




1 引 言
语步是语言学概念, 指实现完整交流功能的一个修辞单位[1]。语步在各种文体中作为最基本的功能模块, 传达了作者的写作意图。在科技论文的摘要中, 研究者一般需要说明其研究的目的、方法、结果以及结论等要素, 这些要素被称为科技论文摘要的语步, 能够精炼地反映科技论文所表的主要意图。
自动识别科技论文摘要的语步, 能够有效找出表达科技论文中研究目的、研究方法、研究结果以及研究结论的句子, 使读者快速掌握科技论文的主要内容, 对于揭示科技论文中的科学知识具有重大意义。近年来, 语步自动识别领域的相关研究得到国内外研究者的关注。国外的研究者在语步识别的相关研究中取得了较大进展, 部分代表性研究成果如表1所示。
表1 国外相关研究成果
本文尝试在大规模语料的基础上, 引入基于深度神经网络(Deep Neural Network, DNN)、循环神经网络(Recurrent Neural Network, RNN)等不同神经网络模型的深度学习方法, 以传统机器学习方法支持向量机(Support Vector Machine, SVM)作为对比基准, 重点对比分析不同深度学习模型在科技论文摘要语步识别上的效果。
2 研究设计
为对比分析不同深度学习模型在科技论文摘要语步识别上的效果, 笔者构建大规模的结构化摘要语料作为训练数据, 开展以支持向量机模型为语步识别的对比基准实验, 分别进行基于深度神经网络、长短期记忆网络(Long Short-Term Memory, LSTM)和Attention-BiLSTM三种深度学习模型的语步识别实验, 在此基础之上, 对比分析各种模型的语步识别效果, 分析效果差异的原因。
2.1 大规模训练语料构建及样本选择
目前很多科技期刊出版的论文采用结构化摘要, 论文作者在提交论文时已经按照固定的结构化摘要模式撰写摘要, 指明其论文的目的、方法、结果、结论等, 可以作为人工标注好的训练语料。
笔者基于各类文献数据库和相关科技期刊, 收集整理共计72万余篇结构化的科技论文摘要, 包含约278万个带有标签的语步数据, 从中筛选出数量最多的4种语步类型: 目的(Purpose)、方法(Methods)、结果(Results)、结论(Conclusions), 共计约112万个语步, 作为本项研究的基础数据。
在训练样本上, 本研究构建数量为10 000和50 000的两个语步数据训练集。具体而言, 笔者对4个类别的语料采用分层随机抽样的方式, 分别从约112万个语步数据中, 选择样本量为10 000和50 000的训练样本。其中每种类别的样本数量相等, 并将这两批训练样本作为各种机器学习模型统一使用的训练集。
在测试样本上, 使用统一的2 000条语步数据作为测试集。在未参与训练的语料中同样采用分层随机抽样的方式, 选取2 000个样本作为统一的测试集, 对各种机器学习模型进行测试。其中每个类别中各500个样本, 并确保与训练集没有重叠。
2.2 对比基准实验的设计
为探究深度学习方法是否在科技论文摘要语步识别中优于传统机器学习方法, 选择一种具有代表性的传统机器学习方法, 开展语步自动识别研究, 作为深度学习方法的对比基准实验。
在进行SVM语步识别实验时, 使用词袋模型作为模型的输入, 并使用One-vs-Rest策略进行多类别的语步识别实验。笔者将语料进行预处理, 抽取文本的特征向量作为模型的输入以训练语步识别模型。通过控制变量的方法, 探究N-gram取值、是否去停用词、词频加权方式等因素对于模型性能的影响, 最终选取性能最好的模型作为深度学习实验的对比基准。
2.3 基于深度学习的语步识别实验设计
为对比分析各深度学习方法在科技论文语步自动识别研究中的应用效果, 笔者设计基于不同深度学习模型的语步识别实验。首先针对神经网络模型的输入, 选择词嵌入模型进行文本的向量化表示。其中在DNN深度神经网络模型中, 使用预训练的词向量作为神经网络模型的输入, 在LSTM模型和基于注意力(Attention)机制的双向LSTM (BiLSTM)模型中, 将词向量表示嵌入到模型中, 随着模型训练结束一起形成最优的文本向量表示。然后分别利用DNN、LSTM和Attention-BiLSTM三种神经网络模型进行语步自动识别实验, 以下是具体的实验设计。
(1) 文本向量化表示
在进行深度学习实验时, 由于模型参数众多, 如果和支持向量机方法一样使用高维词袋模型, 将会导致模型极其复杂, 大大降低实验效率。为此, 笔者引入词嵌入表示方法, 使用低维向量表示词汇和文档, 能够揭示词汇之间的语义关系, 也能直接作为神经网络模型的输入。如图1所示, 使用Word2Vec[10]方法表示词汇和文档。对于每一个词汇, 通过大批量语料库的训练学习, 得到一个低维的词向量。对于每一篇文档, 将文档中的每一个词汇的词向量进行简单堆叠, 每个词向量作为矩阵的一行, 形成文档矩阵。为了保证语料库中每一个输入的文档矩阵大小相同, 规定一个文档最大长度T, 当某篇文档词汇个数t<T时, 则用零向量补足这个矩阵。
图1

(2) 深度神经网络模型
深度神经网络(DNN)是一种有多个隐藏层的感知机模型, 具有多层非线性映射的深层结构, 可以完成复杂的函数逼近, 且能够从大量样本集中学习数据集的多种特征。相比于支持向量机模型, 一方面, DNN具有更强的非线性变换能力[11], 更适用于语步的自动识别问题; 另一方面, 利用词嵌入文本表示和神经网络计算, DNN可以充分挖掘文本数据中的潜在信息。
在进行DNN模型实验时, 笔者构建具有三个隐藏层的深度神经网络模型, 分别在词向量维度、激活 函数、归一化函数等参数设置上进行探索, 找到使模型识别效果较好的参数, 并在样本量为10 000和50 000的情况下进行对比实验。
(3) LSTM模型
循环神经网络(RNN)在普通的神经网络的基础上进一步考虑时序特征, 对于序列问题具有很好的建模能力。长短期记忆网络(LSTM)[12]作为RNN的变体, 通过加入门机制, 更好地保留了时序特征。而文本数据中的上下文关系刚好符合这种时序特征, 因此相比于普通的DNN深度神经网络来说, LSTM深度神经网络模型可能更适用于科技论文摘要的语步自动识别。
为探索LSTM模型在语步识别实验中的效果, 笔者构建5层LSTM网络, 分别为: 词嵌入层、Dropout层、LSTM层、全连接层和Softmax层。分别在词向量维度、激活函数、归一化函数、隐藏神经元个数、损失函数等参数上进行探索, 找到使模型识别效果较好的参数, 并在样本量为10 000和50 000的情况下进行对比实验。
(4) 基于Attention机制的双向LSTM模型
在普通的LSTM神经网络中, 信息传播的方向为从前向后, 因而其只能体现文本中的上文特征。而对于文本数据来说, 下文特征同样也是一个重要的信息。双向LSTM神经网络[13]同LSTM神经网络几乎一致, 只是复制了原有的单向网络层, 在模型中增加了一个反向副本。相比于单向的LSTM神经网络, 双向LSTM进一步捕获了文本中从后向前的信息。因此笔者引入双向LSTM神经网络模型, 以充分体现文本数据中的上下文特征。
以上所有实验设计中, 神经网络模型的输入都是文本的词向量表示, 并未加入文本的其他特征。考虑到人工提取文本特征过于繁琐, 这里引入一种能够自动学习文本特征的方法。Attention机制[14]本质上是在神经网络结构中的加入一层权重向量, 能够对不同的词汇赋予不同的权重, 从而自动发现那些对于语步识别起到关键作用的词, 则这个模型可以从每个句子中捕获重要的语义信息。
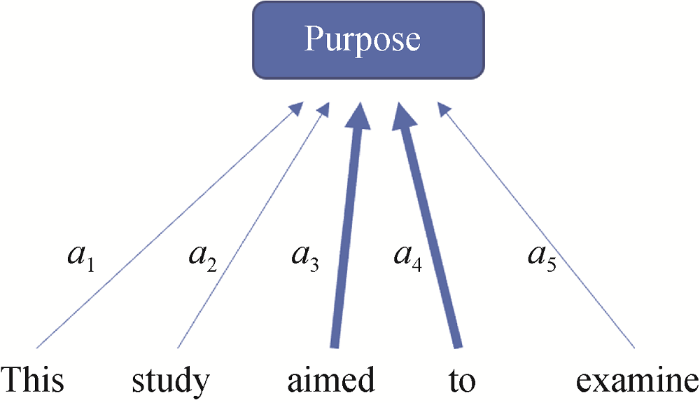
如图2所示, 例句“This study aimed to examine”的语步标签预测为“Purpose”标签时, Attention机制会生成一个权重向量, 对应到每一个词的权值分别为$[{{a}_{1}},{{a}_{2}},{{a}_{3}},{{a}_{4}},{{a}_{5}}]$, 那么这个权重向量中${{a}_{3}}$、${{a}_{4}}$的权值将会高于${{a}_{1}}$、${{a}_{2}}$、${{a}_{5}}$的权值。对于“Purpose”标签, 相比其他词汇, “aimed to”两个词更能体现这一类文本的特征。而这个权重向量正是通过模型的训练学习得到的, 不需要人工的参与也不需要调用任何外部资源。这体现了Attention机制最为重要的特点: 自动发现每个句子中重要的特征词。
图2
为探索基于Attention机制的双向LSTM (Attention- BiLSTM)深度神经网络模型在语步识别实验中的效果, 笔者构建5层Attention-BiLSTM网络, 分别为: 输入层、词嵌入层、双向LSTM层、Attention层和输出层。分别在词向量维度、激活函数、归一化函数、隐藏神经元个数、损失函数、批训练大小等参数上进行探索, 找到使模型识别效果较好的参数, 并在样本量为10 000和50 000的情况下进行对比实验。
2.4 识别效果指标
科技论文摘要语步识别的识别效果可以用查准率(P)、查全率(R)和F1值评估, 如公式(1)-公式(3)所示。
其中, TP(True Positive)表示将正类预测为正类的数量; TN(True Negative)表示将负类预测为负类的数量; FP(False Positive)表示将负类预测为正类的数量; FN(False Negative)表示将正类预测为负类的数量。
本项研究中, 对于每一个实验, 使用查准率、查全率和F1值的平均值验证识别效果。相应的平均值分别为4个语步类别的查准率、查全率和F1值的算术平均数。
3 实验步骤及结果分析
根据以上的实验设计思路, 分别构建SVM、DNN、LSTM和Attention-BiLSTM模型。利用选择好的训练样本和测试集, 进行基于各种方法的语步识别实验。
3.1 基于支持向量机模型的实验
通过控制变量法从样本量差异、N元词、停用词、词频统计方法4方面对模型效果进行对比分析。最终发现, 当样本量为10 000时, 在使用一元词和二元词、不去停用词、使用TF-ID加权方法时效果最好。实验结果如表2所示。
表2 样本量10 000时的支持向量机实验结果
| 类别 | P | R | F1值 |
|---|---|---|---|
| Purpose | 0.8900 | 0.8800 | 0.8900 |
| Methods | 0.9000 | 0.9400 | 0.9200 |
| Results | 0.8700 | 0.9200 | 0.8900 |
| Conclusions | 0.8900 | 0.8200 | 0.8600 |
| 平均值 | 0.8875 | 0.8900 | 0.8900 |
样本量为10 000时, 平均F1值为0.8900。为了验证大样本情况下的实验效果, 将样本量调整至50 000, 当参数为一元词和二元词、不去停用词、使用TF-IDF词频加权方法时效果最好。实验结果如表3所示。
表3 样本量50 000时的支持向量机实验结果
| 类别 | P | R | F1值 |
|---|---|---|---|
| Purpose | 0.9000 | 0.9200 | 0.9100 |
| Methods | 0.9300 | 0.9200 | 0.9300 |
| Results | 0.8700 | 0.9200 | 0.9000 |
| Conclusions | 0.9100 | 0.8400 | 0.8700 |
| 平均值 | 0.9025 | 0.9000 | 0.9025 |
当样本量为50 000时, 模型平均F1值为0.9025, 样本量的增加带来了0.0125的准确率提升。笔者将这两种样本量下实验结果作为对比基准, 并在深度学习方法中探索相同的样本下的实验效果。
3.2 基于DNN神经网络模型的实验
使用DNN神经网络模型, 通过调整相关参数, 设置参数如下: 词向量维度: 300; 隐藏层数量: 3; 隐藏层神经元个数: 512×3; 激活函数: relu(); 损失函数: 交叉熵损失函数; 优化方法: Adam; 批训练大小: 64。在样本量为10 000和50 000的情况下进行实验, 结果如表4所示。
表4 样本量10 000时的DNN模型实验结果
| 类别 | P | R | F1值 |
|---|---|---|---|
| Purpose | 0.8300 | 0.7900 | 0.8100 |
| Methods | 0.8600 | 0.8700 | 0.8700 |
| Results | 0.8000 | 0.8300 | 0.8100 |
| Conclusions | 0.7900 | 0.7900 | 0.7900 |
| 平均值 | 0.8200 | 0.8200 | 0.8200 |
样本量为10 000时, 经过22次迭代, DNN模型达到最佳实验效果, 获得0.8200的平均F1值, 效果不如支持向量机实验。将样本量调整至50 000, 实验结果如表5所示。
表5 样本量50 000时的DNN模型实验结果
| 类别 | P | R | F1值 |
|---|---|---|---|
| Purpose | 0.8500 | 0.8400 | 0.8500 |
| Methods | 0.8800 | 0.9000 | 0.8900 |
| Results | 0.8800 | 0.8100 | 0.8400 |
| Conclusions | 0.7800 | 0.8400 | 0.8100 |
| 平均值 | 0.8475 | 0.8475 | 0.8475 |
当样本量为50 000时, 经过35次迭代, DNN模型达到最佳实验效果, 平均F1值为0.8475。可以看出, 当样本量从10 000增加到50 000时, 模型的平均F1值由0.8200提高到0.8475, 效果仍不如支持向量机实验。但平均F1值的提升量为0.0275, 高于支持向量机模型的提升量, 说明样本量的提升对于深度学习实验来说能够获得更好的效果。
3.3 基于LSTM模型的实验
使用LSTM模型进行实验, 同样经过参数的调整, 设置参数如下: 词向量维度: 300; 隐藏层神经元个数: 800; 激活函数: relu(); 损失函数: 交叉熵损失函数; 优化方法: Adam; 批训练大小: 64。当样本量为10 000的情况下, 实验结果如表6所示。
表6 样本量10 000时的LSTM模型实验
| 类别 | P | R | F1值 |
|---|---|---|---|
| Purpose | 0.7900 | 0.7300 | 0.7600 |
| Methods | 0.8000 | 0.9000 | 0.8500 |
| Results | 0.8200 | 0.7100 | 0.7700 |
| Conclusions | 0.7200 | 0.7800 | 0.7500 |
| 平均值 | 0.7825 | 0.7800 | 0.7825 |
样本量为10 000时, 经过13次迭代, LSTM模型达到最佳实验效果, 获得了0.7825的平均F1值, 效果不如支持向量机实验。将样本量调整至50 000, 实验结果如表7所示。
表7 样本量50 000时的LSTM模型实验
| 类别 | P | R | F1值 |
|---|---|---|---|
| Purpose | 0.9000 | 0.9400 | 0.9200 |
| Methods | 0.9100 | 0.9200 | 0.9200 |
| Results | 0.8800 | 0.8700 | 0.8700 |
| Conclusions | 0.9000 | 0.8500 | 0.8700 |
| 平均值 | 0.8975 | 0.8950 | 0.8950 |
样本量为50 000时, 经过20次迭代, 模型达到最佳实验效果, 获得0.8950的平均F1值。可以看出, 当样本量从10 000增加到50 000时, 模型的平均F1值由0.7825提高到0.8950, 效果仍然不如支持向量机实验。但是平均F1值的提升量为0.1125, 比DNN模型提升更快, 并远高于支持向量机模型的提升量。再一次说明样本量的提升对于深度学习实验来说能够获得更好的效果。
3.4 基于Attention-BiLSTM模型的实验
使用Attention-BiLSTM模型进行实验。经过参数的调整, 将参数设置如下: 词向量维度: 300; 隐藏层神经元个数: 800; 激活函数: tanh(); 损失函数: 交叉熵损失函数; 批训练大小: 64。首先依然使用10 000的样本量, 在经过25次迭代之后, 模型达到最佳实验效果, 结果如表8所示。
表8 样本量10 000时的Attention-BiLSTM模型实验结果
| 类别 | P | R | F1值 |
|---|---|---|---|
| Purpose | 0.9200 | 0.9300 | 0.9300 |
| Methods | 0.9300 | 0.9400 | 0.9300 |
| Results | 0.9200 | 0.9200 | 0.9200 |
| Conclusions | 0.9100 | 0.9000 | 0.9000 |
| 平均值 | 0.9200 | 0.9225 | 0.9200 |
样本量为10 000时, 模型的平均F1值的已经达到0.9200, 远高于以上所有模型的结果。
将样本量从10 000增加到50 000, 使用相同的参数, 经过10次迭代, 模型达到最佳实验效果, 结果如表9所示。
表9 样本量50 000时的Attention-BiLSTM模型实验结果
| 类别 | P | R | F1值 |
|---|---|---|---|
| Purpose | 0.9600 | 0.9500 | 0.9500 |
| Methods | 0.9400 | 0.9500 | 0.9400 |
| Results | 0.9400 | 0.9100 | 0.9300 |
| Conclusions | 0.9200 | 0.9300 | 0.9300 |
| 平均值 | 0.9400 | 0.9350 | 0.9375 |
数据集从10 000提升到50 000时, 模型的预测能力也得到提升, 平均F1值从0.9200提升到0.9375, 达到目前最好的实验效果。这一结果体现了基于Attention机制的双向LSTM模型在科技论文摘要语步识别实验中的优势。
3.5 识别效果差异的统计学分析
为验证多种方法以及两种样本量下的语步识别性能差异是否有意义, 笔者整理了每组实验结果中4种语步类型识别结果的F1值, 如表10所示。
表10 各组实验4种语步识别结果的F1值整理
| 样本量 | 类别 | SVM 模型 | DNN 模型 | LSTM 模型 | Att-BiLSTM 模型 | |
|---|---|---|---|---|---|---|
| 10 000 | Purpose | 0.8900 | 0.8100 | 0.7600 | 0.9300 | |
| Methods | 0.9200 | 0.8700 | 0.8500 | 0.9300 | ||
| Results | 0.8900 | 0.8100 | 0.7700 | 0.9200 | ||
| Conclusions | 0.8600 | 0.7900 | 0.7500 | 0.9000 | ||
| 50 000 | Purpose | 0.9100 | 0.8500 | 0.9200 | 0.9500 | |
| Methods | 0.9300 | 0.8900 | 0.9200 | 0.9400 | ||
| Results | 0.9000 | 0.8400 | 0.8700 | 0.9300 | ||
| Conclusions | 0.8700 | 0.8100 | 0.8700 | 0.9300 | ||
分别以各组对照实验中样本量和方法作为自变量, 以各组实验结果中各类别的F1值作为因变量, 进行方差分析。分别计算出两种样本量情况下及4种方法下方差分析结果中的自由度、离差平方和、均方、F统计量和p值, 以对比不同方法和不同样本量下实验结果的F1值是否有显著差异。其中, 选择0.05作为显著水平, 若p<0.05, 则表示结果具有显著性差异。
针对10 000和50 000两种样本量下实验结果, 首先进行整体的方差分析, 然后分别限定在各方法下对两种样本量的实验结果进行方差分析, 结果如表11所示。
表11 不同样本量下实验结果方差分析结果
| 因子 | 自由度 | 离差平方和 | 均方 | F统计量 | p |
|---|---|---|---|---|---|
| 样本量 (整体) | 1.0 | 0.014450 | 0.014450 | 5.14006 | 0.03075 |
| 样本量 (SVM方法) | 1.0 | 0.000313 | 0.000313 | 0.51020 | 0.50188 |
| 样本量 (DNN方法) | 1.0 | 0.001513 | 0.001513 | 1.32 | 0.29432 |
| 样本量 (LSTM方法) | 1.0 | 0.025313 | 0.025313 | 17.30769 | 0.00594 |
| 样本量 (Att-BiLSTM方法) | 1.0 | 0.000612 | 0.000612 | 4.2 | 0.08632 |
结果表明, 整体来看实验中所使用的两种样本量下实验结果具有显著性差异(p=0.03075<0.05), 说明从总体上看样本量的提升对于模型的效果具有显著影响。其中, LSTM方法下两种样本量的实验结果具有显著性差异(p=0.00594<0.05), 各方法下样本量对结果影响的显著性排序如下: LSTM方法>Att-BiLSTM方法>DNN方法>SVM方法。
针对4种方法下的实验结果, 首先进行整体方差分析, 然后进行方法之间两两对比的方差分析, 结果如表12所示。
表12 不同方法下方差分析结果
| 因子 | 自由度 | 离差平方和 | 均方 | F统计量 | p |
|---|---|---|---|---|---|
| SVM, DNN, LSTM, Att-BiLSTM | 3.0 | 0.050837 | 0.016946 | 9.895377 | 0.000129 |
| SVM, DNN | 1.0 | 0.015625 | 0.015625 | 17.676768 | 0.000883 |
| SVM, LSTM | 1.0 | 0.013225 | 0.013225 | 4.862771 | 0.044665 |
| SVM, Att-BiLSTM | 1.0 | 0.004225 | 0.004225 | 10.803653 | 0.005401 |
| DNN, LSTM | 1.0 | 0.000100 | 0.000100 | 0.032961 | 0.858538 |
| DNN, Att-BiLSTM | 1.0 | 0.036100 | 0.036100 | 51.179747 | 0.000005 |
| LSTM, Att-BiLSTM | 1.0 | 0.032400 | 0.032400 | 12.750527 | 0.003071 |
结果显示, 4种方法实验结果整体之间对比具有显著性差异(p=0.000129<0.05)。根据4种方法的两两之间的方差分析结果, 除DNN与LSTM方法之间结果对比不具有显著性差异(p=0.858538>0.05), 其他方法之间的结果对比均存在显著差异。说明DNN方法与LSTM方法在本实验条件下的效果差别不大, LSTM略好于DNN。总体来看, 不同方法下的模型的识别效果是显著不同的。
3.6 识别效果差异的原因分析
(1) SVM方法在小样本量实验下体现了一定优势, 但大样本量实验下效果提升不够显著, 这与SVM方法的特性相关。SVM方法是通过寻找超平面的方式进行数据的分类。在线性可分的情况下, SVM利用间隔最大化的学习策略寻求一个间隔最大的超平面; 而在线性不可分的情况下, 通过核函数将低维的特征向量空间映射到高维寻求线性可分; 另一方面在SVM模型中, 少数支持向量, 而不是样本空间的维数决定分类结果。因此, 当训练样本从小样本提升到大样本时, 这一方法在进一步学习数据特征方面的优势不足, 不能实现更为细致的拟合能力提升。因此可以看到, SVM方法在训练样本量从10 000提升到50 000时, 识别效果提升最不明显。
(2) DNN方法总体上表现较差, 这与其采用最简单的神经网络结构有关。DNN模型是最基本的神经网络结构, 尤其是文本数据中上下文序列特征无法得以体现, 因此在50 000的样本量下也还未达到较理想的效果。相比于SVM方法, DNN方法具备复杂的网络结构以及大量的参数, 能够实现十分精细的参数调整和学习优化, 因此具有比传统机器学习方法SVM更强大的非线性拟合能力。在样本量增加时, DNN方法获得了更大的效果提升, 体现了一定的潜力。
(3) LSTM方法在样本量增加时效果提升十分显著, 这与其充分考虑了时序特征有关。相比于DNN模型, LSTM模型是更深入、复杂的神经网络模型。在普通神经网络结构的基础上, 融合了循环神经网络结构, 进一步考虑时序特征, 每一个时刻的输出受到上一个时刻的状态的影响。这一模型适合处理语步内容中存在的上下文序列关系。在样本量增大的时候, LSTM方法识别效果提升很快, 体现出其巨大的优势。
(4) 基于Attention机制的BiLSTM神经网络模型在两种样本量下都取得了最好的识别效果, 这与其采用双向LSTM网络结构和Attention机制有关。首先, 相比于单向LSTM网络结构, 双向LSTM网络结构不仅能体现文本数据的上文特征, 也能体现下文特征。其次, Attention机制通过自学习的方式, 获得文本中不同词汇的权重向量, 从而自动提取出对于语步识别起到关键作用的词, 这个模型可以从每个句子中捕获最重要的语义信息, 因而取得更好的识别效果。由于上述机制, Attention-BiLSTM模型超越了其他三个模型, 语步识别效果最好。
4 结 语
本研究对比分析了不同深度学习模型在科技论文摘要语步识别研究中效果及其原因。根据具体的实验结果, 得出研究结论如下:
(1) 在小规模样本实验中, 支持向量机方法具有很好的适应能力, 能获得不错的实验效果, 相比于深度学习方法具有一定的优势。但大规模样本下, 相比于深度学习方法, 提升空间较小。
(2) 相比于支持向量机方法, 深度学习方法在语步识别实验中具有更大的潜力, 能够在大规模样本的实验中迅速获得效果的提升。深度学习方法在大规模样本数据集下更能体现其优越性。
(3) 相比于普通的深度神经网络, LSTM模型尤其是双向LSTM模型能够更好地体现数据的上下文特征, 更加适用于科技论文摘要的语步识别应用。
(4) 相比于传统的特征提取方法, 基于Attention机制的特征自学习模式能够捕获更加契合模型的文本语义特征, 从而取得更佳的实验效果。
本研究主要以笔者收集的结构化论文摘要为训练和测试语料, 由于该领域的研究尚未有通用的测试语料公开以支持测评, 因此本文的研究结果, 在与其他人的结果相比较时, 在可比性上有一定的局限性。另外, 非结构化摘要更加灵活多样, 尚未进行更大规模的非结构化摘要语步识别。
在后续的研究中, 将进一步完成更大样本量的Attention-BiLSTM的模型实验, 并尝试结合特征自学习与人工提取特征的方法, 以在科技论文摘要语步识别研究中探索更完善的深度学习模型。同时还将面向非结构化摘要, 开展语义识别, 解决应用问题, 促进模型的实际应用。
作者贡献声明
张智雄: 提出研究思路, 设计研究方案, 确定论文框架, 撰写、修改论文;
刘欢: 负责Attention-BilSTM实验, 撰写和修改论文;
丁良萍: 收集语料, 负责SVM、LSTM实验, 撰写和修改论文;
吴朋民: 负责DNN实验, 撰写论文;
于改红: 文献调研, 撰写和修改论文。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: zhangzhx@mail.las.ac.cn。
[1] 张智雄. train_move_10000.csv. 10 000条训练数据集.
[2] 张智雄. train_move_50000.csv. 50 000条训练数据集.
[3] 张智雄. test_move_2000.csv. 2 000条测试数据集.
[4] 张智雄. Deep_Learning_Code.zip. 各模型算法实现代码.
[5] 张智雄. anova.xlsx. 实验结果统计表.
[6] 张智雄. anova.py. 实验结果方差分析代码.
参考文献
User-Centric Design and Evaluation of a Semantic Annotation Model for Scientific Documents
An Automated Annotation Process for the SciDocAnnot Scientific Document Model
Corpora for the Conceptualisation and Zoning of Scientific Papers
An Annotation Scheme for Discourse-level Argumentation in Research Articles
Towards Discipline-independent Argumentative Zoning: Evidence from Chemistry and Computational Linguistics
A Multi-layered Annotated Corpus of Scientific Papers
英语学术论文摘要语步结构自动识别模型的构建
[D].
Constructing a Model for the Automatic Identification of Move Structure in English Research Article Abstracts
[D].
英语学术论文摘要语步结构自动识别模型的构建
[J].
Constructing a Model for the Automatic Identification of Move Structure in English Research Article Abstracts
[J].
Efficient Estimation of Word Representations in Vector Space
[OL].
On the Expressive Power of Deep Architectures
Long Short-Term Memory
[J].
Opinion Mining with Deep Recurrent Neural Networks
Recurrent Models of Visual Attention
[OL].

{kind=link}
{kind=link}
{kind=link}
{kind=link}