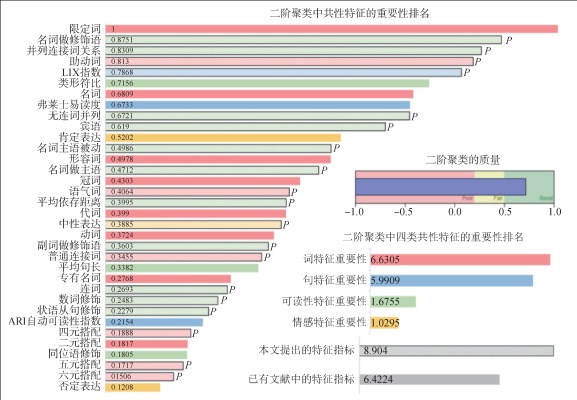
【目的】 挖掘不同语言虚假新闻的共性特征,为跨语言虚假新闻检测提供参考。【方法】 以英语和俄语为例建立数据集,挖掘不同语言虚假新闻在词、句、可读性和情感层面的共性计量特征,将其用于主成分分析、K-means聚类、层次聚类和二阶聚类实验。【结果】 34个共性计量特征用于真假新闻跨语言聚类效果良好,提出的19个新计量特征发挥了更大作用;发现虚假新闻有语言简化和经济化的趋势,倾向于使用短句和简单搭配传达信息,文本更易理解且包含负面表达更少。【局限】 由于当前数据集限制,未能找到同一主题的真假新闻样本进行平行测试。【结论】 不同语言的虚假新闻的确存在同语种无关的共性特征可用于自动聚类,为跨语言虚假新闻检测和甄别研究提供了借鉴。
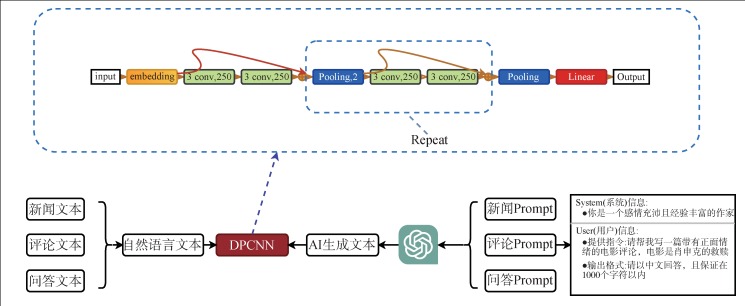
【目的】 为了防止ChatGPT被滥用,本文研究了一种中文情景下的ChatGPT生成文本(AI生成文本)检测方法。【方法】 采用Prompt提示的方式,构建三个不同种类的中文数据集。在这三个数据集上进行模型训练和测试,并从模型类型、文本类型和文本长度等维度,找到一种最优的AI生成文本检测方法。【结果】 首先,通过多种方法对比,基于深度金字塔卷积神经网络的文本分类方法在测试集上准确率达到0.965 5,优于其他方法;其次,经过测试,DPCNN模型具备良好的跨类别能力;最后,不同的文本长度对于模型的准确率具有直接影响。【局限】 以Prompt提示方式生成的中文数据集具有类别上的局限性,本文只构建了三种类别的数据集,并在此数据集上进行模型训练,然而现实中的文本类型是多样的。【结论】 本文提出一种中文情景下的AI生成文本检测方法,其准确率受到文本类型和文本长度的影响。
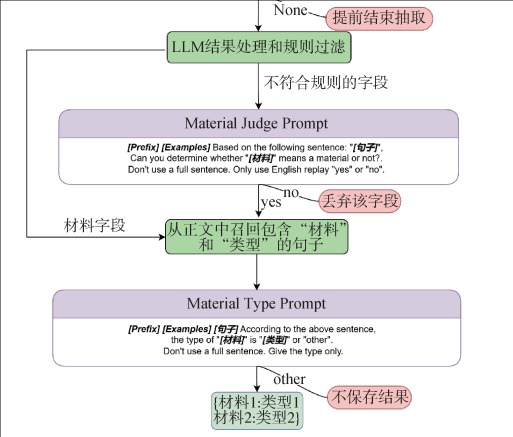
【目的】 从给定的专题研究论文中识别用于有机材料研发所需的实验材料信息,抽取已有研究中给体-受体体系下有机电池材料实体、类型实例。【方法】 利用本地部署的大语言模型和提示工程,将信息抽取任务转化为无需微调的对话式抽取任务。通过在提示模板中添加少量示例并允许大语言模型给出否定回答的方式,识别相应的实例信息。【结果】 在没有使用数据集进行微调的情况下,实现了材料实体和类型的抽取,其中实体识别的准确率为0.98,超过微调的方式,材料类型识别的准确率达到0.94。【局限】 受本地计算资源的约束,本文降低了大语言模型的参数精度,对于长实体的识别性能偏低。【结论】 采用低配本地化部署的基础大语言模型,通过构建合理的提示指令和人机协作模式,可以灵活、高效抽取所需主题下的实验信息。
【目的】 通过循环生成对抗网络和Wasserstein距离改进的生成损失,利用对抗训练提高谣言检测模型在数据样本不平衡、非配对情况下的稳定性和精确度。【方法】 利用生成器和判别器之间的对抗训练实现谣言判别模型的增强。在生成训练过程中引入循环一致性损失和识别损失以实现生成目标的可控性,并使用Wasserstein距离改进模型生成损失,提高生成器的引导效果的同时避免对抗网络训练过程中可能出现的梯度爆炸的问题。【结果】 在不平衡谣言数据集PHEME上,所提模型准确率达到0.869 8,F1值达到0.855 0,与基准模型相比,分别提高了0.006 8和0.018 0。【局限】 基于循环生成对抗网络的谣言检测模型只有两个生成器,因此只能实现两种类别样本的转换,只适用于二分类的谣言检测模型,对于多分类谣言检测任务则无法应用。【结论】 使用Wasserstein距离改进生成损失的循环生成对抗网络可以有效提升谣言检测模型在数据不平衡情况下的谣言检测能力。
【目的】 探索集成不同语料库的方式,从而提升评估词汇复杂程度的综合表现。【方法】 提出一种多领域词汇复杂度评估模型,通过特征泛化模块适应各种领域,在下游微调任务中学习词汇复杂度预测,通过特征融合模块探索手工特征与神经网络深度特征的组合意义。【结果】 在LCP-2021数据集上,本文模型相较于公开的现有最优结果,Pearson系数、MAE、MSE指标分别提升0.014 8、0.001 7、0.000 4,Spearman系数和R2系数的表现则下降0.003 8、0.025 5;集成手工特征后没有明显变化;二次迁移到CWI-2018数据集,本文模型在三个领域上的MAE指标,相较公开的基线结果分别提升0.008 6、0.020 9、0.017 4。【局限】 采用向量拼接集成手工特征和深度特征,未能充分融合不同类型特征;设计特征泛化模块时的算法选择具有一定局限性;可以进一步尝试构建综合数据集。【结论】 集成不同语料库,有助于提升模型在新领域下的整体评估效果。
【目的】 针对现有通用命名实体识别模型在古籍特定领域的局限性,提出一种多任务深度学习模型,专门用于多类型礼俗专名的自动识别,以提升古籍中复杂礼俗专名的识别精度和效率。【方法】 首先构建包含6个类别的礼俗专名标注语料库,然后构建融合古文预训练语言模型的礼俗专名识别和自动标点一体化模型MJL-SikuRoBERTa-BiGRU-CRF。该模型利用SikuRoBERTa和BiGRU训练语料库并获取上下文语义信息,再由CRF层对两个子任务进行标签约束,生成全局最优的专名和标点标签序列。【结果】 所提模型在礼俗专名识别任务上的F1值为84.34%,在自动标点任务上的F1值为75.30%。其中,在宫室、器物、服饰专名类别上效果显著,F1值达到85%以上;在饮食、车具、物产类别上表现稍显不足,F1值为76%~81%。【局限】 模型未在更细粒度专名分类上进行验证。另外,本文尝试对专名识别方法进行数据增强,以提高礼俗专名识别效果,但并没有将其应用于所有类别。【结论】 本文构建的一体化模型更适用于中国古代礼学文献的礼俗专名识别任务,可为古代礼仪信息抽取、知识库自动构建提供有效支持。
【目的】 针对当前多模态情感分析中模态融合与交互不充分、多模态特征提取不完全的问题,提出一种基于跨模态注意力和门控单元融合网络的多模态情感分析方法。【方法】 在多模态特征提取方面,增加视频模态中人物微笑程度特征和人物头部姿势特征,丰富了多模态数据的底层特征;在模态融合方面,利用跨模态注意力机制使模态内部以及模态之间的信息进行更充分的交互,利用门控单元融合网络去除冗余信息,并通过自注意力机制分配注意力权重;最后,通过全连接层输出最终情感分类结果。【结果】 在中文公开数据集CH-SIMS上与先进的Self-MM模型进行对比,实验结果表明,本文提出的方法在二分类准确率、三分类准确率和F1值上分别提升2.22、2.04和1.49个百分点。【局限】 视频中人物的肢体动作在不断变化,不同的肢体动作蕴含不同的情感信息,模型没有考虑到人物在视频中的肢体动作信息。【结论】 本文丰富了多模态数据的底层特征,有效实现模态融合,提升了情感分析的效果。
【目的】 充分利用模态互补性,增强模态之间和模态与标签之间的相关性,实现高度准确的分类效果。【方法】 提出一种基于多模态语义增强及图卷积网络的短视频多标签分类算法,利用短视频中的多模态信息进行多标签分类任务。【结果】 算法分类精度达87.15%,比最优的基准算法提升了6.82个百分点。【局限】 模态融合增强信息存在冗余信息,这些冗余掩盖了模态之间的相关性;此外,基于多模态的多标签分类研究较为有限。【结论】 本文算法能够提高模态之间的互补性,增强模态与类别之间的相关性,提高分类准确性。
【目的】 通过关联标签学习丰富的语义表示,在哈希码中保留更多辨别信息,同时考虑到跨模态语义相似性,保持不同模态间的相关性,更好地弥合模态差距。【方法】 在多标签的关联约束下,挖掘不同模态的公共语义信息以及隐藏的类语义结构,采用高级语义与低级语义联合相似性度量的非对称学习框架,进而量化获得更具强鉴别性的哈希码。【结果】 在MIRFlickr-25K、IAPR TC-12和NUS-WIDE三个多模态基准数据集上,本文方法与7种方法进行实验对比,在5种不同码长情况下,本文方法的平均MAP值比基准模型的最高值分别提升2.1%、5.8%和2.1%。【局限】 所提出方法对多标签数据集更具适用性,对单标签数据的语义相关性挖掘尚有欠缺。【结论】 所提方法保持样本和类语义结构的一致性,并且充分挖掘内在模态特征,有效提高了检索性能。
【目的】 提取用户外部刺激和认知评价指标,构建企业负面事件下微博用户极端情感影响因素模型,利用SHAP解释各特征变量的影响。【方法】 基于认知情感理论、社会影响理论、情感评价模型、LDA模型、扎根理论确定外部刺激和认知评价指标,并将两类指标包含的特征变量作为输入,极端情感变量作为输出,构建极端情感影响因素模型。通过4个模型性能对比,将最优模型与SHAP模型融合进行可视化展示。【结果】 认知评价维度提取出7个特征变量;LGBM模型的准确率、精确率、F1值分别达到0.88、0.90、0.93,优于其他对比模型;从特征变量对微博用户极端情感产生的影响程度来看,认知评价维度普遍高于外部刺激维度,且各特征变量的影响方式有所不同。【局限】 需要探索更多影响因素及更广泛的企业负面事件类型,算法性能有待提高。【结论】 本研究提出的模型优化了扎根编码过程,可视化各特征变量对极端情感的影响程度、影响方向、影响大小及影响方式,可以为企业解决网络口碑负面化的问题提供理论依据。
【目的】 基于开源情报构建一种军事知识图谱的检索式问答服务系统。【方法】 将RoBERTa预训练模型和数据增强技术相结合,解决低资源的军事问答中问句分类和命名实体识别问题,并结合军事领域实体特点提出三维特征的实体链接方法。接着,采用RoBERTa预训练模型和依存句法分析方法,解决简单意图和部分复杂意图问题的关系匹配问题。最终,应用启发式规则完成答案的提取。【结果】 问句分类与实体识别F值分别为99.62%、98.35%,关系抽取准确率达到99.72%,问答系统应用评测平均准确率达到91.70%。【局限】 本问答系统的军事知识图谱存在自动扩展效率低下的问题,因此,影响了问答服务质量。【结论】 本研究实现了一种具备高可解释性和高准确率的军事知识问答智能服务。
【目的】 考虑原始评分信息的准确性及其预测结果的可靠性,以提升推荐系统的准确性。【方法】 从信息输入和输出两方面,设计三种方案为已有推荐算法的预测结果提供可靠性概率。在信息输入方面,借助直觉模糊集理论,提出模糊自然噪声检测机制识别和修正有误评分;在信息输出方面,分别采用二次模糊噪声检测、矩阵分解和深度神经网络获得待预测位置的可靠性概率,并根据设定的可靠性判别条件,识别出不可信的预测评分并对其修正。【结果】 在两个公开数据集上的实验结果显示,与原始推荐算法相比,引入所提模糊自然噪声检测方法和三种可靠性方案后的相应方法在F1值和NDCG评估指标上分别最高提升了6.4%和7.2%。【局限】 所设计的可信推荐策略不适用于只包含隐式反馈的数据集。【结论】 从评估信息可靠性的视角,为提升推荐算法的性能提供了新的解决方案。
【目的】 从技术融合角度出发,综合采用链路预测、指标评价方法识别企业技术机会,为企业进行战略性研发布局提供参考。【方法】 基于目标企业专利数据构建知识元素共现网络,采用链路预测方法识别潜在知识组合,从企业内部技术禀赋、外部创新环境两个角度创建多维指标,评价潜在知识组合的可行性,进而构建潜在知识组合分布图,识别企业技术机会。【结果】 采用6种机器学习算法构建链路预测模型,准确率最高达到0.810。不仅为目标企业精准识别到10项技术机会,更呈现了技术描述与功能模块的对应关系。【局限】 仅关注以IPC对形式呈现的知识组合,对于多个IPC形式的知识组合有待进一步探索。【结论】 结合链路预测方法与多维指标评价方法,能够更精准、细粒度地识别企业技术机会。
【目的】 通过科学量化评价主要发达国家/地区碳中和战略行动政策,推动我国碳达峰碳中和政策的制定与工作部署。【方法】 深度挖掘全球主要发达国家/地区碳中和战略行动政策,优化政策量化PMC指数模型,并以Web of Science核心数据库为文献来源考察碳中和相关技术演化路径,探讨全球碳中和战略行动特点与发展趋势。【结果】 日本在2021年更新颁布的《2050碳中和绿色增长战略》内容制定最为全面。碳中和领域相关学科和技术发展趋势具有交叉性和多边合作性。中国科学院和清华大学是全球碳中和领域机构合作网络关键枢纽。【局限】 研究方法属于传统技术优化手段,研究对象仅针对部分国家/地区。【结论】 制定碳中和战略行动政策时需从国家层面出发,联合尽可能多的领域机构参与研讨,充分利用新兴科研技术,加强全球人才交流与合作,有力支撑能源清洁转型,加快实现“双碳”目标。
【目的】 探索全面综合评价博士学位论文质量等级的新方法。【方法】 将数据包络分析方法应用于博士学位论文综合质量评价,与常规总评分分级方法相比较,探讨是否能得到更为准确、合理、全面的评价结果。【结果】 基于数据包络分析的等级划分是全面评价博士学位论文质量的有效方法,能够识别总评分相似样本的综合质量差异;相较于总评分评级,数据包络分析更能包容学位论文质量表现的多样性,而非仅依据分值高低判断论文质量优劣。研究以抽检“不合格论文”和“优秀博士论文”为标志样本进行有效性验证。【局限】 该分析方法必须基于标准规范的专家评阅分数,虽能确定学位论文综合质量等级,但无法给出学位论文质量“及格线”。“及格线”必须由学科领域专家参与评价后确定。【结论】 与随机抽检的方法不同,数据包络分析具有快速、准确、灵敏的性能特点,在博士教育评价实践中具有实际应用价值。

