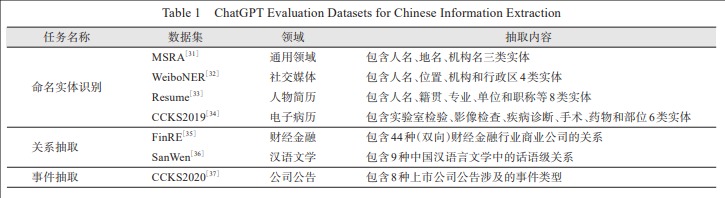
[Objective] This paper evaluates the performance of typical Chinese information extraction tasks such as named entity recognition, relationship extraction, and event extraction with ChatGPT. It also analyzes the performance differences of ChatGPT in different tasks and domains, which provides recommendations for ChatGPT in Chinese contexts. [Methods] We used manual prompts to evaluate the test results with exact matching or loose matching on three typical information extraction tasks across seven datasets. We evaluated the named entity recognition of ChatGPT on MSRA, Weibo, Resume, and CCKS2019 datasets and compared it with GlyceBERT and ERNIE3.0 models. We extracted the relationships with ChatGPT and ERNIE3.0 Titan on FinRE and SanWen datasets. We ran the event extraction of ChatGPT and ERNIE3.0 on the CCKS2020 dataset. [Results] In the named entity recognition task, ChatGPT was outperformed by GlyceBERT and ERNIE3.0 models. ERNIE3.0 Titan was also superior to ChatGPT significantly in the relationship extraction task. In the event extraction task, ChatGPT’s performance was slightly better than ERNIE3.0 under loose matching. [Limitations] The evaluation of ChatGPT’s performance using prompts is subjective, and different prompts may lead to different results. [Conclusions] ChatGPT needs to improve its performance on typical Chinese information extraction tasks, and users should choose appropriate prompts for better results.
[Objective] This paper aims to use a large language model for entity recognition tasks of academic papers. [Methods] We utilized ChatGPT, a large language model, as an entity recognition tool, a pseudo-label generation tool, and a training set generation tool. Then, we analyzed ChatGPT’s performance, price, and time for the tasks. [Results] The F1 of the ChatGPT-based method in all three perspectives is higher than that of the neural network baseline model trained with a small dataset. For example, the F1 from the perspective of entity recognition was 21.4% higher than the model trained by manually annotating 10 abstracts. The ChatGPT-based methods had stable performance on academic paper datasets in different disciplines. [Limitations] We only examined the new method with English academic paper abstract datasets. More research is needed to examine it with the Chinese datasets. [Conclusions] ChatGPT can identify entities from academic paper abstracts with little manually annotated data. The recognition results need to be further filtered to be applied to downstream tasks.
[Objective] This paper comprehensively examines the evolution of public opinion triggered by the metaverse concepts, which provides insights for metaverse-related policies and industry planning. [Methods] We retrieved Weibo textual posts on metaverse-related from September 2021 to February 2023. Then, we utilized BERT and DTM models to extract semantic and topic features. Third, we employed the K-means algorithm for topic clustering and explored their evolutionary patterns. [Results] The public attention on the metaverse originated around NFTs and gaming. With capital speculation within the digital industry, the entertainment and physical industries joined the race. The emergence of ChatGPT further prompted the public’s exploration of the status quo of the metaverse, technology innovation, and prospective applications. [Limitations] We did not include foreign language data from Twitter to compare the focus and trends of the metaverse topics among domestic and international users. [Conclusions] This study examines the characteristics and evolution of social attention on topics related to the meta-universe from quantitative and macro perspectives. It helps us regulate online public opinion in the meta-universe.
[Objective] This paper proposes a data-driven prediction method for dynamic relationships, aiming to provide a new perspective for rapidly updating the financial knowledge graph. [Methods] First, we regularly crawled relevant information from the Internet according to the monitoring list. Then, we used the Mask Language Model to construct a dataset and train the model. Third, we extracted the hierarchical structure of the financial knowledge graph to build a hidden layer of the neural network. The neurons contained in the hidden layer represent named entities. Fourth, we connected the hidden layers by a relationship matrix and predicted the dynamic relationships by updating the connection matrix. [Results] We examined the proposed model with the two equity changes at the beginning of the “Baowan” event. Our new model quickly captured the changes in the relationship between corresponding entities of the financial graph in different periods. [Limitations] Due to the characteristics of unsupervised learning, the predicted relationship is relatively divergent, which requires manual calibration verification. [Conclusions] With sufficient data, the proposed method can effectively capture the changes in the relationship between entities without manual annotation. It will effectively and continuously predict the relationship of the financial knowledge graph.
[Objective] The existing few-shot knowledge graph completion methods could not distinguish the importance of neighbors when dealing with complex relations, which resulting in low performance of entity prediction. The few-shot knowledge graph completion methods could be improved by considering entity neighbor information. [Methods] First, we use a type-aware neighbor coder to learn the implicit type information in the entity neighbor such that the type-aware attention can be obtained and the entity representation can be enhanced. Then, a Transformer encoder is used to capture different meanings of a task relation. Finally, the reference set representation is obtained by jointly matching the prototype network aggregation and predicting the entity. [Results] The proposed method is verified on NELL and Wiki datasets through entity prediction tasks. The results show that the MRR is 1.6% and 1.2% higher than the baseline methods on the two datasets, respectively. [Limitations] Neighbors with lower physical relevance were not filtered, and the noise would affect the distribution of type-aware attention weights. [Conclusions] Experimental results show that the proposed method improves the few-shot knowledge graph completion performance by learning more abundant entity neighbor information.
[Objective] This paper aims to apply dialogue language understanding tasks to dialogue systems with frequent domain updates without sufficient annotated data for model learning. [Methods] We proposed an Information Augmentation Model for Few-shot Spoken Language Understanding (IAM-FSLU). It uses few-shot learning to address the challenges of data scarcity and model adaptability in new and across-domain scenarios with varying intent types and quantities. Additionally, we constructed an explicit relationship between the two tasks of few-shot intent recognition and few-shot slot extraction. [Results] Compared with the non-joint modeling approaches, the F1 score of slot extraction was improved by nearly 30%, and the sentence accuracy rate was improved by nearly 10% in the 1-shot setting. The F1 score of slot extraction was improved by nearly 35%, and the sentence accuracy rate was improved by 12%~16% in the 3-shot setting. [Limitations] The IAM-FSLU model needs further improvement in intention recognition. The sentence accuracy improvement needs to be improved for the slot extraction task. [Conclusions] The overall performance of the IAM-FSLU model is better than other mainstream models.
[Objective] This paper proposes a prediction method based on heterogeneous networks and representation learning. It tries to promote exchanges and cooperation among scientific researchers. [Methods] First, we constructed a heterogeneous scientific research cooperation network with information on scholars, institutions, papers, and journals. According to the different co-occurrence relationships among scholars included in the network, we divided the heterogeneous network into three types of homogenous co-occurrence networks. Then, we used Node2Vec and Doc2Vec to learn the network structure and content attribute features of scholars, respectively. Finally, we merged them to calculate the cosine similarity between scholars. [Results] We examined the new method with datasets in artificial intelligence from WOS. The proposed method’s predicted AUC and F1 values reached 0.987 9 and 0.942 4, respectively, outperforming the baseline methods. [Limitations] The representation of scholar content characteristics does not consider the scholar’s research topics. [Conclusions] The proposed model includes the scholar’s structure and content attributes. It also combines heterogeneous networks and integrates various information, including institutions, papers, and journals. The new method can predict scientific cooperation more effectively.
[Objective] This paper aims to efficiently and accurately identify emerging technologies, which also helps governments and enterprises allocate resources appropriately. [Methods] We took fine-grained technical terms as research objects. We constructed an emerging technology recognition model based on the co-word network’s structural features and semantic representation. Then, we identified emerging terms and quantified their scores. Third, we used the Node2Vec graph representation learning algorithm to encode and semantically represent the vectors of these terms. Finally, we identified emerging terms and technical topics. [Results] We conducted an empirical study with the new model and CNC machine tools. A total of 449 emerging terms and four emerging technology topics (including robot automatic loading and unloading systems, clean and efficient cutting technology, high-speed and high-precision CNC machining centers, and additive-subtractive hybrid manufacturing technology) were identified. [Limitations] We only used patent data, which needs to be expanded to other multi-source heterogeneous data with network relationships like citation and semantic similarity. [Conclusions] Using the co-word and Node2Vec representation learning method, we successfully utilize the co-word network’s structural features and semantic representation between technical terms, which help us identify emerging technologies.
[Objective] The concentration of literature reading is mainly evaluated by manual methods or eye-tracking techniques. This paper uses computer vision technology to automatically detect and receive real-time feedback from the concentration evaluation, which also improves the application of intelligent technology in smart knowledge service. [Methods] First, we detected the head postures of the readers by their vertical and horizontal rotation angles. Then, we scored their fatigue and emotion with the closing eyes or yawning status. Third, we decided the readers’ sentiment based on these expression recognition results. Fourth, we applied the fuzzy comprehensive evaluation algorithm to determine the weight of relevant factors. Finally, we integrated the scores to obtain the reader’s concentration status at different reading processes. [Results] We applied the new model to the actual reading scenes to evaluate the reading concentration of head tilt, fatigue, and negative emotion, and the results were 26.3%, 25.2%, and 6.8% lower than the normal state, respectively. [Limitations] When the literature reading video showed blurred facial features, the detection accuracy was unsatisfactory, which needs improvement. There are also some extreme reading instances to be optimized. [Conclusions] The proposed model can adjust reading strategies and help libraries optimize collection development strategies.
[Objective] This paper utilizes the SPO triples and the dependency syntax to improve the performance of the event detection model.[Methods] We constructed an event detection model EDMC3S combining the semantic information of SPO triples and the type information of dependency syntactic relationship. First, the model generates SPO triples and dependency syntax relation type weight matrix based on the dependency syntax tree of the sentence. Then, we used a multi-head attention mechanism to strengthen the semantic features of SPO triples and a self-attention mechanism to distribute the weight of different dependency relation types. Third, we extracted the global syntactic and semantic features through the multi-order graph attention aggregation network. Finally, we integrated the semantic features of SPO triples and the global features of statements with a connection layer. [Results] We examined the new model on the ACE2005 dataset, and it achieved better classification performance in the two sub-tasks of trigger word recognition and event type classification. On the three evaluation indexes of P, R, and F1, the recognition of trigger words reached 80.6%, 82.4%, and 81.5%, respectively, and the classification of event types reached 78.7%, 80.1%, and 79.4%, respectively. [Limitations] We need to evaluate the new model with more datasets. [Conclusions] The proposed model can improve the effect of event detection in trigger word recognition and event type classification.
[Objective] This paper develops a new model to detect fraud in crowdfunding activities. [Methods] We extracted textual clues from the project description in three dimensions: cognitive load, narrative perspective, and emotional output. Then, we built and optimized ensemble models with resampling and threshold moving methods. [Results] The AUC values of the optimized models reached 0.8. The threshold moving method further improved the models’ performance, and the F1 scores improved by 0.279 on average, with a maximum improvement of 195%. [Limitations] The proposed models only use textual features from the project description and do not consider more dimensional features. [Conclusions] Ensemble model based on resampling and threshold moving methods can effectively identify fraudulent crowdfunding projects.
[Objective] This paper uses transfer learning and multi-task learning to solve the problems of cold start and boundary in Chinese medical literature entity recognition, and further improve the recognition accuracy. [Methods] Firstly, we constructed a hybrid deep learning BERT-BiLSTM-IDCNN-CRF medical literature entity recognition model. Secondly, based on transfer learning, the medical semantic features were enriched through instance, model and feature transfer. Thirdly, we constructed a coarse-grained three-classification task through multi-task learning to assist the main task in utilizing the entity boundary information effectively. Finally, we introduced the self-attention mechanism and highway network to capture global information, optimize deep network training and establish the TLMT-BBIC-HS model. [Results] The model had an F1 value of 92.98% on the Chinese diabetes medical literature dataset, which is 15.99% and 16.44% higher than the benchmark models BERT-BiLSTM-CRF and BERT-IDCNN-CRF. [Limitations] The domain suitability of this model needs to be verified. [Conclusions] The TLMT-BBIC-HS model can transfer and share medical knowledge, which is more suitable for Chinese medical Literature entity recognition. It could effectively extract medical information and construct knowledge graphs and question answering systems.
[Objective] This paper constructs a knowledge graph for Traditional Chinese Medicine(TCM) with multi-source heterogeneous data. It supports research innovation in TCM.[Methods] First, we obtained the TCM patents from the IncoPat database. We retrieved the targets and disease data from the Traditional Chinese Medicine Systems Pharmacology Database and Analysis Platform(TCMSP) and Online Mendelian Inheritance in Man (OMIM). Then, we extracted the entity and relationship of TMC patents with the deep learning information joint extraction model. We also used string matching and dictionaries to finish the data specification and entity alignment. Third, we constructed the TCM knowledge graph based on the ontology structure we designed. Finally, we analyzed the optimization of TCM prescriptions with the frequency analysis and Apriori algorithm. [Results] The ontology structure designed in this paper contains 31 entity types and 48 semantic relationships, covering specific entities such as solutions and technical effects in TCM patents. We examined the effectiveness of the knowledge graph and the efficiency of optimizing prescriptions with the diabetic nephropathy data. [Limitations] It took us a long time to manually annotate some samples to extract textual information.[Conclusions] The knowledge graph constructed in this paper provides data support for TCM research. It also benefits prescription optimization and realizes multivariate research in TCM.
