1 引 言
随着信息技术的快速发展,以互联网和信息技术为支撑的新兴在线学习模式已成为教学与学习的新选择。在线学习的发展能够克服地域差异,改善教育资源分布不均衡问题,提高教学和学习质量。目前的在线学习发展存在一些不足。网络中数据信息量急剧扩增,用户面临着如何从大量信息中找到适合的高质量资源的问题;大多自主学习平台对所有用户采用统一的试题模板,并没有考虑到不同用户的能力和需求差异;传统在线学习平台大多只是提供相关学习资源(如视频、音频、文档等资料)和在线测试等功能,并没有针对性地加入教师的指导、监督功能等,致使用户学习效率变低。
知识的组织可分为4个层次,从上到下依次为学科、知识领域、知识单元和知识点[1 ] 。在教育领域中,对于知识体系的掌握可以分解为对知识点和知识点之间逻辑关系的掌握[2 ] ,并且以知识点为单位进行学习符合人类的认知规律[3 ] 。学习资源不断被创造和改变,而学习资源所在学科对应的知识点基本保持不变,因此,学习资源都应该紧紧围绕不同学科对应的全局知识点体系进行设计。现有的海量学习资源并没有明显的知识点标注,这给用户有效选择学习资源带来了极大阻碍。鉴于此,本文针对学习资源中的文本类型试题的知识点自动标注问题和个性化试题推荐问题进行研究。对学习资源对应的知识点进行自动化标注,一方面能够帮助学习者更有效地查漏补缺,减少无目的性的重复性学习,另一方面能够帮助教育工作者对教育资源进行高效的组织和管理。
2 相关研究
标注是为相关数据或者信息添加其他更多的有效信息。在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] 。所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] 。标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] 。标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等。目前关于学习资源中的试题知识点标注的研究相对较少。
文献[13 ]通过分析领域本体知识的语义环境和资源文档结构两方面信息,利用领域本体所表达的语义环境信息,实现了对农业领域中各类文档资源的语义标注,并提出一种基于本体的文档语义标注改进方法。有学者针对语音数据标注问题,通过引入6元组模型,提出一种“兴趣+收获+报酬”的三位一体的标注方案,并建立一种标注质量控制机制,成功实现了大数据语音语料库的社会标注[14 ] 。也有学者提出一种基于增量层次分析法的学习资源多标签标注方法,根据标签-资源信息构建学习资源多标签标注模型,然后利用层次分析法进行关联程度值处理,选取与学习资源相关程度最大的若干个标签作为标注标签[15 ] 。上述研究在一定程度上实现了基于语义的资源标注,方便用户检索资源并提升学习效率。但在实现过程中涉及大量的专家知识和一些人为主观操作,并且模型对海量数据的适应性不够。如何根据已有的大量学习资源自动地学习并生成有效规则,对新的试题进行相应(多)知识点标注是智能教育领域中的关键问题。
在实际的在线学习活动中,一般的在线学习推荐平台只是根据用户在线的答题错误记录,基于协同过滤、认知诊断或者模糊树匹配方法[16 ,17 ] ,提供或者推荐与错题极其相似的试题[18 ,19 ,20 ] 。这样的推荐结果很可能导致用户重复做相似或者相同的试题,而忽略了试题背后所考察的知识点以及知识点组合,降低了用户的学习效率。在题干和知识点对应的关系中,特定的题干对应特定的知识点,而对于同一知识点,题干的组织方式多种多样,所用语言也千变万化,并且题干相似的试题所考察的知识点可能不同,所以试题推荐可以优先结合考虑试题所考察的固定知识点的相似性并辅助结合试题题干的相似性进行推荐。
结合在线学习平台上的大量学习资源,即已完成人工知识点标注的试题数据和未标注的试题数据,本文提出一种基于语义关联规则的试题知识点自动标注方法(Knowledge Point Annotation based on Semantic Association Rules,KPA-SAR),利用已标注的试题数据生成有效规则,然后利用生成的规则对待标注试题进行(多)知识点标注。此外,对于用户的错题记录,本文提出一套个性化试题推荐框架,能够对特定用户进行个性化试题推荐。
3 试题知识点标注模型
3.1 有效规则生成
为生成试题内容与知识点之间的关联关系,需要对已有标注试题的内容与对应知识点之间的关联关系进行挖掘,本文基于关联规则方法进行有效规则的挖掘。有效规则生成过程主要包括4个阶段,分别是试题文本预处理、多重知识点分割、频繁项集挖掘以及有效规则挖掘,如图1 所示。每道试题内容最多包含三个部分,即试题文档(Document)、试题题干(Question)及其相应的试题选项(Options),其中只有材料题这一题型的试题才有试题文档,如英文阅读理解、语文文言文阅读、政治案例分析、历史材料分析题等;试题题干是所有类型试题都包含的部分,即试题的问题部分;试题选项一般表示选择题对应的所有选项。每道试题后的 KP w supp conf
图1
图1
有效规则生成流程
Fig.1
Generation Process of Effective Rules
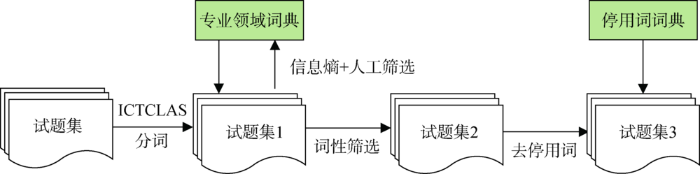
(1)试题文本预处理阶段主要包含三个预处理任务,分别为分词、词性筛选以及去停用词,如图2 所示。
图2
图2
文本预处理流程
Fig.2
Schematic Illustration of Text Preprocessing
对于分词任务,在搜狗细胞词库中搜集相关专业词汇,构建专业领域词典,辅助ICTCLAS系统[21 ] 进行分词操作;分词结果中会出现许多原本属于同一个词而被错分为多个词的情况,如“一元一次方程”被分成“一元”、“一次”和“方程”三个粒度较小的词。为保证分词后语义的准确性,采用信息熵方法对分词后的结果进行词合并 [22 ] 。将满足条件的两个词合并为新的组合词,人工筛选组合词后添加到专业领域词典中,再次对原试题集分词,重复多次。对于词性筛选任务,选取有明确语义概念的实词,如名词、具有名词功能的动词、具有名词功能的形容词、动词性惯用语以及相关数学符号作为研究对象。对于去停用词任务,选取领域内无实际价值的实词(如“问题”、“概念”、“运用”等)构建本领域停用词词典,然后处理后的试题集进行去停用词操作。最后,每道试题都通过一组词语特征集合表示出来。
(2)一道试题可能包含多个知识点,为挖掘试题内容与单个知识点间的关联关系,将一道试题的多个知识点进行分解,分解为一道试题对应单个知识点。如此,涵盖 K K K
(3)基于上述处理好的所有试题以及对应的单一知识点,将每道试题对应的特征词集以及知识点看作一组由词项形成的事务集合,仿照关联规则方法,找到所有事务集合中满足最小支持度的所有频繁项集。显然这个过程会忽略那些出现次数较少但是又不可或缺的知识点。为保证在频繁项集中能够包含上述这些知识点,可以设定不同的知识点具有不同的最小支持度阈值。依据Agrawal等[23 ] 提出的关联规则挖掘方法中的定义, TDB = { T 1 , T 2 , ⋯ , T n } T i = { i 1 , i 2 , ⋯ , i m } I = { i 1 , i 2 , ⋯ , i p } p ≥ m T i ⊆ I X k X k - 项集。项集 X T supp ( X ) TDB X
(1) supp ( X ) = | { T i ∈ I ; X ⊆ T i } | / | TDB |
其中, | { T i ∈ I ; X ⊆ T i } | X TDB
(4)从频繁项集中挖掘出试题内容与知识点之间对应的有效规则是整个过程中最重要的环节。置信度是用来度量生成规则可信程度的重要指标。一个规则 X ⇒ Y X Y
(2) conf ( X ⇒ Y ) = supp ( X ⋃ Y ) supp ( X )
其中,项集 X Y rul e i rul e j rul e i rul e i _ l h s ⇒ rul e i _ r h s , sup p i , con f i rul e j rul e j _ l h s ⇒ rul e j _ r h s , sup p j , con f j rule _ l h s rule _ r h s supp conf rul e i _ r h s = rul e j _ r h s rul e i _ l h s ⊆ rul e j _ l h s rul e i rul e j
经过上述4个阶段,可以从已标注试题集中挖掘出有效的规则集,利用这些有效的规则集,辅助后续阶段的知识点标注任务。
3.2 知识点标注模型
根据生成的有效规则集,可以对未标注的试题进行知识点标注。知识点标注主要包括三个步骤,分别是特征抽取、文本语义相似性计算以及运用标注模型进行标注,如图3 所示。
图3
图3
知识点标注流程
Fig.3
Knowledge Point Annotation Process
特征抽取过程中,同样用ICTCLAS对试题内容进行分词处理,分词过程中,除了有效规则生成阶段中已经生成的领域词典外,将生成的有效规则集中的前件词项也作为专业词加入到领域词典中辅助分词,这样可以使得分词更为准确。分词完成之后,借助哈尔滨工业大学社会计算与信息检索研究中心提供的“同义词词林”等外部资源[24 ] 进行语义相近词的匹配,并将语义相近的词替换为在有效规则集的前件中出现的特征词。最后,同样选取名词、具有名词功能的动词、具有名词功能的形容词、动词性惯用语以及相关数学符号作为抽取出来的特征。
文本语义相似性计算阶段,需要计算有效规则集中每条规则的前件与待标注试题内容语义相似度。对于任意一个待标注试题,计算试题内容的特征词词项集合 dat a i = { w i , 1 , w i , 2 , ⋯ , w i , ni } , i = 1 , ⋯ , n rul e j _ l h s = { w j , 1 , w j , 2 , ⋯ , w j , rj } , j = 1 , ⋯ , M
(3) si m j = sim ( dat a i , rul e j _ l h s ) = | d at a i ⋂ rul e j _ l h s | / max { | dat a i | , | rul e j _ l h s | }
其中, | dat a i | | rul e j _ l h s | dat a i rul e j _ l h s | dat a i ⋂ rul e j _ l h s |
依据上一任务得到的每一条规则对应的支持度和置信度,以及待标注试题 dat a i sim
对有效规则集中的支持度和置信度分别进行归一化,如公式(4)所示。
(4) sup p j = sup p j max t = 1 , ⋯ , M sup p t con f j = con f j max t = 1 , ⋯ , M con f t j = 1 , ⋯ , M
依据每条规则的两个归一化的指标,组合成一个新的规则指标,如公式(5)所示。
(5) pro p j = f ( sup p j , con f j ) = ( sup p j + con f j ) / 2 , j = 1 , ⋯ , M
根据有效规则集中每条规则与待标注试题 dat a i dat a i index 1 i pro p j , j = 1 , ⋯ , M prop index 2
(6) rule _ index = index 2 if | index 1 i | = M index 1 i if index 1 i ⋂ index 2 = ∅ and | index 1 i | < M index 1 i ⋂ index 2 , if index 1 i ⋂ index 2 ≠ ∅ and | index 1 i | < M
可以从中选择出最适合待标注试题 dat a i | index 1 i | = M dat a i prop dat a i index 1 i ⋂ index 2 ≠ ∅ sim prop dat a i index 1 i ⋂ index 2 = ∅ in d ex 1 i dat a i
4 试题知识点标注实验
选取某在线教育机构提供的初中三年级数学和高中历史中已标注的试题作为实验数据集。数学类数据集总共包含2 248道已标注的试题,共167个不同的知识点,每道试题平均有1.61个知识点;历史类数据集总共包含3 483道已标注试题,对应366个不同的知识点,每道试题平均有1.09个知识点。暂时不考虑纯文本工具不能识别的数学试题中的图形和公式符号信息以及历史试题中的图片信息,单纯用试题中的文本数据及可识别的符号数据进行知识点标注实验。
将试题知识点标注看作一个多标签分类问题处理时,即每个知识点表示一个不同的类别,一个试题可能包含有多个知识点标签,则可以用数据挖掘中经典的4种分类方法:朴素贝叶斯(Naïve Bayes)、K最近邻(KNN)、随机森林(Random Forest)以及支持向量机(SVM),进行知识点标注任务。处理过程中,采用10折交叉验证方法进行处理,并用10组数据实验的平均准确度衡量不同分类方法标注的准确度,如公式(7)所示。
(7) Accuracy ( met h o d i ) = | labeled ⋂ test | / | test |
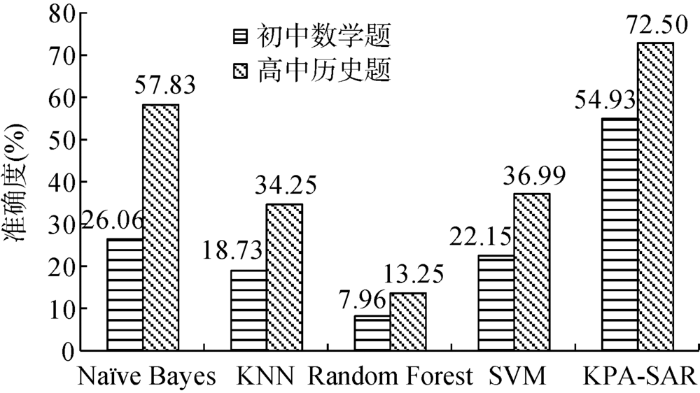
其中,分子表示标注正确的样本数量,分母表示测试样本的总数量。4种对比方法在两类语料上的分类准确度以及本文所提方法(KPA-SAR)的分类准确度结果如图4 所示,标注结果实例如表1 所示。
图4
图4
基于语义关联规则的知识点标注方法与分类方法的准确度对比
Fig.4
Accuracy Comparison of the KPA-SAR with Some Classification Methods
实验结果表明,基于语义关联规则的试题知识点标注方法的标注准确度明显优于其他经典分类方法得到的分类标注结果。KPA-SAR的平均准确度(数学语料54.93%,历史语料72.50%)相比于其他4种方法的平均准确度:朴素贝叶斯(数学语料26.06%,历史语料57.83%)、KNN(数学语料18.73%,历史语料34.25%)、随机森林(数学语料7.96%,历史语料13.25%)和SVM(数学语料22.15%,历史语料36.99%),有较大提升。分类方法下较差的实验结果说明学习资源中试题知识点标注问题不仅仅是一个简单的多标签分类问题,更是背后的语义关联问题。而数据挖掘中现有的分类方法并不能有效地挖掘试题题干与其对应知识点间的语义关联关系。基于语义的关联规则能够在挖掘有效规则的基础上,利用规则前件与待标注试题题干的文本语义相似性程度决定待标注试题中涵盖的知识点。
整体实验的标注准确度普遍偏低(特别是数学题语料),这与知识点体系和已标注试题情况密切相关,最重要的特点是存在知识点交叉和包含关系。特征词匹配只是属于浅层的语义理解,而无法挖掘出试题和知识点间的深层语义关系,而关联规则虽能够挖掘出部分语义关联较强的特征词,但仍不能有效地挖掘出训练集中出现次数较少但语义密切相关的特征词。如表1 中的实例2,模型根据题干中的“函数”、“最大值”和“最小值”等特征词推断出其知识点为“函数值域”,但该试题真正考察的是与“函数”和“切线”相关的“导数”知识点。
从已有知识点划分(教学大纲)看,不同章节的知识点间存在重叠或者包含关系,而不是通常认为的一个教学大纲就类似一个知识树,不同知识点间存在错综的关联关系。如指数函数和幂函数分布在不同的章节,而这两个概念都隶属于另外一个章节——函数。从已有试题标注情况看,部分试题所标注的知识点也存在包含关系,如一个试题,可以标注为“等差数列前n项和”,也可以标注为“等差数列”,也可标注为“数列”等。这种情况随着专家的严格校正后,标注准确度会有所改善。另外,相同方法下高中历史题的标注准确度均优于初中数学题的标注准确度,这与课程的特点密切相关。数学题中公式符号较多,并且相同符号的不同组合构成不同试题,所以导致分词后的数学题之间的差异性小。而历史题几乎是纯语言文字组成的,并且知识点大纲较为清晰,不会存在过多的知识点交叉或者包含关系。另外,数学试题的平均知识点个数相比历史试题的平均知识点个数多,数学试题在标注的时候相当于多标签标注问题,而历史试题在标注的时候相当于单标签标注问题,这也是数学试题标注准确度较低的一个原因。
5 试题推荐应用实例
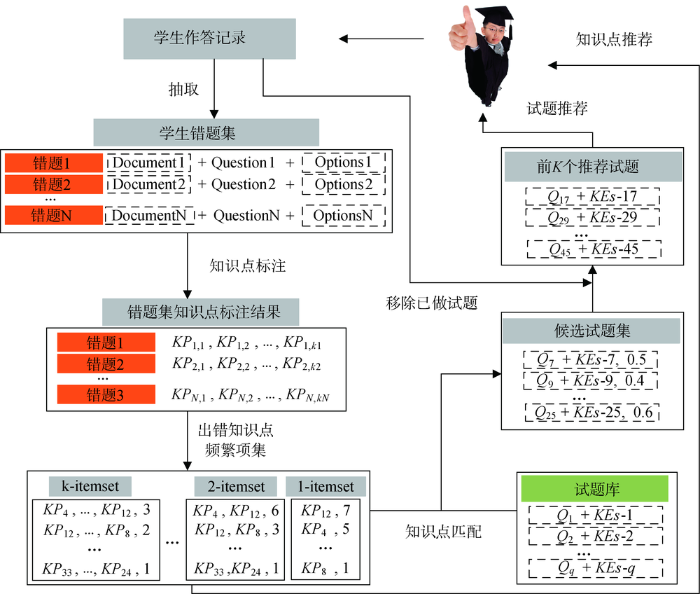
与已有的针对多个用户的在线推荐系统[25 ] 类似,本文对单个用户的多个错误试题的组合进行挖掘,尝试从用户频繁出错试题中发现一些潜在的特点和规律,然后基于此对该用户推荐新的试题或者试题组合。首先基于语义关联规则的知识点标注方法,对用户错题集标注相应的知识点;然后从错题集标注的知识点中挖掘出用户频繁出错的知识点项集,即频繁出错的知识点组合;最后根据所有频繁知识点项集计算与试题库中每个试题对应知识点的相似性程度,依据优先级较高的知识点相似性和优先级相对较低的题干相似性进行单个试题或者多个试题组合的推荐,具体的个性化试题推荐流程如图5 所示。试题库中,每道试题 Q
(8) weig h t ( Q _ KEs ) = ∑ t = 1 k ∑ i = 1 g ( t _ itemset ) sim ( t _ itemset ( i ) , Q _ KEs ) ∑ t = 1 k g ( t _ itemset )
图5
图5
基于知识点关联特性的个性化试题推荐流程
Fig.5
Personalized Question Recommendation Process Based on the Correlation Characteristics Between Knowledge Points
其中, Q _ KEs weig h t ( Q _ KEs ) t _ itemset t t - 频繁项集, k t g ( t _ itemset ) t _ itemset sim
对部分数学错题记录进行实验,推荐结果样例如表2 所示。第一个样例表示针对单个试题的个性化推荐,第二个样例表示针对多个试题组合的个性化推荐。从推荐结果可以看出,此种推荐方法不再单纯追求试题题干的相似性,而更关注试题所考察知识点的相似性。如第一个样例中的第二个推荐试题,试题中没有出现“四棱锥”一词,而其所考察的正是与“四棱锥”相关的知识点;第二个样例的推荐从原试题考察的多项式函数和余弦函数上的导数及切线的相关知识扩充到对数函数以及函数图像相关内容上的导数和切线等知识。
6 结 语
在线学习资源的试题知识点自动标注和个性化试题推荐是智能教育领域中的重要问题。试题知识点自动标注可以帮助学习者有效地获取相关学习内容,提高学习效率,也能够帮助施教者快速总结试题所考察的知识点分布情况,方便考核过程中对知识点体系的平衡以及整体把控。通过对知识点标注问题的研究,本文得到以下结论和启示。
(1)若单纯地将试题知识点标注作为一个分类问题,用经典分类方法,如朴素贝叶斯、K最近邻、随机森林以及支持向量机,经实验验证,效果并不理想,平均准确率只有25%(数学)和36%(历史)左右。
(2)本文所提基于语义关联规则方法,能够充分挖掘试题题干和知识点间对应的有效关联规则,利用未标注试题题干与有效规则前件的语义相似关系,对未标注试题进行知识点标注的平均准确率可以达到54.93%(数学)和72.50%(历史)。
(3)虽然本文所提方法的标注准确度相比其他分类方法有较大提高,但是整体准确度仍然较低,与期望值还有很大差距。试题标注准确度相对较低,其原因有多方面:由于不同学科自身的特点以及学科知识点间的交叉和包含关系,致使训练所用的已标注数据的可靠性不足;本文方法存在一定的局限性,受计算机内存容量和运行速度限制,不能够充分挖掘出每个知识点下所有的有效规则,只能根据一定的筛选条件选择出部分有代表性的规则,这影响了后续的标注准确度。
(4)本文给出的试题推荐方法中,首先综合考虑单个学生错题集中隐藏的知识点,挖掘其中频繁出错的知识点,有针对性地推荐一些知识点相关联的、用户之前没有做过的试题,并且推荐方法中同样涵盖针对单一错题的推荐,所以本文推荐方法考虑的因素更多、应用更广泛。
(5)本文只在数学和历史两类不同类型数据上进行实验,未来可以尝试在所有学科数据上进行实验,并及时完善知识点标注模型。同时,可以尝试将深度学习应用在更大规模的教育数据中,挖掘出语义相近的教育用词,并辅助知识点的标注。
支撑数据
支撑数据由作者自存储,E-mail: dlutguo@dlut.edu.cn。
[1] 魏伟,郭崇慧. 数据支撑.rar. 初三数学+高中历史试题数据.
参考文献
View Option
[1]
Roberts E Engel G Chang C , et al . Computing Curricula 2001: Computer Science
[J]. IEEE Computer Society , 2001 ,34 (1 ):4 -23 .
[本文引用: 1]
[2]
李卫东 , 杨耐生 , 申强华 , 等 . 远程教育杂志
[J]. 远程教育杂志 , 2006 (5 ):34 -37 .
[本文引用: 1]
( Li Weidong Yang Naisheng Shen Qianghua , et al . Development of a Distance-learning Tutoring System Based on Knowledge Points
[J]. Distance Education Journal , 2006 (5 ):34 -37 .)
[本文引用: 1]
[3]
陈智 , 隋光远 , 皮秀云 . 论知识点是人的认知单位
[J]. 心理科学 , 2002 ,25 (3 ):369 -370 .
[本文引用: 1]
( Chen Zhi Sui Guangyuan Pi Xiuyun . Knowledge-Point is a Cognitive Unit
[J]. Psychological Science , 2002 ,25 (3 ):369 -370 .)
[本文引用: 1]
[4]
Oren E Delbru R Möller K , et al . Annotation and Navigation in Semantic Wikis
[C]// Proceedings of the 1st Workshop on Semantic Wikis: From Wiki to Semantics. 2006 .
[本文引用: 1]
[5]
傅柱 . 图书馆学研究
[J]. 图书馆学研究 , 2016 (4 ):10 -17 .
[本文引用: 2]
( Fu Zhu . A Review of Semantic Annotation
[J]. Research on Library Science , 2016 (4 ):10 -17 .)
[本文引用: 2]
[6]
Song Z . Application of Cloud Desktop in Modern Chinese Multi-Category Words Part of Speech Tagging
[J]. Procedia Engineering , 2017 ,174 :1215 -1220 .
[本文引用: 1]
[7]
Meguehout H Bouhadada T Laskri M T . Semantic Role Labeling for Arabic Language Using Case-Based Reasoning Approach
[J]. International Journal of Speech Technology , 2017 ,20 (2 ):363 -372 .
[本文引用: 1]
[8]
邓三鸿 , 王昊 , 秦嘉杭 , 等 . 基于字角色标注的中文书目关键词标引研究
[J]. 中国图书馆学报 , 2012 ,38 (2 ):38 -49 .
[本文引用: 1]
( Deng Sanhong Wang Hao Qin Jiahang , et al . Research on Keywords Indexing for Chinese Bibliography Based on Word Roles Annotation
[J]. Journal of Library Science in China , 2012 ,38 (2 ):38 -49 .)
[本文引用: 1]
[9]
陆伟 , Stephen Robertson . 基于域加权词频法的XML文档级检索实现与评价
[J]. 中国图书馆学报 , 2006 ,32 (6 ):57 -60 .
[本文引用: 1]
( Lu Wei Stephen Robertson . Field-Weighted XML Document Level Retrieval and Evaluation
[J]. Journal of Library Science in China , 2006 ,32 (6 ):57 -60 .)
[本文引用: 1]
[10]
徐雷 , 王晓光 . 叙事型图像语义标注模型研究
[J]. 中国图书馆学报 , 2017 ,43 (5 ):70 -83 .
[本文引用: 1]
( Xu Lei Wang Xiaoguang . Narrative Image Annotation Ontology for Semantic Web
[J]. Journal of Library Science in China , 2017 ,43 (5 ):70 -83 .)
[本文引用: 1]
[11]
Zhao J Glueck M Breslav S , et al . Annotation Graphs: A Graph-Based Visualization for Meta-Analysis of Data Based on User-Authored Annotations
[J]. IEEE Transactions on Visualization and Computer Graphics , 2016 ,23 (1 ):261 -270 .
[本文引用: 1]
[12]
余春 . 中美大学图书馆应用社会标注的比较研究
[J]. 大学图书馆学报 , 2014 ,32 (1 ):83 -89 .
[本文引用: 1]
( Yu Chun . Comparative Study on the Application of Social Tagging in American and Chinese Academic Libraries
[J]. Journal of Academic Libraries , 2014 ,32 (1 ):83 -89 .)
[本文引用: 1]
[13]
陈叶旺 , 李文 , 彭鑫 , 等 . 基于本体的文档语义标注改进方法
[J]. 东南大学学报:自然科学版 , 2009 ,39 (6 ):1109 -1113 .
[本文引用: 1]
( Chen Yewang Li Wen Peng Xin , et al . Improved Semantic Annotation Method for Documents Based on Ontology
[J]. Journal of Southeast University: Natural Science Edition , 2009 ,39 (6 ):1109 -1113 .)
[本文引用: 1]
[14]
李宏言 , 范利春 , 高鹏 , 等 . 大数据语音语料库的社会标注技术
[J]. 清华大学学报:自然科学版 , 2013 ,53 (6 ):908 -912 .
[本文引用: 1]
( Li Hongyan Fan Lichun Gao Peng , et al . Social Annotation Technology for Large Speech Corpora
[J]. Journal of Tsinghua University: Science and Technology , 2013 ,53 (6 ):908 -912 .)
[本文引用: 1]
[15]
吴雷 , 刘贤友 , 孙丙宇 . 基于增量AHP的学习资源多标签标注研究
[J]. 电子技术 , 2015 ,44 (4 ):10 -15 .
[本文引用: 1]
( Wu Lei Liu Xianyou Sun Bingyu . Research on Multi-label Annotation of Learning Resources Based on Incremental AHP
[J]. Electronic Technology , 2015 ,44 (4 ):10 -15 .)
[本文引用: 1]
[16]
朱天宇 , 黄振亚 , 陈恩红 , 等 . 基于认知诊断的个性化试题推荐方法
[J]. 计算机学报 , 2017 ,40 (1 ):176 -191 .
[本文引用: 1]
( Zhu Tianyu Huang Zhenya Chen Enhong , et al . Cognitive Diagnosis Based Personalized Question Recommendation
[J]. Chinese Journal of Computers , 2017 ,40 (1 ):176 -191 .)
[本文引用: 1]
[17]
Wu D Lu J Zhang G . A Fuzzy Tree Matching-Based Personalized E-Learning Recommender System
[J]. IEEE Transactions on Fuzzy Systems , 2015 ,23 (6 ):2412 -2426 .
[本文引用: 1]
[18]
Eyharabide V Amandi A . Ontology-Based User Profile Learning
[J]. Applied Intelligence , 2012 ,36 (4 ):857 -869 .
[本文引用: 1]
[19]
Salehi M Kamalabadi I N . Hybrid Recommendation Approach for Learning Material Based on Sequential Pattern of the Accessed Material and the Learner’s Preference Tree
[J]. Knowledge-Based Systems , 2013 ,48 :57 -69 .
[本文引用: 1]
[20]
Verbert K Manouselis N Ochoa X , et al . Context-aware Recommender Systems for Learning: A Survey and Future Challenges
[J]. IEEE Transactions on Learning Technologies , 2012 ,5 (4 ):318 -335 .
[本文引用: 1]
[21]
Liu Q Zhang H P Yu H , et al . Chinese Lexical Analysis Using Cascaded Hidden Markov Model
[J]. Journal of Computer Research and Development , 2004 ,41 (8 ):1421 -1429 .
[本文引用: 1]
[22]
Wei W Guo C H Chen J F , et al . Textual Topic Evolution Analysis Based on Term Co-occurrence: A Case Study on the Government Work Report of the State Council(1954-2017)
[C]//Proceedings of the 12th International Conference on Intelligent Systems and Knowledge Engineering(ISKE). 2017 : 1 -6 .
[本文引用: 1]
[23]
Agrawal R Imielinski T Swami A N . Mining Association Rules Between Sets of Items in Large Databases
[C]//Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data. 1993 : 207 -216 .
[本文引用: 1]
[24]
哈尔滨工业大学社会计算与信息检索研究中心 . 同义词词林扩展版 [OL].[2017-12-04]. https://www.ltp-cloud.com/download/.
URL
[本文引用: 1]
( Center for Social Computing and Information Retrieval, Harbin Institute of Technology . Synonym Word Forest Expansion Version [OL].[2017-12-04]. https://www.ltp-cloud.com/download/.)
URL
[本文引用: 1]
[25]
Dwivedi P Bharadwaj K K . E-Learning Recommender System for a Group of Learners Based on the Unified Learner Profile Approach
[J]. Expert Systems , 2015 ,32 (2 ):264 -276 .
[本文引用: 1]
Computing Curricula 2001: Computer Science
1
2001
... 知识的组织可分为4个层次,从上到下依次为学科、知识领域、知识单元和知识点[1 ] .在教育领域中,对于知识体系的掌握可以分解为对知识点和知识点之间逻辑关系的掌握[2 ] ,并且以知识点为单位进行学习符合人类的认知规律[3 ] .学习资源不断被创造和改变,而学习资源所在学科对应的知识点基本保持不变,因此,学习资源都应该紧紧围绕不同学科对应的全局知识点体系进行设计.现有的海量学习资源并没有明显的知识点标注,这给用户有效选择学习资源带来了极大阻碍.鉴于此,本文针对学习资源中的文本类型试题的知识点自动标注问题和个性化试题推荐问题进行研究.对学习资源对应的知识点进行自动化标注,一方面能够帮助学习者更有效地查漏补缺,减少无目的性的重复性学习,另一方面能够帮助教育工作者对教育资源进行高效的组织和管理. ...
远程教育杂志
1
2006
... 知识的组织可分为4个层次,从上到下依次为学科、知识领域、知识单元和知识点[1 ] .在教育领域中,对于知识体系的掌握可以分解为对知识点和知识点之间逻辑关系的掌握[2 ] ,并且以知识点为单位进行学习符合人类的认知规律[3 ] .学习资源不断被创造和改变,而学习资源所在学科对应的知识点基本保持不变,因此,学习资源都应该紧紧围绕不同学科对应的全局知识点体系进行设计.现有的海量学习资源并没有明显的知识点标注,这给用户有效选择学习资源带来了极大阻碍.鉴于此,本文针对学习资源中的文本类型试题的知识点自动标注问题和个性化试题推荐问题进行研究.对学习资源对应的知识点进行自动化标注,一方面能够帮助学习者更有效地查漏补缺,减少无目的性的重复性学习,另一方面能够帮助教育工作者对教育资源进行高效的组织和管理. ...
远程教育杂志
1
2006
... 知识的组织可分为4个层次,从上到下依次为学科、知识领域、知识单元和知识点[1 ] .在教育领域中,对于知识体系的掌握可以分解为对知识点和知识点之间逻辑关系的掌握[2 ] ,并且以知识点为单位进行学习符合人类的认知规律[3 ] .学习资源不断被创造和改变,而学习资源所在学科对应的知识点基本保持不变,因此,学习资源都应该紧紧围绕不同学科对应的全局知识点体系进行设计.现有的海量学习资源并没有明显的知识点标注,这给用户有效选择学习资源带来了极大阻碍.鉴于此,本文针对学习资源中的文本类型试题的知识点自动标注问题和个性化试题推荐问题进行研究.对学习资源对应的知识点进行自动化标注,一方面能够帮助学习者更有效地查漏补缺,减少无目的性的重复性学习,另一方面能够帮助教育工作者对教育资源进行高效的组织和管理. ...
论知识点是人的认知单位
1
2002
... 知识的组织可分为4个层次,从上到下依次为学科、知识领域、知识单元和知识点[1 ] .在教育领域中,对于知识体系的掌握可以分解为对知识点和知识点之间逻辑关系的掌握[2 ] ,并且以知识点为单位进行学习符合人类的认知规律[3 ] .学习资源不断被创造和改变,而学习资源所在学科对应的知识点基本保持不变,因此,学习资源都应该紧紧围绕不同学科对应的全局知识点体系进行设计.现有的海量学习资源并没有明显的知识点标注,这给用户有效选择学习资源带来了极大阻碍.鉴于此,本文针对学习资源中的文本类型试题的知识点自动标注问题和个性化试题推荐问题进行研究.对学习资源对应的知识点进行自动化标注,一方面能够帮助学习者更有效地查漏补缺,减少无目的性的重复性学习,另一方面能够帮助教育工作者对教育资源进行高效的组织和管理. ...
论知识点是人的认知单位
1
2002
... 知识的组织可分为4个层次,从上到下依次为学科、知识领域、知识单元和知识点[1 ] .在教育领域中,对于知识体系的掌握可以分解为对知识点和知识点之间逻辑关系的掌握[2 ] ,并且以知识点为单位进行学习符合人类的认知规律[3 ] .学习资源不断被创造和改变,而学习资源所在学科对应的知识点基本保持不变,因此,学习资源都应该紧紧围绕不同学科对应的全局知识点体系进行设计.现有的海量学习资源并没有明显的知识点标注,这给用户有效选择学习资源带来了极大阻碍.鉴于此,本文针对学习资源中的文本类型试题的知识点自动标注问题和个性化试题推荐问题进行研究.对学习资源对应的知识点进行自动化标注,一方面能够帮助学习者更有效地查漏补缺,减少无目的性的重复性学习,另一方面能够帮助教育工作者对教育资源进行高效的组织和管理. ...
Annotation and Navigation in Semantic Wikis
1
2006
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
图书馆学研究
2
2016
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
... [5 ].标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
图书馆学研究
2
2016
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
... [5 ].标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
Application of Cloud Desktop in Modern Chinese Multi-Category Words Part of Speech Tagging
1
2017
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
Semantic Role Labeling for Arabic Language Using Case-Based Reasoning Approach
1
2017
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
基于字角色标注的中文书目关键词标引研究
1
2012
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
基于字角色标注的中文书目关键词标引研究
1
2012
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
基于域加权词频法的XML文档级检索实现与评价
1
2006
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
基于域加权词频法的XML文档级检索实现与评价
1
2006
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
叙事型图像语义标注模型研究
1
2017
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
叙事型图像语义标注模型研究
1
2017
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
Annotation Graphs: A Graph-Based Visualization for Meta-Analysis of Data Based on User-Authored Annotations
1
2016
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
中美大学图书馆应用社会标注的比较研究
1
2014
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
中美大学图书馆应用社会标注的比较研究
1
2014
... 标注是为相关数据或者信息添加其他更多的有效信息.在图书情报学领域,标注得到了较好的发展和应用,通常所说的“标注”指标注的结果[4 ] .所有标注的建立,都是在一定情境下的标注数据和被标注数据之间的关联[5 ] .标注可以划分为传统网络标注、大众标注和语义标注三类[5 ] .标注的任务包括词语词性标注[6 ] 、语义角色标注[7 ,8 ] 、文档类别标注[9 ] 、图像标注[10 ] 、用户特性标注 [11 ] 、社会标注[12 ] 等.目前关于学习资源中的试题知识点标注的研究相对较少. ...
基于本体的文档语义标注改进方法
1
2009
... 文献[13 ]通过分析领域本体知识的语义环境和资源文档结构两方面信息,利用领域本体所表达的语义环境信息,实现了对农业领域中各类文档资源的语义标注,并提出一种基于本体的文档语义标注改进方法.有学者针对语音数据标注问题,通过引入6元组模型,提出一种“兴趣+收获+报酬”的三位一体的标注方案,并建立一种标注质量控制机制,成功实现了大数据语音语料库的社会标注[14 ] .也有学者提出一种基于增量层次分析法的学习资源多标签标注方法,根据标签-资源信息构建学习资源多标签标注模型,然后利用层次分析法进行关联程度值处理,选取与学习资源相关程度最大的若干个标签作为标注标签[15 ] .上述研究在一定程度上实现了基于语义的资源标注,方便用户检索资源并提升学习效率.但在实现过程中涉及大量的专家知识和一些人为主观操作,并且模型对海量数据的适应性不够.如何根据已有的大量学习资源自动地学习并生成有效规则,对新的试题进行相应(多)知识点标注是智能教育领域中的关键问题. ...
基于本体的文档语义标注改进方法
1
2009
... 文献[13 ]通过分析领域本体知识的语义环境和资源文档结构两方面信息,利用领域本体所表达的语义环境信息,实现了对农业领域中各类文档资源的语义标注,并提出一种基于本体的文档语义标注改进方法.有学者针对语音数据标注问题,通过引入6元组模型,提出一种“兴趣+收获+报酬”的三位一体的标注方案,并建立一种标注质量控制机制,成功实现了大数据语音语料库的社会标注[14 ] .也有学者提出一种基于增量层次分析法的学习资源多标签标注方法,根据标签-资源信息构建学习资源多标签标注模型,然后利用层次分析法进行关联程度值处理,选取与学习资源相关程度最大的若干个标签作为标注标签[15 ] .上述研究在一定程度上实现了基于语义的资源标注,方便用户检索资源并提升学习效率.但在实现过程中涉及大量的专家知识和一些人为主观操作,并且模型对海量数据的适应性不够.如何根据已有的大量学习资源自动地学习并生成有效规则,对新的试题进行相应(多)知识点标注是智能教育领域中的关键问题. ...
大数据语音语料库的社会标注技术
1
2013
... 文献[13 ]通过分析领域本体知识的语义环境和资源文档结构两方面信息,利用领域本体所表达的语义环境信息,实现了对农业领域中各类文档资源的语义标注,并提出一种基于本体的文档语义标注改进方法.有学者针对语音数据标注问题,通过引入6元组模型,提出一种“兴趣+收获+报酬”的三位一体的标注方案,并建立一种标注质量控制机制,成功实现了大数据语音语料库的社会标注[14 ] .也有学者提出一种基于增量层次分析法的学习资源多标签标注方法,根据标签-资源信息构建学习资源多标签标注模型,然后利用层次分析法进行关联程度值处理,选取与学习资源相关程度最大的若干个标签作为标注标签[15 ] .上述研究在一定程度上实现了基于语义的资源标注,方便用户检索资源并提升学习效率.但在实现过程中涉及大量的专家知识和一些人为主观操作,并且模型对海量数据的适应性不够.如何根据已有的大量学习资源自动地学习并生成有效规则,对新的试题进行相应(多)知识点标注是智能教育领域中的关键问题. ...
大数据语音语料库的社会标注技术
1
2013
... 文献[13 ]通过分析领域本体知识的语义环境和资源文档结构两方面信息,利用领域本体所表达的语义环境信息,实现了对农业领域中各类文档资源的语义标注,并提出一种基于本体的文档语义标注改进方法.有学者针对语音数据标注问题,通过引入6元组模型,提出一种“兴趣+收获+报酬”的三位一体的标注方案,并建立一种标注质量控制机制,成功实现了大数据语音语料库的社会标注[14 ] .也有学者提出一种基于增量层次分析法的学习资源多标签标注方法,根据标签-资源信息构建学习资源多标签标注模型,然后利用层次分析法进行关联程度值处理,选取与学习资源相关程度最大的若干个标签作为标注标签[15 ] .上述研究在一定程度上实现了基于语义的资源标注,方便用户检索资源并提升学习效率.但在实现过程中涉及大量的专家知识和一些人为主观操作,并且模型对海量数据的适应性不够.如何根据已有的大量学习资源自动地学习并生成有效规则,对新的试题进行相应(多)知识点标注是智能教育领域中的关键问题. ...
基于增量AHP的学习资源多标签标注研究
1
2015
... 文献[13 ]通过分析领域本体知识的语义环境和资源文档结构两方面信息,利用领域本体所表达的语义环境信息,实现了对农业领域中各类文档资源的语义标注,并提出一种基于本体的文档语义标注改进方法.有学者针对语音数据标注问题,通过引入6元组模型,提出一种“兴趣+收获+报酬”的三位一体的标注方案,并建立一种标注质量控制机制,成功实现了大数据语音语料库的社会标注[14 ] .也有学者提出一种基于增量层次分析法的学习资源多标签标注方法,根据标签-资源信息构建学习资源多标签标注模型,然后利用层次分析法进行关联程度值处理,选取与学习资源相关程度最大的若干个标签作为标注标签[15 ] .上述研究在一定程度上实现了基于语义的资源标注,方便用户检索资源并提升学习效率.但在实现过程中涉及大量的专家知识和一些人为主观操作,并且模型对海量数据的适应性不够.如何根据已有的大量学习资源自动地学习并生成有效规则,对新的试题进行相应(多)知识点标注是智能教育领域中的关键问题. ...
基于增量AHP的学习资源多标签标注研究
1
2015
... 文献[13 ]通过分析领域本体知识的语义环境和资源文档结构两方面信息,利用领域本体所表达的语义环境信息,实现了对农业领域中各类文档资源的语义标注,并提出一种基于本体的文档语义标注改进方法.有学者针对语音数据标注问题,通过引入6元组模型,提出一种“兴趣+收获+报酬”的三位一体的标注方案,并建立一种标注质量控制机制,成功实现了大数据语音语料库的社会标注[14 ] .也有学者提出一种基于增量层次分析法的学习资源多标签标注方法,根据标签-资源信息构建学习资源多标签标注模型,然后利用层次分析法进行关联程度值处理,选取与学习资源相关程度最大的若干个标签作为标注标签[15 ] .上述研究在一定程度上实现了基于语义的资源标注,方便用户检索资源并提升学习效率.但在实现过程中涉及大量的专家知识和一些人为主观操作,并且模型对海量数据的适应性不够.如何根据已有的大量学习资源自动地学习并生成有效规则,对新的试题进行相应(多)知识点标注是智能教育领域中的关键问题. ...
基于认知诊断的个性化试题推荐方法
1
2017
... 在实际的在线学习活动中,一般的在线学习推荐平台只是根据用户在线的答题错误记录,基于协同过滤、认知诊断或者模糊树匹配方法[16 ,17 ] ,提供或者推荐与错题极其相似的试题[18 ,19 ,20 ] .这样的推荐结果很可能导致用户重复做相似或者相同的试题,而忽略了试题背后所考察的知识点以及知识点组合,降低了用户的学习效率.在题干和知识点对应的关系中,特定的题干对应特定的知识点,而对于同一知识点,题干的组织方式多种多样,所用语言也千变万化,并且题干相似的试题所考察的知识点可能不同,所以试题推荐可以优先结合考虑试题所考察的固定知识点的相似性并辅助结合试题题干的相似性进行推荐. ...
基于认知诊断的个性化试题推荐方法
1
2017
... 在实际的在线学习活动中,一般的在线学习推荐平台只是根据用户在线的答题错误记录,基于协同过滤、认知诊断或者模糊树匹配方法[16 ,17 ] ,提供或者推荐与错题极其相似的试题[18 ,19 ,20 ] .这样的推荐结果很可能导致用户重复做相似或者相同的试题,而忽略了试题背后所考察的知识点以及知识点组合,降低了用户的学习效率.在题干和知识点对应的关系中,特定的题干对应特定的知识点,而对于同一知识点,题干的组织方式多种多样,所用语言也千变万化,并且题干相似的试题所考察的知识点可能不同,所以试题推荐可以优先结合考虑试题所考察的固定知识点的相似性并辅助结合试题题干的相似性进行推荐. ...
A Fuzzy Tree Matching-Based Personalized E-Learning Recommender System
1
2015
... 在实际的在线学习活动中,一般的在线学习推荐平台只是根据用户在线的答题错误记录,基于协同过滤、认知诊断或者模糊树匹配方法[16 ,17 ] ,提供或者推荐与错题极其相似的试题[18 ,19 ,20 ] .这样的推荐结果很可能导致用户重复做相似或者相同的试题,而忽略了试题背后所考察的知识点以及知识点组合,降低了用户的学习效率.在题干和知识点对应的关系中,特定的题干对应特定的知识点,而对于同一知识点,题干的组织方式多种多样,所用语言也千变万化,并且题干相似的试题所考察的知识点可能不同,所以试题推荐可以优先结合考虑试题所考察的固定知识点的相似性并辅助结合试题题干的相似性进行推荐. ...
Ontology-Based User Profile Learning
1
2012
... 在实际的在线学习活动中,一般的在线学习推荐平台只是根据用户在线的答题错误记录,基于协同过滤、认知诊断或者模糊树匹配方法[16 ,17 ] ,提供或者推荐与错题极其相似的试题[18 ,19 ,20 ] .这样的推荐结果很可能导致用户重复做相似或者相同的试题,而忽略了试题背后所考察的知识点以及知识点组合,降低了用户的学习效率.在题干和知识点对应的关系中,特定的题干对应特定的知识点,而对于同一知识点,题干的组织方式多种多样,所用语言也千变万化,并且题干相似的试题所考察的知识点可能不同,所以试题推荐可以优先结合考虑试题所考察的固定知识点的相似性并辅助结合试题题干的相似性进行推荐. ...
Hybrid Recommendation Approach for Learning Material Based on Sequential Pattern of the Accessed Material and the Learner’s Preference Tree
1
2013
... 在实际的在线学习活动中,一般的在线学习推荐平台只是根据用户在线的答题错误记录,基于协同过滤、认知诊断或者模糊树匹配方法[16 ,17 ] ,提供或者推荐与错题极其相似的试题[18 ,19 ,20 ] .这样的推荐结果很可能导致用户重复做相似或者相同的试题,而忽略了试题背后所考察的知识点以及知识点组合,降低了用户的学习效率.在题干和知识点对应的关系中,特定的题干对应特定的知识点,而对于同一知识点,题干的组织方式多种多样,所用语言也千变万化,并且题干相似的试题所考察的知识点可能不同,所以试题推荐可以优先结合考虑试题所考察的固定知识点的相似性并辅助结合试题题干的相似性进行推荐. ...
Context-aware Recommender Systems for Learning: A Survey and Future Challenges
1
2012
... 在实际的在线学习活动中,一般的在线学习推荐平台只是根据用户在线的答题错误记录,基于协同过滤、认知诊断或者模糊树匹配方法[16 ,17 ] ,提供或者推荐与错题极其相似的试题[18 ,19 ,20 ] .这样的推荐结果很可能导致用户重复做相似或者相同的试题,而忽略了试题背后所考察的知识点以及知识点组合,降低了用户的学习效率.在题干和知识点对应的关系中,特定的题干对应特定的知识点,而对于同一知识点,题干的组织方式多种多样,所用语言也千变万化,并且题干相似的试题所考察的知识点可能不同,所以试题推荐可以优先结合考虑试题所考察的固定知识点的相似性并辅助结合试题题干的相似性进行推荐. ...
Chinese Lexical Analysis Using Cascaded Hidden Markov Model
1
2004
... 对于分词任务,在搜狗细胞词库中搜集相关专业词汇,构建专业领域词典,辅助ICTCLAS系统[21 ] 进行分词操作;分词结果中会出现许多原本属于同一个词而被错分为多个词的情况,如“一元一次方程”被分成“一元”、“一次”和“方程”三个粒度较小的词.为保证分词后语义的准确性,采用信息熵方法对分词后的结果进行词合并 [22 ] .将满足条件的两个词合并为新的组合词,人工筛选组合词后添加到专业领域词典中,再次对原试题集分词,重复多次.对于词性筛选任务,选取有明确语义概念的实词,如名词、具有名词功能的动词、具有名词功能的形容词、动词性惯用语以及相关数学符号作为研究对象.对于去停用词任务,选取领域内无实际价值的实词(如“问题”、“概念”、“运用”等)构建本领域停用词词典,然后处理后的试题集进行去停用词操作.最后,每道试题都通过一组词语特征集合表示出来. ...
Textual Topic Evolution Analysis Based on Term Co-occurrence: A Case Study on the Government Work Report of the State Council(1954-2017)
1
2017
... 对于分词任务,在搜狗细胞词库中搜集相关专业词汇,构建专业领域词典,辅助ICTCLAS系统[21 ] 进行分词操作;分词结果中会出现许多原本属于同一个词而被错分为多个词的情况,如“一元一次方程”被分成“一元”、“一次”和“方程”三个粒度较小的词.为保证分词后语义的准确性,采用信息熵方法对分词后的结果进行词合并 [22 ] .将满足条件的两个词合并为新的组合词,人工筛选组合词后添加到专业领域词典中,再次对原试题集分词,重复多次.对于词性筛选任务,选取有明确语义概念的实词,如名词、具有名词功能的动词、具有名词功能的形容词、动词性惯用语以及相关数学符号作为研究对象.对于去停用词任务,选取领域内无实际价值的实词(如“问题”、“概念”、“运用”等)构建本领域停用词词典,然后处理后的试题集进行去停用词操作.最后,每道试题都通过一组词语特征集合表示出来. ...
Mining Association Rules Between Sets of Items in Large Databases
1
1993
... (3)基于上述处理好的所有试题以及对应的单一知识点,将每道试题对应的特征词集以及知识点看作一组由词项形成的事务集合,仿照关联规则方法,找到所有事务集合中满足最小支持度的所有频繁项集.显然这个过程会忽略那些出现次数较少但是又不可或缺的知识点.为保证在频繁项集中能够包含上述这些知识点,可以设定不同的知识点具有不同的最小支持度阈值.依据Agrawal等[23 ] 提出的关联规则挖掘方法中的定义, TDB = { T 1 , T 2 , ⋯ , T n } T i = { i 1 , i 2 , ⋯ , i m } I = { i 1 , i 2 , ⋯ , i p } p ≥ m T i ⊆ I . 项集 X k X k - 项集.项集 X T supp ( X ) TDB X
1
... 特征抽取过程中,同样用ICTCLAS对试题内容进行分词处理,分词过程中,除了有效规则生成阶段中已经生成的领域词典外,将生成的有效规则集中的前件词项也作为专业词加入到领域词典中辅助分词,这样可以使得分词更为准确.分词完成之后,借助哈尔滨工业大学社会计算与信息检索研究中心提供的“同义词词林”等外部资源[24 ] 进行语义相近词的匹配,并将语义相近的词替换为在有效规则集的前件中出现的特征词.最后,同样选取名词、具有名词功能的动词、具有名词功能的形容词、动词性惯用语以及相关数学符号作为抽取出来的特征. ...
1
... 特征抽取过程中,同样用ICTCLAS对试题内容进行分词处理,分词过程中,除了有效规则生成阶段中已经生成的领域词典外,将生成的有效规则集中的前件词项也作为专业词加入到领域词典中辅助分词,这样可以使得分词更为准确.分词完成之后,借助哈尔滨工业大学社会计算与信息检索研究中心提供的“同义词词林”等外部资源[24 ] 进行语义相近词的匹配,并将语义相近的词替换为在有效规则集的前件中出现的特征词.最后,同样选取名词、具有名词功能的动词、具有名词功能的形容词、动词性惯用语以及相关数学符号作为抽取出来的特征. ...
E-Learning Recommender System for a Group of Learners Based on the Unified Learner Profile Approach
1
2015
... 与已有的针对多个用户的在线推荐系统[25 ] 类似,本文对单个用户的多个错误试题的组合进行挖掘,尝试从用户频繁出错试题中发现一些潜在的特点和规律,然后基于此对该用户推荐新的试题或者试题组合.首先基于语义关联规则的知识点标注方法,对用户错题集标注相应的知识点;然后从错题集标注的知识点中挖掘出用户频繁出错的知识点项集,即频繁出错的知识点组合;最后根据所有频繁知识点项集计算与试题库中每个试题对应知识点的相似性程度,依据优先级较高的知识点相似性和优先级相对较低的题干相似性进行单个试题或者多个试题组合的推荐,具体的个性化试题推荐流程如图5 所示.试题库中,每道试题 Q








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}