ChatGPT的技术基础分析*
钱力 1 , 2 , 3 , 刘熠 , , 1 , 张智雄 1 , 2 , 3 , 李雪思 1 , 2 , 谢靖 1 , 2 , 许钦亚 1 , 2 , 黎洋 1 , 2 , 管铮懿 1 , 2 , 李西雨 1 , 2 , 文森 1 , 2
1 中国科学院文献情报中心 北京 100190
2 中国科学院大学经济与管理学院信息资源管理系 北京 100190
3 国家新闻出版署学术期刊新型出版与知识服务重点实验室 北京 100190
An Analysis on the Basic Technologies of ChatGPT
Qian Li 1 , 2 , 3 , Liu Yi , , 1 , Zhang Zhixiong 1 , 2 , 3 , Li Xuesi 1 , 2 , Xie Jing 1 , 2 , Xu Qinya 1 , 2 , Li Yang 1 , 2 , Guan Zhengyi 1 , 2 , Li Xiyu 1 , 2 , Wen Sen 1 , 2
1 National Science Library, Chinese Academy of Sciences, Beijing 100190, China
2 Department of Information Resources Management, School of Economics and Management, University of Chinese Academy of Sciences, Beijing 100190, China
3 Key Laboratory of New Publishing and Knowledge Services for Scholarly Journals, Beijing 100190, China
通讯作者: 刘熠,ORCID:0000-0002-7360-2091,E-mail:liuyi@mail.las.ac.cn 。
收稿日期: 2023-03-17
基金资助:
国家重点研发计划项目 (2022YFF0711900 )
Corresponding authors: Liu Yi,ORCID:0000-0002-7360-2091,E-mail:liuyi@mail.las.ac.cn 。
Received: 2023-03-17
Fund supported:
National Key R&D Program of China (2022YFF0711900 )
摘要
【目的】 梳理分析ChatGPT相关的语料、算法与模型,为同行业研究提供体系化的参考借鉴。【方法】 通过系统梳理GPT-3发布至今的相关文献与资料,刻画ChatGPT技术的整体架构,并解释与分析其背后的模型、算法与原理。【结果】 通过文献调研,根据现有资料还原了支撑ChatGPT功能的技术细节,梳理了ChatGPT技术的整体架构,解释了ChatGPT整体技术构成。按照ChatGPT的语料体系、预训练算法与模型、微调算法与模型三个层次分析ChatGPT各技术组件的算法原理与模型组成。【局限】 本文调研ChatGPT相关的文献难免存在遗漏,且对部分技术内容的解读还不够深入,一些由笔者推断的内容甚至可能存在错误。【结论】 ChatGPT技术应用的突破,是语料、模型、算法,通过迭代训练不断积累的结果,也是各类算法模型有效组合与集成的结果。
关键词:
ChatGPT ChatGPT技术 生成式预训练模型 人工智能
Abstract
[Objective] Review and analyze the corpus, algorithms and models related to ChatGPT, and provide a systematic reference for peer research. [Methods] This paper systematically reviewed the relevant literature and materials since the release of GPT-3. We depict the overall architecture of ChatGPT technology, and explain and analyze the models, algorithms, and principles behind it. [Results] This paper restores the technical details that support ChatGPT functionality based on limited information through literature research. Rationalizing the overall technical architecture diagram of ChatGPT and explaining each technical component of it. The algorithmic principles and model composition of each technical component of ChatGPT is analyzed at three levels: the corpus system, the pre-training algorithm and model, and the fine-tuning algorithm and model. [Limitations] The investigation of the literature related to ChatGPT inevitably has omissions, and the interpretation of some technical contents is not deep enough. Some contents inferred by the authors may be incorrect. [Conclusions] The breakthrough in the application of ChatGPT technology is the result of continuous accumulation through iterative training of corpora, models and algorithms, as well as the effective combination and integration of various algorithmic models.
Keywords:
ChatGPT ChatGPT Technology Generative Pre-Training Models Artificial Intelligence
本文引用格式
钱力, 刘熠, 张智雄, 李雪思, 谢靖, 许钦亚, 黎洋, 管铮懿, 李西雨, 文森. ChatGPT的技术基础分析* [J]. 数据分析与知识发现, 2023, 7(3): 6-15 doi:10.11925/infotech.2096-3467.2023.0229
Qian Li, Liu Yi, Zhang Zhixiong, Li Xuesi, Xie Jing, Xu Qinya, Li Yang, Guan Zhengyi, Li Xiyu, Wen Sen. An Analysis on the Basic Technologies of ChatGPT [J]. Data Analysis and Knowledge Discovery , 2023, 7(3): 6-15 doi:10.11925/infotech.2096-3467.2023.0229
1 引言
ChatGPT[1 ] 是由OpenAI公司研发的对话系统,能够通过理解和学习人类的语言进行对话,自推出后不仅在学术界与产业界得到广泛关注,也推动了人工智能生成技术(Artificial Intelligence Generated Content,AIGC)的快速发展与市场应用。
ChatGPT可以从5个方面来把握[2 ] :(1)对外表现是一个聊天机器人:能够通过学习和理解人类语言与人进行对话,具有依据对话的上下文环境回答问题的能力,就像人一样与人类进行聊天交流;(2)本质是AIGC:能够在学习人类语言和相关领域知识的基础之上,具备智能化的内容创作能力,从而自动生成特定的内容;(3)关键基础是生成式预训练的转换器(Generative Pre-trained Transformer,GPT):以生成式的自监督学习为基础,从TB级训练数据中学习隐含的语言规律和模式,训练出千亿级别参数量的大规模语言模型;(4)核心技术是InstructGPT:采用基于人类反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF),让人工智能模型的产出和人类的常识、认知、需求、价值观保持一致;(5)与前期类似产品相比,主要特点是编造事实大幅下降,生成的毒内容更少:在一定程度上解决了传统语言模型在复杂多领域的知识利用、演绎推理、欺骗性反应等方面的缺陷,使回答更具有用性和真实性。
OpenAI官方在arXiv与GitHub中公开了ChatGPT模型相关的技术内容,很多学者根据开源信息,从不同的角度对ChatGPT技术进行解析[3 -4 ] 。本文在这些研究基础上,广泛收集相关资料,从中理出ChatGPT的技术架构,揭示其主要组成、关键技术及主要原理,对于理解ChatGPT所表现出的各项能力有一定的意义。
本文尝试从技术的整体架构、实施的数据基础、核心的模型算法三个方面进行探讨性分析,为同行业研究提供体系化的参考借鉴。本文部分内容是在当前公开资料的基础上,笔者根据自身的理解、分析和推断得到,难以避免与未公开的实际情况存在偏差,不足之处还请各位同行予以理解。
2 ChatGPT技术的整体架构分析
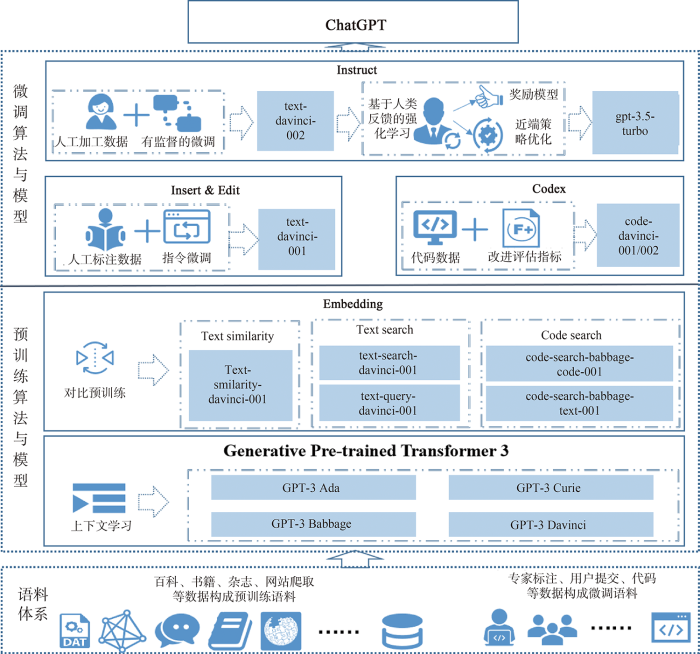
根据收集到的资料,本文整理形成ChatGPT技术的整体架构,如图1 所示。
图1
图1
ChatGPT技术的整体架构
Fig.1
The Structure of ChatGPT Technologies
作为基于Transformer的人工智能应用,ChatGPT主体架构遵从“语料体系+预训练+微调”的基本模式。可以从ChatGPT的语料体系、预训练算法与模型、微调算法与模型三个层次解析ChatGPT的主体架构和主要组件。
(1)语料体系是语言模型的基础。语料体系包括预训练语料与微调语料两个部分,其中预训练语料包括OpenAI从书籍、杂志、百科、论坛等渠道收集,并初步清理后形成的海量无标注文本数据;微调语料包括从开源代码库爬取、专家标注、用户提交等方式收集和加工的高质量有标注文本数据。这些文本数据为ChatGPT学习知识与利用知识,提供了坚实的语料基础。
(2)预训练算法与模型实现预训练大规模语言模型。在大规模训练语料的基础上,OpenAI研发了1 750亿参数量的GPT-3预训练大模型,该模型具备了自然语言理解、自然语言生成与上下文学习(In-Context Learning)的能力,能够针对特定场景,根据人类提示,输出高质量的结果[5 ] 。在此基础上,采用对比预训练(Contrastive Pre-Training,CPT)技术[6 ] ,捕捉文本片段、代码片段的语义相似性与相关性特征,生成更加准确的文本、代码向量,以支持后续微调任务。
(3)微调算法与模型实现面向实际的人工智能应用。在预训练技术与GPT-3模型的基础上,OpenAI进一步研发了Codex模型,赋予GPT-3模型代码生成和代码理解的能力;研发了Insert&Edit模型,赋予GPT-3模型根据对话的上下文插入与修改生成内容的能力;研发了InstructGPT模型[7 ] ,赋予GPT-3模型响应人类指令进而生成更合理答案的能力。
3 ChatGPT的语料体系
海量高质量的语料基础是ChatGPT技术突破的关键要素之一。通过海量无标注语料的预训练,使ChatGPT学习到语言表达模式、文字前后逻辑、知识元间关系等知识内容,在此基础之上利用高质量的标注语料进行针对性的微调,进一步增强其对话能力[8 ] 。本节主要依据OpenAI在arXiv发布的GPT-3[5 ] 、Codex[9 ] 与InstructGPT[7 ] 相关论文以及一些网络开源资料[10 ] 进行总结分析。
ChatGPT的语料体系包括预训练语料与微调语料,具体如下。
3.1 预训练语料
基于现有资料,本文认为,ChatGPT的预训练语料主要包括GPT-1至GPT-3的文本预训练语料。其中,GPT-3的预训练语料集主要由CommonCrawl数据集、Reddit链接、书籍、期刊、英文维基百科数据等组成[5 ] ,总体量约753 GB。ChatGPT的训练数据规模与其同级模型InstructGPT[11 ] 的数据规模相似,都是在GPT-3等模型的数据基础上改进优化而来。具体分布如表1 [10 ] 所示。
3.2 微调语料
ChatGPT的微调语料包括代码微调语料与对话微调语料两部分。
(1)代码微调语料由多种编程语言撰写的代码、代码中的注释、代码的说明文件构成。通过代码语料的微调,ChatGPT具备了代码生成的能力。代码微调语料主要来源于GitHub上的公共代码库,体量达数10亿行代码,以Python文件为主,其中Python文件量达179 GB,各文件大小不超过1 MB[9 ] 。在数据预处理过程中,过滤掉可能是自动生成、平均行长度大于100、最大行长度大于1000或字母数字字符占比较低的文件。以Python文件为例,经过过滤后的文件量为159 GB。该语料覆盖多种编程语言和应用程序领域,包括Web开发、机器学习、数据科学、游戏开发等。通过利用该语料库进行微调,ChatGPT模型具备了理解各种编程语言的语法和语义的能力,能够使用多种编程语言生成和编辑代码。
(2)对话微调语料集囊括了生成、问答、聊天等超过9种类型的标注数据,通过对话语料的微调,使ChatGPT能够应对人类常见的聊天情景。除了对话类型多样外,该语料集还涵盖了20种语言,包括英语、汉语、法语、西班牙语等。对话微调语料以人工标注为主,这些语料来源于标注人员撰写和早期用户的提交。在标注人员撰写方面,OpenAI雇用了40名标注人员,并且对他们进行培训,以手工撰写文本的方式为ChatGPT提供微调语料;在早期用户提交方面,语料主要来源于OpenAI Playground平台的早期用户行为数据,用户可以在该平台与ChatGPT的早期模型对话,并修改机器生成的内容,提交给OpenAI用于后期的模型训练。ChatGPT人工标注的对话语料规模与其同级模型InstructGPT类似,InstructGPT资料显示,对话微调语料分别用于有监督的微调(Supervised Fine-Tuning,SFT)、奖励模型微调(Reward Model,RM)、近端策略优化微调(Proximal Policy Optimization,PPO)三个阶段,其体量和分布情况如表2 [7 ] 所示。
4 ChatGPT的预训练算法与模型
结合图1 ,ChatGPT的预训练算法与模型包括GPT-3与Embedding两个部分。GPT-3的核心是基于Transformer的生成式预训练,包括GPT-3 Ada、GPT-3 Babbage、GPT-3 Curie以及GPT-3 Davinci等一系列模型,这些模型是ChatGPT理解上下文和具备自然语言生成能力的基础。Embedding的核心是对比预训练方法,相关模型包括文本相似性模型、文本搜索模型、代码搜索模型,这些模型是ChatGPT获得文本向量表示能力的基础。
4.1 基于Transformer的生成式预训练模型
基于Transformer的生成式预训练模型是ChatGPT预训练模型的基础,本节主要依据谷歌发布的Transformer模型[12 ] 与OpenAI发布的GPT-3模型[5 ] 进行总结介绍。
(1) Transformer是GPT预训练模型的基础
Transformer是GPT系列模型的基本单元,是目前常见大规模语言模型的核心组件。它由编码器(Encoder)与解码器(Decoder)组成,其中解码器的作用是根据给定文本序列,预测后续文本内容。GPT模型即是利用Transformer解码器部分构建而成。GPT-3是ChatGPT的基础模型,其模型结构包含96层Transformer解码器,采用下一个词预测(Next Word Prediction)的方式进行无监督生成式预训练,从而获得文本生成的能力。
在利用海量无标注语料开展生成式预训练的基础上,GPT-3除了具备文本生成能力外,还获得了很多潜在的自然语言处理能力。OpenAI提出了上下文学习的方式来激发这些潜能[3 ] 。上下文学习即在不修改模型参数的情况下,仅向模型提供少量待执行任务的例子,激发模型执行该项任务的功能。上下文学习存在三种方式:Zero-Shot、One-Shot和Few-Shot。Zero-Shot表示不输入任何示例,只给模型下达一个自然语言指令,让模型完成任务;One-Shot表示下达指令后,只向模型提供一个示例,让模型完成任务;Few-Shot表示下达指令后,提供10~100个示例,让模型完成任务。GPT-3模型通过Zero-Shot与One-Shot,即可完成完形填空、问答、翻译等自然语言处理任务,并达到较好的效果。在部分任务中,通过Few-Shot甚至可以达到SOTA(State of The Art)效果。这种不需要进行任何参数调整,仅需要将问题文本与回答样例一同输入GPT-3模型,即可诱导模型输出答案的功能,意味着GPT-3已经具备理解自然语言、能够根据自然语言进行推理的能力。
GPT-3存在多个版本,这些版本所对应的模型是后续演化出ChatGPT各项功能的基础。其中最主要的模型有GPT-3 Ada、GPT-3 Babbage、GPT-3 Curie以及GPT-3 Davinci[13 ] 。Ada为参数量最低的版本,适用于小型任务,如解析文本、简单分类、地址更正、关键词抽取等。Ada具有最快的响应速度与最少的计算量;Babbage的参数量高于Ada,能够完成简单的任务,如简单分类、语义搜索等,具有较快的响应速度与较少的计算量;Curie参数量高于Babbage,响应速度一般,计算量较大,能够完成语言翻译、复杂分类、情感分类、文本摘要等任务;Davinci是GPT-3中规模最大的模型,参数量有1 750亿,OpenAI发布的诸多大模型,如InstructGPT、Codex等都是在该模型基础上微调得到的。Davinci是能力最强的GPT-3模型,可以完成其他模型所能完成的任何任务,例如复杂意图、因果关系、特定受众文本摘要等,而且完成质量更高。
4.2 基于对比预训练的Embedding模型
基于对比预训练的Embedding模型是ChatGPT文本向量化表征能力的基础。本节主要依据OpenAI官网Embedding模型的相关资料[14 ] 和对比预训练的论文[6 ] 进行总结介绍。
嵌入(Embedding)模型能够针对文本数据,生成表征其语义内容的向量。Embedding模型是GPT-3系列模型之一,主要用于测量文本间的关联性(如相似性或相关性),可以用于执行搜索、聚类、推荐、分类等任务。
OpenAI使用对比预训练方法(CPT)[6 ] ,以得到高质量的文本向量表征。对比预训练的核心思想是在无标注语料中,构建相似的正样本对以及不相似的负样本对,通过拉近相似文本、推开不相似文本,从而有效地学习向量表征。在构建样本对时,OpenAI使用文本中相邻片段作为正样本对,而负样本对则通过随机采样得到。开展对比预训练过程中,采用InfoNCE Loss[15 ] 作为损失函数;以增加正样本对的相似度、减少负样本对的相似度为训练目标。Embedding模型在GPT-3的基础上进行对比预训练,研究表明无监督的对比式学习可以获得更好的文本向量表征,并且在这个方法下得到的文本向量能够媲美通过大量有标注语料微调后的模型。
文献[4 ]指出,文本相似度任务中的向量表征与文本搜索任务中的向量表征存在冲突。例如:“我喜欢吃苹果”与“我讨厌吃苹果”两句话,其文本相似度很低,但是文本搜索的相关度则应该很高。为了解决该问题,OpenAI利用CPT方法分别训练了一系列文本相似度模型与一系列文本搜索模型,并进一步拓展到文本与代码间的相似度计算中,构建了一系列代码搜索模型。具体如表3 所示,表3 内容是在OpenAI公开资料[16 ] 的基础上汇编而成。
5 ChatGPT的微调算法与模型
结合图1 ,ChatGPT的微调算法与模型包括Codex、Insert&Edit、Instruct三个部分。Codex模型基于代码数据微调得到,由code-cushman-001、code-davinci-001与code-davinci-002逐渐演化而来。Insert&Edit模型基于指令微调得到,根据官方公开的文档,本文推断Insert&Edit功能集成至code-davinci-001、text-davinci-001、code-davinci-002、text-davinci-002等模型中。Instruct模型基于人类反馈的强化学习算法得到,利用该算法在text-davinci-002模型的基础上,进一步微调得到text-davinci-003模型与gpt-3.5-turbo模型,其中gpt-3.5-turbo即为ChatGPT。
5.1 基于代码数据微调的Codex模型
基于代码数据微调的Codex模型是ChatGPT代码生成能力的基础。本节主要依据Codex模型的论文[9 ] 进行总结介绍。
代码生成能力是ChatGPT的重要组成部分,Codex模型的主要功能是将自然语言转化为可运行的计算机代码。它能够识别并理解用户提出的编程场景,按照所指定的编程语言和框架自动生成可运行的代码,也可以对用户提交的代码片段进行补全和纠错,帮助用户更快速、准确地编写代码。
ChatGPT的代码编程能力源于Codex[9 ,17 ] 系列模型,该模型是在GPT-3的基础上通过大量的编程代码以及关于代码的描述和注释数据微调得来,引入了单元测试(Unit Tests)和pass@k指标进行模型评估。
单元测试是判断代码可执行与否的标准。由于基于BLEU的文本相似度方法难以有效评估代码生成效果[18 ] ,代码效果的优劣需要由其能否通过单元测试来衡量,因此OpenAI构建了由函数签名、函数注释、函数主体以及多个单元测试构成的评估数据集HumanEval。该数据集完全由人工构建,避免评估所使用的问题出现在训练集中。
pass @k 是整体评估模型代码生成正确性的指标。模型以pass @k 作为量化评估指标,对于同一个问题,模型将生成n 个答案并随机抽取k 个用作评估,k 个答案中有一个通过单元测试,则认为模型输出的结果能够较好地回答该问题。pass @k 的计算方法如公式(1)[19 ] 所示。其中,c 表示n 个输出中通过单元测试的数量。
(1) p a s s @ k = E p r o b l e m s 1 - c n - c k c n k
为进一步提升模型的输出效果,Codex采用核采样算法与设置停止符的方式。核采样的方式使模型能够尽可能生成多样性的结果并降低无关词的干扰,该方法按下一个词预测概率的高低,选出累积概率超过0.95的若干个词作为备选词,通过进一步采样筛选生成文本。设置停止符能够阻止模型连续不断地生成代码。Codex的停止符包括\nclass、\ndef、\n#、\nif、\nprint,模型在输出过程中,如遇到上述停止符,即停止输出。
代码编程模型最早在OpenAI提供的API中命名为code-cushman-001,后基于同一架构,在更大规模的davinci模型上微调,得到code-davinci-001。接着通过与text-davinci-001融合并进行指令微调(Instruction Tuning)得到code-davinci-002,该模型擅长将自然语言翻译成代码,是目前性能最佳的Codex模型[20 ] ,同时也是ChatGPT模型的前身。
5.2 基于指令微调的Insert&Edit模型
基于指令微调的Insert&Edit模型是ChatGPT文本编辑与插入功能的基础。本节主要依据OpenAI官网有关Insert&Edit模型的开源资料[21 -22 ] 进行总结介绍。
Insert&Edit(插入和编辑)是ChatGPT重要的组成功能,改变了以往GPT-3等模型只能在给定的文本结尾进行追加以完善文本内容的情况。具体而言,插入功能使得模型能够在给定文本的中间插入与上下文内容相关且符合上下文逻辑的文本,这一功能使得ChatGPT具备了撰写长文本、实现段落过渡、按照给定大纲生成内容等出色功能[21 ] 。编辑功能是指模型可以对生成的文本结果进行修改,其实现原理是将已经生成的文本和修改命令共同作为内容修改的指令(Instruction)。编辑功能使ChatGPT能够修改文本的表达风格、文本的语言结构,此外还能进行针对性的修改,如拼写修正等[22 ] 。
如ChatGPT的整体架构(图1 )所示,插入和编辑的功能由text-davinci-001模型提供支撑,text-davinci-001模型是在人工标注数据集上对GPT-3进行指令微调后所得。本文并未从OpenAI官网及相关论文中发现太多关于text-davinci-001模型所用的数据集详细情况和训练中的具体细节。结合官方的使用文档和部分学者对GPT系列模型的分析[23 -24 ] ,笔者推断出text-davinci-001模型的训练过程近似于InstructGPT中有监督的微调部分。
text-davinci-001中有监督的微调具体表现为指令微调,即通过给出更明确的指令让模型做出正确的回应。指令微调用于激发模型的语言理解能力,例如根据文本内容进行选项判断等[25 ] 。此外,指令微调的泛化能力较强,具体表现为在经过多个任务的微调后,能够在未知任务上表现出一定的预测能力。text-davinci-001模型能够较好地应对插入和编辑任务,一方面得益于指令微调激发了模型语言理解能力,能够根据明确的指令(已有的文本内容和用户命令)进行回应;另一方面得益于指令微调所带来的强大泛化能力,即使当前的任务类型(如变换文本风格)并没有出现在微调任务中,text-davinci-001也能完成相关任务。
在训练数据集方面,笔者推测text-davinci-001所用的数据集和InstructGPT中所披露的人工标注数据集类似,包括:
①Plain:即标注人员随意编写的任务,需要保证任务类型的多样性(问答、翻译、头脑风暴等);
②Few-Shot:不仅需要通过Prompts编写具体的任务,还需要写出该任务对应的输出结果;
③User-based:从OpenAI的用户反馈中挑选一些任务类型,并根据该任务编写输出。具体的数据集细节可以参看第3节的语料基础部分。
在文本基础上,OpenAI进一步将“插入和编辑”功能拓展至代码中,代码的编辑和插入功能由code-davinci-001模型提供支撑。code-davinci-001模型即Codex模型之一,关于Codex模型的训练细节已经在前文中详细阐明,此处不再赘述。值得额外说明的是,官方已经公开的文档中显示插入和编辑在text-davinci-001中已经具备,目前也可以在code-davinci-002和text-davinci-002中调用,因此可以合理地推断插入和编辑功能在002系列模型中得到保留。
5.3 基于人类反馈的强化学习的Instruct模型
基于人类反馈的强化学习的Instruct模型是ChatGPT符合人类表现对话能力的基础。本节主要依据OpenAI发表的InstructGPT论文[7 ] 进行总结介绍。
InstructGPT是Instruct模型的代表,相较于传统的Transformer或GPT-3,实现了更自然、真实、毒性更小的内容生成,且不会因为训练数据产生明显的偏好。
①InstructGPT生成内容更真实。在测试中,InstructGPT生成真实且信息丰富内容的比率大约是GPT-3的两倍。不仅如此,InstructGPT 模型编造的与输入不一致信息大约为GPT-3模型的一半。
②InstructGPT生成内容更自然。InstructGPT是根据人类撰写的真实数据进行微调的结果,可以根据用户的指令生成更贴近人类语言逻辑的内容。
③InstructGPT生成内容毒性更小。OpenAI使用RealToxicityPrompts数据集测量模型的毒性并进行自动和人工评估。结果表明,InstructGPT模型产生的毒性输出比GPT-3少约25%。
④InstructGPT生成内容没有受到标注者个人偏好影响。OpenAI让一些未参与标注工作的标注人员对比InstructGPT与GPT-3生成的文本,发现InstructGPT生成的内容更符合未参与标注工作的标注人员的偏好。
支撑InstructGPT上述表现的技术来源于基于人类反馈的强化学习(RLHF)。InstructGPT首先通过人工标注数据微调GPT-3.5模型得到有监督的微调(SFT)模型,然后利用RLHF提升模型的输出效果。RLHF技术主要由两个方面组成:奖励模型(RM)与近端策略优化模型(PPO)。
①RM模型使InstructGPT更接近人类表现。在SFT模型的基础上,InstructGPT使SFT模型生成k 个答案,然后通过标注者对这些答案进行排序。经过标注者排序的答案,排序靠前意味着该答案更符合人类表现,反之则意味着该答案偏离人类表现。在计算RM模型的损失时,最大化排序靠前答案与排序靠后答案之间的差值,使模型在生成更符合人类表现的答案时获得更多的奖励。值得说明的是,相对于直接对答案打分,RM模型采用排序的方式能够在一定程度上降低标注者个人偏好对模型训练的影响,同时在判断答案是否更符合人类表现方面保持评判的客观性。总体来说,RM模型推动了InstructGPT输出更接近人类表现的结果。
②利用PPO模型优化文本生成策略。PPO利用训练好的奖励模型,依靠奖励打分更新预训练模型参数。具体而言,在数据集中随机抽取问题,使用PPO模型生成回答,并利用上一阶段训练好的奖励模型给出质量分数。将该分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数[26 ] 。在模型强化学习的过程中,使用KL散度[27 -28 ] 衡量PPO模型与SFT模型输出之间的差异,通过控制该差异的大小,使PPO模型的输出不至于太过偏离SFT模型的输出,从而提升PPO模型参数更新过程中的稳定性。此外,PPO模型在单个自然语言处理任务训练的过程中,加入了其他自然语言处理任务,从而避免PPO模型在当前任务中出现过拟合,同时提升在其他任务中的泛化能力。
根据OpenAI官网内容推断[29 -30 ] ,ChatGPT模型是由GPT-3.5系列模型迭代发展而来。code-davinci-002是GPT-3.5的基础模型,在code-davinci-002模型的基础上,采用指令微调技术,形成text-davinci-002模型,该模型已经具备较好的自然语言理解、文本生成、知识问答、代码撰写、文本内容编辑修改等功能。应用RLHF技术,进一步对其微调,产生了text-davinci-003模型,该模型能够以更高的质量、更长的输出遵循人类指令完成多项自然语言处理任务。在此基础上,进一步优化了人机对话功能,形成了gpt-3.5-turbo模型,即ChatGPT。
6 结语
本文梳理了ChatGPT相关的文献与网络资源,刻画了ChatGPT技术的整体架构图,并根据架构图按照ChatGPT的“语料体系、预训练算法与模型、微调算法与模型”进行体系化的分析与讨论。ChatGPT通过预训练与微调的两阶段学习模式,从海量语料中习得符合人类表现的自然语言文本生成的能力。在预训练阶段,通过大规模无标注语料学习,形成GPT-3基础模型与Embedding模型,为ChatGPT在自然语言理解与生成、上下文学习、文本向量表征等方面奠定基础。在微调阶段利用高质量微调语料与人类反馈强化学习技术,激发了多种自然语言生成能力,形成Codex、Insert&Edit和Instruct等模型,为ChatGPT在代码生成、长文本撰写、符合人类表现对话等方面提供技术支撑。
本文通过文献调研分析,结合研究团队自身的理解,得到了上述关于ChatGPT技术的整体架构和技术组件分析结果,但是仍存在一定的局限性。本文试图通过现有开源资料解析ChatGPT的整体架构,解释架构中各组件的技术原理。鉴于文献调研的局限性,对部分技术内容的解读还不够深入,甚至可能存在一些错误。后续笔者还将继续开展更加广泛的文献调研与更加深入的研究工作。
总之,从ChatGPT的技术基础分析中看到,ChatGPT技术应用的突破并不是无来由的横空出世,而是通过语料数据的积累、算法的突破与应用、模型的快速迭代成的,也是各技术组件有效的组合与集成的结果。人工智能技术发展中,每一个小小的进步都是有价值的,久久为功,不断进步,最终实现了从量变到质变的转换。
作者贡献声明:
刘熠:文献调研,论文整体技术架构梳理,论文撰写、修改和完善;
张智雄:提出论文写作思路和整体框架,参与论文审核、修改;
李雪思,谢靖,许钦亚,黎洋,管铮懿,李西雨:文献调研与部分内容撰写;
参考文献
View Option
[1]
OpenAI . ChatGPT: Optimizing Language Models for Dialogue
[EB/OL]. [2023-03-12 ]. https://openai.com/blog/chatgpt/.
URL
[本文引用: 1]
[2]
张智雄 , 钱力 , 谢靖 , 等 . ChatGPT对科学研究和文献情报工作的影响
[R]. 北京 : 中国科学院文献情报中心, 国家科技文献图书中心 , 2023 .
[本文引用: 1]
Zhang Zhixiong Qian Li Xie Jing et al. The Impact of ChatGPT on Scientific Research and Library & Information Service
[R]. Beijing : National Science Library, Chinese Academy of Sciences, National Science and Technology Digital Library , 2023 .)
[本文引用: 1]
[3]
Zhou C Li Q Li C et al. A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
[OL]. arXiv Preprint, arXiv:2302.09419 .
[本文引用: 2]
[4]
Cao Y H Li S Y Liu Y X et al. A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT
[OL]. arXiv Preprint, arXiv:2303.04226 .
[本文引用: 2]
[5]
Brown T B Mann B Ryder N et al. Language Models are Few-Shot Learners
[OL]. arXiv Preprint, arXiv:2005.14165 .
[本文引用: 4]
[6]
Neelakantan A Xu T Puri R et al. Text and Code Embeddings by Contrastive Pre-Training
[OL]. arXiv Preprint, arXiv: 2201.10005 .
[本文引用: 3]
[7]
Ouyang L Wu J Jiang X et al. Training Language Models to Follow Instructions with Human Feedback
[OL]. arXiv Preprint, arXiv:2203.02155 .
[本文引用: 5]
[8]
Wang F Y Miao Q Li X et al. What does ChatGPT Say: The DAO from Algorithmic Intelligence to Linguistic Intelligence
[J]. IEEE/CAA Journal of Automatica Sinica , 2023 , 10 (3 ): 575 -579 .
DOI:10.1109/JAS.2023.123486
URL
[本文引用: 1]
[9]
Chen M Tworek J Jun H et al. Evaluating Large Language Models Trained on Code
[OL]. arXiv Preprint, arXiv:2107.03374 .
[本文引用: 4]
[10]
Thompson A D What’s in My AI
?[EB/OL]. [2023-03-12 ]. https://lifearchitect.ai/whats-in-my-ai/.
URL
[本文引用: 3]
[11]
OpenAI, Aligning Language Models to Follow Instructions
[EB/OL]. [2023-03-12 ]. https://openai.com/blog/instruction-following/.
URL
[本文引用: 1]
[12]
Vaswani A Shazeer N Parmar N et al. Attention is All You Need
[OL]. arXiv Preprint, arXiv:1706.03762v2 .
[本文引用: 1]
[13]
OpenAI . Models-GPT-3
[EB/OL]. [2023-03-12 ]. https://platform.openai.com/docs/models/gpt-3.
URL
[本文引用: 1]
[14]
Neelakantan A Weng L L Power B et al. Introducing Text and Code Embeddings
[EB/OL]. [2023-03-12 ]. https://openai.com/blog/introducing-text-and-code-embeddings.
URL
[本文引用: 1]
[15]
van den Oord A Li Y Z Vinyals O Representation Learning with Contrastive Predictive Coding
[OL]. arXiv Preprint, arXiv:1807.03748 .
[本文引用: 1]
[16]
OpenAI . What are Embeddings
?[EB/OL]. [2023-03-12 ]. https://platform.openai.com/docs/guides/embeddings/what-are-embeddings.
URL
[本文引用: 1]
[17]
OpeanAI . Code Completion
[EB/OL]. [2023-03-12 ]. https://platform.openai.com/docs/guides/code/.
URL
[本文引用: 1]
[18]
Lachaux M A Roziere B Chanussot L et al. Unsupervised Translation of Programming Languages
[OL]. arXiv Preprint, arXiv:2006.03511 .
[本文引用: 1]
[19]
Kulal S Pasupat P Chandra K et al. SPoC: Search-based Pseudocode to Code
[C]// Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019) . 2019 .
[本文引用: 1]
[20]
OpenAI . Models-Codex
[EB/OL]. [2023-03-12 ]. https://platform.openai.com/docs/models/codex.
URL
[本文引用: 1]
[21]
OpenAI . API Guide Text Completion Inserting Text
[EB/OL]. [2023-03-13 ]. https://platform.openai.com/docs/guides/completion/inserting-text.
URL
[本文引用: 2]
[22]
OpenAI . API Guide Text Completion Editing Text
[EB/OL]. [2023-03-13 ]. .
URL
[本文引用: 2]
[23]
Thompson A D GPT-3.5 + ChatGPT: An Illustrated Overview
[EB/OL]. [2023-03-12 ]. https://lifearchitect.ai/chatgpt/.
URL
[本文引用: 1]
[24]
Fu Y How does GPT Obtain Its Ability? Tracing Emergent Abilities of Language Models to Their Sources
[EB/OL]. [2023-03-12 ]. https://yaofu.notion.site/How-does-GPT-Obtain-its-Ability-Tracing-Emergent-Abilities-of-Language-Models-to-their- Sources-b9a57ac0fcf74f30a1ab9e3e36fa1dc1.
URL
[本文引用: 1]
[25]
Wei J Bosma M Zhao V Y et al. Finetuned Language Models are Zero-Shot Learners
[OL]. arXiv Preprint, arXiv:2109.01652 .
[本文引用: 1]
[26]
Schulman J Klimov O Wolski F et al. Proximal Policy Optimization
[EB/OL]. [2023-03-12 ]. https://openai.com/research/openai-baselines-ppo.
URL
[本文引用: 1]
[27]
Joyce J M Kullback-Leibler Divergence
[A]// International Encyclopedia of Statistical Science [M]. Springer , 2011 : 720 -722 .
[本文引用: 1]
[28]
Gao L Schulman J Hilton J Scaling Laws for Reward Model Overoptimization
[EB/OL]. [2023-03-12 ]. https://openai.com/research/scaling-laws-for-reward-model-overoptimization.
URL
[本文引用: 1]
[29]
OpenAI . Model Index for Researchers
[EB/OL]. [2023-03-12 ]. https://platform.openai.com/docs/model-index-for-researchers.
URL
[本文引用: 1]
[30]
OpenAI . Models-GPT-3.5
[EB/OL]. [2023-03-12 ]. https://platform.openai.com/docs/models/gpt-3-5.
URL
[本文引用: 1]
ChatGPT: Optimizing Language Models for Dialogue
1
... ChatGPT[1 ] 是由OpenAI公司研发的对话系统,能够通过理解和学习人类的语言进行对话,自推出后不仅在学术界与产业界得到广泛关注,也推动了人工智能生成技术(Artificial Intelligence Generated Content,AIGC)的快速发展与市场应用. ...
ChatGPT对科学研究和文献情报工作的影响
1
2023
... ChatGPT可以从5个方面来把握[2 ] :(1)对外表现是一个聊天机器人:能够通过学习和理解人类语言与人进行对话,具有依据对话的上下文环境回答问题的能力,就像人一样与人类进行聊天交流;(2)本质是AIGC:能够在学习人类语言和相关领域知识的基础之上,具备智能化的内容创作能力,从而自动生成特定的内容;(3)关键基础是生成式预训练的转换器(Generative Pre-trained Transformer,GPT):以生成式的自监督学习为基础,从TB级训练数据中学习隐含的语言规律和模式,训练出千亿级别参数量的大规模语言模型;(4)核心技术是InstructGPT:采用基于人类反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF),让人工智能模型的产出和人类的常识、认知、需求、价值观保持一致;(5)与前期类似产品相比,主要特点是编造事实大幅下降,生成的毒内容更少:在一定程度上解决了传统语言模型在复杂多领域的知识利用、演绎推理、欺骗性反应等方面的缺陷,使回答更具有用性和真实性. ...
ChatGPT对科学研究和文献情报工作的影响
1
2023
... ChatGPT可以从5个方面来把握[2 ] :(1)对外表现是一个聊天机器人:能够通过学习和理解人类语言与人进行对话,具有依据对话的上下文环境回答问题的能力,就像人一样与人类进行聊天交流;(2)本质是AIGC:能够在学习人类语言和相关领域知识的基础之上,具备智能化的内容创作能力,从而自动生成特定的内容;(3)关键基础是生成式预训练的转换器(Generative Pre-trained Transformer,GPT):以生成式的自监督学习为基础,从TB级训练数据中学习隐含的语言规律和模式,训练出千亿级别参数量的大规模语言模型;(4)核心技术是InstructGPT:采用基于人类反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF),让人工智能模型的产出和人类的常识、认知、需求、价值观保持一致;(5)与前期类似产品相比,主要特点是编造事实大幅下降,生成的毒内容更少:在一定程度上解决了传统语言模型在复杂多领域的知识利用、演绎推理、欺骗性反应等方面的缺陷,使回答更具有用性和真实性. ...
A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
2
... OpenAI官方在arXiv与GitHub中公开了ChatGPT模型相关的技术内容,很多学者根据开源信息,从不同的角度对ChatGPT技术进行解析[3 -4 ] .本文在这些研究基础上,广泛收集相关资料,从中理出ChatGPT的技术架构,揭示其主要组成、关键技术及主要原理,对于理解ChatGPT所表现出的各项能力有一定的意义. ...
... 在利用海量无标注语料开展生成式预训练的基础上,GPT-3除了具备文本生成能力外,还获得了很多潜在的自然语言处理能力.OpenAI提出了上下文学习的方式来激发这些潜能[3 ] .上下文学习即在不修改模型参数的情况下,仅向模型提供少量待执行任务的例子,激发模型执行该项任务的功能.上下文学习存在三种方式:Zero-Shot、One-Shot和Few-Shot.Zero-Shot表示不输入任何示例,只给模型下达一个自然语言指令,让模型完成任务;One-Shot表示下达指令后,只向模型提供一个示例,让模型完成任务;Few-Shot表示下达指令后,提供10~100个示例,让模型完成任务.GPT-3模型通过Zero-Shot与One-Shot,即可完成完形填空、问答、翻译等自然语言处理任务,并达到较好的效果.在部分任务中,通过Few-Shot甚至可以达到SOTA(State of The Art)效果.这种不需要进行任何参数调整,仅需要将问题文本与回答样例一同输入GPT-3模型,即可诱导模型输出答案的功能,意味着GPT-3已经具备理解自然语言、能够根据自然语言进行推理的能力. ...
A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT
2
... OpenAI官方在arXiv与GitHub中公开了ChatGPT模型相关的技术内容,很多学者根据开源信息,从不同的角度对ChatGPT技术进行解析[3 -4 ] .本文在这些研究基础上,广泛收集相关资料,从中理出ChatGPT的技术架构,揭示其主要组成、关键技术及主要原理,对于理解ChatGPT所表现出的各项能力有一定的意义. ...
... 文献[4 ]指出,文本相似度任务中的向量表征与文本搜索任务中的向量表征存在冲突.例如:“我喜欢吃苹果”与“我讨厌吃苹果”两句话,其文本相似度很低,但是文本搜索的相关度则应该很高.为了解决该问题,OpenAI利用CPT方法分别训练了一系列文本相似度模型与一系列文本搜索模型,并进一步拓展到文本与代码间的相似度计算中,构建了一系列代码搜索模型.具体如表3 所示,表3 内容是在OpenAI公开资料[16 ] 的基础上汇编而成. ...
Language Models are Few-Shot Learners
4
... (2)预训练算法与模型实现预训练大规模语言模型.在大规模训练语料的基础上,OpenAI研发了1 750亿参数量的GPT-3预训练大模型,该模型具备了自然语言理解、自然语言生成与上下文学习(In-Context Learning)的能力,能够针对特定场景,根据人类提示,输出高质量的结果[5 ] .在此基础上,采用对比预训练(Contrastive Pre-Training,CPT)技术[6 ] ,捕捉文本片段、代码片段的语义相似性与相关性特征,生成更加准确的文本、代码向量,以支持后续微调任务. ...
... 海量高质量的语料基础是ChatGPT技术突破的关键要素之一.通过海量无标注语料的预训练,使ChatGPT学习到语言表达模式、文字前后逻辑、知识元间关系等知识内容,在此基础之上利用高质量的标注语料进行针对性的微调,进一步增强其对话能力[8 ] .本节主要依据OpenAI在arXiv发布的GPT-3[5 ] 、Codex[9 ] 与InstructGPT[7 ] 相关论文以及一些网络开源资料[10 ] 进行总结分析. ...
... 基于现有资料,本文认为,ChatGPT的预训练语料主要包括GPT-1至GPT-3的文本预训练语料.其中,GPT-3的预训练语料集主要由CommonCrawl数据集、Reddit链接、书籍、期刊、英文维基百科数据等组成[5 ] ,总体量约753 GB.ChatGPT的训练数据规模与其同级模型InstructGPT[11 ] 的数据规模相似,都是在GPT-3等模型的数据基础上改进优化而来.具体分布如表1 [10 ] 所示. ...
... 基于Transformer的生成式预训练模型是ChatGPT预训练模型的基础,本节主要依据谷歌发布的Transformer模型[12 ] 与OpenAI发布的GPT-3模型[5 ] 进行总结介绍. ...
Text and Code Embeddings by Contrastive Pre-Training
3
... (2)预训练算法与模型实现预训练大规模语言模型.在大规模训练语料的基础上,OpenAI研发了1 750亿参数量的GPT-3预训练大模型,该模型具备了自然语言理解、自然语言生成与上下文学习(In-Context Learning)的能力,能够针对特定场景,根据人类提示,输出高质量的结果[5 ] .在此基础上,采用对比预训练(Contrastive Pre-Training,CPT)技术[6 ] ,捕捉文本片段、代码片段的语义相似性与相关性特征,生成更加准确的文本、代码向量,以支持后续微调任务. ...
... 基于对比预训练的Embedding模型是ChatGPT文本向量化表征能力的基础.本节主要依据OpenAI官网Embedding模型的相关资料[14 ] 和对比预训练的论文[6 ] 进行总结介绍. ...
... OpenAI使用对比预训练方法(CPT)[6 ] ,以得到高质量的文本向量表征.对比预训练的核心思想是在无标注语料中,构建相似的正样本对以及不相似的负样本对,通过拉近相似文本、推开不相似文本,从而有效地学习向量表征.在构建样本对时,OpenAI使用文本中相邻片段作为正样本对,而负样本对则通过随机采样得到.开展对比预训练过程中,采用InfoNCE Loss[15 ] 作为损失函数;以增加正样本对的相似度、减少负样本对的相似度为训练目标.Embedding模型在GPT-3的基础上进行对比预训练,研究表明无监督的对比式学习可以获得更好的文本向量表征,并且在这个方法下得到的文本向量能够媲美通过大量有标注语料微调后的模型. ...
Training Language Models to Follow Instructions with Human Feedback
5
... (3)微调算法与模型实现面向实际的人工智能应用.在预训练技术与GPT-3模型的基础上,OpenAI进一步研发了Codex模型,赋予GPT-3模型代码生成和代码理解的能力;研发了Insert&Edit模型,赋予GPT-3模型根据对话的上下文插入与修改生成内容的能力;研发了InstructGPT模型[7 ] ,赋予GPT-3模型响应人类指令进而生成更合理答案的能力. ...
... 海量高质量的语料基础是ChatGPT技术突破的关键要素之一.通过海量无标注语料的预训练,使ChatGPT学习到语言表达模式、文字前后逻辑、知识元间关系等知识内容,在此基础之上利用高质量的标注语料进行针对性的微调,进一步增强其对话能力[8 ] .本节主要依据OpenAI在arXiv发布的GPT-3[5 ] 、Codex[9 ] 与InstructGPT[7 ] 相关论文以及一些网络开源资料[10 ] 进行总结分析. ...
... (2)对话微调语料集囊括了生成、问答、聊天等超过9种类型的标注数据,通过对话语料的微调,使ChatGPT能够应对人类常见的聊天情景.除了对话类型多样外,该语料集还涵盖了20种语言,包括英语、汉语、法语、西班牙语等.对话微调语料以人工标注为主,这些语料来源于标注人员撰写和早期用户的提交.在标注人员撰写方面,OpenAI雇用了40名标注人员,并且对他们进行培训,以手工撰写文本的方式为ChatGPT提供微调语料;在早期用户提交方面,语料主要来源于OpenAI Playground平台的早期用户行为数据,用户可以在该平台与ChatGPT的早期模型对话,并修改机器生成的内容,提交给OpenAI用于后期的模型训练.ChatGPT人工标注的对话语料规模与其同级模型InstructGPT类似,InstructGPT资料显示,对话微调语料分别用于有监督的微调(Supervised Fine-Tuning,SFT)、奖励模型微调(Reward Model,RM)、近端策略优化微调(Proximal Policy Optimization,PPO)三个阶段,其体量和分布情况如表2 [7 ] 所示. ...
... 对话微调语料在各微调阶段的体量和分布(单位:Token数量)[7 ] ...
... 基于人类反馈的强化学习的Instruct模型是ChatGPT符合人类表现对话能力的基础.本节主要依据OpenAI发表的InstructGPT论文[7 ] 进行总结介绍. ...
What does ChatGPT Say: The DAO from Algorithmic Intelligence to Linguistic Intelligence
1
2023
... 海量高质量的语料基础是ChatGPT技术突破的关键要素之一.通过海量无标注语料的预训练,使ChatGPT学习到语言表达模式、文字前后逻辑、知识元间关系等知识内容,在此基础之上利用高质量的标注语料进行针对性的微调,进一步增强其对话能力[8 ] .本节主要依据OpenAI在arXiv发布的GPT-3[5 ] 、Codex[9 ] 与InstructGPT[7 ] 相关论文以及一些网络开源资料[10 ] 进行总结分析. ...
Evaluating Large Language Models Trained on Code
4
... 海量高质量的语料基础是ChatGPT技术突破的关键要素之一.通过海量无标注语料的预训练,使ChatGPT学习到语言表达模式、文字前后逻辑、知识元间关系等知识内容,在此基础之上利用高质量的标注语料进行针对性的微调,进一步增强其对话能力[8 ] .本节主要依据OpenAI在arXiv发布的GPT-3[5 ] 、Codex[9 ] 与InstructGPT[7 ] 相关论文以及一些网络开源资料[10 ] 进行总结分析. ...
... (1)代码微调语料由多种编程语言撰写的代码、代码中的注释、代码的说明文件构成.通过代码语料的微调,ChatGPT具备了代码生成的能力.代码微调语料主要来源于GitHub上的公共代码库,体量达数10亿行代码,以Python文件为主,其中Python文件量达179 GB,各文件大小不超过1 MB[9 ] .在数据预处理过程中,过滤掉可能是自动生成、平均行长度大于100、最大行长度大于1000或字母数字字符占比较低的文件.以Python文件为例,经过过滤后的文件量为159 GB.该语料覆盖多种编程语言和应用程序领域,包括Web开发、机器学习、数据科学、游戏开发等.通过利用该语料库进行微调,ChatGPT模型具备了理解各种编程语言的语法和语义的能力,能够使用多种编程语言生成和编辑代码. ...
... 基于代码数据微调的Codex模型是ChatGPT代码生成能力的基础.本节主要依据Codex模型的论文[9 ] 进行总结介绍. ...
... ChatGPT的代码编程能力源于Codex[9 ,17 ] 系列模型,该模型是在GPT-3的基础上通过大量的编程代码以及关于代码的描述和注释数据微调得来,引入了单元测试(Unit Tests)和pass@k指标进行模型评估. ...
What’s in My AI
3
... 海量高质量的语料基础是ChatGPT技术突破的关键要素之一.通过海量无标注语料的预训练,使ChatGPT学习到语言表达模式、文字前后逻辑、知识元间关系等知识内容,在此基础之上利用高质量的标注语料进行针对性的微调,进一步增强其对话能力[8 ] .本节主要依据OpenAI在arXiv发布的GPT-3[5 ] 、Codex[9 ] 与InstructGPT[7 ] 相关论文以及一些网络开源资料[10 ] 进行总结分析. ...
... 基于现有资料,本文认为,ChatGPT的预训练语料主要包括GPT-1至GPT-3的文本预训练语料.其中,GPT-3的预训练语料集主要由CommonCrawl数据集、Reddit链接、书籍、期刊、英文维基百科数据等组成[5 ] ,总体量约753 GB.ChatGPT的训练数据规模与其同级模型InstructGPT[11 ] 的数据规模相似,都是在GPT-3等模型的数据基础上改进优化而来.具体分布如表1 [10 ] 所示. ...
... GPT-n的基础预训练数据(单位:GB)[10 ] ...
OpenAI, Aligning Language Models to Follow Instructions
1
... 基于现有资料,本文认为,ChatGPT的预训练语料主要包括GPT-1至GPT-3的文本预训练语料.其中,GPT-3的预训练语料集主要由CommonCrawl数据集、Reddit链接、书籍、期刊、英文维基百科数据等组成[5 ] ,总体量约753 GB.ChatGPT的训练数据规模与其同级模型InstructGPT[11 ] 的数据规模相似,都是在GPT-3等模型的数据基础上改进优化而来.具体分布如表1 [10 ] 所示. ...
Attention is All You Need
1
... 基于Transformer的生成式预训练模型是ChatGPT预训练模型的基础,本节主要依据谷歌发布的Transformer模型[12 ] 与OpenAI发布的GPT-3模型[5 ] 进行总结介绍. ...
Models-GPT-3
1
... GPT-3存在多个版本,这些版本所对应的模型是后续演化出ChatGPT各项功能的基础.其中最主要的模型有GPT-3 Ada、GPT-3 Babbage、GPT-3 Curie以及GPT-3 Davinci[13 ] .Ada为参数量最低的版本,适用于小型任务,如解析文本、简单分类、地址更正、关键词抽取等.Ada具有最快的响应速度与最少的计算量;Babbage的参数量高于Ada,能够完成简单的任务,如简单分类、语义搜索等,具有较快的响应速度与较少的计算量;Curie参数量高于Babbage,响应速度一般,计算量较大,能够完成语言翻译、复杂分类、情感分类、文本摘要等任务;Davinci是GPT-3中规模最大的模型,参数量有1 750亿,OpenAI发布的诸多大模型,如InstructGPT、Codex等都是在该模型基础上微调得到的.Davinci是能力最强的GPT-3模型,可以完成其他模型所能完成的任何任务,例如复杂意图、因果关系、特定受众文本摘要等,而且完成质量更高. ...
Introducing Text and Code Embeddings
1
... 基于对比预训练的Embedding模型是ChatGPT文本向量化表征能力的基础.本节主要依据OpenAI官网Embedding模型的相关资料[14 ] 和对比预训练的论文[6 ] 进行总结介绍. ...
Representation Learning with Contrastive Predictive Coding
1
... OpenAI使用对比预训练方法(CPT)[6 ] ,以得到高质量的文本向量表征.对比预训练的核心思想是在无标注语料中,构建相似的正样本对以及不相似的负样本对,通过拉近相似文本、推开不相似文本,从而有效地学习向量表征.在构建样本对时,OpenAI使用文本中相邻片段作为正样本对,而负样本对则通过随机采样得到.开展对比预训练过程中,采用InfoNCE Loss[15 ] 作为损失函数;以增加正样本对的相似度、减少负样本对的相似度为训练目标.Embedding模型在GPT-3的基础上进行对比预训练,研究表明无监督的对比式学习可以获得更好的文本向量表征,并且在这个方法下得到的文本向量能够媲美通过大量有标注语料微调后的模型. ...
What are Embeddings
1
... 文献[4 ]指出,文本相似度任务中的向量表征与文本搜索任务中的向量表征存在冲突.例如:“我喜欢吃苹果”与“我讨厌吃苹果”两句话,其文本相似度很低,但是文本搜索的相关度则应该很高.为了解决该问题,OpenAI利用CPT方法分别训练了一系列文本相似度模型与一系列文本搜索模型,并进一步拓展到文本与代码间的相似度计算中,构建了一系列代码搜索模型.具体如表3 所示,表3 内容是在OpenAI公开资料[16 ] 的基础上汇编而成. ...
Code Completion
1
... ChatGPT的代码编程能力源于Codex[9 ,17 ] 系列模型,该模型是在GPT-3的基础上通过大量的编程代码以及关于代码的描述和注释数据微调得来,引入了单元测试(Unit Tests)和pass@k指标进行模型评估. ...
Unsupervised Translation of Programming Languages
1
... 单元测试是判断代码可执行与否的标准.由于基于BLEU的文本相似度方法难以有效评估代码生成效果[18 ] ,代码效果的优劣需要由其能否通过单元测试来衡量,因此OpenAI构建了由函数签名、函数注释、函数主体以及多个单元测试构成的评估数据集HumanEval.该数据集完全由人工构建,避免评估所使用的问题出现在训练集中. ...
SPoC: Search-based Pseudocode to Code
1
2019
... pass @k 是整体评估模型代码生成正确性的指标.模型以pass @k 作为量化评估指标,对于同一个问题,模型将生成n 个答案并随机抽取k 个用作评估,k 个答案中有一个通过单元测试,则认为模型输出的结果能够较好地回答该问题.pass @k 的计算方法如公式(1)[19 ] 所示.其中,c 表示n 个输出中通过单元测试的数量. ...
Models-Codex
1
... 代码编程模型最早在OpenAI提供的API中命名为code-cushman-001,后基于同一架构,在更大规模的davinci模型上微调,得到code-davinci-001.接着通过与text-davinci-001融合并进行指令微调(Instruction Tuning)得到code-davinci-002,该模型擅长将自然语言翻译成代码,是目前性能最佳的Codex模型[20 ] ,同时也是ChatGPT模型的前身. ...
API Guide Text Completion Inserting Text
2
... 基于指令微调的Insert&Edit模型是ChatGPT文本编辑与插入功能的基础.本节主要依据OpenAI官网有关Insert&Edit模型的开源资料[21 -22 ] 进行总结介绍. ...
... Insert&Edit(插入和编辑)是ChatGPT重要的组成功能,改变了以往GPT-3等模型只能在给定的文本结尾进行追加以完善文本内容的情况.具体而言,插入功能使得模型能够在给定文本的中间插入与上下文内容相关且符合上下文逻辑的文本,这一功能使得ChatGPT具备了撰写长文本、实现段落过渡、按照给定大纲生成内容等出色功能[21 ] .编辑功能是指模型可以对生成的文本结果进行修改,其实现原理是将已经生成的文本和修改命令共同作为内容修改的指令(Instruction).编辑功能使ChatGPT能够修改文本的表达风格、文本的语言结构,此外还能进行针对性的修改,如拼写修正等[22 ] . ...
API Guide Text Completion Editing Text
2
... 基于指令微调的Insert&Edit模型是ChatGPT文本编辑与插入功能的基础.本节主要依据OpenAI官网有关Insert&Edit模型的开源资料[21 -22 ] 进行总结介绍. ...
... Insert&Edit(插入和编辑)是ChatGPT重要的组成功能,改变了以往GPT-3等模型只能在给定的文本结尾进行追加以完善文本内容的情况.具体而言,插入功能使得模型能够在给定文本的中间插入与上下文内容相关且符合上下文逻辑的文本,这一功能使得ChatGPT具备了撰写长文本、实现段落过渡、按照给定大纲生成内容等出色功能[21 ] .编辑功能是指模型可以对生成的文本结果进行修改,其实现原理是将已经生成的文本和修改命令共同作为内容修改的指令(Instruction).编辑功能使ChatGPT能够修改文本的表达风格、文本的语言结构,此外还能进行针对性的修改,如拼写修正等[22 ] . ...
GPT-3.5 + ChatGPT: An Illustrated Overview
1
... 如ChatGPT的整体架构(图1 )所示,插入和编辑的功能由text-davinci-001模型提供支撑,text-davinci-001模型是在人工标注数据集上对GPT-3进行指令微调后所得.本文并未从OpenAI官网及相关论文中发现太多关于text-davinci-001模型所用的数据集详细情况和训练中的具体细节.结合官方的使用文档和部分学者对GPT系列模型的分析[23 -24 ] ,笔者推断出text-davinci-001模型的训练过程近似于InstructGPT中有监督的微调部分. ...
How does GPT Obtain Its Ability? Tracing Emergent Abilities of Language Models to Their Sources
1
... 如ChatGPT的整体架构(图1 )所示,插入和编辑的功能由text-davinci-001模型提供支撑,text-davinci-001模型是在人工标注数据集上对GPT-3进行指令微调后所得.本文并未从OpenAI官网及相关论文中发现太多关于text-davinci-001模型所用的数据集详细情况和训练中的具体细节.结合官方的使用文档和部分学者对GPT系列模型的分析[23 -24 ] ,笔者推断出text-davinci-001模型的训练过程近似于InstructGPT中有监督的微调部分. ...
Finetuned Language Models are Zero-Shot Learners
1
... text-davinci-001中有监督的微调具体表现为指令微调,即通过给出更明确的指令让模型做出正确的回应.指令微调用于激发模型的语言理解能力,例如根据文本内容进行选项判断等[25 ] .此外,指令微调的泛化能力较强,具体表现为在经过多个任务的微调后,能够在未知任务上表现出一定的预测能力.text-davinci-001模型能够较好地应对插入和编辑任务,一方面得益于指令微调激发了模型语言理解能力,能够根据明确的指令(已有的文本内容和用户命令)进行回应;另一方面得益于指令微调所带来的强大泛化能力,即使当前的任务类型(如变换文本风格)并没有出现在微调任务中,text-davinci-001也能完成相关任务. ...
Proximal Policy Optimization
1
... ②利用PPO模型优化文本生成策略.PPO利用训练好的奖励模型,依靠奖励打分更新预训练模型参数.具体而言,在数据集中随机抽取问题,使用PPO模型生成回答,并利用上一阶段训练好的奖励模型给出质量分数.将该分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数[26 ] .在模型强化学习的过程中,使用KL散度[27 -28 ] 衡量PPO模型与SFT模型输出之间的差异,通过控制该差异的大小,使PPO模型的输出不至于太过偏离SFT模型的输出,从而提升PPO模型参数更新过程中的稳定性.此外,PPO模型在单个自然语言处理任务训练的过程中,加入了其他自然语言处理任务,从而避免PPO模型在当前任务中出现过拟合,同时提升在其他任务中的泛化能力. ...
Kullback-Leibler Divergence
1
2011
... ②利用PPO模型优化文本生成策略.PPO利用训练好的奖励模型,依靠奖励打分更新预训练模型参数.具体而言,在数据集中随机抽取问题,使用PPO模型生成回答,并利用上一阶段训练好的奖励模型给出质量分数.将该分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数[26 ] .在模型强化学习的过程中,使用KL散度[27 -28 ] 衡量PPO模型与SFT模型输出之间的差异,通过控制该差异的大小,使PPO模型的输出不至于太过偏离SFT模型的输出,从而提升PPO模型参数更新过程中的稳定性.此外,PPO模型在单个自然语言处理任务训练的过程中,加入了其他自然语言处理任务,从而避免PPO模型在当前任务中出现过拟合,同时提升在其他任务中的泛化能力. ...
Scaling Laws for Reward Model Overoptimization
1
... ②利用PPO模型优化文本生成策略.PPO利用训练好的奖励模型,依靠奖励打分更新预训练模型参数.具体而言,在数据集中随机抽取问题,使用PPO模型生成回答,并利用上一阶段训练好的奖励模型给出质量分数.将该分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数[26 ] .在模型强化学习的过程中,使用KL散度[27 -28 ] 衡量PPO模型与SFT模型输出之间的差异,通过控制该差异的大小,使PPO模型的输出不至于太过偏离SFT模型的输出,从而提升PPO模型参数更新过程中的稳定性.此外,PPO模型在单个自然语言处理任务训练的过程中,加入了其他自然语言处理任务,从而避免PPO模型在当前任务中出现过拟合,同时提升在其他任务中的泛化能力. ...
Model Index for Researchers
1
... 根据OpenAI官网内容推断[29 -30 ] ,ChatGPT模型是由GPT-3.5系列模型迭代发展而来.code-davinci-002是GPT-3.5的基础模型,在code-davinci-002模型的基础上,采用指令微调技术,形成text-davinci-002模型,该模型已经具备较好的自然语言理解、文本生成、知识问答、代码撰写、文本内容编辑修改等功能.应用RLHF技术,进一步对其微调,产生了text-davinci-003模型,该模型能够以更高的质量、更长的输出遵循人类指令完成多项自然语言处理任务.在此基础上,进一步优化了人机对话功能,形成了gpt-3.5-turbo模型,即ChatGPT. ...
Models-GPT-3.5
1
... 根据OpenAI官网内容推断[29 -30 ] ,ChatGPT模型是由GPT-3.5系列模型迭代发展而来.code-davinci-002是GPT-3.5的基础模型,在code-davinci-002模型的基础上,采用指令微调技术,形成text-davinci-002模型,该模型已经具备较好的自然语言理解、文本生成、知识问答、代码撰写、文本内容编辑修改等功能.应用RLHF技术,进一步对其微调,产生了text-davinci-003模型,该模型能够以更高的质量、更长的输出遵循人类指令完成多项自然语言处理任务.在此基础上,进一步优化了人机对话功能,形成了gpt-3.5-turbo模型,即ChatGPT. ...






{kind=link}
{kind=link}