Extracting Value Elements and Constructing Index System for Calligraphy Works Based on Hyperplane-BERT-Louvain Optimized LDA Model
Pan Xiaoyu1,Ni Yuan2,3(),Jin Chunhua2,Zhang Jian2,3
1Computer School, Beijing Information Science & Technology University,Beijing 100192, China 2School of Economics & Management, Beijing Information Science & Technology University, Beijing 100192, China 3Beijing Key Laboratory of Big Data Decision Making for Green Development, Beijing 100192, China
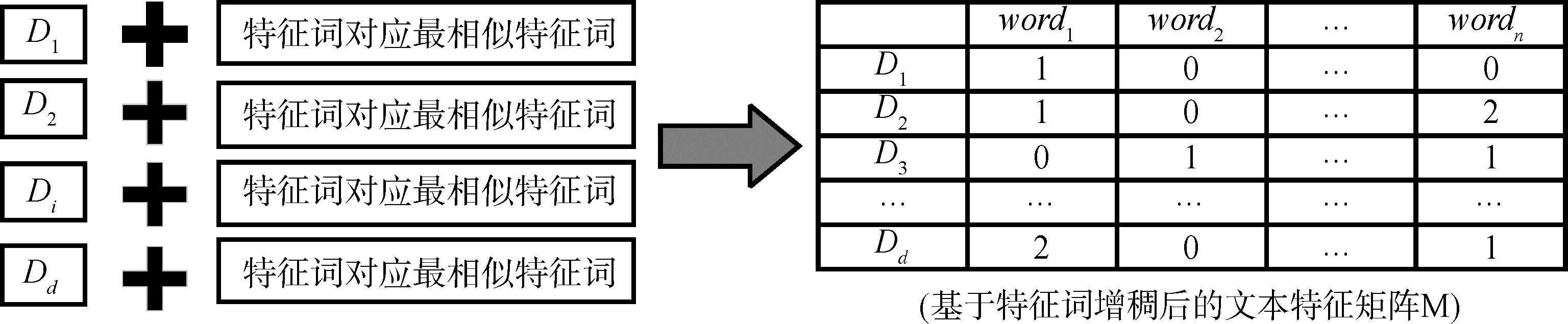
[Objective] This paper uses big data and artificial intelligence to identify the value elements of calligraphy works and provides technical support for their trading activities. It addresses the issue of lacking standards in the assessment of calligraphy works. [Methods] First, we combined the hyperplane algorithm and BERT model to preprocess calligraphy documents by eliminating stop words and expanding semantics to create an optimized corpus with high recognition. Secondly, we constructed a complex semantic network for calligraphy literature and introduced the Louvain algorithm to determine the optimal number of topics by maximizing the modularity of the community network. Finally, we developed a new method based on “Hyperplane-Bert-Louvain-LDA” (HBL-LDA) to construct an assessment index system of calligraphy value. [Results] Compared with LDA, the precision and F value of the topic recognition of the HBL-LDA were increased by 45.00% and 29.46%, respectively. The average topic quality rate was reduced by 0.96, with more high-quality topics identified. We also used regression models to verify the evaluation index system with representative calligraphy works, with the highest accuracy rate of 84.00%. [Limitations] This paper only constructed an evaluation system for calligraphy works, which cannot be applied to other artworks. The BERT model lacks the topic semantic information, which makes it challenging to expand similar feature words. [Conclusions] The new model for calligraphy value evaluation proposed in this paper provides new directions for constructing index systems in other fields.
潘小宇, 倪渊, 金春华, 张健. 基于超平面-BERT-Louvain优化LDA模型的书法作品价值要素提取及指标体系构建*[J]. 数据分析与知识发现, 2023, 7(10): 109-118.
Pan Xiaoyu, Ni Yuan, Jin Chunhua, Zhang Jian. Extracting Value Elements and Constructing Index System for Calligraphy Works Based on Hyperplane-BERT-Louvain Optimized LDA Model. Data Analysis and Knowledge Discovery, 2023, 7(10): 109-118.
(Yu Yan, Zhao Naixuan. Automatic Selection of Domain-Specific Stopwords in Topic Model of Patent Text[J]. Library and Information Service, 2018, 62(11): 120-126.)
doi: 10.13266/j.issn.0252-3116.2018.11.014
[6]
Luhn H P. The Automatic Creation of Literature Abstracts[J]. IBM Journal of Research and Development, 1958, 2(2): 159-165.
doi: 10.1147/rd.22.0159
(Zhang Qianqian. Research on the Construction Method of Enterprise Technology Innovation Index System Based on Text Mining[D]. Beijing: Beijing Jiaotong University, 2021.)
(Feng Kun, Yang Qiang, Chang Xinyi, et al. Customer Satisfaction Evaluation Method for Fresh E-commerce Based on Online Reviews and Stochastic Dominance Rules[J]. Chinese Journal of Management Science, 2021, 29(2): 205-216.)
[10]
杜杏叶. 学术论文关键指标智能化评价研究[D]. 长春: 吉林大学, 2019.
[10]
(Du Xingye. Research on Intelligent Evaluation of Key Indicators of Academic Papers[D]. Changchun: Jilin University, 2019.)
(Xu Xuanhua, Hou Yuzhou, He Jishan. Large Group Decision Making Method Based on Incomplete Probabilistic Linguistic Evaluation Information Considering Authoritative Expert and Its Application in Site Selection of Hot Dry Rock Exploration[J]. Operations Research and Management Science, 2021, 30(8): 7-13.)
doi: 10.12005/orms.2021.0240
(Liu Jiaqi. A Study on User Experience of O2O Takeaway Website——Take Beijing as an Example[D]. Beijing: Capital University of Economics and Business, 2018.)
(Wang Lian, Li Ran, Xu Xiaofei, et al. Multi-dimensional Evaluation Model of Regional Cultural Product Modeling[J]. Packaging Engineering, 2021, 42(20): 389-394, 401.)
(Wang Heng. Influencing Factors and Optimization Orientation of Cultural Tourism Preference—Based on Discrete Choice Model[J]. Social Scientist, 2022(1): 42-51.)
(Zhang Yitao, Wan Changxuan, Liu Xiping, et al. Mining Unstructured Economic Indicators Based on PSP_HDP Topic Model[J]. Journal of Software, 2020, 31(3): 845-865.)
(Liu Jingtao, Li Xiuxia, Shao Zuoyun. A Book Evaluation Method Based on Topic Extraction and Sentiment Analysis[J]. Information Research, 2022(5): 43-49.)
[18]
Blei D M, Ng A Y, Jordan M I. Latent Dirichlet Allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
(Huang Lin, Wang Liya, Ming Xinguo. Product Service Requirement Identification Based on Modified-LDA Model[J]. Industrial Engineering and Management, 2023, 28(1): 42-50.)
(Guan Peng, Wang Yuefen. Identifying Optimal Topic Numbers from Sci-Tech Information with LDA Model[J]. New Technology of Library and Information Service, 2016(9): 42-50.)
(Yang Yang, Jiang Kaizhong, Yuan Mingjun, et al. Selecting Optimal LDA Numbers to Identify News Topics[J]. Data Analysis and Knowledge Discovery, 2022, 6(11): 72-78.)
(Wang Tingting, Han Man, Wang Yu. Optimizing LDA Model with Various Topic Numbers: Case Study of Scientific Literature[J]. Data Analysis and Knowledge Discovery, 2018, 2(1): 29-40.)
[27]
Ladani D J, Desai N P. Automatic Stopword Identification Technique for Gujarati Text[C]// Proceedings of 2021 International Conference on Artificial Intelligence and Machine Vision, Gandhinagar, India. Piscataway, NJ: IEEE, 2021: 1-5.
(Yu Yan, Zhao Naixuan. Choosing Stopwords for Patent Topic Analysis Based on Auxiliary Set[J]. Data Analysis and Knowledge Discovery, 2018, 2(11): 95-103.)
[29]
Alshanik F, Apon A, Herzog A, et al. Accelerating Text Mining Using Domain-Specific Stop Word Lists[C]// Proceedings of 2020 IEEE International Conference on Big Data,Atlanta, GA, USA. Piscataway, NJ: IEEE, 2020: 2639-2648.
[30]
Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[OL]. arXiv Preprint, arXiv: 1810.04805.
[31]
李菲菲. 基于C-LDA的教育领域搜索引擎的研究与实现[D]. 北京: 北京交通大学, 2018.
[31]
(Li Feifei. Research and Realization of the Search Engine in the Field of Education Based on C-LDA[D]. Beijing: Beijing Jiaotong University, 2018.)
[32]
Blondel V D, Guillaume J L, Lambiotte R, et al. Fast Unfolding of Communities in Large Networks[J]. Journal of Statistical Mechanics: Theory and Experiment, 2008, 2008(10): P10008.
(Xu Jin, Deng Leling. Study on Community Detection of Railway Passenger Social Networks Based on Louvain Algorithm[J]. Journal of Shandong Agricultural University (Natural Science Edition), 2018, 49(4): 722-725.)
(Guanqin, Deng Sanhong, Wang Hao. Chinese Stopwords for Text Clustering: A Comparative Study[J]. Data Analysis and Knowledge Discovery, 2017, 1(3): 72-80.)
[35]
张曦元. 基于LDA的博文分类及主题演化研究[D]. 沈阳: 东北大学, 2019.
[35]
(Zhang Xiyuan. Research on Classification and Topic Evolution of Blog Based on LDA[D]. Shenyang: Northeastern University, 2019.)