




1 引言
关键短语抽取是指从文本中自动抽取出能够代表文本主要内容的一组短语,与中文关键词抽取的结果全部为单个词语不同,关键短语抽取的结果是由一个或若干个词语构成的具有更丰富语义信息的短语。例如,“高校”和“图书馆”两个分开的词语所各自表达的含义与“高校图书馆”作为一个整体所表达的含义具有显著差异,关键短语的可理解性和相关性均优于关键词,在学术推荐[1,2]和学术主题发现[3]等应用中具有重要的基础作用。关键短语的抽取分为有监督和无监督两种方式[4],有监督抽取方法将关键短语抽取看作一个分类问题,通过构造候选短语的特征信息,如出现频度、词性、位置、长度等信息,训练分类器实现短语识别。无监督方法则不需要事先提供标注语料,而是根据文档本身的信息,或辅之以通用的外部知识,实现短语抽取。相比而言,无监督方法不需要人工构建训练集,在实践中广为流行。
由于单个的中文词语比英文词语承载了更多的语义信息,目前针对中文文本的相关研究多为关键词抽取,但对于学术文本来说,短语承载了更多信息,以本文所构建的学术文本实验数据集为例,论文作者标记的关键词有72%为短语形式,直接采用关键词抽取难以取得令人满意的效果。此外,英文文本的无监督关键短语抽取算法,通常需要按照一定规则事先抽取出若干连续词语作为候选短语,进而基于统计特征或词图网络特征,抽取关键短语。由于语言差异,中文这种意合型语言在基于规则选择候选短语时,比形合型语言更为困难。例如,把连续的名词串作为候选短语是英文关键短语抽取的主流做法,但对于中文来说,连续的名词类词语构成的词串经常会包含多个独立的语义单元,如“学校/研究/中心/研究员/张三/同志/报告/内容/非常/精彩”,把前面连续8个名词类词语作为一个候选短语,在表达文本语义时粒度过大,而采用N-Gram方式则会为词图构建带来困难。因此,本文针对中文学术文本,提出后识别方法,在词语构成词图并识别关键词语节点之后,设计内部凝聚度和边界自由度两个指标进一步计算词语之间构成短语的能力,并与单个词语节点进行融合排序,实现关键短语抽取。
2 相关研究
无监督关键短语的抽取方法包括基于统计的方法和基于图的方法两大类[4]。基于统计的方法主要以TF-IDF及其变形特征,对候选关键短语进行评分计算和排序,KP-Miner[12]是其代表性算法。为使关键短语集合尽可能全面地覆盖不同的主题,文献[13]提出KeyCluster算法,将候选关键短语聚为若干簇,进而从每个簇里挑选代表性短语。近年来,将统计特征与上下文信息进行结合,是提升关键词抽取效果的新尝试,如YAKE[14]利用英文词语的大小写、与上下文的相关度以及位置信息;Won等[15]则考虑了候选短语的频度、逆文档频度、出现在句子开始的情况、以及短语长度这4类统计信息,并通过形容词和名词组合而成的候选短语以及词干处理,实现英语和葡萄牙语的关键短语抽取。这些统计方法在特征选择方面,都充分考虑了语言特点。
与英文强调关键短语抽取不同,现有的中文研究多面向关键词抽取,图方法在中文无监督抽取中同样占据了主流。夏天等以TextRank算法为基础,先后提出了位置加权[22]、引入LDA的主题加权[23]、引入词向量的聚类加权[24]三类关键词抽取方法,将文档本身的频度、位置等统计信息,文档集整体的主题、语义信息纳入到关键词抽取过程中,确立了文档本身特征加权和引入文档外部知识改进关键词抽取效果的两个方向。文献[25,26,27,28]的研究均可以看作是这一思路的拓展。例如,方俊伟等[28]将候选关键词的使用情况作为先验概率特征值,融入TextRank算法实现学术文本的关键词抽取,相当于将数据集整体知识融入到单篇文档的抽取过程中。
无监督关键短语抽取可以分为三个步骤:候选关键短语选择、候选关键短语的评分计算以及关键短语的排序生成。在候选关键短语选择方面,英文多采用启发式规则,如基于词性、介词、标点符号、词干等构造候选短语。由于中文单个词语能够表达一定的主题意义,同时中文候选短语的选择相对较为困难,导致对中文关键短语的研究较少,整体上尚处于起始阶段[8]。对于学术文本而言,反映文本核心内容的语义单元不仅有单个词语,多个词语尤其是两个词语构成的组合概念更为常见。因此,本文面对中文学术文本的概念表达特点,基于词语在词图中的影响力以及词语之间的内外部组合能力,实现了单一词语和双词词语两种常见形式的关键短语抽取,避免了英文中候选短语的预构造环节,与经典的关键词抽取方法相比,本文方法所获得的结果与作者标记关键词的一致性得到了显著提升。
3 实现方法
为便于体现关键词和关键短语的差异,本文把抽取单元仅包含单个词语的情况称为关键词抽取,否则称为关键短语抽取,即关键短语的抽取结果包含一个或多个词语。
对于中文学术文本而言,关键短语主要由单词和双词两种形式构成,在实验数据集中,符合这两种形式的情况所占比例超过82%,因此,本文把抽取问题限定在单词和双词短语的抽取方面,并提出如图1所示的4步处理流程。
图1
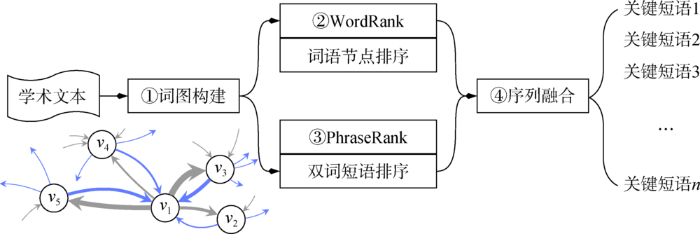
(1)词图构建:基于词语之间的邻接关系构建词图网络;
(2)词语节点排序:在词图网络上计算词语节点的重要性并进行排序;
(3)双词短语排序:在词图网络上计算双词短语的重要性并进行排序;
(4)序列融合:根据排序输出的前N个词语结果集和短语结果集,进行融合排序,并基于融合后的序列获取最终的关键短语。
3.1 词图构建
将文本中的词语作为节点,词语之间的邻接关系作为边,构成的有向带权图,称为词图。词图本质上为一个二元组:
在词图构建过程中,给定一段文本,首先对其进行分词和词性标记,形成原始分词序列,记为
为方便关键短语的抽取,如果
图2
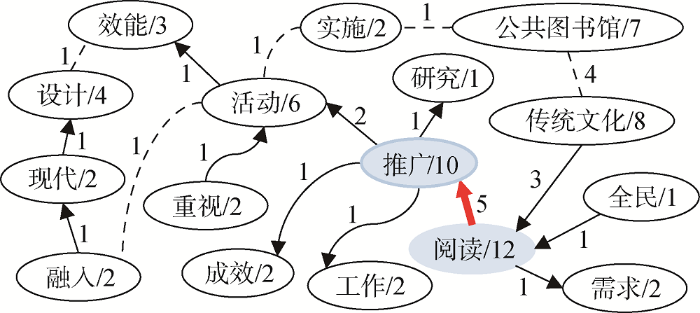
3.2 词语节点排序
词语节点排序(WordRank)是通过一定算法计算词语在词图网络中的重要性,将词语根据重要性大小降序排序,从而获得一组具有高影响力、能够反映文本核心概念的词语结果。单个词语本身也可以构成关键短语,一个词语在词图中起到的作用越大,其成为关键短语的概率就越大。
TextRank是词图当中度量词语重要性的主要方法,该方法以迭代方式按照公式(1)计算节点
其中,
在实践中,TextRank算法还可以将词语频度、长度、位置等信息纳入到计算过程之中,进一步提升词语节点的排序效果。本文基于前期在TextRank方面的相关研究,采用文献[22]的位置加权方法进行节点重要性计算和排序。
令向量
基于公式(2)进行迭代计算,当计算结果收敛之后,向量
理论上,其他TextRank改进算法,也可以用于词语节点排序之中,如LDA主题加权、词向量聚类加权等,本文采用位置加权的原因如下。
(1)针对文献[22]的改进算法,如文献[23-24,26],通常需要特定数据集的训练支撑,并非完全意义上的“无监督”抽取,不易做到“开箱即用”。
(2)针对文献[22]的改进算法,在关键词抽取方面效果有小幅度提升,因此,如果本文的关键短语抽取能够取得较好效果,将本步处理替换为其他相似算法时,整体效果理论上会随之提升,不影响本文方法的适用性。
3.3 双词短语排序
(1) 基本假设
给定两个独立的词语a、b,令
①假设1:词语a、b前后直接相邻出现的次数越多,则
②假设2:长度较短的词语与长度较长的词语相比,具有更高的与其他词语组合成为关键短语的能力。
③假设3:相比其他词语节点,词语a、b结合越紧密,则
④假设4:词语a的左侧相邻的词语种类越多,则词语a越不易于和左侧的其他词语构成关键短语,因此,从a的左侧断开,a与右侧的词语b构成短语的可能性越高。
⑤假设5:词语b的右侧相邻的词语种类越多,则词语b越不易于和其右侧的其他词语构成关键短语,因此,从b的右侧断开,b与左侧的词语a构成短语的可能性越高。
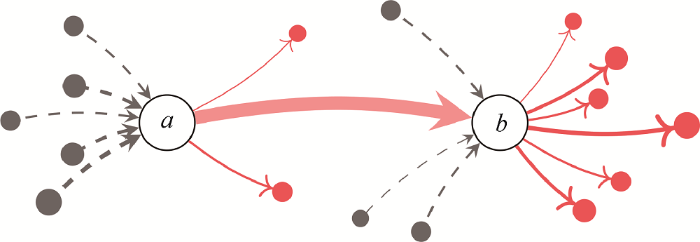
图3给出了以词语a、b为中心的词图片断,边的方向表明两个词语的前后出现顺序,边的粗细代表词对出现的频度大小,虚线表示由其他词语节点指向节点a或b,实线则表示由节点a或b指向其他词语节点。为便于表述,令
图3
(2) 内部凝聚度计算
为反映两个词语构成短语的内部紧密程度,本文提出凝聚度指标(Cohesion Indicator),基于前三个假设计算凝聚度大小。
首先,给定由单个词语作为节点构成的词图,假设1可通过词语节点a、b相邻出现的频度度量,假设2则表明
其中,
其次,假设3用于反映一对词语a、b与其关联节点相比,构成关键短语的相对能力大小。在由a或b构成的所有潜在短语中,
综合公式(3)-公式(6),可得出如下关系。
由于关键短语的抽取结果取决于每个短语得分的相对大小,对公式(7)取对数,不改变排序结果的顺序,为方便运算,本文将
(3) 边界自由度计算
自由度指标(Freedom Indicator)用于度量一个词语与相邻词语自由搭配的能力。基于假设4和假设5,将自由度进一步分为左自由度和右自由度,其中,左自由度指一个词语与左侧的其他词语自由组合的能力,右自由度则指与右侧其他词语自由组合的能力。给定两个邻接的词语
为度量自由度的大小,本文基于信息熵原理,通过公式(9)和公式(10)分别计算词语a的左自由度
其中,对于
本质上,公式(9)-公式(12)的计算结果为边界词语与其他邻接词语随机出现的熵值,熵作为度量事件不确定性的信息单位,其取值反映了词语的自由搭配能力。进一步,
以图3为例,指向词语节点a的入边越多且频度越均匀,则左侧词语与a合并形成关键短语的概率越低;词语节点b的出边越多且频度越均匀,则b与其右侧相邻词语构成短语的概率越低。此时,
(4) 短语权威度计算与排序输出
两个相邻词语
其中,
对所有符合条件的邻接词语对计算权威度,按照权威度由高到低排序,输出TopN个结果作为关键短语参与后续的序列融合处理。
3.4 序列融合
基于短语权威度排序和节点权威度排序,共得到两个独立的序列,即基于加权TextRank得到的词语权威度输出序列和基于短语权威度运算得到的短语序列,此时,还需要进一步将两个独立序列融合排序,在单一序列上获取最终的抽取结果。
令
(1) 无效候选短语的过滤
仅当候选短语
(2) 短语排序重要性调整
对
即候选短语的最终排序重要性,与其本身在短语结果集中的位置以及构成短语的词语在词语结果集中的位置有关,其中,短语原有的排序位置对其最终排序值起主要作用,词语排序位置通过对数运算之后,起次要作用。
(3) 词语排序重要性调整
对于
公式(16)表明,一个词语会随着其在关键短语之中出现的频度而增大排序值,意味着其排序重要性会随之降低。
(4) 合并排序
将候选短语和候选词语两个序列合并在一起,并按照新的排序值进行升序排序,挑选TopN个元素作为最终的关键短语抽取结果。
4 实验
4.1 实验数据
在实验数据方面,本文选择图书馆学、情报学、档案学领域的20本CSSCI(2015-2019)收录的期刊,以中国知网为检索平台,导出2015年-2019年期间所刊登文献的标题、摘要和关键词,并剔除其中的英文文献、人工标记的关键词数量小于等于1的文献,形成实验数据集,数据集共包括17 825条数据,以CSV格式保存,并予以公开。
数据集共包含72 337个关键短语,平均每篇文献包含4.06个关键短语,每个关键短语的平均字符长度为4.45,由1.96个词语构成。不同词语长度的关键短语分布如表1所示。
表1 数据集中关键短语的统计信息
Table 1
| 构词数量 | 平均字符长度 | 出现次数 | 占比 | 累计占比 |
|---|---|---|---|---|
| 1 | 3.34 | 20 303 | 28.07% | 28.07% |
| 2 | 4.33 | 39 028 | 53.95% | 82.02% |
| 3 | 5.95 | 10 005 | 13.83% | 95.85% |
| 4 | 7.46 | 2 142 | 2.96% | 98.81% |
| 5 | 9.48 | 476 | 0.66% | 99.47% |
| 6 | 10.55 | 218 | 0.30% | 99.77% |
| 7 | 12.65 | 79 | 0.11% | 99.88% |
| 8 | 15.59 | 37 | 0.05% | 99.93% |
| 9 | 17.07 | 14 | 0.02% | 99.95% |
| 10 | 16.18 | 22 | 0.03% | 99.98% |
| 其他 | - | 13 | 0.02% | 100.00% |
表1中构词数量是指对作者标记的关键词,进行自动分词后得到的词语数量。其中,多个词语构成的关键短语占比71.93%,表明学术文本在表达概念的时候,多采用短语形式。此外,由单个词语或双词词语构成的关键短语,占比超过80%,这两种情况构成了关键短语的常见形式。处理这两种情况,就可以解决关键短语的主要问题。
4.2 评价指标
为反映算法效果,本文采用两种评价指标,一是常规的准确率
上述评价指标存在如下局限:
(1)需要同时使用三个指标评价效果的优劣;
(2)不能体现排序效果的差异;
(3)排序输出的关键短语数量对评价指标得分有较大影响。
为了用单一指标评价算法的整体效果,并能体现排序效果的差异,本文借鉴信息检索中的
首先,对于任一文档
其中,
如果不限定抽取结果的数量
对所有文档的AP取平均值,即MAP,当算法输出的关键短语数量取值为
显然,算法保留的关键短语数量
即令每个文档
4.3 结果分析
为对比关键短语和关键词在学术文本中表达核心概念的差异,实验分别采用位置加权关键词抽取算法(简称WordRank)和本文提出的关键短语抽取算法(简称PhraseRank),分别对数据集进行自动抽取,并和论文作者的原始标记结果进行对比。WordRank算法涉及的参数均与文献[22]保持一致,关键短语抽取中,词语节点排序和双词短语排序均输出前10个结果,参与两个序列的融合计算。同时,本文公开了所有相关数据和代码 (
根据N取值不同,分别计算关键短语和关键词抽取结果的
图4
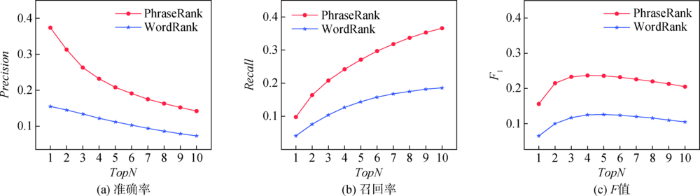
图4
PharseRank与WordRank的P、R、F值对比
Fig.4
P, R and F Comparison of PharseRank and WordRank
图5
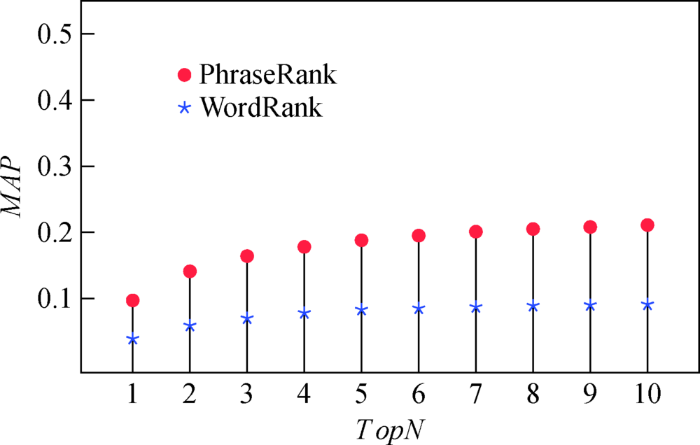
表2 WordRank、PhraseRank的MAP@N和R-MAP对比
Table 2
| 算法 | MAP@3 | MAP@5 | MAP@7 | MAP@10 | R-MAP |
|---|---|---|---|---|---|
| WordRank | 0.070 | 0.083 | 0.087 | 0.091 | 0.077 |
| PhraseRank | 0.164 | 0.188 | 0.201 | 0.211 | 0.176 |
表2中R-MAP一列表明,当算法输出的元素数量限定为人工标记的关键短语数量时,PhraseRank算法平均准确率均值为0.176,远超仅考虑单个词语的WordRank算法,相对提升比例达128.57%。
为便于观察算法表现较差时的抽取情况,本文挑选了
表3 R-AP=0文档的抽取结果示例
Table 3
| 文档标题 | 人工标记 | WordRank | PhraseRank |
|---|---|---|---|
| 面向安全教育的儿童阅读推广研究 | 图书馆, 儿童阅读推广, 安全 | 儿童, 推广, 阅读 | 儿童, 阅读推广, 教育 |
| 图书馆电子书馆配研究 | 馆配市场, 电子书馆配, 图书馆 | 电子书, 图书馆, 文献 | 图书馆电子书, 文献, 市场 |
| 国外基于情感角度的信息搜寻行为研究进展 | 情感, 认知, 信息搜寻行为 | 情感, 信息, 搜寻 | 情感因素, 影响信息, 搜寻 |
| 试析大数据在电子文件管理中的应用 | 大数据, 电子文件管理 | 文件, 电子 | 电子文件, 文件管理 |
| 虚实融合的图书馆空间互动服务模式研究 | 图书馆, 实体空间, 虚拟空间 | 图书馆, 空间, 服务 | 图书馆空间, 服务模式, 互动服务 |
基于以上分析,可以得出如下结论。
(1)对于学术文本的词汇级别的语义分析,关键短语要比单纯的关键词更能在词汇级别上表达学术文本的核心概念。
(2)在词图上应用短语内部凝聚度和边界自由度,并对抽取得到关键短语进行融合排序,显著优于词图节点位置加权得到的关键词抽取结果。
(3)R-MAP指标同时考虑了排序因素和数据集人工标记的结果数量,这个单一指标可以度量不同算法在关键词或关键短语抽取方面的效果差异。
5 结语
本文针对中文学术文本中词汇级别的概念表达多为短语形式的特点,提出一种基于词图的短语权威度计算方法,综合考虑了短语内部的凝聚能力和短语边界的自由组合能力,并与位置加权抽取得到的关键词进行融合排序,实现关键短语抽取。此外,本文基于
针对无监督单文档关键短语抽取的下一步研究:①解决三个及以上词语组成的关键短语识别与抽取问题;②引入句法分析进一步优化词语之间的搭配关系度量方法,提高关键短语抽取效果。
利益冲突声明
作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,
[1] 夏天.paper_abstract.csv.中文学术论文摘要数据集.
参考文献
CSSeer: An Expert Recommendation System Based on CiteseerX
[C]
Document Embeddings vs. Keyphrases vs . Terms for Recommender Systems: A Large-Scale Online Evaluation
[C]
Finding Scientific Topics
[J].
A Review of Keyphrase Extraction
[OL].
Keyword and Keyphrase Extraction Techniques: A Literature Review
[J].
Automatic Keyphrase Extraction: A Survey of the State of the Art
[C]
Key2Vec: Automatic Ranked Keyphrase Extraction from Scientific Articles Using Phrase Embeddings
[C]
自动关键词抽取研究综述
[J].
Review of Research in Automatic Keyword Extraction
[J].
Learning Algorithms for Keyphrase Extraction
[J].
Keyphrase Generation Based on Deep Seq2seq Model
[J].
Automatic Keyphrase Extraction Using Graph-based Methods
[C]
KP-Miner: A Keyphrase Extraction System for English and Arabic Documents
[J].
Clustering to Find Exemplar Terms for Keyphrase Extraction
[C]
A Text Feature Based Automatic Keyword Extraction Method for Single Documents
[A]
Automatic Extraction of Relevant Keyphrases for the Study of Issue Competition
[C]
TextRank: Bringing Order into Text
[C]
Single Document Keyphrase Extraction Using Neighborhood Knowledge
[C]
Automatic Keyword Extraction from Individual Documents[A]// Text Mining: Applications and Theory
[M].
SGRank: Combining Statistical and Graphical Methods to Improve the State of the Art in Unsupervised Keyphrase Extraction
[C]
PositionRank: An Unsupervised Approach to Keyphrase Extraction from Scholarly Documents
[C]
基于图和LDA主题模型的关键词抽取算法
[J].
Graph Based Keyphrase Extraction Using LDA Topic Model
[J].
词语位置加权TextRank的关键词抽取研究
[J].
Study on Keyword Extraction Using Word Position Weighted TextRank
[J].
融合LDA与TextRank的关键词抽取研究
[J].
Study on Keyword Extraction with LDA and TextRank Combination
[J].
词向量聚类加权TextRank的关键词抽取
[J].
Extracting Keywords with Modified TextRank Model
[J].
融合多特征的TextRank关键词抽取方法
[J].
TextRank Keyword Extraction Based on Multi Feature Fusion
[J].
词位置分布加权TextRank的关键词提取
[J].
Extracting Keywords with TextRank and Weighted Word Positions
[J].
基于文档主题结构和词图迭代的关键词抽取方法研究
[J].
Extracting Keywords Based on Topic Structure and Word Diagram Iteration
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}