




1 引 言
随着互联网以及电子商务的快速发展,网购用户数量越来越多,消费者会对已购买的产品发表评论。用户的评论一般包括数字评分和文本,数字评分只能表达用户对产品的整体满意度,并没有解释潜在喜好的理由,比如用户对其购买的手机评分很高可能是由于这个手机续航能力很强或外观好看,但在数字评分中难以体现这些喜好的原因[1]。为克服这种局限,有学者关注挖掘文本评论数据。用户通常会在他们在意的产品某个方面表达自己的观点[1],因此文本评论包含大量有关用户偏好和产品特征的丰富信息,抽取这些方面(属性)特征以及判断对应的属性情感非常重要。通过抽取用户对于产品各个方面的评论的明确观点,可以了解用户对于产品属性的偏好,也可用于对推荐结果做出解释[2]。另外,由于用户的表达方式多样,对于同一个属性,不同用户会用不同的词语表达,因此有必要将那些具有相同语义的属性词聚集在属性面上,从而进行更有价值的用户评论情感分析。本文利用CRF抽取属性词,然后基于ATAE-LSTM分析属性词的情感,最后将属性词聚集到属性面,从而分析产品属性面的情感类别与量化指标。
2 相关研究
(1)在产品属性提取方面,文献[3]最早使用基于关联规则的方法,该方法将出现频率较高的名词或名词短语当作属性词抽取,并且将距离该属性词最近的形容词抽取出来当作观点词。对于有观点词而没有属性词的文本,将距离观点词最近的名词当作属性词抽取。这种方法虽然简单易行,但是对于出现频率高的属性词抽取,容易带入较多噪声(非属性词),从而降低精确率;而对于出现频率低的属性词抽取,召回率也不高。文献[4]对此作了一些改进,采用概率模型剔除一些频率较高但不是属性词的词,但是对于出现频率低的属性词的提取依旧存在召回率低的问题。文献[5,6]运用LDA主题模型抽取产品属性特征,并对抽取的属性词进行LDA主题归类。但是LDA主题模型倾向于抽取出现频率较高且属于全局性的主题词,对于出现频率低的属性词抽取的召回率不高,并且对于细粒度词语的主题分配也不易控制。文献[7]提出的CRF模型在数据切分、序列标注和命名实体识别等自然语言处理任务中表现良好。文献[8]采用CRF抽取产品特征词并用语义知识和上下文相似性完成特征归类。CRF对于上下文信息具有很好的捕捉能力,而且设计特征灵活,能够求得全局最优解,所以通过选取适当且有效的特征,可以精确地抽取出产品的属性词。
近年来,深度学习技术在自然语言处理领域取得重大进展,越来越多的学者采用深度学习的方法实现细粒度情感分析[12,13,14,15,16]。基于深度学习的方法,不需要大量的特征工程就可以很好地捕捉文本的语法和语义信息,注意力机制被广泛应用于自然语言处理、图像识别及语音识别等多种深度学习任务中。注意力机制在文本摘要[17]和阅读理解[18]等自然语言处理领域中表现效果良好。传统的LSTM网络模型,并不能突出文本中的重要信息,而注意力机制通过捕捉文本中的关键部分,可以对属性情感分析任务做优化。为此,文献[19]提出基于注意力机制的长短期记忆网络(Attention-based Long Short-Term Memory with Aspect Embedding,ATAE-LSTM),利用注意力机制计算注意力概率,可以找到某文本属性词的最重要的情感描述部分。
(3)在属性词聚类方面,文献[4-5,20]使用LDA主题模型聚类,虽然主题模型对于细粒度词语的主题分配也不易控制,在一些情境下,原义不同的词语也具有很高的相似性,主题模型无法识别这种情况。文献[21]定义规则抽取产品属性词并训练Word2Vec后,通过K-means算法对抽取的属性词聚类,实现了中文产品属性抽取与聚类,并取得了较好的效果。因此本文使用Word2Vec将这些语义相似的属性词汇聚集到同一个属性面。
3 研究框架与方法
本文提出的基本研究框架如图1所示,分为6个步骤。
图1
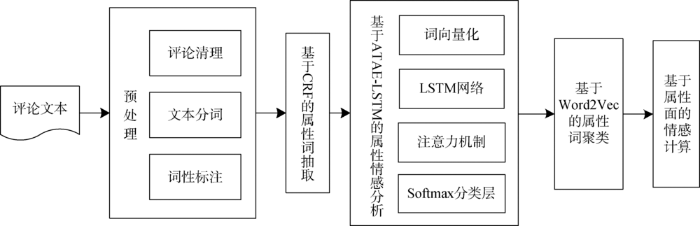
(1)获取评论文本数据;
(2)对所获取的数据作预处理,清理掉无意义的评论数据后对文本进行分词和词性标注;
(3)人工标注分词后的评论文本中的属性,运用CRF方法对标注后的文本进行训练,利用训练后的模型预测测试集评论文本属性词;
(4)运用ATAE-LSTM对提取属性词后的训练集进行训练,基于训练模型对用户评论文本进行属性情感分析;
(5)利用Word2Vec对用户评论文本进行向量化表示,基于Word2Vec向量采用K-means算法进行属性词聚类,可以将具有相似意义的属性词聚集到同一属性面;
(6)计算产品属性面的情感指标。
3.1 基于CRF的属性词抽取
CRF序列标注模型能较好地捕捉上下文信息[22],而且可以灵活设计词的特征,求得全局最优解,通过选取适当且有效的特征,精确地抽取出产品的属性词,因此本文使用CRF抽取产品属性词。
CRF模型在识别评论文本的属性特征时,通过输入观察序列,即经过分词处理的评论文本X={x1,x2,x3,…,xn},计算出所有可能状态序列的条件概率Y={y1,y2,y3,…,yn},并将最大概率作为序列的输出状态。计算方法如公式(1)所示。
其中,Z(x)是归一化因子,是所有可能状态的条件概率之和,计算方法如公式(2)所示。
3.2 基于注意力机制LSTM的属性情感分析
图2
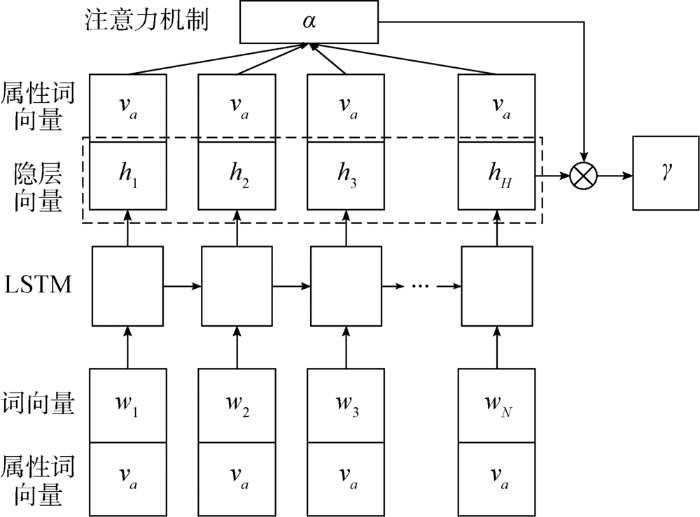
将一段文本中的属性词Word2Vec向量和所有单词Word2Vec向量拼接作为原始向量输入到LSTM层得到隐层向量
其中,α为注意力权重向量,
采用端到端的反向传播算法训练模型,损失函数使用交叉熵函数,如公式(6)所示。加入L2正则化以避免过拟合问题,通过最小化损失函数优化模型,以AdaGrad作为优化方法。
其中,y为期望值,
3.3 基于Word2Vec的属性词聚类
在线评论中相同情境中的词语往往语义相似程度很高,而Word2Vec可以表达相同情境词语的相似性,因此,使用Word2Vec训练词向量,对于抽取出的属性词以Word2Vec进行词向量表征,利用K-means算法对这些属性词进行向量聚类。
图3
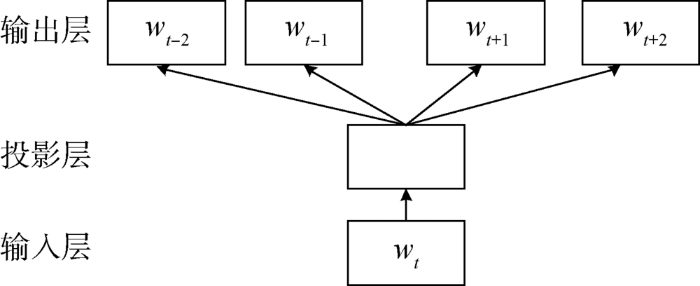
模型包含输入层、投影层、输出层,是在已知当前词wt的前提下预测当前词的上下文词
4 实验设置与结果分析
4.1 实验设置
(1) 数据预处理
通过爬虫技术获取京东商城中包括手机、电脑、衣服、鞋子等多种商品的用户评论数据共5 633 458条,其中包含商品ID、评论内容、评论星级等多个字段。
由于部分用户没有给出评论内容,还有评论内容重复,对这些数据进行剔除,得到2 452 740条有评论内容的数据。通过这些数据基于Skip-gram模型训练Word2Vec,向量维度为200,窗口大小设置为5,利用训练好的向量作为文本中词的表示。选取部分手机评论数据,去除不含产品属性或用户情感的无意义评论以及与商品无关的干扰评论。使用Python自带的Jieba工具包完成评论数据的分词和词性标注。
(2) 属性标注及属性提取
利用CRF提取属性词,属性词的开始词标注为“B”,属性词的中间词和结尾词标注为“I”,其他词语标记为“O”,对1 000条用户评论进行属性词人工提取和标注,标注示例具体如表1所示。
表1 属性词标记示例
Table 1
| 评论 | Pos | Tag | 评论 | Pos | Tag |
|---|---|---|---|---|---|
| 运行/ | v | B | 也/ | d | O |
| 速度/ | n | I | 很/ | d | O |
| 快/ | a | O | 耐用/ | a | O |
| ,/ | x | O | 。 | x | O |
| 电池/ | n | B |
对标注后的用户评论随机抽取800条作为训练集,利用CRF进行学习训练,通过训练后的模型对200条测试数据进行属性预测提取。在测试集共提取出431个属性词,其中358个词与人工标注一致,7个属性词与原来标注不一致,66个非属性词不应该提取,预测精度达到83.6%。(3) ATAE-LSTM属性情感分析从标记数据中选取800条作为训练集,200条作为测试集,情感极性分为三个类别:积极、消极、中性。将标注后的属性词在语料库中进行标记,对语料库进行训练并向量化,将向量化的属性词进行id编码,将向量化的语料库与属性词作为神经网络输入。在TensorFlow中实现该神经网络模型,隐层(Hidden Layer)大小为200,批大小(Batch Size)设置为256,AdaGrad的学习率为0.001,梯度下降的动量为0.9,L2正则化参数为0.001。在测试集中进行属性词情感预测,共预测458个属性词情感,其中包含362个积极情感词、73个消极情感词、23个中性词,与人工标注的情感词相比预测精度达75.0%。(4) 属性词聚类根据训练出的Word2Vec词向量,利用K-means算法将抽取出的属性词聚集到属性面。从图4可知,K值为16时聚类效果相对稳定。属性词的聚类结果如图5所示。
图4
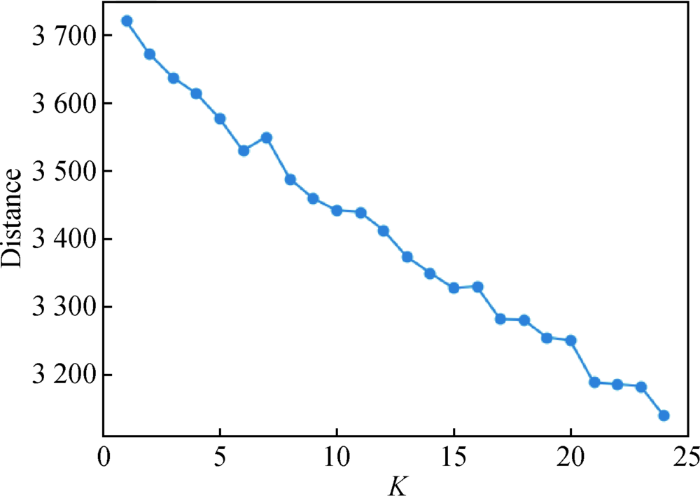
图4
不同聚类数目K下的欧氏距离变化趋势
Fig.4
The Trend of Euclidean Distance Under Different Clustering Number K
图5
4.2 结果分析
使用精确率(P)、召回率(R)、F1 值对模型进行评价,计算方法如公式(8)-(10)所示。
其中,在基于CRF的属性词抽取中,TP表示抽取正确的产品属性数量;FP表示抽取错误的产品属性数量;FN表示没有被抽取出的产品属性数量。在基于ATAE-LSTM的属性情感分析中,也与之类似。在属性词提取实验中,本文采用的CRF属性词提取与文献[3]采用的关联规则方法在本文所采用数据集上进行实验比较,与关联规则方法相比,对于出现频率高的属性词的抽取,本文方法屏蔽了更多噪声(非属性词),从而明显提高了精确率;对于出现频率低的属性词抽取的召回率提升更为明显。在属性情感分析实验中,本文与文献[19]采用的LSTM在本文所采用数据集上进行属性情感分析比较,因LSTM并不能突出文本中的重要信息,而ATAE-LSTM能够通过注意力机制捕捉文本中的关键部分,可以对属性情感分析任务做优化,从而得到更高的精确率和召回率。具体实验结果如表2所示,加黑部分为本文实验结果。
表2 实验结果
Table 2
| 实验 | P | R | F1 |
|---|---|---|---|
| 基于CRF抽取属性词 基于关联规则抽取属性词 | 0.84 0.48 | 0.70 0.14 | 0.76 0.21 |
| 基于ATAE-LSTM属性情感分析 基于LSTM属性情感分析 | 0.78 0.71 | 0.81 0.79 | 0.78 0.73 |
4.3 应 用
对于华为荣耀8手机的1 800条评论数据,运用以上方法,即:用CRF抽取属性词(删除部分没有抽出属性词的数据);运用ATAE-LSTM对抽取出属性词的评论数据(1 183条)进行属性级情感分析;最后通过Word2Vec将语义相似的属性词进行聚类,获得该手机各个属性面的情感指标,所有属性词共聚类成16个属性面,选取3个属性面对其属性词进行情感分析,如表3所示。
表3 部分属性面的情感指标
Table 3
| 属性面 | 属性词 | 正面情感 | 中性情感 | 负面情感 |
|---|---|---|---|---|
| 设计 | 设计 | 75% | 0 | 25% |
| 外形与功能 | 信号 | 4% | 96% | 0 |
| 相机 | 75% | 0 | 25% | |
| 外形 | 89% | 0 | 11% | |
| 摄像头 | 9% | 0 | 91% | |
| 速度 | 充电速度 | 100% | 0 | 0 |
| 系统速度 | 100% | 0 | 0 |
从表3不仅可以看出当前评论中对于这款手机的集中关注点,还可以得到在属性方面的情感类别与量化指标。如在“设计”方面,正面评价居多;而在手机的外形与功能方面,“摄像头”的评价偏向于负面。因此,对于生产商而言,未来该手机的外形与功能方面,需要侧重于对摄像头的改进;对于消费者而言,如果对手机的摄像头要求较高,那么可以考虑不购买该款手机,而对于看重系统运行速度的消费者,可以选择该手机;对于电商平台,如果该手机的评分较高可以解释为是由于手机设计好、运行速度快致使评分高,但是在摄像头方面还存在不足。
5 结 语
本文通过CRF提取手机评论文本中所涉及的属性词,运用ATAE-LSTM对抽取出的属性词进行情感分类,最后基于Word2Vec采用K-means算法将这些属性词聚集到属性面,进而分析用户对于产品属性面的情感。实验表明,该方法在手机产品细粒度情感分析方面效果良好,可以为消费者、产品制造者和管理者等提供详细的决策信息。该方法能够识别较为显性的属性词,但对隐性属性词的效果不佳,特别是与标注的属性词在原始评论上下文存在较大差异的属性词很难有效提取,这也是笔者未来的研究方向。另外,受限于人工标注的需要,用于实验的数据集不够大。
作者贡献声明
薛福亮:提出研究思路,设计研究方案,论文最终版本修订;
刘丽芳:采集、清洗、分析数据,进行实验,起草论文。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: liulifang@stu.tjufe.edu.cn。
[1] 薛福亮,刘丽芳. data.txt. 训练Word2Vec模型的评论数据(包含245 2740条).
[2] 薛福亮,刘丽芳. labeled.xlsx. 人工标注属性词和情感类别的评论数据(包含1 000条).
参考文献
A^ 3NCF: An Adaptive Aspect Attention Model for Rating Prediction
[C]//
Explainable Recommendation via Multi-Task Learning in Opinionated Text Data
[C]//
Mining and Summarizing Customer Reviews
[C]//
Feature Based Summarization of Customers’ Reviews of Online Products
[J].
Mining Topics in Documents: Standing on the Shoulders of Big Data
[C]//
Interactive Topic Modeling
[J].
Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data
[C]//
Fine-grained Product Features Extraction and Categorization in Reviews Opinion Mining
[C]//
基于情感本体的在线评论情感极性及强度分析:以手机为例
[J].
Sentimental Polarity and Strength of Online Cellphone Reviews Based on Sentiment Ontology
[J].
Aspect Term Extraction for Sentiment Analysis in Large Movie Reviews Using Gini Index Feature Selection Method and SVM Classifier
[J].
Feature Selection and Ensemble Construction: A Two-Step Method for Aspect Based Sentiment Analysis
[J].
基于深度学习的社交网络平台细粒度情感分析
[J].
Fine-grained Sentiment Analysis for Social Network Platform Based on Deep-learning Model
[J].
Aspect-based Opinion Summarization with Convolutional Neural Networks
[C]//
Deep Convolutional Neural Network Based Approach for Aspect-Based Sentiment Analysis
[J].
NLANGP at SemEval-2016 Task 5: Improving Aspect Based Sentiment Analysis Using Neural Network Features
[C]//
Learning Multi-Grained Aspect Target Sequence for Chinese Sentiment Analysis
[J].
A Neural Attention Model for Abstractive Sentence Summarization
[C]//
Teaching Machines to Read and Comprehend
[C]//
Attention-Based LSTM for Aspect-Level Sentiment Classification
[C]//
基于情感分析和LDA主题模型的协同过滤推荐算法
[J].
Collaborative Filtering Recommendation Based on Sentiment Analysis and LDA Topic Model
[J].
基于在线评论词向量表征的产品属性提取
[J].
Extraction Product Features from Online Reviews Based on Word-Vector-Representation
[J].
基于CRFs的评价对象抽取特征研究
[J].
Feature Engineering for CRFs Based Opinion Target Extraction
[J].
Distributed Representations of Words and Phrases and Their Compositionality
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}