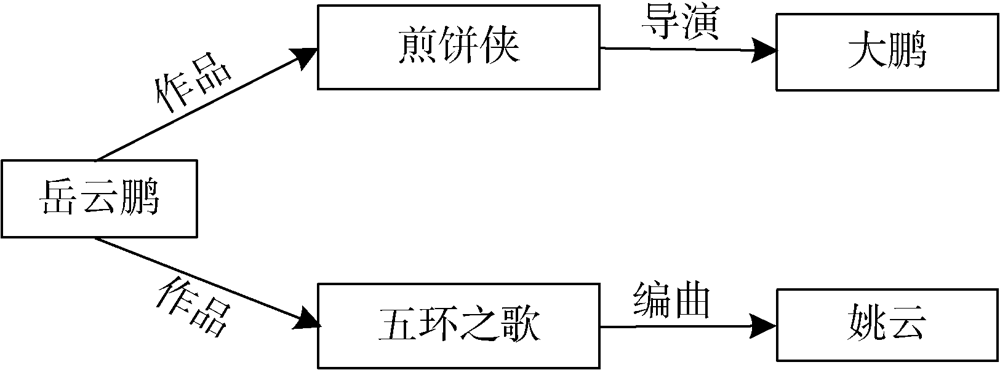
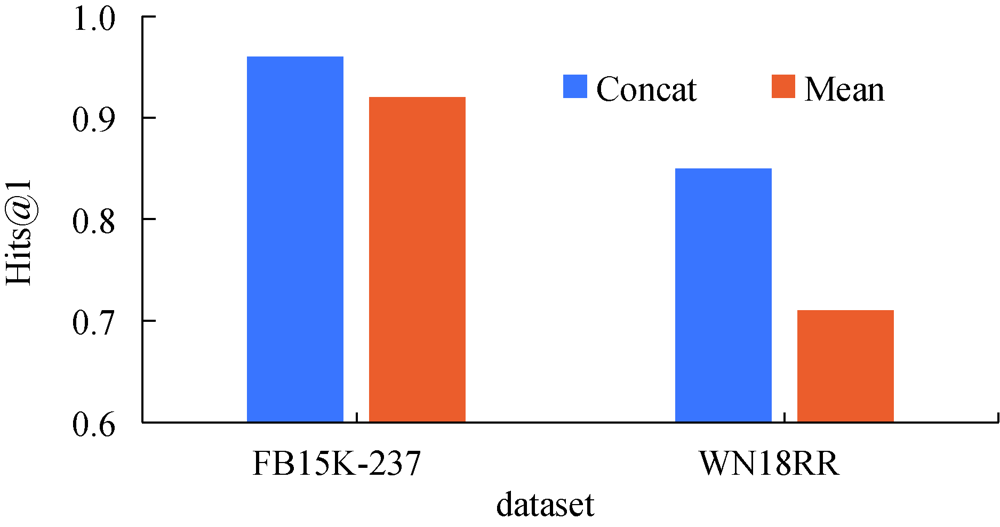
[Objective] This paper proposes a knowledge graph model based on negative sampling and joint relational contexts, aiming to improve the quality of current translation-based knowledge graph embedding models. [Methods] Firstly, we extracted the neighbors of the target instances from the original knowledge graph to generate the context vector. Then, we decided the properties of adjacent relations, which also provided information on the nature or type of a given entity. Third, we used the Concat function to aggregate contexts of the given entities of negative sampling and determined the entity attributes to be replaced. Finally, we adopted the triple embedding of the TransE model to generate negative triples, and improved the similarities of positive and negative triples. [Results] We examined the proposed model with data sets of FB15K-237 and WN18RR. The entity link was 18.3% and 29.2% higher than those of the benchmark model. Meantime, the relationship link was 0.7% better than the optimal result of the benchmark model. [Limitations] Our model only included the semantics of the relational contexts, which is very hard to determine their relative positions. [Conclusions] The proposed sampling strategy effectively improves the quality of negative triples, as well as the accuracy of knowledge graph.
李智杰, 王瑞, 李昌华, 张颉. 联合关系上下文负采样的知识图谱嵌入*[J]. 数据分析与知识发现, 2022, 6(12): 90-98.
Li Zhijie, Wang Rui, Li Changhua, Zhang Jie. Embedding Knowledge Graph with Negative Sampling and Joint Relational Contexts. Data Analysis and Knowledge Discovery, 2022, 6(12): 90-98.
Amit S. Introducing the Knowledge Graph[R]. America: Official Blog of Google, 2012.
[2]
Bollacker K, Cook R, Tufts P. Freebase: A Shared Database of Structured General Human Knowledge[C]// Proceedings of the 22nd AAAI Conference on Artificial Intelligence. 2007: 1962-1963.
Suchanek F M, Kasneci G, Weikum G. YAGO: A Large Ontology from Wikipedia and WordNet[J]. Journal of Web Semantics, 2008, 6(3): 203-217.
doi: 10.1016/j.websem.2008.06.001
[5]
Bizer C, Lehmann J, Kobilarov G, et al. DBpedia - A Crystallization Point for the Web of Data[J]. Journal of Web Semantics, 2009, 7(3): 154-165.
doi: 10.1016/j.websem.2009.07.002
[6]
Li M D, Sun Z Y, Zhang S H, et al. Enhancing Knowledge Graph Embedding with Relational Constraints[J]. Neurocomputing, 2021, 429: 77-88.
doi: 10.1016/j.neucom.2020.12.012
[7]
Li Z F, Liu H, Zhang Z L, et al. Recalibration Convolutional Networks for Learning Interaction Knowledge Graph Embedding[J]. Neurocomputing, 2021, 427: 118-130.
doi: 10.1016/j.neucom.2020.07.137
[8]
Gong F, Wang M, Wang H F, et al. SMR: Medical Knowledge Graph Embedding for Safe Medicine Recommendation[J]. Big Data Research, 2021, 23: 100174.
doi: 10.1016/j.bdr.2020.100174
(Xu Zenglin, Sheng Yongpan, He Lirong, et al. Review on Knowledge Graph Techniques[J]. Journal of University of Electronic Science and Technology of China, 2016, 45(4): 589-606.)
(Shu Shitai, Li Song, Hao Xiaohong, et al. Knowledge Graph Embedding Technology: A Review[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(11): 2048-2062.)
doi: 10.3778/j.issn.1673-9418.2103086
[11]
Bengio Y, Senecal J S. Adaptive Importance Sampling to Accelerate Training of a Neural Probabilistic Language Model[J]. IEEE Transactions on Neural Networks, 2008, 19(4): 713-722.
doi: 10.1109/TNN.2007.912312
pmid: 18390314
[12]
Zhen Y, Ming D, Chang Z, et al. Understanding Negative Sampling in Graph Representation Learning[C]// Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2020: 1666-1676.
[13]
Wang Q, Mao Z D, Wang B, et al. Knowledge Graph Embedding: A Survey of Approaches and Applications[J]. IEEE Transactions on Knowledge and Data Engineering, 2017, 29(12): 2724-2743.
doi: 10.1109/TKDE.2017.2754499
[14]
Bordes A, Usunier N, Garcia-Duran A, et al. Translating Embeddings for Modeling Multi-Relational Data[C]// Proceedings of the 27th Annual Conference on Neural Information Processing Systems. 2013: 2787-2795.
[15]
Socher R, Chen D, Manning C D, et al. Reasoning with Neural Tensor Networks for Knowledge Base Completion[C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. 2013, 26: 926-934.
[16]
Wang Z, Zhang J W, Feng J L, et al. Knowledge Graph Embedding by Translating on Hyperplanes[C]// Proceedings of the 28th AAAI Conference on Artificial Intelligence. 2014: 1112-1119.
[17]
Wang P, Li S, Pan R. Incorporating GAN for Negative Sampling in Knowledge Representation Learning[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. 2018: 2005-2012.
[18]
Sun Z, Deng Z H, Nie J Y, et al. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space[OL]. arXiv Preprint, arXiv: 1902.10197.
(Guo Zhi, Zheng Yanbin, Xia Zhichao, et al. Knowledge Representation Learning Method with Attribute Information[J]. Science Technology and Engineering, 2019, 19(33): 259-265.)
[20]
Duchi J, Hazan E, Singer Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization[J]. Journal of Machine Learning Research, 2011, 12(7): 257-269.
[21]
Toutanova K, Chen D Q. Observed Versus Latent Features for Knowledge Base and Text Inference[C]// Proceedings of the 3rd Workshop on Continuous Vector Space Models and Their Compositionality. 2015: 57-66.
[22]
Dettmers T, Minervini P, Stenetorp P, et al. Convolutional 2D Knowledge Graph Embeddings[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. 2018: 1811-1818.
[23]
Lin Y K, Liu Z Y, Luan H B, et al. Modeling Relation Paths for Representation Learning of Knowledge Bases[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015: 705-714.
[24]
Garcia-Duran A, Bordes A, Usunier N. Composing Relationships with Translations[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015: 286-290.