张李义 , 李一然, 文璇
, 李一然, 文璇
武汉大学信息管理学院 武汉 430072
Zhang Liyi, Li Yiran, Wen Xuan
中图分类号: TP391 G35
通讯作者:
收稿日期: 2018-07-26
修回日期: 2018-07-26
网络出版日期: 2018-11-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】比较不同算法的预测准确率和效率, 以准确预测有重复购买意向的新消费者, 为客户分类提供理论依据。【方法】基于淘宝网某店铺2015年5月-2018年5月的后台数据, 结合订单与消费者信息, 采用不同的机器学习算法分别进行训练。【结果】融合SMOTE算法与随机森林算法的预测准确率最高, 达到96%。【局限】数据量较小, 属性类别不够全面。【结论】基于SMOTE和随机森林的融合算法对重复购买意向的预测有较高的准确率和效率, 可以为预测新消费者的重复购买意向提供参考。
关键词:
Abstract
[Objective] This paper compares the prediction accuracy and efficiency of different machine learning algorithms, aiming to identify new consumers with repeat purchase intentions. It also provides a theoretical framework for customer classification. [Methods] First, we collected the server logs of a dealer on Taobao.com from 2015 to 2018, as well as its orders and consumers’ personal information. And then, we used different algorithms to train the proposed models. [Results] The SMOTE algorithm combined with the random forest algorithm obtained the highest prediction accuracy of 96%. [Limitations] The sample data size needs to be expanded. [Conclusions] The fusion algorithm based on SMOTE and random forest has better performance in predicting repurchase intentions of new consumers.
Keywords:
随着大数据时代的到来, 各行各业都希望从海量的消费者个人基本信息以及历史交易数据中预测消费者未来购买意向, 电子商务领域更是如此。淘宝网作为中国最大的电子商务交易网站, 注册会员将近5亿, 网站日固定浏览量超过6 000万, 每分钟售出商品4.9万件[1]。采用淘宝网消费者交易数据预测消费者未来购买意向在电子商务领域有一定指导意义。
在电子商务领域预测消费者行为指商家通过分析消费者的个人行为特征、历史交易行为、偏好与兴趣等预测出消费者的需求, 从而为客户分类提供依据, 并实现精准化营销。准确预测出有重复购买意向的新消费者, 通过精准营销可以提升新消费者的价值并将其转化为老客户。
当前对重复购买行为预测的研究多使用机器学习算法、参数估计和仿真的方法。使用机器学习算法侧重于算法的集成, 忽略了数据集对结果的影响。一般在一家店铺中重复购买的消费者比例小于单次购买的消费者, 这就存在数据类别不均衡的问题, 往往会造成模型过拟合, 从而影响分类效果。本文通过挖掘消费者网络购物行为数据分布规律, 使用人工合成少数类的方法均衡各类别数量, 并采用机器学习算法预测有重复购买意向的新消费者。
目前, 对消费者重复购买行为预测的方法主要有参数估计、仿真和机器学习。参数估计中的Pareto/NBD模型(后被称为SMC模型)涉及客户活跃度, 用于预测非契约关系中的重复购买行为[2]。该模型假设活跃客户与企业的交易存在随机性, 交易过程服从泊松分布, 一旦客户流失则永久无法赢回。BG/NBD模型在SMC模型的基础上对客户流失点进行改进, 若假设客户在某次购买后立即流失, 即可用该模型进行建模[3]。以上两个模型均在识别客户群、预测购买频率方面得到广泛应用。
国内相关研究中, 李美其等[4]在非契约情境经典的Pareto/NBD模型中引入协变量, 对用户未来购买行为进行预测研究; 马少辉等[5]提出结合Pareto/NBD模型与购买金额期望模型计算有(无)购买历史客户的终生价值, 并根据其设置客户流失预警点; 陈洁等[6]提出使用购买率对在线消费者进行分类, 根据某网上商城的实际购物面板数据, 使用BG/NBD模型通过前26周的消费情况预测后27周的购买次数, 结果具有较高拟合度; 舒方等[7]通过遗传算法将SMC模型和HIPP模型相结合, 提出一种组合预测方法, 对客户重复购买进行预测。国外相关研究中, Marshall[8]放宽假设购买的条件和对客户流失率的限制, 基于Pareto/NBD模型提出一种适用于较大数据集的简单估计过程; Van Oest等[9]在原始BG/NBD模型中加入客户历史购买投诉信息, 发现顾客购买越快, 则退货越快。
概率分布假设模型(NBD-DM随机模型)、M/G/∞队列模型等经典模型也被用来预测消费者重复购买行为。例如, 马宝龙等[10]通过建立NBD-DM随机模型, 提出一种研究消费者重复购买行为的方法, 并指明该方法在战略及营销管理实践上的意义; 吴国华等[11]利用线形分对数回归模型, 给出一种预测日用消费品重购概率的方法, 并说明其在加强营销管理、制定营销计划和评估营销效果上的意义; Tapiero[12]提出区分购买和重复购买过程的M/G/∞队列模型, 可以调和广告学和经济学在购买过程中的应用; Jacobs等[13]为降低局部最优解的风险使用随机启动程序, 并使用条件后验分布进行采样, 最终利用LDA模型预测消费者可能购买的产品组; 王福华等[14]使用参数估计方法提出经常购买的产品生命周期模型, 并采用实证方法对参数估计方法进行验证, 利用模型对企业产品的销售量进行预测; 叶作亮等[15]通过分析商家交易记录数据得出不同于复购理论的结论, 并建立具有强化效应的购 买概率模型, 解释顾客重复购买率呈幂律分布的现 象, 揭示巨大的潜在顾客数量和顾客多次购买的强化效应。
RFM模型也是一种预测消费者重复购买行为的有效方法, 多应用于市场营销领域, 强调根据近期购买能力和实际需求衡量客户的价值和创利能力[16]。该模型本质上是一种客户细分工具, 通过最近一次消费(Recency)、消费频率(Frequency)和消费金额(Monetary)三项指标, 测算客户的消费价值状况, 从而预测未来行为, 为营销决策提供支持。电子商务领域中使用该模型进行消费者行为预测的研究还比较少。张宁等[17]提出一种引入RFM模型并利用用户购物行为进行相似度计算的新型推荐算法, 根据顾客历史消费记录向顾客推荐个性化商品时有较高的准确性; Reimer等[18]模拟RFM模型与营销之间的重要性, 为消费者重复购买预测开发建模框架; Yeh等[19]从购买时间和流失概率两个参数上扩展RFM模型, 并结合伯努利序列推导公式, 通过实证结果证明其预测准确性优于传统RFM方法。
参数估计与RFM模型基于特定营销背景和假设, 适用于小型数据, 无法进行多维度数据处理和潜在客户识别。基于此, 一些学者使用逻辑回归、支持向量机、决策树与神经网络等机器学习算法, 与大型、多维的真实购买数据相结合, 构建预测模型以达到对重复购买消费者的精准识别。例如王萍[20]使用决策树与神经网络分类技术, 建立客户购买倾向分类模型, 并选用国外某零售超市的销售数据作为样本进行客户购买倾向预测。还有一些研究使用算法融合提升预测准确率, 祝歆等[21]融合逻辑回归与支持向量机算法构建预测模型, 基于阿里巴巴电子商务平台的购物行为数据对用户网络购物行为进行预测; Zhao等[22]使用线性回归、朴素贝叶斯和支持向量机等机器学习方法结合阈值移动方法提出一种预测用户购买及偏好的框架。针对训练数据中类别不均衡的问题, 王克利 等[23]提出随机抽样并赋予各类别不同权重的策略, 基于2017年阿里巴巴竞赛获得的用户购物行为数据, 分别使用SVM与随机森林算法进行用户再次购买行为的预测。
目前, 在机器学习领域有两种解决数据中类不均衡的方法: 一种是给训练集分配不同的损失函数, 使不同的类有不同的成本[24]; 另一种是对原始数据集重采样以达到类别均衡, 如欠采样和过采样。欠采样是对训练集里样本数量较多的类别(多数类)进 行欠采样, 抛弃一些样本缓解类不平衡; 过采样是对训练集里样本数量较少的类别(少数类)进行过采样, 合成新的样本缓解类不平衡[25,26,27]。本文采用经典的合成少数类过采样算法(Synthetic Minority Over- sampling Technique, SMOTE)处理类别不均衡问题。
SMOTE是基于随机过采样算法的改进算法。随机过采样采取复制样本的策略增加少数类样本, 容易产生模型过拟合的问题, 使学习到的信息不够泛化, 而SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中[28], 其算法流程如下。
假设训练集少数类的样本数为T, 其中的一个样本i, 其特征向量为xi, $i\in \{1,2,\cdot \cdot \cdot ,T\}$。
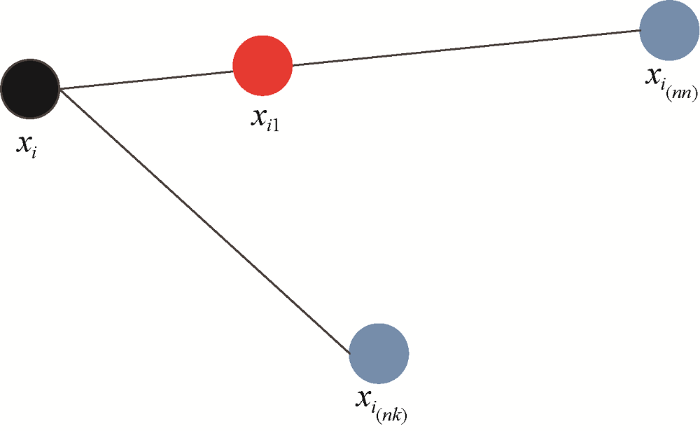
①对于少数类中的每个样本xi, 使用欧氏距离找到其到少数类样本集Smin中所有样本的K个邻近, 记为xi(n), $i\in \{1,2,\cdot \cdot \cdot ,K\}$;
②根据样本不平衡比例设置采样比例N, SMOTE算法认为少数类合成N×T个新样本。对每一个少数类样本xi, 从其K个近邻中随机选取若干个样本, 假设选择的近邻为xi(nn);
③对每一个随机选出的近邻xi(nn), 生成一个0到1之间的随机数rand(0,1), 按照公式(1)与原样本合成新的样本xi1。生成过程如图1所示;
${{x}_{i1}}={{x}_{i}}+\text{rand(}0,1\text{)}\times |{{x}_{i}}-{{x}_{i(nn)}}|$ (1)
④上述步骤重复N次, 合成N个新样本: ${{x}_{i(new)}},$ $new\in \{1,2,\cdot \cdot \cdot ,N\}$。
随机森林(Random Forest, RF)算法的思想最早由Breiman[29]等提出, 作为一种高度灵活的机器学习算法, 拥有广泛的应用前景。随机森林通过集成学习思想将多棵树集成, 它的基本单元是决策树。运用Bagging的思想, 随机森林算法集成所有决策树分类器的投票结果, 最终输出为投票次数最多的类别[29]。其构建过程如下。
①从原始训练集S中使用Bootstraping方法随机有放回地抽取大小和S一样的样本S(i), 共进行n次抽样, 生成n个训练集;
②对n个训练集, 分别训练n个CART决策树模型${{G}_{i}}(x),i\in \{1,2,\cdot \cdot \cdot ,n\}$;
③对第t个决策树模型Gt(x), 假设训练样本特征的维数为W, 随机选择节点上的一部分特征w(w<W), 在wi中根据信息增益指数选择最好的特征进行分裂。对于某个类xi, 其信息定义如公式(2)所示。
$I\text{(}X={{x}_{i}}\text{)}=-{{\log }_{2}}P({{x}_{i}})$ (2)
其中, I(x)表示随机变量的信息, P(xi)表示xi发生的 概率。
④每棵树都按照这样的方式分裂下去, 直到该节点的所有训练样例都属于同一类, 在决策树的分裂过程中不需要剪枝;
⑤将生成的多棵决策树组成随机森林F, 按多棵树分类器投票决定最终分类结果。
模型的泛化误差值越小, 表明其算法性能越好, 随机森林的泛化误差收敛如公式(3)所示[29]。
$\begin{align} & \underset{k\to \infty }{\mathop{\lim }}\,P{{E}^{\text{*}}}={{P}_{X,Y}}({{P}_{\theta }}(h\text{(}X,{{\theta }_{k}})=Y\text{)}- \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \underset{j\ne Y}{\mathop{\max }}\,{{P}_{\theta }}(h\text{(}X,{{\theta }_{k}})=j\text{)}<0) \\ \end{align}$ (3)
其中, PX,Y代表余量函数, $h\text{(}X,{{\theta }_{k}})$代表分类模型序列, 泛化误差收敛反映模型最小化输入样本X对应的正确分类结果Y的得票数超过其他错误分类结果中最多票数的程度。由公式(3)可知, 随机森林模型不会随着决策树数目的增多而陷入过度拟合。
随机森林的各决策树间相关性较小, 模型分类准确率高, 不会过度拟合, 是一个较好的分类模型。
为预测新消费者重复购买意向, 本文从淘宝网某店铺2015年5月-2018年5月的后台订单数据中筛选出重复购买的消费者ID和单次购买的消费者ID, 通过消费者ID爬取反映消费者特性的信息。爬取的消费者特征数据分为消费者个人基本信息、服务难度、近三个月交易数据以及交易行为偏好4大类。爬取 34 221个样本, 其中重复购买消费者3 211个, 单次购买消费者31 010个。
通过对数据进行分析, 结合订单与消费者特性共提取28个属性, 属性及其含义如表1所示。
表1 消费者属性指标集
| 一级属性 | 二级属性 | 属性含义 | |
|---|---|---|---|
| 个人基本信息 | 性别* | {男性; 女性} | |
| 地址* | {一线城市; 二线城市; 三线城市; 四线城市} | ||
| 买家信誉* | {1心; 2心; 3心; 4心; 5心; 1钻; 2钻; 3钻; 4钻; 5钻; 1冠; 2冠; 3冠; 4冠; 5冠} | ||
| 卖家信誉* | {1心; 2心; 3心; 4心; 5心; 1钻; 2钻; 3钻; 4钻; 5钻; 1冠; 2冠; 3冠; 4冠; 5冠} | ||
| 是否实名认证* | {已认证; 未认证} | ||
| 是否有头像* | {是; 否} | ||
| 服务难度 | 异常情况 | 被其他卖家拦截次数 | 消费者被其他淘宝卖家拦截的次数 |
| 是否是云黑名单成员* | {是; 否} | ||
| 服务难度 | 是否给过其他卖家中差评* | {是; 否} | |
| 退款次数 | 消费者的淘宝历史退款次数 | ||
| 退款率 | 消费者的淘宝历史退款次数/总成交次数 | ||
| 评价信誉 | 发出好评率 | 消费者发出的好评数/发出的评价总数 | |
| 收到好评率 | 消费者收到的好评数/收到的评价总数 | ||
| 消费水平 | 购买能力* | 消费者在淘宝的购买能力等级(1-10级) | |
| 购买积极性* | 消费者在淘宝的购买积极性等级(1-10级) | ||
| 交易数据(近三个月) | 历史交易金额 | 消费者近三个月在淘宝的交易总金额 | |
| 历史成交次数 | 消费者近三个月在淘宝的交易成交次数 | ||
| 历史关闭次数 | 消费者近三个月在淘宝的订单关闭次数 | ||
| 订单支付率 | 消费者近三个月在淘宝的支付订单数/总订单数 | ||
| 支付积极性* | 消费者近三个月在淘宝的支付积极性等级 | ||
| 平均客单价 | 消费者近三个月在淘宝的交易总金额/成交次数 | ||
| 近三个月浏览本店次数 | 消费者近三个月浏览本店的次数 | ||
| 交易行为偏好 | 交易平台偏好 | {手机端; 电脑端; 聚划算} | |
| 折扣敏感度* | {不敏感; 一般敏感; 比较敏感; 非常敏感} | ||
属性指标中包含类别型变量和数值型变量, 在进行数据分析前需要将所有数据转化为同度量的数值型数据。处理方法如下。
(1) 类别型变量, 先分类再进行量化。以“地址”为例: 按照一、二、三、四线城市划分标准[30], 将消费者所在城市依次归类到这4类城市, 用1代表“一线城市”, 2代表“二线城市”, 3代表“三线城市”, 4代表“四线城市”; 再如, 在“买家信誉”和“卖家信誉”中, 不同的图标代表不同的信誉值区间, 按照信誉值区间大小将其分为15个等级, 分别用数字1-15表示。其他类别型变量的转化同理。
(2) 数值型变量, 直接用爬取到的原始数值。由于各属性间的数量级不同, 在进行分类时通常会因为较大量级的属性而忽略较小量级的属性, 因此本文统一将数据标准化, 使数据转化为同度量指标。
本实验分为运用独立样本T检验方法进行特征提取、使用合成少数类过采样技术(SMOTE)对不均衡数据集进行处理和运用随机森林(RF)算法分类预测三个阶段。其中独立样本T检验使用SPSS19.0软件实现, 对数据的处理以及分类算法使用PyCharm作为实验平台, 运用Python语言实现。
由于实验提取的属性个数较多, 部分属性在两类间差异过小, 并不能作为分类依据, 使用Python语言 绘制的属性间相关性如图2所示, 大多数指标间相关性较低, 因此本文采用独立样本T检验进行特征提取。
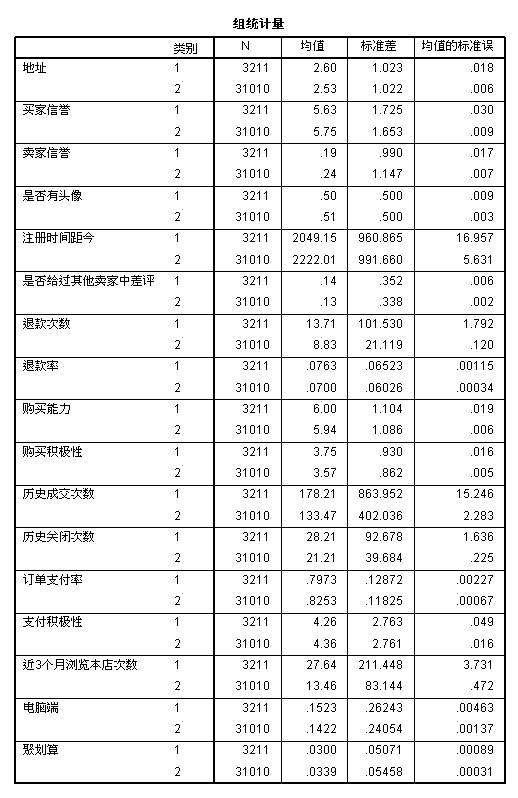
通过T检验共提取出17个有显著性差异的属性, 属性数据集的统计性描述如图3所示。利用消费者的个人基本信息、服务难度、历史交易行为和交易行为偏好揭示重复购买消费者和单次购买消费者的区别。以“历史成交次数”为例, 重复购买消费者近三个月的平均成交次数为178.21次, 高于单次购买消费者近三个月的平均成交次数133.47次。
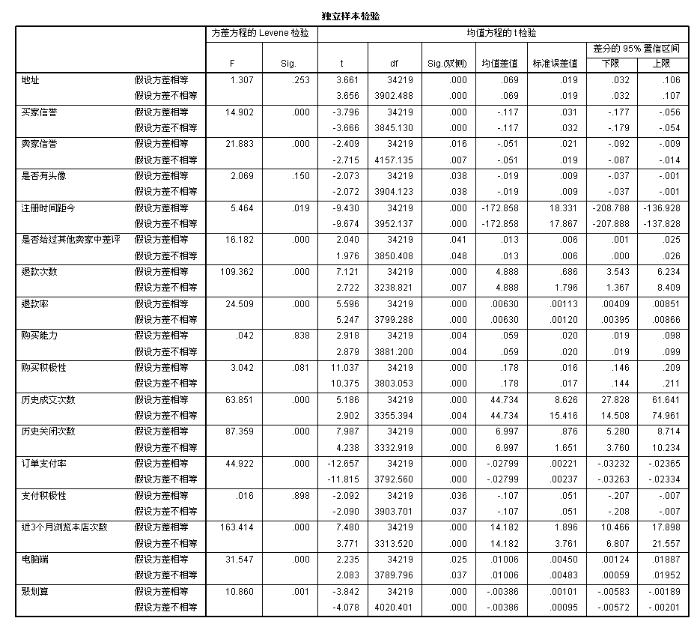
提取出的消费者属性特征独立样本T检验结果如图4所示。其中, “地址”方差方程Levene检验结果显示F值为1.307, Sig.值为0.253, 表示方差齐性检验没有显著差异, 因此在均值方程的T检验结果中参考第一行数据, 即Sig.=0.000, 两样本均数差别有显著性意义。其他属性特征的检验结果均显示显著性差异明显, 因此将上述17个属性用于分类模型进行新消费者重复购买意愿预测。
在本研究爬取的数据中, 重复购买消费者与单次购买消费者数量上存在较大差异, 因此本文采取SMOTE算法扩充少数类, 使两类样本在训练集和测试集上分布均匀。扩充后样本量达62 020条, 其中重复购买消费者样本量增加到31 010条。
本文分别使用Bagging_K近邻算法模型(Bagging_KNN)、SMOTE-Bagging_K近邻算法模型(SMOTE-Bagging_KNN)、决策树算法模型(Decision_tree)、SMOTE-决策树算法模型(SMOTE- Decision_tree)、随机森林算法模型(RF)以及SMOTE-随机森林算法模型(SMOTE-RF)对数据进行训练。
采用准确率(Precision)和召回率(Recall)这两 个在评判分类器中最常用的分类指标作为新消费 者重复购买意向预测的评判标准, 并使用F-score进行总体性能评价[31]。计算方法如公式(4)-公式(6) 所示。
$Precision=\frac{|TP|}{|TP|+|FP|}$ (4)
$Recall=\frac{|TP|}{|TP|+|FN|}$ (5)
$F-score=\frac{2\times Precison\times Recall}{Precision+Recall}$ (6)
其中, $|TP|$表示将重复购买消费者正确判定为重复购买消费者的数量; $|FP|$表示将单次购买消费者错误判定为重复购买消费者的数量; $|FN|$表示 将重复购买消费者错误判定为单次购买消费者的 数量。
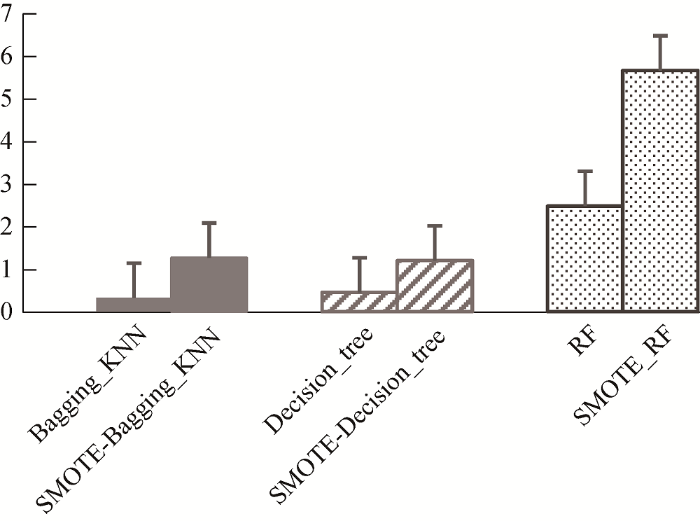
对不同分类模型均选用最优参数将其优化 到最佳结果, 如表2所示。各分类模型训练时长如图5所示。
表2 各分类模型性能对比
| 分类模型 | Precision | Recall | F-Score | 训练 时长(s) |
|---|---|---|---|---|
| Bagging_KNN | 0.88 | 0.90 | 0.86 | 0.320 |
| SMOTE-Bagging_KNN | 0.87 | 0.87 | 0.87 | 1.254 |
| Decision_tree | 0.83 | 0.82 | 0.82 | 0.446 |
| SMOTE-Decision_tree | 0.89 | 0.89 | 0.89 | 1.188 |
| RF | 0.88 | 0.90 | 0.86 | 2.458 |
| SMOTE-RF | 0.96 | 0.95 | 0.95 | 5.614 |
(1) 对比表2中各模型的预测结果, 可以看出Bagging_KNN和RF模型的准确率、召回率以及F-score值相等且高于Decision_tree。无论从准确率、召回率还是性能上来说, 集成算法模型在重复购买意愿预测中都有优越性。
(2) 对比Decision_tree和SMOTE-Decision_tree, RF和SMOTE-RF的准确率、召回率以及F-score值与不融合SMOTE的算法模型对比, 融合SMOTE的算法模型在不均衡数据集上有较大的性能提升。SMOTE-Bagging_KNN与Bagging_KNN相比, 虽然在准确率和召回率上没有提升, 但F-score值的提升说明融合SMOTE后其综合性能有所提升。同时, 与其他两种融合SMOTE的算法对比, SMOTE-RF在三个指标中都表现出最大优势, 其性能提升幅度高于SMOTE-Bagging_KNN(1%)和SMOTE-Decision_tree (7%), 较原来提升近10%, 达95%。可以看出, 在数据集不均衡的情况下, 使用SMOTE对数据进行处理, 能大幅提高分类准确率, 且融合SMOTE的随机森林算法模型在新消费者重复购买意愿预测中有较高的精确度和较优的性能。
(3) 由图5可以看出, 虽然SMOTE-RF模型的训练时间相对较长, 但是相较于不融合SMOTE的算法, RF模型融合SMOTE后增加的训练时间比例最少, SMOTE-RF模型的训练时间约是RF模型的2倍, 而Bagging_KNN模型和Decision_tree模型融合SMOTE后的训练时间分别约是原来的4倍和3倍。
综上, 融合SMOTE的随机森林算法模型在电子商务平台新消费者重复购买意向预测方面有更好的性能。该模型能够为淘宝卖家准确预测出新消费者的重复购买意向, 有助于做好客户分类并进行精准营销。
本文以淘宝网某店铺消费者的个人基本信息、历史交易行为及偏好为研究对象, 使用机器学习算法对新消费者重复购买意向进行预测。实验发现集成算法的预测结果优于单一算法。
机器学习算法虽然以数据为驱动, 但在特征选择、数据集各类别数量、训练集与测试集的划分上采用不同的标准可能有不同的结果。针对数据集极不均衡的情况, 本文使用合成少数类过采样算法SMOTE增加少数类的数据量, 使数据集中各类别数量相对均衡, 减少模型过拟合。使用SMOTE算法在保留原始数据完整性的基础上增加总数据量, 对训练集来说, 有足够多的信息资源进行模拟学习。在此基础上, 测试融合SMOTE算法与Bagging_KNN、Decision_tree和RF算法的优越性。使用SMOTE算法对数据进行处理时预测准确率和模型性能都有一定的提升, 证明在分类时处理类别不均衡的重要性。SMOTE-RF准确率最高, 达96%, 说明在使用Bagging思想进行算法集成时Decision_tree作为分类器比KNN作为分类器更好, 进一步说明RF更适合处理多指标样本。
虽然本文的数据集及算法在预测重复购买意向的准确率上有一定程度的提升, 但是在数据量上还存在局限, 算法上也还不够自主, 需要人工挑选特征。在未来工作中, 要继续跟踪收集数据, 不断扩充数据量, 并在数据达到一定量时使用深度学习进行模型框架的搭建, 使准确率、召回率以及F-score有更大提升。
张李义: 提出研究思路和研究命题, 设计研究方案;
李一然, 文璇: 采集数据, 设计实验过程;
李一然: 预处理及分析数据, 完成实验, 起草论文;
张李义, 李一然: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: yiran_li94@sina.com。
[1] 张李义, 李一然, 文璇. Repurchased.csv. 重复购买与单次购买消费者数据集.
| [1] |
阿里巴巴多元化战略分析 [J].Analysis of Diversification Strategy in Alibaba [J]. |
| [2] |
Counting Your Customers: Who are They and What will They Do Next? [J].https://doi.org/10.1287/mnsc.33.1.1 URL [本文引用: 1] 摘要
This article is concerned with counting and identifying those customers who are still active. The issue is important in at least three settings: monitoring the size and growth rate of a firm's ongoing customer base, evaluating a new product's success based on the pattern of trial and repeat purchases, and targeting a subgroup of customers for advertising and promotions. We develop a model based on the number and timing of the customers' previous transactions. This approach allows computation of the probability that any particular customer is still active. Several numerical examples are used to illustrate applications of the model.
|
| [3] |
客户分析与统计建模[D] .Statistical Models for Customer-base Analysis[D] . |
| [4] |
基于购买行为及评论行为的用户购买预测研究 [J].
随着网络消费的兴起,第三方点评网站也在蓬勃发展,针对非契约情景下用户未来购买行为预测是用户终身价值评估、用户流失管理等研究领域的关键。为了实现用户购买预测研究,选取了大众点评网的用户数据,结合大众点评网的用户行为特征,借鉴非契约情境中经典的Pareto/NBD模型对用户购买行为进行预测研究,同时尝试在原模型的基础上引入协变量,取得了较理想的改进效果,揭示了大众点评网评论平台中的用户评论数据对用户购买数据的预测作用。
Customer Purchase Prediction Based on Buying Behavior and Comment Behavior [J].
随着网络消费的兴起,第三方点评网站也在蓬勃发展,针对非契约情景下用户未来购买行为预测是用户终身价值评估、用户流失管理等研究领域的关键。为了实现用户购买预测研究,选取了大众点评网的用户数据,结合大众点评网的用户行为特征,借鉴非契约情境中经典的Pareto/NBD模型对用户购买行为进行预测研究,同时尝试在原模型的基础上引入协变量,取得了较理想的改进效果,揭示了大众点评网评论平台中的用户评论数据对用户购买数据的预测作用。
|
| [5] |
Pareto/NBD模型实证与应用研究 [J].https://doi.org/10.3969/j.issn.1672-0334.2006.05.007 URL [本文引用: 1] 摘要
对客户未来购买行为预测是客户终身价值评估、客户流失管理等研究领域的关键。近年来由于客户关系管理的兴起,Schmittlein等提出的Pareto/NBD模型作为在非契约条件下描述客户重复购买行为的基础模型得到关注和应用,但对该模型还缺乏实证检验。对Pareto/NBD模型的有关研究进行了简单的回顾,以某专业视频设备零售商近5年的客户购买数据作为样本,用最大似然法进行参数估计,对Pareto/NBD模型有关客户活跃度、客户未来购买期望等方面的预测性能进行实证检验。提出结合Pareto/NBD模型与购买金额期望模型计算有(无)购买历史客户的客户终生价值、根据客户终生价值设置客户流失预警点等方法。
Empirical Study on Pareto/NBD Model and Its Applications [J].https://doi.org/10.3969/j.issn.1672-0334.2006.05.007 URL [本文引用: 1] 摘要
对客户未来购买行为预测是客户终身价值评估、客户流失管理等研究领域的关键。近年来由于客户关系管理的兴起,Schmittlein等提出的Pareto/NBD模型作为在非契约条件下描述客户重复购买行为的基础模型得到关注和应用,但对该模型还缺乏实证检验。对Pareto/NBD模型的有关研究进行了简单的回顾,以某专业视频设备零售商近5年的客户购买数据作为样本,用最大似然法进行参数估计,对Pareto/NBD模型有关客户活跃度、客户未来购买期望等方面的预测性能进行实证检验。提出结合Pareto/NBD模型与购买金额期望模型计算有(无)购买历史客户的客户终生价值、根据客户终生价值设置客户流失预警点等方法。
|
| [6] |
在线渠道消费者动态品牌选择购买率预测 [J].Forecasting the Purchase Rate of Online Consumer’s Dynamic Brand Choice [J]. |
| [7] |
客户重复购买的组合预测方法 [J].https://doi.org/10.3969/j.issn.1006-2475.2015.05.014 URL [本文引用: 1] 摘要
SMC模型是由Schmittlein等人提出,用于描述非契约客户关系情景下客户的重复购买行为。该模型假设客户重复购买行为服从泊松过程,客户一旦流失则不会被赢回。 HIPP模型是由马少辉等人提出,该模型假设客户不会永久流失,而是在活跃和不活跃的状态之间转换。然而在现实中,永久流失和暂时流失的客户都是可能存在的。因此,SMC模型可能会低估重复购买的概率,而HIPP模型可能会高估重复购买的概率。本文提出一种客户重复购买的组合预测方法。该方法利用SMC模型和HIPP模型分别对客户重复购买进行预测,通过遗传算法寻找这2个模型的最优组合权值。通过实证分析,验证了组合预测方法的优越性。
A Composition Forecasting Approach of Customer Repeat Purchasing [J].https://doi.org/10.3969/j.issn.1006-2475.2015.05.014 URL [本文引用: 1] 摘要
SMC模型是由Schmittlein等人提出,用于描述非契约客户关系情景下客户的重复购买行为。该模型假设客户重复购买行为服从泊松过程,客户一旦流失则不会被赢回。 HIPP模型是由马少辉等人提出,该模型假设客户不会永久流失,而是在活跃和不活跃的状态之间转换。然而在现实中,永久流失和暂时流失的客户都是可能存在的。因此,SMC模型可能会低估重复购买的概率,而HIPP模型可能会高估重复购买的概率。本文提出一种客户重复购买的组合预测方法。该方法利用SMC模型和HIPP模型分别对客户重复购买进行预测,通过遗传算法寻找这2个模型的最优组合权值。通过实证分析,验证了组合预测方法的优越性。
|
| [8] |
A Simple Heuristic for Obtaining Pareto/NBD Parameter Estimates [J].https://doi.org/10.1007/s11002-013-9272-z URL [本文引用: 1] 摘要
In an influential study, Schmittlein et al. ( 1987 ) proposed the pareto/negative binomial distribution (P/NBD) model to predict purchase behavior of customers. Despite its recognized relevance, this model has some drawbacks as follows: (1) it does not allow a zero transaction rate, (2) it assumes convenient but not necessarily realistic gamma distributions for the transaction and drop-out rates across customers, and (3) the estimation procedure requires complicated computations. The purpose of this study is to relax the assumption that purchases and drop-out rates are distributed according to a gamma distribution and propose a simple estimation procedure for the individual parameters that can be applied even if the number of customers is large. A simulation exercise and empirical applications to real datasets compare the simple model proposed with the P/NBD model. The results show that the simple procedure is better in cases where the number of transactions and/or the observation period is large. Copyright Springer Science+Business Media New York 2015
|
| [9] |
Erratum to: Extending the BG/NBD: A Simple Model of Purchases and Complaints [J].https://doi.org/10.1016/j.ijresmar.2011.08.001 URL [本文引用: 1] 摘要
78 We incorporate complaints into the well-known purchase-only BG/NBD model. 78 The proposed model is easy to implement and leads to improved forecasts. 78 Though being rare and non-transactional, complaints change inference on purchasing. 78 Complaints increase drop-out after purchase more than they increase purchasing. 78 There is more heterogeneity in drop-out following a purchase than a complaint.
|
| [10] |
回报计划对重复购买行为模式的影响研究 [J].https://doi.org/10.3969/j.issn.1002-1566.2007.03.013 URL [本文引用: 1] 摘要
客户回报计划已成为一种重要的关系营销手段。本文在讨论回报计划如何对稳定市场结构下的重复购买行为产生影响的基础上,通过建立NBD-DM随机模型,提供了一种研究消费者重复购买行为的模型方法,并利用一组护肤品品类销售的固定样本组数据(panel data)对该方法进行了实证分析。结果表明NBD-DM模型是研究消费者重复购买行为的有效模型方法,并且证实回报计划在改变客户重复购买行为上的有效性,其是企业建立长期客户关系的有效手段。最后讨论了结论对战略及营销管理实践的意义。
Effect of Reward Programs on Repeat-purchase Behavior Patterns [J].https://doi.org/10.3969/j.issn.1002-1566.2007.03.013 URL [本文引用: 1] 摘要
客户回报计划已成为一种重要的关系营销手段。本文在讨论回报计划如何对稳定市场结构下的重复购买行为产生影响的基础上,通过建立NBD-DM随机模型,提供了一种研究消费者重复购买行为的模型方法,并利用一组护肤品品类销售的固定样本组数据(panel data)对该方法进行了实证分析。结果表明NBD-DM模型是研究消费者重复购买行为的有效模型方法,并且证实回报计划在改变客户重复购买行为上的有效性,其是企业建立长期客户关系的有效手段。最后讨论了结论对战略及营销管理实践的意义。
|
| [11] |
顾客购买行为影响因素分析及重购概率的预测 [J].https://doi.org/10.3969/j.issn.1004-6062.2005.01.023 URL [本文引用: 1] 摘要
顾客购买行为是市场营销研究的重要内容之一。目前已有一些文献通过引入几个属性变量,构建起描述顾客购买行为或预测购买概率的随机模型。本文在前人研究的基础上,首先分析了对顾客购买行为影响较大的顾客购买决策、前后两次购买间隔时间、顾客重购行为和顾客逃逸等因素,而后将这些因素综合考虑,给出预测日用消费品重购概率的一种方法,并用实际数据对预测方法进行检验,预测的结果与实际数据非常接近。本方法的特点一是预测精度较高,二是具有一般性,适用于一般的日用消费品。
Analyzing the Main Elements of Customer Purchase Behavior and Predicting the Probability of Customer Repurchase [J].https://doi.org/10.3969/j.issn.1004-6062.2005.01.023 URL [本文引用: 1] 摘要
顾客购买行为是市场营销研究的重要内容之一。目前已有一些文献通过引入几个属性变量,构建起描述顾客购买行为或预测购买概率的随机模型。本文在前人研究的基础上,首先分析了对顾客购买行为影响较大的顾客购买决策、前后两次购买间隔时间、顾客重购行为和顾客逃逸等因素,而后将这些因素综合考虑,给出预测日用消费品重购概率的一种方法,并用实际数据对预测方法进行检验,预测的结果与实际数据非常接近。本方法的特点一是预测精度较高,二是具有一般性,适用于一般的日用消费品。
|
| [12] |
The NBD Repeat Purchase Process and M / G /∞ Queues [J].https://doi.org/10.1016/S0925-5273(98)00254-0 URL [本文引用: 1] 摘要
This paper considers the repeat purchase process as an M/ G/∞ queue. Special cases are derived including the NBD (Negative Binomial Distribution) model which is shown to be robust under a broad set of assumptions regarding the process of repeat purchase. Applications are considered. In particular, we consider issues of truthfulness in advertising (called here advertising signal reliability) regarding the product life distribution, etc. and its effects on repeat purchase. Using this application we contrast problems of “quantity” and “quality” of advertising.
|
| [13] |
Model-based Purchase Predictions for Large Assortments [J].https://doi.org/10.1287/mksc.2016.0985 URL [本文引用: 1] 摘要
Being able to accurately predict what a customer will purchase next is of paramount importance to successful online retailing. In practice, customer purchase history data is readily available to make such predictions, sometimes complemented with customer characteristics. Given the large assortments maintained by online retail- ers, scalability of the prediction method is just as important as its accuracy. We study two classes of models that use such data to predict what a customer will buy next: A novel approach that uses latent Dirichlet allocation (LDA), and mixtures of Dirichlet-Multinomials (MDM). A key benefit of a model-based approach is the potential to accommodate observed customer heterogeneity through the inclusion of predictor variables. We show that LDA can be extended in this direction while retaining its scalability. We apply the models to purchase data from an online re- tailer and contrast their predictive performance with that of a collaborative filter and a discrete choice model. Both LDA and MDM outperform the other meth- ods. Moreover, LDA attains performance similar to that of MDM while being far more scalable, rendering it a promising approach to purchase prediction in large assortments.
|
| [14] |
重复与经常购买的产品生命周期模型的参数估计 [J].https://doi.org/10.3969/j.issn.1000-3894.2004.08.008 URL [本文引用: 1] 摘要
本文在分析重复购买的产品生命周期模型的基础上,提出了经常购买的产品生命周期模型,详细讨论了两个模型的参数估计方法,同时采用实例对这些参数估计方法进行了验证,并分析了参数估计的结果。进一步,使用两个模型对企业产品的销售量做了预测,表明了模型的参数估计方法及预测方法的有效性。
Parameter Estimations for Life Cycle Models of Repetitive and Frequent Purchased Product [J].https://doi.org/10.3969/j.issn.1000-3894.2004.08.008 URL [本文引用: 1] 摘要
本文在分析重复购买的产品生命周期模型的基础上,提出了经常购买的产品生命周期模型,详细讨论了两个模型的参数估计方法,同时采用实例对这些参数估计方法进行了验证,并分析了参数估计的结果。进一步,使用两个模型对企业产品的销售量做了预测,表明了模型的参数估计方法及预测方法的有效性。
|
| [15] |
C2C环境中顾客重复购买行为的实证与建模 [J].
通过分析C2C商家的交易记录,发现单个商家的顾客重复购买次数呈幂律分布,这与重复购买理 论以往得到的购买次数为负二项分布的结论不同.基于C2C交易的实际情况,建立了具有购买强化效应的购买概率模型,模型很好的解释了顾客重复购买率呈幂律 分布的现象.实证和模型表明,C2C环境中,顾客购买次数的分布具有很长的尾部,大量顾客有低的购买次数,而少数顾客有很高的重复购买次数;模型还揭示了 巨大的潜在顾客数量和顾客多次购买的强化效应是造成重复购买分布呈幂律形式的重要原因.
Modeling and Empirical Research of Repeat Purchase Behavior in C2C Ecommerce [J].
通过分析C2C商家的交易记录,发现单个商家的顾客重复购买次数呈幂律分布,这与重复购买理 论以往得到的购买次数为负二项分布的结论不同.基于C2C交易的实际情况,建立了具有购买强化效应的购买概率模型,模型很好的解释了顾客重复购买率呈幂律 分布的现象.实证和模型表明,C2C环境中,顾客购买次数的分布具有很长的尾部,大量顾客有低的购买次数,而少数顾客有很高的重复购买次数;模型还揭示了 巨大的潜在顾客数量和顾客多次购买的强化效应是造成重复购买分布呈幂律形式的重要原因.
|
| [16] |
Boosting Response with RFM [J]. |
| [17] |
一种基于RFM模型的新型协同过滤个性化推荐算法 [J].https://doi.org/10.11959/j.issn.1000-0801.2015180 URL [本文引用: 1] 摘要
为了提高个性化推荐效果及预测准确度,特别是针对传统算法中评分矩阵过于稀疏等问题提出一种新颖的协同过滤算法。该算法首先利用RFM模型合理地筛选用户信息,其次通过黏性客户的消费记录稠密化用户一项目评分矩阵,并改进了传统相似度计算公式。通过仿真实验证实了算法的准确性.最后将其应用于一套具有个性化商品推荐功能的系统原型中,证明了该推荐算法的有效性及实用性。
A Novel Personalized Recommendation Algorithm of Collaborative Filtering Based on RFM Model [J].https://doi.org/10.11959/j.issn.1000-0801.2015180 URL [本文引用: 1] 摘要
为了提高个性化推荐效果及预测准确度,特别是针对传统算法中评分矩阵过于稀疏等问题提出一种新颖的协同过滤算法。该算法首先利用RFM模型合理地筛选用户信息,其次通过黏性客户的消费记录稠密化用户一项目评分矩阵,并改进了传统相似度计算公式。通过仿真实验证实了算法的准确性.最后将其应用于一套具有个性化商品推荐功能的系统原型中,证明了该推荐算法的有效性及实用性。
|
| [18] |
Modeling Repeat Purchases in the Internet When RFM Captures Past Influence of Marketing [OL]. |
| [19] |
Knowledge Discovery on RFM Model Using Bernoulli Sequence [J].https://doi.org/10.1016/j.eswa.2008.07.018 URL [本文引用: 1] 摘要
The objective of this paper is to introduce a comprehensive methodology to discover the knowledge for selecting targets for direct marketing from a database. This study expanded RFM model by including two parameters, time since first purchase and churn probability. Using Bernoulli sequence in probability theory, we derive out the formula that can estimate the probability that one customer will buy at the next time, and the expected value of the total number of times that the customer will buy in the future. This study also proposed the methodology to estimate the unknown parameters in the formula. This methodology leads to more efficient and accurate selection procedures than the existing ones. In the empirical part we examine a case study, blood transfusion service, to show that our methodology has greater predictive accuracy than traditional RFM approaches.
|
| [20] |
运用数据挖掘技术预测客户购买倾向——方法与实证研究 [J].Forecasting Customer Purchase Trend Based on Data Mining Technology——Method and Case Study [J]. |
| [21] |
基于机器学习融合算法的网络购买行为预测研究 [J].
选择适合的机器学习算法是在社会经济研究领域进行大数据分析及提高预测效果的关键。在很多情况下,通过融合训练两种或两种以上有差异的算法,能够显著提高算法的泛化能力以提高预测效果。基于阿里巴巴电子商务平台购物行为数据,分别应用Logistic回归、支持向量机以及这两种算法的融合构建了预测模型。实证结果表明,融合后模型比单一模型具备更好的预测效果。
Research on Network Purchase Behavior Prediction Based on Machine Learning Fusion Algorithm [J].
选择适合的机器学习算法是在社会经济研究领域进行大数据分析及提高预测效果的关键。在很多情况下,通过融合训练两种或两种以上有差异的算法,能够显著提高算法的泛化能力以提高预测效果。基于阿里巴巴电子商务平台购物行为数据,分别应用Logistic回归、支持向量机以及这两种算法的融合构建了预测模型。实证结果表明,融合后模型比单一模型具备更好的预测效果。
|
| [22] |
Purchase Prediction Using TMall-specific Features [J].https://doi.org/10.1002/cpe.3720 URL [本文引用: 1] 摘要
Summary Historical user activity, such as online shopping recommendations, content personalization, and advertising clicking rates, is a critical component of building user profiles to predict purchases and preferences. Alongside the rapid development of e-commerce, purchase prediction has become an increasingly important consideration for a wide variety of retail platforms. This paper proposes a framework which combines machine learning methods with a threshold-moving approach to predict sets of pairs (user id and brand id,) in terms of whether a certain brand is purchased by a specified user according to his or her historical activity records. Three specific feature groups are extracted: click features, purchase features, and collect-and-cart features using a dataset from Tmall, a Chinese business-to-consumer online retail platform. Next, seven user purchase prediction experiments with different combinations of the three feature groups are conducted, and the purchase prediction performance is observed. Results showed that a combination of all three feature groups, with 27 features in total, provided valuable purchase prediction contributions and performed favorably. Also, three feature groups are proved to be relative independent, and our prediction model identified the most important feature, from the collect-and-cart feature group. Detailed result analysis validated the effectiveness of both the extracted features and proposed machine learning methods. Copyright 2016 John Wiley & Sons, Ltd.
|
| [23] |
基于阿里巴巴大数据重复购买预测的实证研究 [J].An Empirical Study of Repeat Purchase Forecast-Based on Big Data from Alibaba [J]. |
| [24] |
Reducing Misclassification Costs [C]// |
| [25] |
Addressing the Curse of Imbalanced Training Sets: One-Sided Selection [C]// |
| [26] |
The Class Imbalance Problem: Significance and Strategies [C]// |
| [27] |
Data Mining for Direct Marketing: Problems and Solutions [C]// |
| [28] |
SMOTE: Synthetic Minority Over-sampling Technique [J].https://doi.org/10.1613/jair.953 URL [本文引用: 1] 摘要
Abstract: An approach to the construction of classifiers from imbalanced datasets is described. A dataset is imbalanced if the classification categories are not approximately equally represented. Often real-world data sets are predominately composed of "normal" examples with only a small percentage of "abnormal" or "interesting" examples. It is also the case that the cost of misclassifying an abnormal (interesting) example as a normal example is often much higher than the cost of the reverse error. Under-sampling of the majority (normal) class has been proposed as a good means of increasing the sensitivity of a classifier to the minority class. This paper shows that a combination of our method of over-sampling the minority (abnormal) class and under-sampling the majority (normal) class can achieve better classifier performance (in ROC space) than only under-sampling the majority class. This paper also shows that a combination of our method of over-sampling the minority class and under-sampling the majority class can achieve better classifier performance (in ROC space) than varying the loss ratios in Ripper or class priors in Naive Bayes. Our method of over-sampling the minority class involves creating synthetic minority class examples. Experiments are performed using C4.5, Ripper and a Naive Bayes classifier. The method is evaluated using the area under the Receiver Operating Characteristic curve (AUC) and the ROC convex hull strategy.
|
| [29] |
Random Forests [J].https://doi.org/10.1023/A:1010933404324 URL [本文引用: 3] |
| [30] |
商业地产开发视角下的中国城市评估体系 [J].
选取经济、社会、生活、环境等24项评价指标,对中国112个城市进行评估,构建出商业地产开发的城市坐标体系,并对一二三线城市进行等级层次划分。从中发现,除了北京、上海、广州、深圳之外,天津、南京、杭州、重庆、武汉成为新一线城市,二三线城市与传统划分结果也具有差异之处,并组成不同的等级层次。在空间分布上,新的一线城市成为中国国土开发的“钻石结构”顶点与重要节点,并以长三角、珠三角的二三线城市分布相对密集、发育程度较高。
China’s Urban Assessment System from the Perspective of Commercial Real Estate Development [J].
选取经济、社会、生活、环境等24项评价指标,对中国112个城市进行评估,构建出商业地产开发的城市坐标体系,并对一二三线城市进行等级层次划分。从中发现,除了北京、上海、广州、深圳之外,天津、南京、杭州、重庆、武汉成为新一线城市,二三线城市与传统划分结果也具有差异之处,并组成不同的等级层次。在空间分布上,新的一线城市成为中国国土开发的“钻石结构”顶点与重要节点,并以长三角、珠三角的二三线城市分布相对密集、发育程度较高。
|
| [31] |
F-Score and ROC: A Family of Discriminant Measures for Performance Evaluation[A]// AI 2006: Advances in Artificial Intelligence [M]. |

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}