
 , 杜婉钰, 郑楠
, Du Wanyu, Zheng Nan
, 杜婉钰, 郑楠
, Du Wanyu, Zheng Nan
【目的】结合深度学习, 分析股市数值数据和财经新闻, 提高股票涨跌预测准确率。【方法】建立基于事件的新闻分类模型, 使用多输入的循环神经网络建立基于新闻事件、资金流向和公司财务的个股走势预测模型, 提升股票预测准确率。【结果】引入新闻文本后模型预测准确率进一步提升, 其中, 采矿业准确率达到76.22%, 医药制造业准确率达到77.36%。【局限】未验证新闻标题与新闻文章对股价影响程度的差异, 且新闻事件的分类是基于一年内的新闻数据集进行人工划分, 数据集不具备完整性和代表性。【结论】引入新闻事件作为股票预测模型的特征之一, 能够提升预测的准确率。
[Objective] This paper tries to predict stock trends with the help of deep learning models, financial data and related news events. [Methods] First, we built a classification model for news events. Then, we used the recurrent neural networks to construct a forecasting model for stock trends based on news, capital flows and corporate financial reports. [Results] The prediction accuracy was improved by the proposed model (76.22% and 77.36% for the mining and pharmaceutical manufacturing industries). [Limitations] We did not examine the different impacts of news headlines and full-texts on stock market. We only chose news events from the past one year, which needs to be expanded. [Conclusions] News events could improve the accuracy of predicting stock trends.
中国证券市场人口基数大, 市场潜力巨大。沪深A股市场每天都会产生海量数据信息(主要包括公司财务数据和个股新闻数据), 但是如何有效利用信息为投资者选股提供决策支持, 一直是学界和业界努力解决的问题。本文在考虑沪深A股的股价、公司财务、资金流向等定量信息的基础上, 引入新闻报道等定性信息, 使用深度学习中的循环神经网络对数据进行学习, 自动学习出时间序列数据间的隐含关系。本文拓展了深度学习在金融领域的应用, 提升了股票涨跌预测的准确率, 从而为投资者提供更加准确可靠的选股决策支持。
已有大量研究表明新闻媒体会对股价产生影响。Birz应用报纸报道和电报的新闻标题证明了宏观经济新闻会影响股票价格[1]。
计算机科学领域对新闻与股市间关系的研究, 主要采用文本挖掘、机器学习等技术, 预测新闻对股价涨跌的影响。Nassirtoussi等基于新闻标题对短期外汇价格进行预测[2]。由于影响股票走势的因素很多, 仅考虑新闻对股价进行预测, 准确率并不高。Li等和Schumaker等认为只使用文本信息可能过于限制, 可以通过结合股票涨跌趋势等信息, 构建预测模型[3,4]。
经济学领域主要将新闻转化为一个反映市场情绪的指标, 结合公司基本面等指标, 建立股票走势预测模型。Tetlock等基于新闻情感预测公司未来利润[5]。但实际股票市场中发布的新闻, 很多都不包含鲜明的情感倾向, 多是对客观事件的总结和报道。因此, 孔翔宇等使用新闻主题替代新闻情感, 分析新闻与股价的关系[6]。
因此, 本文对新闻事件进行事件分类而非情感分类, 结合公司财务数据, 建立个股涨跌预测模型, 进一步提升股票预测的准确率。
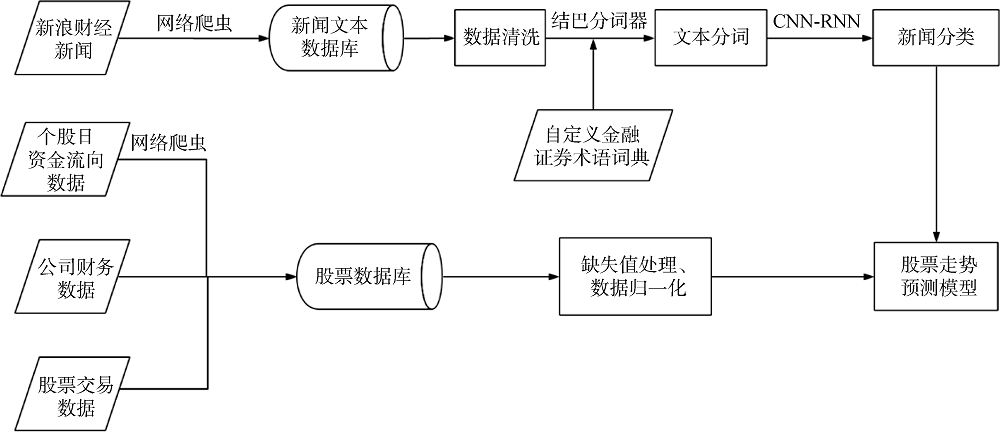
本文模型的主要流程如图1所示。
(1) 编写爬虫程序获取新浪财经数据(个股新闻数据、个股资金流向数据等);
(2) 对财务数据和文本数据进行预处理;
(3) 按照事件分类对新闻短文本进行类别划分, 借助深度学习提取事件类别;
(4) 以14天为时间窗口, 在引入个股资金流向、市盈率、市净率、流通市值等财务数据的基础上引入新闻事件类别进行深度学习二分类问题建模, 预测个股走势。
(1) 划分个股新闻事件类别。为降低情感等主观因素的影响, 本文选取客观的财经事件, 定义了80种金融事件类别, 如表1所示(鉴于篇幅限制, 只列出部分内容)。
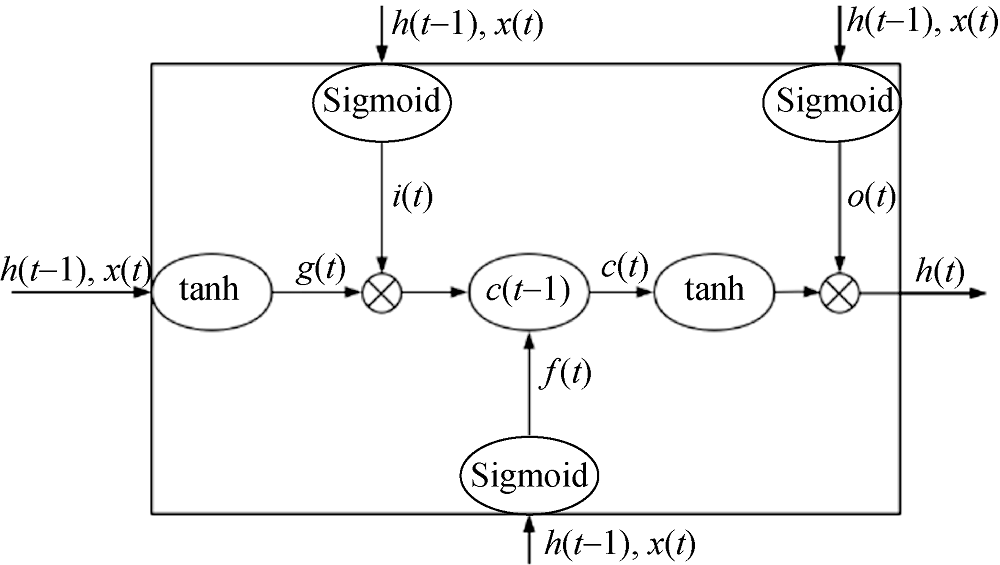
第一层将词语转成300维词向量; 第二层利用三个大小分别为3、4、5的卷积核以标题为单位对词语同时进行卷积; 第三层将卷积的结果拼接成一维向量后, 利用LSTM单元(长短时记忆)进行学习; 最后一层为全连接层, 输出预测类别。
为了检验分类器的准确性, 将获取的新闻标题, 随机按8:2的比例划分训练集和检验集用于新闻标题事件分类器训练。新闻标题事件分类器的性能如表2所示。
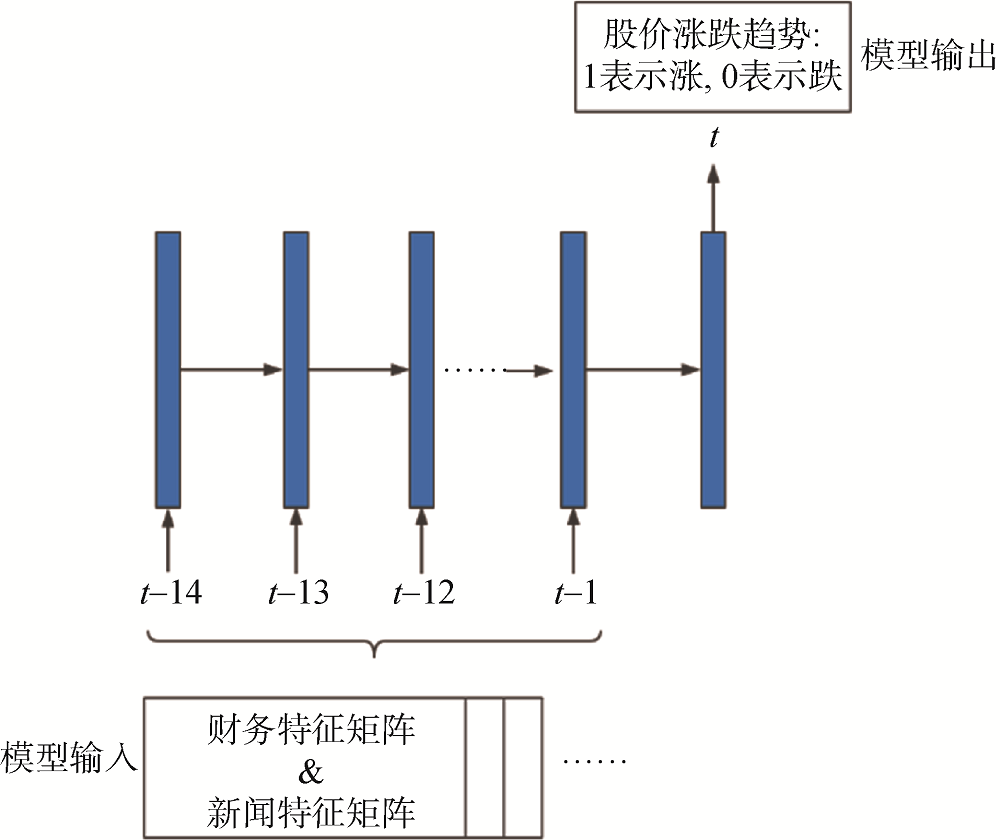
本文将个股涨跌预测问题转化为不同涨跌幅阈值下的二分类问题: 当股价涨跌幅小于阈值时, 判定为负样本, 即股价下跌; 反之, 则判定为正样本, 即股价上涨。
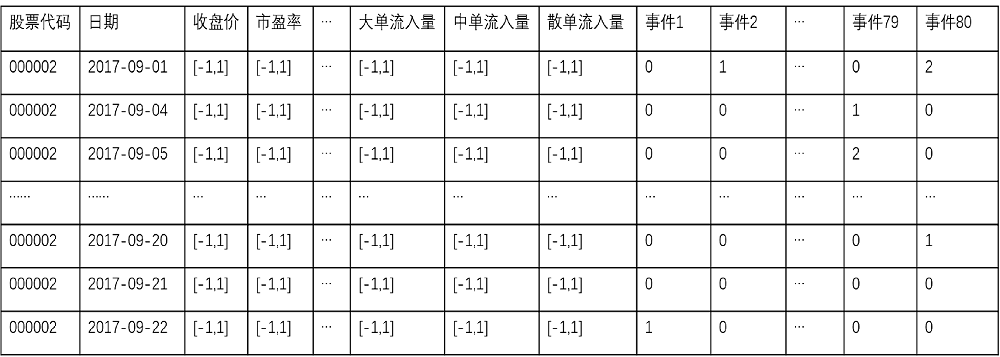
个股走势预测模型的输入数据结构如图3所示。其中, 将财务数据进行归一化处理; 右边部分的80种事件类型与股票代码和日期相对应, 表示对应日期下, 某一股票在对应新闻事件下的数量统计。
通过新闻事件分类器对每支股票每天出现的新闻标题进行事件分类, 得到对应的新闻事件(一条新闻对应一个事件); 通过统计当天所有新闻事件出现的次数, 得到新闻事件频数统计矩阵。由于一支股票一天内可能出现多条新闻, 且新闻与新闻间可能存在相关性(如交易事件类中的“资金流出”可能与股权类中的“减持”有关), 并非完全相互独立。因此本文选择出现概率最高的事件进行加和作为统计结果, 而非将新闻与新闻间的事件概率相乘作为统计结果。
(1) Single-input LSTM预测模型。选取第
实验结果证明, Single-input LSTM模型在引入新闻事件后, 预测准确率并未得到提升。经分析后认为, 原因在于在实际数据集中, 每只股票每天出现的新闻最多有2-3条, 将80类新闻事件以频数统计矩阵的形式输入后, 产生了一个巨大的稀疏矩阵。根据神经网络的参数更新公式[13], 稀疏矩阵会大大影响网络的梯度更新。
$\Delta {{\omega }_{ij}}=-\eta \frac{\partial E}{\partial {{\omega }_{ij}}}$ (1)
$~\frac{\partial E}{\partial {{\omega }_{ij}}}=\frac{\partial E}{\partial {{o}_{j}}}\frac{\partial {{o}_{j}}}{\partial ne{{t}_{j}}}\frac{\partial ne{{t}_{j}}}{\partial {{\omega }_{ij}}}={{\delta }_{j}}{{o}_{i}}$ (2)
${{\delta }_{j}}=\left\{ \begin{align} & ({{o}_{j}}-{{t}_{j}}){{o}_{j}}(1-{{o}_{j}}) 若j是输出层节点 \\ & (\sum\nolimits_{l\in L}{{{\omega }_{jl}}{{\delta }_{l}}}){{o}_{j}}(1-{{o}_{j}}) 若j是隐藏层节点 \\ \end{align} \right.$ (3)
其中, ${{\omega }_{ij}}$为神经网络的参数, $\Delta {{\omega }_{ij}}$为神经网络参数的更新量, $\eta $为学习率, $\partial E/(\partial {{\omega }_{ij}})$表示神经网络损失函数
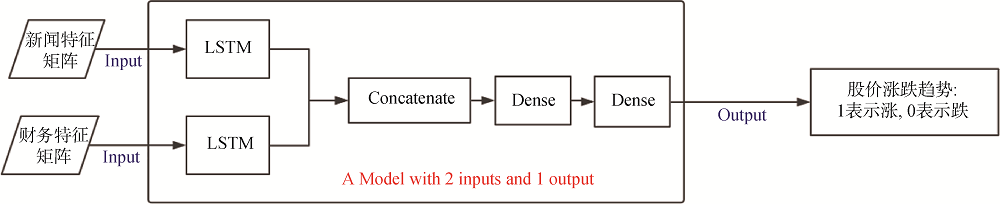
(2) Multi-input LSTM预测模型。为解决Single-input LSTM预测模型存在的问题, 对模型结构进行调整: 将财务特征矩阵和新闻特征矩(见表3和表4), 分别输入到两个LSTM单元中, 再将两个LSTM单元的输出进行合并, 输入全连接神经网络中, 最后输出对第
其中,
张建波等研究表明我国不同的行业因不同的需求弹性和资本结构有不同的经济周期敏感性, 使行业间股票价格波动率具有很大的差异性[14]。
因此本文对不同行业分别进行训练: 选取采矿业作为周期性行业代表, 医药制造业作为弱周期性行业代表。利用Wind数据库①(①https://www.wind.com.cn/newsite/edb.html.)和爬虫程序分别导出个股财务数据133 781条和获取个股新闻数据92 275条。训练区间为2015年11月1日至2017年11月1日, 回测区间为2017年11月1日至2018年1月12日。
本文使用结巴分词器对文本进行分词。结巴分词②(②https://github.com/fxsjy/jieba.)是一个通用的中文分词工具, 此处的财务新闻分词属于特定领域语料库, 因此需要引入自定义的停用词、股票财经专有名词词典等, 进一步提高分词的准确率。
载入自定义股票财经专有名词词典, 如图7所示。该词典包括A股公司全称、简称、证券代码、高管姓名、新兴词汇等。
使用SIGHAN国际计算语言学会(ACL)中文语言处理小组的评分脚本对分词效果进行评测。人工对1 582条句子进行分词后, 导入训练集词表和测试集的切分文件, 测试自定义的分词效果。评测结果表明, 在引入自定义分词规则后, 新闻分词的准确率、召回率均得到大幅提升。具体分词准确率(Precision)、召回率(Recall)和F值(F-measure)如表5所示。
为验证引入新闻后模型的预测准确率, 笔者添加未引入新闻的LSTM[11]进行对比; 此外, 为验证引入新闻后的Multi-input LSTM股价预测模型的优越性, 添加传统股价预测模型SVM[15]进行对比, 实验结果如表6所示。
由表6可得, 未引入新闻的LSTM模型准确率高于引入新闻的Single-input LSTM模型; 由于引入新闻的Multi-input LSTM模型减缓了新闻事件矩阵作为输入之一的稀疏性, 准确率达到最高, 说明该模型能够提取财经新闻中的定性信息, 提高股价预测的准确率。
同时可以看到医药制造业的准确率在全部测试模型中的准确率均高于采矿业: 药品需求价格弹性较低, 且国际经验表明, 医药需求与宏观经济的相关度较小, 行业周期性很弱, 即使经济萧条时期也不受太大影响; 而采矿业产品价格呈周期性波动, 和国内或国际经济波动相关性较强[16]。
关于模型对于行业或者板块的依赖性, 实验设置9组股价涨跌幅阈值进行比较, 实验结果如表7所示。当股价涨跌幅阈值设为3%时, 采矿业引入新闻后的模型预测准确率达到最高; 当股价涨跌幅阈值设为2%时, 医药制造业的模型预测准确率达到最高。且采矿业引入新闻后的预测准确率高于或等于引入新闻前的数量为6, 而医药制造业为8, 因此笔者认为模型对于医药制造业的预测更稳定。
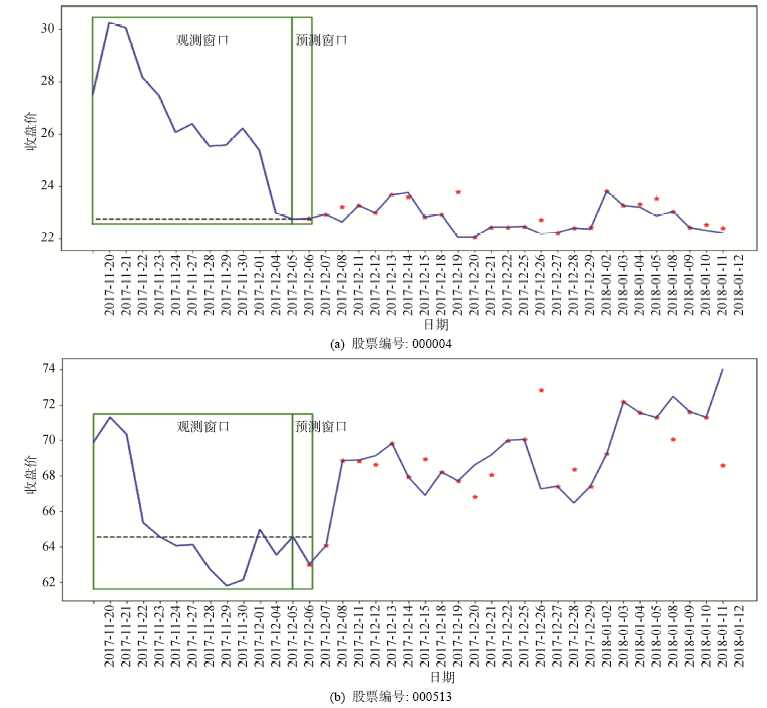
为了直观展示模型预测效果, 对回测期间的示例股票收盘价进行绘图, 如图8所示。实线表示股票收盘价实际走势。
由于对股票第14天的涨跌进行预测, 属于二分类问题, 无法直接在收盘价上体现。因此以第13天的收盘价为水平线, 若预测第14天涨, 将“*”标志纵坐标设为第13天收盘价与第13天、第14天收盘价差值之和; 否则, 设为之差。例如: 实际第13天与第14天收盘价分别为13.29和12.62, 同时预测第14天股票会跌, 因此“*”标志的纵坐标为$13.29-\left| (13.29-12.62) \right|=12.62$。因此, 若“*”标志在实线上, 则表示预测正确; 反之预测错误。由图8可以看出, 模型的预测结果与实际股价走势基本保持一致, 说明该模型能够较为准确地预测个股走势。
本文研究验证了引入新闻事件作为股票预测模型的特征, 能够提升股价预测的准确率, 并搭建了自动化新闻事件提取模型与股价预测模型。在对新闻文本的分析方面, 还存在进一步的探索空间。通过新闻标题对新闻事件进行提取, 没有验证新闻标题与新闻文章对股价影响程度的差异; 此外, 新闻事件的分类是基于一年内的新闻数据集进行人工划分的, 数据集不具备完整性和代表性, 部分特殊重大财经事件没有考虑在内, 未来需要进一步完善与扩充事件分类。
张梦吉: 进行新闻短文本分类, 股票价格时间序列分析, 论文最终版本修订;
杜婉钰: 爬虫编写, 数据获取与数据预处理, 股票价格时间序列分析, 论文撰写与修订;
郑楠: 数据预处理, 文献收集, 财务指标与股价的相关性分析, 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 18742088458@163.com, wd5jq@virginia.edu。
[1] 张梦吉, 杜婉钰. StockWithTextTrainset.csv. 实验训练集, 包含股票代码、资金流向数据和新闻事件数据.
[2] 张梦吉, 杜婉钰. StockWithTextTestset.csv. 实验测试集, 包含股票代码、资金流向数据和新闻事件数据.
| [1] |
URL
[本文引用:1]
|
| [2] |
|
| [3] |
[本文引用:1]
|
| [4] |
[本文引用:1]
|
| [5] |
|
| [6] |
[本文引用:1]
|
| [7] |
|
| [8] |
[本文引用:1]
|
| [9] |
[本文引用:1]
|
| [10] |
URL
[本文引用:1]
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
[本文引用:1]
|
| [15] |
|
| [16] |
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}