Mining Multilingual Options Through Classification and Translation
3
2004
... CLSA最早可追溯到2004年,研究学者首次探索性地通过机器翻译(Machine Translation)来解决跨语言情感分析问题[1 ] .诸多研究表明,CLSA能够将英语语言下积累的研究成果在其他语言情境中推广应用.例如,Wan[2 ] 利用英语标注的情感分类数据,通过机器翻译实现对中文文本的情感分类预测.Vulić等[3 ] 通过跨语言词向量实现英语和荷兰语的相互检索. ...
... 2004年,Shanahan等[1 ] 首次探索性地通过机器翻译解决跨语言情感分析问题,如图1 所示.在之后近10年间,机器翻译一直是跨语言文本情感分析的主要方法,其基本思想是使用机器翻译系统将文本从一种语言翻译到另一种语言[5 ⇓ ⇓ ⇓ -9 ] ,从而实现多语言文本到单一语言文本的转换. ...
... [
1 ]
Cross-Lingual Sentiment Analysis Based on Machine Translation Fig.1 ![]()
将源语言的带标注数据翻译为目标语言[10 -11 ] ,利用翻译后的数据训练情感分类器,实现对目标语言未标记数据的预测.也有一些研究将目标语言的未标注数据翻译为源语言,在源语言中进行情感分类预测[7 -8 ,12 ] .此外,一部分研究兼顾上述两种翻译方向,创建从源语言到目标语言和从目标语言到源语言两种不同的视图,以弥补一些翻译局限(Translation Limitations)[9 ,13 ⇓ -15 ] . ...
Using Bilingual Knowledge and Ensemble Techniques for Unsupervised Chinese Sentiment Analysis
1
2008
... CLSA最早可追溯到2004年,研究学者首次探索性地通过机器翻译(Machine Translation)来解决跨语言情感分析问题[1 ] .诸多研究表明,CLSA能够将英语语言下积累的研究成果在其他语言情境中推广应用.例如,Wan[2 ] 利用英语标注的情感分类数据,通过机器翻译实现对中文文本的情感分类预测.Vulić等[3 ] 通过跨语言词向量实现英语和荷兰语的相互检索. ...
Monolingual and Cross-Lingual Information Retrieval Models Based on (Bilingual) Word Embeddings
1
2015
... CLSA最早可追溯到2004年,研究学者首次探索性地通过机器翻译(Machine Translation)来解决跨语言情感分析问题[1 ] .诸多研究表明,CLSA能够将英语语言下积累的研究成果在其他语言情境中推广应用.例如,Wan[2 ] 利用英语标注的情感分类数据,通过机器翻译实现对中文文本的情感分类预测.Vulić等[3 ] 通过跨语言词向量实现英语和荷兰语的相互检索. ...
Efficient Estimation of Word Representations in Vector Space[OL]
2
... CLSA的研究发展与机器学习、神经网络模型密不可分,从总的研究脉络上可分为两个阶段:早期是跨语言情感分析研究阶段,主要包括基于机器翻译及其改进的方法、基于平行语料库(Parallel Corpora)的方法和基于双语情感词典的方法;自2013年Mikolov等[4 ] 提出分布式词向量表示模型Word2Vec,以及随着机器学习算法和神经网络模型的快速发展,跨语言情感分析进入了新的研究阶段,不再停留在对基于机器翻译或基于平行语料库等有监督(Supervised)方法的改进,而是逐渐发展到弱监督(Weakly-Supervised)、完全无监督(Fully-Unsupervised)的跨语言情感分析.本文贡献如下: ...
... 随着分布式词向量表示模型Word2Vec[4 ] 、GloVe[36 ] 和ELMO[37 ] 被相继提出,文本的语义开始通过词嵌入(Word Embedding)向量进行表示.跨语言词嵌入(Cross-Lingual Word Embedding,CLWE)能够获得源语言和目标语言在同一语义空间下的词向量表示.基于CLWE,含义相同、来自不同语言的单词具有相同或相似的向量表征.英语和西班牙语的一组单词在特征空间中的CLWE分布情况如图3 所示.可见,语义相同的双语单词在空间中的位置彼此靠近,如西班牙单词“gato”与英文单词“cat”的位置相比于“dog”或“pig”更为接近.基于CLWE的跨语言情感分析依赖于CLWE的生成质量,近年来,许多研究者致力于开展CLWE生成研究. ...
Computational Approaches to Subjectivity and Sentiment Analysis: Present and Envisaged Methods and Applications
1
2014
... 2004年,Shanahan等[1 ] 首次探索性地通过机器翻译解决跨语言情感分析问题,如图1 所示.在之后近10年间,机器翻译一直是跨语言文本情感分析的主要方法,其基本思想是使用机器翻译系统将文本从一种语言翻译到另一种语言[5 ⇓ ⇓ ⇓ -9 ] ,从而实现多语言文本到单一语言文本的转换. ...
Multilingual Subjectivity Analysis Using Machine Translation
1
2008
... 2004年,Shanahan等[1 ] 首次探索性地通过机器翻译解决跨语言情感分析问题,如图1 所示.在之后近10年间,机器翻译一直是跨语言文本情感分析的主要方法,其基本思想是使用机器翻译系统将文本从一种语言翻译到另一种语言[5 ⇓ ⇓ ⇓ -9 ] ,从而实现多语言文本到单一语言文本的转换. ...
Sentiment Polarity Detection in Spanish Reviews Combining Supervised and Unsupervised Approaches
2
2013
... 2004年,Shanahan等[1 ] 首次探索性地通过机器翻译解决跨语言情感分析问题,如图1 所示.在之后近10年间,机器翻译一直是跨语言文本情感分析的主要方法,其基本思想是使用机器翻译系统将文本从一种语言翻译到另一种语言[5 ⇓ ⇓ ⇓ -9 ] ,从而实现多语言文本到单一语言文本的转换. ...
... 将源语言的带标注数据翻译为目标语言[10 -11 ] ,利用翻译后的数据训练情感分类器,实现对目标语言未标记数据的预测.也有一些研究将目标语言的未标注数据翻译为源语言,在源语言中进行情感分类预测[7 -8 ,12 ] .此外,一部分研究兼顾上述两种翻译方向,创建从源语言到目标语言和从目标语言到源语言两种不同的视图,以弥补一些翻译局限(Translation Limitations)[9 ,13 ⇓ -15 ] . ...
Cross-Language Text Classification Using Structural Correspondence Learning
2
2010
... 2004年,Shanahan等[1 ] 首次探索性地通过机器翻译解决跨语言情感分析问题,如图1 所示.在之后近10年间,机器翻译一直是跨语言文本情感分析的主要方法,其基本思想是使用机器翻译系统将文本从一种语言翻译到另一种语言[5 ⇓ ⇓ ⇓ -9 ] ,从而实现多语言文本到单一语言文本的转换. ...
... 将源语言的带标注数据翻译为目标语言[10 -11 ] ,利用翻译后的数据训练情感分类器,实现对目标语言未标记数据的预测.也有一些研究将目标语言的未标注数据翻译为源语言,在源语言中进行情感分类预测[7 -8 ,12 ] .此外,一部分研究兼顾上述两种翻译方向,创建从源语言到目标语言和从目标语言到源语言两种不同的视图,以弥补一些翻译局限(Translation Limitations)[9 ,13 ⇓ -15 ] . ...
Co-Training for Cross-Lingual Sentiment Classification
2
2009
... 2004年,Shanahan等[1 ] 首次探索性地通过机器翻译解决跨语言情感分析问题,如图1 所示.在之后近10年间,机器翻译一直是跨语言文本情感分析的主要方法,其基本思想是使用机器翻译系统将文本从一种语言翻译到另一种语言[5 ⇓ ⇓ ⇓ -9 ] ,从而实现多语言文本到单一语言文本的转换. ...
... 将源语言的带标注数据翻译为目标语言[10 -11 ] ,利用翻译后的数据训练情感分类器,实现对目标语言未标记数据的预测.也有一些研究将目标语言的未标注数据翻译为源语言,在源语言中进行情感分类预测[7 -8 ,12 ] .此外,一部分研究兼顾上述两种翻译方向,创建从源语言到目标语言和从目标语言到源语言两种不同的视图,以弥补一些翻译局限(Translation Limitations)[9 ,13 ⇓ -15 ] . ...
Comparative Experiments Using Supervised Learning and Machine Translation for Multilingual Sentiment Analysis
1
2014
... 将源语言的带标注数据翻译为目标语言[10 -11 ] ,利用翻译后的数据训练情感分类器,实现对目标语言未标记数据的预测.也有一些研究将目标语言的未标注数据翻译为源语言,在源语言中进行情感分类预测[7 -8 ,12 ] .此外,一部分研究兼顾上述两种翻译方向,创建从源语言到目标语言和从目标语言到源语言两种不同的视图,以弥补一些翻译局限(Translation Limitations)[9 ,13 ⇓ -15 ] . ...
Multilingual Subjectivity: Are More Languages Better?
1
2010
... 将源语言的带标注数据翻译为目标语言[10 -11 ] ,利用翻译后的数据训练情感分类器,实现对目标语言未标记数据的预测.也有一些研究将目标语言的未标注数据翻译为源语言,在源语言中进行情感分类预测[7 -8 ,12 ] .此外,一部分研究兼顾上述两种翻译方向,创建从源语言到目标语言和从目标语言到源语言两种不同的视图,以弥补一些翻译局限(Translation Limitations)[9 ,13 ⇓ -15 ] . ...
Density Based Active Self-Training for Cross-Lingual Sentiment Classification
1
2014
... 将源语言的带标注数据翻译为目标语言[10 -11 ] ,利用翻译后的数据训练情感分类器,实现对目标语言未标记数据的预测.也有一些研究将目标语言的未标注数据翻译为源语言,在源语言中进行情感分类预测[7 -8 ,12 ] .此外,一部分研究兼顾上述两种翻译方向,创建从源语言到目标语言和从目标语言到源语言两种不同的视图,以弥补一些翻译局限(Translation Limitations)[9 ,13 ⇓ -15 ] . ...
Bi-View Semi-Supervised Active Learning for Cross-Lingual Sentiment Classification
1
2014
... 将源语言的带标注数据翻译为目标语言[10 -11 ] ,利用翻译后的数据训练情感分类器,实现对目标语言未标记数据的预测.也有一些研究将目标语言的未标注数据翻译为源语言,在源语言中进行情感分类预测[7 -8 ,12 ] .此外,一部分研究兼顾上述两种翻译方向,创建从源语言到目标语言和从目标语言到源语言两种不同的视图,以弥补一些翻译局限(Translation Limitations)[9 ,13 ⇓ -15 ] . ...
Cross-Lingual Sentiment Classification via Bi-View Non-Negative Matrix Tri-Factorization
1
2011
... 将源语言的带标注数据翻译为目标语言[10 -11 ] ,利用翻译后的数据训练情感分类器,实现对目标语言未标记数据的预测.也有一些研究将目标语言的未标注数据翻译为源语言,在源语言中进行情感分类预测[7 -8 ,12 ] .此外,一部分研究兼顾上述两种翻译方向,创建从源语言到目标语言和从目标语言到源语言两种不同的视图,以弥补一些翻译局限(Translation Limitations)[9 ,13 ⇓ -15 ] . ...
Bilingual Co-Training for Sentiment Classification of Chinese Product Reviews
2
2011
... 将源语言的带标注数据翻译为目标语言[10 -11 ] ,利用翻译后的数据训练情感分类器,实现对目标语言未标记数据的预测.也有一些研究将目标语言的未标注数据翻译为源语言,在源语言中进行情感分类预测[7 -8 ,12 ] .此外,一部分研究兼顾上述两种翻译方向,创建从源语言到目标语言和从目标语言到源语言两种不同的视图,以弥补一些翻译局限(Translation Limitations)[9 ,13 ⇓ -15 ] . ...
... 由于目标语言和源语言之间存在固定的内在结构(Fixed Intrinsic Structure)和不同的术语分布(Term Distribution),即便采用最好的翻译系统,机器翻译的失误仍然会带来约10%的文本情感扭曲或反转现象[15 ] .为克服机器翻译质量对跨语言情感分析的影响,相关研究尝试对基于机器翻译的跨语言情感分析进行改进,具体的改进思路有:借助对源语言情感词典的翻译[16 ] 、对源语言的训练集进行优化[17 ] 、设置标准数据集对机器翻译进行优化[18 ] 、使用多种源语言的标记数据[19 ] 以及将目标语言未标记数据[20 ] 添加到训练集.部分早期跨语言情感分析的代表研究如表1 所示,其中*标注的是近年关于基于机器翻译改进的代表性论文,&标注的是近年基于平行语料库的代表性论文. ...
Latent Sentiment Model for Weakly-Supervised Cross-Lingual Sentiment Classification
2
2011
... 由于目标语言和源语言之间存在固定的内在结构(Fixed Intrinsic Structure)和不同的术语分布(Term Distribution),即便采用最好的翻译系统,机器翻译的失误仍然会带来约10%的文本情感扭曲或反转现象[15 ] .为克服机器翻译质量对跨语言情感分析的影响,相关研究尝试对基于机器翻译的跨语言情感分析进行改进,具体的改进思路有:借助对源语言情感词典的翻译[16 ] 、对源语言的训练集进行优化[17 ] 、设置标准数据集对机器翻译进行优化[18 ] 、使用多种源语言的标记数据[19 ] 以及将目标语言未标记数据[20 ] 添加到训练集.部分早期跨语言情感分析的代表研究如表1 所示,其中*标注的是近年关于基于机器翻译改进的代表性论文,&标注的是近年基于平行语料库的代表性论文. ...
... 为解决基于机器翻译的CLSA存在的泛化问题,尤其是当源语言和目标语言的文本属于不同领域时效果不佳的问题,He[16 ] 提出一种弱监督的潜在情感模型(Latent Sentiment Model, LSM),在隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)模型中融入从源语言的情感词典中通过机器翻译得到的目标语言可用的情感先验知识.LSM将该情感先验知识纳入LDA模型中对目标语言文本进行情感分类,LDA主题分类的类别数等于情感分类的类别数. ...
Cross-Lingual Sentiment Classification: Similarity Discovery Plus Training Data Adjustment
2
2016
... 由于目标语言和源语言之间存在固定的内在结构(Fixed Intrinsic Structure)和不同的术语分布(Term Distribution),即便采用最好的翻译系统,机器翻译的失误仍然会带来约10%的文本情感扭曲或反转现象[15 ] .为克服机器翻译质量对跨语言情感分析的影响,相关研究尝试对基于机器翻译的跨语言情感分析进行改进,具体的改进思路有:借助对源语言情感词典的翻译[16 ] 、对源语言的训练集进行优化[17 ] 、设置标准数据集对机器翻译进行优化[18 ] 、使用多种源语言的标记数据[19 ] 以及将目标语言未标记数据[20 ] 添加到训练集.部分早期跨语言情感分析的代表研究如表1 所示,其中*标注的是近年关于基于机器翻译改进的代表性论文,&标注的是近年基于平行语料库的代表性论文. ...
... 为使源语言的训练集合样本更接近目标语言的文本,Zhang等[17 ] 提出对源语言的训练集合样本进行优化选择(Refinement),通过相似度计算将与目标语言高度相似的样本作为改进后的训练样本,构建一个以目标语言为中心的跨语言情感分类器,通过选择有效的训练样本来消除源语言和目标语言之间的语义分布差异.Al-Shabi等[18 ] 研究机器翻译引入的噪声对CLSA的影响,提出通过设置标准数据集优化机器翻译,并以英语为源语言、阿拉伯语为目标语言进行实验.首先通过英语的标记数据集训练多个机器学习算法,例如朴素贝叶斯、支持向量机,再用训练好的模型预测目标语言的情感类别,选出表现最好的模型;最后通过该模型确定噪声与情感分类精度之间的关系.研究表明,该方法训练出的最优模型能够为阿拉伯语这类资源稀缺的语种生成可靠的训练数据. ...
Cross-Lingual Sentiment Classification from English to Arabic Using Machine Translation
2
2017
... 由于目标语言和源语言之间存在固定的内在结构(Fixed Intrinsic Structure)和不同的术语分布(Term Distribution),即便采用最好的翻译系统,机器翻译的失误仍然会带来约10%的文本情感扭曲或反转现象[15 ] .为克服机器翻译质量对跨语言情感分析的影响,相关研究尝试对基于机器翻译的跨语言情感分析进行改进,具体的改进思路有:借助对源语言情感词典的翻译[16 ] 、对源语言的训练集进行优化[17 ] 、设置标准数据集对机器翻译进行优化[18 ] 、使用多种源语言的标记数据[19 ] 以及将目标语言未标记数据[20 ] 添加到训练集.部分早期跨语言情感分析的代表研究如表1 所示,其中*标注的是近年关于基于机器翻译改进的代表性论文,&标注的是近年基于平行语料库的代表性论文. ...
... 为使源语言的训练集合样本更接近目标语言的文本,Zhang等[17 ] 提出对源语言的训练集合样本进行优化选择(Refinement),通过相似度计算将与目标语言高度相似的样本作为改进后的训练样本,构建一个以目标语言为中心的跨语言情感分类器,通过选择有效的训练样本来消除源语言和目标语言之间的语义分布差异.Al-Shabi等[18 ] 研究机器翻译引入的噪声对CLSA的影响,提出通过设置标准数据集优化机器翻译,并以英语为源语言、阿拉伯语为目标语言进行实验.首先通过英语的标记数据集训练多个机器学习算法,例如朴素贝叶斯、支持向量机,再用训练好的模型预测目标语言的情感类别,选出表现最好的模型;最后通过该模型确定噪声与情感分类精度之间的关系.研究表明,该方法训练出的最优模型能够为阿拉伯语这类资源稀缺的语种生成可靠的训练数据. ...
Cross-Lingual Sentiment Classification Using Multiple Source Languages in Multi-View Semi-Supervised Learning
3
2014
... 由于目标语言和源语言之间存在固定的内在结构(Fixed Intrinsic Structure)和不同的术语分布(Term Distribution),即便采用最好的翻译系统,机器翻译的失误仍然会带来约10%的文本情感扭曲或反转现象[15 ] .为克服机器翻译质量对跨语言情感分析的影响,相关研究尝试对基于机器翻译的跨语言情感分析进行改进,具体的改进思路有:借助对源语言情感词典的翻译[16 ] 、对源语言的训练集进行优化[17 ] 、设置标准数据集对机器翻译进行优化[18 ] 、使用多种源语言的标记数据[19 ] 以及将目标语言未标记数据[20 ] 添加到训练集.部分早期跨语言情感分析的代表研究如表1 所示,其中*标注的是近年关于基于机器翻译改进的代表性论文,&标注的是近年基于平行语料库的代表性论文. ...
... 为了改进基于机器翻译方法的跨语言情感分析,Hajmohammadi等[19 ⇓ -21 ] 首先从增加源语言种类入手,提出一种基于多源语言多视图的CLSA模型[19 ] .该模型将多个源语言的标记数据作为训练集,尝试克服单一源语言的机器翻译所导致的词汇覆盖问题,使不能被覆盖的词汇有可能从另一源语言的翻译中得到覆盖.随后,提出基于机器翻译将目标语言的未标记数据整合到学习过程中,进一步提高性能[20 ] .利用主动学习从翻译成源语言的目标语言无标记文本中选择信息量最大、最可信的样本进行人工标记,丰富只有源语言带标记文本的训练数据.最后,为克服源语言和目标语言的术语分布不同的问题,提出一种基于多视图的半监督学习模型[21 ] ,将多种源语言的标记数据作为训练集,通过自动机器翻译从源语言和目标语言的文档中创建多个视图,并将目标语言中未标记的数据合并到多视图半监督学习模型中,从而提高跨语言情感分析的性能. ...
... [19 ].该模型将多个源语言的标记数据作为训练集,尝试克服单一源语言的机器翻译所导致的词汇覆盖问题,使不能被覆盖的词汇有可能从另一源语言的翻译中得到覆盖.随后,提出基于机器翻译将目标语言的未标记数据整合到学习过程中,进一步提高性能[20 ] .利用主动学习从翻译成源语言的目标语言无标记文本中选择信息量最大、最可信的样本进行人工标记,丰富只有源语言带标记文本的训练数据.最后,为克服源语言和目标语言的术语分布不同的问题,提出一种基于多视图的半监督学习模型[21 ] ,将多种源语言的标记数据作为训练集,通过自动机器翻译从源语言和目标语言的文档中创建多个视图,并将目标语言中未标记的数据合并到多视图半监督学习模型中,从而提高跨语言情感分析的性能. ...
Combination of Active Learning and Self-Training for Cross-Lingual Sentiment Classification with Density Analysis of Unlabelled Samples
3
2015
... 由于目标语言和源语言之间存在固定的内在结构(Fixed Intrinsic Structure)和不同的术语分布(Term Distribution),即便采用最好的翻译系统,机器翻译的失误仍然会带来约10%的文本情感扭曲或反转现象[15 ] .为克服机器翻译质量对跨语言情感分析的影响,相关研究尝试对基于机器翻译的跨语言情感分析进行改进,具体的改进思路有:借助对源语言情感词典的翻译[16 ] 、对源语言的训练集进行优化[17 ] 、设置标准数据集对机器翻译进行优化[18 ] 、使用多种源语言的标记数据[19 ] 以及将目标语言未标记数据[20 ] 添加到训练集.部分早期跨语言情感分析的代表研究如表1 所示,其中*标注的是近年关于基于机器翻译改进的代表性论文,&标注的是近年基于平行语料库的代表性论文. ...
... 为了改进基于机器翻译方法的跨语言情感分析,Hajmohammadi等[19 ⇓ -21 ] 首先从增加源语言种类入手,提出一种基于多源语言多视图的CLSA模型[19 ] .该模型将多个源语言的标记数据作为训练集,尝试克服单一源语言的机器翻译所导致的词汇覆盖问题,使不能被覆盖的词汇有可能从另一源语言的翻译中得到覆盖.随后,提出基于机器翻译将目标语言的未标记数据整合到学习过程中,进一步提高性能[20 ] .利用主动学习从翻译成源语言的目标语言无标记文本中选择信息量最大、最可信的样本进行人工标记,丰富只有源语言带标记文本的训练数据.最后,为克服源语言和目标语言的术语分布不同的问题,提出一种基于多视图的半监督学习模型[21 ] ,将多种源语言的标记数据作为训练集,通过自动机器翻译从源语言和目标语言的文档中创建多个视图,并将目标语言中未标记的数据合并到多视图半监督学习模型中,从而提高跨语言情感分析的性能. ...
... [20 ].利用主动学习从翻译成源语言的目标语言无标记文本中选择信息量最大、最可信的样本进行人工标记,丰富只有源语言带标记文本的训练数据.最后,为克服源语言和目标语言的术语分布不同的问题,提出一种基于多视图的半监督学习模型[21 ] ,将多种源语言的标记数据作为训练集,通过自动机器翻译从源语言和目标语言的文档中创建多个视图,并将目标语言中未标记的数据合并到多视图半监督学习模型中,从而提高跨语言情感分析的性能. ...
Graph-Based Semi-Supervised Learning for Cross-Lingual Sentiment Classification
2
2015
... 为了改进基于机器翻译方法的跨语言情感分析,Hajmohammadi等[19 ⇓ -21 ] 首先从增加源语言种类入手,提出一种基于多源语言多视图的CLSA模型[19 ] .该模型将多个源语言的标记数据作为训练集,尝试克服单一源语言的机器翻译所导致的词汇覆盖问题,使不能被覆盖的词汇有可能从另一源语言的翻译中得到覆盖.随后,提出基于机器翻译将目标语言的未标记数据整合到学习过程中,进一步提高性能[20 ] .利用主动学习从翻译成源语言的目标语言无标记文本中选择信息量最大、最可信的样本进行人工标记,丰富只有源语言带标记文本的训练数据.最后,为克服源语言和目标语言的术语分布不同的问题,提出一种基于多视图的半监督学习模型[21 ] ,将多种源语言的标记数据作为训练集,通过自动机器翻译从源语言和目标语言的文档中创建多个视图,并将目标语言中未标记的数据合并到多视图半监督学习模型中,从而提高跨语言情感分析的性能. ...
... [21 ],将多种源语言的标记数据作为训练集,通过自动机器翻译从源语言和目标语言的文档中创建多个视图,并将目标语言中未标记的数据合并到多视图半监督学习模型中,从而提高跨语言情感分析的性能. ...
Joint Bilingual Sentiment Classification with Unlabeled Parallel Corpora
3
2011
... 基于平行语料库的CLSA代表性论文(见表1 ),主要思路为:借助目标语言的未标记数据[22 ] 、通过平行数据的学习来扩大词汇覆盖率[23 ] 、通过平行语料库生成目标语言的情感词典[24 ] 以及借助少量并行数据和大规模的不并行数据[25 ] . ...
... Lu等[22 ] 首次提出借助无标注的平行语料库提高基于有标注的平行语料库获得的情感分类器性能.认为未标注的语料库中的平行语句也应具有相同的情感极性,因此提出在句子级别同时联合每种语言的标记数据和未标记平行数据,使用标记数据基于最大熵分类器进行期望最大化(Expectation Maximization,EM)迭代更新,逐步提高两个单语分类器对未标记平行语句的预测一致性,以最大化平行语料库的预测一致性.实验表明,该方法对两种语言的情感分类准确率均有提升. ...
... 然而,Lu等[22 ] 要求两种语言都有带标记的数据,这些数据通常不易获得.因此,Meng等[23 ] 提出一种生成性跨语言混合模型(Generative Cross-Lingual Mixture Model, CLMM),去除对目标语言标记数据的要求,不依赖不可靠的机器翻译标记数据,而是利用双语并行数据弥合源语言和目标语言之间的语言差别.CLMM通过拟合参数最大化双语平行数据的可能性,从未标记的平行语料库中学习情感词,显著提高词汇覆盖率,从而提高跨语言情感分类的准确率. ...
Cross-Lingual Mixture Model for Sentiment Classification
2
2012
... 基于平行语料库的CLSA代表性论文(见表1 ),主要思路为:借助目标语言的未标记数据[22 ] 、通过平行数据的学习来扩大词汇覆盖率[23 ] 、通过平行语料库生成目标语言的情感词典[24 ] 以及借助少量并行数据和大规模的不并行数据[25 ] . ...
... 然而,Lu等[22 ] 要求两种语言都有带标记的数据,这些数据通常不易获得.因此,Meng等[23 ] 提出一种生成性跨语言混合模型(Generative Cross-Lingual Mixture Model, CLMM),去除对目标语言标记数据的要求,不依赖不可靠的机器翻译标记数据,而是利用双语并行数据弥合源语言和目标语言之间的语言差别.CLMM通过拟合参数最大化双语平行数据的可能性,从未标记的平行语料库中学习情感词,显著提高词汇覆盖率,从而提高跨语言情感分类的准确率. ...
Cross-Lingual Sentiment Lexicon Learning with Bilingual Word Graph Label Propagation
4
2015
... 基于平行语料库的CLSA代表性论文(见表1 ),主要思路为:借助目标语言的未标记数据[22 ] 、通过平行数据的学习来扩大词汇覆盖率[23 ] 、通过平行语料库生成目标语言的情感词典[24 ] 以及借助少量并行数据和大规模的不并行数据[25 ] . ...
... 基于平行语料库的CLSA方法示意如
图2 所示.平行语料库包括大量平行句对的集合,通过将平行句对中两个对齐的单词连接起来,构建语言间的映射关系.例如,
图2 (b)是两个表达相同语义的中英文句子,即一组平行句对.句对中的中文单词“快乐”与英语单词“happy”对应,可以说这两个单词对齐(Word-Aligned).
图2 (a)将平行语料库中两种语言的单词作为节点,通过语料库的单词对齐及同义词、反义词等信息建立节点间联系,从而构建语言间的关系.
10.11925/infotech.2096-3467.2022.0472.F0002 图2 基于平行语料库的CLSA方法<sup>[<xref ref-type="bibr" rid="b24">24</xref>]</sup> Structure of CLSA Based on Parallel Corpora Fig.2 ![]()
Lu等[22 ] 首次提出借助无标注的平行语料库提高基于有标注的平行语料库获得的情感分类器性能.认为未标注的语料库中的平行语句也应具有相同的情感极性,因此提出在句子级别同时联合每种语言的标记数据和未标记平行数据,使用标记数据基于最大熵分类器进行期望最大化(Expectation Maximization,EM)迭代更新,逐步提高两个单语分类器对未标记平行语句的预测一致性,以最大化平行语料库的预测一致性.实验表明,该方法对两种语言的情感分类准确率均有提升. ...
... 在将情感信息从源语言传递到目标语言的过程中,现有方法[27 -28 ] 使用少量词汇翻译源语言,从而导致目标语言的情感词汇覆盖率较低.为解决该问题,Gao等[24 ] 提出一种基于平行语料库和词对齐构建的双语词图方法,从现有源语言(英语)情感词典中学习到目标语言的情感词典,从而将情感信息从英语情感词转移到目标语言的情感词上. ...
... 完成双语情感词典构建后,研究者基于双语情感词典开展跨语言情感分析研究.例如,Gao等[24 ] 提出LibSVM模型,结合双语情感词典对NTCIR数据集中的数据进行情感分类.He等[34 ] 基于中文-越南语双语词典,利用卷积神经网络对中越新闻进行情感分析研究.Zabha等[35 ] 使用中文-马来语双语情感词典,利用情感得分统计(Term Counting)方法对马来语的推特文本进行情感分析. ...
A Subspace Learning Framework For Cross-Lingual Sentiment Classi?cation With Partial Parallel Data
3
2015
... 基于平行语料库的CLSA代表性论文(见表1 ),主要思路为:借助目标语言的未标记数据[22 ] 、通过平行数据的学习来扩大词汇覆盖率[23 ] 、通过平行语料库生成目标语言的情感词典[24 ] 以及借助少量并行数据和大规模的不并行数据[25 ] . ...
... 大规模文档对齐(Document-Aligned)或者句子对齐(Sentence-Aligned)的平行数据很难获得,通常只存在少量的平行数据以及大量不平行的各语言下的文本.Zhou等[25 ] 提出一种子空间学习框架同时学习源语言和目标语言间少量的文档对齐数据和大量的非对齐数据.研究者认为,文档对齐的并行数据在两种不同的语言中描述着相同的语义,它们应该在相同的分类任务中共享相同的潜在表示,通过此共享表示来减少源语言和目标语言之间的语言差距[25 ] . ...
... [25 ]. ...
跨语言文本分类技术研究进展
1
2010
... 平行语料库是由相互翻译的文本组成的语料库.基于平行语料库的CLSA无需借助翻译系统,以平行或可比语料(Comparable Corpora)为基础完成源语言和目标语言的空间转换[26 ] ,是早期CLSA的主要方法之一. ...
跨语言文本分类技术研究进展
1
2010
... 平行语料库是由相互翻译的文本组成的语料库.基于平行语料库的CLSA无需借助翻译系统,以平行或可比语料(Comparable Corpora)为基础完成源语言和目标语言的空间转换[26 ] ,是早期CLSA的主要方法之一. ...
Is Machine Translation Ripe for Cross-Lingual Sentiment Classification?
2
2011
... 在将情感信息从源语言传递到目标语言的过程中,现有方法[27 -28 ] 使用少量词汇翻译源语言,从而导致目标语言的情感词汇覆盖率较低.为解决该问题,Gao等[24 ] 提出一种基于平行语料库和词对齐构建的双语词图方法,从现有源语言(英语)情感词典中学习到目标语言的情感词典,从而将情感信息从英语情感词转移到目标语言的情感词上. ...
... 该问题一直是CLSA研究的一大难点.现有大部分研究选择英语作为源语言,原因主要有两点:一是英语的情感资源和标注语料较为丰富;二是基于英语的单语情感分析相关研究更多,具有较多的模型选择.然而,固定源语言会带来语言差距不一致的问题,从而影响CLSA的性能.近年来,部分研究扩大源语言的选择范围,将日语、德语、西班牙语等多种语言作为源语言[27 ] .Rasooli等[58 ] 在此基础上提出一个新的假设:“是否使用同一家族的语言作为源语言,能够提高CLSA的准确性?”;对斯洛文尼亚语和克罗地亚语的实验结果印证了这一假设(两者均属于印欧语系斯拉夫语族南部语支). ...
Learning Multilingual Subjective Language via Cross-Lingual Projections
1
2007
... 在将情感信息从源语言传递到目标语言的过程中,现有方法[27 -28 ] 使用少量词汇翻译源语言,从而导致目标语言的情感词汇覆盖率较低.为解决该问题,Gao等[24 ] 提出一种基于平行语料库和词对齐构建的双语词图方法,从现有源语言(英语)情感词典中学习到目标语言的情感词典,从而将情感信息从英语情感词转移到目标语言的情感词上. ...
Automatically Generating a Sentiment Lexicon for the Malay Language
1
2016
... 基于机器翻译的双语情感词典构建,将已有单语情感词典经机器翻译后得到跨语言情感词典,实现较为简单.Darwich等[29 ] 将印尼语WordNet和英语WordNet通过机器翻译后映射得到马来西亚语的情感词典,该方法对于资源较为丰富的语言有较好的表现,但是对于资源相对稀缺的语言表现并不理想:经过5轮迭代后生成的情感词典准确性只有0.563. ...
English and Malay Cross-Lingual Sentiment Lexicon Acquisition and Analysis
1
2017
... 基于同义词词集的双语情感词典构建利用现有单语同义词词集,通过一些映射方法得到跨语言情感词典.Nasharuddin等[30 ] 设置跨语言情感词典生成器(Cross-Lingual Sentiment Lexicon Acquisition),根据同义词集和词性将马来西亚语情感词典映射到英语情感词典中形成双语词典.Sazzed[31 ] 通过英语WordNet和孟加拉语评论语料库获取孟加拉语近义词集,并以此生成孟加拉语情感词典. ...
Development of Sentiment Lexicon in Bengali Utilizing Corpus and Cross-Lingual Resources
1
2020
... 基于同义词词集的双语情感词典构建利用现有单语同义词词集,通过一些映射方法得到跨语言情感词典.Nasharuddin等[30 ] 设置跨语言情感词典生成器(Cross-Lingual Sentiment Lexicon Acquisition),根据同义词集和词性将马来西亚语情感词典映射到英语情感词典中形成双语词典.Sazzed[31 ] 通过英语WordNet和孟加拉语评论语料库获取孟加拉语近义词集,并以此生成孟加拉语情感词典. ...
Sentiment Lexicon Generation for an Under-Resourced Language
1
2014
... 基于平行语料库的双语情感词典构建是近年来较为常用的双语情感词典构建方法,该方法通过对两种语言的平行语料库进行分析和抽取后构建双语情感词典.Vania等[32 ] 基于英语和印度尼西亚语的平行语料库,从中抽取情感模式(Sentiment-Pattern)信息并构建双语情感词典.Chang等[33 ] 使用多语言语料库基于Skip-Gram生成保留上下文语境的单语词向量表示,而后计算英语词向量与其对应的翻译为中文的词向量之间的最优转化矩阵,通过这个转化矩阵将英语的情感单词词向量转化为中文空间中的词向量,利用余弦相似度构造中英跨语言情感词典. ...
An Approach to Cross-Lingual Sentiment Lexicon Construction
1
2019
... 基于平行语料库的双语情感词典构建是近年来较为常用的双语情感词典构建方法,该方法通过对两种语言的平行语料库进行分析和抽取后构建双语情感词典.Vania等[32 ] 基于英语和印度尼西亚语的平行语料库,从中抽取情感模式(Sentiment-Pattern)信息并构建双语情感词典.Chang等[33 ] 使用多语言语料库基于Skip-Gram生成保留上下文语境的单语词向量表示,而后计算英语词向量与其对应的翻译为中文的词向量之间的最优转化矩阵,通过这个转化矩阵将英语的情感单词词向量转化为中文空间中的词向量,利用余弦相似度构造中英跨语言情感词典. ...
Sentiment Classification Method for Chinese and Vietnamese Bilingual News Sentence Based on Convolution Neural Network
1
2018
... 完成双语情感词典构建后,研究者基于双语情感词典开展跨语言情感分析研究.例如,Gao等[24 ] 提出LibSVM模型,结合双语情感词典对NTCIR数据集中的数据进行情感分类.He等[34 ] 基于中文-越南语双语词典,利用卷积神经网络对中越新闻进行情感分析研究.Zabha等[35 ] 使用中文-马来语双语情感词典,利用情感得分统计(Term Counting)方法对马来语的推特文本进行情感分析. ...
Developing Cross-Lingual Sentiment Analysis of Malay Twitter Data Using Lexicon-Based Approach
1
2019
... 完成双语情感词典构建后,研究者基于双语情感词典开展跨语言情感分析研究.例如,Gao等[24 ] 提出LibSVM模型,结合双语情感词典对NTCIR数据集中的数据进行情感分类.He等[34 ] 基于中文-越南语双语词典,利用卷积神经网络对中越新闻进行情感分析研究.Zabha等[35 ] 使用中文-马来语双语情感词典,利用情感得分统计(Term Counting)方法对马来语的推特文本进行情感分析. ...
GloVe: Global Vectors for Word Representation
1
2014
... 随着分布式词向量表示模型Word2Vec[4 ] 、GloVe[36 ] 和ELMO[37 ] 被相继提出,文本的语义开始通过词嵌入(Word Embedding)向量进行表示.跨语言词嵌入(Cross-Lingual Word Embedding,CLWE)能够获得源语言和目标语言在同一语义空间下的词向量表示.基于CLWE,含义相同、来自不同语言的单词具有相同或相似的向量表征.英语和西班牙语的一组单词在特征空间中的CLWE分布情况如图3 所示.可见,语义相同的双语单词在空间中的位置彼此靠近,如西班牙单词“gato”与英文单词“cat”的位置相比于“dog”或“pig”更为接近.基于CLWE的跨语言情感分析依赖于CLWE的生成质量,近年来,许多研究者致力于开展CLWE生成研究. ...
Deep Contextualized Word Representations
3
2018
... 随着分布式词向量表示模型Word2Vec[4 ] 、GloVe[36 ] 和ELMO[37 ] 被相继提出,文本的语义开始通过词嵌入(Word Embedding)向量进行表示.跨语言词嵌入(Cross-Lingual Word Embedding,CLWE)能够获得源语言和目标语言在同一语义空间下的词向量表示.基于CLWE,含义相同、来自不同语言的单词具有相同或相似的向量表征.英语和西班牙语的一组单词在特征空间中的CLWE分布情况如图3 所示.可见,语义相同的双语单词在空间中的位置彼此靠近,如西班牙单词“gato”与英文单词“cat”的位置相比于“dog”或“pig”更为接近.基于CLWE的跨语言情感分析依赖于CLWE的生成质量,近年来,许多研究者致力于开展CLWE生成研究. ...
... 近年来,以ELMo[37 ] 、BERT[72 ] 和GPT-3[73 ] 为代表的预训练模型(Pre-Trained Model,PTM)被相继提出并应用于CLSA领域.相关研究尝试基于PTM构建一个精通各种语言的模型.预训练模型本质上是一种迁移学习(Transfer Learning),包括预训练和微调两个步骤:首先在原任务上预先训练一个初始模型,然后在下游任务(目标任务)中继续对该模型进行精调(Fine-Tune),从而达到提高下游任务性能的目的.预训练阶段使用自监督学习技术,从大规模数据(数亿个参数)中学习到与具体任务无关的初始模型;微调阶段则针对具体的任务进行修正,得到任务相关的最终模型. ...
... 预训练模型在CLSA任务上表现优异,相关研究尝试将跨语言预训练模型应用于实践.Bataa等[79 ] 为解决英-日语言对的CLSA性能较低问题,分别验证了ELMo[37 ] 、ULMFiT[82 ] 和BERT[72 ] 预训练模型在英-日语言对的跨语言情感分析效果.结果表明,基于预训练模型的性能相比基于三倍数据集的任务特定模型(如RNN、LSTM、KimCNN、Self-Attention和RCNN)性能更好.在对话系统的多语言识别问题中,Gupta等[80 ] 基于BERT[72 ] 、Multi-BERT[75 ] 、XLM-RoBERTa[77 ] 以及TweetEval[83 ] 等4种预训练模型,分别比较其在两种语言对(泰米尔语-英语和马拉雅拉姆语-英语)中语码转换(Code-Switching)的效果.其中,TweetEval模型的主要思想是:基于RoBERTa预训练模型解决Tweet自媒体数据的7个分类任务,例如情感分析、情绪识别等.结果表明,TweetEval模型在零样本(Zero-Shot)的预训练任务中取得了较好的性能,优于利用BERT、Multi-BERT、XLM-RoBERTa三种模型的跨语种迁移效果. ...
Learning Bilingual Word Embeddings with (Almost) No Bilingual Data
7
2017
... 随着分布式词向量表示模型Word2Vec
[4 ] 、GloVe
[36 ] 和ELMO
[37 ] 被相继提出,文本的语义开始通过词嵌入(Word Embedding)向量进行表示.跨语言词嵌入(Cross-Lingual Word Embedding,CLWE)能够获得源语言和目标语言在同一语义空间下的词向量表示.基于CLWE,含义相同、来自不同语言的单词具有相同或相似的向量表征.英语和西班牙语的一组单词在特征空间中的CLWE分布情况如
图3 所示.可见,语义相同的双语单词在空间中的位置彼此靠近,如西班牙单词“gato”与英文单词“cat”的位置相比于“dog”或“pig”更为接近.基于CLWE的跨语言情感分析依赖于CLWE的生成质量,近年来,许多研究者致力于开展CLWE生成研究.
10.11925/infotech.2096-3467.2022.0472.F0003 图3 英语和西班牙语的CLWE示意<sup>[<xref ref-type="bibr" rid="b38">38</xref>]</sup> Schematic of CLWE in English and Spanish Fig.3 ![]()
早期的CLWE主要采用有监督方法,依赖于源语言和目标语言之间的平行语料库或双语种子词典[39 ⇓ -41 ] 作为跨语言监督信号.然而对于大多数语言,这样的平行语料和双语种子词典并不容易获得.因此,半监督方法被提出,尝试用更小规模的语料或者种子词典减少对监督信息的依赖,并在一些语言对上取得了较好的结果,例如在英-法双语词典生成任务中获得37.27%的翻译准确率,在英-德双语词典生成任务中获得接近40%的翻译准确率[38 ] .近年来,无监督的方法成为跨语言词嵌入生成的研究热点[42 ⇓ ⇓ -45 ] ,主要原因在于无监督方法无需借助任何平行语料库或者种子词典,适用的语种范围更广泛,可移植性更强.总结有监督、半监督和无监督跨语言词嵌入生成的研究思路、优点和缺点,如表2 所示. ...
... 早期的CLWE主要采用有监督方法,依赖于源语言和目标语言之间的平行语料库或双语种子词典[39 ⇓ -41 ] 作为跨语言监督信号.然而对于大多数语言,这样的平行语料和双语种子词典并不容易获得.因此,半监督方法被提出,尝试用更小规模的语料或者种子词典减少对监督信息的依赖,并在一些语言对上取得了较好的结果,例如在英-法双语词典生成任务中获得37.27%的翻译准确率,在英-德双语词典生成任务中获得接近40%的翻译准确率[38 ] .近年来,无监督的方法成为跨语言词嵌入生成的研究热点[42 ⇓ ⇓ -45 ] ,主要原因在于无监督方法无需借助任何平行语料库或者种子词典,适用的语种范围更广泛,可移植性更强.总结有监督、半监督和无监督跨语言词嵌入生成的研究思路、优点和缺点,如表2 所示. ...
... 根据采用的种子词典以及生成转移矩阵 W [51 ] 、基于多语言概率模型得到种子词典[52 ] 、利用单语词向量的相似度构造种子词[38 ] 、在CLWE中考虑emoji表情信息[53 ] 以及考虑句子的情感信息[54 ] . ...
... Artetxe等[38 ] 基于两种语言的单语词向量之间的相似度构造种子词典,将相似度最接近的两个单词看作对应的翻译,并加入种子词典中.研究结果表明,基于构造好的初始解,通过迭代自学习方法能够从25个单词对的种子词典中得到高质量的CLWE映射;该方法在初始解不够好时容易陷入局部最优解,因此不适用于规模较小的CLWE生成. ...
... Artetxe等[38 ] 等在半监督CLWE方法的基础上,提出一种无监督模型Vecmap来构造初始解,摆脱对小规模种子词典的依赖.Vecmap模型基于假设:不同语言中具有相同语义的单词应该具有相同的分布,以此构造初始解的单词对.该方法在英语-意大利语、英语-德语双语词典生成任务中均达到48%的准确率,在英语-西班牙语双语词典生成任务中也获得了37%的准确率[57 ] . ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
... 由于可选模型和语料库数量的限制,仅通过较少人工处理或机器预处理即能够用作源语言的语言数目相对较少.特别地,对于一些亚洲语言、非洲语言或欧洲语言,如印地语、斯洛伐克语、乌尔都语,很难获取足够数量的训练数据进行实验[38 ,89 -90 ] .在未来的工作中,能否提供包含更多语种的可用数据集,或许成为CLSA泛化模型研究的一大掣肘.如果可用数据集进一步丰富,则对于给定目标语言,如何选择源语言或许有望成为CLSA的热门研究之一. ...
Improving Vector Space Word Representations Using Multilingual Correlation
1
2014
... 早期的CLWE主要采用有监督方法,依赖于源语言和目标语言之间的平行语料库或双语种子词典[39 ⇓ -41 ] 作为跨语言监督信号.然而对于大多数语言,这样的平行语料和双语种子词典并不容易获得.因此,半监督方法被提出,尝试用更小规模的语料或者种子词典减少对监督信息的依赖,并在一些语言对上取得了较好的结果,例如在英-法双语词典生成任务中获得37.27%的翻译准确率,在英-德双语词典生成任务中获得接近40%的翻译准确率[38 ] .近年来,无监督的方法成为跨语言词嵌入生成的研究热点[42 ⇓ ⇓ -45 ] ,主要原因在于无监督方法无需借助任何平行语料库或者种子词典,适用的语种范围更广泛,可移植性更强.总结有监督、半监督和无监督跨语言词嵌入生成的研究思路、优点和缺点,如表2 所示. ...
Bilingual Word Embeddings for Phrase-Based Machine Translation
1
2013
... 早期的CLWE主要采用有监督方法,依赖于源语言和目标语言之间的平行语料库或双语种子词典[39 ⇓ -41 ] 作为跨语言监督信号.然而对于大多数语言,这样的平行语料和双语种子词典并不容易获得.因此,半监督方法被提出,尝试用更小规模的语料或者种子词典减少对监督信息的依赖,并在一些语言对上取得了较好的结果,例如在英-法双语词典生成任务中获得37.27%的翻译准确率,在英-德双语词典生成任务中获得接近40%的翻译准确率[38 ] .近年来,无监督的方法成为跨语言词嵌入生成的研究热点[42 ⇓ ⇓ -45 ] ,主要原因在于无监督方法无需借助任何平行语料库或者种子词典,适用的语种范围更广泛,可移植性更强.总结有监督、半监督和无监督跨语言词嵌入生成的研究思路、优点和缺点,如表2 所示. ...
Bilingual Word Embeddings from Non-Parallel Document-Aligned Data Applied to Bilingual Lexicon Induction
1
2015
... 早期的CLWE主要采用有监督方法,依赖于源语言和目标语言之间的平行语料库或双语种子词典[39 ⇓ -41 ] 作为跨语言监督信号.然而对于大多数语言,这样的平行语料和双语种子词典并不容易获得.因此,半监督方法被提出,尝试用更小规模的语料或者种子词典减少对监督信息的依赖,并在一些语言对上取得了较好的结果,例如在英-法双语词典生成任务中获得37.27%的翻译准确率,在英-德双语词典生成任务中获得接近40%的翻译准确率[38 ] .近年来,无监督的方法成为跨语言词嵌入生成的研究热点[42 ⇓ ⇓ -45 ] ,主要原因在于无监督方法无需借助任何平行语料库或者种子词典,适用的语种范围更广泛,可移植性更强.总结有监督、半监督和无监督跨语言词嵌入生成的研究思路、优点和缺点,如表2 所示. ...
A Survey of Cross-Lingual Word Embedding Models
1
2019
... 早期的CLWE主要采用有监督方法,依赖于源语言和目标语言之间的平行语料库或双语种子词典[39 ⇓ -41 ] 作为跨语言监督信号.然而对于大多数语言,这样的平行语料和双语种子词典并不容易获得.因此,半监督方法被提出,尝试用更小规模的语料或者种子词典减少对监督信息的依赖,并在一些语言对上取得了较好的结果,例如在英-法双语词典生成任务中获得37.27%的翻译准确率,在英-德双语词典生成任务中获得接近40%的翻译准确率[38 ] .近年来,无监督的方法成为跨语言词嵌入生成的研究热点[42 ⇓ ⇓ -45 ] ,主要原因在于无监督方法无需借助任何平行语料库或者种子词典,适用的语种范围更广泛,可移植性更强.总结有监督、半监督和无监督跨语言词嵌入生成的研究思路、优点和缺点,如表2 所示. ...
On the Role of Seed Lexicons in Learning Bilingual Word Embeddings
1
2016
... 早期的CLWE主要采用有监督方法,依赖于源语言和目标语言之间的平行语料库或双语种子词典[39 ⇓ -41 ] 作为跨语言监督信号.然而对于大多数语言,这样的平行语料和双语种子词典并不容易获得.因此,半监督方法被提出,尝试用更小规模的语料或者种子词典减少对监督信息的依赖,并在一些语言对上取得了较好的结果,例如在英-法双语词典生成任务中获得37.27%的翻译准确率,在英-德双语词典生成任务中获得接近40%的翻译准确率[38 ] .近年来,无监督的方法成为跨语言词嵌入生成的研究热点[42 ⇓ ⇓ -45 ] ,主要原因在于无监督方法无需借助任何平行语料库或者种子词典,适用的语种范围更广泛,可移植性更强.总结有监督、半监督和无监督跨语言词嵌入生成的研究思路、优点和缺点,如表2 所示. ...
Towards Cross-Lingual Distributed Representations Without Parallel Text Trained with Adversarial Autoencoders
4
2016
... 早期的CLWE主要采用有监督方法,依赖于源语言和目标语言之间的平行语料库或双语种子词典[39 ⇓ -41 ] 作为跨语言监督信号.然而对于大多数语言,这样的平行语料和双语种子词典并不容易获得.因此,半监督方法被提出,尝试用更小规模的语料或者种子词典减少对监督信息的依赖,并在一些语言对上取得了较好的结果,例如在英-法双语词典生成任务中获得37.27%的翻译准确率,在英-德双语词典生成任务中获得接近40%的翻译准确率[38 ] .近年来,无监督的方法成为跨语言词嵌入生成的研究热点[42 ⇓ ⇓ -45 ] ,主要原因在于无监督方法无需借助任何平行语料库或者种子词典,适用的语种范围更广泛,可移植性更强.总结有监督、半监督和无监督跨语言词嵌入生成的研究思路、优点和缺点,如表2 所示. ...
... 现有研究对无监督的CLWE生成采用以下思路提高性能:优化词语相似度矩阵[55 ] 、使用对抗性编码器[44 ,56 ] 、优化迭代自学习的初始解[57 ] 、引入同一语言家族的多个源语言等方法[58 ] . ...
... Barone[44 ] 首次尝试使用对抗性自动编码器(Adversarial Auto-Encoder,AAE)将源语言的词嵌入向量映射到目标语言的词嵌入向量空间中.该方法能够在一定程度上提高两种语言的语义信息转换,但是如果训练数据不是平行语料,实验结果并不理想.Shen等[56 ] 利用AAE学习双语的平行文本,通过线性变换矩阵将两种语言映射到同一共享向量空间,将其作为BiGRU模型的输入,获得最终的预测结果.将AAE引入BiGRU后,提升效果明显,在亚马逊产品评论数据集上的F1值达到78.6%. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
跨语言词向量研究综述
1
2020
... 早期的CLWE主要采用有监督方法,依赖于源语言和目标语言之间的平行语料库或双语种子词典[39 ⇓ -41 ] 作为跨语言监督信号.然而对于大多数语言,这样的平行语料和双语种子词典并不容易获得.因此,半监督方法被提出,尝试用更小规模的语料或者种子词典减少对监督信息的依赖,并在一些语言对上取得了较好的结果,例如在英-法双语词典生成任务中获得37.27%的翻译准确率,在英-德双语词典生成任务中获得接近40%的翻译准确率[38 ] .近年来,无监督的方法成为跨语言词嵌入生成的研究热点[42 ⇓ ⇓ -45 ] ,主要原因在于无监督方法无需借助任何平行语料库或者种子词典,适用的语种范围更广泛,可移植性更强.总结有监督、半监督和无监督跨语言词嵌入生成的研究思路、优点和缺点,如表2 所示. ...
跨语言词向量研究综述
1
2020
... 早期的CLWE主要采用有监督方法,依赖于源语言和目标语言之间的平行语料库或双语种子词典[39 ⇓ -41 ] 作为跨语言监督信号.然而对于大多数语言,这样的平行语料和双语种子词典并不容易获得.因此,半监督方法被提出,尝试用更小规模的语料或者种子词典减少对监督信息的依赖,并在一些语言对上取得了较好的结果,例如在英-法双语词典生成任务中获得37.27%的翻译准确率,在英-德双语词典生成任务中获得接近40%的翻译准确率[38 ] .近年来,无监督的方法成为跨语言词嵌入生成的研究热点[42 ⇓ ⇓ -45 ] ,主要原因在于无监督方法无需借助任何平行语料库或者种子词典,适用的语种范围更广泛,可移植性更强.总结有监督、半监督和无监督跨语言词嵌入生成的研究思路、优点和缺点,如表2 所示. ...
Modeling Language Discrepancy for Cross-Lingual Sentiment Analysis
3
2017
... 有监督的CLWE模型需要依靠大量的双语平行文本,根据生成CLWE方法和模型的不同,现有工作在对情感表达的语言差异建模[46 ] 、借助机器翻译的单词词对[47 ] 、在跨语言词向量中加入情感信息[48 ] 、基于方面级(Aspect-Level)细粒度的跨语言词嵌入[49 ] 以及研究单词的词序调整对跨语言词嵌入生成的影响[50 ] 等方面开展有监督的跨语言词嵌入生成研究. ...
... Chen等[46 ] 认为现有的跨语言情感分析中语言的差异性(Language Discrepancy)被大大忽略,因此提出对情感表达中固有的语言差异进行建模,以更好地进行跨语言情感分析.给定源语言及其翻译文档构成的混合情感空间,语言差异被建模为源语言和目标语言在每个特定极性下的固定转移向量,基于目标语言文档与其翻译副本之间的转移向量来确定目标语言文档的情感. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
Cross-Lingual Sentiment Analysis Without (Good) Translation
4
2017
... 有监督的CLWE模型需要依靠大量的双语平行文本,根据生成CLWE方法和模型的不同,现有工作在对情感表达的语言差异建模[46 ] 、借助机器翻译的单词词对[47 ] 、在跨语言词向量中加入情感信息[48 ] 、基于方面级(Aspect-Level)细粒度的跨语言词嵌入[49 ] 以及研究单词的词序调整对跨语言词嵌入生成的影响[50 ] 等方面开展有监督的跨语言词嵌入生成研究. ...
... Abdalla等[47 ] 采用向量空间矩阵转换的方法,借助由机器翻译获得的2 000个单词对,计算从源语言到目标语言向量空间的转换矩阵.研究结果发现,当单词对的翻译质量较低时,情感信息仍然是高度保存的,不影响词向量转换矩阵的生成质量.为更好地适应跨语言情感分析任务,Dong等[48 ] 在Abdalla等[47 ] 工作的基础上,在生成跨语言词向量的同时加入情感信息,基于标注的双语平行语料库,将潜在的情感信息编码到CLWE模型中. ...
... [47 ]工作的基础上,在生成跨语言词向量的同时加入情感信息,基于标注的双语平行语料库,将潜在的情感信息编码到CLWE模型中. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
Cross-Lingual Propagation for Deep Sentiment Analysis
3
2018
... 有监督的CLWE模型需要依靠大量的双语平行文本,根据生成CLWE方法和模型的不同,现有工作在对情感表达的语言差异建模[46 ] 、借助机器翻译的单词词对[47 ] 、在跨语言词向量中加入情感信息[48 ] 、基于方面级(Aspect-Level)细粒度的跨语言词嵌入[49 ] 以及研究单词的词序调整对跨语言词嵌入生成的影响[50 ] 等方面开展有监督的跨语言词嵌入生成研究. ...
... Abdalla等[47 ] 采用向量空间矩阵转换的方法,借助由机器翻译获得的2 000个单词对,计算从源语言到目标语言向量空间的转换矩阵.研究结果发现,当单词对的翻译质量较低时,情感信息仍然是高度保存的,不影响词向量转换矩阵的生成质量.为更好地适应跨语言情感分析任务,Dong等[48 ] 在Abdalla等[47 ] 工作的基础上,在生成跨语言词向量的同时加入情感信息,基于标注的双语平行语料库,将潜在的情感信息编码到CLWE模型中. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
Improving Word Embedding Coverage in Less-Resourced Languages Through Multi-Linguality and Cross-Linguality
3
2019
... 有监督的CLWE模型需要依靠大量的双语平行文本,根据生成CLWE方法和模型的不同,现有工作在对情感表达的语言差异建模[46 ] 、借助机器翻译的单词词对[47 ] 、在跨语言词向量中加入情感信息[48 ] 、基于方面级(Aspect-Level)细粒度的跨语言词嵌入[49 ] 以及研究单词的词序调整对跨语言词嵌入生成的影响[50 ] 等方面开展有监督的跨语言词嵌入生成研究. ...
... 现有大部分跨语言情感分析模型仅覆盖较粗糙的情感分析,如句子级情感分析、文档级情感分析.Akhtar等[49 ] 关注于更加细粒度的方面级情感分析,结合负采样的双语连续跳跃元语法的模型(Bilingual-SGNS)对两种语言进行词嵌入向量表示,使两种语言被映射到同一共享向量空间中.在方面级的多语言情感分析任务中,该模型的准确率达到76%;在实体级跨语言情感分析任务中,该模型的准确率也达到60%以上. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
3
... 有监督的CLWE模型需要依靠大量的双语平行文本,根据生成CLWE方法和模型的不同,现有工作在对情感表达的语言差异建模[46 ] 、借助机器翻译的单词词对[47 ] 、在跨语言词向量中加入情感信息[48 ] 、基于方面级(Aspect-Level)细粒度的跨语言词嵌入[49 ] 以及研究单词的词序调整对跨语言词嵌入生成的影响[50 ] 等方面开展有监督的跨语言词嵌入生成研究. ...
... Atrio等[50 ] 注意到语言之间的词序存在差异,进而研究词序对跨语言情感分析研究的影响.以英语为源语言、西班牙语和加泰罗尼亚语为目标语言的双语平行语料库作为数据集,对目标语言进行词序调整,包括名词-形容词调整(Noun-Adjective)和全部调整(Reordered).研究发现,词序调整有助于短文本的情感分析任务,例如方面级或者句子级别,而不适用于文档级别的CLSA任务. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
Cross-Lingual Induction of Selectional Preferences with Bilingual Vector Spaces
3
2010
... 根据采用的种子词典以及生成转移矩阵 W [51 ] 、基于多语言概率模型得到种子词典[52 ] 、利用单语词向量的相似度构造种子词[38 ] 、在CLWE中考虑emoji表情信息[53 ] 以及考虑句子的情感信息[54 ] . ...
... Peirsman等[51 ] 在构建双语词向量空间时舍弃了双语平行语料库或大样本双语词典,而使用双语同根词(Cognates)构成小样本种子词典,并以此作为初始解构造双语词向量空间,生成双语词向量.Vulić等[52 ] 认为两种语言的单词映射存在一对一或一对多的映射关系.基于一对一映射关系,直接构造一对一映射的种子词典作为初始解;基于一对多映射关系,使用多语言概率主题模型(Multilingual Probabilistic Topic Modeling)生成一对一映射的种子词典,并只保留对称翻译词对作为初始解进行CLWE的生成. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
A Study on Bootstrapping Bilingual Vector Spaces from Non-Parallel Data (and Nothing Else)
3
2013
... 根据采用的种子词典以及生成转移矩阵 W [51 ] 、基于多语言概率模型得到种子词典[52 ] 、利用单语词向量的相似度构造种子词[38 ] 、在CLWE中考虑emoji表情信息[53 ] 以及考虑句子的情感信息[54 ] . ...
... Peirsman等[51 ] 在构建双语词向量空间时舍弃了双语平行语料库或大样本双语词典,而使用双语同根词(Cognates)构成小样本种子词典,并以此作为初始解构造双语词向量空间,生成双语词向量.Vulić等[52 ] 认为两种语言的单词映射存在一对一或一对多的映射关系.基于一对一映射关系,直接构造一对一映射的种子词典作为初始解;基于一对多映射关系,使用多语言概率主题模型(Multilingual Probabilistic Topic Modeling)生成一对一映射的种子词典,并只保留对称翻译词对作为初始解进行CLWE的生成. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
Emoji-Powered Representation Learning for Cross-Lingual Sentiment Classification
3
2019
... 根据采用的种子词典以及生成转移矩阵 W [51 ] 、基于多语言概率模型得到种子词典[52 ] 、利用单语词向量的相似度构造种子词[38 ] 、在CLWE中考虑emoji表情信息[53 ] 以及考虑句子的情感信息[54 ] . ...
... Chen等[53 ] 认为微博和推特用户评论中的表情符号可以作为跨语言情感分析的纽带,提出一个基于表情的CLSA表征学习框架Ermes.在Word2Vec词向量模型的基础上,Ermes使用emoji表情符号补充情感监督信息,基于注意力的堆叠双向LSTM模型,获得源语言和目标语言融合情感信息的句子表征.在这个过程中,需要借助机器翻译系统获得与源语言标注数据对应的目标语言伪平行语料. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
Bilingual Sentiment Embeddings: Joint Projection of Sentiment across Languages
3
2018
... 根据采用的种子词典以及生成转移矩阵 W [51 ] 、基于多语言概率模型得到种子词典[52 ] 、利用单语词向量的相似度构造种子词[38 ] 、在CLWE中考虑emoji表情信息[53 ] 以及考虑句子的情感信息[54 ] . ...
... Barnes等[54 ] 提出一种双语情感词嵌入(Bilingual Sentiment Embeddings, BLSE)表示,借助一个小的双语词典和源语言标注的情感数据,得到源语言和目标语言映射到同一个共享向量空间、同时携带情感信息的变换矩阵.以英语为源语言,西班牙语和加泰罗尼亚语为目标语言进行验证,BLSE能够借助源语言的情感信息提升CLSA性能,但是也容易在功能词的向量表示上分配太多的情感信息. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
BilBOWA: Fast Bilingual Distributed Representations Without Word Alignments
5
2015
... 现有研究对无监督的CLWE生成采用以下思路提高性能:优化词语相似度矩阵[55 ] 、使用对抗性编码器[44 ,56 ] 、优化迭代自学习的初始解[57 ] 、引入同一语言家族的多个源语言等方法[58 ] . ...
... Gouws等[55 ] 发现有监督及半监督的CLWE普遍存在两个问题:一是训练耗时过长,不适用于大规模数据集;二是过分依赖双语平行语料库.因此,Gouws等[55 ] 首次尝试将无监督方法应用到跨语言词嵌入中,即无需单词级别的双语平行语料库,提出一种BilBOWA模型生成CLWE.该方法在英语-德语、德语-英语CLSA任务中的准确率分别达到86.5%和75.0%,远高于Hermann等[59 ] 提出的BiCVM模型以及Chandar等[60 ] 提出的BAEs模型.同时,BilBOWA优化了词向量映射矩阵的计算,大大缩短训练时间,仅需BAEs[60 ] 训练时间的1/800. ...
... [55 ]首次尝试将无监督方法应用到跨语言词嵌入中,即无需单词级别的双语平行语料库,提出一种BilBOWA模型生成CLWE.该方法在英语-德语、德语-英语CLSA任务中的准确率分别达到86.5%和75.0%,远高于Hermann等[59 ] 提出的BiCVM模型以及Chandar等[60 ] 提出的BAEs模型.同时,BilBOWA优化了词向量映射矩阵的计算,大大缩短训练时间,仅需BAEs[60 ] 训练时间的1/800. ...
... 综上,基于无监督的CLWE能够获得较好的双语词嵌入向量,并且在下游CLSA任务上有比较突出的表现.例如,BilBOWA模型[55 ] 在英语-德语的CLSA中准确率达到85%以上.TL-AAE-BiGRU模型[56 ] 在英语-中文、英语-德语的亚马逊评论数据集上F1值达到78%以上. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
Cross-Lingual Sentiment Analysis via AAE and BiGRU
4
2020
... 现有研究对无监督的CLWE生成采用以下思路提高性能:优化词语相似度矩阵[55 ] 、使用对抗性编码器[44 ,56 ] 、优化迭代自学习的初始解[57 ] 、引入同一语言家族的多个源语言等方法[58 ] . ...
... Barone[44 ] 首次尝试使用对抗性自动编码器(Adversarial Auto-Encoder,AAE)将源语言的词嵌入向量映射到目标语言的词嵌入向量空间中.该方法能够在一定程度上提高两种语言的语义信息转换,但是如果训练数据不是平行语料,实验结果并不理想.Shen等[56 ] 利用AAE学习双语的平行文本,通过线性变换矩阵将两种语言映射到同一共享向量空间,将其作为BiGRU模型的输入,获得最终的预测结果.将AAE引入BiGRU后,提升效果明显,在亚马逊产品评论数据集上的F1值达到78.6%. ...
... 综上,基于无监督的CLWE能够获得较好的双语词嵌入向量,并且在下游CLSA任务上有比较突出的表现.例如,BilBOWA模型[55 ] 在英语-德语的CLSA中准确率达到85%以上.TL-AAE-BiGRU模型[56 ] 在英语-中文、英语-德语的亚马逊评论数据集上F1值达到78%以上. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
A Robust Self-Learning Method for Fully Unsupervised Cross-Lingual Mappings of Word Embeddings
3
2018
... 现有研究对无监督的CLWE生成采用以下思路提高性能:优化词语相似度矩阵[55 ] 、使用对抗性编码器[44 ,56 ] 、优化迭代自学习的初始解[57 ] 、引入同一语言家族的多个源语言等方法[58 ] . ...
... Artetxe等[38 ] 等在半监督CLWE方法的基础上,提出一种无监督模型Vecmap来构造初始解,摆脱对小规模种子词典的依赖.Vecmap模型基于假设:不同语言中具有相同语义的单词应该具有相同的分布,以此构造初始解的单词对.该方法在英语-意大利语、英语-德语双语词典生成任务中均达到48%的准确率,在英语-西班牙语双语词典生成任务中也获得了37%的准确率[57 ] . ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
Cross-Lingual Sentiment Transfer with Limited Resources
4
2018
... 现有研究对无监督的CLWE生成采用以下思路提高性能:优化词语相似度矩阵[55 ] 、使用对抗性编码器[44 ,56 ] 、优化迭代自学习的初始解[57 ] 、引入同一语言家族的多个源语言等方法[58 ] . ...
... Rasooli等[58 ] 在无监督的基础上考虑了语系家族对于CLWE的影响,选取来自同一语言家族、资源丰富的语言作为多个源语言,通过多种源语言的方法缩小目标语言和源语言之间的差异,并采用标注投影和直接迁移这两种不同场景下情感分析的迁移方法,为那些没有标记情感训练数据且机器翻译能力较小的语言设置鲁棒性的情感分析系统.结果表明,使用同一语系家族的语言能够提升跨语言情感分析任务的准确度,例如,斯洛文尼亚语和克罗地亚语、英语和瑞典语. ...
... Cross-Lingual Sentiment Analysis Based on CLWE
Table3 作者 模型 特点 数据来源 语种 准确率/% Chen等[46 ] RBST 将语言差异建模为源语言和目标语言在每个特定极性下的固定转移向量,基于此向量确定目标语言文档情感 亚马逊产品评论数据; 英-中 81.5 Abdalla等[47 ] SVM; 借助由机器翻译获得的单词对来计算从源语言到目标语言向量空间的转换矩阵 谷歌新闻数据集;西班牙十亿单词语料库;维基百科数据;谷歌万亿单词语料库;中文酒店评论数据集 英-中 F: 77.0 英-西 F: 81.0 Dong等[48 ] DC-CNN 基于标注的双语平行语料库,将潜在的情感信息编码到跨语言词向量中 SST影评;TA旅游网站评论;AC法国电视剧评论;SE16-T5餐馆评论;AFF亚马逊美食评论 英-西 85.93 英-荷 79.30 英-俄 93.26 英-德 92.31 英-捷 93.69 英-意 96.48 英-法 92.97 英-日 88.08 Akhtar等[49 ] Bilingual-SGNS 结合负采样的双语连续跳跃元语法模型构建两种语言的词嵌入向量表示并映射至同一空间,用于细粒度方面级情感分析 印地语ABSA数据集;英语SemEval-2014数据集 英-印 多语言设置:76.29 跨语言设置:60.39 Atrio等[50 ] SVM; SNN; BiLSTM 对目标语言进行词序调整以提高短文本情感分析的性能 OpeNER语料库; 英-西 Bi: F=65.1 英-加 Bi: F=65.6 Peirsman等[51 ] Cross-Lingual Selectional Preferences Model 使用双语同根词构成的小样本种子词典作为初始解构造双语词向量空间,生成双语词向量 TiGer语料库;AMT 西-英 47.0 德-英 48.0 Vulić等[52 ] MuPTM 利用多语言概率模型对单词间一对多的映射关系生成一一映射的种子词典,以此作为初始解生成跨语言词向量 维基百科文章 西-英 89.1 意-英 88.2 Artetxe等[38 ] Self-Learning Framework 基于两种语言单语词向量间的相似度构造种子词典 英-意数据集; 英-意 37.27 英-德 39.60 英-芬 28.16 Chen等[53 ] Ermes 将emoji表情符号作为补充情感监督信息,获得源-目标语言融合情感信息的句子表征 亚马逊产品评论数据;推特数据 英-日 80.17 英-法 86.5 英-德 86.6 Barnes等[54 ] BLSE 借助一个小的双语词典和源语言带标注的情感数据,得到双语映射到同一个共享向量空间、同时携带情感信息的变换矩阵 OpeNER;MultiBooked数据集 英-西 Bi:F=80.3 4-C:F=50.3 英-加 Bi:F=85.0 4-C:F=53.9 英-巴 Bi:F=73.5 4-C:F=50.5 Gouws等[55 ] BiBOWA 利用粗糙的双语数据,基于优化过的词语相似度矩阵计算方法无监督地生成跨语言词向量 路透社RCV1/RCV2多语语料库;EuroParl 英-德 86.5 德-英 75.0 Barone等[44 ] AAE 首次使用对抗性自动编码器将源语言词向量映射到目标语言词向量空间中 维基百科语料库;路透社语料库;2015 News Commentary语料库 英-意 — 英-德 — Shen等[56 ] TL-AAE- 利用对抗自动编码器学习双语平行文本,通过线性变换矩阵将双语映射到同一向量空间 亚马逊产品评论数据 英-中 F: 78.57 英-德 Artetxe等[57 ] Vecmap 利用无监督模型Vecmap构造初始解,去除对小规模种子词典的依赖 英-意数据集;EuroParl;OPUS; 英-意 48.13 英-德 48.19 英-芬 32.63 英-西 37.33 Rasooli等[58 ] NBLR+ 使用多种源语言缩小源-目标语言间的差异,并采用标注投影和直接迁移两种迁移方法为资源稀缺的语言构造健壮的情感分析系统 推特数据;SentiPer;SemEval 2017 Task 4;BQ;EuroParl;LDC;GIZA++;维基百科文章 单源设置 英-中 F: 66.8 英-德 F: 51.0 英-瑞典 F: 49.0 英-克、英-匈、英-波斯、英-波兰等实验性能详见文献[58] 多源设置 德 F: 54.7 波兰 F: 54.6 英 F: 54.0 阿拉伯语、保加利亚语、中文、克罗地亚语等实验性能详见文献[58]
4 基于生成对抗网络的方法 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
... 该问题一直是CLSA研究的一大难点.现有大部分研究选择英语作为源语言,原因主要有两点:一是英语的情感资源和标注语料较为丰富;二是基于英语的单语情感分析相关研究更多,具有较多的模型选择.然而,固定源语言会带来语言差距不一致的问题,从而影响CLSA的性能.近年来,部分研究扩大源语言的选择范围,将日语、德语、西班牙语等多种语言作为源语言[27 ] .Rasooli等[58 ] 在此基础上提出一个新的假设:“是否使用同一家族的语言作为源语言,能够提高CLSA的准确性?”;对斯洛文尼亚语和克罗地亚语的实验结果印证了这一假设(两者均属于印欧语系斯拉夫语族南部语支). ...
1
... Gouws等[55 ] 发现有监督及半监督的CLWE普遍存在两个问题:一是训练耗时过长,不适用于大规模数据集;二是过分依赖双语平行语料库.因此,Gouws等[55 ] 首次尝试将无监督方法应用到跨语言词嵌入中,即无需单词级别的双语平行语料库,提出一种BilBOWA模型生成CLWE.该方法在英语-德语、德语-英语CLSA任务中的准确率分别达到86.5%和75.0%,远高于Hermann等[59 ] 提出的BiCVM模型以及Chandar等[60 ] 提出的BAEs模型.同时,BilBOWA优化了词向量映射矩阵的计算,大大缩短训练时间,仅需BAEs[60 ] 训练时间的1/800. ...
An Autoencoder Approach to Learning Bilingual Word Representations
2
2014
... Gouws等[55 ] 发现有监督及半监督的CLWE普遍存在两个问题:一是训练耗时过长,不适用于大规模数据集;二是过分依赖双语平行语料库.因此,Gouws等[55 ] 首次尝试将无监督方法应用到跨语言词嵌入中,即无需单词级别的双语平行语料库,提出一种BilBOWA模型生成CLWE.该方法在英语-德语、德语-英语CLSA任务中的准确率分别达到86.5%和75.0%,远高于Hermann等[59 ] 提出的BiCVM模型以及Chandar等[60 ] 提出的BAEs模型.同时,BilBOWA优化了词向量映射矩阵的计算,大大缩短训练时间,仅需BAEs[60 ] 训练时间的1/800. ...
... [60 ]训练时间的1/800. ...
Simple Task-Specific Bilingual Word Embeddings
1
2015
... 尽管基于无监督的CLWE无需借助双语平行文本或语料库,减少了对数据的依赖,在性能上也有较好的表现,但仍存在一定的缺点.Gouws等[61 ] 研究发现,基于无监督的CLWE模型对于语言对的选择非常敏感.对于部分语言对,依靠完全无监督的CLWE难以得到高质量的双语词向量表示.此外,无监督CLWE基于假设:不同语言间具有相同含义的单词,应具有相似的词嵌入向量,从而依靠单语下的词嵌入向量生成CLWE.这一假设在语义和语法结构相差较大的两个语种之间不一定成立,例如英语-日语、西班牙语-中文语言对.因此,无监督的CLWE对初始解的要求较高,容易在迭代过程中陷入局部最优解甚至较差解中. ...
Generative Adversarial Networks
1
2020
... 生成对抗网络(Generation Adversarial Network,GAN)由Goodfellow等[62 ] 提出,在图像生成任务方面取得了巨大成功,近年来被应用于CLSA. ...
Adversarial Deep Averaging Networks for Cross-Lingual Sentiment Classification
5
2018
... 基于GAN的跨语言情感分析代表工作有Chen等[63 ] 提出的ADAN模型和Feng等[64 ] 提出的CLIDSA/CLCDSA模型.同时,生成对抗网络的变种也被广泛应用于跨语言情感分类,如条件生成对抗网络(Conditional GAN)、基于Wasserstein距离的Wasserstein GAN模型等. ...
... Chen等[63 ] 提出一种对抗深度平均网络模型(Adversarial Deep Averaging Network, ADAN),通过特征提取器和语言鉴别器的多次迭代提取源语言和目标语言中的语言无关特征.在对抗学习中尝试最小化源语言和目标语言分布的Wasserstein距离,保证特征提取器能够提取出源语言和目标语言的语言无关特征. ...
... 受ADAN模型[63 ] 启发,Antony等[65 ] 提出一个用多种资源丰富语言的单语数据集训练得到语言不变的情感分析器(Language Invariant Sentiment Analyzer,LISA).LISA使用多语言无监督和监督词向量模型MUSE(Multilingual Unsupervised and Supervised Embeddings)中的无监督方法[66 ] ,将其他语种的语义空间对齐到英语的语义空间,进而建立多语言词嵌入.LISA模型由提取特征的多语种序列编码器、鉴别特征语种的语言鉴别器和预测情感的情感分析器构成,通过编码器和鉴别器的对抗训练优化交叉熵损失函数.结果表明,LISA模型不适用于零样本学习,但在有限数据下可实现最优性能. ...
... Feng等[64 ] 借助多个语言多个领域的源语言标注数据和目标语言的大量无标注数据,提出一个端到端的基于自动编码-解码器的跨语言跨领域情感分析(Cross Lingual Cross Domain Sentiment Analysis,CLCDSA)模型.区别于Chen等[63 ] 使用ADAN或者LSTM作为语言特征提取器,CLCDSA模型利用自动编码-解码器作为语言特征提取器,对语言建模(Language Modeling),并从源语言和目标语言大量的无标注数据中提取语言无关特征.CLCDSA模型在英-法、英-德以及英-日德的亚马逊评论数据集分别取得84.6%、88.0%和81.9%的准确率. ...
... 就目前的研究成果来看,不存在一个适用于所有场景的跨语言泛化模型(Cross-Lingual Generalization Model).针对CLSA的方法有很多,例如基于机器翻译、基于平行语料库、基于跨语言词嵌入的方法等,但尚未找到一个在所有CLSA任务中均表现较好的泛化模型.例如,ADAN模型在英-法数据集上表现良好,但是在英-日数据集上表现较差[63 ] ;MUSE模型涉及包含45种语言的110个双语任务,但其在不同语言之间的表现差异较大[66 ] .产生这一现象的原因是不同语言之间的差异性,现有大部分研究将英语作为唯一源语言,因此针对不同的目标语言,很难基于一个统一的模型同时平衡英语和多种语言之间的差异. ...
Towards a Unified End-to-End Approach for Fully Unsupervised Cross-Lingual Sentiment Analysis
2
2019
... 基于GAN的跨语言情感分析代表工作有Chen等[63 ] 提出的ADAN模型和Feng等[64 ] 提出的CLIDSA/CLCDSA模型.同时,生成对抗网络的变种也被广泛应用于跨语言情感分类,如条件生成对抗网络(Conditional GAN)、基于Wasserstein距离的Wasserstein GAN模型等. ...
... Feng等[64 ] 借助多个语言多个领域的源语言标注数据和目标语言的大量无标注数据,提出一个端到端的基于自动编码-解码器的跨语言跨领域情感分析(Cross Lingual Cross Domain Sentiment Analysis,CLCDSA)模型.区别于Chen等[63 ] 使用ADAN或者LSTM作为语言特征提取器,CLCDSA模型利用自动编码-解码器作为语言特征提取器,对语言建模(Language Modeling),并从源语言和目标语言大量的无标注数据中提取语言无关特征.CLCDSA模型在英-法、英-德以及英-日德的亚马逊评论数据集分别取得84.6%、88.0%和81.9%的准确率. ...
Leveraging Multilingual Resources for Language Invariant Sentiment Analysis
1
2020
... 受ADAN模型[63 ] 启发,Antony等[65 ] 提出一个用多种资源丰富语言的单语数据集训练得到语言不变的情感分析器(Language Invariant Sentiment Analyzer,LISA).LISA使用多语言无监督和监督词向量模型MUSE(Multilingual Unsupervised and Supervised Embeddings)中的无监督方法[66 ] ,将其他语种的语义空间对齐到英语的语义空间,进而建立多语言词嵌入.LISA模型由提取特征的多语种序列编码器、鉴别特征语种的语言鉴别器和预测情感的情感分析器构成,通过编码器和鉴别器的对抗训练优化交叉熵损失函数.结果表明,LISA模型不适用于零样本学习,但在有限数据下可实现最优性能. ...
Word Translation Without Parallel Data
2
... 受ADAN模型[63 ] 启发,Antony等[65 ] 提出一个用多种资源丰富语言的单语数据集训练得到语言不变的情感分析器(Language Invariant Sentiment Analyzer,LISA).LISA使用多语言无监督和监督词向量模型MUSE(Multilingual Unsupervised and Supervised Embeddings)中的无监督方法[66 ] ,将其他语种的语义空间对齐到英语的语义空间,进而建立多语言词嵌入.LISA模型由提取特征的多语种序列编码器、鉴别特征语种的语言鉴别器和预测情感的情感分析器构成,通过编码器和鉴别器的对抗训练优化交叉熵损失函数.结果表明,LISA模型不适用于零样本学习,但在有限数据下可实现最优性能. ...
... 就目前的研究成果来看,不存在一个适用于所有场景的跨语言泛化模型(Cross-Lingual Generalization Model).针对CLSA的方法有很多,例如基于机器翻译、基于平行语料库、基于跨语言词嵌入的方法等,但尚未找到一个在所有CLSA任务中均表现较好的泛化模型.例如,ADAN模型在英-法数据集上表现良好,但是在英-日数据集上表现较差[63 ] ;MUSE模型涉及包含45种语言的110个双语任务,但其在不同语言之间的表现差异较大[66 ] .产生这一现象的原因是不同语言之间的差异性,现有大部分研究将英语作为唯一源语言,因此针对不同的目标语言,很难基于一个统一的模型同时平衡英语和多种语言之间的差异. ...
Personalized Microblog Sentiment Classification via Adversarial Cross-Lingual Multi-Task Learning
1
2018
... Wang等[67 ] 提出一种基于对抗性跨语言多任务学习(Adversarial Cross-Lingual Multi-Task Learning)的个性化微博情绪分类模型.为了解决现有微博情感分类工作在单语数据集下缺少大规模可用的微博用户数据的问题,该模型利用用户在新浪微博、推特等不同平台发表的不同语言的帖子作为数据源,使用对抗学习分别训练语言无关编码器和特定语言编码器,分别提取用户的语言无关特征以及特定语言特征,提高CLSA分析性能. ...
Improving Cross-Lingual Sentiment Analysis via Conditional Language Adversarial Nets
1
2021
... Kandula等[68 ] 从域对抗神经网络DANN[69 ] 和条件对抗领域迁移CDAN[70 ] 获得启发,提出一种端到端的、基于条件语言对抗网络(Conditional Language Adversarial Network,CLAN)的CLSA模型.情感分类器接受语言模型提取的特征,同时将情感分类器的情感预测结果作为条件,再基于提取的特征进行互协方差运算后,输入语言鉴别器.通过语言模型和鉴别器的条件对抗训练,多次迭代提升提取特征的语言无关性,进而提高预测正确率.Pelicon等[71 ] 使用斯洛文尼亚语数据集训练了基于多语言BERT的新闻情感分类模型.该模型在微调前加入了中间处理步骤,对掩码语言模型和情感分类任务进行联合学习,直接利用情感信息丰富BERT模型,获得了高质量的输入表示.同时,模型分别测试了用新闻开头、开头结尾和全文生成文档表示的方法,以克服BERT模型不能有效处理长文档的缺陷. ...
Domain-Adversarial Training of Neural
1
2016
... Kandula等[68 ] 从域对抗神经网络DANN[69 ] 和条件对抗领域迁移CDAN[70 ] 获得启发,提出一种端到端的、基于条件语言对抗网络(Conditional Language Adversarial Network,CLAN)的CLSA模型.情感分类器接受语言模型提取的特征,同时将情感分类器的情感预测结果作为条件,再基于提取的特征进行互协方差运算后,输入语言鉴别器.通过语言模型和鉴别器的条件对抗训练,多次迭代提升提取特征的语言无关性,进而提高预测正确率.Pelicon等[71 ] 使用斯洛文尼亚语数据集训练了基于多语言BERT的新闻情感分类模型.该模型在微调前加入了中间处理步骤,对掩码语言模型和情感分类任务进行联合学习,直接利用情感信息丰富BERT模型,获得了高质量的输入表示.同时,模型分别测试了用新闻开头、开头结尾和全文生成文档表示的方法,以克服BERT模型不能有效处理长文档的缺陷. ...
Conditional Adversarial Domain Adaptation
1
2018
... Kandula等[68 ] 从域对抗神经网络DANN[69 ] 和条件对抗领域迁移CDAN[70 ] 获得启发,提出一种端到端的、基于条件语言对抗网络(Conditional Language Adversarial Network,CLAN)的CLSA模型.情感分类器接受语言模型提取的特征,同时将情感分类器的情感预测结果作为条件,再基于提取的特征进行互协方差运算后,输入语言鉴别器.通过语言模型和鉴别器的条件对抗训练,多次迭代提升提取特征的语言无关性,进而提高预测正确率.Pelicon等[71 ] 使用斯洛文尼亚语数据集训练了基于多语言BERT的新闻情感分类模型.该模型在微调前加入了中间处理步骤,对掩码语言模型和情感分类任务进行联合学习,直接利用情感信息丰富BERT模型,获得了高质量的输入表示.同时,模型分别测试了用新闻开头、开头结尾和全文生成文档表示的方法,以克服BERT模型不能有效处理长文档的缺陷. ...
Zero-Shot Learning for Cross-Lingual News Sentiment Classification
1
2020
... Kandula等[68 ] 从域对抗神经网络DANN[69 ] 和条件对抗领域迁移CDAN[70 ] 获得启发,提出一种端到端的、基于条件语言对抗网络(Conditional Language Adversarial Network,CLAN)的CLSA模型.情感分类器接受语言模型提取的特征,同时将情感分类器的情感预测结果作为条件,再基于提取的特征进行互协方差运算后,输入语言鉴别器.通过语言模型和鉴别器的条件对抗训练,多次迭代提升提取特征的语言无关性,进而提高预测正确率.Pelicon等[71 ] 使用斯洛文尼亚语数据集训练了基于多语言BERT的新闻情感分类模型.该模型在微调前加入了中间处理步骤,对掩码语言模型和情感分类任务进行联合学习,直接利用情感信息丰富BERT模型,获得了高质量的输入表示.同时,模型分别测试了用新闻开头、开头结尾和全文生成文档表示的方法,以克服BERT模型不能有效处理长文档的缺陷. ...
BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding
4
... 近年来,以ELMo[37 ] 、BERT[72 ] 和GPT-3[73 ] 为代表的预训练模型(Pre-Trained Model,PTM)被相继提出并应用于CLSA领域.相关研究尝试基于PTM构建一个精通各种语言的模型.预训练模型本质上是一种迁移学习(Transfer Learning),包括预训练和微调两个步骤:首先在原任务上预先训练一个初始模型,然后在下游任务(目标任务)中继续对该模型进行精调(Fine-Tune),从而达到提高下游任务性能的目的.预训练阶段使用自监督学习技术,从大规模数据(数亿个参数)中学习到与具体任务无关的初始模型;微调阶段则针对具体的任务进行修正,得到任务相关的最终模型. ...
... 多语言BERT(Multilingual BERT,Multi-BERT)由Devlin等[72 ] 提出,是由12层Transformer组成的预训练模型,使用104种语言的单语维基百科页面数据进行训练.Multi-BERT训练时没有使用任何标注数据,也没有使用任何翻译机制来计算语言的表示,所有语言共享一个词汇表和权重,通过掩码语言建模(Masked Language Modeling)进行预训练.Pires等[75 ] 对Multi-BERT进行大量探索性的实验,发现Multi-BERT在零样本跨语言模型任务中表现出色,尤其是在相似语言之间进行跨语言迁移时效果最好.然而,Multi-BERT会在某些语言对的多语言表示上表现出系统性的缺陷(Systematic Deficiencies). ...
... 预训练模型在CLSA任务上表现优异,相关研究尝试将跨语言预训练模型应用于实践.Bataa等[79 ] 为解决英-日语言对的CLSA性能较低问题,分别验证了ELMo[37 ] 、ULMFiT[82 ] 和BERT[72 ] 预训练模型在英-日语言对的跨语言情感分析效果.结果表明,基于预训练模型的性能相比基于三倍数据集的任务特定模型(如RNN、LSTM、KimCNN、Self-Attention和RCNN)性能更好.在对话系统的多语言识别问题中,Gupta等[80 ] 基于BERT[72 ] 、Multi-BERT[75 ] 、XLM-RoBERTa[77 ] 以及TweetEval[83 ] 等4种预训练模型,分别比较其在两种语言对(泰米尔语-英语和马拉雅拉姆语-英语)中语码转换(Code-Switching)的效果.其中,TweetEval模型的主要思想是:基于RoBERTa预训练模型解决Tweet自媒体数据的7个分类任务,例如情感分析、情绪识别等.结果表明,TweetEval模型在零样本(Zero-Shot)的预训练任务中取得了较好的性能,优于利用BERT、Multi-BERT、XLM-RoBERTa三种模型的跨语种迁移效果. ...
... [72 ]、Multi-BERT[75 ] 、XLM-RoBERTa[77 ] 以及TweetEval[83 ] 等4种预训练模型,分别比较其在两种语言对(泰米尔语-英语和马拉雅拉姆语-英语)中语码转换(Code-Switching)的效果.其中,TweetEval模型的主要思想是:基于RoBERTa预训练模型解决Tweet自媒体数据的7个分类任务,例如情感分析、情绪识别等.结果表明,TweetEval模型在零样本(Zero-Shot)的预训练任务中取得了较好的性能,优于利用BERT、Multi-BERT、XLM-RoBERTa三种模型的跨语种迁移效果. ...
Language Models are Few-Shot Learners
1
2020
... 近年来,以ELMo[37 ] 、BERT[72 ] 和GPT-3[73 ] 为代表的预训练模型(Pre-Trained Model,PTM)被相继提出并应用于CLSA领域.相关研究尝试基于PTM构建一个精通各种语言的模型.预训练模型本质上是一种迁移学习(Transfer Learning),包括预训练和微调两个步骤:首先在原任务上预先训练一个初始模型,然后在下游任务(目标任务)中继续对该模型进行精调(Fine-Tune),从而达到提高下游任务性能的目的.预训练阶段使用自监督学习技术,从大规模数据(数亿个参数)中学习到与具体任务无关的初始模型;微调阶段则针对具体的任务进行修正,得到任务相关的最终模型. ...
Pre-Trained Models for Natural Language Processing: A Survey
2
2020
... 预训练模型在CLSA上的优势可以总结为三个方面[74 ] : ...
... (1)由于包含的参数数量巨大,预训练模型训练和微调的代价都十分昂贵,对算力的要求也非常高[84 ] ,例如OpenAI的GPT-3模型包含1 750亿参数、DeepMind的Gopher模型包含2 800亿参数.海量的模型参数和算力要求使得预训练模型很难应用于线上任务(Online Services)和在资源有限设备(Resource-restricted Devices)上运行[74 ] .因此,PTM的未来发展应研究解决这一问题,在现有软硬件条件下设计更为有效的模型结构,例如通过优化器或者训练技巧实现更为高效的自监督预训练任务等. ...
How Multilingual is Multilingual BERT?
5
2019
... 2019年以来基于预训练模型的CLSA相关代表性研究如表4 所示,包括Multilingual BERT[75 ] 、XLM[76 ] 、XLM-RoBERTa[77 ] 、MetaXL[78 ] 等模型. ...
... Cross-Lingual Sentiment Analysis Based on Pre-Trained Model
Table4 作者 模型 任务 优点 缺点 数据集 Pires等[75 ] Multilingual BERT 零次跨语言模式迁移 在零样本跨语言任务中表现出色,尤其是当源和目标相似时 在某些语言对的多语言表示上表现出系统性的缺陷 Code-Switching Hindi, English Universal Dependencies Corpus Lample等[76 ] XLM 预训练模型的跨语言表征 利用平行语料引导模型表征对齐,提升预训练模型的跨语言表征性能 训练数据规模相对较小,尤其对于资源较少的语言 MultiUN, IIT Bombay Corpus, EUbookshop Corpus Conneau等[77 ] XLM-RoBERTa 跨语言分类、序列标注和问答 使用大规模多语言预训练,在跨语言分类、序列标注和问答上表现出色 模型有大量的代码合成词,导致系统无法理解句子的内在含义 Common Crawl Corpus in 100 Languages, Wikipedia Corpus Xia等[78 ] MetaXL 跨语言情感分析的多语言传输 使目标语言和源语言在表达空间中更接近,具有良好的传输性能 尚未探索在预训练模型的多个层上放置多个转换网络 亚马逊产品评论数据,SentiPers, Sentiraama Bataa等[79 ] ELMo 针对日语的情感分类 使用知识迁移技术和预训练模型解决日语情感分类 没有执行K折交叉验证 Japanese Rakuten Review Binary, Five Class Yahoo Datasets Gupta等[80 ] BERT 情感分析中的任务型预训练和跨语言迁移 针对性强,表现良好,可作为未来情感分析任务的基线模型 在特定数据集上的跨语言传输效果不理想,没有显著提高模型的性能 Tamil-English, Malayalam English, SentiMix Hinglish
多语言BERT(Multilingual BERT,Multi-BERT)由Devlin等[72 ] 提出,是由12层Transformer组成的预训练模型,使用104种语言的单语维基百科页面数据进行训练.Multi-BERT训练时没有使用任何标注数据,也没有使用任何翻译机制来计算语言的表示,所有语言共享一个词汇表和权重,通过掩码语言建模(Masked Language Modeling)进行预训练.Pires等[75 ] 对Multi-BERT进行大量探索性的实验,发现Multi-BERT在零样本跨语言模型任务中表现出色,尤其是在相似语言之间进行跨语言迁移时效果最好.然而,Multi-BERT会在某些语言对的多语言表示上表现出系统性的缺陷(Systematic Deficiencies). ...
... 多语言BERT(Multilingual BERT,Multi-BERT)由Devlin等[72 ] 提出,是由12层Transformer组成的预训练模型,使用104种语言的单语维基百科页面数据进行训练.Multi-BERT训练时没有使用任何标注数据,也没有使用任何翻译机制来计算语言的表示,所有语言共享一个词汇表和权重,通过掩码语言建模(Masked Language Modeling)进行预训练.Pires等[75 ] 对Multi-BERT进行大量探索性的实验,发现Multi-BERT在零样本跨语言模型任务中表现出色,尤其是在相似语言之间进行跨语言迁移时效果最好.然而,Multi-BERT会在某些语言对的多语言表示上表现出系统性的缺陷(Systematic Deficiencies). ...
... 预训练模型在CLSA任务上表现优异,相关研究尝试将跨语言预训练模型应用于实践.Bataa等[79 ] 为解决英-日语言对的CLSA性能较低问题,分别验证了ELMo[37 ] 、ULMFiT[82 ] 和BERT[72 ] 预训练模型在英-日语言对的跨语言情感分析效果.结果表明,基于预训练模型的性能相比基于三倍数据集的任务特定模型(如RNN、LSTM、KimCNN、Self-Attention和RCNN)性能更好.在对话系统的多语言识别问题中,Gupta等[80 ] 基于BERT[72 ] 、Multi-BERT[75 ] 、XLM-RoBERTa[77 ] 以及TweetEval[83 ] 等4种预训练模型,分别比较其在两种语言对(泰米尔语-英语和马拉雅拉姆语-英语)中语码转换(Code-Switching)的效果.其中,TweetEval模型的主要思想是:基于RoBERTa预训练模型解决Tweet自媒体数据的7个分类任务,例如情感分析、情绪识别等.结果表明,TweetEval模型在零样本(Zero-Shot)的预训练任务中取得了较好的性能,优于利用BERT、Multi-BERT、XLM-RoBERTa三种模型的跨语种迁移效果. ...
... 本文总结了CLSA的主要研究方法,这些方法各有其优缺点.一方面,基于Multi-BERT等预训练模型的方法成为近年来CLSA研究的主流方法,相关研究在更多语言种类、更大数据集上进行了测试[75 ⇓ -77 ] ,将目标语言研究对象推广至中文、印地语、马来西亚语等资源更加稀缺或同英语距离更远的语种,验证其方法的性能;未来一段时间,基于预训练模型的CLSA方法及其改进是主流的研究方向.但是也需要看到,基于预训练模型的方法对算力要求较高;处理不同语言对的CLSA任务时仍需进一步微调,应用于不同语言对时,性能差别较大.这些问题制约了基于预训练模型的CLSA研究的大规模推广应用. ...
4
... 2019年以来基于预训练模型的CLSA相关代表性研究如表4 所示,包括Multilingual BERT[75 ] 、XLM[76 ] 、XLM-RoBERTa[77 ] 、MetaXL[78 ] 等模型. ...
... Cross-Lingual Sentiment Analysis Based on Pre-Trained Model
Table4 作者 模型 任务 优点 缺点 数据集 Pires等[75 ] Multilingual BERT 零次跨语言模式迁移 在零样本跨语言任务中表现出色,尤其是当源和目标相似时 在某些语言对的多语言表示上表现出系统性的缺陷 Code-Switching Hindi, English Universal Dependencies Corpus Lample等[76 ] XLM 预训练模型的跨语言表征 利用平行语料引导模型表征对齐,提升预训练模型的跨语言表征性能 训练数据规模相对较小,尤其对于资源较少的语言 MultiUN, IIT Bombay Corpus, EUbookshop Corpus Conneau等[77 ] XLM-RoBERTa 跨语言分类、序列标注和问答 使用大规模多语言预训练,在跨语言分类、序列标注和问答上表现出色 模型有大量的代码合成词,导致系统无法理解句子的内在含义 Common Crawl Corpus in 100 Languages, Wikipedia Corpus Xia等[78 ] MetaXL 跨语言情感分析的多语言传输 使目标语言和源语言在表达空间中更接近,具有良好的传输性能 尚未探索在预训练模型的多个层上放置多个转换网络 亚马逊产品评论数据,SentiPers, Sentiraama Bataa等[79 ] ELMo 针对日语的情感分类 使用知识迁移技术和预训练模型解决日语情感分类 没有执行K折交叉验证 Japanese Rakuten Review Binary, Five Class Yahoo Datasets Gupta等[80 ] BERT 情感分析中的任务型预训练和跨语言迁移 针对性强,表现良好,可作为未来情感分析任务的基线模型 在特定数据集上的跨语言传输效果不理想,没有显著提高模型的性能 Tamil-English, Malayalam English, SentiMix Hinglish
多语言BERT(Multilingual BERT,Multi-BERT)由Devlin等[72 ] 提出,是由12层Transformer组成的预训练模型,使用104种语言的单语维基百科页面数据进行训练.Multi-BERT训练时没有使用任何标注数据,也没有使用任何翻译机制来计算语言的表示,所有语言共享一个词汇表和权重,通过掩码语言建模(Masked Language Modeling)进行预训练.Pires等[75 ] 对Multi-BERT进行大量探索性的实验,发现Multi-BERT在零样本跨语言模型任务中表现出色,尤其是在相似语言之间进行跨语言迁移时效果最好.然而,Multi-BERT会在某些语言对的多语言表示上表现出系统性的缺陷(Systematic Deficiencies). ...
... 为提高预训练模型的跨语言表征性能,Lample等[76 ] 基于跨语言模型(Cross-Lingual Language Model)提出了三种预训练任务,分别是因果语言模型(Causal Language Modeling,CLM)、掩模语言模型(Masked Language Modeling,MLM)和翻译语言模型(Translation Language Modeling,TLM).其中,CLM和MLM是无监督方式,只依赖于单语言数据学习跨语言表示;TLM是有监督方式,不考虑单语种的文本流,而是借助平行语料数据提高跨语言模型的预训练效果.训练时随机遮盖源语言句子和目标语言句子中的一些单词,当预测被遮盖的词时,TLM首先通过该句子的上下文进行推断,若推断失败,TLM还能够借助对应源句子的翻译内容,引导模型将源语言和目标语言的表征对齐.实验结果表明,TLM作为有监督方法,以高出平均准确率4.9%的优势刷新了跨语言自然语言推断任务(Cross-Lingual Natural Language Inference,XNLI)的最优记录. ...
... 本文总结了CLSA的主要研究方法,这些方法各有其优缺点.一方面,基于Multi-BERT等预训练模型的方法成为近年来CLSA研究的主流方法,相关研究在更多语言种类、更大数据集上进行了测试[75 ⇓ -77 ] ,将目标语言研究对象推广至中文、印地语、马来西亚语等资源更加稀缺或同英语距离更远的语种,验证其方法的性能;未来一段时间,基于预训练模型的CLSA方法及其改进是主流的研究方向.但是也需要看到,基于预训练模型的方法对算力要求较高;处理不同语言对的CLSA任务时仍需进一步微调,应用于不同语言对时,性能差别较大.这些问题制约了基于预训练模型的CLSA研究的大规模推广应用. ...
5
... 2019年以来基于预训练模型的CLSA相关代表性研究如表4 所示,包括Multilingual BERT[75 ] 、XLM[76 ] 、XLM-RoBERTa[77 ] 、MetaXL[78 ] 等模型. ...
... Cross-Lingual Sentiment Analysis Based on Pre-Trained Model
Table4 作者 模型 任务 优点 缺点 数据集 Pires等[75 ] Multilingual BERT 零次跨语言模式迁移 在零样本跨语言任务中表现出色,尤其是当源和目标相似时 在某些语言对的多语言表示上表现出系统性的缺陷 Code-Switching Hindi, English Universal Dependencies Corpus Lample等[76 ] XLM 预训练模型的跨语言表征 利用平行语料引导模型表征对齐,提升预训练模型的跨语言表征性能 训练数据规模相对较小,尤其对于资源较少的语言 MultiUN, IIT Bombay Corpus, EUbookshop Corpus Conneau等[77 ] XLM-RoBERTa 跨语言分类、序列标注和问答 使用大规模多语言预训练,在跨语言分类、序列标注和问答上表现出色 模型有大量的代码合成词,导致系统无法理解句子的内在含义 Common Crawl Corpus in 100 Languages, Wikipedia Corpus Xia等[78 ] MetaXL 跨语言情感分析的多语言传输 使目标语言和源语言在表达空间中更接近,具有良好的传输性能 尚未探索在预训练模型的多个层上放置多个转换网络 亚马逊产品评论数据,SentiPers, Sentiraama Bataa等[79 ] ELMo 针对日语的情感分类 使用知识迁移技术和预训练模型解决日语情感分类 没有执行K折交叉验证 Japanese Rakuten Review Binary, Five Class Yahoo Datasets Gupta等[80 ] BERT 情感分析中的任务型预训练和跨语言迁移 针对性强,表现良好,可作为未来情感分析任务的基线模型 在特定数据集上的跨语言传输效果不理想,没有显著提高模型的性能 Tamil-English, Malayalam English, SentiMix Hinglish
多语言BERT(Multilingual BERT,Multi-BERT)由Devlin等[72 ] 提出,是由12层Transformer组成的预训练模型,使用104种语言的单语维基百科页面数据进行训练.Multi-BERT训练时没有使用任何标注数据,也没有使用任何翻译机制来计算语言的表示,所有语言共享一个词汇表和权重,通过掩码语言建模(Masked Language Modeling)进行预训练.Pires等[75 ] 对Multi-BERT进行大量探索性的实验,发现Multi-BERT在零样本跨语言模型任务中表现出色,尤其是在相似语言之间进行跨语言迁移时效果最好.然而,Multi-BERT会在某些语言对的多语言表示上表现出系统性的缺陷(Systematic Deficiencies). ...
... 在XLM基础上,Conneau等[77 ] 提出一种基于Transformer的多语言掩码模型XLM-RoBERTa,证明了使用大规模多语言预训练的模型可以显著提高跨语言迁移任务的性能.相较于XLM,XLM-RoBERTa主要在三个方面进行改进: ...
... 预训练模型在CLSA任务上表现优异,相关研究尝试将跨语言预训练模型应用于实践.Bataa等[79 ] 为解决英-日语言对的CLSA性能较低问题,分别验证了ELMo[37 ] 、ULMFiT[82 ] 和BERT[72 ] 预训练模型在英-日语言对的跨语言情感分析效果.结果表明,基于预训练模型的性能相比基于三倍数据集的任务特定模型(如RNN、LSTM、KimCNN、Self-Attention和RCNN)性能更好.在对话系统的多语言识别问题中,Gupta等[80 ] 基于BERT[72 ] 、Multi-BERT[75 ] 、XLM-RoBERTa[77 ] 以及TweetEval[83 ] 等4种预训练模型,分别比较其在两种语言对(泰米尔语-英语和马拉雅拉姆语-英语)中语码转换(Code-Switching)的效果.其中,TweetEval模型的主要思想是:基于RoBERTa预训练模型解决Tweet自媒体数据的7个分类任务,例如情感分析、情绪识别等.结果表明,TweetEval模型在零样本(Zero-Shot)的预训练任务中取得了较好的性能,优于利用BERT、Multi-BERT、XLM-RoBERTa三种模型的跨语种迁移效果. ...
... 本文总结了CLSA的主要研究方法,这些方法各有其优缺点.一方面,基于Multi-BERT等预训练模型的方法成为近年来CLSA研究的主流方法,相关研究在更多语言种类、更大数据集上进行了测试[75 ⇓ -77 ] ,将目标语言研究对象推广至中文、印地语、马来西亚语等资源更加稀缺或同英语距离更远的语种,验证其方法的性能;未来一段时间,基于预训练模型的CLSA方法及其改进是主流的研究方向.但是也需要看到,基于预训练模型的方法对算力要求较高;处理不同语言对的CLSA任务时仍需进一步微调,应用于不同语言对时,性能差别较大.这些问题制约了基于预训练模型的CLSA研究的大规模推广应用. ...
MetaXL: Meta Representation Transformation for Low-Resource Cross-Lingual Learning
3
... 2019年以来基于预训练模型的CLSA相关代表性研究如表4 所示,包括Multilingual BERT[75 ] 、XLM[76 ] 、XLM-RoBERTa[77 ] 、MetaXL[78 ] 等模型. ...
... Cross-Lingual Sentiment Analysis Based on Pre-Trained Model
Table4 作者 模型 任务 优点 缺点 数据集 Pires等[75 ] Multilingual BERT 零次跨语言模式迁移 在零样本跨语言任务中表现出色,尤其是当源和目标相似时 在某些语言对的多语言表示上表现出系统性的缺陷 Code-Switching Hindi, English Universal Dependencies Corpus Lample等[76 ] XLM 预训练模型的跨语言表征 利用平行语料引导模型表征对齐,提升预训练模型的跨语言表征性能 训练数据规模相对较小,尤其对于资源较少的语言 MultiUN, IIT Bombay Corpus, EUbookshop Corpus Conneau等[77 ] XLM-RoBERTa 跨语言分类、序列标注和问答 使用大规模多语言预训练,在跨语言分类、序列标注和问答上表现出色 模型有大量的代码合成词,导致系统无法理解句子的内在含义 Common Crawl Corpus in 100 Languages, Wikipedia Corpus Xia等[78 ] MetaXL 跨语言情感分析的多语言传输 使目标语言和源语言在表达空间中更接近,具有良好的传输性能 尚未探索在预训练模型的多个层上放置多个转换网络 亚马逊产品评论数据,SentiPers, Sentiraama Bataa等[79 ] ELMo 针对日语的情感分类 使用知识迁移技术和预训练模型解决日语情感分类 没有执行K折交叉验证 Japanese Rakuten Review Binary, Five Class Yahoo Datasets Gupta等[80 ] BERT 情感分析中的任务型预训练和跨语言迁移 针对性强,表现良好,可作为未来情感分析任务的基线模型 在特定数据集上的跨语言传输效果不理想,没有显著提高模型的性能 Tamil-English, Malayalam English, SentiMix Hinglish
多语言BERT(Multilingual BERT,Multi-BERT)由Devlin等[72 ] 提出,是由12层Transformer组成的预训练模型,使用104种语言的单语维基百科页面数据进行训练.Multi-BERT训练时没有使用任何标注数据,也没有使用任何翻译机制来计算语言的表示,所有语言共享一个词汇表和权重,通过掩码语言建模(Masked Language Modeling)进行预训练.Pires等[75 ] 对Multi-BERT进行大量探索性的实验,发现Multi-BERT在零样本跨语言模型任务中表现出色,尤其是在相似语言之间进行跨语言迁移时效果最好.然而,Multi-BERT会在某些语言对的多语言表示上表现出系统性的缺陷(Systematic Deficiencies). ...
... 基于预训练模型的CLSA研究属于一种迁移学习,需要大规模的单语语料进行预训练或者一定数量的标注数据进行精调.因此,对于资源匮乏的语言,其迁移学习效果并不理想.此外,语言之间的表示差距(Representation Gap)进一步加剧了资源匮乏语言的迁移学习难度.为解决这一问题,Xia等[78 ] 提出一种基于元学习(Meta-Learning)框架的MetaXL模型来弥合语言之间的表示差距,使得源语言和目标语言在表达空间上更加接近,提高跨语言迁移学习的性能.实验表明,与Multi-BERT和XLM-RoBERTa相比,MetaXL在跨语言情感分析和命名实体识别任务中的性能平均提高2.1%.未来可以通过增加源语言的数量、优化多个语言表示转换网络的位置以提高MetaXL的性能. ...
An Investigation of Transfer Learning-Based Sentiment Analysis in Japanese
2
2019
... Cross-Lingual Sentiment Analysis Based on Pre-Trained Model
Table4 作者 模型 任务 优点 缺点 数据集 Pires等[75 ] Multilingual BERT 零次跨语言模式迁移 在零样本跨语言任务中表现出色,尤其是当源和目标相似时 在某些语言对的多语言表示上表现出系统性的缺陷 Code-Switching Hindi, English Universal Dependencies Corpus Lample等[76 ] XLM 预训练模型的跨语言表征 利用平行语料引导模型表征对齐,提升预训练模型的跨语言表征性能 训练数据规模相对较小,尤其对于资源较少的语言 MultiUN, IIT Bombay Corpus, EUbookshop Corpus Conneau等[77 ] XLM-RoBERTa 跨语言分类、序列标注和问答 使用大规模多语言预训练,在跨语言分类、序列标注和问答上表现出色 模型有大量的代码合成词,导致系统无法理解句子的内在含义 Common Crawl Corpus in 100 Languages, Wikipedia Corpus Xia等[78 ] MetaXL 跨语言情感分析的多语言传输 使目标语言和源语言在表达空间中更接近,具有良好的传输性能 尚未探索在预训练模型的多个层上放置多个转换网络 亚马逊产品评论数据,SentiPers, Sentiraama Bataa等[79 ] ELMo 针对日语的情感分类 使用知识迁移技术和预训练模型解决日语情感分类 没有执行K折交叉验证 Japanese Rakuten Review Binary, Five Class Yahoo Datasets Gupta等[80 ] BERT 情感分析中的任务型预训练和跨语言迁移 针对性强,表现良好,可作为未来情感分析任务的基线模型 在特定数据集上的跨语言传输效果不理想,没有显著提高模型的性能 Tamil-English, Malayalam English, SentiMix Hinglish
多语言BERT(Multilingual BERT,Multi-BERT)由Devlin等[72 ] 提出,是由12层Transformer组成的预训练模型,使用104种语言的单语维基百科页面数据进行训练.Multi-BERT训练时没有使用任何标注数据,也没有使用任何翻译机制来计算语言的表示,所有语言共享一个词汇表和权重,通过掩码语言建模(Masked Language Modeling)进行预训练.Pires等[75 ] 对Multi-BERT进行大量探索性的实验,发现Multi-BERT在零样本跨语言模型任务中表现出色,尤其是在相似语言之间进行跨语言迁移时效果最好.然而,Multi-BERT会在某些语言对的多语言表示上表现出系统性的缺陷(Systematic Deficiencies). ...
... 预训练模型在CLSA任务上表现优异,相关研究尝试将跨语言预训练模型应用于实践.Bataa等[79 ] 为解决英-日语言对的CLSA性能较低问题,分别验证了ELMo[37 ] 、ULMFiT[82 ] 和BERT[72 ] 预训练模型在英-日语言对的跨语言情感分析效果.结果表明,基于预训练模型的性能相比基于三倍数据集的任务特定模型(如RNN、LSTM、KimCNN、Self-Attention和RCNN)性能更好.在对话系统的多语言识别问题中,Gupta等[80 ] 基于BERT[72 ] 、Multi-BERT[75 ] 、XLM-RoBERTa[77 ] 以及TweetEval[83 ] 等4种预训练模型,分别比较其在两种语言对(泰米尔语-英语和马拉雅拉姆语-英语)中语码转换(Code-Switching)的效果.其中,TweetEval模型的主要思想是:基于RoBERTa预训练模型解决Tweet自媒体数据的7个分类任务,例如情感分析、情绪识别等.结果表明,TweetEval模型在零样本(Zero-Shot)的预训练任务中取得了较好的性能,优于利用BERT、Multi-BERT、XLM-RoBERTa三种模型的跨语种迁移效果. ...
Task-Specific Pre-Training and Cross Lingual Transfer for Sentiment Analysis in Dravidian Code-Switched Languages
2
2021
... Cross-Lingual Sentiment Analysis Based on Pre-Trained Model
Table4 作者 模型 任务 优点 缺点 数据集 Pires等[75 ] Multilingual BERT 零次跨语言模式迁移 在零样本跨语言任务中表现出色,尤其是当源和目标相似时 在某些语言对的多语言表示上表现出系统性的缺陷 Code-Switching Hindi, English Universal Dependencies Corpus Lample等[76 ] XLM 预训练模型的跨语言表征 利用平行语料引导模型表征对齐,提升预训练模型的跨语言表征性能 训练数据规模相对较小,尤其对于资源较少的语言 MultiUN, IIT Bombay Corpus, EUbookshop Corpus Conneau等[77 ] XLM-RoBERTa 跨语言分类、序列标注和问答 使用大规模多语言预训练,在跨语言分类、序列标注和问答上表现出色 模型有大量的代码合成词,导致系统无法理解句子的内在含义 Common Crawl Corpus in 100 Languages, Wikipedia Corpus Xia等[78 ] MetaXL 跨语言情感分析的多语言传输 使目标语言和源语言在表达空间中更接近,具有良好的传输性能 尚未探索在预训练模型的多个层上放置多个转换网络 亚马逊产品评论数据,SentiPers, Sentiraama Bataa等[79 ] ELMo 针对日语的情感分类 使用知识迁移技术和预训练模型解决日语情感分类 没有执行K折交叉验证 Japanese Rakuten Review Binary, Five Class Yahoo Datasets Gupta等[80 ] BERT 情感分析中的任务型预训练和跨语言迁移 针对性强,表现良好,可作为未来情感分析任务的基线模型 在特定数据集上的跨语言传输效果不理想,没有显著提高模型的性能 Tamil-English, Malayalam English, SentiMix Hinglish
多语言BERT(Multilingual BERT,Multi-BERT)由Devlin等[72 ] 提出,是由12层Transformer组成的预训练模型,使用104种语言的单语维基百科页面数据进行训练.Multi-BERT训练时没有使用任何标注数据,也没有使用任何翻译机制来计算语言的表示,所有语言共享一个词汇表和权重,通过掩码语言建模(Masked Language Modeling)进行预训练.Pires等[75 ] 对Multi-BERT进行大量探索性的实验,发现Multi-BERT在零样本跨语言模型任务中表现出色,尤其是在相似语言之间进行跨语言迁移时效果最好.然而,Multi-BERT会在某些语言对的多语言表示上表现出系统性的缺陷(Systematic Deficiencies). ...
... 预训练模型在CLSA任务上表现优异,相关研究尝试将跨语言预训练模型应用于实践.Bataa等[79 ] 为解决英-日语言对的CLSA性能较低问题,分别验证了ELMo[37 ] 、ULMFiT[82 ] 和BERT[72 ] 预训练模型在英-日语言对的跨语言情感分析效果.结果表明,基于预训练模型的性能相比基于三倍数据集的任务特定模型(如RNN、LSTM、KimCNN、Self-Attention和RCNN)性能更好.在对话系统的多语言识别问题中,Gupta等[80 ] 基于BERT[72 ] 、Multi-BERT[75 ] 、XLM-RoBERTa[77 ] 以及TweetEval[83 ] 等4种预训练模型,分别比较其在两种语言对(泰米尔语-英语和马拉雅拉姆语-英语)中语码转换(Code-Switching)的效果.其中,TweetEval模型的主要思想是:基于RoBERTa预训练模型解决Tweet自媒体数据的7个分类任务,例如情感分析、情绪识别等.结果表明,TweetEval模型在零样本(Zero-Shot)的预训练任务中取得了较好的性能,优于利用BERT、Multi-BERT、XLM-RoBERTa三种模型的跨语种迁移效果. ...
NLP-CUET@LT-EDI-EACL2021: Multilingual Code-Mixed Hope Speech Detection Using Cross-Lingual Representation Learner
1
2021
... 实验表明,XLM-RoBERTa在跨语言分类、序列标注和知识问答三个基准测试中取得了迄今为止最好的结果,在资源缺乏的语种上表现也非常出色.XLM-RoBERTa的缺点是使用该模型可能有大量的代码合成词(Code Mixed Words),导致系统无法理解句子的内在含义[81 ] . ...
Universal Language Model Fine-Tuning for Text Classification
1
2018
... 预训练模型在CLSA任务上表现优异,相关研究尝试将跨语言预训练模型应用于实践.Bataa等[79 ] 为解决英-日语言对的CLSA性能较低问题,分别验证了ELMo[37 ] 、ULMFiT[82 ] 和BERT[72 ] 预训练模型在英-日语言对的跨语言情感分析效果.结果表明,基于预训练模型的性能相比基于三倍数据集的任务特定模型(如RNN、LSTM、KimCNN、Self-Attention和RCNN)性能更好.在对话系统的多语言识别问题中,Gupta等[80 ] 基于BERT[72 ] 、Multi-BERT[75 ] 、XLM-RoBERTa[77 ] 以及TweetEval[83 ] 等4种预训练模型,分别比较其在两种语言对(泰米尔语-英语和马拉雅拉姆语-英语)中语码转换(Code-Switching)的效果.其中,TweetEval模型的主要思想是:基于RoBERTa预训练模型解决Tweet自媒体数据的7个分类任务,例如情感分析、情绪识别等.结果表明,TweetEval模型在零样本(Zero-Shot)的预训练任务中取得了较好的性能,优于利用BERT、Multi-BERT、XLM-RoBERTa三种模型的跨语种迁移效果. ...
TweetEval: Unified Benchmark and Comparative Evaluation for Tweet Classification
1
... 预训练模型在CLSA任务上表现优异,相关研究尝试将跨语言预训练模型应用于实践.Bataa等[79 ] 为解决英-日语言对的CLSA性能较低问题,分别验证了ELMo[37 ] 、ULMFiT[82 ] 和BERT[72 ] 预训练模型在英-日语言对的跨语言情感分析效果.结果表明,基于预训练模型的性能相比基于三倍数据集的任务特定模型(如RNN、LSTM、KimCNN、Self-Attention和RCNN)性能更好.在对话系统的多语言识别问题中,Gupta等[80 ] 基于BERT[72 ] 、Multi-BERT[75 ] 、XLM-RoBERTa[77 ] 以及TweetEval[83 ] 等4种预训练模型,分别比较其在两种语言对(泰米尔语-英语和马拉雅拉姆语-英语)中语码转换(Code-Switching)的效果.其中,TweetEval模型的主要思想是:基于RoBERTa预训练模型解决Tweet自媒体数据的7个分类任务,例如情感分析、情绪识别等.结果表明,TweetEval模型在零样本(Zero-Shot)的预训练任务中取得了较好的性能,优于利用BERT、Multi-BERT、XLM-RoBERTa三种模型的跨语种迁移效果. ...
Cross-Lingual Learning for Text Processing: A Survey
1
2021
... (1)由于包含的参数数量巨大,预训练模型训练和微调的代价都十分昂贵,对算力的要求也非常高[84 ] ,例如OpenAI的GPT-3模型包含1 750亿参数、DeepMind的Gopher模型包含2 800亿参数.海量的模型参数和算力要求使得预训练模型很难应用于线上任务(Online Services)和在资源有限设备(Resource-restricted Devices)上运行[74 ] .因此,PTM的未来发展应研究解决这一问题,在现有软硬件条件下设计更为有效的模型结构,例如通过优化器或者训练技巧实现更为高效的自监督预训练任务等. ...
1
... (2)现有基于预训练模型的CLSA取得最好的效果是Multi-BERT在MLDoc[85 ] 数据集的英-德语言对上,准确率达到90.0%;最差的效果是在英-中语言对上,准确率仅为43.88%[86 ] .不同语言对之间的差异较大,说明预训练模型虽然可以通过大规模的数据学习到语言无关的特征,并在零样本的CLSA任务、尤其是相似语言对之间的CLSA任务上取得了较好的性能,但仍然不能作为一个通用的泛化模型适用于不同的语言对.PTM应用于不同语言对时,需要根据语言的迁移进行微调,其缺点是低效.每个语言对都有各自不同的微调参数.其中一种解决方案是固定PTM的原始参数,针对特定任务添加一个小的可调适配模块[87 ] . ...
A Robust Self-Learning Framework for Cross-Lingual Text Classification
1
2019
... (2)现有基于预训练模型的CLSA取得最好的效果是Multi-BERT在MLDoc[85 ] 数据集的英-德语言对上,准确率达到90.0%;最差的效果是在英-中语言对上,准确率仅为43.88%[86 ] .不同语言对之间的差异较大,说明预训练模型虽然可以通过大规模的数据学习到语言无关的特征,并在零样本的CLSA任务、尤其是相似语言对之间的CLSA任务上取得了较好的性能,但仍然不能作为一个通用的泛化模型适用于不同的语言对.PTM应用于不同语言对时,需要根据语言的迁移进行微调,其缺点是低效.每个语言对都有各自不同的微调参数.其中一种解决方案是固定PTM的原始参数,针对特定任务添加一个小的可调适配模块[87 ] . ...
Parameter-Efficient Transfer Learning for NLP
1
2019
... (2)现有基于预训练模型的CLSA取得最好的效果是Multi-BERT在MLDoc[85 ] 数据集的英-德语言对上,准确率达到90.0%;最差的效果是在英-中语言对上,准确率仅为43.88%[86 ] .不同语言对之间的差异较大,说明预训练模型虽然可以通过大规模的数据学习到语言无关的特征,并在零样本的CLSA任务、尤其是相似语言对之间的CLSA任务上取得了较好的性能,但仍然不能作为一个通用的泛化模型适用于不同的语言对.PTM应用于不同语言对时,需要根据语言的迁移进行微调,其缺点是低效.每个语言对都有各自不同的微调参数.其中一种解决方案是固定PTM的原始参数,针对特定任务添加一个小的可调适配模块[87 ] . ...
MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer
2
2020
... 一些研究意识到此问题,通过增加源语言的语种来减少源与目标语言之间的差距.此外,Pfeiffer等[88 ] 提出MAD-X模型,利用现有跨语言或多语言情感分析模型,通过调节器(Adapter)调节模型的参数和设置,使其能够有针对性地适用于特定的目标语言.基于MAD-X改进后,F1值有不同程度的提升,其中最高提高了6%.Pfeiffer等[88 ] 还指出,属于同一语言家族的语言之间差异最小,同一语言家族的两种语言间进行CLSA能够最大程度提高MAD-X的性能.例如缅甸语和闽东语均属于汉藏语系,使用缅甸语作为源语言能够使得针对闽东语的跨语言情感分析准确率提升最大,反之亦然. ...
... [88 ]还指出,属于同一语言家族的语言之间差异最小,同一语言家族的两种语言间进行CLSA能够最大程度提高MAD-X的性能.例如缅甸语和闽东语均属于汉藏语系,使用缅甸语作为源语言能够使得针对闽东语的跨语言情感分析准确率提升最大,反之亦然. ...
ArbEngVec: Arabic-English Cross-Lingual Word Embedding Model
1
2019
... 由于可选模型和语料库数量的限制,仅通过较少人工处理或机器预处理即能够用作源语言的语言数目相对较少.特别地,对于一些亚洲语言、非洲语言或欧洲语言,如印地语、斯洛伐克语、乌尔都语,很难获取足够数量的训练数据进行实验[38 ,89 -90 ] .在未来的工作中,能否提供包含更多语种的可用数据集,或许成为CLSA泛化模型研究的一大掣肘.如果可用数据集进一步丰富,则对于给定目标语言,如何选择源语言或许有望成为CLSA的热门研究之一. ...
RUBERT: A Bilingual Roman Urdu BERT Using Cross Lingual Transfer Learning
1
... 由于可选模型和语料库数量的限制,仅通过较少人工处理或机器预处理即能够用作源语言的语言数目相对较少.特别地,对于一些亚洲语言、非洲语言或欧洲语言,如印地语、斯洛伐克语、乌尔都语,很难获取足够数量的训练数据进行实验[38 ,89 -90 ] .在未来的工作中,能否提供包含更多语种的可用数据集,或许成为CLSA泛化模型研究的一大掣肘.如果可用数据集进一步丰富,则对于给定目标语言,如何选择源语言或许有望成为CLSA的热门研究之一. ...





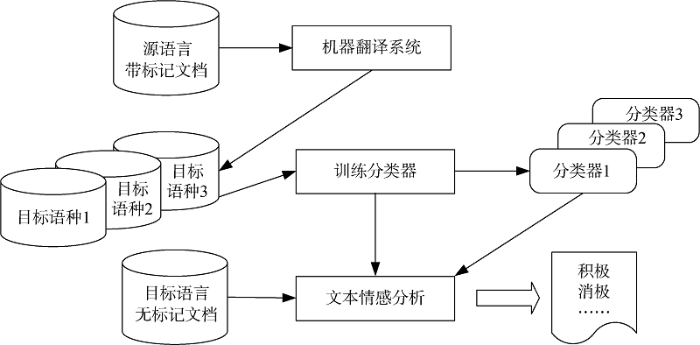
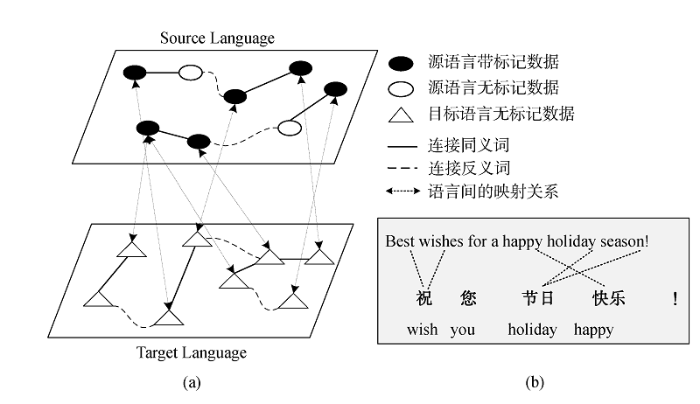
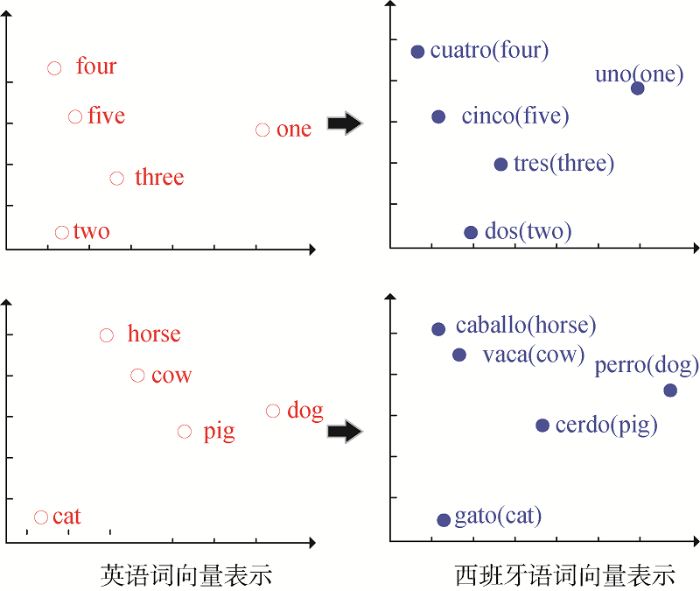

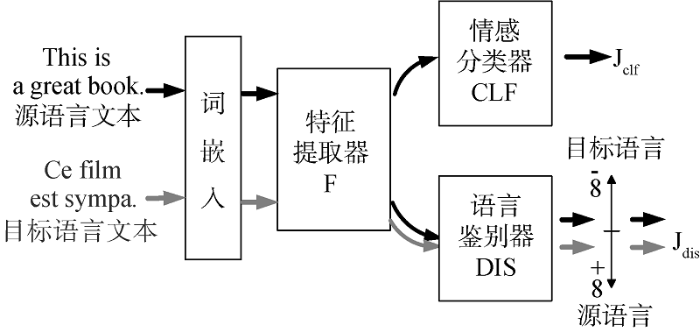


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}