1 引言
学科交叉是伴随社会和学科的不断发展出现的一种综合性科学活动[1 ] ,不同学科之间的交叉地带在科学研究中会被认为是科技创新的重要来源[2 ] ,存在可能的科学前沿问题。识别学科交叉地带的科学研究活动,探寻具有前沿性质的学科交叉研究领域、知识或主题,对于引导相关科学研究、加快促进科技创新具有重要价值。为探索支持学科交叉领域的研究工作,2020年11月,国家自然科学基金委员会成立了交叉科学部;2021年1月,国务院学位委员会、教育部增设了“交叉学科”门类。随着学科交叉研究活动的不断深入,面对激增的、复杂异构的科技文献数据,构建智能化、自动化的学科交叉知识分析、识别与预警决策系统,可辅助相关机构制定政策,引导科研人员从事相关研究,也是学科交叉研究需要重点关注的方向。
深度学习技术不断被应用于自然语言处理领域相关任务,并取得了较之以往更为有效的效果。这为深入挖掘分析科技文献内容,识别学科交叉知识、主题提供了重要的技术支撑。对科技文献内容进行分析并获取学科交叉知识,较使用引文、作者数据更为直观、准确、有效,是学科交叉知识发现的重要研究方向[3 ] 。通过识别出学科交叉地带的科学研究成果,进而利用各种不同的分析方法提取学科交叉知识[4 ⇓ ⇓ -7 ] ,是从科技文献的内容中发现学科交叉知识的重要途径。学科交叉知识发现与预警决策系统的建设,应侧重于实时跟踪学科交叉研究地带的科研活动,即具有不同学科标签的科技文献数据,进而挖掘获取学科交叉研究态势、主题等,辅助引导相关科研活动。相关研究中,科技文献的学科属性,或来自收录科技文献的各种异构学术数据库,或来自科技文献发表于某学科领域的期刊/会议的学科信息,但一些学科交叉研究科技文献由于各种原因被赋予单一的学科信息,不能很好地反映科技文献的多个学科研究性质。笔者认为可通过文本分类算法在已有科技文献及学科分类数据的基础上训练文本分类模型,实时识别、增加新的学科交叉研究科技文献数据到数据分析系统,为学科交叉知识分析与挖掘提供动态实时数据,达到及时跟踪学科交叉地带的知识或研究主题的目的。相对于使用复杂参数设置的聚类算法识别学科交叉研究科技文献的方法,基于科技文献数据训练文本分类模型,实时跟踪发现学科交叉研究科技文献,更具实际应用价值,如:学科交叉研究科技文献的学科信息可直接在研究方向层面跟踪学科融合态势;学科交叉研究科技文献数据直接聚类可获取科技文献层面的学科交叉研究方向;主题分析可获取更为细化的学科交叉研究主题、知识等。
目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] 。文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性。科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一。学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息。结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据。
针对发现具有学科交叉研究性质的科技文献,本文的主要贡献为:
(1)基于科学计量学领域相关研究中对科技文献分类错误与学科间相互依赖关系的解析,提出了一种将学科领域专家提供的科技文献学科标签信息与机器学习文本分类算法预测的科技文献学科分类数据相结合,共同判别科技文献学科交叉研究性质的模型。
(2)通过在实验数据上人工标注科技文献的学科交叉研究性质,进而制定方案并验证所提出方法的有效性及可行性。实验结果表明,模型融入学科领域专家提供的已有科技文献学科标签信息后,模型识别科技文献学科交叉研究性质的能力在F1评价指标上得到有效提升。
本文研究目标主要侧重于验证笔者所提出的将文本分类算法与已有标签数据相结合,应用于学科交叉科技文献识别的可行性,而非侧重于构建性能更好的多标签分类模型。
2 相关工作
2.1 学科及其分类体系
学科及其分类体系是人们在认识和探索自然界的过程中形成的系统化的知识体系。学科交叉研究中,学科分类体系是界定期刊、论文、作者、关键词等学科属性的依据,是分析学科间知识融合、交流活动的前提。学科分类体系的建立需要基于相关学科领域专家长期的经验及知识积累,将相同或相似的研究领域划分到特定的学科分支之下。常见的学科分类体系有杜威十进制图书分类法、美国国会图书馆图书分类法、Thomson-ISI WoS分类体系、JCR分类体系、中国图书馆分类法、中国国家自然科学基金委员会的学科分类等。通过各种途径建立的学科分类标准侧重于对以往知识体系的划分,难以及时反映学科结构发生的变化。因此有研究使用科技文献的引文分析等,将科技文献形成聚类,从而探究学科的交叉结构,但该方法需要设置合适的聚类算法参数等,划分的精确度存在不足。
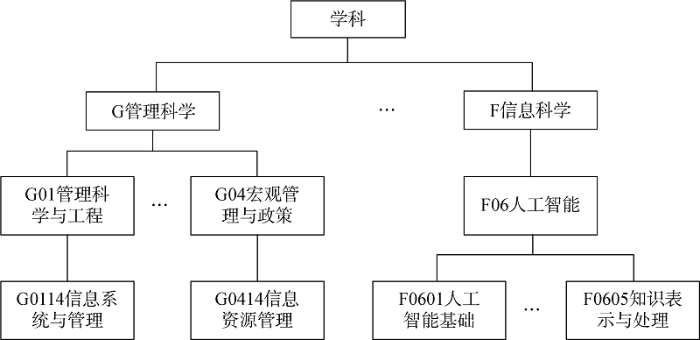
学科分类体系一般为层次的树状结构,如图1 所示(以2019年中国国家自然科学基金委员会的学科分类体系部分代码为例),学科自顶向下不断分解为更加细化的多个学科分支或研究方向,位于同一分支之下的研究方向,其研究内容、主题相对更为接近。
图1
图1
树状层次结构的学科分类体系
Fig.1
Tree-Like Hierarchical of Disciplinary Classification System
从学科体系的层次结构可知,学科分类体系中各个学科、子学科之间的关系是一种从学科分类树的叶节点到分类树的根部节点、自底向上单向隶属的关系,如在图1 中,G0414∈G04∈G,其中∈表示隶属于关系。由于本文使用的数据采用层次结构的分类体系,因此可将科技文献的学科标签解析为多个位于不同层次的学科标签,如科技文献属于“F0607”学科,其学科标签可以解析为“F”、“F06”、“F0607”,以此类推。笔者希望通过此方法构建学科标签的层次关系,并为科技文献赋予多个宏观或微观的学科或子学科标签。本文具有学科交叉性质的科技文献,主要指其同时具有F和G学科信息。
2.2 科技文献分类及相关研究
科技文献中包含不同学科或研究领域的代表性知识,是将科技文献进行学科划分的依据。随着科技文献数量的快速增长,基于人工方式将科技文献划分到合适的学科体系是极具挑战的工作。学科交叉研究科技文献的学科信息标注工作,需要分类专家具备多个学科的专业知识及信息素养。该工作涉及更多的学科领域知识,其复杂程度要高于普通的科技文献学科分类。
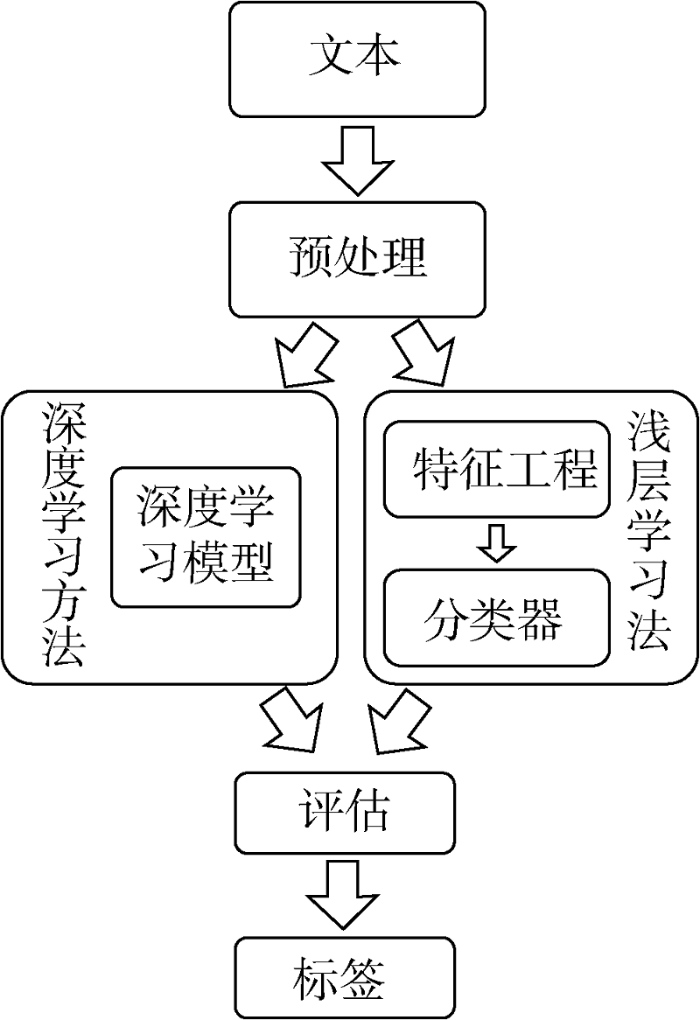
文本数据是科技文献的表现形式之一。对科技文献进行学科分类,可通过提取科技文献的文本中包含的不同学科或研究方向的知识特征信息,然后利用数据分类模型实现。Li等[18 ] 将文本分类分为基于浅层学习的文本分类方法和基于深度学习的文本分类方法,如图2 所示。
图2
图2
文本分类流程[18 ]
Fig.2
Text Classification Flowchart
基于浅层学习的文本分类方法,是先将文本进行特殊处理,然后使用分类算法实现文本分类。常见的文本表示方式包括BOW、N-gram、TF-IDF、Word2Vec和GloVe等,分类算法包括朴素贝叶斯、最近邻分类、决策树与随机森林、支持向量机等。基于深度学习进行文本分类的方法,深度学习模型可以同时完成文本特征工程和分类任务,目前代表性的模型有FastText、TextCNN、TextRNN、TextRCNN、BERT等。按照输出标签类别的不同,文本分类可分为二分类、多分类、多标签分类三种,其中二分类任务的标签有两种,分类模型输出的结果只能为其中的一个;多分类任务输出的标签可以有多个种类,分类模型输出的取值为其中一个;多标签分类任务可以同时输出多个标签。本文中对科技文献进行学科分类,是通过将科技文献的学科标签转换为具有层次关系的多个标签,是一种多标签分类任务。
在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型。也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象。科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路。识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中。
3 科技文献学科交叉研究性质识别模型
3.1 模型设计
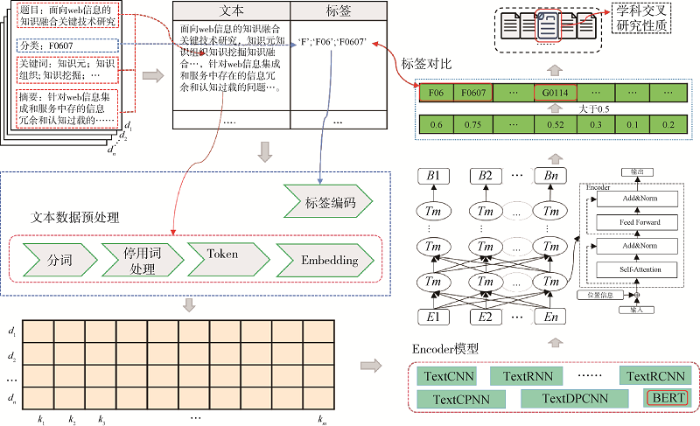
本文模型将多标签分类模型作为其关键组成部分,通过对比不同的可进行文本分类的深度学习相关模型的分类性能,为Encoder部分选取合适的分类模型。然后以选定的训练完成的文本分类模型,预测测试集数据中科技文献的学科标签。再通过对比测试集数据中科技文献的预测学科标签和已有学科标签,实现科技文献学科交叉研究性质识别。模型如图3 所示。
图3
图3
科技文献学科交叉研究识别模型
Fig.3
Identification Model for Interdisciplinary Research of Sci-Tech Literature
(1)数据处理。将科技文献数据集中的学科标签按照学科的层次结构处理为多个标签,对标签进行One-Hot处理,同时对文本进行分词、去除停用词等处理。最后将数据集划分为训练集、验证集、测试集。
(2)Encoder部分模型选取。对比常用的文本多标签分类模型,将Macro-F1作为评价模型在测试集上性能的指标,选取适合当前数据集的文本分类模型。
(3)科技文献学科标签预测。将选定的Encoder部分的文本分类模型在训练集、验证集上进行训练,获取模型最优参数。将训练好的模型用于预测测试集中科技文献的学科标签。
(4)科技文献学科交叉研究性质识别。对比测试集中科技文献已有学科信息、模型预测学科信息,识别测试集中科技文献的学科交叉研究性质。
本文提出的科技文献学科交叉研究性质识别模型与传统的依靠分类算法识别科技文献学科交叉研究性质方法的区别在于,不仅将分类模型预测为多个不同学科标签的科技文献视为学科交叉研究,如实验数据中原属F学科的科技文献经文本分类模型后被预测为F、G学科标签;还将经分类模型后,学科标签完全被预测为另外一个学科的科技文献视为学科交叉研究,如F学科的科技文献被预测为另外的G学科标签。实验结果证明,模型融入学科领域专家提供的已有科技文献学科标签信息后,其识别科技文献学科交叉研究性质的能力得到明显提升。
3.2 多标签分类模型及选择
在学科分类体系下,以图1 中G0104学科代码下的项目为例,该学科代码下的项目可以属于G0104,也可以属于更为宏观的G、G01。因此,在学科分类体系下的科技文献可以解析为多个学科标签,多个标签之间可以是上下位的从属关系,如G、G01,也可以是位于同一层级的平行关系,如G01、F06。基于此,将当前任务属性定义为多标签分类。对于科技文献的多标签分类模型,本文主要选取FastText[20 ] 、TextCNN[21 ] 、TextRNN[22 ] 、TextRCNN[23 ] 、TextDPCNN[24 ] 、TextCRNN[25 ] 、HAN[26 ] 、BERT[27 ] 等,并评价其在当前数据集上的分类效果。为选取合适的多标签分类模型,相关模型在4.1节的实验数据上进行性能对比。相关模型在训练集上进行数据训练,验证集上Macro-F1指标最优时,保存模型的参数。各个模型在测试集上Macro-F1、Micro-F1的结果如表1 所示。
TextRCNN、TextDPCNN和BERT模型在测试集上的分类性能基本相当。鉴于各个模型每次运行获取的Macro-F1值会有轻微浮动,以及BERT模型基于词的动态向量在相关任务场景的有效性,结合人工对测试集上提取结果的简单分析,笔者认为BERT模型可以更好地理解文本信息,更适合当前任务。
Transformer由Encoder和Decoder组成,BERT通常使用Transformer的Encoder部分。Encoder部分输入为文本中的字嵌入向量表示信息,然后加上每个字在文本中的位置信息,输入Self-Attention层,再经Add&Norm层,其中Add是将Self-Attention层的输出和输入相加,Norm是将相加的结果进行归一化。归一化结果输入Feed Forward层,Feed Forward层的输出再经过一个Add&Norm层,输出归一化处理后的结果。Transformer中的Encoder部分最重要的组成部分为自注意力机制,其主要作用为使词不仅包含自身的语义信息,且能包含与其他词的语义关系,是一种更加全局的表达方式。Transformer一般采用Multi-Head Self-Attention机制,其计算方法如公式(1)-公式(3)所示[28 ] 。
(1) M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 , … , h e a d h ) W O
(2) h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V )
(3) A t t e n t i o n ( Q , K , V ) = s o f t m a x Q K T d V
其中,W i Q , W i K , W i V i 个head 的权重矩阵,W O Concat (·)表示拼接函数。
BERT模型经过一个全连接层,得到文本表示,最后通过Sigmod激活函数进行多标签分类。模型训练过程中,针对多标签分类任务,采用二元交叉熵损失(Binary Cross Entropy Loss,BCELoss)作为模型的损失函数,如公式(4)所示。
(4) H p ( q ) = - 1 N ∑ i = 1 N y i · l o g y ^ i + 1 - y i · l o g 1 - y ^ i
F1指标是衡量二分类精确度的一种指标,计算方法如公式(5)所示。
(5) F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l
针对多标签分类任务,主要有Micro-F1和Macro-F1两种指标,其中Micro-F1指标是先计算多标签分类中所有类别总的Precision和Recall,然后计算F1;Macro-F1指标是先分别计算每一个类的Precision和Recall,获取每一个类的F1,然后对所有类的F1求平均值。本文将Macro-F1指标作为相关模型选取的主要标准和依据。
3.3 学科交叉研究识别方法
本文模型为科技文献学科交叉研究性质识别模型。为对比分类算法直接预测科技文献学科交叉性质,与融入科技文献已有标签数据共同判别科技文献学科交叉研究性质的实际效果。本文中使用两个不同的学科交叉研究性质科技文献识别标准:
S1:将训练的文本分类模型在测试集上预测的具有多个学科标签的科技文献(如同时具有“F”、“G”标签),作为学科交叉研究;
S2:在S1的基础上,还将科技文献数据经过训练模型后,完全预测为另外一个学科标签的科技文献(如文中F学科的项目被预测为G学科的项目),作为学科交叉研究。
3.4 模型效果评价方法
由于所选测试集中每条数据的学科标签同时具有F、G学科的数据为0条,首先对测试集数据进行学科交叉研究性质的标注,标注原则为:只关注测试集的数据中是否同时包含F、G学科的代表性知识,作为科技文献是否为学科交叉研究的依据。经过三轮相关领域不同人员的标注以及结果对比,最终标注学科交叉研究数据55条。
使用训练好的文本分类模型在测试集上预测学科标签,并依据S1和S2对比学科交叉研究性质科技文献识别结果。分别将人工标注测试集数据的标签、分类模型在测试集上的预测学科标签设置为两个类别,属于学科交叉研究的科技文献标签设置为1,不属于学科交叉研究的科技文献标签设置为0。由于人工标注为学科交叉研究性质的项目数据较少(486条中的55条),因此在实验分析中主要关注所提模型识别学科交叉研究类别(标注为1的学科标签)的效果。
4 实验及分析
4.1 实验数据
选取具有学科交叉特征的不同学科科技文献进行模型验证。实验数据使用国家自然科学基金资助项目的题目、关键词、摘要等文本信息,科技文献的组成结构也包含上述信息,因此实验所选数据不影响模型在科技文献数据上的使用。实验选取2011年-2019年国家自然科学基金“F06人工智能”、“G0114信息系统与管理”、“G0414信息资源管理”学科项目作为实验对象(2019年公布的申请代码数据)。“人工智能”学科隶属于信息科学部,“信息系统与管理”、“信息资源管理”隶属于管理科学部,前者属于计算机学科范畴,后者属于管理学科范畴。本文实验将G0114、G0414对应项目划分到“G信息管理”学科,将F06对应项目划分到“F人工智能”学科。将2011年-2018年的数据随机提取80%作为训练集,剩余20%作为验证集;2019年的数据作为测试集。由于在测试集中有33条数据属于只在2019年出现的“F0610”子学科,故为验证模型的有效性,将该部分数据从测试集中删除。最终,选取2011年-2019年“人工智能”项目2 624个,“信息管理”项目620个,共计3 244个,生成的数据集包含训练集2 206条,验证集552条,测试集486条。实验中,将数据的学科标签按照学科的层次关系转换为15个学科标签作为科技文献的标签数据,例如:项目学科代码为“F06”,转换为“F”、“F06”;项目学科代码为“F0601”,转换为“F”、“F06”、“F0601”。
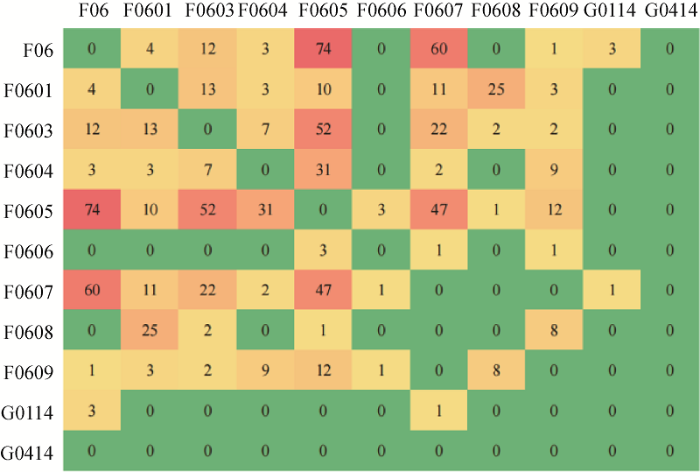
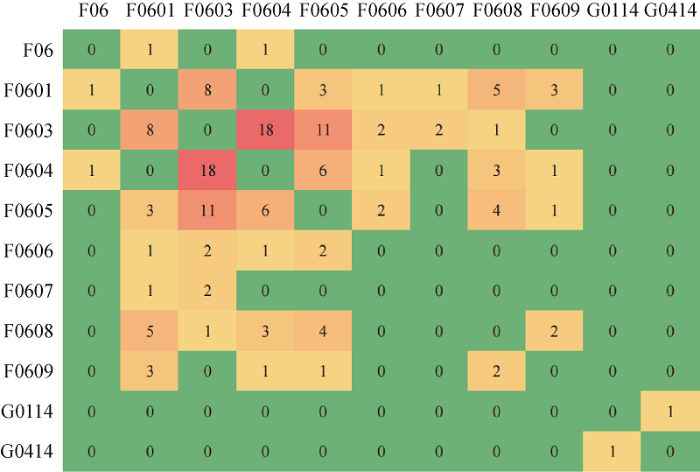
对2011年-2018年和2019年同时标注为两个学科分支的项目数量分别进行统计,生成热力图,如图4 和图5 所示。
图4
图4
标注为不同学科分支的项目分布(2011-2018)
Fig.4
Distribution of the Projects Marked as Different Discipline Branches(2011-2018)
图5
图5
标注为不同学科分支的项目分布(2019)
Fig.5
Distribution of the Projects Marked as Different Discipline Branches(2019)
标注为学科交叉研究性质的项目更多的是F学科分支之下的学科交叉,G学科和F学科之下的学科分支之间交叉数据很少。在标注项目的学科信息时,科研人员更倾向于将其标注为自己较为熟悉的学科领域信息,如“F”学科的申请人员更易将其学科代码标注为“F”学科下的子学科。在对2019年的项目数据进行人工解读时,发现一些项目的研究明显属于“F”和“G”学科的研究,但科研人员并未进行多学科标注,此类现象在科技文献的学科交叉知识发现研究中也有一定体现。因此,重新对测试集上的数据进行学科性质的人工标注,以便验证文中提出的将已有学科标签与模型预测标签数据相结合,识别学科交叉研究科技文献的可行性。
4.2 参数设置
选取BERT作为多标签文本分类的模型,相关参数设置如表2 所示。为验证项目不同部分文本在进行多标签分类任务时的作用,选取项目关键词、题目、摘要组成不同的数据集分别进行多标签分类。构建三个数据集进行实验:Data1,项目关键词数据;Data2,项目关键词和题目数据;Data3,项目关键词、题目和摘要数据。不同数据集上的分类性能如表3 所示。使用更多的文本信息时,获取的最终结果更为合理。因此,本文实验最终使用Data3数据集。
4.3 实验结果
多次实验发现,使用S2评价标准获取的学科交叉研究项目的F1值均远高于使用S1评价标准。对模型识别结果进行分析,结果如表4 所示。结合已有标签数据和模型预测数据获取项目学科交叉研究性质,比直接基于模型预测具有较大的性能提升。
按照S2标准,获取学科交叉研究项目20条,其中3条不属于学科交叉研究。为深入分析本文模型识别结果的合理性,对学科交叉研究项目结果进行解析。使用S2标准提取学科交叉研究项目,并将结果划分为两种类型,一种是将单学科性质的项目识别为多学科标签,如表5 所示(共7条,表中呈现4条示例);另外一种是将项目标签完全预测为另外一个学科的标签,如表6 所示(共13条,表中呈现4条示例)。通过对比人工标注的结果,标签分类错误的项目绝大部分都属于学科交叉研究,这可以在一定程度上验证文献[17 ]的相关结论和本文思路的合理性。
4.4 结果分析
识别为学科交叉研究项目(见表5 )共获取7条实验结果,相关项目均具有学科交叉研究性质。识别为其他学科项目(见表6 )共获取13条实验结果,除3个项目不具有学科交叉研究性质外,其他项目均具有明显的学科交叉研究性质。
经对表5 和表6 的实验结果进行解读,相关数据绝大部分都包含两个学科的研究主题。但在表6 中有3条数据不具有另外一个学科的特征,而被错误赋予了其他学科的标签,经过初步解析,笔者认为可能原因是分类模型学习到的一些文本特征更多为另外一个学科的特征,但是这些特征在另外一个学科并非代表性学科知识。
4.5 结果评价
通过文本多标签分类算法预测项目新的学科标签,其预测出的新学科标签数据与已有学科标签数据不一致,其原因之一为该项目文本中具有其他学科的文本特征,从而导致该数据出现错误,即科研人员选择学科时主观上认为是某个学科,而实际情况是该研究也包含了另外一个学科的研究主题(文本特征)。从此角度可以认为此类科技文献位于学科划分的边界,具有倾向于学科交叉研究的特点。因此将错误的学科分类数据看作学科交叉研究具有一定的合理性,这也可从科技文献学科交叉识别标准S2效果优于S1得到支持。但是,基于文本分类的方法也会使分类模型学习到不能作为另外一个学科的文本特征信息,导致模型识别学科交叉项目出现错误,如表6 中的3条错误结果。
在人工标注的学科交叉研究项目中,有38条未出现在表5 、表6 。笔者对这38条数据进行简单解读,认为这类数据中包含的其他学科特征信息没有被文本分类模型学习到,可在后续研究中从其他方面提升分类模型的敏感性,如:目前实验的训练集中包含的数据数量较少,需要提高训练集包含的学科的研究内容的全面性;实验的训练集中同时包含人工智能学科和信息管理学科标签的数据很少,因此,为训练集提供更多的、合适的科技文献多学科标签数据也是后续的改进方向等。
结合相关实验结果,笔者认为基于文本分类错误信息识别学科交叉研究是一种融合学科领域专家经验与机器学习文本分类方法,进而决策科技文献是否是学科交叉研究性质的研究思路,是值得尝试和关注的研究方向。
5 结语
通过相关实验,笔者认为科技文献学科交叉研究性质的识别,除了可以从分类算法性能方面进行关注外,还可以从科技文献数据被赋予学科信息时的特点出发展开相关研究。本文将文本分类模型预测科技文献学科标签与科技文献已有学科标签相结合,将不同学科间文本分类错误数据具有学科交叉研究性质的特征,作为科技文献学科交叉研究识别的依据,是值得进一步关注的研究方向。但目前模型在学科交叉研究性质科技文献上召回率指标较低,后续研究可从以下方面完善现有模型不足:
(1)模型训练数据收集的全面性。实验中的训练集数据相对较少,文本分类模型实际学习到的文本特征信息与标签之间的关系信息还存在欠缺。多标签分类模型的数据训练集应包括较为全面的科技资源,以为模型提供更为丰富的特征信息。
(2)科技文献文本特征数据抽取的相关研究。文本多标签分类的依据与文本中包含的一些文本特征信息存在一定关系,但是一些不能代表科技文献的特征信息被模型学习到以后,会使模型在预测时出现错误。如何提取出科技文献中的重要特征信息,如何评价模型是否已经学习到数据集的重要特征,如何选择更好的模型评价指标等,仍然是下一步需要关注的方向。
(3)科技文献知识图谱构建的必要性。实验数据集中同时包含F、G学科的数据几乎为0,这也对多标签分类模型学习各个学科的相关文本特征带来了一定困难。笔者认为,为使模型能应用于学科交叉知识发现预警预测平台,还需要从知识图谱角度对科技文献进行管理,以提供高质量的、完善的科技文献数据。
作者贡献声明
利益冲突声明
支撑数据
参考文献
View Option
[1]
Klein J T A Conceptual Vocabulary of Interdisciplinary Science[A]//StehrN, WeingartP
Practising Interdisciplinarity [M]. Toronto : University of Toronto Press , 2000 : 3 -24 .
[本文引用: 1]
[2]
Easton D The Division Integration , and Transfer of Knowledge
[J]. Bulletin of the American Academy of Arts and Sciences , 1991 , 44 (4 ): 8 -27 .
DOI:10.2307/3824130
URL
[本文引用: 1]
[3]
许海云 , 董坤 , 隗玲 . 学科交叉主题识别与预测方法研究 [M]. 北京 : 科学技术文献出版社 , 2019 .
[本文引用: 1]
( Xu Haiyun Dong Kun Wei Ling Research on Interdisciplinary Topics Identification and Prediction Methods [M]. Beijing : Scientific and Technical Documents Publishing House , 2019 .)
[本文引用: 1]
[4]
魏建香 . 学科交叉知识发现及其可视化研究 [D]. 南京 : 南京大学 , 2010 .
[本文引用: 1]
( Wei Jianxiang Interdiscipline Knowledge Discovery and Its Visualization Research [D]. Nanjing : Nanjing University , 2010 .)
[本文引用: 1]
[5]
Dong K Xu H Y Luo R et al. An Integrated Method for Interdisciplinary Topic Identification and Prediction: A Case Study on Information Science and Library Science
[J]. Scientometrics , 2018 , 115 (2 ): 849 -868 .
DOI:10.1007/s11192-018-2694-x
URL
[本文引用: 1]
[6]
Ba Z C Cao Y J Mao J et al. A Hierarchical Approach to Analyzing Knowledge Integration Between Two Fields—A Case Study on Medical Informatics and Computer Science
[J]. Scientometrics , 2019 , 119 (3 ): 1455 -1486 .
DOI:10.1007/s11192-019-03103-1
URL
[本文引用: 1]
[7]
阮光册 , 夏磊 . 学科间交叉研究主题识别——以图书情报学与教育学为例
[J]. 情报科学 , 2020 , 38 (12 ): 152 -157 .
[本文引用: 1]
( Ruan Guangce Xia Lei Research on Interdisciplinary Topics Identification—A Case Study of Library & Information Science and Education
[J]. Information Science , 2020 , 38 (12 ): 152 -157 .)
[本文引用: 1]
[8]
Deshmukh P R Borhade B Support Vector Machine Classifier for Research Discipline Area Selection
[C]// Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems. IEEE , 2017 : 462 -466 .
[本文引用: 2]
[9]
王昊 , 叶鹏 , 邓三鸿 . 机器学习在中文期刊论文自动分类研究中的应用
[J]. 现代图书情报技术 , 2014 (3 ): 80 -87 .
[本文引用: 2]
( Wang Hao Ye Peng Deng Sanhong The Application of Machine-Learning in the Research on Automatic Categorization of Chinese Periodical Articles
[J]. New Technology of Library and Information Service , 2014 (3 ): 80 -87 .)
[本文引用: 2]
[10]
刘晓东 , 倪浩然 . 深度学习技术在学科融合研究中的应用
[J]. 数据与计算发展前沿 , 2020 (5 ): 99 -109 .
[本文引用: 2]
( Liu Xiaodong Ni Haoran Application of Deep Learning Technology in Discipline Integration Research
[J]. Frontiers of Data & Computing , 2020 (5 ): 99 -109 .)
[本文引用: 2]
[11]
Xiao M Qiao Z Y Fu Y J et al. Expert Knowledge-Guided Length-Variant Hierarchical Label Generation for Proposal Classification
[C]// Proceedings of the 2021 IEEE International Conference on Data Mining. IEEE , 2021 : 757 -766 .
[本文引用: 2]
[12]
Kowsari K Brown D E Heidarysafa M et al. HDLTex: Hierarchical Deep Learning for Text Classification
[C]// Proceedings of the 16th IEEE International Conference on Machine Learning and Applications. IEEE , 2017 : 364 -371 .
[本文引用: 2]
[13]
Haghighian Roudsari A Afshar J Lee W et al. PatentNet: Multi-Label Classification of Patent Documents Using Deep Learning Based Language Understanding
[J]. Scientometrics , 2022 , 127 (1 ): 207 -231 .
DOI:10.1007/s11192-021-04179-4
URL
[本文引用: 2]
[14]
Xiao M Qiao Z Fu Y et al. Who Should Review Your Proposal? Interdisciplinary Topic Path Detection for Research Proposals
[OL]. arXiv Preprint , arXiv: 2203.10922.
[本文引用: 2]
[15]
黄学坚 , 刘雨飏 , 马廷淮 . 基于改进型图神经网络的学术论文分类模型
[J]. 数据分析与知识发现 , 2022 , 6 (10 ): 93 -102 .
[本文引用: 2]
( Huang Xuejian Liu Yuyang Ma Tinghuai Classification Model for Scholarly Articles Based on Improved Graph Neural Network
[J]. Data Analysis and Knowledge Discovery , 2022 , 6 (10 ): 93 -102 .)
[本文引用: 2]
[16]
刘浏 , 王东波 . 基于论文自动分类的社科类学科跨学科性研究
[J]. 数据分析与知识发现 , 2018 , 2 (3 ): 30 -38 .
[本文引用: 2]
( Wang Dongbo Identifying Interdisciplinary Social Science Research Based on Article Classification
[J]. Data Analysis and Knowledge Discovery , 2018 , 2 (3 ): 30 -38 .)
[本文引用: 2]
[17]
Lyutov A Uygun Y Hütt M T Machine Learning Misclassification of Academic Publications Reveals Non-Trivial Interdependencies of Scientific Disciplines
[J]. Scientometrics , 2021 , 126 (2 ): 1173 -1186 .
DOI:10.1007/s11192-020-03789-8
URL
[本文引用: 6]
[18]
Li Q Peng H Li J et al. A Survey on Text Classification: From Shallow to Deep Learning[OL]
arXiv Preprint , arXiv: 2008.00364.
[本文引用: 2]
[19]
Yegros-Yegros A Rafols I D'Este P Does Interdisciplinary Research Lead to Higher Citation Impact? The Different Effect of Proximal and Distal Interdisciplinarity
[J]. PLoS One , 2015 , 10 (8 ): e0135095 .
DOI:10.1371/journal.pone.0135095
URL
[本文引用: 2]
[20]
Joulin A Grave E Bojanowski P et al. Bag of Tricks for Efficient Text Classification
[C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics . 2017 : 427 -431 .
[本文引用: 1]
[21]
Kim Y Convolutional Neural Networks for Sentence Classification
[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing . 2014 : 1746 -1751 .
[本文引用: 1]
[22]
Liu P Qiu X Huang X Recurrent Neural Network for Text Classification with Multi-Task Learning
[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence . 2016 .
[本文引用: 1]
[23]
Lai S Xu L Liu K et al. Recurrent Convolutional Neural Networks for Text Classification
[C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence . 2015 .
[本文引用: 1]
[24]
Johnson R Zhang T Deep Pyramid Convolutional Neural Networks for Text Categorization
[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics . 2017 : 562 -570 .
[本文引用: 1]
[25]
Zhou C Sun C Liu Z et al. A C-LSTM Neural Network for Text Classification[OL]
arXiv Preprint, arXiv: 1511.08630.
[本文引用: 1]
[26]
Yang Z Yang D Dyer C et al. Hierarchical Attention Networks for Document Classification
[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies . 2016 .
[本文引用: 1]
[27]
Devlin J Chang M W Lee K et al. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding
[OL]. arXiv Preprint, arXiv: 1810.04805.
[本文引用: 1]
[28]
Vaswani A Shazeer N Parmar N et al. Attention is All You Need
[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . 2017 .
[本文引用: 1]
A Conceptual Vocabulary of Interdisciplinary Science[A]//StehrN, WeingartP
1
2000
... 学科交叉是伴随社会和学科的不断发展出现的一种综合性科学活动[1 ] ,不同学科之间的交叉地带在科学研究中会被认为是科技创新的重要来源[2 ] ,存在可能的科学前沿问题.识别学科交叉地带的科学研究活动,探寻具有前沿性质的学科交叉研究领域、知识或主题,对于引导相关科学研究、加快促进科技创新具有重要价值.为探索支持学科交叉领域的研究工作,2020年11月,国家自然科学基金委员会成立了交叉科学部;2021年1月,国务院学位委员会、教育部增设了“交叉学科”门类.随着学科交叉研究活动的不断深入,面对激增的、复杂异构的科技文献数据,构建智能化、自动化的学科交叉知识分析、识别与预警决策系统,可辅助相关机构制定政策,引导科研人员从事相关研究,也是学科交叉研究需要重点关注的方向. ...
Transfer of Knowledge
1
1991
... 学科交叉是伴随社会和学科的不断发展出现的一种综合性科学活动[1 ] ,不同学科之间的交叉地带在科学研究中会被认为是科技创新的重要来源[2 ] ,存在可能的科学前沿问题.识别学科交叉地带的科学研究活动,探寻具有前沿性质的学科交叉研究领域、知识或主题,对于引导相关科学研究、加快促进科技创新具有重要价值.为探索支持学科交叉领域的研究工作,2020年11月,国家自然科学基金委员会成立了交叉科学部;2021年1月,国务院学位委员会、教育部增设了“交叉学科”门类.随着学科交叉研究活动的不断深入,面对激增的、复杂异构的科技文献数据,构建智能化、自动化的学科交叉知识分析、识别与预警决策系统,可辅助相关机构制定政策,引导科研人员从事相关研究,也是学科交叉研究需要重点关注的方向. ...
1
2019
... 深度学习技术不断被应用于自然语言处理领域相关任务,并取得了较之以往更为有效的效果.这为深入挖掘分析科技文献内容,识别学科交叉知识、主题提供了重要的技术支撑.对科技文献内容进行分析并获取学科交叉知识,较使用引文、作者数据更为直观、准确、有效,是学科交叉知识发现的重要研究方向[3 ] .通过识别出学科交叉地带的科学研究成果,进而利用各种不同的分析方法提取学科交叉知识[4 ⇓ ⇓ -7 ] ,是从科技文献的内容中发现学科交叉知识的重要途径.学科交叉知识发现与预警决策系统的建设,应侧重于实时跟踪学科交叉研究地带的科研活动,即具有不同学科标签的科技文献数据,进而挖掘获取学科交叉研究态势、主题等,辅助引导相关科研活动.相关研究中,科技文献的学科属性,或来自收录科技文献的各种异构学术数据库,或来自科技文献发表于某学科领域的期刊/会议的学科信息,但一些学科交叉研究科技文献由于各种原因被赋予单一的学科信息,不能很好地反映科技文献的多个学科研究性质.笔者认为可通过文本分类算法在已有科技文献及学科分类数据的基础上训练文本分类模型,实时识别、增加新的学科交叉研究科技文献数据到数据分析系统,为学科交叉知识分析与挖掘提供动态实时数据,达到及时跟踪学科交叉地带的知识或研究主题的目的.相对于使用复杂参数设置的聚类算法识别学科交叉研究科技文献的方法,基于科技文献数据训练文本分类模型,实时跟踪发现学科交叉研究科技文献,更具实际应用价值,如:学科交叉研究科技文献的学科信息可直接在研究方向层面跟踪学科融合态势;学科交叉研究科技文献数据直接聚类可获取科技文献层面的学科交叉研究方向;主题分析可获取更为细化的学科交叉研究主题、知识等. ...
1
2019
... 深度学习技术不断被应用于自然语言处理领域相关任务,并取得了较之以往更为有效的效果.这为深入挖掘分析科技文献内容,识别学科交叉知识、主题提供了重要的技术支撑.对科技文献内容进行分析并获取学科交叉知识,较使用引文、作者数据更为直观、准确、有效,是学科交叉知识发现的重要研究方向[3 ] .通过识别出学科交叉地带的科学研究成果,进而利用各种不同的分析方法提取学科交叉知识[4 ⇓ ⇓ -7 ] ,是从科技文献的内容中发现学科交叉知识的重要途径.学科交叉知识发现与预警决策系统的建设,应侧重于实时跟踪学科交叉研究地带的科研活动,即具有不同学科标签的科技文献数据,进而挖掘获取学科交叉研究态势、主题等,辅助引导相关科研活动.相关研究中,科技文献的学科属性,或来自收录科技文献的各种异构学术数据库,或来自科技文献发表于某学科领域的期刊/会议的学科信息,但一些学科交叉研究科技文献由于各种原因被赋予单一的学科信息,不能很好地反映科技文献的多个学科研究性质.笔者认为可通过文本分类算法在已有科技文献及学科分类数据的基础上训练文本分类模型,实时识别、增加新的学科交叉研究科技文献数据到数据分析系统,为学科交叉知识分析与挖掘提供动态实时数据,达到及时跟踪学科交叉地带的知识或研究主题的目的.相对于使用复杂参数设置的聚类算法识别学科交叉研究科技文献的方法,基于科技文献数据训练文本分类模型,实时跟踪发现学科交叉研究科技文献,更具实际应用价值,如:学科交叉研究科技文献的学科信息可直接在研究方向层面跟踪学科融合态势;学科交叉研究科技文献数据直接聚类可获取科技文献层面的学科交叉研究方向;主题分析可获取更为细化的学科交叉研究主题、知识等. ...
1
2010
... 深度学习技术不断被应用于自然语言处理领域相关任务,并取得了较之以往更为有效的效果.这为深入挖掘分析科技文献内容,识别学科交叉知识、主题提供了重要的技术支撑.对科技文献内容进行分析并获取学科交叉知识,较使用引文、作者数据更为直观、准确、有效,是学科交叉知识发现的重要研究方向[3 ] .通过识别出学科交叉地带的科学研究成果,进而利用各种不同的分析方法提取学科交叉知识[4 ⇓ ⇓ -7 ] ,是从科技文献的内容中发现学科交叉知识的重要途径.学科交叉知识发现与预警决策系统的建设,应侧重于实时跟踪学科交叉研究地带的科研活动,即具有不同学科标签的科技文献数据,进而挖掘获取学科交叉研究态势、主题等,辅助引导相关科研活动.相关研究中,科技文献的学科属性,或来自收录科技文献的各种异构学术数据库,或来自科技文献发表于某学科领域的期刊/会议的学科信息,但一些学科交叉研究科技文献由于各种原因被赋予单一的学科信息,不能很好地反映科技文献的多个学科研究性质.笔者认为可通过文本分类算法在已有科技文献及学科分类数据的基础上训练文本分类模型,实时识别、增加新的学科交叉研究科技文献数据到数据分析系统,为学科交叉知识分析与挖掘提供动态实时数据,达到及时跟踪学科交叉地带的知识或研究主题的目的.相对于使用复杂参数设置的聚类算法识别学科交叉研究科技文献的方法,基于科技文献数据训练文本分类模型,实时跟踪发现学科交叉研究科技文献,更具实际应用价值,如:学科交叉研究科技文献的学科信息可直接在研究方向层面跟踪学科融合态势;学科交叉研究科技文献数据直接聚类可获取科技文献层面的学科交叉研究方向;主题分析可获取更为细化的学科交叉研究主题、知识等. ...
1
2010
... 深度学习技术不断被应用于自然语言处理领域相关任务,并取得了较之以往更为有效的效果.这为深入挖掘分析科技文献内容,识别学科交叉知识、主题提供了重要的技术支撑.对科技文献内容进行分析并获取学科交叉知识,较使用引文、作者数据更为直观、准确、有效,是学科交叉知识发现的重要研究方向[3 ] .通过识别出学科交叉地带的科学研究成果,进而利用各种不同的分析方法提取学科交叉知识[4 ⇓ ⇓ -7 ] ,是从科技文献的内容中发现学科交叉知识的重要途径.学科交叉知识发现与预警决策系统的建设,应侧重于实时跟踪学科交叉研究地带的科研活动,即具有不同学科标签的科技文献数据,进而挖掘获取学科交叉研究态势、主题等,辅助引导相关科研活动.相关研究中,科技文献的学科属性,或来自收录科技文献的各种异构学术数据库,或来自科技文献发表于某学科领域的期刊/会议的学科信息,但一些学科交叉研究科技文献由于各种原因被赋予单一的学科信息,不能很好地反映科技文献的多个学科研究性质.笔者认为可通过文本分类算法在已有科技文献及学科分类数据的基础上训练文本分类模型,实时识别、增加新的学科交叉研究科技文献数据到数据分析系统,为学科交叉知识分析与挖掘提供动态实时数据,达到及时跟踪学科交叉地带的知识或研究主题的目的.相对于使用复杂参数设置的聚类算法识别学科交叉研究科技文献的方法,基于科技文献数据训练文本分类模型,实时跟踪发现学科交叉研究科技文献,更具实际应用价值,如:学科交叉研究科技文献的学科信息可直接在研究方向层面跟踪学科融合态势;学科交叉研究科技文献数据直接聚类可获取科技文献层面的学科交叉研究方向;主题分析可获取更为细化的学科交叉研究主题、知识等. ...
An Integrated Method for Interdisciplinary Topic Identification and Prediction: A Case Study on Information Science and Library Science
1
2018
... 深度学习技术不断被应用于自然语言处理领域相关任务,并取得了较之以往更为有效的效果.这为深入挖掘分析科技文献内容,识别学科交叉知识、主题提供了重要的技术支撑.对科技文献内容进行分析并获取学科交叉知识,较使用引文、作者数据更为直观、准确、有效,是学科交叉知识发现的重要研究方向[3 ] .通过识别出学科交叉地带的科学研究成果,进而利用各种不同的分析方法提取学科交叉知识[4 ⇓ ⇓ -7 ] ,是从科技文献的内容中发现学科交叉知识的重要途径.学科交叉知识发现与预警决策系统的建设,应侧重于实时跟踪学科交叉研究地带的科研活动,即具有不同学科标签的科技文献数据,进而挖掘获取学科交叉研究态势、主题等,辅助引导相关科研活动.相关研究中,科技文献的学科属性,或来自收录科技文献的各种异构学术数据库,或来自科技文献发表于某学科领域的期刊/会议的学科信息,但一些学科交叉研究科技文献由于各种原因被赋予单一的学科信息,不能很好地反映科技文献的多个学科研究性质.笔者认为可通过文本分类算法在已有科技文献及学科分类数据的基础上训练文本分类模型,实时识别、增加新的学科交叉研究科技文献数据到数据分析系统,为学科交叉知识分析与挖掘提供动态实时数据,达到及时跟踪学科交叉地带的知识或研究主题的目的.相对于使用复杂参数设置的聚类算法识别学科交叉研究科技文献的方法,基于科技文献数据训练文本分类模型,实时跟踪发现学科交叉研究科技文献,更具实际应用价值,如:学科交叉研究科技文献的学科信息可直接在研究方向层面跟踪学科融合态势;学科交叉研究科技文献数据直接聚类可获取科技文献层面的学科交叉研究方向;主题分析可获取更为细化的学科交叉研究主题、知识等. ...
A Hierarchical Approach to Analyzing Knowledge Integration Between Two Fields—A Case Study on Medical Informatics and Computer Science
1
2019
... 深度学习技术不断被应用于自然语言处理领域相关任务,并取得了较之以往更为有效的效果.这为深入挖掘分析科技文献内容,识别学科交叉知识、主题提供了重要的技术支撑.对科技文献内容进行分析并获取学科交叉知识,较使用引文、作者数据更为直观、准确、有效,是学科交叉知识发现的重要研究方向[3 ] .通过识别出学科交叉地带的科学研究成果,进而利用各种不同的分析方法提取学科交叉知识[4 ⇓ ⇓ -7 ] ,是从科技文献的内容中发现学科交叉知识的重要途径.学科交叉知识发现与预警决策系统的建设,应侧重于实时跟踪学科交叉研究地带的科研活动,即具有不同学科标签的科技文献数据,进而挖掘获取学科交叉研究态势、主题等,辅助引导相关科研活动.相关研究中,科技文献的学科属性,或来自收录科技文献的各种异构学术数据库,或来自科技文献发表于某学科领域的期刊/会议的学科信息,但一些学科交叉研究科技文献由于各种原因被赋予单一的学科信息,不能很好地反映科技文献的多个学科研究性质.笔者认为可通过文本分类算法在已有科技文献及学科分类数据的基础上训练文本分类模型,实时识别、增加新的学科交叉研究科技文献数据到数据分析系统,为学科交叉知识分析与挖掘提供动态实时数据,达到及时跟踪学科交叉地带的知识或研究主题的目的.相对于使用复杂参数设置的聚类算法识别学科交叉研究科技文献的方法,基于科技文献数据训练文本分类模型,实时跟踪发现学科交叉研究科技文献,更具实际应用价值,如:学科交叉研究科技文献的学科信息可直接在研究方向层面跟踪学科融合态势;学科交叉研究科技文献数据直接聚类可获取科技文献层面的学科交叉研究方向;主题分析可获取更为细化的学科交叉研究主题、知识等. ...
学科间交叉研究主题识别——以图书情报学与教育学为例
1
2020
... 深度学习技术不断被应用于自然语言处理领域相关任务,并取得了较之以往更为有效的效果.这为深入挖掘分析科技文献内容,识别学科交叉知识、主题提供了重要的技术支撑.对科技文献内容进行分析并获取学科交叉知识,较使用引文、作者数据更为直观、准确、有效,是学科交叉知识发现的重要研究方向[3 ] .通过识别出学科交叉地带的科学研究成果,进而利用各种不同的分析方法提取学科交叉知识[4 ⇓ ⇓ -7 ] ,是从科技文献的内容中发现学科交叉知识的重要途径.学科交叉知识发现与预警决策系统的建设,应侧重于实时跟踪学科交叉研究地带的科研活动,即具有不同学科标签的科技文献数据,进而挖掘获取学科交叉研究态势、主题等,辅助引导相关科研活动.相关研究中,科技文献的学科属性,或来自收录科技文献的各种异构学术数据库,或来自科技文献发表于某学科领域的期刊/会议的学科信息,但一些学科交叉研究科技文献由于各种原因被赋予单一的学科信息,不能很好地反映科技文献的多个学科研究性质.笔者认为可通过文本分类算法在已有科技文献及学科分类数据的基础上训练文本分类模型,实时识别、增加新的学科交叉研究科技文献数据到数据分析系统,为学科交叉知识分析与挖掘提供动态实时数据,达到及时跟踪学科交叉地带的知识或研究主题的目的.相对于使用复杂参数设置的聚类算法识别学科交叉研究科技文献的方法,基于科技文献数据训练文本分类模型,实时跟踪发现学科交叉研究科技文献,更具实际应用价值,如:学科交叉研究科技文献的学科信息可直接在研究方向层面跟踪学科融合态势;学科交叉研究科技文献数据直接聚类可获取科技文献层面的学科交叉研究方向;主题分析可获取更为细化的学科交叉研究主题、知识等. ...
学科间交叉研究主题识别——以图书情报学与教育学为例
1
2020
... 深度学习技术不断被应用于自然语言处理领域相关任务,并取得了较之以往更为有效的效果.这为深入挖掘分析科技文献内容,识别学科交叉知识、主题提供了重要的技术支撑.对科技文献内容进行分析并获取学科交叉知识,较使用引文、作者数据更为直观、准确、有效,是学科交叉知识发现的重要研究方向[3 ] .通过识别出学科交叉地带的科学研究成果,进而利用各种不同的分析方法提取学科交叉知识[4 ⇓ ⇓ -7 ] ,是从科技文献的内容中发现学科交叉知识的重要途径.学科交叉知识发现与预警决策系统的建设,应侧重于实时跟踪学科交叉研究地带的科研活动,即具有不同学科标签的科技文献数据,进而挖掘获取学科交叉研究态势、主题等,辅助引导相关科研活动.相关研究中,科技文献的学科属性,或来自收录科技文献的各种异构学术数据库,或来自科技文献发表于某学科领域的期刊/会议的学科信息,但一些学科交叉研究科技文献由于各种原因被赋予单一的学科信息,不能很好地反映科技文献的多个学科研究性质.笔者认为可通过文本分类算法在已有科技文献及学科分类数据的基础上训练文本分类模型,实时识别、增加新的学科交叉研究科技文献数据到数据分析系统,为学科交叉知识分析与挖掘提供动态实时数据,达到及时跟踪学科交叉地带的知识或研究主题的目的.相对于使用复杂参数设置的聚类算法识别学科交叉研究科技文献的方法,基于科技文献数据训练文本分类模型,实时跟踪发现学科交叉研究科技文献,更具实际应用价值,如:学科交叉研究科技文献的学科信息可直接在研究方向层面跟踪学科融合态势;学科交叉研究科技文献数据直接聚类可获取科技文献层面的学科交叉研究方向;主题分析可获取更为细化的学科交叉研究主题、知识等. ...
Support Vector Machine Classifier for Research Discipline Area Selection
2
2017
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
机器学习在中文期刊论文自动分类研究中的应用
2
2014
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
机器学习在中文期刊论文自动分类研究中的应用
2
2014
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
深度学习技术在学科融合研究中的应用
2
2020
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
深度学习技术在学科融合研究中的应用
2
2020
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
Expert Knowledge-Guided Length-Variant Hierarchical Label Generation for Proposal Classification
2
2021
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
HDLTex: Hierarchical Deep Learning for Text Classification
2
2017
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
PatentNet: Multi-Label Classification of Patent Documents Using Deep Learning Based Language Understanding
2
2022
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
Who Should Review Your Proposal? Interdisciplinary Topic Path Detection for Research Proposals
2
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
基于改进型图神经网络的学术论文分类模型
2
2022
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
基于改进型图神经网络的学术论文分类模型
2
2022
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
基于论文自动分类的社科类学科跨学科性研究
2
2018
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
基于论文自动分类的社科类学科跨学科性研究
2
2018
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
Machine Learning Misclassification of Academic Publications Reveals Non-Trivial Interdependencies of Scientific Disciplines
6
2021
... 目前,科技文献的学科属性界定可通过文本分类算法实现[8 ⇓ ⇓ ⇓ ⇓ ⇓ ⇓ -15 ] ,现有方法主要关注分类算法的性能提升,也有研究通过文本错误分类信息构建衡量学科交叉性的指标[16 ] .文献[17 ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... ]提出了一种通过文本分类的错误数据揭示学科间相互依赖关系的方法,同时证明学科间被分类错误的科技文献具有更易被引用的可能,与学科交叉研究更易受到引用的特性具有一致性.科技文献分类错误的原因有很多,除了与分类模型性能、数据集的特点等有关外,科技文献中包含另外一个学科较为明显的特征信息也是导致分类错误的原因之一.学科交叉相关研究中,科技文献的学科信息主要通过期刊学科分类、数据库已有学科分类体系等进行界定,此类方法获取的学科信息融入了学科领域专家的知识经验,可称为已有学科领域专家提供的学科信息.结合文献[17 ],笔者认为当科技文献经分类模型预测的学科信息与原有学科不一致时,科技文献的原有学科信息依旧可以作为科技文献的学科性质之一,与预测信息一起作为识别科技文献学科交叉研究性质的依据. ...
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
... ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
... 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
... 按照S2标准,获取学科交叉研究项目20条,其中3条不属于学科交叉研究.为深入分析本文模型识别结果的合理性,对学科交叉研究项目结果进行解析.使用S2标准提取学科交叉研究项目,并将结果划分为两种类型,一种是将单学科性质的项目识别为多学科标签,如表5 所示(共7条,表中呈现4条示例);另外一种是将项目标签完全预测为另外一个学科的标签,如表6 所示(共13条,表中呈现4条示例).通过对比人工标注的结果,标签分类错误的项目绝大部分都属于学科交叉研究,这可以在一定程度上验证文献[17 ]的相关结论和本文思路的合理性. ...
A Survey on Text Classification: From Shallow to Deep Learning[OL]
2
... 文本数据是科技文献的表现形式之一.对科技文献进行学科分类,可通过提取科技文献的文本中包含的不同学科或研究方向的知识特征信息,然后利用数据分类模型实现.Li等[18 ] 将文本分类分为基于浅层学习的文本分类方法和基于深度学习的文本分类方法,如图2 所示. ...
... [
18 ]
Text Classification Flowchart Fig.2 ![]()
基于浅层学习的文本分类方法,是先将文本进行特殊处理,然后使用分类算法实现文本分类.常见的文本表示方式包括BOW、N-gram、TF-IDF、Word2Vec和GloVe等,分类算法包括朴素贝叶斯、最近邻分类、决策树与随机森林、支持向量机等.基于深度学习进行文本分类的方法,深度学习模型可以同时完成文本特征工程和分类任务,目前代表性的模型有FastText、TextCNN、TextRNN、TextRCNN、BERT等.按照输出标签类别的不同,文本分类可分为二分类、多分类、多标签分类三种,其中二分类任务的标签有两种,分类模型输出的结果只能为其中的一个;多分类任务输出的标签可以有多个种类,分类模型输出的取值为其中一个;多标签分类任务可以同时输出多个标签.本文中对科技文献进行学科分类,是通过将科技文献的学科标签转换为具有层次关系的多个标签,是一种多标签分类任务. ...
Does Interdisciplinary Research Lead to Higher Citation Impact? The Different Effect of Proximal and Distal Interdisciplinarity
2
2015
... 在对科技文献进行学科分类的相关研究中,文献[8 ]采用支持向量机分类算法,为论文选择合适的学科研究领域,实现论文的快速分类;文献[9 ]利用特征加权和浅层次分类法实现期刊论文的中图法分类;文献[10 ]设计了一个一对多的分类模型,并应用卷积神经网络对中国科学院产出的8个不同主题的研究论文摘要进行分类;文献[11 ]提出一个Encoder-Decoder架构的层次多标签分类算法,为科研项目分类场景提供结合人工智能的解决方案;文献[12 ]提出一种分层深度学习模型HDLTex,用于科研成果的自动组织和分类;文献[13 ]基于深度学习模型对专利科技文献进行分类;文献[14 ]通过建模学科之间的语义关系和复杂文本的类型信息,提出一个基于深度模型的科技文献分类方法;文献[15 ]提出一种基于多头注意力机制和残差网络结构的改进型图神经网络学术论文分类模型.也有学者从其他视角对科技文献分类展开研究,如文献[16 ]利用文本分类算法对社会科学类论文进行分类,尝试利用分类结果中的错误信息作为衡量相关学科跨学科性的指标;文献[17 ]利用机器学习的文本分类算法对学术出版物进行学科分类,并利用错误的分类数据揭示学科之间的相互依赖关系,在文献[17 ]中结合文献[19 ]认为跨学科文献可以获取更高引用的结论,发现学科之间(如图1 中的F和G学科)被错误分类的科技文献更倾向于获取更高的引用数据,且这不是一种随机现象.科技文献基于文本分类算法进行学科分类,分类的效果与分类算法模型、训练语料等都有密切关系,现有科技文献学科分类研究比较侧重于在算法层面实现分类性能的提升,但文献[17 ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
... ,19 ]通过关注文本分类错误数据,进行学科交叉问题的研究,为本文提供了新的研究思路.识别科技文献的学科交叉研究性质,除了可以从算法模型、语料库层面进行优化外,还可尝试关注文本分类错误的其他原因,如科技文献的学科标签只被标注为研究人员熟知的领域等,并将此类原因融入提升相关模型识别科技文献学科交叉研究性质的研究中. ...
Bag of Tricks for Efficient Text Classification
1
2017
... 在学科分类体系下,以图1 中G0104学科代码下的项目为例,该学科代码下的项目可以属于G0104,也可以属于更为宏观的G、G01.因此,在学科分类体系下的科技文献可以解析为多个学科标签,多个标签之间可以是上下位的从属关系,如G、G01,也可以是位于同一层级的平行关系,如G01、F06.基于此,将当前任务属性定义为多标签分类.对于科技文献的多标签分类模型,本文主要选取FastText[20 ] 、TextCNN[21 ] 、TextRNN[22 ] 、TextRCNN[23 ] 、TextDPCNN[24 ] 、TextCRNN[25 ] 、HAN[26 ] 、BERT[27 ] 等,并评价其在当前数据集上的分类效果.为选取合适的多标签分类模型,相关模型在4.1节的实验数据上进行性能对比.相关模型在训练集上进行数据训练,验证集上Macro-F1指标最优时,保存模型的参数.各个模型在测试集上Macro-F1、Micro-F1的结果如表1 所示. ...
Convolutional Neural Networks for Sentence Classification
1
2014
... 在学科分类体系下,以图1 中G0104学科代码下的项目为例,该学科代码下的项目可以属于G0104,也可以属于更为宏观的G、G01.因此,在学科分类体系下的科技文献可以解析为多个学科标签,多个标签之间可以是上下位的从属关系,如G、G01,也可以是位于同一层级的平行关系,如G01、F06.基于此,将当前任务属性定义为多标签分类.对于科技文献的多标签分类模型,本文主要选取FastText[20 ] 、TextCNN[21 ] 、TextRNN[22 ] 、TextRCNN[23 ] 、TextDPCNN[24 ] 、TextCRNN[25 ] 、HAN[26 ] 、BERT[27 ] 等,并评价其在当前数据集上的分类效果.为选取合适的多标签分类模型,相关模型在4.1节的实验数据上进行性能对比.相关模型在训练集上进行数据训练,验证集上Macro-F1指标最优时,保存模型的参数.各个模型在测试集上Macro-F1、Micro-F1的结果如表1 所示. ...
Recurrent Neural Network for Text Classification with Multi-Task Learning
1
2016
... 在学科分类体系下,以图1 中G0104学科代码下的项目为例,该学科代码下的项目可以属于G0104,也可以属于更为宏观的G、G01.因此,在学科分类体系下的科技文献可以解析为多个学科标签,多个标签之间可以是上下位的从属关系,如G、G01,也可以是位于同一层级的平行关系,如G01、F06.基于此,将当前任务属性定义为多标签分类.对于科技文献的多标签分类模型,本文主要选取FastText[20 ] 、TextCNN[21 ] 、TextRNN[22 ] 、TextRCNN[23 ] 、TextDPCNN[24 ] 、TextCRNN[25 ] 、HAN[26 ] 、BERT[27 ] 等,并评价其在当前数据集上的分类效果.为选取合适的多标签分类模型,相关模型在4.1节的实验数据上进行性能对比.相关模型在训练集上进行数据训练,验证集上Macro-F1指标最优时,保存模型的参数.各个模型在测试集上Macro-F1、Micro-F1的结果如表1 所示. ...
Recurrent Convolutional Neural Networks for Text Classification
1
2015
... 在学科分类体系下,以图1 中G0104学科代码下的项目为例,该学科代码下的项目可以属于G0104,也可以属于更为宏观的G、G01.因此,在学科分类体系下的科技文献可以解析为多个学科标签,多个标签之间可以是上下位的从属关系,如G、G01,也可以是位于同一层级的平行关系,如G01、F06.基于此,将当前任务属性定义为多标签分类.对于科技文献的多标签分类模型,本文主要选取FastText[20 ] 、TextCNN[21 ] 、TextRNN[22 ] 、TextRCNN[23 ] 、TextDPCNN[24 ] 、TextCRNN[25 ] 、HAN[26 ] 、BERT[27 ] 等,并评价其在当前数据集上的分类效果.为选取合适的多标签分类模型,相关模型在4.1节的实验数据上进行性能对比.相关模型在训练集上进行数据训练,验证集上Macro-F1指标最优时,保存模型的参数.各个模型在测试集上Macro-F1、Micro-F1的结果如表1 所示. ...
Deep Pyramid Convolutional Neural Networks for Text Categorization
1
2017
... 在学科分类体系下,以图1 中G0104学科代码下的项目为例,该学科代码下的项目可以属于G0104,也可以属于更为宏观的G、G01.因此,在学科分类体系下的科技文献可以解析为多个学科标签,多个标签之间可以是上下位的从属关系,如G、G01,也可以是位于同一层级的平行关系,如G01、F06.基于此,将当前任务属性定义为多标签分类.对于科技文献的多标签分类模型,本文主要选取FastText[20 ] 、TextCNN[21 ] 、TextRNN[22 ] 、TextRCNN[23 ] 、TextDPCNN[24 ] 、TextCRNN[25 ] 、HAN[26 ] 、BERT[27 ] 等,并评价其在当前数据集上的分类效果.为选取合适的多标签分类模型,相关模型在4.1节的实验数据上进行性能对比.相关模型在训练集上进行数据训练,验证集上Macro-F1指标最优时,保存模型的参数.各个模型在测试集上Macro-F1、Micro-F1的结果如表1 所示. ...
A C-LSTM Neural Network for Text Classification[OL]
1
... 在学科分类体系下,以图1 中G0104学科代码下的项目为例,该学科代码下的项目可以属于G0104,也可以属于更为宏观的G、G01.因此,在学科分类体系下的科技文献可以解析为多个学科标签,多个标签之间可以是上下位的从属关系,如G、G01,也可以是位于同一层级的平行关系,如G01、F06.基于此,将当前任务属性定义为多标签分类.对于科技文献的多标签分类模型,本文主要选取FastText[20 ] 、TextCNN[21 ] 、TextRNN[22 ] 、TextRCNN[23 ] 、TextDPCNN[24 ] 、TextCRNN[25 ] 、HAN[26 ] 、BERT[27 ] 等,并评价其在当前数据集上的分类效果.为选取合适的多标签分类模型,相关模型在4.1节的实验数据上进行性能对比.相关模型在训练集上进行数据训练,验证集上Macro-F1指标最优时,保存模型的参数.各个模型在测试集上Macro-F1、Micro-F1的结果如表1 所示. ...
Hierarchical Attention Networks for Document Classification
1
2016
... 在学科分类体系下,以图1 中G0104学科代码下的项目为例,该学科代码下的项目可以属于G0104,也可以属于更为宏观的G、G01.因此,在学科分类体系下的科技文献可以解析为多个学科标签,多个标签之间可以是上下位的从属关系,如G、G01,也可以是位于同一层级的平行关系,如G01、F06.基于此,将当前任务属性定义为多标签分类.对于科技文献的多标签分类模型,本文主要选取FastText[20 ] 、TextCNN[21 ] 、TextRNN[22 ] 、TextRCNN[23 ] 、TextDPCNN[24 ] 、TextCRNN[25 ] 、HAN[26 ] 、BERT[27 ] 等,并评价其在当前数据集上的分类效果.为选取合适的多标签分类模型,相关模型在4.1节的实验数据上进行性能对比.相关模型在训练集上进行数据训练,验证集上Macro-F1指标最优时,保存模型的参数.各个模型在测试集上Macro-F1、Micro-F1的结果如表1 所示. ...
BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding
1
... 在学科分类体系下,以图1 中G0104学科代码下的项目为例,该学科代码下的项目可以属于G0104,也可以属于更为宏观的G、G01.因此,在学科分类体系下的科技文献可以解析为多个学科标签,多个标签之间可以是上下位的从属关系,如G、G01,也可以是位于同一层级的平行关系,如G01、F06.基于此,将当前任务属性定义为多标签分类.对于科技文献的多标签分类模型,本文主要选取FastText[20 ] 、TextCNN[21 ] 、TextRNN[22 ] 、TextRCNN[23 ] 、TextDPCNN[24 ] 、TextCRNN[25 ] 、HAN[26 ] 、BERT[27 ] 等,并评价其在当前数据集上的分类效果.为选取合适的多标签分类模型,相关模型在4.1节的实验数据上进行性能对比.相关模型在训练集上进行数据训练,验证集上Macro-F1指标最优时,保存模型的参数.各个模型在测试集上Macro-F1、Micro-F1的结果如表1 所示. ...
Attention is All You Need
1
2017
... Transformer由Encoder和Decoder组成,BERT通常使用Transformer的Encoder部分.Encoder部分输入为文本中的字嵌入向量表示信息,然后加上每个字在文本中的位置信息,输入Self-Attention层,再经Add&Norm层,其中Add是将Self-Attention层的输出和输入相加,Norm是将相加的结果进行归一化.归一化结果输入Feed Forward层,Feed Forward层的输出再经过一个Add&Norm层,输出归一化处理后的结果.Transformer中的Encoder部分最重要的组成部分为自注意力机制,其主要作用为使词不仅包含自身的语义信息,且能包含与其他词的语义关系,是一种更加全局的表达方式.Transformer一般采用Multi-Head Self-Attention机制,其计算方法如公式(1)-公式(3)所示[28 ] . ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}