1 引言
随着社交媒体、新闻、体育、教育等各个领域数据的快速增长, 人工从数据中提取相关信息变成一件费时费力的事情[1 ] 。主题模型因能够在一系列文档中发现抽象主题的特点而受到广泛关注[2 ,3 ] 。主题关键词提取是指从文本中提炼出能够体现其主题核心内容的短语和单词的过程。主题关键词自动提取的目标是需要一个从这些数据源中提取相关信息的自动化系统。传统的主题关键词提取模型通常是根据词的统计信息对关键词进行排序, 例如, 词频和逆文档频率方法[4 ] , 没有充分考虑文档主题结构对关键词提取的影响。Text Rank[5 ] 在一定程度上考虑了文档词与词之间的关系, 但仍趋向于选择更频繁的单词作为关键字。此外, 关键词和文档的词汇统计特征往往存在一些差异, 因此, 有些与主题相关度较大但是词频较低的关键词往往会被忽略。
词嵌入[6 ] , 即词在低维向量空间中的表示, 在构建基于上下文的连续单词向量模型中起着越来越重要的作用。词嵌入能够捕捉句子的语义, 并且可以用于计算单词的相似度, 因此被广泛应用于各类自然语言处理任务中。同时, 网络结构能很好地描述整个网络中关键(核心)节点的范围。因此, 在考虑文档主题分布的基础上, 本文提出融合关键词向量和关键词网络的关键词提取方法(LdaVecNet)。使用主题模型(LDA)[7 ] 对关键词进行初步提取, 同时使用Word2Vec[8 ] 对单词进行向量化表示; 基于词向量的相似性传播构建每个主题下的关键词网络; 最后, 使用核心节点发现算法获取主题关键词。通过实验分析, 证明该方法可以通过综合考虑语义和统计特征来有效提取关键词。
2 相关工作
2.1 主题关键词提取
主题关键词提取是通过选择主题词集中的单词子集来实现的。这个过程可以看作是识别主题集中最具代表性的单词, 这些单词能够提供与主题相关的信息。
(1) 简单统计学方法: 这些方法通常比较粗糙, 不划分训练集, 侧重于从文本的非语言特征获得统计数据, 例如文档中的单词位置、词频和逆文档频率等, 然后利用这些特征构建关键词列表。Cohen[9 ] 利用n-gram模型进行数据统计, 自动发现文档中的关键字。此外, 还有词频(Term Frequency, TF)[10 ] 、词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)[11 ,12 ] 、词共现[13 ] 以及PAT-tree[14 ] 等多种方法的组合。这些方法的共同特点是词频是该词能否作为关键字的主要标准。
(2) 语言学方法: 该方法利用文字的语言特征来进行文本关键字的检测和提取, 主要融合词法分析[15 ] 、句法分析[16 ] 、语篇分析[17 ] 等方法。其中, 用于词法分子的资源主要有电子词典、TreeTagger、WordNet、n-grams模型、POS pattern等。
(3) 机器学习方法: 关键词提取也可以看作是一个机器学习问题, 该方法以已标注的训练数据为输入。常用的训练模型有隐马尔可夫模型[18 ] 、支持向量机(Support Vector Machine, SVM)[19 ] 、朴素贝叶斯模型(Naïve Bayes, NB)[20 ] 等。
(4) 主题关键词提取: 主题模型因其能够简单有效地发现文档主题而被广泛使用, 因此, 一些研究将关键词提取转换为主题检测问题。潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)[7 ] 、Lda2Vec[2 ] 以及PLDA[21 ] 等, 都是使用主题模型解决问题的。
2.2 主题词向量
词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示。词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的。因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证。Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型。文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法。基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究。
同时, 随着表示学习研究的广泛应用, 自然语言处理领域出现了大量词语的表示学习与传统方法相结合的研究, 其中文献[31 ]将Word2Vec与TextRank方法相结合, 进行关键词提取研究。文献[32 ,33 ]在此基础上, 将词向量聚类加权再与TextRank相结合进行关键词抽取。而文献[34 ]则是把Word2Vec和TextRank相结合应用到时政类新闻的关键词抽取中。
已有研究更加注重关键词的词频以及关键词与主题的关系。往往忽略了词频较低但是与主题关联较高的关键词检测。因此, 本文创新性地提出利用主题关键词向量、词的相似性传播和关键词网络结构, 进行主题关键词的优化提取。
3 主题关键词提取模型
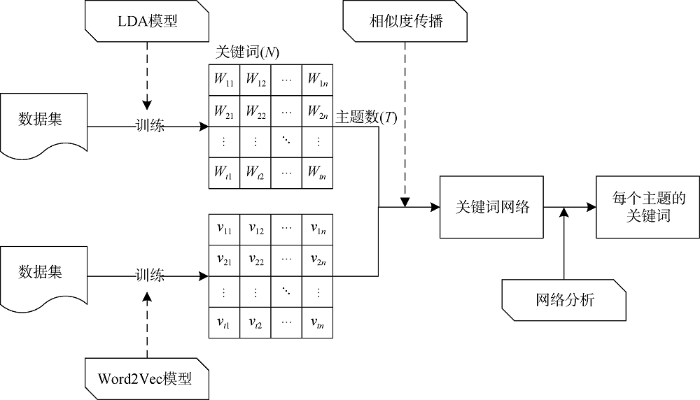
词嵌入技术能够有效准确地将文本中的词语用低维度向量表示, LDA主题模型能够准确地进行文档主题发现, 网络结构分析能够有效地实现核心节点的发现。因此, 本文提出一种LdaVecNet模型, 使用LDA模型获取文档的潜在主题, 并构建关键词矩阵; 利用Word2Vec对语料进行训练, 获得每个词的向量表示, 利用词向量的相似度传播算法构建每个主题下的关键词网络; 最后通过关键词网络结构分析获得每个网络中的TopN个核心节点, 即关键词。LdaVecNet模型的框架如图1 所示。
图1
3.1 基于主题模型的关键词检测
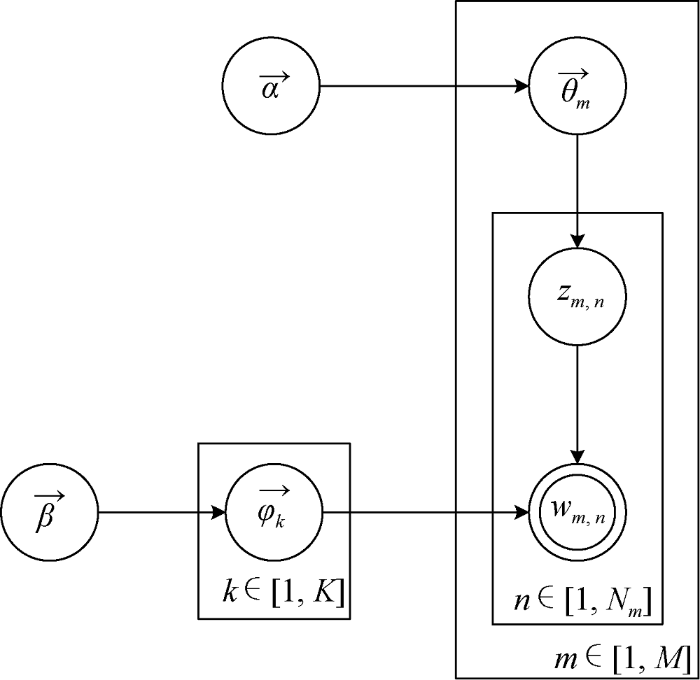
LDA模型是典型的有向概率图模型, 由参数$(\alpha ,\beta )$确定, $\alpha $反映文档集合中隐含主题间的相对强弱, $\beta $刻画所有隐含主题自身的概率分布。LDA生成概率模型如图2 所示。其中${{\theta }_{m}}$表示文档主题的概率分布, ${{\varphi }_{k}}$表示特定主题词的概率分布, $M$表示文档集的文本数, $k$表示文档集的主题数, N 表示每篇文档包含的特征词数。
图2
LDA模型的输出主要包含4个文件。wordidmap.dat文件对语料库中的所有单词进行唯一编号; model_phi.dat文件保存的是每个主题所对应的向量, 其中每个向量表示该主题在每个词上的分布; model_theta.dat保存文档-主题向量, 即每一篇文档在各个主题下的分布; model_twords.dat保存每个主题下的关键从属概率。从model_twords.dat中获取每个主题下的TopN个词作为初选关键词。
3.2 基于Word2Vec的关键词表示
基于神经网络的分布表示一般称为词向量、词嵌入(Word Embedding)或分布式表示(Distributed Representation)。神经网络词向量表示技术通过神经网络技术对上下文, 以及上下文与目标词之间的关系进行建模。由于神经网络较为灵活, 这类方法的最大优势在于可以表示复杂的上下文。如果使用包含词序信息的n-gram作为上下文, 当n增加时, n-gram的总数会呈指数级增长, 此时会遇到维数灾难问题。而神经网络在表示n-gram时, 可以通过一些组合方式对n个词进行组合, 参数个数仅以线性速度增长。具有这一优势, 神经网络模型可以对更复杂的上下文进行建模, 在词向量中包含更丰富的语义信息。Mikolov等[22 ] 提出Skip-gram模型和CBOW。他们设计两个模型的主要目的是希望用更高效的方法获取词向量, 本文使用Mikolov等提出的Word2Vec模型训练原始语料并获取词向量, 选择连续词袋模型(CBOW)预测关键词的概率, 设置滑动窗口为5, 则可以通过窗口内的上下文单词对目标词进行预测, 如公式(1)所示。
(1) $P({{w}_{t}}|{{w}_{t-k}},...,{{w}_{t-1}},{{w}_{t+1}},...,{{w}_{t+k}})$
选择负采样算法, 其中每个单词选择$k$个负样本。根据Mikolov等提出的模型要求, 对于小型数据集, 负样本k 的数量在5-20范围内, 而对于大型数据集, k 可以小到2-5范围内。所以选择k= 5, 负采样集中于上下文中的学习词向量, 可以增大正样本的概率同时降低负样本的概率。具体参数设置如表1 所示。
基于Word2Vec模型中的CBOW方法对文本进 行训练, 可以从模型中获取所有单词的低维度向量化表示。
3.3 基于网络传播的关键词提取
网络结构能够有效表示节点之间的关系, 网络结构的度量也能够直观体现节点的重要程度。因此, 应用网络结构对同一主题下的词进行网络化构建, 并在此基础上应用网络结构分析, 发现网络结构中的重要节点, 从而获取主题关键词。
基于每个主题中TopN个关键词及其词向量表示进行相似词计算, 采用余弦值对词与词之间的相似度进行度量, 如公式(2)所示。
(2) $Sim({{w}_{i}},{{w}_{j}})=\cos \theta =\frac{{{{\vec{w}}}_{i}}\cdot {{{\vec{w}}}_{j}}}{\left| {{{\vec{w}}}_{i}} \right|\cdot \left| {{{\vec{w}}}_{j}} \right|}=\frac{\sum\limits_{i=1}^{n}{({{x}_{i}}{{y}_{i}})}}{\sqrt{\sum\limits_{i=1}^{n}{{{({{x}_{i}})}^{2}}}}\times \sqrt{\sum\limits_{i=1}^{n}{{{({{y}_{i}})}^{2}}}}}$
其中, $Sim({{w}_{i}},{{w}_{j}})$表示单词${{w}_{i}}$和单词${{w}_{j}}$之间的词向量余弦相似度值, ${{\vec{w}}_{i}}$表示单词${{w}_{i}}$的向量化表示。
主题关键词网络表示第k 个主题中关键词所组成的网络, 如公式(3)所示。
(3) $G(T{{P}_{k}})=\left\{ V(T{{P}_{k}}),E,W \right\}$
其中, $G(T{{P}_{k}})$表示单词在主题k 上的网络结构; $V(T{{P}_{k}})$表示该主题下所有的单词集合, 即网络节点集合; $W=\left\{ w\left| w=Sim({{w}_{i}},{{w}_{j}}) \right. \right\}$表示边上的权重, 即单词之间的相似度值; $E\text{=}\left\{ e\left| w>\theta \right. \right\}$表示$G(T{{P}_{k}})$的边的集合, 当边权重$w$大于阈值$\theta $时, 保留节点之间的边, 否则删除。
PageRank算法是由Google创始人Brin等[35 ] 提出的一种网页排名算法, 其核心思想是通过研究网络的拓扑结构和计算页面的入度(即页面被链接的次数), 进而确定该页面的排名顺序。页面的入度越大, 那么其重要性就越大, 排名也越靠前。同时它还考虑了指向目标页面的其他页面自身的PageRank值。
采用网络结构中的PageRank值作为衡量节点在网络中重要程度的标准, 把词在主题中的重要性, 转化为节点在网络中的影响力。计算每个主题下词的PageRank值, 并取PageRank值前TopN个词作为该主题的关键词。具体步骤如下。
(1) 基于$Sim({{w}_{i}},{{w}_{j}})$计算每个主题下词的相似度, 作为两节点之间的权重;
(2) 设置阈值, 过滤相似度低于阈值的边, 构建每个主题的网络结构$G(T{{P}_{k}})$;
(3) 计算每个主题网络$G(T{{P}_{k}})$的网络结构特征, 计算PageRank值并按降序排列;
(4) 取每个主题下的Top-20个节点作为主题词网络的核心节点输出, 将其对应的词作为该主题的关键词集合。
①□基于NLPIR对文本数据$D$进行分词, 获取语料集合${{D}_{1}}$;
②基于领域词词典和停止词词典对语料集合${{D}_{1}}$进行预处理获取语料集合${{D}_{2}}$;
③应用LDA主题模型处理语料集合${{D}_{2}}$文件, 生成矩阵词集$Topic-KeyWord{{s}_{m\times n}}$;
④应用Word2Vec中的CBOW模型处理语料集合${{D}_{1}}$文件, 获取词向量模型;
⑥ Foreach w in KeyWords(n ):
⑦ 应用步骤④生成的词向量模型, 计算w 相似度最高的TopN个词: WordSet
⑨ 计算主题t 下的边的权重阈值, 构建网络G (TPt )
⑩ 应用PageRank算法计算网络G (TPt )中节点的PR值
4 实验设计与分析
4.1 实验数据集
爬取某高校网站5万条中文通知公告数据, 数据仅包含公告的标题和内容文本。忽略其他信息, 如新闻链接、时间戳和作者身份等。
考虑到预处理对结果的重要影响, 采用jieba分词对文本数据进行初步分词, 在此基础上, 通过词频统计、领域特有名词提取、去停用词、实验文本数据分析等方法进行自定义领域词典的构建。优化jieba分词系统中的领域词典, 进行实验文本数据的分词。对于包含新闻标题的文本, 采用上述分词方法进行预处理操作, 将得到的文本作为LDA的输入数据。同样, 对于包含新闻标题和新闻内容的文本, 也采用上述分词方法进行预处理操作, 并将得到的文本作为词向量模型的输入数据。其中, 停用词词典如表2 所示。
4.2 LDA主题聚类
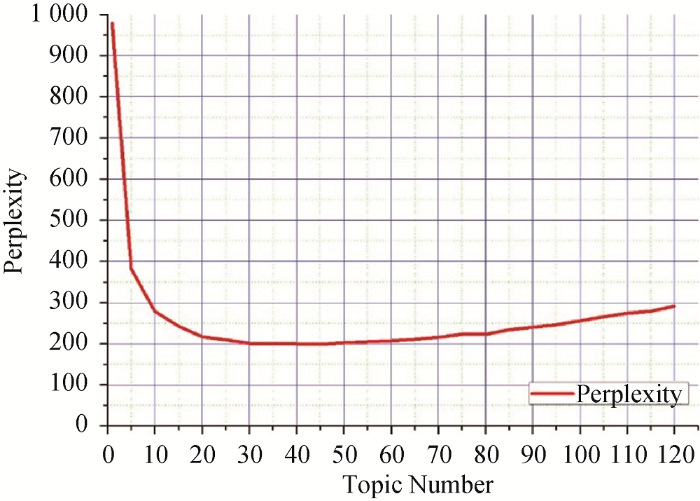
LDA中Topic个数的确定是一个困难的问题。当各个Topic之间的相似度最小时, 即为合适的Topic个数。采用Blei等[7 ] 提出的方法, 即通过Perplexity值确定LDA主题数量, 计算方法如公式(4)所示。
(4) $perplexity={{e}^{\frac{-\sum\limits_{i=1}^{N}{\log \sum\limits_{j=1}^{K}{P({{w}_{i}}\left| {{t}_{j}} \right.)}}\times P({{t}_{j}}\left| d \right.)}{N}}}$
由此, 能够画出Topic Number-Perplexity曲线如图3 所示。将主题数定为40个可以使Perplexity值较小而主题数不至于过多。每个主题取其Top100个单词作为该主题的初始关键词集合。通过LDA中获得的文档-主题分布, 将每个文档划分到其分布概率最高的一个或几个主题中, 由此获得每个主题中包含的文档。
图3
4.3 Word2Vec词向量学习及相似度计算
使用Word2Vec中基于负采样算法的CBOW模型, 对语料进行词向量学习并获得相应模型, 其目标函数如公式(5)所示。
(5) $L\text{=}\sum\limits_{w\in C}{\log p(Context(w)\left| w \right.)}$
提取每个主题下前100个单词, 并计算和提取每个单词相似度前5的词。表3 列出了不同主题下关键词相似度Top5的词, 如与“国家奖学金”相关的关键词中会包含其他同奖学金相关的关键词如“省政府奖学金”等, 与“停电”相关的关键词中则会包含与日常生活相关的关键词如“停水”等。
4.4 关键词网络构建
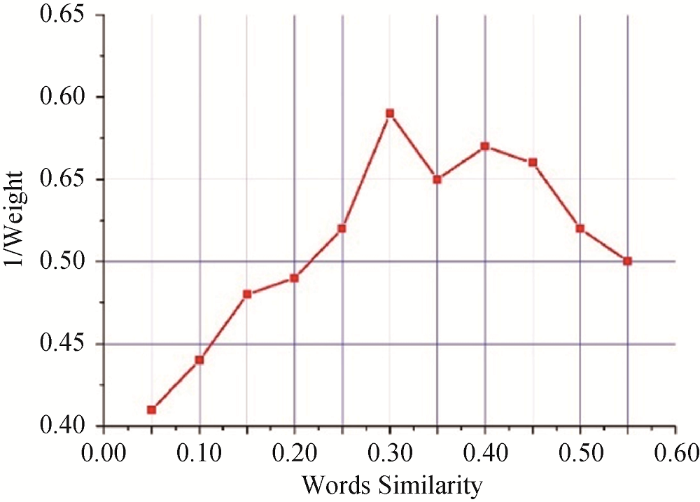
在构建关键词网络过程中, 采用权重阈值过滤的方法确定词与词之间的边, 因此, 构建权重阈值与关键词之间的平均相似度变化曲线, 如图4 所示, 相似度为0.3时, 最终获得的每个主题下Top20的关键词之间的相似度平均值最高, 因此设置边的权重阈值为0.3, 构造相应的关键词网络。
图4
5 实验结果分析
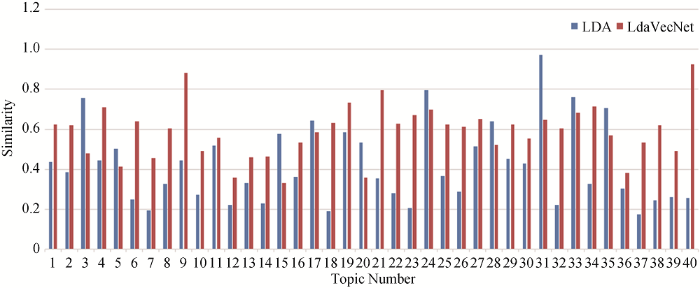
在获得的每个主题的Top20个关键词中, 本文方法在主题关键词的平均相似度上比LDA总体提高14.75%, 如图5 所示。
图5
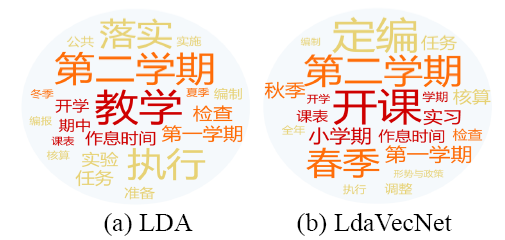
本文方法具有能够有效表示主题的特点, 以云图的形式展示LdaVecNet与LDA获得的关键词的对比如图6 -图9 所示。其中, 字体代表该词在相应方法 (LDA/LdaVecNet) 下的值, 字体颜色越深表示其与主题的相关程度越大, 字体越大, 代表关键词在主题中出现次数越多。
图6
图7
图8
图9
(1) 红色词是A类词汇, 即最能代表该主题中心内容的词;
(2) 橙色词是B类词汇, 即与该主题比较相关的;
(3) 黄色词是C类词汇, 即仅通过该词无法识别该主题内容。
由图6 关键词对比可知, 这是一个关于“教学任务”主题的通知类, 可以发现本文方法获得的A类和B类关键词相较LDA获得的明显较多, 且一些词频相对较小, 主题更加相关的词也呈现在A类词集中, 且A类关键词中涵盖的相应类别更多, 比如“小学期”、“实习”等在LDA中均未出现。
由图7 关键词对比可知, 这是一个关于“评优”主题的通知类, LDA得到的前两类关键词中, 名词、动词、形容词分布均衡, 主要原因是“推荐”“优秀”“候选人”“十大”等词在该类的新闻标题文本中具有较高词频, LdaVecNet则能筛选出更多有实际意义的名词, 如“优秀学生”“标兵”等, 且这些词往往在这Top20个词中排名较靠前, 而往往名词更能代表主题的含义。
由图8 关键词对比可知, 这是一个关于文献数据使用的主题, 本文方法能够直观呈现文献、数据库以及一些相关的论文数据库名称, 例如文献、CNKI、JCR、Elsevier等都被分到A类词汇中。而LDA方法呈现的更多是图书馆、数据库以及电子等词频较高的词, 例如数据库、图书馆、论文、培训等词被分到A类词汇中。
根据图9 关键词可以看出, 这是一个关于“奖学金及比赛”主题的通知类, LdaVecNet方法获得的有关奖学金和比赛种类的名词更能表达该主题下通知的内涵, 即工程制图技术大赛、齐鲁大学生机器人大赛、研究生学业奖学金、国家励志奖学金等被分到A类词汇中, 且发现更多低词频高主题相关的词。
6 结语
表示学习技术能够准确有效地将文本中的词语用低维度向量表示, LDA能够准确地进行文档主题发现, 网络结构能够有效地实现核心节点的发现, 因此, 本文融合词嵌入和LDA技术, 实现主题关键词的初步获取以及关键词网络构建, 而后, 应用网络结构分析方法, 实现主题关键词的二次过滤。同时, 通过实验验证本文方法能够有效发现低词频高主题相关的关键词。下一步将继续应用词嵌入、LDA以及网络结构的优点, 深入探索关键词与主题的关系, 通过更多的数据验证本文方法; 同时, 深入研究主题关键词与主题之间的标准量化分析方法, 实现实验结果的量化分析。
支撑数据
支撑数据由作者自存储, E-mail: 1008lichao@163.com。
[1] 李超, 胡晓慧. 原始数据_新闻标题及新闻内容.rar. 原始数据.
[2] 李超, 胡晓慧. 实验过程数据.rar. 实验中间数据.
[3] 李超, 胡晓慧. 实验结果数据.rar. 实验结果数据.
作者贡献声明
曾庆田: 提出研究思路, 设计研究方案, 修改论文;
胡晓慧: 实验数据预处理, 进行实验, 起草论文;
李超: 实验结果分析, 设计论文框架, 论文最终版本修订。
参考文献
View Option
[1]
Bharti S K Babu K S . Automatic Keyword Extraction for Text Summarization: A Survey
[OL]. arXiv Preprint, arXiv: 1704 . 03242 .
[本文引用: 1]
[2]
Moody C E . Mixing Dirichlet Topic Models and Word Embeddings to Make Lda2vec
[OL]. arXiv Preprint, arXiv: 1605 . 02019 .
[本文引用: 3]
[3]
庞贝贝 , 苟娟琼 , 穆文歆 . 面向高校学生深度辅导领域的主题建模和主题上下位关系识别研究
[J]. 数据分析与知识发现 , 2018 ,2 (6 ):92 -101 .
[本文引用: 1]
( Pang Beibei Gou Juanqiong Mu Wenxin . Extracting Topics and Their Relationship from College Student Mentoring
[J]. Data Analysis and Knowledge Discovery , 2018 ,2 (6 ):92 -101 .)
[本文引用: 1]
[4]
Nadkarni P M . An Introduction to Information Retrieval: Applications in Genomics
[J]. The Pharmacogenomics Journal , 2002 ,2 (2 ):96 -102 .
[本文引用: 1]
[5]
Pawar D D Bewoor M S Patil S H . Text Rank: A Novel Concept for Extraction Based Text Summarization
[J]. International Journal of Computer Science & Information Technology , 2014 ,5 (3 ):3301 -3304 .
[本文引用: 1]
[6]
Lai S Liu K He S , et al . How to Generate a Good Word Embedding
[J]. IEEE Intelligent Systems , 2016 ,31 (6 ):5 -14 .
[本文引用: 1]
[7]
Blei D M Ng A Y Jordan M I . Latent Dirichlet Allocation
[J]. Journal of Machine Learning Research , 2003 ,3 :993 -1022 .
[本文引用: 3]
[8]
Mikolov T Chen K Corrado G , et al . Efficient Estimation of Word Representations in Vector Space
[OL]. arXiv Preprint, arXiv: 1301 . 3781 .
[本文引用: 1]
[9]
Cohen J D . Highlights: Language- and Domain-Independent Automatic Indexing Terms for Abstracting
[J]. Journal of the American Society for Information Science , 1995 ,46 (3 ):162 -174 .
[本文引用: 1]
[10]
Luhn H P . A Statistical Approach to Mechanized Encoding and Searching of Literary Information
[J]. IBM Journal of Research and Development , 1957 ,1 (4 ):309 -317 .
[本文引用: 1]
[11]
姚兆旭 , 马静 . 面向微博话题的“主题+观点”词条抽取算法研究
[J]. 现代图书情报技术 , 2016 (7 ):78 -86 .
[本文引用: 1]
( Yao Zhaoxu Ma Jing . Extracting Topic and Opinion from Microblog Posts with New Algorithm
[J]. New Technology of Library and Information Service , 2016 (7 ):78 -86 .)
[本文引用: 1]
[12]
覃世安 , 李法运 . 文本分类中TF-IDF方法的改进研究
[J]. 现代图书情报技术 , 2013 (10 ):27 -30 .
[本文引用: 1]
( Qin Shian Li Fayun . Improved TF-IDF Method in Text Classification
[J]. New Technology of Library and Information Service , 2013 (10 ):27 -30 .)
[本文引用: 1]
[13]
Matsuo Y Ishizuka M . Keyword Extraction from a Single Document Using Word Co-occurrence Statistical Information
[J]. International Journal on Artificial Intelligence Tools , 2004 ,13 (1 ):157 -169 .
[本文引用: 1]
[14]
Zhao Z Li C Zhang Y , et al . Identifying and Analyzing Popular Phrases Multi-dimensionally in Social Media Data
[J]. International Journal of Data Warehousing & Mining , 2015 ,11 (3 ):98 -112 .
[本文引用: 1]
[15]
Barzilay R Elhadad M Using Lexical Chains for Text Summarization
[C]. //Proceedings of the ACL Workshop on Intelligent Scalable Text Summarization. 1997 .
[本文引用: 1]
[16]
Hulth A Improved Automatic Keyword Extraction Given More Linguistic Knowledge
[C]// Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing. 2003 : 216 -223 .
[本文引用: 1]
[17]
Salton G Singhal A Mitra M , et al . Automatic Text Structuring and Summarization
[J]. Information Processing & Management , 1997 ,33 (2 ):193 -207 .
[本文引用: 1]
[18]
Conroy J M O’leary D P Text Summarization via Hidden Markov Models
[C]// Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 2001 : 406 -407 .
[本文引用: 1]
[19]
Zhang K Xu H Tang J et al . Keyword Extraction Using Support Vector Machine
[C]// Proceedings of the 2006 International Conference on Web-Age Information Management. 2006 : 85 -96 .
[本文引用: 1]
[20]
Frank E Paynter G W Witten I H et al . Domain-Specific Keyphrase Extraction
[C]// Proceedings of the 16th International Joint Conference on Artificial Intelligence. 1999 ,2 :668 -673 .
[本文引用: 1]
[21]
Liu Z Chen X Zheng Y et al . Automatic Keyphrase Extraction by Bridging Vocabulary Gap
[C]// Proceedings of the 15th Conference on Computational Natural Language Learning. 2011 : 135 -144 .
[本文引用: 1]
[22]
Mikolov T Sutskever I Chen K et al . Distributed Representations of Words and Phrases and Their Compositionality
[C]// Proceedings of the 2013 International Conference on Neural Information Processing Systems. 2013 ,26 :3111 -3119 .
[本文引用: 2]
[23]
Liu Y Liu Z Chua T S et al . Topical Word Embeddings
[C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence. 2015 : 2418 -2424 .
[本文引用: 1]
[24]
Chang J Boyd-Graber J Gerrish S et al . Reading Tea Leaves: How Humans Interpret Topic Models
[C]// Proceedings of the 22nd International Conference on Neural Information Processing Systems. 2009 : 288 -296 .
[本文引用: 1]
[25]
王婷婷 , 韩满 , 王宇 . LDA模型的优化及其主题数量选择研究——以科技文献为例
[J]. 数据分析与知识发现 , 2018 ,2 (1 ):29 -40 .
[本文引用: 1]
( Wang Tingting Han Man Wang Yu . Optimizing LDA Model with Various Topic Numbers: Case Study of Scientific Literature
[J]. Data Analysis and Knowledge Discovery , 2018 ,2 (1 ):29 -40 .)
[本文引用: 1]
[26]
陈磊 , 李俊 . 基于LF-LDA和Word2vec的文本表示模型研究
[J]. 电子技术 , 2017 (7 ):1 -5 .
[本文引用: 1]
( Chen Lei Li Jun . Text Representation Model Based on LF-LDA and Word2Vec
[J]. Electronic Technology , 2017 (7 ):1 -5 .)
[本文引用: 1]
[27]
Liu W Dong W . A Question Recommendation Model Based on LDA and Word2Vec
[A]// Hussain A, Ivanovic M. Electronics, Communications and Networks IV [M]. 2015 : 1527 -1531 .
[本文引用: 1]
[28]
董文 . 基于LDA和Word2Vec的推荐算法研究
[D]. 北京: 北京邮电大学 , 2015 .
[本文引用: 1]
( Dong Wen . Research of Recommendation Algorithm Based on LDA and Word2Vec
[D]. Beijing: Beijing University of Posts and Telecommunications , 2015 .)
[本文引用: 1]
[29]
Wang Z Ma L Zhang Y A Hybrid Document Feature Extraction Method Using Latent Dirichlet Allocation and Word2Vec
[C]// Proceedings of the 1st International Conference on Data Science in Cyberspace. 2016 : 98 -103 .
[本文引用: 1]
[30]
韦强申 . 领域关键词抽取: 结合LDA与Word2Vec
[D]. 贵阳: 贵州师范大学 , 2016 .
[本文引用: 1]
( Wei Qiangshen . Keyword Extraction Based on LDA and Word2Vec
[D]. Guiyang: Guizhou Normal University , 2016 .)
[本文引用: 1]
[31]
宁建飞 , 刘降珍 . 融合Word2Vec与TextRank的关键词抽取研究
[J]. 现代图书情报技术 , 2016 (6 ):20 -27 .
[本文引用: 1]
( Ning Jianfei Liu Jiangzhen . Using Word2Vec with TextRank to Extract Keywords
[J]. New Technology of Library and Information Service , 2016 (6 ):20 -27 .)
[本文引用: 1]
[32]
夏天 . 词向量聚类加权TextRank的关键词抽取
[J]. 数据分析与知识发现 , 2017 ,1 (2 ):28 -34 .
[本文引用: 1]
( Xia Tian . Extracting Keywords with Modified TextRank Model
[J]. Data Analysis and Knowledge Discovery , 2017 ,1 (2 ):28 -34 .)
[本文引用: 1]
[33]
Wen Y Yuan H Zhang P Research on Keyword Extraction Based on Word2Vec Weighted TextRank
[C]// Proceedings of the 2nd International Conference on Computer and Communications. 2017 : 2109 -2113 .
[本文引用: 1]
[34]
刘奇飞 , 沈炜域 . 基于Word2Vec和TextRank的时政类新闻关键词抽取方法研究
[J]. 情报探索 , 2018 (6 ):22 -27 .
[本文引用: 1]
( Liu Qifei Shen Weiyu . Research of Keyword Extraction of Political News Based on Word2Vec and TextRank
[J]. Information Research , 2018 (6 ):22 -27 .)
[本文引用: 1]
[35]
Brin S Page L The Anatomy of a Large-Scale Hyper Textual Web Search Engine
[C]// Proceedings of the 7th International Conference on World Wide Web. 1998 ,30 :107 -117 .
[本文引用: 1]
Automatic Keyword Extraction for Text Summarization: A Survey
1
... 随着社交媒体、新闻、体育、教育等各个领域数据的快速增长, 人工从数据中提取相关信息变成一件费时费力的事情[1 ] .主题模型因能够在一系列文档中发现抽象主题的特点而受到广泛关注[2 ,3 ] .主题关键词提取是指从文本中提炼出能够体现其主题核心内容的短语和单词的过程.主题关键词自动提取的目标是需要一个从这些数据源中提取相关信息的自动化系统.传统的主题关键词提取模型通常是根据词的统计信息对关键词进行排序, 例如, 词频和逆文档频率方法[4 ] , 没有充分考虑文档主题结构对关键词提取的影响.Text Rank[5 ] 在一定程度上考虑了文档词与词之间的关系, 但仍趋向于选择更频繁的单词作为关键字.此外, 关键词和文档的词汇统计特征往往存在一些差异, 因此, 有些与主题相关度较大但是词频较低的关键词往往会被忽略. ...
Mixing Dirichlet Topic Models and Word Embeddings to Make Lda2vec
3
... 随着社交媒体、新闻、体育、教育等各个领域数据的快速增长, 人工从数据中提取相关信息变成一件费时费力的事情[1 ] .主题模型因能够在一系列文档中发现抽象主题的特点而受到广泛关注[2 ,3 ] .主题关键词提取是指从文本中提炼出能够体现其主题核心内容的短语和单词的过程.主题关键词自动提取的目标是需要一个从这些数据源中提取相关信息的自动化系统.传统的主题关键词提取模型通常是根据词的统计信息对关键词进行排序, 例如, 词频和逆文档频率方法[4 ] , 没有充分考虑文档主题结构对关键词提取的影响.Text Rank[5 ] 在一定程度上考虑了文档词与词之间的关系, 但仍趋向于选择更频繁的单词作为关键字.此外, 关键词和文档的词汇统计特征往往存在一些差异, 因此, 有些与主题相关度较大但是词频较低的关键词往往会被忽略. ...
... (4) 主题关键词提取: 主题模型因其能够简单有效地发现文档主题而被广泛使用, 因此, 一些研究将关键词提取转换为主题检测问题.潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)[7 ] 、Lda2Vec[2 ] 以及PLDA[21 ] 等, 都是使用主题模型解决问题的. ...
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
面向高校学生深度辅导领域的主题建模和主题上下位关系识别研究
1
2018
... 随着社交媒体、新闻、体育、教育等各个领域数据的快速增长, 人工从数据中提取相关信息变成一件费时费力的事情[1 ] .主题模型因能够在一系列文档中发现抽象主题的特点而受到广泛关注[2 ,3 ] .主题关键词提取是指从文本中提炼出能够体现其主题核心内容的短语和单词的过程.主题关键词自动提取的目标是需要一个从这些数据源中提取相关信息的自动化系统.传统的主题关键词提取模型通常是根据词的统计信息对关键词进行排序, 例如, 词频和逆文档频率方法[4 ] , 没有充分考虑文档主题结构对关键词提取的影响.Text Rank[5 ] 在一定程度上考虑了文档词与词之间的关系, 但仍趋向于选择更频繁的单词作为关键字.此外, 关键词和文档的词汇统计特征往往存在一些差异, 因此, 有些与主题相关度较大但是词频较低的关键词往往会被忽略. ...
面向高校学生深度辅导领域的主题建模和主题上下位关系识别研究
1
2018
... 随着社交媒体、新闻、体育、教育等各个领域数据的快速增长, 人工从数据中提取相关信息变成一件费时费力的事情[1 ] .主题模型因能够在一系列文档中发现抽象主题的特点而受到广泛关注[2 ,3 ] .主题关键词提取是指从文本中提炼出能够体现其主题核心内容的短语和单词的过程.主题关键词自动提取的目标是需要一个从这些数据源中提取相关信息的自动化系统.传统的主题关键词提取模型通常是根据词的统计信息对关键词进行排序, 例如, 词频和逆文档频率方法[4 ] , 没有充分考虑文档主题结构对关键词提取的影响.Text Rank[5 ] 在一定程度上考虑了文档词与词之间的关系, 但仍趋向于选择更频繁的单词作为关键字.此外, 关键词和文档的词汇统计特征往往存在一些差异, 因此, 有些与主题相关度较大但是词频较低的关键词往往会被忽略. ...
An Introduction to Information Retrieval: Applications in Genomics
1
2002
... 随着社交媒体、新闻、体育、教育等各个领域数据的快速增长, 人工从数据中提取相关信息变成一件费时费力的事情[1 ] .主题模型因能够在一系列文档中发现抽象主题的特点而受到广泛关注[2 ,3 ] .主题关键词提取是指从文本中提炼出能够体现其主题核心内容的短语和单词的过程.主题关键词自动提取的目标是需要一个从这些数据源中提取相关信息的自动化系统.传统的主题关键词提取模型通常是根据词的统计信息对关键词进行排序, 例如, 词频和逆文档频率方法[4 ] , 没有充分考虑文档主题结构对关键词提取的影响.Text Rank[5 ] 在一定程度上考虑了文档词与词之间的关系, 但仍趋向于选择更频繁的单词作为关键字.此外, 关键词和文档的词汇统计特征往往存在一些差异, 因此, 有些与主题相关度较大但是词频较低的关键词往往会被忽略. ...
Text Rank: A Novel Concept for Extraction Based Text Summarization
1
2014
... 随着社交媒体、新闻、体育、教育等各个领域数据的快速增长, 人工从数据中提取相关信息变成一件费时费力的事情[1 ] .主题模型因能够在一系列文档中发现抽象主题的特点而受到广泛关注[2 ,3 ] .主题关键词提取是指从文本中提炼出能够体现其主题核心内容的短语和单词的过程.主题关键词自动提取的目标是需要一个从这些数据源中提取相关信息的自动化系统.传统的主题关键词提取模型通常是根据词的统计信息对关键词进行排序, 例如, 词频和逆文档频率方法[4 ] , 没有充分考虑文档主题结构对关键词提取的影响.Text Rank[5 ] 在一定程度上考虑了文档词与词之间的关系, 但仍趋向于选择更频繁的单词作为关键字.此外, 关键词和文档的词汇统计特征往往存在一些差异, 因此, 有些与主题相关度较大但是词频较低的关键词往往会被忽略. ...
How to Generate a Good Word Embedding
1
2016
... 词嵌入[6 ] , 即词在低维向量空间中的表示, 在构建基于上下文的连续单词向量模型中起着越来越重要的作用.词嵌入能够捕捉句子的语义, 并且可以用于计算单词的相似度, 因此被广泛应用于各类自然语言处理任务中.同时, 网络结构能很好地描述整个网络中关键(核心)节点的范围.因此, 在考虑文档主题分布的基础上, 本文提出融合关键词向量和关键词网络的关键词提取方法(LdaVecNet).使用主题模型(LDA)[7 ] 对关键词进行初步提取, 同时使用Word2Vec[8 ] 对单词进行向量化表示; 基于词向量的相似性传播构建每个主题下的关键词网络; 最后, 使用核心节点发现算法获取主题关键词.通过实验分析, 证明该方法可以通过综合考虑语义和统计特征来有效提取关键词. ...
Latent Dirichlet Allocation
3
2003
... 词嵌入[6 ] , 即词在低维向量空间中的表示, 在构建基于上下文的连续单词向量模型中起着越来越重要的作用.词嵌入能够捕捉句子的语义, 并且可以用于计算单词的相似度, 因此被广泛应用于各类自然语言处理任务中.同时, 网络结构能很好地描述整个网络中关键(核心)节点的范围.因此, 在考虑文档主题分布的基础上, 本文提出融合关键词向量和关键词网络的关键词提取方法(LdaVecNet).使用主题模型(LDA)[7 ] 对关键词进行初步提取, 同时使用Word2Vec[8 ] 对单词进行向量化表示; 基于词向量的相似性传播构建每个主题下的关键词网络; 最后, 使用核心节点发现算法获取主题关键词.通过实验分析, 证明该方法可以通过综合考虑语义和统计特征来有效提取关键词. ...
... (4) 主题关键词提取: 主题模型因其能够简单有效地发现文档主题而被广泛使用, 因此, 一些研究将关键词提取转换为主题检测问题.潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)[7 ] 、Lda2Vec[2 ] 以及PLDA[21 ] 等, 都是使用主题模型解决问题的. ...
... LDA中Topic个数的确定是一个困难的问题.当各个Topic之间的相似度最小时, 即为合适的Topic个数.采用Blei等[7 ] 提出的方法, 即通过Perplexity值确定LDA主题数量, 计算方法如公式(4)所示. ...
Efficient Estimation of Word Representations in Vector Space
1
... 词嵌入[6 ] , 即词在低维向量空间中的表示, 在构建基于上下文的连续单词向量模型中起着越来越重要的作用.词嵌入能够捕捉句子的语义, 并且可以用于计算单词的相似度, 因此被广泛应用于各类自然语言处理任务中.同时, 网络结构能很好地描述整个网络中关键(核心)节点的范围.因此, 在考虑文档主题分布的基础上, 本文提出融合关键词向量和关键词网络的关键词提取方法(LdaVecNet).使用主题模型(LDA)[7 ] 对关键词进行初步提取, 同时使用Word2Vec[8 ] 对单词进行向量化表示; 基于词向量的相似性传播构建每个主题下的关键词网络; 最后, 使用核心节点发现算法获取主题关键词.通过实验分析, 证明该方法可以通过综合考虑语义和统计特征来有效提取关键词. ...
Highlights: Language- and Domain-Independent Automatic Indexing Terms for Abstracting
1
1995
... (1) 简单统计学方法: 这些方法通常比较粗糙, 不划分训练集, 侧重于从文本的非语言特征获得统计数据, 例如文档中的单词位置、词频和逆文档频率等, 然后利用这些特征构建关键词列表.Cohen[9 ] 利用n-gram模型进行数据统计, 自动发现文档中的关键字.此外, 还有词频(Term Frequency, TF)[10 ] 、词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)[11 ,12 ] 、词共现[13 ] 以及PAT-tree[14 ] 等多种方法的组合.这些方法的共同特点是词频是该词能否作为关键字的主要标准. ...
A Statistical Approach to Mechanized Encoding and Searching of Literary Information
1
1957
... (1) 简单统计学方法: 这些方法通常比较粗糙, 不划分训练集, 侧重于从文本的非语言特征获得统计数据, 例如文档中的单词位置、词频和逆文档频率等, 然后利用这些特征构建关键词列表.Cohen[9 ] 利用n-gram模型进行数据统计, 自动发现文档中的关键字.此外, 还有词频(Term Frequency, TF)[10 ] 、词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)[11 ,12 ] 、词共现[13 ] 以及PAT-tree[14 ] 等多种方法的组合.这些方法的共同特点是词频是该词能否作为关键字的主要标准. ...
面向微博话题的“主题+观点”词条抽取算法研究
1
2016
... (1) 简单统计学方法: 这些方法通常比较粗糙, 不划分训练集, 侧重于从文本的非语言特征获得统计数据, 例如文档中的单词位置、词频和逆文档频率等, 然后利用这些特征构建关键词列表.Cohen[9 ] 利用n-gram模型进行数据统计, 自动发现文档中的关键字.此外, 还有词频(Term Frequency, TF)[10 ] 、词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)[11 ,12 ] 、词共现[13 ] 以及PAT-tree[14 ] 等多种方法的组合.这些方法的共同特点是词频是该词能否作为关键字的主要标准. ...
面向微博话题的“主题+观点”词条抽取算法研究
1
2016
... (1) 简单统计学方法: 这些方法通常比较粗糙, 不划分训练集, 侧重于从文本的非语言特征获得统计数据, 例如文档中的单词位置、词频和逆文档频率等, 然后利用这些特征构建关键词列表.Cohen[9 ] 利用n-gram模型进行数据统计, 自动发现文档中的关键字.此外, 还有词频(Term Frequency, TF)[10 ] 、词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)[11 ,12 ] 、词共现[13 ] 以及PAT-tree[14 ] 等多种方法的组合.这些方法的共同特点是词频是该词能否作为关键字的主要标准. ...
文本分类中TF-IDF方法的改进研究
1
2013
... (1) 简单统计学方法: 这些方法通常比较粗糙, 不划分训练集, 侧重于从文本的非语言特征获得统计数据, 例如文档中的单词位置、词频和逆文档频率等, 然后利用这些特征构建关键词列表.Cohen[9 ] 利用n-gram模型进行数据统计, 自动发现文档中的关键字.此外, 还有词频(Term Frequency, TF)[10 ] 、词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)[11 ,12 ] 、词共现[13 ] 以及PAT-tree[14 ] 等多种方法的组合.这些方法的共同特点是词频是该词能否作为关键字的主要标准. ...
文本分类中TF-IDF方法的改进研究
1
2013
... (1) 简单统计学方法: 这些方法通常比较粗糙, 不划分训练集, 侧重于从文本的非语言特征获得统计数据, 例如文档中的单词位置、词频和逆文档频率等, 然后利用这些特征构建关键词列表.Cohen[9 ] 利用n-gram模型进行数据统计, 自动发现文档中的关键字.此外, 还有词频(Term Frequency, TF)[10 ] 、词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)[11 ,12 ] 、词共现[13 ] 以及PAT-tree[14 ] 等多种方法的组合.这些方法的共同特点是词频是该词能否作为关键字的主要标准. ...
Keyword Extraction from a Single Document Using Word Co-occurrence Statistical Information
1
2004
... (1) 简单统计学方法: 这些方法通常比较粗糙, 不划分训练集, 侧重于从文本的非语言特征获得统计数据, 例如文档中的单词位置、词频和逆文档频率等, 然后利用这些特征构建关键词列表.Cohen[9 ] 利用n-gram模型进行数据统计, 自动发现文档中的关键字.此外, 还有词频(Term Frequency, TF)[10 ] 、词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)[11 ,12 ] 、词共现[13 ] 以及PAT-tree[14 ] 等多种方法的组合.这些方法的共同特点是词频是该词能否作为关键字的主要标准. ...
Identifying and Analyzing Popular Phrases Multi-dimensionally in Social Media Data
1
2015
... (1) 简单统计学方法: 这些方法通常比较粗糙, 不划分训练集, 侧重于从文本的非语言特征获得统计数据, 例如文档中的单词位置、词频和逆文档频率等, 然后利用这些特征构建关键词列表.Cohen[9 ] 利用n-gram模型进行数据统计, 自动发现文档中的关键字.此外, 还有词频(Term Frequency, TF)[10 ] 、词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)[11 ,12 ] 、词共现[13 ] 以及PAT-tree[14 ] 等多种方法的组合.这些方法的共同特点是词频是该词能否作为关键字的主要标准. ...
Using Lexical Chains for Text Summarization
1
1997
... (2) 语言学方法: 该方法利用文字的语言特征来进行文本关键字的检测和提取, 主要融合词法分析[15 ] 、句法分析[16 ] 、语篇分析[17 ] 等方法.其中, 用于词法分子的资源主要有电子词典、TreeTagger、WordNet、n-grams模型、POS pattern等. ...
Improved Automatic Keyword Extraction Given More Linguistic Knowledge
1
2003
... (2) 语言学方法: 该方法利用文字的语言特征来进行文本关键字的检测和提取, 主要融合词法分析[15 ] 、句法分析[16 ] 、语篇分析[17 ] 等方法.其中, 用于词法分子的资源主要有电子词典、TreeTagger、WordNet、n-grams模型、POS pattern等. ...
Automatic Text Structuring and Summarization
1
1997
... (2) 语言学方法: 该方法利用文字的语言特征来进行文本关键字的检测和提取, 主要融合词法分析[15 ] 、句法分析[16 ] 、语篇分析[17 ] 等方法.其中, 用于词法分子的资源主要有电子词典、TreeTagger、WordNet、n-grams模型、POS pattern等. ...
Text Summarization via Hidden Markov Models
1
2001
... (3) 机器学习方法: 关键词提取也可以看作是一个机器学习问题, 该方法以已标注的训练数据为输入.常用的训练模型有隐马尔可夫模型[18 ] 、支持向量机(Support Vector Machine, SVM)[19 ] 、朴素贝叶斯模型(Naïve Bayes, NB)[20 ] 等. ...
Keyword Extraction Using Support Vector Machine
1
2006
... (3) 机器学习方法: 关键词提取也可以看作是一个机器学习问题, 该方法以已标注的训练数据为输入.常用的训练模型有隐马尔可夫模型[18 ] 、支持向量机(Support Vector Machine, SVM)[19 ] 、朴素贝叶斯模型(Naïve Bayes, NB)[20 ] 等. ...
Domain-Specific Keyphrase Extraction
1
1999
... (3) 机器学习方法: 关键词提取也可以看作是一个机器学习问题, 该方法以已标注的训练数据为输入.常用的训练模型有隐马尔可夫模型[18 ] 、支持向量机(Support Vector Machine, SVM)[19 ] 、朴素贝叶斯模型(Naïve Bayes, NB)[20 ] 等. ...
Automatic Keyphrase Extraction by Bridging Vocabulary Gap
1
2011
... (4) 主题关键词提取: 主题模型因其能够简单有效地发现文档主题而被广泛使用, 因此, 一些研究将关键词提取转换为主题检测问题.潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)[7 ] 、Lda2Vec[2 ] 以及PLDA[21 ] 等, 都是使用主题模型解决问题的. ...
Distributed Representations of Words and Phrases and Their Compositionality
2
2013
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
... 基于神经网络的分布表示一般称为词向量、词嵌入(Word Embedding)或分布式表示(Distributed Representation).神经网络词向量表示技术通过神经网络技术对上下文, 以及上下文与目标词之间的关系进行建模.由于神经网络较为灵活, 这类方法的最大优势在于可以表示复杂的上下文.如果使用包含词序信息的n-gram作为上下文, 当n增加时, n-gram的总数会呈指数级增长, 此时会遇到维数灾难问题.而神经网络在表示n-gram时, 可以通过一些组合方式对n个词进行组合, 参数个数仅以线性速度增长.具有这一优势, 神经网络模型可以对更复杂的上下文进行建模, 在词向量中包含更丰富的语义信息.Mikolov等[22 ] 提出Skip-gram模型和CBOW.他们设计两个模型的主要目的是希望用更高效的方法获取词向量, 本文使用Mikolov等提出的Word2Vec模型训练原始语料并获取词向量, 选择连续词袋模型(CBOW)预测关键词的概率, 设置滑动窗口为5, 则可以通过窗口内的上下文单词对目标词进行预测, 如公式(1)所示. ...
Topical Word Embeddings
1
2015
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
Reading Tea Leaves: How Humans Interpret Topic Models
1
2009
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
LDA模型的优化及其主题数量选择研究——以科技文献为例
1
2018
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
LDA模型的优化及其主题数量选择研究——以科技文献为例
1
2018
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
基于LF-LDA和Word2vec的文本表示模型研究
1
2017
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
基于LF-LDA和Word2vec的文本表示模型研究
1
2017
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
A Question Recommendation Model Based on LDA and Word2Vec
1
2015
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
基于LDA和Word2Vec的推荐算法研究
1
2015
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
基于LDA和Word2Vec的推荐算法研究
1
2015
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
A Hybrid Document Feature Extraction Method Using Latent Dirichlet Allocation and Word2Vec
1
2016
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
领域关键词抽取: 结合LDA与Word2Vec
1
2016
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
领域关键词抽取: 结合LDA与Word2Vec
1
2016
... 词嵌入已经广泛地应用于语言模型[22 ] 中, 它通过Skip-Gram模型和连续词袋(Continuous Bag-Of-Words, CBOW)模型, 从大规模语料中学习词表示.词嵌入可以将单词的句法和语义信息编码成空间中的连续矢量, 语义相似的单词在矢量空间中距离也是相近的.因此, 出现了大量词向量与主题模型相结合的研究, 其中, Liu等[23 ] 使用LDA与Word2Vec相结合的方法, 提出主题词嵌入模型, 该模型主要思路是: LDA模型为语料库中的每个单词分配主题, 基于单词和主题学习主题词嵌入(Topic Word Embedding, TWE), 并通过基于上下文的单词相似度和文本分类对TWE模型进行验证.Moody[2 ] 提出Lda2Vec模型, 一个通过结合Dirichlet分布的主题向量潜在文档级混合的词向量学习模型.文献[24 ,25 ]探讨了混合稀疏文档表示与密集词和主题向量的混合方法.基于LDA和Word2Vec的结合, 还可以进行文本表示[26 ] , 文本推荐算法[27 ,28 ] , 文档特征提取[29 ] 和领域关键词抽取[30 ] 等研究. ...
融合Word2Vec与TextRank的关键词抽取研究
1
2016
... 同时, 随着表示学习研究的广泛应用, 自然语言处理领域出现了大量词语的表示学习与传统方法相结合的研究, 其中文献[31 ]将Word2Vec与TextRank方法相结合, 进行关键词提取研究.文献[32 ,33 ]在此基础上, 将词向量聚类加权再与TextRank相结合进行关键词抽取.而文献[34 ]则是把Word2Vec和TextRank相结合应用到时政类新闻的关键词抽取中. ...
融合Word2Vec与TextRank的关键词抽取研究
1
2016
... 同时, 随着表示学习研究的广泛应用, 自然语言处理领域出现了大量词语的表示学习与传统方法相结合的研究, 其中文献[31 ]将Word2Vec与TextRank方法相结合, 进行关键词提取研究.文献[32 ,33 ]在此基础上, 将词向量聚类加权再与TextRank相结合进行关键词抽取.而文献[34 ]则是把Word2Vec和TextRank相结合应用到时政类新闻的关键词抽取中. ...
词向量聚类加权TextRank的关键词抽取
1
2017
... 同时, 随着表示学习研究的广泛应用, 自然语言处理领域出现了大量词语的表示学习与传统方法相结合的研究, 其中文献[31 ]将Word2Vec与TextRank方法相结合, 进行关键词提取研究.文献[32 ,33 ]在此基础上, 将词向量聚类加权再与TextRank相结合进行关键词抽取.而文献[34 ]则是把Word2Vec和TextRank相结合应用到时政类新闻的关键词抽取中. ...
词向量聚类加权TextRank的关键词抽取
1
2017
... 同时, 随着表示学习研究的广泛应用, 自然语言处理领域出现了大量词语的表示学习与传统方法相结合的研究, 其中文献[31 ]将Word2Vec与TextRank方法相结合, 进行关键词提取研究.文献[32 ,33 ]在此基础上, 将词向量聚类加权再与TextRank相结合进行关键词抽取.而文献[34 ]则是把Word2Vec和TextRank相结合应用到时政类新闻的关键词抽取中. ...
Research on Keyword Extraction Based on Word2Vec Weighted TextRank
1
2017
... 同时, 随着表示学习研究的广泛应用, 自然语言处理领域出现了大量词语的表示学习与传统方法相结合的研究, 其中文献[31 ]将Word2Vec与TextRank方法相结合, 进行关键词提取研究.文献[32 ,33 ]在此基础上, 将词向量聚类加权再与TextRank相结合进行关键词抽取.而文献[34 ]则是把Word2Vec和TextRank相结合应用到时政类新闻的关键词抽取中. ...
基于Word2Vec和TextRank的时政类新闻关键词抽取方法研究
1
2018
... 同时, 随着表示学习研究的广泛应用, 自然语言处理领域出现了大量词语的表示学习与传统方法相结合的研究, 其中文献[31 ]将Word2Vec与TextRank方法相结合, 进行关键词提取研究.文献[32 ,33 ]在此基础上, 将词向量聚类加权再与TextRank相结合进行关键词抽取.而文献[34 ]则是把Word2Vec和TextRank相结合应用到时政类新闻的关键词抽取中. ...
基于Word2Vec和TextRank的时政类新闻关键词抽取方法研究
1
2018
... 同时, 随着表示学习研究的广泛应用, 自然语言处理领域出现了大量词语的表示学习与传统方法相结合的研究, 其中文献[31 ]将Word2Vec与TextRank方法相结合, 进行关键词提取研究.文献[32 ,33 ]在此基础上, 将词向量聚类加权再与TextRank相结合进行关键词抽取.而文献[34 ]则是把Word2Vec和TextRank相结合应用到时政类新闻的关键词抽取中. ...
The Anatomy of a Large-Scale Hyper Textual Web Search Engine
1
1998
... PageRank算法是由Google创始人Brin等[35 ] 提出的一种网页排名算法, 其核心思想是通过研究网络的拓扑结构和计算页面的入度(即页面被链接的次数), 进而确定该页面的排名顺序.页面的入度越大, 那么其重要性就越大, 排名也越靠前.同时它还考虑了指向目标页面的其他页面自身的PageRank值. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}