侯银秀, 李伟卿, 王伟军 , 张婷婷
, 张婷婷
Hou Yinxiu, Li Weiqing, Wang Weijun, Zhang Tingting
中图分类号: G35
通讯作者:
收稿日期: 2017-05-22
修回日期: 2017-07-11
网络出版日期: 2017-08-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】识别并获取细粒度的用户偏好信息, 优化图书个性化推荐的效果。【方法】使用情感分析方法对用户图书评论进行属性层文本挖掘, 通过用户本身的图书评论获取用户对图书属性的偏好; 基于每本图书的所有评论的情感计算获得其属性评分; 将用户偏好矩阵、图书属性得分矩阵进行匹配, 从而实现用户对图书属性情感偏好的个性化推荐。【结果】利用亚马逊图书评论数据作为数据来源分别对传统的协同过滤方法与本文提出的推荐方法进行实验对比。结果表明, 本文提出的方法在准确性、召回率、覆盖率上分别提高了0.030、0.097、0.2812。【局限】未考虑时间因素对用户偏好的影响, 并且属性类型的全面程度受亚马逊图书评论数量和质量的限制。【结论】本文计算用户对图书属性的情感得分, 得到细粒度的用户偏好信息, 并通过与图书属性的得分进行匹配, 提升了图书个性化推荐的效果。
关键词:
Abstract
[Objective] This paper identifies the fine-grained preferences of online bookstore users, aiming to optimize the personalized book recommendation service. [Methods] First, we conducted sentiment analysis of the book features through readers’ comments, which indicated their preferences. Then, we calculated the books’ sentiment scores based on the readers’ comments. Finally, the user preferences matrix and the sentiment scores matrix were matched to personalize the book recommendation. [Results] We retrieved the needed data from Amazon’s book comments, and then conducted an experiment to compare the results of our new method with those of the traditional collaborative filtering methods. We found that the proposed method improved the precision, recall and coverage by 0.030, 0.097, 0.2812. [Limitations] We did not consider the impacts of time on user’s preferences, and the feature types might not be comprehensive due to the limited number and quality of Amazon’s book comments. [Conclusions] The proposed method improves the performance of personalized book recommendation service.
Keywords:
近年来, 推荐系统被证明是一种解决信息过载和长尾物品问题的有效工具, 已经与日常生活息息相关, 如在阅读新闻资讯、网上购物、聆听音乐、观看视频时, 都能看到各种各样的推荐。对于用户, 推荐系统可以帮助快速找到感兴趣的信息或物品, 从而减轻用户的认知负担, 改善用户体验, 增加用户粘性。图书个性化推荐最早是亚马逊为了提升长尾图书的用户抵达率而提出的, 据VentureBeat统计, 图书个性化推荐为亚马逊贡献了35%的销售额[1]。
图书个性化推荐系统以协同过滤为主, 通过对用户-项目评分矩阵中评分数据的统计, 计算用户或项目的相似性, 将相似度高的近邻用户喜欢的图书推荐给目标用户。这种方法得到了广泛的应用, 但是仍然有一些不足: 评分数据虽然能表示用户对商品的态度, 但不能解释用户评分产生差异的详细原因; 这种方法假设给出相似评分的用户具有类似的喜好, 但近邻用户并不能完全客观、真实地反映用户自身的偏好。同时, 内容特征也会影响推荐效果, 这类推荐系统[2]从标签、评论或博客、微博等形式的用户生成内容中收集用户、商品以及用户对商品的描述信息, 并据此将用户可能喜欢的商品推荐给用户。这种方法融合了语义信息, 过滤了用户不感兴趣的图书资源, 缺点是难以区分图书内容的质量。而且, 筛选关键词和标签的做法无法识别用户的情感态度, 也无法挖掘出用户对图书细节方面的情感态度。而情感对人类认知和购买决策行为具有重要的影响和作用。Hu等[3]研究了图书销量与用户评论数量及评论情感之间的关系, 发现在线评论数量及用户反馈中的情感体验均能影响产品销量。Sohail等[4]和Diao等[5]研究发现属性层面的情感分析方法能够提高推荐的准确性。因此, 为了更深入地挖掘用户对图书属性的偏好, 蕴含丰富用户意见和观点的评论内容无疑最具分析价值。用户评论中不仅包括用户提及的图书属性, 还包括对属性的情感态度(关注和挑剔程度), 即通过对用户评论内容的分析, 可以获取用户对图书属性的偏好, 并以此为推荐依据向用户推荐更加符合其偏好的图书。刘凯等[6-7]指出准确地获取用户偏好信息是个性化推荐的基础, 并提出基于商品自组织层次聚类的用户偏好表示模型。而通过对用户评论内容进行属性层情感分析, 可以对用户偏好信息进行更为细粒度的解读, 获取用户对商品属性的偏好。因此, 在团队的前期研究基础上, 为了改善推荐的效果, 帮助企业更为便捷、快速地获取用户意见并提供优质的个性化推荐服务, 本文筛选出影响用户偏好的图书属性, 采用情感分析技术提取用户图书评论中蕴含的属性层面的观点作为推荐依据, 并计算出用户偏好矩阵、图书属性得分矩阵, 依据用户对图书属性的偏好和图书历史评论的情感分析结果之间的匹配程度, 将最符合用户偏好的图书推荐给用户。
关于图书个性化推荐的研究现状梳理主要从推荐方法和推荐依据的选择两个方面展开。
(1) 图书个性化推荐方法主要有内容推荐、协同过滤推荐和混合推荐方法等。最初的图书个性化推荐根据用户的搜索、浏览、购买、注册等行为涉及的主题信息推测用户感兴趣的书籍, 推荐给用户具有相似主题或者标签的图书。但是, 由于用户的能力和专业水平的差异也会造成用户产生这些行为, 因此使用这种方法挖掘用户偏好会产生偏差[8]。因此要精准匹配图书资源与用户偏好, 基于内容的推荐直接利用所购图书主题等信息做出推荐还有待改进。主流的协同过滤方法引入相似用户或者相似群体[9]的评分也就是观点信息, 借助用户历史行为(包括浏览购买评价等)的共同性等指标, 将近邻用户所购的图书列入推荐列表。这种方法通过大量评分数据计算用户或商品之间的相似性, 采用聚类技术等方法改进推荐效果[10]。此外, 为了克服单一推荐方式的数据不足等缺点, 混合方法也应用到图书个性化推荐研究中。Najafabadi等[11]从用户的交互记录中提取相似偏好, 采用关联规则和聚类技术结合的方法从简单的数据中挖掘用户相关性, 获得了较好的推荐结果。
(2) 图书个性化推荐依据的选择多以图书主题、用户评分评论、人口统计学信息、社交网络行为、时间信息为主。王伟军等[12]针对协同过滤可扩展性和数据稀疏性问题, 加入了时间约束因素, 以克服无法找到相似用户数据的困难。Qiu等[13]则在评分数据基础上融入评论文本, 采用评论文本的主题分布表示商品特征, 挖掘评论文本在推荐系统中的价值。社交网络信息也是部分学者进行用户偏好建模考虑的因素, 社交网络信息细分为推荐信任程度、社交关系等[14], 学者将这些因素融合到传统的推荐方法中, 完善推荐系统依据的参数, 并且提高了商品的推荐准确性。本团队在前期研究中提出, 个性化推荐系统主要面向系统使用的主体——用户的实际行为与真实主观感受, 以“人”的偏好为本[15]。现有图书个性化推荐的研究主要依据近邻用户的评分信息预测用户可能感兴趣的商品, 未能挖掘出用户的真实主观感受。不同于评分购买记录信息, 用户评论是用户自身对商品属性的主观表达。细粒度情感分析方法从短语和词级别识别情感词及其情感倾向, 对提取本文需要的用户对图书属性的情感偏好信息最为合适。
此外, 笔者团队在先前的研究中通过自组织聚类的方法构建即时偏好、短期偏好和长期偏好的复合模型[16], 并通过实验验证了用户偏好模型可以提高推荐效果[6]。因此, 在前期研究的基础上, 本文结合属性层面的情感分析技术获取更细粒度的用户偏好信息, 提出一种基于用户偏好和商品属性情感得分的情感匹配推荐方法: 获取图书评论数据, 并使用自然语言处理工具对数据进行分析, 获取影响用户对图书偏好程度的属性特征; 采用情感分析技术进行观点挖掘, 分别从用户自身评论和图书的历史评论中计算得到用户偏好矩阵和图书属性得分矩阵; 计算用户与图书在属性层面的情感匹配程度作为推荐的依据, 并采用亚马逊图书商城的实际数据验证本文提出的推荐方法的有效性。
在对用户和图书进行属性层情感匹配分析前, 需要对评论数据进行清洗与处理, 筛选出影响用户对图书偏好程度的属性。常见的提取商品属性的方法有人工标注和自然语言处理两种方法。由于人工标注不适合大规模的实验文本, 因此, 本文采用自然语言处理工具从评论文本中抽取与图书相关的属性特征。为了获取用户偏好矩阵、图书属性得分矩阵, 选用基于情感词典的情感分析方法来计算与特征词距离最近的观点词语的情感分数, 通过对用户自身评论和商品历史评论的情感分析, 得到用户偏好矩阵和图书属性得分矩阵, 直接利用情感匹配方法计算两个矩阵的相似度, 并以此为依据进行推荐。
为了提取图书属性并进行情感分析, 本文选用亚马逊图书商城的真实评论作为实验数据。使用斯坦福大学提供的“Stanford Large Network Dataset Collection: Amazon Reviews”数据集, 由于数据集规模较大, 选取评论较多的2013年7月-2014年7月之间, 共36 770条图书评论数据作为实验数据[17]。图书评论数据集的信息包括产品和用户信息、评分信息、评论文本、认为评论信息有用等内容。亚马逊图书主要使用协同过滤、热门商品和热门新品三种推荐方法。由于亚马逊图书商城要求购买之后才能够发表评论, 因此获取的评论信息具有较高可靠性。经过对无效数据和重复数据的清洗和整理, 共计得到有效评论文本220 459条, 图书数量6 506本, 用户21 096名。每本图书的平均评论数量约为34条, 每个用户的平均评论数量约为10条。
商品属性提取方法主要有人工标注和自然语言处理工具两种。李实等[18]人工标注了数码产品和图书等商品的评论文本, 根据最小最大覆盖原则建立能覆盖评论数据集的最小属性集合, 但是这种方法处理数据尤其是大规模评论费时费力。He等[19]主要采用依存句法方式, 采用词性标注提取商品属性。Sohail等[4]同样使用依存句法分析提取图书的属性并对比权重, 总结为“Occurrence”、“Helpfulness”、“Material”、“Availability”、“Irrelevancy”、“Price”等6类属性。这种方法可以从数据中充分挖掘出用户提及的商品属性, 故本文使用英文分词工具CoreNLP①(①https://stanfordnlp.github.io/CoreNLP/.) (Java自然语言分析库)中的分词和词性标注工具处理评论文本。笔者发现, 除了“mind”、“topic”等名词或动名词形式外, 图书评论者还经常使用“difficult”、“useful”等形容词表示难度、实用性等方面属性。因此, 本文将属性词常见词性(名词、动名词、名词短语、形容词等)抽取出来, 作为图书属性词集的候选词。使用WordNet 2.1版本②(②http://wordnet.princeton.edu/wordnet/download/old-versions/.)提供的同义词集合Synset扩充候选词集, 减少由于词性限制造成的误差; 评论文本中经常使用不同词语描述相同图书属性, 需要将同类图书属性加以合并以便后续情感分析。公式(1)为WordNet语义相似度计算公式, 以此合并图书领域属性词。
$similarity({{W}_{1}},{{W}_{2}})=\frac{\sum\nolimits_{i\in (1,\cdots ,|S{{W}_{1}})}^{{{\max }_{j\in (1,\cdots ,|S{{W}_{2}})}}}{(similarity(SW{{1}_{i}},SW{{2}_{j}}))+\sum\nolimits_{i\in (1,\cdots ,|S{{W}_{2}})}^{{{\max }_{j\in (1,\cdots ,|S{{W}_{1}})}}}{(similarity(SW{{2}_{i}},SW{{1}_{j}}))}}}{|S{{W}_{1}}+S{{W}_{2}}|}$ (1)
其中, |SW1|为文档中的意义解释个数; |SW2|为文档中的意义解释个数。两个词语之间的距离越小, 语义相似度越大[20]。例如, Similarity(thesis, topic) = 0.648, Similarity (useful, effective) = 0.65, 设置相似度阈值为0.6, 则“thesis”和“topic”合并为一类特征, “useful”和“effective”合并为一类, 相似的描述可以有“spirit”、“soul”、“belief”、“heart”等。这些词语表达形式不同, 但是描述的含义是基本相同的。根据分词工具CoreNLP从评论文本提取出候选词后, 笔者利用语义相似度计算来确保属性候选词分类的合理性。
表1为最后汇总出用户在实验评论文本中所提及的7大类属性, 分别为“内容和主题思想(mind)”、“结构和形式(structure)”、“实用性(practice)”、“趣味性(interest)”、“难度和专业性(difficulty)”、“价格(cost)”、“质量(quality)”。
表1 图书属性词表
| 编号 | 类型 | 图书属性词 |
|---|---|---|
| 1 | 内容和主题思想(mind) | mind, content, thesis, topic, thought, story, setting, plot, detail, spirit, soul, idea, belief, concept, ideal, sensation, heart, thinking, thinker, theory, event, deeds, reflections, feel, feeling, view, emotion, essence, mood, humanity, characters, memories, opinion |
| 2 | 结构和形式(structure) | structure, framework, layout, chapter, length, clue, thread, passages, circus |
| 3 | 实用性(practice) | practice, purpose, use, useful, information, device, advice, technique, effective, creative, meaningful, impact, progress, discoveries |
| 4 | 趣味性(interest) | hobby, interest, interested, interesting, moved, exciting, excite, excited, delight, delightful, surprised, delighted, pleasure, joy, joyous, joys, enjoy, enjoyable, taste, enthusiast, pleasure |
| 5 | 难度和专业性(difficulty) | depth, difficult, difficulty, classic, readability, specialty, profession, major |
| 6 | 价格(cost) | price, cost, value |
| 7 | 质量(quality) | quality, hardcover, paperback, package, paper, cover, print, printed |
对于图书这类商品, 不仅属性词会有专有名词, 评价词语也会由于领域的专业性而产生特定的词汇。提取评价词语的效果受情感词典影响较大。本文选取WordNet辞典生成的情感词典SentiWordNet[21], 该词典通过对WordNet中的词条进行情感分类, 标注出属于positive和negative类别的每个词条的权重大小。此外, 情感词典还包括象征着情感强度的程度词, 例如“very”、“so much”, 还有表达着情感倾向的否定词语, 例如“not”、“nothing”等。因此, 使用词性标注工具将图书评论中涉及到形容词、带有否定倾向的形容词组加入到情感词典中, 扩大了情感词典的规模以及在图书领域的专业性。根据扩展后的词典, 将图书领域7类属性的观点态度划分为5类情感等级, 分别是Very Negative、Negative、Neutral、Positive、Very Positive。这5类情感词语的情感等级和对应的情感极性如表2所示, 例如等级2代表中立性的情感, 极性为0。
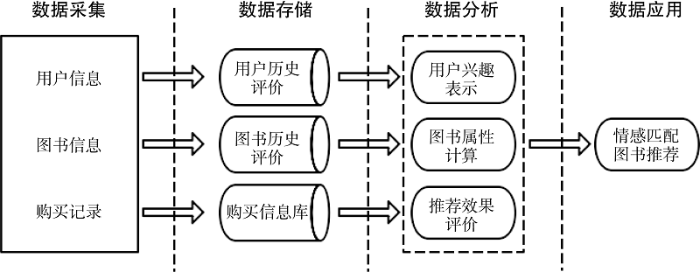
基于用户偏好与图书属性情感匹配的图书个性化推荐方法的主要思想是: 如果用户对图书属性的评分较低, 证明用户对这一属性较为挑剔, 且绝对值越大, 用户的挑剔程度越高。如果用户对图书某一属性的评分较高, 表示用户对这一属性有容忍度, 且绝对值越大, 容忍度越高。推荐流程如图1所示。
(1) 数据采集和存储阶段, 收集用户和图书的相关信息。用户和图书信息包括用户和图书的基本信息及评论信息。将用户和图书的基本信息和历史评价存储到数据库中; 而购买记录存储的购买信息数据库则作为后续推荐效果的评价依据。
(2) 数据分析阶段, 需要对采集到的用户和图书评论信息进行细粒度情感分析。借助情感分析词典和自然语言处理工具对评论信息进行处理, 获取用户偏好和图书属性的情感得分。
(3) 数据应用阶段, 将用户偏好矩阵和图书属性得分矩阵进行匹配计算。将用户u对商品属性t的偏好记为向量${{U}_{ui}}=({{U}_{u1}},{{U}_{u2}},{{U}_{u3}},{{U}_{u4}},\cdots )$, Uui表示用户u对第i个特征的偏好程度。商品p的属性t的情感得分为${{P}_{pi}}=({{P}_{p1}},{{P}_{p2}},{{P}_{p3}},{{P}_{p4}},\cdots )$, Ppi表示商品p的第i个特征的情感得分。本文采用余弦相似度[22]衡量用户和图书属性层的情感匹配程度, 余弦相似度计算可以从方向上区分用户和图书之间的差异, 通过减去均值修正用户和图书之间的度量标准不统一的问题。在此采用sim(X,Y)表示用户和商品之间的情感匹配值, 如公式(2)所示。
$sim(X,Y)=\cos \theta =\frac{\cdot }{||{{U}_{ui}}||\cdot ||{{P}_{pi}}||}$ (2)
根据公式(2)的计算结果, 选取与用户偏好最接近的k本图书, 并将其推荐给用户。
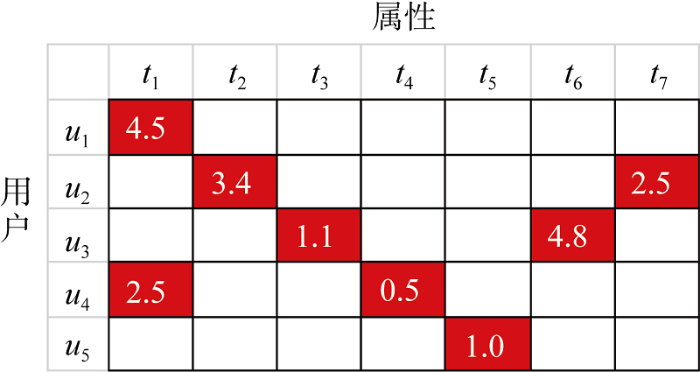
为了识别用户对图书属性的偏好, 对用户自身评论数据中所有用户情感值进行汇总统计。由于本文分析的是不同用户各自的兴趣观点, 因此认为所有观点持有者的评论权重是相等的。针对识别出来的图书属性词, 采用SentiByTerm算法计算最近情感词语的得分。本文根据第3节提出的情感分类方法进行用户属性情感倾向值的求解。用户偏好的表示转化为情感汇总计算任务, 也就是计算观点持有者某个属性类对应的情感平均值, 计算方法如公式(3)所示。
$\overline{{{U}_{{{t}_{l}}}}}=\frac{\sum\limits_{j=1}^{{{n}_{{{t}_{i}}}}}{{{U}_{{{t}_{i,j}}}}}}{{{n}_{{{t}_{i}}}}}$ (3)
其中, ti为属性类, nti为属性类ti在某用户历史评论中的总次数, ${{U}_{{{t}_{i,j}}}}$为评论中第j次出现的属性类ti对应的情感倾向值, $\overline{{{U}_{{{t}_{l}}}}}$为某个用户所有评论中的属性类所对应的平均情感倾向值。用户为u, 属性类用t表示, 用户偏好矩阵如图2所示。
用户偏好矩阵是指用户对图书属性的偏好程度。为了便于采用上述情感匹配公式, 将计算所得情感得分减2, 即可得到代表正负极性的情感得分。如果值大于0, 那么用户对该产品特征持有肯定态度, 小于0则证明该产品得到的评价是否定的, 值为0则表示持中立态度。经过计算得到结果如表3所示。
表3 用户偏好表示(部分用户偏好)
| 用户 | t1 (内容) | t2 (结构) | t3 (实用性) | t4 (趣味性) | t5 (专业性) | t6 (价格) | t7 (质量) |
|---|---|---|---|---|---|---|---|
| u1 | 1.56 | 0.00 | 0.83 | 2.63 | 1.18 | 0.00 | 1.00 |
| u2 | -1.00 | 0.53 | 0.76 | 0.00 | 1.42 | 1.56 | -1.83 |
| u3 | 1.00 | 1.89 | -2.00 | 0.00 | 0.00 | 1.56 | 0.34 |
| u4 | 0.00 | 2.00 | -1.82 | 0.34 | 1.88 | 1.57 | -2.00 |
| u5 | 0.80 | -2.00 | 1.55 | 0.59 | 0.35 | 2.00 | -2.00 |
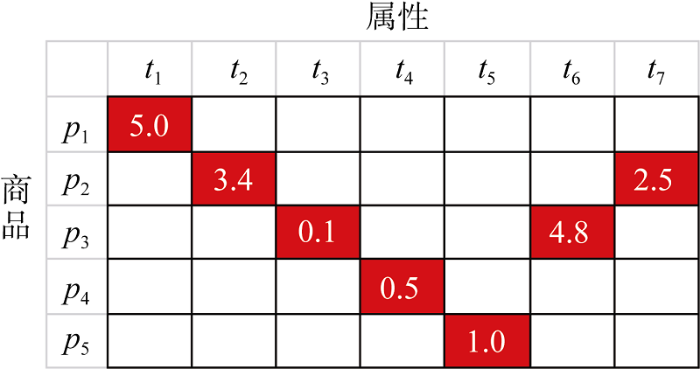
为了评估推荐效果, 对图书属性情感得分加以计算。商品属性得分计算如公式(4)所示。
$\overline{{{P}_{{{t}_{l}}}}}=\frac{\sum\limits_{j=1}^{{{n}_{{{t}_{i}}}}}{{{P}_{{{t}_{i,j}}}}}}{{{n}_{{{t}_{i}}}}}$ (4)
其中, ti为属性类, ${{n}_{{{t}_{i}}}}$为属性类出现的总次数,${{P}_{{{t}_{i,j}}}}$为商品历史评论中第j出现的属性类ti对应的情感倾向值, $\overline{{{P}_{{{t}_{l}}}}}$为某个商品所有评论中的属性类所对应的平均情感倾向值。商品用$p$表示, 属性类用t表示, 图书属性得分矩阵如图3所示。
图书属性矩阵就是计算所有参与评论用户对每个图书属性的情感倾向。将产品的情感得分减2, 即可得到能反映图书属性情感得分的矩阵。结果如表4所示。
表4 图书属性情感分析(部分图书得分)
| 图书 | t1 (内容) | t2 (结构) | t3 (实用性) | t4 (趣味性) | t5 (专业性) | t6 (价格) | t7 (质量) |
|---|---|---|---|---|---|---|---|
| p1 | -0.56 | 0 | -0.29 | 1 | -1 | 0 | 1 |
| p2 | 0.14 | 0 | -0.57 | 0.44 | 0.33 | 1 | 0 |
| p3 | -0.34 | 0 | -0.67 | 0 | 0 | 1 | -0.4 |
| p4 | -0.21 | -0.08 | -0.68 | -2 | -1 | 0 | -0.67 |
| p5 | 0.2 | 0 | -0.33 | 0 | 0.5 | 0 | 0 |
| p6 | 0 | 0 | -0.17 | 0 | 0 | 0 | -0.67 |
| p7 | -0.49 | 0 | 0.95 | 0 | -1 | 1 | 0 |
| p8 | -0.4 | 0 | -1.33 | 1 | -1 | 0 | -1 |
| p9 | -0.13 | 0 | -0.71 | 0.07 | 1 | 0 | 0 |
根据用户自身评论和商品历史评论分别计算用户偏好矩阵和图书属性得分矩阵。用户偏好矩阵大小为m×t, m代表用户数量, ti代表商品属性类别, $\overline{{{U}_{{{t}_{i}}}}}$表示用户u对属性ti的平均情感倾向值, 如果用户没有对该类属性进行评价, 则分数取0。图书属性得分矩阵大小为n×t, n代表商品数量, ti代表商品属性类别, $\overline{{{P}_{{{t}_{i}}}}}$代表商品p在属性类ti上的情感评分。
利用用户偏好矩阵和图书属性情感得分矩阵进行相似度计算, 计算出与待推荐用户相似度Top10的商品, 得到推荐结果。实验效果的测评采用准确率、召回率与覆盖率三个指标[23]。本实验将数据集划分为训练集和测试集两个部分, 训练集用来产生推荐结果, 测试集对结果进行比较与评估。在根据用户偏好与商品属性的情感匹配进行推荐实验后, 另外采用传统的基于项目的推荐(Item-base)和基于用户的推荐(User- base)进行比较。为了避免推荐系统中数据稀疏问题, 影响实验比较, 本文选用评论总数大于30的用户数据, 共有163位用户和4 287本图书, 26 160条评论数据进行实验。表5为三种方法推荐效果的比较。
表5 Item-base、User-base与基于用户偏好与商品属性的情感分析推荐算法结果对比
| 推荐算法 | 正确推荐数量 | 推荐数量 | 准确率 | 召回率 | 覆盖率 |
|---|---|---|---|---|---|
| Item-base | 244 | 1 630 | 0.1497 | 0.1124 | 0.3418 |
| User-base | 249 | 1 630 | 0.1528 | 0.1285 | 0.3051 |
| 本文方法 | 298 | 1 630 | 0.1828 | 0.1382 | 0.5863 |
图书个性化推荐采用基于用户偏好与商品属性的情感分析的推荐算法相对于传统的Item-base和User-base将推荐的准确率提高了0.030, 召回率提高了0.097, 覆盖提高了0.2812。在基于用户偏好与商品属性的推荐算法中, 不需要寻找相似用户或类似商品, 而是将用户的情感倾向和商品的情感得分直接匹配, 筛选出满足用户偏好的商品。由于本文在基于项目的协同过滤方法基础上, 通过挖掘用户对图书属性的偏好, 使得推荐结果更加符合用户需求。对于评论较少的用户而言, 采用的是亚马逊的“认为此评论有用”原则, 将用户赞同过的评论作为用户的观点和偏好, 减少冷启动问题带来的偏差。从实验结果来看, 本文提出的基于用户偏好和商品属性的推荐算法提高了图书个性化推荐效果。
传统的图书个性化推荐主要依据近邻用户的评分信息做出推荐, 无法完全客观、真实地表示用户自身的偏好以及详细的原因。虽然有学者结合图书主题、作者、体裁等属性研究用户偏好, 但是没有深入挖掘用户的意见和情感态度。本文采用情感分析技术从商品属性层面获取用户偏好和图书在不同属性方面的情感得分, 对用户和图书进行属性层情感匹配并根据匹配结果做出推荐。
本文对用户自身评论和商品历史评论进行属性层面的情感匹配分析, 为图书个性化推荐提供了一种新的方法。在梳理现有图书个性化推荐方法和推荐依据参数的基础上, 本文总结了现有图书个性化推荐研究存在的不足之处; 获取用户对图书属性特征的偏好, 对用户偏好进行更细粒度的刻画; 为降低依据近邻用户偏好产生推荐的误差, 使用情感分析方法构建用户偏好矩阵和图书属性得分矩阵, 提出了依据用户偏好和商品属性情感得分直接匹配的推荐方法, 提升了推荐效果, 并为网络书店图书个性化推荐提供了新的思路。
本研究也存在一些不足: 本文将图书属性汇总归纳为7类, 但商品属性尚不够完善, 需要更加完善地挖掘影响用户偏好的图书属性; 用户偏好会随着时间的推移而发生变化, 没有考虑时间因素对用户偏好的影响; 受评论数据量和质的影响较大, 建议与协同过滤方法结合使用效果更佳; 在计算图书属性得分矩阵时, 没有考虑用户的权重。而初级用户和有经验用户发表的意见权威性有所不同, 用户的意见权重因素将是下一步探索的内容。
侯银秀: 构建推荐模型, 处理数据, 撰写论文;
李伟卿: 完成情感计算和推荐实验;
王伟军: 提出研究命题及研究思路, 修改论文;
张婷婷: 结论概括, 论文修改。
所有作者声明不存在利益冲突关系。
支撑数据见期刊网络版http://www.infotech.ac.cn。
[1] 侯银秀. 图书情感得分.xlsx. 图书评论情感得分.
[2] 侯银秀. 用户情感得分.xlsx. 用户评论情感得分.
| [1] |
个性化推荐系统的研究进展 [J].https://doi.org/10.3321/j.issn:1002-008X.2009.01.001 URL [本文引用: 1] 摘要
互联网技术的迅猛发展把我们带进了信息爆炸的时代。海量信息的同时呈现,一方面使用户很难从中发现自己感兴趣的部分,另一方面也使得大量少人问津的信息成为网络中的“暗信息”,无法被一般用户获取。个性化推荐系统通过建立用户与信息产品之间的二元关系,利用已有的选择过程或相似性关系挖掘每个用户潜在感兴趣的对象,进而进行个性化推荐,其本质就是信息过滤。个性化推荐系统不仅在社会经济中具有重要的应用价值,而且也是一个非常值得研究的科学问题。事实上,它是目前解决信息过载问题最有效的工具。文中根据推荐算法的不同,分别介绍了协同过滤系统,基于内容的推荐系统,混合推荐系统,以及最近兴起的基于用户一产品二部图网络结构的推荐系统。并结合这些推荐系统的特点以及存在的缺陷,提出了改进的方法和未来可能的若干研究方向。推荐系统的研究受到了信息科学、计算数学、统计物理学、认知科学等多学科的关注,它与管理科学、消费行为等研究也密切相关。能够为不同学科领域的科研工作者研究推荐系统提供借鉴,有助于我国学者了解该领域的主要进展。
Research Progress of Personalized Recommendation System [J].https://doi.org/10.3321/j.issn:1002-008X.2009.01.001 URL [本文引用: 1] 摘要
互联网技术的迅猛发展把我们带进了信息爆炸的时代。海量信息的同时呈现,一方面使用户很难从中发现自己感兴趣的部分,另一方面也使得大量少人问津的信息成为网络中的“暗信息”,无法被一般用户获取。个性化推荐系统通过建立用户与信息产品之间的二元关系,利用已有的选择过程或相似性关系挖掘每个用户潜在感兴趣的对象,进而进行个性化推荐,其本质就是信息过滤。个性化推荐系统不仅在社会经济中具有重要的应用价值,而且也是一个非常值得研究的科学问题。事实上,它是目前解决信息过载问题最有效的工具。文中根据推荐算法的不同,分别介绍了协同过滤系统,基于内容的推荐系统,混合推荐系统,以及最近兴起的基于用户一产品二部图网络结构的推荐系统。并结合这些推荐系统的特点以及存在的缺陷,提出了改进的方法和未来可能的若干研究方向。推荐系统的研究受到了信息科学、计算数学、统计物理学、认知科学等多学科的关注,它与管理科学、消费行为等研究也密切相关。能够为不同学科领域的科研工作者研究推荐系统提供借鉴,有助于我国学者了解该领域的主要进展。
|
| [2] |
Collaborative Recommendation with User Generated Content [J].https://doi.org/10.1016/j.engappai.2015.07.012 URL [本文引用: 1] 摘要
ABSTRACT In the age of Web 2.0, user generated content (UGC), such as user review and social tag, ubiquitously exists on the Internet. Although there exist different kinds of UGC in recommender systems, the existing works only studied a single kind of UGC in each of their papers. Thus, the previous works lose a chance to uncover the similar effects of different kinds of UGC in recommender systems. In this paper, we propose a unified way to utilize various types of UGC to enhance the recommendation accuracy. We build two novel statistical models, which are based on collaborative filtering and topic modeling. Incorporating UGC text, one model focuses on learning user preferences, and the other model aims to learn user preferences and item aspects jointly. With an effective parameter estimation algorithm, our models can not only acquire prediction values of missing ratings, but also produce interpretable topics. We conducted comprehensive experiments on three real-world datasets. The experimental results demonstrate that our proposed models can achieve large improvements compared to several well-known baseline models.
|
| [3] |
Ratings Lead You to the Product, Reviews Help You Clinch It? The Mediating Role of Online Review Sentiments on Product Sales [J].https://doi.org/10.1016/j.dss.2013.07.009 URL [本文引用: 1] 摘要
It is generally assumed that ratings are a numeric representation of text sentiments and their valences are consistent. This however may not always be true. Using a panel of data on over 4000 books from Amazon.com, we develop a multiple equation model to examine the inter-relationships between ratings, sentiments, and sales. We find that ratings do not have a significant direct impact on sales but have an indirect impact through sentiments. Sentiments, however, have a direct significant impact on sales. Our findings also indicate that the two most accessible types of reviews – most helpful and most recent – play a significant role in determining sales. This suggests that information that is easily accessible and cognitive effort-reducing heuristics play a role in online purchase decisions. This study advances our understanding on the inter-relationship between ratings, sentiments, and sales and sheds insight on the relevance of ratings and sentiments over a sequential decision making process.
|
| [4] |
Book Recommendation System Using Opinion Mining Technique [C]// |
| [5] |
Jointly Modeling Aspects, Ratings and Sentiments for Movie Recommendation (JMARS) [C]// |
| [6] |
User-Oriented Real-Time Preference Obtaining Screen Visual Hotspots Recognition Based on the Research of Eye Movement Experiments [C]// |
| [7] |
|
| [8] |
基于读者借阅二分网络的图书可推荐质量测度方法及个性化图书推荐服务 [J].https://doi.org/10.3969/j.issn.1001-8867.2013.03.021 URL [本文引用: 1] 摘要
本文首先提出一种利用读者借阅 行为特征来判断图书可推荐质量的思路,并结合读者图书借阅关系所形成的二分网络结构,设计了一种测度图书可推荐质量的迭代算法,从而为个性化图书推荐服务 提供了良好的推荐客体。在上述研究的基础上,结合图书类别目录层次、标题语义信息的提取处理方法、基于加权XML模型的用户个性化模式表达方法及其权值扩 散策略,提出了三种图书馆个性化图书推荐服务的形式,分别是特定主题的图书推荐服务、现有所借图书的修正型推荐服务和新书推荐服务。最后,文章对相关测试 实验及其效果做了必要的说明。图9。表10。参考文献13。
The Measures of Books’ Recommending Quality and Personalized Book Recommendation Service Based on Bipartite Network of Readers and Books’ Lending Relationship [J].https://doi.org/10.3969/j.issn.1001-8867.2013.03.021 URL [本文引用: 1] 摘要
本文首先提出一种利用读者借阅 行为特征来判断图书可推荐质量的思路,并结合读者图书借阅关系所形成的二分网络结构,设计了一种测度图书可推荐质量的迭代算法,从而为个性化图书推荐服务 提供了良好的推荐客体。在上述研究的基础上,结合图书类别目录层次、标题语义信息的提取处理方法、基于加权XML模型的用户个性化模式表达方法及其权值扩 散策略,提出了三种图书馆个性化图书推荐服务的形式,分别是特定主题的图书推荐服务、现有所借图书的修正型推荐服务和新书推荐服务。最后,文章对相关测试 实验及其效果做了必要的说明。图9。表10。参考文献13。
|
| [9] |
基于用户群体影响的协同过滤推荐算法 [J].https://doi.org/10.3772/j.issn.1000-0135.2013.03.009 URL [本文引用: 1] 摘要
协同过滤是推荐系统中广泛使用的推荐技术,对推荐结果可解释强.基于用户的协同过滤是一种重要的系统推荐方法,用户评分数据的极端稀疏性制约着系统的推荐质量.针对上述情况,提出一种基于用户群体影响的协同过滤推荐算法.首先,定义了用户群体的概念并根据群体影响提出两条相应准则;然后,计算用户相似性时,不仅考虑了用户个体之间的相似性,而且考虑了用户所处群体之间的相似性.该算法不仅可以更加精确地刻画用户之间相似度,而且一定程度上增强了推荐系统的稳定性.实验结果表明,该算法能有效地提高系统的推荐质量,而且满足所提出的两条准则.
Collaborative Filtering Recommendation Algorithm Based on User Group Influence [J].https://doi.org/10.3772/j.issn.1000-0135.2013.03.009 URL [本文引用: 1] 摘要
协同过滤是推荐系统中广泛使用的推荐技术,对推荐结果可解释强.基于用户的协同过滤是一种重要的系统推荐方法,用户评分数据的极端稀疏性制约着系统的推荐质量.针对上述情况,提出一种基于用户群体影响的协同过滤推荐算法.首先,定义了用户群体的概念并根据群体影响提出两条相应准则;然后,计算用户相似性时,不仅考虑了用户个体之间的相似性,而且考虑了用户所处群体之间的相似性.该算法不仅可以更加精确地刻画用户之间相似度,而且一定程度上增强了推荐系统的稳定性.实验结果表明,该算法能有效地提高系统的推荐质量,而且满足所提出的两条准则.
|
| [10] |
A Clustering Based Approach to Improving the Efficiency of Collaborative Filtering Recommendation [J].https://doi.org/10.1016/j.elerap.2016.05.001 URL [本文引用: 1] 摘要
In collaborative filtering recommender systems, products are regarded as features and users are requested to provide ratings to the products they have purchased. By learning from the ratings, such a recommender system can recommend interesting products to users. However, there are usually quite a lot of products involved in E-commerce and it would be very inefficient if every product needs to be considered before making recommendations. We propose a novel approach which applies a self-constructing clustering algorithm to reduce the dimensionality related to the number of products. Similar products are grouped in the same cluster and dissimilar products are dispatched in different clusters. Recommendation work is then done with the resulting clusters. Finally, re-transformation is performed and a ranked list of recommended products is offered to each user. With the proposed approach, the processing time for making recommendations is much reduced. Experimental results show that the efficiency of the recommender system can be greatly improved without compromising the recommendation quality.
|
| [11] |
Improving the Accuracy of Collaborative Filtering Recommendations Using Clustering and Association Rules Mining on Implicit Data [J].https://doi.org/10.1016/j.chb.2016.11.010 URL [本文引用: 1] 摘要
The recommender systems are recently becoming more significant in the age of rapid development of the Internet technology due to their ability in making a decision to users on appropriate choices. Collaborative filtering (CF) is the most successful and most applied technique in the design of recommender systems where items to an active user will be recommended based on the past rating records from like-minded users. Unfortunately, CF may lead to the poor recommendation when user ratings on items are very sparse in comparison with the huge number of users and items in user-item matrix. To overcome this problem, this research applies the users implicit interaction records with items to efficiently process massive data by employing association rules mining. It captures the multiple purchases per transaction in association rules, rather than just counting total purchases made. To do this, a modified preprocessing is implemented to discover similar interest patterns among users based on multiple purchases done. In addition, the clustering technique has been employed in our technique to reduce the size of data and dimensionality of the item space as the performance of association rules mining. Then, similarities between items based on their features were computed to make recommendations. The experiments were conducted and the results were compared with basic CF and other extended version of CF techniques including K-Means clustering, hybrid representation, and probabilistic learning by using public dataset, namely, Million Song dataset. The experimental results demonstrated that our technique achieves the better performance when compared to the basic CF and other extended version of CF techniques in terms of Precision, Recall metrics, even when the data is very sparse.
|
| [12] |
一种面向用户偏好定向挖掘的协同过滤个性化推荐算法 [J].
【目的】解决协同过滤推荐的可扩展性问题和数据稀疏性问题。【方法】提出一种面向用户偏好定向挖掘的协同过滤算法。该算法以时间为约束,第一阶段先寻找基于项目的弱相似用户;第二阶段基于用户关联性和属性相似性进行定向挖掘,形成推荐集合。【结果】实验结果表明,新算法的时间复杂度降低一个数量级,并且数据越稀疏,推荐精度的领先优势越大。【局限】该算法基于用户已表现出的偏好进行深度推荐,对未表现出的其他偏好暂未涉及。【结论】该算法在提升可扩展性的同时,对数据稀疏性也有很强的适应能力。
A Collaborative Filtering Personalized Recommendation Algorithm Through Directionally Mining User’ Preferences [J].
【目的】解决协同过滤推荐的可扩展性问题和数据稀疏性问题。【方法】提出一种面向用户偏好定向挖掘的协同过滤算法。该算法以时间为约束,第一阶段先寻找基于项目的弱相似用户;第二阶段基于用户关联性和属性相似性进行定向挖掘,形成推荐集合。【结果】实验结果表明,新算法的时间复杂度降低一个数量级,并且数据越稀疏,推荐精度的领先优势越大。【局限】该算法基于用户已表现出的偏好进行深度推荐,对未表现出的其他偏好暂未涉及。【结论】该算法在提升可扩展性的同时,对数据稀疏性也有很强的适应能力。
|
| [13] |
Aspect-based Latent Factor Model by Integrating Ratings and Reviews for Recommender System [J].https://doi.org/10.1016/j.knosys.2016.07.033 URL [本文引用: 1] 摘要
In this work, we aim to propose a novel model, called Aspect-based Latent Factor Model (ALFM) to integrate ratings and review texts via latent factor model, in which by integrating rating matrix, user-review matrix and item-attribute matrix, the user latent factors and item latent factors with word latent factors can be derived. Our proposed model aggregates all review texts of the same user on the respective items and builds a user-review matrix by word frequencies. Similarly, an item review is considered as all review texts of the same item collected from respective users. According to different information abstracted from review texts, we introduce two different kinds of item-attribute matrix to integrate the item-word frequencies and polarity scores of corresponding words. Experimental results on real-world data sets from amazon.com illustrate that our model can not only perform better than traditional models and art-of-state models on rating prediction task, but also accomplish cross-domain task through transferring word embedding.
|
| [14] |
A Social Recommender Mechanism for E-commerce: Combining Similarity, Trust, and Relationship [J].https://doi.org/10.1016/j.dss.2013.02.009 URL [本文引用: 1] 摘要
Online business transactions and the success of e-commerce depend greatly on the effective design of a product recommender mechanism. This study proposes a social recommender system that can generate personalized product recommendations based on preference similarity, recommendation trust, and social relations. Compared with traditional collaborative filtering approaches, the advantage of the proposed mechanism is its comprehensive consideration of recommendation sources. Accordingly, our experimental results show that the proposed model outperforms other benchmark methodologies in terms of recommendation accuracy. The proposed framework can also be effectively applied to e-commerce retailers to promote their products and services. (C) 2013 Elsevier B.V. All rights reserved.
|
| [15] |
个性化推荐系统理论探索: 从系统向用户为中心的演进 [J].https://doi.org/10.16353/j.cnki.1000-7490.2016.03.011 URL [本文引用: 1] 摘要
与面向机器的推荐系统不同,个性化推荐系统面向的是作为系统使用主体的人。推荐系统发展的实践呼唤以用户为中心的个性化推荐系统理论体系的形成与完善。文章试图从理论上抽象并构建这一体系,分别从学科基础、发展阶段、本质、体系构架和评价指标5个方面进行具体阐释,首次提出个性化推荐系统的本质是认知助手,以及情境、用户、资源融合下的H3W体系构架。本文有待开展进一步的细致工作对该理论体系进行补充、完善和修正。
Exploration on Personalized Recommendation System Theory: Evolution from System-centric to User-centric [J].https://doi.org/10.16353/j.cnki.1000-7490.2016.03.011 URL [本文引用: 1] 摘要
与面向机器的推荐系统不同,个性化推荐系统面向的是作为系统使用主体的人。推荐系统发展的实践呼唤以用户为中心的个性化推荐系统理论体系的形成与完善。文章试图从理论上抽象并构建这一体系,分别从学科基础、发展阶段、本质、体系构架和评价指标5个方面进行具体阐释,首次提出个性化推荐系统的本质是认知助手,以及情境、用户、资源融合下的H3W体系构架。本文有待开展进一步的细致工作对该理论体系进行补充、完善和修正。
|
| [16] |
认知视角下网络用户偏好复合模型的构建与验证 [D].A Composite User Preference Model: An Experimental Model from a Cognitive Perspective [D]. |
| [17] |
Hidden Factors and Hidden Topics: Understanding Rating Dimensions with Review Text [C]// |
| [18] |
中文网络客户评论的产品特征挖掘方法研究 [J].https://doi.org/10.3321/j.issn:1007-9807.2009.02.015 URL [本文引用: 1] 摘要
随着互联网的广泛应用,在Blog、BBS、Wiki等网络站点中出现了大量的针对商品或服务的客户评论,这些客户评论中所包含的丰富信息,对企业管理具有重要的价值.通过数据挖掘算法对客户针对某一产品的大量评论进行分析,可以挖掘出这些产品的主要特征,并有望进一步发现客户对这些特征的意见和态度.在英文世界中已经有学者开始对这一研究进行探索,然而由于语言结构等方面的差异,英文的研究成果尚无法直接应用于中文客户评论的挖掘中.本研究针对中文的特点,提出了面向中文的客户评论挖掘方法.该方法基于改进关联规则算法实现了针对中文产品评论的产品特征信息挖掘.本研究采用通过互联网获得的针对手机、数码相机、书籍等5种产品的评论语料,对该方法进行了数据实验,实验结果初步验证了该方法有效性.
Mining Features of Products from Chinese Customer Online Reviews [J].https://doi.org/10.3321/j.issn:1007-9807.2009.02.015 URL [本文引用: 1] 摘要
随着互联网的广泛应用,在Blog、BBS、Wiki等网络站点中出现了大量的针对商品或服务的客户评论,这些客户评论中所包含的丰富信息,对企业管理具有重要的价值.通过数据挖掘算法对客户针对某一产品的大量评论进行分析,可以挖掘出这些产品的主要特征,并有望进一步发现客户对这些特征的意见和态度.在英文世界中已经有学者开始对这一研究进行探索,然而由于语言结构等方面的差异,英文的研究成果尚无法直接应用于中文客户评论的挖掘中.本研究针对中文的特点,提出了面向中文的客户评论挖掘方法.该方法基于改进关联规则算法实现了针对中文产品评论的产品特征信息挖掘.本研究采用通过互联网获得的针对手机、数码相机、书籍等5种产品的评论语料,对该方法进行了数据实验,实验结果初步验证了该方法有效性.
|
| [19] |
Mining Feature-Opinion from Reviews Based on Dependency Parsing [J].https://doi.org/10.1142/S0218194016710029 URL [本文引用: 1] 摘要
The manual reading of all the product reviews to find a satisfying item is not only labor-intensive, but also tedious for the consumers. In this paper, we propose a feature-opinion mining approach to automatically summarize the reviews, which is based on dependency parsing. Specifically, in our approach we first utilize a regression model to generate sentiment word, including phrase and its sentiment weight, and then we extract the feature based on the dependency relationship between feature word and sentiment word, finally we assign a score to the feature according to the dependency relationship. The experimental results demonstrate that our approach can effectively mine the feature-opinion from reviews.
|
| [20] |
Improving Selection of Synsets from WordNet for Domain-specific Word Sense Disambiguation [J].https://doi.org/10.1016/j.csl.2016.06.003 URL [本文引用: 1] 摘要
Word Sense Disambiguation (WSD) is a fundamental task useful for Information Retrieval, Information Extraction, web search, and indexing, among others. In the literature there exist several works dedicated to generic WSD task, but in recent years domain-specific WSD has attracted the attention of several researchers. In this sense, this paper describes an approach for domain-specific WSD by selecting the predominant sense (synset from WordNet) of ambiguous words. To achieve it the method uses two corpora: the domain-specific test corpus (containing target ambiguous words) and a domain-specific auxiliary corpus (obtained by using relevant words from the domain-specific test corpus ). The approach has four main stages: (1) auxiliary corpus generation; (2) related features extraction (from the auxiliary corpus); (3) test features extraction (from the test corpus); and (4) features integration . The proposed approach has been tested on domain-specific corpora (Sports and Finance) and on one balanced corpus, BNC. Even though our WSD approach showed some limitations when dealing with the general-domain corpus, the obtained results for domain-specific corpora, which are our main interest, were better than those reported in previous works.
|
| [21] |
Word Sense Disambiguation Based Sentiment Lexicons for Sentiment Classification [J].https://doi.org/10.1016/j.knosys.2016.07.030 URL [本文引用: 1] 摘要
Sentiment analysis has attracted much attention from both researchers and practitioners as word-of-mouth (WOM) has a significant influence on consumer behavior. One core task of sentiment analysis is the discovery of sentimental words. This can be done efficiently when an accurate and large-scale sentiment lexicon is used. SentiWordNet is one such lexicon which defines each synonym set within WordNet with sentiment scores and orientation. As human language is ambiguous, an exact sense for a word in SentiWordNet needs to be justified according to the context in which the word occurs. However, most sentiment-based classification tasks extract sentimental words from SentiWordNet without dealing with word sense disambiguation (WSD), but directly adopt the sentiment score of the first sense or average sense. This paper proposes three WSD techniques based on the context of WOM documents to build WSD-based SentiWordNet lexicons. The experiments demonstrate that an improvement is achieved when the proposed WSD-based SentiWordNet is used.
|
| [22] |
一种结合用户评分信息的改进好友推荐算法 [J].An Improved Friend Recommendation Algorithm Combined with User Rating Information [J]. |
| [23] |
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}