




1 引言
随着互联网的飞速发展以及人民对精神文化需求的提升,网络在线音乐已占据了国人日常娱乐生活的重要部分,截至2020年3月,我国网络音乐用户规模达6.35亿,占网民整体的70.3%[1],以QQ音乐、网易云音乐等为代表的数字化音乐平台纷纷涌现。移动互联网作为音乐传播链条中的新媒介,打破了音乐创作者和听众间的时空界限,使音乐传播范围更广、速度更快;但在线音乐平台等网络媒介对音乐信息的筛选环节薄弱,从而导致大量碎片般的音乐信息充斥网络空间,有价值的音乐信息被淹没于内容泛滥、品质粗劣的音乐信息洪流之中[2]。而数据分析、挖掘技术的发展,可以帮助确定影响在线音乐传播的因素,以及对音乐信息的优劣加以甄别,从而采取相应措施引导听众接收积极向上的音乐作品。
在线音乐平台中的网易云音乐是国内首个推出用户定制歌单功能的音乐App[3],用户可以按照自己的喜好创建歌单,对歌单的封面、名称、简介、类别等进行编辑,也可以收听、收藏、分享其他人创建的歌单。但用户创建的歌单质量参差不齐,质量的高低多数情况下可以通过歌单传播效果——播放量这一数据体现,优质歌单的播放量可达数千万甚至上亿。因此,为营造健康的音乐文化传播环境以及推动中国音乐文化市场发展,音乐平台需要对歌单质量进行把关。探究歌单播放量的影响因素并进行相应预测,有利于音乐网站对歌单优劣进行初步判断,进一步为用户推送更多优质歌单,促进在线音乐平台更好的发展。
本文选取网易云音乐歌单作为研究对象,试图探讨深度学习和机器学习算法在歌单播放量预测方面的优劣,以及不同歌单特征对预测效果的影响程度。在算法方面,随机森林(Random Forest,RF)和XGBoost(eXtreme Gradient Boosting)是目前机器学习算法中效果最好的两个算法,深度神经网络(Deep Neural Network,DNN)相比机器学习算法具有更大的计算能力,在复杂的连续数据预测问题上往往效果更佳。因此,针对本文数据提出假设H1:DNN的预测准确率高于XGBoost和RF。在特征方面,歌单的初始播放量、收藏量、转发量、评论数可看作是歌单的评价信息,数值越高,代表歌单越受欢迎,由于这些数字比文字更为直观,且用户普遍存在从众心理,使歌单的评价特征比歌单自身的文本特征更具吸引力。由此本文提出假设H2:歌单的评价特征对播放量的影响最为显著;假设H3:歌单自身文本特征(歌单名称和简介)只能在一定程度上帮助提升播放量的预测准确率。此外,由于初始播放量大的歌单一般创建时间较长,其播放量的增长趋势更为稳定,与歌单特征之间的关系更为密切,很少出现激增的情况。由此本文提出假设H4:针对初始播放量更大的歌单,预测准确率更高。根据以上4个假设,本文展开了研究与分析。
2 相关研究
网易云音乐的定制化歌单功能,是用户生成内容(User Generated Content,UGC)的形式之一,针对研究内容,本文对影响因素及预测问题研究方法、预测算法和歌单等UGC扩散效果的影响因素三个方面进行文献调研。
影响因素的分析方法包括回归分析[4]、定性比较分析[5]、扎根理论方法[6]、QAP(Quadratic Assignment Procedure)回归[7]等。预测方法可分为定性和定量两种方式,定性预测方法仅对事物发展趋势和未来状态进行预测和概括性描述,大多是进行影响因素分析的因素分析法[8];而定量预测方法则根据数据体现的变量关系,建立一定的模型进行预测。本文采取定量预测方法,构建算法模型时需先对歌单文本进行预训练。Word2Vec作为早期自然语言处理中常用的词向量方法,也被看作静态的预训练技术,BERT(Bidirectional Encoder Representations from Transformers)等预训练语言模型的提出,推动自然语言处理进入了动态预训练技术的时代[9]。两种技术在预测问题中经常被用来表征文本。例如,黄丽明等[10]利用Word2Vec和GloVe两种方式生成股票新闻文本向量,结合深度学习算法对股票价格进行预测;张晗等[11]分别采用BERTBASE模型的全连接层和随机森林算法构建心理特质预测模型等。
在预测算法上,RF实现简单且预测能力强,能较好地容忍异常值和噪声,不容易过拟合[12]。Malekipirbazari等[13]提出一种基于RF的借款人状态预测分类方法,在识别良好借款人方面优于FICO信用评分和LC等级。XGBoost能够发现复杂数据之间的依赖关系以及从大量数据集中学习到有趣的模型,从而被广泛应用于解决分类、回归、预测等问题上[14]。Pan[15]利用XGBoost对我国天津市PM2.5小时浓度进行预测,实验结果显示XGBoost结果优于支持向量机(Suppoer Vector Machine,SVM)、多元线性回归等方法。自2006年深度学习愈加流行以来[16],DNN被广泛应用于分类和回归问题。Wu等[17]提出一种基于DNN的交通流预测模型,该模型可以自动学习确定过去交通流的重要性;Putin等[18]训练DNN利用基础血液测试来预测人类年龄。RF、XGBoost和DNN三种算法被广泛应用于多种预测场景,各有千秋。
通过文献调研发现,现有的研究存在以下不足。
(1)针对音乐歌单的研究,大多是从营销策略、情感体验等角度进行探讨,很少有对歌单播放量的预测以及影响因素分析。
(2)针对预测问题的研究多采用单一算法,算法间的对比分析不足。
因此,本文采取三种不同算法,融合歌单自身数值特征、文本特征和歌单创建者特征来预测12 h后歌单的播放量,通过多组对比实验探讨歌单播放量与歌单不同特征间的依赖关系。
3 数据来源与模型构建
3.1 研究总体框架
针对引言中提出的假设,本文设计的研究总体框架如图1所示。对网易云音乐歌单数据进行采集后,首先将歌单特征划分为数值数据和文本数据并分别进行预处理,对数值数据去重、剔除缺失值以及归一化,对文本数据分别利用Word2Vec和BERT模型进行预训练,得到文本向量;其次分别构建RF、XGBoost、DNN模型,确定算法结果最优时的参数;最后采用不同算法、选取不同特征、利用不同数据集进行对照实验,依据评价指标对实验结果进行分析评估。
图1
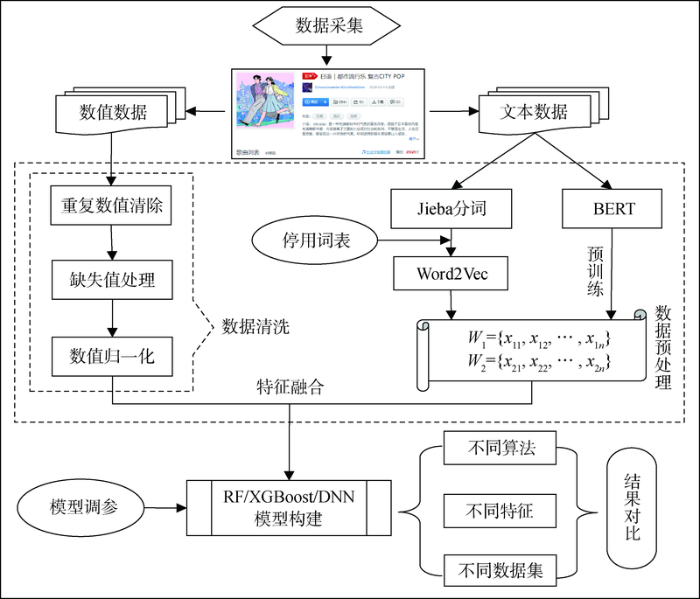
3.2 数据来源及预处理
本文选择对网易云音乐歌单12 h后的播放量进行预测,主要原因如下。
(1)网易云音乐平台的歌单推荐每日都会进行更新,且随机性很强,导致在同样长的时间段中(如一个月)有些歌单被重复推荐多次,而有些歌单只被推荐一次,这种不可控因素可能会导致播放量两极分化愈发严重,从而影响预测效果。
(2)歌单得到推荐时可以看作是歌单播放量增长较为活跃的时期,一般来讲,歌单创建时间越久,其播放量增长会越稳定,但稳定期究竟是在歌单创建多久之后,界线难以确定。
(3)用户对于自己创建的歌单具有随时编辑修改的权利,若选取较长时间段后的播放量进行预测,用户可能对歌单信息进行过多次更新,此举对歌单播放量的影响难以进行量化研究。
因此,本文选择在同一天中得到推荐的歌单能够极大程度消除以上三个因素的影响。
由于网易云音乐每个歌单最多可选择三个标签,导致不同大类下会出现很多相同的歌单,所以为避免歌单重复率过高,本文只选取“情感”这个大类下的所有类别歌单,具体类别如表1所示。
表1 歌单类别及数字表示
Table 1
| 类别 | 数字表示 | 类别 | 数字表示 |
|---|---|---|---|
| 怀旧 | 1 | 孤独 | 7 |
| 清新 | 2 | 感动 | 8 |
| 浪漫 | 3 | 兴奋 | 9 |
| 伤感 | 4 | 快乐 | 10 |
| 治愈 | 5 | 安静 | 11 |
| 放松 | 6 | 思念 | 12 |
使用八爪鱼采集器对这12个类别下的歌单信息进行爬取,在数据预处理过程中,网易云音乐官方账号粉丝真实数量不详,所以将其创建的歌单剔除;由于一个歌单最多可添加三个标签,即归属于三个类别,所以不同的类别下可能有相同的歌单,对这些歌单进行去重处理;存在一条数据缺失多个特征值的现象,所以将这些信息不完整的歌单剔除;由于后续需要对歌单简介文本进行向量化处理,所以将歌单简介为空或只有符号的歌单剔除。
本文获取的网易云音乐歌单数据中,歌单的收藏量最高可达上百万,而歌曲数、推荐顺序、创建者动态数等其他特征数值大多在1 000以下,歌单特征的数值范围不一致,可能会导致算法运行效率低下,所以要对数据进行归一化处理,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确收敛到最优解。归一化方法如公式(1)所示。
其中,
经过数据预处理后,本文从12个情感类别中共选取11 595个歌单,每个类别下的歌单数量差距不大。由此可见,选取的歌单均匀分布于各个情感类别中,不会因歌单类别分布不均衡对实验结果造成影响。所有歌单的播放量在1~182 534 656次不等,平均值达到1 102 631次。由于最大值与最小值之间差距过大,为方便可视化展示,对播放量取以10为底数的对数,按照步长为1划分区间,得到播放量落在每个区间的歌单数量,如图2所示。根据图表分析,超过半数的歌单播放量为103~106。歌单数量从1~106范围内逐渐增多,超过106后数量逐渐减少。歌单播放量近似于偏态分布,符合网易云音乐歌单总体的一般特征,因此“情感”大类下的11 595个歌单具有代表性。
图2
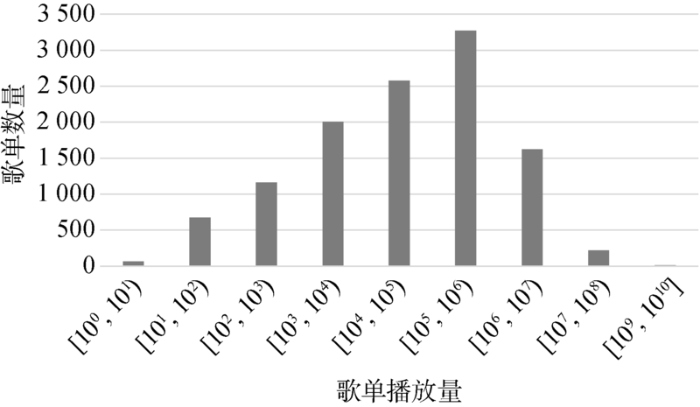
通过统计分析,了解到网易云音乐每日推荐的歌单具有以下特点。
(1)歌单播放量分布十分不均,极差巨大,表明网易云音乐会同时推荐热门歌单和小众歌单,热门歌单可以保证多数用户的体验,而小众歌单也可以满足不同人群的需求;而如此大的极差可能导致实验效果差,所以需对数据进行归一化处理。
(2)每个类别下的歌单数量差距不大,表明网易云音乐比较注重歌单类别间的数量平衡,也避免了类别对实验结果的影响。
3.3 歌单特征选取
本文获取的歌单具体特征如表2所示。其中,序号1~9即从歌单链接到歌单创建时间这9个字段为歌单自己本身的数值特征,序号2~5为本文认为对播放量影响较大的因素,记为F1;序号6~9记为F2。序号10~15即用户昵称到用户创建歌单数这6个字段为歌单创建者的特征,将序号11~15记为F3;序号16~17即歌单名称歌单简介为歌单自身的文本特征,记为F4。Susarla等 [23]研究发现,内容创建者关注其他用户越多,那么其内容也越受关注,一般认为在网络在中活跃度较高的用户,更能受到其他用户的关注[22],用户创建的歌单也就更可能获得更高的播放量。所以除歌单自身特征外,本文也获取了歌单创作者特征,除用户昵称外,序号11~15这5条信息体现了歌单创建者在网易云音乐社区的活跃度,对歌单的播放量可能会造成一定影响。
表2 获取的歌单数据信息
Table 2
| 序号 | 字段名称 | 字段类型 | 主要内容 | 组合标记 |
|---|---|---|---|---|
| 1 | 歌单链接 | 字符型 | 用于唯一表示每个歌单(只用于标识,不作为特征选取) | |
| 2 | 歌单起始播放量 | 数值型 | 第一次爬取歌单信息时歌单的播放量 | F1 |
| 3 | 歌单收藏量 | 数值型 | 歌单被多少个用户收藏,方便用户反复收听 | |
| 4 | 歌单转发量 | 数值型 | 歌单被多少个用户转发分享至其他平台(如微信朋友圈、微博、QQ空间等) | |
| 5 | 歌单评论数 | 数值型 | 用户对该歌单发表的评论数 | |
| 6 | 歌单歌曲数 | 数值型 | 歌单共收录了多少歌曲 | F2 |
| 7 | 歌单推荐顺序 | 数值型 | 按照每个类别下歌单排列的位置顺序依次标号 | |
| 8 | 歌单类别 | 数值型 | 12个类别,用数字1~12表示 | |
| 9 | 歌单创建时间 | 数值型 | 将创建日期换算为距2020.5.24(即爬取数据当日)的天数 | |
| 10 | 用户昵称 | 字符型 | 创建歌单的用户名称(只用于标识,不作为特征选取) | |
| 11 | 用户动态数 | 数值型 | 创建歌单的用户个人主页中发表的动态总数 | F3 |
| 12 | 用户关注数 | 数值型 | 创建歌单的用户关注其他用户的数量 | |
| 13 | 用户粉丝数 | 数值型 | 创建歌单的用户被其他用户关注的数量 | |
| 14 | 用户等级 | 数值型 | 创建歌单的用户等级,一般等级越高,代表活跃度越高 | |
| 15 | 用户创建歌单数 | 数值型 | 创建歌单的用户创建的歌单总数 | |
| 16 | 歌单名称 | 文本型 | 由中英文、特殊符号等组成的文本数据,不允许为空值 | F4 |
| 17 | 歌单简介 | 文本型 | 由中英文、特殊符号等组成的文本数据,通常是对歌单特征、内容的描述 | |
| 18 | 12h后歌单播放量 | 数值型 | 间隔12h后第二次爬取时歌单的播放量,即本文进行预测的数值 |
间隔12h进行第二次数据爬取时,爬取内容只需包含歌单链接与歌单播放量,其中歌单链接用以寻找对应的歌单,12h后的歌单播放量即为本文要进行预测分析的数据。
3.4 歌单文本嵌入
采用Word2Vec和BERT两种方法对文本进行处理。Word2Vec[24]是谷歌于2013年提出的词嵌入方法,用来将非结构化的文本转化为结构化的词向量,能够根据给定的语料库,将文本中的词语映射到一个低维的实数向量空间[25]。本文获取的歌单特征包含“歌单名称”和“歌单简介”这两个文本字段,为了能将二者作为特征输入预测算法,将这两个文本信息拼接在一起,以哈尔滨工业大学停用词表、百度停用词表等为基础,去除文本数据中无意义的符号和字词,采用Jieba工具进行分词后,使用网上大语料训练好的Word2Vec模型对本文数据进行向量化,该Word2Vec模型的训练语料包括百度百科、搜狐新闻与小说,所以能较为全面地处理本文歌单文本数据。由于每个歌单的文本由不止一词构成,需要利用词向量有效地表示歌单文档,常见的文档向量表示方法有:对文档所包含的所有词向量求平均值[26]、对词向量聚类[27]、利用TF-IDF(Term Frequency-Inverse Document Frequency)求加权平均值[28]等。本文选取第一种方式,在将每个歌单的文本数据转换为128维的词向量后,将词向量相加求平均值,以此表示该歌单的文本向量,后续作为输入预测算法中的特征。BERT[29]是谷歌于2018年提出的一种基于深度学习的语言表示模型。基于BERT模型的自然语言处理任务包括预训练和微调两个过程。在预训练过程中,利用大规模没有标注过的网页新闻、百科知识等文本语料,通过自监督训练学习文本的语言特征,得到深层次的文本向量表示,形成相应文本的预训练模型;在微调过程中,将预训练得到的模型作为起始模型,根据具体的下游任务(如分类、序列标注等),输入人工标注好的数据集,对初始模型作进一步拟合与收敛,从而得到一个可用的深度学习模型实现特定的自然语言处理任务[30]。本文采用Keras版本下的BERT模型,该模型可以直接调用官方发布的预训练权重,由于只需对歌单文本特征进行提取,所以不涉及微调过程。通过使用官方预训练好的中文模型chinese_L-12_H-768_A-12,调用Keras-BERT中的extract_embeddings方法即可将歌单文本转化为固定的768维句向量。
3.5 算法的选择
因此,RF回归函数为
其中,
其中,
3.6 评价指标
本文采用回归预测中常用的拟合优度R2和平均绝对误差(Mean Absolute Error,MAE)作为预测效果评估的评价指标,分别如公式(7)和公式(8)所示。
其中,
其中,y为真实值;
Acc取值位于[0,1]区间,越接近1,表示播放量预测正确的歌单占比越大,即算法的预测准确率越高。
4 实验结果及分析
4.1 模型参数选取
表3 RF算法的参数设置
Table 3
| 参数名 | 参数值 |
|---|---|
| n_estimators | 150 |
| max_depth | 50 |
| max_features | auto |
| min_samples_leaf | 1 |
| bootstrap | True |
表4 XGBoost算法的参数设置
Table 4
| 参数名 | 参数值 |
|---|---|
| learning rate | 0.1 |
| n_estimators | 150 |
| max_depth | 10 |
| min_child_weight | 1 |
| gamma | 0.4 |
| Colsample_bytree | 0.9 |
| subsample | 0.8 |
(2) DNN模型参数选取
DNN模型需要调节的参数较多,对预测结果影响较大且取值范围较大的参数包括隐藏层数、batch_size和epoch,本文选取歌单所有数值特征,首先对隐藏层数进行确定。由于最后的输出结果是一个预测值,在输出层前需设置一层输出维度为1的全连接层,所以隐藏层数从2开始。隐藏层数与R2和Acc值的变化关系如表5所示。可以看出,当隐藏层数为6时,Acc和R2都达到最大值,随着隐藏层数增加,R2和Acc在下降,所以选取隐藏层数为6层。
表5 DNN隐藏层数与R2和Acc的变化关系
Table 5
| 隐藏层数 | R2 | Acc |
|---|---|---|
| 2 | 0.866 0 | 0.745 6 |
| 3 | 0.871 4 | 0.771 2 |
| 4 | 0.888 0 | 0.815 4 |
| 5 | 0.888 8 | 0.796 8 |
| 6 | 0.889 0 | 0.844 0 |
| 7 | 0.880 4 | 0.838 0 |
| 8 | 0.866 5 | 0.803 2 |
DNN的batch_size决定了每次训练时的样本个数,最小值可以取1,最大值则为训练集样本总个数,一般取2n,由于本文训练集样本数接近10 000,所以batch_size的范围设定为[32,512],在隐藏层数设定为6层的基础上,改变batch_size大小,记录R2和Acc值变化情况,如表6所示。可以看到,当batch_size取128时,R2和Acc值基本达到最大值,所以设定batch_size为128。
表6 DNN的batch_size与R2和Acc的变化关系
Table 6
| Batch_size | R2 | Acc |
|---|---|---|
| 32 | 0.824 2 | 0.672 1 |
| 64 | 0.880 2 | 0.791 3 |
| 128 | 0.889 0 | 0.844 0 |
| 256 | 0.888 6 | 0.821 7 |
| 512 | 0.887 9 | 0.818 2 |
最后选择epoch值,在上述两个参数确定的情况下,以MAE作为损失函数,绘制epoch和训练集损失值train_loss、测试集损失值val_loss的变化关系。如图3所示,当epoch为20时,train_loss和val_loss基本达到最低点,且随着epoch的增加也并无太大变化,所以确定epoch为20。
图3
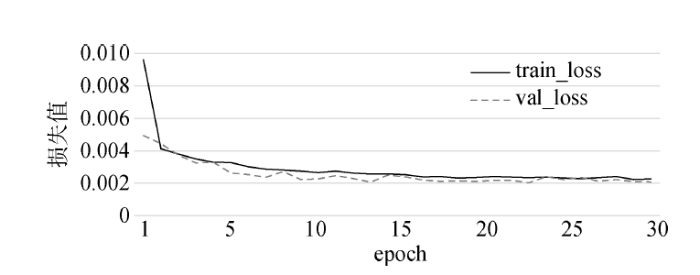
图3
epoch与train_loss、val_loss的变化关系
Fig.3
The Relationship Between epoch and train_loss and val_loss
最终确定DNN的参数,如表7所示。
表7 DNN的参数设置
Table 7
| 参数名 | 参数值 |
|---|---|
| 隐藏层数 | 6 |
| batch_size | 128 |
| epoch | 20 |
| 每层units(输出维度) | 300/150/50/10/5/1 |
| dropout | 0.1 |
| learning rate_method | Adam(算法) |
| activation(激活函数) | ReLU |
4.2 歌单播放量预测及分析
本文实验采用5折交叉验证的方法划分训练集和验证集,即将处理好的歌单数据共分成5份,其中4份作为训练集,剩余一份作为验证集,每种实验重复5次,最终的实验结果取5次实验结果的平均值,从而尽量减少数据的不平衡对实验结果造成的影响。
(1) 相同特征环境下不同预测算法对比实验
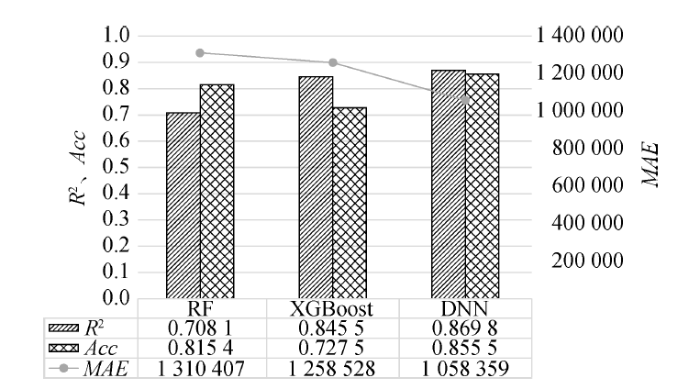
首先选取歌单所有特征,即F1+F2+F3+F4,分别采用三种算法对12h后歌单播放量进行预测,通过实验结果了解预测情况,并确定后续实验所用算法。考虑到使用Keras-BERT训练的文本特征维度较高,容易造成机器学习算法过拟合,所以F4采取Word2Vec向量化结果,实验结果如图4所示。可以看出,DNN的R2与Acc值均大于RF和XGBoost,且MAE值小于RF和XGBoost,三个指标中DNN的表现都更优,表明假设H1成立,相比RF和XGBoost,DNN对12 h后歌单播放量的预测准确率更高。因此,在后续实验中,均采用DNN算法,能够最大限度地提升预测效果。
图4
(2) 两种算法模型下不同特征对比实验
在已确定采用DNN算法作为预测算法的基础上,分别选取不同的特征对歌单播放量进行预测。首先歌单的特征可以分为两大类——数值特征(F1+F2+F3)和文本特征(F4),数值特征又可以继续划分为歌单自身特征(F1+F2)和歌单创建者特征(F3)两类,其中F1被认为是歌单的评价特征,如图5所示。
图5
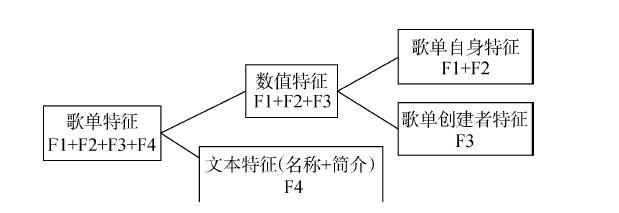
本文对特征的选取分为以下5种方式。
①仅选取认为对歌单播放量影响较大的评价特征F1。
②选取F2+F3+F4,即排除F1外的所有的特征,与第①种特征选取方式结合到一起,可以验证歌单的初始播放量、评论、收藏、转发数量是否对播放量影响最大。
③选取歌单自身的所有特征F1+F2+F4,即排除歌单创建者活跃度因素。
④选取歌单所有的数值特征F1+F2+F3,即去掉文本特征F4。
⑤选取歌单所有的特征F1+F2+F3+F4,包括数值特征和文本特征,与③结合可以探讨歌单创建者活跃度对播放量的影响程度,与④结合可以分析歌单的文本特征是否能帮助提升预测效果。其中,文本特征分别采用Word2Vec和BERT模型进行处理。
5种特征选取方式实验结果如图6所示。
图6
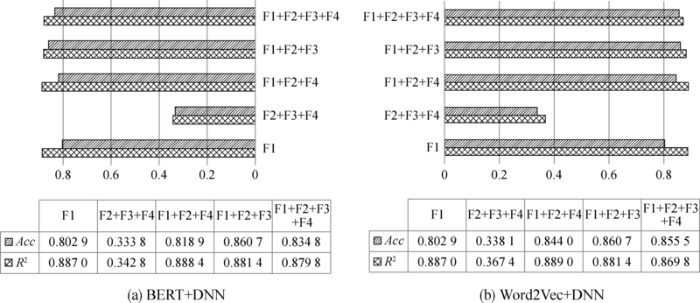
图6
两种模型不同特征对比实验
Fig.6
Comparative Experiments with Different Features of the Two Models
由图6可以得出以下结论:
根据特征选取方式①和②,仅用F1预测准确率就可达80%以上,而去掉F1时,两种模型预测准确率均大大降低,R2和Acc均不足0.4,由此证明歌单的初始播放量、评论、收藏、转发数量是对播放量影响最大的因素,分析原因有以下几点:第一,信息传播与接受理论表明,在产品质量信息不对称的情况下,消费者需要通过在线评论搜索降低自身决策的不确定性[36]。同样,当用户不了解歌单好坏时,需要通过翻阅评论来获取信息,评论越丰富,越吸引更多听众参与;评论数越多且初始播放量越高,表明歌单基础听众越多,用户的从众心理也会促使其对歌单进行收听。第二,用户对歌单进行收藏操作后,即可在自己的个人主页找到收藏的歌单,因此,收藏量越大,表明有越多用户会进行反复收听。第三,当用户转发歌单至其他社交软件时,会使歌单传播至更广的范围,社交圈内的好友收听行为促使歌单播放量进一步增长。综上,以上4个影响因素与播放量大小密切相关、同步增长,对播放量增长影响作用最大,假设H2成立。
根据特征选取方式①和③、①和④可知,当加入更多的歌单特征时,两种模型的预测效果均得到一定的提升,说明除了F1特征外,其他特征也在一定程度影响歌单播放量,但影响作用较小,如创建时间越长、推荐顺序越靠前的歌单越容易获得更高的播放量等。因此,网易云音乐重点关注影响作用大的因素,即可大致确定播放量的未来增长趋势,并可考虑将这些数值因素放在更为显著的位置,方便用户挖掘优质歌单,进一步促进优质歌单播放量增长,形成正向循环。
根据特征选取方式③和⑤,加入歌单创建者活跃度特征F3时,两种模型R2稍有下降,但Acc得到提升,总体而言预测准确率升高,说明用户活跃度对歌单播放量会产生影响,粉丝数量大、在网络中交互频繁的高活跃度用户创建的歌单,更容易被更大范围的用户浏览到,并获得高播放量。
根据特征选取方式④和⑤,加入歌单名称和简介时,两种模型的R2和Acc值均有所下降,播放量预测效果变差,说明歌单的文本信息不仅没有提升预测准确率,反而造成了干扰,假设H3不成立。分析原因,可能是听众很少关注歌单的描述,且由于网易云音乐对歌单名称和简介格式并无约束,歌单的描述字数过多时会导致信息折叠,需再次点击歌单简介才能获取到全文,一些用户可能会因为多出的这一项操作步骤而直接忽略歌单描述,且歌单简介大多排版凌乱、符号众多、文字琐碎、语言迥异,很多时候与歌单中的歌曲信息无关,导致用户很难迅速从歌单简介中提取到关键信息,甚至会造成无关信息摄入过量,因此歌单文本特征与播放量之间无密切联系,影响了预测性能。
将两种模型结果进行对比,发现Word2Vec+DNN的预测效果要优于BERT+DNN,探究原因可能是利用BERT预处理后的文本向量维度较高,导致所需的样本数大大增加。根据“休斯(Hughes)现象”或“休斯效应”,虽然新增加的特征提升了特征提取与分类器的计算复杂度,但通常分类器的性能在一定程度上能够得到改善,但在实际应用中,特征维数增加到某个临界点后,继续增加反而会导致分类器的性能变差。
(3) 最优算法性能下不同数据集对比实验
由以上实验结果可知,当采用DNN算法并选取特征F1+F2+F3时,歌单的播放量预测效果最佳,所以本文将最优算法性能下的预测值与验证集的真实值进行对比,由于数值范围区间过大,为便于展示,将数值取以2为底的对数,并将真实值按从小到大的顺序进行排列,结果如图7所示。
图7
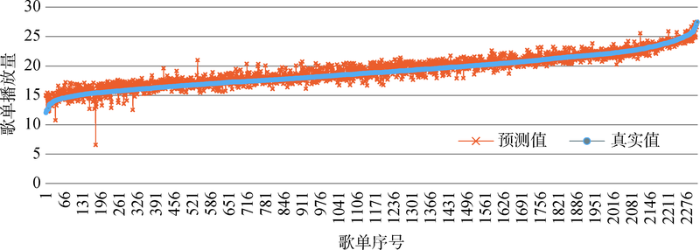
图7
DNN预测值与真实值对比
Fig.7
Comparing the Predicted Values of DNN with the True Values
图8
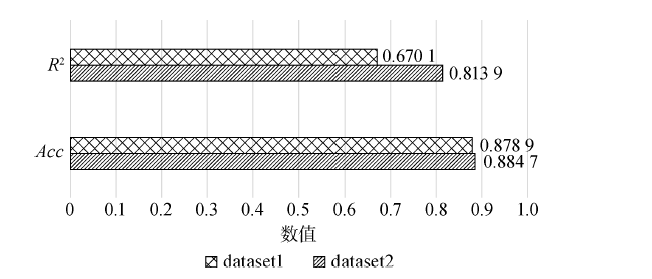
根据实验结果可以得出以下结论。第一,dataset1的R2小于dataset2,由图7也可以看出播放量小的一侧出现了较多的明显离群点,DNN对于初始播放量大的歌单数值曲线拟合更佳。探究原因,可能是播放量超过10万的歌单一般创建时间较早,其播放量与歌单特征的变化趋势较为一致,所以根据歌单特征预测的数值与真实值间的差距不会过大;而播放量小于10万的歌单,可能会因为创建时间较迟,跟随热度而被网易云音乐推荐到首页导致播放量骤增,播放量增长受到一些偶然因素影响,所以会出现预测结果误差较大的情况,造成R2较小。第二,dataset1和dataset2的Acc值差距并不大,表明偶然因素不会过多影响整体的预测准确率,歌单的播放量最主要还是受到歌单特征的影响,假设H4不成立。综上,网易云音乐网站首页的位置会弱化歌单初始播放量、评论数等特征的影响,吸引到众多用户,导致播放量急剧增长,因此平台将初始播放量较低的歌单推荐到首页前,需要对歌单的内容加以鉴别,保证歌单质量;同时,由于首页的歌单数量很少,所以个别样本不会影响整体播放量增长趋势,预测准确率仍保持在较高且稳定的水平。
5 结语
本文以网易云音乐为例,利用RF、XGBoost、DNN 三种算法以及Word2Vec和BERT两种文本表示方法对歌单12h后的播放量进行预测,并选取歌单不同特征、在不同数据集上进行对照实验,探讨歌单播放量的影响因素。实验结果表明,对于本文的数据集,DNN在三种算法中的预测准确率最高;歌单的初始播放量、评论、收藏、转发数是影响歌单播放量的最大因素,而歌单的文本描述则对播放量预测造成了干扰;歌单初始播放量的大小并不会影响DNN算法的预测准确率。
根据实验结果,为网易云音乐与其他同类音乐网站提出以下建议。
(1)重点关注歌单的初始播放量、评论、收藏、转发量,用于粗略判断歌单的优劣,为用户推送更多高质量的歌单,提升用户体验,同时对播放量长时间处于较低水平的歌单内容加强审查,保证健康向上的音乐传播环境。
(2)将歌单的初始播放量、评论、收藏、转发量这4组数据放在更为醒目的位置,有助于听众挑选到优质歌单并促进播放量的进一步增长。
(3)为粉丝数量大、活跃度高的优质歌单创建者提供更多支持,如提高其创建歌单的曝光度,以此激励其继续创建优质歌单,提高用户粘性与对平台的贡献度。
(4)对歌单名称及简介进行一定约束,如简化表达、突出关键信息、要求与歌单内容相关等,方便听众从众多歌单中挑选其喜欢的音乐。
本文工作依然存在可完善之处。其一,由于网易云音乐歌单推荐每日会进行更新,是不可控制的因素,所以只研究歌单12 h后的播放量,时间距离较短;其二,采取DNN这一较为传统的深度学习算法,目前流行的还有用于图像识别的卷积神经网络(Convolutional Neural Networks,CNN)、处理时序数据的循环神经网络(Recurrent Neural Networks,RNN)以及在二者基础上的长短期记忆网络(Long Short-Term Memory,LSTM)等,后续将考虑应用这些模型扩充对比实验。
作者贡献声明
刘渊晨:数据收集,实验论证和论文撰写;
王昊:提供研究思路,设计研究方案;
高亚琪:参与讨论研究思路。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: mf1914046@smail.nju.edu.cn。
[1] 刘渊晨. 网易云音乐歌单数据.xlsx. 本文实验所用的全部歌单数据.
[2] 刘渊晨. 歌单文本向量化.xlsx. 采用Word2Vec和BERT对歌单文本处理后的结果.
[3] 刘渊晨. dataset1.xlsx. 播放量小于10万的歌单集合.
[4] 刘渊晨. dataset2.xlsx. 播放量大于等于10万的歌单集合.
参考文献
第45次中国互联网络发展状况统计报告
[R].
The 45th China Statistical Report on Internet Development
[R].
移动互联网时代中国音乐文化传播思考
[J].
Thoughts on the Dissemination of Chinese Musical Culture in the Era of Mobile Internet
[J].
网易云音乐定制化营销发展策略研究
[J].
Research on Netease Cloud Music Customization Marketing Development Strategy
[J].
社会化问答用户信息搜寻的影响因素研究——一种混合方法的视角
[J].
Analyzing the Influencing Factors of Internet Users’ Information-seeking Behavior: A Mixed-method Perspective
[J].
心理因素联动对创业者决策逻辑的影响——一个基于QCA方法的研究
[J].
The Impact of Psychological Factors on Entrepreneurs’ Decision Logics: A Fuzzy-Set Qualitative Comparative Analysis
[J].
用户视角下的学术社交网络信息质量影响因素研究——基于扎根理论方法
[J].
The Influence Factors of Information Quality in Academic Social Networks from User' Perspective Based on Grounded Theory
[J].
“一带一路”电子产品贸易格局演变特征及影响因素研究——基于复杂网络分析方法
[J].
Research on Structural Change Characteristics and Influencing Factors of Electronic Products Trade Network along the Belt and Road: Based on Complex Network Analysis Method
[J].
稀土产品价格决定: 影响因素与预测方法综述
[J].
Review of Rare Earth Price: Influencing Factors and Forecasting Methods
[J].
面向自然语言处理的预训练技术研究综述
[J].
Survey of Natural Language Processing Pre-training Techniques
[J].
基于循环神经网络和深度学习的股票预测方法
[J].
A Stock Prediction Method Based on Recurrent Neural Network and Deep Learning
[J].
面向网络文本的BERT心理特质预测研究
[J/OL].
A Study on Predicting Psychological Traits of Online Text by BERT
[J/OL].
随机森林方法研究综述
[J].
A Review of Technologies on Random Forests
[J].
Risk Assessment in Social Lending via Random Forests
[J].DOI:10.1016/j.eswa.2015.02.001 URL [本文引用: 1]
XGBoost: A Scalable Tree Boosting System
[C]//
Application of XGBoost Algorithm in Hourly PM2.5 Concentration Prediction
[J].DOI:10.1088/1755-1315/113/1/012127 URL [本文引用: 1]
A Fast Learning Algorithm for Deep Belief Nets
[J].DOI:10.1162/neco.2006.18.7.1527 URL [本文引用: 1]
A Hybrid Deep Learning Based Traffic Flow Prediction Method and Its Understanding
[J].DOI:10.1016/j.trc.2018.03.001 URL [本文引用: 1]
Deep Biomarkers of Human Aging: Application of Deep Neural Networks to Biomarker Development
[J].
What Makes a Helpful Online Review? A Study of Customer Reviews on amazon.com
[J].DOI:10.2307/20721420 URL [本文引用: 1]
The Effect of Word of Mouth on Sales: Online Book Reviews
[J].DOI:10.1509/jmkr.43.3.345 URL [本文引用: 1]
社会化问答知识分享用户感知有用性影响因素研究——以知乎为例
[J].
Research on Influencing Factors of User Perceived Usefulness of Knowledge Sharing in Social Q&A——A Case Study of Zhihu
[J].
信息过载视角下用户创建资源列表扩散效果的影响因素研究——以网易云音乐为例
[J].
Research on the Influencing Factors of the User Generated Resource List Diffusion Effect in the Perspective of Information Overload——Take Netease Cloud Music as an Example
[J].
Social Networks and the Diffusion of User-Generated Content: Evidence from YouTube
[J].DOI:10.1287/isre.1100.0339 URL [本文引用: 1]
Efficient Estimation of Word Representations in Vector Space
[C]//
Deep Learning for Chinese Word Segmentation and POS Tagging
[C]//
Document Classification with Distributions of Word Vectors
[C]//
Bag-of-Concepts: Comprehending Document Representation Through Clustering Words in Distributed Representation
[J].DOI:10.1016/j.neucom.2017.05.046 URL [本文引用: 1]
基于Word2Vec的一种文档向量表示
[J].
Document Vector Representation Based on Word2Vec
[J].
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[OL].
BERT模型的主要优化改进方法研究综述
[J].
A Review on Main Optimization Methods of BERT
[J].
Random Forests
[J].DOI:10.1023/A:1010933404324 URL [本文引用: 1]
随机森林综述
[D].
A Review of Random Forests
[D].
Higgs Boson Discovery with Boosted Trees
[C]//
基于XGBoost的雾霾预测方法
[J].
Haze Prediction Method Based on XGBoost
[J].
基于深度神经网络的砂岩储层孔隙度预测方法
[J].
Prediction Method of Reservoir Porosity Based on Deep Neural Network
[J].
Informational Influence in Organizations: An Integrated Approach to Knowledge Adoption
[J].DOI:10.1287/isre.14.1.47.14767 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}