1 引言
伴随平台经济发展,弹幕凭借高互动性和参与性成为视频传播的重要载体。弹幕是一种特殊的实时评论,兼具信息、情感和时间三种属性。在时序变化的弹幕背后,蕴含着一条观众与内容之间情感沟通的隐形通道,即弹幕情感曲线,弹幕情感曲线反映了“故事”演化中用户实时情感的变化趋势[1 -2 ] ,是对视频内容的一种侧面刻画,对视频传播效果也具有潜在的重要影响。此外,基于情感曲线把握用户的情感行为与情感模式,是视频市场精细化运营的必然趋势。因此,弹幕视频情感曲线生成与挖掘成为学者关注的热点。
情感曲线本质是情感时间序列。在序列生成阶段,准确量化单一序数情感值是后续处理的基础,由于弹幕文本具有非书面化、随意性的特点,传统基于规范文本的情感量化方法不能直接有效地迁移至弹幕领域。在情感曲线的聚类阶段,弹幕社交属性导致弹幕情感时序间存在相位偏移,另外,弹幕数据在一定时间内的聚集会导致弹幕情感变化的高度不连续,进一步增加了情感曲线生成与挖掘的难度。目前学界关于弹幕情感曲线对视频传播效果的影响与解释仍比较模糊,难以有效支撑视频运营决策。针对上述问题,本文从弹幕领域特定情感词典扩充构建、K-shape算法情感序列聚类和曲线传播效果特征挖掘等三个方面,对弹幕视频情感曲线深度挖掘展开研究。
2 国内外研究现状
弹幕的价值在于同时包含内容传递[3 ] 、情感互动[4 -5 ] 和即时性[6 ] 等多方面特殊属性,其中情感互动性[7 ] 对视频传播效果有重要影响。因此,对于视频弹幕的研究也主要在于主题提取、情感分析和时序分析三个方面。
弹幕评论的主题提取重点关注提取视频及视频片段的主题信息,形成关键词便于用户方的检索、摘要、推荐和平台方的视频组织管理。Wu等[8 ] 为研究视频弹幕对视频标签化的作用而提出TPTM模型,该模型考虑视频语义、用户偏见并识别用户交互因素作为构建LDA模型的先验知识,以解决弹幕文本噪声大、局部文本稀疏带来的模型准确性问题。Lv等[9 ] 为消除弹幕文本中大量网络用语、实现时间序列精准匹配而提出T-DSSM模型,该模型采用窗口采样的方法,将时序相隔较近的弹幕作为语义识别的基本单位,而不相关弹幕则直接被剔除。Yang等[10 ] 在各个时序节点通过社群监测理论进行语义关联聚类,有效消除了弹幕评论的内生交互性干扰。 Filippova等[11 ] 证明了结合多源异构数据(视频和文本)的监督器强于单一预测分类器,观众评论等文本信息对视频主题分类均有重要的特征贡献。
在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题。Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类。Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序。洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐。吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本。Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异。王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注。综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上。文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别。尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率。
完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘。庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段。Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法。Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距。郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化。王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势。特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究。例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法。李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系。Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式。周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题。何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘。由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入。
3 研究思路与方法
3.1 研究思路
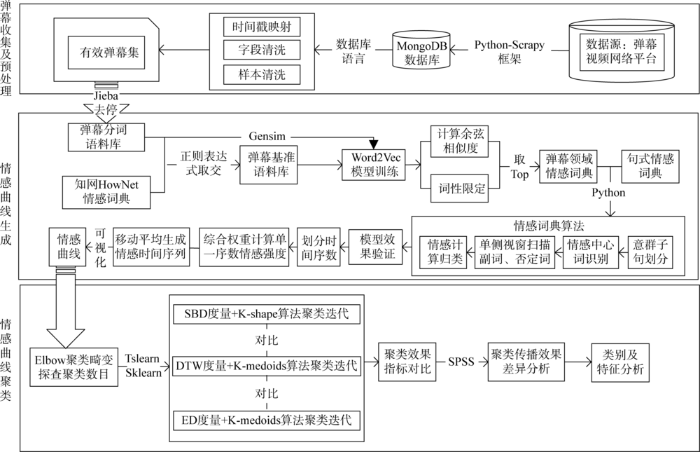
本研究主要解决情感时间序列准确生成与聚类的问题,探索优质传播效果影片的情感曲线特征,整体的技术路线如图1 所示。
图1
图1
总体技术路线
Fig.1
Technical Route
首先,应当选择合适的弹幕视频网络平台和弹幕文本题材,确保数据来源的规范。使用网络爬虫和数据库技术对相关视频平台的弹幕数据进行采集、保存和预处理。
在情感曲线的生成阶段。情感曲线是弹幕情感曲线聚类的基础。刻画准确反映观众情绪随时序变动的趋势,依赖于单位文本中包含的弹幕情感值的精准量化。基于对弹幕文本研究的梳理,本研究采用情感词典算法进行量化处理。为提升情感词典模型准确率,适应弹幕领域扩展了情感词典,鉴于弹幕语料大规模和词句简短的特性,采用分布式文本向量表示模型Word2Vec对大量弹幕语料进行训练,通过词性限定,依据余弦相似度计算结果扩展Pos情感词表和Neg情感词表,使用情感词典算法进行弹幕情感极性的量化,该算法基于一般情感词典分词模型,并为准确处理弹幕语境中反语、网络用语等情况而设置了特殊句式词典,以期提升模型鲁棒性。在模型验证阶段,设置了扩展情感词典前后情感词典主客观分类效果的对比实验。最后,随机抽样一定数量的弹幕样本,计算混淆矩阵,验证模型分类有效性。在情感曲线实际的生成阶段,为提升情感时间序列的准确性和平稳性,本研究提出综合权重计算单位序数情感和移动平均法,一定程度上保证了形态失真与时序平稳之间的平衡。
在情感曲线的聚类探索阶段。使用Elbow准则探测不同聚类类别对整体聚类畸变度的影响,从而科学确定最佳的聚类数量。本研究采用K-shape算法进行情感时间序列聚类。该算法时间序列相似度采用基于形状的相似度度量(Shaped-Based Distance,SBD),在进行时序簇类划分前,会预先动态计算该时序与簇中心的位移时间窗,以一定的边缘形态丢失风险,保证两者情感时间序列不存在滞后或前置性。在聚类中心更新的原则上,K-shape算法在计算聚类中心时,对斯坦纳树问题进行等价转化,极大提升了聚类中心迭代效率,避免了情感时序簇迭代过程中的失真,所提取的中心序列会保持与源簇在升降趋势和变化幅度的一致趋势,以精确表征时间曲线集群的高聚集形态。为对比不同时序相似度设置及算法组合的效果优劣,设置了K-medoids与欧氏距离(Euclidean Distance,ED)、动态时间扭曲距离(Dynamic Time Warping,DTW)与本算法在戴维森堡丁指数(Davies-Bouldin Index, DBI)等指标上的对比实验。最后,采用一定指标作为簇类传播效果的表征差异性分析探索,比对和提取聚类间的传播效果与特征。
3.2 研究方法及模型
鉴于弹幕文化存在特殊语法和语言习惯,在一般的弹幕情感词典分析之前,需要先确认是否是弹幕否定句式、特殊语言现象,例如“要是……就好了”“希望……是个好人”,或者是“!!!”“233”“2333”,对其作特有的句式分析,其情感权重以人工标注方式取积极、消极情感词典的平均权重。而对于一般弹幕文本S S 1 S 2 S n W s e W d e W a d S e n t S i
(1) S e n t S i = O W d e × O W a d × O W s e
其中,O W d e O W a d O W s e k O W d e = ( - 1 ) k S
(2) S e n t S = ∑ n i = 1 s i
根据S e n t S
(3) S S = 1 0 - 1 S e n t S > 0 S e n t S = 0 S e n t S < 0
0、1、- 1 分别对应客观结果、主观积极结果、主观消极结果。
基于情感分类的结果,应确定一定时间间隔作为时间序列单一序数的采样时间窗口,采用一定方法量化单一序数情感值,对情感时间序列进行预处理,以达到聚类的前置条件。
构建可供分析的离散型时间序列,必须选择合适的时间窗口,平衡时间序列的维度和单一时序情感的准确性。在情感分类时,本研究有无法达到实体或属性层次情感粒度的局限性,因此,以弹幕内容情感存在强关联、一般弹幕间情感连续性和控制序列维度三个条件选择时间窗口。鉴于弹幕一般情感极性连续的情况,但在一定时间窗口内,仍必须考虑它们之间的相互作用,聚焦于最突出的情感极性。因此,单一序数情感值计算如公式(4)所示。
(4) S e n t i = ∑ S e n t S i = P S e n t s i × O P + ∑ S e n t S i = N S e n t s i × O N
其中,∑ S e n t S = P S e n t s O P
按照以上方法采样弹幕数据,不会存在遗漏,也不会产生重叠,但视频弹幕情感值分布不均匀、不独立,单纯的不重叠采样会在窗口边缘造成较大的波动。根据时间序列理论[31 ] ,对弹幕序列数据进行移动平均,可以保证序列本身的平稳性,还有利于过滤弹幕情感值的高频噪声,使得时间序列形态上更为平滑,如公式(5)所示。
(5) S ' [ n ] = 1 M ∑ k = 0 M - 1 S [ n - k ]
其中,S [ n ] S ' [ n ] M 指移动平均步长,序列平滑能力随M
情感时间序列聚类是一种基础而重要的无监督挖掘方法,广泛应用于关键性能指标(KPI)异常检验、股票房价预测、趋势挖掘等领域。K-shape算法[32 ] 是一种基于时间序列本身的聚类方法,即数据不经过任何处理或稍加处理即可进行时间序列聚类的方法,K-means、K-medoids算法也同属此类。不同于基于特征、基于先验时间序列模型的方法,基于原始时间序列聚类的方法,高度依赖时间序列相似度度量设置。本研究提出SBD-K-shape算法,采用基于形状的相似度度量(SBD),并据此更新聚类质心,相比于采用传统度量方法的K-means等算法,更有利于挖掘时间序列形态间的相似度,从根本上保证了升降趋势及幅度变化在时移变动情况下仍保持相似度不变性,在时序相位偏移迭代中的趋势保持性能也存在一定优势。此类算法要求较高的算力,在数据采集和处理阶段应保证时间序列的维度,如果时间序列取样的时间分辨率设置得过于精细,则后期需采用降维算法以提高计算的效率。
时间序列之间的相似度是衡量两个时间序列相似程度的一个重要指标,是时间序列聚类、分类、异常发现等诸多数据挖掘的基础。欧氏距离和动态时间扭曲距离(DTW)是计算时间序列相似性时经常采用的两种度量方式,如公式(6)和公式(7)所示。欧氏距离对时间序列异常维度非常敏感,一些轻微的变化可能使欧氏距离的变化很大,而动态时间弯曲距离可以有效消除欧氏距离这个缺陷,并且可以使用在时间序数不一致的情形。动态时间弯曲已广泛应用在社会科学、医学、音频信号与处理等领域。
(6) D E D X , Y = ∑ i = 1 n ( x i - y i ) 2
对于时间序列X = [ x 1 , x 2 , … , x n ] Y = [ y 1 , y 2 , … , y m ]
(7) D D T W ( X , Y ) = t ( n , m )
t ( i , j ) = D E D ( x i , y j ) + m i n { t ( i - 1 , j - 1 ) , t ( i - 1 , j ) , t ( i , j - 1 ) }
其中,t ( i , j ) D E D ( x i , y j ) ( i , j ) ( 0,0 ) ( n , m )
在使用K-shape对时间序列进行相似性比较之前,首先对两序列X 、Y 进行预处理,X = [ x 1 , x 2 , … , x n ] Y = [ y 1 , y 2 , … , y m ] X 的时间窗适量平移以便两序列的全局比较,经过平移后的时间序列如公式(8)所示。
(8) X ( s ) = [ 0 , ⋯ , 0 ⏞ | s | , x 1 , x 2 , ⋯ , x m - s ] s ≥ 0 [ x 1 - s , ⋯ , x m - 1 , x m , 0 , ⋯ , 0 ⏟ | s | ] s < 0
其中,s 为时间序列X 内所有可能的平移量,s ∈ [ - m , m ] s ≥0,则X 的时间序列向右移s 个单位;若s <0,则X 的时间序列向左移s 个单位。
得到互相关序列C w ( X , Y ) = [ c 1 , c 2 , ⋯ c w ] 2 m - 1 c w = R w - m ( X , Y ) w ∈ { 1,2 , ⋯ , 2 m - 1 } R k ( X , Y )
(9) R k ( X , Y ) = ∑ l = 1 m - k x l + k y l k ≥ 0 R - k ( Y , X ) k < 0
计算使c w w Y , X s = w - m C w ( X , Y ) C n , w ( X , Y )
(10) C n , w ( X , Y ) = C w ( X , Y ) R 0 ( X , X ) R 0 ( Y , Y )
其中,R 0
基于此时间序列相似性判断D S B D
(11) D S B D ( X , Y ) = 1 - m a x w C w ( X , Y ) R 0 ( X , X ) R 0 ( Y , Y )
其中,D S B D D S B D
每类聚类中心代表时间序列曲线在每一个聚类的中心形态特征。K-means算法是通过计算每类数据中各个坐标序列相对应数值的算术平均值来提取每类簇聚类中心,但是这种方式提取的聚类中心往往不能准确反映每类簇的典型特征,K-shape算法提取聚类中心将其视作一个优化选择问题,目标是找到与每类时间序列平方和最小的序列,即斯坦纳树优化问题,如公式(12)所示。
(12) c k * = a r g m i n c k ∑ u i ∈ P k D S B D ( c k , u i ) 2 c k ∈ R
其中,P k k c k *
互相关方法提取的是两时间序列的相似性而非差异性,可同化公式(12)为一个最大化问题,由此可得出公式(13)。每次迭代中,利用前次迭代中心作为参考并利用互相关法将所有序列与参考序列对齐。
(13) μ k * = a r g m a x μ k ∑ u i ∈ P k C n , w 2 ( u i , μ k ) = a r g m a x μ k μ k T ∑ u i ∈ P k ( u i u i T ) 2 μ k
(14) μ k * = a r g m a x μ k μ k T Q T S Q μ k μ k T μ k = a r g m a x μ k μ k T M μ k μ k T μ k
其中,μ k = μ k Q Q = I - O / m I O M = Q T S Q S ∑ u i ∈ P k ( u i u i T ) 2
μ k * M
4 研究过程
4.1 数据采集及预处理
本研究选择文化纪录片作为视频弹幕题材,一定程度上可以从数据采集环节规范弹幕数据,降低后期数据清洗的难度。利用分布式爬虫框架Scrapy流式采集Bilibili网站的纪录片《国家宝藏》前20集的弹幕数据,存储于MongoDB数据库中的原始数据共包含320 000条记录,字段包括视频序号、弹幕时间戳、弹幕字号、用户ID及弹幕内容等,随后进行字段、样本清洗。首先使用数据库语言实现仅保留弹幕内容、用户ID、弹幕发表相对时间等字段,使用jieba模块进行分词预处理,结果如表1 所示。接着,依据哈尔滨工业大学的停用词表,删除无意义弹幕、因去停而导致空白或无效的弹幕,最后共删除42 111条弹幕样本,语料库中最终保留有效弹幕分词样本279 889条。
4.2 情感曲线生成
以知网HowNet词典为基准词典。知网词典的原始结构为中文正面评价词语3 730个、中文负面评价词语3 116个、中文正面情感词语836个、中文负面情感词语1 254个、程度副词232个。将同一类型的情感词和评价词进行合并,形成积极词和消极词两个词典。利用正则表达式模块将弹幕分词语料库与积极词典和消极词典分别取交集,形成积极和消极两种极性的基准词词库。
训练Word2Vec词向量模型。使用Gemsim模块将279 889条弹幕构成的弹幕分词语料导入基于CBOW的Word2Vec模型进行训练。训练出分词的词向量,为减少计算量,设置词向量维度为400,模型参数设置如表2 所示。
为保证扩展词为有效的形容词词性,采用jieba对弹幕分词语料进行词性标注,输出保存为弹幕形容分词词表。利用Word2Vec模型输出词向量,计算与基准词间的余弦相似度,取其中属于形容词的前5个词对情感词典进行扩充,手动排除不合适的词语。最终,积极词典扩充了858个词,消极词典扩充了410个词,截取部分扩展词展示如表3 所示。
情感词典在弹幕领域适应扩展了1 268个词汇,在原词典8 936的词汇量基础上扩展14%,扩展词、基准词极性上保持一致,词性扩充性能良好。
使用Python实现情感词典模型,为后期查验单个弹幕数据的情感量化情况而输出分析日志,该日志包含弹幕情感值总分、所有意群子句分数、所有意群中积极情感成分分数、所有意群中消极情感成分分数和所有意群中参与实际计算的否定、副词、情感词词表。最后,在已经进行情感分类的弹幕数据中,随机抽取500条弹幕,采用人工方式进行情感标注,得到分类模型的混淆矩阵,模型评价结果汇总如表5 -表8 所示,并与完全基于知网词典的主客观二分类结果(表4 )进行对比。
综上,基于扩展情感词典的模型在主客观分类上表现良好,F1值达到0.89,对比表4 和表5 数据,基于扩展情感词典能使模型在主客观分类任务中被正确分类的正确率提高123%;但在极性分类上表现稍弱,F1值仅为0.79,整体上性能表现良好。
本研究根据弹幕内容情感存在对应关联性、弹幕一般情感连续性和控制序列维度等条件选择时间窗口。观察视频内容与相关反响弹幕的相对时间,发现平均有21.6秒的相对错位。但考虑到弹幕用户对于视频文化内容、旁白配乐、主持人角色等多个视频内容及元素产生的共鸣,弹幕情感标注的虽是不同内容实体,但同片段情感极性几乎保持连续。因而取剪辑片段时长30秒作为单位序列的采样窗口。
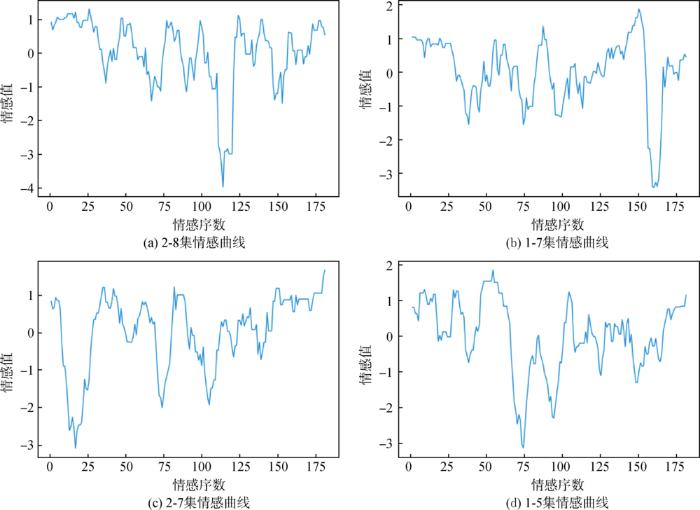
使用Pandas模块,依据弹幕的相对时间进行时间序数划分、综合权重量化单一序数情感值,利用Matplotlib模块对情感时间序列进行绘制,结果如图2 所示。
图2
图2
纪录片中4部典型的情感曲线
Fig.2
Four Typical Emotional Curves in Documentaries
①对4种典型的情感曲线,在波峰、波谷所反映的转折区间进行情感分析日志检查可以检验情感曲线生成的效果,即情感曲线是否反映了片段中弹幕真实情感的变化。例如,在图2 (a)中的前期,曲线包络线整体呈现积极情感,查阅弹幕情感分析日志,该时间段观众对舞台、演员等视频内容整体较满意。后续当视频播放至序数25,28,39,100时,情感曲线呈现转折。综上,情感曲线很好地反映了弹幕用户的情感动态。
②情感曲线序数处在情感值极点处,弹幕数量比一般情感序数处平均高出50%,这一定程度说明极点可以反映影片片段受关注的程度。情感曲线都包含多个峰谷交替区间和多个显著的情感极点。定义极性点与右侧紧邻的极性点形成的区间存在跨越情感极性(即跨越原点)的为“第一类”极点,根据该区间的升降趋势,又划分为“第一类上”、“第一类下”极点。极点与右侧紧邻极点形成的区间不存在跨越情感极性的极点的称为“第二类”极点,同样根据区间升降趋势,划分为“第二类上”、“第二类下”极点。“第一类”极点右侧所表征的大幅度情感转折现象,除了由镜头转场导致情感值转向外,弹幕情感波动极大地被意见领袖现象所影响,并且会持续多个片段序数。
综上,情感曲线在形态上的解释性较强,曲线之间存在共性。由②可知,视频的精彩程度主要取决于“争议看点”和“精彩看点”。“争议看点”主要由意见领袖话题转移所引发,“精彩看点”则由用户群对视频相关主体内容的友好讨论和一致认同所形成。
4.3 基于K-shape算法的情感序列聚类
本文采取Elbow法则[33 ] 来确定最佳聚类数,时间序列畸变程度会随着聚类数目变化,而最佳的聚类数目是时间序列取得最小畸变程度时聚类数目的取值。其中,对于一个簇而言,簇畸变程度是每个簇中心与簇内样本点的平方距离误差和,而聚类畸变程度则是所有聚类的畸变程度。Elbow原则以聚类畸变程度最小为目标。
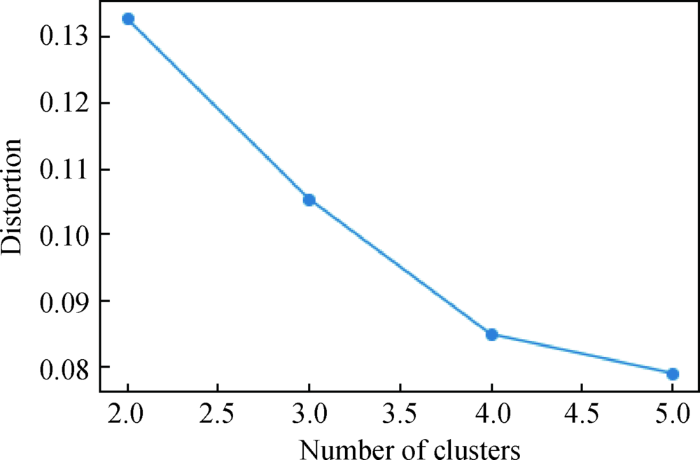
利用Python第三方专门应用于时间序列数据分析的Tslearn模块,对时间序列进行标准化,使每一条时间序列的均值和方差分别为0和1。使用Tslearn中的K-shape模型,在聚类数目2~5进行试探,绘制畸变程度随聚类数目变化的曲线,如图3 所示。当聚类数目在3~4时畸变值骤降,在4~5时畸变值下降减缓,因此为避免过度分类可取临界值4为最佳聚类数目。
图3
图3
确定最佳聚类数量的Elbow方法
Fig.3
Elbow Method for Determining the Optimal Number of Clusters
基于已经获得的最佳聚类数目,利用K-shape对本文20个时间序列进行聚类。为了解不同模型在同一个时间序列上的聚类效果,使用基于K-means改进的K-medoids等算法对时间序列同时进行处理。最后,采用时间序列处理模块Tslearn[34 ] 的聚类轮廓系数(SI)和机器学习框架Scikit-learn中提供的专门应用于序列数据聚类效果评估的戴维森堡丁指数(DBI)接口对聚类结果进行评估,具体聚类效果评价指标如表9 所示。
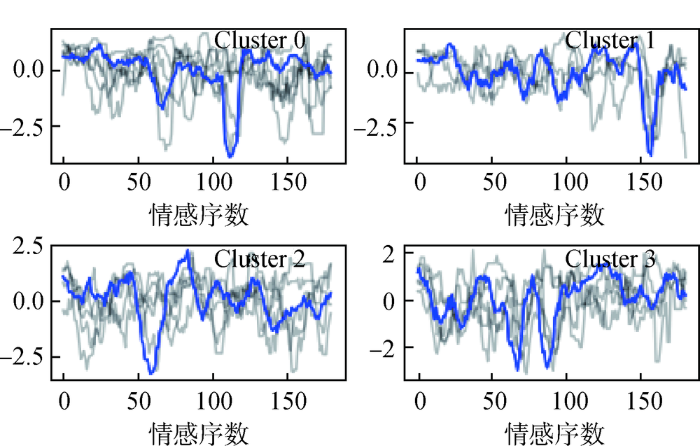
由表9 可知,K-shape+SBD方案在两个聚类评价指标上均优于K-medoids聚类算法,轮廓系数为0.47、戴维森堡丁指数为1.13。聚类效果良好,这说明基于SBD度量的K-shape算法在聚类挖掘上有优势,同簇序列具有更好的同质性。K-shape聚类的具体情况如表10 所示,包括时间序列所指示的样本和其对应的标签。由表10 可知,每一个聚类标签下都分布着4~6个视频样本,聚类较为均匀。算法规整了不同时序的相位偏移,与源簇呈现局部平行的趋势。
图4
图4
情感曲线K-shape聚类结果
Fig.4
Sentiment Curve K-shape Clustering Results
由图4 可知,影片的情感曲线呈现4类趋势。由于基于K-shape聚类的方法挖掘的各时间序列在形态上的相似性,归为一簇的所有序列,可以看作由簇心局部平移后收缩扩张所形成。因此,4种聚类的基本形态可以归纳为“双V型”、“单V后置型”、“单V前置型”和“W型”,在形态上有规律可循。
(1) 基本形态为“双V型”的情感曲线,在时间区间上存在较高比例的平坦区间,该区间包括较多“精彩看点”,在时间区间中部存在两个极大降幅的“争议看点”,以形状包含不连续的“双V”形状为明显特征。
(2) 基本形态为“单V后置型”的情感曲线,在时间区间上存在一个极大降幅的“争议看点”,且在时间维度上,分布于时间序列后半段,而其他区间不包含明显的“精彩看点”。
(3) 基本形态为“单V前置型”的情感曲线,在区间上存在两个相邻设置的极大降幅的“争议看点”,分布于中后段,呈“V型”,在影片之初存在较多的“精彩看点”。
(4) 基本形态为“W型”的情感曲线,存在曲线波动区间,表现为“W型”循环重复,不同于“单V后置型”情感曲线,其“争议看点”相邻且成对出现,升降幅度变化更大,曲线整体都无“精彩看点”分布。
4.4 基于差异性分析的聚类传播效果分析
为深入探查不同形态曲线对传播效果的影响,以视频点赞量作为表征视频传播效果的因变量,20个视频数据的聚类类别作为因子,导入到SPSS Statistics25中,进行单因素ANOVA分析。在进行ANOVA差异分析前,先验证组间的方差齐性,其结果如表11 所示。
可见,基于平均值、中位数等P值均大于显著性水平0.05,因此接受原假设,不同聚类类别组间样本方差不存在明显统计性差异。进而,单因素方差分析通过方差齐性检验。在“事后多重比较”中选取最小显著性差异法(LSD)进行统计分析,结果如表12 所示,不同聚类类别概率P值均小于0.05,因此否定原假设,点赞数量在不同组间存在显著性差异。以传播效果由好及坏的聚类排序是0>2>3>1。
综合聚类类别、曲线聚类形态和特征、传播效果差异性分析,可得:
(1)具有聚类0和聚类2这两类弹幕情感形态的视频更受观众欢迎。原因在于:该两类在曲线形态上比聚类1和聚类3在整体曲线形态上,存在更多“精彩看点”,视频弹幕讨论环境更友好,易促进观众产生沉浸式观感,且剧情更跌宕起伏。
(2)聚类2传播效果差于聚类0,原因在于:聚类2的“精彩看点”设置较少且仅出现在影片前段,中后段存在大量的“争议看点”。“精彩看点”设置提前有助于影片一开始吸引观众,使得聚类2和聚类0在传播效果上具有先发优势,但多数“争议看点”片段仍会到来,这使得影片进行到中后段仍然会被观众带入到激烈的弹幕讨论中,而非关注影片内容本身。再者,聚类0的“精彩看点”分布均匀,少量的“争议看点”置于中后段,这均保证了视频的传播效果。
(3)聚类1和聚类3在曲线形态上传播效果最差。聚类3和聚类1均有大量“争议看点”,几乎没有“精彩看点”,情感曲线整体都在直上直下的趋势中发展,这是在弹幕视频制作过程中需要避免的。
5 结语
(1)本研究提出Word2Vec扩充情感词典算法可以有效提升情感量化模型的性能。在实证阶段,通过大规模弹幕数据挖掘和词性控制,依据余弦相似度扩充的词汇和基准词汇在情感极性上保持高度一致,在弹幕语料情感分类中表现优异,可以提升主客观二分类结果正确率约123%,且使模型在主客观、极性分类等工作中的F1值分别提升至到0.89、0.79。
(2)本研究采用综合权重计算情感值、移动平均法生成的情感曲线可以有效表达影片观众的情感波动变化趋势。情感曲线上部分存在内容与情感非完全同步现象,原因在于个别用户的意见领袖行为。视频的传播效果与“争议看点”、“精彩看点”的位置有关。
(3)本研究采用SBD-K-Shape算法聚类情感时序,从轮廓系数等聚类指标上看,聚类效果明显优于DTW-K-medoids和ED-K-medoids两种算法组合。本算法消除了情感时序间的相位偏移从而聚类均匀,簇心形态特征明确,在实证层面证实了SBD-K-shape算法在弹幕情感时间序列聚类任务中有良好性能。
(4)聚类及相应视频反响效果评估显示,具有“双V型”形态情感曲线的传播效果最为良好,其反应的特征是,由用户认同与友好交流原因导致的“精彩看点”在视频制作时应更多地被设置,时间尺度上应保持均匀并尽可能前置。由用户争议产生的“争议看点”则应该尽量避免,并且应尽可能放到视频中后段,以避免在视频前期就因个别观众独特且具破坏力的视角转移了大量用户的视线,从而降低对影片本身的兴趣。
(1)扩展情感词典的过程仅考虑词性、词向量间余弦相似度,扩充限制手段过于单一,例如可使用TF-IDF指标进一步限制词频,从而避免手动过滤的效率低下。
(2)情感词典算法在处理弹幕文本情感量化时,对于网络用语、流行语或不含中心形容词的句子实际仍有一定的局限性。
(3)K-shape算法的SBD度量方案在曲线存在位移相似性的聚类问题上存在优势,但也存在极个别同步曲线位移导致相似度计算异常的问题。
(4)对情感时间序列聚类的结果,描述、解释和特征提取的程度仍然相对不足。
(5)弹幕数据仅取自文化类型的视频,目的是规范语料、降低数据清洗的难度。因而,分析结果不一定具备通用性。
作者贡献声明
张腾:提出研究思路,采集、清洗和分析数据,程序实现,论文起草;
利益冲突声明
支撑数据
支撑数据由作者自存储,E-mail: zhangtengbailong@163.com。
[1] 张腾,倪渊. adj_list_drop_dupilicates.txt. 去重形容词表.
[2] 张腾,倪渊. Clustering.py. 聚类代码文件.
[3] 张腾,倪渊. Corpus_Prepro_Train.py. 词典词向量生成代码.
[4] 张腾,倪渊. Dic_classifiers.py. 情感量化代码.
[5] 张腾,倪渊. Gen_Curve.py. 生成情感曲线、时间序列.
[6] 张腾,倪渊. Get_adj_list.py. 形容词标记代码.
[7] 张腾,倪渊. guobao_danmu.model.Word2Vec 模型文件.
[8] 张腾,倪渊. guobao_danmu.vector. 向量索引文件.
[9] 张腾,倪渊. Load_mod_Gen_new_dic.py. 扩充新词典代码.
[10] 张腾,倪渊. neg_dic_final.txt. 扩充消极情感词典文件.
[11] 张腾,倪渊. pos_dic_final.txt. 扩充积极情感词典文件.
[12] 张腾,倪渊. 弹幕传播效果差异分析.sav.SPSS 差异性分析.
[13] 张腾,倪渊. time_series_output.xlsx. 情感量化、分序数结果.
[14] 张腾,倪渊. 表格数据.xlsx. 弹幕处理结果.
[15] 张腾,倪渊. 国宝_excel_output.zip. 情感量化结果.
[16] 张腾,倪渊. 国宝原始数据集文件夹. 原始数据集.
参考文献
View Option
[1]
Nickerson R S . Confirmation Bias: A Ubiquitous Phenomenon in Many Guises
[J]. Review of General Psychology , 1998 , 2 (2 ): 175 -220 .
[本文引用: 1]
[2]
Konnegut K . Palm Sunday [M]. New York : Rosettabooks LLC , 1981 .
[本文引用: 1]
[3]
江含雪 . 传播学视域中的弹幕视频研究 [D]. 武汉 : 华中师范大学 , 2014 .
[本文引用: 1]
(Jiang Hanxue . The Research of Barrage Video from Communication Vision [D]. Wuhan : Central China Normal University , 2014 .)
[本文引用: 1]
[4]
陈沫 . 弹幕技术在电视行业的应用与发展
[J]. 新闻爱好者 , 2015 (10 ): 83 -85 .
[本文引用: 1]
(Chen Mo . Application and Development of Barrage Technology in TV Industry
[J]. Journalism Lover , 2015 (10 ): 83 -85 .)
[本文引用: 1]
[5]
谢梅 , 何炬 , 冯宇乐 . 大众传播游戏理论视角下的弹幕视频研究
[J]. 新闻界 , 2014 (2 ): 37 -40 .
[本文引用: 1]
(Xie Mei He Ju Feng Yule . Research on Barrage Video from the Perspective of Mass Communication Game Theory
[J]. Press Circles , 2014 (2 ): 37 -40 .)
[本文引用: 1]
[6]
詹雪美 . 浅析弹幕视频网站在我国的发展
[J]. 大众科技 , 2014 , 16 (10 ): 232 -233 .
[本文引用: 1]
(Zhan Xuemei . Development of Barrage of Video Website in China
[J]. Popular Science & Technology , 2014 , 16 (10 ): 232 -233 .)
[本文引用: 1]
[7]
张艺凝 . 互动视角下弹幕视频研究 [D]. 南京 : 南京师范大学 , 2015 .
[本文引用: 1]
(Zhang Yining . Research on Barrage Video from Interactive Perspective [D]. Nanjing : Nanjing Normal University , 2015 .)
[本文引用: 1]
[8]
Wu B Zhong E H Tan B , et al . Crowdsourced Time-Sync Video Tagging Using Temporal and Personalized Topic Modeling
[C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY , USA : ACM , 2014 : 721 -730 .
[本文引用: 1]
[9]
Lv G Y Xu T Chen E H , et al . Reading the Videos: Temporal Labeling for Crowdsourced Time-Sync Videos Based on Semantic Embedding
[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence . 2016 :3000 -3006 .
[本文引用: 1]
[10]
Yang W M Ruan N Gao W Y , et al . Crowdsourced Time-Sync Video Tagging Using Semantic Association Graph
[C]// Proceedings of the 2017 IEEE International Conference on Multimedia and Expo . 2017 : 547 -552 .
[本文引用: 1]
[11]
Filippova K Hall K B . Improved Video Categorization from Text Metadata and User Comments
[C]// Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China . 2011 :835 -842 .
[本文引用: 1]
[12]
Yamamoto T Nakamura S . Leveraging Viewer Comments for Mood Classification of Music Video Clips
[C]// Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, NY , USA : ACM , 2013 : 797 .
[本文引用: 1]
[13]
Murakami N Ito E . Emotional Video Ranking Based on User Comments
[C]// Proceedings of the 13th International Conference on Information Integration and Web-based Applications and Services . 2011 : 499 -502 .
[本文引用: 1]
[14]
洪庆 , 王思尧 , 赵钦佩 , 等 . 基于弹幕情感分析和聚类算法的视频用户群体分类
[J]. 计算机工程与科学 , 2018 , 40 (6 ): 1125 -1139 .
[本文引用: 1]
(Hong Qing Wang Siyao Zhao Qinpei , et al . Video User Group Classification Based on Barrage Comments Sentiment Analysis and Clustering Algorithms
[J]. Computer Engineering & Science , 2018 , 40 (6 ): 1125 -1139 .)
[本文引用: 1]
[15]
吴法民 , 吕广奕 , 刘淇 , 等 . 视频实时评论的深度语义表征方法
[J]. 计算机研究与发展 , 2019 , 56 (2 ): 293 -305 .
[本文引用: 1]
(Wu Famin Lü Guangyi Liu Qi , et al . Deep Semantic Representation of Time-Sync Comments for Videos
[J]. Journal of Computer Research and Development , 2019 , 56 (2 ): 293 -305 .)
[本文引用: 1]
[16]
Tran N K Cheng W W . Multiplicative Tree-Structured Long Short-Term Memory Networks for Semantic Representations
[C]// Proceedings of the 7th Joint Conference on Lexical and Computational Semantics. Stroudsburg, PA , USA : Association for Computational Linguistics , 2018 : 276 -286 .
[本文引用: 1]
[17]
王晓艳 . 基于图像分析的网络视频弹幕的情感分类研究与应用 [D]. 北京 : 北京邮电大学 , 2018 .
[本文引用: 1]
(Wang Xiaoyan . Research and Application of Emotion Classification of Network Video Barrage Based on Image Analysis [D]. Beijing : Beijing University of Posts and Telecommunications , 2018 .)
[本文引用: 1]
[18]
Turney P D Littman M L . Measuring Praise and Criticism: Inference of Semantic Orientation from Association
[J]. ACM Transactions on Information Systems , 2003 , 21 (4 ): 315 -346 .
[本文引用: 1]
[19]
陈晓东 . 基于情感词典的中文微博情感倾向分析研究 [D]. 武汉 : 华中科技大学 , 2012 .
[本文引用: 1]
(Chen Xiaodong . Research on Sentiment Dictionary Based Emotional Tendency Analysis of Chinese MicroBlog [D]. Wuhan : Huazhong University of Science and Technology , 2012 .)
[本文引用: 1]
[20]
庄须强 . 基于深度学习的弹幕评论情感分析研究 [D]. 济南 : 山东师范大学 , 2018 .
[本文引用: 1]
(Zhuang Xuqiang . Research on Emotional Analysis of Barrage Comments Based on Deep Learning [D]. Jinan : Shandong Normal University , 2018 .)
[本文引用: 1]
[21]
Hao X F Xu S J Zhang X M . Barrage Participation and Feedback in Travel Reality Shows: The Effects of Media on Destination Image Among Generation Y
[J]. Journal of Destination Marketing & Management , 2019 , 12 : 27 -36 .
[本文引用: 1]
[22]
Eickhoff C Li W Vries A P . Exploiting User Comments for Audio-Visual Content Indexing and Retrieval
[C]// Proceedings of the 35th European Conference on Information Retrieval Research . 2013 : 38 -49 .
[本文引用: 1]
[23]
郑飏飏 , 徐健 , 肖卓 . 情感分析及可视化方法在网络视频弹幕数据分析中的应用
[J]. 现代图书情报技术 , 2015 (11 ): 82 -90 .
[本文引用: 1]
(Zheng Yangyang Xu Jian Xiao Zhuo . Utilization of Sentiment Analysis and Visualization in Online Video Bullet-Screen Comments
[J]. New Technology of Library and Information Service , 2015 (11 ): 82 -90 .)
[本文引用: 1]
[24]
王敏 , 徐健 . 视频弹幕与字幕的情感分析与比较研究
[J]. 图书情报知识 , 2019 (5 ): 109 -119 .
[本文引用: 1]
(Wang Min Xu Jian . Emotional Analysis and Comparative Study of Bullet-Screen Comments and Subtitles
[J]. Documentation, Information & Knowledge , 2019 (5 ): 109 -119 .)
[本文引用: 1]
[25]
熊燕 . 运用情感曲线改造服务
[J]. 现代商业 , 2011 (15 ): 17 .
[本文引用: 1]
(Xiong Yan . Using Emotional Curve to Transform Service
[J]. Modern Business , 2011 (15 ): 17 .)
[本文引用: 1]
[26]
李致萱 , 刘澜 , 张斯嘉 , 等 . 基于情感曲线的高速铁路旅客个性化服务评价权重设计
[J]. 铁道运输与经济 , 2020 , 42 (1 ): 6 -11 .
[本文引用: 1]
(Li Zhixuan Liu Lan Zhang Sijia , et al . A Design of Individualized Passenger Transport Service Evaluation Weight Based on Emotion Curve for High-Speed Railway
[J]. Railway Transport and Economy , 2020 , 42 (1 ): 6 -11 .)
[本文引用: 1]
[27]
Reagan A J Mitchell L Kiley D , et al . The Emotional Arcs of Stories are Dominated by Six Basic Shapes
[J]. EPJ Data Science , 2016 , 5 : 31 .
[本文引用: 1]
[28]
周启元 . 基于小说文本情感曲线的下载量预测研究 [D]. 南京 : 南京大学 , 2017 .
[本文引用: 1]
(Zhou Qiyuan . Research on Downloading Volume Prediction Based on Sentiment Curves of Novels [D]. Nanjing : Nanjing University , 2017 .)
[本文引用: 1]
[29]
何跃 , 朱灿 , 朱婷婷 , 等 . 微博热点话题情感趋势研究
[J]. 情报理论与实践 , 2018 , 41 (7 ): 155 -160 .
[本文引用: 1]
(He Yue Zhu Can Zhu Tingting , et al . Research on the Emotional Tendency of Hot Topics in Micro-Blogs
[J]. Information Studies: Theory & Application , 2018 , 41 (7 ): 155 -160 .)
[本文引用: 1]
[30]
吕建伟 . 基于情感序列的突发事件分析与预测 [D]. 南京 : 南京邮电大学 , 2020 .
[本文引用: 1]
(Lü Jianwei . Analysis and Prediction of Emergencies Based on Emotion Sequences [D]. Nanjing : Nanjing University of Posts and Telecommunications , 2020 .)
[本文引用: 1]
[31]
Knopp J Li J T . Signal Processing for Communications
[C]// Proceedings of the 2005 IEEE Global Telecommunications Conference . 2005 .
[本文引用: 1]
[32]
Ives Z . Technical Perspective: K-Shape: Efficient and Accurate Clustering of Time Series
[J]. ACM SIGMOD Record , 2016 , 45 (1 ): 68 .
[本文引用: 1]
[33]
Thorndike R L . Who Belongs in the Family?
[J]. Psychometrika , 1953 , 18 (4 ): 267 -276 .
[本文引用: 1]
[34]
Tslearn使用轮廓系数(Silhouette_Score)评估KShape聚类效果 [EB/OL]. [2021 -06 -10 ]. https://blog.csdn.net/qq_37960007/article/details/107937212.
URL
[本文引用: 1]
(Tslearn Uses Silhouette_Score to Evaluate KShape Clustering Effect [EB/OL]. [2021 -06 -10 ]. https://blog.csdn.net/qq_37960007/article/details/107937212.)
URL
[本文引用: 1]
Confirmation Bias: A Ubiquitous Phenomenon in Many Guises
1
1998
... 伴随平台经济发展,弹幕凭借高互动性和参与性成为视频传播的重要载体.弹幕是一种特殊的实时评论,兼具信息、情感和时间三种属性.在时序变化的弹幕背后,蕴含着一条观众与内容之间情感沟通的隐形通道,即弹幕情感曲线,弹幕情感曲线反映了“故事”演化中用户实时情感的变化趋势[1 -2 ] ,是对视频内容的一种侧面刻画,对视频传播效果也具有潜在的重要影响.此外,基于情感曲线把握用户的情感行为与情感模式,是视频市场精细化运营的必然趋势.因此,弹幕视频情感曲线生成与挖掘成为学者关注的热点. ...
1
1981
... 伴随平台经济发展,弹幕凭借高互动性和参与性成为视频传播的重要载体.弹幕是一种特殊的实时评论,兼具信息、情感和时间三种属性.在时序变化的弹幕背后,蕴含着一条观众与内容之间情感沟通的隐形通道,即弹幕情感曲线,弹幕情感曲线反映了“故事”演化中用户实时情感的变化趋势[1 -2 ] ,是对视频内容的一种侧面刻画,对视频传播效果也具有潜在的重要影响.此外,基于情感曲线把握用户的情感行为与情感模式,是视频市场精细化运营的必然趋势.因此,弹幕视频情感曲线生成与挖掘成为学者关注的热点. ...
1
2014
... 弹幕的价值在于同时包含内容传递[3 ] 、情感互动[4 -5 ] 和即时性[6 ] 等多方面特殊属性,其中情感互动性[7 ] 对视频传播效果有重要影响.因此,对于视频弹幕的研究也主要在于主题提取、情感分析和时序分析三个方面. ...
1
2014
... 弹幕的价值在于同时包含内容传递[3 ] 、情感互动[4 -5 ] 和即时性[6 ] 等多方面特殊属性,其中情感互动性[7 ] 对视频传播效果有重要影响.因此,对于视频弹幕的研究也主要在于主题提取、情感分析和时序分析三个方面. ...
弹幕技术在电视行业的应用与发展
1
2015
... 弹幕的价值在于同时包含内容传递[3 ] 、情感互动[4 -5 ] 和即时性[6 ] 等多方面特殊属性,其中情感互动性[7 ] 对视频传播效果有重要影响.因此,对于视频弹幕的研究也主要在于主题提取、情感分析和时序分析三个方面. ...
弹幕技术在电视行业的应用与发展
1
2015
... 弹幕的价值在于同时包含内容传递[3 ] 、情感互动[4 -5 ] 和即时性[6 ] 等多方面特殊属性,其中情感互动性[7 ] 对视频传播效果有重要影响.因此,对于视频弹幕的研究也主要在于主题提取、情感分析和时序分析三个方面. ...
大众传播游戏理论视角下的弹幕视频研究
1
2014
... 弹幕的价值在于同时包含内容传递[3 ] 、情感互动[4 -5 ] 和即时性[6 ] 等多方面特殊属性,其中情感互动性[7 ] 对视频传播效果有重要影响.因此,对于视频弹幕的研究也主要在于主题提取、情感分析和时序分析三个方面. ...
大众传播游戏理论视角下的弹幕视频研究
1
2014
... 弹幕的价值在于同时包含内容传递[3 ] 、情感互动[4 -5 ] 和即时性[6 ] 等多方面特殊属性,其中情感互动性[7 ] 对视频传播效果有重要影响.因此,对于视频弹幕的研究也主要在于主题提取、情感分析和时序分析三个方面. ...
浅析弹幕视频网站在我国的发展
1
2014
... 弹幕的价值在于同时包含内容传递[3 ] 、情感互动[4 -5 ] 和即时性[6 ] 等多方面特殊属性,其中情感互动性[7 ] 对视频传播效果有重要影响.因此,对于视频弹幕的研究也主要在于主题提取、情感分析和时序分析三个方面. ...
浅析弹幕视频网站在我国的发展
1
2014
... 弹幕的价值在于同时包含内容传递[3 ] 、情感互动[4 -5 ] 和即时性[6 ] 等多方面特殊属性,其中情感互动性[7 ] 对视频传播效果有重要影响.因此,对于视频弹幕的研究也主要在于主题提取、情感分析和时序分析三个方面. ...
1
2015
... 弹幕的价值在于同时包含内容传递[3 ] 、情感互动[4 -5 ] 和即时性[6 ] 等多方面特殊属性,其中情感互动性[7 ] 对视频传播效果有重要影响.因此,对于视频弹幕的研究也主要在于主题提取、情感分析和时序分析三个方面. ...
1
2015
... 弹幕的价值在于同时包含内容传递[3 ] 、情感互动[4 -5 ] 和即时性[6 ] 等多方面特殊属性,其中情感互动性[7 ] 对视频传播效果有重要影响.因此,对于视频弹幕的研究也主要在于主题提取、情感分析和时序分析三个方面. ...
Crowdsourced Time-Sync Video Tagging Using Temporal and Personalized Topic Modeling
1
2014
... 弹幕评论的主题提取重点关注提取视频及视频片段的主题信息,形成关键词便于用户方的检索、摘要、推荐和平台方的视频组织管理.Wu等[8 ] 为研究视频弹幕对视频标签化的作用而提出TPTM模型,该模型考虑视频语义、用户偏见并识别用户交互因素作为构建LDA模型的先验知识,以解决弹幕文本噪声大、局部文本稀疏带来的模型准确性问题.Lv等[9 ] 为消除弹幕文本中大量网络用语、实现时间序列精准匹配而提出T-DSSM模型,该模型采用窗口采样的方法,将时序相隔较近的弹幕作为语义识别的基本单位,而不相关弹幕则直接被剔除.Yang等[10 ] 在各个时序节点通过社群监测理论进行语义关联聚类,有效消除了弹幕评论的内生交互性干扰. Filippova等[11 ] 证明了结合多源异构数据(视频和文本)的监督器强于单一预测分类器,观众评论等文本信息对视频主题分类均有重要的特征贡献. ...
Reading the Videos: Temporal Labeling for Crowdsourced Time-Sync Videos Based on Semantic Embedding
1
2016
... 弹幕评论的主题提取重点关注提取视频及视频片段的主题信息,形成关键词便于用户方的检索、摘要、推荐和平台方的视频组织管理.Wu等[8 ] 为研究视频弹幕对视频标签化的作用而提出TPTM模型,该模型考虑视频语义、用户偏见并识别用户交互因素作为构建LDA模型的先验知识,以解决弹幕文本噪声大、局部文本稀疏带来的模型准确性问题.Lv等[9 ] 为消除弹幕文本中大量网络用语、实现时间序列精准匹配而提出T-DSSM模型,该模型采用窗口采样的方法,将时序相隔较近的弹幕作为语义识别的基本单位,而不相关弹幕则直接被剔除.Yang等[10 ] 在各个时序节点通过社群监测理论进行语义关联聚类,有效消除了弹幕评论的内生交互性干扰. Filippova等[11 ] 证明了结合多源异构数据(视频和文本)的监督器强于单一预测分类器,观众评论等文本信息对视频主题分类均有重要的特征贡献. ...
Crowdsourced Time-Sync Video Tagging Using Semantic Association Graph
1
2017
... 弹幕评论的主题提取重点关注提取视频及视频片段的主题信息,形成关键词便于用户方的检索、摘要、推荐和平台方的视频组织管理.Wu等[8 ] 为研究视频弹幕对视频标签化的作用而提出TPTM模型,该模型考虑视频语义、用户偏见并识别用户交互因素作为构建LDA模型的先验知识,以解决弹幕文本噪声大、局部文本稀疏带来的模型准确性问题.Lv等[9 ] 为消除弹幕文本中大量网络用语、实现时间序列精准匹配而提出T-DSSM模型,该模型采用窗口采样的方法,将时序相隔较近的弹幕作为语义识别的基本单位,而不相关弹幕则直接被剔除.Yang等[10 ] 在各个时序节点通过社群监测理论进行语义关联聚类,有效消除了弹幕评论的内生交互性干扰. Filippova等[11 ] 证明了结合多源异构数据(视频和文本)的监督器强于单一预测分类器,观众评论等文本信息对视频主题分类均有重要的特征贡献. ...
Improved Video Categorization from Text Metadata and User Comments
1
2011
... 弹幕评论的主题提取重点关注提取视频及视频片段的主题信息,形成关键词便于用户方的检索、摘要、推荐和平台方的视频组织管理.Wu等[8 ] 为研究视频弹幕对视频标签化的作用而提出TPTM模型,该模型考虑视频语义、用户偏见并识别用户交互因素作为构建LDA模型的先验知识,以解决弹幕文本噪声大、局部文本稀疏带来的模型准确性问题.Lv等[9 ] 为消除弹幕文本中大量网络用语、实现时间序列精准匹配而提出T-DSSM模型,该模型采用窗口采样的方法,将时序相隔较近的弹幕作为语义识别的基本单位,而不相关弹幕则直接被剔除.Yang等[10 ] 在各个时序节点通过社群监测理论进行语义关联聚类,有效消除了弹幕评论的内生交互性干扰. Filippova等[11 ] 证明了结合多源异构数据(视频和文本)的监督器强于单一预测分类器,观众评论等文本信息对视频主题分类均有重要的特征贡献. ...
Leveraging Viewer Comments for Mood Classification of Music Video Clips
1
2013
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
Emotional Video Ranking Based on User Comments
1
2011
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
基于弹幕情感分析和聚类算法的视频用户群体分类
1
2018
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
基于弹幕情感分析和聚类算法的视频用户群体分类
1
2018
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
视频实时评论的深度语义表征方法
1
2019
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
视频实时评论的深度语义表征方法
1
2019
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
Multiplicative Tree-Structured Long Short-Term Memory Networks for Semantic Representations
1
2018
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
1
2018
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
1
2018
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
Measuring Praise and Criticism: Inference of Semantic Orientation from Association
1
2003
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
1
2012
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
1
2012
... 在20世纪90年代末,学者们已经开始了对弹幕情感属性的探究,主要面向视频和用户分类、热度预测、标签情感标注等问题.Yamamoto等[12 ] 以弹幕文本中的形容词、单词长度和副歌文本作为特征,使用基于支持向量机分类器实现了对音乐剪辑视频的情感分类.Murakami等[13 ] 提出一种基于弹幕情感的视频推荐排序方法,使用情感词典算法对弹幕文本进行情感分类,并根据不同情感类别进行加权计算情感值以最终情感值排序确定视频排序.洪庆等[14 ] 提出一种弹幕用户聚类算法,该方法使用基于大连理工情感本体库情感词典的方法对不同用户进行积极和消极情感值的计算,随后采用K-means进行用户聚类,相关结论可以有效应用于视频推荐.吴法民等[15 ] 提出一种高鲁棒性、能深度挖掘短文本语义的循环神经网络模型,可以有效识别弹幕隐含语义,以充分理解和分析面向视频的短文本.Tran等[16 ] 将句法树与循环神经网络(RNN)相结合,通过句法结构分析提取更重要的情感信息,强化特征之间的关联,在情感极性分类任务中表现优异.王晓艳[17 ] 提出一种结合长短记忆神经网络(LSTM)和RNN的网络结构模型来进行弹幕情感分类,该分类结果用于标注HC-FCM算法提取出的关键帧,有效实现关键帧的精准标注.综上,由于弹幕文本自身具有的种种特性,有逐步与规范文本情感分析发展方向脱离的趋势,具体体现在分析粒度和处理方法上.文本情感分析呈现向细粒度方向发展,弹幕情感分析粒度仍停留在句子级别.尽管LSTM等深度学习模型在处理分词序列中具有优势,相关深度学习网络结构类型和层次构建的方法相当成熟,但弹幕情感分类方法通常仍选用情感词典模型,并借鉴常规文本互信息PMI等模型[18 -19 ] 进行词典扩展以提高模型的准确率. ...
1
2018
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
1
2018
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
Barrage Participation and Feedback in Travel Reality Shows: The Effects of Media on Destination Image Among Generation Y
1
2019
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
Exploiting User Comments for Audio-Visual Content Indexing and Retrieval
1
2013
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
情感分析及可视化方法在网络视频弹幕数据分析中的应用
1
2015
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
情感分析及可视化方法在网络视频弹幕数据分析中的应用
1
2015
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
视频弹幕与字幕的情感分析与比较研究
1
2019
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
视频弹幕与字幕的情感分析与比较研究
1
2019
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
运用情感曲线改造服务
1
2011
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
运用情感曲线改造服务
1
2011
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
基于情感曲线的高速铁路旅客个性化服务评价权重设计
1
2020
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
基于情感曲线的高速铁路旅客个性化服务评价权重设计
1
2020
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
The Emotional Arcs of Stories are Dominated by Six Basic Shapes
1
2016
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
1
2017
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
1
2017
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
微博热点话题情感趋势研究
1
2018
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
微博热点话题情感趋势研究
1
2018
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
1
2020
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
1
2020
... 完全基于弹幕时序属性的研究主要是精彩片段提取和情感时间序列挖掘.庄须强[20 ] 采用注意力(Attention)机制强化的LSTM网络,优化输入弹幕分词特征变量的同时,加入视频片段重要性评分以提取视频的高光片段.Hao等[21 ] 提出通过识别视频情节边界来识别和抽取精彩视频部分的方法.Eickhoff等[22 ] 对YouTube视频用户评论进行分析,利用时间序列推断出视听内容的潜在标签和索引术语,缩小查询和文档描述关键词之间的词汇匹配差距.郑飏飏等[23 ] 从弹幕情感类别雷达图、情感词词云图、弹幕情感曲线方面探究了情感曲线的可视化.王敏等[24 ] 则以大连理工情感词典分别构建了字幕、弹幕序列的情感曲线,挖掘出优秀视频片段的字幕弹幕交互趋势.特别地,对于其他具有时间特性的文本,也有值得借鉴参考的研究.例如,熊燕[25 ] 提出一种从客户体验的情感曲线中提取改善服务方向的方法.李致萱等[26 ] 通过绘制铁路部门各环节服务的情感曲线量化旅客服务评价,以此为基础得到能够真实反映旅客个性化服务需求的铁路服务指标评价权重体系.Reagan等[27 ] 基于情感词典方法提出一种有效的小说情感曲线绘制方法,其研究结论表明众多小说的情感曲线存在一些共有的情感模式.周启元[28 ] 则改进了Reagan等的研究,提出一种小说的可变长情感曲线生成方法,通过引入高斯过程解决了使用情感曲线预测小说下载量的问题.何跃等[29 ] 、吕建伟[30 ] 对微博话题进行情感分析序列化,对舆论趋势进行聚类挖掘并采用TF-IDF算法实现情感转折点的事件挖掘.由此可见,完全基于弹幕时间序列视角的已有研究基础还稍显薄弱,应用前景却比较广阔,关于情感曲线的探索工作有待进一步深入. ...
Signal Processing for Communications
1
2005
... 按照以上方法采样弹幕数据,不会存在遗漏,也不会产生重叠,但视频弹幕情感值分布不均匀、不独立,单纯的不重叠采样会在窗口边缘造成较大的波动.根据时间序列理论[31 ] ,对弹幕序列数据进行移动平均,可以保证序列本身的平稳性,还有利于过滤弹幕情感值的高频噪声,使得时间序列形态上更为平滑,如公式(5)所示. ...
Technical Perspective: K-Shape: Efficient and Accurate Clustering of Time Series
1
2016
... 情感时间序列聚类是一种基础而重要的无监督挖掘方法,广泛应用于关键性能指标(KPI)异常检验、股票房价预测、趋势挖掘等领域.K-shape算法[32 ] 是一种基于时间序列本身的聚类方法,即数据不经过任何处理或稍加处理即可进行时间序列聚类的方法,K-means、K-medoids算法也同属此类.不同于基于特征、基于先验时间序列模型的方法,基于原始时间序列聚类的方法,高度依赖时间序列相似度度量设置.本研究提出SBD-K-shape算法,采用基于形状的相似度度量(SBD),并据此更新聚类质心,相比于采用传统度量方法的K-means等算法,更有利于挖掘时间序列形态间的相似度,从根本上保证了升降趋势及幅度变化在时移变动情况下仍保持相似度不变性,在时序相位偏移迭代中的趋势保持性能也存在一定优势.此类算法要求较高的算力,在数据采集和处理阶段应保证时间序列的维度,如果时间序列取样的时间分辨率设置得过于精细,则后期需采用降维算法以提高计算的效率. ...
Who Belongs in the Family?
1
1953
... 本文采取Elbow法则[33 ] 来确定最佳聚类数,时间序列畸变程度会随着聚类数目变化,而最佳的聚类数目是时间序列取得最小畸变程度时聚类数目的取值.其中,对于一个簇而言,簇畸变程度是每个簇中心与簇内样本点的平方距离误差和,而聚类畸变程度则是所有聚类的畸变程度.Elbow原则以聚类畸变程度最小为目标. ...
1
2021
... 基于已经获得的最佳聚类数目,利用K-shape对本文20个时间序列进行聚类.为了解不同模型在同一个时间序列上的聚类效果,使用基于K-means改进的K-medoids等算法对时间序列同时进行处理.最后,采用时间序列处理模块Tslearn[34 ] 的聚类轮廓系数(SI)和机器学习框架Scikit-learn中提供的专门应用于序列数据聚类效果评估的戴维森堡丁指数(DBI)接口对聚类结果进行评估,具体聚类效果评价指标如表9 所示. ...
1
2021
... 基于已经获得的最佳聚类数目,利用K-shape对本文20个时间序列进行聚类.为了解不同模型在同一个时间序列上的聚类效果,使用基于K-means改进的K-medoids等算法对时间序列同时进行处理.最后,采用时间序列处理模块Tslearn[34 ] 的聚类轮廓系数(SI)和机器学习框架Scikit-learn中提供的专门应用于序列数据聚类效果评估的戴维森堡丁指数(DBI)接口对聚类结果进行评估,具体聚类效果评价指标如表9 所示. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}