




1 引 言
行为金融学(Behavioral Finance)认为过去的金融理论假设资本市场参与者都是理性的, 并遵循利益最大化的原则。但实际上投资者并不是完全理性的[1,2], 投资者的情绪容易受到其他投资者的情绪影响, 进而对其理性决策产生影响。随着Web2.0技术的广泛应用, 投资者可以在社交媒体中获取相关资讯并发表评论。有研究基于推特[3,4,5]、微博[6,7,8]、新闻[9]和贴吧[10]以及论坛[11]分析了文本情感对股票的预测作用, 或者从格兰杰因果关系[12,13]和主题发现[14]角度进行验证, 证明推特或微博文本中的情感倾向可以用来预测股市涨跌。另一些研究者基于行情平台, 探讨投资者处理能力, 包括: 信息解读[15]、意见分歧[16]以及投资者关注[17,18]。
同时, 有研究者关注股市评论情感倾向的挖掘方法, 试图构建更加高效的情感分析模型, 以提高预测模型的精确度。涉及到的模型有: 关联规则概念图 谱[19]、偏最小二乘法[20]、主题/情感连接模型[21]等。但是这些模型侧重点是用户主动表达出的情感, 没有考虑用户行为。另一方面, 预测模型本身也是影响预测精度的重要原因之一, 因此有研究者对预测模型进行比较研究或者改进提升, 包括: 随机森林与朴素贝叶斯和支持向量机等的比较[22]、支持向量机与人工神经网络的融合[23]、稀疏矩阵分解模型[24]、因式分解机[25]、LSTM[26]。这些研究从股市评论文本中提取数据, 虽然股市评论能直接反映出投资者情感倾向, 但是网络推手、网络水军的极端评论也混杂在正常评论中, 使得股市评论的可信度大大降低。
除评论文本以外, 用户的交互行为同样隐含投资者的情感倾向。在社交媒体中, 用户除了可以发表评论外, 还可以关注知名财经博主并转发他们的文章, 即“转载行为”。此外还有“点赞行为”和“提及行为”, 虽然用户行为难以量化, 但这类数据的分析不易受到极端评论的影响。当大量用户相互转发文章后会产生基于转载行为的社会网络。单一的转载行为只隐含了一个用户的情感倾向, 而由大量转载行为构成的社会网络关系则能反映用户群体的情感倾向。因此对用户群体的情感倾向可以从社会关系的角度进行分析。目前对股市社会网络的研究从多种角度展开。有通过社交媒体展示的活动与VIX指数对市场风险度量研究技术投资者和非技术投资者之间的差异[27], 也有研究家庭社会网络对居民股市参与的影响力[28]。还有研究信息质量与股价同步性的内在关联性, 发现信息质量与股价同步性呈现非线性U型关系[29]。但是对于社交媒体上基于用户交互行为的社会网络与股市研究较少。
由于基于社交媒体用户行为的社会网络与股市的研究比较少, 社会网络与股市的相关性及其预测能力尚不明确。如果能够证明二者之间的关系, 那么可以将用户社会网络的参数引入预测模型, 以提高股市预测的精确度。因此, 本文试图探究用户交互行为的社会网络与股市的相关性和因果关系。从新浪财经博客版块获取知名度较高的财经博主在一段时间内的博文及其转载者, 设置时间快照构建网络图; 提取网络属性并与上证指数进行相关性分析, 筛选出具有相关性的属性; 最后利用格兰杰因果关系检验, 分析社会网络对股市的预测能力。
2 研究设计
本文的研究目标是检验以下两个假设:
(1) 社交媒体用户交互行为的社会网络与股市具有相关性。
(2) 社交媒体用户交互行为的社会网络与股市具有因果关系。
2.1 构建网络图
利用新浪财经博客文章的转载构建转载网络图。虽然微博和贴吧也可以构建网络图, 但由于微博的显示界面限制, 大部分财经博主所发的微博都是关于某一篇股票博客文章的消息, 最终都链接到博客。而贴吧的股票资讯则较为混乱, 帖主所写的文章质量也参差不齐。选择“转载”则是因为“关注”具有长期稳定性, 无法在短时间内体现出时间变化特征。同时“转载”行为代表了用户对文章的认可, 体现出用户对博主观点的情感倾向。根据已有研究, 用户的情感倾向可以作为解释变量, 以提高股市预测的精确度[6,7]。虽然“转载”是一种具有方向性的拓扑结构, 但是研究仅仅关注网络结构, 并不关心网络图中的信息传播, 因此本文所构建的网络图是一种无向、有权重的网络图, 以此反映网络的基本结构。网络图的具体定义为${{G}^{t}}=({{V}^{t}},{{E}^{t}})$, 其中字母$t$代表第$t$个时间段, 且$t\in T$, ${{G}^{t}}\in {{G}^{T}}$, $T$是时间段集合, ${{G}^{T}}$是网络图样本集合。${{V}^{t}}$是第$t$时间段内图${{G}^{t}}$的节点集合, ${{E}^{t}}$是边的集合。在新浪财经博客社会网络中, 一个节点代表一个在新浪财经博客上注册的用户, 可以是一个博主或转载者。具体定义为${{V}^{t}}=\{{{n}_{1}},{{n}_{2}},...,{{n}_{N}}\}$, 其中$|{{V}^{t}}|={{N}_{t}}$, 表示在第$t$时间段内的节点数量。一条边代表第$t$时间段内一个博客用户从另一博客用户处转载了至少一篇文章, 边的权重表示转载的数量。边的具体定义为: ${{E}^{t}}=\{{{e}_{1}},{{e}_{2}},...,{{e}_{M}}\}$, 其中$|{{E}^{t}}|={{M}_{t}}$, 表示在第$t$时间段内边的数量, ${{e}_{ij}}=({{u}_{i}},{{u}_{j}},{{u}_{ij}})$表示一条连接博客用户${{u}_{i}}$和${{u}_{j}}$的边, 权重是${{w}_{ij}}$, 且对任意${{e}_{ij}}$, ${{w}_{ij}}\ge 1$。
2.2 网络拓扑属性
(1) 平均节点度(Average Degree)。网络中的节点度是连接该节点的边的数量或与该节点有连接的其他节点数量。在新浪财经博客社会网络中, 节点${{n}_{i}}$的度代表用户${{u}_{i}}$与其他博客用户的交流情况, 包括用户${{u}_{i}}$的文章被其他用户转载或用户${{u}_{i}}$转载了其他用户的博客文章, 反映用户${{u}_{i}}$与其他用户的信息交流频繁程度。而网络图的平均节点度则反映了整个网络图的信息流动情况。平均节点度的计算方法如公式(1)所示。
其中, ${{k}_{i}}$表示节点${{n}_{i}}$的度, ${{N}_{t}}$表示在$t$时间段内网络图的节点总数。
(2) 网络密度(Density)。网络密度$d(G)$可用于刻画网络中节点间相互连边的密集程度, 定义为网络中实际存在的边数与可容纳的边数上限的比值。社会网络中常用来测量社会关系的密集程度以及演化趋势。图${{G}^{t}}$的网络密度计算如公式(2)所示。
图1
本文网络密度的实际含义是博客用户对其他用户关注的广泛性。即用户${{u}_{i}}$除了转载某一位博主的文章以外还转载了多少其他博主文章, 反映用户${{u}_{i}}$获取股票博客信息来源的多样性。
(3) 平均边权重(Average Edge Weight)。边的权重是指在时间段$t$中, 用户${{u}_{i}}$转载某一个博主文章的次数。如果一条边的权重越大, 则说明用户转载某一博主的文章次数越多, 该用户对博主的关注度很高并且对博主文章的认可度也较高。平均边权重则是计算网络图中所有边的平均权重, 反映在这段时间中博客的受众对单一博主的关注程度和文章的认可度。与网络密度所代表的受众获取信息来源多样性的实际含义相反, 平均边权重代表博主受众获取信息来源的专一性, 计算方法如公式(3)所示。
其中, ${{M}_{t}}$是在网络图${{G}^{t}}$的边数, ${{w}_{i}}$是第$i$条边的权重系数。
(4) 平均阅读量(Average Read)和平均点赞数(Average Like)。博客属于一种“点到面”的信息转播形式, 而具有较大影响力的股票博主位于“点”的位置, 广大受众群体位于“面”的位置。因此股票博主的博客文章的情感倾向、内容属性等因素都会对整个博客转载网络产生影响。所以有必要提取股票博主文章的相关属性, 选择文章的阅读量和点赞数来反映文章的基本属性。统计平均阅读量和平均点赞数主要是为了反映在某个时间段内, 博客文章的影响力和受众对这些文章的认可度。平均阅读量和平均点赞数需要计算两次平均值, 首先计算在时间段t内, 每一个至少发表过一篇文章的博主的所有文章平均阅读量和点赞数作为博主的一项属性, 再计算这些博主的阅读量和点赞数属性的平均值。具体计算方法如公式(4)和公式(5)所示。
其中, ${{n}_{t}}$代表至少发表过一篇文章的博主的数量; ${{m}_{i}}$代表第t个时间段第i个博主所发表文章的数量, 且$i=1,2,...,{{n}_{t}}$; ${{r}_{tij}}$代表第t个时间段内所发表的第j篇文章的阅读量; ${{l}_{tij}}$是对应文章的点赞数。
网络参数的现实意义解释如表1所示。
表1 网络参数的现实意义
| 参数名称 | 解释 |
|---|---|
| 平均节点度 | 网络结构基本属性 |
| 密度 | 用户所关注博主的多样性 |
| 平均边权重 | 用户对关注博主的专一程度 |
| 平均阅读量 | 博主的影响力 |
| 平均点赞数 | 受众对博客文章的认可度 |
2.3 格兰杰因果关系
格兰杰因果检验是一种统计学假设检验, 用以确定是否一个时间序列对另一个时间序列预测有用, 该方法在1969年被首次提出。其定义为: 在包含变量X、Y过去信息的条件下, 对变量Y的预测效果要优于单独由Y的过去信息对Y进行的预测效果, 即变量X有助于解释变量Y的将来变化, 则认为变量X是引致变量Y的格兰杰原因[30]。格兰杰因果关系检验假设有关y和x每一变量的预测的信息全部包含在这些变量的时间序列之中。检验要求对变量进行估计, 拟合公式如公式(6)和公式(7)所示。
其中, 白噪声${{u}_{1t}}$和${{u}_{2t}}$假定不相关。公式(6)假定当前y与y自身以及x的过去值有关, 其零假设H0: ${{\alpha }_{1}}={{\alpha }_{2}}=...={{\alpha }_{a}}=0$; 而公式(7)对x也假定了类似的行为, 其零假设H0: ${{\delta }_{1}}={{\delta }_{2}}=...={{\delta }_{s}}=0$。
进行格兰杰因果关系检验的一个前提条件是时间序列必须具有平稳性, 否则可能会出现虚假回归问题。因此在进行格兰杰因果关系检验之前应先对各指标时间序列的平稳性进行单位根检验(Unit Root Test)。常用增广的迪基-富勒(Augmented Dickey-Fuller, ADF)检验分别对各指标序列的平稳性进行单位根检验。
3 实证分析
3.1 数据集
利用Scrapy爬虫框架编写爬虫程序, 提取新浪财经博客(http://blog.sina.com.cn/lm/stock/)“财经博客排行”版块上影响力在前92名的博主。从他们各自的博客主页上爬取2016年1月1日-2017年12月30日所发表博客文章的相关数据, 包括: 每篇文章的标题、作者姓名、发表日期、阅读量、点赞数、转载者, 共有55 974篇博客文章的相关数据。选取一个月作为一个时间周期, 分割原始数据的时间跨度。最终分割出24个月的时间段样本, 各时间段数据分布如表2所示。
表2 数据集描述
| 时间 | 当月至少发表过一篇博文的 博主的数量 | 博文总数量 | 时间 | 当月至少发表过一篇博文的 博主的数量 | 博文总数量 |
|---|---|---|---|---|---|
| 2016,1 | 48 | 1 132 | 2017,1 | 71 | 2 415 |
| 2016,2 | 53 | 1 458 | 2017,2 | 69 | 2 885 |
| 2016,3 | 56 | 1 497 | 2017,3 | 74 | 2 641 |
| 2016,4 | 56 | 1 587 | 2017,4 | 76 | 2 746 |
| 2016,5 | 61 | 1 738 | 2017,5 | 77 | 3 068 |
| 2016,6 | 64 | 1 957 | 2017,6 | 78 | 2 837 |
| 2016,7 | 64 | 2 049 | 2017,7 | 80 | 2 886 |
| 2016,8 | 66 | 2 012 | 2017,8 | 77 | 2 822 |
| 2016,9 | 71 | 1 905 | 2017,9 | 76 | 2 236 |
| 2016,10 | 65 | 2 521 | 2017,10 | 75 | 2 902 |
| 2016,11 | 66 | 2 614 | 2017,11 | 76 | 2 919 |
| 2016,12 | 68 | 2 299 | 2017,12 | 78 | 2 848 |
从原始数据的时间分布可以看出, 并不是所有的92名博主每个月都在新浪财经博客上发表文章。但随着时间推移, 每个月至少发表一篇文章的博主数量在增加, 每个月总的发文数量也在增长。
3.2 网络结构变化描述
图2
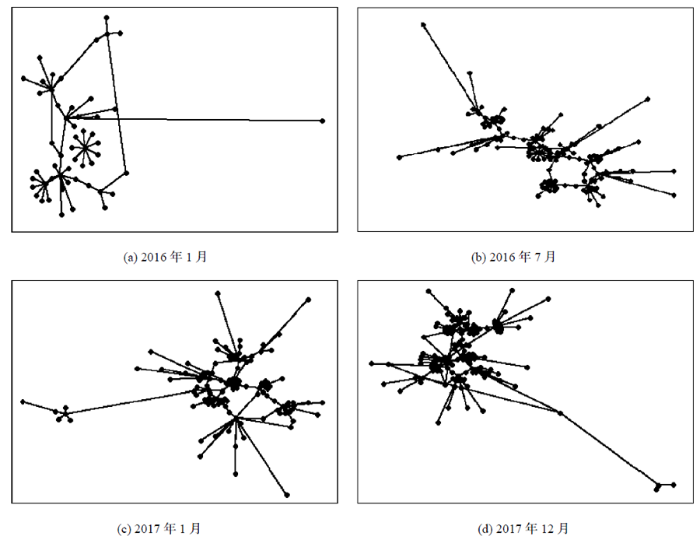
随着时间推移, 博主文章的转载网络在发生变化。2016年1月的网络较为简单, 节点之间的联系也不紧密, 但2016年7月之后网络图发生了较大变化, 较为明显的变化是网络图中节点数量在增加, 边也在增加。节点的增加可以解释为有更多的用户加入财经博客, 并转载文章。边的增加则有可能是由于节点增加所导致或者是两个节点之间出现联系。如果是由于节点增加所产生的边数增加则没有太大意义, 如果是由于两个未连接的节点发生了连接, 则说明网络图中节点之间的联系在加强。对于这种情况, 需要通过计算网络图的密度进一步解释。
对于总网络图只能通过拓扑属性来测量网络结构, 本文选取网络图的节点数(Nodes Counts)、平均度(Average Degree)、边数(Edges Counts)、平均边权重(Average Edge Weight)和密度(Density)等属性。选取平均阅读量(Average Read)反映当月博主文章的影响力, 平均点赞数(Average Like)反映当月受众对博客文章的认可度。以月份作为自变量, 每种属性作为因变量, 绘制各个属性的时间序列如3所示。
图3

图3(a)显示出节点数在2016年1月-2017年9月呈现下降趋势, 并且在2017年9月到达最小值, 然后开始增加。而通过对比图3(b)可以看出节点变化与边的变化趋势非常相似。研究分析认为这是由于网络的密度较低造成的。在新浪财经博客中, 用户关注很少的几个股票博主, 而博主节点在整个网络图节点中所占比例很小, 因此节点数量与边的数量很接近, 从而导致节点变化与边的变化趋势也很相似。图3(c)显示出平均边权重在2016年1月-2017年7月呈现上升趋势, 并且在2017年7月到达最大值, 然后开始下降。图3(d)反映了网络密度呈现波动上升的趋势。图3(e)和图3(f)分别表示博客文章的平均阅读量和平均点赞数, 二者均呈现下降趋势, 并且二者的变化趋势十分相似。平均阅读量的下降反映了文章的影响力在逐渐下降, 以及文章受众对博客文章的认可度也在下降。
3.3 社会网络与股市相关性分析
本文关注股票市场对于网络结构的影响, 选取上证指数MA.MA3作为反映股市的一项指标。MA.MA3在本文中的定义是: “上证指数20个月每个月最后一个交易日收盘价的移动均值”, 该指标由通达信软件导出。选取MA·MA3的原因是在于新浪财经博客对股市的讨论是基于历史数据, 同时通过对博客文章的评论的观察, 发现财经博客社区用户对股市的整体关注时段约为过去的一年半。因此选取MA·MA3指标可以涵盖过去一年半股市变化情况的信息。MA·MA3如图4所示, 其计算公式如公式(8)所示。其中Mt是t时期的移动均值, N是平均项数, N=20, yt-i是t-i期的观察数, 即t-i期的收盘价。对MA3·MA3与平均阅读量、平均点赞数、节点数、边数、密度和平均权重进行偏相关分析, 结果如表3所示。
图4

表3 偏相关分析结果
| 控制变量 | 变量 | MA·MA3 | |
|---|---|---|---|
| 相关性 | 显著性 | ||
| Average Read、Average Like、Nodes Counts、Edges Counts、Density | Average Edges Weight | -.442 | .058 |
| Average Like、Nodes Counts、Edges Counts、Average Edges Weight、Density | Average Read | -.406 | .084 |
| Edges Counts、Average Edges Weight、Density、Average Read、Average Like | Nodes Counts | -.434 | .063 |
| Average Edges Weight、Nodes Counts、Density、Average Read、Average Like | Edges Counts | .247 | .307 |
| Average Read、Average Like、Nodes Counts、Edges Counts、Average Edges Weight | Density | -.508 | .026* |
| Nodes Counts、Edges Counts、Average Edges Weight、Density、Average Read | Average Like | .486 | .035* |
通过对检验结果的分析, 发现平均阅读量、节点数、边数和平均权重与MA·MA3的相关性显著水平均大于0.05, 并不显著。仅密度和平均点赞数与MA·MA3的相关性是显著的。MA·MA3与密度的偏相关系数是-0.508, 显著性检验的t统计量是0.026; 与平均点赞数的偏相关系数是0.486, 显著性检验的t统计量是0.035。因此在显著性水平0.05的条件下, MA·MA3与网络图的密度具有负相关性, 与平均点赞数具有正相关性。进一步对MA·MA3与密度、MA·MA3与平均点赞数进行回归分析, 结果如表4所示。通过散点图, 发现MA·MA3与密度之间存在二次项的关系, MA·MA3与平均点赞数之间存在线性关系, 因此使用曲线拟合, 分析二者的线性关系, 如图5所示。
表4 回归分析结果
| 均方和 | 自由度 | 均方 | F统计量 | 显著性 | ||
|---|---|---|---|---|---|---|
| MA·MA3与 密度回归分析 | 回归 | .000 | 2 | .000 | 8.071 | .003 |
| 残差 | .000 | 21 | .000 | |||
| 总体 | .000 | 23 | ||||
| 未标准化系数 | 标准误差 | 标准化系数 | t统计量 | 显著性 | ||
| MA·MA3 | -4.526E-5 | .000 | -42.849 | -2.760 | .012 | |
| MA·MA3 ** 2 | 6.637E-9 | .000 | 42.367 | . | . | |
| 常数 | .078 | .028 | 2.819 | .010 | ||
| 均方和 | 自由度 | 均方 | F统计量 | 显著性 | ||
| MA·MA3与 平均点赞数 回归分析 | 回归 | 39138.341 | 1 | 39138.341 | 16.050 | .001 |
| 残差 | 53647.400 | 22 | 2438.518 | |||
| 总体 | 92785.741 | 23 | ||||
| 未标准化系数 | 标准误差 | 标准化系数 | t统计量 | 显著性 | ||
| MA·MA3 | .373 | .093 | .649 | 4.006 | .001 | |
| 常数 | -1036.985 | 313.440 | -3.308 | .003 |
图5

根据表4可知, MA·MA3与密度的回归分析结果中可以看出回归方程的显著性检验统计量是0.003, 说明方程显著, 回归效果较好。一次项MA·MA3的系数是-4.526×10-5, 标准化系数是-42.849; 二次项MA·MA32的系数是6.637×10-9, 标准化系数是42.367。由于网络图的密度非常小, 软件未能显示出二次项系数的显著性检验统计量, 仅显示一次项的显 著性检验统计量0.012。图5(a)显示, 当MA·MA3小于3 400点时, 网络密度与均值呈现负相关; 当均值大于3 400点时, 网络密度与均值呈现正相关。根据表4中MA·MA3与平均点赞数的回归分析结果, 可以看出回归方程的显著性检验统计量为0.001, 说明方程显著。自变量MA·MA3的系数是0.373, 显著性检验统计量为0.001, 说明系数显著。如图5(b)所示, 可以看出随着MA·MA3的增大, 平均点赞数也在增加。
对于MA·MA3与密度呈“U”型曲线关系的原因, 通过查阅文献, 笔者认为可以从两个角度来解释:
(1) 投资者过度自信。DHS模型是Daniel, Hirsheifer和Subramanyam于1998年提出的[32]。该模型假设投资者进行投资决策时会有两种偏差, 一是过度自信(Overconfidence), 二是有偏自我评价(Biased Self Attribution)或归因偏差。投资者通常高估自己的预测能力, 低估自己的预测误差; 过分相信私人信息, 低估公开信息。在DHS模型中, 过度自信投资者是指那些高估私人信息低估公开信息的投资者, 他们赋予私人信号比先验信息更高的权重, 引起反应过度。当包含噪声的公开信息到来时, 价格的无效偏差得到部分矫正, 当更多的公开信息到来后, 反应过度的价格趋于反转。归因偏差是指当事件与投资者的行动一致时, 投资者将其归功于自己的判断; 当事件与行动不一致时, 投资者将其归因于外在噪声。即把成功归因于自己的英明, 把失败归于外部因素[32]。根据曲线拟合图, 当MA·MA3小于3 400点时, 用户过度自信较高, 对博主即公开信息的关注度较低; 当MA·MA3大于3 400点时, 用户过度自信较低, 对公开信息的关注度较高。
(2) 股价同步性与社交网络信息质量的U型关系。社交网络信息质量与股价同步性有显著的非线性U型相关关系, 即随着社交网络信息质量水平的提升, 股价同步性逐渐降低到最小值, 而后又逐渐提高[29]。平均点赞数反映了博客的信息质量, 且与MA·MA3具有正相关关系。因此, 随着MA·MA3的增加, 信息质量也在提升。此时股价同步性降低, 个股与市场平均变动关系减弱, 投资者减少了对公共信息的关注度。当MA·MA3继续增加, 信息质量继续提升时, 股价 同步性达到最低点, 而后开始增加。此时个股与市场平均变动关系增强, 投资者开始提高对公共信息的关注度。
极值点位于3 400点的原因可能与平台社区的内部因素有关, 包括社区用户的决策水平、信息处理能力等。具体的影响因素需要进一步研究。
3.4 社会网络与股市的格兰杰因果关系分析
偏相关分析和回归分析仅显示出社会网络与股市的相关关系, 但二者更深层次的关系, 例如因果关系还无法确定。本文探究用户交互行为的社会网络与股市的因果关系。但由于影响股市和社会网络的因素有很多, 无法控制所有影响因素, 因此采用格兰杰因果检验论证两者之间的关系。在进行格兰杰因果检验之前, 首先对MA·MA3、密度和平均点赞数进行时间序列平稳性检验, 采用Dicker-Fuller单位根检验, 结果如表5所示。
表5 平稳性检验
| 检验统计量 | 1%评判值 | 5%评判值 | 10%评判值 | |
|---|---|---|---|---|
| MA·MA3 | -0.66 | -3.75 | -3.00 | -2.63 |
| Z检验P值=0.86 | ||||
| Density | -2.78 | |||
| Z检验P值=0.06 | ||||
| Average Like | -2.39 | |||
| Z检验P值=0.15 | ||||
可以看出三个时间序列变量的检验统计量均大于-3.00, 其P值均大于0.05, 并不显著, 说明三个时间序列均不平稳。对于非平稳时间序列的格兰杰因果检验, 需要分析数据是否具有协整关系, 若存在协整关系则可以进行格兰杰因果检验。协整秩的检验结果如表6所示。
表6 协整秩检验(样本: 2-24, 观测数=23)
| 滞后阶数 | 参数 | 对数似然函数 | 特征值 | 统计量 | 5%评判值 |
|---|---|---|---|---|---|
| 0 | 3 | -41.42 | . | 37.98 | 29.68 |
| 1 | 8 | -29.85 | 0.63 | 14.82* | 15.41 |
| 2 | 11 | -22.91 | 0.45 | 0.94 | 3.76 |
| 3 | 12 | -22.44 | 0.04 |
当采用一阶滞后时, 协整秩为1的模型统计量14.82小于15.41, 具有显著性。因此, 在一阶滞后时数据之间具有协整性, 可以构建VAR模型进行格兰杰因果检验。格兰杰因果检验的结果如表7所示。在模型1中, MA·MA3作为被解释变量, 密度作为解释变量, P值为0.99, 远大于0.05, 因此密度不能作为MA·MA3的格兰杰因; 在模型2中, 平均点赞数作为解释变量时, P值为0.06, 大于0.05, 但小于0.1。因此在0.1的显著性水平下, 可以认为平均点赞数能够作为MA·MA3的格兰杰因。在模型3中, MA·MA3作为被解释变量, 密度和平均点赞数作为解释变量, 同样在0.1的显著性水平下二者可以作为MA·MA3的格兰杰因。在模型4和模型7中, MA·MA3作为解释变量, 密度和平均点赞数分别作为被解释变量, P值均大于0.1。因此, MA·MA3并不能作为密度和平均点赞数的格兰杰因。在模型5和模型8中, 密度和平均点赞数互为解释变量和被解释变量, 其P值均小于0.05, 说明密度和平均点赞数互为格兰杰因果。
表7 格兰杰因果检验
| 方程 | 剔除 | F统计量 | 自由度 | P值 | |
|---|---|---|---|---|---|
| 1 | MA·MA3 | Density | .00 | 1 | 0.99 |
| 2 | MA·MA3 | Average Like | 4.18 | 1 | 0.06* |
| 3 | MA·MA3 | ALL | 3.29 | 2 | 0.06* |
| 4 | Density | MA·MA3 | .00 | 1 | 0.95 |
| 5 | Density | Average Like | 7.61 | 1 | 0.01** |
| 6 | Density | ALL | 4.96 | 2 | 0.02** |
| 7 | Average Like | MA·MA3 | 1.92 | 1 | 0.18 |
| 8 | Average Like | Density | 5.04 | 1 | 0.04** |
| 9 | Average Like | ALL | 3.58 | 2 | 0.05** |
3.5 实验结论
(1) 在财经博客社会网络变化描述中, 节点数与边数的变化趋势相似。这是由于在新浪财经博客社会网络中受众只关注很少几个博主, 所产生的转载网络的边也仅限于受众和其所关注的博主。同时博主节点在整个网络节点中所占比例非常小。因此节点数与边的数量接近, 并且变化趋势也相似。正是这个原因导致网络的密度也非常小。博主节点的文章平均阅读量和平均点赞数的时间演化过程中, 平均阅读量和平均点赞数都呈现下降趋势, 且二者的变化趋势十分相似。可能原因是受众在阅读博主文章后, 会结合股市的涨跌情况做出自己的判断, 选择继续关注博主并转载博主的优质博文或者取消对博主的关注, 由此导致这两个指标发生变化。
(2) 在股票博客社会网络与股市的相关性分析中, 发现MA·MA3对网络图的密度和博主节点的平均点赞数具有相关关系。通过回归分析, 发现MA·MA3与密度具有二次项的关系。当MA·MA3小于3 400点时, 网络密度与MA·MA3具有负相关性; 当均值大于3 400点时, 密度与MA·MA3具有正相关性。根据DHS模型和本文对网络密度的定义, 出现这种现象的原因是当MA·MA3小于3 400点时, 社区用户具有较高的过度自信, 股价同步性较低, 减少对其他博主的关注度; 当MA·MA3大于3 400点时, 用户的过度自信降低, 股价同步性提升, 增加对其他博主的关注度。
(3) 在股票博客社会网络与股市的格兰杰因果关系分析中, 发现MA·MA3并不能成为网络密度和平均点赞的格兰杰因。也就是说MA·MA3并不能导致用户的社会网络结构发生改变。而当MA·MA3作为被解释变量, 平均点赞数作为解释变量, 显著性水平取0.1时, 平均点赞数可以作为MA·MA3的格兰杰因。结合回归分析的结果, MA·MA3与平均点赞数具有正相关关系, 因此平均点赞数在较为宽松的条件下可以作为解释变量, 以提高对MA·MA3预测的精确度。
4 结 语
本文利用新浪财经博客的“财经博客排行”版块中2016年和2017年的数据, 以30天为一个周期作为时间快照, 构建了24个财经博主博客文章转载网络图。提取网络拓扑属性, 并与MA·MA3进行相关性分析, 发现MA·MA3与网络密度和博主节点的平均点赞数属性具有显著的相关性。进一步对其进行回归分析, 发现MA·MA3与密度具有二次项的关系, 与平均点赞数具有线性关系。即在MA·MA3小于3 400点时, 密度与MA·MA3具有负相关性; 大于3 400点时, 密度与MA·MA3具有正相关性。而平均点赞数与MA·MA3具有正相关性。最后通过格兰杰因果关系的检验, 发现在较为宽松的条件下, 平均点赞数是MA·MA3的 格兰杰因, 可以作为解释变量以提高股市预测的精 确度。
行为金融学的研究认为, 社交媒体上投资者情绪可以用来预测股市, 而本文认为社交媒体用户交互行为的社会网络关系也可以用来提高股市预测的精确度。但是由于财经博客文本较长, 文章语言变化多样, 本文没有探究博客文章的情感倾向, 可能遗漏了重要信息。因此在未来研究中可以将文章的情感倾向纳入用户交互行为网络中, 探究与股市的关系。另一方面, 由于算法优化问题, 所选取的网络属性均为基本属性, 没有研究复杂的网络属性。例如计算最短路径的Dijkstra算法和Floyd算法的时间复杂度分别为$O({{n}^{2}})$ 和$O({{n}^{3}})$, 而最小的网络图也有2 500个节点, 在实际计算过程中发现以上两种算法都无法在短时间内得到计算结果。因此可以对算法进行优化, 研究复杂属性与股市的关系。
作者贡献声明
何跃: 提出研究思路, 设计研究方案;
王欣瑞: 采集数据, 进行实验分析, 论文起草与最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: 402216179@qq.com。
[1] 王欣瑞, 何跃. 博客转载数据.xlsx. 新浪财经博客top92博主2016年-2017年月度博客文章转载数据.
[2] 王欣瑞, 何跃. 博客文章点赞数阅读量.xlsx. 新浪财经博客top92博主2016年-2017年月度博客文章点赞数和阅读量数据.
[3] 王欣瑞, 何跃. 网络图统计数据.xlsx. 24个网络图拓扑结构属性统计数据.
参考文献
行为金融理论对效率市场假说的挑战
[J].
The Challenge of Behavior Economic Theory to Efficient Market Hypojournal
[J].
Social Mood and Financial Economics
[J].
DOI:10.1007/s11356-019-06686-7
URL
PMID:31836971
[本文引用: 1]

This research work reconnoiters the impact of nonrenewable energy (NRE) consumptions, environmental pollution, and mortality rate on human capital in the presence of economic growth and two common diseases, measles and tuberculosis (TB) in Pakistan. The study uses data from 1995 to 2017 and employs the Autoregressive Distributive Lag (ARDL) model to investigate cointegration and long-run dynamics. Results indicate that nonrenewable energy (oil, coal, and gas) increase air pollution, measles, TB cases, and mortality rate, which affect the human capital in Pakistan. The results of the ARDL confirm the long-run and short-run effects of fossils fuels, air pollution, and diseases on human capital. The results of the Granger Causality confirm the feedback hypothesis between nonrenewable consumption and human capital, between air pollution and human capital. Measles and TB diseases Granger cause human capital. The study recommends some essential points for energy management, environmental management, and diseases control programs to uplift the human capital in Pakistan.
Twitter Mood Predicts the Stock Market
[J].
DOI:10.1016/j.jocs.2010.12.007
URL
[本文引用: 1]
Behavioral economics tells us that emotions can profoundly affect individual behavior and decision-making. Does this also apply to societies at large, i.e. can societies experience mood states that affect their collective decision making? By extension is the public mood correlated or even predictive of economic indicators? Here we investigate whether measurements of collective mood states derived from large-scale Twitter feeds are correlated to the value of the Dow Jones Industrial Average (DJIA) over time. We analyze the text content of daily Twitter feeds by two mood tracking tools, namely OpinionFinder that measures positive vs. negative mood and Google-Profile of Mood States (GPOMS) that measures mood in terms of 6 dimensions (Calm, Alert, Sure, Vital, Kind, and Happy). We cross-validate the resulting mood time series by comparing their ability to detect the public's response to the presidential election and Thanksgiving day in 2008. A Granger causality analysis and a Self-Organizing Fuzzy Neural Network are then used to investigate the hypothesis that public mood states, as measured by the OpinionFinder and GPOMS mood time series, are predictive of changes in DJIA closing values. Our results indicate that the accuracy of DJIA predictions can be significantly improved by the inclusion of specific public mood dimensions but not others. We find an accuracy of 86.7% in predicting the daily up and down changes in the closing values of the DJIA and a reduction of the Mean Average Percentage Error (MAPE) by more than 6%. (C) 2011 Elsevier B.V.
Using Twitter to Predict the Stock Market Where is the Mood Effect?
[J].
DOI:10.1016/j.scitotenv.2019.135995
URL
PMID:31841909
[本文引用: 1]
We investigated the occurrence, distribution, and potential sources of 10 organophosphorus flame retardants (OPFRs) in road dust from the urban area of Dalian, China, as well as their associated human exposures and health risks. The total concentration of Σ10OPFRs ranged from 300 to 7480 ng/g with a median of 1600 ng/g. Relatively high concentrations were observed mainly near prosperous business districts or dense residential areas. Tris(2-chloroethyl) phosphate (TCEP), tris(1-chloro-2-propyl) phosphate (TCIPP), and triphenylphosphine oxide (TPPO) were detected in all dust samples. TCIPP was the dominant congener, followed by TPPO. It was found that traffic flow can obviously influence the concentration of OPFRs in road dust, suggesting vehicles may be the major sources of OPFRs in road dust, presumably from materials used in their interiors. Correlations between certain OPFRs and population density indicate a significant influence by anthropogenic activities on OPFR levels. The average daily doses (ADD) of Σ10OPFRs via ingestion, inhalation and dermal absorption from road dust were evaluated as 0.26 and 0.087 ng/(kg-bw·d) for children and adults respectively, with dust ingestion as the main exposure pathway of OPFRs. Although the exposure risk of OPFRs via road dust was relatively low in Dalian, further studies on the exposure of OPFRs are still necessary due to combined effects with other exposure pathways.
Market Sentiment Dispersion and Its Effects on Stock Return and Volatility
[J].DOI:10.1007/s12525-017-0254-5 URL [本文引用: 1]
基于微博情绪信息的股票市场预测
[J].
Predicting the Stock Market Based on Microblog Mood
[J].
社交媒体的投资者涨跌情绪与证券市场指数
[J].
Investors’ Bullish Sentiment of Social Media and Stock Market Indices
[J].
基于微博情感分析的股市加权预测方法研究
[J].
Research on Stock Market Weighted Prediction Method Based on Micro-Blog Sentiment Analysis
[J].
Text Mining for Market Prediction: A Systematic Review
[J].
DOI:10.1016/j.eswa.2014.06.009
URL
[本文引用: 1]
The quality of the interpretation of the sentiment in the online buzz in the social media and the online news can determine the predictability of financial markets and cause huge gains or losses. That is why a number of researchers have turned their full attention to the different aspects of this problem lately. However, there is no well-rounded theoretical and technical framework for approaching the problem to the best of our knowledge. We believe the existing lack of such clarity on the topic is due to its interdisciplinary nature that involves at its core both behavioral-economic topics as well as artificial intelligence. We dive deeper into the interdisciplinary nature and contribute to the formation of a clear frame of discussion. We review the related works that are about market prediction based on online-text-mining and produce a picture of the generic components that they all have. We, furthermore, compare each system with the rest and identify their main differentiating factors. Our comparative analysis of the systems expands onto the theoretical and technical foundations behind each. This work should help the research community to structure this emerging field and identify the exact aspects which require further research and are of special significance. (C) 2014 Elsevier Ltd.
Sentiment Analysis on Social Media for Stock Movement Prediction
[J].DOI:10.1016/j.eswa.2015.07.052 URL [本文引用: 1]
基于文本价格融合模型的股票趋势预测
[J].
Predicting Stock Prices with Text and Prices Combined Model
[J].
A Study of Social Network Effects on the Stock Market
[J].
DOI:10.1371/journal.pone.0179479
URL
PMID:28658307
[本文引用: 1]
The aim of this study was to explore the reasons behind medicine shortages from the perspective of pharmaceutical companies and pharmaceutical wholesalers in Finland. The study took the form of semi-structured interviews. Forty-one pharmaceutical companies and pharmaceutical wholesalers were invited to participate in the study. The pharmaceutical companies were the member organizations of Pharma Industry Finland (PIF) (N = 30) and the Finnish Generic Pharmaceutical Association (FGPA) (N = 7). One company which is a central player in the pharmaceutical market in Finland but does not belong to PIF or FGPA was also invited. The pharmaceutical wholesalers were those with a nationwide distribution network (N = 3). A total of 30 interviews were conducted between March and June 2016. The data were subjected to qualitative thematic analysis. The most common reasons behind medicine shortages in Finland were the small size of the pharmaceutical market (29/30), sudden or fluctuating demand (28/30), small stock sizes (25/30), long delivery time (23/30) and a long or complex production chain (23/30). The reasons for the medicine shortages were supply-related more often than demand-related. However, the reasons were often complex and there was more than one reason behind a shortage. Supply-related reasons behind shortages commonly interfaced with the country-specific characteristics of Finland, whereas demand-related reasons were commonly associated with the predictability and attractiveness of the market. Some reasons, such as raw material shortages, were considered global and thus had similar effects on other countries.
基于分位数Granger因果的网络情绪与股市收益关系研究
[J].
Exploring the Relationship Between Internet Sentiment and Stock Market Returns Based on Quantile Granger Causality Analysis
[J].
Assessing the Usefulness of Online Message Board Mining in Automatic Stock Prediction Systems
[J].DOI:10.1016/j.jocs.2017.01.001 URL [本文引用: 1]
社交媒体、投资者信息获取和解读能力与盈余预期——来自“上证e互动”平台的证据
[J].
Investor Sophistication and Earning Expectation: Evidence from SSE E-Interaction
[J].
投资者信息能力: 意见分歧与股价崩盘风险——来自社交媒体“上证e互动”的证据
[J].
Investor Information Ability: Opinion Division and Stock Market Crash Risk: Evidence from SSE E-Interaction
[J].
投资者关注和股市表现——基于雪球关注度的研究
[J].
Investor Attention and Market Performance:Evidence Based on “Xueqiu Attention”
[J].
社交媒体投资者关注、投资者情绪对中国股票市场的影响
[J].
The Study of Social Media Investor Attention and Sentiment’s Influence on Chinese Stock Market
[J].
Discovering Public Sentiment in Social Media for Predicting Stock Movement of Publicly Listed Companies
[J].DOI:10.1016/j.is.2016.10.001 URL [本文引用: 1]
A PLS Approach to Measuring Investor Sentiment in Chinese Stock Marke
[J].
DOI:10.1155/2013/720818
URL
PMID:25083120
[本文引用: 1]
In 2001, Friedman et al. conjectured the existence of a "firewall effect" in which individuals who are infected with HIV, but remain in a state of low infectiousness, serve to prevent the virus from spreading. To evaluate this historical conjecture, we develop a new graph-theoretic measure that quantifies the extent to which Friedman's firewall hypothesis(FH)holds in a risk network. We compute this new measure across simulated trajectories of a stochastic discrete dynamical system that models a social network of 25,000 individuals engaging in risk acts over a period of 15 years. The model's parameters are based on analyses of data collected in prior studies of the real-world risk networks of people who inject drugs (PWID) in New York City. Analysis of system trajectories reveals the structural mechanisms by which individuals with mature HIV infections tend to partition the network into homogeneous clusters (with respect to infection status) and how uninfected clusters remain relatively stable (with respect to infection status) over long stretches of time. We confirm the spontaneous emergence of network firewalls in the system and reveal their structural role in the nonspreading of HIV.
Sentiment Analysis on Social Media for Stock Movement Prediction
[J].DOI:10.1016/j.eswa.2015.07.052 URL [本文引用: 1]
Predicting Stock and Stock Price Index Movement Using Trend Deterministic Data Preparation and Machine Learning Techniques
[J].DOI:10.1016/j.eswa.2014.07.040 URL [本文引用: 1]
Predicting Stock Market Index Using Fusion of Machine Learning Techniques
[J].DOI:10.1016/j.eswa.2014.10.031 URL [本文引用: 1]
Trade the Tweet: Social Media Text Mining and Sparse Matrix Factorization for Stock Market Prediction
[J].DOI:10.1016/j.irfa.2016.10.009 URL [本文引用: 1]
Exploiting Social Media for Stock Market Prediction with Factorization Machine
[C]//
基于深度学习和股票论坛数据的股市波动率预测精度研究
[J].
Research on Prediction Accuracy of Stock Market Volatility Based on Deep Learning and Stock Forum Data
[J].
The Impact Technical and Non-Technical Investors Have on the Stock Market: Evidence from the Sentiment Extracted from Social Networks
[J].DOI:10.1016/j.jbef.2017.07.003 URL [本文引用: 1]
家庭社会网络与股市参与
[J].
Home Social Networks and Stock Participation
[J].
社交网络、投资者关注与股价同步性
[J].
Social Networks, Investor Attention and Stock Price Synchronicity
[J].
Investigating Causal Relations by Econometric Models and Cross-spectral Methods
[J].DOI:10.2307/1912791 URL [本文引用: 1]
在线社会网络的测量与分析
[J].
Measurement and Analysis of Online Social Networks
[J].
Investor Psychology and Security Market Under- and Overreactions
[J].DOI:10.1111/0022-1082.00077 URL [本文引用: 2]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}