




1 引 言
网络社会的迅猛发展催生大量在线评论,在线评论反馈网络用户的真实体验、感受及观点,富含有价值信息。借助情感分析技术从评论资讯中发掘出人们的观点、评价、态度以及情感[1],对社会生活和经济生活产生了深远影响。在评论挖掘领域,情感分析粒度由粗至细,粗粒度分析多针对篇章或语句,细粒度分析则聚焦评价对象及特征。面向特征的情感分析需要首先明确评价对象及其属性[2],在自然语言表达中,对象特征往往以显性或隐性方式呈现。例如,酒店评论句“位置很不错,房间的设施也很好!”中有“位置”和“设施”两个明确的显性特征;又如 “房间面临马路,太吵,睡不好觉。”中没有明确的特征词,却暗含“居住环境”这一隐性特征。目前,特征级的情感分析研究主要集中于显性特征的辨识及“特征-观点”对的判断[3,4,5,6],有效识别隐性特征尽管能显著提升情感分析的精准度,但相关研究较少。隐性特征识别是细粒度情感分析研究的难点[7]。
本研究面向中文领域,就隐性特征识别问题展开探讨。对基于关系推断和分类的两类主流识别方法进行对比,并尝试引入基于深度学习的词向量模型优化算法,探寻提升隐性特征自动识别算法性能的可行方案;同时分析数据均衡性对算法性能的影响。
2 相关研究
隐性特征识别的基本思路是:先抽取“特征-观点”对,分析观点词和显性特征词间的修饰关系,根据修饰关系建立“显性特征-观点词-隐性特征”三者的映射,以明确隐性特征语义。梳理相关文献发现,目前大多数研究以产品评论为语料,主要针对英文[2],方法上可归为关系推断法、主题聚类法及分类法。
Zhang等[8]首先构建显性特征词与关联词的共现矩阵,采用双向传播算法[3]抽取“特征-观点”对并构建共现矩阵,据此生成观点词对应的候选特征词集,最后根据候选特征词和语句中相关词项的共现关系确定语句的隐性特征语义。该方法不仅考虑了特征词与观点词的对应关系,同时也考虑了特征词和其他非观点词间的关联。Sun等[9]同样利用显性特征词与观点词间的共现关系抽取候选特征词,并通过上下文引入语义,提升隐性特征识别的准确度。两个研究均是在明确评论句中蕴含了隐性特征的前提下进行分析,Schouten等[10]则既判断评论句是否蕴含隐性特征,又对特征进行识别。研究者利用标注了隐性特征的语料集建立显性特征词及其相关词共现矩阵,通过计算显性特征与待测语句中各词项的共现分确定待测语句蕴含的隐性特征。Hai等[11]的识别方法利用关联规则,借助显性特征与观点词的共现矩阵,挖掘“观点词→特征词”的关联规则;通过语句中的观点词搜索和观点词匹配的规则确定其隐性特征语义。Wang等[12]运用多个指标确立“特征指示词→特征词”的关联规则,并根据出现频次和词性生成特征词的候选指示词,根据特征指示词的重要度,生成关联规则推断语句的隐性特征语义。
若将隐性特征识别看作分类问题,机器学习方法可用于识别隐性特征。Xu等[15]预先定义特征类别,将在显性特征句集中得到的约束和先验知识纳入隐主题模型LDA得到特征类别的相关词语,以这些词语为特征对评论句建模,通过构建SVM分类器识别隐性特征。Hajar等[16]结合语料和WordNet词典,采用朴素贝叶斯分类器识别隐性特征。邱云飞等[17]根据词性及相关规则获得候选特征词和指示词,利用指示词间的相似度对候选特征词聚类,获得隐性特征类别;再利用
综上,词向量在显性特征提取和情感分类中已有大量应用,隐性特征识别中引入词向量的研究尚未发现。因此,本文在对比关系推断法和分类法的基础上,借助词向量表达扩展特征指示词,引入语义优化隐性特征的自动识别方法。
3 隐性特征自动识别
本文将关系推断法和分类法在隐性特征识别任务中的表现进行对比。对于关系推断法,重点探讨蕴含隐性特征的评论句与特征类别的关联计算;分类法则侧重特征建模,提出引入词向量增强评论句的特征表达能力,优化隐性特征识别分类模型的思路。整体研究架构如图1所示。
图1
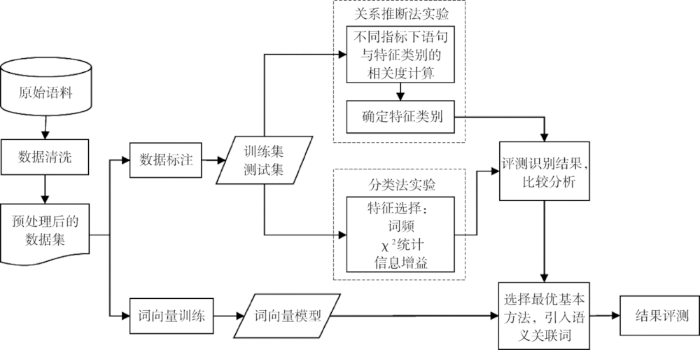
在实验过程中,发现数据均衡性对算法性能存在较大影响。为此,本研究构造了一个均衡数据集,并分别在原始数据集(非均衡)和均衡数据集上运行算法,以获取最佳的隐性特征识别模型。
3.1 Word2Vec词向量模型
图2
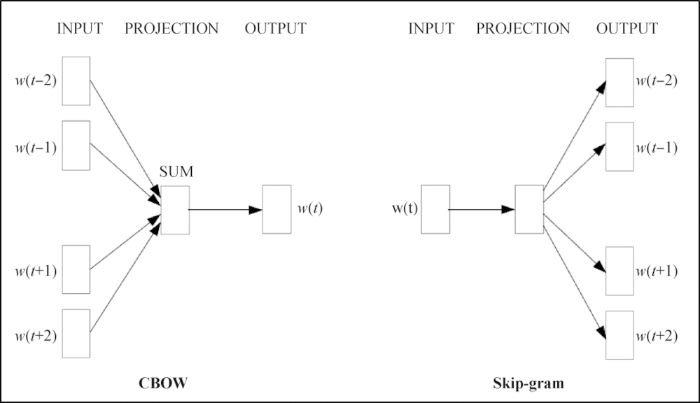
本研究利用Word2Vec词向量挖掘词语的语义关联词。词向量构建借助Python的Gensim工具包,选择CBOW模型,向量维度100,上下文窗口尺寸5,训练语料为147 156条酒店评论。将词项在
用词向量内积测度词语间的语义关联度,如公式(1)所示。
利用构建的词向量,通过语义关联度计算获得与“地铁站”关联度最高的10个词项如表1所示。
表1 “地铁站”的语义关联词
Table1
| 词项 | 语义关联度 | 词项 | 语义关联度 |
|---|---|---|---|
| 地铁口 | 0.875 | 商业街 | 0.685 |
| 地铁 | 0.869 | 解放碑 | 0.685 |
| 轻轨站 | 0.739 | 春熙路 | 0.681 |
| 公交站 | 0.727 | 夫子庙 | 0.664 |
| 王府井 | 0.694 | 车站 | 0.661 |
3.2 基于关系推断的隐性特征识别法
(1) 词项与特征类属的相关度计算
为此,本研究将句中的非观点词也纳入特征指示候选词;另一方面,引入两个指标测度词项的特征指示力,分别是共现得分Coo_score以及指示强度Ind_index。
① 共现得分Coo_score
该指标表征词项与特征类的共现关系,参考Schouten等[10]的研究,计算方法如公式(2)所示。其中,
② 指示强度Ind_index
指示强度表征词项区分特征类别的能力,采用
其中,
对于在F的特征指示词序列中未出现的词项,令
在实验语料上提取酒店领域的特征类指示词示例如表2所示。
表2 酒店领域的特征指示词示例
Table 2
| 特征类别 | 特征指示词 |
|---|---|
| 员工素质 | 热情 阿姨 亲切 礼貌 帮忙 客人 行李 顾客 询问 友好 |
| 地理位置 | 方便 地铁站 地铁 分钟 距离 远 步行 走 出行 外滩 |
| 酒店服务 | 入住 退 办理 房 时间 升级 慢 免费 长 现金 手续 安排 |
| 清洁程度 | 烟味 打扫 干净 灰 脏 蟑螂 清洗 清洁 臭 灰尘 整洁 |
| 舒适程度/居住环境 | 吵 安静 舒适 睡 晚上 舒服 休息 静 睡眠 闹 半夜 |
| 基本设施/用品配置 | 洗澡 水 淋浴 旧 床头 公共 方便 无线 提供 双人床 沐浴 |
| 价格 | 元 贵 便宜 收费 收 钱 税 物超所值 高 物有所值 |
| 食物 | 吃 餐 餐點 餐飲 面食 粗粮 套餐 用餐 餐 好吃 Brunch |
(2) 语句与特征类属的相关度计算
本研究采用三种方案计算语句S与特征类F的关联度,即单指标方案Coo_score和Ind_index以及组合指标方案Coo_score+Ind_index。令待测语句
(3) 基于词向量的语义扩展
上述共现得分Coo_socre和指示强度Ind_index计算都只考虑了训练语料中的词对特征类别产生的影响,若待测语句中的某词项语料集未涵盖,则会被忽略,结果导致相关度计算结果出现偏差。为充分利用语句中词项的特征指示作用,本研究引入词向量对待测语句中的词项进行语义扩展,将语义关联词纳入Coo_socre和Ind_index的计算。以Coo_socre为例进行说明:设
3.3 基于分类的隐性特征识别
基于标注了特征类属的语料,隐性特征识别可转化为一个文本多分类问题。尽管如此,实际研究中,隐性特征识别并不简单等同于一般性文本分类任务,算法设计需考虑到其特殊性。一则,待测评论句多为短文本,传统词袋模型会引发数据稀疏问题,可能不适用;另则,辨识隐性特征需获得有效特征指示词,基于词共现的特征选择策略可能会忽略语料未涵盖却十分重要的指示词,影响分类效果。
增强语句的特征表达是解决上述问题的可行方案。例如,Hajar等[16]利用WordNet的同/反义和派生关系对基本特征指示词进行扩展,以一定方式过滤噪音后,再通过构建朴素贝叶斯分类模型识别隐性特征。该研究证明,词项扩充能够有效提升识别精度。本研究借鉴这一思路,但也注意到,词典扩充法会受制于词典,对词典没有收纳,而特定领域或语境下存在的词间语义关系仍无法捕获。如“支付宝”和“信用卡”词典中无关联,但酒店评论中两词均指向“支付方式”,二者语义关联密切。对于隐性特征识别任务,获得语义相关的有效指示词是增强语句特征描述的重要途径。相较于词典扩充,从领域语料中挖掘词间语义关系,能更有效地引入特征指示词,获得更好的分类效果。
为此,本研究分别基于词频、
4 实验与分析
4.1 数据及预处理
(1) 词向量构建语料
图3
(2) 评测语料
参考网站设定的酒店评价指标,通过阅读分析,将酒店评论的特征主题划分为八类,分别是员工素质、地理位置、舒适程度/居住环境、基本设施/用品配置、价格、食物、清洁程度和酒店服务。采用人工方式构建酒店领域的特征词典:以名词为候选特征词,依词频从高到低排序(取前2 000个词),人工筛选特征词(前2 000个词的总词频占所有名词词频的90%以上);并补充部分非名词的特征词项,最终生成的特征词典共涵盖456个词项,示例如表3所示。
表3 酒店领域特征词典示例
Table 3
| 特征类别 | 特征词 |
|---|---|
| 员工素质 | 态度 前台 员工 服务员 店员 服务生 接待员 |
| 地理位置 | 位置 交通 地点 周边 景点 地段 |
| 舒适程度/居住环境 | 氛围 噪音 舒适度 隔音 安全感 安全性 舒适感 |
| 基本设施/用品配置 | 设施 空调 卫生间 浴室 用品 设备 热水 装饰 摆设 |
| 价格 | 价格 性价比 服务费 价位 房价 价钱 费用 |
| 食物 | 早餐 餐饮 美食 早饭 中餐 食品 餐点 |
| 清洁程度 | 味道 气味 清洁度 卫生 |
| 酒店服务 | 效率 服务 服務 |
基于特征词典,从语料中抽取不含特征词项的评论句作为分析语料,采用人工标注生成评测数据。数据标注遵照设定的规则,如表4所示。
表4 数据标注规则
Table 4
| 规则 | 规则说明 |
|---|---|
| 规则1 | 若标注人员认为评论句评价了酒店的某特征F,则明确标注为F;如果F不属于上述8类中的任何一类,标注为“其他”; |
| 规则2 | 若是针对酒店整体的评价或表达用户自身感受的评论句,如“大致上都还是很满意的。”,则认为语句不包含评价特征,标注为“无”; |
| 规则3 | 对于不包含任何特征或含有多个评价特征的评论句,标注为“无”。 |
原始评论句共10 249条,经分句、筛选、标注后返回结果经质检(抽样测试标注精度达90%),共获得含8个隐性特征的评论句2 045条,各特征类语句分布如表5所示。
表5 标注的隐性特征句特征类别分布
Table 5
| 特征类属 | 含隐性特征语句量 | 分布占比(%) |
|---|---|---|
| 地理位置 | 694 | 33.936 |
| 酒店服务 | 416 | 20.342 |
| 基本设施/用品配置 | 347 | 16.968 |
| 舒适程度/居住环境 | 259 | 12.665 |
| 员工素质 | 120 | 5.867 |
| 价格 | 84 | 4.108 |
| 清洁程度 | 72 | 3.521 |
| 食物 | 53 | 2.593 |
(3) 测评指标
实验测评指标采用准确率Accuracy、精准度Precision(P)、召回率Recall(R)和综合指标F1值。因特征主题有8个类别,整体模型评价取8个类别指标的宏平均。
4.2 实验结果与分析
根据图1,设计两组实验,采用5折交叉验证。在评测语料上,对比分析基于相关度计算的关系推断法和基于特征选择的分类法在隐性特征识别任务中的表现。在此基础上,对综合表现最好的方法进行优化,利用词向量引入语义关联词,观测语义信息对算法产生的影响。
(1) 基于关系推断的隐性特征识别实验
对3.2节提及的三种关联度计算方法进行实验,检验基于Coo_score和Ind_index两个单指标以及组合指标模式Coo_score+Ind_index进行隐性特征识别的效果。
结果如图4所示,单指标模式中,Coo_score隐性特征识别方法准确率较高而召回率较低,Ind_index方法则是召回率较高,组合模式整体表现最好,在保持Coo_score的高精确率的同时使召回率进一步提升。
图4
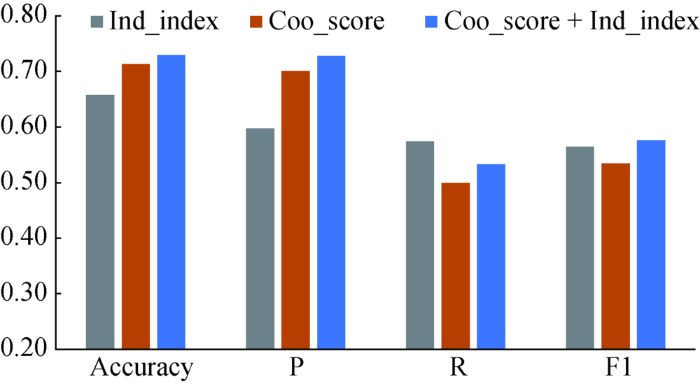
图4
隐性特征抽取结果(基于关系推断法)
Fig.4
Results of Implicit Feature Identification(Relationship-based Inference Method)
(2) 基于分类的隐性特征识别实验
采用朴素贝叶斯算法构建分类器,调用Python的Scikit-learn里的BernoulliNB算法,分别以词频、信息增益、
① 特征维度的影响
考察特征维度对算法性能的影响,实验结果如图5所示,性能评测指标为F1值。可以看到,特征空间在400维之后,各特征选择方案下的F1趋于稳定。因此,后续实验中,将特征空间维度设为500。
图5
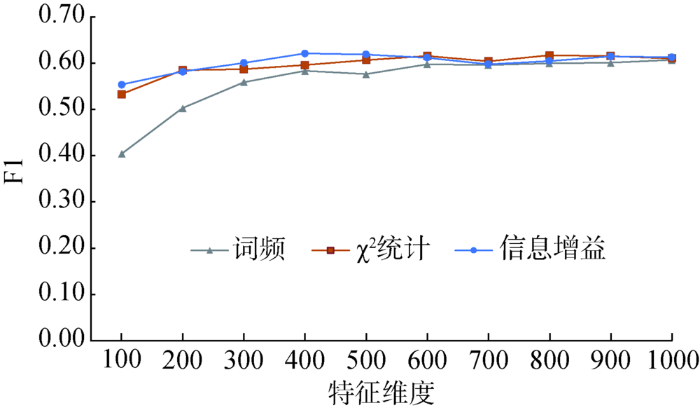
图5
不同特征维度下三种特征选择方案的F1指标
Fig.5
F1-score Based on Three Feature Selection Strategies
② 特征选择方案的影响
考察并选择最佳的特征选择方案,结果如图6所示。在研究数据集上,三种特征选择方案中,基于信息增益的分类模型的综合表现(F1)最优,其次是
图6
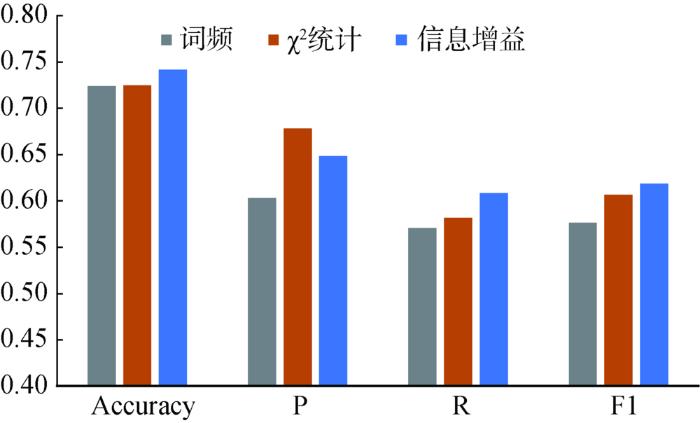
图6
不同特征选择方案下模型的分类效果
Fig.6
Performance of Classifiers Based on Different Feature Selection Models
③ 关系推断法与分类法识别效果对比
分别采用关系推断法和分类法对评论句的隐性特征进行判断,实验结果如表6所示。总体观察,在评测数据集上,分类法整体表现优于关系推断法。三个分类方案的综合指标(F1)均优于表现最好的关系推断法,即
表6 关系推断法与分类法的实验结果
Table 6
| 方法 | 方案 | 宏平均 | |||
|---|---|---|---|---|---|
| Accuracy | P | R | F1 | ||
| 关系推断法 | 0.713 | 0.701 | 0.499 | 0.535 | |
| 0.658 | 0.597 | 0.574 | 0.564 | ||
| 0.729 | 0.728 | 0.533 | 0.576 | ||
| 分类法 | 词频 | 0.724 | 0.603 | 0.571 | 0.576 |
| 0.725 | 0.678 | 0.582 | 0.607 | ||
| 信息增益 | 0.742 | 0.648 | 0.609 | 0.619 | |
(3) 引入词向量的隐性特征识别
① 多分类模型的整体表现
由于基于信息增益的分类算法整体表现最优,对其做进一步优化,将基于词向量的语义关联词引入语句模型,通过增强语句表达能力提升分类判断力;同时检验词向量在隐性特征识别任务中的作用。具体方法如3.3节所述,评测采用5折交叉验证,结果如表7所示。
表7 引入语义关联词前后信息增益法实验结果
Table 7
| 方法 | 宏平均 | ||
|---|---|---|---|
| P | R | F1 | |
| 信息增益 | 0.648 | 0.609 | 0.619 |
| 信息增益+引入关联词 | 0.638 | 0.668 | 0.644 |
引入语义关联词后F1提升0.025。召回率从引入语义关联词前的0.609升至0.668。语义关联词的引入改善了特征矩阵的稀疏性,语句模型中因纳入了更多与特征主题有关的信息,质量增强。
② 各主题特征分类模型表现
原始评论语料中,特征因获得关注度不同,导致不同特征类样本分布不均衡。某些特征的样本量较充分,有的则偏少。实验语料中“地理位置”对应评论样本较多,而“食物”则较少。语义关联词对分类模型的作用因样本数量不均衡而有所不同,如表8所示。
表8 面向具体特征的隐性特征识别结果
Table 8
| 特征类别 | 样本占比(%) | 引入语义关联词前 | 引入语义关联词后 | ||||
|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | ||
| 地理位置 | 33.936 | 0.886 | 0.909 | 0.897 | 0.943 | 0.896 | 0.918 |
| 酒店服务 | 20.342 | 0.820 | 0.754 | 0.783 | 0.840 | 0.699 | 0.761 |
| 基本设施/用品配置 | 16.968 | 0.572 | 0.736 | 0.642 | 0.605 | 0.705 | 0.650 |
| 舒适程度/居住环境 | 12.665 | 0.702 | 0.595 | 0.6435 | 0.6344 | 0.6117 | 0.622 |
| 员工素质 | 5.867 | 0.655 | 0.593 | 0.621 | 0.549 | 0.6876 | 0.609 |
| 价格 | 4.108 | 0.656 | 0.567 | 0.599 | 0.685 | 0.7251 | 0.700 |
| 清洁程度 | 3.521 | 0.533 | 0.435 | 0.454 | 0.474 | 0.4657 | 0.459 |
| 食物 | 2.593 | 0.363 | 0.279 | 0.312 | 0.374 | 0.5511 | 0.430 |
| 宏平均 | - | 0.649 | 0.609 | 0.619 | 0.638 | 0.668 | 0.644 |
样本量较充足的特征类,如“地理位置”,在引入语义关联词后,精准度提升(0.886→0.943),召回率略降(0.909→0.896),整体F1从0.897升至0.918。而样本量偏少的特征类,如“食物”(53条评论),引入语义关联词后,精准率变化不大,但召回率提升明显(0.279→0.551),整体F1从0.312升至0.430。在其他各类上,也观察到类似的指标变化规律,见图7。对于样本数量较多的“地理位置”、“酒店服务”和“基本设施/用品配置”,语义关联词引入主要增强的是语句的语义表达能力,精准率普遍提升。对于样本量偏少的“价格”、“清洁程度”和“食物”,语义关联词引入则主要对召回率产生作用,语料中未出现或未被选为特征词的词被纳入模型,相当于充实了特征类的信息,矩阵稀疏性得以改善。
图7
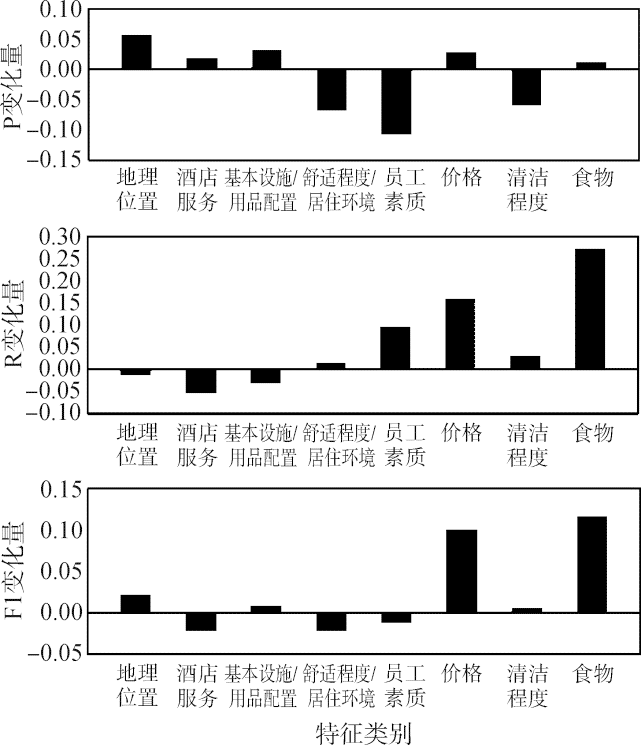
图7
引入语义关联词后各指标变化情况
Fig.7
Index Changes After Semantic-related Terms Introduced into the Model
但实验也发现,同为样本量偏少的“清洁程度”,其召回率的提升幅度较“价格”和“食物”两个特征类明显偏低。原因可能在于该特征类对应的特征词明确,主题范围窄,即使少量样本也覆盖了关键的特征词项,如“干净”、“整洁”、“脏”等,因此由语义关联词产生的优化效果不明显。“食物”、“价格”不同,这两类的特征词涵盖面宽泛,样本量少时,训练集覆盖到的关键特征词有限,语义关联词的引入扩充了特征词项,因此优化效果显著。
综上,实验表明以信息增益为特征选择指标,引入语义关联词的分类模型整体表现最好,但分类表现通常会受样本数量的影响,样本偏少的特征类识别效果略差。同时,实验发现,引入语义关联词能够有效弥补样本量少的不足,显著提升模型召回率。对于主题宽泛的特征类,作用尤其明显。具体示例如图8所示。
图8

4.3 数据均衡性对结果的影响
原始数据集中各类别样本不均衡,会导致算法训练结果偏向于样本量较多的类别,影响算法性能。为此,本文针对数据均衡性问题做了进一步探究。
实验中对数量多的类别(“地理位置”、“酒店服务”、“基本设施/用品配置”、“舒适程度/居住环境”、“员工素质”)进行随机采样,对数量少的类别(“价格”、“清洁程度”、“食物”)增加采样,各类别样本量取100,生成均衡语料集。在均衡语料集上采用5折交叉验证进行实验,结果如图9所示。
图9
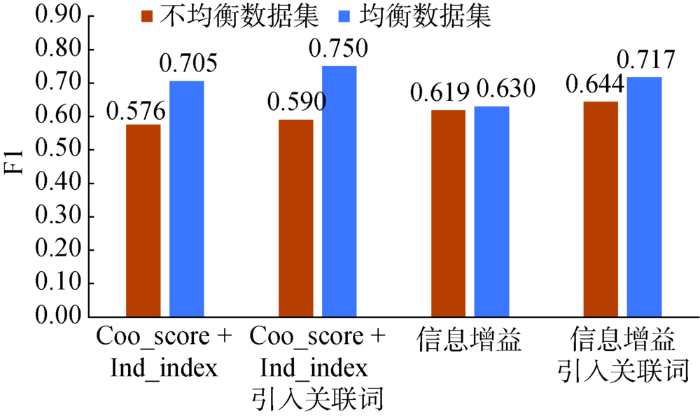
各算法在均衡数据集上的性能指标均显著优于原始非均衡数据集。
表9 不同数据集上-各方案实验结果
Table 9
| 数据集 | 方案 | P | R | F1 |
|---|---|---|---|---|
| 不均衡数据集 | 0.728 | 0.533 | 0.576 | |
| 信息增益法 | 0.648 | 0.609 | 0.619 | |
| 0.730 | 0.547 | 0.590 | ||
| 信息增益+引入关联词 | 0.638 | 0.668 | 0.643 | |
| 均衡数据集 | 0.717 | 0.717 | 0.705 | |
| 信息增益法 | 0.655 | 0.630 | 0.630 | |
| 0.754 | 0.759 | 0.750 | ||
| 信息增益+引入关联词 | 0.726 | 0.718 | 0.717 |
可见,数据集的均衡性直接影响算法性能,且对基于共现的关系推断法影响尤为明显。基于信息增益的分类法对样本量更敏感,语义关联词的引入能够有效改善分类法的性能。因此,在实际应用中,在数据量偏少而样本类别均衡的情况下,关系推断法是优选建模方案;若样本类别不均衡,分类法有更好的表现,尽管对数量少的类别的识别效果略差,但引入语义关联词能有效弥补数据量少的不足,显著提升分类模型的识别精度。
5 结 语
目前对特征级情感分析的研究主要集中于显性特征抽取及显性特征观点对的识别,隐性特征抽取研究重要但富有挑战。本研究聚焦这一主题,探讨从在线评论中自动抽取隐性特征的有效方法。这一研究对提升特征级情感分析的精度有重要意义,能帮助用户从大量在线评论中获取更为完整和准确的信息。
本文对比分析基于指标的关系推断和基于特征选择的分类算法两类隐性特征识别方法,提出引入词向量改进原方法的优化策略,实验证明引入词向量获得其语义上的关联词,能够更好地利用领域语料,进行隐性特征的自动识别。同时针对语料中的样本不均衡问题,探讨了数据均衡性对算法的影响。本文的主要研究结论可归为以下三点:
(1)对于隐性特征识别任务,若不考虑语料集类别均衡问题,分类法优于关系推断法。关系推断法基于词项的共现关系以及对分类的贡献,因判断依据较单一,整体表现不及分类算法。
(2)分类法中,基于信息增益特征选择策略的模型表现最优。但分类法对样本量敏感,特征样本偏少的情况下,模型表现受影响。本研究通过引入基于词向量的语义关联词改善语句模型,增强了语句的表达能力,有效地提升了模型的识别精准率和召回率。
(3)两类算法均受数据集类别样本均衡性的影响,样本类别均衡的数据集下算法性能更优,且关系推断法受均衡性影响更大。实际应用中,应根据研究语料的实际状况选择合适的建模方案。
研究中的不足主要有以下两点:
(1)训练词向量的语料规模不大,未来可考虑用更大规模和更多来源的数据;
(2)实验中所用的语料集数据量偏少,进行样本均衡性实验时,由于“食物”类别的数据量较少,导致均衡语料每个类别的数据量设定受限(100),未来可扩充数据集进行更深入的实验。
进一步的研究将从以下两方面展开:在线评论中普遍存在主题特征样本分布不均衡的情况,对于样本量偏少的主题类别,要想获得大量的训练数据,则需要进行更多的人工标注,如何进一步优化语句模型,在不增加标注工作量的情况下提升模型的识别准确率,还需要深入的研究。另一方面,不同于显性特征能抽取出“特征-观点”对,大多数隐性特征句中不含有观点词,如何判断不含观点词的主观语句的情感倾向是一个值得探索的新问题。
作者贡献声明
聂卉:提出研究问题,设计实验方案,论文修改及最终版本修订;
何欢:设计研究方案,负责实验,数据采集及分析,撰写论文。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail:623942541@qq.com。
[1] 何欢.酒店评论.rar. Booking.com酒店评论原始语料.
[2] 何欢.隐性特征识别标注数据.rar. 实验中使用的不均衡数据集和均衡数据集.
[3] 何欢.booking_hotel.model. 以酒店评论语料训练的词向量模型.
[4] 何欢.酒店领域特征词典.txt. 研究中构建的酒店领域特征词典.
[5] 何欢.隐性特征识别结果.rar. 在均衡数据集和不均衡数据集上的隐性特征识别结果.
参考文献
Implicit Aspect Extraction in Sentiment Analysis: Review, Taxonomy, Opportunities, and Open Challenges
[J].
Expanding Domain Sentiment Lexicon Through Double Propagation
[C]//
Extracting Product Features from Online Reviews for Sentimental Analysis
[C]//
Aspect-Based Opinion Polling from Customer Reviews
[J].
中文在线评论的产品特征与观点识别:跨领域的比较研究
[J].
Extracting Product Features and Opinions from Chinese Online Reviews: A Comparative Study on Multi-domains
[J].
细粒度情感分析研究综述
[J].
Research Review on Fine-grained Sentiment Analysis
[J].
Extracting Implicit Features in Online Customer Reviews for Opinion Mining
[C]//
A Novel Context-based Implicit Feature Extracting Method
[C]//
Finding Implicit Features in Consumer Reviews for Sentiment Analysis
[C]//
Implicit Feature Identification via Co-occurrence Association Rule Mining
[C]//
Implicit Feature Identification via Hybrid Association Rule Mining
[J].
现代图书情报技术
[J].
Implicit Feature Identification in Product Reviews
[J].
An Association-Based Unified Framework for Mining Features and Opinion Words
[J].
Implicit Feature Identification in Chinese Reviews Using Explicit Topic Mining Model
[J].
Hybrid Approach to Extract Adjectives for Implicit Aspect Identification in Opinion Mining
[C]//
商品隐式评价对象提取的方法研究
[J].
Research on Extracting Method of Commodities Implicit Opinion Targets
[J].
EXPRS: An Extended PageRank Method for Product Feature Extraction from Online Consumer Reviews
[J].
基于正则化主题建模的隐式产品属性抽取
[J].
Implicit Product Feature Extraction Through Regularized Topic Modeling
[J].
在线用户评论细粒度属性抽取
[J].
Fine-grained Aspect Extraction from Online Customer Reviews
[J].
基于在线评论词向量表征的产品属性提取
[J].
Extraction Product Features from Online Reviews Based on Word-Vector-Representation
[J].
基于词向量的领域情感词典构建
[J].
Building of Domain Sentiment Lexicon Based on Word2Vec
[J].
A Neural Probabilistic Language Model
[J].
Efficient Estimation of Word Representations in Vector Space
[OL].
面向中文微博的观点句识别研究
[J].
Study of Subjective Sentence Identification Oriented to Chinese Microblog
[J].
LTP: A Chinese Language Technology Platform
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}