




1 引言
本文提出一种多维度个人学术轨迹绘制框架与分析方法。从不同维度构建一个较为全面系统的学术轨迹绘制框架,并通过丰富的可视化形式呈现,能够完整、直观地展现学者的学术轨迹,全面深入剖析学者的研究内容和特点,凸显学者学术生涯中的主要贡献。
2 研究综述
现有个人学术轨迹相关研究主要分为两个方向:一是以叙述方式为主,对学者的研究历程和贡献进行总结概括。例如,通过学术大家的学术轨迹反映某研究主题的发展历程[13-14];对重要学者的学术成果进行评述,肯定其学术贡献[15-16];自传式总结回顾个人的学术生涯 [17-18]。此类研究通常以学术大家、名家为对象,高度概括并凸显学者的学术成就。该方法对普通学者适用性不够且以归纳总结为主,分析的主观性较强。二是通过文献计量和文本挖掘方法从研究主题、引用关系或影响力角度呈现学者的学术轨迹。例如,文献[6]利用LDA主题模型对以遗传学家谈家桢为核心的学术谱系进行研究,探索其研究主题的变化及知识传承的规律。文献[8]利用Pajek、VOSviewer和Nvivo等工具对Hope A. Olson的学术论文进行深入分析,构建以学者为中心的被引作者网络、施引作者网络、合著者网络、语义网络,分析其在知识组织领域的学术工作和贡献。文献[19]提出学术迹指标,绘制学术矩阵评价学者的综合性学术影响力。文献[7]基于上海交通大学特藏资源,对李政道教授的多类型成果进行标引并分析其研究轨迹和学术影响力。还有一些研究落脚于学者的学术生涯研究或重要文献发现,例如,文献[9]将自引网络与内容分析相结合,利用NodeXL工具,挖掘学者的研究主题并根据点入中心度等指标发现重要文献。文献[20]基于学者合作网络和论文相似网络的双层网络模型,分析学者的学术发展阶段及研究主题。
综上,对学术成果进行统计分析和内容挖掘是个人学术轨迹绘制的重要方法,并在实践中得到了应用。但现有个人学术轨迹分析维度还比较分散,缺乏一个完整的绘制框架,对研究全貌展现不足;学术数据的分析层次较浅,对主题内容的结构及沿袭关系的挖掘还不够深入;分析工具各有侧重,数据分析和可视化呈现形式还比较单一。本文构建多维度个人学术轨迹绘制框架,综合运用统计分析、语义挖掘和可视化技术,从不同维度深入分析并呈现学者的研究特征,全面、动态、深入地绘制个人学术轨迹,拓展个人学术成果分析维度,丰富可视化呈现形式。
3 学术轨迹绘制框架设计与数据准备
3.1 框架设计
轨迹是指动点在空间的位置随时间连续变化而形成的曲线。个人学术轨迹以时间序列为引线,以学术成果为切入点,描绘学者研究的时空演变过程。本文从宏观和微观两个层面构建学术轨迹绘制框架。
宏观层面主要关注学者的学术全貌,呈现研究发展过程,包括研究产出和研究主题两个维度。一般来讲,产出论文的数量越多,表明该学者的研究工作越活跃;以第一作者或通讯作者身份发表的论文越多,表明该学者在研究中的主导性越强。本文从研究的活跃度和主导性描述学者的研究状态,通过研究状态分布图直观呈现不同时间段学者的研究状态。研究主题是描述学者研究的重要特征维度。首先通过主题建模从全局角度描述文本特征,提取学者研究主题内容;再挖掘文档间潜在语义联系,将单篇论文聚合到相应的主题中;进而绘制具有时序特征的研究主题聚类图。不仅能整体把握学者研究的主题内容,挖掘研究重点,还能从研究的持续性、产出率、主导性等方面对各主题进行分析,识别重点主题。
微观层面旨在从不同维度建立知识单元间的联系,呈现知识流动过程和研究的内部结构,凸显重要研究节点,包括研究脉络发展和内容演进两个维度。一方面,以引用关系为切入点,建立论文间的相互联系,绘制自引时序网络图。自引时序网络图能刻画学者学术研究的沿袭发展过程,展现研究脉络发展;此外,对自引网络结构的分析亦能体现学者的研究特点,发现重要文献。另一方面,关键词可以细粒度观察学者的研究内容及其变化,也在一定程度上弥补了自引时序网络的不足。通过关键词聚类和共现,建立研究内容间的联系,绘制关键词热力分布图,呈现研究的知识内容及演化过程。
本文从宏观全貌和微观结构、时间序列和空间演变、统计分析和主题聚合、引用关系和内容演进等多层次、多角度绘制学者的学术轨迹,展现学者的研究发展历程,剖析并凸显重要主题和关键节点。具体分析框架如图1所示。
图1

3.2 数据准备
以冰冻圈科学领域A和B两位学者为例,展示个人学术轨迹绘制方法和流程,呈现可视化效果并进行分析验证。两位学者研究持续时间长,论文数量多,有较完整的基础数据;研究学科相近又各有侧重,可以进行适当的对比分析。为尽可能完整地收集到学者的论文数据,从Web of Science数据库获取英文期刊和会议论文数据,从CSCD数据库获取中文期刊论文数据,从CNKI会议获取中文会议论文数据,除去人物传记、卷首语、书评及重复数据等,共获得学者A的论文517篇,学者B的论文528篇。数据收集时间为2021年12月。
4 个人学术轨迹绘制与分析
4.1 基于研究产出的研究状态分布
(1) 研究状态四象限划分
依据生命周期理论[24],科研人员的学术生命周期可分为初创期、发展期、成熟期和衰退期。研究产出数量能够反映学者研究的活跃程度,是学术生命周期划分的重要依据[25],也能够反映学者的成长阶段及研究特征[26],是个人学术轨迹的基础指标。但学者的研究生涯既遵循一定的顺序性,又具有阶段性和个性化的特点,仅从线性时间序列对研究阶段进行划分具有局限性。考虑到在代表作评价、职称评审、人才选拔等工作中大都只认可第一作者或通讯作者论文,本文在研究活跃度的基础上引入研究主导性维度,将学者的第一作者和通讯作者论文称为“主导论文”,通过主导论文数量占比反映研究过程中学者的主导性。将研究活跃度和主导性相结合,能够呈现学者研究的非线性发展过程,观察不同时间段学者的研究状态。
结合学术生命周期理论和研究的阶段性特点,将学者的研究状态分为积累状态、上升状态、巅峰状态和稳定状态,如图2所示。
图2

积累状态是指研究活跃度和主导性都比较低,通常处于研究的积累、休整或衰退阶段。上升状态是指学者以独立或自主研究为主,研究主导性高;但由于科研合作较少等原因,研究成果的产出量不如稳定状态和巅峰状态。稳定状态是指研究活跃度高但主导性低,学者论文产出数量较多但多以非主导地位参与研究;或者因为广泛的科研合作,论文产出量大,导致主导论文占比下降。巅峰状态是指研究活跃度和研究主导性都很高,既是研究的主导者又有广泛的科研合作,处于研究的巅峰期。从整个研究生涯来看,积累状态-上升状态-巅峰/稳定状态交替的发展反映了学者从科研新人逐渐成长为成熟研究者的过程;就个人而言,现阶段所处的研究状态、每种状态持续时间的长短、不同研究状态间的过度和转换体现了学者的研究特点和发展态势。
(2) 实证与分析
绘制学者A和B的研究状态分布,如图3所示。横轴为论文数量,纵轴为主导论文占比,横坐标轴值为所有年份主导论文占比的中位数,纵坐标轴值为所有年份论文产出数量的中位数,点代表该年学者的研究状态。
图3

从研究状态的阶段性来看,学者A在1979年-1984年、1988年-1993年主要处于研究上升状态,1994年-1998年处于研究积累状态,1999年-2015年主要处于研究的稳定和巅峰状态。其中,2000年、2004年-2007年、2013年研究成果突出;2016年以后,大部分年份又回落到积累状态。学者B在1981年-1988年处于研究积累状态,1989年-1998年主要处于研究上升状态,1999年以后基本处于研究的稳定和巅峰状态,其中1999年、2000年、2002年、2009年、2014年和2020年研究成果突出;近几年,学者B仍在坚持科学研究,主要处于研究稳定状态。
此外,随着学者研究生涯的不断发展,划分研究状态的坐标轴会变化,同一年份的研究状态也会有变化,这种变化体现了学者研究的动态过程。例如,从2010年-2020年的纵向对比来看,学者A的年均论文产出量和主导论文占比均有所下降,结合学者A的年龄,A可能处于研究生涯的衰退阶段。学者B的年均论文产量从12.51篇增加到13.89篇,主导论文占比下降约4%,其目前处于研究稳定期,但有下降趋势。需要说明的是,研究状态反映的是学者自身研究的相对状态,不同学者间不具有可比性。
从研究产出角度定义并划分学者的研究状态,能够反映学者的研究发展动态。一般来讲,近几年处于上升状态和巅峰状态的学者有更好的发展空间,可以为人才引进工作提供参考。
4.2 基于文本聚类的研究主题轨迹
图4

(1) 数据预处理
获得论文的标题、关键词和摘要作为初始数据。学者的论文既有中文又有英文,将英文数据翻译为中文,统一语种。导入专业词典可以提高分词质量,本文导入《冰冻圈科学辞典》。对数据进行分词、去停等预处理。
(2) 确定最佳主题数
LDA主题建模需要先确定最优主题数,主题数的选择直接影响模型的聚类效果。困惑度常用来度量一个概率分布或概率模型预测样本的好坏程度,是常用的最优主题数选取方法。一般而言,困惑度随主题数量的增多呈现先下降后上升的趋势,拐点处可作为最优主题数。将测试主题数设置为1~10,依据模型在数据集上的困惑度表现选取最优主题数。经计算,学者A的最优主题数为7,学者B的最优主题数为4。从主题数量来看,学者A的研究主题较宽泛而学者B的研究主题相对聚集。
(3) 主题聚类及可视化
利用Python编程语言、Sklearn工具包构建LDA主题模型,分别得到主题-词汇和文档-主题概率分布。在论文聚类结果中加入时间维度,并区分是否为主导论文,利用Seaborn进行可视化呈现,结果如图5所示,每个点代表一篇论文,蓝色为主导论文,红色为非主导论文,研究主题聚类图清晰展现了学者各研究主题的论文分布和时间轴上的发展轨迹。
图5

(4) 研究主题轨迹分析
根据每个主题的词汇分布,可以提取研究的主题内容。学者A的7个研究主题分别是:0-生态环境与可持续发展研究;1-干旱半干旱地区植被恢复研究;2-内陆河流域水资源研究;3-西北地区生物群落及气候变化研究;4-青藏高原冻土区覆盖及环境研究;5-冻土工程建设研究;6-区域水文过程研究。一般而言,研究持续时间长、成果产出数量多、主导论文占比高的主题即是学者研究的重点主题。主题4和5是学者A研究的重点主题。LDA聚类后,主题4(青藏高原冻土区覆盖及环境研究)的词汇主要包括“多年冻土、冻土、青藏高原、面积、活动层、分布、二氧化碳、冻结、气候、作用、冻融、退化、高原、甲烷、解冻、通量,冰川”等,这些词汇展示了学者在青藏高原冰川冻土方面的具体研究内容。主题4是学者A学术生涯的起点,并贯穿其几乎整个学术生涯,是该学者研究最持久的主题;该主题下主导论文共27篇,占比28.1%,亦是研究主导性最高的主题。主题5(冻土工程建设研究)的重点是青藏铁路建设,相关主题词有“青藏铁路、路基、多年冻土、路堤、工程、方法、建设、措施、温度、对流、地温、铁路、保护、冻土、降低、冷却路基”等。主题5的主导论文占比也较高,为25.6%;尤其是2000年-2010年,该主题有多篇论文密集产出,是这一时间段学者研究的重点主题,也非常具有典型性。
学者B的研究主题相对集中,分别是:0-南极地区冰川研究;1-冰冻圈科学与社会发展研究;2-气候变化与环境科学研究;3-青藏高原地区冰川研究。其中,主题0(南极地区冰川研究)是最典型的研究主题,重点主题词有“冰芯、南极、冰盖、雪坑、记录、离子、浓度、样品、海冰、分布、积雪、堆积率、伊丽莎白公主地、考察、同位素”等。1985年-2000年,该主题有多篇主导论文,是这一时期学者的研究重点。根据背景资料和论文内容发现,该时期学者B多次参与南极考察,围绕所采集的南极冰雪样品产出了丰硕的研究成果。主题3(青藏高原地区冰川研究)是学者研究生涯的起点,该主题的论文数量较多,但主导论文较少,学者B在相关研究中并不占主导地位;主题1(冰冻圈科学与社会发展研究)是近年来学者关注的重点主题,该主题研究开始时间较早,持续有主导论文产出,且近年来论文产出数量和主导论文占比都明显高于其他主题。
综上,在文本聚类基础上加入时间维度,从研究主题角度绘制学者的学术轨迹,能够宏观把握学者的研究内容,关注学者的研究重点。
4.3 基于自引网络的研究脉络发展
(1) 自引时序网络绘制
由于HistCite仅能处理英文数据,且可视化呈现的自由度不够,本文利用BibExcel和Pajek实现自引时序网络的自动化绘制。利用BibExcel实现中英双语引文识别和自引网络构建,并导出为.net文件;编辑.net文件,通过节点位置赋值增加论文时间信息,通过节点颜色赋值区分是否为主导论文;将.net文件导入Pajek绘制自引时序网络图。
学者A共517篇论文,其中的285篇论文构成473条引用关系。学者B共528篇论文,其中347篇文献构成756条引用关系。绘制的自引时序网络如图6所示,每个节点代表一篇论文,节点名称为论文编号,连接节点的有向边代表引用关系。
图6

自引时序网络呈现了学者的研究脉络发展。①节点密集程度和时间序列反映了学者的研究发展过程。总体而言,学者A和学者B都属于高产学者,节点的密集程度显示学者B的产出量略高。从时间序列来看,学者A在1984年-1990年产出了大量主导论文,为后续研究奠定了坚实的基础;2000年-2002年论文产出数量多,2008年以后论文数量有所减少,2018年以后明显减少。对学者B而言,2000年-2004年论文产出最为密集,2006年-2020年论文产出数量仍比较多,处于研究的成熟期。②节点颜色反映学者研究的主导性和合作情况。学者A的主导论文占比明显高于学者B,A在学术研究中的主导性高于B,而B的研究合作更加广泛。一般在学术生涯前期,主导论文占比较大,随着研究合作的广泛和深入,主导论文占比有所降低。此外,还可以结合实际需要调整节点颜色和形状,区分作者合作信息、主题内容信息等。③连边的密集程度可凸显关键文献及其影响力。学者A早期发表的非主导论文10在其后续研究中产生了较大影响;论文80、论文460、论文498引用了较多前期论文,是对前期研究的集成和继承。学者B早期发表的主导论文1、非主导论文6对后续研究产生了较大影响,论文27、论文28附近的连边非常密集,可视为学者B研究中的重要文献。
(2) 自引时序网络分析
复杂网络、社会网络理论和方法常用于分析引文网络的结构特点。网络中所有节点度的平均值称为网络的平均度,k =
学者特征向量中心性最高的前10篇论文如表1所示,特征向量中心性与被引频次并不是完全的正相关关系。学者A排名靠前的Top10论文集中于主题4和主题5,这与4.2节的结论相印证。其中论文74、51、100、112,可视为学者A的重要论文。学者B中心性高的论文主要集中在主题3,但该主题并不是学者B研究的重点主题。学者B的重要论文27、41、6、28涉及到多个研究主题。
表1 自引网络中特征向量中心性Top10论文
Table 1
| 学者A特征向量中心性Top10论文 | 学者B特征向量中心性Top10论文 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 序号 | 文献编号 | 所属 主题 | 特征向量 中心性 | 自引 频次 | 是否主 导论文 | 序号 | 文献编号 | 所属 主题 | 特征向量 中心性 | 自引 频次 | 是否主 导论文 |
| 1 | 论文73 | 主题4 | 0.478 7 | 41 | 否 | 1 | 论文29 | 主题3 | 0.625 2 | 51 | 否 |
| 2 | 论文74 | 主题5 | 0.366 9 | 30 | 是 | 2 | 论文51 | 主题3 | 0.525 8 | 46 | 否 |
| 3 | 论文51 | 主题5 | 0.344 5 | 34 | 是 | 3 | 论文27 | 主题2 | 0.357 7 | 34 | 是 |
| 4 | 论文134 | 主题4 | 0.342 6 | 22 | 否 | 4 | 论文41 | 主题3 | 0.269 6 | 44 | 是 |
| 5 | 论文138 | 主题4 | 0.322 7 | 22 | 否 | 5 | 论文44 | 主题3 | 0.267 4 | 16 | 否 |
| 6 | 论文99 | 主题4 | 0.313 3 | 24 | 否 | 6 | 论文67 | 主题3 | 0.165 9 | 23 | 否 |
| 7 | 论文42 | 主题5 | 0.267 5 | 22 | 是 | 7 | 论文38 | 主题3 | 0.129 8 | 14 | 否 |
| 8 | 论文100 | 主题4 | 0.198 3 | 9 | 是 | 8 | 论文34 | 主题3 | 0.055 2 | 4 | 否 |
| 9 | 论文14 | 主题4 | 0.135 9 | 37 | 否 | 9 | 论文6 | 主题1 | 0.054 0 | 37 | 否 |
| 10 | 论文112 | 主题4 | 0.127 3 | 10 | 否 | 10 | 论文28 | 主题0 | 0.050 6 | 51 | 是 |
4.4 基于关键词演进的研究内容分析
自引网络基于引用关系建立论文间的相互联系,呈现学者的研究发展脉络。但自引对研究内容的描述是间接的,也受制于学者的自引习惯和期刊的自引规定。关键词是论文内容的直接体现,关键词在时间序列上的变化能从内容角度呈现学者的研究演进过程。4.2节从主题层面宏观呈现学者的研究内容,本节从关键词演进角度更细致地呈现典型主题下的知识结构及演化过程。具体分析步骤如图7所示。
图7
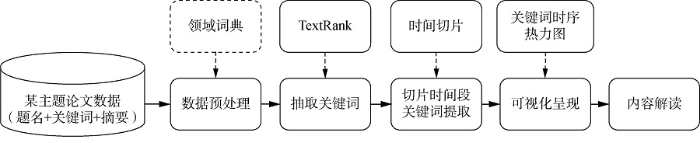
图7
基于关键词演进的研究内容分析流程
Fig.7
Process of Research Content Analysis Based on Keyword Evolution
(1) 数据准备与预处理
依据主题聚类分析,选取学者典型主题下的论文数据,包括标题、关键词、摘要。对数据进行预处理,加载领域词典进行分词、去停。
(2) 关键词抽取
(3) 时间切片和关键词选取
依据论文发表时间,每5年切分为一个时间片;由于研究初期论文较少,1990年之前的论文全部划为一个时间片,共分为7个时间片。将同一时间片内相同的关键词合并,权值相加;某关键词出现的频次越高,在论文中的重要性越大,该关键词对时间片上研究内容的表达能力就越强。按照关键词权值倒序排列,选取适当数量关键词。经测试发现,当关键词数量为20时,内容的聚合性更好。因此,选取权值最大的20个关键词表达该时间片的研究内容。
(4) 可视化呈现
图8

(5) 研究内容解读
关键词时序热力图横向可以观察某时间段学者的研究内容和关键点,纵向可以观察不同研究内容在时间序列上的变化。
学者A冻土工程建设研究的主要内容和时序演进过程,7个时间片共得到48个关键词。总体来看,青藏铁路、铁路、路基、路堤、冻土、多年冻土等关键词很好地表达了该主题的研究内容。从时间维度来看,1995年以前的研究关键词可以分为三类:①电阻、热敏电阻、材料、计算;②冻土、厚层地下冰、冰川、冻结;③路堤、工程、提防、位移;这些研究为青藏铁路建设研究奠定了基础。2000年以后,明显出现了研究重点的转移和聚合,青藏铁路建设,尤其是多年冻土区铁路路基、路堤工程建设成为研究重点。此外,冷却、冷却路基、温度、设计、方法、影响、变化也从不同方面突出该主题的内容细节。
学者B南极地区冰川研究的主要内容和时序演进过程,7个时间片共得到45个关键词。南极洲是该主题最突出的关键词,南极冰盖和气候研究是该主题的持续关注点;冰盖、冰芯、变化、记录等关键词表达了该主题的研究重点。从时间维度来看,1990年以前主要关注格陵兰冰盖、纳尔逊冰帽、气候变化、雪的密实化等;1990年-2000年,南极冰盖、冰芯、冰川学研究成为重点;2000年以后延续了冰盖、冰芯相关研究,增加了气候变化、兰伯特冰川、粒子浓度等关键词,尤其是近年来对冰川化学、冰芯气候记录和气候变化的关注度增加。
5 总结
本文提出一种多维度个人学术轨迹绘制框架和可视化呈现方法,从宏观和微观两个层面,研究产出、研究主题、研究脉络、内容演进4个维度,运用统计分析、语义技术和可视化分析等多种方法,通过研究状态分布图、研究主题轨迹图、自引时序网络图和关键词时序热力分布图,绘制个人学术轨迹。与现有研究和工具平台相比,该方法分析维度更加全面,数据分析更加深入,可视化呈现更加丰富,可用于学术画像、学者评价、代表作遴选等工作实践中,也能为个人学术成果集成和分析平台提供借鉴。
该方法仍有一些不足之处。限于数据的可获得性和分析方法,个人学术轨迹绘制的原始数据主要是论文数据,专利、项目等其他形式学术成果数据的整合还需进一步研究;所使用的绘制工具涉及多个软件,如果能实现这些工具的平台化集成和整合,将大大提高使用的便捷程度,促进相关实践应用。
作者贡献声明
谢珍:方案设计,数据收集和处理,论文撰写和修改;
马建霞:论文选题,方案设计和修改,论文修改;
胡文静:论文修改。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
[1] 谢珍.个人学术轨迹绘制案例数据及代码. DOI:10.57760/sciencedb.j00133.00128.
参考文献
中国管理哲学30年: 学术轨迹、焦点透视与逻辑理路
[J].
30 Years of Chinese Management Philosophy: The Track, the Focus and the Logic
[J].
社会运行学派的学术轨迹与学派实践——兼论郑杭生先生的学派情怀
[J].
Academic Track and School Practice of Social School—Also on Mr. Zheng Hangsheng’s School Feelings
[J].
1923-2008年我国图书馆学方法论体系研究轨迹探寻与思考
[J].
Tracking and Thinking the Research on the Library Science Methodology System(1923-2008)
[J].
国际顶级学术期刊《Nature》的发展轨迹及启示
[J].
The Development Path and Inspiration of Nature
[J].
基于LDA主题模型的学术谱系内知识传承研究——以谈家桢为核心的遗传学学术谱系为例
[J].
DOI:10.13266/j.issn.0252-3116.2018.10.011
[本文引用: 2]

<strong>[Purpose/significance]</strong> Academic pedigree promotes science development by the way of knowledge inheritance. It is of great reference value to study the characteristics of knowledge transmission and explore the effect of inheritance model on academic output, and it is of great reference value for the relevant departments to find out the law of talent growth and formulate scientific and technological personnel training policy.<strong>[Method/process]</strong> By the method of LDA topic model, this paper took the journal literature of genetics published in CNKI database as research object, and quoted the concept of "hereditary" and "variation" in biology. Then, according to the topic similarity, we divided pedigree members into "hereditary scholars", "variation scholars" and "non-hereditary non-variation scholars", and analyzed the academic performance of these three kinds of scholars.<strong>[Result/conclusion]</strong> The results show that the academic performance of "hereditary scholars" and "variation scholars" in the academic pedigree of Tan Jiazhen is relatively high; The number of "non-hereditary non-variation scholars" is the largest, but their academic performance is relatively low; For different topics, the distribution of "variation scholars" and "hereditary scholars" is significantly different.
Research on Knowledge Inheritance of Academic Pedigree Based on LDA Topic Model—A Case Study of Genetics Pedigree with the Core of Tan Jiazhen
[J].
DOI:10.13266/j.issn.0252-3116.2018.10.011
[本文引用: 2]
<strong>[Purpose/significance]</strong> Academic pedigree promotes science development by the way of knowledge inheritance. It is of great reference value to study the characteristics of knowledge transmission and explore the effect of inheritance model on academic output, and it is of great reference value for the relevant departments to find out the law of talent growth and formulate scientific and technological personnel training policy.<strong>[Method/process]</strong> By the method of LDA topic model, this paper took the journal literature of genetics published in CNKI database as research object, and quoted the concept of "hereditary" and "variation" in biology. Then, according to the topic similarity, we divided pedigree members into "hereditary scholars", "variation scholars" and "non-hereditary non-variation scholars", and analyzed the academic performance of these three kinds of scholars.<strong>[Result/conclusion]</strong> The results show that the academic performance of "hereditary scholars" and "variation scholars" in the academic pedigree of Tan Jiazhen is relatively high; The number of "non-hereditary non-variation scholars" is the largest, but their academic performance is relatively low; For different topics, the distribution of "variation scholars" and "hereditary scholars" is significantly different.
基于多源数据融合的学科领域专家研究轨迹和学科影响分析——以李政道教授为例
[J].
Study on the Academic Trace and Influence of the Subject Expert Based on Multi-Source Data Fusion: A Case Study of Prof.Tsung-Dao Lee
[J].
Bibliometric Approach to the Contributions of Hope A. Olson to Knowledge Organization
[J].
基于自引网络和内容分析的学者研究主题挖掘
[J].
Mining Authors Research Topics Based on Their Self-Citation Network and Content Analysis
[J].
从施莱辛格的学术轨迹看国际口译研究的发展态势
[J].
On the Development Trend of International Interpretation Research from Schlesinger’s Academic Track
[J].
Joan Scott and Role in the History of Construction of Gender Relations
[J].
Helena Rasiowa-A View of the Academic Trajectory and the Influence upon Polish and International Scientific Community
[C]//
从历史学到海洋人文社会科学——杨国桢先生的学术轨迹
[J].
From History to Marine Humanities and Social Sciences—Mr Yang Guozhen’s Academic Track
[J].
个人学术轨迹的自我剖析
[J].
Self-Analysis of Personal Academic Trajectory
[J].
Intellectual Practices: An Interview with Philip Schlesinger
[J].
The“Academic Trace”of the Performance Matrix: A Mathematical Synthesis of the h-index and the Integrated Impact Indicator
[J].DOI:10.1002/asi.23075 URL [本文引用: 2]
Author-Centered Bibliometrics Through CAMEOs: Characterizations Automatically Made and Edited Online
[J].DOI:10.1023/A:1019607522125 URL [本文引用: 1]
Exploring Scholarly Data with Rexplore
[C]//
AMiner: Toward Understanding Big Scholar Data
[C]//
生命周期理论
[EB/OL]. [
Life Cycle Theory
[EB/OL]. [
Creative Productivity and Age: A Mathematical Model Based on a Two-Step Cognitive Process
[J].DOI:10.1016/0273-2297(84)90020-0 URL [本文引用: 1]
国家杰出青年科学基金项目负责人成长特征研究——基于学术生命周期理论与数据分析
[J].
Research on the Growth Characteristics of Project Leaders of National Science Fund for Distinguished Young Scholars—Based on Academic Life Cycle Theory and Data Analysis
[J].
Latent Semantic Indexing: A Probabilistic Analysis
[J].DOI:10.1006/jcss.2000.1711 URL [本文引用: 1]
Latent Dirichlet Allocation
[J].
Tracking the Follow-Up of Work in Progress Papers
[J].
DOI:10.1007/s11192-017-2631-4
PMID:29491547
[本文引用: 1]
Academic conferences offer numerous submission tracks to support the inclusion of a variety of researchers and topics. Work in progress papers are one such submission type where authors present preliminary results in a poster session. They have recently gained popularity in the area of Human Computer Interaction (HCI) as a relatively easier pathway to attending the conference due to their higher acceptance rate as compared to the main tracks. However, it is not clear if these work in progress papers are further extended or transitioned into more complete and thorough full papers or are simply one-off pieces of research. In order to answer this we explore self-citation patterns of four work in progress editions in two popular HCI conferences (CHI2010, CHI2011, HRI2010 and HRI2011). Our results show that almost 50% of the work in progress papers do not have any self-citations and approximately only half of the self-citations can be considered as true extensions of the original work in progress paper. Specific conferences dominate as the preferred venue where extensions of these work in progress papers are published. Furthermore, the rate of self-citations peaks in the immediate year after publication and gradually tails off. By tracing author publication records, we also delve into possible reasons of work in progress papers not being cited in follow up publications. In conclusion, we speculate on the main trends observed and what they may mean looking ahead for the work in progress track of premier HCI conferences.
社会网络分析在引文评价中的应用研究
[J].The paper introduces social network analysis(SNA) into citation evaluation to improve evaluation method and complement evaluation index. From the structure of citation network and it’s properties to the connotation and metaepistemology of SNA, the applicability of SNA applicatied to citation analysis is proved. What the advantadges of citation evaluation based on SNA are: automatically generating cited weight, eliminating the influence of self-citing to evaluation, beneficial to developing stratified evaluation, adding evaluation index based on acknowledge transmission, and promoting classified evaluation.
Research on the Application of Social Network Analysis to Citation Evaluation
[J].The paper introduces social network analysis(SNA) into citation evaluation to improve evaluation method and complement evaluation index. From the structure of citation network and it’s properties to the connotation and metaepistemology of SNA, the applicability of SNA applicatied to citation analysis is proved. What the advantadges of citation evaluation based on SNA are: automatically generating cited weight, eliminating the influence of self-citing to evaluation, beneficial to developing stratified evaluation, adding evaluation index based on acknowledge transmission, and promoting classified evaluation.
Study on the Research Evolution of Nobel Laureates 2018 Based on Self-Citation Network
[J].
DOI:10.1108/JD-02-2019-0027
URL
[本文引用: 1]
Science is a continuum of experiences consisting of authors and their publications, and the authors’ experience is an integral part of their work that gets reflected through self-citations. Thus, self-citations can be employed in measuring the relevance between publications and tracking the evolution of research. The paper aims to discuss this issue.
基于作者自引的知识扩散分析
[J].
Knowledge Diffusion Analysis Based on Author Self-Citation
[J].
Self-Citations, Co-Authorships and Keywords: A New Approach to Scientists’ Field Mobility?
[J].DOI:10.1007/s11192-007-1680-5 URL [本文引用: 1]
Exploring a Researcher’s Personal Research History Through Self-Citation Network and Citation Identity
[J].DOI:10.3743/KOSIM.2012.29.1.157 URL [本文引用: 1]
TextRank: Bringing Order into Texts
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}