




1 引 言
庞大的网民群体加之社交媒体平台的开放性与移动互联的便捷性,使得网络数据规模急剧膨胀,带来严重的信息过载问题。面对凌乱无序、良莠不齐的海量数据,如何从中快速发现有价值的信息,便于普通用户了解事件来龙去脉,方便政府与企业开展舆情监测工作,已成为迫切需求。在学术界,研究人员尝试从话题粒度上重新组织网络数据,以期从海量数据中快速把握舆情主题,尤其是网民关注的焦点与热点主题。然而,现有研究多停留在针对热点事件的回溯性分析,使得舆情预警与管理工作始终处于被动的问题解决层面。如果可以在舆情形成的初始阶段发现苗头性信息,面对负面情绪进行正确的舆论方向引导,避免事态进一步恶化;面对积极情绪则借此推动政府与企业形象建设,发挥预警工作的前瞻性,其效果与意义必定远大于舆论形成后的补救工作。
因此,本研究立足于实现从实时、动态的舆情数据中检测并预判其中哪些话题有可能成为热门主题,并将这些主题称为潜在热点主题。通过识别潜在热点主题,以帮助确定舆情监测重点,为舆情处理与应对工作争取机动时间,真正满足舆情预警的现实要求。
2 相关研究
2.1 网络舆情潜在热点主题定义
本研究认为网络舆情潜在热点主题指从网络舆情数据流中检测出来的并且在其出现后较短一段时间内即可吸引大量网民、媒体关注进而成为热点的网络舆情主题。网络舆情潜在热点主题识别则是从实时、动态的网络舆情信息流中检测主题,并在该主题成为热门主题之前,将其预先识别出来的一系列技术方法的总称。
2.2 网络舆情潜在热点主题发现研究现状
(1)热点主题趋势预测多是以主题相关微博/帖子数、主题热度/流行度作为预测目标,使用基于传统统计学的ARIMA模型、马尔可夫模型、灰色预测等方法,利用主题前期发展过程中采集到的特征值预测主题后期趋势。但上述方法往往仅能适应线性的或平稳的时序数据,这与实际的舆情主题发展规律不符。为适应舆情主题非线性、上下波动的发展趋势,支持向量机、神经网络等方法被引入到舆情主题的趋势预测中,如Jamali等[3]选取C4.5、K近邻和SVM三种分类模型,用于对Digg.com Story流行度进行预测。Hong等[4]利用Logistic Regression预测推文转发数范围。但关于热点主题趋势预测的研究从总体上来说,多局限于单步预测,即用前几个时间窗的观测值预测下一个时间窗或者接下来几个时间窗中各个窗口的属性值,预测结果往往呈现出舆情热度在连续几个时间窗口中上下波动的状态,多数研究止步于预测结果的展示,很少对这种波动状态对应的整体趋势进行分析与总结,也没有就预测结果提出相应的舆情应对策略。
(3)热点话题预判研究与本文的研究目标近似,目前使用较多的是阈值预测法,当话题热度大于阈值时,则可判定当前话题在未来有成为热门的可能。如李永兴[11]利用话题热度、话题热度曲线一阶增长率、话题热度移动平均线一阶增长率三个值对话题进行预判,当三者均大于各自阈值时,判定当前话题属于热点话题。姚海波[12]采集与统计当前主题在1小时内最大微博量以及24小时内最大积累量,认为当两者均大于各自阈值时,可判定话题为热门话题。这种热点话题预测方法的预测结果完全取决于人工设置的热度阈值,而对于如何确定阈值缺少统一、科学的标准。此外,Nikolov[15]将微博话题转化为时间序列,通过将新增话题的时间序列与已知话题的序列进行匹配,从而确定新增话题热门与否,但该方法依赖已知的话题集合,不符合微博话题多样且动态变化的现实特征。
无论是趋势预测研究还是转发行为预测研究中都有不少研究者引入了分类思想,因此,本研究将该思想引入到网络舆情潜在热点主题识别过程中,将潜在热点主题的识别视作是否热门的分类问题,通过选取能最大程度区分热门与非热门话题的特征项,构建基于分类的主题识别模型,弥补现有热点主题预判研究中依赖人工设置阈值的不足,以真正实现从实时、动态的数据流中预先识别出那些未来有可能成为热点的舆情主题。
3 网络舆情潜在热点主题识别建模
3.1 总体框架
本文提出的网络舆情潜在热点主题识别方法主要可分为以下两部分:自动识别实时发布的微博数据中所包含的舆情主题;将潜在热点主题的识别视作分类问题,通过选取特征变量、构建分类模型,识别出微博舆情主题中哪些主题可能在未来成为热点。整体架构如图1所示。
图1
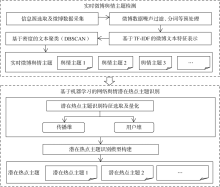
图1
网络舆情潜在热点主题识别框架
Fig. 1
The Framework for Identifying Potential Hot Topics of Network Public Opinion
该框架主要包含实时微博舆情主题检测和基于机器学习的网络舆情潜在热点主题识别两个方面。
(1) 实时微博舆情主题检测
本研究选择新浪微博作为研究平台,由于无法实现监测与跟踪所有微博用户,所以从意见领袖角度出发,参照微博榜单①(①
(2) 基于机器学习的网络舆情潜在热点主题识别
以识别出的主题作为进一步的研究对象,将潜在热点主题的识别视作分类问题,选取并量化能表征主题是否会成为热点的特征项,选择Logistic Regression与SVM两种机器学习分类模型作为潜在热点主题识别的候选模型,利用人工标注的数据对模型进行训练,利用准确率、召回率及F1值比较两种分类模型效果,寻找最佳的潜在热点主题识别模型。最后,利用训练好的模型对新产生的舆情主题进行分类,识别出其中可能成为热点的主题,即潜在热点主题。
3.2 增量式实时舆情主题检测
基于Single-Pass增量式聚类思想,结合DBSCAN密度聚类方法实现从真实、动态的网络舆情数据流中获取主题。实时舆情主题检测算法如下所示。
输入:主题集合T(初始状态为空);微博数据集W。
输出:更新后的主题集合T;微博-主题对应关系。
(1)对采集到的微博数据进行噪声过滤、分词及停用词过滤处理,利用VSM模型与TF-IDF算法进行文本特征向量表示。此时,若主题集合T为空,则执行步骤(2),否则跳转至步骤(3);
(2)利用DBSCAN算法对步骤(1)中处理好的数据集合进行聚类操作,根据聚类结果,更新主题集合T。其中,主题集合T中的每个主题由该主题下所有微博中筛选出的TF-IDF值最高的且词性为名词、动词和形容词的前10个词汇表示;
(3)遍历采集到的所有微博数据,将每条微博文本依次与主题集合T中的已有主题进行相似度计算,如果相似度计算结果中的最大值大于预设的相似度阈值
(4)对于步骤(3)中相似度计算后没有匹配到主题的微博子集,跳转至步骤(2)进行聚类处理。
由于微博平台数据的产生是一个动态更新的过程,因此,该算法需定时(如每隔1小时)唤醒,实现增量式地检测实时采集到的微博数据中的舆情主题。
3.3 基于机器学习的网络舆情潜在热点主题识别
本研究将潜在热点主题的识别视作二分类问题,即对3.2节中实时检测出的主题进行分类,那些被划分到热门类别中的主题就是潜在热点主题,即未来有可能成为热点的主题。
(1) 潜在热点主题识别特征选取及量化
通过分析舆情热度计算相关的研究,同时结合潜在热点主题自身特点及潜在热点主题预判的现实需求,本研究从传播维与用户维两个维度出发,提出包括主题传播影响力(特征1-4)、主题相关用户活跃度(特征5)、主题相关用户受关注度(特征6-7)与用户微博影响力(特征8-10)等4个层面的潜在热点主题识别特征,如表1所示。
表1 潜在热点主题识别特征
Table 1
| 序号 | 特征量化 |
|---|---|
| 1 | 单位时间内主题相关微博增量 |
| 2 | 单位时间内主题相关微博的评论增量 |
| 3 | 单位时间内主题相关微博的转发增量 |
| 4 | 单位时间内主题相关微博的点赞增量 |
| 5 | 主题相关用户最近30天内的日均发博数 |
| 6 | 主题相关用户最近30天内的粉丝互动h指数 |
| 7 | 主题相关用户的高质量粉丝数 |
| 8 | 主题相关用户最近30天内的微博平均评论数 |
| 9 | 主题相关用户最近30天内的微博平均转发数 |
| 10 | 主题相关用户最近30天内的微博平均点赞数 |
①传播维
传播维从信息传播的角度反映网民主体对舆情主题的关注程度[17]。相比非热门主题,热门主题往往更能吸引网民关注,引发主体共鸣。随着主题传播范围的逐步扩大,传播影响力不断加深,舆情主题就有爆发成为热门主题的可能。在微博平台上,这种传播效应最直观的表现形式就是主题相关微博量的增多,以及微博评论、转发、点赞数量(简称“转评赞数量”)的增长。因此,本文通过持续监测与观察这些统计数据在单位时间里的变化量随时间推进的动态变化情况,以期从信息传播的过程中发现网络舆情的苗头性信息,从而达到预先识别潜在热点主题的目标。
②用户维
本研究参考现有关于用户影响力的研究,从用户活跃度、用户受关注度与用户微博影响力三个方面全面衡量用户的影响力。
1)用户活跃度
文献[17]将用户活跃度称为用户影响力的产生动力,换句话说,一个用户如果只是名义上的高影响力用户,却在微博平台上不进行任何活动,那么用户的实际影响力难以得到体现。因此,用户活跃度是衡量用户影响力的因素之一。现有研究多以用户的日均发博数作为衡量标准,计算方法为:用户微博总数除以用户微博账号创建时长。这种计算方法并不能衡量当前用户最近的活跃程度,尤其在无法实现对全部微博用户进行监测的情况下。所以只有最近活跃度高的用户才更具监测价值,因此,本研究采用用户最近30天内日均发博数作为用户活跃度的测量项。
2)用户受关注度
用户受关注度表征用户在信息传播过程中可能的受众范围。受众范围越广,其所发信息越容易被更多用户接收,参与讨论与转发的用户规模就越大,信息经层层转发与扩散,相关舆情就越容易进一步演化为舆论。本研究借鉴PageRank思想及h指数,将高质量粉丝数和粉丝互动h指数作为用户受关注度的衡量标准。
高质量粉丝数:借鉴PageRank思想[18],当某一用户的入链用户节点(即关注当前用户的用户节点)具有高影响力时,可认为该用户必然也是重要的用户节点。反之,当该用户拥有众多高影响力入链节点时,其发布的信息经这些高影响力的入链用户转发,会吸引更多的用户关注,相关舆情越容易成为舆论焦点。因此,通过微博平台提供的用户粉丝群博主分布情况,选择拥有一定粉丝规模且具体微博认证的大V用户,利用这些博主的数量(即高质量粉丝数)代替粉丝数作为用户受关注度的测量项之一,以消除虚假粉丝数对用户影响力的干扰。
粉丝互动h指数:将信息计量学中用于评价研究人员个人研究成就的h指数[19]用于评价微博用户影响力,将微博用户发布的微博类比研究人员发表的论文,微博粉丝互动数(转评赞数量的综合指标)类比研究人员论文的被引频次,引入粉丝互动h指数这一新指标。该指标的具体获取方式为:利用微博提供的降序排列的粉丝互动数列表,找出其中序号小于或等于其对应的互动数的最大值,该值即为当前用户的粉丝互动h指数。该指标同时从数量与质量两个角度衡量用户真实的受关注度,消除了那些与博主毫无互动的“僵尸粉”的干扰。
3)用户微博影响力
用户受关注度反映用户潜在的信息传播覆盖度,用户所发微博的微博影响力表征用户真实的信息传播范围。为保证用户微博影响力的时效性,仍以用户最近30天内所发微博的相关统计量作为参考依据,最终的用户微博影响力计算如公式(1)所示。
其中,
(2)潜在热点主题识别模型构建
本研究将潜在热点主题识别转化为分类问题,即将潜在热点主题识别过程视作对实时舆情主题检测中获得的新主题进行判断,将其分为热门或非热门类别,其中分为热门类别的主题即为在未来有可能成为热门的主题。而在分类模型的选择上,支持向量机(SVM)、Logistic Regression、朴素贝叶斯是较为常用且理想的选择。但由于表1中特征变量之间并非相互独立,不能完全满足朴素贝叶斯的条件独立性假设,因此,选取SVM与Logistic Regression两种分类模型,利用事先人工标注好的训练数据集
4 实验及结果分析
由于技术及微博平台本身的限制,无法动态、实时地获取所有用户发布的所有微博,但考虑到意见领袖在话题传播与引导方面发挥着加速传播与引导的作用,因此,从意见领袖入手,将其作为进一步实验的信息来源。意见领袖选取标准及来源如表2所示。
表2 意见领袖选取类别及参考来源
Table 2
| 意见领袖所属类别 | 参考来源 |
|---|---|
| 政务类 | 微博榜单及2017年度人民日报·政务指数微博影响力报告[20] |
| 传统媒体类(含报纸、杂志、媒体网站等) | 微博榜单 |
| 互联网类 | |
| 自媒体人气大V类 | |
| 娱乐类 | |
| 财经类 | 新浪全媒体影响力排行榜②(② |
本实验基于移动版新浪微博①(①
4.1 增量式实时舆情主题检测实验
利用Python语言编制增量式主题检测算法,该算法主要实现了以下7个功能:对意见领袖最新发布微博及转评赞数量的采集与自动保存;微博数据预处理;微博文本特征向量表示;微博文本聚类;聚类簇所属主题的词汇表示;新增微博与已有主题的相似度计算;微博与所属主题对应关系的自动保存。
为实现提前发现未来可能的热点主题、满足事前预警的需求,实验设置该程序每隔1小时执行一次,每次执行时长约5分钟。在实验期间内,最终聚类得到的主题数为8 787个。程序执行结果的部分效果展示如图2所示。
图2

为保证下一步潜在热点主题识别实验的科学性、提高实验准确性,逐条阅览采集到的所有微博,对程序自动聚类结果进行合并与修正,对每个类别对应的主题内容进行人工归纳与总结。具体的总结规则如下:
(1)如果聚类主题与出现在微博热搜榜的某一话题属同一内容,则用微博热搜榜上对应的话题代表该聚类主题;
(2)如果聚类主题与微博热搜榜上所有话题都不属于同一内容,但聚类主题下的微博文本中包含主题标识符“【】---”或“# #”,则用主题标识符之间的内容作为该类别对应的主题内容;
(3)若以上两种情况均不满足,则采用人工总结方式为类别赋予主题内容。
上述三种规则的主题与微博示例如图3所示。
图3

图3
三种规则类别主题内容赋予示例
Fig.3
Example of Topic Content Assignment for Three Categories of Rules
4.2 基于机器学习的潜在热点主题识别实验
(1) 训练样本选择
潜在热点主题识别实验选择Logistic Regression与SVM两种分类模型,均属监督学习范畴,即使用人工标注的数据集进行学习,继而利用学习好的模型进行新样本预测。考虑到人工标注的时间成本问题,及本研究的目的是为政府与企业的网络舆情监测与引导工作提供支持,因此在人工标注之前,先对4.1节实验中检测出的舆情主题进行人工筛选与过滤,得到用于人工标注的样本数量为2 143条。其中,被过滤的主题类型及具体过滤原因如表3所示。
表3 舆情主题人工过滤类型及原因说明
Table 3
| 被过滤的主题类型 | 过滤原因 |
|---|---|
| 已登录微博热搜榜的主题 | 无预测价值 |
| 综合新闻或事件回顾 | 已失去时效性 |
| 交通、天气、股票等实时播报 | 日常或周期性事件,突发程度低,网络舆情监测价值或提前预警必要性较低 |
| 系列活动的日常报道 | |
| 周期性事件 | |
| 娱乐新闻、明星八卦 | 不属于本研究的目标服务群体 |
| 城市、图书、影视、音乐等推荐与分享 | 多数微博用户用于吸引粉丝的日常分享,不含较重大的社会事件或突发事件,监测价值较低 |
| 招聘启事、商业广告 | |
| 人物访谈、人物简介、名人名言 | |
| 搞笑段子、鸡汤文字 | |
| 粉丝福利、日常互动 | |
| 食谱、生活技巧、知识科普 | |
| 便民提示、安全提醒 | |
| 世界杯等体育赛事 | 该类事件属全民关注,极易登上微博热搜榜,提前预警的必要性低 |
(2) 特征量化
为预测与识别潜在的热点主题,本研究提出特征变量的选取应使用动态特征,而动态特征属于时间序列特征,需要设置不同的时间间隔,考查不同时间间隔内各统计信息的变化情况。将时间窗设置为3小时,统计各主题自首次出现(即首条微博发布时间)至出现3小时(
①考虑到有些热门主题的相关微博可能在午夜首次出现,但由于此时正处于人们休息睡眠期间,在一段时间里并不会引起广泛关注。如果时间上限设置太小,那么考查的时间间隔内各统计信息变化幅度不明显,使得热门与非热门主题区别度较低;
②经统计,本实验采集到的各热门主题首次登上热搜榜的时间与其在采集到的数据集合中首次出现的时间差值最大为95小时(该话题为#网购银环蛇被咬身亡#),平均值约为15小时。为满足事前预警的需要,时间上限的取值应小于15小时,最终将其设置为12小时。
表4 潜在热点主题识别特征项
Table 4
| 序号 | 特征 | 序号 | 特征 |
|---|---|---|---|
| 1 | 17 | ||
| 2 | 18 | ||
| 3 | 19 | ||
| 4 | 20 | ||
| 5 | 21 | ||
| 6 | 22 | ||
| 7 | 23 | ||
| 8 | 24 | ||
| 9 | 25 | ||
| 10 | 26 | ||
| 11 | 27 | ||
| 12 | 28 | ||
| 13 | 29 | ||
| 14 | 30 | ||
| 15 | 31 | ||
| 16 | 32 |
图4

(3) 数据标注
实验主题样本按照以下规则进行人工标注:
①若主题样本在首次出现后的两天内登上微博热搜榜,则视为正样本,标记为1;
②若主题样本在首次出现后的两天内未登上微博热搜榜,则视为负样本,标记为0。
需要特别说明的是,存在部分热门主题其首次出现时间远远早于其登上微博热搜榜的时间,虽然这类主题最终属于热门主题,但在本研究中仍将此类主题标记为负样本,这是因为本研究将潜在热点主题定义为自其出现后较短一段时间内即可引起网民及媒体关注,而上述类型主题并不具备一经发布便能较快引起关注、成为焦点的能力,因此将其视为负样本。人工标注样本示例如图5所示。
图5

(4) 实验结果分析
通过对Logistic Regression与SVM两种分类模型准确率、召回率与F值进行比较,选择最终潜在热点主题识别模型。其中,Logistic Regression借助Python Sklearn包实现,SVM则利用台湾大学林智仁教授等开发的LIBSVM实现。
为保证模型对比与效果评价的准确性与科学性,对两种分类模型分别进行15次验证,借助LIBSVM包中subset.py程序将标注数据随机划分为训练集与测试集两部分,其中700个样本作为测试集,其余样本用作模型训练。两种分类模型效果对比结果如表5所示。
表5 潜在热点主题识别实验结果
Table 5
| 实验次数 | Logistic Regression | SVM | ||||
|---|---|---|---|---|---|---|
| 准确率 | 召回率 | F1值 | 准确率 | 召回率 | F1值 | |
| 1 | 0.66 | 0.88 | 0.75 | 0.82 | 0.67 | 0.74 |
| 2 | 0.69 | 0.83 | 0.75 | 0.75 | 0.71 | 0.73 |
| 3 | 0.65 | 0.80 | 0.72 | 0.78 | 0.64 | 0.70 |
| 4 | 0.67 | 0.84 | 0.75 | 0.84 | 0.65 | 0.73 |
| 5 | 0.63 | 0.86 | 0.73 | 0.69 | 0.76 | 0.72 |
| 6 | 0.70 | 0.89 | 0.78 | 0.70 | 0.67 | 0.69 |
| 7 | 0.67 | 0.89 | 0.77 | 0.87 | 0.73 | 0.79 |
| 8 | 0.66 | 0.81 | 0.73 | 0.90 | 0.64 | 0.74 |
| 9 | 0.67 | 0.83 | 0.74 | 0.78 | 0.65 | 0.71 |
| 10 | 0.67 | 0.89 | 0.77 | 0.88 | 0.67 | 0.76 |
| 11 | 0.75 | 0.85 | 0.79 | 0.83 | 0.64 | 0.72 |
| 12 | 0.68 | 0.79 | 0.73 | 0.84 | 0.65 | 0.73 |
| 13 | 0.65 | 0.88 | 0.75 | 0.76 | 0.85 | 0.80 |
| 14 | 0.71 | 0.86 | 0.78 | 0.73 | 0.73 | 0.73 |
| 15 | 0.63 | 0.85 | 0.72 | 0.79 | 0.67 | 0.73 |
| 均值 | 0.67 | 0.85 | 0.75 | 0.80 | 0.69 | 0.73 |
可以看出,Logistic Regression在召回率方面表现优于SVM,而SVM具有更好的预测准确率,最高可达0.90,说明SVM在同样样本量的情况下具有更好的泛化能力,由训练数据集训练得到的预测模型也可很好地适应测试数据。虽然从F1值来看,Logistic Regression预测效果要比SVM略好,但其准确率均值不足0.70,究其原因,主要有以下两点。
①仅以部分意见领袖为信息来源,导致标注样本集中主题的各项特征值并非主题的真实反映,仅属于该主题在微博平台上真实信息量的一部分,使得一个热门主题反而与一些非热门主题表现出相似的特征分布;
②微博热搜榜单的形成离不开微博工作人员的审核与人工干预,使得一些引发网民热议的舆情主题并不能登上微博热搜榜单。由于在人工标注过程中,主题热门与非热门的判定仅取决于该主题是否在两天时间内登上过微博热搜榜,所以很多在特征分布上表现得像热门的舆情主题,由于其并未登上微博热搜榜,只能将其标注为非热门主题。
基于以上两点,Logistic Regression模型在预测过程中会将一些非热门主题归为热门类别,最终导致模型准确率下降。
笔者认为潜在热点主题识别问题,召回率相比准确率显得更为重要,因为在舆情预警工作中尽可能防患于未然,并尽量避免造成亡羊补牢的局面。因此,Logistic Regression更适合作为潜在热点主题识别模型。
5 结 语
本研究将潜在热点主题的识别过程视作主题热门与否的分类问题,通过持续监测与统计主题相关的动态特征指标,将获得的数据样本经人工标注后用于模型训练,训练好的模型即可用于对后期新增主题的判别。实验整体效果显示,Logistic Regression相比于SVM更适合作为潜在热点主题识别模型,且在召回率上表现良好。本研究尚处于初探阶段,在潜在热点主题识别特征选取方面尚不全面,缺少对主题内容维度的度量,且缺少在多样化社交媒体平台的应用。未来将进一步改进上述不足,以帮助政府与企业细化、明确舆情监测重点,在舆情预警工作中化被动为主动,及早做好舆情引导工作。
作者贡献声明
丁晟春:提出研究思路,设计研究方案;
俞沣洋:提出潜在热点主题流程并进行特征量化,论文起草;
李真:参与设计研究方案,开展实验,论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: todingding@163.com。
[1]丁晟春, 俞沣洋, 李真.LabledDataSet.xls.已标注微博数据.
参考文献
网络舆情潜在影响力指标体系构建及应用
[J].
The Construction and Application of Potential Influence Index System for Network Public Opinions
[J].
在线论坛中潜在影响力主题的发现研究
[J].
Study on Potential Influence Topic in On-line Community
[J].
Digging Digg: Comment Mining, Popularity Prediction, and Social Network Analysis
[C]//
Predicting Popular Messages in Twitter
[C]//
The Pulse of News in Social Media: Forecasting Popularity
[C]//
支持向量机修正ARIMA误差的微博热点预测
[J].
Microblogging Hot Topic Prediction Based on Correcting ARIMA Error by Support Vector Machine
[J].
Hot Topic Trend Prediction of Topic Based on Markov Chain and Dynamic Backtracking
[C]//
基于组合灰色模型的网络舆情预测研究
[J].
Prediction of Online Public Opinion Based on Combination Grey Model
[J].
基于神经网络的微博舆情预测方法
[J].
Neural Network-Based Public Opinion Prediction Method for Microblog
[J].
融合热点话题的微博转发预测研究
[J].
Research on Weibo Forwarding Prediction Based on Hot Topics
[J].
网络热点话题检测与趋势预测技术研究
[D].
Research on Technologies of Hot Topic Detection and Topic Trend Prediction
[D].
微博热点话题检测与趋势预测研究
[D].
Detection and Trend Prediction Research of Hot Topic of Micro-Blogging
[D].
基于微博的负面热点新闻早期预测分析
[D].
Based on Microblogging Early Forecast and Analyze Negative Hot News
[D].
基于中文微博的话题趋势预测系统的设计与实现
[D].
Design and Implementation of Trending Topic Prediction System Based on Chinese Microblogging
[D].
Trend or No Trend: A Novel Nonparametric Method for Classifying Time Series
[D].
Realtime Online Hot Topics Prediction in Sina Weibo for News Earlier Report
[C]//
现代图书情报技术
[J].
Influence Index Model of Micro-blog User
[J].
Reprint of: The Anatomy of a Large-scale Hypertextual Web Search Engine
[J].
An Index to Quantify an Individual’s Scientific Research Output
[J].
2017年度人民日报·政务指数微博影响力报告
[EB/OL].[
2017 People’s Daily·Government Affairs Index Weibo Impact Report
[EB/OL]. [

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}