1 引 言
随着移动互联网的发展, 互联网用户每天需要接触和处理大量的文本形式信息, 对文本进行自动化处理可以大大提高用户体验, 进而提高相关企业的营利水平。文本表现为一个由文字和标点符号组成的字符串, 由字或者字符组成词, 由词组成短语, 进而形成句、段、章、篇的结构[1 ] , 是一种非结构化或半结构化的数据组织形式, 因此不能直接被计算机识别, 故需将文本转化为统一的、结构化的形式, 上述转化过程被称为文本表示[2 ] 。文本的表示和建模是众多自然语言处理(Natural Language Processing, NLP)任务的基石, 例如文本分类、聚类、摘要、相似性或者相关性估计[3 ] 。其中最常见的表示形式是向量。
LDA主题模型(LDA Topic Model)是一种统计学习模型, 可以较好地对文本主题建模。神经网络的发展为NLP带来新的方法。词向量成为当前神经网络的主要输入形式; 而卷积神经网络可以识别一个文本序列中的n元语法。同时, 自然语言处理往往会遇到未登录词(Out of Vocabulary Words), 在字(符)粒度上的工作可以减弱该问题的影响。
基于以上分析, 本文提出一种文本向量表示模型, 使用词向量、卷积神经网络以及LDA主题模型得到文本的词粒度、主题粒度以及字粒度特征向量, 并通过“融合门”机制将上述特征向量融合得到最终的文本向量。
2 研究现状
早期对于文本向量表示的研究主要基于词袋模型[4 ] 。词袋模型存在维度灾难、无法保留词序信息、语义鸿沟等问题, 故效果受限。后来LDA主题模型[5 ] 将文本表示为隐含主题的概率分布, 极大改善了文本高维稀疏性, 能较好地提取文本主题粒度的信息, 被广泛用于文本分类[6 ] 、文本生成[7 ] 和推荐系统[8 ] 等。
神经网络为文本向量表示带来了新的方法。词向量也被称为词嵌入(Word Embedding)。Word2Vec[9 ,10 ] 是目前应用最为广泛的词嵌入模型之一。针对特定任务, 研究人员对其进一步优化[11 ,12 ] 。
文本是由词构成的, 在得到词嵌入后, 可以通过一些池化策略得到文本简单的表示, 例如最大化池化、最小化池化以及平均池化[13 ] 。这些池化策略仅仅用到词层面的特征, 而当文本中词的顺序发生变化时, 文本向量保持不变。在统计学习方法中, 研究人员通过n元语法(n-gram)反映词序现象, 并且取得更好的结果。在神经网络学习方法中, 卷积神经网络[14 ] (Convolutional Neural Networks, CNN)在给定位置附近通过定长窗口捕获构成特征[15 ] , 作用与n元语法相仿, 故被称为n元语法探测器。CNN最初用于解决计算机视觉(Computer Vision, CV)问题, 随后CNN及其变种被应用到自然语言处理领域[16 ] , 如句子建模[17 ] 、情感分析[18 ] 等。当整个文本序列信息对任务语义理解重要性较低时, CNN的表现更佳[19 ] 。
NLP面临的关键问题之一是未知语言现象, 而未登录词是一种典型未知语言现象。字(符)级别上的工作很大程度上降低了上述问题的难度。因为可能的字(符)数量远远小于词汇数量。以英文为例, 组成英文单词的字母共有26个, 而英文单词数量有数十万个。故在文本向量中加入字(符)粒度信息也是一个有益的尝试[20 ] 。当前研究主要是针对字母文字(Alphabet), 而汉语与字母文字不同, 是一种语素文字。在汉语字(符)粒度, 研究人员主要采用以下两种方式: 通过拼音将汉字转为字母序列[21 ,22 ] , 即拼音化处理; 将汉语词汇拆分到单字[23 ] 。与后者汉语单字嵌入模型相比, 前者汉字拼音化处理会丢失更多汉字内在的信息。值得注意的是, 在字(符)级别上工作是非常具有挑战性的, 因为字(符)和语法、语义之间的关系较为松散。完全依赖字符效果可能不佳, 故字(符)粒度信息应当作为词粒度信息与主题粒度信息的一个补充。
针对不同粒度信息得到的特征向量之间的融合问题, 当前研究主要采用拼接的方式。这种方法操作简单, 不过隐性上将各种本不处于同一层次的信息当作同一层次的信息处理, 在逻辑上缺少考量, 无法反映出各种层次信息的区别[24 ] ; 同时容易导致最终得到的文本向量维度过高, 模型过拟合, 降低模型的表现。门限循环单元[25 ] (Gated Recurrent Units, GRU)通过更新门将两个向量融合。为融合不同粒度信息得到的特征向量, 本文引入与GRU更新门类似的“融合门”机制。
3 融合多粒度信息的文本向量表示模型
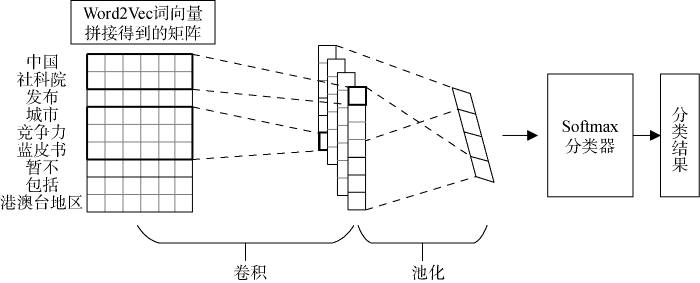
基于词向量与卷积神经网络的文本表示模型大多面向特定任务, 其通过Word2Vec算法或者预训练结果得到文本中词的稠密向量表示, 即词向量。随后将这些词向量按照文本中的顺序拼接起来作为卷积神经网络的输入。经过卷积神经网络的卷积、池化操作后得到文本向量。最后将文本向量转入下游任务, 如情感分类、文本分类等, 结构如图1 所示。
图1
以往统计学习方法需要人类专家设计描述样本的特征, 这个过程被称为“特征工程” (Feature Engineering)。以卷积神经网络为代表的深度学习模型在一定程度上模仿了人类的认知过程, 具有强大的学习能力, 可以自己产生好的特征。研究证明, 基于词向量与卷积神经网络的模型, 即Text-CNN, 取得了具有竞争力的结果, 本文将该模型作为基准(Baseline)。
3.1 建模过程
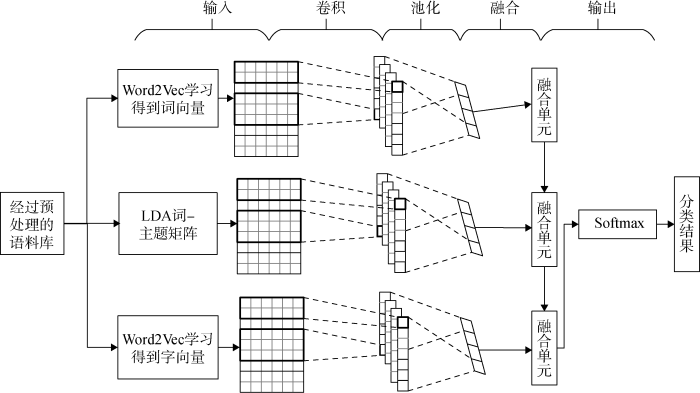
本文模型架构如图2 所示, 具体分为: 输入层、卷积层、池化层、融合层和输出层。
3.2 输入层
利用卷积神经网络学习文本中各个粒度微妙的特征。卷积神经网络接受的输入是矩阵形式, 故需要将非结构化的文本表示为向量矩阵形式。为充分提取文本中的语义信息, 分别从“词”、“主题”和“字”粒度入手。
“词”粒度信息的提取通过Word2Vec实现。Word2Vec通过构建当前词的上下文语境, 将词表示为具有相同维度的低维稠密词向量。将每个词对应的词向量按照文本中的顺序拼接起来得到当前文本的词向量矩阵${{x}_{1:n}}={{[{{x}_{1}},{{x}_{2}},\cdots ,{{x}_{i}},\cdots ,{{x}_{n}}]}^{\text{T}}}\in {{R}^{n\times t}}$, 其中n 表示文本中词的数量, t 表示词向量的维度, xi 表示第i 个词的词向量。
图2
“主题”粒度信息由LDA主题模型提取。LDA建模后会得到一个主题-词矩阵表示主题在各个词上的分布情况。可以将上述矩阵转置得到词-主题矩阵, 该矩阵的每一行表示一个词对不同主题的表示能力。与对词向量的处理方式类似, 将文本中每个词对应的词-主题向量按照文本中的顺序拼接得到文本的词-主题矩阵${{y}_{1:n}}={{[{{y}_{1}},{{y}_{2}},\cdots ,{{y}_{j}},\cdots ,{{y}_{n}}]}^{\text{T}}}\in {{R}^{n\times k}}$, 其中n 是文本中词的数量, k 表示LDA模型超参数之一的主题数量, yj 表示第j 个词的词-主题向量。
“字”粒度信息也是通过Word2Vec提取。通过Word2Vec模型学习得到文本中每个字的字(词)向量, 将文本中每个字所对应的字(词)向量按照顺序拼接起来得到文本的字(词)向量矩阵${{z}_{1:m}}={{[{{z}_{1}},{{z}_{2}},\cdots ,{{z}_{p}},\cdots ,{{z}_{m}}]}^{\text{T}}}\in {{R}^{m\times r}}$, 其中m 是文本中字的数量, r 表示字(词)向量的维度, zp 表示第p 个字的字(词)向量。
3.3 卷积层和池化层
卷积层和池化层是卷积神经网络的重要组成部分。卷积层用于提取局部特征, 而池化层用于得到主要的特征, 减轻过拟合程度, 提高模型的泛化能力。
卷积操作是由过滤器(Filter)完成的。与图像中过滤器二维卷积操作不同, 文本中过滤器是一维卷积。例如文本在输入层被转化为一个$m\times d$的矩阵, 过滤器${{W}_{c}}\in {{R}^{h\times d}}$, h 表示过滤器移动的窗口大小。一个过滤器卷积生成特征向量计算过程如公式(1)所示。
(1) $c=f(conv(X\times {{W}_{c}})+b)$
其中, $f()$表示神经网络中常用的激活函数, 如ReLU, tanh, Iden等, conv 表示卷积过程, b 表示偏置向量。过滤器生成一个特征向量$c{{f}_{i}}\in {{R}^{m-h+1}}$。在对文本的操作中, 通常会设置多个大小不同的窗口, 例如$h=(3,4,5)$, 对于每个不同大小的窗口也可以设置多个过滤器, 用$[c{{f}_{1}},c{{f}_{2}},\cdots ,c{{f}_{l}}]$表示。对每一组特征向量进行池化操作得到最具代表性的特征。本文采用最大化池化策略, 即从每一个特征向量中选取最大的元素作为该特征向量的表示, 如公式(2)所示。
(2) $cf=[\max \{c{{f}_{1}}\},\max \{c{{f}_{2}}\},\cdots ,\max \{c{{f}_{l}}\}]$
将得到的三个表示不同粒度信息的特征向量传入融合层。
3.4 融合层和输出层
融合层将三个表示不同粒度信息的特征向量进行融合, 降低最终文本向量的维度, 受GRU以及文献[24 ]的启发, 本文计算融合门如公式(3)-公式(6)所示。
(3) ${{z}_{t}}=\sigma ({{W}_{z}}\cdot [{{h}_{t-1}},x_{t}^{*}])$
(4) ${{r}_{t}}=\sigma ({{W}_{r}}\cdot [{{h}_{t-1}},x_{t}^{*}])$
(5) ${{\tilde{h}}_{t}}=\tanh (W\cdot [{{r}_{t}}\times {{h}_{t-1}},{{x}_{t}}])$
(6) ${{h}_{t}}=(1-{{z}_{t}})\times {{h}_{t-1}}+{{z}_{t}}\times {{\tilde{h}}_{t}}$
该融合门将${{h}_{t-1}}$与${{x}_{t}}$融合为${{h}_{t}}$。其中, ${{z}_{t}}$是运算得到的元素值在0-1之间的向量, 用来决定信息应该融合的程度; $x_{t}^{*}$是${{x}_{t}}$经过投影变换后得到的与${{h}_{t-1}}$维度相同的向量。
输出层是一个Softmax分类器, 用来得到对应文本的分类结果, 计算方式如公式(7)所示。
(7) $p({{y}_{k}})=\frac{\exp ({{s}_{k}}\times {{v}_{m}}+{{b}_{k}})}{\sum\nolimits_{i=1}^{n}{\exp ({{s}_{i}}\times {{v}_{m}}+{{b}_{i}})}}$
其中, $p({{y}_{k}})$表示该文本属于${{y}_{k}}$的概率, ${{s}_{k}}$表示权重系数, ${{b}_{k}}$表示偏置, ${{v}_{m}}$表示第m 篇文本的最终文本向量。
4 实 验
4.1 实验过程
采用搜狗实验室的全网新闻数据(SogouCA)[26 ] , 这是一个公开易获取的数据集, 可用于文本分类、事件检测跟踪、新词发现、命名实体识别和自动摘要等任务。选取汽车、财经、科技、健康、体育、旅游、教育、招聘、文学和军事10个领域文本, 每个领域500篇文档。数据集经过了常见的文本预处理, 包括分词、去停用词等。其中分词调用“结巴”中文分词[27 ] , 停用词(Stop Word)表是经过中文停用词表、哈尔滨工业大学停用词表、四川大学机器智能实验室停用词库、百度停用词表[28 ] 及网上各种资源集成并去重后得到的。同时使用10折交叉验证(10-Fold Cross-Validation), 训练集和测试集之间彼此不重叠, 不包含重复文本。
实验的评价指标有4个: 准确率(Accuracy)、查准率(Precision)、查全率(Recall)和F1值(F-score)。混淆矩阵(Confusion Matrix)如表1 所示。
真正例指将正例预测为正例, 假反例指将正例预测为反例, 假正例指将反例预测为正例, 真反例指将反例预测为反例。准确率、查准率、查全率以及F1值的计算公式如公式(8)-公式(11)所示。
(2) $Accuracy=\frac{TP+TN}{TP+TN+FP+FN}$
(3) $Precision=\frac{TP}{TP+FP}$
(4) $Recall=\frac{TP}{TP+FN}$
(5) $F-score=\frac{2\times Precision\times Recall}{Precision+Recall}$
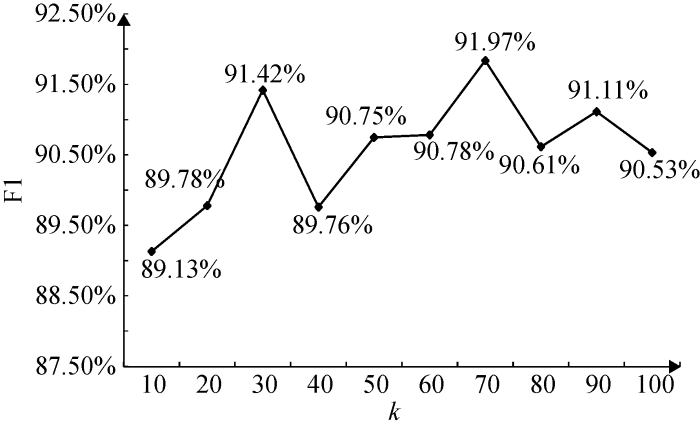
调用Scikit-Learn[29 ] 中的LDA主题模型包提取文本“主题”粒度信息, 根据GibbsLDA++手册[30 ] , 取$\alpha \text{=}0.5$、$\beta \text{=}0.1$, 其中$\alpha $和$\beta $分别是文本-主题分布和主题-词分布的先验超参数。关于LDA主题数量k 的确定, 对不同主题数的LDA-CNN进行实验, 实验结果如图3 所示。根据实验结果, LDA-CNN在主题数为70时F1值最高, 故确定LDA主题模型主题数$k=70$。
图3
使用的词向量通过Gensim[31 ] 对语料库学习得到, 其中词向量的维度为100维。基于TensorFlow[32 ] 搭建卷积神经网络。提取各个粒度信息的卷积神经网络参数如表2 所示。
4.2 实验结果分析
当前对于文本向量的研究主要集中在词粒度和主题粒度, 对于字粒度的研究较少, 且字(符)与语义之间的关系较为松散。为验证字粒度信息对于语义的表示能力, 对基于字向量的卷积神经网络展开实验。与基于词向量和词-主题矩阵的卷积神经网络模型, 即词向量-CNN及LDA-CNN的对比如表3 所示。如无特别说明, 本文实验结果均是5次实验结果的平均值。
其中, 词向量-CNN是本文的基准模型, 该模型也被称为Text-CNN, 将Word2Vec得到的词嵌入按照词在文本中的顺序拼接起来作为卷积神经网络的输入, 在卷积、池化之后得到文本向量, 随后进行Softmax分类。字向量-CNN与词向量-CNN类似, 区别是通过Word2Vec得到字的稠密向量表示, 即字向量。LDA-CNN将LDA模型得到的主题-词矩阵经过转置后得到的词-主题矩阵作为卷积神经网络的输入, 其余操作与词向量-CNN相同。
可以发现, 字向量-CNN表现不如词向量-CNN, 说明字粒度信息对于文本语义信息的表示能力不如词粒度信息。不过, 字向量-CNN仍然取得了较好效果, 这说明将字粒度信息作为文本语义信息的一个补充是合理且可行的。
值得注意的是, 以LDA输出结果作为输入的卷积神经网络(LDA-CNN)在以上三种模型中取得了最好的结果, 这说明在字、词和主题粒度信息中, 主题粒度信息在文本分类任务中的作用更加显著。
在单粒度信息基础上, 对词、字以及主题三种粒度信息两两一组即词粒度和主题粒度、字粒度和主题粒度、词粒度和字粒度进行实验, 实验根据信息融合方式的不同分为两部分: 三种粒度信息两两一组首尾相连得到最终文本向量, 即融合方式为简单拼接; 三种信息两两一组且引入融合门。实验结果如表4 和表5 所示。
结合单粒度信息实验结果, 可以发现三种粒度信息两两一组与单粒度信息相比表现有好有坏。总体而言, 两两一组简单拼接模型表现好于其中较差的单粒度信息模型, 差于表现较好的单粒度信息模型, 例如词向量-CNN表现差于LDA-CNN, 而词-主题简单拼接模型表现好于词向量-CNN, 差于LDA-CNN。对两两一组引入融合门模型而言, 除字-主题外, 其余两两一组引入融合门机制模型表现优于任一单粒度信息模型。
对比表4 和表5 , 可以发现引入融合门机制的模型表现均优于对应拼接模型, 一定程度上说明了融合门机制在融合不同特征向量方面比简单拼接效果更好。另外, 可以得到与4.2 (1)节相似的结论, 即对于文本分类任务, 主题粒度、词粒度、字粒度信息显著性依次递减。
为比较本文提出的融合门机制与简单拼接机制, 对三种粒度信息在不同特征向量融合方式下进行实验, 实验结果如表6 所示。
值得注意的是, 拼接后的效果反而较LDA-CNN有所下降, 原因可能是拼接后得到的文本向量维度过高, 模型陷入过拟合。
从表6 可以发现, 引入融合门机制的模型效果好于引入拼接的模型, 说明融合门机制在不同特征向量融合效果方面较拼接更优。同时本文提出的引入融合门机制的模型效果较基准模型在各项指标上均取得了较大进步。
5 结 语
为提高文本向量对于文本语义的表示能力, 本文在主题粒度信息和词粒度信息基础上引入字粒度信息; 为降低最终文本向量的维度, 提高模型表现, 引入“融合门”机制, 将上述各粒度信息融合得到最终的文本向量。在文本分类任务中, 本文所提模型准确率、查准率、查全率和F1值较基准方法Text-CNN分别提高0.0240, 0.0205, 0.0177, 0.0191。需要指出的是, 本文所提文本向量表示方法不仅可应用于文本分类, 还可应用在自然语言处理其他领域, 如情感分类等, 具有一定的扩展性。
本文主要通过卷积神经网络提取文本中各粒度信息, 尽管卷积神经网络得到的文本向量对词序较为敏感而优于词向量简单池化得到的文本向量, 但是这种对于词序的敏感大多限制在局部, 并没有考虑到更大范围序列。循环神经网络(Recurrent Neural Networks, RNN)使得依赖更长序列的模型成为可能。故如何将循环神经网络应用到文本向量表示是下阶段研究的重点。而且本文所用语料库规模较小, Word2Vec模型的效果也受到影响。
作者贡献声明
聂维民: 提出研究思路, 设计研究方案, 采集、清洗和分析数据, 负责实验, 起草论文;
支撑数据
支撑数据由作者自存储, E-mail: majing5525@126.com。
[1] 聂维民, 陈永洲, 马静. corpus_seg.rar. 语料分词结果.
[2] 聂维民, 陈永洲, 马静. code.rar. 程序源码.
[3] 聂维民, 陈永洲, 马静. result.xlsx. 实验结果.
参考文献
View Option
[1]
宗成庆 . 统计自然语言处理 [M]. 第2版. 北京 : 清华大学出版社 , 2013 : 416 -419 .
[本文引用: 1]
( Zong Chengqing Statistical Natural Language Processing [M]. The 2nd Edition. Beijing : Tsinghua University Press , 2013 : 416 -419 .)
[本文引用: 1]
[2]
芮伟康 . 基于语义的文本向量表示方法研究
[D]. 合肥: 中国科学技术大学 , 2017 .
[本文引用: 1]
( Rui Weikang . A Research on Text Vector Representation Based on Semantics
[D]. Hefei: University of Science and Technology of China , 2017 .)
[本文引用: 1]
[3]
牛力强 . 基于神经网络的文本向量表示与建模研究
[D]. 南京: 南京大学 , 2016 .
[本文引用: 1]
( Niu Liqiang . A Research on Text Vector Representations and Modelling Based on Neural Networks
[D]. Nanjing: Nanjing University , 2016 .)
[本文引用: 1]
[4]
Salton G Wong A Yang C S . A Vector Space Model for Automatic Indexing
[J]. Communications of the ACM , 1975 ,18 (11 ):613 -620 .
[本文引用: 1]
[5]
Blei D M Ng A Y Jordan M I . Latent Dirichlet Allocation
[J]. Journal of Machine Learning Research , 2003 ,3 :993 -1022 .
[本文引用: 1]
[6]
姚全珠 , 宋志理 , 彭程 . 基于LDA模型的文本分类研究
[J]. 计算机工程与应用 , 2011 ,47 (13 ):150 -153 .
[本文引用: 1]
( Yao Quanzhu Song Zhili Peng Cheng . Research on Text Categorization Based on LDA
[J]. Computer Engineering and Applications , 2011 ,47 (13 ):150 -153 .)
[本文引用: 1]
[7]
徐艳华 , 苗雨洁 , 苗琳 , 等 . 基于LDA模型的HSK作文生成
[J]. 数据分析与知识发现 , 2018 ,2 (9 ):80 -87 .
[本文引用: 1]
( Xu Yanhua Miao Yujie Miao Lin , et al . Generating HSK Writing Essays with LDA Model
[J]. Data Analysis and Knowledge Discovery , 2018 ,2 (9 ):80 -87 .)
[本文引用: 1]
[8]
Kim Y Shim K . TWILITE: A Recommendation System for Twitter Using a Probabilistic Model Based on Latent Dirichlet Allocation
[J]. Information Systems , 2014 ,42 :59 -77 .
[本文引用: 1]
[9]
Mikolov T Sutskever I Chen K et al . Distributed Representations of Words and Phrases and Their Compositionality
[C]// Proceedings of the Neural Information Processing Systems 2013 . 2013 .
[本文引用: 1]
[10]
Mikolov T Chen K Corrado G , et al . Efficient Estimation of Word Representations in Vector Space
[OL]. arXiv Preprint, arXiv: 1301.3781 .
[本文引用: 1]
[11]
Tang D Qin B Liu T . Aspect Level Sentiment Classification with Deep Memory Network
[OL]. arXiv Preprint, arXiv: 1605.08900 .
[本文引用: 1]
[12]
杜慧 , 徐学可 , 伍大勇 , 等 . 基于情感词向量的微博情感分类
[J]. 中文信息学报 , 2017 ,31 (3 ):170 -176 .
[本文引用: 1]
( Du Hui Xu Xueke Wu Dayong , et al . A Sentiment Classification Method Based on Sentiment-Specific Word Embedding
[J]. Journal of Chinese Information Processing , 2017 ,31 (3 ):170 -176 .)
[本文引用: 1]
[13]
李心蕾 , 王昊 , 刘小敏 , 等 . 面向微博短文本分类的文本向量化方法比较研究
[J]. 数据分析与知识发现 , 2018 ,2 (8 ):41 -50 .
[本文引用: 1]
( Li Xinlei Wang Hao Liu Xiaomin , et al . Comparing Text Vector Generators for Weibo Short Text Classification
[J]. Data Analysis and Knowledge Discovery , 2018 ,2 (8 ):41 -50 .)
[本文引用: 1]
[14]
LeCun Y Bengio Y . Convolutional Networks for Images, Speech, and Time Series
[J]. The Handbook of Brain Theory and Neural Networks , 1995 : 3361 .
[本文引用: 1]
[15]
Deng L Liu Y . Deep Learning in Natural Language Processing [M]. Singapore : Springer Singapore , 2018 : 226 -229 .
[本文引用: 1]
[16]
Collobert R Weston J Bottou L , et al . Natural Language Processing (Almost) from Scratch
[J]. Journal of Machine Learning Research , 2011 ,12 :2493 -2537 .
[本文引用: 1]
[17]
Lei T Barzilay R Jaakkola T Molding CNNs for Text: Non-linear, Non-consecutive Convolutions
[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal. 2015 .
[本文引用: 1]
[18]
Zhang Y Roller S Wallace B C MGNC-CNN: A Simple Approach to Exploiting Multiple Word Embeddings for Sentence Classification
[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, California, USA. Stroudsburg, Pennsylvania, USA: Association for Computational Linguistics , 2016 : 1522 -1527 .
[本文引用: 1]
[19]
Yin W Kann K Yu M , et al . Comparative Study of CNN and RNN for Natural Language Processing
[OL]. arXiv Preprint, arXiv: 1702.01923 .
[本文引用: 1]
[20]
Dos Santos C Gatti M Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts
[C]// Proceedings of the 25th International Conference on Computational Linguistics, Dublin, Ireland. Dublin, Ireland: Dublin City University and Association for Computational Linguistics , 2014 : 69 -78 .
[本文引用: 1]
[21]
Zhang X Zhao J LeCun Y . Character-Level Convolutional Networks for Text Classification
[C]// Proceedings of the 2015 Neural Information Processing Systems. 2015 .
[本文引用: 1]
[22]
余本功 , 张连彬 . 基于CP-CNN的中文短文本分类研究
[J]. 计算机应用研究 , 2018 ,35 (4 ):1001 -1004 .
[本文引用: 1]
( Yu Bengong Zhang Lianbin . Chinese Short Text Classification Based on CP-CNN
[J]. Application Research of Computers , 2018 ,35 (4 ):1001 -1004 .)
[本文引用: 1]
[23]
Zheng X Chen H Xu T Deep Learning for Chinese Word Segmentation and POS Tagging
[C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, Washington, USA. Stroudsburg, Pennsylvania, USA: Association for Computational Linguistics , 2013 : 647 -657 .
[本文引用: 1]
[24]
王毅 , 谢娟 , 成颖 . 结合LSTM和CNN混合架构的深度神经网络语言模型
[J]. 情报学报 , 2018 ,37 (2 ):194 -205 .
[本文引用: 2]
( Wang Yi Xie Juan Cheng Ying . Deep Neural Networks Language Model Based on CNN and LSTM Hybrid Architecture
[J]. Journal of the China Society for Scientific and Technical Information , 2018 ,37 (2 ):194 -205 .)
[本文引用: 2]
[25]
Cho K Van Merrienboer B Gulcehre C , et al . Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation
[OL]. arXiv Preprint, arXiv: 1406.1078 .
[本文引用: 1]
[26]
Wang C Zhang M Ma S et al . Automatic Online News Issue Construction in Web Environment
[C]// Proceedings of the 17th International Conference on World Wide Web, Beijing, China. New York, USA: Association for Computational Linguistics , 2008 : 457 -466 .
[本文引用: 1]
[27]
“结巴”中文分词: 做最好的Python中文分词组件[EB/OL]. (2017-08-28). [2018-12-25]. https://pypi.org/project/jieba/.
URL
[本文引用: 1]
( “Jieba” Chinese Text Segmentation: Built to be the Best Python Chinese Word Segmentation Module[EB/OL]. (2017 -08-28). [2018-12-25]. https://pypi.org/project/jieba/.)
URL
[本文引用: 1]
[28]
中文数据预处理材料 [EB/OL]. [2018-12-25].https://github.com/foowaa/Chinese_from_dongxiexidian.
URL
[本文引用: 1]
( Chinese Data Preprocessing Material [EB/OL]. [2018-12-25].https://github.com/foowaa/Chinese_from_dongxiexidian.)
URL
[本文引用: 1]
[29]
Pedregosa F Varoquaux G Gramfort A , et al . Scikit-Learn: Machine Learning in Python
[J]. Journal of Machine Learning Research , 2011 ,12 :2825 -2830 .
[本文引用: 1]
[30]
Phan X H Nguyen C T . GibbsLDA++: A C/C++ Implementation of Latent Dirichlet Allocation (LDA)
[EB/OL]. [ 2018 - 12 - 25 ]. http://gibbslda.sourceforge.net/.
URL
[本文引用: 1]
[31]
Řehůřek R Sojka P Software Framework for Topic Modelling with Large Corpora
[C]// Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta. Luxembourg: European Language Resources Association , 2010 : 45 -50 .
[本文引用: 1]
[32]
Abadi M Agarwal A Barham P , et al . TensorFlow: Large-scale Machine Learning on Heterogeneous Systems [EB/OL]. [2018-12-25].https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf.
URL
[本文引用: 1]
1
2013
... 随着移动互联网的发展, 互联网用户每天需要接触和处理大量的文本形式信息, 对文本进行自动化处理可以大大提高用户体验, 进而提高相关企业的营利水平.文本表现为一个由文字和标点符号组成的字符串, 由字或者字符组成词, 由词组成短语, 进而形成句、段、章、篇的结构[1 ] , 是一种非结构化或半结构化的数据组织形式, 因此不能直接被计算机识别, 故需将文本转化为统一的、结构化的形式, 上述转化过程被称为文本表示[2 ] .文本的表示和建模是众多自然语言处理(Natural Language Processing, NLP)任务的基石, 例如文本分类、聚类、摘要、相似性或者相关性估计[3 ] .其中最常见的表示形式是向量. ...
1
2013
... 随着移动互联网的发展, 互联网用户每天需要接触和处理大量的文本形式信息, 对文本进行自动化处理可以大大提高用户体验, 进而提高相关企业的营利水平.文本表现为一个由文字和标点符号组成的字符串, 由字或者字符组成词, 由词组成短语, 进而形成句、段、章、篇的结构[1 ] , 是一种非结构化或半结构化的数据组织形式, 因此不能直接被计算机识别, 故需将文本转化为统一的、结构化的形式, 上述转化过程被称为文本表示[2 ] .文本的表示和建模是众多自然语言处理(Natural Language Processing, NLP)任务的基石, 例如文本分类、聚类、摘要、相似性或者相关性估计[3 ] .其中最常见的表示形式是向量. ...
基于语义的文本向量表示方法研究
1
2017
... 随着移动互联网的发展, 互联网用户每天需要接触和处理大量的文本形式信息, 对文本进行自动化处理可以大大提高用户体验, 进而提高相关企业的营利水平.文本表现为一个由文字和标点符号组成的字符串, 由字或者字符组成词, 由词组成短语, 进而形成句、段、章、篇的结构[1 ] , 是一种非结构化或半结构化的数据组织形式, 因此不能直接被计算机识别, 故需将文本转化为统一的、结构化的形式, 上述转化过程被称为文本表示[2 ] .文本的表示和建模是众多自然语言处理(Natural Language Processing, NLP)任务的基石, 例如文本分类、聚类、摘要、相似性或者相关性估计[3 ] .其中最常见的表示形式是向量. ...
基于语义的文本向量表示方法研究
1
2017
... 随着移动互联网的发展, 互联网用户每天需要接触和处理大量的文本形式信息, 对文本进行自动化处理可以大大提高用户体验, 进而提高相关企业的营利水平.文本表现为一个由文字和标点符号组成的字符串, 由字或者字符组成词, 由词组成短语, 进而形成句、段、章、篇的结构[1 ] , 是一种非结构化或半结构化的数据组织形式, 因此不能直接被计算机识别, 故需将文本转化为统一的、结构化的形式, 上述转化过程被称为文本表示[2 ] .文本的表示和建模是众多自然语言处理(Natural Language Processing, NLP)任务的基石, 例如文本分类、聚类、摘要、相似性或者相关性估计[3 ] .其中最常见的表示形式是向量. ...
基于神经网络的文本向量表示与建模研究
1
2016
... 随着移动互联网的发展, 互联网用户每天需要接触和处理大量的文本形式信息, 对文本进行自动化处理可以大大提高用户体验, 进而提高相关企业的营利水平.文本表现为一个由文字和标点符号组成的字符串, 由字或者字符组成词, 由词组成短语, 进而形成句、段、章、篇的结构[1 ] , 是一种非结构化或半结构化的数据组织形式, 因此不能直接被计算机识别, 故需将文本转化为统一的、结构化的形式, 上述转化过程被称为文本表示[2 ] .文本的表示和建模是众多自然语言处理(Natural Language Processing, NLP)任务的基石, 例如文本分类、聚类、摘要、相似性或者相关性估计[3 ] .其中最常见的表示形式是向量. ...
基于神经网络的文本向量表示与建模研究
1
2016
... 随着移动互联网的发展, 互联网用户每天需要接触和处理大量的文本形式信息, 对文本进行自动化处理可以大大提高用户体验, 进而提高相关企业的营利水平.文本表现为一个由文字和标点符号组成的字符串, 由字或者字符组成词, 由词组成短语, 进而形成句、段、章、篇的结构[1 ] , 是一种非结构化或半结构化的数据组织形式, 因此不能直接被计算机识别, 故需将文本转化为统一的、结构化的形式, 上述转化过程被称为文本表示[2 ] .文本的表示和建模是众多自然语言处理(Natural Language Processing, NLP)任务的基石, 例如文本分类、聚类、摘要、相似性或者相关性估计[3 ] .其中最常见的表示形式是向量. ...
A Vector Space Model for Automatic Indexing
1
1975
... 早期对于文本向量表示的研究主要基于词袋模型[4 ] .词袋模型存在维度灾难、无法保留词序信息、语义鸿沟等问题, 故效果受限.后来LDA主题模型[5 ] 将文本表示为隐含主题的概率分布, 极大改善了文本高维稀疏性, 能较好地提取文本主题粒度的信息, 被广泛用于文本分类[6 ] 、文本生成[7 ] 和推荐系统[8 ] 等. ...
Latent Dirichlet Allocation
1
2003
... 早期对于文本向量表示的研究主要基于词袋模型[4 ] .词袋模型存在维度灾难、无法保留词序信息、语义鸿沟等问题, 故效果受限.后来LDA主题模型[5 ] 将文本表示为隐含主题的概率分布, 极大改善了文本高维稀疏性, 能较好地提取文本主题粒度的信息, 被广泛用于文本分类[6 ] 、文本生成[7 ] 和推荐系统[8 ] 等. ...
基于LDA模型的文本分类研究
1
2011
... 早期对于文本向量表示的研究主要基于词袋模型[4 ] .词袋模型存在维度灾难、无法保留词序信息、语义鸿沟等问题, 故效果受限.后来LDA主题模型[5 ] 将文本表示为隐含主题的概率分布, 极大改善了文本高维稀疏性, 能较好地提取文本主题粒度的信息, 被广泛用于文本分类[6 ] 、文本生成[7 ] 和推荐系统[8 ] 等. ...
基于LDA模型的文本分类研究
1
2011
... 早期对于文本向量表示的研究主要基于词袋模型[4 ] .词袋模型存在维度灾难、无法保留词序信息、语义鸿沟等问题, 故效果受限.后来LDA主题模型[5 ] 将文本表示为隐含主题的概率分布, 极大改善了文本高维稀疏性, 能较好地提取文本主题粒度的信息, 被广泛用于文本分类[6 ] 、文本生成[7 ] 和推荐系统[8 ] 等. ...
基于LDA模型的HSK作文生成
1
2018
... 早期对于文本向量表示的研究主要基于词袋模型[4 ] .词袋模型存在维度灾难、无法保留词序信息、语义鸿沟等问题, 故效果受限.后来LDA主题模型[5 ] 将文本表示为隐含主题的概率分布, 极大改善了文本高维稀疏性, 能较好地提取文本主题粒度的信息, 被广泛用于文本分类[6 ] 、文本生成[7 ] 和推荐系统[8 ] 等. ...
基于LDA模型的HSK作文生成
1
2018
... 早期对于文本向量表示的研究主要基于词袋模型[4 ] .词袋模型存在维度灾难、无法保留词序信息、语义鸿沟等问题, 故效果受限.后来LDA主题模型[5 ] 将文本表示为隐含主题的概率分布, 极大改善了文本高维稀疏性, 能较好地提取文本主题粒度的信息, 被广泛用于文本分类[6 ] 、文本生成[7 ] 和推荐系统[8 ] 等. ...
TWILITE: A Recommendation System for Twitter Using a Probabilistic Model Based on Latent Dirichlet Allocation
1
2014
... 早期对于文本向量表示的研究主要基于词袋模型[4 ] .词袋模型存在维度灾难、无法保留词序信息、语义鸿沟等问题, 故效果受限.后来LDA主题模型[5 ] 将文本表示为隐含主题的概率分布, 极大改善了文本高维稀疏性, 能较好地提取文本主题粒度的信息, 被广泛用于文本分类[6 ] 、文本生成[7 ] 和推荐系统[8 ] 等. ...
Distributed Representations of Words and Phrases and Their Compositionality
1
2013
... 神经网络为文本向量表示带来了新的方法.词向量也被称为词嵌入(Word Embedding).Word2Vec[9 ,10 ] 是目前应用最为广泛的词嵌入模型之一.针对特定任务, 研究人员对其进一步优化[11 ,12 ] . ...
Efficient Estimation of Word Representations in Vector Space
1
... 神经网络为文本向量表示带来了新的方法.词向量也被称为词嵌入(Word Embedding).Word2Vec[9 ,10 ] 是目前应用最为广泛的词嵌入模型之一.针对特定任务, 研究人员对其进一步优化[11 ,12 ] . ...
Aspect Level Sentiment Classification with Deep Memory Network
1
... 神经网络为文本向量表示带来了新的方法.词向量也被称为词嵌入(Word Embedding).Word2Vec[9 ,10 ] 是目前应用最为广泛的词嵌入模型之一.针对特定任务, 研究人员对其进一步优化[11 ,12 ] . ...
基于情感词向量的微博情感分类
1
2017
... 神经网络为文本向量表示带来了新的方法.词向量也被称为词嵌入(Word Embedding).Word2Vec[9 ,10 ] 是目前应用最为广泛的词嵌入模型之一.针对特定任务, 研究人员对其进一步优化[11 ,12 ] . ...
基于情感词向量的微博情感分类
1
2017
... 神经网络为文本向量表示带来了新的方法.词向量也被称为词嵌入(Word Embedding).Word2Vec[9 ,10 ] 是目前应用最为广泛的词嵌入模型之一.针对特定任务, 研究人员对其进一步优化[11 ,12 ] . ...
面向微博短文本分类的文本向量化方法比较研究
1
2018
... 文本是由词构成的, 在得到词嵌入后, 可以通过一些池化策略得到文本简单的表示, 例如最大化池化、最小化池化以及平均池化[13 ] .这些池化策略仅仅用到词层面的特征, 而当文本中词的顺序发生变化时, 文本向量保持不变.在统计学习方法中, 研究人员通过n元语法(n-gram)反映词序现象, 并且取得更好的结果.在神经网络学习方法中, 卷积神经网络[14 ] (Convolutional Neural Networks, CNN)在给定位置附近通过定长窗口捕获构成特征[15 ] , 作用与n元语法相仿, 故被称为n元语法探测器.CNN最初用于解决计算机视觉(Computer Vision, CV)问题, 随后CNN及其变种被应用到自然语言处理领域[16 ] , 如句子建模[17 ] 、情感分析[18 ] 等.当整个文本序列信息对任务语义理解重要性较低时, CNN的表现更佳[19 ] . ...
面向微博短文本分类的文本向量化方法比较研究
1
2018
... 文本是由词构成的, 在得到词嵌入后, 可以通过一些池化策略得到文本简单的表示, 例如最大化池化、最小化池化以及平均池化[13 ] .这些池化策略仅仅用到词层面的特征, 而当文本中词的顺序发生变化时, 文本向量保持不变.在统计学习方法中, 研究人员通过n元语法(n-gram)反映词序现象, 并且取得更好的结果.在神经网络学习方法中, 卷积神经网络[14 ] (Convolutional Neural Networks, CNN)在给定位置附近通过定长窗口捕获构成特征[15 ] , 作用与n元语法相仿, 故被称为n元语法探测器.CNN最初用于解决计算机视觉(Computer Vision, CV)问题, 随后CNN及其变种被应用到自然语言处理领域[16 ] , 如句子建模[17 ] 、情感分析[18 ] 等.当整个文本序列信息对任务语义理解重要性较低时, CNN的表现更佳[19 ] . ...
Convolutional Networks for Images, Speech, and Time Series
1
1995
... 文本是由词构成的, 在得到词嵌入后, 可以通过一些池化策略得到文本简单的表示, 例如最大化池化、最小化池化以及平均池化[13 ] .这些池化策略仅仅用到词层面的特征, 而当文本中词的顺序发生变化时, 文本向量保持不变.在统计学习方法中, 研究人员通过n元语法(n-gram)反映词序现象, 并且取得更好的结果.在神经网络学习方法中, 卷积神经网络[14 ] (Convolutional Neural Networks, CNN)在给定位置附近通过定长窗口捕获构成特征[15 ] , 作用与n元语法相仿, 故被称为n元语法探测器.CNN最初用于解决计算机视觉(Computer Vision, CV)问题, 随后CNN及其变种被应用到自然语言处理领域[16 ] , 如句子建模[17 ] 、情感分析[18 ] 等.当整个文本序列信息对任务语义理解重要性较低时, CNN的表现更佳[19 ] . ...
1
2018
... 文本是由词构成的, 在得到词嵌入后, 可以通过一些池化策略得到文本简单的表示, 例如最大化池化、最小化池化以及平均池化[13 ] .这些池化策略仅仅用到词层面的特征, 而当文本中词的顺序发生变化时, 文本向量保持不变.在统计学习方法中, 研究人员通过n元语法(n-gram)反映词序现象, 并且取得更好的结果.在神经网络学习方法中, 卷积神经网络[14 ] (Convolutional Neural Networks, CNN)在给定位置附近通过定长窗口捕获构成特征[15 ] , 作用与n元语法相仿, 故被称为n元语法探测器.CNN最初用于解决计算机视觉(Computer Vision, CV)问题, 随后CNN及其变种被应用到自然语言处理领域[16 ] , 如句子建模[17 ] 、情感分析[18 ] 等.当整个文本序列信息对任务语义理解重要性较低时, CNN的表现更佳[19 ] . ...
Natural Language Processing (Almost) from Scratch
1
2011
... 文本是由词构成的, 在得到词嵌入后, 可以通过一些池化策略得到文本简单的表示, 例如最大化池化、最小化池化以及平均池化[13 ] .这些池化策略仅仅用到词层面的特征, 而当文本中词的顺序发生变化时, 文本向量保持不变.在统计学习方法中, 研究人员通过n元语法(n-gram)反映词序现象, 并且取得更好的结果.在神经网络学习方法中, 卷积神经网络[14 ] (Convolutional Neural Networks, CNN)在给定位置附近通过定长窗口捕获构成特征[15 ] , 作用与n元语法相仿, 故被称为n元语法探测器.CNN最初用于解决计算机视觉(Computer Vision, CV)问题, 随后CNN及其变种被应用到自然语言处理领域[16 ] , 如句子建模[17 ] 、情感分析[18 ] 等.当整个文本序列信息对任务语义理解重要性较低时, CNN的表现更佳[19 ] . ...
Molding CNNs for Text: Non-linear, Non-consecutive Convolutions
1
2015
... 文本是由词构成的, 在得到词嵌入后, 可以通过一些池化策略得到文本简单的表示, 例如最大化池化、最小化池化以及平均池化[13 ] .这些池化策略仅仅用到词层面的特征, 而当文本中词的顺序发生变化时, 文本向量保持不变.在统计学习方法中, 研究人员通过n元语法(n-gram)反映词序现象, 并且取得更好的结果.在神经网络学习方法中, 卷积神经网络[14 ] (Convolutional Neural Networks, CNN)在给定位置附近通过定长窗口捕获构成特征[15 ] , 作用与n元语法相仿, 故被称为n元语法探测器.CNN最初用于解决计算机视觉(Computer Vision, CV)问题, 随后CNN及其变种被应用到自然语言处理领域[16 ] , 如句子建模[17 ] 、情感分析[18 ] 等.当整个文本序列信息对任务语义理解重要性较低时, CNN的表现更佳[19 ] . ...
MGNC-CNN: A Simple Approach to Exploiting Multiple Word Embeddings for Sentence Classification
1
2016
... 文本是由词构成的, 在得到词嵌入后, 可以通过一些池化策略得到文本简单的表示, 例如最大化池化、最小化池化以及平均池化[13 ] .这些池化策略仅仅用到词层面的特征, 而当文本中词的顺序发生变化时, 文本向量保持不变.在统计学习方法中, 研究人员通过n元语法(n-gram)反映词序现象, 并且取得更好的结果.在神经网络学习方法中, 卷积神经网络[14 ] (Convolutional Neural Networks, CNN)在给定位置附近通过定长窗口捕获构成特征[15 ] , 作用与n元语法相仿, 故被称为n元语法探测器.CNN最初用于解决计算机视觉(Computer Vision, CV)问题, 随后CNN及其变种被应用到自然语言处理领域[16 ] , 如句子建模[17 ] 、情感分析[18 ] 等.当整个文本序列信息对任务语义理解重要性较低时, CNN的表现更佳[19 ] . ...
Comparative Study of CNN and RNN for Natural Language Processing
1
... 文本是由词构成的, 在得到词嵌入后, 可以通过一些池化策略得到文本简单的表示, 例如最大化池化、最小化池化以及平均池化[13 ] .这些池化策略仅仅用到词层面的特征, 而当文本中词的顺序发生变化时, 文本向量保持不变.在统计学习方法中, 研究人员通过n元语法(n-gram)反映词序现象, 并且取得更好的结果.在神经网络学习方法中, 卷积神经网络[14 ] (Convolutional Neural Networks, CNN)在给定位置附近通过定长窗口捕获构成特征[15 ] , 作用与n元语法相仿, 故被称为n元语法探测器.CNN最初用于解决计算机视觉(Computer Vision, CV)问题, 随后CNN及其变种被应用到自然语言处理领域[16 ] , 如句子建模[17 ] 、情感分析[18 ] 等.当整个文本序列信息对任务语义理解重要性较低时, CNN的表现更佳[19 ] . ...
Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts
1
2014
... NLP面临的关键问题之一是未知语言现象, 而未登录词是一种典型未知语言现象.字(符)级别上的工作很大程度上降低了上述问题的难度.因为可能的字(符)数量远远小于词汇数量.以英文为例, 组成英文单词的字母共有26个, 而英文单词数量有数十万个.故在文本向量中加入字(符)粒度信息也是一个有益的尝试[20 ] .当前研究主要是针对字母文字(Alphabet), 而汉语与字母文字不同, 是一种语素文字.在汉语字(符)粒度, 研究人员主要采用以下两种方式: 通过拼音将汉字转为字母序列[21 ,22 ] , 即拼音化处理; 将汉语词汇拆分到单字[23 ] .与后者汉语单字嵌入模型相比, 前者汉字拼音化处理会丢失更多汉字内在的信息.值得注意的是, 在字(符)级别上工作是非常具有挑战性的, 因为字(符)和语法、语义之间的关系较为松散.完全依赖字符效果可能不佳, 故字(符)粒度信息应当作为词粒度信息与主题粒度信息的一个补充. ...
Character-Level Convolutional Networks for Text Classification
1
2015
... NLP面临的关键问题之一是未知语言现象, 而未登录词是一种典型未知语言现象.字(符)级别上的工作很大程度上降低了上述问题的难度.因为可能的字(符)数量远远小于词汇数量.以英文为例, 组成英文单词的字母共有26个, 而英文单词数量有数十万个.故在文本向量中加入字(符)粒度信息也是一个有益的尝试[20 ] .当前研究主要是针对字母文字(Alphabet), 而汉语与字母文字不同, 是一种语素文字.在汉语字(符)粒度, 研究人员主要采用以下两种方式: 通过拼音将汉字转为字母序列[21 ,22 ] , 即拼音化处理; 将汉语词汇拆分到单字[23 ] .与后者汉语单字嵌入模型相比, 前者汉字拼音化处理会丢失更多汉字内在的信息.值得注意的是, 在字(符)级别上工作是非常具有挑战性的, 因为字(符)和语法、语义之间的关系较为松散.完全依赖字符效果可能不佳, 故字(符)粒度信息应当作为词粒度信息与主题粒度信息的一个补充. ...
基于CP-CNN的中文短文本分类研究
1
2018
... NLP面临的关键问题之一是未知语言现象, 而未登录词是一种典型未知语言现象.字(符)级别上的工作很大程度上降低了上述问题的难度.因为可能的字(符)数量远远小于词汇数量.以英文为例, 组成英文单词的字母共有26个, 而英文单词数量有数十万个.故在文本向量中加入字(符)粒度信息也是一个有益的尝试[20 ] .当前研究主要是针对字母文字(Alphabet), 而汉语与字母文字不同, 是一种语素文字.在汉语字(符)粒度, 研究人员主要采用以下两种方式: 通过拼音将汉字转为字母序列[21 ,22 ] , 即拼音化处理; 将汉语词汇拆分到单字[23 ] .与后者汉语单字嵌入模型相比, 前者汉字拼音化处理会丢失更多汉字内在的信息.值得注意的是, 在字(符)级别上工作是非常具有挑战性的, 因为字(符)和语法、语义之间的关系较为松散.完全依赖字符效果可能不佳, 故字(符)粒度信息应当作为词粒度信息与主题粒度信息的一个补充. ...
基于CP-CNN的中文短文本分类研究
1
2018
... NLP面临的关键问题之一是未知语言现象, 而未登录词是一种典型未知语言现象.字(符)级别上的工作很大程度上降低了上述问题的难度.因为可能的字(符)数量远远小于词汇数量.以英文为例, 组成英文单词的字母共有26个, 而英文单词数量有数十万个.故在文本向量中加入字(符)粒度信息也是一个有益的尝试[20 ] .当前研究主要是针对字母文字(Alphabet), 而汉语与字母文字不同, 是一种语素文字.在汉语字(符)粒度, 研究人员主要采用以下两种方式: 通过拼音将汉字转为字母序列[21 ,22 ] , 即拼音化处理; 将汉语词汇拆分到单字[23 ] .与后者汉语单字嵌入模型相比, 前者汉字拼音化处理会丢失更多汉字内在的信息.值得注意的是, 在字(符)级别上工作是非常具有挑战性的, 因为字(符)和语法、语义之间的关系较为松散.完全依赖字符效果可能不佳, 故字(符)粒度信息应当作为词粒度信息与主题粒度信息的一个补充. ...
Deep Learning for Chinese Word Segmentation and POS Tagging
1
2013
... NLP面临的关键问题之一是未知语言现象, 而未登录词是一种典型未知语言现象.字(符)级别上的工作很大程度上降低了上述问题的难度.因为可能的字(符)数量远远小于词汇数量.以英文为例, 组成英文单词的字母共有26个, 而英文单词数量有数十万个.故在文本向量中加入字(符)粒度信息也是一个有益的尝试[20 ] .当前研究主要是针对字母文字(Alphabet), 而汉语与字母文字不同, 是一种语素文字.在汉语字(符)粒度, 研究人员主要采用以下两种方式: 通过拼音将汉字转为字母序列[21 ,22 ] , 即拼音化处理; 将汉语词汇拆分到单字[23 ] .与后者汉语单字嵌入模型相比, 前者汉字拼音化处理会丢失更多汉字内在的信息.值得注意的是, 在字(符)级别上工作是非常具有挑战性的, 因为字(符)和语法、语义之间的关系较为松散.完全依赖字符效果可能不佳, 故字(符)粒度信息应当作为词粒度信息与主题粒度信息的一个补充. ...
结合LSTM和CNN混合架构的深度神经网络语言模型
2
2018
... 针对不同粒度信息得到的特征向量之间的融合问题, 当前研究主要采用拼接的方式.这种方法操作简单, 不过隐性上将各种本不处于同一层次的信息当作同一层次的信息处理, 在逻辑上缺少考量, 无法反映出各种层次信息的区别[24 ] ; 同时容易导致最终得到的文本向量维度过高, 模型过拟合, 降低模型的表现.门限循环单元[25 ] (Gated Recurrent Units, GRU)通过更新门将两个向量融合.为融合不同粒度信息得到的特征向量, 本文引入与GRU更新门类似的“融合门”机制. ...
... 融合层将三个表示不同粒度信息的特征向量进行融合, 降低最终文本向量的维度, 受GRU以及文献[24 ]的启发, 本文计算融合门如公式(3)-公式(6)所示. ...
结合LSTM和CNN混合架构的深度神经网络语言模型
2
2018
... 针对不同粒度信息得到的特征向量之间的融合问题, 当前研究主要采用拼接的方式.这种方法操作简单, 不过隐性上将各种本不处于同一层次的信息当作同一层次的信息处理, 在逻辑上缺少考量, 无法反映出各种层次信息的区别[24 ] ; 同时容易导致最终得到的文本向量维度过高, 模型过拟合, 降低模型的表现.门限循环单元[25 ] (Gated Recurrent Units, GRU)通过更新门将两个向量融合.为融合不同粒度信息得到的特征向量, 本文引入与GRU更新门类似的“融合门”机制. ...
... 融合层将三个表示不同粒度信息的特征向量进行融合, 降低最终文本向量的维度, 受GRU以及文献[24 ]的启发, 本文计算融合门如公式(3)-公式(6)所示. ...
Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation
1
... 针对不同粒度信息得到的特征向量之间的融合问题, 当前研究主要采用拼接的方式.这种方法操作简单, 不过隐性上将各种本不处于同一层次的信息当作同一层次的信息处理, 在逻辑上缺少考量, 无法反映出各种层次信息的区别[24 ] ; 同时容易导致最终得到的文本向量维度过高, 模型过拟合, 降低模型的表现.门限循环单元[25 ] (Gated Recurrent Units, GRU)通过更新门将两个向量融合.为融合不同粒度信息得到的特征向量, 本文引入与GRU更新门类似的“融合门”机制. ...
Automatic Online News Issue Construction in Web Environment
1
2008
... 采用搜狗实验室的全网新闻数据(SogouCA)[26 ] , 这是一个公开易获取的数据集, 可用于文本分类、事件检测跟踪、新词发现、命名实体识别和自动摘要等任务.选取汽车、财经、科技、健康、体育、旅游、教育、招聘、文学和军事10个领域文本, 每个领域500篇文档.数据集经过了常见的文本预处理, 包括分词、去停用词等.其中分词调用“结巴”中文分词[27 ] , 停用词(Stop Word)表是经过中文停用词表、哈尔滨工业大学停用词表、四川大学机器智能实验室停用词库、百度停用词表[28 ] 及网上各种资源集成并去重后得到的.同时使用10折交叉验证(10-Fold Cross-Validation), 训练集和测试集之间彼此不重叠, 不包含重复文本. ...
1
2017
... 采用搜狗实验室的全网新闻数据(SogouCA)[26 ] , 这是一个公开易获取的数据集, 可用于文本分类、事件检测跟踪、新词发现、命名实体识别和自动摘要等任务.选取汽车、财经、科技、健康、体育、旅游、教育、招聘、文学和军事10个领域文本, 每个领域500篇文档.数据集经过了常见的文本预处理, 包括分词、去停用词等.其中分词调用“结巴”中文分词[27 ] , 停用词(Stop Word)表是经过中文停用词表、哈尔滨工业大学停用词表、四川大学机器智能实验室停用词库、百度停用词表[28 ] 及网上各种资源集成并去重后得到的.同时使用10折交叉验证(10-Fold Cross-Validation), 训练集和测试集之间彼此不重叠, 不包含重复文本. ...
1
2017
... 采用搜狗实验室的全网新闻数据(SogouCA)[26 ] , 这是一个公开易获取的数据集, 可用于文本分类、事件检测跟踪、新词发现、命名实体识别和自动摘要等任务.选取汽车、财经、科技、健康、体育、旅游、教育、招聘、文学和军事10个领域文本, 每个领域500篇文档.数据集经过了常见的文本预处理, 包括分词、去停用词等.其中分词调用“结巴”中文分词[27 ] , 停用词(Stop Word)表是经过中文停用词表、哈尔滨工业大学停用词表、四川大学机器智能实验室停用词库、百度停用词表[28 ] 及网上各种资源集成并去重后得到的.同时使用10折交叉验证(10-Fold Cross-Validation), 训练集和测试集之间彼此不重叠, 不包含重复文本. ...
1
... 采用搜狗实验室的全网新闻数据(SogouCA)[26 ] , 这是一个公开易获取的数据集, 可用于文本分类、事件检测跟踪、新词发现、命名实体识别和自动摘要等任务.选取汽车、财经、科技、健康、体育、旅游、教育、招聘、文学和军事10个领域文本, 每个领域500篇文档.数据集经过了常见的文本预处理, 包括分词、去停用词等.其中分词调用“结巴”中文分词[27 ] , 停用词(Stop Word)表是经过中文停用词表、哈尔滨工业大学停用词表、四川大学机器智能实验室停用词库、百度停用词表[28 ] 及网上各种资源集成并去重后得到的.同时使用10折交叉验证(10-Fold Cross-Validation), 训练集和测试集之间彼此不重叠, 不包含重复文本. ...
1
... 采用搜狗实验室的全网新闻数据(SogouCA)[26 ] , 这是一个公开易获取的数据集, 可用于文本分类、事件检测跟踪、新词发现、命名实体识别和自动摘要等任务.选取汽车、财经、科技、健康、体育、旅游、教育、招聘、文学和军事10个领域文本, 每个领域500篇文档.数据集经过了常见的文本预处理, 包括分词、去停用词等.其中分词调用“结巴”中文分词[27 ] , 停用词(Stop Word)表是经过中文停用词表、哈尔滨工业大学停用词表、四川大学机器智能实验室停用词库、百度停用词表[28 ] 及网上各种资源集成并去重后得到的.同时使用10折交叉验证(10-Fold Cross-Validation), 训练集和测试集之间彼此不重叠, 不包含重复文本. ...
Scikit-Learn: Machine Learning in Python
1
2011
... 调用Scikit-Learn[29 ] 中的LDA主题模型包提取文本“主题”粒度信息, 根据GibbsLDA++手册[30 ] , 取$\alpha \text{=}0.5$、$\beta \text{=}0.1$, 其中$\alpha $和$\beta $分别是文本-主题分布和主题-词分布的先验超参数.关于LDA主题数量k 的确定, 对不同主题数的LDA-CNN进行实验, 实验结果如图3 所示.根据实验结果, LDA-CNN在主题数为70时F1值最高, 故确定LDA主题模型主题数$k=70$. ...
GibbsLDA++: A C/C++ Implementation of Latent Dirichlet Allocation (LDA)
1
2018
... 调用Scikit-Learn[29 ] 中的LDA主题模型包提取文本“主题”粒度信息, 根据GibbsLDA++手册[30 ] , 取$\alpha \text{=}0.5$、$\beta \text{=}0.1$, 其中$\alpha $和$\beta $分别是文本-主题分布和主题-词分布的先验超参数.关于LDA主题数量k 的确定, 对不同主题数的LDA-CNN进行实验, 实验结果如图3 所示.根据实验结果, LDA-CNN在主题数为70时F1值最高, 故确定LDA主题模型主题数$k=70$. ...
Software Framework for Topic Modelling with Large Corpora
1
2010
... 使用的词向量通过Gensim[31 ] 对语料库学习得到, 其中词向量的维度为100维.基于TensorFlow[32 ] 搭建卷积神经网络.提取各个粒度信息的卷积神经网络参数如表2 所示. ...
1
... 使用的词向量通过Gensim[31 ] 对语料库学习得到, 其中词向量的维度为100维.基于TensorFlow[32 ] 搭建卷积神经网络.提取各个粒度信息的卷积神经网络参数如表2 所示. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}