




1 引 言
随着自媒体时代的来临, 微博已成为人们发表观点、表达情感的重要途经之一。中国互联网络信息中心(China Internet Network Information Center, CNNIC)发布的《第43次中国互联网络发展状况统计报告》显示: 截至2018年12月, 中国微博用户已达3.51亿[1]。除对身边的新鲜事和社会热点事件进行评论外, 越来越多的微博用户开始发表自己对于某种产品或者服务的评价。微博商品评论作为社交媒体环境下的新型表现形式, 相较于传统电商平台评论往往较少涉及虚假评论以及刷单现象, 真实性更强[2]。对其进行分析和挖掘, 可以更为准确地反映用户对于产品的态度。但受到发文字数的限制以及强交互性的影响, 微博评论的观点更加密集, 表达口语性更高, 分析难度也更大。因此, 面向微博的商品评论挖掘已逐渐成为文本分析领域的研究热点。
评论挖掘(Opinion Mining)指运用自然语言处理、文本分析等相关技术对网络中海量评论进行意见抽取的过程[3], 可以确保在信息不失真的前提下, 从大量评论数据中提取有价值的内容, 并将其凝练为简洁、结构化的形式。评论挖掘的研究工作主要可以分为两个方面: 情感标签的抽取即评价对象与观点词关系的抽取; 观点词或句的情感极性计算。其中情感标签抽取效果直接影响到观点挖掘的粒度和情感极性计算的效果。因此本文重点围绕情感标签的抽取展开, 面向微博商品评论, 研究抽取产品评价对象与观点词之间对应关系的方法, 以生成基于特征评价的产品描述, 更好地为商家了解顾客需求、改进产品性能和服务以及为消费者高效地获取在线商品评论中的有效信息提供帮助[4,5]。
2 相关研究
评价对象与评价短语关系的抽取是整个情感标签抽取工作的核心, 在商品评论中评价对象(f)亦称特征词, 是评论的客体, 一般为产品的某个部件或是某个属性; 评价短语(s)则是用户主观感受的表达, 是用于形容评价对象的一个短句或者词组。如果一个评价对象f明确出现在评论文本r中, 那么f称为r的显式特征, f和其所对应的情感短语s所组成的情感标签<f,s>称为一个显式标签, 同理如果f没有在r中明确出现, 而是被暗指, 那么将f称为r的一个隐式特征, 此时这个被暗指的特征f和其所对应的情感短语s所组成的情感标签<f,s>称为一个隐式标签[10]。现阶段显式标签抽取的方式主要有两种:
相对于显式标签, 隐式标签的提取则相对困难, 尤其在以微博为代表的新型网络社交媒体环境下, 由于其评论字数的限制以及用户间强交互性的影响, 具有内容复杂、口语性强和非结构化的特点[20]。其中充斥着大量用户间约定俗成的隐式表达, 如在电子产品领域“发烫”往往修饰的是电池, 但用户一般较少使用“电池发烫”这样的语句, 而是直接使用“发烫”或者“有点发烫”进行评价, 这些使用习惯增加了特征提取的难度。隐式标签提取的主要思想是发现评价对象与情感词之间的搭配关系, 进而根据这些关系对评价对 象进行有效的填补[21], 发现方法包括基于TF-IDF算法[22]、基于共词网络[23]以及基于网络分析的TextRank算法[24]。但这些方法都存在一些局限性, 如TF-IDF算法和共词网络考虑了特征词和情感词的频次但忽略了词与词之间的关系; 而TextRank算法构造的是无向无权网络, 并不能准确描述词与词之间出现的频次。因此, 如何更好地描述评价对象与情感词之间的关系, 进而发现其中的特殊搭配关系是研究的重点。
综上所述, 现阶段情感标签抽取的研究中还存在着以下局限:
(1) 评价单元划分的准确率不高;
(2) 显式标签抽取规则的覆盖率较低;
(3) 特征词与情感词关系的描述方式单一, 缺少多维高效的发现算法。
针对上述问题, 本文提出一种面向微博商品评论的情感标签抽取方法。该方法借助依存句法分析可以从语义层次上划分评价单元并进行显式标签的抽取, 通过NodeRank算法对评价对象与情感词之间的修饰关系进行综合描述, 进而提高对隐式表达的识别效果。利用新浪微博平台的真实评论数据对本文方法进行实证研究。
3 情感标签抽取框架
3.1 情感标签抽取框架概述
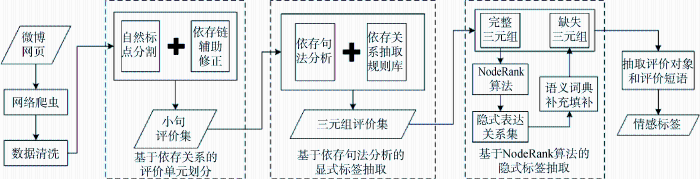
情感标签抽取框架如图1所示。针对现阶段情感标签抽取研究的局限性, 本文主要对情感标签的抽取流程作如下改进:
(1) 评价单元划分: 在自然标点分割的基础上, 考虑各个小句之间的关系, 增加依存链的辅助修正;
(2) 显式标签抽取: 在已有研究的基础上采用依存句法分析进行关系抽取并制定了更加详细的抽取规则;
(3) 隐式标签抽取: 采用基于二分加权网络的NodeRank算法, 建立特征词与情感词的无向有权网络来揭示特征词与情感词之间的特殊搭配关系, 进而提取隐式表达关系, 并利用WordSimilarity语义词典进行补充填补。
上述情感标签抽取的三个环节并不相互独立, 评价单元的准确划分为显式与隐式标签的抽取提供了基础, 在语义层面上的显式标签抽取不仅提高了自身的抽取正确率而且为隐式表达关系揭示提供了保障。
图1
3.2 基于依存关系的评价单元划分
句子的成分可以分为主语、谓语、宾语、定语等, 其间的结构又可以分为主谓、动宾、定中等结构。依存句法分析就是通过计算机技术识别句子中的成分以及成分关系的方法。
图2
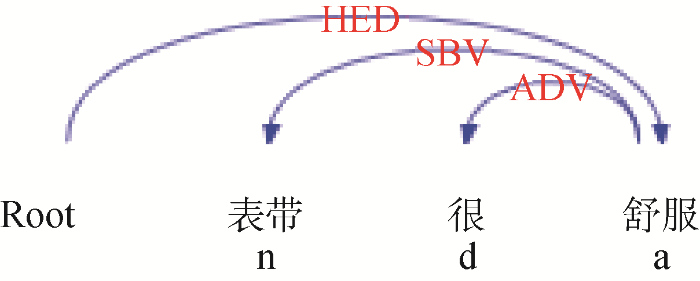
表1 本文涉及的主要依存关系表
| 依存关系 | 关系类型 | 示例 |
|---|---|---|
| SBV | 主谓关系 | 做工细腻(做工细腻) |
| ATT | 定中关系 | 是个好手表(手表好) |
| COO | 并列关系 | 外观和手感(外观手感) |
| VOB | 动宾关系 | 可惜没有蜂窝网络(没有网络) |
| ADV | 状中关系 | 外观非常漂亮(非常漂亮) |
| CMP | 动补关系 | 心率监测一般(一般监测) |
| HED | 核心关系 | 整句的核心 |
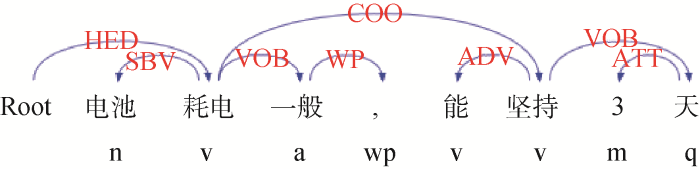
元的划分规则进行重新定义, 以增强划分的准确性与完整性。将句号、分号、问号、感叹号这些表示句意结束的标点定义为强分隔符, 将逗号、顿号这些表示句意暂停的标点定义为弱分隔符。对于一个句子先按文中的标点进行切割, 对于弱分隔符使用依存链进行辅助纠正, 如果弱分隔符两边存在为COO(并列关系)、LAD(左附加关系)、RAD(右附加关系)的依存关系, 则取消该弱分隔符的分割作用, 将该依存链连接的两个小句合并。
评价单元提取示意图如图3所示, 评论“电池耗电一般, 能坚持3天”, 在语意上“能坚持3天”是对“耗电一般”的补充描述; 在句法结构上, COO依存关系跨越逗号连接了“电池耗电一般”和“能坚持3天”两个小句, “耗电”和“坚持”属并列结构同共同对“电池”进行修饰, 故在此取消逗号的分割作用, 将其合并作为一个评价单元处理。
图3
3.3 基于依存句法分析的显式标签抽取
采用<评价对象, 评价短语, 评价核心词>三元组的方式对评价集进行存储。其中, 评价对象是商品的某个部件或某个属性(如: 电池、价格); 评价短语为一组连续出现的词组, 由程度副词、否定词和评价核心词组合而成; 评价核心词是直接和评价对象产生依存关系的词。利用词性以及词对间的依存关系, 制定抽取规则如表2所示。
表2 依存关系抽取规则
| 依存关系 | 提取规则 | 说明 |
|---|---|---|
| SBV | 提取<SBV的修饰词, SBV核心词依存链扩展, SBV的核心词> | 此时句中的主语为SBV的修饰词, 谓语为SBV的核心词 |
| SBV+VOB | 提取<SBV的修饰词, VOB全依存链扩展, VOB全依存链> | 此时句中谓语既是SBV的核心词同时也是VOB的核心词 |
| SBV+CMP | 提取<SBV的修饰词, CMP全依存链扩展, CMP全依存链> | 此时句中谓语既是SBV的核心词同时也是CMP的核心词 |
| SBV+COO | 提取<SBV的修饰词, SBV核心词依存链扩展, SBV的核心词>; <COO的修饰词, SBV核心词依存链扩展, SBV的核心词> | 此时句中的主语由SBV的修饰词和COO的修饰词共同 构成 |
| VOB | 提取<VOB的修饰词, VOB的核心词依存链扩展, VOB的核心词> | 若VOB修饰词的POS=n或j且核心词的POS=v |
| VOB | 提取<VOB的核心词, VOB的修饰词依存链扩展, VOB的修饰词> | 若VOB修饰词的POS=a或b或i且核心词的POS=v |
| CMP | 提取<CMP的核心词, CMP的修饰词依存链扩展, CMP的修饰词> | 无 |
(注: a:形容词; b:修饰名词的词; j:缩写词; n:名词; v:动词。)
补充规则: 对于以上规则, 在对评价对象进行抽取时, 包含所有对应规则内的ATT关系, 对相应依存链边界进行补充; 在对评价短语进行抽取时, 包含所有对应规则内的ATT及ADV关系, 对相应依存链边界进行补充。
3.4 基于NodeRank算法的隐式标签抽取
在微博这类典型的用户自生成文本环境下, 用户的语言简练自由, 个性化更强, 并不是所有文本都会明确提及评价商品的某个部件或者属性, 如评论“偶尔有点卡顿, 很失望”, 文本中用户并没有提到有关产品的特征词, 但基于人们的日常使用经验, 不难发现“卡顿”描述的是“操作系统”这个特征。隐式特征提取的关键在于如何发现这些情感词和特征的特殊搭配关系。因此, 本文结合复杂网络的相关理论, 基于二分加权网络的NodeRank算法从网络拓扑结构分析的角度对产品特征词与情感词之间的“特殊性”进行排序, 并利用情感词对特征词进行映射, 从而更好地识别评论中的隐式特征。
基于已抽取的评价集, 从中抽取评价对象和评价核心词构建二分加权网络G(F,S), 以清晰直观地发现情感词与产品特征之间的关系, 如图4所示。网络图左侧的节点为评价单元中的评价对象, 右侧节点为评价单元中的评价核心词, 节点间的连线表示评价核心词与评价对象存在修饰关系, 连线上的数字权重表示评价核心词与评价对象在同一情感单元中出现的频次, 即评价核心词与评价对象在同一情感单元内出现, 两节点间产生连线, 出现的频次越高连线上的权重 越大。
图4
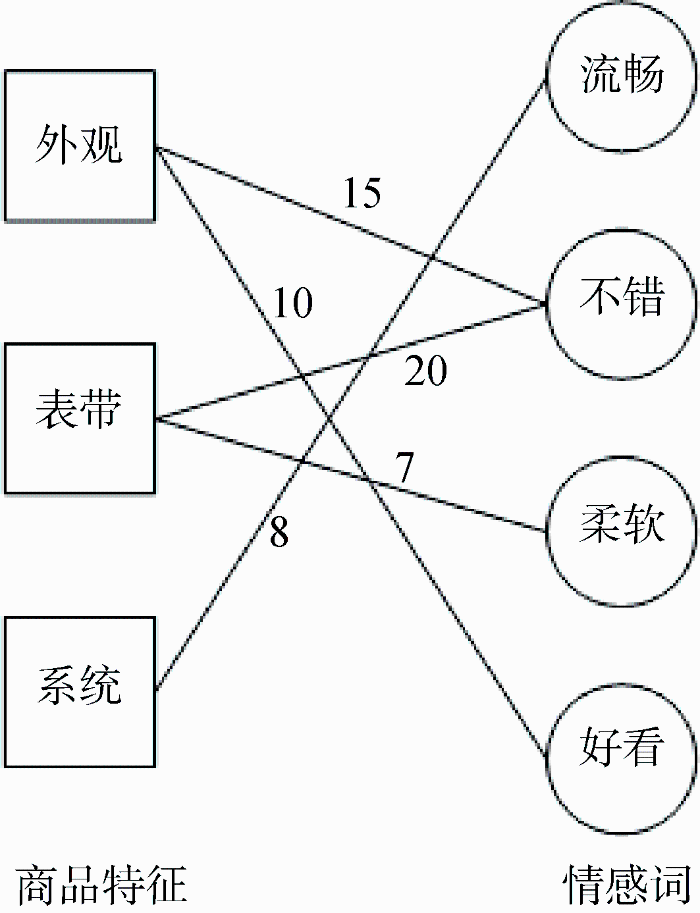
其中, d表示二分网络的基尼系数, $NR(s)$反映二分网络中情感词s的特殊程度, $w({{f}_{i}}\cdot s)$表示指向情感词s边连的权重, $\sum\nolimits_{j=1}^{m}{w({{f}_{i}}\cdot {{f}_{j}})}$表示特征词${{f}_{i}}$所有出边的权值。NR(s)的值越小, 表明其在二分网络中的特殊性越大。进而通过边连的权值选取所连接的权值最大的特征词作为该情感词的组合。
依据所选出的隐式表达关系联合WordSimilarity语义词典, 对缺少评价对象的三元组进行填补。优先使用本文发现的隐式表达关系集进行填补, 若不存在, 则利用WordSimilarity语义词典进行辅助填补。填补规则伪代码如下:
If三元组中不缺少评价对象
结束填补
Else
If隐式表达关系集中存在关于评价核心词的映射
使用本文发现的隐式表达关系集进行填补
Else
使用WordSimilarity语义词典, 按高相似系数优先的原
则对评价对象进行填补
Endif
Endif
4 实验分析
4.1 实验数据
选取日常生活中使用较为广泛的智能手表和手机作为实验对象, 通过Python编写网络爬虫程序, 以Apple Watch4、Mate20为关键词并对话题#Apple Watch 4#、# Apple Watch 4代#、#Mate 20#、#华为Mate 20#在新浪微博平台进行评论数据爬取, 爬取时间截至2019年3月18日, 共获取数据12 753条。由于平台的开放性, 原始评论数据中包含因用户转发而产生的重复数据以及商品宣传、促销活动等无关数据。因此, 编写Python程序进行数据去重, 对于重复数据只保留一条原始微博; 而宣传和促销类微博往往会包含一些特征词如“转发抽奖”、“集赞送”、“taobao.com”等, 通过关键词粗筛结合人工细筛的方式对无关数据进行清洗。最终获取微博语料1 417条, 其中智能手表评论674条, 手机评论743条, 形成待分析的智能手表评论数据集和手机评论数据集。
4.2 实验过程
根据本文定义的小句划分规则, 分别对两个数据集进行小句划分, 1 417条微博共被分为3 199个评价单元, 其中智能手表评论1 416个, 手机评论1 783个。通过Python调用哈尔滨工业大学语言云平台①(①http://www.ltp-cloud.com/.)API, 依据提取规则对数据集进行显式标签抽取, 根据抽取结果是否缺少评价对象将其分为完整三元组和缺失三元组。
表3 智能手表评论特征-情感词搭配特殊性排序(部分)
| 智能手表 | 手机 | |||||
|---|---|---|---|---|---|---|
| 情感词 | 特征词 | NR值 | 情感词 | 特征词 | NR值 | |
| 厚 | 表盘 | 0.0053 | 流畅 | 系统 | 0.0051 | |
| 好看 | 外观 | 0.0053 | 耐用 | 电池 | 0.0051 | |
| 划痕 | 屏幕 | 0.0056 | 漏光 | 屏幕 | 0.0051 | |
| 瑕疵 | 手表 | 0.0056 | 刺眼 | 屏幕 | 0.0054 | |
| LOW | 表带 | 0.0062 | 划痕 | 屏幕 | 0.0054 | |
| 轻便 | 佩戴 | 0.0062 | 抗用 | 电池 | 0.0067 | |
| 透气 | 表带 | 0.0062 | 噪音 | 通话 | 0.0067 | |
| 柔软 | 表带 | 0.0068 | 卡顿 | 系统 | 0.0073 | |
| 捂汗 | 表带 | 0.0068 | 黑点 | 屏幕 | 0.0073 | |
| 炫酷 | 外观 | 0.0068 | 沾指纹 | 背壳 | 0.0085 | |
| 掉皮 | 表带 | 0.0075 | 浴霸 | 摄像头 | 0.0085 | |
| 漂亮 | 外观 | 0.0075 | 噪点 | 相机 | 0.0085 | |
| 黑点 | 屏幕 | 0.0083 | 美轮美奂 | 颜色 | 0.0093 | |
| 透汗 | 表带 | 0.0083 | 杠杠的 | 质量 | 0.0093 | |
| 省电 | 电池 | 0.0088 | 贵 | 价格 | 0.0102 | |
| 友好 | 系统 | 0.0088 | 酷 | 手机 | 0.0102 | |
| 抗用 | 电池 | 0.0096 | 毛刺 | 中框 | 0.0115 | |
| 时尚 | 外观 | 0.0096 | 掉漆 | 手机 | 0.0115 | |
| 迟钝 | 系统 | 0.0112 | 清透 | 屏幕 | 0.0115 | |
依据提取出的隐式特征关系联合WordSimilarity语义词典并依照填补规则, 进行缺失三元组填补, 形成最终的情感标签。
4.3 评价指标
使用准确率(P)、召回率(R)和F-Measure(F)以人工标注的情感标签作为标准, 对实验结果进行评估。人工标注的基本规则如下: 对于显式标签, 标注评论中的评价对象和评价短语; 对于隐式标签, 标注其中的
评价短语并人工对评价对象进行填补。标注过程由两名工作人员独立完成, 第三人对标注结果进行核实, 对于不一致的标注结果, 通过三人商议决定。评价指标的具体含义如下: 准确率指抽取结果中正确情感标签数与抽取出的情感标签总数的比值; 召回率是指抽取结果中正确情感标签数与实际存在的情感标签总数的比值; F-Measure是综合准确率和召回率的评价指标。准确率、召回率和F-Measure计算方法如公式(2)-公式(4)所示。
其中, A表示抽取结果中正确的个数, B表示抽取结果中错误的个数, C表示遗漏个数。
4.4 情感标签抽取结果分析
本次情感标签抽取实验的统计结果如表4所示, 在召回率上, 两个数据集显式和隐式标签的抽取都高于85%, 表现良好。如对于内容相对密集的评论“不仅外观炫酷, 功能强大还非常省电”, 本文方法可以准确识别其中两个显式标签, 分别为<外观, 炫酷>和<功能, 强大>, 并对隐式表达“省电”进行了填补, 得到隐式标签<电池, 非常省电>。这与融入依存句法分析对小句进行改进划分有密切的关系, 准确的小句划分是精准、无遗漏地抽取评价对象的基础。在准确率上, 两个数据集显式标签抽取的准确率同样高于85%, 充分证明了本文提取规则的高覆盖率。对于隐式标签, 智能手表的抽取准确率为76.3%, 手机为76.5%, 低于显式特征提取的准确率86.9%和88.9%, 有待进一步提高。笔者通过对原始评论的回溯发现其与用户的少数“非特殊性”表达有关, 如“棒棒哒”这个情感词可以被用来描述多个特征, 而将这类通用情感词具体地划分到某一具体特征上时, 容易产生偏差。总体上, 与人工识别结果进行比对, 本文方法在总体准确率、召回率和F值上均有较好结果, 其中总体抽取结果的综合F值为85.3%, 抽取结果较为理想。
表4 抽取结果表
| 数据集 | P | R | F值 | |
|---|---|---|---|---|
| 智能手表 | 显式标签 | 86.9% | 87.1% | 87.0% |
| 隐式标签 | 76.3% | 86.1% | 80.9% | |
| 总体 | 82.7% | 86.7% | 84.7% | |
| 手机 | 显式标签 | 88.9% | 88.0% | 88.4% |
| 隐式标签 | 76.5% | 86.2% | 81.1% | |
| 总体 | 84.3% | 87.4% | 85.8% | |
| SUM | 显式标签 | 88.0% | 87.6% | 87.8% |
| 隐式标签 | 76.4% | 86.1% | 81.0% | |
| 总体 | 83.6% | 87.1% | 85.3% | |
4.5 对比实验
表5 对比实验结果
| 本文方法 | 文献[22]方法 | |||||
|---|---|---|---|---|---|---|
| P | R | F值 | P | R | F值 | |
| 显式标签 | 88.0% | 87.6% | 87.8% | 82.8% | 82.4% | 82.6% |
| 隐式标签 | 76.4% | 86.1% | 81.0% | 72.2% | 81.3% | 76.5% |
| 总体 | 83.6% | 87.1% | 85.3% | 78.7% | 82.0% | 80.3% |
从总体F值可见, 本文抽取方法优于对比方法。同时, 从显式标签和隐式标签抽取的准确率和召回率来看, 本文方法也均高于对比方法。显式标签抽取的优越性证明了本文基于依存句法分析抽取方法的优势以及所设置抽取规则的高覆盖率和完整性。对比方法主要依靠频繁项集进行显式标签抽取的策略往往会遗漏一些较少被评论的产品特征且容易抽取一些无关信息, 如对评论“防水功能刚测试了一下, 很赞”, 本文抽取方法能直接抽取出评价对象(防水功能)和评论短语(很赞), 避免了“刚测试了一下”这些冗余信息的干扰, 使抽取结果更为精炼。隐式标签抽取的优越性与本文使用NodeRank算法从词间修饰关系和词频两个角度, 对全部产品特征进行综合隐式表达关系发现有着密切联系。对比方法利用TF-IDF对同一特征类的情感词进行计算, 然而, 对不同特征类分别进行表达关系的“特殊性”计算, 容易遗漏用户集中评论的产品特征下的表达关系。本文方法弥补了这一不足, 如对评论“就是有点捂汗”, 可以准确地还原 “捂汗”所修饰的特征词“表带”, 而对比方法未能对“捂汗”这一隐式表达的评价对象进行准确填补。
5 结 语
本文面向微博商品评论, 针对特征级情感分析问题, 提出基于依存句法分析和NodeRank算法的情感标签抽取方法, 并通过实证与对比实验, 验证了本文方法的有效性。该方法提高了商品情感标签抽取的准确率, 为后续的情感极性分类工作提供了基础, 有一定的方法学意义, 还能实现综合显式和隐式的情感标签抽取, 使之可以更好地服务于厂家产品改进以及用户商品选购。
但是, 本文仍存在一定局限: 在隐式标签的抽取中未能充分考虑用户的“非特殊性”情感表达。未来笔者将对该类情感表达的隐式情感标签填补问题作进一步探索, 并针对情感标签进行情感极性分类, 以提高挖掘结果的现实意义。
作者贡献声明
李博诚: 设计研究方案, 进行实验, 起草并完善论文;
张云秋: 确定论文选题, 完善研究方案, 论文最终版本修订;
杨铠西: 数据采集和预处理, 数据分析。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: 1015436131@qq.com。
[1] 李博诚. 实验数据. rar. 本文实验及对比实验使用的评论数据.
[2] 李博诚. 实验代码. rar. 本文实验中涉及的程序代码.
[3] 李博诚. 对比实验代码. rar. 对比实验中涉及的程序代码.
[4] 李博诚. 实验抽取结果. xlsx. 本文方法的抽取结果.
[5] 李博诚. 对比实验抽取结果. xlsx. 对比方法的抽取结果.
[6] 李博诚. 隐式表达关系集. xlsx. 本文方法提取的隐式表达关系.
[7] 李博诚. 人工标注的情感标签. xlsx. 人工对情感标签进行的标注结果.
参考文献
第43次《中国互联网络发展状况统计报告》
[R/OL].(2019-02-28). [2019-03-02]. http://cnnic.cn/gywm/xwzx/rdxw/20172017_7056/201902/t20190228_70643.htm.
The 43rd China Internet Development Statistics Report
[R/OL].(2019-02-28). [2019-03-02]. http://cnnic.cn/gywm/xwzx/rdxw/20172017_7056/201902/t20190228_70643.htm. )
微博产品评论挖掘模型研究
[J].
Research on Microblogging Product Reviews Mining Model
[J].
基于微博的产品评论挖掘: 情感分析的方法
[J].
Product Reviews Mining from Microblogging Based on Sentiment Analysis
[J].
基于SVM的中文微博观点倾向性识别
[J].
Chinese Micro-blogging Opinion Recognition Based on SVM Model
[J].
中文微博观点句识别及评价对象抽取
[D].
Recognition of Chinese Microblog Sentiment Polarity and Extraction of Opinion Target
[D].
基于汽车领域的中文微博意见挖掘研究
[D].
A Study on Chinese Microblog Opinion Mining Based on Automobile Domain
[D].
基于主题的微博小句内评价对象与评价词分析
[J].
Analysis of Objects and Evaluation Words in Microblog Clause Based on Topic
[J].
面向中文微博的观点句识别研究
[J].
Study of Subjective Sentence Identification Oriented to Chinese Microblog
[J].
商品隐式评价对象提取的方法研究
[J].
Research on Extracting Method of Commodities Implicit Opinion Tar-gets
[J].
A Hybrid System for Emotion Extraction from Suicide Notes
[J].
A Hybrid Method of Sentiment Key Sentence Identification Using Lexical Semantics and Syntactic Dependencies
基于领域本体、情感词典的商品评论倾向性分析
[J].
Analysing Propensity of Product Reviews Based on Domain Ontology and Sentiment Lexicon
[J].
Predicting the Semantic Orientation of Emoticons
[J].
基于词共现和情感元素的突发话题检测算法
[J].
Bursty Topic Detection Based on Word Co-Occurrence and Emotions
[J].
Dependency Driven Semantic Approach to Product Features Extraction and Summarization Using Customer Reviews
[J].
基于依存分析与特征组合的微博情感分析
[J].
Micro-blog Opinion Analysis Based on Syntactic Dependency and Feature Combination
[J].
依存句法模板下的商品特征标签抽取研究
[J].
Using Dependency Parsing Pattern to Extract Product Feature Tags
[J].
基于话题聚类及情感强度的中文微博舆情分析
[J].
Analysis of the Public Opinion of Chinese Microblog Based on Topic Clustering and Emotional Intensity
[J].
网络文本评论中产品特征抽取综述
[J].
Overview of Extracting Product Feature from Text Reviews
[J].
基于特征本体的微博产品评论情感分析
[J].
Sentiment Analysis of Microblog Product Reviews Based on Feature Ontology
[J].
A Product Feature Inference Model for Mining Implicit Customer Preferences Within Large Scale Social Media Networks
基于主题的SE-TextRank情感摘要方法
[J].
SE-TextRank Opinion Summarization Method Based on Topic Model
[J].
基于层叠条件随机场的微博商品评论情感分类
[J].
Product Reviews Sentiment Classification in Micro-blog Based on Cascaded Conditional Random Field
[J].
NodeRank: An Algorithm to Assess State Enumeration Attack Graphs

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}