




1 以SQL为中心的技术栈
1969年,Codd提出关系模型(Relational Model),旨在以元组(Tuple)和关系(Relation)来表达和组织数据[1]。遵循关系模型的数据库即关系数据库,或称为关系数据库管理系统(RDBMS)。1974年,IBM开始第一个关系数据库System R的研发;1979年,Oracle公司推出第一个商业数据库Oracle。随后,关系数据库得到迅猛发展,并逐渐成为主导的数据库类型,包括DB2、SAP Sybase、Informix等。
RDBMS广泛应用于联机事务处理(OnLine Transaction Processing,OLTP)和联机分析处理(OnLine Analytical Processing,OLAP)的场景,OLAP系统一般以数据仓库(Data Warehouse,DW)作为基础,即从数据仓库中抽取详细数据的一个子集并经过必要的聚集存储到OLAP存储器中供前端分析工具读取[2]。作为商业智能的关键部分,数据仓库主要用以数据的统计分析,可进一步区分为关系OLAP(Relational OLAP,ROLAP)、多维OLAP(Multidimensional OLAP,MOLAP)和混合型OLAP(Hybrid OLAP,HOLAP)三种类型。其中,ROLAP直接采用RDBMS存储;MOLAP则将OLAP分析所用到的多维数据存储为多维数组的形式,形成“数据立方体”的结构,底层仍以RDBMS为主,综合列式存储、内存数据管理等系统搭建而成。
SQL语言在云计算和大数据时代仍占有重要地位,这方面的应用具体表现为三种形态:SQL on Hadoop、SQL over NoSQL以及Analytical SQL。
(1) SQL on Hadoop
(2) SQL over NoSQL
(3) Analytical SQL
SQL语言不仅用于数据库的查询分析和ETL,还被扩展到更多数据分析的场合。多维分析的例子如Apache Kylin[15],基于HBase存储,通过采用预计算和分层立方体的方法实现了多维数据的统计和快速查询,其中统计的语言采用SQL,如图1所示。2018年,谷歌在BigQuery[16]服务上推出BigQueryML[17],作为BigQuery功能的一部分,BigQueryML可以让数据科学家和分析师在大型的结构化或半结构化的数据集上构建和部署机器学习模型。另外一个例子是SQLFlow[18],SQLFlow的目标是将SQL引擎和AI引擎连接起来,仅需使用几行SQL代码即能描述整个应用或者产品背后的数据流和AI构造。其中所涉及的SQL引擎包括MySQL、Oracle、Hive、SparkSQL、Flink等,AI引擎包括TensorFlow、PyTorch等深度学习系统,也包括XGBoost、LibLinear、LibSVM等传统机器学习系统。
图1
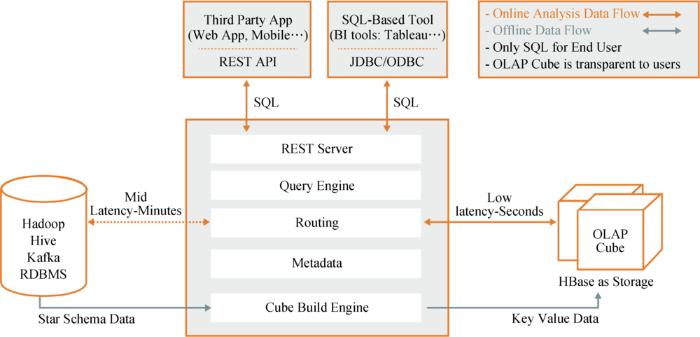
图1
Apache Kylin提供SQL的多维统计接口[15]
Fig.1
Multidimensional Analysis Interface of SQL in Apache Kylin
可以看出,在过去50年的数据管理与分析技术的发展历史中,SQL及关系模型扮演着极其重要的角色。图2从模型、语言、关键技术、工具、场景、应用等层次展示出以SQL为中心的技术栈,信息系统一旦采用以SQL为中心的技术栈,就意味着具有更大的技术开放性、稳定性和可扩展性。
图2

2 新型大数据技术栈的需求
大数据技术和应用的迅猛发展,给占据主导地位的SQL技术栈带来了新的挑战,这些挑战主要包括:多元异构数据的融合管理、大规模关系网络的管理与复杂的网络分析需求。
2.1 多元异构数据的融合管理需求
传统的RDBMS不能高效地管理多元异构数据,这些冲突主要体现在以下方面。
(1)RDBMS“先建模(Schema First)”的模式带来建模的不灵活性。
(2)传统架构很难支持水平扩展。
(3)SQL引擎所秉承的ACID(Atomicity,Consistency,Isolation,Durability)原则,成为实现轻型数据管理的沉重包袱。
SQL/NoSQL/NewSQL技术虽然实现了对多元数据的管理,但数据的孤岛化问题仍然存在,各类数据管理系统之间还是存在明显的边界。基于此,业界推出了诸如Multi-model Database[24]、Polystore等混合式数据管理系统架构,以及Lambda[25]、Kappa[26]等混搭式大数据架构,然而,这种混搭式的技术架构又大大增加了开发和运维的成本及难度。如图3所示,作为Polystore的一个典型实现系统,BigDAWG[27]将数据划分为关系型数据区、数组区以及文本区,底层分别基于PostgreSQL、SciDB、Accumulo作为存储,这种架构要求开发人员掌握不同系统之间的Cast语法,并要求运维人员熟练掌握三类数据库系统,难度较大。
图3

2.2 大规模关系网络的管理需求
2006年以来,知识图谱应用的迅猛发展,更刺激了对大规模关系网络的管理需求。知识图谱本质上是一种叫作语义网络(Semantic Network)的知识库,即具有有向图结构的一个知识库[30]。以学术领域为例,Springer Nature于2017年推出SciGraph关联开放数据平台[31],发布了科研资助机构、科研项目及拨款、会议、科研单位和出版物的信息,该平台计划累计15~20亿的三元组。另外,微软和清华大学推出了OAG[32],旨在整合全球学术知识图谱、公开共享学术图谱数据,并提供相关学术搜索和数据挖掘服务。截至2019年1月,OAG 2.0版本包含约7亿实体数据和约20亿实体之间的链接关系。
表1 关系网络数据集的数据规模示例
Table 1
| 名称 | 顶点规模 | 边规模 | 描述 |
|---|---|---|---|
| Wiki-Talk | 2 394 385篇文章 | 5 021 410条交流关系 | Wikipedia Talk网络 |
| Amazon0601 | 403 394类商品 | 3 387 388条“合买”(Co-purchasing) | Amazon产品合买记录 |
| Flickr | 11 195 144张照片 | 34 734 221条“喜欢” | Flickr照片及“喜欢”记录 |
| USA Patents | 3 774 768项专利 | 16 518 948条引用关系 | 美国专利(1975~1999年)及引用关系 |
| DBLP Data | 4 215 613篇论文 | 9 086 030条与作者的关系 | DBLP论文及作者关系 |
| musae-github | 37 700个深度开发者 | 289 003条“关注” | GitHub开发者关系网络 |
| roadNet-CA | 1 965 206个路口 | 2 766 607条道路 | California公路网络 |
2.3 复杂的网络分析需求
在社交网络、通信网络、计算机网络、道路网络等场景,也存在较大的数据挖掘分析的需求,包括节点分析、结构分析、路径查找、网络演化分析等。
以AMiner学术知识图谱为例,AMiner系统收集了7 900多万条论文信息、3 900多万条研究者信息,1.3亿论文引用关系、780万个知识实体以及3万多个学术会议/期刊的信息;AMiner同时提供了领域知识发展趋势可视化分析、人才专家排名与关系分析、引文溯源等功能[35]。这些功能的实现建立在复杂网络分析的基础上,如根据学者之间的合作关系进行学者社区发现、根据论文引用网络对学术成果进行分类、根据引文网络结构对论文进行重要性排序等。
利用网络生物学的方法对高通量基因表达数据进行分析和挖掘已经成为生物信息学重要的研究方向[36]。目前人们已经对各种类型的分子生物网络进行了广泛的研究,如基因共表达网络(Gene Co-expression Network)、基因调控网络(Gene Regulatory Network)、蛋白质相互作用网络(Protein-protein Interaction Network)、代谢网络(Metabolic Network)等。针对科研人员这一类网络需要提供高效的在线分析功能,如针对全球开放生物资源、文献、序列和疾病等万种数据源100亿级关联数据的知识发现,需在秒级时间内实现6步以上关联挖掘[37]。
从这些场景中,可以看出,“关系”作为一种重要类型的数据,广泛地存在于各种场景中,甚至比原始的“表记录”数据具备更大的规模,上层应用需要针对庞大的关系网络进行关系查询、计算和挖掘。然而,传统的关系模型采用分表的形式组织数据,缺少对关系的原生支持,当涉及表间数据的关系查询时,计算效率会大幅度下降,这种劣势在大规模数据下表现得尤为明显。
3 以图为中心的新型大数据技术栈
面对多元异构数据的融合管理、大规模关系网络的管理与复杂的网络分析需求,需要采取新的技术手段并构建新型的技术栈,这种技术栈应该具有如下特征。
(1)对信息世界的数据具有高度的表达能力,能很好地涵盖或映射到现有的SQL模型和NoSQL模型,如关系模型、KV模型、列式模型、文档模型、图模型。
(2)具备灵活的关系管理和关系计算分析的能力。
(3)要自成一体,软件栈自下而上保持简单自洽,而不是多种方法的混搭。
3.1 图数据模型的优势
图数据的基本类型是G=(V,E),V是图G的顶点集合,E是图G的边集合。图的边可以有方向,即当一张图是有向图时,对于任何的顶点u,v∈V,(u,v)≠(v,u)。
与关系模型相比,图数据模型具备如下优势。
(1)表达直观:图数据模型首先将世界里的数据表达成顶点和关系,其次再定义顶点和关系具有它们的属性。
(2)结构灵活:图的schema不需要预先定义,可以动态调整图的结构,以及增减顶点、边的属性。
(3)原生支持关系:图数据模式天然地适合处理事物之间的关系。
对于具有M个主键的A表和N个主键的B表,关系模型可借助中间关系表和Join操作来处理两表主键之间的关联关系,中间关系表的搜索空间是两表主键的笛卡尔积,即O(mn),对B表主键做了索引后,搜索空间可以优化为O(mlog(n));而在图数据模型里,主键(顶点)之间的关联关系被直接存储为边。实现这样的查询往往只需要O(m)的搜索空间:通过一个顶点,获取到它的边,是一个O(1)的操作。
图模型具有超强的表达能力,可以将关系模型、KV模型、列式模型和文档模型通过一些映射方法,映射成图模型,映射如表2所示。
表2 图数据模型对其他模型的表达能力
Table 2
| 映射方法 | 顶点 | 边 |
|---|---|---|
| 关系模型 | 表的一行映射成一个顶点,每一列列映射成顶点的属性 | 主外键关联映射成边 |
| KV模型 | 一个KV对映射成一个具有一个属性的顶点 | 无 |
| 列式模型 | 表的一行映射成一个顶点,每一列列映射成顶点的属性 | 无 |
| 文档模型 | 一个文档映射成一个顶点,文档的字段映射成顶点的属性 | 文档的嵌套关系映射成边 |
3.2 图技术发展现状
近十几年来,图模型及其关键技术,包括图数据库、图计算、图分析挖掘、图可视化等,得到了充分发展。
近年来,数据库管理系统的发展趋势如图4所示。可以看出,图数据库的发展势头迅猛。比较主流的图数据库系统有Neo4j、OrientDB、JanusGraph、Cosmos DB、InfiniteGraph等。为了应对大规模数据的管理,通常会采用分布式架构、副本等机制实现存储和查询。例如,JanusGraph采用“分布式查询引擎+分布式存储引擎”的组合架构,其数据存储支持Cassandra、HBase、BerkeleyDB,索引存储支持Elasticsearch、Solr、Lucene。
图4

图5

典型的图算法有PageRank、Label Propagation、Random Walk等。典型的图挖掘任务有社区网络分析(社区发现/图分割、连通子图发现)、图分类、图聚类、频繁子图模式发现等。为了使用深度学习方法有效实现图挖掘,往往需要借助于图嵌入(Graph Embedding)[47]和图神经网络(Graph Neural Network,GNN)[48]技术。图嵌入技术包括DeepWalk、Text-Associated DeepWalk (TADW)、Discriminative Matrix Factorization(DMF)等;图神经网络包括图卷积神经网络(Graph Convolutional Network,GCN)[49]和图注意力网络[50]等。
3.3 图技术应用现状
图模型及其技术在企业信息服务、互联网金融、生物医疗、公共安全等领域都有着深入的应用。
在企业信息服务领域,图技术得到广泛的应用。例如,“天眼查”基于政府公开数据,包括工商数据、法律诉讼、新闻动态、企业年报等全量信息,在线提供全国包含2亿家社会实体、90余种数据维度的信息, 涵盖企业名称、机构类型、地域、经营状况、知识产权等信息,并提供了查人、查关系、查风险、查“老赖”、天眼地图、高级搜索等功能。
图6
3.4 以图为中心的新型大数据技术栈
综上,图数据模型具备表达直观、结构灵活、关系管理高效等多种优势,图技术的发展日趋成熟完善,图技术的应用场景也越来越丰富。基于此,本文提出以图(而不是以SQL)为中心构建新型大数据技术栈的思路。该技术栈具备如下特征。
(1)满足软件栈的层次关系:即上层调用下层的服务。
(2)面向大数据场景:区分于传统的单机、关系型数据管理场景,充分考虑到大数据时代的数据湖、数据中台等需求,同时有效兼容Hadoop/Spark生态。
(3)以图为中心(Graph Centric):提倡采用“一张图”而不是“一堆表”来构建数据基础设施,同时提供系列基于图的数据管理、处理、分析方法。
完整的技术栈包括模型、语言、关键技术、工具、场景、应用等几个层次,设计如图7所示。
图7

与传统的SQL技术栈相比,新型技术栈的特色组件包括:基于图模型的数据湖、图数据仓库、gETL、图数据中台。
(1) 基于图模型的数据湖
数据湖概念的提出,旨在为企业提供一个完整的存储库,用以存储原始的或初加工的数据,包括结构化数据(数据库表等)、半结构化数据(CSV、log、XML、JSON)和非结构化数据(邮件、文档、二进制图像、音频、视频等)[64]。
由于数据湖的多源异构特征,目前针对数据湖的管理往往采用一些混搭的架构完成,如采用分布式文件系统实现非结构化文档的存储、采用HDFS存储结构化和半结构化的数据。华为云基于“云存储+CarbonData”构建的新一代数据湖,实现了实时数据接入、DB数据同步、高性能查询和分析等能力,使云化数据湖可以真正成为企业数据架构的基础。AWS于2019年推出数据湖管理工具AWS Lake Formation,对数据进行撷取、清理、分类、转换以及保护的工作,方便后续分析或是机器学习使用。Databricks则将数据湖和数据仓库结合起来,形成LakeHouse方案,并推出Delta Lake[65]。Delta Lake采用Bronze表、Silver表和Gold表三类表分别存储摄取数据、转换数据以及特征工程数据,并维护它们之间的流转,如图8所示。
图8
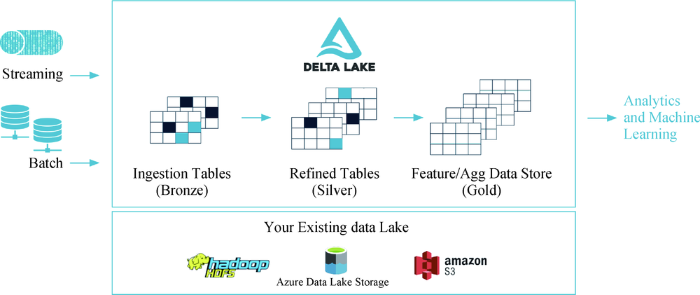
本技术栈提出基于“一张图”而不是“一堆表”构建数据湖的思路,与传统方法相比,图数据模型可以管理跨域数据、结构化与非结构化数据之间的关系,同时还可以管理分级数据之间的血缘关系。
(2) 图数据仓库
与数据湖的用途不一样,数据仓库主要处理历史的、结构化的数据。传统的数据仓库很难实现跨数据集或数据域的处理,同时提供的分析服务以多维统计分析为主,包括钻取(Roll-up和Drill-down)、切片(Slice)、切块(Dice)以及旋转(Pivot)等多维操作。
本技术栈提出图数据仓库的概念,提倡基于图模型和图技术构建数据仓库。与传统的数据仓库相比,在多维统计分析服务之外,图数据仓库更适合对图的要素进行统计,如实体统计、关系统计、社区发现、聚类等。图数据的统计同样具有不同的粒度,可以定义上卷(Roll-up)和下钻(Drill-down)等操作[66]。
ETL在数据仓库的构建过程中扮演着重要的角色,为了与传统的SQL ETL区分开,本技术栈提出gETL。gETL指针对图数据的抽取、转换和载入工作,包括从原始的结构化、非结构化文本中进行实体抽取、关系抽取和预测、实体消歧等。以抽取任务为例,gETL可以将CSV、JSON、XML、SQL等格式的多源数据,转换成“顶点-边”的图数据。
(3) 图数据中台
数据中台的概念最早由阿里巴巴提出,旨在通过企业内外部多源异构的数据采集、治理、建模、分析和应用,实现One Data(汇聚企业各种数据)、One ID(数据遵循相同的标准和统一标识)、One Service(提供统一的数据服务)的目标[67]。
在数据中台中,基于图模型及图技术可以更好地实现One Linked Data(汇聚并关联企业各种数据)、One Traceable ID(数据遵循相同标准和统一可追溯的标识)和One Graph Service(提供统一的图服务)。图可以表达数据之间的关联以及ETL过程中的数据血缘,从而实现数据资产中内容的关联化以及ID的可溯源。如图9所示,可以针对应用的需求定制“图谱服务”,如针对某类实体的画像、针对某两类实体的合作网络、跨实体间的路径发现等。图计算后台完成这些复杂任务的调度与执行,前端的图数据应用通过服务接口的调用,即可展示出相应的界面。
图9

考虑到图在语义网、开放数据、知识图谱等知识应用方面具有较大的价值。在模型层引入资源描述框架(RDF)模型,在工具层引入RDF数据库,数据中台可以基于RDF Graph构建富含语义的知识图谱。
综上所述,与以SQL为中心的技术栈进行对比, 以图为中心的技术栈在数据库、数据湖、数据仓库、ETL、大数据中台的构建方面具备一些特色和优势,如表3所示。
表3 以SQL、图为中心的技术栈之间的比较
Table 3
| 工具技术 | 以SQL为中心的技术栈 | 以图为中心的技术栈 |
|---|---|---|
| 数据库 | 关系数据库 查询语言为SQL 驱动包括ODBC、JDBC、DAO等 | 图数据库 查询语言包括Cypher、SPARQL、Gremlin等 |
| 数据湖 | 结构化、半结构化、非结构化数据的集中混搭式管理 其中结构化数据以关系表为主 | 一张图管理:基于图的结构化、半结构化、非结构化数据的融合管理 |
| 数据仓库 | 多维数据仓库 | 多维数据仓库+图数据仓库,增强关系挖掘、社区挖掘等能力 |
| ETL | ETL多基于SQL进行 | gETL:以图数据为主,包括实体抽取、关系抽取、实体消歧、链接预测等任务 |
| 大数据中台 | 数据服务以SQL报表、数据库CRUD为主 | 图数据:提倡以图为核心实现数据资产的管理,服务以网络分析、图谱可视化为主中台 |
4 智能融合数据管理系统PandaDB
传统的数据湖采用多种管理系统的混搭完成结构化、半结构化、非结构化数据的存储,在这种方案中,结构化、半结构化数据采用SQL、NoSQL数据库进行存储,非结构化数据存储在本地文件系统或分布式文件系统(HDFS、CEPH、MooseFS等)中。这种存储方式存在一个明显的不足:非结构化数据的数据游离于数据库之外,针对非结构化数据的内容理解严重依赖于上层应用程序;同时,非结构化数据与结构化数据之间存在的天然的关联未能得到很好的揭示,如人物照片与人物信息之间的关联、论文PDF与论文元数据之间的关联、视频与应用案例之间的关联等。
本文提出智能融合数据管理系统PandaDB,旨在实现大规模结构化、非结构化数据的统一存储和查询,同时通过集成人工智能的计算能力,实现对非结构化数据内在信息的透明化访问。
4.1 非结构化数据的表达
PandaDB基于属性图模型实现结构化、非结构化数据的融合管理。如图10所示,在属性图中,非结构化数据表达成一个Package类型的数据属性,Package与String、Integer、Date等属性类型一起,构成PandaDB的类型系统。
图10
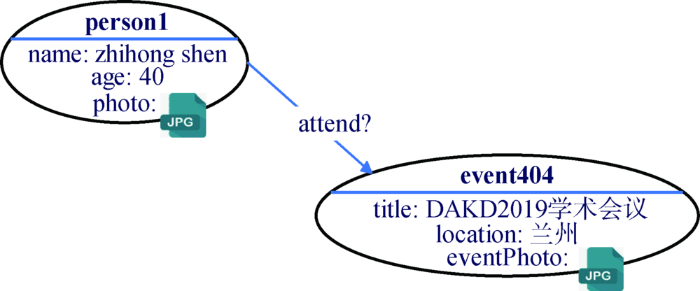
图10
采用属性图表示结构化、非结构化数据
Fig.10
Structured and Unstructured Data in Property Graph Model
Package的原始数据表达为一个二进制大对象(Binary Large Object, BLOB),通过打开一个二进制流实现BLOB的读写。此外,为了增强PandaDB对Package的理解能力,Package属性可以通过两种方式动态扩展为次级属性。
(1) 次级属性集方法
将Package扩展为多个二级属性的集合。例如,将一个名为photo的Package属性扩展为:{type:"car", plateNumber:"京X12345", color:"red"},其中,type、plateNumber、color即为二级属性。
(2) 次级属性图方法
将Package扩展为一个场景描述的属性图。例如,将一个名为photo的Package属性扩展为如下的属性图:[:person{type:"boy"}]-(:SIT_ON)-[:horse{color:"white"}]
该属性图用以描述“一个男孩骑着一匹白马”的场景,其中包含两个表示实体的顶点、一个表示位置关系的边。
4.2 统一查询语言
PandaDB针对标准化的Cypher语法进行扩展,称为CypherPlus,该扩展支持Package的数据表示、属性抽取以及语义计算。
(1)数据表示:在Cypher语言中采用<schema://path>的方式表达Package数据源,schema可以为FILE、HTTP(S)、FTP(S)、BLOB等多种类型。
(2)属性抽取:定义了var->propertyKey的操作符,如针对photo属性执行photo->plateNumber,即可抽取到photo中的车牌号。
(3)语义计算:针对Package属性的计算,如计算两张图片之间是否相似、是否包含等。目前CypherPlus支持的语义操作符如表4所示。
表4 CypherPlus针对Package定义的语义操作符
Table 4
| 操作符 | 含义 | 示例 |
|---|---|---|
| :: | 计算x和y之间的相似度 | x::y=0.7 |
| ~: | 计算x和y是否相似? | x~:y=true |
| !: | 计算x和y是否不相似? | x!:y=false |
| <: | 计算x是否在y里 | x<:y=true |
| >: | 计算x是否包含y | y>:x=true |
针对图10所示的图数据,执行如下查询:
match (p:Person),(e:Event) where p.photo<: e.eventPhoto create (p)-[:attend]->(e)
如果人物person1在event404事件的照片中出现,则会在它们之间构建一条attend边。以上语句中,->和<:即为CypherPlus的属性抽取操作符和语义计算操作符。
4.3 基于AI的非结构化数据信息抽取
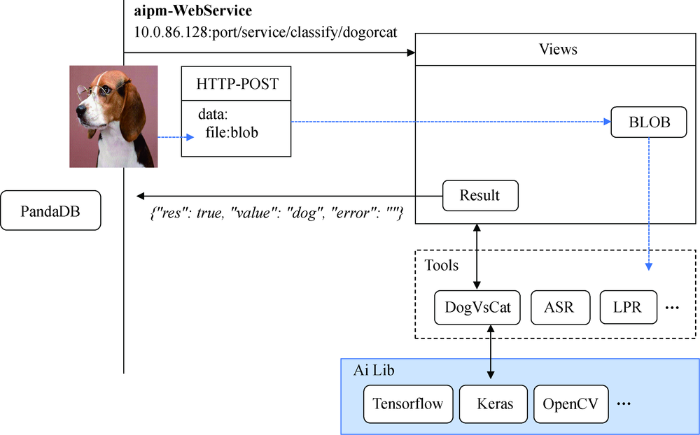
针对非结构化数据的信息抽取任务(包括次级属性集、次级属性图的抽取),PandaDB定义了AIPM模块。AIPM模块采用“框架+插件”的架构,提供基于CPU/GPU等异构计算资源、针对大规模非结构化数据进行的多元化AI计算服务,包括文本相似度计算、语音识别、动物分类、头像识别等。如需新的服务,按照AIPM的规范封装集成一个新的插件即可。
图11为AIPM技术架构,为屏蔽非结构化数据信息抽取方法的复杂依赖问题,AIPM通过容器技术屏蔽了不同算法之间的依赖冲突,并实现了AI算子的快速部署。
图11
4.4 查询引擎与加速机制
PandaDB基于openCypher开源项目,实现对主流的Cypher查询语言的支持。Cypher是Neo4j提出的一种适用于开发人员、数据科学家和运营专业人员的声明式语言。同时,Cypher也致力于ISO标准图形查询语言(Graph Query Language,GQL)的制定。openCypher项目提供了Cypher开发的相关资源,包括Cypher语言规范、样式指南、兼容性工具等。
如图12所示,与SQL查询引擎机理类似,Cypher查询语言的执行也经过解析、语义检查、逻辑计划、物理计划等阶段。PandaDB结合逻辑计划、存储引擎、索引结构生成物理计划,从而实现了Cypher查询能力。
图12

属性是属性图的主要要素,为了提供大规模属性存储的能力,同时加速对属性的检索性能,PandaDB设计了属性外置(External Property Store)的机制,即将大规模的属性存储在外部的一个支持全文索引的文档数据库中,同时采取谓词下推和列剪枝的方法,优先执行属性过滤。
4.5 分布式架构设计与实现
PandaDB针对非结构化数据、属性数据、图结构数据采取分布式存储结构,同时依赖分布式Cypher执行引擎完成查询任务。集群采用Apache Zookeeper作为协调器,从而避免了单点故障和压力过载。系统总体架构如图13所示。
图13

在PandaDB v0.1版本中,图存储基于Neo4j社区版实现,BLOB的存储基于Apache HBase实现,属性存储基于Apache Solr实现;在PandaDB v0.2版本中,为进一步提高系统的整体性能,降低运维成本,则采取自主的存储引擎,包括分布式非结构化数据存储RegionFS、分布式属性存储Bamboo等。
5 结语
自20世纪70年代起,关系模型及SQL语言统治数据管理与分析的世界已长达50年之久,从数据库到数据仓库,即便在大数据时代,它们仍然以SQL on Hadoop、SQL over NoSQL、Analytical SQL等多种形态展示出强大的生命力。本文在新的技术挑战和应用场景下,结合关系模型存在的不足和图数据模型的突出优势,提出基于图模型的数据湖、图数据仓库、gETL、图数据中台等思路,并继而提出以图为中心的新型大数据技术栈。
该技术栈在世界微生物数据中心知识服务平台[68]、国家自然科学基金大数据知识管理服务平台[69]、烟草科研数据融合与关联挖掘关键技术研究(简称TobaccoRDP)等项目中得到部分或完整的实践。TobaccoRDP通过图技术栈的应用,汇聚了来自烟草科研知识图谱、烟草育种大数据平台、烟叶质量大数据分析服务平台的多元异构数据,构建了统一的烟草科研数据湖,并形成图数据中台,提供了面向应用的主题库、多维统计、地理信息统计、学术知识图谱等形式的服务。TobaccoRDP采用PandaDB作为核心组件,实现了对数据湖和数据仓库的构建与管理,在数据资源存储与检索中性能良好,同时对图分析和挖掘提供了良好的支撑。
与传统的SQL技术栈相比,以图为中心的大数据技术栈具备模型表达能力强、关系网络分析挖掘能力强等优势,可以有效地实现多元异构数据的融合管理、大规模关系网络的管理与复杂的网络分析。然而,作为一种新型的全套方案,以图为中心的技术栈无论是在图数据仓库、gETL、图数据中台等技术的成熟度方面,还是在完整的应用生态方面,与SQL技术栈还存在较大的差距。但随着技术与应用的不断深入,这些不足会逐渐得以克服,以图为中心的新型大数据技术栈终将在企业信息服务、互联网金融、生物医疗、公共安全等应用场景发挥更大的价值。
作者贡献声明
沈志宏:提出研究思路,设计研究方案,负责主要内容的撰写;
赵子豪:负责2.3、3.3、4.3节等内容的撰写,负责格式修订和图片编辑;
王海波:负责3.3、3.4节;TobaccoRDP应用等内容的撰写,并对技术栈的架构做出补充。
利益冲突声明
所有作者声明不存在利益冲突关系。
参考文献
Derivability, Redundancy and Consistency of Relations Stored in Large Data Banks
[J].
Providing OLAP (On-Line Analytical Processing) to User-analysts. An IT Mandate
[R].
The Kettle Open Source Data Integration Project
[EB/OL]. [
Talend - A Cloud Data Integration Leader (modern ETL)
[EB/OL]. [
Enterprise Cloud Data Management | Informatica
[EB/OL]. [
Oracle GoldenGate
[EB/OL]. [
Hive: A Warehousing Solution over a Map-reduce Framework
[J].
Impala: A Modern, Open-Source SQL Engine for Hadoop
[C]
SQL Interface for Solr Cloud
[EB/OL]. [
Apache Calcite: A Foundational Framework for Optimized Query Processing over Heterogeneous Data Sources
[C]
The CQL Continuous Query Language: Semantic Foundations and Query Execution
[J].
Fusion Insight LibrA: Huawei’s Enterprise Cloud Data Analytics Platform
[J].
Apache Kylin | Analytical Data Warehouse for Big Data
[EB/OL]. [
What is BigQuery?
[C]
BigQuery ML
[EB/OL]. [
SQLFlow: A Bridge Between SQL and Machine Learning
[OL].
Big Data: Issues, Challenges, Tools and Good Practices
[C]
Function-based Solution Retrieval and Semantic Search in Mechanical Engineering
[C]
The NoSQL Principles and Basic Application of Cassandra Model
[C]
CAP Twelve Years Later: How the “Rules” Have Changed
[J].
Multi-model Data Management: What's New and What's Next?
[C]
Lambda Architecture for Cost-effective Batch and Speed Big Data Processing
[C]
Questioning the Lamba Architecture
[EB/OL]. [
The BigDAWG Polystore System
[J].
What is Twitter, a Social Network or a News Media?
[C]
Four Degrees of Separation
[C]
知识图谱研究进展
[J].
The Research Advances of Knowledge Graph
[J].
SN SciGraph-A Linked Open Data Platform for the Scholarly Domain
[EB/OL]. [
OAG: Toward Linking Large-scale Heterogeneous Entity Graphs
[C]
Stanford Large Network Dataset Collection
[EB/OL]. [
BigDND: Big Dynamic Network Data
[EB/OL]. [
AMiner: Toward Understanding Big Scholar Data
[C]
基因共表达网络的构建及分析方法研究综述
[J].
A Review of the Construction and Analysis of Gene Co-expression Network
[J].
科学大数据管理:概念、技术与系统
[J].
Scientific Big Data Management: Concepts,Technologies and System
[J].
Heterogeneous Graph Neural Networks for Malicious Account Detection
[C]
Enhancing Metro Network Resilience via Localized Integration with Bus Services
[J].
Planning Guidelines for Metro-bus Interchanges by Means of a Pedestrian Microsimulation Model
[J].
TGraph: A Temporal Graph Data Management System
[C]
Efficient Snapshot Retrieval over Historical Graph Data
[C]
DBMS Popularity Broken down by Database Model
[EB/OL]. [
A Bridging Model for Parallel Computation
[J].
Pregel: A System for Large-scale Graph Processing
[C]
图计算框架回顾
[EB/OL]. [
Review of Graph Calculation Framework
[EB/OL]. [
Graph Embedding and Extensions: A General Framework for Dimensionality Reduction
[J].
DOI:10.1109/TPAMI.2007.12
URL
PMID:17108382
[本文引用: 1]

Over the past few decades, a large family of algorithms - supervised or unsupervised; stemming from statistics or geometry theory - has been designed to provide different solutions to the problem of dimensionality reduction. Despite the different motivations of these algorithms, we present in this paper a general formulation known as graph embedding to unify them within a common framework. In graph embedding, each algorithm can be considered as the direct graph embedding or its linear/kernel/tensor extension of a specific intrinsic graph that describes certain desired statistical or geometric properties of a data set, with constraints from scale normalization or a penalty graph that characterizes a statistical or geometric property that should be avoided. Furthermore, the graph embedding framework can be used as a general platform for developing new dimensionality reduction algorithms. By utilizing this framework as a tool, we propose a new supervised dimensionality reduction algorithm called Marginal Fisher Analysis in which the intrinsic graph characterizes the intraclass compactness and connects each data point with its neighboring points of the same class, while the penalty graph connects the marginal points and characterizes the interclass separability. We show that MFA effectively overcomes the limitations of the traditional Linear Discriminant Analysis algorithm due to data distribution assumptions and available projection directions. Real face recognition experiments show the superiority of our proposed MFA in comparison to LDA, also for corresponding kernel and tensor extensions.
The Graph Neural Network Model
[J].
DOI:10.1109/TNN.2008.2005605
URL
PMID:19068426
[本文引用: 1]
Many underlying relationships among data in several areas of science and engineering, e.g., computer vision, molecular chemistry, molecular biology, pattern recognition, and data mining, can be represented in terms of graphs. In this paper, we propose a new neural network model, called graph neural network (GNN) model, that extends existing neural network methods for processing the data represented in graph domains. This GNN model, which can directly process most of the practically useful types of graphs, e.g., acyclic, cyclic, directed, and undirected, implements a function tau(G,n) is an element of IR(m) that maps a graph G and one of its nodes n into an m-dimensional Euclidean space. A supervised learning algorithm is derived to estimate the parameters of the proposed GNN model. The computational cost of the proposed algorithm is also considered. Some experimental results are shown to validate the proposed learning algorithm, and to demonstrate its generalization capabilities.
Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering
[C]
Graph Attention Networks
[C]
Rethinking Perceptual Organization: The Role of Uniform Connectedness
[J].
WebVOWL: Web-based Visualization of Ontologies
[C]
RDF Data Exploration and Visualization
[C]
RelFinder: Revealing Relationships in RDF Knowledge Bases
[C]
GeaBase: A High-performance Distributed Graph Database for Industry-scale Applications
[J].
知识图谱研究综述
[J].
Review on Knowledge Graphs
[J].
Chem2Bio2RDF Dashboard: Ranking Semantic Associations in Systems Chemical Biology Space
[C]
BioNav: An Ontology-based Framework to Discover Semantic Links in the Cloud of Linked Data
[C]
Uncloaking Terrorist Networks
[J].
Understanding People Lifestyles: Construction of Urban Movement Knowledge Graph from GPS Trajectory
[C]
Opinion-aware Knowledge Graph for Political Ideology Detection
[C]
The Spread of Obesity in a Large Social Network over 32 Years
[J].
DOI:10.1056/NEJMsa066082
URL
PMID:17652652
[本文引用: 1]
BACKGROUND: The prevalence of obesity has increased substantially over the past 30 years. We performed a quantitative analysis of the nature and extent of the person-to-person spread of obesity as a possible factor contributing to the obesity epidemic. METHODS: We evaluated a densely interconnected social network of 12,067 people assessed repeatedly from 1971 to 2003 as part of the Framingham Heart Study. The body-mass index was available for all subjects. We used longitudinal statistical models to examine whether weight gain in one person was associated with weight gain in his or her friends, siblings, spouse, and neighbors. RESULTS: Discernible clusters of obese persons (body-mass index [the weight in kilograms divided by the square of the height in meters], > or =30) were present in the network at all time points, and the clusters extended to three degrees of separation. These clusters did not appear to be solely attributable to the selective formation of social ties among obese persons. A person's chances of becoming obese increased by 57% (95% confidence interval [CI], 6 to 123) if he or she had a friend who became obese in a given interval. Among pairs of adult siblings, if one sibling became obese, the chance that the other would become obese increased by 40% (95% CI, 21 to 60). If one spouse became obese, the likelihood that the other spouse would become obese increased by 37% (95% CI, 7 to 73). These effects were not seen among neighbors in the immediate geographic location. Persons of the same sex had relatively greater influence on each other than those of the opposite sex. The spread of smoking cessation did not account for the spread of obesity in the network. CONCLUSIONS: Network phenomena appear to be relevant to the biologic and behavioral trait of obesity, and obesity appears to spread through social ties. These findings have implications for clinical and public health interventions.
Dynamic Spread of Happiness in a Large Social Network: Longitudinal Analysis over 20 Years in the Framingham Heart Study
[J].
Data Lake: A New Ideology in Big Data Era
[C]
Graph OLAP: Towards Online Analytical Processing on Graphs
[C]
建设数据中台,赋能创新改革
[J].
Building Data Middle Platform, Enable Creative Innovation
[J].
World Data Centre for Microorganisms: An Information Infrastructure to Explore and Utilize Preserved Microbial Strains Worldwide
[J].
DOI:10.1093/nar/gkw903
URL
PMID:28053166
[本文引用: 1]
The World Data Centre for Microorganisms (WDCM) was established 50 years ago as the data center of the World Federation for Culture Collections (WFCC)-Microbial Resource Center (MIRCEN). WDCM aims to provide integrated information services using big data technology for microbial resource centers and microbiologists all over the world. Here, we provide an overview of WDCM including all of its integrated services. Culture Collections Information Worldwide (CCINFO) provides metadata information on 708 culture collections from 72 countries and regions. Global Catalogue of Microorganism (GCM) gathers strain catalogue information and provides a data retrieval, analysis, and visualization system of microbial resources. Currently, GCM includes >368 000 strains from 103 culture collections in 43 countries and regions. Analyzer of Bioresource Citation (ABC) is a data mining tool extracting strain related publications, patents, nucleotide sequences and genome information from public data sources to form a knowledge base. Reference Strain Catalogue (RSC) maintains a database of strains listed in International Standards Organization (ISO) and other international or regional standards. RSC allocates a unique identifier to strains recommended for use in diagnosis and quality control, and hence serves as a valuable cross-platform reference. WDCM provides free access to all these services at www.wdcm.org.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}