature”、“vol. 432”、“pp. 173-178”这6个部分。
(2) 基于表示学习的分割数据向量化表示
将专利科学引文数据进行切割后, 便可以训练分类特征。由于选取的分类特征包括各分割块间相似性的计算, 因此需先对各分割块进行向量化表示, 再进行计算。各分割块均由数个词语或数字组成, 因此依然使用表示学习方法Doc2Vec构建分割数据向量。
(3) 分类特征训练
本实验选取的第一个分类特征是各个分割块与标题类元数据的相似性, 在向量空间中, 可以使用两者间的距离表示相似性。因此, 首先人工标注出一部分专利科学引文标题, 将这些标题向量化后进行聚类, 得到标题类元数据的聚类中心, 以这个聚类中心作为标题类元数据的代表。聚类中心采用K-means算法进行计算。得到标题类聚类中心之后, 需计算各分割块到该聚类中心的距离, 以表示各分割块与标题类元数据的相似度。采用欧式距离作为向量间距离的度量标准。欧氏距离(Euclidean Distance)是一个通常采用的距离定义, 即在m维空间中两个点之间的真实距离, 优势在于简洁性和通用性。
本实验选取的第二个分类特征是分割块在专利科学引文中的位置。格式标准的专利科学引文数据中, 每种类型的元数据在专利科学引文中的位置是相对固定的。以GB/T 7714格式的专利科学引文数据为例, 该类引文中元数据一般按照“作者、标题、出版社、日期、卷号、页码”的顺序排列, 可以认为在此类引文中, 第一个分割块的内容可能是此条引文的作者, 而第二或第三个分割块的内容可能是此条引文的标题。因此, 实验中分别以“0.1”、“0.2”、“0.3”、“0.X”表示第一、第二、第三、第X个分割块的位置, 作为此分割块位置的特征值。同样以“Soutschek. J. et al. Therapeutic silencing of an endogenous gene by systemic administration of modified siRNAs. Nov. 2004. Nature. vol. 432. pp. 173-178.”为例, 该条数据各分割块的位置特征如表4所示。
(4) 基于机器学习的专利科学引文标题抽取
本实验的目标是抽取专利科学引文元数据中的标题, 可以将该目标看作一个二值分类问题, 将所有测试数据分为“专利科学引文标题”和“其他类型元数据”两类。由于标题抽取与专利科学引文识别同为二值分类问题, 因此同样选择支持向量机作为标题抽取的分类算法。在分类特征确定之后, 选取一部分数据作为训练集, 对其所属类别进行人工标注。利用支持向量机对经过标注的数据进行训练, 最后将剩下的测试集放入分类器, 分为“专利科学引文标题”和“其他元数据”两类, 即可得到所需的专利科学引文标题。
采用信息抽取领域最常用的精确率(Precision, P)、召回率(Recall, R) 以及调和平均值(F1-Meature, F1)作为指标, 对实验结果进行评价, 如公式(1)-公式(3)所示。
P=$\frac{正确识别出的数据条数}{识别出的数据总条数}$ (1)
R=$\frac{正确识别的数据条数}{所有待识别的数据条数}$ (2)
F1=$\frac{2\times \text{P}\times \text{R}}{(\text{P}+\text{R})}$ (3)
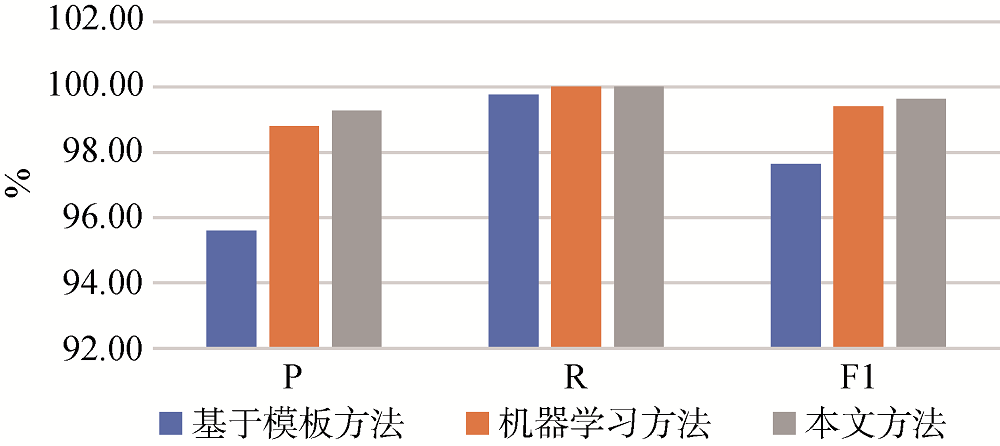
USPTO网站上基因领域的1 000条公开专利引文数据作为实验数据, 其中800条为训练集, 200条为测试集, 部分实验结果如表5所示。与此同时, 设计两个对比实验: 对比实验1利用实验数据中的分割符设计模板, 进行基于模板的专利科学引文识别实验; 对比实验2将实验数据以TF-IDF的形式进行表示, 利用支持向量机进行识别。对比实验结果如图2所示。
从识别结果和对比实验结果可以看出, 三种方法均能完成对专利科学引文的识别, 本文方法的识别效果是三种方法中最好的。对比实验1基于模板的方法抽取精确率较低, 可能是由于模板的设计不够完善, 没有穷尽专利科学引文的所有特点。对比实验2与本文方法的识别效果均较为理想。究其原因, 可能是由于专利引文数据均为结构化数据, 专利科学引文与非专利科学引文结构差异较大, 区别较为显著。本文方法在精确率上相对于对比实验2有0.47%的提升, 由于这两种方法的差异仅在于向量构建阶段, 因此可以认为, 表示学习方法对词的语义信息的利用, 对于后续识别结果起到积极作用。
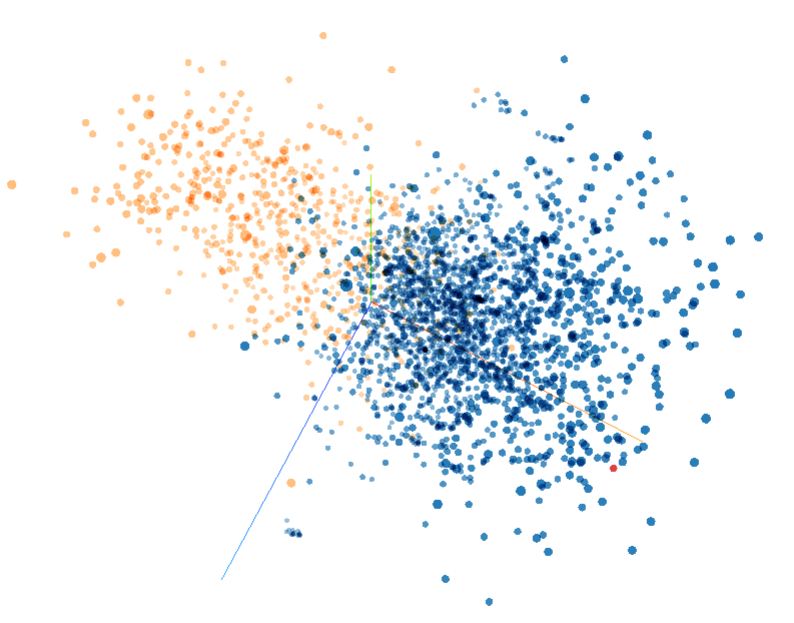
经过识别得到的专利科学引文数据共805条, 其中部分数据中标题缺失, 例如“Baulcombe et al. The Plant Cell (1996) 8:1833-1844.”, 为避免这类数据对抽取结果的干扰, 在人工标注过程中剔除这类数据。对实验数据进行分割、向量化表示后, 应用TensorFlow (http://projector.tensorflow.org)提供的向量可视化工具, 绘制这些向量在三维空间中的位置关系如图3所示。其中黄色部分代表标题类元数据, 蓝色部分代表非标题类元数据, 分别聚集在空间中不同位置。
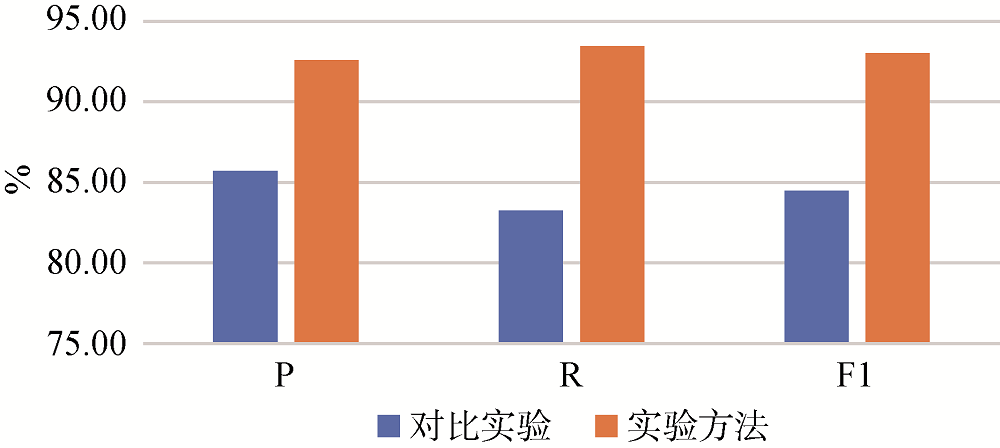
计算分割单位到标题类的距离以及位置特征作为分类特征, 对标题元数据进行抽取, 结果如表6所示。同样地, 利用TF-IDF方法对实验数据进行向量化表示, 使用支持向量机进行抽取作为对比实验, 实验结果如图4所示。
从表6及图4可以看到, 本实验选取的两种方法均基本实现了对标题元数据的自动抽取这一目标, 在召回率和精确率上都要高于对比实验方法, 特别是在精确率上较对比实验方法的结果有6.88%的提升, 由于这两种方法仅在向量化表示阶段存在差异, 因此可以认为, 实验方法引入表示学习方法, 将语义特征作为分类特征, 是精确率提高的原因之一。与传统的特征提取方法相比, Doc2Vec表示学习方法通过利用词的上下文更好地表示语义信息; 与另一种表示学习方法Word2Vec相比, Doc2Vec在利用词的上下文语义信息基础上, 还可以通过paragraph ID利用整个句子或段落的语义信息, 这是其优势所在。
当然, 实验方法仍然存在一定缺陷。由于实验数据格式不尽相同, 以及不规范格式的存在, 导致标题类元数据在引文中的位置并不固定, 对数据的位置特征会产生一定影响, 后续可以适当降低位置特征在分类特征中的权重, 并相应提高语义特征权重, 可能会进一步提高抽取精确率。除此之外, 数据分割的结果也直接影响标题抽取结果, 后续可以对数据分割方法进行改进, 如引进更多数据分割规则等, 也有助于提高最后的抽取效果。
本文介绍了一种专利科学引文识别及标题抽取方法, 具体包括专利引文数据的采集以及预处理、专利科学引文识别和专利科学引文标题的自动抽取三个部分。从实验结果来看, 通过本文方法能够实现专利科学引文的识别及标题自动抽取, 与对比实验相比, 精确率分别提高0.47%及6.88%。因此笔者认为, 将表示学习方法引入专利科学引文标题抽取的工作中, 对词的语义信息特征加以利用, 能够对专利科学引文识别及标题抽取的结果产生积极影响。利用本文方法得到的专利科学引文标题等内容元数据, 可以实现更准确的科学技术间关联关系的分析, 但是本文方法也存在一些不足:
(1) 分类模型的训练集需要通过人工标注获取, 相对于无监督的分类算法更为耗时;
(2) 当前仅能够针对同一研究领域中的专利科学引文, 对于不同研究领域中的专利科学引文, 很难找到其标题间语义的相似性;
(3) 当前的研究还处于初步阶段, 标题抽取流程中的数据分割规则以及抽取精确率方面还有待进一步完善和提高。
后续研究可以从以下方向加以扩展:
(1) 对专利科学引文的识别可以更加细致, 将著作、会议、数据库文件等其他非专利引文的类型也识别出来;
(2) 元数据抽取的类型可以进一步扩展, 目前只是抽取了专利科学引文的标题, 可以在此基础上继续对专利科学引文分析所需要的期刊、作者、时间等元数据进行抽取;
(3) 扩大实验数据量, 这有助于构建更合理的词向量模型, 实现更为准确的专利科学引文识别及标题抽取。
张金柱: 提出研究思路, 设计研究方案, 修改论文;
胡一鸣: 进行实验, 起草论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: zhangjinzhu@njust.edu.cn。
[1] 张金柱, 胡一鸣. SRPextract.rar. 专利科学引文识别及标题抽取实验程序实现.
[2] 张金柱, 胡一鸣. Experimental data.rar. 实验数据.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}