




1 引言
近年来,充分发挥云计算、大数据、人工智能等新技术手段,提高宏观经济运行决策水平,已经成为各界高度共识。从全球范围来看,政府治理模式正在从传统的韦伯模式和新公共管理(New Public Management,NPM)模式过渡到数字治理(Digital Era Governance,DEG)模式,其基本特征就是将大数据和数字化技术置于机构层级的核心位置,推动数字化的整体性政府建设,在决策模式上高度强调“使用数据来理解公民,并为政策制定提供依据”[1]。充分发挥大数据技术优势,助力提升国家经济监测预测和宏观调控水平,已经大势所趋。国务院2015年发布的《促进大数据发展行动纲要》(国发〔2015〕50号)专门指出[2],要建立运行平稳、安全高效的经济运行新机制,实现对经济运行更为准确的监测、分析、预测、预警,提高决策的针对性、科学性和时效性。从研究方法论的视角看,大数据在打通经济学“均衡范式”与“演化范式”、形成宏中微观一体化的经济分析框架,有效衔接经济学艺术(Art of Economics)、实证经济学(Positive Economics)与规范经济学(Normative Economics)方面[3]具有独特作用。本文从大数据经济学的上述特点出发,论述在国家层面发挥我国独特制度优势,构建政企一体化的数据归集和治理体系,建设支撑宏中微观经济运行分析的“国家经济大脑”的基本思路。
2 国内外相关领域的实践探索
2.1 国外的实践探索
2012年3月29日,美国白宫网站发布的《大数据研究和发展倡议》(Big Data Research and Development Initiative)[4]提出,实施大数据计划旨在帮助美国获得从海量复杂数据集中萃取知识的能力,借此提高国家应对急迫挑战的水平,大数据上升成为美国的国家战略。此后,主要西方发达国家均发布与大数据相关的宏观政策优化战略,如澳大利亚政府发布的《公共服务大数据战略》、法国政府发布的《数字化路线图》、英国政府发布的《把握数据带来的机遇:英国数据能力战略》等[5]。总体而言,目前西方发达国家政府运用大数据开展宏观经济监测预测的实践尚处在起步阶段,但也形成了一些成熟经验和模式。
(1)利用大数据技术丰富和提升传统统计手段。美国经济研究局(National Bureau of Economic Research, NBER)2019年3月举办了 “面向21世纪的经济统计大数据”(Big Data for 21st Century Economic Statistics)专题研讨会,与会者集中探讨了利用网络自然语言数据[6]、众包数据[7]、商业扫码数据[8]、交易数据[9]等新型数据归集方式构建失业率等统计指标。通过此次会议还可以发现,美国宏观经济运行的多个相关部门都在积极探索利用大数据等新技术手段改进宏观经济运行分析。例如,美国经济分析局(Bureau of Economic Analysis,BEA)尝试对比机器学习和替代性数据在经济预测中的效果[10];美国劳工统计局(Bureau of Labor Statistics,BLS)尝试利用第三方数据、企业数据和Web抓取的零售商API数据优化消费者价格指数(Consumer Price Index,CPI)的数据采集[11];美国人口普查局利用机器学习和公共数据尝试自动化生成北美工业分类系统(North American Industry Classification System,NAICS)代码[12]等。
(3)构建全国大集中的政府宏观决策数据中心。在这方面,澳大利亚社会保障服务信息中心(Centrelink)和新加坡的“风险评估和水平扫描”系统(RAHS)是代表案例。Centrelink 是澳大利亚联邦政府的一个政府机构,是公共事业部(Human Services Portfolio)的六大机构之一,在联邦和各州都设有,并在堪培拉设有两个大型数据中心,与联邦和各州的税务、金融、警局等部门实现联网共享,并运用大数据分析技术构建了一系列围绕就业、社会福利、医保等领域的风险预测评估模型[14]。新加坡建设RAHS最初目的是应对恐怖主义和传染病,后来逐渐扩展到住房、交通、教育、安全等各个领域,不仅可以帮助新加坡各级部门监测和识别恐怖袭击等风险事件,还可以帮助政府规划采购周期和预算、预测经济走势、制定移民政策和研究房地产市场[1]。
2.2 国内的实践探索
国家发展改革委作为我国宏观经济运行的核心部门,在运用大数据手段开展宏观经济分析研判方面起步很早。早在2015年,我国就组建了国家发展改革委互联网大数据分析中心,并启动建设国家发展改革委互联网大数据分析系统。2016年,国家发展改革委办公厅正式印发的《关于推进全国发展改革系统大数据工作的指导意见》(发改办厅〔2016〕1993号)提出,要“围绕发展改革系统履行职能,建设国家和省两级宏观决策可视化平台,充分应用可视化技术,围绕投资、工业、交通、能源、农业等重点领域开发经济地图,建设基于地理信息可视化的宏观经济运行大数据监测分析‘一张图’,形成涵盖宏观决策各方面的数据汇聚展示系统,支撑各级发展改革委领导会商与综合研判”。2017年,《国家发展改革委“智慧发改”建设规划》(发改办厅〔2017〕1959号)正式印发,提出打造智慧决策大脑的设想,要求“面向重大决策需求,构建‘智慧发改’决策算法库、模型库、指标库、知识库,开展各类大数据分析指标与传统统计指标的回归比对和关联分析,逐步推动经验智慧与人工智能融合创新,为加强和创新宏观调控提供强有力技术支撑”。根据文件要求,将原国家发展改革委互联网大数据分析中心更名为国家发展改革委大数据中心,推进归集位置信息、电子商务、交通物流、招投标、专利软著、自媒体等各种大数据资源,并面向国家发展改革委等上级机构开展重大政策大数据评估研究,目前已经完成500余期大数据决策参考报告,取得了较大决策影响力。
地方层面,海南、重庆、河北、杭州、宁波等地方政府也由当地宏观部门牵头,在利用大数据开展宏观经济分析方面开展了大量有益探索。例如,2017年11月,依托国家发展改革委大数据中心重庆分中心建设的重庆经济社会发展大数据决策支持平台项目正式启动,归集重庆市经济社会运行相关的17亿条数据资源,并构建了产业地图、投资地图、消费地图、外贸地图、创新地图、人才地图等分析板块;河北省发展改革委提出加快“全委信息化系统整合及大数据建设”的工作任务,通过构建信息资源目录和大数据系统实现了河北省发展改革委全委政务信息资源共享、建立完善的宏观经济数据采集渠道、宏观经济大数据融合分析及可视化展示等目标,并将时序算法、预测算法、相关性算法、聚类算法、影响因素等5类算法应用于宏观经济分析全生命周期[15];海南省发展改革委依托国家发展改革委大数据中心海南分中心建设了海南省宏观经济决策大数据分析系统,发布了《2018年海南省经济社会发展大数据分析报告》等一系列重要研究报告[16];深圳市发展改革委、青岛市发展改革委先后启动“智慧发改”工程,全面提升产业决策和重大项目事中事后监管水平;宁波市地税局启动了“宁波税收发展指数”课题研究,基于地方税收大数据开展挖掘应用,课题组将反映经济运行的税收指数通过构建指标、合成统一数值的方法,所形成的税收指数与统计局发布的生产价格指数(Producer Price Index,PPI)相关性达70%左右[17]。
3 构建国家经济大脑的基本思路
未来,应吸收借鉴美国、澳大利亚、新加坡等国通过归集数据开展宏观决策的成功经验,充分发挥我国独特的制度优势,有效归集和开发利用全社会范围内经济运行相关数据,建设集宏中微观经济运行分析于一体的“国家经济大脑”,助力实现国家治理体系和治理能力现代化。总体设计思路遵循以下原则。
3.1 在数据基础上,坚持政府数据与社会数据相统一
当前,随着互联网、物联网、移动通信等社会化数据源渠道的飞速发展,全社会数据资源正在从过去政府掌握80%的全社会公共数据资源逐渐转变为社会化数据资源占绝大多数的新格局。梅宏指出,在当前万物互联化、数据泛在化的大背景下,越来越多物理实体的实时状态被采集、传输和汇聚,从而使数字化的范围蔓延到整个物理世界,物联网数据将成为人类掌握的数据集中最主要的组成部分[18]。正因如此,习近平总书记在中央政治局第二次集体学习时指出,要加快公共服务领域数据集中和共享,推进同企业积累的社会数据进行平台对接,形成社会治理强大合力。要想系统描述和刻画全社会经济运行全貌,就要形成覆盖政府、企业、社会机构、个人和海外相关信息,跨层级、跨地域、跨系统、跨部门、跨业务的数据采集汇聚机制,强化陆海空天电网数据资源全领域、全要素统筹,实现对全国范围内信息化、网络化、可视化和智能化的数字集成创新,实现“一人一档、一物一档、一事一档、一机一档”的国家一体化数据资源体系框架,有效增强国家数据资源的纵横联动和协同管理能力。通过各类数据的深度整合和关联应用,深刻刻画国家政治、经济、文化等各方面发展状况,揭示宏观经济结构和微观社会状况。
3.2 在分析手段上,坚持均衡范式与演化范式相统一
过去百余年来,经济学研究领域的均衡范式和演化范式呈现逐渐融合的态势。一方面,主流经济学近年来发展出的博弈论、行为经济学、实验经济学、信息经济学、新制度学派等分支已经吸收、借鉴了演化范式下对部分理性、创新扩散、路径依赖等的论述;另一方面,复杂经济学、演化经济学等则将新古典(均衡)经济学看作是演化经济学(或非均衡经济学)的一个特例[19]。目前,大数据在均衡和演化两个方向上都在发挥重要作用:在均衡范式下,由于大数据在分析时效性、颗粒度、热点识别等方面的优势,主流经济学界开始大量尝试基于大数据的计量经济学方法创新;在演化范式下,通过将基于主体建模(Agent Based Model,ABM)、演化博弈论、机器学习等新技术方法与大数据相结合,形成人类真实主体(Human Subject,HS)数据和计算虚拟主体(Computational Agent,CA)数据之间的对比,有效支撑宏观经济风险识别和趋势预测。因此,在构建国家经济大脑时,应当力图将演化分析和均衡分析方法融为一体。在这一方向上,20世纪70年代,英国科学哲学家罗伊·巴斯卡(Roy Bhaskar)提出了批评实在论[20],在沟通实证主义(大致对应于均衡范式)和非实证主义(大致对应于演化范式)两大范式方面取得了较大影响力,成为20世纪后半叶“英美哲学研究领域中最令人震撼的发展”[21]。特别是巴斯卡提出社会系统具有不同于自然界的涌现特征,并主要表现在三个方面[22],即行为依赖性(Activity-dependence)、观念依赖性(Concept-dependence)和时空依赖性(Space-time-dependence),对本文研究框架的构建具有重要借鉴作用。
另外,从前期对国内外宏观经济大数据监测预测领域的研究方法的梳理也可以看到,目前经济运行大数据分析所使用的方法大致可以分为4类(见表1):一是统计分析方法,如ARMA模型、LASSO算法、向量自回归(Vector AutoRegressive,VAR)、灰度关联分析、协整检验、主成分分析、多元线性回归、时序分析等,主要是将利用大数据手段构建的各种新指标与传统计量经济学的分析模型相结合,实际上是均衡范式在大数据环境下的进一步延续;二是复杂网络方法,如社会网络分析(Social Network Analysis,SNA)、图模式识别、网络特征空间、二部图分析等,这类方法主要侧重于对微观经济主体的行为关联性进行分析挖掘,识别其中的潜在模式和演化趋势,大致可以对应于演化范式下的行为依赖性分析;三是人工智能方法,如潜在语义分析、支持向量机、贝叶斯分类、观点识别、新词发现、情感分析、回归树、随机森林、卷积神经网络等,这类方法目前在宏观经济中主要应用场景是对微观行为主体的观点性文本进行分析挖掘,大致对应于演化范式下的观念依赖性分析;四是时空分析方法,如时空分布、位置分布、行为轨迹分析、区域关联网络分析等,这类方法大致可以对应于演化范式下的时空依赖性分析。
表1 大数据经济分析的主要方法及代表性研究
Table 1
| 研究范式 | 方法类型 | 代表性成果 | |
|---|---|---|---|
| 均衡范式 | 统计分析 | Müller等[23](2006); Cavallo等[24](2016); Kholodilin等[25](2009); Schneider等[26](2016);Artola等[27](2015) | |
| 演化范式 | 行为依赖性 | 复杂网络 | Bustos等[28](2012); Tacchella等[29](2012); Cristelli等[30](2015); Hidalgo等[31](2009); Gao[32](2015) |
| 观念依赖性 | 人工智能 | Liu等[33](2014); Levenberg等[34](2013); Llorente等[35](2015) | |
| 时空依赖性 | 时空分析 | Neffke等[36](2011); Gao[32](2015); Doll等[37](2006); Salesses等[38](2013); 杨振山等[39](2015) | |
3.3 在应用方向上,坚持监测预测与风险监管相统一
从应用方向上看,当前国家经济大脑建设的主要用途包括两个方面。一是运用大数据手段改进经济监测预测的效果。在经济监测方面,应用大数据手段可以提高经济运行监测的时效性、精准性和客观性,如通过开展经济现时预测(Nowcasting)研究帮助人们更快地应对经济运行可能出现的趋势性、苗头性问题,通过应用异常检验、新事件探测等技术手段发现海量经济数据中隐藏的新业态、新模式等。在经济预测方面,大数据不仅可以改进传统统计预测模型的预测表现,还可以运用多主体复杂性建模、时空演化预测、行为预测、基于机器学习自动识别先行性指标等手段建立全新经济预测模型。二是近年来随着贸易争端等不断升级,国际国内经济形势日趋复杂,加之中央政府大力推进“放管服”改革,各级政府在防范化解重大风险、加强重大政策重大项目事中事后监管等方面面临的挑战日益增加,亟待利用大数据手段强化监管手段,提升风险识别与防范能力。而传统经济学理论模型对于风险的识别与应对一直是一个软肋。正如著名经济学家布莱恩·阿瑟指出,经济学理论本身存在一个根本性弱点,即“缺乏一种能够在政策实施之前找到可能的失败模式的系统方法”[40]。未来,通过运用新技术手段,对经济运行过程中的异常点、突变点、奇异点进行识别预测,对涉及重大政策、重大项目的风险领域开展预测预警,将成为宏观经济运行分析的又一理论和应用“蓝海”。
从大数据视角看待经济运行,可以构建一个以中观层面的规则、结构、机制及其涌现性分析为切入,向上向下统筹宏观和微观经济分析的新框架。正如多普菲(Kurt Dopfer)所指出的:“在经济演化过程中,无论是微观角度(复杂的规则结构构成系统,如公司)还是宏观角度(规则总体的复杂结构,如工业和经济),它们都建立在中观视角之上[41]。”从这一角度,可以分别从微观、中观和宏观三个层面思考和规划国家经济大脑的技术框架。
4 微观层面:构建微观经济运行动态本体库
在大数据时代,构成各种复杂经济现象的微观主体(如企业、机构、个人、商品等)的行为数据、关联关系、基本属性等信息可以通过多种方法进行全面及时的收集和整理,从而为这些复杂现象提供了坚实的数据基础。正如维克托·迈尔·舍恩伯格等所说:“有了大数据的帮助,我们不会再将世界看作是一连串我们认为或是自然或是社会现象的事件,我们会意识到本质上世界是由信息构成的[42]。”基于此,在国家经济大脑建设的微观层面,应当着眼于利用大数据手段快速构建领域本体和通用本体,形成对海量微观主体行为演变和关系网络的快速挖掘能力。具体而言,其主要任务包括以下方面。
4.1 建立政企一体化数据归集汇聚体系
应当综合考虑政府、企业、个人、海外、互联网、物联网等多种数据来源,形成与国家经济运行相关各方面数据源的统一汇聚机制。其中,政府数据来源主要指国家平台(如全国信用信息共享平台、全国公共资源交易平台、全国投资项目在线审批监管平台等)、各部委平台(如公安、人社、税务、市场监管、民政、教育等)和各地方政务数据整合共享平台;企业数据来源是指企业生产经营全生命周期各类数据(如工商登记注册、税务、海关、就业社保、投融资、专利软著等);个人数据来源主要是指自然人工作和生活中产生的各类行为数据(如移动位置、出行、教育、消费、通信等);海外数据来源是指“一带一路”沿线等重点国家基本概况、经济产业、政策法规、规划计划、项目工程、投资贸易、科研机构、企业组织、旅游及文化交流、社会舆情等各方面信息;互联网数据来源是指互联网上的公开信息(如新闻、微博、微信、学术智库、电商评论、房产等);物联网数据来源是指从智能硬件设备(如可穿戴设备、车辆、智能家居、工业控制等)中获取数据资源。通过开展覆盖政务数据和社会化数据资源的数据标准化稽查、清洗、消减、转换、去重、打标、校验、修复、聚合、分级分类、血缘分析等数据治理和质量提升活动,不断提高大数据分析挖掘的可靠性。
4.2 建立面向微观经济主体的动态本体库体系
在归集汇聚相关数据的基础上,构建人、企、车、物、事、地等微观经济对象的动态本体库。以企业工商注册信息、个人证件号、车牌号等个体唯一标识为主线,依托统一编码对接相关数据资源,对本体对象(Objects)、属性(Properties)和关系(Relationships)进行抽象化处理,依托复杂网络分析方法及大规模图计算技术,实现动态本体图谱的展现、布局、搜索、统计、分析、推理、演绎和学习,支持动态本体混合检索、路径发现、频繁子图挖掘、关键节点识别、社团发现等功能,形成多维度分析、多视角监测、多领域应用的动态本体图谱分析能力。
目前,国家发展改革委大数据中心已经联合数联铭品(BBD)等业内相关企业开发了微观经济主体的动态本体(Dynamic Ontology)管理系统,如图1所示。将不同类型本体(企业、个人、事件、文档等)建模的基本维度划分为对象、属性和关系三个方面,通过关联打通工商企业注册信息库、投资项目在线审批监管平台、全国信用信息共享平台和国家公共资源交易平台等若干国家级大数据平台数据资源,初步实现了“重大战略-重大政策-重大项目-企业-自然人”5类本体的关联关系构建。例如,通过重大政策和项目招标文本的自然语言处理,自动关联识别“重大战略落实政策”“重大政策配套项目”等本体关联关系;通过重大项目招投标和空间位置数据,自动识别关联“重大项目招中标企业”“重大项目建设地点人流变动”等本体关联关系;通过企业工商注册信息关联识别“企业交叉持股关系”“企业股东和高管组成”等本体关联关系。特别是在企业本体构建方面,已实现以企业统一社会信用代码为主线,对全国3 000万家企业和5 000万家个体工商户的工商注册、就业招聘、招投标、投融资、专利软著、社会信用、行政审批、法院判决等共78大类、1 828个指标项进行统一关联。
图1
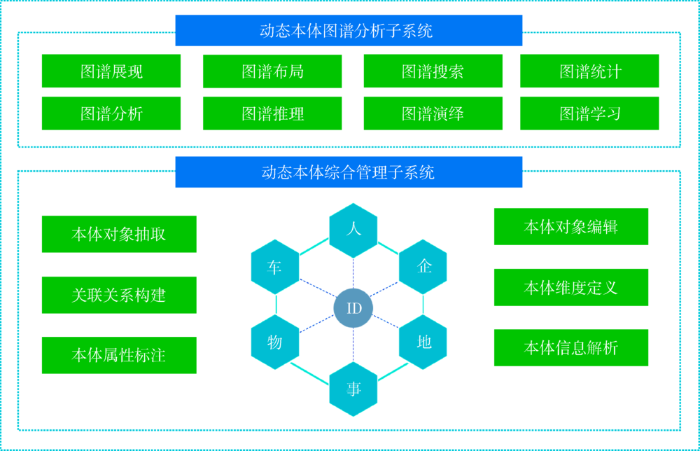
图1
数据资源动态本体组织管理系统框架
Fig.1
Framework of Data Resource Dynamic Ontology Organization Management System
5 中观层面:构建中观经济大数据仿真分析平台
正如前面所论述的,从经济社会运行的中观层面来看,复杂经济系统凸显的行为依赖性、观念依赖性和时空依赖性等三个基本特征,既可以基于微观层面的经济动态本体进行仿真模拟,又可以归总并呈现为宏观层面经济运行监测预测的基本规律。因此,构建国家经济大脑的中观系统,就是要整合复杂网络、自然语言理解和时空分析三大类算法模型,将其作为模拟仿真中观经济现象的技术支撑。
5.1 以复杂网络分析为核心的行为依赖性仿真分析
与自然科学研究不同,社会科学研究的对象与人高度相关。批判实在论认为,社会经济关系、结构和机制的存在具有对人的活动的依赖性,它既是人自身各种行为的社会化结果,又是存在于行为者之间的相对持久的社会关系[43]。正如诺贝尔经济学奖获得者Solow指出的:“所有狭义的经济行为都植根于社会制度、习俗、信仰和态度的网络之中[44]。”行为经济学则认为,情境往往决定了人们如何决策[45],因此,可以利用对情境的研究来解释甚至预测人们的经济行为。大数据相比传统统计手段一个最大的优势就是可以通过非干预的方法获取经济社会主体行为方方面面的“痕迹”数据。通过归集政府、企业、个人等各类微观经济主体的行为数据,可以刻画政企之间(如工程项目招投标)、企业之间(如企业间持股关系、商业合同、创新合作等)、企业与个人之间(如企业招聘、消费记录等)、个人与个人之间(如社交关系、亲友关系、位置关联等)的主体关系,构建以微观主体为节点、以主体间关联关系为边的经济社会运行复杂网络,并运用图计算、网络社群挖掘、复杂网络演化分析、社会网络等分析方法识别经济运行主体的行为依赖性突现现象和演化规律。这方面技术方法和应用已十分成熟,如布莱恩·阿瑟基于复杂网络演化模型,对资本市场中资产价格变动的自我强化、集群波动(Clusted Volatility)和突然渗透(Sudden Percolation)三种涌现现象进行了预测模拟[40];Hidalgo等基于国别间贸易数据构建了“国家-产品”二部图网络,基于网络拓扑结构刻画国家经济复杂性,并实现对国家发展潜力的预测[31];Tacchella等基于“国家-产品”矩阵关系,利用非线性迭代算法刻画国家发展潜力和产品复杂性,较好地解释了不同国家的经济竞争力变化趋势[29];笔者也曾基于专利文本数据构建企业技术创新网络[46],基于税务发票进销项数据构建某市企业发票网络,并基于启发式社团发现模型对相关领域演化态势进行预测分析。
该子系统的基本分析功能如下。
(1)统计特征分析。即对复杂网络基本拓扑指标的统计分析,如平均路径长度、聚集系数、度值、小世界和无标度特性等。
(2)社团发现。典型算法如模块度优化算法、谱分析法、k-社团算法、模糊聚类算法等。
(3)链路预测。包括相似性预测、最大似然估计预测、概率模型预测等[47]。
(4)重要节点发现。结合网络局部属性、全局属性、网络位置等指标,基于PageRank、LeaderRank和HITS等算法度量超大规模网络中节点重要程度[48]。
(5)社会网络分析。研究社会行动者(包括人员、集团、组织或其他信息)与知识处理实体之间的关系和流动,并对其进行映射测量[49]。
(6)知识图谱分析。基于“实体-关系-实体”三元组以及实体相关属性的键值对,通过实体相互联结从而构成网状的知识结构[50]。
5.2 以自然语言处理为基础的观念依赖性仿真分析
批判实在论认为,经济社会中的结构、关系、机制的存在与行为者自身的价值判断、观点立场、利益抉择等具有内在关联性[51]。如果说行为依赖性是社会结构的“表象”,那么观念依赖性则是社会结构的“内在”。长期以来,经济学领域对于主体预期、情绪等的策略始终是“世界性难题”[52],传统手段只能通过实验、问卷调查等方式收集样本,但样本覆盖面、抽样误差以及实验的人为干预性等问题大大影响了结果的可信度。随着互联网的飞速发展,用户数量动辄数千万甚至数亿的社交媒体工具层出不穷。人们越来越习惯于将自己对经济、社会、文化等各方面的观点和看法通过互联网社交媒体渠道与他人分享,这为利用大数据手段开展社会群体观点和社会心态研究提供了便利途径。2015年以来,国家发展改革委大数据中心基于所归集的海量互联网社交媒体数据,构建了网民针对经济社会运行和特定政策的社会心理预期监测指标,如网民信心指数、政策满意度、政策关注度等,并对网民消费心理预期和满意度[53],以及双创、供给侧结构性改革、数字经济等领域重大政策的满意度等[13]进行评估分析。除了开展社会心态监测分析之外,利用自然语言处理等技术,还可以进一步构建微观经济社会主体的大数据认知模型。例如,国家发展改革委大数据中心基于12358网上价格举报系统的网民投诉举报数据,通过构建行为特征集和深度学习等手段,建立“职业举报人”行为自动识别模型[54]。基于不同的微观主体行为模型,可以基于行为链条开展主体经济行为预测。
该子系统的基本分析功能应当涵盖面向互联网超大规模文本的字、词、句子、段落以及篇章等各层面的分析处理功能[55],具体如下。
(1)词法分析。将输入句子从字序列转化为词和词性序列。
(2)句法分析。基于句法结构树、依存关系图等手段将输入句子从词序列形式转化为树状或图状结构。
(3)词义消歧与指代消解。确定在给定上下文语境中多义词的词义和指代词的先行语等。
(4)命名实体识别。完成人名、地名、组织机构名、数量表达式、时间短语、货币短语和百分比等的识别。
(5)文本分类与聚类。基于词袋模型(Bag of Words Model)、向量空间模型(Vector Space Model)、特征选择、特征转换和话题分析等技术实现对自然语言文本的自动分类和聚类,并整合决策树、随机森林、RIPPER算法、贝叶斯分类器、线性分类器、支持向量机、最大熵分类器、神经网络等多种经典算法。
(6)情感分析。实现在词向量表示学习、句子级表示学习(循环神经网络、递归神经网络、卷积神经网络等)和篇章级表示学习层面,利用深度学习算法实现文本情感分类。
5.3 以地理信息系统为依托的时空依赖性仿真分析
Bhaskar认为,既然社会关系、结构和机制依赖于人们的行为与观念,那么其就不可避免地对行为主体所处的时空条件产生依赖,而不会具备时空上的恒定性和普遍性[22]。由于新古典经济学是模仿牛顿机械力学建立起来的,因此其并不考虑时间和空间问题。罗伯特·索洛曾调侃道:“你可以从时间机器中丢弃一个现代经济学家……在任何时候,任何地点,他使用个人电脑,就可以建立起经济理论,甚至不需要知道时间和地点[44]。”保罗·克鲁格曼也指出,新古典传统的通用做法是“避开地理问题——大部分模型构建将世界想象为没有运输成本的世界”[56],是“没有尺度的仙境”[57]。大数据时代的到来,使得基于个体粒度的海量时空轨迹来获取人类移动模式成为可能[58]。现实世界中,超过80%的数据都与地理位置有关[59],对于经济研究而言,个体、企业、产业、工程项目等研究对象等都有十分明确的时空分布特征。正因如此,时空大数据研究是当前大数据领域十分热门的一个分支。构建以地理信息系统为依托的时空依赖性仿真分析平台,大致包含三方面技术功能。一是传统意义上的地理信息技术在宏观经济分析中的应用,利用可见光、热红外等多波段卫星遥感数据,开展数据融合、变化检测、目标特征提取等技术研究,在识别违法违规工程建筑、监测项目施工进度、灾害应急响应、评估社会治理成效等应用中辅助分析决策。二是将各种经济社会运行相关数据在一个地理信息平台上实现时空叠加和比对分析。例如,针对部分政府投资的重大工程项目,可以基于项目位置信息叠加卫星高分遥感图片、项目用电量、周边人流密集度、路网拥堵情况等多重图层,实现对重大投资项目建设进度和实施效果的精准分析[60]。三是从时空关联的角度开展分析挖掘。例如,笔者在牵头规划粤港澳大湾区大数据中心时,提出基于产业链、人才链、创新链、资金流和数据链“五链协同”模型[61],建立大湾区“9+2”城市一体化大数据监测体系。
该子系统的基本分析功能应当包括以下4个层面。
(1)在传统地理信息系统技术的基础上,整合深度学习等人工智能算法,如采用矢量瓦片、动态渲染等技术实现对城市群、地市、区县、街镇、自然街区、500米网格等多个层面超大数据集地理可视化。
(2)实现对多源数据的一体化组织,在地理图层上整合手机信令、土地利用分类地图、POI、统计指标数据、企业注册信息、专利、投资项目等具有空间区位(区域范围和位置)和时间属性的结构化和非结构化数据源,以“空间+时间”作为数据统一组织主键。
(3)对经济运行微观主体的商业合同、消费记录、创新合作、股权关联、投资项目等多源数据背后蕴含的线索信息建立关联,在个人、企业、区域等不同层面上进行关联分析,实现对复杂时空经济现象背后运行机制的深度挖掘。
(4)综合运用数据和功能的容器化、基于互联网技术特征的微服务化、机器学习模块化、轻量级Web和移动端高效可视化等时空大数据新技术优势,构建“可用即可见”的轻量、灵活、实时的时空大数据分析研判平台,有效支撑描述分析、解释分析和探索分析等不同维度的宏观决策需求[62]。
6 宏观层面:构建宏观经济监测预测大数据平台
基于微观层面经济动态本体和中观层面经济涌现仿真分析平台的坚实基础,在宏观层面,可以进一步围绕经济运行和重大风险防范等需求,构建经济运行监测、经济预测和风险识别“三位一体”的宏观经济监测预测大数据平台。
6.1 建立宏观经济监测指标库
大数据技术的飞速发展和普及,使得人们可以在采集经济运行某一剖面全样本数据的基础上,通过整合多源数据,形成一些具有一定经济学含义的监测指标体系。在国家经济大脑中,本文结合国家发展改革委大数据中心自2015年以来的实践与探索,构建了常态化监测分析经济社会运行情况的指标体系。目前指标大致分为以下方面。
(1) 监测经济动力的指数
主要分析宏观经济“三驾马车”运行情况,核心指数如下。
①投资强度指数。基于国家公共资源交易平台所收集的各级政府财政投资工程项目的招中标数据,可分析不同行业、不同地方政府投资项目的规模、金额、建设进度等信息,从而常态化监测主要固定资产投资领域的投资强度变化。
②消费活跃度指数。基于运营商和互联网全球定位系统(Global Positioning System,GPS)定位数据,可分析主要城市核心商圈周边区域的人流变化情况,通过对比研究周末和工作日、白天和夜间人群变动,可以对重点城市消费水平、夜间经济活力等进行分析监测。例如,“2019中国居民消费大数据指数”[63],对北京、上海、沈阳、武汉等十余个国内重点城市夜间经济活力进行对比。
③消费升级指数。消费升级指数旨在量化中国消费结构及质量升级状况。例如,财新传媒和数联铭品(BBD)等联合发布的“中国消费升级指数”[64],基于电商消费统计数据,通过计算相邻两个月一组相同商品的消费变化情况(月度环比),将每个月的消费升级指数环比连乘得到消费升级指数。
④贸易活跃度指数。通过广泛采集全球各国贸易进出口数据,可以形成对全球贸易结构和贸易活跃度变化情况的常态化监测指标。例如,国家信息中心联合相关机构发布的《“一带一路”贸易合作大数据报告》[65],涵盖了全球144个国家及地区的贸易统计数据库,占全球贸易总量95%以上。
(2) 监测产业运行的指数
监测产业运行的核心指数如下。
①反映产业运行情况的典型实物量指标。例如,笔者曾尝试基于税务发票数据开发制造业润滑油指数,其基本原理是工业企业往往提前2~3个月左右时间采购润滑油,故润滑油购买量变化在很大程度上反映企业主对未来经营前景的预期。通过提取分行业分地区的润滑油增值税票信息,就可以得到对具体地区或行业的未来景气预期。
②产业用工指数。例如,国家发展改革委大数据中心联合佰职数据等,通过采集去重全国数百家主流招聘网站发布的招聘需求数据,分析检测不同行业、不同地区、不同岗位的招聘需求人数、岗位薪资待遇水平、应届生薪酬水平和招聘投岗比等指标。
③初创企业活力指数。将成立时间较短(如一年以内)的企业定义为初创企业,考察这些企业自成立以来发生的网络招聘、专利、投融资、招中标等经营活动占比,将有生产经营行为的企业视为“存活”概率较大的企业,从而对不同领域的创业活力进行对比分析。
④产业运行风险指数。通过企业发生的一些负面经营行为,如行政处罚、法院裁判、失信被执行、被投诉等事件的发生比重变化来反映产业风险程度,该值越高,一定程度上说明产业风险相对基期增长越快。
⑤产业创新能力指数。将企业信息与专利申请数据精准匹配后,能够挖掘出包括高技术企业、战略性新兴产业在内的各类产业、在各地区、分不同所有制、分不同注册规模、处于不同生命周期企业的专利申请情况[48],从而分析各行业、各区域的产业创新能力发展情况。
(3) 监测区域发展的指数
监测区域发展的核心指数如下。
②基于工商注册资本的产业集聚度指数。产业集聚度是产业经济学经典指标,通过引入企业工商注册资本信息,可以分地区、分行业计算赫芬达尔-赫希曼指数(Herfindahl-Hirschman Index,HHI),从而弥补传统统计数据时间滞后和区域颗粒度的不足。
③产业辐射度指数。该指数主要基于工商注册数据进行计算,通过对比分析企业注册地和企业股东的注册地,计算不同地域间产业持股关系变化,从而分析不同地域在不同行业领域中的对外产业辐射能力。例如,国家发展改革委大数据中心曾对华南某市高技术企业外向辐射度进行分析[68]。
④产业迁移指数。一家企业注销后,其控股股东在之后两年于原省之外设立企业,视为一次产业迁移。通过计算不同行业、不同地区的产业迁移指数,可以较为系统地监测和分析区域和行业的基本运行情况。
⑤重点城市和产业功能区常住人口变动指数。基于常住人口统计指标定义,对重点城市、重点产业功能区移动人群迁移轨迹进行建模分析,析取出符合常住人口迁徙标准的移动终端数量,并推算常住人口数量,从而较好地弥补统计数据不足。例如,国家发展改革委大数据中心曾对雄安新区成立以来科技人才流入情况[13]和深圳市各区常住人口变化情况进行分析。
⑥重点交通枢纽周边人流量变动指数。对机场、车站、海关等周边区域人流变动情况进行分析监测,以对区域间人流和物流变化情况进行推算。
6.2 建立宏观经济预测分析平台
(1) 对传统预测模型的优化改进
通过将大数据指标整合进传统统计预测模型,实现对传统预测效果的提升。其基本原理就是刘涛雄等提出的“两步法”,该方法的基本步骤为:首先,仅使用传统统计信息选择初步最优预测模型;然后将互联网搜索行为加入选择的模型中;最终确定最优模型[71]。
(2) 基于复杂网络的预测模型
目前,复杂网络中的链路预测方法已经成为该领域研究的一个重要热点,即通过网络中已知的节点信息、网络结构信息等预测网络中任意两个节点之间产生链接的可能性[72]。在构建经济主体关联网络的基础上,可以综合运用相似性预测、最大似然估计预测、概率模型预测等方法开展复杂网络链路预测,从而实现对经济运行复杂网络未来走势的预测。
(3) 基于行为链条的预测模型
(4) 基于时空演化的预测模型
6.3 构建宏观经济风险监测预警平台
随着国际国内经济形势的日趋复杂,现代西方经济学在识别和预测风险方面的理论缺陷越来越明显。布莱恩·阿瑟曾指出,均衡范式下的经济学理论从根本上缺乏对重大风险的预测预警能力,因为其“坚持均衡分析,假定系统会快速地向一个没有任何行为主体有动机偏离其当前行为的地方收敛,并且会稳定在那里,因此剥削行为不可能发生。基于这种认识,经济学家的普遍倾向是,设计政策并对其结果进行一些模拟,但是不会充分地探讨行为假设的稳健性,不能将那些因系统性的剥削而可能失败的地方识别出来[40]。”运用大数据方法,则可以较好地弥补传统均衡经济学的这一缺陷。
(1) 构建风险识别模型库
针对自然人方面,重点围绕犯罪热点预测、疫情传播预测、人群聚集点风险、互联网金融、网络诈骗、非法传销等问题进行风险识别建模。针对法人方面,重点围绕涉及重大政策、重大项目的违法违规、社会纠纷、实施进度、金融杠杆率、流动性风险、社会信用风险、影子银行、违法犯罪、外部冲击等重点风险领域开展建模分析。例如,在互联网金融领域,可以重点围绕非法集资企业精准画像、非法集资关联特征抽取、核心控制人捕捉、异常风险事件发现、虚设项目空壳公司预警、欺诈风险识别等显性风险点,以及企业投资网络、自然人股东多处投资、多家公司兼任高管、多层次隐性控制等隐性风险点进行综合建模,开展金融风险模型训练、数据测试集校验建模,形成分区域、分领域、分行业的金融风险预测预警体系,不断强化宏观经济风险识别和应对处置能力,切实防范潜在运行风险。通过构建两类微观主体的行为风险识别模型库,实现对中观层面异常点、突变点、奇异点的及时识别和定位,从而帮助人们提前分析发现经济运行的重大风险点。
(2) 构建风险评级体系
利用机器学习、风险模型、专家评分等多种手段,构建覆盖自然人和法人的风险识别特征库,在整合归集多种数据源的基础上,对不同行业、不同层级的评估对象进行风险评级,以实现更加精准、超前的风险识别与预测预警。例如,国家发展改革委大数据中心曾联合数联铭品等企业,探索从企业工商变更、关联关系演变、招聘行为变化等数据中抽取非法集资样本企业的行为特征,结合深度学习等算法形成企业经营风险评估模型,并研发了企业静态风险特征指数和企业动态风险特征指数。其中,企业静态风险特征指数考虑了企业股权结构合理度、高管业务专注度、企业投资行为、人才结构变化、关联网络存续时间等静态特征。企业动态风险特征指数则侧重描述企业行为变化的稳定性和趋势性,从核心企业群关联度、关联企业行业/地域扩散特征、关联方增长构成等方面出发,刻画时间演化规律,用以评估企业的动态风险行为及泡沫化风险。
(3) 构建风险压力测试平台
未来,面对日趋复杂的宏观经济环境,需要坚持底线思维,形成对重大宏观经济政策成效和风险层级的测试仿真环境。布莱恩·阿瑟曾指出:“设计一个政策体系并简单地分析是远远不够的,即便是相当细致深入的模拟政策结果也是不够的。我们不能把社会系统和经济系统视为一组没有改变动机的行为,而必须把它们视为一种总会引发进一步的行为、诱致进一步的策略、导致系统性改变的激励网络。我们需要仿效结构工程学、流行病学或加密科学等学科中的做法,预测我们所研究的系统中可能被剥削的地方。我们需要对我们的政策设计进行压力测试,来找出它们的弱点,看看我们能否‘打破’它们[40]。”在宏观经济分析中,通过归集各方面数据资源,构建重大外部事件对宏观经济运行情况的“极限测试环境”,具有重要现实意义。
7 结语
诺贝尔经济学奖获得者埃尔文·罗斯(Alvin Roth)曾把经济学理论划分为三类,即“与理论经济学家对话”(Speaking to Theorists)、“寻找事实”(Searching for Facts)和“在王子耳边低语”(Whispering in the Ears of Princes)[88]。按照这一分类,大数据经济学主要专注于政策应用领域,具有很浓厚的工具色彩[89],可以算作比较典型的第三类经济学理论,即通过对政策制定者所关心的主题加以实证考察,实现学界与政界的直接对话,并含有直接或间接的政策目的,其更接近于政策科学的视角[90]。本文按照均衡范式与演化范式相统一的基本思路,探讨构建了在宏中微观三个层面相互打通的一体化经济运行分析框架,并将其命名为“国家经济大脑”,希望本文的若干思考和建议能够为国家宏观决策部门和高校科研机构后续开展相关领域研究提供有益借鉴。
作者贡献声明
王建冬:收集、分析文献,论文起草;
于施洋:提出研究思路,论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: wangjd@sic.gov.cn。
[1] 王建冬. 部分城市夜间消费指数基础测算数据.doc.
[2] 王建冬. 高铁沿线地区灯光指数基础测算数据.doc.
[3] 王建冬. 华南某市高技术企业外向辐射度基础测算数据.doc.
[4] 王建冬. 雄安新区成立以来科技人才流入情况基础测算数据.doc.
参考文献
Governments and Citizens Getting to Know Each Other? Open, Closed, and Big Data in Public Management Reform
[J].
国务院关于印发促进大数据发展行动纲要的通知
[EB/OL]. [
The State of Council of the PRC-Notice of the Development of Big Data
[EB/OL]. [
Big Data is a Big Deal
[EB/OL]. [
主要发达国家大数据政策比较研究
[J].
Comparative Studies on Big Data Policy of Main Developed Countries
[J].
Transforming Naturally Occurring Text Data into Economic Statistics: The Case of Online Job Vacancy Postings [A]//Big Data for 21st Century Economic Statistics
[M].
Nowcasting the Local Economy: Using Yelp Data to Measure Economic Activity[A]//Big Data for 21st Century Economic Statistics
[M].
A Machine Learning Analysis of Seasonal and Cyclical Sales in Weekly Scanner Data[A]//Big Data for 21st Century Economic Statistics
[M].
From Transactions Data to Economic Statistics: Constructing Real-Time, High-Frequency, Geographic Measures of Consumer Spending[A]//Big Data for 21st Century Economic Statistics
[M].
Off to the Races: A Comparison of Machine Learning and Alternative Data for Predicting Economic Indicators[A]//Big Data for 21st Century Economic Statistics
[M].
Big Data in the U.S. Consumer Price Index: Experiences & Plans[A]//Big Data for 21st Century Economic Statistics
[M].
Using Public Data to Generate Industrial Classification Codes[A]//Big Data for 21st Century Economic Statistics
[M].
Anticipatory Government: Integrating Big Data for Smaller Government
[C]//
政务信息资源目录及宏观经济大数据系统的建设及应用
[J].
Construction and Application of Government Information Resource Catalog and Macroeconomic Big Data System
[J].
《2018年海南省经济社会发展大数据分析报告》出炉
[EB/OL]. [
“Hainan Economic and Social Development Big Data Analysis Report 2018”Released
[EB/OL]. [
税收大数据预测经济走势的宁波经验
[N].
Ningbo Experience of Using Tax Big Data to Predict Economic Trends
[N].
建设数字中国:把握信息化发展新阶段的机遇
[EB/OL]. [
Building Digital China: Seizing Opportunities in the New Stage of Informatization Development
[EB/OL]. [
A Realist Theory of Science
[M].
Critical Realism: An Introduction to Roy Bhaskar’s Philosophy
[M].
The Possibility of Naturalism: A Philosophical Critique of the Contemporary Human Sciences
[M].
Recent Developments in the Swiss CPI:Scanner Data,Telecommunications and Health Price Collection
[C]
The Billion Prices Project: Using Online Prices for Measurement and Research
[J].
Google Searches as a Means of Improving the Nowcasts of Key Macroeconomic Variables
[R/OL].
Forecasting Sales of New and Existing Products Using Consumer Reviews: A Random Projections Approach
[J].DOI:10.1016/j.ijforecast.2015.08.005 URL [本文引用: 1]
Can Internet Searches Forecast Tourism Inflows?
[J].DOI:10.1108/IJM-12-2014-0259 URL [本文引用: 1]
The Dynamics of Nestedness Predicts the Evolution of Industrial Ecosystems
[J].
DOI:10.1371/journal.pone.0049393
URL
PMID:23185326
[本文引用: 1]

In economic systems, the mix of products that countries make or export has been shown to be a strong leading indicator of economic growth. Hence, methods to characterize and predict the structure of the network connecting countries to the products that they export are relevant for understanding the dynamics of economic development. Here we study the presence and absence of industries in international and domestic economies and show that these networks are significantly nested. This means that the less filled rows and columns of these networks' adjacency matrices tend to be subsets of the fuller rows and columns. Moreover, we show that their nestedness remains constant over time and that it is sustained by both, a bias for industries that deviate from the networks' nestedness to disappear, and a bias for the industries that are missing according to nestedness to appear. This makes the appearance and disappearance of individual industries in each location predictable. We interpret the high level of nestedness observed in these networks in the context of the neutral model of development introduced by Hidalgo and Hausmann (2009). We show that the model can reproduce the high level of nestedness observed in these networks only when we assume a high level of heterogeneity in the distribution of capabilities available in countries and required by products. In the context of the neutral model, this implies that the high level of nestedness observed in these economic networks emerges as a combination of both, the complementarity of inputs and heterogeneity in the number of capabilities available in countries and required by products. The stability of nestedness in industrial ecosystems, and the predictability implied by it, demonstrates the importance of the study of network properties in the evolution of economic networks.
A New Metrics for Countries’ Fitness and Products’ Complexity
[J].
DOI:10.1038/srep00723
URL
PMID:23056915
[本文引用: 2]
Classical economic theories prescribe specialization of countries industrial production. Inspection of the country databases of exported products shows that this is not the case: successful countries are extremely diversified, in analogy with biosystems evolving in a competitive dynamical environment. The challenge is assessing quantitatively the non-monetary competitive advantage of diversification which represents the hidden potential for development and growth. Here we develop a new statistical approach based on coupled non-linear maps, whose fixed point defines a new metrics for the country Fitness and product Complexity. We show that a non-linear iteration is necessary to bound the complexity of products by the fitness of the less competitive countries exporting them. We show that, given the paradigm of economic complexity, the correct and simplest approach to measure the competitiveness of countries is the one presented in this work. Furthermore our metrics appears to be economically well-grounded.
The Heterogeneous Dynamics of Economic Complexity
[J].
DOI:10.1371/journal.pone.0117174
URL
PMID:25671312
[本文引用: 1]
What will be the growth of the Gross Domestic Product (GDP) or the competitiveness of China, United States, and Vietnam in the next 3, 5 or 10 years? Despite this kind of questions has a large societal impact and an extreme value for economic policy making, providing a scientific basis for economic predictability is still a very challenging problem. Recent results of a new branch--Economic Complexity--have set the basis for a framework to approach such a challenge and to provide new perspectives to cast economic prediction into the conceptual scheme of forecasting the evolution of a dynamical system as in the case of weather dynamics. We argue that a recently introduced non-monetary metrics for country competitiveness (fitness) allows for quantifying the hidden growth potential of countries by the means of the comparison of this measure for intangible assets with monetary figures, such as GDP per capita. This comparison defines the fitness-income plane where we observe that country dynamics presents strongly heterogeneous patterns of evolution. The flow in some zones is found to be laminar while in others a chaotic behavior is instead observed. These two regimes correspond to very different predictability features for the evolution of countries: in the former regime, we find strong predictable pattern while the latter scenario exhibits a very low predictability. In such a framework, regressions, the usual tool used in economics, are no more the appropriate strategy to deal with such a heterogeneous scenario and new concepts, borrowed from dynamical systems theory, are mandatory. We therefore propose a data-driven method--the selective predictability scheme--in which we adopt a strategy similar to the methods of analogues, firstly introduced by Lorenz, to assess future evolution of countries.
The Building Blocks of Economic Complexity
[J].
DOI:10.1073/pnas.0900943106
URL
PMID:19549871
[本文引用: 2]
For Adam Smith, wealth was related to the division of labor. As people and firms specialize in different activities, economic efficiency increases, suggesting that development is associated with an increase in the number of individual activities and with the complexity that emerges from the interactions between them. Here we develop a view of economic growth and development that gives a central role to the complexity of a country's economy by interpreting trade data as a bipartite network in which countries are connected to the products they export, and show that it is possible to quantify the complexity of a country's economy by characterizing the structure of this network. Furthermore, we show that the measures of complexity we derive are correlated with a country's level of income, and that deviations from this relationship are predictive of future growth. This suggests that countries tend to converge to the level of income dictated by the complexity of their productive structures, indicating that development efforts should focus on generating the conditions that would allow complexity to emerge to generate sustained growth and prosperity.
Quantifying Local Industry Structure of China
[EB/OL].
Uncovering Patterns of Inter-Urban Trip and Spatial Interaction from Social Media Check-in Data
[J].
DOI:10.1371/journal.pone.0086026
URL
PMID:24465849
[本文引用: 1]
The article revisits spatial interaction and distance decay from the perspective of human mobility patterns and spatially-embedded networks based on an empirical data set. We extract nationwide inter-urban movements in China from a check-in data set that covers half a million individuals within 370 cities to analyze the underlying patterns of trips and spatial interactions. By fitting the gravity model, we find that the observed spatial interactions are governed by a power law distance decay effect. The obtained gravity model also closely reproduces the exponential trip displacement distribution. The movement of an individual, however, may not obey the same distance decay effect, leading to an ecological fallacy. We also construct a spatial network where the edge weights denote the interaction strengths. The communities detected from the network are spatially cohesive and roughly consistent with province boundaries. We attribute this pattern to different distance decay parameters between intra-province and inter-province trips.
Economic Prediction Using Heterogeneous Data Streams from the World Wide Web
[C]
Social Media Fingerprints of Unemployment
[J].
DOI:10.1371/journal.pone.0128692
URL
PMID:26020628
[本文引用: 1]
Recent widespread adoption of electronic and pervasive technologies has enabled the study of human behavior at an unprecedented level, uncovering universal patterns underlying human activity, mobility, and interpersonal communication. In the present work, we investigate whether deviations from these universal patterns may reveal information about the socio-economical status of geographical regions. We quantify the extent to which deviations in diurnal rhythm, mobility patterns, and communication styles across regions relate to their unemployment incidence. For this we examine a country-scale publicly articulated social media dataset, where we quantify individual behavioral features from over 19 million geo-located messages distributed among more than 340 different Spanish economic regions, inferred by computing communities of cohesive mobility fluxes. We find that regions exhibiting more diverse mobility fluxes, earlier diurnal rhythms, and more correct grammatical styles display lower unemployment rates. As a result, we provide a simple model able to produce accurate, easily interpretable reconstruction of regional unemployment incidence from their social-media digital fingerprints alone. Our results show that cost-effective economical indicators can be built based on publicly-available social media datasets.
How do Regions Diversify over Time? Industry Relatedness and the Development of New Growth Paths in Regions
[J].
Mapping Regional Economic Activity from Night-Time Light Satellite Imagery
[J].
The Collaborative Image of the City: Mapping the Inequality of Urban Perception
[J].
DOI:10.1371/journal.pone.0068400
URL
PMID:23894301
[本文引用: 1]
A traveler visiting Rio, Manila or Caracas does not need a report to learn that these cities are unequal; she can see it directly from the taxicab window. This is because in most cities inequality is conspicuous, but also, because cities express different forms of inequality that are evident to casual observers. Cities are highly heterogeneous and often unequal with respect to the income of their residents, but also with respect to the cleanliness of their neighborhoods, the beauty of their architecture, and the liveliness of their streets, among many other evaluative dimensions. Until now, however, our ability to understand the effect of a city's built environment on social and economic outcomes has been limited by the lack of quantitative data on urban perception. Here, we build on the intuition that inequality is partly conspicuous to create quantitative measure of a city's contrasts. Using thousands of geo-tagged images, we measure the perception of safety, class and uniqueness; in the cities of Boston and New York in the United States, and Linz and Salzburg in Austria, finding that the range of perceptions elicited by the images of New York and Boston is larger than the range of perceptions elicited by images from Linz and Salzburg. We interpret this as evidence that the cityscapes of Boston and New York are more contrasting, or unequal, than those of Linz and Salzburg. Finally, we validate our measures by exploring the connection between them and homicides, finding a significant correlation between the perceptions of safety and class and the number of homicides in a NYC zip code, after controlling for the effects of income, population, area and age. Our results show that online images can be used to create reproducible quantitative measures of urban perception and characterize the inequality of different cities.
大数据对人文—经济地理学研究的促进与局限
[J].
Opportunities and Limitations of Big Data Applications to Human and Economic Geography: The State of the Art
[J].
Micro-meso-macro
[J].
Economic History and Economics
[J].
基于启发式社团发现模型的创新态势研判算法
[J/OL].
Algorithm of Innovation Situation Analysis Based on Heuristic Model of Community Detection
[J/OL].
复杂网络链路预测
[J].
Link Prediction on Complex Networks
[J].
复杂网络中节点重要性排序的研究进展
[J].
Node Importance Ranking of Complex Networks
[J].
社会网络大数据分析框架及其关键技术
[J].
Social Networks Based on Big Data: Analytical Framework and Key Techniques
[J].
知识图谱构建技术综述
[J].
Knowledge Graph Construction Techniques
[J].
Plato etc: The Problems of Philosophy and Their Resolution
[M].
大数据情绪指数与经济学研究: 现状、问题与展望
[J].
Big Data Sentiment Index and Economic Research——Current Situation, Problems and Prospects
[J].
面向类不平衡问题的“职业举报人”识别方法
[J].
Identification Method of “Professional Whistleblower” Based on Class Imbalance Problem
[J].
自然语言处理的研究与发展
[J].
Research and Development of Natural Language Processing
[J].
“新经济地理学”在哪里?
[A]
Where is “New Economic Geography”
[A]
城市群经济网络与经济增长——基于大数据与网络分析方法的研究
[J].
Economic Networks and Economic Growth of Urban Agglomeration: An Integrated Approach of Big Data and Network Analysis
[J].
时空大数据分析技术在传染病预测预警中的应用
[J].
Application of Spatio-temporal Big Data Analysis Technologies in Forecasting and Early Warning of Infectious Diseases
[J].
数字经济背景下数据与其他生产要素的协同联动机制研究
[J].
Research on the Synergetic Linkage Mechanism of Data and Other Factors of Production under the Background of Digital Economy
[J].
多模态时空大数据可视分析方法综述
[J].
The Review of Visual Analysis Methods of Multi-modal Spatio-temporal Big Data
[J].
2019中国居民消费大数据指数发布
[EB/OL]. [
2019 Chinese Residents’ Consumption Big Data Index Released
[EB/OL]. [
研究报告:服务消费升级增长趋势最显著
[EB/OL]. [
Research Report: Service Consumption Upgrade Growth Trend is the Most Significant
[EB/OL]. [
“一带一路”贸易合作大数据报告
[EB/OL]. [
“Belt and Road” Trade Cooperation Big Data Report
[EB/OL]. [
A Global Poverty Map Derived from Satellite Data
[J].
Census from Heaven: An Estimate of the Global Human Population Using Night-time Satellite Imagery
[J].
大数据视角下企业发展瓶颈问题及对策——以S市国家高新技术企业为例
[J].
Bottleneck Problems and Countermeasures for Enterprise Development from the Perspective of Big Data——Taking National High-tech Enterprises in City S as an Example
[J].
Big Data Analytics: Turning Big Data into Big Money
[M].
基于大数据的宏观经济预测和分析
[J].
Macroeconomic Prediction and Analysis Based on Big Data
[J].
互联网搜索行为能帮助我们预测宏观经济吗?
[J].
Can Internet Search Behavior Help to Forecast the Macro Economy?
[J].
复杂网络中的社团发现与链路预测
[D].
Community Detection and Link Prediction of Complex Network
[D].
A Monthly Consumption Indicator for Germany Based on Internet Search Query Data
[J].
Predicting Consumer Behavior with Web Search
[J].
DOI:10.1073/pnas.1005962107
URL
PMID:20876140
[本文引用: 1]
Recent work has demonstrated that Web search volume can
Internet Search Behavior as an Economic Forecasting Tool: The Case of Inflation Expectations
[J].
Google Econometrics and Unemployment Forecasting
[J].
Using Web-based Search Data to Predict Macroeconomic Statistics
[J].
大数据背景下中国季度失业率的预测研究——基于网络搜索数据的分析
[J].
The Forecast of China’s Quarterly Unemployment Rate in the Background of Big Data——Analysis Based on Network Search Data
[J].
The Future of Prediction: How Google Searches Foreshadow Housing Prices and Sales
[A]
News Sensitivity and the Cross-Section of Stock Returns
[J].
Anticipating Stock Market Movement with Google and Wikipedia[A]//Nonlinear Phenomena in Complex Systems: From Nano to Macro Scale
[M].
Twitter Mood Predicts the Stock Market
[J].
基于时空数据驱动的交通流预测
[J].
Traffic Flow Prediction Based on Spatiotemporal Data
[J].
基于卷积神经网络的雾霾时空演化预测方法研究
[D].
Research on Forecast Method of Spatio-temporal Evolution of Haze Based on CNN
[D].
Combining Satellite Imagery and Machine Learning to Predict Poverty
[J].
DOI:10.1126/science.aaf7894
URL
PMID:27540167
[本文引用: 1]
Reliable data on economic livelihoods remain scarce in the developing world, hampering efforts to study these outcomes and to design policies that improve them. Here we demonstrate an accurate, inexpensive, and scalable method for estimating consumption expenditure and asset wealth from high-resolution satellite imagery. Using survey and satellite data from five African countries--Nigeria, Tanzania, Uganda, Malawi, and Rwanda--we show how a convolutional neural network can be trained to identify image features that can explain up to 75% of the variation in local-level economic outcomes. Our method, which requires only publicly available data, could transform efforts to track and target poverty in developing countries. It also demonstrates how powerful machine learning techniques can be applied in a setting with limited training data, suggesting broad potential application across many scientific domains.
实验经济学概述
[A]
An Overview of Experimental Economics
[A]
大数据预测与大数据时代的经济学预测
[J].
Big Data Prediction and Economic Prediction in the Era of Big Data
[J].

{kind=link}
{kind=link}