王宇 , 李秀秀
, 李秀秀
大连理工大学管理与经济学部 大连 116024
Wang Yu, Li Xiuxiu
中图分类号: TP391
通讯作者:
收稿日期: 2017-05-27
修回日期: 2017-07-23
网络出版日期: 2017-08-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】通过对电子商务评论文本的分析和处理, 获取有效的商家信誉信息, 从客观角度建立商家信誉维度体系。【方法】基于HNC理论的同行优先原理和文本挖掘方法提出改进的评论文本主题词抽取方法和主题词聚类算法, 并进行类簇标签抽取及各类簇权重计算。【结果】生成商家信誉维度体系及各维度权重, 以京东平台手机评论文本为实例, 构建商家信誉维度体系, 并对其进行评价, 证明方法的可行性与有效性。【局限】受HNC词库不全的影响需手工生成一部分字词符号, 在应用到更大规模的评论文本处理时可能会存在限制。【结论】利用本文提出的方法建立的商家信誉维度体系能够客观地反映出用户真正关心的商品指标。
关键词:
Abstract
[Objective] This paper proposes a new method to evaluate business reputation based on e-commerce comments. [Methods] First, we modified the key word extraction and clustering algorithm based on the HNC theory and text mining methods. Then, we extracted the cluster labels and calculated the weight of each cluster of the collected comments. [Results] We established a business reputation dimension system, with cellphone users’ reviews posted on the Jingdong Online Shopping Platform. [Limitations] Some of the word symbols were generated manually due to the incomplete HNC thesaurus, which posed negative effects to larger-scale comments analysis. [Conclusions] The business reputation evaluation system can identify the commodity features that users really care about.
Keywords:
近年来, 电子商务以及社交媒体蓬勃发展。最新数据显示, 2016第三季度中国电子商务市场交易规模达到5.2万亿元, 同比增长30.8%, 其中网络购物市场交易规模1.15万亿元, 同比增长23.6% [1]; 2016年社交媒体用户达到23.1亿人, 相当于全球人口的31%, 新增社交媒体用户2.19亿人, 年增幅10% [2]。
随着网上商家数量的快速增长, 商品种类、数量的极大丰富, 商家信誉状况却良莠不齐, 并有大量假货充斥其中, 加之商品评价信息多以非结构化的形式存在于网络中, 消费者很难仅从商家对商品的描述中辨别真伪, 做出正确购买决策。因此如何对评论短文本进行有效的分析和处理, 以获取有效的商家信誉信息, 从而建立商家信誉维度体系, 已经成为研究的热点问题。鲁文[3]基于相关理论模型从4个维度构建了包含17个量化指标的电子商务在线信誉的影响模型。茹永梅[4]运用层次分析法和模糊综合评价法对O2O电子商务中的商家信誉进行度量, 建立基于模糊理论的O2O电子商务商家信誉评估模型。吴维芳等[5]利用Word2Vec对酒店评论进行特征抽取和降维, 结合情感分析技术, 研究影响酒店用户满意度的因素。
但目前商家信誉评价研究大部分都专注于数值化的研究方式, 却忽视了客户的定性评论对卖者信誉度的影响。调查结果表明, 在电子商务交易决策过程中, 交易双方越来越重视社会网络中其他参与者(如朋友、其他消费者、意见领袖、第三方平台等)的评价, 原因在于这些评价能为商家改善服务、提高信誉水平提供参考, 为消费者做出购买决策提供依据。虽然赵学锋等[6-7]通过文本聚类对在线零售商的客户评论进行维度分析, 扩展原有的信誉维度。但时至今日, 电子商务迅速发展, 尤其在与社交网络互相融合之后, 使得评论文本越来越带有社会化的特征, 文本量巨大, 语言灵活随意, 文本长短不一, 且包含较多无关信息。这些特征使得简单的聚类方法在面对如此大规模的评论文本时聚类的效果和准确度都将大大降低。
针对现有的商家信誉评价指标体系的不足, 本文从用户评论的角度, 基于HNC理论[8], 利用HNC同行优先原则对大量用户评论文本抽取主题词, 将主题词映射到HNC字词库, 采用基于HNC的词语相似度计算改进传统的CURE算法, 提出一种新的针对评论文本的主题词聚类方法; 在此基础上构建商家信誉指标体系, 并对这种方法构建的指标体系进行检验和评价。
主题词即能够表达文本主题的规范化词语或词组。传统的主题词抽取方法主要针对长文本, 但评论文本长度短, 不存在标题、首末句等词语位置信息, 并且句型不规范, 往往隐藏主语。本文提出一种针对评论文本的主题词抽取方法。
针对评论文本的特点[9], 依据词性、词频率和词共现对评论中的高频主题词进行初步抽取。考虑主题词的广泛性以及同义词合并中不可避免的不完善情况, 抽取主题词不能完全排除低频词, 需要主题词间的词频有一定的差异[10-11]。因此, 对于已经初步抽取出的高频主题词, 通过依存句法提取出修饰这些主题词的形容词, 并按照词频排序, 只保留高频形容词, 再针对未提取出高频主题词的评论文本, 提取该形容词修饰的名词作为主题词。例如评论文本“鞋子收到了, 保暖性很好, 鞋底很厚, 超出预期。”名词集合为{鞋子, 保暖性, 鞋底}, “鞋子”是通用词将被删除, 而“鞋底”、“保暖性”无法达到主题词初步抽取的词频要求, 针对该评论文本, 通过初步抽取无法抽取出主题词, 则进入扩展主题词。假如抽取评论文本集合的高频形容词集为{满意, 快, 好, 合适…}, 抽取该条评论文本的形容词集为{好, 厚}。可发现“好”包含在高频形容词集中, “厚”不包含在内。根据依存句法发现“好”修饰的名词为“保暖性”, 则“保暖性”进入主题词集合, 如图1所示。
经过主题词扩展, 可认为已经抽取出覆盖面足够广泛的主题词。对于仍然没有抽取出主题词的文本, 有两种可能: 一是评论文本确实不包含主题词, 或词汇过于生僻, 对于此种情况不作处理; 二是由于评论文本句型不规范, 隐藏了主题词或主语, 对于这种情况利用HNC“同行优先”原理进行处理。“同行优先”是HNC理论处理语义块内部语义距离的重要原则, 可以简单理解为能够相互搭配或者相互修饰的词语具有相似的义项符号[12]。比如, “无私uc3ae02”、“远大gub01”、“奉献vc3ae02”、“目标grb01”, 可以看出, “无私”和“奉献”以及“远大”和“目标”这两对常用搭配各自的HNC符号比较接近, 与不搭配的词语义项符号则相差较远[13]。
利用这一特性, 对于隐藏主语的评论文本, 可提取该评论文本的形容词, 比较该形容词与前面抽取出的主题词HNC符号相似度。当该形容词与某一主题词的HNC义项相似度超过设定阈值, 并且与其他主题词同该形容词的相似度之差大于设定阈值, 则认为该评论文本隐藏的主语为该主题词, 该主题词词频加1。
设抽取出的主题词集合为W={w1, w2, …, wn}, 某条未抽取出主题词的评论文本包含形容词a, 则对于所有的wi, 按照文献[14]提供的方法计算HNC相似度sim(a, wi), 并取最大值。若主题词wp与形容词a的相似度最大, 即sim(a, wp)=max{sim(a, wi)}, 且sim(a, wp)>α, sim(a, wp)-sim(a, wi)>β, 则主题词wp的词频tf (wp)=tf (wp)+1。例如, 评论文本“挺满意的, 很便宜, 值得购买”经过主题词初步抽取以及主题词扩展, 都不能抽取出主题词, 则抽取该评论文本形容词集合为{满意, 便宜}, 假设抽取出的主题词集合为{质量, 服务, 物流, 款式, 价格…}, 分别计算“满意”、“便宜”同主题词集合中各词汇的HNC相似度, 发现“满意”同多个主题词的相似度在0.4-0.5之间, 彼此差值很小, 因此不能确定搭配主题词; “便宜”仅与主题词“价格”的相似度超过0.9, 同其他主题词的相似度均在0.4以下, 因此认为“便宜”隐藏的主题词为“价格”, “价格”的词频加1。
HNC理论以语义表达为基础, 是一套完整、强大的语义网络描述体系。作为服务于汉语理解的语言知识库的重要组成部分, 词知识库的建设也一直是HNC理论研究的重要工作。但目前包含HNC在内的各种词库如WordNet、同义词词林等, 都存在词库覆盖不全的问题。HNC理论将概念(词汇)分为抽象概念和具体概念, 抽象概念用五元组和语义网络表达, 具体概念采用向抽象概念的基元概念和基本概念挂靠的方式表达。评论文本中抽取的词汇基本属于具体概念, 对于这些抽取词汇中不包含在现有HNC词库中的部分, 采用上述“类别符号+挂靠”的方式进行补充是可行的。
为了满足后续的聚类要求, 设计一种基于HNC符号的主题词表示方法, 即四元组表示法: {主题词, 词频, HNC符号, 来源}。其中, 主题词即主题词本身; 词频是主题词在评论文本集中出现的总次数; HNC符号是主题词映射到HNC字词库的HNC义项符号; 来源是标识哪些评论文本包含该主题词或隐含该主题词或者经过同义词合并的近义词。
这样的表示方法为主题词引入了准确的语义信息, 后续聚类过程的聚类对象就不再是简单的词形, 而是含有语义的HNC符号, 使得聚类结果更加精确。另外, 保留主题词来源这一属性, 可以在主题词聚类完成后, 将主题词聚类簇还原为对应的评论文本类簇, 便于对聚类簇的分析和描述。
文本聚类有很多算法, 比如划分法、层次法、密度法等, 但适于对评论短文本聚类的算法却很少。CURE(Clustering Using REpresentatives)算法[15]采用多个代表点表示整个类簇, 获得的类质量较高, 并且在处理大数据量时采用随机取样、分区的方法提高其效率, 比较适合用于评论文本的挖掘。但当簇的密度、分布不均匀时, CURE算法会导致选取到不合理的代表点, 造成不合理的簇合并。考虑到评论文本主题词的特性, 本文提出基于HNC符号的改进CURE聚类算法。
(1) 代表点的选取算法
代表点影响因子和簇中心点的定义如下。
①代表点影响因子
设数据集簇$C=\{{{d}_{1}},{{d}_{2}},\cdots ,{{d}_{n}}\}$, 其中${{d}_{i}}$为簇中的数据点, n为簇C中数据点个数, 簇C的代表点集合为$S(C)=\{{{d}_{p1}},{{d}_{p2}},\cdots ,{{d}_{pm}}\}$, m为代表点个数, 则代表点${{d}_{pj}}$的影响因子为$FIW({{d}_{pj}})=\tfrac{|{{c}_{j}}|}{|c|}\times \tfrac{{{f}_{j}}}{N}$, 其中$|{{c}_{j}}|$为簇C中与代表点${{d}_{pj}}$相似度最大的数据点个数, $|c|$为簇C中的主题词总数, fj为代表点主题词${{d}_{pj}}$的词频, N为类簇C中所有主题词的词频和, 即$N=\sum\limits_{j=1}^{n}{{{f}_{j}}}$。
②簇中心点
设数据集簇C={d1, d2, …, dn}, 其中di为簇中的数据点, n为簇C中数据点个数, 簇中心点${{d}_{mean}}$是与其他主题词相似度的均值最大的点, 即${{d}_{mean}}$满足$sim({{d}_{mean}},{{d}_{pj}})=$ ${{\max }_{d\in C-\{{{d}_{pj}}\}}}\left( \sum{sim(d,{{d}_{pj}})}/n \right)$, 其中${{d}_{mean}}\in \{d\}$。
其中, 簇中心点中代表点的相似度计算, 采用文献[14]提出的基于HNC语义的相似度计算方法。
代表点的选取算法如下:
输入: 数据集簇$C=\{{{d}_{1}},{{d}_{2}},\cdots ,{{d}_{n}}\}$, 最大代表点个数m, 影响因子FIW阈值η
输出: 簇C的代表点集合${{S}_{c}}$
Begin
calculate dmean(C)//计算簇中心点
initiate Sc={dmean (C)}//选取簇中心点作为第一个代表点
for each di in C- Sc {
for each dj in Sc {
calculate simdidj
similarity.add(simdidj)
}
//将simdidj保存在临时数组similarity中
}
calculate max(similarity)//对于C-Sc中每一个数据点, 计算其与已选代表点相似度的最大值
for each simdidj in similarity{
if(simdidj == max(similarity))
max-similarity.add(simdidj)
}
calculate min(max-similarity)//选取与已选代表点最大相似度值最小的点
for each simdidj in max-similarity
if(simdidj == min(max-similarity) and fiw(di)>η and
length(Sc)<m)
Sc = Sc∪{di}
End
其中, 代表点的数量m根据原始数据集的数据量决定, 在实际实验中影响因子FIW阈值η为$\frac{1}{4m}$。
(2) 基于HNC符号的改进CURE聚类算法
代表点选取规则改进后, 在最终聚类簇的数量上, CURE算法需要提前设定最终聚类簇的个数。改进算法不设置最终类簇的数目, 而是通过控制簇合并时的相似度阈值w来调节类簇的合并, 具体步骤如下:
①所有代表主题词的HNC符号$\{{{h}_{1}},{{h}_{2}},\cdots ,{{h}_{n}}\}$, 对于每一个${{h}_{i}}$创建一个簇${{C}_{i}}$, 即$C=\{{{C}_{1}},{{C}_{2}},\cdots ,{{C}_{n}}\}$, ${{C}_{i}}=\{{{h}_{i}}\}$, ${{C}_{i}}$的代表点集合$S({{C}_{i}})=\{{{h}_{i}}\}$。
②如果簇集C的数目|C|< 2, 执行终止。
③找出簇集C中距离最近的两个簇${{C}_{u}}$和${{C}_{v}}$, 如果$dist({{C}_{u}},{{C}_{v}})>w$, 执行中止。
④合并簇${{C}_{u}}$、${{C}_{v}}$, ${{C}_{new}}={{C}_{u}}\bigcup {{C}_{v}}$, 计算簇${{C}_{new}}$的中心点, 按上一节方法计算簇${{C}_{new}}$的代表点集合$S({{C}_{new}})$。
⑤更新簇集C: $C=C-{{C}_{u}}-{{C}_{v}}+{{C}_{new}}$, 执行步骤②。
评论主题词经过聚类算法处理后得到的聚类簇集隐含着消费者关注的关于商家的信誉维度信息, 对这些簇集进行标签抽取及命名即得到商家的信誉维度。另外, 作为一个完整的维度体系, 还需要为每个维度指标确定权重。
类簇集标签的抽取即从类簇中选择若干个具有代表性的词语表达整个类簇的主题。目前大多数类簇标签抽取方法都是简单地选取词频最高或者是TF-IDF值最大的若干个词语作为类簇标签[16-18], 但构成类簇标签的词语之间往往存在一定的关联性, 而在上述关于类簇标签抽取的研究中, 并没有考虑词语之间的关联性和逻辑关系。HNC理论在构建词语的HNC符号时, 通常是基于局部联想脉络, 将概念之间存在关联的词语映射到相同或者相近的概念基元符号上, 计算机通过解释相应的符号就可以把握概念之间的关联性。
基于HNC的“同行优先”原则考虑词语之间的关联概念节点(即概念基元)是否相同, 将类簇中的词语划分为不同的词语集合, 计算所有词语集合的权重, 将权重最大的词语集合作为每个类簇的标签。同时, 每个类簇标签所对应的词语集合的权重也就是相应的信誉维度权重。
某一个维度的权重体现了该维度在整个评价体系中的相对重要程度。由主题词簇集形成的指标体系, 考虑每个聚类簇中主题词的数量S、词语的词频TF以及词语与类簇中其他词语的语义相似度$Sim({{w}_{i}},{{w}_{j}})$总和的均值等三个因素综合评价维度的权重, 其计算如公式(1)所示。
${{W}_{weight}}={{\alpha }_{1}}\times S+{{\alpha }_{2}}\times TF+{{\alpha }_{3}}\times \bar{S}im({{w}_{i}},{{w}_{j}})$ (1)
其中, $\bar{S}im({{w}_{i}},{{w}_{j}})=\frac{\sum\limits_{i=1,i\ne j}^{{{C}_{length}}}{Sim({{w}_{i}},{{w}_{j}})}}{{{C}_{length}}-1}$, ${{C}_{length}}$表示每个类簇中包含的词语个数。${{\alpha }_{1}}+{{\alpha }_{2}}+{{\alpha }_{3}}=1$, 根据实际经验和多次实验调整, 这里${{\alpha }_{1}},{{\alpha }_{2}},{{\alpha }_{3}}$依次取0.5, 0.3, 0.2。
如果某个维度中包含的主题词数量越多, 包含的主题词频次越高, 则代表它在更多的评论文本中被提及, 被更多的消费者重视, 权重应该越高, 也就是说某一维度的重要性与其包含的主题词总量成正比。类簇标签抽取算法实现如下:
输入: 所有的类簇集合。
输出: 类簇标签集合。
①对类簇中的所有词语进行权重计算, 对每个类簇任意选择一个词语${{w}_{i}}$作为初始的词语集合。
②对每个类簇中剩余的词语逐个进行判断, 首先判断是否和词语${{w}_{i}}$拥有相同的关联概念节点, 如果两个词语存在相同的关联概念节点, 则将这个词语加入该词语集合中; 如果不存在相同的关联概念节点, 则依据HNC给出的概念关联式判断该词语与词语${{w}_{i}}$是否存在某种逻辑关系, 如果两个词语存在某种逻辑关系, 则将这个词语加入该词语集合中。如果上述两种情况都不满足, 则将该词语加入新的词语集合。
③对每个类簇中剩余的词语重复执行步骤②, 直至所有词语都加入到相应的词语集合中。
④对所有生成的词语集合进行权重计算, 选取权重最大的词语集合作为每个类簇的标签。
测试数据随机抓取于京东网站, 共1 850条手机评论, 筛选过滤字数过少以及无效的评论文本, 剩余1 000条用于实验, 由人工审阅提取主题词, 对于省略主题词的文本, 人为分配主题词并对提取出的主题词进行分类处理。其中主题词数量由于涉及到词频调整, 因此从不同评论文本中抽取出的相同主题词, 主题词数量做累加。
实验主要分为两个部分, 分别测试主题词抽取方法以及主题词聚类方法的效果。评价方法按照主题词抽取结果以及聚类结果与人工判断结果越吻合越好的原则, 采用准确率、召回率对主题词抽取结果和聚类结果进行评估, 定义如下。
(1) 主题词抽取: 设人工审阅评论文本得到的主题词数量为n, 主题词抽取方法得到的主题词数量为m, m个主题词中与人工审阅结果吻合的主题个数为e, 则主题词抽取的准确率P、召回率R的计算分别如公式(2)和公式(3)所示。
$P=\frac{e}{n}$ (2)
$R=\frac{e}{m}$ (3)
(2) 主题词聚类: 设l(ci)是类簇ci的簇标签, l(dj)是第j个主题词人工标记的类别, ni是自动聚类簇ci包含的主题词数目, mi是人工分类dj包含的主题词数目, k是类簇数目。主题词聚类的准确率P’、召回率R’的计算如公式(4)和公式(5)所示。
$P,=\frac{1}{k}\sum\limits_{i=1}^{k}{\sum\limits_{j=1}^{{{n}_{i}}}{\frac{1}{{{n}_{i}}}\delta (l({{c}_{i}}),l({{d}_{j}}))}}$ (4)
$R,=\frac{1}{k}\sum\limits_{i=1}^{k}{\sum\limits_{j=1}^{{{m}_{i}}}{\frac{1}{{{m}_{i}}}\delta (l({{c}_{i}}),l({{d}_{j}}))}}$ (5)
其中, $\delta (x,y)=\left\{ \begin{align} & 0\ \ x\ne y \\ & 1\ \ x=y \\ \end{align} \right.$。
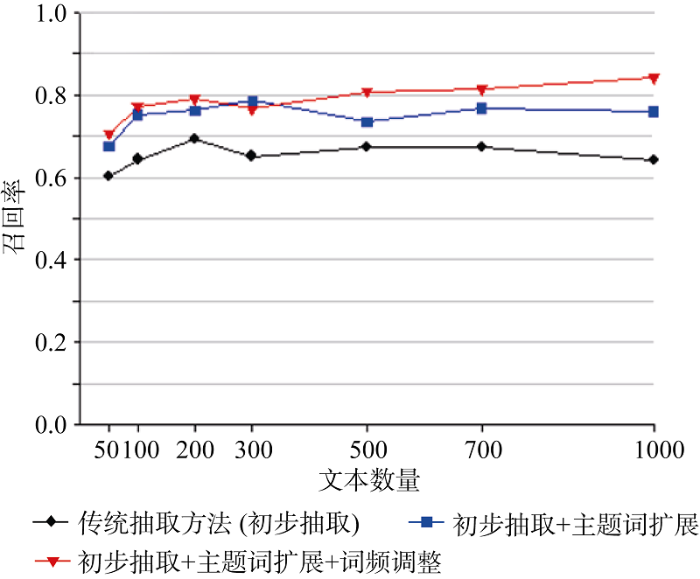
实验中, 分别使用传统基于词性的主题词抽取方法(初步抽取)、初步抽取+主题词扩展、 初步抽取+主题词扩展+基于HNC的词频调整三种方法, 进行主题词抽取, 检验三种方法的准确率、召回率, 并对比分析。实验结果如图2和图3所示。
从上述主题词抽取的实验效果看, 基于句法分析的主题词扩展以及基于 HNC 的词频调整, 相对于初步抽取的结果, 在准确率、召回率上都具有明显的提升。另外, 三种抽取方法初期都显现出准确率与召回率随文本数量的增加而增加的特性, 随后在一定范围内波动, 加入基于HNC的词频整调的方法, 表现出的增长性更加稳定, 这主要是由于HNC对于隐藏主语的提取是在与前两步抽取出的主题词比对的基础上进行的, 文本量越多, 抽取出的主题词越丰富, 比对的效果也就越好。当然在不累计词频的情况下, 后两种方法的效果是一致的。
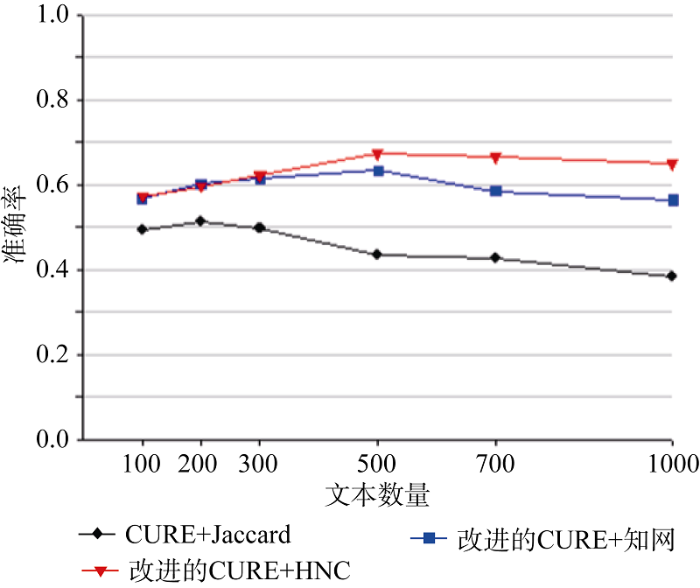
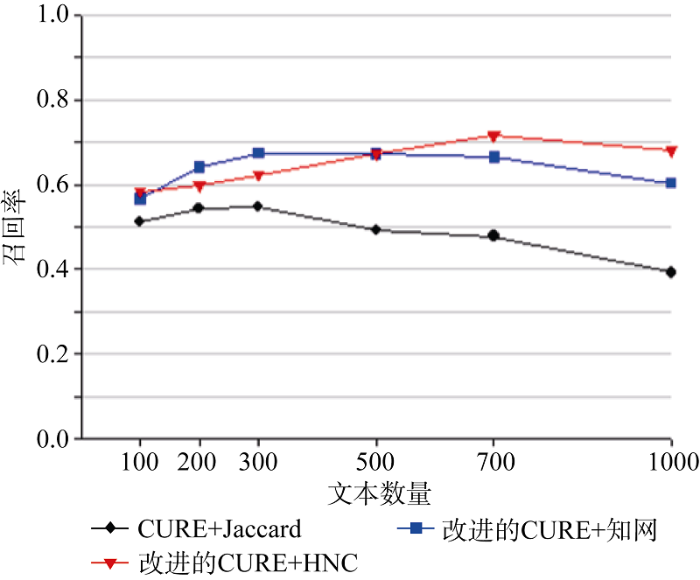
实验中, 分别使用传统的CURE方法+Jaccard相似度计算方法、改进的CURE方法+基于知网的相似度计算方法、改进的 CURE方法+基于HNC的相似度计算方法三种方法进行聚类, 验证三种方法的准确率、召回率, 并对比分析。实验结果如图4和图5所示。
从聚类实验效果看, 本文提出的聚类算法在聚类的准确率和召回率上相对于传统CURE算法以及基于知网的算法都有提升, 体现了算法改进的合理性以及HNC在语义相似度计算上的优势。另外, 在时间复杂度上, 改进后的CURE算法与传统CURE算法一致, 仍是O(n2), 聚类准确率的提升并没有以时间为代价, 对孤立点的处理也保持了传统CURE算法的优势。因此该方法比较适用于大规模的评论文本主题词聚类。
为了在实践中应用本文提出的商家信誉维度体系构建方法, 以京东为研究平台, 利用其提供的开放API抓取手机产品的评论语料7 856条, 经过无效评论过滤筛选等处理, 剩余有效评论语料5 394条。手机产品评论均来自京东自营, 涉及iPhone6、华为P7、小米2等15种手机型号, 评论时间跨度为2014年5月-2015年3月, 检索词为“手机”, 筛选字段为“京东自营”, 部分评论数据如图6所示。
(1) 主题词抽取。采用中国科学院计算技术研究所研发的ICTCLAS2015分词系统对评论文本进行分词并标注词性, 使用第2节提出的主题词抽取方法, 共抽取主题词776个(累计词频6 187), 将抽取出的主题词与HNC字词库映射, 以{主题词, 词频, HNC符号, 来源}四元组形式存储。
(2) 主题词聚类。采用主题词聚类算法对评论文本中抽取出的主题词进行聚类, 最终得到9个大类簇, 35个小类簇(词频累计数量小于20), 另有194个词类别不确定或属于孤立点。
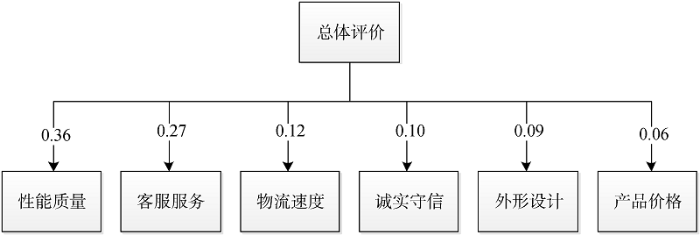
(3) 商家信誉维度体系构建。依据第4节方法为聚类得到的大类簇进行标签抽取, 确定前6个类簇描述作为评价指标, 以此建立信誉指标体系, 并计算6个维度的权重, 其结果如表1所示。
表1 聚类结果
| 序号 | 维度名称 | 簇标签 | 主题词数量 (累计词频) | 权重 |
|---|---|---|---|---|
| 1 | 性能质量 | 屏幕-性能-系统-电池 | 1 743 | 0.36 |
| 2 | 客服服务 | 服务-客服-态度 | 1 300 | 0.27 |
| 3 | 物流速度 | 快递-物流 | 578 | 0.12 |
| 4 | 诚实守信 | 正品-正版-原装 | 482 | 0.10 |
| 5 | 外形设计 | 外形-外观 | 424 | 0.09 |
| 6 | 产品价格 | 价-价格 | 289 | 0.06 |
建立的商家信誉维度体系如图7所示。从图7得到的信誉维度体系可以发现, 1性能质量、5外形设计和6产品价格是关于产品自身的, 2客服服务、3物流速度和4诚实守信是关于商家服务的。文献[6]也曾通过评论文本聚类研究数码产品信誉维度体系的建立, 并将维度设置为8个, 如图8所示。
对比图7和图8可以发现, 图7中多了“外形设计”, 而少了“交易安全性”、“售后服务”以及“品牌声誉”三项。分析原因笔者认为, 关于“交易安全性”, 随着网购交易形式的进化, 尤其是第三方担保出现之后, 对于网购交易安全性的担忧已经越来越少, 评论中已很少涉及到对于交易安全的担忧; 关于“售后服务”, 目前在大多数网购平台, 手机这类由实体厂家生产的产品售后服务均由生产厂家提供, 第三方网站作为中间媒介或担保的角色, 因此该项在客户评论中也未体现; 关于“品牌声誉”, 文献[6]选取的评论文本来自于“中关村在线”网站, 该网站相对于京东这种商务网站用户人群更为专业, 评论更为深入, 而且评论文本不仅包括手机, 还包括电脑等其他数码产品, 这些可能是其品牌声誉的来源, 而从本文抽取的评论中无法体现出这一点; 对于本文结果中多出的“外形设计”一项, 说明随着手机出现时间的延续, 各品牌在硬件性能方面逐渐趋同, 用户消费能力不断提升, 消费者在购买时不仅考量硬件方面, 也正在越来越多关注外形设计等软实力方面。
在电子商务不断快速发展的背景下, 商家数量的快速增长与商家水平的参差不齐, 使得商家信誉评价问题越发紧迫与重要。用户评论文本是隐藏商家信誉信息的宝藏, 随着Web2.0不断成熟, 用户生成内容(UGC)呈现爆发式增长, 热门商品下的评价数量成千上万, 大量的评论文本在给用户带来重要信息的同时, 也给用户的阅读浏览带来了很大的负担, 使得用户无法快速获取有用信息。这也显示出评论文本挖掘工作的重要性和现实价值。
针对商家信誉评价的实际需要, 以及评论文本区别于传统长文本的特点, 本文主要在传统的基于词性词频的抽取方法基础上, 对主题词进行扩展和词频调整, 以发现隐藏的主题词信息; 将HNC语义信息引入到改进的CURE聚类算法, 将待聚类的主题词映射到HNC字词库, 采用基于HNC符号的词语相似度计算, 提出改进的CURE聚类算法; 依据聚类簇中主题词的HNC符号提出类簇标签抽取方法, 建立商家信誉维度, 并计算出每个维度的权重; 进行算法的实验验证和实例分析。
王宇: 提出研究问题及研究思路, 设计研究方案;
李秀秀: 采集、分析数据, 起草、修订论文;
王宇, 李秀秀: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 1434002120@qq.com。
[1] 李秀秀. TextReview.xlsx. 实例分析中抓取的原始产品评论数据集.
[2] 李秀秀. Review.xlsx. 实例分析中经过筛选处理的有效评论数据集.
[3] 李秀秀. KeyWords.xlsx. 实例分析中抽取的所有主题词.
[4] 李秀秀. ClusteringResults.xlsx. 实例分析中的主题词聚类结果.
[5] 李秀秀. HNCDatabase.mdb. HNC符号映射中用到的HNC字词知识库.
| [1] |
2016年第三季度电子商务核心数据发布[EB/ OL]. [The 3rd Quarter of 2016 E-commerce Core Data Release [EB/OL]. [ |
| [2] |
2016年全球互联网、社交媒体、移动设备普及情况报告 [EB/OL]. [2016 Global Internet, Social Media, Mobile Device Popularity Report [EB/OL]. [ |
| [3] |
社会化电子商务在线信誉的模型构建及实证研究 [D].Model Construction and Empirical Study on Online Reputation of Social Commerce [D]. |
| [4] |
基于模糊理论的O2O模式商家信誉评估模型 [J].Reputation Evaluation Model for O2O Mode Businesses Based on Fuzzy Theory [J]. |
| [5] |
评论文本对酒店满意度的影响: 基于情感分析的方法 [J].
【目的】通过对评论文本进行文本分析,研究影响酒店用户满意度的因素,为酒店管理者提供建议。【方法】利用word2Vec对Tripadvisor.com酒店评论进行特征抽取和降维,结合情感分析技术,提取每类特征对应的情感,构建计量经济模型分析酒店特征评价与用户满意度的关系。【结果】研究结果表明:(1)评论文本的情感表达越积极满意度越高,但这种影响并非线性的,而是呈现“u”形的;(2)用户评论文本中提到的特征类别数越多,该用户越有可能倾向不满意;(3)消费者对豪华型酒店和经济型酒店特征类别的关注存在显著差异,消费者对前者更关注员工服务,对后者更注重清洁度;(4)对豪华型酒店,消费者满意度受到网络(Intemet)这个特征维度的显著影响,而对于经济型酒店该维度的影响则不显著。【局限】样本的选择不够全面,未来可爬取多个城市数据进行更全面分析。【结论】从评论文本角度建立了酒店特征与消费者满意度的联系,为酒店在线口碑研究提供了理论依据。
The Impacts of Reviews on Hotel Satisfaction: A Sentiment Analysis Method [J].
【目的】通过对评论文本进行文本分析,研究影响酒店用户满意度的因素,为酒店管理者提供建议。【方法】利用word2Vec对Tripadvisor.com酒店评论进行特征抽取和降维,结合情感分析技术,提取每类特征对应的情感,构建计量经济模型分析酒店特征评价与用户满意度的关系。【结果】研究结果表明:(1)评论文本的情感表达越积极满意度越高,但这种影响并非线性的,而是呈现“u”形的;(2)用户评论文本中提到的特征类别数越多,该用户越有可能倾向不满意;(3)消费者对豪华型酒店和经济型酒店特征类别的关注存在显著差异,消费者对前者更关注员工服务,对后者更注重清洁度;(4)对豪华型酒店,消费者满意度受到网络(Intemet)这个特征维度的显著影响,而对于经济型酒店该维度的影响则不显著。【局限】样本的选择不够全面,未来可爬取多个城市数据进行更全面分析。【结论】从评论文本角度建立了酒店特征与消费者满意度的联系,为酒店在线口碑研究提供了理论依据。
|
| [6] |
基于文本聚类的电子零售商信誉维度发现研究 [J].https://doi.org/10.3772/j.issn.1000-0135.2011.01.010 URL [本文引用: 1] 摘要
信誉管理系统在促进顾客对电子零售商的信任过程中起着越来越重要的作用,它是电子零售商取得成功的重要因素和保证.顾客的文本评论是信誉管理系统的一个重要组成部分,其中蕴含了大量的零售商的实际交易和信誉信息.本文从顾客文本评论的视角,采用文本挖掘技术对大量的顾客评论进行文本聚类,通过分类整理和知识提取,以期找出顾客最关注的电子零售商的信誉维度.本研究选取国内最大的IT 专业网站---中关村在线作为研究对象,通过一个应用实例详细说明了通过文本聚类发现电子零售商信誉维度的方法和过程.本研究对电子零售商的信誉维度知识发现具有重要意义,也能为电子零售商提高服务质量提供参考.
Study on the Discovery of Reputation Dimension of Online Merchants Based on Text-clustering [J].https://doi.org/10.3772/j.issn.1000-0135.2011.01.010 URL [本文引用: 1] 摘要
信誉管理系统在促进顾客对电子零售商的信任过程中起着越来越重要的作用,它是电子零售商取得成功的重要因素和保证.顾客的文本评论是信誉管理系统的一个重要组成部分,其中蕴含了大量的零售商的实际交易和信誉信息.本文从顾客文本评论的视角,采用文本挖掘技术对大量的顾客评论进行文本聚类,通过分类整理和知识提取,以期找出顾客最关注的电子零售商的信誉维度.本研究选取国内最大的IT 专业网站---中关村在线作为研究对象,通过一个应用实例详细说明了通过文本聚类发现电子零售商信誉维度的方法和过程.本研究对电子零售商的信誉维度知识发现具有重要意义,也能为电子零售商提高服务质量提供参考.
|
| [7] |
基于客户评论和语料库的在线酒店信誉维度挖掘 [J].
<html dir="ltr"><head><title></title></head><body>以携程网上消费者对酒店的文本评论为研究对象,通过对文本评论中的词语进行聚类,得到其中隐含的消费者最关注的酒店评价维度。为保证词语聚类的效果,引入语料库作为对比文档,通过分词、特征项表示、特征词编码标注、词义相似度计算以及基于DBSCAN的文本聚类过程,得到最后的评价维度,并以实例详细说明每个过程中所采用的方法及步骤。</body></html>
Exploration of Dimensions of the Online Hotel Reputation Based on Customers’ Text Comments and Corpus [J].
<html dir="ltr"><head><title></title></head><body>以携程网上消费者对酒店的文本评论为研究对象,通过对文本评论中的词语进行聚类,得到其中隐含的消费者最关注的酒店评价维度。为保证词语聚类的效果,引入语料库作为对比文档,通过分词、特征项表示、特征词编码标注、词义相似度计算以及基于DBSCAN的文本聚类过程,得到最后的评价维度,并以实例详细说明每个过程中所采用的方法及步骤。</body></html>
|
| [8] |
|
| [9] |
Wikipedia Based Approach for Clustering Keyword of Reviews [J].https://doi.org/10.4304/jsw.9.9.2246-2250 URL [本文引用: 1] 摘要
A novel method based on Wikipedia for clustering keyword of reviews is proposed. Users can quickly finding the themes they interest through it. First the method extracts keywords, then calculates word similarity based on Wikipedia to generate similarity matrix, finally uses k-means to cluster. The performance is better than the methods which based on How-net and Word-net. The accuracy is around 77%.
|
| [10] |
一种基于词共现图的文档主题词自动抽取方法 [J].https://doi.org/10.3321/j.issn:0469-5097.2006.02.006 URL [本文引用: 1] 摘要
主题词抽取是文本自动处理的基础性工作.在对现有主题词抽取方法深入研究的基础上,提出了一种基于词共现图的文档主题词自动抽取方法;该方法以基于词频统计方法为基础,利用在词共现图形成的主题信息以及不同主题间的连接特征信息自动地提取文档中的主题词,旨在找出一些非高频词且又对主题贡献大的词.实验表明了该抽取方法抽取出的主题词更能准确地符合了作者的主题.
A Kind of Automatic Text Keyphrase Extraction Method Based on Word Co-occurrence [J].https://doi.org/10.3321/j.issn:0469-5097.2006.02.006 URL [本文引用: 1] 摘要
主题词抽取是文本自动处理的基础性工作.在对现有主题词抽取方法深入研究的基础上,提出了一种基于词共现图的文档主题词自动抽取方法;该方法以基于词频统计方法为基础,利用在词共现图形成的主题信息以及不同主题间的连接特征信息自动地提取文档中的主题词,旨在找出一些非高频词且又对主题贡献大的词.实验表明了该抽取方法抽取出的主题词更能准确地符合了作者的主题.
|
| [11] |
一种基于词聚类的中文文本主题抽取方法 [J].https://doi.org/10.3724/SP.J.1087.2005.0754 URL Magsci [本文引用: 1] 摘要
<p>提出了一种基于词聚类的中文文本主题抽取方法,该方法利用相关度对词的共现进行分 析,建立词之间的语义关联,并生成代表某一主题概念的用种子词表示的词类。对于给定文档,先进 行特征词抽取,再借助词类生成该文档的主题因子,最后按权重输出主题因子,作为文本的主题。实 验结果表明,该方法具有较高的抽准率。</p>
Novel Chinese Text Subject Extraction Method Based on Word Clustering [J].https://doi.org/10.3724/SP.J.1087.2005.0754 URL Magsci [本文引用: 1] 摘要
<p>提出了一种基于词聚类的中文文本主题抽取方法,该方法利用相关度对词的共现进行分 析,建立词之间的语义关联,并生成代表某一主题概念的用种子词表示的词类。对于给定文档,先进 行特征词抽取,再借助词类生成该文档的主题因子,最后按权重输出主题因子,作为文本的主题。实 验结果表明,该方法具有较高的抽准率。</p>
|
| [12] |
|
| [13] |
|
| [14] |
基于HNC理论的词语相似度计算 [J].https://doi.org/10.3969/j.issn.1003-0077.2014.02.005 URL Magsci 摘要
该文运用自然语言处理的概念层次网络(Hierarchical Network of Concepts,HNC)理论提出了一种词语相似度计算方法。该方法利用HNC理论词汇层面联想的概念表述体系,根据HNC映射符号的编码规则和符号映射理论,综合概念内涵、概念外部特征、概念类别和组合符号来计算词语的相似度,并与基于知网的词语相似度算法和人工的主观判断的相似度进行了比较分析。实验结果表明,该方法能够较好地反映词语之间的语义差别,与人的直观判断基本一致,是一种有效可行的方法。
A New Measure of Semantic Similarity Based on Hierarchical Network of Concepts [J].https://doi.org/10.3969/j.issn.1003-0077.2014.02.005 URL Magsci 摘要
该文运用自然语言处理的概念层次网络(Hierarchical Network of Concepts,HNC)理论提出了一种词语相似度计算方法。该方法利用HNC理论词汇层面联想的概念表述体系,根据HNC映射符号的编码规则和符号映射理论,综合概念内涵、概念外部特征、概念类别和组合符号来计算词语的相似度,并与基于知网的词语相似度算法和人工的主观判断的相似度进行了比较分析。实验结果表明,该方法能够较好地反映词语之间的语义差别,与人的直观判断基本一致,是一种有效可行的方法。
|
| [15] |
层次聚类方法的CURE算法研究 [J].Research on CURE Algorithm of Hierarchical Clustering Method [J]. |
| [16] |
短文本聚类及聚类结果描述方法研究 [D].Research on Short Text Clustering and Cluster Description Method [D]. |
| [17] |
词向量聚类加权TextRank的关键词抽取 [J].
Extracting Keywords with Modified TextRank Model [J].
|
| [18] |
文本检索结果聚类及类别标签抽取技术研究 [D].Research on Text Retrieval Results Clustering and Label Extraction [D]. |

/
| 〈 |
|
〉 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}