




1 引言
数字文献资源及相关技术的发展对科学交流起到了极大的推动作用,同时也为科研资助单位和学术机构在资助分配和个人职称评定及人才遴选等工作中提供了重要信息。但数字文献资源中普遍存在作者名歧义现象,其给文献检索、文献计量与科学评价分析等任务带来的不准确性成为一个重大挑战,因此,作者名消歧方法的研究受到信息检索、数据挖掘等领域的持续关注。
作者名歧义包括一人多名和一名多人(作者重名)两种情况,本文研究的是作者重名消歧问题。作者重名是指文献中不同作者有相同的姓名,从而造成姓名上的歧义。作者重名消歧则是从同名作者中分辨出真实的作者个数以达到文献准确聚合的目的。学术文献的作者重名消歧研究多采用特征工程法,通过作者特征(如邮箱、机构、地址等)、内容特征(如合作者、特征词、学科分类等)及外部特征测度文献间的相似性,然后利用聚类算法将文献划分到同质组中实现消歧。由于数据的可获取性或安全性等原因,在一些情境下难以获取丰富的文献信息导致特征工程法的消歧效果不佳,因此学者开始尝试从关系数据出发利用图结构模型解决作者重名消歧问题。基于图结构模型方法通过提取文献中的实体及其关系构建网络,并采用网络表示学习在保留节点间相似度的同时将高度复杂的节点关系表示成低维向量,进而实现作者重名消歧。已有的基于图结构模型方法主要采用作者合著关系或文献著者关系这类简单关系,然而实际的文献信息网络通常是异质信息网络,包含多种类型的节点(如作者、文献、出版物、主题等)和关系(如著作关系、出版关系、合著关系等),同质网络或简单的异质信息网络仅利用单一或少量类型的关系数据难以捕获文献信息网络中丰富的语义关系,致使消歧结果的准确性不高。近年来,异质信息网络表示学习方法快速发展,能够对更为复杂的网络关系建模学习,为从文献信息网络中学习更全面的语义及结构信息提供了有效途径。本文考虑基于异质信息网络从文献信息中抽取更加多元的节点和关系进行融合,充分利用文献实体关系进行作者重名消歧。
2 相关研究现状
2.1 异质信息网络表示学习
异质信息网络是一种包含多种类型的对象或关系的网络,与传统的同质网络(仅包含一种类型的对象和关系)相比,异质信息网络能反映不同类型对象的复杂异质交互关系,更适合建模各类实际系统,有助于利用网络中全面的结构信息和丰富的语义信息进行精准的知识发现。早期的网络数据分析多基于邻接矩阵这种高维稀疏的编码方式,但随着现实网络中数据规模的不断扩大,这种方式在存储空间、计算复杂度等方面都面临着严峻挑战,网络表示学习(或网络嵌入)将节点映射到一个低维空间的稠密向量表示,同时最大程度地保留原网络中的结构信息和特性,进而可以有效地应用到节点分类、链路预测和推荐等数据挖掘任务中[1]。近年,学者在异质信息网络表示学习方面取得了一系列的研究成果,根据是否利用节点属性信息可分为仅利用网络拓扑结构的浅层模型和同时利用网络拓扑结构与节点属性信息的深层模型。考虑到作者重名消歧任务中融合节点属性信息势必会增加模型的时间和空间复杂度,在面向大规模数据集消歧时缺乏实用性,且本文研究的目的是充分利用丰富的文献实体关系进行消歧,因此仅对异质信息网络表示学习的浅层模型相关方法进行介绍。
异质信息网络与同质网络在结构上存在很大的不同,DeepWalk、Node2Vec等经典的同质网络表示学习模型难以直接用于异质信息网络,其中最大的挑战就是如何在表示学习中保留异质节点和关系所表征的丰富的语义关系。部分研究尝试将异质信息网络拆分成多个简单子网络,并采用不同方式分别对子网络表示学习,这类方法虽然能降低表示学习的难度和计算复杂度,但显然也会损失部分语义信息[2]。在异质信息网络中,不同对象之间可以通过不同路径进行连接,且不同路径表示对象之间的不同关系,这些路径被称为元路径[3]。由于元路径能捕获不同类型节点的语义和结构关系,更多的研究采用元路径抽取异质信息网络的特征和子结构从而进行网络表示学习。受DeepWalk通过随机游走获取网络结构特征的启发,Metapath2Vec提出基于预先定义的元路径进行随机游走产生符合指定元路径方案的随机游走序列,并利用Skip-gram算法学习节点向量表示[4]。HINE(Heterogeneous Information Network Embedding)同样采用基于元路径的随机游走计算节点间的局部和全局相似度,并通过最小化两种相似度优化节点嵌入[5]。以上两种方法均是基于用户定义的元路径进行网络表示学习,对元路径的选择依赖较大,且需要借助领域专家的先验知识选择最优的元路径。HIN2Vec基于随机游走和负采样生成代表不同语义的元路径集合,通过将网络表示学习转化为两个节点间是否存在确定的元路径的二分类问题,采用神经网络模型同时学习节点和元路径的表示向量[6]。JUST引入Jump和Stay策略,在随机游走过程中以指定的转移概率选择下一个节点类型,以此为每个节点生成元路径,并利用Skip-gram算法得到节点向量表示,从而避免需要预先定义元路径的问题[7]。除上述具有一定代表性的方法外,学者还提出了其他一些利用网络拓扑结构进行异质信息网络表示学习的方法,但实际应用较少,不再逐一介绍。
2.2 基于异质信息网络的作者重名消歧
文献信息网络是典型的异质信息网络,在异质信息网络表示学习研究中,学者常利用文献中的实体和关系构建异质信息网络(如经典的Author-Paper-Venue网络模型,APV),通过使用提出的表示学习算法将网络中的节点表示为低维向量并用于实体的分类或聚类任务,从而验证方法的有效性,但目前基于异质信息网络的作者重名消歧研究还处于探索阶段。Ma等提出Mech-RL方法,基于7种元路径采样对异质文献信息网络(Organization-Author-Paper-Venue模型网络,OAPV)表示学习,同时结合文献内容信息的嵌入得到文献节点的向量表示,并通过聚类实现消歧[8]。Zhang等认为两篇文献若拥有许多共同作者或作者的合著者中共同作者较多,则很可能是同一个人所著,通过融合作者合著网络、文献-作者网络和文献网络对文献节点表示学习,进而达到消歧目的[9]。余传明等采用同样的网络模型,利用LINE、DeepWalk和成对相似性排序分别对三个网络表示学习,并融合得到文献节点的向量表示[10]。Wang等利用生成对抗网络模型融合内容表示和关系表示测度文献相似性,其中关系表示采用的是Node2Vec方法对文献异质信息网络表示学习,由于Node2Vec方法不能区分网络中节点和边的类型,因此该研究并未充分利用网络中的语义信息[11]。Qiao等在作者重名消歧中考虑了文献间的CoAuthor、CoVenue和CoTitle关系,并采用异构图卷积网络嵌入方法融合文献网络的结构信息和节点属性信息对文献进行表示[12]。
从上述相关研究可以看出,已有的基于异质信息网络的作者重名消歧方法可以分为两类,一类是仅利用网络结构信息进行消歧,另一类是将网络结构信息与节点属性信息融合实现消歧,后者涉及对文本内容嵌入,时间和空间复杂度较高。两类方法多是基于简单的异质文献信息网络,只考虑少量类型的节点和边,虽然个别研究中融合了较多的文献实体及关系,但采用的网络表示方法无法充分捕获异质节点和边表征的语义信息。因此,本文考虑构建节点及边的类型更丰富的异质文献信息网络模型,并应用异质信息网络表示学习方法对节点进行更准确的嵌入,进而充分利用文献中的实体关系数据实现无监督的作者重名消歧。
3 方法介绍
3.1 相关问题定义
(1) 作者重名消歧
作者重名消歧通常是指给定一个重名作者A的文献集合,通过找出一个映射将文献集合划分为互不相交的子集,使每个子集的文献尽可能来自唯一的现实作者。不同于已有研究多通过计算文献间的相似性实现作者重名消歧,本文基于异质文献信息网络对作者节点进行表示学习,并将表示向量应用于聚类分析获得消歧结果。
(2) 异质文献信息网络表示学习
如图1所示,异质文献信息网络是一个有向网络,可以用G(V,E)表示,V和E代表网络中的节点和边,分别对应文献中的实体及其关系,网络中包含多种类型的节点和边。网络表示学习是通过一种映射得到一个低维向量空间来表示网络中的节点及其复杂关系,以便灵活地应用到各种机器学习任务中。
图1
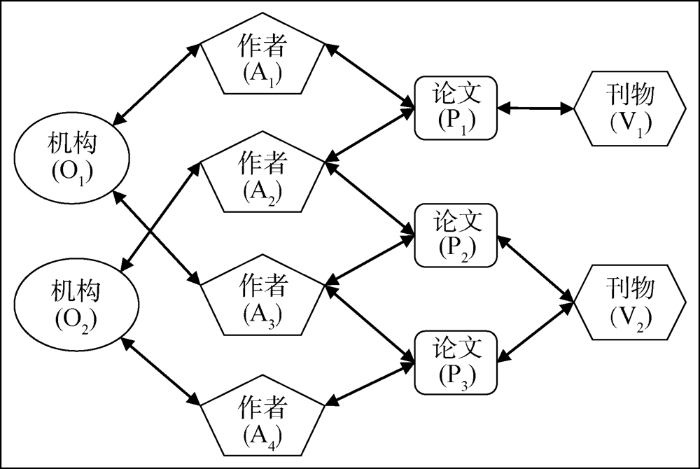
(3) 元路径
异质信息网络中元路径是两个节点间的关系集合,可用
3.2 作者重名消歧方法框架
本文提出的作者重名消歧方法框架如图2所示,包含异质文献信息网络构建、作者表示、聚类消歧和强规则匹配4部分。
图2
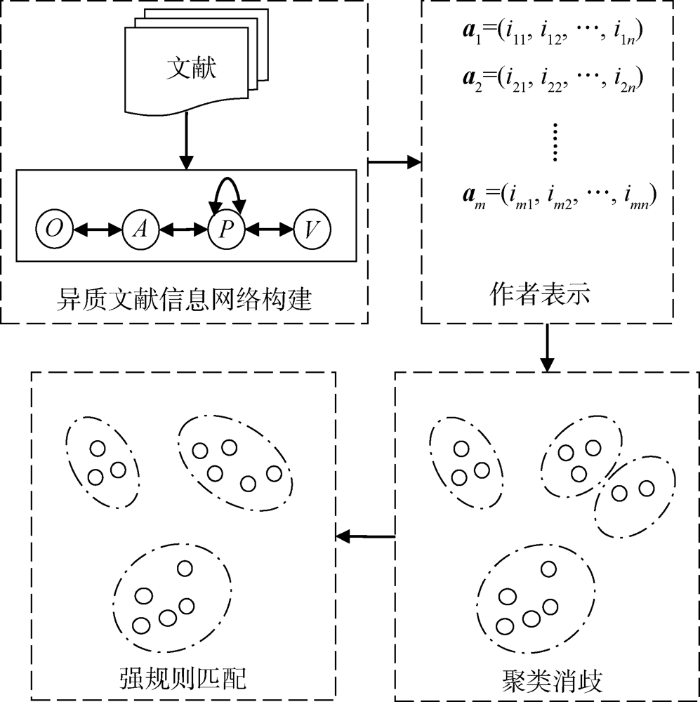
(1) 异质文献信息网络构建
为充分利用学术文献中的关系数据进行消歧,本文考虑了多种类型的实体及关系构建异质文献信息网络(OAPV网络)。OAPV网络包含4种类型的节点,分别为机构(O)、作者(A)、文献(P)和刊物(V),同时还包含4种类型的关系,分别为机构-作者隶属关系(O-A)、作者-文献著作关系(A-P)、文献-文献相似性关系(P-P)以及文献-刊物出版关系(P-V)。在网络构建过程中涉及对机构名称的消歧和文献相似性的计算,具体实现方法说明如下。
① 机构名称消歧
由于文献中同一个署名机构的写法有多种形式,因此需预先对机构名称进行消歧处理。本文采用文本相似性判断两个机构是否相同,首先对文献中的机构地址文本进行分词处理并转换为向量空间,然后采用向量间的夹角余弦值评估相似度,当余弦值不小于0.75时判定两个机构相同,否则为不同机构。需要说明的是,本文采用的机构名称消歧方法无法消除机构更名的歧义现象,可能会造成机构更名前后的同一作者被识别成不同作者,这一不足将通过后续的强规则匹配在一定程度上进行弥补。
② 文献相似性计算
其中,
此外,本文是基于作者表示向量处理消歧任务,在构建网络时将每个待消歧的重名作者编号作为独立的节点,而其他重名作者则默认为同一个作者。
(2) 作者表示
作者表示模块是以异质文献信息网络作为输入,采用网络表示学习方法将网络中的作者节点表示为低维向量,用于后续的聚类消歧。一个好的异质信息网络表示学习方法应该充分利用异质节点和关系捕获丰富的语义信息,元路径代表了节点对之间的特定关系,能体现丰富的语义信息,在异质信息网络表示学习中有着广泛应用,但已有方法多是基于预先设定的元路径存在一定的局限。一方面,元路径的设定依赖领域专家知识,主观性较强;另一方面,仅利用少量的元路径难以全面捕获语义信息。对比多种方法后,本文采用HIN2Vec模型[6]进行表示学习,该模型考虑了节点间各种不同类型的关系,表示结果保留了更多的语义信息,其实现过程分为训练数据准备和表示学习两个阶段。
首先,基于随机游走和负采样生成训练数据,不同于按照预先设定元路径游走的方式,HIN2Vec模型随机选择游走节点,采样时将网络中的每个节点都作为随机游走的起始点,生成长度为
然后,利用神经网络模型进行表示学习,其核心思想是设计了一个逻辑二元分类器,预测任意给定节点对之间是否存在特定的目标关系(元路径),通过多任务预测(每个任务对应于一条元路径)联合学习一个模型,同时得到节点和元路径的向量表示。神经网络模型的训练数据是四元组
(3) 聚类消歧
基于作者向量表示结果,利用聚类算法将重名作者划分为互不相交的子集,每个子集代表一个现实作者。K-Means和层次凝聚聚类是作者重名消歧中常用的两种聚类算法,实际应用中前者需要给定初始聚类数,而后者需要解决聚类结束条件的问题。本文采用近邻传播算法(Affinity Propagation)聚类,该算法以数据点的相似性矩阵为基础,迭代计算矩阵中每个数据点的吸引度和归属度,并对吸引度和归属度求和确定聚类中心[15]。近邻传播算法无需指定最终聚类簇的个数,在作者重名消歧中有着广泛应用。
(4) 强规则匹配
由于学术文献信息可能存在缺失(尤其是参考文献信息)和前文提到的机构更名歧义问题,在构建异质文献信息网络的实际过程中无法全面获取实体间的真实关系,使表示结果难以充分体现作者间的相似性,从而导致聚类消歧存在过于碎片化的情况,即现实中的同一作者被划为多个聚类簇。合著关系是作者重名消歧的重要依据,如果同一作者被划为多个聚类簇,那么这些聚类簇所代表的作者之间大概率会存在共同的合著者,尽管本文构建的异质文献信息网络和采用的网络表示学习方法考虑了作者的合著关系和相关语义信息,但经过网络嵌入和聚类分析后相关信息被压缩,并不能充分体现在消歧结果中。因此,在聚类消歧结果的基础上,进一步利用合著关系进行强规则匹配,将具有共同合著者的类合并作为同一个作者,以期在一定程度上优化消歧结果的碎片化问题。为了确保基于合著关系消歧的鲁棒性,仅将共同合著者数量不少于两人的类进行合并。
3.3 评价方法
评价对于机器学习任务至关重要,选取K-Metric指标[16]衡量作者重名消歧方法的有效性。K-Metric是类平均纯度(Average Cluster Purity,ACP)和作者平均纯度(Average Author Purity,AAP)的几何平均值。其中,ACP衡量算法生成的聚类簇相对于人工参考簇的纯度,通过检验生成的聚类簇是否只包含参考簇中的记录,测度聚类错误的记录总数;AAP衡量算法将同一个作者划分为多个聚类簇的水平,检验了生成的聚类簇的碎片化程度。ACP、AAP和K-Metric指标的计算方式如公式(5)所示。
其中,
4 实验与结果
4.1 数据集
AMiner、DBLP、CiteSeerX等是作者重名消歧研究常用的实验数据集,但以上数据集缺少本文方法所需的引文信息,因此选择以AMiner[17]数据集为基础,利用Web of Science数据库重新检索相关文献记录构建数据集。AMiner平台整合了DBLP、CiteSeerX等在线学术数据,其提供的人名消歧数据集包含100个作者姓名的文献记录并标引了真实作者,文献发表的时间跨度范围为1996-2016年。从AMiner数据集中选取6个歧义程度不同的作者姓名,将每个作者姓名的文献记录与Web of Science数据库检索结果进行匹配,匹配成功的文献记录作为最终的实验数据用于方法有效性的评估,实验数据集的论文量和真实作者数量如表1所示。
表1 实验数据集
Table 1
| 作者姓名 | 相关论文量 | 真实作者数量 |
|---|---|---|
| Hongbin Liang | 179 | 10 |
| Guorong Chen | 267 | 14 |
| Qi Hu | 142 | 42 |
| Jian Du | 149 | 45 |
| Xi Huang | 233 | 45 |
| Jia Xu | 444 | 87 |
4.2 对比方法
为了验证本文提出的网络模型和强规则匹配对消歧效果的影响,设计了以下两种方法进行对比分析。
(1)经典Author-Paper-Venue网络模型(APV)方法。理论上,在网络模型中融入更丰富的异质节点和关系能得到更有意义的作者表示,进而提升消歧结果的准确性。为验证这一推论,将本文OAPV网络模型和经典的APV网络模型的消歧结果进行对比。
(2)无强规则匹配(Non-SFM)方法。在聚类消歧的基础上增加强规则匹配有助于解决聚类簇过于碎片化的问题,通过与Non-SFM方法的对比,将检验Non-SFM方法的碎片化程度以及强规则匹配对其的解决效果。
4.3 实验结果分析
表2 作者重名消歧实验结果对比
Table 2
| 作者姓名 | 本文方法 | APV方法 | Non-SFM方法 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ACP | AAP | K-Metric | ACP | AAP | K-Metric | ACP | AAP | K-Metric | |
| Hongbin Liang | 0.987 | 0.911 | 0.948 | 0.889 | 0.237 | 0.459 | 0.938 | 0.379 | 0.596 |
| Guorong Chen | 0.918 | 0.848 | 0.882 | 0.911 | 0.161 | 0.383 | 0.919 | 0.286 | 0.513 |
| Qi Hu | 0.816 | 0.915 | 0.864 | 0.323 | 0.343 | 0.333 | 0.816 | 0.915 | 0.864 |
| Jian Du | 0.771 | 0.969 | 0.864 | 0.589 | 0.836 | 0.701 | 0.772 | 0.910 | 0.838 |
| Xi Huang | 0.821 | 0.817 | 0.819 | 0.758 | 0.534 | 0.636 | 0.688 | 0.728 | 0.708 |
| Jia Xu | 0.769 | 0.591 | 0.674 | 0.730 | 0.469 | 0.585 | 0.787 | 0.540 | 0.652 |
| 平均值 | 0.847 | 0.842 | 0.842 | 0.700 | 0.430 | 0.516 | 0.820 | 0.626 | 0.695 |
首先对比分析APV和Non-SFM方法的消歧效果。Non-SFM方法是基于OAPV网络模型获取作者的表示向量,相较于APV方法,前者在网络模型中进一步融入机构节点、机构-作者隶属关系以及文献相似关系,二者均是采用HIN2Vec计算作者的表示向量。从评价指标来看,APV方法的ACP、AAP和K-Metric指标的平均值均偏低,尤其是AAP平均值仅为0.430,表明该方法消歧结果的碎片化程度很高;Non-SFM方法下每个作者的消歧准确性均有所提高,K-Metric平均值提升了34.69%,而ACP和AAP的平均值则分别提升了17.14%和45.58%。分析认为,Non-SFM方法通过在网络模型中增加更多类型的节点和关系,为作者表示学习提供了更加丰富的语义信息,进而得到的作者表示结果更加准确,消歧结果在聚类纯度和碎片化程度两方面均有提升,其中聚类纯度达0.820,但碎片化程度仍需优化。
进一步对比分析Non-SFM方法和本文方法的消歧效果。本文方法在Non-SFM方法聚类消歧的基础上增加了强规则匹配,以期解决碎片化程度较高的问题。从评价指标来看,本文方法的ACP平均值变化不大,但AAP和K-Metric平均值分别提升了34.50%和21.15%。分析认为,利用共同合著者进行强规则匹配,能有效解决基于异质文献信息网络的作者重名消歧中碎片化程度过高的问题。
4.4 扩展分析
在作者表示学习过程中,表示向量的维数反映了保留的网络语义信息的多少,其对消歧效果有直接影响,因此有必要分析作者表示向量维数对消歧方法的影响,为实际应用提供最优的维数参考。在保持HIN2Vec算法其他超参数不变的前提下(均采用算法默认值),分别计算三种方法在不同作者表示向量维数(10~100)下的K-Metric指标,结果如图3所示。随着表示向量维数的增加,本文方法中5个作者的K-Metric指标值均先呈现增长趋势,随后小幅波动变化,当维数为60左右时效果最佳,不同维数下作者Hongbin Liang的消歧效果较为平稳;Non-SFM方法中,作者Xi Huang、Hongbin Liang和Guorong Chen的K-Metric指标值呈下降或先下降后波动变化的趋势,其他作者的K-Metric指标值则先增加后小幅波动变化;APV方法中,大部分作者在维数为10~20时K-Metric指标值最高(Qi Hu除外),随后呈现下滑或波动下滑趋势,作者Qi Hu的K-Metric指标值虽然一开始呈现增加趋势,但当维数超过30时较为平稳。分析认为,在基于异质信息网络利用实体关系数据进行作者重名消歧时,如果作者名称歧义程度较小或实体及关系类型较少,较低的维数足以表达网络语义信息,进而取得最优的消歧结果,反之,需要较高的维数表达网络语义信息。综合看来,APV方法由于考虑的实体及关系类型较少,容易确定最优维数参数,但整体的消歧效果较差;Non-SFM方法融合了更加丰富的实体关系数据后,消歧效果有了较大提升,但当作者名称歧义程度相差较大时,最优维数变化也较大;本文方法在Non-SFM方法的基础上增加了强规则匹配,进一步提升了消歧效果,同时使最优维数在60附近,表明该方法对作者表示向量维数的稳定性更高。
图3
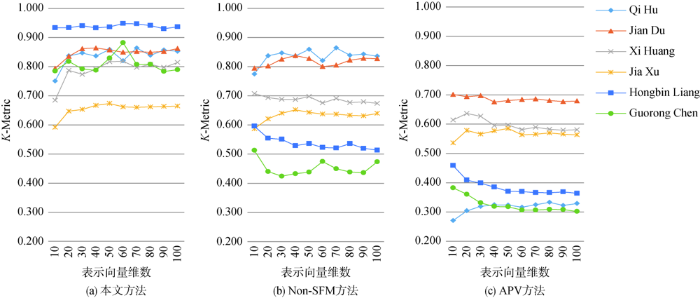
图3
表示向量维数对不同方法效果的影响
Fig.3
The Influence of Embedding Dimensions on Different Methods Performance
5 结语
本文提出一种新的基于异质信息网络表示学习的学术文献作者重名消歧方法。该方法从文献信息中抽取多种类型的实体及关系构建异质信息网络,在利用HIN2Vec获取作者节点的表示向量的基础上,采用近邻传播算法对作者进行聚类消歧,最后通过强规则匹配将具有共同合著者的多个聚类簇进行合并,得到最终的消歧结果。在构建的Web of Science测试数据集下的实验结果表明,本文方法具有良好的消歧效果且对作者表示向量维数的稳定性较高,对学术文献作者重名消歧具有一定的借鉴意义。本文方法构建的异质网络模型考虑了更多类型的节点和关系,较经典的APV网络模型为作者表示学习提供了更加丰富的语义信息,能得到更准确的作者表示向量,进而全面提升消歧效果;同时,本文方法利用共同合著者进行强规则匹配,有效地解决了消歧结果的碎片化问题。需要说明的是,即使不考虑强规则匹配,消歧效果也较经典的APV方法有显著提升。另外,作者表示向量维数对本文方法消歧效果的影响分析表明,当作者名歧义程度相差较大时,该方法对作者表示向量维数具有较高的稳定性。
本文仍存在一些不足之处,如对歧义程度最大的作者(Jia Xu)的消歧效果明显低于其他作者,可能是由于该作者的异质文献信息网络中的关系十分稀疏,影响了节点的表示学习效果,具体原因有待进一步分析;在构建异质信息网络时以文献间的引文相似关系替代文本相似关系,虽然降低了计算的复杂度,但同时要求文献记录包含参考文献信息,因此方法的应用场景具有一定的局限性。
作者贡献声明
邓启平:设计研究方案,进行实验,起草论文;
陈卫静,嵇灵:采集、清洗和标引数据;
张宇娥:提出研究思路,论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: dengqp@uestc.edu.cn。
[1] 邓启平. wos.zip. Web of Science论文消歧数据集.
[2] 邓启平. ResultData.zip. 实验数据消歧结果及评价指标明细.
参考文献
面向异质信息网络的表示学习方法研究综述
[J].
Survey on Representation Learning Methods Oriented to Heterogeneous Information Network
[J].
PTE: Predictive Text Embedding Through Large-Scale Heterogeneous Text Networks
[C]
科学计量中多源数据融合方法研究述评
[J].
Research on Multi-Source Data Fusion Method in Scientometrics
[J].
Metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[C]
HINE: Heterogeneous Information Network Embedding
[C]
HIN2Vec: Explore Meta-Paths in Heterogeneous Information Networks for Representation Learning
[C]
Are Meta-paths Necessary?: Revisiting Heterogeneous Graph Embeddings
[C]
A Name Disambiguation Module for Intelligent Robotic Consultant in Industrial Internet of Things
[J].DOI:10.1016/j.ymssp.2019.106413 URL [本文引用: 1]
Name Disambiguation in Anonymized Graphs Using Network Embedding
[C]
基于网络表示学习的作者重名消歧研究
[J].
Author Name Disambiguation with Network Embedding
[J].
Author Name Disambiguation on Heterogeneous Information Network with Adversarial Representation Learning
[C]
Unsupervised Author Disambiguation Using Heterogeneous Graph Convolutional Network Embedding
[C]
Incremental Author Name Disambiguation Using Author Profile Models and Self-Citations
[J].
Incremental Author Name Disambiguation for Scientific Citation Data
[C]
Clustering by Passing Messages Between Data Points
[J].DOI:10.1126/science.1136800 URL [本文引用: 1]
Author Name Disambiguation Using a Graph Model with Node Splitting and Merging Based on Bibliographic Information
[J].DOI:10.1007/s11192-014-1289-4 URL [本文引用: 1]
Name Disambiguation in AMiner: Clustering, Maintenance, and Human in the Loop
[C]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}