原欣伟 , 杨少华, 王超超, 杜占河
, 杨少华, 王超超, 杜占河
西安理工大学经济与管理学院 西安 710054
Yuan Xinwei, Yang Shaohua, Wang Chaochao, Du Zhanhe
中图分类号: C93 F27
通讯作者:
收稿日期: 2017-07-14
修回日期: 2017-08-8
网络出版日期: 2017-11-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】为了发挥用户创新社区及领先用户在企业开放式创新中的作用, 对用户创新社区情境下的领先用户识别方法进行研究。【方法】结合领先用户特征, 利用用户创新社区中的用户数据, 从用户内容信息和行为数据两方面抽取用户特征, 并在此基础上提出基于随机森林分类的领先用户识别方法。并以小米社区的MIUI论坛为例进行实例分析。【结果】实验结果表明, 本文提出的识别方法在领先用户和非领先用户之间具有较好的区分度。【局限】不同产品领域用户创新社区的用户生成内容和行为数据有一定差异, 本文仅以讨论小米手机操作系统的MIUI论坛为例, 涉及其他产品领域用户创新社区时, 用户特征抽取和相应的训练模型可能需要依具体情况适当调整。【结论】本文方法是一种适合用户创新社区情境的领先用户识别方法, 可以和传统方法有机结合, 以进一步提高此类社区领先用户识别的效率和效力。
关键词:
Abstract
[Objective] This paper aims to identify the lead players of user innovation communities to promote the open innovation for enterprises. [Methods] First, we extracted features of the users from related content and behavior data of the innovation community. Then, we proposed a method to idenfity the lead users based on Random Forest classification model. Finally, we examine our new method with real data from the MIUI forum of Xiaomi community. [Results] The proposed method could identify the lead and non-lead users. [Limitations] Only examined our method with the MIUI forum, therefore, adjustments were needed to use it for other user innovation communities. [Conclusions] The proposed method could identify lead users from various online communities more efficiently and effectively.
Keywords:
近年来, 用户创新已成为一种重要趋势, 许多企业开始将用户创新纳入企业创新体系中, 以更准确地了解用户需求、提升效率、降低产品开发周期和生产成本[1]。信息技术的飞速发展为用户创新提供了更为开放的平台, 众多企业纷纷创建或资助创建用户创新社区(User Innovation Community, UIC), 以使用户可以更方便地参与企业创新活动, 创造和分享与产品创新相关的知识[2-3]。UIC是以计算机网络为沟通媒介, 聚焦于产品问题解决或产品方案开发的分布式用户群体[4]。许多公司, 如Dell、Starbucks、IBM、奥迪汽车公司、微软、宝马等, 都在不断探索如何更高效地从用户创新社区中吸取并利用宝贵的用户知识[5-6]。
在用户创新社区的用户群体中, 领先用户是活跃而稀缺的创新主体[7]。与一般用户相比, 他们通常拥有更丰富的产品知识, 更期望从创新中获益。因此, 领先用户往往具有更强烈的创新精神和更出众的创新能力, 可以为企业创新做出极具价值的贡献。对于领先用户的贡献, Lüthje及其研究团队进行了很多开拓性研究, 进而提出领先用户参与产品创新的“领先用户法”: 界定某一焦点产品/细分市场的领先用户特性; 识别符合这些特性的领先用户; 领先用户参与产品概念开发; 在目标市场和更广泛的用户群中验证基于领先用户的产品概念价值[8]。从“领先用户法”可见, 领先用户识别是利用领先用户进行产品创新的重要环节。因此, 如何从用户群体中识别出领先用户, 以充分发挥用户创新的潜能, 实现用户创新价值的最大化, 成为用户创新社区创新活动中的关键问题。
传统的领先用户识别方法, 如群体筛选法(Mass Screening)、金字塔法(Pyramiding)[9]等尽管依然可以用于用户创新社区的领先用户识别, 但群体筛选法效率低下或金字塔法覆盖范围有限等问题限制了它们在用户创新社区情境下的大规模应用。因此, 一些更适合用户创新社区的领先用户识别方法, 如网络志法(Netnography)[10]、众包法(Crowdsourcing)[11]等应运而生。但网络志法需要对用户发布内容进行细致的人工分析, 众包法本质上是一种创新任务的用户招募和聚集方法, 都没有充分发挥用户创新社区大量用户数据的自动挖掘和处理功能。在这一背景下, 近年来国内外的一些学者开始将目光聚焦于创新社区中领先用户的自动识别方法[12-17]。目前, 这方面研究还很不完善, 特别是针对国内用户创新社区情境的领先用户自动识别研究还比较缺乏。基于此, 本文在回顾已有识别方法基础上, 提出一种基于用户特征抽取和随机森林分类的领先用户识别方法, 并以国内典型的用户创新社区——小米社区为例进行实证分析, 以便为国内用户创新社区领先用户的自动识别提供参考。
领先用户概念的提出者Von Hippel指出, 领先用户应具备两个基本特征: 领先用户的需求领先于普通用户; 领先用户具有强烈的创新动机[7]。此后, 学者们纷纷对领先用户的特征进行论述和拓展。表1总结了国内外相关文献中提及的领先用户主要特征。
表1 领先用户特征
| 特征 | 主要来源 |
|---|---|
| 具有领先于普通用户的需求 | Von Hippel E (1986)[7] |
| 具有强烈的创新动机 | Von Hippel E (1986)[7] |
| 期望从需求解决方案中获得高收益 | Morrison P D等(2004)[18]; Spann M等(2009)[19]; Oosterloo A(2010)[20] |
| 对现有产品表现出强烈不满 | Lüthje C等(2004)[8]; Conradie P D等(2016)[21]; Belz F M等(2010)[10]; Pajo S等(2013)[22] |
| 作为意见领袖的潜质 | Belz F M等(2010)[10]; Pajo S等(2013)[22] |
| 参与性 | Lüthje C等(2004)[8]; Belz F M等(2010)[10]; Pajo S等(2013)[22] |
| 比普通用户更快速地采纳新产品 | Pajo S等(2013)[22] |
| 较强创新能力 | Belz F M等(2010)[10]; 何国正等(2009)[23] |
| 拥有丰富的产品知识 | Lüthje C 等(2004) [8]; Belz F M 等(2010) [10] |
| 拥有丰富的产品使用经验 | Lüthje C等(2004)[8]; Conradie P D等(2016)[21]; Belz F M等(2010)[10]; Pajo S等(2013)[22] |
可以看出, 领先用户的特征主要表现在需求、创新动机、创新期望、对产品的不满、意见领袖潜质、参与性、新产品采纳速度、创新能力、产品知识和产品使用经验等方面。从领先用户的这些特征不难看出, 相对于普通用户, 领先用户在产品开发和市场化方面发挥着更大的作用。
领先用户对于企业创新的作用已经被众多学者所证实, 学者们一致认为, 领先用户识别是领先用户法中最为重要的环节[8,24]。在早期的领先用户识别研究中, 领先用户主要是通过群体筛选法进行识别[9]。群体筛选法是一种常用的领先用户研究方法, 运用这种方法, 企业通过问卷或者访谈的形式从大量的用户群体中搜集每个成员的信息, 并通过这些信息判断用户是否具备领先用户特征。然而, 由于领先用户的稀缺性, 这种方法显得过于成本高昂而效率低下。随后, 一种名为金字塔[9]的方法开始走进研究者的视线。通过这种方法, 研究者有针对性地对特定领域的知名人士进行访谈, 并请求他们推荐比其更具领先用户特征的用户。无论是群体筛选法还是金字塔法, 都有其局限性: 群体筛选法过分依赖大量的用户样本, 在成本和效率两方面不如人意; 而金字塔法虽然一定程度上解决了群体筛选法的成本、效率问题, 但其接触到的仅仅是金字塔所覆盖到的部分用户, 能够识别出的领先用户比较有限[25]。而且, 这两种方法基于研究者的自我评价或对他人的评价进行, 识别结果一定程度上缺乏客观性。
随着互联网技术的飞速发展, 企业纷纷建立了自己的用户创新社区, 学者们开始将一些网络研究的方法用于领先用户的识别研究。其中, 比较有代表性的是网络志法和众包法[11]。网络志法是一种定性研究方法, 研究者通过对创新社区中大量用户的观察来分析用户是否具备如下5个特征: 超乎一般用户的需求; 对现有产品的不满; 丰富的产品知识和使用经验;强烈的创新参与感;作为意见领袖的潜质, 并据此判断某用户是否是领先用户或非领先用户。Belz等通过研究Utopia社区的案例证实了这种方法在领先用户识别中的适用性[10]。与网络志法不同, 众包法是一种利用信息技术实现业务外包的方法。在利用众包法进行领先用户识别时, 企业通过社区招募并聚集有意向参与企业创新的用户, 并通过用户发表的创新观点以及反馈的产品信息确定某用户是否具备领先用户特征[26]。网络志法和众包法发挥了网络的优势, 但它们的局限性在于: 网络志法依靠研究者对用户主题和评论内容进行人工分析, 效率不高, 并且一定程度上忽视了社区中大量的用户行为数据; 众包法本质上是一种创新任务的用户招募和聚集方法, 对招募的用户仍然需要继续识别是否为领先用户。
近年来, 一些学者尝试将数据挖掘和机器学习用于用户创新社区中领先用户的自动识别。Pajo等提出基于数据挖掘技术的领先用户自动识别框架(Fast Lead User Identification, FLUID), 并以Twitter中的用户数据验证了该框架的有效性[12-13]。Martínez-Torrest提出基于遗传算法、模拟退火算法、粒子群优化算法等进化算法的创新社区创新者识别方法[14]。叶三龙、陈以增等利用聚类算法对用户创新社区中的领先用户识别进行研究[15-16]。赵晓煜等探讨了朴素贝叶斯分类在创新社区领先用户自动识别中的应用[17]。这方面研究仍处于起步阶段, 还很不完善。基于此, 本文针对国内用户创新社区情境, 提出一种基于用户特征抽取和随机森林分类的领先用户识别方法, 以期为国内用户创新社区领先用户的自动识别提供借鉴。
数据挖掘和机器学习技术为用户创新社区中领先用户的快速识别提供了可能。本文利用数据挖掘手段抽取用户特征, 然后基于用户特征数据, 应用随机森林分类算法对用户进行分类, 以实现用户创新社区中领先用户的自动识别。
在众多机器学习分类算法中选择随机森林分类算法的主要依据在于:
(1) 按照机器学习分类方法的不同, 可分为有监督式分类、无监督式分类以及半监督式分类三种类型。鉴于本文的研究目的并非仅仅根据用户的特征数据将用户分为两类或者多类, 而是希望训练出一个能够自动识别领先用户的分类模型, 因此采用有监督式学习分类算法进行模型的构建。随机森林分类算法可以符合这一要求。
(2) 相比其他有监督式分类算法, 随机森林分类算法对高维数据具有较强的处理能力, 并且对于不均衡数据处理效果较好。用户创新社区中用户的特征通常是高维的, 本文选取的用户特征包含12个维度; 同时, 由于领先用户的稀缺性, 领先用户与非领先用户的比例是不均衡的。
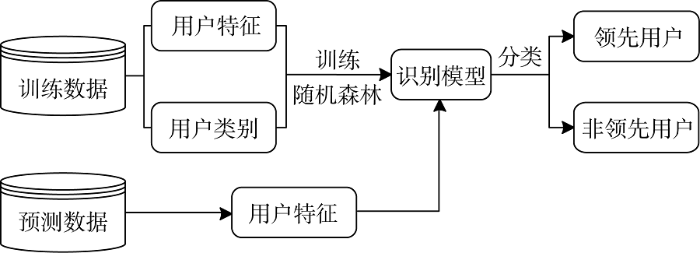
从这两点来看, 在进行用户创新社区领先用户识别模型构建时, 随机森林是一种比较理想的分类算法。因此, 本文主要采用随机森林分类算法构建领先用户识别模型。利用随机森林分类算法建立识别模型时, 需要训练数据和算法的综合参与, 模型的构建和实现流程如图1所示。
用户创新社区积累了大量的用户特征信息, 这些信息为领先用户的识别提供了数据, 使研究者通过分析用户特征判断用户是否具有领先性成为可能。在用户创新社区中, 用户特征以两种形式呈现: 用户生成的内容信息; 用户的行为数据。用户生成的内容信息指用户在所发表的主题及回复内容中所呈现出来的兴趣特点和价值取向。用户行为数据指通过用户在社区中的行为和活动产生的具体数据, 如发表主题的数量, 获得积分的大小等。
(1) 用户生成内容信息特征抽取
通过观察国内主流用户创新社区(如小米社区、海尔社区等), 可以发现用户生成内容呈现模块化特征, 即用户发表的内容通常处于不同的板块中。这些板块划分的依据主要是产品类型和主题功能。基于产品类型划分的板块主要体现产品的区分度, 用户创新社区中一般有诸多针对产品划分的板块。而基于主题功能划分的板块则和用户发表主题的目的相对应, 更能够体现帖子的内容信息特征。用户发表的内容按照主题功能主要分为产品功能讨论、产品建议、问题反馈和创意分享等。产品功能讨论、产品建议和问题反馈往往能体现出用户的产品需求、具备的产品知识、产品使用经验、对现有产品的不满等用户特征。创意分享则一定程度上可以反映出用户的创新动机和创新能力。这些特征可以映射到表1的领先用户特征。因此, 社区中用户生成的内容信息, 可以作为分析用户领先特征, 进而判断某用户是否为领先用户的数据来源之一。
阅读用户发布的内容信息, 人工判断用户是否满足领先用户特征, 进而识别领先用户, 不失为一种有效的领先用户识别方法(如网络志法)。但这样做无疑需要大量的时间和人工成本, 也不利于领先用户的自动识别。为了自动便捷地分析用户的内容信息, 本文利用文本挖掘技术, 对用户发布的主题内容进行词频分析, 在此基础上结合专家意见筛选出能够表现用户领先特征的特征词集, 然后利用熵权法[27]对特征词集中的词语进行客观赋权, 求得特征词集中各词语的信息熵, 进而求得用户内容信息的综合评分。具体处理方式如下:
假设从m个用户的主题内容中提取的特征词集中共包含n个词语, 第j个词在第i个用户的主题中出现的频次记为xij, 则用户特征词频矩阵可用X=[xij]表示。由于所提取的词语都是对用户创新特征的反映, 可对用户的特征词频矩阵进行正向线性转换, 如公式(1)所示。
${{y}_{ij}}=\frac{{{x}_{ij}}-\min ({{x}_{j}})}{\max ({{x}_{j}})-\min ({{x}_{j}})}$ (1)
其中, min(xj)为m个用户中第j个词语的最小词频, max(xj)为m个用户中第j个词语的最大词频。由此, 可求得标准化后的各元素在每列中所占的比重, 如公式(2)所示。
${{p}_{ij}}=\frac{{{y}_{ij}}}{\sum\limits_{i=1}^{m}{{{y}_{ij}}}}$ (2)
由此, 可求得特征词集中各词语的信息熵, 如公式(3)所示。
${{e}_{j}}=-K\sum\limits_{i=1}^{m}{{{p}_{ij}}\ln ({{p}_{ij}})}$ (3)
其中, $K=1/\ln (m)$, 则信息熵的冗余度如公式(4)所示。
${{d}_{j}}=1-{{e}_{j}}$ (4)
第j个词语的权重如公式(5)所示。
${{w}_{j}}=\frac{{{d}_{j}}}{\sum\limits_{j=1}^{n}{{{d}_{j}}}}$ (5)
用户的内容信息得分如公式(6)所示。
$Contentscor{{e}_{i}}=\sum\limits_{j=1}^{n}{{{y}_{ij}}{{w}_{j}}}$ (6)
利用文本挖掘和词频分析进行用户生成内容信息特征抽取的优势在于: 词频具有易获取性, 可以利用网络爬虫工具直接从网页中获取; 能够反映用户领先特征的词语保留了较多的用户领先特征信息, 特征词频能够在一定程度上反映出用户的领先水平; 由于提取的特征词频是确切的数值, 而且权重是使用熵权法等客观赋权法求得的, 因此, 利用词频求得的综合得分具有较强的客观性。
(2) 用户行为数据特征抽取
除了用户生成的内容信息, 社区中还存在大量用户的活动轨迹和行为数据。这些行为数据包括: 体现用户参与行为的特征数据, 如积分、在线时长、发表的主题数、评论数等; 体现用户社区影响的特征数据, 如贡献值、威望值、主题平均点击量、主题平均回复量、精华帖数量等; 体现用户关系建立行为的特征数据, 如好友数、个人空间访问量等。这些特征同样和表1的领先用户特征具有一定的映射关系(如表2所示), 可以作为判断领先用户的特征数据来源。表2数据具有易于获取和量化、相对客观的特点, 适合借助数据挖掘和机器学习技术进行自动获取和分析。
表2 用户行为特征数据抽取
| 行为特征 | 具体指标 | 指标含义 | 体现的领先用户特征 |
|---|---|---|---|
| 参与 | 积分 | 用户通过签到、发表主题和评论、保持在线以及参与社区论坛活动等方式获得的积分 | 参与性、产品知识 和使用经验 |
| 主题数 | 用户发表主题的数量 | ||
| 评论数 | 用户对他人主题的评论数 | ||
| 在线时长 | 用户在社区中所花费的时间长短 | ||
| 社区影响 | 贡献值 | 社区对用户贡献的认可, 在一些社区通过贡献值这一指标体现出来 | 产品知识和使用经验、 意见领袖潜质、创新 能力 |
| 威望值 | 社区对用户发表主题质量的肯定, 在一些社区通过威望值这一指标体现出来 | ||
| 主题平均回复量 | 用户发表的主题所获得的平均回复数量, 即主题平均回复量=主题总回复数量/主题数量 | ||
| 主题平均点击量 | 用户发表的主题所获得的平均点击数量, 即主题平均点击量=主题总点击数量/主题数量 | ||
| 精华帖数量 | 当用户发表的主题得到社区认可的精华帖数量 | ||
| 关系建立 | 好友数 | 用户在社区中的好友数量 | 参与性、意见领袖潜质 |
| 空间访问量 | 用户在社区中的个人主页空间的被访问数量 |
随机森林(Random Forest)是一种集成学习算法, 其中包含多棵决策树作为基本分类器, 通过集成学习后得到的一个组合分类器。当因变量为分类变量时, 随机森林将对数据进行分类处理。在分类模型的训练过程中, 随机森林会应用Bootstrap方法从原始数据集有放回地随机抽取K个与其同样大小的训练样本集, 并由此构建K棵决策树。对决策树每个节点进行分裂时, 从全部属性中随机抽取一个属性子集, 再根据信息增益从这个子集中选择一个最优属性进行节点分裂。待分类样本的所属类别最终由随机森林中的每棵决策树投票决定[28]。由于分类结果不太受自变量多重共线的干扰, 而且能够稳健地处理缺失数据和非均衡数据[29], 随机森林不仅备受研究者的关注, 在实际中也得到广泛应用。
针对本文的创新社区领先用户识别问题, 利用随机森林分类方法, 当将一位未知类别用户的包含内容和行为两维度的N个特征(本文N=12)输入到训练好的随机森林模型后, 随机森林的每棵决策树都独立对该用户进行分类决策, 并根据多数表决原则最终投票判断该用户是否为领先用户(或非领先用户), 如公式(7)所示。
$\begin{align} & User\{Contentscore;\ Behavior(Participation_{i=1}^{m};\ \\ & \ \ \ \ \ \ Influence_{j=1}^{n};\ Relationship_{k=1}^{p})\}\xrightarrow{Classify} \\ & \ \ \ \ \ \ \{LeadUser,non\text{-}LeadUser\}\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ \end{align}$ (7)
其中, Contentscore代表用户内容信息得分; Behavior代表用户行为数据, 包括Participation(参与)、Influence(社区影响)和Relationship(关系建立)三个子维度; m、n、p分别代表每个子维度抽取的特征数; LeadUser和non-LeadUser分别代表通过随机森林分类识别出的领先用户和非领先用户。
在上述模型的构建过程中, 作为一种有监督学习过程, 需要生成训练数据, 以便能通过已知类别样本数据的训练, 构建一个能够自动识别领先用户的分类模型, 并通过测试数据验证分类模型的有效性。
训练数据和测试数据的产生可借助传统的群体筛选法、金字塔法或网络志法, 以人工识别的方式生成。通过训练数据和测试数据获得一个理想的分类模型后, 即可以用其进行领先用户识别。
MIUI论坛是小米公司创立的吸引用户参与小米手机操作系统——MIUI系统研发、创新和推广的用户创新社区。在MIUI论坛中, 用户与小米人员协作, 通过产品技术和使用经验交流、共同解决问题和知识共创, 为MIUI系统的不断完善做出了突出贡献。MIUI论坛拥有大量的用户资源, 其中不乏拥有领先需求和较强创新能力的领先用户。以MIUI论坛中的用户为例, 对本文提出的领先用户识别方进行实证分析。
(1) 数据收集
由于领先用户是一种稀缺的创新资源, 在用户群体中是相对少数的部分[7,9]。因此不适合完全通过随机选取的方式获取。本文主要通过对MIUI论坛中与新功能讨论有关的用户主题和评论进行阅览的方式: 如果发现用户发表主题与产品功能显著无关, 则排除该用户, 否则根据用户主题初步判断该用户是领先用户或非领先用户的可能性, 并纳入样本。通过对用户发表主题和评论的长期观察(部分用户及主题示例如表3所示), 初步锁定了352名用户。过滤掉一些在观察期间不够活跃的用户, 将剩余的332名用户作为实验样本。
表3 部分用户及主题示例
| 用户ID | 主题核心内容 | 主题发表平台 |
|---|---|---|
| 137748*** | 提供解决卡机问题的5种方法 | PC |
| 94494*** | 提供谷歌套件的安装教程 | PC |
| 182392*** | 汇总了小米手机存在的已知问题 | PC |
| 1579712*** | 建议优化自动升级体验 | 小米手机4 |
| 310*** | 提出通话录音对方声音偏低的 改进建议 | PC |
| 1594000*** | 反馈手机软件安装问题 | 小米手机4c |
(2) 样本数据的人工分类
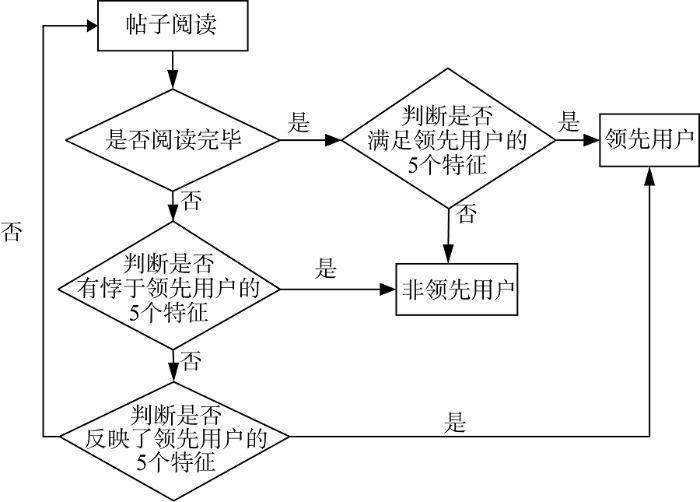
本文采用网络志法对实验样本进行人工分类, 以生成模型构建的训练数据和模型检验的测试数据。选择网络志法进行训练数据和测试数据人工分类的依据在于:
①由于事先对这些用户进行了长期的观察, 对这些用户的网络内容已经有了较为细致的了解, 为利用网络志法奠定了良好的基础;
②通过对这些用户的长期观察, 发现他们的网络内容信息较为完备, 其中不仅存在能反映其领先特征的内容, 还存在大量能够反映非领先特征的内容, 为利用网络志法识别领先用户和非领先用户带来便利;
③为保证尺度的一致性, 验证模型的预测数据应尽量选择和训练数据一样的人工分类方法, 而网络志法较少受研究条件限制, 可以随时对用户展开人工分类。基于网络志法的样本数据人工分类过程如图2所示[10-11]。
在利用网络志法进行样本数据人工分类过程中, 结合了MIUI论坛中一些资深用户的意见, 并在识别后邀请专家对识别结果进行审核。期间根据专家意见还适当进行了用户样本的删减和增补。最终, 识别出的结果中有32名用户的类别与专家意见不一致, 因此对这些用户数据进行剔除处理。本文最终使用50名领先用户和250名非领先用户的样本数据。
(3) 用户内容信息的特征提取
利用网络爬虫工具对这些用户发表的帖子和相关主题进行提取, 并采用文本分析工具对用户发表内容进行词频分析。在统计的词语中, 通过听取专家以及MIUI论坛一些资深用户的意见过滤掉那些与创新行为显著无关的词语。最终, 提取了118个特征词构成特征词集, 利用公式(1)-公式(3)计算每个特征词的信息熵, 如表4所示。
表4 用户特征词提取及信息熵计算
| 词语 | 信息熵 | 词语 | 信息熵 | 词语 | 信息熵 | 词语 | 信息熵 |
|---|---|---|---|---|---|---|---|
| 安卓 | 0.316213 | 还原 | 0.223788 | 权限 | 0.734063 | 工具箱 | 0.262723 |
| 备份 | 0.611726 | 唤醒 | 0.658948 | 缺点 | 0.310863 | 工艺 | 0.201891 |
| 壁纸 | 0.610224 | 技能 | 0.324151 | 缺陷 | 0.264289 | 功耗 | 0.372700 |
| 避免 | 0.578136 | 技巧 | 0.345415 | 容量 | 0.494894 | 功率 | 0.201180 |
| 边框 | 0.451883 | 技术 | 0.593708 | 设定 | 0.410444 | 功能 | 0.793653 |
| 编程 | 0.273725 | 架构 | 0.241603 | 设计 | 0.609646 | 共享 | 0.509798 |
| 编译 | 0.259703 | 脚本 | 0.332176 | 深刻 | 0.257540 | 故障 | 0.273800 |
| 标准 | 0.684879 | 教程 | 0.598938 | 释放 | 0.190585 | 管理 | 0.789340 |
| 补丁 | 0.401210 | 解码 | 0.209270 | 授权 | 0.553083 | 规格 | 0.211333 |
| 参考 | 0.676205 | 解锁 | 0.302388 | 刷新 | 0.485019 | 耗电 | 0.613368 |
| 参照 | 0.219423 | 进程 | 0.599015 | 思考 | 0.229520 | 频段 | 0.424151 |
| 差异 | 0.187917 | 禁止 | 0.602119 | 提升 | 0.557852 | 频率 | 0.502831 |
| 沉浸 | 0.511611 | 精简 | 0.304325 | 突破 | 0.318078 | 品牌 | 0.239496 |
| 程度 | 0.491713 | 精密 | 0.218749 | 推荐 | 0.695444 | 品质 | 0.345167 |
| 程序 | 0.742381 | 精品 | 0.570579 | 挖掘 | 0.097196 | 平衡 | 0.187100 |
| 触摸屏 | 0.301239 | 均衡 | 0.357329 | 完美 | 0.713902 | 评测 | 0.487002 |
| 传感器 | 0.450762 | 开放 | 0.615575 | 维护 | 0.469622 | 评估 | 0.323698 |
| 创新 | 0.494803 | 开启 | 0.766367 | 系列 | 0.667252 | 屏蔽 | 0.734825 |
| 创造 | 0.337468 | 框架 | 0.483972 | 细节 | 0.567618 | 瓶颈 | 0.183485 |
| 搭载 | 0.370015 | 扩展 | 0.419518 | 细腻 | 0.251230 | 清理 | 0.724261 |
| 代码 | 0.637274 | 流畅 | 0.667485 | 限制 | 0.704581 | 运行 | 0.770446 |
| 颠覆 | 0.282982 | 流程 | 0.249353 | 协议 | 0.377887 | 增强 | 0.567740 |
| 对象 | 0.169484 | 路径 | 0.338769 | 虚拟 | 0.597106 | 制式 | 0.461678 |
| 二进制 | 0.186764 | 乱码 | 0.509190 | 渲染 | 0.325471 | 主板 | 0.462250 |
| 服务器 | 0.636913 | 美化 | 0.148695 | 研发 | 0.301277 | 专家 | 0.231291 |
| 改进 | 0.701178 | 命令 | 0.387072 | 研究 | 0.467130 | 字符 | 0.296423 |
| 改善 | 0.311125 | 模块 | 0.652269 | 验证 | 0.636157 | 最强 | 0.295451 |
| 根据 | 0.684804 | 内存 | 0.725427 | 移植 | 0.410075 | 最新 | 0.809079 |
| 根目录 | 0.318490 | 内核 | 0.460854 | 引领 | 0.261932 | ||
| 工程师 | 0.684590 | 配置 | 0.613033 | 优化 | 0.710139 |
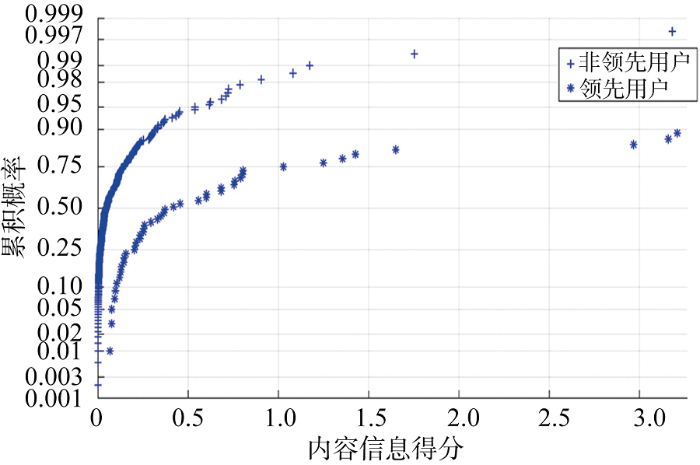
进一步利用公式(4)-公式(6)求得每个用户的内容信息得分, 该得分在领先用户和非领先用户中的分布状况如图3所示。
可见, 领先用户的内容信息得分概率分布一直处于非领先用户的下方, 说明与非领先用户相比, 领先用户的内容信息得分总体处于较高水平。
(4) 用户行为数据的特征提取
MIUI论坛中存在大量易于提取的体现用户行为特征的数据, 这些数据包括反映用户参与行为的积分、在线时长、主题数和评论数, 反映用户社区影响的主题平均点击量、主题平均回复量、精华帖数量、贡献值和威望值以及反映用户关系建立行为的好友数量和空间访问量。
①反映用户参与行为的特征提取
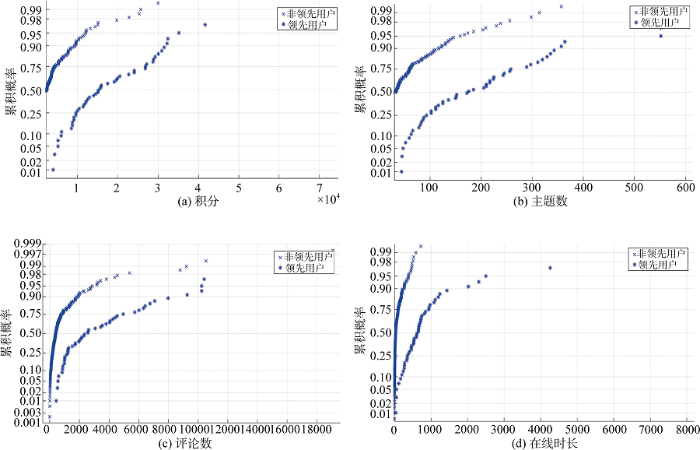
反映用户参与行为的特征包括积分、主题数、评论数和在线时长。提取实验样本有关数据, 这些数据在领先用户和非领先用户之间的分布如图4所示。
用户积分是用户参与行为和活跃度的一种直接体现。
1)图4(a)中在低积分值区间上, 非领先用户的分布比例明显高于领先用户, 而领先用户在高积分值上的分布比例明显高于非领先用户。用户发表的主题数可以通过MIUI论坛直接获取。
2)图4(b)整体上领先用户发表的主题数明显高于非领先用户。与发表主题一样, 发表评论是用户参与社区活动的一种较为直接的形式。
3)从图4(c)的评论数概率分布图来看, 领先用户发表的评论数整体上高于非领先用户。在MIUI论坛中, 用户在线时长可以直接从用户资料中获取。由于在线时长是一个动态数据, 变化速度较快, 在一个很短的时间内获取了样本用户的在线时长信息。
4)图4(d)展示了在线时长在领先用户和非领先用户的概率分布。尽管两类用户之间的在线时长取值区间有一部分重叠, 但整体而言, 领先用户的在线时长明显大于非领先用户。
②反映用户社区影响的特征提取
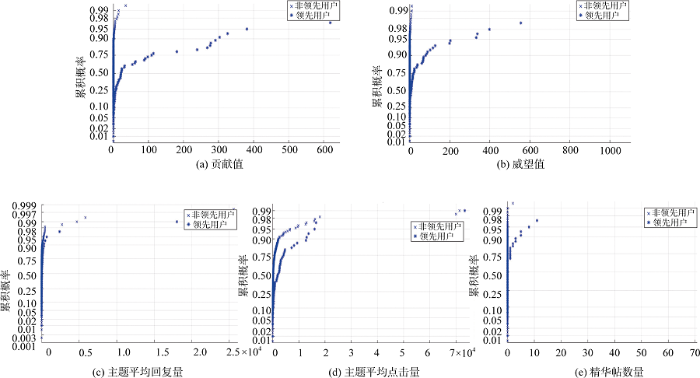
反映用户社区影响的特征包括贡献值、威望值、主题平均回复量、主题平均点击量和精华帖数量。提取实验样本有关数据, 这些数据在领先用户和非领先用户之间的分布如图5所示。贡献值体现了用户对社区的贡献大小。在MIUI论坛的荣誉开发区发帖回帖才有机会获得贡献值, 因此, 贡献值也代表论坛对用户的一种肯定。MIUI论坛中, 贡献值直接从用户资料中获取。
1)图5(a)中领先用户的贡献值明显高于非领先用户。MIUI论坛中, 用户发表的主题, 如技术帖、原创帖等, 得到了社区管理者的认可, 则有可能获得威望值。威望值同样可以直接从用户资料中获取。
2)图5(b)中两类用户在威望值上的区分度较大, 整体上领先用户威望值明显大于非领先用户。通过“主题平均回复量=主题总回复数量/主题数量”这一公式获取用户的主题平均回复量。
3)由图5(c)可知, 领先用户的主题平均回复量总体上高于非领先用户。主题平均点击量是一个用户所有主题所获查看量的算术平均值, 通过“主题平均点击量=主题总点击数量/主题数量”这一公式获取领先用户。
4)由图5(d)中主题平均点击量分布状况可知, 尽管主题平均点击量在领先用户和非领先用户中的分布差异不如前面几个指标明显, 但领先用户的概率分布图像始终位于非领先用户分布图像的下方, 说明领先用户的主题平均点击量总体上高于非领先用户。精华帖体现了社区管理者对用户所发表主题阅读价值的一种肯定。
5)图5(e)体现了样本中领先用户和非领先用户精华帖数量分布状况的差异。大部分非领先用户的精华帖数量很少, 乃至接近于0, 而一定比例的领先用户则拥有精华帖。
③反映用户关系的特征提取
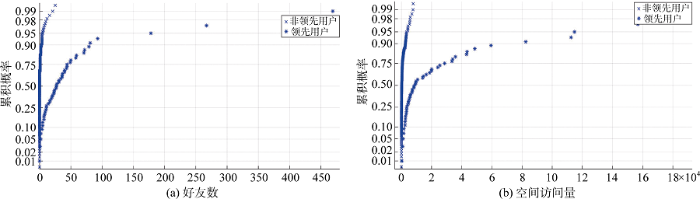
反映用户关系的特征包括好友数和空间访问量, 这些数据在领先用户和非领先用户之间的分布如图6所示。
用户好友数通过用户的社区个人空间获取。两类用户的好友数分布状况如图6(a)所示。可见, 总体上, 领先用户的好友数明显高于非领先用户。作为衡量用户关系的一个指标, 空间访问量体现了一个用户在社区中的人气。通过用户的社区个人空间首页获取用户的个人空间访问量。两类用户的空间访问量分布状况如图6(b)所示。可见, 领先用户的空间访问量明显高于非领先用户。
基于样本用户特征数据, 利用随机森林分类算法进行识别模型的训练, 以获得一个有效的领先用户识别模型。利用R语言的randomForest包进行随机森林分类算法的具体实现。从300名样本用户中随机选取30名领先用户与30名非领先用户共同构成训练数据集以进行识别模型的训练。使用randomForest工具建立包含500 棵决策树的随机森林模型。通过模型训练, 得到的混淆矩阵如表5所示, 对领先用户的识别准确率为93.33%。
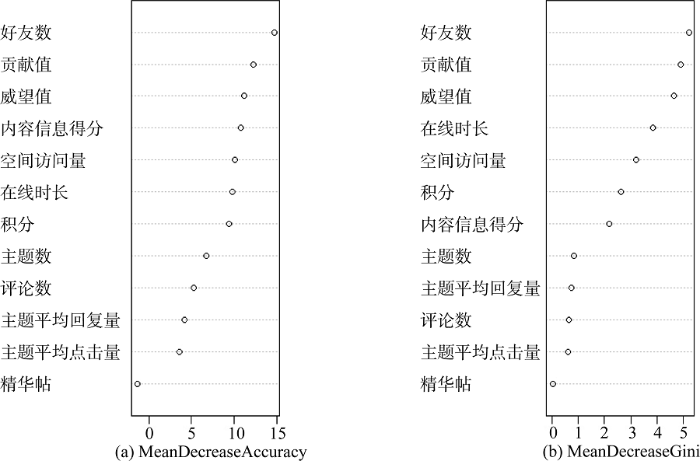
为测度分类中使用的各用户特征指标对识别结果的重要性程度, 利用VarImpPlot函数构建输入变量重要性测度散点图, 如图7所示。
MeanDecreaseAccuracy衡量把一个变量的取值变为随机数, 随机森林预测准确性的降低程度, 该值越大表示该变量的重要性越大。MeanDecreaseGini是通过基尼(Gini)指数计算每个变量对分类树每个节点上观测值的异质性的影响, 从而比较变量的重要性, 该值越大表示该变量的重要性越大。根据MeanDecrease Accuracy, 输入变量(各用户特征指标)的重要性程度从高到低依次为好友数(14.71%)、贡献值(12.27%)、威望值(11.15%)、内容信息得分(10.80%)、空间访问量(10.14%)、在线时长(9.80%)、积分(9.38%)、主题数(6.74%)、评论数(5.23%)、主题平均回复量(4.20%)、主题平均点击量(3.58%)、精华帖数量(-1.37%)。根据MeanDecreaseGini, 输入变量(各用户特征指标)的重要性程度从高到低依次为好友数(5.21)、贡献值(4.90)、威望值(4.63)、在线时长(3.85)、空间访问量(3.21)、积分(2.63)、内容信息得分(2.19)、主题数(0.82)、主题平均回复量(0.74)、评论数(0.66)、主题平均点击量(0.61)、精华帖数量(0.02)。综合来看, 好友数对领先用户识别结果的贡献度最大(MeanDecreaseAccuracy=14.71%、MeanDecreaseGini=5.21), 其次是贡献值、威望值、内容信息得分、空间访问量、在线时长等。而精华帖数量的重要性程度最低(MeanDecreaseAccuracy= -1.37%、MeanDecreaseGini=0.02)。究其原因, 是因为在MIUI论坛中, 精华帖主要是科普或者产品推广有关的主题。不可否认, 不少精华帖是领先用户发表的, 但由于不少领先用户也并未发表精华帖, 因此这一指标对识别结果的贡献并不突出。总体而言, 在MIUI论坛中, 好友数、贡献值、威望值、内容信息得分、空间访问量、在线时长等用户特征是比较有效的领先用户识别指标。
分别从剩余的240名用户中随机抽取20、40、80、160名非领先用户与剩余的20名领先用户组成不同均衡状态的测试集, 以检验所建立识别模型在不同用户比例下的分类效果。利用predict函数对不同类别用户比例的测试集进行识别, 识别结果如表6-表9所示。可见, 该模型对测试集中领先用户的识别准确率为95%, 在均衡与非均衡数据情景下, 对非领先用户的识别准确率均在95%以上。可见, 在均衡与非均衡数据情景下, 本文所建立的识别模型对于MIUI论坛中的领先用户都具有较高的识别准确率。
为了对比随机森林分类模型和其他机器学习分类模型的优劣, 本文选择同样属于有监督式分类算法的BP神经网络模型和支持向量机分类模型(C-SVM)。所构建BP神经网络模型包含1个隐含层, 隐含层包括4个节点, 误差函数选择交叉熵损失函数。所建支持向量机模型类型为分类模型, 核函数选择径向基核函数, 利用径向基函数通过十折交叉验证寻找预测误差最小的参数组合。使用同样的训练集数据对上述模型进行训练, 并使用同样的4组测试集数据对模型进行测试。不同模型的识别结果以及与随机森林分类模型的对比如表10所示。
表10 三种模型的识别准确率
| 领先用户(20名) | 非领先用户(20名) | 非领先用户(40名) | 非领先用户(80名) | 非领先用户(160名) | |
|---|---|---|---|---|---|
| BP神经网络模型 | 85.00% | 70.00% | 72.50% | 78.75% | 76.11% |
| C-SVM分类模型 | 85.00% | 90.00% | 87.50% | 93.75% | 94.44% |
| 随机森林分类模型 | 95.00% | 95.00% | 95.00% | 96.25% | 95.63% |
可见, 随机森林分类模型在不同均衡比例的测试数据集下, 对领先用户和非领先用户的识别准确率均优于其他两种模型, 由此说明本文提出的基于随机森林分类模型的识别方法能够较准确地识别社区中的领先用户(非领先用户)。
本文针对用户创新社区中领先用户的特性, 从用户生成内容信息和用户行为数据两方面提取用户特征数据, 并利用随机森林分类算法建立基于用户特征数据的领先用户识别模型。通过MIUI论坛中真实用户数据的实验表明, 本文提取的用户特征和所构建的分类模型能有效地识别用户创新社区中的领先用户, 为此类社区领先用户的自动识别提供有益思路。而且, 本文方法和传统方法也可以有机结合, 例如, 通过本文方法进行社区领先用户的自动识别和初选, 然后利用群体筛选法、金字塔法或网络志法在初选用户的基础上进行二次筛选, 以提高此类社区领先用户识别的效率和效力。
本文局限在于: 不同产品领域用户创新社区的用户生成内容和行为数据有一定差异, 仅以讨论小米手机操作系统的MIUI论坛为例, 当涉及其他产品领域用户创新社区时, 用户特征抽取和相应的训练模型可能需要依具体情况适当调整; 实验所用样本规模偏小, 相比MIUI论坛的海量用户, 所选实验用户数量仍然偏少。
后续研究可以从两方面进一步完善: 加强对用户特征的提取, 例如尝试不同的用户内容信息特征提取方法(如TF-IDF、信息增益等), 考虑用户发帖时间间隔、发帖频率等更多元的用户行为数据等; 扩大样本数量, 构建更复杂、更智能的领先用户识别模型, 如利用深度学习算法进行建模等。
原欣伟: 提出研究思路, 设计研究方案, 论文最终版本修订;
杨少华: 数据收集和清理, 负责实验, 论文起草;
王超超: 协助数据收集和清理;
杜占河: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: yuanxinwei@xaut.edu.cn。
[1] 原欣伟, 杨少华, 王超超, 杜占河. user_data.rar. 从MIUI论坛抓取的用户基础数据.
[2] 原欣伟, 杨少华, 王超超, 杜占河. user_data.xls. 从用户基础数据中抽取的用户特征数据.
[3] 原欣伟, 杨少华, 王超超, 杜占河. train.txt. 训练集数据.
[4] 原欣伟, 杨少华, 王超超, 杜占河. predict1(40样本).txt. 测试集数据(20个非领先用户).
[5] 原欣伟, 杨少华, 王超超, 杜占河. predict2(60样本).txt. 测试集数据(40个非领先用户).
[6] 原欣伟, 杨少华, 王超超, 杜占河. predict3(100样本).txt. 测试集数据(80个非领先用户).
[7] 原欣伟, 杨少华, 王超超, 杜占河. predict4(180样本).txt. 测试集数据(160个非领先用户).
| [1] |
顾客参与新产品开发对企业技术创新绩效的影响机制——基于B-B情境下的实证研究 [J].Mechanism of Impact of Customer Participation in New Product Development on Technological Innovation Performance of Enterprises: An Empirical Research in B-B Context [J]. |
| [2] |
Why Would Online Gamers Share Their Innovation-conducive Knowledge in the Online Game User Community? Integrating Individual Motivations and Social Capital Perspectives [J].https://doi.org/10.1016/j.chb.2010.11.022 URL [本文引用: 1] 摘要
The user community has been an important external source of a firm's product or service innovation. Users' innovation-conducive knowledge sharing enables the community to work as a vital source of innovation. But, traditional economic theories of innovation seem to provide few explanations about why such knowledge sharing takes place for free in the user community. Therefore, this study investigates what drives community users to freely share their innovation-conducive knowledge, using the theory of planned behavior. Based on an empirical analysis of the data from 1244 members of a South Korean online game user community, it reveals that intrinsic motivation, shared goals, and social trust are salient factors in promoting users' innovation-conducive knowledge sharing. Extrinsic motivation and social tie, however, were found to affect such sharing adversely, contingent upon whether a user is an innovator or a non-innovator. The study illustrates how social capital, in addition to individual motivations, forms and influences users' innovation-conducive knowledge sharing in the online gaming context. (C) 2010 Elsevier Ltd. All rights reserved.
|
| [3] |
Collaborating to Create: The Internet as a Platform for Customer Engagement in Product Innovation [J].https://doi.org/10.1002/dir.20046 URL [本文引用: 1] 摘要
Abstract In the networked world, firms are recognizing the power of the Internet as a platform for co-creating value with customers. We focus on how the Internet has impacted the process of collaborative innovation—a key process in value co-creation. We outline the distinctive capabilities of the Internet as a platform for customer engagement, including interactivity, enhanced reach, persistence, speed, and flexibility, and suggest that firms can use these capabilities to engage customers in collaborative product innovation through a variety of Internet-based mechanisms. We discuss how these mechanisms can facilitate collaborative innovation at different stages of the New Product Development process (back end vs. front end stages) and for differing levels of customer involvement (high reach vs. high richness). We present two detailed exploratory case studies to illustrate the integrated and systematic usage of Internet-based collaborative innovation mechanisms—Ducati from the motorbike industry and Eli Lilly from the pharmaceutical industry. We derive implications for managerial practice and academic research on collaborative innovation.
|
| [4] |
A Man on the Inside: Unlocking Communities as Complementary Assets [J].https://doi.org/10.1016/j.respol.2006.09.011 URL [本文引用: 1] 摘要
Since Teece's seminal paper explaining who were the gainers from technological innovation, increased globalization and the information and communication technology revolution have brought new ways for firms to organize and appropriate from innovation. A new more open model of innovation suggests that firms can benefit from sources of innovation that stem from outside the firm. The central theme of this paper is how firms try to unlock communities as complementary assets. These communities exist outside firm boundaries beyond ownership or hierarchical control. Because of practices developed by communities to protect their work, firms need to assign individuals to work in these communities in order to gain access to developments and, to an extent, influence the direction of the community. Using network analysis we show that some software firms sponsor individuals to act strategically within a free and open source software (FOSS) community. Firm sponsored individuals interact with more individuals than interact with them, and also they seek to interact with central individuals in the community. However, we can see differences in how individuals interact, depending on whether their affiliation is with a dedicated FOSS firm or an incumbent in the software industry. Apparently, some firm managers believe they need man on the inside to be able to gain access to communities.
|
| [5] |
Virtual Lead User Communities: Drivers of Knowledge Creation for Innovation [J].https://doi.org/10.1016/j.respol.2011.08.006 URL [本文引用: 1] 摘要
This study examines the creation of innovation-related knowledge in virtual communities visited mainly by lead users. Such communities enable firms to access a large number of lead users in a cost-efficient way. A propositional framework relates lead users’ characteristics to unique virtual community features to examine their potential impact on the development of valuable innovation knowledge. The authors empirically validate this framework by analyzing online contributions of lead users for mobile service innovation projects. The findings indicate that the value of their contributions stems from their ability to suggest solutions instead of simply describing problems or stating customer needs. Lead users’ technical expertise also makes them particularly well-suited to develop new functionalities, but less so for design and usability improvements. The digital context favors the creation of explicit knowledge that can be easily integrated into the development of new products. Finally, contributions given by lead users in a proactive way contain more novel insights than reactive contributions such as answers to community members’ questions. The findings should help managers stimulate, identify, and improve the use of lead users’ input in virtual communities.
|
| [6] |
Consumer Empowerment Through Internet-based Co-creation [J].https://doi.org/10.2753/MIS0742-1222260303 URL [本文引用: 1] 摘要
Cost-efficient and multimedia-rich interaction opportunities offered by the Internet and the existence of online communities have made virtual co-creation a suitable means of creating value and improving the overall success of new products. Information technology enables new forms of producer--consumer collaboration in new product development processes. However, little research exists on consumers' experiences during virtual co-creation tasks. Drawing on the literature on organizational behavior, we introduce the construct of consumer empowerment to describe consumers' perceived influence on product design and decision making. This paper presents the first large-scale empirical study investigating how consumers are empowered through Internet-based co-creation activities. To analyze the impact of applied interaction tools, 727 consumers having taken part in virtual co-creation projects were asked about their experienced tool support, their perceived empowerment, how much they enjoyed the task, and their readiness to participate in future co-creation opportunities. The results show that consumers engaging in co-creation feel more or less empowered. The level of experienced empowerment depends on the design of the applied virtual interaction tool, the related enjoyment of the virtual interaction, the participants' task and product involvement, as well as their creativity and lead-user characteristics. The design of the interaction tool determines to what extent consumers with varying capabilities are able to solve the assigned co-creation task. It determines the consumers' perceived empowerment and experienced enjoyment. Both the levels of perceived empowerment and enjoyment have a strong impact on the consumers' willingness to participate in future virtual new product development projects. These findings contribute to a better understanding of antecedents and consequences of successful consumer co-creation. They provide recommendations on how to design a compelling virtual new product co-creation experience.
|
| [7] |
Lead Users: A Source of Novel Product Concepts [J].https://doi.org/10.1287/mnsc.32.7.791 URL [本文引用: 5] |
| [8] |
The Lead User Method: An Outline of Empirical Findings and Issues for Future Research [J].https://doi.org/10.1111/j.1467-9310.2004.00362.x URL [本文引用: 6] 摘要
Abstract In order to reduce the risks of failure usually associated with NPD, leading companies such as 3M, HILTI, or Johnson&Johnson are increasingly working with so-called Lead Users. Their identification and involvement is supported by the Lead User method a multi stage approach aiming to generate innovative new product concepts and to enhance the effectiveness of cross-functional innovation teams. While the Lead User method is frequently cited in the literature, yet, there are only limited attempts to comprehensively discuss how this approach is embedded in theories and empirical findings of innovation and marketing research. Therefore the Lead User method is in the focus of the present paper, both with respect to its theoretical foundation and its implementation into the innovation management system. First, empirical research on user innovations is reviewed to clarify the theoretical foundation of the Lead User method. Second the attention is drawn to the Lead User practice by discussing the various process steps of this specific approach on the basis of two applications of the method. Based on this discussion, we outline open questions related with the practical implementation of the Lead User method in order to start an agenda for future research.
|
| [9] |
Pyramiding: Efficient Search for Rare Subjects [J].https://doi.org/10.1016/j.respol.2009.07.005 URL [本文引用: 4] |
| [10] |
Netnography as a Method of Lead User Identification [J].https://doi.org/10.1111/j.1467-8691.2010.00571.x URL [本文引用: 9] 摘要
Lead users are rare subjects, which are difficult to detect. In theory and practice, mass screening is the main method of lead user identification. It is a standardized, quantitative approach, based on screening a large number of potentially relevant users. Shortcomings of screening are low sample efficiency, high search costs and the reliance on the self-assessment of respondents. Thus, the elaboration of lead user identification methods is still a major challenge to researchers in the field. In this paper, we propose netnography as a new method of lead user identification. Netnography, made up of internet and ethnography, is an approach to analyse online communities systematically. The empirical results of our explorative study of the online community utopia show that 9 out of 40 of the most active online community members possess lead user attributes (22.5 per cent). Hence, we may conclude that netnography is a viable method of lead user identification, which relies on external assessments instead of self-assessments and is probably less costly than mass screening.
|
| [11] |
The Search for Innovative Partners in Co-creation: Identifying Lead Users in Social Media Through Netnography and Crowdsourcing [J].https://doi.org/10.1016/j.jengtecman.2015.08.004 URL [本文引用: 3] 摘要
Despite the extensive literature on the benefits of netnography and crowdsourcing for insight and idea generation, little research has been conducted on their practical relevance and application for identifying lead users. We address this gap through an analysis of 24 lead user projects investigating the viability, underlying processes, and main differences of these new search strategies. We argue that both methods justify the significant investments by additionally providing a user-centric basis for subsequent ideation sessions with lead users. Our findings contribute to user innovation literature by demonstrating new ways of identifying these highly valuable users in the social media age.
|
| [12] |
Fast Lead User Identification Framework [J].https://doi.org/10.1016/j.proeng.2015.12.434 URL [本文引用: 2] 摘要
Large portion of product innovation and development is accomplished by customers and only a small segment of the customer population engages in such innovation activities. Empirical research has shown that users in this subgroup, called lead users, tend to experience needs before the rest of the marketplace and stand to benefit greatly by finding solutions to those needs. To meet the challenge of quickly and effectively identifying lead users and uncovering their innovation ideas, the authors propose a fast and systematic approach, called Fast Lead User IDentification (FLUID), utilizing data mining techniques to identify lead users on social networking sites. The paper describes the steps taken to build and optimize the FLUID system to effectively identify lead users on the micro-blogging site Twitter. This entails studies using validated lead user questionnaires resulting in clusters of lead and non-lead Twitter users for a single product. The gathered online user metadata and behavior are then used as training data for the automated system. An overview of data processing techniques and relations to the empirically derived lead user characteristics are presented. Finally, classification algorithms that help to separate lead users from non-lead users are discussed, including optimization leading to the validation of the proposed approach. By making use of data-mining techniques on data rich sites like social networking sites, the FLUID approach minimizes the resource and time costs in identifying lead users and this provides a step towards systematizing the fuzzy-front end of the new product development process.
|
| [13] |
Automated Feature Extraction from Social Media for Systematic Lead User Identification [J].https://doi.org/10.1080/09537325.2016.1220517 URL [本文引用: 1] 摘要
Manufacturers strive to rapidly develop novel products and offer solutions that meet the emerging customer needs. The Lead User Method, emerging from studies on sources of innovation by the scientific community, offers a validated approach to identify users with innovation ideas to support rapid and successful new product development process. The approach has been more recently applied on online communities, where collection and analysis of rich user data are performed by expert practitioners. In this paper, feature extraction techniques are outlined, that enable automated classification and identification of lead users that are present in online communities. The authors describe two case studies to construct a classification model that is then used to identify online lead users for confectionery products, and to evaluate the outlined feature extraction techniques. The presented research points to opportunities in automated identification within the lead user approach that further reduce the resource and time costs.
|
| [14] |
Application of Evolutionary Computation Techniques for the Identification of Innovators in Open Innovation Communities [J].https://doi.org/10.1016/j.eswa.2012.10.070 URL [本文引用: 1] 摘要
Open innovation represents an emergent paradigm by which organizations make use of internal and external resources to drive their innovation processes. The growth of information and communication technologies has facilitated a direct contact with customers and users, which can be organized as open innovation communities through Internet. The main drawback of this scheme is the huge amount of information generated by users, which can negatively affect the correct identification of potentially applicable ideas. This paper proposes the use of evolutionary computation techniques for the identification of innovators, that is, those users with the ability of generating attractive and applicable ideas for the organization. For this purpose, several characteristics related to the participation activity of users though open innovation communities have been collected and combined in the form of discriminant functions to maximize their correct classification. The right classification of innovators can be used to improve the ideas evaluation process carried out by the organization innovation team. Besides, obtained results can also be used to test lead user theory and to measure to what extent lead users are aligned with the organization strategic innovation policies. (c) 2012 Elsevier Ltd. All rights reserved.
|
| [15] |
基于聚类分析的网络社区领先用户发现研究 [D].Lead User Identification in Online Communities Based on Cluster Analysis [D]. |
| [16] |
以小米为例基于Biclustering对领先用户的识别方法 [A Biclustering-Based Lead User Identification Methodology Applied to Xiaomi [C]// |
| [17] |
协同创新社区中领先用户的自动识别方法 [J].https://doi.org/10.3963/j.issn.2095-3852.2014.04.022 URL [本文引用: 2] 摘要
针对随着互联网的发展和普及, 协同创新社区成为顾客参与企业创新活动的重要途径的现状,提出了一种协同创新社区中领先用户的识别方法。首先,基于领先用户的相关理论,提出了用于识别领 先用户的评价指标;其次,采用朴素贝叶斯分类等数据挖掘方法对用户留存在创新社区中的内容信息和互动信息进行分析,计算出用户的各项评价指标值,进而对各 评价指标值进行综合,获得各用户的"领先性"得分,并甄选出创新社区中具有出色创新能力和积极创新意愿的领先用户;最后,通过实例验证了该方法的有效性。
Method for Identifying Lead Users in Online Innovation Communities [J].https://doi.org/10.3963/j.issn.2095-3852.2014.04.022 URL [本文引用: 2] 摘要
针对随着互联网的发展和普及, 协同创新社区成为顾客参与企业创新活动的重要途径的现状,提出了一种协同创新社区中领先用户的识别方法。首先,基于领先用户的相关理论,提出了用于识别领 先用户的评价指标;其次,采用朴素贝叶斯分类等数据挖掘方法对用户留存在创新社区中的内容信息和互动信息进行分析,计算出用户的各项评价指标值,进而对各 评价指标值进行综合,获得各用户的"领先性"得分,并甄选出创新社区中具有出色创新能力和积极创新意愿的领先用户;最后,通过实例验证了该方法的有效性。
|
| [18] |
The Nature of Lead Users and Measurement of Leading Edge Status [J].https://doi.org/10.1016/j.respol.2003.09.007 URL [本文引用: 1] 摘要
“Lead users” are defined as being at the leading edge of markets, and as having a high incentive to innovate. Empirical research has shown the value of lead user need and solution data to new product development processes. However, the nature of the lead user construct itself has not been studied to date. In this paper we fill this significant gap by proposing and evaluating a continuous analog to the lead user construct, which we call leading edge status (LES). We establish the validity and reliability of LES and examine the characteristics of users having high levels of this variable. We also offer a first exploration of how LES is related to traditional measures in diffusion theory such as dispositional innovativeness and time of adoption (TOA). We find a strong relationship and explain how users with high LES can offer a contribution to both predicting and accelerating early product adoption.
|
| [19] |
Identification of Lead Users for Consumer Products via Virtual Stock Markets [J].https://doi.org/10.1111/j.1540-5885.2009.00661.x URL [本文引用: 1] 摘要
Newly launched products in the consumer goods and services markets show high failure rates. To reduce the failure rates, companies can integrate innovative and knowledgeable customers, the so-called lead users, into the new product development process. However, the detection of such lead users is difficult, especially in consumer product markets with very large customer bases. A new and potentially valuable approach toward the identification of lead users involves the use of virtual stock markets, which have been proposed and applied for political and business forecasting but not for the identification of experts such as lead users. The basic concept of virtual stock markets is bringing a group of participants together via the Internet and allowing them to trade shares of virtual stocks. These stocks represent a bet on the outcome of future market situations, and their value depends on the realization of these market situations. In this process, a virtual stock market elicits and aggregates the assessments of its participants concerning future market developments. Virtual stock markets might also serve as a feasible instrument to filter out lead users, primarily for the following two reasons. First, a self-selection effect might occur because sophisticated consumers with a higher involvement in the product of interest decide to participate in virtual stock markets. Second, a performance effect is likely to arise because well-performing participants in virtual stock markets show a better understanding of the market than their (already self-selected) fellow participants. So far, only limited information exists about these two effects and their relation to lead user characteristics. The goal of this paper is to analyze the feasibility of virtual stock markets for the identification of lead users. The results of this empirical study show that virtual stock markets can be an effective instrument to identify lead users in consumer products markets. Furthermore, the results show that not all lead users perform well in virtual stock markets. Hence, virtual stock markets allow identifying lead users with superior abilities to forecast market success.
|
| [20] |
Organizations as Professional Communities in the Post-modern Era [J].
What is the meaning of social context for the connection between Psychologists and Social Workers with the organization they work for? Many professionals are searching for both professional space, and a fitting connectedness to the organization. This connection seems to be greatly influenced by social developments. This article will show that organizations are important communities of the future that will partially adopt the function of family and township connections. By conscious deployment of organization-communities, as a manager it is possible to bind professionals to an organization that offers them freedom and challenge.
|
| [21] |
Product Ideation by Persons with Disabilities: An Analysis of Lead User Characteristics [C]// |
| [22] |
Analysis of Automatic Online Lead User Identification [A]//Smart Product Engineering [M]. |
| [23] |
消费品行业领先用户识别方法研究 [J].
目前,从普通消费者群体中识别出领先用户仍然是一个难点.文章通 过研究发现,可以将顾客能力作为衡量领先用户的维度来对其进行识别.领先用户之所以领先于普通消费者,是因为他们在相关的领域内有领先的顾客能力,其中, 领先用户在相关领域的创新能力、沟通能力、合作能力和知识能力这几方面强于普通用户,因而成为领先用户.因此,通过确定和比较顾客的这几种能力,能力较强 者即可认为是领先用户.这种通过衡量顾客能力来识别领先用户的方法在消费品行业相对比较容易实现,可以便于企业用来选择合适的顾客参与企业研发.
Lead User Identification in Consumer Goods Industry [J].
目前,从普通消费者群体中识别出领先用户仍然是一个难点.文章通 过研究发现,可以将顾客能力作为衡量领先用户的维度来对其进行识别.领先用户之所以领先于普通消费者,是因为他们在相关的领域内有领先的顾客能力,其中, 领先用户在相关领域的创新能力、沟通能力、合作能力和知识能力这几方面强于普通用户,因而成为领先用户.因此,通过确定和比较顾客的这几种能力,能力较强 者即可认为是领先用户.这种通过衡量顾客能力来识别领先用户的方法在消费品行业相对比较容易实现,可以便于企业用来选择合适的顾客参与企业研发.
|
| [24] |
User-centric Innovations in New Product Development—Systematic Identification of Lead Users Harnessing Interactive and Collaborative Online- tools [J].https://doi.org/10.1142/S1363919608002096 URL [本文引用: 1] 摘要
The following sections are included:IntroductionLiterature ReviewConceptual FrameworkConceptual Linkage ead-User Criteria and Web 2.0Being ahead of a market trendHigh expected benefitsUser investmentUser dissatisfactionSpeed of adoptionUser expertiseUse experienceProduct-related knowledgeUser motivationExtrinsic motivationIntrinsic motivationExtreme needs and circumstances of product useOpinion leadership and word-of-mouthOnline commitment and participation as a pre-requisite of lead usernessConclusion and Future ResearchReferences Introduction Literature Review Conceptual Framework Conceptual Linkage ead-User Criteria and Web 2.0Being ahead of a market trendHigh expected benefitsUser investmentUser dissatisfactionSpeed of adoptionUser expertiseUse experienceProduct-related knowledgeUser motivationExtrinsic motivationIntrinsic motivationExtreme needs and circumstances of product useOpinion leadership and word-of-mouthOnline commitment and participation as a pre-requisite of lead userness Being ahead of a market trend High expected benefitsUser investmentUser dissatisfactionSpeed of adoption User investment User dissatisfaction Speed of adoption User expertiseUse experienceProduct-related knowledge Use experience Product-related knowledge User motivationExtrinsic motivationIntrinsic motivation Extrinsic motivation Intrinsic motivation Extreme needs and circumstances of product use Opinion leadership and word-of-mouth Online commitment and participation as a pre-requisite of lead userness Conclusion and Future Research References
|
| [25] |
基于应用扩展和网络论坛的领先用户识别方法研究 [J].https://doi.org/10.3969/j.issn.1672-884X.2011.09.013 URL Magsci [本文引用: 1] 摘要
<p>回顾了领先用户识别的电话网络法,分析了它的应用局限性。电话网络法只适合领先用户相对分散的情况下,企业需要找到部分领先用户为企业新产品概念开发贡献产品创意。但当领先用户的应用扩展到产品推广之后,为了使领先用户在市场中的领导地位能影响普通用户,并进一步带来更好的新产品绩效,需要找到目标群体中的全部领先用户。网络论坛的设立使得领先用户在产品开发论坛中相对集中,从而问卷法识别领先用户的效率能够得到保证。确立了识别领先用户的三大指标:市场或技术趋势、客户收益、信息复杂性。用统计学与概率论的方法建立了领先用户的识别模型。</p>
Research on Lead User Identification on the Basis of Application Extending and Netnews [J].https://doi.org/10.3969/j.issn.1672-884X.2011.09.013 URL Magsci [本文引用: 1] 摘要
<p>回顾了领先用户识别的电话网络法,分析了它的应用局限性。电话网络法只适合领先用户相对分散的情况下,企业需要找到部分领先用户为企业新产品概念开发贡献产品创意。但当领先用户的应用扩展到产品推广之后,为了使领先用户在市场中的领导地位能影响普通用户,并进一步带来更好的新产品绩效,需要找到目标群体中的全部领先用户。网络论坛的设立使得领先用户在产品开发论坛中相对集中,从而问卷法识别领先用户的效率能够得到保证。确立了识别领先用户的三大指标:市场或技术趋势、客户收益、信息复杂性。用统计学与概率论的方法建立了领先用户的识别模型。</p>
|
| [26] |
How to Work a Crowd: Developing Crowd Capital Through Crowdsourcing [J].https://doi.org/10.1016/j.bushor.2014.09.005 URL [本文引用: 1] 摘要
Traditionally, the term ‘crowd’ was used almost exclusively in the context of people who self-organized around a common purpose, emotion or experience. Today, h
|
| [27] |
Maximum Entropy Principle and Emerging Applications [M]. |
| [28] |
Random Forests [J].https://doi.org/10.1023/A:1010933404324 URL [本文引用: 1] |
| [29] |
Statistical Modeling: The Two Cultures [J].https://doi.org/10.1214/ss/1009213726 URL [本文引用: 1] 摘要
There are two cultures in the use of statistical modeling to reach conclusions from data. One assumes that the data are generated by a given stochastic data model. The other uses algorithmic models and treats the data mechanism as unknown. The statistical community has been committed to the almost exclusive use of data models. This commitment has led to irrelevant theory, questionable conclusions, and has kept statisticians from working on a large range of interesting current problems. Algorithmic modeling, both in theory and practice, has developed rapidly in fields outside statistics. It can be used both on large complex data sets and as a more accurate and informative alternative to data modeling on smaller data sets. If our goal as a field is to use data to solve problems, then we need to move away from exclusive dependence on data models and adopt a more diverse set of tools.
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}