刘健 , 毕强
, 毕强
Liu Jian, Bi Qiang
中图分类号: G250.7
通讯作者:
收稿日期: 2016-05-9
修回日期: 2016-06-19
网络出版日期: 2016-09-25
版权声明: 2016 《现代图书情报技术》编辑部 《现代图书情报技术》编辑部
基金资助:
展开
摘要
【目的】解决传统数字文献资源内容服务推荐中无法充分挖掘资源语义信息等问题。【方法】通过设定本体推理规则对用户查询关键词进行语义扩展, 提出一种新的语义相似度计算方法计算文献资源内容相似度。按照相似度大小对搜索结果进行排序, 将排名较高的文献推荐给目标用户。【结果】实验结果证明, 该方法能够较准确地计算语义相似度, 并能够对用户需求进行有效推荐。【局限】缺少对数字资源的大规模采集, 实验案例较少。【结论】该方法充分挖掘数字文献资源的语义信息并进行有效推荐, 为数字资源内容服务推荐提供一种新思路。
关键词:
Abstract
[Objective] This paper tries to improve the traditional content recommendation service of digital literature, which cannot fully exploit the semantic information of the literature. [Methods] First, we introduced the Ontology reasoning rules to the recommendation system, and then semantically extended the user’s query. Second, we calculated the similarity of the literature to rank. Finally, we recommend those top ranked literature to the users. [Results] The proposed algorithm can calculate the semantic similarity among literature and successful recommend documents to the users. [Limitations] Only examined the new method with relatively small data sets. [Conclusions] The proposed algorithm could effectively exploit the semantic information of target literature and offer a new way to recommend digital resource to the users.
Keywords:
以用户为中心, 根据用户的个性化需求开展具有针对性和主动性的信息服务, 是提高信息服务质量和信息资源使用效率的重要手段[1]。资源服务推荐是满足用户个性化价值追求的有效手段之一[2]。目前, 基于内容的推荐[3]、基于协同过滤推荐[4-6]、以及基于情境的推荐[7-10]等资源服务推荐方法得到了较好的应用和推广。然而, 上述推荐方法大多利用关键词词频作为计算依据, 不能准确表达数字文献资源的语义信息[11], 难以区分数字文献资源的品质和风格[12], 导致数字文献资源的结构化程度较低, 限制了资源的有效利用和共享[13], 无法充分挖掘用户潜在的信息需求[14-15]。
本文将本体作为反映资源属性关系的模型, 提出一种基于本体规则推理和语义相似度计算的数字文献资源推荐方法, 以此解决推荐系统中资源的语义缺乏、结构化程度低等问题[16-17], 并充分挖掘用户潜在需求, 为数字资源内容服务推荐提供一种新思路。
本体体现的是特定领域知识结构的概念体系, 反映了特定领域的通用观点及其明确的概念和概念间关系的集合, 侧重领域概念层次上的术语及术语关系的表达, 为知识组织和共享提供精确控制[18]。基于本体的推荐方法可以有效解决推荐系统中语义缺乏、结构化程度低等问题[19], 因而成为学者关注的热点。目前, 主要有基于本体规则推理的资源推荐、基于本体语义相似度的资源推荐、基于本体语义描述的资源推荐等方式。基于本体规则推理的资源推荐是将语义网本体语言同推理机(如Jess、Pallet等)结合起来, 通过设定、添加规则和进行逻辑推理, 发掘隐含的语义关联关系, 将关联度较高的资源推荐给目标用户[20-22]。基于本体语义相似度的资源推荐通过构建领域本体对多源信息进行整合, 整合后的本体属性可以反映资源特征, 再通过计算该本体中各个概念节点属性及本体网络结构的相似度从而得到相似资源, 进而提高推荐质量[16, 23-25]。基于本体语义描述的资源推荐将本体引入到推荐系统中, 使用OWL语言对用户和项目信息进行描述, 然后与协同过滤、基于内容推荐等传统推荐模型相结合并计算用户偏好信息与项目信息的相似性。用户和项目具备了语义信息的同时, 也提高了资源信息的结构化描述水平, 并且可以有效提高推荐的召回率和准确率[26-28]。
然而基于本体规则推理的资源推荐仅通过设定推荐规则挖掘用户需求, 但并未充分描述资源的语义信息; 基于本体语义相似度资源推荐由于存在关键词和索引词之间的多重表达差异而无法表达用户的真实需求; 基于本体语义描述的资源推荐由于使用传统的推荐算法而存在用户冷启动、评分矩阵稀疏等问题导致推荐结果精度不高。本文提出一种基于本体推理规则和语义相似度计算的推荐方法, 以解决推荐系统中存在的资源语义信息挖掘不充分、无法表达用户需求等问题, 进而增强推荐系统的语义表达与处理能力。
本体推理可以发现本体中隐含的逻辑关系、检查本体和知识的相容性、对实例进行自动分类[29]。这有利于保证本体构建的正确性和一致性, 并可以将松散的概念、属性、实例等联系起来, 形成一个完善的知识库, 从而优化本体, 降低本体维护的成本[30]。Hayes定义了D推导规则集, 此规则集是从一个RDF图推导出一组标准推导规则[31]。由于D推导规则存在不完备性, Ter Horst对其进行补充[32], 称为D*推导规则集。这个规则集允许空白节点出现在三元组谓词位置上, 以保证RDFS的完备性。OWL作为RDFS的扩展, 解决了RDFS中存在的不支持基数约束、类的布尔组合、属性的限制等问题。Horrocks等将OWL1 DL与规则集成, 基于Horn子句的RuleML中一个子集构造出语义网规则语言SWRL[33]。作为语义网框架, Jena也支持规则推理。Jena同SWRL类似, 语法规则格式要求严格、与OWL描述方式相近, 并且可以采用正向和反向推理, 因此本文采用Jena规则对概念进行扩展推理。
语义相似度是指两个概念间的相似程度[17], 已经被应用于词义消歧[34]、自动检索[35-36]、图像分类及标注[37-38]、信息抽取[39]、信息检索[40-41]等领域。按照计算方法的不同分为: 基于距离的方法、基于内容的方法和基于属性的方法等。基于距离的计算方法是在层次网络中使用路径长度来量化两个概念之间的语义距离[42]。两个概念的语义距离越大, 即路径长度越长, 则相似性越小。在层次网络中, 全部有向边距离的权值都为1, 即将各个节点视为同等重要, 这样可以根据层次网络中构成最短路径的有向边数量计算两个概念的语义距离。该模型假设所有边权值都为1, 但在实际情况中, 节点的位置信息、节点的类型和节点之间的关联强度等因素都会影响其重要性, 学者在此基础上对该模型进行改进。例如, Leacock等考虑了本体分类体系树自身的深度对概念相似度的影响, 提出了改进的语义相似度计算模型[43]。基于内容的方法[44]认为两个概念共享的信息会影响二者的语义相似度。在层次网络中, 概念子节点是对其父节点的细化和具体化, 子节点包含父节点的信息内容, 这样可以通过计算公共父节点概念所包含的信息内容计算子节点概念之间的相似度。基于属性的方法[45]是利用事物之间不同的属性特征区别事物。两个事物的公共属性越多, 相似度越高。因此, 可以利用两个概念对应的属性集的相似程度计算概念的语义相似度。然而, 上述计算方法没有考虑本体结构信息, 不能充分体现和揭示概念之间的语义关系, 导致相似度计算的结构精度不高。本文提出的语义相似度计算方法, 包含密度、深度和属性三种影响因素, 可较为准确地计算出概念语义相似度。
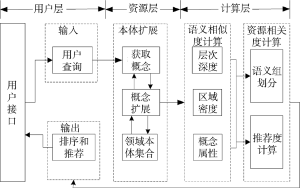
基于本体规则推理和语义相似度计算的数字文献资源推荐方法是通过将用户输入概念扩展为一组相似概念, 实现本体的细粒度查询, 利用扩展后的概念与文献资源本身包含的语义信息进行语义相似度计算, 将相似度较高的文献推荐给目标用户, 从而向用户提供有价值的个性化资源推荐服务。构建的推荐流程如图1所示。首先用户输入关键词, 利用本体知识库中的领域本体规则推理对输入关键词进行概念集扩展, 得到扩展查询条件; 其中资源层进行领域概念抽取, 并根据抽取的领域知识创建本体, 建立本体知识库; 计算层将查询条件映射到本体实例(采用关键字匹配的方法), 计算扩展后概念集与资源的语义相似度; 最后, 对推荐度进行排序, 并将推荐度较高的数字文献推荐给目标用户。
(1) 语义推理
利用同义语义扩展进行语义推理, 设定的规则包括概念上下位关系及相似关系。RDF作为语义网本体描述语言, 规范了以三元组形式陈述的数据模型。RDFS可以用来表示简单的术语及其关系, 例如类包含、属性包含、属性的定义域和值域等。由RDF和RDFS描述的推理规则具有反转性、传递性、继承性及部分性等。例如: {v p w|p rdfs:domain u.} =v rdfs:type u. (rdfs2)、{v p w|p rdfs:subPropertyOf q.} =v q w. (rdfs7)[20]。OWL作为RDFS的扩展, 可以解决RDFS中存在的不支持基数约束、类的布尔组合、属性的限制等问题。OWL类和属性的推理规则具体包括: owl:sameAs、owl: intersectionOf、someValuesFrom 和allValuesFrom等。在OWL本体的定义中, 利用owl:sameAs描述同义关系, 由rdfs:subClassOf 描述上下位关系, 并且二者都具有传递性。例如如果存在(?x rdfs: subClassOf ?y), 且(?y rdfs:subClassOf ?z), 那么则可以得到(?x rdfs: subClassOf ?z)。同样如果(?x owl:sameAs ?y), 且(?y owl:sameAs ?z), 则得到(?x owl:sameAs ?z)。虽然并未对x和z的关系进行在定义, 但可以利用两个直接的定义推理得出二者隐含的定义, 这就是推理机的作用。
Jena作为创建本体应用的Java框架结构, 支持包括对RDF、RDFS、OWL等本体描述语言进行解析, 对RDF文件和模型进行处理, 对RDF模型持续性存储, 基于规则的推理等功能。Jena提供基于规则的推理机(如RDFS Reasoner、OWL Reasoner等)包含传递推理、RDFS规则推理、OWL-Lite推理等推理功能, 也包含通用规则推理和第三方推理引擎推理功能。Jena规则与规则推理机绑定, 规则推理机通过调用bindSchema与模型或模式绑定[30]。由于Jena功能较为全面, 因此选择Jena对本文设定的规则进行推理。
以下是对计算机推理的部分自定义产生式规则:
@prefixcomputer:<http://www.xh.com/computer.owl#>.
@include<RDFS>.
@include<OWL>.
String rules=
“[Rulel:(?x rdfs:subClassOf ?y), (?y rdfs:subClassOf ?z)->(?x
rdfs:subClassOf ?z)]”+“[Rule2:(?x owl:sameAs ?y), (?y
owl:sameAs ?z)->(?x owl:sameAs ?z)]”
//根据自定义推理规则创建对应的推理机
Reasoner reasoner=new GenericRuleReasoner
(Rule.ParseRules(rules))
//根据自定义的推理机创建包含推理关系的数据模型
InfMfodel inf=ModelFactory.createlnfModel(reasoner, rawData)
(2) 语义相似度的计算
在领域本体构成的本体层次网络中, 子节点是父节点概念的细化, 子节点概念的含义比父节点更加具体。因此, 概念所处位置深度越深, 周围节点密度越大, 表示概念包含的信息量越多。如果网络中子节点概念和父节点概念共同属性越多, 那么二者关系相似度越高, 有向边权重赋值越大。基于此, 本文提出了语义相似度算法如公式(1), 其中影响因素包括层次深度、区域密度和概念属性。
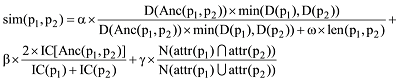
其中, 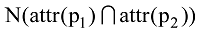
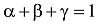
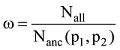
基于本体的语义相似度改进算法的描述如下所示:
输入: 抽象概念术语集合ACS;
输出: 待推荐文献资源及相似度;
Begin:
①For each ig∈抽象概念术语集合ACS
②在Glossary表中查找与概念术语ig相似的概念存入A1, 并将数字文献资源概念放入字符串数组A2
//Glossary表为本文构建的本体中所有的概念集合
③While count(A1)≠0&&count(A2) ≠0
④从数组A1中取出一个概念和从数组A2中取出一个概念并计算其相似度Simvalue
⑤If sim(ig, ig1)>阈值
⑥Do 扩展后抽象概念术语集合EACSig=EACSig 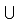
⑦Simvalue=Simvalue+sim(ig, ig1)
Endif
Endwhile
End
(3) 推荐方法设计
本文提出的推荐方法可以用如下伪代码进行表示:
输入: 用户查询概念C;
输出: 符合用户需求的数字文献资源;
Begin
①获得输入概念c
②通过Jena进行语义推理, 获得扩展的概念集合C={c1, c2,…cn}
③查询资源库中包含S(C)中的任意概念的文献资源, 形成STMP(C, P)
④将扩展后的概念集合同描述文献资源的概念集合进行相关度计算
⑤按照公式Recd=Simvalue/N计算推荐度
//N为相似度的计算次数
⑥If Recd大于阈值
⑦Do 用户设定推荐资源数量r
按照推荐度大小将r个资源Items推荐给用户
Endif
End
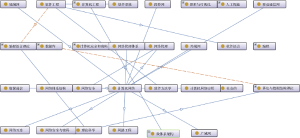
本文构建的计算机领域本体使用的概念术语主要来源于《计算机科学技术百科全书》[46]和《中国图书馆分类法》[47]。《计算机科学技术百科全书》收录了计算机领域概念中的完整术语, 收词范围较广, 词汇分类及定义规范, 权威性强, 因此将其作为构建计算机领域本体的参考。利用Protégé①(①http://protege.stanford.edu/.)中OntoGraf功能, 可以显示构建本体的效果图。以计算机科学为中心形成可视的关联图如图2所示:
本文构建的计算机领域本体包含1 000多个具有可检意义的计算机领域概念、属性及其相互关系。
(1) 相似度检验
本文计算10组具有代表性概念的语义相似度, 并与文献[42-43]提出的计算方法进行对比实验。另外, 为了对比实验效果, 采用咨询的方式获得人工对于语义相似度的判断。咨询对象包括计算机专业、情报专业、经济专业的硕士生和博士生, 共有20人。通过对该组概念语义评价问题进行语义相似度判定。语义相似度的评判范围是[0-1], 0表示两个概念完全不同, 1表示两个概念语义相同。对专业及非专业的受测者各进行两次试验, 并对同一概念语义相似度的评测结果取平均值。
表1中的Sim1和Sim2为文献[42-43]语义相似度方法计算得到的结果; Sim3为本文提出的方法进行语义相似度计算后得到的结果, 最后一项为人工判断的结果。
表1 概念语义相似度计算结果
| 词汇1 | 词汇2 | Sim1 | Sim2 | Sim3 | 人工判断 |
|---|---|---|---|---|---|
| 信息 | 信念 | 0.5 | 0.416 | 0.468 | 0.465 |
| 软件 | C语言 | 0.333 | 0.380 | 0.362 | 0.357 |
| 软件 | 面向对象 | 0.417 | 0.385 | 0.492 | 0.507 |
| 软件 | 构件 | 0.571 | 0.568 | 0.435 | 0.422 |
| 电路 | 存储器 | 0.736 | 0.752 | 0.603 | 0.621 |
| 加法器 | 寄存器 | 0.375 | 0.522 | 0.303 | 0.299 |
| 网络通信 | 光纤 | 1.000 | 1.000 | 0.804 | 0.778 |
| 局域网 | 以太网 | 0.231 | 0.230 | 0.205 | 0.109 |
| 图形学 | 等值面 | 0.387 | 0.397 | 0.285 | 0.291 |
| 多媒体 | 流媒体 | 0.380 | 0.388 | 0.355 | 0.357 |
由表1可知, 对比分析Sim1、Sim2、Sim3这三列, 前5行可以看出这三种算法计算结果均比较符合目标用户的主观判断, 但是对于概念节点附近密度较大或者公共属性较多的概念, 会导致相似度计算结果并不合理, 而本文提出的方法能够较为准确地计算出概念相似度, 使语义相似度计算结果符合目标用户的主观判断。
(2) 推荐检验
为了检验该推荐方法, 从知网下载800篇计算机领域的文献作为数据集, 这些文献包含题目、摘要和关键词。由于关键词可以描述文章的主题, 因此选用关键词作为文章的语义描述。利用F评价指标比较不同数据集的推荐效果, F评价指标[48]包括查准率(Precision)和查全率(Recall)两项指标, F值越高, 推荐效果越好。
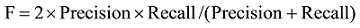
其中, Precision与Recall计算方法分别为:

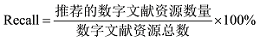
实验结果如表2所示。由表2可知, 采用本文方法得到的文献资源推荐结果F值随着文献数量的增加而提高。由于充分考虑了本体知识库中关于概念密度和概念属性等本体的结构特征, 使得本文的概念相似度计算方法计算得到的结果可以更准确地反映文献资源间的语义相似性, 丰富了文献资源语义信息, 提高了语义相关度计算效果, 并对目标用户进行有效的推荐。
表2 本文算法F评价指标
| 测试集数据 | 测试数字文献资源 | 数字文献资源推荐总数 | 成功推荐数目 | P | R | F值 |
|---|---|---|---|---|---|---|
| 10% | 80 | 40 | 16 | 0.400 | 0.5 | 0.44 |
| 30% | 240 | 120 | 54 | 0.450 | 0.5 | 0.477 |
| 50% | 400 | 200 | 93 | 0.465 | 0.5 | 0.482 |
| 70% | 560 | 280 | 142 | 0.507 | 0.5 | 0.504 |
| 90% | 720 | 360 | 201 | 0.558 | 0.5 | 0.528 |
本文提出了一种基于本体规则推理和语义相似度计算的数字文献资源内容服务推荐方法。该方法利用Jena规则推理对用户输入的概念进行语义扩展, 将扩展后的概念集与数字文献资源自身语义信息进行相似度计算和排序, 得出推荐度较高的文献并推荐给目标用户。结果表明, 该方法能够比较准确地反映概念之间的语义关系及计算概念节点之间的语义相似度, 可以充分挖掘用户需求并形成具有针对性的数字资源内容服务推荐。由于采集的文献资源数量和内容丰富程度不够, 并且推荐结果由用户判断其推荐的准确程度, 具有一定的主观性; 为了对比推荐效果, 本文的查全率设定为0.5, 并没有随着测试文献的数量增加而增加, 以上导致了本文F值低于现有的推荐算法。因此, 提高推荐方法的F值及推荐文献资源的丰富程度也是今后研究的重点。
毕强: 提出研究命题及研究思路;
刘健: 论文撰写, 数据处理及实证研究;
刘庆旭: 英文摘要撰写及修改;
王福: 摘要撰写及论文修改。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: tomosliu9999@126.com。
[1] 刘健, 毕强. Glossary.csv. 本体概念集合.
[2] 刘健, 毕强. CNKI.resoures.sql. 知网下载资源数据库文件.
[3] 刘健, 毕强. Similarity.doc. 相似度调查表.

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}