




1 引言
在现有研究基础上,本研究提出一种面向趋势预测的主题演化分析方法,从外部数量特征和内部文本特征两个层面构建严谨的数理模型,并结合人工解读,对研究主题的趋势进行预测分析,为相关研究提供一定的参考借鉴。
2 相关研究
2.1 主题探测与追踪
已有研究主要利用TDT技术对论文、专利和基金项目等数据进行主题探测与跟踪,揭示科学与技术主题发展演化规律。概括来说,目前科学与技术主题识别研究中,主题时序变化研究不够充分,并且主要采取以人工观察主题识别结果的方式预测分析主题变化,导致学科情报预测分析效率低、主观性强。
2.2 主题演化及其预测分析
主题演化及其预测分析旨在帮助用户更加快速有效地发现文本数据中的主要内容,识别主题及其关联关系,有效增强用户的认知和洞察能力,从而帮助人们快速把握科技发展趋势。
随着研究的深入,部分学者认识到现有主题演化研究在时序分析、语义分析两个方面存在一定的不足,并尝试进行改进。在主题演化时序分析方面,齐亚双等[18]基于动态主题模型(Dynamic Topic Models, DTM),通过构建主题强度时序演化模型,分析国内外情报学领域的研究主题演化过程,对比分析了研究内容和研究热度异同点;陈伟等[19]基于主题识别与演化分析方法,利用双重随机过程的隐马尔可夫模型对船用柴油机技术领域的主题演化趋势进行定量预测,分析各时期主题的分布特征和演变规律,并通过实证验证了方法的准确性和有效性;李静等[20]提出一种基于时间序列分析和支持向量机模型的基金项目新兴主题趋势分析方法,在LDA主题识别的基础上,构建新兴主题特征变化的时间序列数据,并利用支持向量机模型进行趋势分析。在主题演化语义分析方面,刘自强等[21]提出一种语义分类的学科主题演化分析方法,将研究主题分为研究问题、研究方法和研究技术三类,利用相似度算法计算相邻子时期主题间的相似度,构建学科主题演化图谱分析某学科领域研究问题、研究方法和研究技术的变化,实现深度、细致的学科主题演化分析。关鹏等[22]提出基于LDA模型的主题语义演化分析方法,利用生命周期理论和主题相似度计算,将学科领域发展过程中主题之间的语义关联进行量化,同时利用主题词的语义信息解析主题在发展过程中的语义演化模式。
可见,研究大多进行主题演化现状可视化分析,对于主题演化的时序变化和语义内容变化趋势分析不足;虽然,部分研究开始关注主题演化时间序列分析以及语义分析,但对于主题演化的时序分析,主要通过构建主题演化时间序列模型,以人工解读为主的方式分析主题演化时序变化趋势;而对于主题演化的语义分析,主要计算主题词之间的语义关联情况辅助进行主题演化分析。如何结合主题演化时序分析和语义分析,从主题强度和主题内容两个层面进行主题演化趋势分析,有待于进一步深入研究。
综上所述,本研究提出一种面向趋势预测的主题演化分析方法,通过构建Word2Vec模型(语义分析)和ARIMA模型(时序分析),综合内部语义特征和外部主题强度特征,从内外两个层面对主题演化趋势进行预测分析,拓展、深化现有主题演化研究。
3 方法框架
本研究提出面向趋势预测的主题演化分析方法框架,可以概括为4个主要步骤:
(1)学科主题识别与时间序列构建。在数据预处理基础上,基于LDA模型进行主题探测并通过构建主题强度变化时间序列进行主题追踪,为后续分析奠定基础。
(2)基于线性回归拟合的热点主题筛选。利用线性回归模型值对主题强度时间序列数据进行拟合,并结合均值计算筛选热点主题。
(3)基于ARIMA模型的热点主题强度演化趋势预测。基于ARIMA模型预测热点主题未来5年的发展趋势。
(4)基于Word2Vec模型的热点主题内容演化趋势预测。基于近三年的数据训练Word2Vec模型,预测热点主题内容变化趋势。
3.1 学科主题识别与时间序列构建
利用Python的Gensim、Pandas工具包进行学科主题识别与时间序列构建,基本步骤如下:
(1)预处理与主题识别。调用Gensim、Pandas等工具包进行数据读取、预处理(英文大小写转换、去除停助词等)和LDA主题识别等。
(2)主题时间序列构建。在Python中自定义函数def get_lda_topic_distr_per_year(year,corpora,lda_model,debug = False),具体功能为:获取各个主题的年度概率分布(即某主题在不同年度的强度变化),从而构建主题趋势时间序列数据,为后续主题趋势预测奠定数据基础。
3.2 基于线性回归拟合的热点主题筛选
在主题识别与主题强度时间序列构建结果的基础上进行热点主题的筛选,使用Python的Scikit-learn工具包进行线性回归(Linear Regression, LR)拟合。本研究将热点主题界定为:主题强度高于平均值并且整体呈现上升趋势的主题,基于线性回归拟合的热点主题筛选的基本步骤如下:
(1)计算各个主题强度时间序列的平均值,过滤掉低于平均值的主题;
(2)利用线性回归模型对主题强度时间序列进行拟合,对比各个主题时间序列所构建线性回归模型的斜率,通过排序选取值得关注的热点主题。
3.3 基于ARIMA模型的热点主题强度演化趋势预测
ARIMA模型的标准格式为ARIMA(p, d, q),p, d, q为模型基本参数:p为自回归项,d为差分阶数,q为移动平均项数,计算方法如公式(1)[26]所示。
其中,
表1 模型参数确定
Table 1
| 模型 | 自相关函数(ACF) | 偏自相关函数(PACF) |
|---|---|---|
| AR(p) | 拖尾 | p阶后截尾 |
| MA(q) | q阶后截尾 | 拖尾 |
| ARMA(p, q) | q阶后拖尾 | p阶后拖尾 |
拖尾是指:始终有非零取值,不会在k(常数)大于某个常数后就恒等于零(或在0附近随机波动);截尾是指:在大于某个常数k后快速趋于0为k阶截尾。在ACF、PACF初步判定的基础上,遍历所有可能参数计算模型BIC值(计量经济学工具包Statsmodels提供相应计算函数),其中最小值为最优参数,从而可确定最后模型参数。
基于ARIMA模型检验函数对所确定的模型进行4步检验:残差序列检验、残差分布检验、残差QQ图检验和Ljung-Box检验,通过检验即可用于时序预测分析。在模型构建的基础上,通过统计建模和计量经济学工具包Statsmodels中集成的get_prediction()、conf_int()函数获得主题趋势预测值和相关的置信区间。
(1)对原始数据的近9年(2010年-2018年)进行拟合,以判断模型的有效性;
(2)对主题时间序列未来5年(2019年-2023年)的趋势进行预测。
3.4 基于Word2Vec模型的热点主题内容演化趋势预测
图1
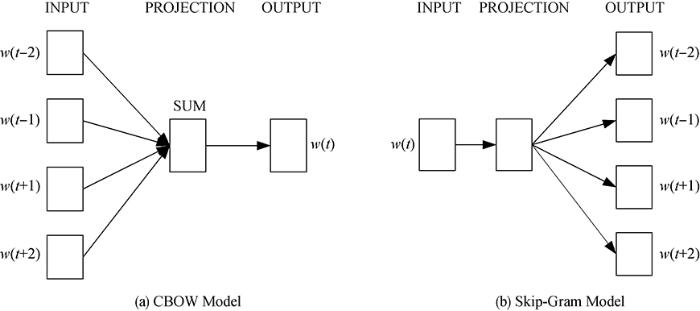
图1
CBOW模型和Skip-Gram模型示意图[29]
Fig.1
Schematic Diagram of CBOW Model and Skip-Gram Model
CBOW模型(Continuous Bag-Of-Word Model)又称连续词袋模型,是一个三层神经网络,该模型的特点是输入已知上下文,输出对当前单词的预测;而Skip-Gram模型顺序和CBOW模型相反,即已知当前词语,预测上下文。
长时间来看,科学技术随着时间的发展,其内容也会发生变化,但是,短时间内(3~5年)科学技术研究内容变化较小,表示研究内容的词汇不会突然产生或消失。大部分研究是一个渐进过程,从文本词汇层面来看,很多研究论文中的词汇是该研究主题内部词汇的排列组合,所以,根据词向量和语义距离计算的方法进行主题内容短期预测(后续3~5年)是可行的。
根据前文所得热点主题的下位主题词,通过训练Word2Vec模型(选择CBOW模型,基于近三年的数据以保证预测词汇内容的时效性和新颖性),输出下位主题词的预测,具体细分为两个步骤:
(1)选取近三年的数据,利用Word2Vec模型训练词向量;
(2)将热点主题的下位主题词作为词典,遍历上一步训练的词向量结果,查找热点主题语义相似度最接近的词汇,从而辅助热点主题内容趋势分析。
4 实证研究
4.1 数据源及其预处理
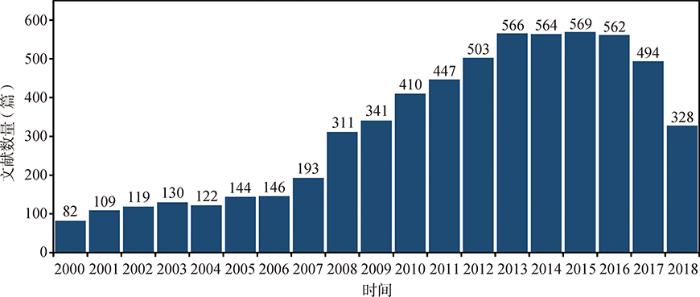
在干细胞(Stem Cell)领域进行实证研究,由于美国是干细胞研究的领先国家,主要以美国干细胞研究论文作为数据来源。具体选择Web of Science数据库收录的干细胞领域相关文献,检索策略为:以“stem cell*”作为检索词进行题名检索,时间跨度为2000年1月1日-2018年12月31日共19年,国家/地区为USA,文献类型为Article,基金资助机构限定为美国国立卫生研究院(National Institutes of Health,NIH)、美国国家癌症研究所(National Cancer Institute,NCI)和美国卫生与公共服务部(Health and Human Services,HHS),这三个机构资助的干细胞研究在一定程度上能够代表美国政府资助的干细胞重点研究方向。检索结果为6 140篇,论文数量各个年度的分布情况如图2所示。
图2
4.2 主题识别
基于LDA模型的主题识别过程中,主题个数的确定是十分重要的步骤,本研究选择工具包Gensim自带的一致性模型CoherenceModel()函数计算主题最优个数,其中,关键算法参数设置为compute_coherence_values(dictionary=id2word, corpus=corpus, texts=data_lemmatized, start=5, limit=45, step=5),并使用Matplotlib工具包绘制主题个数与一致性分数对应关系折线图,结果如图3所示。
图3
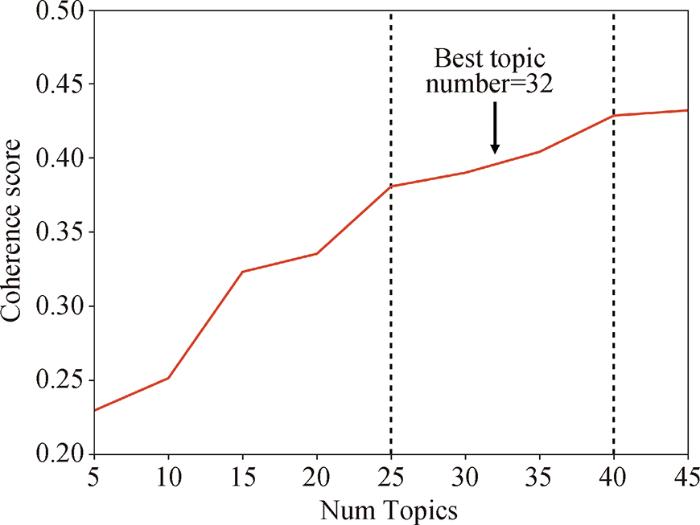
表2 美国干细胞领域研究主题列表(部分)
Table 2
| 主题序号 | 主题词 |
|---|---|
| Topic1 | acute|intestinal|hematopoietic|kinase|term|epithelial| promote|transplantation|expansion|marrow |
| Topic2 | pathway|cancer|embryonic|hematopoietic|virus|cell| aldehyde|signature|maintenance|gland |
| Topic3 | regulation|marrow|hematopoietic|embryonic|biology| inhibitor|cancer|pluripotent|rescue|inhibits |
| Topic4 | resistance|cell|effect|hematopoietic|cancer|imaging| transplantation|long|bioactive|colorectal |
| Topic5 | cell|cancer|breast|pancreatic|new|hematopoietic| targeting|transplantation|pluripotency|embryonic |
| …… | …… |
4.3 主题时间序列构建与热点主题筛选结果
在LDA主题识别结果的基础上,基于自定义的函数def get_lda_topic_distr_per_year()实现主题强度变化时间序列数据的构建;计算主题强度均值,过滤掉低于平均值的主题;在此基础上,利用线性回归模型计算各个主题强度变化的全局斜率(Slope),筛选出主题强度高于均值并且近年来发展趋势良好的热点主题,最后筛选出5个热点主题。
为更加直观有效地观察主题强度变化时间序列数据及其线性回归拟合情况,绘制32个主题时间序列及其线性回归拟合的折线图,并为5个热点主题添加星形标记,如图4所示。
图4
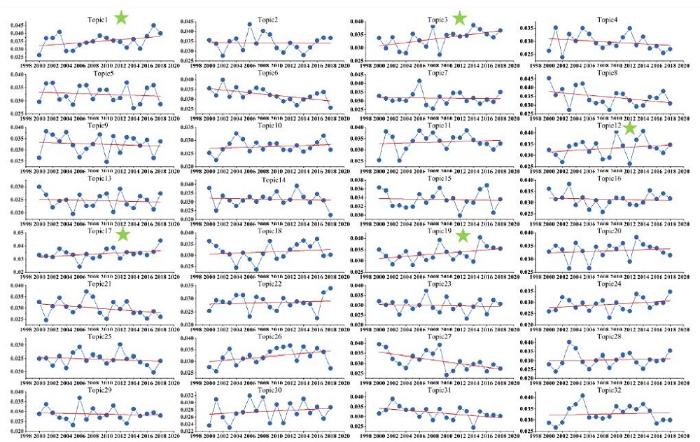
图4
干细胞领域主题时间序列(2000年-2018年)
Fig.4
Time Series of Theme in Stem Cell Field (2000-2018)
经过计算筛选,最后得到Topic1、Topic3、Topic12、Topic17和Topic19这5个热点主题(斜率排名Topic1>Topic3>Topic17>Topic19>Topic12),基于ARIMA模型和Word2Vec模型从外部数量特征(主题强度)和主题内容(主题词汇)两个维度对这5个热点主题的发展趋势进行具体测度分析。
4.4 热点主题强度演化趋势预测结果分析
根据研究方法所述步骤对5个热点主题进行ARIMA模型构建,其中ARIMA模型的构建中参数确定和模型检验是十分重要的步骤,具体实验过程中利用BIC指标确定模型参数,即遍历所有可能参数计算模型BIC值,其中最小值为最优参数,从而可确定最后模型参数,结果如表3所示。
表3 模型参数确定
Table 3
| ARIMA(p,d,q) | BIC | ARIMA(p,d,q) | BIC |
|---|---|---|---|
| ARIMA(0, 0, 1) | BIC:-77.88 | ARIMA(1, 2, 0) | BIC:-111.36 |
| ARIMA(0, 0, 2) | BIC:-80.42 | ARIMA(1, 2, 1) | BIC:-113.48 |
| ARIMA(0, 1, 1) | BIC:-127.98 | ARIMA(1, 2, 2) | BIC:-107.37 |
| ARIMA(0, 1, 2) | BIC:-119.46 | ARIMA(2, 0, 0) | BIC:-133.28 |
| ARIMA(0, 2, 1) | BIC:-110.23 | ARIMA(2, 0, 1) | BIC:-140.00 |
| ARIMA(0, 2, 2) | BIC:-109.99 | ARIMA(2, 0, 2) | BIC:-125.84 |
| ARIMA(1, 0, 0) | BIC:-136.18 | ARIMA(2, 1, 0) | BIC:-130.73 |
| ARIMA(1, 0, 1) | BIC:-139.63 | ARIMA(2, 1, 1) | BIC:-127.64 |
| ARIMA(1, 0, 2) | BIC:-132.44 | ARIMA(2, 1, 2) | BIC:-116.59 |
| ARIMA(1, 1, 0) | BIC:-136.13 | ARIMA(2, 2, 0) | BIC:-112.62 |
| ARIMA(1, 1, 1) | BIC:-129.06 | ARIMA(2, 2, 1) | BIC:-115.63 |
| ARIMA(1, 1, 2) | BIC:-117.46 | ARIMA(2, 2, 2) | BIC:-103.39 |
确定模型参数之后,对模型构建结果进行4步检验,结果如图5所示。
图5
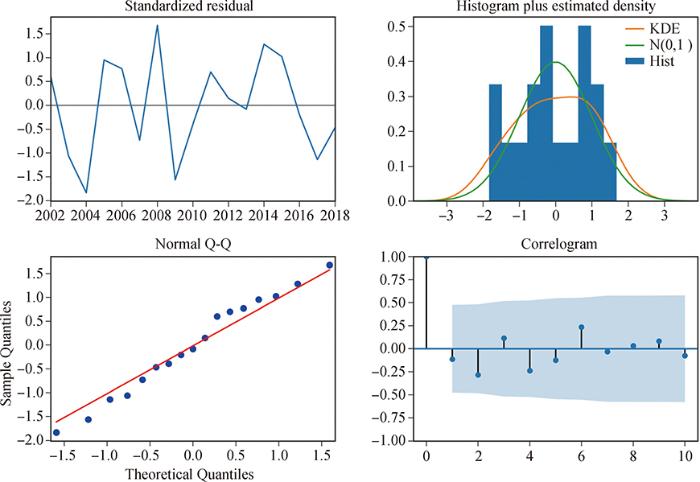
图6
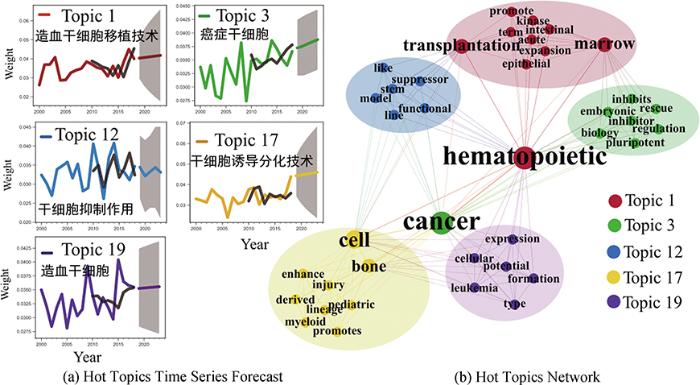
虽然整体来看5个热点主题全局斜率排名Topic1>Topic3>Topic17>Topic19>Topic12,但从ARIMA模型预测结果来看,未来5年Topic3发展趋势最明显,Topic12的上升趋势表现一定波动性,而Topic19上升趋势最小。
4.5 热点主题内容趋势预测结果分析
选择2016年-2018年的数据训练Word2Vec模型(CBOW模型),在此基础上,两两计算词向量之间的距离,根据5个热点主题的下位主题词作为词典筛选词向量,进而得到热点主题的下位主题词与词向量的距离,最后分别筛选每个下位主题词语义距离最近的三个词汇作为内容预测结果。
根据计算、筛选得到的各个热点主题下位主题词的向量,利用T-SNE(T-distributed Stochastic Neighbor Embedding)对各个热点主题词向量进行降维可视化,以揭示热点主题内容之间的语义距离辅助热点主题内容趋势的解读分析,5个热点主题的内容趋势预测结果与T-SNE降维结果如图7所示。图中,以桑基图绘制5个热点主题内容趋势结果,具体每个桑基图左边5个词汇为热点主题的下位主题词,右边与之相连的三个词表示语义距离最近的3个词汇。比如Topic1为造血干细胞移植技术,其中一个下位主题词intestinal,近三年与其语义距离最近的词汇主要有function、homeostasis和neural;最后的散点图可视化了5个热点主题的相对语义距离(已去除离群点)。结合强度趋势和内容趋势结果,在主题-词分布结果的基础上,对热点主题内容趋势进行解读分析。
图7
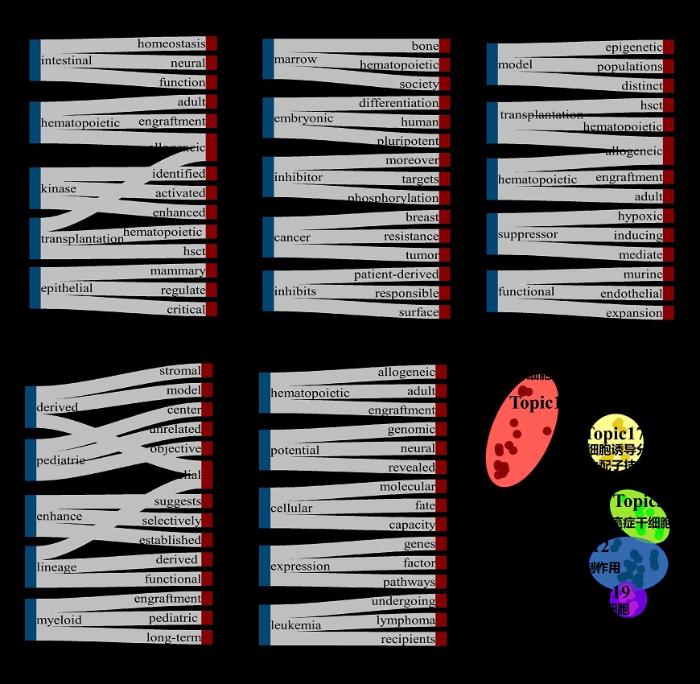
Topic1:造血干细胞移植技术。从主题强度趋势结果来看,造血干细胞移植治疗癌症主题呈现一定的上升趋势。从主题内容趋势结果来看,同种异体移植(allogeneic transplantation)、肠道稳态(intestinal homeostasis)等内容是该主题未来的热点研究方向。
Topic3:癌症干细胞。从主题强度趋势结果来看,癌症干细胞主题呈现一定的上升趋势。从主题内容趋势结果来看,造血骨髓(hematopoietic bone marrow)、胚胎分化(embryonic differentiation)、乳腺癌(breast cancer)等内容是该主题未来的热点研究方向。
Topic12:干细胞抑制作用。从主题强度趋势结果来看,干细胞抑制作用主题呈现波动上升趋势。从主题内容趋势结果来看,异基因造血干细胞移植(allogeneic hematopoietic stem cell transplantation, allo-HSCT)、髓源性抑制细胞(myeloid derived suppressor cell)等内容是该主题未来的热点研究方向。
Topic17:干细胞诱导分化、衍生配子技术。从主题强度趋势结果来看,干细胞诱导分化、衍生配子技术主题呈现轻微的上升趋势。从主题内容趋势结果来看,基质细胞衍生因子(stromal cell derived factor)、小儿急性髓性白血病(pediatric acute myeloid leukemia)等内容是该主题未来的热点研究方向。
Topic19:造血干细胞。从主题强度趋势结果来看,造血干细胞主题呈现轻微的上升趋势。从主题内容趋势结果来看,异基因造血干细胞(allogeneic hematopoietic stem cells)、潜在基因组(potential genomic)和基因表达途径(gene expression pathways)等内容是该主题未来的热点研究方向。
4.6 对比验证
图8
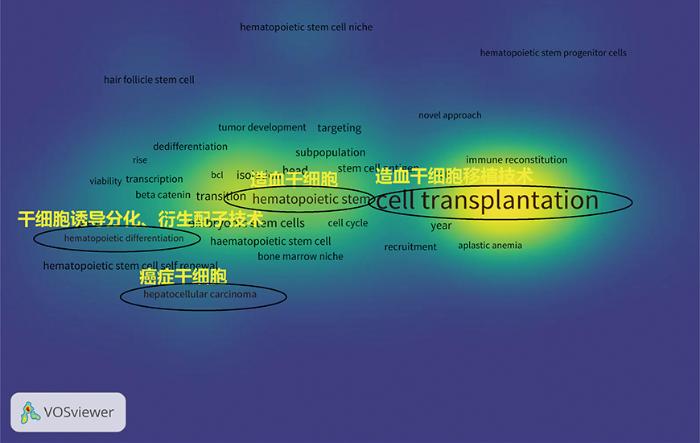
图8
基于VOSviewer的干细胞领域研究热点图
Fig.8
Research Hotspot of Stem Cell Based on VOSviewer
分析图8可知,本研究提出的方法优于基于VOSviewer的方法,不仅能识别出基于VOSviewer的方法识别出的所有主题,还能识别新的主题,比如:干细胞移植(cell transplantation)、造血干细胞(hematopoietic stem cells)、造血干细胞分化(hematopoietic differentiation)、肝细胞癌(hepatocellular carcinoma)等与本研究识别出的热点主题Topic1造血干细胞移植技术、Topic3癌症干细胞、Topic17干细胞诱导分化、衍生配子技术和Topic19造血干细胞相对应,并且本文方法还能识别出热点主题Topic12干细胞抑制作用;此外,从分析维度与粒度上来看本文方法也在一定程度上优于基于VOSviewer的方法,比如:本文方法能够从主题强度和主题内容两个层面对研究热点进行预测分析,而基于VOSviewer的方法难以预测分析其发展趋势。
4.7 讨论
目前主题演化分析研究中,主要通过构建主题强度演化时间序列并通过人工解读主题下位词汇进行主题演化趋势分析,并且在实际应用中存在以主题演化现状分析为主而趋势分析不足、主题内容难以解读等缺点;本研究提出一种面向趋势预测的热点主题演化分析方法,通过构建ARIMA模型(时序分析)和Word2Vec模型(语义分析),综合外部主题强度特征和内部语义特征,从内外两个层面对主题演化趋势进行预测分析。
外部主题强度特征、内部主题语义特征都属于学科领域研究主题识别及其演化的重要特征,外部主题强度特征、内部主题语义特征和主题时序演化三者的有机结合可更为深入地分析学科领域研究主题演化的发展过程与规律的。与现有方法相比,本研究的创新之处在于:
(1)从主题强度特征来看,相较于目前研究中通过主观分析主题强度时间序列来分析其变化趋势,ARIMA模型预测方法能够更加严谨、有效地预测细微的变化;
(2)从主题内容特征来看,相较于目前研究中简单罗列主题词汇解读主题趋势,基于Word2Vec模型预测主题内容变化能够更加直观、准确地分析主题后续的研究内容。
本研究所提方法能够在一定程度上拓展、丰富主题演化研究的视角,对于丰富情报学领域主题演化分析的方法体系具有一定意义。
5 结语
本研究提出内外特征融合的热点主题趋势测度方法,综合运用自然语言处理、数量统计和可视化技术,基于ARIMA模型和Word2Vec模型从主题强度变化和主题内容变化两个维度对主题趋势进行测度,从而分析领域热点主题的发展趋势。以美国干细胞研究领域为例,选取WOS数据库收录的论文作为数据源,利用本文学科主题趋势预测方法进行实证研究,证明该方法是可行、有效的,与现有方法相比,在一定程度上提高了结果趋势分析的严谨性与可解读性。
本研究的不足之处在于基于Word2Vec模型对主题内容趋势进行分析主要以单个词汇为基础,解读过程中可能存在歧义,限制结果分析的效果。未来将探索提高主题内容趋势分析结果的语义信息含量,比如将Word2Vec模型与句法、语法分析等语义分析技术相结合得到相应的短语、短句,提升主题内容趋势测度结果的可解读性。
作者贡献声明
岳丽欣:提出研究思路,撰写论文;
刘自强:进行实验,实验分析与论文撰写;
胡正银:设计研究方案,论文审阅与修改。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据:
支撑数据由作者自存储,E-mail:1224615932@qq.com。
[1]刘自强. 实验代码.rar. 各模型算法实现代码.
[2]刘自强. LDA主题识别结果.csv. LDA主题识别结果.
[3]刘自强. ARIMA模型.rar. ARIMA模型构建结果.
[4]刘自强. Word2Vec词向量.rar. Word2Vec模型构建结果.
参考文献
国际科技前沿分析的方法和途径
[J].
Methods and Approaches of International S&T Front Analysis
[J].
多维度视角下学科主题演化可视化分析方法研究——以我国图书情报领域大数据研究为例
[J].
Research on Visualization Analysis Method of Discipline Topics Evolution from the Perspective of Multi-Dimensions: A Case Study of the Big Data in the Field of Library and Information Science in China
[J].
基于文本挖掘的美国NSF生物科学部新兴前沿项目主题分析
[J].
Topic Analysis of Projects from Emerging Frontiers Division of NSF’s Directorate for Biological Science Based on Text Mining
[J].
基于时间序列模型的研究热点分析预测方法研究
[J].
Research on the Forecasting Method of Research Hotspots Analysis Based on Time Series Model
[J].
论文和专利相结合的研究前沿识别方法研究
[J].
Study on the Method of Identifying Research Fronts Based on Scientific Papers and Patents
[J].
Characterizing Knowledge Diffusion of Nanoscience & Nanotechnology by Citation Analysis
[J].
DOI:10.1007/s11192-009-0090-2
URL
[本文引用: 1]

This study investigates the knowledge diffusion patterns of Nanoscience & Nanotechnology (N&N) by analyzing the overall research interactions between N&N and nano-related subjects through citation analysis. Three perspectives were investigated to achieve this purpose. Firstly, the overall research interactions were analyzed to identify the dominant driving forces in advancing the development of N&N. Secondly, the knowledge diffusion intensity between N&N and nano-related subjects was investigated to determine the areas most closely related to N&N. Thirdly, the diffusion speed was identified to detect the time distance of knowledge diffusion between N&N and nano-related subjects. The analysis reveals that driving forces from the outside environment rather than within N&N itself make the foremost contributions to the development of N&N. From 1998 to 2007, Material Science, Physics, Chemistry, N&N, Electrical & Electronic and Metallurgy & Metallurgical Engineering are the key contributory and reference subjects for N&N. Knowledge transfer within N&N itself is the quickest. And the speed of knowledge diffusion from other subjects to N&N is slower than that from N&N to other subjects, demonstrating asymmetry of knowledge diffusion in the development of N&N. The results indicate that N&N has matured into a relatively open, diffuse and dynamic system of interactive subjects.
研究主题的知识流动测度及其实证分析——以H指数研究为例
[J].
The Measurement of Knowledge Flow in Research Subject with an Empirical Analysis——Taking H-index Study as an Example
[J].
k-clique社区知识创新演化方法研究
[J].
Knowledge Innovational Evolution Analysis Based on k-clique Community Network
[J].
Latent Dirichlet Allocation
[J].
Dynamic Topic Models
[C]//
基于LDA与新兴主题特征分析的新兴主题探测研究
[J].
Detection of Emerging Topics Based on LDA and Feature Analysis of Emerging Topics
[J].
基于基金项目数据的研究前沿主题探测方法
[J].
The Method of Research Front Topic Detection Based on the Fund Project Data
[J].
Mapping Change in Large Networks
[J].
DOI:10.1371/journal.pone.0008694
URL
PMID:20111700
[本文引用: 1]
Change is a fundamental ingredient of interaction patterns in biology, technology, the economy, and science itself: Interactions within and between organisms change; transportation patterns by air, land, and sea all change; the global financial flow changes; and the frontiers of scientific research change. Networks and clustering methods have become important tools to comprehend instances of these large-scale structures, but without methods to distinguish between real trends and noisy data, these approaches are not useful for studying how networks change. Only if we can assign significance to the partitioning of single networks can we distinguish meaningful structural changes from random fluctuations. Here we show that bootstrap resampling accompanied by significance clustering provides a solution to this problem. To connect changing structures with the changing function of networks, we highlight and summarize the significant structural changes with alluvial diagrams and realize de Solla Price's vision of mapping change in science: studying the citation pattern between about 7000 scientific journals over the past decade, we find that neuroscience has transformed from an interdisciplinary specialty to a mature and stand-alone discipline.
基于NEViewer的学科主题演化可视化分析
[J].
Analysis on Evolution of Research Topics in a Discipline Based on NEViewer
[J].
Impact, and Dissemination: A Topic-Level Analysis
[J].DOI:10.1002/asi.2015.66.issue-11 URL [本文引用: 1]
基于主题变迁的领域发展路径智能化识别——以人工智能为例
[J].
Intelligent Identification of Field Development Trajectory Based on Topic Evolution: A Case Study of Artificial Intelligence
[J].
The Distribution of Flora in the Alpine Zone
[J].DOI:10.1111/nph.1912.11.issue-2 URL [本文引用: 1]
基于DTM的国内外情报学研究主题热度演化对比研究
[J].
A Comparative Study on Topic Heats Evolution in the Field of Information Science Between the Domestic and Foreign Research Based on DTM
[J].
基于LDA-HMM的专利技术主题演化趋势分析——以船用柴油机技术为例
[J].
Analysis of the Evolutionary Trend of Technical Topics in Patents Based on LDA and HMM: Taking Marine Diesel Engine Technology as an Example
[J].
基于时间序列分析和SVM模型的基金项目新兴主题趋势预测与可视化研究
[J].
Prediction and Visualization of Emerging Topics of Fund Sponsored Projects Based on Time Series Analysis and SVM Model
[J].
语义分类的学科主题演化分析方法研究——以我国图书情报领域大数据研究为例
[J].
Research on the Discipline Topic Evolution Analysis Method of Semantic Classification——A Case Study of Big Data in the Field of Library and Information Science in China
[J].
基于LDA的主题语义演化分析方法研究——以锂离子电池领域为例
[J].
Analyzing Topic Semantic Evolution with LDA: Case Study of Lithium Ion Batteries
[J].
长时间序列多源遥感数据的森林干扰监测算法研究进展
[J].
Review of Remote Sensing Algorithms for Monitoring Forest Disturbance from Time Series and Multi-source Data Fusion
[J].
基于Landsat时间序列的湖南省会同县杉木人工林干扰历史重建与林龄估算
[J].
Reconstruction of Stand-replacement Disturbance and Stand Age of Chinese Fir Plantation Based on a Landsat Time Series in Huitong County, Hunan
[J].
基于ARIMA时间序列模型的稀土氧化物价格预测研究
[J].
Forecast of Price of Rare Earths Neodymium Oxide and Dysprosium Oxide Based on ARIMA Time Series Model
[J].
时间序列预测模型研究综述
[J].
Summary on Time Series Forecasting Model
[J].
基于ARIMA模型的信息构建研究主题趋势预测研究
[J].
Thematic Trend Prediction of Information Architecture Based on the ARIMA Model
[J].
Word2vec的工作原理及应用探究
[J].
Exploration of the Working Principle and Application of Word2vec
[J].
Distributed Representations of Words and Phrases and Their Compositionality
[C]//
基于VOSviewer的我国各省市科研热点领域分析
[J].
Research on Spotlights Analysis for Different Regions in China by VOSviewer
[J].
基于VOSviewer的2016-2018年国内外信息素养热点分析
[J].
Analysis on Information Literacy Hotspots at Home and Abroad Between 2016 and 2018 with VOSviewer
[J].
基于VOSviewer的山东省生物技术领域国内及国际研究现状分析
[J].
Analysis of the Domestic and International Research Situation of Biotechnology in Shandong Province by VOSviewer
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}