曲佳彬
Qu Jiabin
中图分类号: TP393
通讯作者:
收稿日期: 2017-11-7
修回日期: 2017-12-3
网络出版日期: 2018-01-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】针对采用LDA模型识别出的主题中往往含有一些无意义的主题, 严重影响演化分析的精确性问题, 本文提出采用主题过滤和主题关联的方式, 构建学科主题在时间序列上的演化路径, 并分析主题在内容上的演化情况。【方法】计算主题在所有文献中出现的概率, 识别并过滤边缘主题; 根据主题中词汇分布的倾向性, 识别并过滤无意义的噪音主题。将过滤后的主题作为主题演化分析的主题, 通过计算相邻时间段中主题间的JS散度识别相关主题, 从而根据主题间的相关关系构建主题演化路径。【结果】以“机器学习”领域的文献为例, 构建学科主题演化路径, 展示主题间的新生、消亡、继承、分裂和合并5种演化方式, 并以微观的“图像识别”为例, 验证了方法的有效性。【局限】在构建主题演化路径时, 采用人工判断方法设置阈值, 具有一定的主观性。【结论】本文方法避免了不重要的边缘主题和无意义的噪音主题对相邻时间段中相关主题识别造成的干扰, 提高了所构建的主题演化路径的准确性, 能够更为准确地展示学科主题的演化规律。
关键词:
Abstract
[Objective] There are lots of irrelevant results among the topics identified by the LDA model, which poses negative effects to the accuracy of evolution analysis. This paper constructs topics evolution paths to analyze their evolution by filtering out noises and calculating relevance. [Methods] First, we filtered out irrelevant topics by their probability of appearing in all documents and the word propensity distribution of topics. Then, we calculated the Jensen-Shannon Divergence to identify related topics. Finally, we constructed the topic evolution paths based on the correlation between topics. [Results] The effectiveness of the proposed method was examined with scientific literature on “machine learning”, which yielded five evolution paths, i.e. rebirth, extinction, succession, division and merger. [Limitations] There are some subjective factors involving the estimated threshold values. [Conclusions] The proposed method could avoid the interference of noise topics, and then identify relevant topics from adjacent time intervals. It helps us discover the evolution of discipline topics more accurately.
Keywords:
学科主题演化是指以词语为表征的学科主题在时间序列上的发展和变化规律, 通过对学科主题演化过程进行分析, 能够帮助科研人员快速了解某一学科领域的研究热点和发展趋势, 指导科研工作的进一步开展[1,2]。随着自然语言处理技术的发展, 主题模型逐渐成为学科主题研究的主要方法之一, 它能够深入挖掘“文本-主题-词语”之间的隐含关系, 从文本的词汇分布角度描述其中隐含的主题信息。隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)模型是目前主题模型中的基础模型, 其基本思想是: 将文档看作是一组主题的概率分布, 将主题看作是一组词汇的概率分布, 两者均符合二项式分布; 对于一篇文档和一个主题, 其主题分布和词汇分布也是不确定的, 两者均符合狄利克雷分布; 按照“以一定概率选择某个主题, 然后从该主题中以一定概率选择某个词汇”这一过程随机生成文档中的每个词汇, 最后将该过程重复多次生成整个文档[3,4]。LDA模型在识别大规模文档集中的潜在主题时效果良好, 逐渐成为分析学科主题演化的主要工具。
利用LDA模型进行学科主题演化分析的主要过程是: 根据文献发表时间将文献离散到若干个时间段内(譬如按年度划分), 利用LDA模型抽取各个时间段内的“主题-词语”概率分布, 采用相似度算法计算相邻时间段内主题的相关性, 并从时间序列上研究主题的强度变化、内容迁移和生命周期。在此过程中, 主题识别的精确性是基础, 决定了后续步骤中构建的主题演化路径的准确性和完整性。采用主题模型进行主题识别, 一方面主题个数难以确定, 造成识别的主题粒度难以掌握; 另一方面, 大量无意义主题的存在影响了后续的演化分析。鉴于此, 本文提出一种基于主题过滤和主题关联的学科主题演化分析方法, 在利用主题模型进行文献主题识别的基础上, 以主题在所有文献中出现的概率和主题中词汇分布的倾向性作为过滤指标, 过滤识别出的主题, 将过滤后的主题作为主题演化分析的主体。
主题演化研究中时间维度是首要考虑的问题, 依据时间维度引入方式的不同, 大致可分为三种演化分析方法[5]:
(1) 将时间维度作为可观测值, 在LDA模型中加入时间属性, 衍生出带有时间标签的新的文档生成模型, 从该模型可得到主题随时间的演化趋势, 其代表模型有Topic Over Time(TOT)[6]。
(2) 利用LDA模型从文献集合的所有文献中识别主题, 从中选取高概率主题。按文献发表时间计算主题在各个时间段的分布, 构建主题演化路径。
(3) 根据文献发表时间, 将文献离散到不同时间段内, 利用LDA模型识别每个时间段内的主题, 根据相邻时间段内主题间的相关性构建演化路径。
从以上主题演化分析方法可以看出, 第一种演化分析方法虽然考虑了文献的时间属性, 但是利用衍生模型(如TOT)从每个时间段内识别的主题个数一般是固定的, 鉴于不同时间段内文献数量有很大区别, 固定的主题个数显然不符合实际情况。此外, TOT模型仅可展示主题在不同时间段的强度变化, 忽略了主题内容的变化。第二种分析方法同样也存在识别的主题个数固定且仅能分析主题强度变化的问题。此外, 该方法为了保证主题在每个时间段都出现, 仅选择高概率主题进行演化分析, 因此文献时间段和高概率主题的选择对主题强度的演化有较大影响。第三种分析方法根据每个时间段内的文献数量灵活选择识别的主题个数, 可从主题强度变化和内容变化两方面分析演化规律, 因此目前主题演化分析多采用第三种方法[7,8,9,10]。
第三种演化分析方法的关键是构建相邻时间段内主题间的关联关系, 即后一时间段内的主题对前一时间段内的主题的依赖关系。已有研究主要是通过计算主题间的相似性实现, 常用的相似性度量有余弦相似度和KL(Kullback-Leibler)散度及其变种JS(Jensen- Shannon Divergence)散度。崔凯等使用KL散度计算相邻时间段内主题的相似性, 从而建立主题间的关联关系, 并进行简单的学科主题强度演化分析, 而对于学科主题内容的演化只涉及了主题词的变化[11]; 秦晓慧等采用余弦相似度计算相邻时间段主题的相似性, 并定义了判别主题间是否有较强关联的规则, 从而过滤掉相似度较小的主题, 以提高主题关联的准确性[12]; 李湘东等把时间因素引入到LDA 模型中, 采用JS散度计算相邻时间段主题间的相似性, 探测科技期刊主题的强度和内容随时间变化的规律[13]。
此外, 有学者直接采用动态主题模型(Dynamic Topic Model, DTM)[14]识别学科主题并分析学科主题的演化问题。齐亚双等以国内外情报学领域的核心期刊为数据源, 利用DTM模型从主题强度和词汇变化角度分析国内外情报学研究主题的变化情况[15]。DTM模型的主要思想是将文献离散到不同时间段, 针对不同时间段构建主题模型, 并将当前时间段主题模型的参数作为下一时间段主题模型的参数, 这样模型本身就考虑了相邻时间段主题间的关联关系, 能够直接从主题的强度变化和内容变化上分析演化规律, 但其缺点是针对不同时间段只能设置相同的主题个数, 并不考虑不同时间段内文献数量的差异, 这显然与实际情况不符。
综上所述, 主题模型逐渐成为学科主题研究的主要方法, LDA模型的研究与改进都是为了有效识别主题, 主题间相似性计算是为了构建主题间的关联关系。鉴于利用LDA模型识别出的主题有很大噪音, 有些主题不能清晰表达语义, 因此会极大干扰主题间关联关系的判断。因此, 本文从以下三个方面进行研究:
(1) 确定每个时间段内识别的主题个数。采用主题平均相似度和困惑度相结合的方法, 动态地确定采用LDA模型识别出的每个时间段内的最优主题个数。
(2) 对无意义的噪音主题进行过滤, 识别出意义表达明确且与文献相关性较大的主题。采用主题在所有文献中出现的概率和主题中词汇分布的倾向性相结合的方法。
(3) 对不同时间段中的相关主题进行识别, 构建主题间的关联关系。采用JS散度计算相邻时间段内主题间的相似度识别相关主题, 从而构建学科主题内容演化路径。
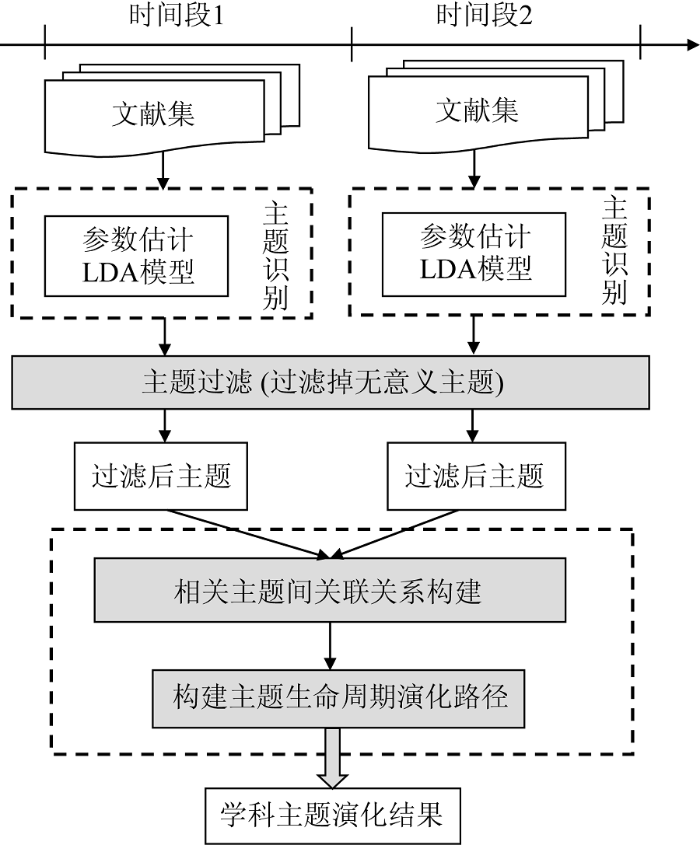
主题通常是由文献中识别出的富含语义的词汇构成, 从时间序列角度展示主题强度与内容的迁移和变化情况, 能够反映出学科主题演化的规律和趋势。然而, 采用主题模型往往会识别出很多无意义的主题, 严重影响了对文献真实主题的判定以及主题演化分析的准确性, 本文采用主题过滤的方式, 提高主题演化分析的效果。基于主题过滤的学科主题演化分析流程如图1所示。
(1) 主题识别: 选取时间段, 譬如每年为一个时间段或者两年为一个时间段, 将文献集中的文献按照发表时间分配到相应的时间段中, 利用LDA模型识别出每个时间段中文献的多个主题。
(2) 主题过滤: 过滤掉无意义的主题, 避免干扰相邻时间段内相关主题的识别和判定。
(3) 主题相似性计算: 针对过滤后的主题, 通过计算相邻时间段中主题的相似性, 建立主题间的关联关系。
(4) 主题演化路径构建: 根据相邻时间段中主题向前和向后的推理, 推演出学科主题在内容和结构上的变化路径。
在利用LDA主题模型对每个时间段内的文献进行主题识别时, 需要预先设定识别的主题个数K, 参数K的设定将直接影响主题识别的效果。如果主题个数K设定过大, 会造成识别出的主题分布稀疏, 文献主题不成体系; 反之, 则会导致主题过于宽泛, 无法反映文献的核心内容[16]。由于文献集合中文献的发表时间具有很大随机性, 分布在各个时间段中的文献数量有很大不同, 因此每个时间段内识别的主题个数也应不相同。在本研究中采用困惑度和平均相似度相结合的方法动态地确定每个时间段内识别的主题个数。
困惑度是在统计语言模型中评估语言模型优劣的一个指标, 可理解为对于一篇文献D, 所训练出来的模型对文献D属于哪个主题的不确定程度, 困惑度越低说明模型的泛化能力越强[17]。困惑度的计算如公式(1)[3]所示。
$Perplexity(D)=\exp \left\{ -\frac{\sum\limits_{m=1}^{M}{\log p{{({{W}_{m}})}_{{}}}}}{\sum\limits_{m=1}^{M}{{{N}_{m}}}} \right\}$ (1)
其中, Perplexity(D)表示模型的困惑度, Nm表示测试集中第m个文档的词汇数, M为测试集中的文档数, p(Wm)表示第m个文档中词汇的概率分布。
随着潜在主题个数K的增加, 模型的困惑度大致呈下降趋势, 但通常会出现一些明显拐点, 这些拐点反映出在某个主题数时模型的泛化能力明显提高, 因此可以根据这些拐点大致估计主题个数。但是有研究表明, 单纯地通过困惑度确定主题个数往往不够精确, 主题识别度并不高[18,19], 因此还需考虑其他因素, 其中主题平均相似度是另一个重要衡量指标。主题平均相似度是指识别出的所有主题间的平均差异程度, 通常基于JS散度来衡量, 如公式(2)所示[20]。
$avg\_sim({{T}_{i}},{{T}_{j}})=\frac{\sum\limits_{i=1}^{k-1}{\sum\limits_{j=i+1}^{k}{JS({{T}_{i}}||{{T}_{j}})}}}{K\times (K-1)/2}$ (2)
其中, Ti和Tj分别表示两个主题, JS(Ti||Tj)表示两个主题Ti和Tj间的JS散度(即两个主题间的相似度)。迭代计算两两主题间的相似度, 通过求平均值得到所有主题间的平均相似度。
根据JS散度的定义, 其值越大两个主题越不相似, 因此主题间的平均相似度越大, 说明主题之间的差异越大。随着主题个数的增加, 主题间的平均相似度一般呈增大趋势, 但通常也会出现一些明显的拐点, 这些拐点反映出在某个主题数时识别的主题有明显不同。因此, 本研究综合考虑“困惑度-主题个数”和“主题平均相似度-主题个数”分布曲线中的拐点来确定要识别的主题个数, 使得在该主题个数时, LDA模型的泛化能力和识别出的主题的差异性综合达到最优。
对于每个时间段内识别出的文献主题, 即使采用较科学的方法确定最优的主题个数, 其中有些主题所含词汇之间的相关性仍然很小, 很难表达一个清晰的含义。无意义主题的存在不仅增加了计算工作量, 而且容易造成实际不相关主题间的关联, 影响主题演化路径的准确推演[20]。鉴于这种情况, 有必要对噪音主题实施过滤。主题过滤主要通过两个步骤实现: 根据主题在所有文献中的权重进行粗略过滤, 过滤掉在所有文献中出现概率低的主题; 根据主题中词汇分布的倾向性, 过滤掉语义不明确的主题。
(1) 基于主题分布的边缘主题识别与过滤
采用LDA模型识别出的主题在各个文献中的分布概率有很大不同, 只有在所有文献中出现概率均较高的主题, 才是反映某个时间段内文献主要内容的核心主题, 对于分析主题演化有重要意义; 反之, 那些在多数文献中出现概率较低的主题, 则很可能是边缘化甚至无意义的主题, 对分析学科主题演化作用不仅不大, 而且有可能干扰学科主题演化的分析效果。因此, 对于利用LDA模型识别出的某个时间段中的K个主题, 根据其在文献中的概率分布情况, 可设置阈值对边缘主题进行过滤, 阈值通过如下方法进行设定: 计算每个主题Ti(i=1, 2, …, k)在文献中的累加概率Pi; 除以时间段内的文献数量m进行归一化处理, 得到该主题在文献集中的权重Wi, 该值反映了主题Ti在文献集中的覆盖程度; 将Wi按照从大到小的顺序进行排列, 选择它们的中位数作为过滤阈值。
(2) 基于词汇分布的无意义主题识别与过滤
采用LDA模型识别出的主题可表示为一组词汇的概率分布。这些词汇之间的相关语义往往描述了一个完整的含义, 即为该主题所要表达的内容[21]。如果这些词汇无法表达一个清晰的含义, 通常认为该主题是无意义的, 需要进行过滤。对于语义表达明确的主题, 反映主题内容的词汇往往出现概率比较高, 呈现出明显的倾向性[22]; 相反, 对于语义表达不明确的主题, 则没有这种词汇分布的倾向性, 主题词的概率分布往往比较平均。
为了量化表示主题词汇分布的这一倾向性, 采用信息熵进行度量。信息熵是在信息论中衡量信息不确定程度的一个指标。当一个随机变量的分布越具有倾向性, 该变量的信息熵也会越小, 表示其不确定性也越小。一个主题可看作是一组词汇的随机分布, 每个词汇的出现概率越具有倾向性, 则该主题的熵值越小, 其越能凸显主题的内容。根据LDA模型输出的“主题-词汇”分布, 可计算出每个主题的信息熵, 其计算如公式(3)所示[23]。
$Entropy(T)=-K\sum\limits_{j=1}^{m}{{{P}_{j}}}\ln ({{P}_{j}})$ (3)
其中, K为常数, Pj表示主题T中第j个词的出现概率, 该主题中共包含m个词汇。
表1表示为语义明确和语义不明确的两个主题的词汇概率分布与信息熵对比, 前者的信息熵小于后者, 反映出明显的词汇倾向性。根据主题词汇分布的倾向性, 可以设置信息熵阈值以过滤掉意义不明确的主题, 阈值则采用人工训练的方式确定。选取一组训练文献, 利用LDA模型识别出K个主题后, 手工筛选出语义明确的一组主题, 分别计算其信息熵, 采用这些主题的平均熵值作为过滤阈值。
表1 主题的词汇概率分布
| 语义明确主题中的词汇 | 词汇分布概率 | 语义不明确主题中的词汇 | 词汇分 布概率 |
|---|---|---|---|
| 多分类 | 0.03297 | 自然语言处理 | 0.02686 |
| 支持向量机 | 0.02890 | 纹路 | 0.02533 |
| 样本 | 0.02484 | 语料 | 0.02488 |
| 增量学习 | 0.02022 | 短语 | 0.02450 |
| 分类 | 0.02004 | 人脸 | 0.02419 |
| 检验 | 0.01625 | 模型 | 0.02374 |
| KNN | 0.01576 | 名词 | 0.02389 |
| 信息熵值 | 0.18 | 信息熵值 | 0.22 |
在识别出的相邻时间段内的主题中, 只有相关主题才能构成主题间的演化关系。为了识别相关主题, 笔者通过计算主题间的相似度来判别两个主题其是否具有相关性。
在相似性度量中, 余弦相似度通过测量两个向量之间夹角的余弦值来度量向量之间的相似性, 但是对于两个时间段内的主题来说, 这种度量方法并不适合。一方面, 相邻时间段内的主题是由不同的LDA模型从不同的文献集中识别出来, 因此识别出的主题并不位于同一向量空间中; 另一方面, 采用LDA模型识别出的主题被表示为一组词汇的概率分布, 而非传统的词汇向量, 因此概率分布间的距离要比余弦相似度更加适于衡量这两者之间的相似性。对于衡量相同事件空间里两个概率分布的差异情况, KL散度(即KL距离或相对熵)是一个主要指标, 其计算如公式(4)所示[24]。
$KL(p||q)=\sum\limits_{i=1}^{n}{p({{x}_{i}})\log \frac{p({{x}_{i}})}{q({{x}_{i}})}}$ (4)
其中, $KL(p||q)$为两个概率分布p和q间的KL距离, xi为概率分布p和q中的第i个词汇, 两个概率分布p和q中的词汇总数均是n。
鉴于KL散度具有不对称性, 即KL(p||q)≠KL(q||p), 并不是一个真正的距离度量, 有学者在KL散度的基础上提出其变种JS散度, 弥补了KL散度的不对称性, 将其改造成为一个真正的距离度量, 如公式(5)[20]所示。
$JS(p||q)=\frac{1}{2}KL(p||\frac{p+q}{2})+\frac{1}{2}KL(q||\frac{p+q}{2})$ (5)
JS散度通常在0到1之间波动, JS值越小, 说明两个主题间的相似性越大。鉴于JS散度作为距离度量比KL散度更为科学, 在本研究中全部采用该度量计算主题间的相似性。
在计算位于不同时间段内两个主题间的JS散度时, 由于这两个主题来自不同的文献集, 不共享同一词汇空间, 因此需对这两个主题中的词汇进行补0操作, 对于两个主题中不重叠的词汇, 在不出现的主题中加以补充并设置其概率为0, 使得两个主题中所含词汇完全相同。
通过度量相邻时间段内主题间的相似性, 可以判断在时间序列上某一主题前后的变化情况, 从而构建主题演化路径。假设j表示当前时间段, j+1表示下一时间段, j-1表示前一时间段, 则Tj为当前时间段内的主题集合, Tj+1为后一时间段内的主题集合, Tj-1为前一时间段内的主题集合, ε表示两个主题间的相似度阈值, 小于该阈值的两个主题被认为具有相关性, 反之则无相关性。相似度阈值采用人工判断的方式确定, 首先根据3.3节所述的主题相关性计算结果, 从两个时间段中手工筛选出K对相似性较大的主题(即两个主题间的JS散度较小), 采用这K对主题的平均JS散度作为相似度阈值。
根据相关主题的前后顺序, 定义相邻时间段内主题间的两种相关关系:
①前向主题: 针对时间段j中的某个主题$T_{j}^{m}$, 找出上一时间段j-1中与$T_{j}^{m}$最相似的主题$T_{j-1}^{n}$, 如果其满足$JS(T_{j}^{m},T_{j-1}^{n})$$\le $ε, 则$T_{j-1}^{n}$为$T_{j}^{m}$的前向主题。
②后向主题: 针对时间段j中的某个主题$T_{j}^{m}$, 找出下一时间段j+1中与主题$T_{j}^{m}$最相似的主题$T_{j+1}^{n}$, 如果其满足$JS(T_{j}^{m},T_{j+1}^{n})$$\le $ε, 则$T_{j+1}^{n}$为$T_{j}^{m}$的后向主题。
根据当前主题与其前向主题和后向主题的关联关系, 可推演出主题的演化情况, 分为新生、消亡、继承、分裂和合并5种演化方式, 具体定义如下[25]。
①新生的主题: 对于当前时间段中的某个主题$T_{j}^{m}$, 如果其不存在前向主题, 则认为$T_{j}^{m}$为新生主题。
②消亡的主题: 对于当前时间段中的某个主题$T_{j}^{m}$, 如果其不存在后向主题, 则认为$T_{j}^{m}$为消亡主题。
③继承的主题: 对于当前时间段中的某个主题$T_{j}^{m}$, 如果其存在前向主题$T_{j-1}^{n}$, 并且主题$T_{j-1}^{n}$的后向主题也是$T_{j}^{m}$, 则认为主题$T_{j}^{m}$继承于主题$T_{j-1}^{n}$。
④分裂的主题: 对于当前时间段中的某个主题$T_{j}^{m}$, 如果前一时间段j-1中存在某个主题$T_{j-1}^{n}$与主题$T_{j}^{m}$相似, 即$\exists $$T_{j-1}^{n}$∈Tj-1, 使得$JS(T_{j}^{m},T_{j-1}^{n})$$\le $ε, 而主题$T_{j-1}^{n}$的后向主题是$T_{j}^{k}$(k≠m), 则认为主题$T_{j-1}^{n}$分裂成为主题$T_{j}^{m}$和$T_{j}^{k}$。
⑤合并的主题: 对于当前时间段中的某个主题$T_{j}^{m}$, 如果后一时间段j+1中存在某个主题$T_{j+1}^{n}$与主题$T_{j}^{m}$相似, 即$\exists $$T_{j+1}^{n}$∈Tj+1, 使得$JS(T_{j}^{m},T_{j+1}^{n})$$\le $ε, 而主题$T_{j+1}^{n}$的前向主题是$T_{j}^{k}$(k≠m), 则认为主题$T_{j}^{m}$和$T_{j}^{k}$合并为 主题$T_{j+1}^{n}$。
为验证本文所提出的学科主题演化分析方法的有效性, 以“机器学习”领域为例进行学科主题演化的实证分析。为了获得分析语料, 以“机器学习”为检索词, 以主题为检索项, 以2007年-2016年为时间跨度, 从CNKI的中国学术期刊网络出版总库中检索得到5 930篇中文期刊论文的题录数据, 并从中抽取出每篇论文的标题和摘要作为主题识别和分析的语料。将上述语料进行时间离散, 以两年为单位, 按照论文的发表年度将其划分到5个不同的时间段中(即2007-2008, 2009-2010, 2011-2012, 2013-2014, 2015-2016)。以清华大学的THULAC[26]作为分词工具, 对标题和摘要文本进行汉语分词处理, 并去除停用词。为了达到更好的分词效果, 自定义用户词典, 将文献中的作者关键词和叙词表中有关计算机技术的术语添加到用户词典, 提高机器学习领域语料分词的正确性。
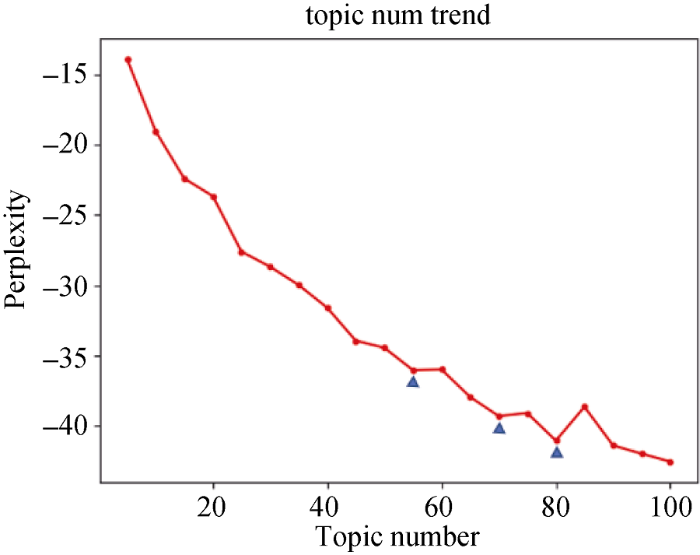
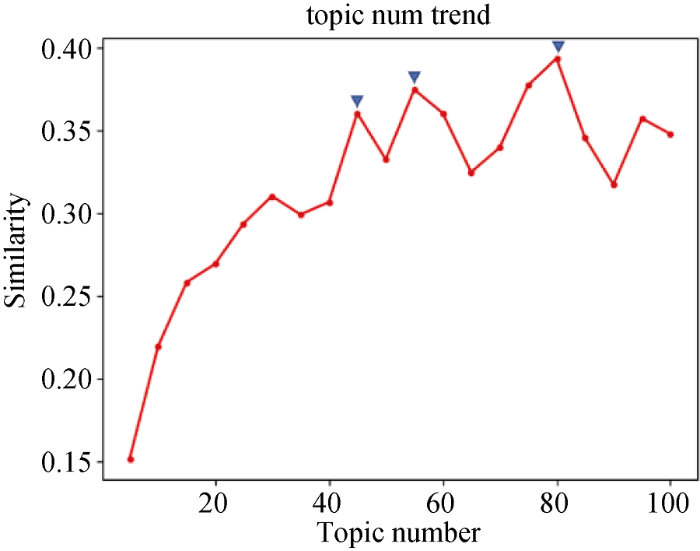
采用LDA模型分别识别出5个时间段内文献的主题。根据3.1节所述, 预先设定几个不同的主题个数K, 分别计算每个时间段内不同主题个数下的主题困惑度和平均相似度, 得到“困惑度-主题个数”和“主题平均相似度-主题个数”两条分布曲线。以2007-2008时间段为例, 预估主题个数K从5到100, 步行为5, 根据困惑度公式(1)得到图2所示的困惑度随主题个数的变化曲线; 根据主题平均相似度计算公式(2), 得到图3所示的主题平均相似度随主题个数的变化曲线。
从图2和图3可以看出, 在2007-2008时间段中, 困惑度曲线在主题数为55、71和80时出现拐点(三角形标记), 主题平均相似度曲线则在主题数为45、58和80时出现拐点(三角形标记), 两者在主题数80时拐点重合, 且主题平均相似度最大。根据本文所提主题个数确定方法, 设定该时间段内的主题个数为80。
表2为在2007-2008时间段内采用LDA模型识别出的80个主题中的部分主题。针对每个主题, 只展示在主题中出现概率较高的前10个词汇。
表2 2007-2008时间段“机器学习”领域的部分主题
| 主题序号 | 主题 | 主题词汇 |
|---|---|---|
| T 4 | 模式识别 | 粗糙集理论 分类 模式识别 遥感 构造 评价 基准 函数 损失 适应性 |
| T 8 | 支持向量机 | 多类分类 模糊支持向量机 样本 增量学习 分类 检验 KNN 函数 查全率 样本 |
| T 21 | 故障诊断 | 诊断 最小化 经验 风险 变化 样本 支持向量机 高纬 线性 企业 |
| T35 | 图像识别 | 图像 特征 核函数 支持向量机 识别 算法 分类器 检测 过滤 空间 |
| T64 | Agent系统 | Agent 服务 强化学习 指导 数学模型 函数 标注 仿真 策略 分支 |
| T53 | 朴素贝叶斯 | 智能 系统 朴素贝叶斯 学习 效率 决策 环境 知识 规则 先验 |
| T23 | / | 自然语言 纹路 语料 短语 人脸 处理 模型 名词 统计 信息 |
| T26 | / | 随机 模糊性 编程 毕业 统计分析 最终 不完整数据 办理 公文 知识 |
| T48 | / | 正确性 查询 目的 流程模式 主观 指标 地名 大坝 教学质量 标识 |
从表2可以看出, 有些主题所含的高概率词汇能够较好地反映主题的内容, 譬如, 主题T 35所含词汇基本都与“图像识别”相关, 如“图像”、“特征”、“核函数”等。但是并不是所有主题都是具有清晰、明确的含义, 譬如, 主题T 23中的词汇“自然语言”、“名词”、“短语”反映的是“自然语言处理”方面的内容, 而“纹路”、“人脸”等词汇则反映的是“图像识别”方面的内容, 因此有必要对这些内容表达不明确的主题进行过滤。
根据3.2节的主题过滤方法, 对每个时间段内的主题设置过滤阈值, 首先过滤掉在文献集中概率较低的边缘主题, 然后在此基础上过滤掉信息熵值较大的无意义主题。譬如, 在2007-2008时间段内共有文献996篇, 识别出80个主题, 对每个主题在每篇文献中的概率进行累加并除以文献总数得到归一化的主题权值, 将80个主题的权值由大到小进行排序, 中位数为0.025, 因此将过滤阈值设置为0.025, 过滤掉概率较低的25个主题。为了确定无意义主题的过滤阈值, 在2007-2008时间段内手工筛选10个含义非常清晰的主题, 计算得到它们的平均信息熵值为0.2, 将该值作为阈值, 过滤掉24个信息熵值大于0.2的无意义主题。表3为各个时间段所含的文献数量, 以及采用LDA模型初始识别的主题个数和经过过滤后保留的主题个数。
表3 数据集各时间段中所含文献数、识别的主题数和过滤后的主题
| 时间窗口 | 文献数 | 识别的主题数 | 过滤后的主题数 |
|---|---|---|---|
| 2007-2008 | 996 | 80 | 31 |
| 2009-2010 | 973 | 95 | 33 |
| 2011-2012 | 989 | 76 | 29 |
| 2013-2014 | 1 089 | 88 | 35 |
| 2015-2016 | 1 886 | 115 | 52 |
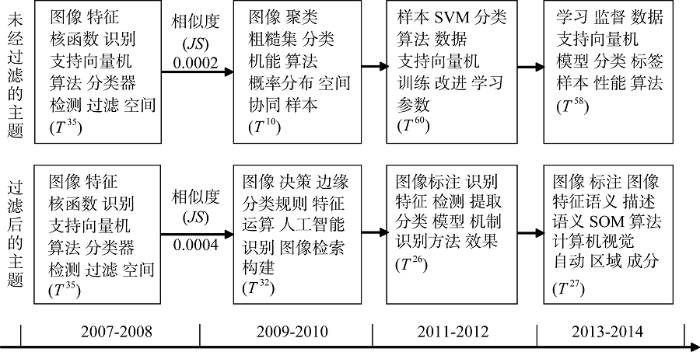
为了验证经过主题过滤是否对主题关联关系构建和主题演化分析有更好的效果, 采用3.3节和3.4节所述的方法, 针对未经过滤的主题和经过过滤后的主题分别构建主题演化路径, 并对主题内容的迁移情况进行分析。图4为“机器学习”领域中有关“图像识别”这一微观领域的主题在过滤和未过滤两种情况下的演化路径。
从图4可以看出, 在2009-2010时间段, 主题T 35在上述两种情况下分别演化为T 10和T 32, 主题中的词汇均发生明显变化, 未过滤情况下的主题T 10(JS= 0.0002)比过滤情况下的主题T 32(JS=0.0004)与主题T 35更相似, 但是主题T 10其实是一个无清晰含义的主题, 它的存在干扰了主题演化路径的构建。这种错误具有迭代性, 一环出现错误, 以至于演化路径中的主题T 60和T 58变成“支持向量机”方面的主题, 而“图像识别”领域本应与“图像标注、图像分类”等内容更相关。采用本文提出的过滤方法, 可将无意义主题T 10过滤掉, 使得相邻时间段中的主题更加密切, 避免演化路径中发生主题偏移, 从而使主题演化路径的构建更加合理、准确。
针对本研究中的实验数据, 以生命周期较长的“图像识别”这一微观领域为例, 构建主题演化路径, 并对主题内容的演化情况进行详细分析。根据3.3节的主题相似性计算方法, 采用公式(5)计算两个相邻时间段中主题的JS散度, 得到主题的相似度矩阵, 表4为有关“图像识别”的部分主题在2011-2012和2013-2014两个时间段内的相似性矩阵。
表4 有关“图像识别”的部分主题的相似性矩阵
| 主题 | $T_{11-12}^{26}$ | $T_{11-12}^{68}$ | $T_{11-12}^{13}$ | … | $T_{11-12}^{7}$ |
|---|---|---|---|---|---|
| $T_{13-14}^{27}$ | 0.00052 | 0.00031 | 0.00105 | … | 0.00131 |
| $T_{13-14}^{31}$ | 0.00333 | 0.02381 | 0.00093 | … | 0.00601 |
| $T_{13-14}^{66}$ | 0.00493 | 0.00512 | 0.00104 | … | 0.00079. |
在(2007-2008)-(2009-2010)和(2009-2010)-(2011- 2012)两个相邻时间段分别手工筛选出5对相似性较大的主题(即两个主题间的JS散度较小), 计算得到这10对主题的平均JS散度为0.0007, 将该值设置为主题间的相似性阈值, 即ε=0.0007。
采用3.4节的演化路径推理方法, 构建出“图像识别”领域的主题演化路径, 如图5所示。对于所涉及主题的词汇分布, 如表5所示。
表5 “图像识别”领域主题中词汇的演变情况
| 主题编号 | 主题 | 主题词 |
|---|---|---|
| $T_{07-08}^{35}$ | 图像识别 | 图像 特征 核函数 支持向量机 识别 算法 分类器 检测 过滤 空间 |
| $T_{09-10}^{32}$ | 图像识别 | 图像 人脑 边缘 分类规则 特征 运算 人工智能 识别 图像检索 构建 |
| $T_{11-12}^{26}$ | 提取图像特征并标注 | 图像标注 识别 特征 检测 提取 分类 模型 机制 识别方法 效果 |
| $T_{11-12}^{68}$ | 图像特征标注 | 图像 标注 图像特征 语义描述 语义 SOM算法 计算机视觉 自动 区域 成分 |
| $T_{13-14}^{27}$ | 图像标注与识别 | 图像 标注 特征 检测 识别 特征提取 人脸 算法 目标 空间 |
| $T_{15-16}^{41}$ | 基于深度学习的图像识别 | 深度学习 图像处理 视觉 行为识别 多层 领域 计算机视觉 底层 高层 学习 |
| $T_{15-16}^{87}$ | 图像识别的用途 | 图像处理 人工智能 精度 特征提取 功能 表征 图像分类 序列 DNA 二维 |
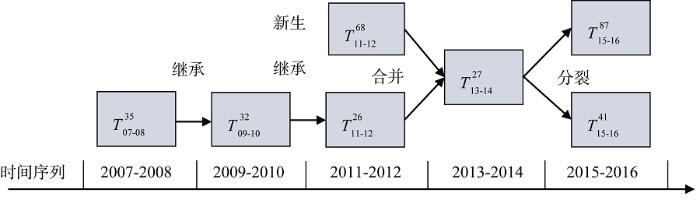
图5中每个节点表示某一时间段中的某一主题, 节点之间的连线表示主题间的演化关系, 具体包括新生、继承、合并、分裂和消亡5种子关系。有关“图像识别”的三个主题$T_{07-08}^{35}$、$T_{09-10}^{32}$、$T_{11-12}^{26}$在2007-2008、2009-2010、2011-2012时间段内存在继承关系, 但是这三个主题在词汇分布上的变化, 反映出主题内容的变化和迁移, 由开始的图像特征识别, 逐渐过渡到图像、分类、特征提取上。在2011-2012时间段产生了新主题$T_{11-12}^{68}$, 内容主要包括图像特征、语义描述、语义等反映图像描述类的词汇。在2013-2014时间片发生了主题合并, 2011-2012时间段的两个主题$T_{\text{11-12}}^{\text{68}}$和$T_{11-12}^{26}$合并为主题$T_{13-14}^{27}$。在2015-2016时间段, 从主题$T_{13-14}^{27}$中分裂出两个主题$T_{15-16}^{41}$和$T_{15-16}^{87}$, 这两个主题都与图像识别和分类相关, 主题$T_{\text{15-16}}^{\text{41}}$主要反映了深度学习在图像识别中的应用, 是在图像识别中引入了新方法, 而主题$T_{15-16}^{87}$则主要反映图像特征的提取、分类及应用。
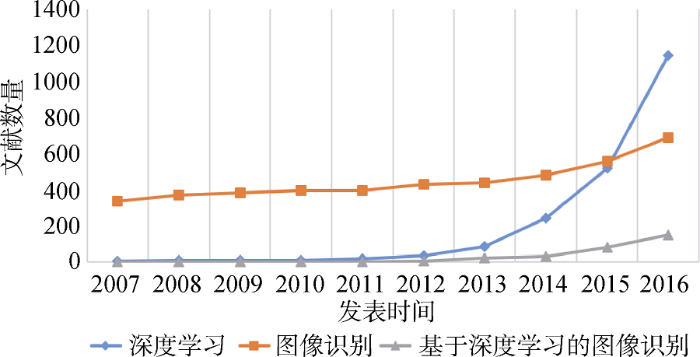
为了进一步验证所构建的有关“图像识别”领域的主题演化路径, 将其与CNKI的中国学术期刊网络出版总库中的发文量曲线对比。分别以“深度学习”、“图像识别”和“深度学习+图像识别”为检索词, 以主题为检索项, 以2007-2016年为时间跨度, 从数据库中检索, 并获取三条发文量曲线, 如图6所示。
从图6可以看出, 在2015-2016年有关深度学习的文献呈大幅上涨趋势, 说明在这个时间段针对深度学习的研究明显加快, 在此时间段有关图像识别的文献也明显增加, 而基于深度学习的图像识别文献增加的更为明显, 由此可推断, 在此时间段深度学习开始逐渐应用于图像识别领域。因此, 图5所示的演化路径在2015-2016时间段分裂出两个新主题$T_{15-16}^{41}$(基于深度学习的图像识别)和$T_{15-16}^{87}$(图像识别的用途)是合理的, 符合实际情况。
针对“机器学习”领域中的所有实验数据, 所构建的宏观演化路径如图7所示(同样设置阈值ε=0.0007), 分别涉及“故障诊断”、“模式识别”、“支持向量机”和“Agent系统”等代表性主题。
图7中, 演化路径自上向下进行, 同一时间段的主题分布在同一水平线上, 主题间的连线代表主题间具有相关性, 构成各类演化关系, 与图5类似, 在此不做详述。
本文提出一种基于主题过滤和主题关联的主题演化分析改进方法, 以主题在文献中的贡献率和主题中词汇的概率分布为依据, 过滤掉无意义的噪音主题, 将不同时间段中过滤后的主题按相似性建立关联, 提高了相邻时间段内主题间的关联准确性, 并可根据主题向前、向后推理构建主题的演化路径。
在构建主题内容演化路径时, 主题相似度阈值(ε)过大或过小都会影响演化路径的构建。本文采用人工判断的方式, 以相邻时间段最相似的K对主题的平均JS散度作为阈值设置标准, 这种方法具有一定的主观性, 难免造成主题演化路径的误差, 需进一步研究如何更科学地选择阈值。此外, 本研究是以文献的标题和整篇摘要为语料对学科主题的内容迁移和生命周期变化进行粗粒度演化分析。随着语义出版的发展, 对学术文献的研究逐渐深入到细粒度层面, 如结构化摘要等。学科主题的演化也应从这些深度结构化信息入手, 如抽取结构化摘要中的问题、方法和结论等信息, 从细粒度层面研究学科主题演化问题。
曲佳彬: 提出研究思路, 分析数据, 进行实验, 起草及修改论文;
欧石燕: 提出研究方向, 论文修改及最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: jiabinqu@ytu.edu.cn。
[1] 曲佳彬. topic.zip. LDA模型识别的主题及过滤后的主题.
[2] 曲佳彬. simTopic.cvs. 主题相似度矩阵.
| [1] |
基于共词分析的学科主题演化方法改进研究 [J].
学科主题演化是情报分析人员采用一定的信息技术方法观察主题在时 间维度上的发展、变化趋势以及不同主题之间的交互作用,它已成为情报研究的一项重要内容。基于词频或共现词频的共词分析方法难以反映主题词对间更层次的语 义关系,针对这一情况,提出一种改进的共词分析方法,该方法体现主题词、主题和文档间的层次语义关系,以更微观、精确的语义层面展现主题演化过程。
Research on the Improvement of Subject Evolution Method Based on Co-word Analysis [J].
学科主题演化是情报分析人员采用一定的信息技术方法观察主题在时 间维度上的发展、变化趋势以及不同主题之间的交互作用,它已成为情报研究的一项重要内容。基于词频或共现词频的共词分析方法难以反映主题词对间更层次的语 义关系,针对这一情况,提出一种改进的共词分析方法,该方法体现主题词、主题和文档间的层次语义关系,以更微观、精确的语义层面展现主题演化过程。
|
| [2] |
基于共词分析法的学科主题演化研究进展与分析 [J].https://doi.org/10.13266/j.issn.0252-3116.2015.05.020 URL [本文引用: 1] 摘要
[目的/意义]分析学科主题演化趋势,对科研人员研究学科知识、决策层规划学科布局都有重要意义。相比于词频分析法和共引分析法,共词分析法的优势是能深入文献内部,从微观角度揭示学科主题演化规律。分析中国国内基于共词分析法的学科主题演化研究现状,以期为相关研究人员提供参考和借鉴。[方法/过程]采用人工判读法提炼出基于共词分析法的学科主题演化研究分析流程的5个步骤,并对每个步骤中研究人员使用的策略、分析手段和工具进行归纳总结。[结果/结论]数据集的来源数据库主要有综合类、专门类和引文类等3种,检索策略有基于词、基于期刊和复合检索策略等3种;共词分析对象来源主要为作者关键词,关键词选取主要基于关键词词频、关键词头现词频和前两者相结合3个角度;构建共词矩阵时使用得最多的归一化系数为ochiai系数;最常用的主题演化分析手段为聚类分析和社会网络分析图谱;使用得最频繁的工具为SPSS软件。
Development and Analysis of Subject Theme Evolution Based on Co-word Analysis Method [J].https://doi.org/10.13266/j.issn.0252-3116.2015.05.020 URL [本文引用: 1] 摘要
[目的/意义]分析学科主题演化趋势,对科研人员研究学科知识、决策层规划学科布局都有重要意义。相比于词频分析法和共引分析法,共词分析法的优势是能深入文献内部,从微观角度揭示学科主题演化规律。分析中国国内基于共词分析法的学科主题演化研究现状,以期为相关研究人员提供参考和借鉴。[方法/过程]采用人工判读法提炼出基于共词分析法的学科主题演化研究分析流程的5个步骤,并对每个步骤中研究人员使用的策略、分析手段和工具进行归纳总结。[结果/结论]数据集的来源数据库主要有综合类、专门类和引文类等3种,检索策略有基于词、基于期刊和复合检索策略等3种;共词分析对象来源主要为作者关键词,关键词选取主要基于关键词词频、关键词头现词频和前两者相结合3个角度;构建共词矩阵时使用得最多的归一化系数为ochiai系数;最常用的主题演化分析手段为聚类分析和社会网络分析图谱;使用得最频繁的工具为SPSS软件。
|
| [3] |
Latent Dirichlet Allocation [J]. |
| [4] |
基于LDA模型的研究领域热点及趋势分析 [J].LDA-based Research Domain Hotspots and Trend Analysis [J]. |
| [5] |
基于LDA话题演化研究方法综述 [J].https://doi.org/10.3969/j.issn.1003-0077.2010.06.007 URL Magsci [本文引用: 1] 摘要
语义数据的内积计算是个难点问题,制约了有关语义数据的核分类方法的研究和发展。针对此问题,通过给出一种语义数据相异性度量测度的新定义、计算语义数据内积的简化方法、研究核方法和支撑向量机中的核函数的本质,提出了一种语义数据的核分类方法,并把方法向语义数据、连续属性构成的异构数据的分类问题进行了拓展。仿真实验表明方法具有一定的抗离群数据干扰能力,方法的总体性能优于文献中已有的其他方法。通过在异常检测领域中的应用研究,说明方法能高效地实现不平衡数据的分类,具有一定的实用价值。
A Survey of Topic Evolution Based on LDA [J].https://doi.org/10.3969/j.issn.1003-0077.2010.06.007 URL Magsci [本文引用: 1] 摘要
语义数据的内积计算是个难点问题,制约了有关语义数据的核分类方法的研究和发展。针对此问题,通过给出一种语义数据相异性度量测度的新定义、计算语义数据内积的简化方法、研究核方法和支撑向量机中的核函数的本质,提出了一种语义数据的核分类方法,并把方法向语义数据、连续属性构成的异构数据的分类问题进行了拓展。仿真实验表明方法具有一定的抗离群数据干扰能力,方法的总体性能优于文献中已有的其他方法。通过在异常检测领域中的应用研究,说明方法能高效地实现不平衡数据的分类,具有一定的实用价值。
|
| [6] |
Topic over Time: A Non-Markov Continuous-Time Model of Topical Trends [C] // |
| [7] |
基于LDA挖掘计算机科学文献的研究主题 [J].
【目的】运用文本挖掘技术自动从海量科技文献中提取研究主题并探测其研究趋势。【方法】以《中文核心期刊要目总览(2014年版))—"TP自动化技术、计算机技术"栏目前10种期刊刊载的计算机科学类(Computer Science)文献为研究对象,借助LDA主题模型,考虑科技文献的发表时间信息,挖掘出典型话题,并根据主题强度分析主题的演化趋势。【结果】18个研究话题中有7个主题强度上升的主题和6个主题强度下降的主题。【局限】仅分析了国内计算机领域的前10种期刊,期刊范围不够大,也未考虑国外计算机领域的期刊文献。【结论】该方法能够深入挖掘计算机领域期刊文献的话题,帮助从事该领域研究的学者了解主题的演化趋势并寻找新兴研究主题。
Extracting Topics of Computer Science Literature with LDA Model [J].
【目的】运用文本挖掘技术自动从海量科技文献中提取研究主题并探测其研究趋势。【方法】以《中文核心期刊要目总览(2014年版))—"TP自动化技术、计算机技术"栏目前10种期刊刊载的计算机科学类(Computer Science)文献为研究对象,借助LDA主题模型,考虑科技文献的发表时间信息,挖掘出典型话题,并根据主题强度分析主题的演化趋势。【结果】18个研究话题中有7个主题强度上升的主题和6个主题强度下降的主题。【局限】仅分析了国内计算机领域的前10种期刊,期刊范围不够大,也未考虑国外计算机领域的期刊文献。【结论】该方法能够深入挖掘计算机领域期刊文献的话题,帮助从事该领域研究的学者了解主题的演化趋势并寻找新兴研究主题。
|
| [8] |
基于种子文档LDA话题的演化研究 [J].Topic Evolution Based on Seminal Document and Topic Model [J]. |
| [9] |
一种话题演化建模与分析方法 [J].https://doi.org/10.3724/SP.J.1004.2012.01690 URL [本文引用: 1] 摘要
根据时序关系将文本流划分为连续时间片中的文本集,在线抽取各时间片中隐含的子话题,采用模型选择方法动态确定各时间片包含的子话题数,以历史时间片的子话题信息作为当前子话题发现的先验知识,基于OLDA(Online latent Dirichlet allocation)模型抽取各时间片包含的子话题,通过Gibbs抽样对话题模型参数进行估计;对子话题进行关联分析,定义子话题产生、消亡、继承、分裂和合并五种演化类型,提出基于相对熵的子话题关联分析方法,根据子话题语义相似度和时序关系建立子话题间的关联,由具有时序关系和内容关联的子话题组成话题,通过子话题内容和强度的变化描述话题演化.基于真实网络新闻的话题演化分析实验表明,本文提出的话题演化分析方法能够有效检测网络新闻话题内容和强度的演化.
Modeling and Analyzing Topic Evolution [J].https://doi.org/10.3724/SP.J.1004.2012.01690 URL [本文引用: 1] 摘要
根据时序关系将文本流划分为连续时间片中的文本集,在线抽取各时间片中隐含的子话题,采用模型选择方法动态确定各时间片包含的子话题数,以历史时间片的子话题信息作为当前子话题发现的先验知识,基于OLDA(Online latent Dirichlet allocation)模型抽取各时间片包含的子话题,通过Gibbs抽样对话题模型参数进行估计;对子话题进行关联分析,定义子话题产生、消亡、继承、分裂和合并五种演化类型,提出基于相对熵的子话题关联分析方法,根据子话题语义相似度和时序关系建立子话题间的关联,由具有时序关系和内容关联的子话题组成话题,通过子话题内容和强度的变化描述话题演化.基于真实网络新闻的话题演化分析实验表明,本文提出的话题演化分析方法能够有效检测网络新闻话题内容和强度的演化.
|
| [10] |
基于主题关联的知识演化路径识别研究——以3D打印领域为例 [J].https://doi.org/10.13266/j.issn.0252-3116.2016.05.015 URL [本文引用: 1] 摘要
[目的 /意义]科技创新需要快速发现特定科技领域中关键知识衍生与演化的路径,探索未来的知识创新趋势,为此,有必要对知识演化路径进行动态可视化研究。[方法 /过程]从主题关联的角度入手,以3D打印领域为例,基于LDA识别出科技创新主题并进行分阶段细化分析,探测主题集群内部与外部的关联强度,识别出主题不同生命周期的演化能力及其演化类型。[结果 /结论]实验结果表明,该方法从主题关联的角度入手,构建了基于时间序列的知识演化路径,丰富了知识管理和信息计量的理论研究方法,在实践上则有助于探测科技创新知识。
Identification of Knowledge Evolutionary Path Based on Topic Relevance: Taking the Case of 3D Printing Field [J].https://doi.org/10.13266/j.issn.0252-3116.2016.05.015 URL [本文引用: 1] 摘要
[目的 /意义]科技创新需要快速发现特定科技领域中关键知识衍生与演化的路径,探索未来的知识创新趋势,为此,有必要对知识演化路径进行动态可视化研究。[方法 /过程]从主题关联的角度入手,以3D打印领域为例,基于LDA识别出科技创新主题并进行分阶段细化分析,探测主题集群内部与外部的关联强度,识别出主题不同生命周期的演化能力及其演化类型。[结果 /结论]实验结果表明,该方法从主题关联的角度入手,构建了基于时间序列的知识演化路径,丰富了知识管理和信息计量的理论研究方法,在实践上则有助于探测科技创新知识。
|
| [11] |
一种基于LDA的在线主题演化挖掘模型 [J].https://doi.org/10.3969/j.issn.1002-137X.2010.11.037 URL [本文引用: 1] 摘要
基于文本内容的隐含语义分析建立在线主题演化计算模型,通过追踪不同时间片内主题的变化趋势进行主题演化分析。将Latent Dirichlet Allocation(LDA)模型扩展到在线文本流,建立并实现了在线LDA模型;利用前一时间片的后验概率影响当前时间片的先验概率来维持主题间的连续性;根据改进的增量Gibbs算法进行推理,获取主题-词和文档-主题的概率分布,利用Kullback Leibler(KL)相对熵来衡量主题之间的相似度,从而发现主题演化中的"主题遗传"和"主题变异"。实验结果表明,该模型能从互联网语料中找出主题的演化趋势,具有良好的效果。
LDA-based Model for Online Topic Evolution Mining [J].https://doi.org/10.3969/j.issn.1002-137X.2010.11.037 URL [本文引用: 1] 摘要
基于文本内容的隐含语义分析建立在线主题演化计算模型,通过追踪不同时间片内主题的变化趋势进行主题演化分析。将Latent Dirichlet Allocation(LDA)模型扩展到在线文本流,建立并实现了在线LDA模型;利用前一时间片的后验概率影响当前时间片的先验概率来维持主题间的连续性;根据改进的增量Gibbs算法进行推理,获取主题-词和文档-主题的概率分布,利用Kullback Leibler(KL)相对熵来衡量主题之间的相似度,从而发现主题演化中的"主题遗传"和"主题变异"。实验结果表明,该模型能从互联网语料中找出主题的演化趋势,具有良好的效果。
|
| [12] |
基于LDA主题关联过滤的领域主题演化研究 [J].
【目的】发现领域文献中主题的新生、消亡、继承、分裂和合并的演化轨迹。【方法】根据文献出版时间划分多个时间窗口,通过LDA主题模型识别各个时间窗口中的主题;利用主题关联(Topic Association)过滤规则确定相邻时间窗口主题间的演化关系;形成连续时间段内主题新生、消亡、继承、分裂和合并的演化轨迹。【结果】在保证主题延续性的条件下,更准确地识别主题的新生、消亡、继承、分裂和合并的演化类型。【局限】固定的时间窗口,未考虑主题演化周期的多样性。【结论】该方法可以有效降低LDA主题模型中相似度较小主题的干扰,提升主题演化关系识别的准确性。
Topic Evolution Research on a Certain Field Based on LDA Topic Association Filter [J].
【目的】发现领域文献中主题的新生、消亡、继承、分裂和合并的演化轨迹。【方法】根据文献出版时间划分多个时间窗口,通过LDA主题模型识别各个时间窗口中的主题;利用主题关联(Topic Association)过滤规则确定相邻时间窗口主题间的演化关系;形成连续时间段内主题新生、消亡、继承、分裂和合并的演化轨迹。【结果】在保证主题延续性的条件下,更准确地识别主题的新生、消亡、继承、分裂和合并的演化类型。【局限】固定的时间窗口,未考虑主题演化周期的多样性。【结论】该方法可以有效降低LDA主题模型中相似度较小主题的干扰,提升主题演化关系识别的准确性。
|
| [13] |
基于LDA模型的科技期刊主题演化研究 [J].https://doi.org/10.3969/j.issn.1002-1965.2014.07.021 URL [本文引用: 1] 摘要
提出一种基于LDA(Latent Dirichlet Allocation)潜在语义模型、全面研究科技期刊主题演化过程的方法。该方法根据科技期刊的特点引入时间因素,使用困惑度确定最优主题数目,通过LDA主题提取结果及JS散度,实现主题在强度和内容两方面的演化研究,并对不同时间窗口的主题稳定性做出相应分析。实验结果表明该方法可以较好地分析某一特定科技期刊的主题随时间的强度演化规律以及主题内容的演化趋势。
On Topic Evolution of a Scientific Journal Based on LDA Model [J].https://doi.org/10.3969/j.issn.1002-1965.2014.07.021 URL [本文引用: 1] 摘要
提出一种基于LDA(Latent Dirichlet Allocation)潜在语义模型、全面研究科技期刊主题演化过程的方法。该方法根据科技期刊的特点引入时间因素,使用困惑度确定最优主题数目,通过LDA主题提取结果及JS散度,实现主题在强度和内容两方面的演化研究,并对不同时间窗口的主题稳定性做出相应分析。实验结果表明该方法可以较好地分析某一特定科技期刊的主题随时间的强度演化规律以及主题内容的演化趋势。
|
| [14] |
Dynamic Topic Models [C]// |
| [15] |
基于DTM的国内外情报学研究主题热度演化对比研究 [J].
[目的/意义] 为揭示情报学领域近15年的研究方向和发展演化情况,了解和掌握研究主题热度的动态变化。[方法/过程] 基于动态主题模型(Dynamic Topic Model),以国内外情报学领域影响因子较高的6本核心期刊作为数据集,分析国内外情报学研究主题演化过程,从主题热度的宏观维度和词语变化的微观角度入手,对比分析主题的研究内容和研究热度异同点,以期为我国情报学研究提供参考和借鉴。[结果/结论] 研究结果表明,国内情报学研究内容偏重实际应用,国外偏重于技术与方法的创新;同一研究主题在不同时期涉及研究内容差别明显,导致其研究热度随着时间推移发生变化;相对于国内,国外情报学研究主题传承性和递进性更强,热度变化较小。
A Comparative Study on Topic Heats Evolution in the Field of Information Science Between the Domestic and Foreign Research Based on DTM [J].
[目的/意义] 为揭示情报学领域近15年的研究方向和发展演化情况,了解和掌握研究主题热度的动态变化。[方法/过程] 基于动态主题模型(Dynamic Topic Model),以国内外情报学领域影响因子较高的6本核心期刊作为数据集,分析国内外情报学研究主题演化过程,从主题热度的宏观维度和词语变化的微观角度入手,对比分析主题的研究内容和研究热度异同点,以期为我国情报学研究提供参考和借鉴。[结果/结论] 研究结果表明,国内情报学研究内容偏重实际应用,国外偏重于技术与方法的创新;同一研究主题在不同时期涉及研究内容差别明显,导致其研究热度随着时间推移发生变化;相对于国内,国外情报学研究主题传承性和递进性更强,热度变化较小。
|
| [16] |
国内基于主题模型的科技文献主题发现及演化研究进展 [J].https://doi.org/10.13266/j.issn.0252-3116.2016.03.019 URL [本文引用: 1] 摘要
[目的 /意义]分析中国国内基于主题模型的科技文献主题发现及演化研究进展,以期为相关研究人员提供参考借鉴及研究思路。[方法 /过程]选取中国知网(CNKI)数据库及万方数据知识服务平台作为文献来源,检索并筛选相关文献,通过人工判读提炼出基于主题模型的科技文献主题发现及演化研究的分析流程,并采用文献分析法对流程中国内研究人员所使用到的策略、方法、分析手段等进行归纳和总结。[结果 /结论]研究已初具规模,形成较为完整的分析流程,同时各个流程环节上所涉及到的策略、方法和分析手段较为多样化。另外,也存在着一些问题:主题模型方法在科技文献领域的应用尚且不成熟,主题数目固定,缺少对主题模型应用效果的评价方法与准则。
Research Progress of Scientific and Technical Literature Topic Detection and Evolution Based on Topic Model in China [J].https://doi.org/10.13266/j.issn.0252-3116.2016.03.019 URL [本文引用: 1] 摘要
[目的 /意义]分析中国国内基于主题模型的科技文献主题发现及演化研究进展,以期为相关研究人员提供参考借鉴及研究思路。[方法 /过程]选取中国知网(CNKI)数据库及万方数据知识服务平台作为文献来源,检索并筛选相关文献,通过人工判读提炼出基于主题模型的科技文献主题发现及演化研究的分析流程,并采用文献分析法对流程中国内研究人员所使用到的策略、方法、分析手段等进行归纳和总结。[结果 /结论]研究已初具规模,形成较为完整的分析流程,同时各个流程环节上所涉及到的策略、方法和分析手段较为多样化。另外,也存在着一些问题:主题模型方法在科技文献领域的应用尚且不成熟,主题数目固定,缺少对主题模型应用效果的评价方法与准则。
|
| [17] |
A Density-based Method for Adaptive LDA Model Selection [J].https://doi.org/10.1016/j.neucom.2008.06.011 URL [本文引用: 1] 摘要
Topic models have been successfully used in information classification and retrieval. These models can capture word correlations in a collection of textual documents with a low-dimensional set of multinomial distribution, called “topics”. However, it is important but difficult to select the appropriate number of topics for a specific dataset. In this paper, we study the inherent connection between the best topic structure and the distances among topics in Latent Dirichlet allocation (LDA), and propose a method of adaptively selecting the best LDA model based on density. Experiments show that the proposed method can achieve performance matching the best of LDA without manually tuning the number of topics.
|
| [18] |
科技情报分析中LDA主题模型最优主题数确定方法研究 [J].
【目的】有效确定科技情报分析中LDA主题模型的最优主题数目。【方法】利用主题相似度度量潜在主题之间的差异,同时结合困惑度提出一种确定LDA最优主题数目的方法,该方法既考虑主题抽取效果同时也考虑模型对新文档的泛化能力。【结果】获取国内新能源领域的科技文献作为数据集,实证结果表明本文提出的最优LDA主题数确定方法与单纯使用困惑度相比,具有更高的主题抽取查准率(91.67%)、F值(86.27%)及科技文献推荐精度(71.25%)。【局限】未针对其他类型的数据集进行新方法的验证,如微博短文本、XML文档等。【结论】本文方法能够有效地从科技文献数据集中抽取辨识度较高的主题,并能够提高科技文献推荐效果。
Identifying Optimal Topic Numbers from Sci-Tech Information with LDA Model [J].
【目的】有效确定科技情报分析中LDA主题模型的最优主题数目。【方法】利用主题相似度度量潜在主题之间的差异,同时结合困惑度提出一种确定LDA最优主题数目的方法,该方法既考虑主题抽取效果同时也考虑模型对新文档的泛化能力。【结果】获取国内新能源领域的科技文献作为数据集,实证结果表明本文提出的最优LDA主题数确定方法与单纯使用困惑度相比,具有更高的主题抽取查准率(91.67%)、F值(86.27%)及科技文献推荐精度(71.25%)。【局限】未针对其他类型的数据集进行新方法的验证,如微博短文本、XML文档等。【结论】本文方法能够有效地从科技文献数据集中抽取辨识度较高的主题,并能够提高科技文献推荐效果。
|
| [19] |
一种基于密度的自适应最优LDA模型选择方法 [J].A Method of Adaptively Selecting Best LDA Model Based on Density [J]. |
| [20] |
On the Eectiveness of the Skew Divergence for Statistical Language Analysis [C]// |
| [21] |
Topic Significance Ranking of LDA Generative Models[A]// Machine Learning and Knowledge Discovery in Databases [M]. |
| [22] |
基于LDA的中文科技文献话题演化研究 [D].The Research on Topic Evolution for Chinese Literature of Science and Technology Based on LDA [D]. |
| [23] |
Information Theory, Inference, and Learning Algorithms [M]. |
| [24] |
Divergence Measures Based on Shannon Entropy [J].https://doi.org/10.1109/18.61115 URL [本文引用: 1] 摘要
A novel class of information-theoretic divergence measures based on the Shannon entropy is introduced. Unlike the well-known Kullback divergences, the new measures do not require the condition of absolute continuity to be satisfied by the probability distributions involved. More importantly, their close relationship with the variational distance and the probability of misclassification error are established in terms of bounds. These bounds are crucial in many applications of divergence measures. The measures are also well characterized by the properties of nonnegativity, finiteness, semiboundedness, and boundedness
|
| [25] |
话题追踪与演化分析技术研究 [D].Research on Topic Tracking and Evolution Analysis Technique [D]. |
| [26] |
THULAC: 一个高效的中文词法分析工具包 [EB/OL]. [THULAC: An Efficient Chinese Lexical Analysis Toolkit [EB/OL]. [ |

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}