胡忠义 , 王超群, 吴江
, 王超群, 吴江
Hu Zhongyi, Wang Chaoqun, Wu Jiang
中图分类号: G353
通讯作者:
收稿日期: 2017-04-10
修回日期: 2017-05-29
网络出版日期: 2017-06-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】充分利用多源网络评估数据和URL异常特征数据, 研究提高钓鱼网站识别准确性的可行性方案。【方法】采用8种机器学习技术, 对比研究网络评估数据与传统的URL异常特征数据在钓鱼网站识别中的性能, 并融合两类数据研究进一步提高钓鱼网站识别准确性的可行性方案。【结果】在钓鱼网站识别中, 相比于传统的URL异常特征, 利用网络评估数据可以取得更好的识别效果。融合两类数据对于提高识别准确性有一定帮助。【局限】未考虑钓鱼网站与正常网站的数量存在严重的不均衡问题。【结论】充分利用多源网络评估数据和URL异常特征数据识别钓鱼网站的方法是比较合理和有效的, 对后续相关研究具有一定的借鉴意义。
关键词:
Abstract
[Objective] This study aims to identify phishing websites more effectively with the help of online evaluation data and URL abnormal features. [Methods] First, we used eight machine learning techniques to compare the performance of various online evaluation data and URL abnormal features in identifying phishing websites. Then, we proposed a new method to improve the accuracy of the identification procedures. [Results] We found that the evaluation data had better performance than abnormal features of URL. Combining the two data sets could improve the identification performance. [Limitations] We did not consider the difference between the numbers of phishing sites and the good ones. [Conclusions] Online evaluation data and URL abnormal features could help us identify phishing websites effectively, which indicates the direction of future studies.
Keywords:
近年来, 随着互联网的高速发展, 网民数量急剧增加, 在电子商务及电子金融产业日渐繁荣的同时, 网络安全问题日益凸显。病毒、盗号、木马、钓鱼等黑客行为对互联网环境造成极其恶劣的影响, 其中钓鱼网站的危害尤其严重。钓鱼网站是一种基于社会工程学的攻击手段, 不法分子通过垃圾邮件、聊天工具、手机短信或网页虚假广告发送大量声称来自于银行或其他知名机构的欺骗性信息, 意图引诱用户给出敏感信息(如用户名、口令、手机号、银行账号和密码)。根据2016年6月中国互联网协会发布的《中国网民权益保护调查报告(2016)》, 中国互联网用户近一年来因个人信息泄露、诈骗信息等问题, 导致总体损失约915亿元。
为了阻止用户访问钓鱼网站并最大程度地减小用户损失, 互联网厂商采用黑白名单技术, 推出了用于识别钓鱼网站的浏览器检测插件[1-2]。但是, 随着钓鱼网站数量的急剧增加, 黑白名单技术并不能有效地解决钓鱼网站的识别问题, 不少学者尝试基于URL异常特征构建识别模型, 用以有效识别钓鱼网站[3-9]。有学者借助互联网上可公开获取的网站评估数据, 开展了基于网络评估数据的钓鱼网站识别技术研究[10]。尽管基于URL异常特征的识别技术和基于网络评估数据的识别技术均取得了较好的效果, 但尚未有研究对比这两类技术在钓鱼网站识别中的性能。因此, 本文采用8种机器学习技术, 对比两类识别技术在钓鱼网站识别中的性能, 并尝试融合两类多源数据, 研究进一步提高钓鱼网站识别准确率的可行性方案。
鉴于钓鱼网站危害极大, 国内外研究提出了多种不同的解决方案, 如基于黑名单的识别技术和基于URL异常特征的机器学习识别技术。其中, 基于黑白名单的识别技术多采用浏览器插件形式实现[1-2], 如微软IE浏览器的Phishing Filter、谷歌出品的Google Safe Browsing、搜狗网页安全卫士等。基于事先维护的钓鱼网站黑名单列表, 当用户访问的网站在黑名单中时, 浏览器会弹出警示框, 提醒用户当前访问的网站是钓鱼网站, 进而阻止用户访问该钓鱼网站。虽然这些基于黑名单技术的检测方式简单直接, 但在实践运行中效果欠佳。如, 为了测试现有浏览器厂商或第三方厂商提供的各种浏览器防钓鱼网站插件, Zhang等[2]设计了一种自动检测平台。针对该平台收集的200个钓鱼网址和516个合法网址, 10个流行的防钓鱼网站插件中只有两个工具可以识别出60%以上的钓鱼网址。究其原因, 主要是由于黑名单往往是通过网民举报和人工审核等方式建立的, 具有一定的滞后性; 同时, 随着钓鱼网站数量的急剧增加, 使得建立一份完整的黑白名单的难度越来越大。因此这种方法虽然技术简单, 但无法从本质上检测钓鱼网络攻击。
基于URL异常特征的识别技术利用钓鱼网站的URL特征, 基于机器学习算法构造用以识别钓鱼网站的分类器模型。如, Blum等[3]从URL中提取词汇特征并构建可信度加权的分类算法。黄华军等[4]通过分析网站域名结构上的特征和语义上的特征, 抽取10多个有效特征, 用以构建和测试基于支持向量机的分类模型, 达到了较好的识别效果。Ma等[5-6]构建的恶意网站的识别模型中, 则采用了URL词汇特征和主机特征。基于URL中提取出的敏感特征, 曾传璜等[7]设计了改进的AdaCostBoost算法, 实验结果表明, 该检测方法具有较优的检测性能。相比黑白名单识别技术, 基于URL异常特征的钓鱼网站识别技术不再需要人工去标注钓鱼网站, 工作效率有了很大提高[8], 且能够在一定程度上应对钓鱼网站的快速变化。但是, URL仿照性较强, 仅仅通过URL异常特征识别钓鱼网站可能会造成较高的误判率和漏判率[9], 风险较大。
近年, Hu等[10]融合网站的多源网络评估数据构建多种机器学习模型, 用于识别钓鱼网站。该研究利用互联网上可公开获取的评估数据(如知名互联网公司测评的域名评估数据、社交平台关注数据等), 构造网站评估数据的特征向量, 并采用多种稳健的机器学习算法, 构建钓鱼网站识别模型。结果表明各机器学习模型可以较好地利用网络评估数据识别钓鱼网站。该方法符合当前大数据分析中充分融合多源数据的潮流, 实现识别钓鱼网站的目的。然而, 该研究仅仅验证了各机器学习模型利用网络评估数据在识别钓鱼网站中的有效性, 而所提方法与传统方法如基于URL异常特征的识别技术相比, 是否具有更好的识别效果, 并未加以验证, 且进一步融合两类特征变量是否能更好地提高钓鱼网站的识别性能也仍未知。
因此, 本文针对钓鱼网站识别问题, 对比研究多源网络评估数据与URL特征数据在钓鱼网站识别中的性能, 并融合两类多源数据特征, 进一步探究提高钓鱼网站识别准确性的可行性方案, 以期为相关的钓鱼网站识别研究提供参考。
本文的主要创新包括: 采用8种经典的机器学习技术系统地评价基于不同特征变量识别钓鱼网站的性能; 采用Boruta技术进行特征选择, 剔除冗余特征变量, 提高模型性能; 基于多个评价指标, 全面对比分析了URL特征数据、多源网络评估数据及融合两类特征数据识别钓鱼网站的性能。
为了更为准确地识别钓鱼网站, 本文提出融合多源网络评估数据及URL特征的识别模型。图1描述了该技术的详细流程。主要包括数据采集与预处理、特征选择、模型构建与验证三部分。
(1) 数据采集与预处理
为了构建融合多源网络评估数据及URL特征的钓鱼网站识别模型, 从PhishTank、Alexa等钓鱼网站名录和知名站点名录收集网站URLs集; 从Moz、Majestic、Google、Alexa等第三方知名网站评估平台收集网络评估数据; 经数据清理、筛选、抽取等处理后得到URL异常特征变量和网络评估特征变量, 并融合两类特征向量得到多源特征集合。
(2) 特征选择
上述收集提取的URL异常特征、网络评估特征及融合两类特征的多源特征集合, 可能存在一些不相关或者冗余的特征变量, 这些变量不仅会影响模型的识别精度, 还会增加模型的复杂度, 进而降低效率, 因此使用特征选择技术去除多余变量是必要的。为此, 本研究采用Boruta算法[11]进行特征变量的筛选, 以去除多余的变量、提高模型识别精度。
Boruta是一种特征选择算法, 通过创建混合副本的所有特征增加了随机性, 而且使用特征重要性指标(默认设定为平均减少精度)评估每个特征的重要性, 每次迭代的时候都会比较每一个真实的特征变量是否比最好的阴影特征具有更高的重要性, 以此为依据删除不重要的特征[11]。在Boruta执行完变量筛选后, 会对数据集中变量的意义给出明确的解释。
(3) 模型构建与验证
为了有效评估不同特征变量在钓鱼网站识别中的性能, 本文采用决策树、支持向量机、K近邻法、朴素贝叶斯、人工神经网络、AdaBoost、Bagging、随机森林8种经典的机器学习技术构建识别模型, 这些模型在数据挖掘和机器学习领域得到广泛应用, 同时也是钓鱼网站识别研究中的常用技术。其中, 决策树、支持向量机、K近邻法、朴素贝叶斯、人工神经网络属于单一模型, AdaBoost、Bagging、随机森林属于集成模型。值得注意的是, 集成模型集合了多个弱学习器, 相比于单一模型, 往往具有更高的准确性[12-13]。基于以上8种机器学习技术, 采用十折交叉验证, 通过准确率(Accuracy)、查全率(Recall)、查准率(Precision)、F值(F-measure) 4种评价指标, 全面评估和对比基于URL异常特征、网络评估特征、多源融合特征的钓鱼网站识别模型和性能。
为了研究网络评估数据与传统的URL异常特征数据在识别钓鱼网站中的性能, 本研究既获取了网站的URL特征数据, 又获取了网站的网络评估数据。一共获取了2 000条URL数据, 这些URL截至2016年7月31日仍然可以解析。为了消除数据不平衡问题, 数据集中合法网址和钓鱼网址各占一半。1 000条钓鱼网站数据从PhishTank①(①http://www.phishtank.com/.)中获取。1 000条合法网站数据从Alexa②(②http://www.alexa.com/.)获取, 且这些合法网站既有访问量很大的网站, 也有访问量极少的, 并在Alexa中排名特别靠后(如1 000万以后)的网站。
(1) URL特征变量
通过对已有相关文献的分析, 选取7个钓鱼网站的特征变量, 组成URL特征向量FV:
FV=<F1, F2, F3, F4, F5, F6, F7>
F1: length, URL长度, 一般可信网站URL的长度小于23, URL过长的网站, 就有可能是钓鱼网站。
F2: isContainIp, URL中是否含有IP地址, 为逃避域名的注册或用户的检查, 用十进制掩饰的基于 IP 地址的URL 地址是一种在钓鱼网站中常用的手段。
F3: isContainSensitiveWord, URL中是否包含敏感词汇, 敏感词汇包括admin、login、manage、root、account、bank、password等, 当网址中出现较多敏感词汇时, 可能就是钓鱼网站为了获取用户的信息而设置的。
F4: isContainSpecailCharactor, URL中是否出现异常字符, 异常字符包括-、~、!、@、#、$、%、*等, 如果网址的异常字符过多, 该网站很有可能就是钓鱼网站。
F5: countOfDot, URL域名级数, 当URL中包含过多的域名级数时, 很可能是钓鱼网站模仿合法网站, 故意加入产品信息。
F6: countOfSlash, URL目录级数, 设置较多的路径级数时可以让用户眼花缭乱以至于无法辨别出是钓鱼网站。
F7: count, URL中长单词(长度超过20)的个数, 正常网站中出现长单词的次数很少。
(2) 互联网评估数据
针对互联网评估数据, 分别从Moz、Majestic、Google、Alexa共4家知名网络采集多源网站评估数据, 经处理, 得到包含16个变量的评估数据特征向量FV:
FV=<F8, F9, F10, F11, F12, F13, F14, F15, F16, F17, F18, F19, F20, F21, F22, F23>
①Moz评估数据
F8: Moz’s Domain Authority, Moz公司给出的域名在搜索引擎中排名的预测。
F9: MozRank, 代表一个链接流行度评分。
F10: Moz’s Total Backlinks, 反映一个网站的所有反向链接, 反向链接越多, 说明这个网站越受欢迎。
②Majestic评估数据
F11: Majestic’s Citation Flow, 用来度量引用来源, 通过引用排名, 显示一个网站的受欢迎程度。
F12: Majestic’s Trust Flow, 用来度量信任来源, 表明一个网站和可信赖网站的亲密程度。
F13: Majestic’s Backlinks, 反映网站反向链接的指标。
F14: Majestic’s Reference Domains, 引用域, 是指外部链接指向当前网站的个数。
社交网站分享度: 可以反映出各个网站在社交网站的受欢迎程度, 社交网站的受欢迎度排名越高, 网站的权威性越高。
F15: Facebook Shares, 在Facebook的受欢迎程度。
F16: Twitter Tweets, 在Twitter的受欢迎程度。
F17: Google Plus Shares, 在Google Plus的受欢迎程度。
③Google评估数据
F18: Google’s Page Rank, 是Google通过网站之间的超链接关系确定的网站排行榜。
F19: Google’s Page Speed, 是Google评估网页加载速度的指标。
④Alexa评估数据
F20: Alexa’s Rank, 通过网站的访问量确定网站排名, 访问量越大, 排名越靠前, 网站越受欢迎。
F21: Alexa’s 1 Month Reach, 网站最近1个月的平均每天访问量。
F22: Alexa’s 3 Month Reach, 网站最近3个月的平均每天访问量。
F23: Alexa’s Median Load, 使用Alexa特有的算法计算出的页面平均加载速度。
判断一个网站是钓鱼网站, 还是正常网站, 是典型的二分类问题。在现实生活中正常网站的数量远多于钓鱼网站的数量, 钓鱼网站更容易出现错分, 另外钓鱼网站的错分代价更大, 因此钓鱼网站的识别率更重要。所以本文不采用总体分类性能指标, 而是采用二分类问题的混合矩阵进行评估, 如表1所示。
其中, 钓鱼网站样本为P, 正常网站样本为N, FP是指将正常网站样本错分成钓鱼网站的数目, FN 是指将钓鱼网站样本错分成正常网站的数目, TP和TN分别表示钓鱼网站和正常网站样本被正确分类的数目。
据此得到4类性能评价指标, 分别如公式(1)-公式(4)所示。
$\text{Accuracy=}\frac{\text{TP+TN}}{\text{TP+TN+FP+FN}}$ (1)
$\text{Recall=}\frac{\text{TP}}{\text{TP+FN}}$ (2)
$\text{Precision=}\frac{\text{TP}}{\text{FP+TP}}$ (3)
$\text{F-measure=}\frac{\text{2}\times \text{Recall}\times \text{Precision}}{\text{Recall}+\text{Precision}}$ (4)
从公式(4)可知, 性能指标 F-measure既考虑钓鱼网站样本的查全率又考虑查准率, 只有在查全率和查准率的值都比较大的前提下, F-measure值才会很大, 因此能综合地体现出分类器对正常网站和钓鱼网站的分类效果, 而且侧重于体现钓鱼网站样本的分类效果。
为了探究提高钓鱼网站识别准确率的可行性方案, 对比研究基于URL异常特征的识别技术、基于网络评估数据的识别技术和融合两类特征变量的识别技术在钓鱼网站识别中的性能表现。为了消除指标之间的量纲影响, 对特征向量进行归一化处理, 随后采用8种机器学习技术分别对三类特征向量构建识别模型, 并最终通过指标对比分析基于三类不同特征向量的识别模型的识别性能。
数据采集、处理及识别模型的训练等所有实验均在R语言环境下进行, 实验涉及到的“rpart”、“e1071”、“kknn”、“nnet”、“adabag”、“randomForest”、“Boruta”等程序包均可下载①(①程序包下载地址: http://cran.r-project.org/.)。
(1) 特征选择
在收集的URL特征中, 可能存在一些不相关或者冗余的变量, 这些变量不仅会影响模型识别精度, 还会增加模型的复杂度, 进而降低效率。因此, 首先基于Boruta特征选择方法[11], 对含有7个URL特征变量的数据进行变量筛选, 结果如图2所示。
图2展示了Boruta计算的各变量的重要性, 其中, 红色和绿色的盒状图分别代表拒绝变量和确认变量的Z分数。蓝色的盒状图对应一个阴影变量的最小、平均和最大Z分数。可知, isContainIp(是否含有IP)和isContainSensitiveWord(是否含有敏感词汇)两个变量被拒绝, 其余的5个被确认。
(2) 结果分析
基于已确认的5个URL特征变量, 采用决策树、支持向量机、K近邻法、朴素贝叶斯、人工神经网络、AdaBoost、Bagging、随机森林8种机器学习技术分别构建识别模型, 且每个模型均采用十折交叉验证的方式进行训练和测试, 每组实验均重复10次以防止随机影响, 最后计算这些实验的各评测指标的统计平均值。实验结果如表2所示。
表2 8种方法的评估结果
| 方法 | 准确率 | 查准率 | 查全率 | F值 |
|---|---|---|---|---|
| 决策树 | 0.5935 | 0.9099 | 0.2150 | 0.3433 |
| SVM | 0.6340 | 0.7744 | 0.3780 | 0.5074 |
| K近邻法 | 0.6205 | 0.6411 | 0.5610 | 0.5954 |
| 朴素贝叶斯 | 0.5990 | 0.9720 | 0.2040 | 0.3362 |
| 人工神经网络 | 0.6420 | 0.7535 | 0.4290 | 0.5457 |
| AdaBoost | 0.6435 | 0.7500 | 0.4400 | 0.5534 |
| Bagging | 0.6445 | 0.7587 | 0.4260 | 0.5443 |
| 随机森林 | 0.6390 | 0.7828 | 0.3850 | 0.5155 |
从表2可以看出, 仅仅使用URL异常特征进行网站识别的性能不是很好。其中, F值最高的为K近邻法(0.5954), 且该方法的查全率0.5610也是所有方法中最高的, 但准确率和查准率相比三种集成模型略差一些。决策树、SVM、朴素贝叶斯三种单一方法虽然有相对较高的查准率, 但是其查全率和F值很差, 这说明它们将大多数钓鱼网站都识别为正常网站。三种集成模型(AdaBoost、Bagging和随机森林)相对其他模型, 4个性能指标都比较适中, 表现比较稳健, 这主要在于这些模型是由众多弱模型集成而来, 受噪声等随机因素的影响相对个体模型而言比较小。
总体来看, 仅仅使用URL异常特征进行钓鱼网站的识别, 效果不是很好, 这主要是由于URL样式极易模仿和学习, 导致URL异常特征特别有限, 因而仅仅依赖URL异常特征进行钓鱼网站的识别是远远不够的。
(1) 特征选择
采用Boruta进行特征变量的筛选, 以剔除冗余变量。各变量的重要性和检测结果如图3所示。
可知, 16个变量均被认为是重要的。其中, GooglePageRank、RefDomains和GooglePlusShares是所有变量中最重要的三个。
(2) 结果分析
基于筛选得到的16个网络评估变量构建识别模型, 实验结果如表3所示。
表3 8种方法的评估结果
| 方法 | 准确率 | 查准率 | 查全率 | F值 |
|---|---|---|---|---|
| 决策树 | 0.8810 | 0.8576 | 0.9160 | 0.8845 |
| SVM | 0.9145 | 0.9026 | 0.9310 | 0.9159 |
| K近邻法 | 0.9115 | 0.9030 | 0.9240 | 0.9126 |
| 朴素贝叶斯 | 0.7455 | 0.6659 | 0.9890 | 0.7956 |
| 人工神经网络 | 0.8695 | 0.9226 | 0.8460 | 0.8818 |
| AdaBoost | 0.9415 | 0.9335 | 0.9500 | 0.9412 |
| Bagging | 0.9230 | 0.9174 | 0.9310 | 0.9234 |
| 随机森林 | 0.9415 | 0.9355 | 0.9500 | 0.9421 |
从表3可以看出, 使用网络评估数据进行网站识别的准确率较高, 除了朴素贝叶斯算法外, 其余算法的准确率都在0.85以上, 而且F值在0.88以上, 相比仅利用URL异常特征进行识别有很大的提升。其中,
三个集成学习模型的各性能指标均大于0.91, 与其他单一模型相比具有明显的优势。这得益于这些集成学习模型在模型构建中的集成机制, 且对于含有16个输入变量的识别问题更加有效。
此外, 同URL异常特征的结果一样, 朴素贝叶斯表现是最差的, 虽然查全率高达0.9890, 但F值、查准率和准确率却是最低的, 分别为0.7956、0.6659和0.7455, 这意味着该方法将大多数正确网站识别为钓鱼网站, 这与基于URL特征识别的结果恰恰相反。朴素贝叶斯是建立在特征变量相互独立的基础上的一种分类器[14], 很显然, 本研究中收集的变量并非一定是独立的, 这导致了该方法表现很差。
总的来看, 基于网络特征数据进行识别的准确率较高, 基本上可以正确地识别出钓鱼网站。
(1) 特征选择
融合7个URL异常特征变量和16个网络评估数据特征, 并采用Boruta进行特征变量的筛选, 结果如图4所示。
可知, 3个变量被拒绝, 分别是isContainIp(是否含有IP), isContainSensitiveWord(是否含有敏感词汇)以及isContainSpecialCharactor(是否有特殊字符), 其余20个变量均被认为是重要的。
(2) 结果分析
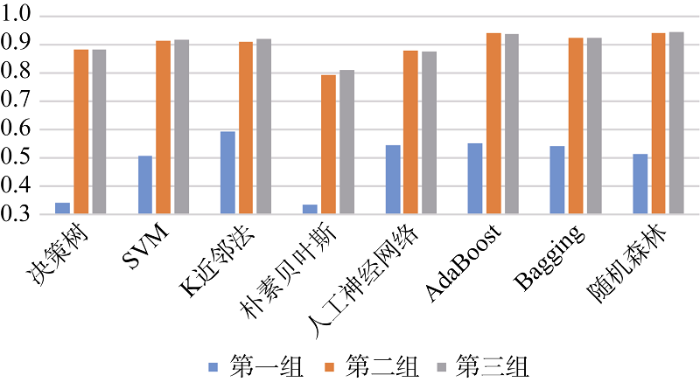
采用融合URL特征与网络评估数据的20个变量构建钓鱼网站识别模型, 实验结果如表4所示。同时, 为了便于同基于URL异常特征的模型和基于网络评估数据的模型对比, 图5给出了8种机器学习模型在采用不同变量特征时识别性能的对比结果。
表4 8种方法的评估结果
| 方法 | 准确率 | 查准率 | 查全率 | F值 |
|---|---|---|---|---|
| 决策树 | 0.8810 | 0.8576 | 0.9160 | 0.8845 |
| SVM | 0.9119 | 0.9280 | 0.9194 | 0.9185 |
| K近邻法 | 0.9200 | 0.9133 | 0.9300 | 0.9208 |
| 朴素贝叶斯 | 0.7690 | 0.6881 | 0.9880 | 0.8108 |
| 人工神经网络 | 0.8945 | 0.8879 | 0.8710 | 0.8776 |
| AdaBoost | 0.9415 | 0.9383 | 0.9430 | 0.9403 |
| Bagging | 0.9230 | 0.9174 | 0.9310 | 0.9234 |
| 随机森林 | 0.9435 | 0.9363 | 0.9530 | 0.9442 |
从表4可以看出, 在融合两类数据特征的情况下, 8种机器学习识别模型中, 朴素贝叶斯算法除查全率稍高之外, 准确率、查准率和F值是最差的。如上文所述, 这主要是由于变量间不一定相互独立所致。随机森林作为集成学习模型里的佼佼者, 基于一定概率产生众多随机向量[15], 不仅可以有效构建多决策树以生成集成模型, 还起到特征变量选择的作用。与已有研究中较好的表现一致[10, 12-13], 表4中的随机森林在准确率和F值上均是最好的。
对比图5中三组不同特征变量的实验结果可以看出, 第二组和第三组的F值要远高于第一组, 表明基于URL异常特征的识别模型并不能很好地进行钓鱼网站的识别, 而基于网络评估数据以及融合两类特征的识别模型则能够较准确地识别钓鱼网站; 同时, 与只使用网络评估数据相比, 融合两类特征的识别模型其结果准确率有一定的提高。这再次反映出网络评估数据在识别钓鱼网站中的有效性, 也说明探索融合多种不同来源的特征变量以提高钓鱼网站识别性能是可行的。另外, 相比于前5个单一模型, 集成了多个弱学习器的集成模型取得了更高的F值, 实现了更好地识别钓鱼网站的目的, 再次表明了集成模型的高效与准确。
本文采用8种机器学习技术, 对比研究了传统的基于URL异常特征的识别模型与最近的基于网络评估数据的识别模型在识别钓鱼网站问题上的性能, 并融合两类特征变量, 探究提高钓鱼网站识别准确性的可行性方案。实证结果表明, 基于URL异常特征的识别模型不能很好地进行钓鱼网站的识别, 而基于网络评估数据的识别模型具有较高的识别准确性, 且融合两类特征向量的识别模型对钓鱼网站的识别准确性有一定提高。由于网络评估数据收集便捷, 处理方式较为简单, 因此在已有识别技术的基础上融合该类型特征变量是值得应用并推广的。
然而, 在实际生活中, 钓鱼网站与正常网站的比例是不均衡的, 在之后的研究中将针对这一类别不均衡问题, 研究更先进的机器学习技术与识别模型。此外, 网站页面信息是识别钓鱼网站的另一重要数据, 未来会尝试融合包括URL特征、页面信息、网络评估数据等更多不同来源的特征变量, 以进一步提高钓鱼网站的识别准确性。
胡忠义, 王超群, 吴江: 提出研究思路, 设计研究方案;
王超群, 胡忠义: 数据处理, 负责实验, 论文起草;
胡忠义, 吴江, 王超群: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: zhongyi.hu@whu.edu.cn。
[1] 胡忠义, 王超群, 吴江. Phishsites.csv. 钓鱼网站列表.
[2] 胡忠义, 王超群, 吴江. extractedFeatures.zip. 提取的特征向量.
| [1] |
An Empirical Analysis of Phishing Blacklists [C]// |
| [2] |
Phinding Phish: Evaluating Anti-phishing Tools [C]// |
| [3] |
Lexical Feature Based Phishing URL Detection Using Online Learning [C]// |
| [4] |
基于异常特征的钓鱼网站 URL 检测技术 [J].Detection of Phishing URL Based on Abnormal Feature [J]. |
| [5] |
Identifying Suspicious URLs: An Application of Large-scale Online Learning [C]// |
| [6] |
Beyond Blacklists: Learning to Detect Malicious Web Sites from Suspicious URLs [C]// |
| [7] |
AdaCostBoost 算法的网络钓鱼检测 [J].
针对日益严重的网络钓鱼攻击, 提出机器学习的方法进行钓鱼网站的检测和判断. 首先, 根据URL提取敏感特征, 然后, 采用AdaBoost算法进行训练出分类器, 再用训练好的分类器对未知URL检测识别. 最后, 针对非平衡代价问题, 采用了改进后的AdaBoost算法--AdaCostBoost, 加入代价因子的计算. 实验结果表明, 文中提出的网络钓鱼检测方法, 具有较优的检测性能.
Phishing Detection System Based on AdaCostBoost Algorithm [J].
针对日益严重的网络钓鱼攻击, 提出机器学习的方法进行钓鱼网站的检测和判断. 首先, 根据URL提取敏感特征, 然后, 采用AdaBoost算法进行训练出分类器, 再用训练好的分类器对未知URL检测识别. 最后, 针对非平衡代价问题, 采用了改进后的AdaBoost算法--AdaCostBoost, 加入代价因子的计算. 实验结果表明, 文中提出的网络钓鱼检测方法, 具有较优的检测性能.
|
| [8] |
Design and Evaluation of a Real-time URL Spam Filtering Service [C]// |
| [9] |
基于贝叶斯和支持向量机的钓鱼网站检测方法 [J].Phishing Detection Approach Based on Naïve Bayes and Support Vector Machine [J]. |
| [10] |
Identifying Malicious Web Domains Using Machine Learning Techniques with Online Credibility and Performance Data [C]// |
| [11] |
Feature Selection with the Boruta Package [J].https://doi.org/10.18637/jss.v036.i11 URL [本文引用: 3] 摘要
This article describes a bR/b package bBoruta/b, implementing a novel feature selection algorithm for finding emph{all relevant variables}. The algorithm is designed as a wrapper around a Random Forest classification algorithm. It iteratively removes the features which are proved by a statistical test to be less relevant than random probes. The bBoruta/b package provides a convenient interface to the algorithm. The short description of the algorithm and examples of its application are presented.
|
| [12] |
A Decision-theoretic Generalization of On-line Learning and an Application to Boosting [J].https://doi.org/10.1007/3-540-59119-2_166 URL [本文引用: 2] 摘要
In the first part of the paper we consider the problem of dynamically apportioning resources among a set of options in a worst-case on-line framework. The model we study can be interpreted as a broad, abstract extension of the well-studied on-line prediction model to a general decision-theoretic setting. We show that the multiplicative weight-update Littlestone-Warmuth rule can be adapted to this model, yielding bounds that are slightly weaker in some cases, but applicable to a considerably more general class of learning problems. We show how the resulting learning algorithm can be applied to a variety of problems, including gambling, multiple-outcome prediction, repeated games, and prediction of points in ℝ n . In the second part of the paper we apply the multiplicative weight-update technique to derive a new boosting algorithm. This boosting algorithm does not require any prior knowledge about the performance of the weak learning algorithm. We also study generalizations of the new boosting algorithm to the problem of learning functions whose range, rather than being binary, is an arbitrary finite set or a bounded segment of the real line.
|
| [13] |
Using Support Vector Machine Ensembles for Target Audience Classification on Twitter [J].https://doi.org/10.1371/journal.pone.0122855 URL PMID: 4395415 [本文引用: 2] 摘要
The vast amount and diversity of the content shared on social media can pose a challenge for any business wanting to use it to identify potential customers. In this paper, our aim is to investigate the use of both unsupervised and supervised learning methods for target audience classification on Twitter with minimal annotation efforts. Topic domains were automatically discovered from contents shared by followers of an account owner using Twitter Latent Dirichlet Allocation (LDA). A Support Vector Machine (SVM) ensemble was then trained using contents from different account owners of the various topic domains identified by Twitter LDA. Experimental results show that the methods presented are able to successfully identify a target audience with high accuracy. In addition, we show that using a statistical inference approach such as bootstrapping in over-sampling, instead of using random sampling, to construct training datasets can achieve a better classifier in an SVM ensemble. We conclude that such an ensemble system can take advantage of data diversity, which enables real-world applications for differentiating prospective customers from the general audience, leading to business advantage in the crowded social media space.
|
| [14] |
An Essay Towards Solving a Problem in the Doctrine of Chances [J].https://doi.org/10.1007/BF02883540 URL [本文引用: 1] 摘要
Page 1. EE 590 Directed Reading Prof: Gerald B. Sheblé Student: GuillermoGutiérrez-Alcaraz Date: August 2001 Page 2. Figures and Charts in Chapter 1 ByGuillermo Gutiérrez Figure 1-1: Traditional Decision Process (page 5) Page 3.
|
| [15] |
Random Forests [J].https://doi.org/10.1023/A:1010933404324 URL Magsci [本文引用: 1] 摘要
<a name="Abs1"></a>Random forests are a combination of tree predictors such that each tree depends on the values of a random vector sampled independently and with the same distribution for all trees in the forest. The generalization error for forests converges a.s. to a limit as the number of trees in the forest becomes large. The generalization error of a forest of tree classifiers depends on the strength of the individual trees in the forest and the correlation between them. Using a random selection of features to split each node yields error rates that compare favorably to Adaboost (Y. Freund & R. Schapire, <i>Machine Learning</i>: <i>Proceedings of the Thirteenth International conference</i>, ***, 148–156), but are more robust with respect to noise. Internal estimates monitor error, strength, and correlation and these are used to show the response to increasing the number of features used in the splitting. Internal estimates are also used to measure variable importance. These ideas are also applicable to regression.
|

/
| 〈 |
|
〉 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}