1 引 言
作者重名消歧是指针对现实中的作者重名(即作者名不能唯一标识一个真实作者)问题,将来自于不同领域的多个同名作者文献加以自动化区分的过程,在知识网络研究和文献信息检索等任务中具有重要作用。知识网络研究方面,作者重名消歧对于准确地构建科研合作网络和引文推荐网络、降低网络节点的噪声、改进相关模型的效果具有重要促进作用;文献信息检索方面,尽可能使文献按照不同的真实作者进一步区分,能够有效减少检索结果的不确定性与冗余性,使系统更好地辅助研究者,提高科研活动的效率。在上述背景下,研究者围绕作者重名消歧开展了若干研究,并取得了一些成果,但仍然存在不足。从数据上来看,现有研究多集中在个人档案、新闻以及专利等方面的作者重名消歧上,对于科技文献作者重名消歧的研究相对较少;从方法上来看,现有研究多数通过定义各种规则提取作者实体的特征(如作者的个人信息等),这种以特征工程为主的方式需要较多人工参与,实现过程繁琐,且无法充分利用实体关系信息;从消歧模型上来看,现有研究较多地集中在监督学习模型上,对于无监督学习的研究相对较少。
近年来,网络表示学习作为利用机器学习手段的自动特征提取方式,得到了广泛应用。不同于人工建立特征,网络表示学习方法将网络节点投影到低维连续的特征空间,在有效保留网络关系信息的同时降低了时间与空间复杂度。对于文献系统中的作者重名消歧问题,可通过作者、文献以及作者与文献之间的联系建立网络,适合使用网络表示学习来建立作者与文献的特征,以改善消歧效果。鉴于此,本文使用网络表示学习方法,根据合作关系建立作者网络、文献网络以及作者-文献网络,在此基础上学习作者与文献特征,使用聚类算法按真实作者划分文献,完成科研合作网络中的作者重名消歧任务。
2 研究现状
2.1 作者重名消歧
针对作者重名消歧问题,依据研究情境及方法的不同,可分为基于内容信息的研究以及基于网络的研究两方面。前者通过对比实体自身内容信息(文本或其他元数据)的相似性或差异性来消除歧义;后者通过实体间的关系建立网络并提取特征,结合机器学习模型消除歧义。
在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上。例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%。刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体。周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%。郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%。此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型。例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%。Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%。基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境。
在基于网络的研究中,Hermansson等[9 ] 提出基于图核的方法,通过捕捉节点间局部邻居结构的相似性,使用支持向量机对节点进行分类,准确率达60%-80%。Saha等[10 ] 提出利用节点周围带时间戳的网络结构的无监督重名消歧方法,AUC值达80%以上。基于网络的方法通常利用网络结构信息作为特征,仅仅将文献或作者视作网络中的节点,而节点特征的建立只依据节点之间的关系,很少涉及到节点内部的属性,因此推广到其他种类、其他领域的数据相对容易。但这类研究成果相对较少,且研究重心多集中于机器学习模型而不是网络表示学习方法。
2.2 网络表示学习
传统的网络表示一般使用维数较多的稀疏向量,但是高维向量会使用较多的存储空间,运算时也需要更多的运行时间。为解决上述问题,研究者尝试通过网络表示学习为节点获取能够保留网络信息的低维稠密向量表示[11 ] 。目前研究主要分为不考虑节点自身信息和考虑节点自身信息两方面。
(1)在不考虑节点自身信息的研究中,随机游走采样节点的方法最具有代表性。例如,Perozzi等[12 ] 提出DeepWalk算法,使用随机游走采集节点样本序列,并首次将语言建模的思想引入到网络表示学习中,将节点序列视作词序列,进而将用于词表示的Skip-gram模型[13 ,14 ] 用于学习网络表示。Grover等[15 ] 提出Node2Vec算法,该算法对DeepWalk方法进行改进,具体的处理是改变采集随机游走序列的方式。该算法丰富了节点相似性的定义,即同质性和结构相似性;然后设计对应的带偏好的随机游走过程实现节点采样,这使得该算法可以更全面地捕捉节点之间的关系。陈丽等[16 ] 在DeepWalk的基础上,对节点与边的表示学习加以区分,提出基于边采样的网络表示学习模型。除了使用随机游走采样节点的方法,也有直接采样节点对的方法。例如,Tang等[17 ] 提出LINE方法,不仅考虑由节点链接所代表的一阶相似度,还考虑了由于节点之间拥有共同邻居而定义的二阶相似度,对拥有链接的节点对,以最大化这两种相似度进行损失函数建模并优化。Wang等[18 ] 提出SDNE方法,首次真正地将深度学习模型应用到表示学习中,该方法选择的相似度与LINE方法一样,也是一阶与二阶相似度,模型由监督部分(基于拉普拉斯特征映射)与无监督部分(基于深度自编码器)组成,分别负责学习一阶与二阶相似度并生成节点向量表示。
(2)在考虑节点自身信息的研究中,Yang等[19 ] 提出的TADW将DeepWalk中的随机游走过程转化为矩阵分解形式,再利用矩阵乘法将文本特征融入到该过程中以学习保留文本信息的节点向量表示。Tu等[20 ] 提出的CANE则在学习节点结构表示的同时,利用带有注意力机制的卷积神经网络学习节点文本表示。此外,刘正铭等[21 ] 建立神经网络,并以神经网络中参数共享的方式融合节点结构表示和节点文本表示的学习。
值得说明的是,当前网络表示学习的相关研究较多地集中在同构网络数据(网络中的节点和边为单一类型)上。而事实上,在作者重名消歧等相关任务中,异构网络数据(网络中的节点和边并不是单一类型,而是对多种类型现实实体的抽象)更具有代表性。例如,在作者-文献网络中,不仅包含作者节点,也包含文献节点;对应地,作者节点与文献节点间的边代表二者间的著作关系。如何针对异构网络进行表示学习,从而解决文献数据中的作者重名消歧问题成为当前研究所面临的新挑战。鉴于此,本文在探究异构网络情境下网络表示学习的基础上,通过实证研究检验其在作者重名消歧任务中的效果。
3 研究设计
3.1 问题定义
本文基于网络表示学习方法探究作者重名消歧问题,即将一组由于作者同名而被错误聚合在一起(但实际上是由不同现实作者完成)的文献进行合理的网络特征表示,然后通过合适的聚类器将文献重新划分,并尽可能使重新划分后的每一组文献都来自于唯一现实作者。
3.2 研究方法
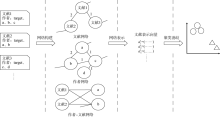
基于网络表示学习的作者重名消歧方法模型结构如图1 所示。
图1
图1
基于网络表示学习的作者重名消歧框架
Fig.1
Framework of Author Name Disambiguation Based on Network Embedding
(1)网络构建模块,将结构化的文献著作数据转化为三种网络形式(即作者网络、文献网络以及作者-文献网络)的数据;
(2)网络表示模块,根据已建立好的三种网络对文献生成对应的特征表示向量;
(3)聚类消歧模块,文献表示向量在这一模块中作为输入,采用无监督学习的方式,使用层次凝聚聚类器完成文献划分。
3.3 功能模块
文献数据最初的组织形式并非网络,而是与某一歧义作者名相关的一组结构化文献特征信息(如作者、机构和关键词等)。运用网络表示学习获取作者和文献表示,需要将结构化数据以网络图的形式重新组织。
①作者网络反映文献中作者之间的合作情况,使用图 G a = ( A , E a ) , A a i E a e ij a a i a j w ij a
②文献网络依据文献之间的相似性建立,使用图 G d = ( D , E d ) D d i E d e ij d d i A i 1 参与 d i A i 2 d i A i 2 A i 1 A i 2 ⊃ A i 1 A i 1 A i 2 N G a ( b ) , b ∈ A i 1 d i b G a A i 2 = A i 1 ⋃ N G a ( b ) , b ∈ A i 1 A i 2 ⋂ A j 2 ≠ ∅ d i , d j e ij d w ij d = | A i 2 ⋂ A j 2 |
③作者-文献网络反映作者与文献之间的著作归属关系,使用图 G ad = ( A ⋃ D , E ad ) A ⋃ D E ad e ij a i d j
作为模型的主要模块,该模块的任务是将构建好的三种网络作为输入,进行融合训练,以生成可以用作聚类器输入的文献节点表示。基于网络表示学习处理消歧任务,对于网络图 G = ( V , E ) R v i u i | V | d [17 ] ;对于文献网络,由于该网络中节点的边通过扩展合作关系(作者及作者的合作者)定义而产生相对于作者网络更长的路径,因此选择采样方式更接近于深度优先搜索的DeepWalk方法[12 ] ;对于作者-文献网络,采用适用于异构网络的成对相似性排序(Pairwise Similarity Ranking)方法[25 ] 对其进行表示。
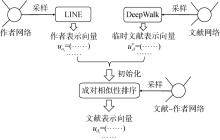
采用图2 所示的流程融合三种网络的表示。使用LINE方法对作者网络生成作者节点表示 u a i u d i * u d i
图2
图2
作者与文献的网络表示模型
Fig.2
Network Representation Model for Authors and Documents
使用LINE方法生成作者节点的表示时,会涉及到一阶与二阶两种节点相似度。这两种相似度在LINE模型中的数学定义如公式(1)和公式(2)所示。其中, p 1 p 2 u V p 1 a i a j p 2 a i a j
(1) p 1 ( a i , a j ) = 1 1 + exp ( - u a i 1 T ⋅ u a j 1 )
(2) p 2 ( a j | a i ) = exp ( u a j 2 T ⋅ u a i 1 ) ∑ k = 1 | V | exp ( u a k 2 T ⋅ u a i 1 )
以最小化先验与后验分布间的KL散度为优化目标,一阶和二阶相似度的损失函数( O 1 O 2 a i a j w ij a w ij a a i w ij a / ∑ k ∈ N i w ik a N i a i u a i
(3) O 1 = - ∑ e ij a ∈ E a w ij a log p 1 ( a i , a j )
(4) O 2 = - ∑ e ij a ∈ E a n w ij a log p 2 ( a j | a i )
使用DeepWalk方法生成文献节点的表示。使用随机游走(Random Walk)对文献网络中的节点进行采样,即对于每一个文献节点 d i t ( d i , d i + 1 , … , d i + t - 1 )
使用Skip-gram模型从这些随机游走序列中生成节点表示,其损失函数 L ( u d c ) w 为预先定义 d c p d c u d c p u d i *
(5) L ( u d c ) = min ( - log p ( d c - w , … , d c - 1 , d c + 1 , … , d c + w | u d c ) )
对于以上两种节点表示在作者与文献网络上的融合训练,使用成对相似性排序法。该方法基于一个基本的假设:有边连接的节点对的相似性应当比无边连接的节点对的相似性要高。由于本文最终需要获得的是文献节点的表示向量,因此,以一个文献节点 d i a j a t S ( d i , a j ) > S ( d i , a t )
(6) p [ S ( d i , a j ) > S ( d i , a t ) | u d i , u a j , u a t ] = σ [ S ( d i , a j , a t ) ]
(7) S ( d i , a j , a t ) = S ( d i , a j ) - S ( d i , a t )
其中,σ代表Sigmoid函数, S ( d i , a j ) S ( d i , a t ) d i a j a t
通过网络表示模块获取到的文献表示向量,即可作为特征输入到聚类器中,对应真实作者将文献正确划分,从而完成对作者的消歧。采用层次凝聚聚类,将每一个样本都看作一个独立的簇,选择距离最近的两个簇合并,反复迭代此过程直至达到预设的聚类数量。选择该方法的原因在于本文所涉及的网络总节点数与总边数规模较小,该方法作为凝聚型的聚类方法,相对于划分型的聚类方法更侧重于保留节点间已存在的相似性,而不至于忽略一些不够显著的关联。
4 实验与结果
4.1 数据集
实验所使用的数据集分别来源于研究者社会网络搜索与挖掘系统ArnetMiner[22 ] 、学术搜索引擎CiteSeerX[23 ] 以及计算机科学文献数据库DBLP[24 ] 。选择以上三组数据集的理由如下。
(1)数据由一系列存在歧义名字的文件所组成。文件内存放与该歧义作者名有著作关系的结构化文献元数据,包括真实作者标签(label)、标题(title)以及作者列表(authors)等。其形式为XML格式,结构规范易于解析,适合本文实验(基本格式如表1 所示);
(2)本实验可以根据作者列表提取文献合著关系并建立网络,同时真实作者标签可用于判定文献是否被正确归类;
(3)三组不同来源的数据集各方面特征具有差异,可以使实验设计更加全面。
进一步从ArnetMiner、CiteSeerX和DBLP数据集中各选取10组歧义最明显(即同名真实作者数最多)的子数据集(即名字引用文件)用于实验。不使用三个数据集中所有子数据集来测试消歧方法的原因在于:
(1)实验中每一个文件本身相对独立(按不同名字聚合),因此在测试环节每个子数据集能够独立用于本文的基础实验,并应分别加以评估;
(2)选择歧义最为明显的子数据集作为实验数据在作者重名消歧的相关研究中较为普遍[5 ,24 -25 ] ;
(3)部分子数据集对应真实作者数过少,或是文件中文献条目数量不足,类别数过少的情况降低了实验的说服力,因此在实证研究中未予采用。
4.2 基线方法
为对比本文方法与其他方法在作者重名消歧任务上的效果差异,选择目前使用较多的4种方法作为基线方法。
(1)作者列表特征(AuthorList)方法[25 ] 。该方法针对数据集每一文献条目中包含的作者列表进行简单建模,即根据文献对应的作者列表中作者的出现情况构造二值的表示向量,若该作者出现在作者列表中(参与该文献著作),则向量对应位置的值置1,反之置0。以这种方式构造的表示向量作为文献特征输入到层次凝聚聚类器(Hierarchical Agglomerative Clustering, HAC)中进行聚类,完成消歧任务。
(2)使用非负矩阵分解过滤后的作者列表特征(AuthorList-NMF)方法[25 ] 。该方法对作者列表特征法进行优化。由于作者列表特征法所获得的二值表示向量比较稀疏,因此可以对这些稀疏向量构成的矩阵使用非负矩阵分解法进行降维,进一步得到稠密的表示向量,输入到层次凝聚聚类器中。
(3)匿名图网络嵌入消歧(Name Disambiguation in Anonymized Graphs Using Network Embedding,NDNE)方法[25 ] 。该方法从文献合著信息中抽取出作者与文献间、作者与作者间以及文献与文献间的三类关系,并基于这些关系建立对应的网络图结构。针对这些网络图结构设计成对相似性排序方法学习网络图中的文献节点表示。最终,将取得的表示向量作为输入,使用层次凝聚聚类方法完成消歧。
(4)基于网络嵌入的作者消歧(A Network-Embedding Based Method for Author Disambiguation, ADNE)方法[24 ] 。该方法同样采取依据文献信息建立网络图的做法,不同的是,该方法建立的是作者间、标题间、出版机构间、摘要间以及作者单位间的网络图。此外,用于聚类的方法也换成了层次密度聚类(Hierarchical Density-Based Spatial Clustering of Applications with Noise,HDBSCAN)以及仿射传播聚类(Affinity Propagation,AP)。
4.3 评价指标与参数设置
选用常用于评估分类或聚类任务效果的Macro-F1值,作为消歧任务的评估指标。
有关各方法网络表示模块的超参数配置,由于基线方法(1)和(2)为直接提取结构特征的方法,因此无特殊超参数设置;对于基于成对相似性排序的基线方法(3)和(4),依照基线方法(4)在其代码实现中的设置,将表示向量维度设置为40,随机梯度下降学习率设为0.1,损失函数中的正则化系数设为0.1,优化迭代轮次设为2。同时,本文方法中涉及到以上参数的部分,与以上设置保持一致。此外,DeepWalk的随机游走序列长度设为10,每一个节点生成序列数量为2;LINE选择采集的相似度类型会在4.5节扩展实验中进一步讨论。
4.4 基础实验结果与分析
按照本文对作者重名消歧任务的定义,对选择出的每个子数据集都进行一次“构建网络-网络表示-聚类消歧”的流程,即对每一个歧义名从文献的角度完成消歧。每个文件完成以上流程之后,通过Macro-F1指标评价聚类效果。
通过表2 可以看出,在ArnetMiner数据集上,本文方法在6个子数据集上(Lei Wang,Jing Zhang,Yang Wang,Wei Xu,Gang Chen和Lei Chen)取得最优效果,且优于排在第二位的NDNE方法1%-6%;在其他4个子数据集(Yu Zhang,Bin Li,Hao Wang和Bo Liu)上取得了次优的效果。通过表3 可以看出,在CiteSeerX数据集上,本文方法取得了次优的效果。通过表4 可以看出,在DBLP数据集上,本文方法在3个子数据集(Yang Wang, Minsoo Kim和Rui Wang)上取得了最优效果,且在未取得最优效果的大多数子数据集上也取得了次优效果。
为探究以上实验结果的原因,结合数据集的统计特征进行分析。表5 呈现了实验中涉及到的三组(每组10个)来自不同数据集的子数据集的特征,以及根据这些子数据集建立的网络特征的平均值。三组数据集在歧义明显程度、网络稠密程度与网络规模方面存在差异。
(1)从歧义明显程度来看,平均真实作者数(即消歧类别数)越多,歧义越明显。可以看出,ArnetMiner组平均文献条目数较少,消歧类别数却最多,则该组歧义最为明显。本文方法在该组上表现最好,表明其具有细粒度的区分能力,可以应对高度歧义的文献数据。
(2)从网络稠密程度来看,ArnetMiner组与DBLP组平均文献条目数相近,但后者的平均边数(文献网络)比前者高1 554.7,平均节点度数(文献网络)高于前者11.3,可认为后者的文献网络稠密程度远高于前者。以此为前提,实验结果中本文方法在ArnetMiner组上相对于DBLP组上的性能提高且优于NDNE,表明本文模型通过引入DeepWalk方法,使用随机游走采样更容易捕捉到稀疏网络中节点的相似度。
(3)从网络规模来看,CiteSeerX组的平均文献条目数与平均边数(文献网络)都远高于其他两组,即规模明显大于其他两组。在此情况下,包括本文方法在内的所有方法在CiteSeerX组上的效果都有明显下降;同时,回顾实验参数设置,所有涉及网络表示学习的方法的学习迭代轮次都仅为2。因此,判断在CiteSeerX组上的效果下降是由于数据规模增大之后各方法学习不充分所导致的。在本文的实证研究中,为保证实验一致性,并未在对CiteSeerX组进行学习时增加学习迭代轮次,有关迭代轮次对模型的影响将在扩展实验部分进一步讨论。
4.5 扩展实验结果与分析
为探究不同超参数对模型效果的影响,进行一系列扩展实验,检验模型在不同情境下的效果差异。
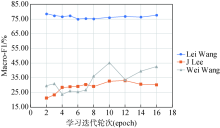
在网络表示学习过程中,通常一次采样一定数量的节点,将节点对应的表示向量按损失函数的目标进行更新,并重复此过程。在实验过程中,保持其他参数与基础实验时一致,将学习的迭代轮次从2提高到16(小于8的时候每次增加1轮,从8开始每次增加2轮),并在三组数据集中歧义最明显的三个子数据集(即Lei Wang,J Lee和Wei Wang)上,测试本文方法的效果变化。实验结果如图3 所示,本文方法在Lei Wang(来自ArnetMiner)上效果趋于稳定,受到迭代轮次的影响较小;在Wei Wang(来自DBLP)上,随着迭代轮次的增加,效果虽然出现振荡,但总体呈上升趋势;在J Lee(来自CiteSeerX)上,随着迭代轮次的增加,效果缓慢地上升,在本文选取的区间内,总体上升约10%,验证了关于提升学习迭代轮次可适应更大规模网络的推测。
图3
图3
学习迭代轮次对模型效果的影响
Fig.3
The Influence of Learning Iteration Numbers on Model Performance
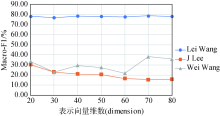
网络表示学习目的在于为节点生成一个维数相对较低的表示向量。该向量的维数(Dimension)需要在学习之前人为定义,不同的维数可以反映表示向量保留网络信息的多少,或是对网络信息压缩程度的高低。在实验过程中,保持其他参数与基础实验时一致,考察表示向量维数在20-80之间变化时,在歧义最明显的三个子数据集上对模型效果的影响,结果如图4 所示。在Lei Wang(来自ArnetMiner)上维数的变化没有带来明显影响,这说明对于该数据集,实验选定的维数区间都能够充分表达网络信息;在Wei Wang(来自DBLP)上,效果在该区间有小幅度上升,并在维数为70时最佳;在J Lee(来自CiteSeerX)上,效果在该区间有小幅度下降,说明对于该数据集,维数已经足以表达网络信息,不需要进一步增加。
图4
图4
表示向量维数对模型效果的影响
Fig.4
The Influence of Embedding Dimensions on Model Performance
本文对作者网络使用LINE方法生成节点表示。LINE会对网络节点的一阶和二阶相似度进行建模并各生成一组节点表示,再拼接为最终的表示,以分别保留网络局部与全局信息。LINE可根据具体情况的不同,选择只对两种相似度中的一种进行建模。在作者重名消歧情境下,考虑到所面向的作者网络数据规模远小于社交网络(LINE最初的设计是面向社交网络),网络中“局部”与“全局”的差异并不明显。因此,有必要探究LINE选择不同相似度标准时对模型整体的影响。
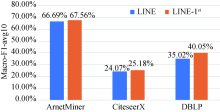
具体而言,分别在模型中选用两种相似度标准的LINE(即采用一阶二阶混合的LINE和仅建模一阶相似度的LINE-1st )分别学习作者节点表示,完成聚类消歧任务并评估这两种做法的差别,结果如图5 所示。保持其他参数与基础实验时一致,对三组数据集都用两种LINE方法各执行一次流程并评估效果(由每组10个子数据集上的Macro-F1值的平均值衡量)。可以看出,使用仅建模一阶相似度的LINE会取得更好的效果。其中,在ArnetMiner和CiteSeerX上,后者的效果略高于前者,差距在1%左右;在DBLP上二者的差距最为明显,后者的效果高于前者的5%。实验结果表明,在规模较小的作者网络上建模侧重于网络全局信息的二阶相似度会使生成的网络表示效果变差。因此,在基础实验中选用LINE-1st 与基线方法进行对比。
图5
图5
LINE相似度选择对模型效果的影响
Fig.5
The Influence of LINE Similarity Measures on Model Performance
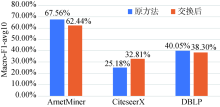
本文模型中作者网络训练使用LINE,而文献网络训练使用DeepWalk。为探究不同网络表示学习方法对模型效果的影响,尝试交换DeepWalk与LINE的训练对象(即作者网络训练使用Deepwalk,而文献网络的训练使用LINE),所带来的影响如图6 所示。在交换训练对象之后,DBLP组上的效果下降约2%,ArnetMiner组上的效果下降约5%。实验结果表明,通过DeepWalk与LINE交换学习对象并不能有效提升模型的效果,相反在有的数据集上其效果反而出现下降。
图6
图6
DeepWalk与LINE交换训练对象的影响
Fig.6
The Influence of Switching DeepWalk and LINE on Model Performance
4.6 讨 论
为解决作者重名消歧问题,本文在三种不同数据集上针对各种模型开展基础实验,并对比各项模型参数进行扩展实验。
①本文方法和基线方法中最优的NDNE方法均在部分数据集上取得了最优效果。这两种方法采用同样的网络建立方式,即建立作者、文献以及作者-文献三种关系网络。根据已有的定义可知,此三种网络建立的基础均为合著关系。这说明,合著关系仍然是科研合作网络中作者以及文献的相似度建模的最有效、最可靠的依据。
②基线方法ADNE表现相对较弱,说明在合著关系之外建模更多的关系,并不一定能显著提高消歧效果。原因一方面在于有些数据缺少相关的信息而导致部分关系无法建立(如出版机构和所属单位等);另一方面是因为有些关系(如摘要的匹配)需要自然语言处理方法来完成,增加了模型的不确定性。
③未考虑任何关系的两种作者列表建模方法表现一般,间接证明了合著关系建模的重要性。
④本文方法在较为稀疏的ArnetMiner上表现较好,在较为稠密的CiteSeerX上表现弱于前者,表明将经典同构网络表示学习方法融合到对科研合作网络的表示学习过程中具有可行性,但当目标科研合作网络的特性与传统同构网络(如规模大且稀疏的社交网络)差异较大时,该做法并不能有效改善消歧效果。
(2)在参数对模型的影响方面,本文探究了学习迭代轮次、表示向量维数、LINE选择学习的相似度以及改变模型结构对模型效果的影响。
①从迭代轮次来看,本文模型在增加学习迭代轮次时,模型的效果会出现提升,但达到一定程度时便不再有明显的提升,表明在进行网络表示学习时应选择恰当的轮次数,盲目增加轮次数不仅无法提升效果,还会延长训练时间。
②从表示向量维数来看,不同的数据集需要不同的维数才能适当地表达网络信息,说明该参数依赖于特定的数据集。
③从LINE中相似度标准的选择来看,实验结果表明在网络规模相对较小的情况下,通过LINE仅采样一阶相似度会取得更好的效果。
④从模型结构来看,由于DeepWalk与LINE各自的特性,采用LINE训练作者网络同时DeepWalk训练文献网络时,模型效果更好。
(3)从模型的扩展性来看,尽管本文在英文数据集上进行作者重名消歧,由于模型并未对语言类型加以限制,因此理论上可以推广到其他语言的作者重名消歧中。就重名消歧的本质而言,模型旨在解决不同实体对应的网络节点的类别归属问题,因而理论上并不局限于作者重名消歧。例如,当网络节点变为词汇、网络连接变为共现关系时,则模型转换为解决共词网络的语义消歧问题。与此类似,当网络节点为社交网络用户时,模型转换为解决社交网络的用户重名消歧问题。从这个意义上来讲,可以将模型理解为通过融合网络表示学习和无监督学习来解决网络节点消歧问题,因而理论上能够推广到更多的场景和任务中。
(4)从模型的实际应用来看,本文通过从结构化文献数据中建立三种合作网络,融合不同的网络表示学习方法学习文献节点表示,并采用无监督学习方法,将文献节点表示作为特征,使用层次凝聚聚类按照真实作者对文献进行正确划分,具有重要的应用价值。一方面,目前与知识网络相关的研究(如科研合作推荐、作者引文推荐和科研网络分析等)多数未能考虑网络中的作者重名消歧问题,使得网络中的节点带有较大的噪声,从而降低了各种科学模型的效果,本文对于改进上述研究具有重要促进作用。另一方面,在作者重名消歧方面,多数模型由人工定义特征抽取规则,且以监督学习的方式运行,需要耗费较多人力进行标注,特征抽取工作相对繁琐且不易推广,采用本文提出的模型能够大大降低构建监督学习训练集的时间和成本。
5 结 语
本文提出一种新的基于网络表示学习的作者重名消歧方法。该方法通过将存在作者重名歧义的结构化文献数据转化为网络结构的数据,并将已有的网络表示学习方法融合进文献节点的表示学习过程中,使用层次凝聚聚类器对文献进行正确的划分。实验结果表明,本文方法可以取得较好的消歧效果。本文实验还对比各种基于网络表示学习的消歧方法的效果,探究各种参数对本文模型的影响,并进行相应的分析,为今后网络表示学习在作者重名消歧上的应用提供了新的思路。
本文的不足之处在于:没有对更多的网络表示学习方法(如Node2Vec、SDNE)在该问题上的应用进行探究,后续将考虑尝试引入更多样的网络表示学习方法解决作者重名消歧问题,进一步优化已有方法;受制于数据集的限制,仅对英文情境下的作者重名消歧进行探究,后续将研究更多语言情境下的作者重名消歧问题。
支撑数据
支撑数据由作者自存储,E-mail: Yuchuanming2003@126.com。
[1] 余传明.arnetminer.zip. ArnetMiner学术搜索引擎消歧数据集.
[2] 余传明.citeseerx.zip. CtieSeerX学术搜索引擎消歧数据集.
[3] 余传明.dblp.zip. DBLP计算机科学数据库消歧数据集.
参考文献
View Option
[1]
章顺瑞 , 游宏梁 . 现代图书情报技术
[J]. 现代图书情报技术 , 2010 (11 ):64 -68 .
[本文引用: 1]
( Zhang Shunrui You Hongliang . Chinese People Name Disambiguation by Hierarchical Clustering
[J]. New Technology of Library and Information Service , 2010 (11 ):64 -68 .)
[本文引用: 1]
[2]
肖晶 , 梁冰 , 张晓丹 , 等 . 现代图书情报技术
[J]. 现代图书情报技术 , 2012 (5 ):55 -59 .
[本文引用: 1]
( Xiao Jing Liang Bing Zhang Xiaodan , et al . Author Disambiguation Rules and Algorithm for Article Level Data
[J]. New Technology of Library and Information Service , 2012 (5 ):55 -59 .)
[本文引用: 1]
[3]
刘斌 , 赵升 , 孙笑明 , 等 . 我国专利数据中发明家姓名消歧算法研究
[J]. 情报学报 , 2016 ,35 (4 ):405 -414 .
[本文引用: 1]
( Liu Bin Zhao Sheng Sun Xiaoming , et al . Research on Inventors’ Names Disambiguation Algorithm in Chinese Patent Data
[J]. Journal of the China Society for Scientific and Technical Information , 2016 ,35 (4 ):405 -414 .)
[本文引用: 1]
[4]
周杰 , 李弼程 , 唐永旺 . 基于关键证据与E 2 LSH的增量式人名聚类消歧方法
[J]. 情报学报 , 2016 ,35 (7 ):714 -722 .
[本文引用: 1]
( Zhou Jie Li Bicheng Tang Yongwang . Incremental Clustering Method Based on Key Evidence and E 2 LSH for Person Name Disambiguation
[J]. Journal of the China Society for Scientific and Technical Information , 2016 ,35 (7 ):714 -722 .)
[本文引用: 1]
[5]
郭舒 . 现代图书情报技术
[J]. 现代图书情报技术 , 2013 (7/8 ):69 -74 .
[本文引用: 2]
( Guo Shu . Research on Author Name Disambiguation Algorithm in the Literature Database
[J]. New Technology of Library and Information Service , 2013 (7/8 ):69 -74 .)
[本文引用: 2]
[6]
Han H Giles L Zha H , et al . Two Supervised Learning Approaches for Name Disambiguation in Author Citations
[C]//Proceedings of the 4th ACM/IEEE-CS Joint Conference on Digital libraries, Tucson, Arizona, USA. New York, USA: ACM , 2004 : 296 -305 .
[本文引用: 1]
[7]
Giles C L Zha H Han H . Name Disambiguation in Author Citations Using a K-way Spectral Clustering Method
[C]//Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries, Denver, Colorado, USA. New York, USA: ACM , 2005 : 334 -343 .
[本文引用: 1]
[8]
Tang J Fong A C M Wang B , et al . A Unified Probabilistic Framework for Name Disambiguation in Digital Library
[J]. IEEE Transactions on Knowledge and Data Engineering , 2012 ,24 (6 ):975 -987 .
[本文引用: 1]
[9]
Hermansson L Kerola T Johansson F , et al . Entity Disambiguation in Anonymized Graphs Using Graph Kernels
[C]//Proceedings of the 22nd ACM International Conference on Information and Knowledge Management, San Francisco, California, USA. New York, USA: ACM , 2013 : 1037 -1046 .
[本文引用: 1]
[10]
Saha T K Zhang B Hasan M A . Name Disambiguation from Link Data in a Collaboration Graph Using Temporal and Topological Features
[J]. Social Network Analysis and Mining , 2015 ,5 (1 ):1 -14 .
[本文引用: 1]
[11]
涂存超 , 杨成 , 刘知远 , 等 . 网络表示学习综述
[J]. 中国科学:信息科学 , 2017 ,47 (8 ):32 -48 .
[本文引用: 1]
( Tu Cunchao Yang Cheng Liu Zhiyuan , et al . Network Representation Learning: An Overview
[J]. Scientia Sinica (Informationis) , 2017 ,47 (8 ):32 -48 .)
[本文引用: 1]
[12]
Perozzi B Al-Rfou R Skiena S . DeepWalk: Online Learning of Social Representations
[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, USA. 2014 : 701 -710 .
[本文引用: 2]
[13]
Mikolov T Chen K Corrado G , et al . Efficient Estimation of Word Representations in Vector Space
[OL]. arXiv Preprint , arXiv: 1301.3781.
[本文引用: 1]
[14]
Mikolov T Sutskever I Chen K , et al . Distributed Representations of Words and Phrases and Their Compositionality
[C]//Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, USA. USA: Curran Associates , 2013 : 3111 -3119 .
[本文引用: 1]
[15]
Grover A Leskovec J . Node2vec: Scalable Feature Learning for Networks
[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, California, USA. 2016 : 855 -864 .
[本文引用: 1]
[16]
陈丽 , 朱裴松 , 钱铁云 , 等 . 基于边采样的网络表示学习模型
[J]. 软件学报 , 2018 ,29 (3 ):756 -771 .
[本文引用: 1]
( Chen Li Zhu Peisong Qian Tieyun , et al . Edge Sampling Based Network Embedding Model
[J]. Journal of Software , 2018 ,29 (3 ):756 -771 .)
[本文引用: 1]
[17]
Tang J Qu M Wang M , et al . LINE: Large-scale Information Network Embedding
[C]// Proceedings of the 24th International Conference on World Wide Web, Florence, Italy. 2015 : 1067 -1077 .
[本文引用: 2]
[18]
Wang D Peng C Zhu W . Structural Deep Network Embedding
[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, California, USA. 2016 : 1225 -1234 .
[本文引用: 1]
[19]
Yang C Liu Z Zhao D , et al. Network Representation Learning with Rich Text Information[C]// Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina . San Francisco, California, USA : AAAI Press , 2015 : 2111 -2117 .
[本文引用: 1]
[20]
Tu C Liu H Liu Z , et al . CANE: Context-Aware Network Embedding for Relation Modeling
[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada. ACL , 2017 : 1722 -1731 .
[本文引用: 1]
[21]
刘正铭 , 马宏 , 刘树新 , 等 . 一种融合节点文本属性信息的网络表示学习算法
[J]. 计算机工程 , 2018 ,44 (11 ):165 -171 .
[本文引用: 1]
( Liu Zhengming Ma Hong Liu Shuxin , et al . A Network Representation Learning Algorithm Fusing with Textual Attribute Information of Nodes
[J]. Computer Engineering , 2018 ,44 (11 ):165 -171 .)
[本文引用: 1]
[22]
ArnetMiner Name Disambiguation Dataset [EB/OL]. [2019 -01 -01 ].https://www.aminer.cn/disambiguation.
URL
[本文引用: 1]
[23]
CiteSeerX Name Disambiguation Dataset
[EB/OL]. [2019 -01 -01 ]. http://clgiles.ist.psu.edu/data/.
URL
[本文引用: 1]
[24]
Xu J Shen S Q Li D S , et al . A Network-embedding Based Method for Author Disambiguation
[C]// Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy. New York, USA: ACM , 2018 : 1735 -1738 .
[本文引用: 3]
[25]
Zhang B Hasan M A . Name Disambiguation in Anonymized Graphs Using Network Embedding
[C]// Proceedings of the 2017 ACM Conference on Information and Knowledge Management, Singapore. New York, USA: ACM , 2017 : 1239 -1248 .
[本文引用: 5]
现代图书情报技术
1
2010
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
现代图书情报技术
1
2010
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
现代图书情报技术
1
2012
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
现代图书情报技术
1
2012
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
我国专利数据中发明家姓名消歧算法研究
1
2016
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
我国专利数据中发明家姓名消歧算法研究
1
2016
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
基于关键证据与E 2 LSH的增量式人名聚类消歧方法
1
2016
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
基于关键证据与E 2 LSH的增量式人名聚类消歧方法
1
2016
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
现代图书情报技术
2
2013
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
... (2)选择歧义最为明显的子数据集作为实验数据在作者重名消歧的相关研究中较为普遍[5 ,24 -25 ] ; ...
现代图书情报技术
2
2013
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
... (2)选择歧义最为明显的子数据集作为实验数据在作者重名消歧的相关研究中较为普遍[5 ,24 -25 ] ; ...
Two Supervised Learning Approaches for Name Disambiguation in Author Citations
1
2004
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
Name Disambiguation in Author Citations Using a K-way Spectral Clustering Method
1
2005
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
A Unified Probabilistic Framework for Name Disambiguation in Digital Library
1
2012
... 在基于内容信息的研究中,学者将重点放在内容相关的作者实体特征提取上.例如,章顺瑞等[1 ] 将文本中的词进行向量表示,使用层次聚类进行消歧;肖晶等[2 ] 提出针对NSTL数据库的人名消歧规则集,结合模糊匹配算法完成消歧,且在该数据库上F值达到90%.刘斌等[3 ] 面向专利数据,通过分析多种特征并对比相似度来消除发明家姓名的歧义,通过相似度高低可有效区分不同发明家实体.周杰等[4 ] 针对增量式文档集基于关键证据与E2 LSH进行人名消歧,F值可达74%.郭舒[5 ] 提出基于GHOST算法的消歧方法,根据文献元数据的相似程度建立文献特征并聚类消除作者名歧义,在DBLP部分数据集上平均F1值为61.6%.此外,也有学者在使用内容信息的前提下,尝试改变所使用的机器学习模型.例如,Han等[6 ] 和Giles等[7 ] 先后使用监督学习与无监督学习模型进行作者重名文献的划分,对于监督学习模型,使用朴素贝叶斯分类器以及支持向量机的方法,平均准确率均接近70%;对于无监督学习模型,使用谱聚类算法,平均准确率为63.5%.Tang等[8 ] 在统一概率框架下,使用马尔可夫随机场算法划分文献,相对于常见聚类算法,F1值提升10%-30%.基于内容信息的方法虽然针对性强,可以保证较高的准确率,但这类方法往往通过人工定义的规则提取实体特征,而同样的规则迁移到其他数据上则不再适用,导致难以推广到不同的情境. ...
Entity Disambiguation in Anonymized Graphs Using Graph Kernels
1
2013
... 在基于网络的研究中,Hermansson等[9 ] 提出基于图核的方法,通过捕捉节点间局部邻居结构的相似性,使用支持向量机对节点进行分类,准确率达60%-80%.Saha等[10 ] 提出利用节点周围带时间戳的网络结构的无监督重名消歧方法,AUC值达80%以上.基于网络的方法通常利用网络结构信息作为特征,仅仅将文献或作者视作网络中的节点,而节点特征的建立只依据节点之间的关系,很少涉及到节点内部的属性,因此推广到其他种类、其他领域的数据相对容易.但这类研究成果相对较少,且研究重心多集中于机器学习模型而不是网络表示学习方法. ...
Name Disambiguation from Link Data in a Collaboration Graph Using Temporal and Topological Features
1
2015
... 在基于网络的研究中,Hermansson等[9 ] 提出基于图核的方法,通过捕捉节点间局部邻居结构的相似性,使用支持向量机对节点进行分类,准确率达60%-80%.Saha等[10 ] 提出利用节点周围带时间戳的网络结构的无监督重名消歧方法,AUC值达80%以上.基于网络的方法通常利用网络结构信息作为特征,仅仅将文献或作者视作网络中的节点,而节点特征的建立只依据节点之间的关系,很少涉及到节点内部的属性,因此推广到其他种类、其他领域的数据相对容易.但这类研究成果相对较少,且研究重心多集中于机器学习模型而不是网络表示学习方法. ...
网络表示学习综述
1
2017
... 传统的网络表示一般使用维数较多的稀疏向量,但是高维向量会使用较多的存储空间,运算时也需要更多的运行时间.为解决上述问题,研究者尝试通过网络表示学习为节点获取能够保留网络信息的低维稠密向量表示[11 ] .目前研究主要分为不考虑节点自身信息和考虑节点自身信息两方面. ...
网络表示学习综述
1
2017
... 传统的网络表示一般使用维数较多的稀疏向量,但是高维向量会使用较多的存储空间,运算时也需要更多的运行时间.为解决上述问题,研究者尝试通过网络表示学习为节点获取能够保留网络信息的低维稠密向量表示[11 ] .目前研究主要分为不考虑节点自身信息和考虑节点自身信息两方面. ...
DeepWalk: Online Learning of Social Representations
2
2014
... (1)在不考虑节点自身信息的研究中,随机游走采样节点的方法最具有代表性.例如,Perozzi等[12 ] 提出DeepWalk算法,使用随机游走采集节点样本序列,并首次将语言建模的思想引入到网络表示学习中,将节点序列视作词序列,进而将用于词表示的Skip-gram模型[13 ,14 ] 用于学习网络表示.Grover等[15 ] 提出Node2Vec算法,该算法对DeepWalk方法进行改进,具体的处理是改变采集随机游走序列的方式.该算法丰富了节点相似性的定义,即同质性和结构相似性;然后设计对应的带偏好的随机游走过程实现节点采样,这使得该算法可以更全面地捕捉节点之间的关系.陈丽等[16 ] 在DeepWalk的基础上,对节点与边的表示学习加以区分,提出基于边采样的网络表示学习模型.除了使用随机游走采样节点的方法,也有直接采样节点对的方法.例如,Tang等[17 ] 提出LINE方法,不仅考虑由节点链接所代表的一阶相似度,还考虑了由于节点之间拥有共同邻居而定义的二阶相似度,对拥有链接的节点对,以最大化这两种相似度进行损失函数建模并优化.Wang等[18 ] 提出SDNE方法,首次真正地将深度学习模型应用到表示学习中,该方法选择的相似度与LINE方法一样,也是一阶与二阶相似度,模型由监督部分(基于拉普拉斯特征映射)与无监督部分(基于深度自编码器)组成,分别负责学习一阶与二阶相似度并生成节点向量表示. ...
... 作为模型的主要模块,该模块的任务是将构建好的三种网络作为输入,进行融合训练,以生成可以用作聚类器输入的文献节点表示.基于网络表示学习处理消歧任务,对于网络图 G = ( V , E ) R v i u i | V | d [17 ] ;对于文献网络,由于该网络中节点的边通过扩展合作关系(作者及作者的合作者)定义而产生相对于作者网络更长的路径,因此选择采样方式更接近于深度优先搜索的DeepWalk方法[12 ] ;对于作者-文献网络,采用适用于异构网络的成对相似性排序(Pairwise Similarity Ranking)方法[25 ] 对其进行表示. ...
Efficient Estimation of Word Representations in Vector Space
1
... (1)在不考虑节点自身信息的研究中,随机游走采样节点的方法最具有代表性.例如,Perozzi等[12 ] 提出DeepWalk算法,使用随机游走采集节点样本序列,并首次将语言建模的思想引入到网络表示学习中,将节点序列视作词序列,进而将用于词表示的Skip-gram模型[13 ,14 ] 用于学习网络表示.Grover等[15 ] 提出Node2Vec算法,该算法对DeepWalk方法进行改进,具体的处理是改变采集随机游走序列的方式.该算法丰富了节点相似性的定义,即同质性和结构相似性;然后设计对应的带偏好的随机游走过程实现节点采样,这使得该算法可以更全面地捕捉节点之间的关系.陈丽等[16 ] 在DeepWalk的基础上,对节点与边的表示学习加以区分,提出基于边采样的网络表示学习模型.除了使用随机游走采样节点的方法,也有直接采样节点对的方法.例如,Tang等[17 ] 提出LINE方法,不仅考虑由节点链接所代表的一阶相似度,还考虑了由于节点之间拥有共同邻居而定义的二阶相似度,对拥有链接的节点对,以最大化这两种相似度进行损失函数建模并优化.Wang等[18 ] 提出SDNE方法,首次真正地将深度学习模型应用到表示学习中,该方法选择的相似度与LINE方法一样,也是一阶与二阶相似度,模型由监督部分(基于拉普拉斯特征映射)与无监督部分(基于深度自编码器)组成,分别负责学习一阶与二阶相似度并生成节点向量表示. ...
Distributed Representations of Words and Phrases and Their Compositionality
1
2013
... (1)在不考虑节点自身信息的研究中,随机游走采样节点的方法最具有代表性.例如,Perozzi等[12 ] 提出DeepWalk算法,使用随机游走采集节点样本序列,并首次将语言建模的思想引入到网络表示学习中,将节点序列视作词序列,进而将用于词表示的Skip-gram模型[13 ,14 ] 用于学习网络表示.Grover等[15 ] 提出Node2Vec算法,该算法对DeepWalk方法进行改进,具体的处理是改变采集随机游走序列的方式.该算法丰富了节点相似性的定义,即同质性和结构相似性;然后设计对应的带偏好的随机游走过程实现节点采样,这使得该算法可以更全面地捕捉节点之间的关系.陈丽等[16 ] 在DeepWalk的基础上,对节点与边的表示学习加以区分,提出基于边采样的网络表示学习模型.除了使用随机游走采样节点的方法,也有直接采样节点对的方法.例如,Tang等[17 ] 提出LINE方法,不仅考虑由节点链接所代表的一阶相似度,还考虑了由于节点之间拥有共同邻居而定义的二阶相似度,对拥有链接的节点对,以最大化这两种相似度进行损失函数建模并优化.Wang等[18 ] 提出SDNE方法,首次真正地将深度学习模型应用到表示学习中,该方法选择的相似度与LINE方法一样,也是一阶与二阶相似度,模型由监督部分(基于拉普拉斯特征映射)与无监督部分(基于深度自编码器)组成,分别负责学习一阶与二阶相似度并生成节点向量表示. ...
Node2vec: Scalable Feature Learning for Networks
1
2016
... (1)在不考虑节点自身信息的研究中,随机游走采样节点的方法最具有代表性.例如,Perozzi等[12 ] 提出DeepWalk算法,使用随机游走采集节点样本序列,并首次将语言建模的思想引入到网络表示学习中,将节点序列视作词序列,进而将用于词表示的Skip-gram模型[13 ,14 ] 用于学习网络表示.Grover等[15 ] 提出Node2Vec算法,该算法对DeepWalk方法进行改进,具体的处理是改变采集随机游走序列的方式.该算法丰富了节点相似性的定义,即同质性和结构相似性;然后设计对应的带偏好的随机游走过程实现节点采样,这使得该算法可以更全面地捕捉节点之间的关系.陈丽等[16 ] 在DeepWalk的基础上,对节点与边的表示学习加以区分,提出基于边采样的网络表示学习模型.除了使用随机游走采样节点的方法,也有直接采样节点对的方法.例如,Tang等[17 ] 提出LINE方法,不仅考虑由节点链接所代表的一阶相似度,还考虑了由于节点之间拥有共同邻居而定义的二阶相似度,对拥有链接的节点对,以最大化这两种相似度进行损失函数建模并优化.Wang等[18 ] 提出SDNE方法,首次真正地将深度学习模型应用到表示学习中,该方法选择的相似度与LINE方法一样,也是一阶与二阶相似度,模型由监督部分(基于拉普拉斯特征映射)与无监督部分(基于深度自编码器)组成,分别负责学习一阶与二阶相似度并生成节点向量表示. ...
基于边采样的网络表示学习模型
1
2018
... (1)在不考虑节点自身信息的研究中,随机游走采样节点的方法最具有代表性.例如,Perozzi等[12 ] 提出DeepWalk算法,使用随机游走采集节点样本序列,并首次将语言建模的思想引入到网络表示学习中,将节点序列视作词序列,进而将用于词表示的Skip-gram模型[13 ,14 ] 用于学习网络表示.Grover等[15 ] 提出Node2Vec算法,该算法对DeepWalk方法进行改进,具体的处理是改变采集随机游走序列的方式.该算法丰富了节点相似性的定义,即同质性和结构相似性;然后设计对应的带偏好的随机游走过程实现节点采样,这使得该算法可以更全面地捕捉节点之间的关系.陈丽等[16 ] 在DeepWalk的基础上,对节点与边的表示学习加以区分,提出基于边采样的网络表示学习模型.除了使用随机游走采样节点的方法,也有直接采样节点对的方法.例如,Tang等[17 ] 提出LINE方法,不仅考虑由节点链接所代表的一阶相似度,还考虑了由于节点之间拥有共同邻居而定义的二阶相似度,对拥有链接的节点对,以最大化这两种相似度进行损失函数建模并优化.Wang等[18 ] 提出SDNE方法,首次真正地将深度学习模型应用到表示学习中,该方法选择的相似度与LINE方法一样,也是一阶与二阶相似度,模型由监督部分(基于拉普拉斯特征映射)与无监督部分(基于深度自编码器)组成,分别负责学习一阶与二阶相似度并生成节点向量表示. ...
基于边采样的网络表示学习模型
1
2018
... (1)在不考虑节点自身信息的研究中,随机游走采样节点的方法最具有代表性.例如,Perozzi等[12 ] 提出DeepWalk算法,使用随机游走采集节点样本序列,并首次将语言建模的思想引入到网络表示学习中,将节点序列视作词序列,进而将用于词表示的Skip-gram模型[13 ,14 ] 用于学习网络表示.Grover等[15 ] 提出Node2Vec算法,该算法对DeepWalk方法进行改进,具体的处理是改变采集随机游走序列的方式.该算法丰富了节点相似性的定义,即同质性和结构相似性;然后设计对应的带偏好的随机游走过程实现节点采样,这使得该算法可以更全面地捕捉节点之间的关系.陈丽等[16 ] 在DeepWalk的基础上,对节点与边的表示学习加以区分,提出基于边采样的网络表示学习模型.除了使用随机游走采样节点的方法,也有直接采样节点对的方法.例如,Tang等[17 ] 提出LINE方法,不仅考虑由节点链接所代表的一阶相似度,还考虑了由于节点之间拥有共同邻居而定义的二阶相似度,对拥有链接的节点对,以最大化这两种相似度进行损失函数建模并优化.Wang等[18 ] 提出SDNE方法,首次真正地将深度学习模型应用到表示学习中,该方法选择的相似度与LINE方法一样,也是一阶与二阶相似度,模型由监督部分(基于拉普拉斯特征映射)与无监督部分(基于深度自编码器)组成,分别负责学习一阶与二阶相似度并生成节点向量表示. ...
LINE: Large-scale Information Network Embedding
2
2015
... (1)在不考虑节点自身信息的研究中,随机游走采样节点的方法最具有代表性.例如,Perozzi等[12 ] 提出DeepWalk算法,使用随机游走采集节点样本序列,并首次将语言建模的思想引入到网络表示学习中,将节点序列视作词序列,进而将用于词表示的Skip-gram模型[13 ,14 ] 用于学习网络表示.Grover等[15 ] 提出Node2Vec算法,该算法对DeepWalk方法进行改进,具体的处理是改变采集随机游走序列的方式.该算法丰富了节点相似性的定义,即同质性和结构相似性;然后设计对应的带偏好的随机游走过程实现节点采样,这使得该算法可以更全面地捕捉节点之间的关系.陈丽等[16 ] 在DeepWalk的基础上,对节点与边的表示学习加以区分,提出基于边采样的网络表示学习模型.除了使用随机游走采样节点的方法,也有直接采样节点对的方法.例如,Tang等[17 ] 提出LINE方法,不仅考虑由节点链接所代表的一阶相似度,还考虑了由于节点之间拥有共同邻居而定义的二阶相似度,对拥有链接的节点对,以最大化这两种相似度进行损失函数建模并优化.Wang等[18 ] 提出SDNE方法,首次真正地将深度学习模型应用到表示学习中,该方法选择的相似度与LINE方法一样,也是一阶与二阶相似度,模型由监督部分(基于拉普拉斯特征映射)与无监督部分(基于深度自编码器)组成,分别负责学习一阶与二阶相似度并生成节点向量表示. ...
... 作为模型的主要模块,该模块的任务是将构建好的三种网络作为输入,进行融合训练,以生成可以用作聚类器输入的文献节点表示.基于网络表示学习处理消歧任务,对于网络图 G = ( V , E ) R v i u i | V | d [17 ] ;对于文献网络,由于该网络中节点的边通过扩展合作关系(作者及作者的合作者)定义而产生相对于作者网络更长的路径,因此选择采样方式更接近于深度优先搜索的DeepWalk方法[12 ] ;对于作者-文献网络,采用适用于异构网络的成对相似性排序(Pairwise Similarity Ranking)方法[25 ] 对其进行表示. ...
Structural Deep Network Embedding
1
2016
... (1)在不考虑节点自身信息的研究中,随机游走采样节点的方法最具有代表性.例如,Perozzi等[12 ] 提出DeepWalk算法,使用随机游走采集节点样本序列,并首次将语言建模的思想引入到网络表示学习中,将节点序列视作词序列,进而将用于词表示的Skip-gram模型[13 ,14 ] 用于学习网络表示.Grover等[15 ] 提出Node2Vec算法,该算法对DeepWalk方法进行改进,具体的处理是改变采集随机游走序列的方式.该算法丰富了节点相似性的定义,即同质性和结构相似性;然后设计对应的带偏好的随机游走过程实现节点采样,这使得该算法可以更全面地捕捉节点之间的关系.陈丽等[16 ] 在DeepWalk的基础上,对节点与边的表示学习加以区分,提出基于边采样的网络表示学习模型.除了使用随机游走采样节点的方法,也有直接采样节点对的方法.例如,Tang等[17 ] 提出LINE方法,不仅考虑由节点链接所代表的一阶相似度,还考虑了由于节点之间拥有共同邻居而定义的二阶相似度,对拥有链接的节点对,以最大化这两种相似度进行损失函数建模并优化.Wang等[18 ] 提出SDNE方法,首次真正地将深度学习模型应用到表示学习中,该方法选择的相似度与LINE方法一样,也是一阶与二阶相似度,模型由监督部分(基于拉普拉斯特征映射)与无监督部分(基于深度自编码器)组成,分别负责学习一阶与二阶相似度并生成节点向量表示. ...
1
2015
... (2)在考虑节点自身信息的研究中,Yang等[19 ] 提出的TADW将DeepWalk中的随机游走过程转化为矩阵分解形式,再利用矩阵乘法将文本特征融入到该过程中以学习保留文本信息的节点向量表示.Tu等[20 ] 提出的CANE则在学习节点结构表示的同时,利用带有注意力机制的卷积神经网络学习节点文本表示.此外,刘正铭等[21 ] 建立神经网络,并以神经网络中参数共享的方式融合节点结构表示和节点文本表示的学习. ...
CANE: Context-Aware Network Embedding for Relation Modeling
1
2017
... (2)在考虑节点自身信息的研究中,Yang等[19 ] 提出的TADW将DeepWalk中的随机游走过程转化为矩阵分解形式,再利用矩阵乘法将文本特征融入到该过程中以学习保留文本信息的节点向量表示.Tu等[20 ] 提出的CANE则在学习节点结构表示的同时,利用带有注意力机制的卷积神经网络学习节点文本表示.此外,刘正铭等[21 ] 建立神经网络,并以神经网络中参数共享的方式融合节点结构表示和节点文本表示的学习. ...
一种融合节点文本属性信息的网络表示学习算法
1
2018
... (2)在考虑节点自身信息的研究中,Yang等[19 ] 提出的TADW将DeepWalk中的随机游走过程转化为矩阵分解形式,再利用矩阵乘法将文本特征融入到该过程中以学习保留文本信息的节点向量表示.Tu等[20 ] 提出的CANE则在学习节点结构表示的同时,利用带有注意力机制的卷积神经网络学习节点文本表示.此外,刘正铭等[21 ] 建立神经网络,并以神经网络中参数共享的方式融合节点结构表示和节点文本表示的学习. ...
一种融合节点文本属性信息的网络表示学习算法
1
2018
... (2)在考虑节点自身信息的研究中,Yang等[19 ] 提出的TADW将DeepWalk中的随机游走过程转化为矩阵分解形式,再利用矩阵乘法将文本特征融入到该过程中以学习保留文本信息的节点向量表示.Tu等[20 ] 提出的CANE则在学习节点结构表示的同时,利用带有注意力机制的卷积神经网络学习节点文本表示.此外,刘正铭等[21 ] 建立神经网络,并以神经网络中参数共享的方式融合节点结构表示和节点文本表示的学习. ...
1
2019
... 实验所使用的数据集分别来源于研究者社会网络搜索与挖掘系统ArnetMiner[22 ] 、学术搜索引擎CiteSeerX[23 ] 以及计算机科学文献数据库DBLP[24 ] .选择以上三组数据集的理由如下. ...
CiteSeerX Name Disambiguation Dataset
1
2019
... 实验所使用的数据集分别来源于研究者社会网络搜索与挖掘系统ArnetMiner[22 ] 、学术搜索引擎CiteSeerX[23 ] 以及计算机科学文献数据库DBLP[24 ] .选择以上三组数据集的理由如下. ...
A Network-embedding Based Method for Author Disambiguation
3
2018
... 实验所使用的数据集分别来源于研究者社会网络搜索与挖掘系统ArnetMiner[22 ] 、学术搜索引擎CiteSeerX[23 ] 以及计算机科学文献数据库DBLP[24 ] .选择以上三组数据集的理由如下. ...
... (2)选择歧义最为明显的子数据集作为实验数据在作者重名消歧的相关研究中较为普遍[5 ,24 -25 ] ; ...
... (4)基于网络嵌入的作者消歧(A Network-Embedding Based Method for Author Disambiguation, ADNE)方法[24 ] .该方法同样采取依据文献信息建立网络图的做法,不同的是,该方法建立的是作者间、标题间、出版机构间、摘要间以及作者单位间的网络图.此外,用于聚类的方法也换成了层次密度聚类(Hierarchical Density-Based Spatial Clustering of Applications with Noise,HDBSCAN)以及仿射传播聚类(Affinity Propagation,AP). ...
Name Disambiguation in Anonymized Graphs Using Network Embedding
5
2017
... 作为模型的主要模块,该模块的任务是将构建好的三种网络作为输入,进行融合训练,以生成可以用作聚类器输入的文献节点表示.基于网络表示学习处理消歧任务,对于网络图 G = ( V , E ) R v i u i | V | d [17 ] ;对于文献网络,由于该网络中节点的边通过扩展合作关系(作者及作者的合作者)定义而产生相对于作者网络更长的路径,因此选择采样方式更接近于深度优先搜索的DeepWalk方法[12 ] ;对于作者-文献网络,采用适用于异构网络的成对相似性排序(Pairwise Similarity Ranking)方法[25 ] 对其进行表示. ...
... (2)选择歧义最为明显的子数据集作为实验数据在作者重名消歧的相关研究中较为普遍[5 ,24 -25 ] ; ...
... (1)作者列表特征(AuthorList)方法[25 ] .该方法针对数据集每一文献条目中包含的作者列表进行简单建模,即根据文献对应的作者列表中作者的出现情况构造二值的表示向量,若该作者出现在作者列表中(参与该文献著作),则向量对应位置的值置1,反之置0.以这种方式构造的表示向量作为文献特征输入到层次凝聚聚类器(Hierarchical Agglomerative Clustering, HAC)中进行聚类,完成消歧任务. ...
... (2)使用非负矩阵分解过滤后的作者列表特征(AuthorList-NMF)方法[25 ] .该方法对作者列表特征法进行优化.由于作者列表特征法所获得的二值表示向量比较稀疏,因此可以对这些稀疏向量构成的矩阵使用非负矩阵分解法进行降维,进一步得到稠密的表示向量,输入到层次凝聚聚类器中. ...
... (3)匿名图网络嵌入消歧(Name Disambiguation in Anonymized Graphs Using Network Embedding,NDNE)方法[25 ] .该方法从文献合著信息中抽取出作者与文献间、作者与作者间以及文献与文献间的三类关系,并基于这些关系建立对应的网络图结构.针对这些网络图结构设计成对相似性排序方法学习网络图中的文献节点表示.最终,将取得的表示向量作为输入,使用层次凝聚聚类方法完成消歧. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}